Descargar la presentación
La descarga está en progreso. Por favor, espere

1
ANÁLISIS E INTERPRETACIÓN DE RESULTADOS ESTADISTICOS
DIPLOMADO DE ESPECIALIZACION DE POSTGRADO EN ASESORIA DE TESIS ANÁLISIS E INTERPRETACIÓN DE RESULTADOS ESTADISTICOS Dr. Carlos Calderón Cabada Lima, Junio 2006

2
PRUEBAS ESTADISTICAS PARAMETRICAS
Prueba “t” de Student

3
¿QUE ES LA PRUEBA “t” ? ES UNA PRUEBA ESTADISTICA PARA EVALUAR SI DOS GRUPOS DIFIEREN ENTRE SI DE MANERA SIGNIFICATIVA RESPECTO DE SUS MEDIAS.

4
SIMBOLO “ t “

5
SE CALCULA PARA MUESTRAS PEQUEÑAS DE DISTRIBUCION NORMAL

6
SE CALCULA PARA MUESTRAS GRANDES DE DISTRIBUCION NORMAL

7
Se trata de comparar dos grupos:
HIPOTESIS A PROBAR Se trata de comparar dos grupos: La hipótesis alternativa plantea que los grupos difieren significativamente entre si y la hipótesis nula propone que los grupos no difieren significativamente entre si.

8
EL NIVEL DE MEDICION DE LAS VARIABLES ES EL DE INTERVALO O RAZON
VARIABLE INVOLUCRADA LA COMPARACION SE REALIZA SOBRE LA VARIABLE INDEPENDIENTE, SI EXISTEN OTRAS SE DEBE EFECTUAR VARIAS PRUEBAS “t” UNA POR CADA VARIABLE. EL NIVEL DE MEDICION DE LAS VARIABLES ES EL DE INTERVALO O RAZON

9
INTERPRETACION PARA GRUPOS PEQUEÑOS (n < 30) X la media del grupo.
µ la media poblacional S la Desv. Estandar n = tamaño de muestra

10
INTERPRETACION Para saber si el valor “t” es significativo, se aplica la formula y se calculan los grados de libertad. La prueba “t” se basa en una distribución muestral o poblacional de diferencia de medias conocidas como la “t de Student”, Esta distribución es identificada por los grados de libertad, los cuales constituyen el numero de maneras como los datos pueden variar libremente.

11
RECOMENDACION Mientras mayor sea el numero de grados de libertad la distribución “t de Student” se acerca mas a ser una distribución normal. Si los grados de libertad exceden los 120 la Distribución Normal es utilizada como una aproximación adecuada de la “t de Student”. Calculado “t” y los gl (grados de libertad) SE ELIGE el nivel de significancia y se compara el valor obtenido con el mostrado en la Tabla
 SE ELIGE el nivel de significancia y se compara el valor obtenido con el mostrado en la Tabla.")
12
Distribución t-Student
Para muestras pequeñas de población normal t1- t(v) PRUEBA “t”
 PRUEBA t")
13
CALCULO DE LOS GRADOS DE LIBERTAD
gl = (N1 + N2) – 2 N1 y N2 representan al tamaño de cada grupo comparado.
 – 2. N1 y N2 representan al tamaño de cada grupo comparado.")
14
EVALUACION DE RESULTADOS
Si nuestro valor calculado es igual o mayor que el de la Tabla, se acepta la hipótesis alternativa. Pero si el valor es menor se acepta la hipótesis nula. USO DE LA TABLA……..

15
EJERCICIOS Tomar la Tabla “t” y calcular: Media Muestral =
Media Poblacional = α = n = gl. (t-1) =
 =")
16
DESCANSO

17
Valor crítico o tabulado
HIPOTESIS A CONTRASTAR Se definen: Las hipótesis nula y alternativa con una distribución de probabilidad conocida Regla de decisión(nivel de significación a) Valor crítico o tabulado datos de la muestra Se calcula una medida asociada a la hipótesis que se desea docimar Se comparan los valores calculado con tabulado ¿se rechaza Ho? H1 SI NO Se extraen conclusiones
 Valor crítico o tabulado. datos de la muestra. Se calcula una medida asociada a la hipótesis que se desea docimar. Se comparan los valores calculado con tabulado. ¿se rechaza Ho H1. SI. NO. Se extraen conclusiones.")
18
Utilizar prueba de Z Si ¿Se conoce ? No Si Utilizar prueba de Z Es n ≥ 30? No Utilizar prueba de Z Si Si ¿Se conoce? No ¿Se sabe q la población es normal? Utilizar prueba de t Utilizar prueba de Z (por el teorema central del límite) Si No ¿Se conoce? No Utilizar prueba de Z (por el teorema central del límite) Si Utilizar una prueba no paramétrica Es n ≥ 30?
 Si. No. ¿Se conoce No. Utilizar prueba de Z (por el teorema central del límite) Si. Utilizar una prueba no paramétrica. Es n ≥ 30")
19
Esquema cuando se comprar la diferencia entre dos medias o proporciones muéstrales
Se acepta la hipótesis nula si el estadístico de la prueba cae dentro de esta región. Se rechaza la hipótesis nula Se rechaza la hipótesis nula Area A = área B y (A+B) = el nivel deseado de significancia Area A Area B Valor teórico de la diferencia + Valor critico Valor critico
 = el nivel deseado de significancia. Area A. Area B. Valor teórico de la diferencia. + Valor critico. Valor critico.")
22
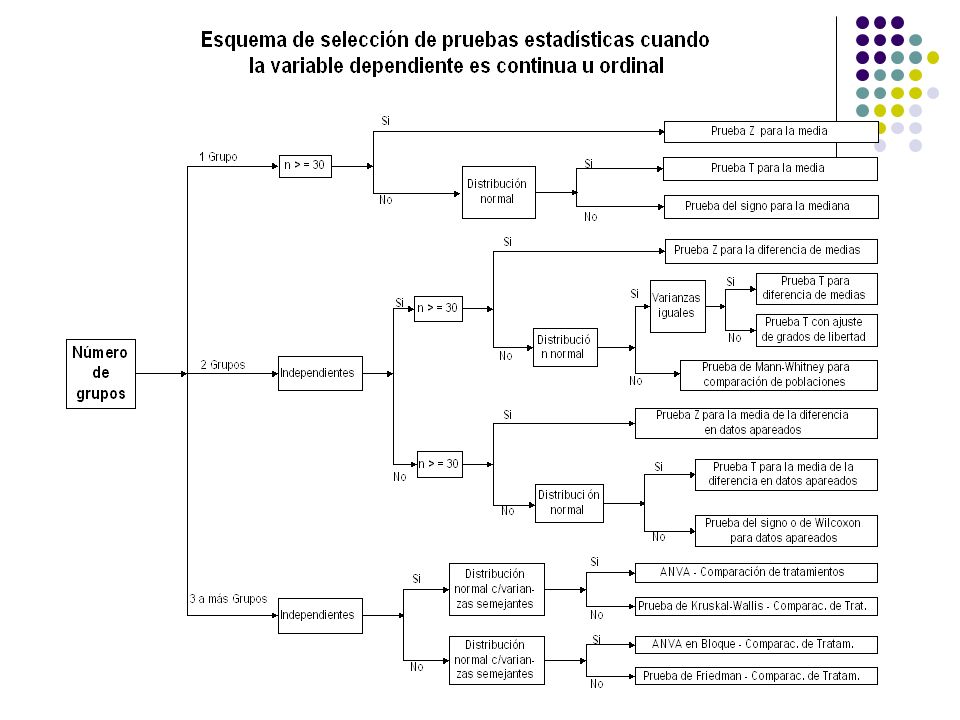
Hipótesis estadística según Número de grupo y tipo de variable

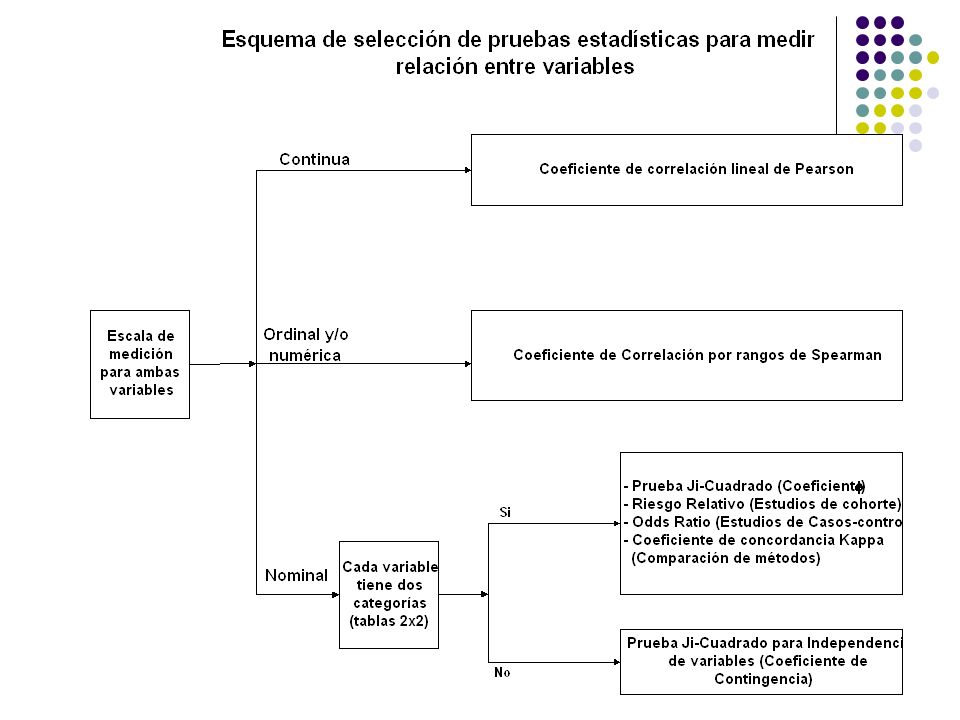
23
Prueba de Correlación de Rango de SPEARMAN

24
PRUEBA DE CORRELACION DE RANGO DE SPEARMAN
El coeficiente de correlación por rango se define como: Donde: N: # de observaciones, # de individuos o fenómenos clasificados por rango. di: Diferencia en los rangos atribuida a dos características diferentes del i-ésimo individuo o fenómeno. La correlación por rangos de Spearman mide la relación entre dos variables que han sido clasificadas por orden de menos a mayor (o de mayor a menor)
")
25
Puntuación en el examen Clasificación por rendimiento
EJEMPLO Una empresa contrató a 7 técnicos en informática, que fueron sometidos a un examen de conocimientos básicos. Luego de un año de servicio, se calificó su rendimiento en el trabajo. A continuación, se muestran los resultados: Técnico Puntuación en el examen Clasificación por rendimiento J. Manzo 82 4 M. Contreras 73 7 C. Gutarra 60 6 F. Olaechea 80 3 D. Barrientos 67 5 F. Estombelo 94 1 J. Cordova 89 2

26
1º Se elabora la clasificación de las puntuaciones del examen
Se utiliza la correlación por rangos de Spearman para determinar, si hay relación entre las calificaciones del examen y el rendimiento en el trabajo 1º Se elabora la clasificación de las puntuaciones del examen Técnico Puntuación en el examen Clasificación por el examen (X) Clasificación por rendimiento (Y) J. Manzo 82 3 4 -1 1 M. Contreras 73 5 7 -2 C. Gutarra 60 6 F. Olaechea 80 D. Barrientos 67 F. Estombelo 94 J. Cordova 89 2
 Clasificación por rendimiento (Y) J. Manzo M. Contreras C. Gutarra F. Olaechea. 80. D. Barrientos. 67. F. Estombelo. 94. J. Cordova")
27
2º Se calcula del coeficiente de correlación por rangos de Spearman rs:
Un coeficiente de correlación oscila entre -1 y 1; los resultados muestran una fuerte relación positiva entre las puntuaciones de examen de cada técnico y su rendimiento en le trabajo

28
Contrastando la hipotes:
H0: ρs = 0, no hay relación entre las dos variables H1: ρs ≠ 0, hay relación entre las dos variables Tabla N, con α=0.10, n=7; los valores críticos serían: ± Se acepta Se Rechaza Se Rechaza 0.05 0.05 0.857 Valor critico Valor critico Como rs está fuera de la región de aceptación, rechazamos la H0. Se concluye, al 90% de confianza, existe relación entre las puntuaciones del examen y el orden de rendimiento en el trabajo

29
Intervalo de confianza para la diferencia de medias
b) Si las varianzas 12 y 22 son desconocidas Para muestras grandes donde
 Si las varianzas 12 y 22 son desconocidas. Para muestras grandes. donde.")
30
Cambiar de tema

31
ANALISIS NO PARAMETRICO

32
CONSIDERACIONES La mayoría no de estos análisis no requiere de presupuestos acerca de la forma de la Distribución Poblacional. Las Variables no necesariamente deben estar medidas en un nivel de intervalo (orden y categoría cero no real) o de razón ( el cero es real) . Pueden analizarse datos nominales (sin orden ni categoría -Sexo) u ordinales (orden de mayor a menor- primero, segundo). En todo caso la variables deben ser categóricas. ( en días, meses, años, etc.)
 o de razón ( el cero es real) . Pueden analizarse datos nominales (sin orden ni categoría -Sexo) u ordinales (orden de mayor a menor- primero, segundo). En todo caso la variables deben ser categóricas. ( en días, meses, años, etc.)")
33
METODOS O PRUEBAS NO PARAMETRICAS MAS EMPLEADAS
1) LA Ji CUADRADA – CHI-CUADRADA 2) COEFICIENTES DE CORRELACION E INDEPENDNENCIA PARA TABULACIONES CRUZADAS. 3) LOS COEFICIENTES DE CORRELACION PARA RANGOS ORDENADOS DE SPERMAN Y KENDALL
 LA Ji CUADRADA – CHI-CUADRADA. 2) COEFICIENTES DE CORRELACION E INDEPENDNENCIA PARA TABULACIONES CRUZADAS. 3) LOS COEFICIENTES DE CORRELACION PARA RANGOS ORDENADOS DE SPERMAN Y KENDALL.")
34
Ji - CUADRADA Es una prueba estadística para evaluar hipótesis acerca de la relación entre dos variables. Se simboliza por : א² Prueba hipotesis Correlacionales Variables involucradas : dos ( no considera relaciones causales) Nivel de medicion de variables: Nominal y Ordinal.
 Nivel de medicion de variables: Nominal y Ordinal.")
35
Ji - CUADRADA La Chi – Cuadrada se calcula a traves de una Tabla de contingencia o Tabulacion cruzada, que constituye una Tabla de dos dimensiones o matriz de dos x dos. Cada dimension contiene una variable. Cada variable se subdivide en dos o mas categorias.

36
Distribución Ji-Cuadrado
La Prueba Ji-Cuadrado Distribución Ji-Cuadrado Supóngase que se tiene una serie de variables aleatorias independientes con distribución normal estándar, , entonces la variable aleatoria , sigue una distribución Ji-Cuadrado.

37
La Prueba Ji-Cuadrado FUNCIÓN DE DENSIDAD MEDIA Y VARIANZA.

38
Procedimientos para usar el análisis de ji cuadrada y probar la independencia de dos variables nominales Hipótesis nula: Las variables son independientes Se construye o se obtiene una tabla de tabulación cruzada para las frecuencias reales observadas (Oij ) Suponiendo que las variables son independientes, se construye una tabla de tabulación cruzada para las frecuencias teóricas ( Eij) Se determina el nivel de significado deseado en la prueba. Se determina el valor calculado del estadístico ji cuadrada
 Suponiendo que las variables son independientes, se construye una tabla de tabulación cruzada para las frecuencias teóricas ( Eij) Se determina el nivel de significado deseado en la prueba. Se determina el valor calculado del estadístico ji cuadrada.")
39
Tabla 4. Distribución de ji-cuadrado Probabilidad de un valor superior
USO DE LA TABLA Tabla 4. Distribución de ji-cuadrado Probabilidad de un valor superior Grados de libertad 0,1 0,05 0,025 0,01 0,005 1 2,71 3,84 5,02 6,63 7,88 2 4,61 5,99 7,38 9,21 10,60 3 6,25 7,81 9,35 11,34 12,84 4 7,78 9,49 11,14 13,28 14,86 5 9,24 11,07 12,83 15,09 16,75 6 10,64 12,59 14,45 16,81 18,55 7 12,02 14,07 16,01 18,48 20,28 8 13,36 15,51 17,53 20,09 21,95 9 14,68 16,92 19,02 21,67 23,59 10 15,99 18,31 20,48 23,21 25,19 El área sombreada de naranja representa la probabilidad que se determinada por , donde: es el valor critico del margen superior de la tabla, y son los grados de libertad del margen izquierdo de la tabla.

40
Tabla 4. Distribución de ji-cuadrado Probabilidad de un valor superior
Probabilidad de un valor superior Grados de libertad 0,1 0,05 0,025 0,01 0,005 1 2,71 3,84 5,02 6,63 7,88 2 4,61 5,99 7,38 9,21 10,60 3 6,25 7,81 9,35 11,34 12,84 4 7,78 9,49 11,14 13,28 14,86 5 9,24 11,07 12,83 15,09 16,75 6 10,64 12,59 14,45 16,81 18,55 7 12,02 14,07 16,01 18,48 20,28 8 13,36 15,51 17,53 20,09 21,95 9 14,68 16,92 19,02 21,67 23,59 10 15,99 18,31 20,48 23,21 25,19 Uso de la tabla Ji-Cuadrado

41
EJEMPLO Martha Revilla, directora de mantenimiento de la calidad en MEGA, elige 29 bicicletas y halla una varianza en la distancia entre ejes de 32.7 pulgadas cuadradas. Si la señora Revilla tienen que garantizar que la variación no supere 27 pulgadas cuadradas ¿indica esto que se cumplen las normas de producción? (α=0.05) Hipótesis Prueba de una cola a la derecha
 Hipótesis. Prueba de una cola a la derecha.")
42
0.05 41.337 33.91 Como X2=33.91< la señora Revilla no rechazará la H0 y confiará al 95% en que se cumplen las normas de producción

43
Prueba de una cola a la izquierda
¿Que pasaría, si las instrucciones de la señora Revilla fueran que la variación se mantuviera inferior a 27 pulgadas cuadradas? Prueba de una cola a la izquierda 0.05 16.928 33.91 X2 =33.91, la señora Revilla no rechazará la H0 y confiará al 95% en que se cumplen las normas de producción

44
La señora Revilla, ahora elabora un intervalo de confianza del 90% para la varianza de la distancia entre ejes. 0.90 0.05 0.05 16.928 41.337 0.95 Revilla puede confiar al 90% en que la varianza de la distancia entre ejes se encuentra entre y pulgadas cuadradas

45
Prueba Ji-Cuadrado de Independencia
H0: Las variables X e Y son independientes H1: Existe asociación entre X e Y Y X Categ. 1 ...... Categ. s Total Cat. 1 O11 O1s R1 ..... Cat. r Or1 Ors Rr C1 Cs n

46
Prueba Ji-Cuadrado de Independencia
Estadística

47
Ejemplo de Prueba Ji-Cuadrado de independencia
Para verificar la suposición de que la fabricación de cierto producto está asociado con enfermedades respiratorias, a 450 trabajadores de una empresa que fabrica el producto se evaluó respecto a la presencia de síntomas de alteraciones respiratorias y se los clasificó a su vez de acuerdo al nivel de exposición al producto. Los resultados se presentan en la tabla siguiente: Presencia de Síntoma Nivel de Exposición Total Alto Medio Bajo Si 175 43 27 245 No 90 60 55 205 265 103 82 450

48
Frecuencias Esperadas:
H0: Las alteraciones respiratorias son independientes de la exposición al producto. H1: Las alteraciones respiratorias están asociadas a la exposición al producto Frecuencias Esperadas: Por ejemplo: Presencia de Síntoma Nivel de Exposición Total Alto Medio Bajo Si 144.3 56.1 44.6 245 No 120.7 46.9 37.4 205 265 103 82 450

49
Estadística

50
Que sigue una distribución Ji-cuadrado con
(n-1)*(C-1)=( 2-1)*(3-1)=2 grados de libertad En conclusión, se rechaza la H0 (p < 0.05), es decir las alteraciones respiratorias están asociadas a la exposición al producto
*(C-1)=( 2-1)*(3-1)=2 grados de libertad. En conclusión, se rechaza la H0 (p < 0.05), es decir las alteraciones respiratorias están asociadas a la exposición al producto.")
51
Distribución F de Snedecor
Si y son variables Ji-cuadrado distribuidas en forma independiente con y grados de libertad, respectivamente, la variable sigue la distribución F con y grados de libertad.

52
Tabla F de Fisher α=0.05 con letra normal. α=0.01 con letra negrita

53
Ejemplo de uso de la tabla F de Fisher

54
Ejemplo de Aplicación Deseamos probar las hipótesis:
De dos aulas de 5ª año de secundaria se tomaron muestras de tamaños 10 y 15 de las notas promedios de alumnos para probar si la dispersión de las notas es la misma para las dos aulas. Los resultados obtenidos son los siguientes: Aula 1: 15, 16, 12, 14, 14, 15, 16, 13, 14, 15. Aula 2: 12, 14, 15, 16, 16, 17, 15, 16, 18, 14, 12, 15, 16, 14, 13. Deseamos probar las hipótesis:

55
Luego Si , entonces para las cuantilas y Luego concluimos que la dispersión de las notas entre los alumnos para las dos aulas de 5ª año son las mismas, pues no se encuentra diferencia significativa.

56
EJEMPLO La compañía llantera Good Year del Perú, ha efectuado un estudio sobre los hábitos de manejo de varios grupos ocupacionales. En una muestra de 35 profesores universitarios, el número promedio de kilómetros recorridos al año fue de 14,500 con una desviación standart de 3,200 km. En una muestra de 40 dentistas, el kilometraje fue de 13,400, con una desviación standart de 1,950 km. Se tiene

57
Primero se verificará la condición siguiente: 1 2
Planteamos las Hipótesis:

58
Se rechaza la H0, es decir que 1 2
Para α=0.05 0.025 0.95 0.025 0.515 1.9 2.693 Se rechaza la H0, es decir que 1 2

59
Y los valores críticos son: -1,220.3 y +1,220.3
Luego, se prueba la hipótesis: Diferencia de las medias muestrales Valores críticos Y los valores críticos son: -1,220.3 y +1,220.3

60
+1050 = diferencia observada entre las medias muestrales.
Se acepta la hipótesis nula Se Rechaza Se Rechaza Área =0.025 Área =0.025 Z= -1.96 Z= +1.96 Valor critico Valor critico +1050 = diferencia observada entre las medias muestrales.

61
Ejercicio Como la diferencia entre las medias muestrales es de 1050 millas y se acepta un margen de error de millas, en consecuencia, no hay diferencias significativas entre los dos grupos

62
EJEMPLO Freddy Lopez, operador de la cadena de restaurantes “Las Tejas””, ha hecho una encuesta entre los clientes en dos ciudades, pues desea averiguar si les gustaría que en el menú se incluyeran sandwiches de jamón y queso. De las 500 personas encuestadas en la capital, 200 contestaron afirmativamente, mientras que 150 de las 300 encuestadas en una ciudad cercana también contestaron afirmativamente. Freddy quiere saber si, en un nivel de 0.05 esos resultados son significativamente diferente. En resumen

63
Se tiene Primero se determinará si se cumple lo siguiente: 1 ≠ 2
Planteamos las Hipótesis:

64
Se rechaza la H0, es decir que 1 ≠ 2
Para α=0.05 0.025 0.95 0.025 0.8184 1.228 0.576 Se rechaza la H0, es decir que 1 ≠ 2

65
Y los valores críticos son: -0.071 y +0.071
Luego, se prueba la hipótesis: Diferencia de las proporciones muestrales Valores críticos Y los valores críticos son: y

66
Se acepta la hipótesis nula
Se rechaza Se rechaza Área =0.025 Área =0.025 Z= -1.96 Z= +1.96 Diferencia observada entre las proporciones muestrales = ( ) =-0.10 -0.071 Valor critico +0.071 Valor critico
 = Valor. critico Valor critico.")
67
Ejercicio Como la diferencia entre las proporciones muestrales es de y se acepta un margen de error de 0.071, en consecuencia, si hay diferencias significativas entre los dos grupos

68
FIN MUCHAS GRACIAS

Presentaciones similares