Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Análisis de Datos Atmosféricos Regresión lineal 1 Francisco Estrada Porrúa

2
Contenido 1. ¿Qué es el modelo de regresión y cuál es su propósito? 2. ¿Cómo determinar la confiabilidad/calidad de un modelo estadístico? 3. Pasos en modelación empírica 4. Supuestos de regresión 5. Mínimos cuadrados ordinarios (MCO) 6. Propiedades de los estimadores y supuestos 7. Medidas de bondad de ajuste 8. Evaluación de supuestos 9. Corrección de supuestos
 6. Propiedades de los estimadores y supuestos 7. Medidas de bondad de ajuste 8. Evaluación de supuestos 9. Corrección de supuestos.")
3
¿Qué es el modelo de regresión y cuál es su propósito? Y t =a+bX t +u t Predecir o estimar la media de Y con respecto a X, cuantificar relación entre variables, aprender sobre el proceso E(Y t | I t )=a+bX t (componente sistemático) en general: E(Y t | I t )≠ E(Y t | H t )≠ E(Y t ) Ejemplos E(T df,t )=15ºC; E(T df,t | mayo)=18ºC E(T df,t ) ≠ E(T df,t | ENSO) ≠ E(T df,t | ENSO,…)
=a+bX t (componente sistemático) en general: E(Y t | I t )≠ E(Y t | H t )≠ E(Y t ) Ejemplos E(T df,t )=15ºC; E(T df,t | mayo)=18ºC E(T df,t ) ≠ E(T df,t | ENSO) ≠ E(T df,t | ENSO,…).")
4
a+bXt Línea de regresión

5
¿Qué representan los coeficientes de regresión?

6
Es decir, representa los efectos de sobre Y dado lo que ya explicaron el resto de las variables independientes incluidas en el modelo Cadarepresenta el efecto parcial de sobre Y

7
¿Qué representa u t ? ¿Qué implica u t para el modelo de regresión? El error aleatorio permite que ante mismos valores de las variables explicativas, el efecto sobre Y t sea variado, de pendiendo de la interacción de otros factores. Relación determinística Relación estocástica Modelo probabilístico

8
Y t =a+bX t +u t μ t =a+bX t Componente sistemático u t Componente aleatorio (no sistemático) I t debe ser tal que u t no tiene información sistemática (u t similar a ruido blanco) ¿Cómo sabemos cual I t es el bueno?
 I t debe ser tal que u t no tiene información sistemática (u t similar a ruido blanco) ¿Cómo sabemos cual I t es el bueno")
9
I t =(AMO, SOI) I t =(AMO, SOI, SOLAR, VOLCANO) I t =(AMO, SOI, SOLAR, VOLCANO, GHG) I t =(AMO, SOI, TRF,…) Ejemplo: modelos de regresión para T global TtTt μtμt utut
 I t =(AMO, SOI, SOLAR, VOLCANO) I t =(AMO, SOI, SOLAR, VOLCANO, GHG) I t =(AMO, SOI, TRF,…) Ejemplo: modelos de regresión para T global TtTt μtμt utut")
10
¿Cómo determinar la confiabilidad/calidad de un modelo estadístico? Dos maneras comunes pero inadecuadas 1. Teoría únicamente

11
¿Cómo determinar la confiabilidad/calidad de un modelo estadístico? Dos maneras comunes pero inadecuadas 2. Reglas de dedo y maximización de R 2

12
Pasos en modelación empírica Teoría Modelo estimable Recolección de datos Estimación del modelo ¿Es el modelo estadísticamente adecuado? NoSí Reformular el modeloInterpretación del modelo Uso del modelo Análisis, pronóstico, etc. ¿Tiene sentido? Reespecificación

13
Recomendaciones para la modelación empírica Graficar datos es esencial No olvidar que un modelo estadístico es un conjunto de suposiciones probabilísticas Ningún resultado de inferencia estadística debe ser utilizado para concluir algo a menos de que se haya establecido que el modelo es estadísticamente adecuado Ninguna teoría, por sofisticada que sea, puede arreglar o validar un modelos estadístico inadecuado Un buen modelo empírico debe sintetizar los modelos estadístico y teórico sin que ninguno de los dos quede mal representado

14
Supuestos del modelo de regresión lineal Correcta especificación Forma funcional Permanencia estructural Normalidad No autocorrelación Homoscedasticidad Exogeneidad E(u t |X i,t )=0; cov(u t |X i,t )=0 No multicolinealidad Varianza de variables (excepto a) es >0 T >k ~ i.i.d
=0; cov(u t |X i,t )=0 No multicolinealidad Varianza de variables (excepto a) es >0 T >k ~ i.i.d")
15
Supuestos del modelo de regresión lineal Correcta especificación El componente sistemático propuesto es el correcto, no hay variables de más ni de menos. Variables omitidas Variables redundantes

16
Correcta especificación: el caso de variables omitidas Modelo verdadero: Modelo estimado: Entonces donde El coeficiente es insesgado únicamente si y/o son iguales a cero. recoge parcialmente el efecto de Zt sobre yt.

17
Correcta especificación: el caso de variables redundantes Modelo verdadero: Modelo estimado: es insesgado Pero es mayor. ¿Porqué importa? Es más fácil aceptar la hipótesis nula

18
Forma funcional Se asume que el modelo de regresión clásico es lineal Ojo: lineal en los parámetros no en las variables

19
Permanencia estructural Los parámetros de la regresión son estables y válidos para toda la muestra La relación entre las variables es estable durante el periodo de muestra

20
Normalidad Los errores de la regresión se distribuyen de manera normal Pruebas de hipótesis (t, chi-sq, F…) requieren normalidad ~ i.i.d ~ t ~ F ~
 requieren normalidad ~ i.i.d ~ t ~ F ~")
21
Homoscedasticidad La varianza de u t es constante (no cambia ni con t ni con los valores de X t ) El coeficiente de regresión sigue siendo insesgado pero no así los errores estándar de los coeficientes. Estadísticos de prueba ya nos son válidos

22
No autocorrelación Los errores u t son independientes Autocorrelación de primer orden Autocorrelación de orden k El coeficiente de regresión sigue siendo insesgado. Los errores estándar y estadísticos de prueba ya nos son válidos

23
Exogeneidad u t y X t son independientes. Implica que x t y u t tienen una influencia separada y aditiva sobre y t. Si x t y u t están correlacionadas no es posible determinar sus efectos individuales sobre y t. Si no se cumple, las estimaciones no son validas. Los residuales son ortogonales a las variables explicativas y al los valores ajustados de yt (¿por qué?)
.")
24
¿Por qué no habría exogeneidad? donde Ut contiene los efectos de un montón de variables que afectan a yt (pero se supone que no de manera sistemática). En este caso zt si afecta de forma sistemática. Para resolver este problema se necesita el método de variables instrumentales (no lo vamos a ver)
. En este caso zt si afecta de forma sistemática. Para resolver este problema se necesita el método de variables instrumentales (no lo vamos a ver).")
25
Multicolinealidad Los regresores no están correlacionados: x t y z t tienen una influencia separada y aditiva sobre y t. Si x t y z t están correlacionadas no es posible determinar sus efectos individuales sobre yt. Multicolinealidad perfecta Alguna de las variables incluidas en el modelo es una combinación lineal de otras variables. No se puede estimar la regresión (X’X no es invertible) Multicolinealidad imperfecta Las variables explicativas están altamente correlacionadas. X’X es cercana a no ser invertible: problemas numéricos. El modelo sí se puede estimar pero los errores estándar están inflados y pequeños cambios en la regresión modifican mucho los valores de los coeficientes estimados.
 Multicolinealidad imperfecta Las variables explicativas están altamente correlacionadas. X’X es cercana a no ser invertible: problemas numéricos. El modelo sí se puede estimar pero los errores estándar están inflados y pequeños cambios en la regresión modifican mucho los valores de los coeficientes estimados..")
26
Repaso: Supuestos del modelo de regresión lineal Correcta especificación Forma funcional Permanencia estructural Normalidad No autocorrelación Homoscedasticidad Exogeneidad E(u t |X i,t )=0; cov(u t |X i,t )=0 No multicolinealidad Varianza de variables (excepto a) es >0 T >k ~ i.i.d
=0; cov(u t |X i,t )=0 No multicolinealidad Varianza de variables (excepto a) es >0 T >k ~ i.i.d")
27
Estimación por Mínimos Cuadrados Ordinarios (MCO o LS)
")
28
Mínimos Cuadrados Ordinarios (MCO o LS) Así como para estimar la media y la varianza (por ejemplo) encontramos estimadores con propiedades deseables, lo mismo vamos a hacer para los coeficientes de regresión. A los estimadores de los coeficientes de regresión les vamos a pedir que sean: 1) Insesgados 2) Mínima varianza 3) Consistentes
 Insesgados 2) Mínima varianza 3) Consistentes.")
29
1) Insesgado Las estimaciones que se hagan del parámetro pueden estar muy lejos parámetro real o poblacional pero en promedio obtendremos el valor verdadero Insesgado Sesgado
 Insesgado Las estimaciones que se hagan del parámetro pueden estar muy lejos parámetro real o poblacional pero en promedio obtendremos el valor verdadero Insesgado Sesgado")
30
2) Mínima varianza (eficiente) Entre todos los estimadores insesgados se va a escoger el de mínima varianza
 Mínima varianza (eficiente) Entre todos los estimadores insesgados se va a escoger el de mínima varianza")
31
Consistencia Un estimador es consistente si según el tamaño de la muestra aumente, más me voy a acercar al verdadero valor del parámetro

32
Teorema de Gauss-Markov Dados los supuestos anteriores los estimadores de MCO son de mínima varianza dentro de la clase de estimadores lineales insesgados. MELI (BLUE): Mejores estimadores lineales insesgados (también son consistentes) Lineal, insesgado y de mínima varianza (eficiente)
: Mejores estimadores lineales insesgados (también son consistentes) Lineal, insesgado y de mínima varianza (eficiente).")
33
Mínimos cuadrados ordinarios Y x (u i ) 2 uiui Minimizar los errores al cuadrado: 1)No se cancelan positivos y negativos (E(ui)=0) 2)Función de pérdida: MCO penaliza más por errores más grandes que por errores más pequeños
 2 uiui Minimizar los errores al cuadrado: 1)No se cancelan positivos y negativos (E(ui)=0) 2)Función de pérdida: MCO penaliza más por errores más grandes que por errores más pequeños")
34
MCO regresión simple Derivar parcialmente con respecto a los parámetros, obtener las condiciones de primer orden y resolver (TAREA) Estimadores de Mínimos Cuadrados Ordinarios
 Estimadores de Mínimos Cuadrados Ordinarios")
35
Regresión múltiple donde

37
Estimador de MCO

38
¿Es realmente un estimador insesgado?

39
¿Es un estimador insesgado?

40
¿ Es realmente de mínima varianza?

43
Supuesto de normalidad

44
Normalidad y pruebas de hipótesis

45
Resumen MCO Normalidad es necesaria para realizar pruebas de hipótesis

46
Medidas de bondad de ajuste

48
Problemas de la R 2 Si aumento el número de variables explicativas forzosamente la R 2 va a aumentar R 2 (ajustada)=1-(1- R 2 )(T-1)/(T-k) penaliza al incluir más variables explicativas Si regreso dos variables con tendencia la R 2 va a ser muy alta y probablemente la relación sea espuria. Regla de dedo: Desconfiar de regresiones con R 2 muy altas

49
Problemas de la R 2 El tamaño de la R 2 no es muy importante. La R 2 por sí sola no da evidencias a favor o en contra de un modelo (se quiere aproximar el proceso generador de datos, no maximizar la R 2 ) La calidad estadística de un modelo y su utilidad para inferencia depende de que se cumplan los supuestos den los que el modelo descansa Una vez que se cumplen los supuestos podemos ver que tan bueno es el ajuste utilizando la R 2 o R 2 la ajustada. Solo así tiene sentido hablar de la R 2
 La calidad estadística de un modelo y su utilidad para inferencia depende de que se cumplan los supuestos den los que el modelo descansa Una vez que se cumplen los supuestos podemos ver que tan bueno es el ajuste utilizando la R 2 o R 2 la ajustada. Solo así tiene sentido hablar de la R 2.")
50
Evaluación de supuestos Principio de adición de variables

51
Evaluación de supuestos Principio de adición de variables

52
Evaluación de supuestos

53
Pruebas para la evaluación de supuestos

54
Ramsey RESET Es una prueba general para detectar errores de especificación en el modelo Además de detectar una forma funcional incorrecta sirve para detectar: Errores por variables omitidas Correlación entre las variables explicativas y el término de error (no exogeneidad)
")
55
Ramsey RESET

58
Correcta especificación

61
No autocorrelación

62
No autocorrelación: Durbin-Watson

66
Autocorrelación: Breusch- Godfrey

67
Autocorrelación: Ljung-Box

68
Normalidad: Q-Q plots

69
Normalidad: histograma y estadísticas descriptivas Normal Asimetría = 0 Curtosis = 3

70
Normalidad: Jarque-Bera S = Asimetría K = Curtosis

71
Homoscedasticidad: gráficas Homoscedasticidad Heteroscedasticidad

72
Homoscedasticidad: White

73
Homoscedasticidad: ARCH

75
Permanencia estructural: Chow

78
Permanencia estructural: Quandt-Andrews

79
Permanencia estructural: errores recursivos

80
Permanecia estructural: CUSUM

81
Permanecia estructural: CUSUMQ

82
Multicolinealidad

83
Corrección de supuestos ¿Tiene sentido? Reespecificación Teoría Modelo estimable Recolección de datos Estimación del modelo ¿Es el modelo estadísticamente adecuado? NoSí Reformular el modeloInterpretación del modelo Uso del modelo Análisis, pronóstico, etc.

84
Soluciones genéricas: MCG

86
Outliers Efectos sobre normalidad, forma funcional, valores estimados de betas…

87
Variables dummy Observaciones aberrantes Cambios estructurales Estacionalidad Diferencias en medias Clasificación de observaciones Etc..

88
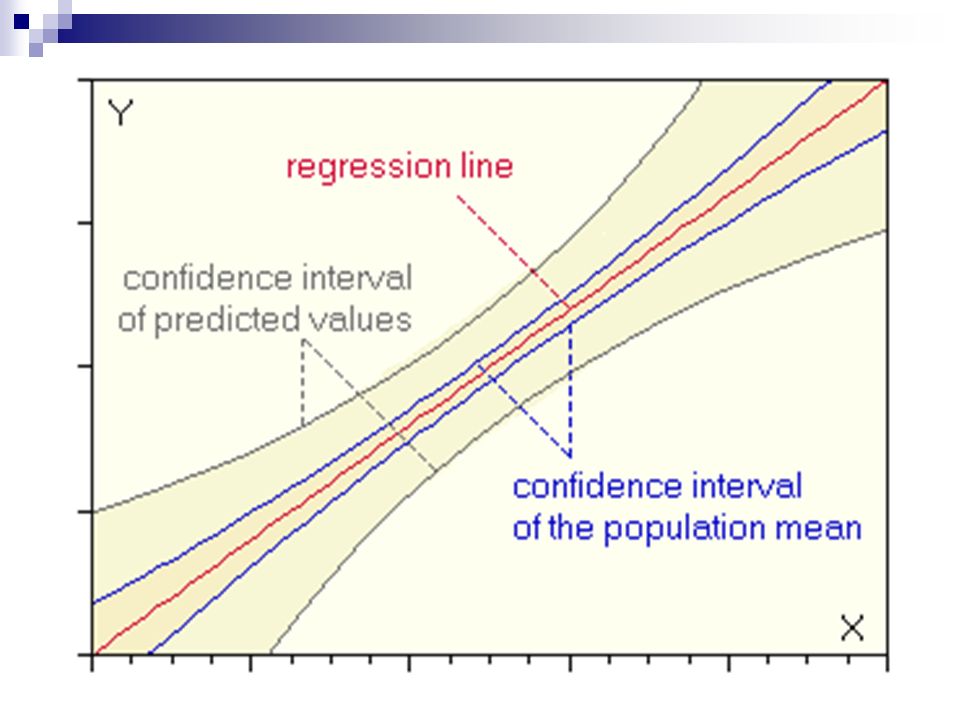
Predicción media (intervalos de la media estimada) Predicción: sustituir valores particulares de X en la regresión estimada
 Predicción: sustituir valores particulares de X en la regresión estimada")
89
Predicción individual (datos fuera de muestra) Predicción: sustituir valores particulares de X en la regresión estimada
 Predicción: sustituir valores particulares de X en la regresión estimada")
91
Evaluación de la predicción

92
0<U<1

93
Modelos de series de tiempo ARMA y VAR

94
Series de tiempo: descomposición Tendencia Ciclo Estacionalidad Componente irregular Componente aleatorio puro

95
Procesos estocásticos

99
Estacionariedad estricta

100
Estacionariedad débil o de segundo orden

101
Procesos estocásticos estacionarios

102
Procesos estacionarios: media móvil

103
Procesos estocásticos no estacionarios (ejemplo)
")
104
Procesos autorregresivos de primer orden

106
Box-Jenkins: Método para modelos ARMA(p,q) Pasos del método:
 Pasos del método:")
107
Comportamiento de las funciones de autocorrelación y de auto correlación parcial

108
Criterios para la selección de p y q

109
Condiciones de estabilidad Ecuación característica inversa Condición de estabilidad

110
Condiciones de estabilidad Ecuación característica inversa Encontrar las soluciones usando Raíces reales Raíces complejas Condición de estabilidad: Las raíces de la ecuación característica deben caer dentro del circulo unitario

111
Condiciones de estabilidad Eje horizontal: parte real Eje vertical: parte imaginaria

112
VAR(1)
")
Presentaciones similares



















>")

>")















>")
