Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Modelos de Variable Dependiente Binaria -Logit y Probit-
Maestría en Evaluación de Proyectos ITBA-UCEMA Daniel Lema

2
Modelos Logit y Probit Modelos de regresión donde la variable dependiente es binaria o dummy Por ejemplo: Un modelo que trata de explicar los factores determinantes de que una familia sea propietaria de una casa. En particular, cuantificar la relación entre ingreso y propiedad

3
Se selecciona una muestra de hogares y se registra el ingreso y si la familia es propietaria o no de una casa. El modelo puede expresarse Yi=a + b Xi + ei Donde Yi = 1 si el hogar es propietario de su casa y cero en caso contrario. Xi es el ingreso del hogar i

4
Se puede aplicar MCO a este problema
Pero existen 3 inconvenientes 1. Las predicciones del modelo no necesariamente estarán entre cero y uno

5
2. Considere el término de error
2. Considere el término de error. Para un valor dado de Xi el término de error sólo puede tomar uno de los siguientes dos valores ei = 1 – a – bXi cuando Yi = 1 ei = – a – bXi cuando Yi = 0 En consecuencia los errores no se distribuyen como una normal (de hecho lo hacen como una binomial) 3. Se puede demostrar que los errores son heteroscedásticos
 3. Se puede demostrar que los errores son heteroscedásticos.")
6
Estos problemas no impiden absolutamente la aplicación de MCO
Se puede ajustar por heteroscedasticidad Los errores no normales son menos problemáticos en muestras grandes Predicciones negativas o mayores a uno no son un problema serio (pueden ignorarse, por ej.)
")
7
Sin embargo, algunos supuestos del modelo son restrictivos
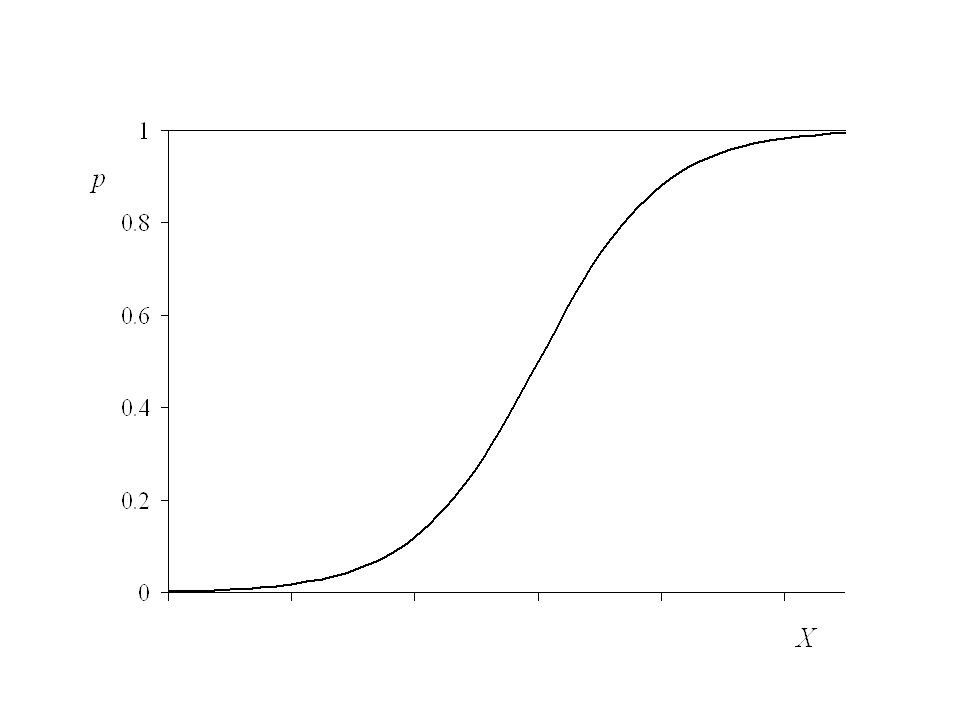
Por ejemplo la constancia del efecto marginal de un cambio en el ingreso sobre la probabilidad de ser propietario (b) Esperaríamos un efecto bajo para ingresos muy bajos y muy altos. Y un efecto mayor para ingresos promedio. Esto implicaría una relación de este tipo entre probabilidad de ser propietario e ingreso
 Esperaríamos un efecto bajo para ingresos muy bajos y muy altos. Y un efecto mayor para ingresos promedio. Esto implicaría una relación de este tipo entre probabilidad de ser propietario e ingreso.")
9
La relación es no lineal
La variable dependiente está restringida entre cero y uno Dos modelos producen una relación de este tipo Un modelo basado en la función logística Un modelo derivado de una función de distribución normal acumulada

10
Modelo Logit Expresando el modelo explícitamente en términos de probabilidades tenemos Pi = a + b Xi Donde Pi es la probabilidad de que el hogar i sea propietario de una casa Una relación que genera un gráfico como el anterior es:

11
Definimos la razón de probabilidades (odds ratio) como:
En el caso de la propiedad de casas representa la razón de la probabilidad de que una familia posea una casa respecto de la probabilidad de que no la posea. Por ejemplo, si Pi = 0.8 significa que las probabiliades son 4 a 1 a favor de que la familia posea una casa (0.8/0.2)
")
12
Si tomamos el logaritmo natural de la razón de probabilidades obtenemos
Entonces, el Li resulta lineal en X y también en los parámetros L es llamado modelo Logit

13
La interpretación del modelo es la siguiente:
b es la pendiente y mide el cambio en L ocasionado por un cambio unitario en X, es decir, dice cómo el logaritmo de las porbabilidades a favor de tener una casa cambian a mediada que el ingreso cambia en una unidad. a es el valor de L si el ingreso es cero

14
Dado un nivel de ingreso X
Dado un nivel de ingreso X* si se desea estimar la probabilidad de tener una casa (y no las probabilidades a favor de tener una casa) se puede calcular a partir de la definición de Pi una vez estimados los parámetros. El método de estimación es por Máxima Verosimilitud (MV)
 se puede calcular a partir de la definición de Pi una vez estimados los parámetros. El método de estimación es por Máxima Verosimilitud (MV)")
15
El Modelo Probit La aproximación al problema es similar al Logit pero se supone una relación no lineal distinta (aunque muy similar) entre Xi y Pi Se basa en la distribución normal acumulada Se supone que la decisión de poseer o no una casa depenede de un índice I (conocido como variable latente)
")
16
El índice I está determinado por una o varias variables explicativas
El índice I está determinado por una o varias variables explicativas. Por ej ingreso Cuanto mayor sea el índice mayor la probabilidad de tener una casa Ii = a + b Xi Se supone un umbral crítico I* a partir del cuál, si I supera a I* entonces una familia posee una casa. El umbral I*, al igual que I, no es observable Si se supone que está distribuido normalmente con la misma media y varianza es posible estimar los parámetros del índice y también alguna información sobre el I*.

17
Pi = P (Y=1|X) = P(I*i ≤ Ii)
= P(Zi ≤ a + b Xi) = F(a + b Xi) Donde Z es una variable estándar normal, Z ~ N(0, s2) F es la función de distribución normal acumulada
 = F(a + b Xi) Donde. Z es una variable estándar normal, Z ~ N(0, s2) F es la función de distribución normal acumulada.")
18
Explícitamente

19
Pi = F(Ii) Pi Pr (I*i≤ Ii) Ii = a + b Xi + ∞ - ∞
 Pi Pr (I*i≤ Ii) Ii = a + b Xi + ∞ - ∞")
20
Interpretación de los Coeficientes
Una diferencia fundamental respecto a los modelos lineales es que la influencia que tienen las variables explicativas sobre la probabilidad de elegir la opción dada por yi = 1 (la derivada parcial, dyi/dxi = βk en los modelos lineales) no es independiente del vector de características xi. Una primera aproximación a la relación entre las variables explicativas y la probabilidad resultante es calcular los efectos marginales sobre la variable latente (y*) .
 no es independiente del vector de características xi. Una primera aproximación a la relación entre las variables explicativas y la probabilidad resultante es calcular los efectos marginales sobre la variable latente (y*) .")
21
Si el efecto marginal expresa el cambio de la variable dependiente provocado por un cambio unitario en una de las independientes manteniendo el resto constante, los parámetros estimados del Logit y el Probit reflejan el efecto marginal de las xik en yi de la misma forma que en el MLP, puesto qe E (y*|x) = x´β.
 = x´β.")
22
Los efectos marginales pueden construirse sobre la probabilidad y, de hecho, este es el tipo de presentación más frecuente. El efecto de la k−ésima variable explicativa, manteniendo el resto constante, puede ser calculado como: siendo F (.) la función de distribución y f (.) la función de densidad.
 la función de distribución y f (.) la función de densidad.")
23
Por lo tanto, en un modelo binario la influencia que tienen las explicativas sobre la probabilidad de elegir la opción dada por yi = 1 no depende simplemente del valor los coeficientes, sino también del valor que toman las variables explicativas. Por ej: El efecto marginal máximo ocurrirá cuando Pr (y = 1) = 0.5
 = 0.5.")
24
Esto significa que, a diferencia de lo que ocurre en el MLP, el efecto de una variable sobre la probabilidad varía con el valor de esa variable (es decir, no es independiente del vector de características xi).
.")
25
En Logit En Probit

26
Los resultados previos suponen que si bien los coeficientes de estos modelos no son directamente interpretables, sus valores relativos si lo son. Por ej. el cociente βj/ βk mide la importancia relativa de los efectos marginales de las variables xj y xk. Dado que los efectos marginales varian con x resulta conveniente calcularlos para valores concretos de la variable. Los “efectos marginales medios”, obtenidos a partir de la media muestral de la variable, son una de las formas más comunes de presentación de losresultados

27
También se puede calcular, por ejemplo, el efecto medio respecto al conjunto de las
observaciones:

28
Inferencia La inferencia no presenta diferencias sustanciales respecto al Modelo Lineal Gaussiano, por lo que para llevar a cabo hipótesis sobre el valor de un coeficiente puede emplearse un estadístico de la t−Student tradicional (aunque, siendo rigurosos, la distribución apropiada sería la Normal).(ratio z) Por su parte, para contrastar la validez de un conjunto de restricciones como las que definen la significación global del modelo puede el test de razón de verosimilitud (LR)
.(ratio z) Por su parte, para contrastar la validez de un conjunto de restricciones como las que definen la significación global del modelo puede el test de razón de verosimilitud (LR)")
29
LR

30
Por ultimo, una forma de evaluación del modelo es la que se deriva de la bondad del ajuste.
Evidentemente, al tratarse de modelos no lineales carece de sentido plantear la bondad del ajuste en los t´erminos que definen el coeficiente de determinación (R2). Existen criterios alternativos que, en cierto modo, siguen la misma idea. Todas estas medidas deben interpretarse con cierta cautela Su validez como criterios de selección del modelo es ciertamente limitada.
. Existen criterios alternativos que, en cierto modo, siguen la misma idea. Todas estas medidas deben interpretarse con cierta cautela. Su validez como criterios de selección del modelo es ciertamente limitada.")
31
Una medida es el pseudo R2 de Mc Fadden:
En este caso, si los coeficientes son poco significativos la capacidad explicativa del modelo será muy reducida y el Loglikelihood sin restricciones será muy similar al L0; por el contrario, cuanto mayor sea la capacidad explicativa del modelo, más proximo estará R2 a uno.

Presentaciones similares

>")

















