Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Modelos de Variable Dependiente Binaria MLP-Logit - Probit-
UNIVERSIDAD NACIONAL JORGE BASADRE GROHOMANN ESCUELA DE POSTGRADO Modelos de Variable Dependiente Binaria MLP-Logit - Probit-

2
MODELOS DE ELCCION DISCRETA BINARIA
Modelos de regresión donde la variable dependiente es binaria o dummy, categóricas, dicótomas, binarias, ficticias o cualitativas. Por ejemplo: Un modelo que trata de explicar los factores determinantes de que una familia sea propietaria de una casa. En particular, cuantificar la relación entre ingreso y propiedad

3
Se selecciona una muestra de hogares y se registra el ingreso y si la familia es propietaria o no de una casa. El modelo puede expresarse Yi=a + b Xi + ei Donde Yi = 1 si el hogar es propietario de su casa y cero en caso contrario. Xi es el ingreso del hogar i

4
Se puede aplicar MCO a este problema
Pero existen 3 inconvenientes 1. Las predicciones del modelo no necesariamente estarán entre cero y uno

5
2. Considere el término de error
2. Considere el término de error. Para un valor dado de Xi el término de error sólo puede tomar uno de los siguientes dos valores ei = 1 – a – bXi cuando Yi = 1 ei = – a – bXi cuando Yi = 0 En consecuencia los errores no se distribuyen como una normal (de hecho lo hacen como una binomial) 3. Se puede demostrar que los errores son heteroscedásticos
 3. Se puede demostrar que los errores son heteroscedásticos.")
6
Estos problemas no impiden absolutamente la aplicación de MCO
Se puede ajustar por heteroscedasticidad Los errores no normales son menos problemáticos en muestras grandes Predicciones negativas o mayores a uno no son un problema serio (pueden ignorarse, por ej.)
")
7
Sin embargo, algunos supuestos del modelo son restrictivos
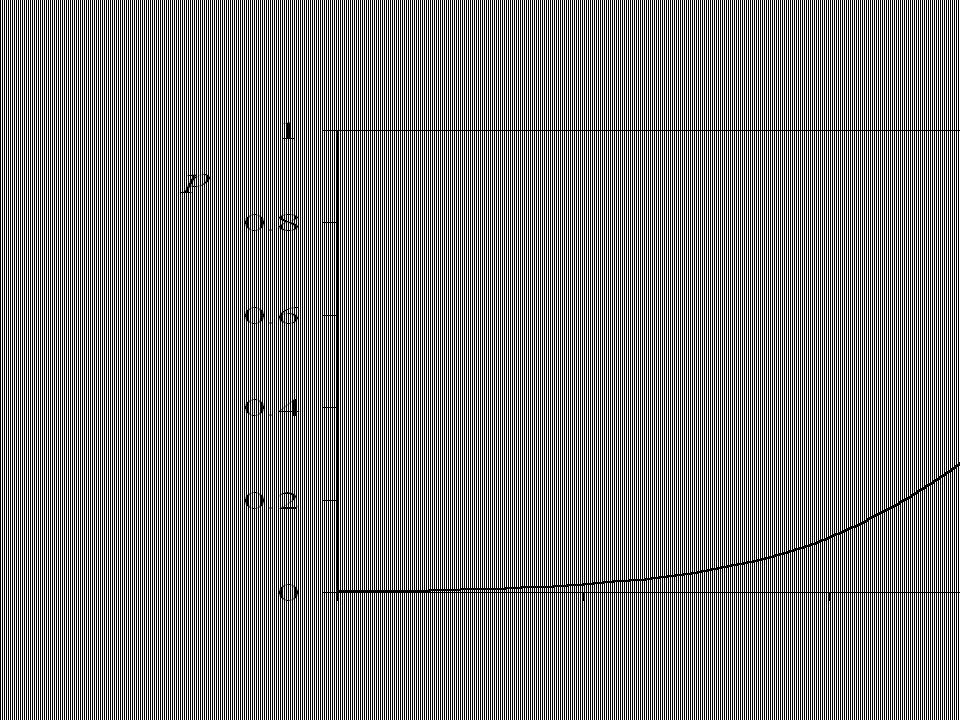
Por ejemplo la constancia del efecto marginal de un cambio en el ingreso sobre la probabilidad de ser propietario (b) Esperaríamos un efecto bajo para ingresos muy bajos y muy altos. Y un efecto mayor para ingresos promedio. Esto implicaría una relación de este tipo entre probabilidad de ser propietario e ingreso
 Esperaríamos un efecto bajo para ingresos muy bajos y muy altos. Y un efecto mayor para ingresos promedio. Esto implicaría una relación de este tipo entre probabilidad de ser propietario e ingreso.")
9
La relación es no lineal
La variable dependiente está restringida en la que tiene solo dos posibles respuestas excluyentes entre cero y uno Los modelos producen una relación de este tipo son: MODELO LINEAL DE PROBABILIDAD MODELO LOGIT MODELO PROBIT

10
MODELO LINEAL DE PROBABILIAD
Partimos del modelo de regresión lineal habitual. Una de cuya hipótesis es : Lo que nos lleva a escribir el modelo:

11
Pero el caso de los modelos de la elección discreta En lo que el conjunto de elección tiene solo dos alternativas posibles mutuamente excluyentes . Y es una variable aleatoria de Bernoulli de parámetro P, lo que nos permite escribir: Estamos ahora ante el modelo lineal de probabilidad, donde, por ejemplo, mide la variación en la probabilidad de éxito ( y=1) ante la variación unitaria en x1 ( con todas las demás variables constantes) Como Y es una variable aleatoria de Bernoulli
 ante la variación unitaria en x1 ( con todas las demás variables constantes) Como Y es una variable aleatoria de Bernoulli .")
12
Para cada observación Ya que Y es una variable aleatoria de Bernoulli Como estamos entonces ante un modelo con heteroscedasticidad porque la varianza del error no es constante y no cumple la hipótesis de normalidad por lo que aplicamos el método de máxima verosimilitud Mediante el método de WHITE . Y su estimación será: Se puede interpretar como una estimación de la probabilidad de éxito (de que y=1) en algunas aplicaciones tiene sentido interpretar como la probabilidad de éxito cuando todas la xi valen cero
 en algunas aplicaciones tiene sentido interpretar como la probabilidad de éxito cuando todas la xi valen cero.")
13
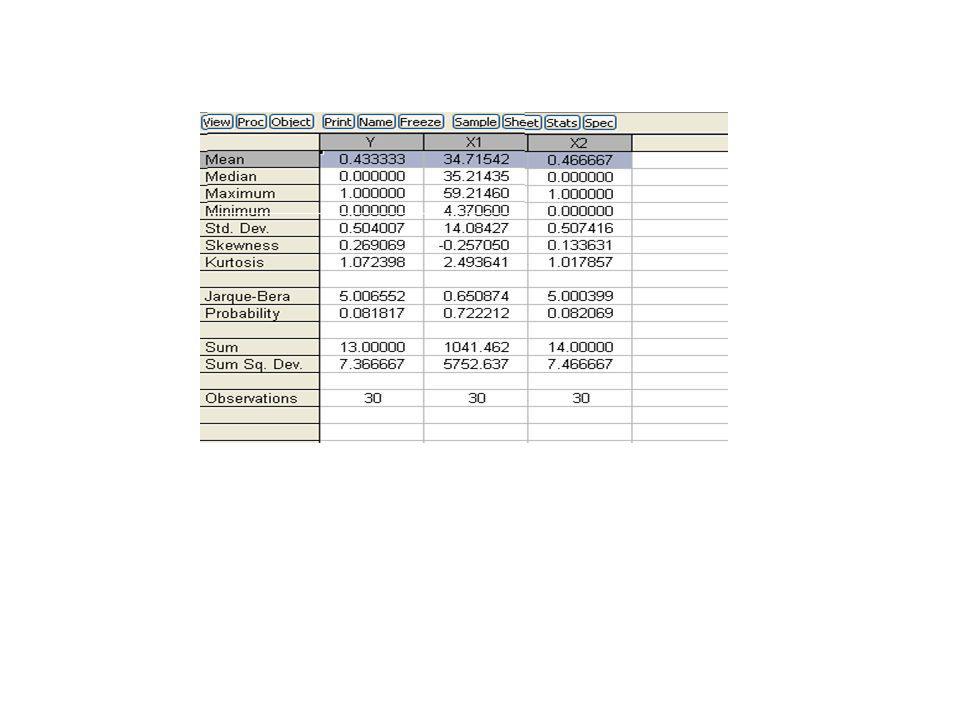
Ejemplo: El departamento de comercialización de una agencia de viajes y entretenimiento que opera mediante tarjetas de crédito está a punto de iniciar una campaña para convencer a los actuales clientes que poseen una tarjeta de crédito estándar de la compañía para que la cambien por una de sus tarjetas premium. La principal decisión que enfrenta el departamento de comercialización tiene que ver con la cuestión de saber a cuáles de los clientes con tarjeta estándar debe dirigirse la campaña. Los datos disponibles correspondientes a una muestra de 30 poseedores de tarjeta, que fueron contactados durante la campaña del año anterior, indican lo siguiente: El poseedor pasó de tener una estándar a una tarjeta premium: 1= SI, 0= No (Variable X1) Cantidad total de adquisiciones por tarjeta el año anterior, estuvo medida en miles de dólares gastados (variable X2). Si el poseedor de tarjetas de crédito estándar tiene tarjetas adicionales para otros miembros de su familia: 1= Si lo tiene, 0= No lo tiene. Los datos son los siguientes:
 Cantidad total de adquisiciones por tarjeta el año anterior, estuvo medida en miles de dólares gastados (variable X2). Si el poseedor de tarjetas de crédito estándar tiene tarjetas adicionales para otros miembros de su familia: 1= Si lo tiene, 0= No lo tiene. Los datos son los siguientes:")
14
Comportamiento de adquisición Gastos anuales
Posesión de tarjeta de crédito adicional 1 4.3706 8.1263 31.322 30.228

15
SOLUCION Planteamos el siguiente MLP Luego usando EVIEWS:

16
Pero el problema relevante en un MPL es la heteroscedasticidad.

17
Usamos la prueba de white para determinar la heteroscedasticidada

18
Como se puede observar los P-valores de F y Chi-cuadrado son mayores que 0.05 luego no existe heteroscedasticidad

19
Como algunos coeficientes son no significativos
Como algunos coeficientes son no significativos. Utilizaremos entonces para la estimación el METODO ROBUSTO DE WHITE según la fig.

20
Se observa que todas las variables son significativas y se tienen los signos esperados, tambien se observa una fuerte significación conjunta. El modelo será: Pest= X X2

21
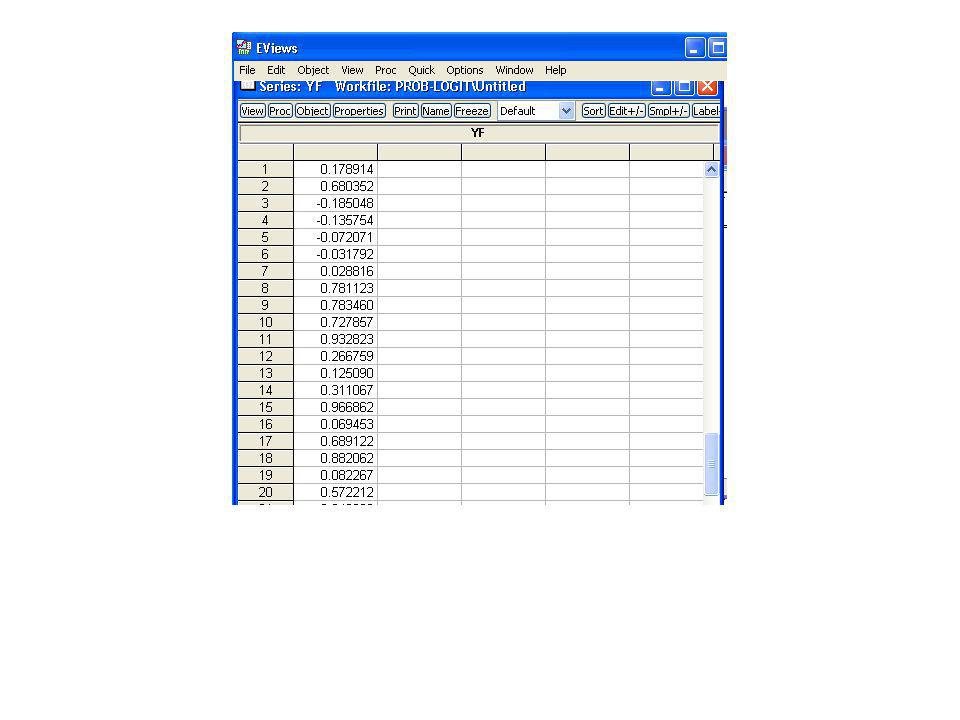
Uno de los problemas del modelo de MLP es que las estimaciones de las probabilidades algunas pueden ser menores que 0 o mayores que 1 podemos calcular para todas las tarjetas de crédito. Para ello se hace clik en forecast y se obtiene la fig. siguiente luego aceptar.

22
se obtiene todas las estimaciones de Pest
se obtiene todas las estimaciones de Pest. Y haciendo doble clik en yf se observa los valores de las probabilidaes.

24
Modelo Logit Expresando el modelo explícitamente en términos de probabilidades tenemos Pi = a + b Xi Donde Pi es la probabilidad de que el hogar i sea propietario de una casa Una relación que genera un gráfico como el anterior es:

25
Definimos la razón de probabilidades (odds ratio) como:
En el caso de la propiedad de casas representa la razón de la probabilidad de que una familia posea una casa respecto de la probabilidad de que no la posea. Por ejemplo, si Pi = 0.8 significa que las probabiliades son 4 a 1 a favor de que la familia posea una casa (0.8/0.2)
")
26
Si tomamos el logaritmo natural de la razón de probabilidades obtenemos
Entonces, el Li resulta lineal en X y también en los parámetros L es llamado modelo Logit En este caso usamos la regresión logística

27
Curva Logística P=Y 1 X -a +a

29
Li es el logaritmo de la razón de probabilidades y es lineal en los parámetros.
En los modelos Logit se pueden añadir varias regresoras X1, X2, …Xk. Tanto Z como L varían de –a a +a. Si L el Logit es positivo, significa que cuando el valor de las regresoras se incrementa, aumenta la posibilidad que la regresada sea igual a 1 (lo cual indica que sucederá algo de interés). Si L es negativo, las posibilidades de que la regresada iguale a 1 disminuyen conforme el valor de X se incrementa en magnitud. La interpretación del Logit es: b1 la pendiente, mide el cambio en L ocasionado por un cambio unitario en X. Dice cómo el Logaritmo de la razón de probabilidades a favor de poseer una casa cambia a medida que el ingreso cambia en una unidad. La intersección no tiene sentido físico. Si se desea estimar la probabilidad de poseer una casa usar la expresión:
. Si L es negativo, las posibilidades de que la regresada iguale a 1 disminuyen conforme el valor de X se incrementa en magnitud. La interpretación del Logit es: b1 la pendiente, mide el cambio en L ocasionado por un cambio unitario en X. Dice cómo el Logaritmo de la razón de probabilidades a favor de poseer una casa cambia a medida que el ingreso cambia en una unidad. La intersección no tiene sentido físico. Si se desea estimar la probabilidad de poseer una casa usar la expresión:")
30
Para lo cual debe disponerse previamente de Zi= α+bX

31
La interpretación del modelo es la siguiente:
b es la pendiente y mide el cambio en L ocasionado por un cambio unitario en X, es decir, dice cómo el logaritmo de las porbabilidades a favor de tener una casa cambian a mediada que el ingreso cambia en una unidad. a es el valor de L si el ingreso es cero

32
Dado un nivel de ingreso X
Dado un nivel de ingreso X* si se desea estimar la probabilidad de tener una casa (y no las probabilidades a favor de tener una casa) se puede calcular a partir de la definición de Pi una vez estimados los parámetros. El método de estimación es por Máxima Verosimilitud (MV)
 se puede calcular a partir de la definición de Pi una vez estimados los parámetros. El método de estimación es por Máxima Verosimilitud (MV)")
33
El Modelo Probit La aproximación al problema es similar al Logit pero se supone una relación no lineal distinta (aunque muy similar) entre Xi y Pi Se basa en la distribución normal acumulada Se supone que la decisión de poseer o no una casa depenede de un índice I (conocido como variable latente)
")
34
El índice I está determinado por una o varias variables explicativas
El índice I está determinado por una o varias variables explicativas. Por ej ingreso Cuanto mayor sea el índice mayor la probabilidad de tener una casa Ii = a + b Xi Se supone un umbral crítico I* a partir del cuál, si I supera a I* entonces una familia posee una casa. El umbral I*, al igual que I, no es observable Si se supone que está distribuido normalmente con la misma media y varianza es posible estimar los parámetros del índice y también alguna información sobre el I*.

35
Pi = P (Y=1|X) = P(I*i ≤ Ii)
= P(Zi ≤ a + b Xi) = F(a + b Xi) Donde Z es una variable estándar normal, Z ~ N(0, s2) F es la función de distribución normal acumulada
 = F(a + b Xi) Donde. Z es una variable estándar normal, Z ~ N(0, s2) F es la función de distribución normal acumulada.")
36
Explícitamente

37
Pi = F(Ii) Pi Pr (I*i≤ Ii) Ii = a + b Xi + ∞ - ∞
 Pi Pr (I*i≤ Ii) Ii = a + b Xi + ∞ - ∞")
38
Interpretación de los Coeficientes
Una diferencia fundamental respecto a los modelos lineales es que la influencia que tienen las variables explicativas sobre la probabilidad de elegir la opción dada por yi = 1 (la derivada parcial, dyi/dxi = βk en los modelos lineales) no es independiente del vector de características xi. Una primera aproximación a la relación entre las variables explicativas y la probabilidad resultante es calcular los efectos marginales sobre la variable latente (y*) .
 no es independiente del vector de características xi. Una primera aproximación a la relación entre las variables explicativas y la probabilidad resultante es calcular los efectos marginales sobre la variable latente (y*) .")
39
Si el efecto marginal expresa el cambio de la variable dependiente provocado por un cambio unitario en una de las independientes manteniendo el resto constante, los parámetros estimados del Logit y el Probit reflejan el efecto marginal de las xik en yi de la misma forma que en el MLP, puesto qe E (y*|x) = x´β.
 = x´β.")
40
siendo F (.) la función de distribución y f (.) la función de densidad
Por lo tanto, en un modelo binario la influencia que tienen las explicativas sobre la probabilidad de elegir la opción dada por yi = 1 no depende simplemente del valor los coeficientes, sino también del valor que toman las variables explicativas. Por ej: El efecto marginal máximo ocurrirá cuando Pr (y = 1) = 0.5
 = 0.5.")
41
Esto significa que, a diferencia de lo que ocurre en el MLP, el efecto de una variable sobre la probabilidad varía con el valor de esa variable (es decir, no es independiente del vector de características xi).
.")
42
En Logit En Probit

43
Los resultados previos suponen que si bien los coeficientes de estos modelos no son directamente interpretables, sus valores relativos si lo son. Por ej. el cociente βj/ βk mide la importancia relativa de los efectos marginales de las variables xj y xk. Dado que los efectos marginales varian con x resulta conveniente calcularlos para valores concretos de la variable. Los “efectos marginales medios”, obtenidos a partir de la media muestral de la variable, son una de las formas más comunes de presentación de losresultados

44
Inferencia La inferencia no presenta diferencias sustanciales respecto al Modelo Lineal Gaussiano, por lo que para llevar a cabo hipótesis sobre el valor de un coeficiente puede emplearse un estadístico de la t−Student tradicional (aunque, siendo rigurosos, la distribución apropiada sería la Normal).(ratio z) Por su parte, para contrastar la validez de un conjunto de restricciones como las que definen la significación global del modelo puede el test de razón de verosimilitud (LR)
.(ratio z) Por su parte, para contrastar la validez de un conjunto de restricciones como las que definen la significación global del modelo puede el test de razón de verosimilitud (LR)")
45
Por ultimo, una forma de evaluación del modelo es la que se deriva de la bondad del ajuste.
Evidentemente, al tratarse de modelos no lineales carece de sentido plantear la bondad del ajuste en los t´erminos que definen el coeficiente de determinación R2. Existen criterios alternativos que, en cierto modo, siguen la misma idea. Todas estas medidas deben interpretarse con cierta cautela Su validez como criterios de selección del modelo es ciertamente limitada.

46
Una medida es el pseudo R2 de Mc Fadden:
En este caso, si los coeficientes son poco significativos la capacidad explicativa del modelo será muy reducida y el Loglikelihood sin restricciones será muy similar al L0; por el contrario, cuanto mayor sea la capacidad explicativa del modelo, más próximo estará R2 a uno.

47
Criterios para seleccionar uno mejor modelo:
a) El coeficiente de determinación corregido de McFadden. Conforme a este criterio el mejor modelo es aquel que presente el mayor coeficiente de determinación (R2 ) ajustado; b) La Suma de Cuadrados Residuales (SCR): el cual sugiere que el mejor modelo será el que tenga un valor más pequeño de este estadístico; c) El criterio de información de Akaike (CIA): establece que cuanto más bajo es su valor, mejor es el modelo; d) El Criterio de Schwartz (CS): postula que cuanto menor es el valor de este criterio, mejor será el modelo;
 El coeficiente de determinación corregido de McFadden. Conforme a este criterio el mejor modelo es aquel que presente el mayor coeficiente de determinación (R2 ) ajustado; b) La Suma de Cuadrados Residuales (SCR): el cual sugiere que el mejor modelo será el que tenga un valor más pequeño de este estadístico; c) El criterio de información de Akaike (CIA): establece que cuanto más bajo es su valor, mejor es el modelo; d) El Criterio de Schwartz (CS): postula que cuanto menor es el valor de este criterio, mejor será el modelo;")
48
f) Estadístico de máxima verosimilitud (LR): el valor experimental obtenido y el teórico de este estadístico permite contrastar la hipótesis nula de no significatividad conjunta de los coeficientes de las variables explicativas del modelo. Los resultados de la estimación de estos estadísticos, sin excepción, sugieren que el modelo logit tiene un mayor grado de eficiencia para explicar el fenómeno analizado, en tanto que el coeficiente de determinación (R2) de McFadden, la suma de cuadrados residuales, el criterio de información de Akaike, y los criterios de Schwartz y Hannan-Quinn, así como el estadístico de máxima verosimilitud (LR), registran valores más favorables, comparados con los resultados del modelo probit
 de McFadden, la suma de cuadrados residuales, el criterio de información de Akaike, y los criterios de Schwartz y Hannan-Quinn, así como el estadístico de máxima verosimilitud (LR), registran valores más favorables, comparados con los resultados del modelo probit.")
49
e) Criterio de Hannan-Quinn: establece igualmente que cuanto menor sea el valor de este criterio, más adecuado resulta el modelo . f) Estadístico de máxima verosimilitud (LR): el valor experimental obtenido y el teórico de este estadístico permite contrastar la hipótesis nula de no significatividad conjunta de los coeficientes de las variables explicativas del modelo. Los resultados de la estimación de estos estadísticos, sin excepción, sugieren que el modelo logit tiene un mayor grado de eficiencia para explicar el fenómeno analizado, en tanto que el coeficiente de determinación (R2 ) de McFadden, la suma de cuadrados residuales, el criterio de información de Akaike, y los criterios de Schwartz y Hannan-Quinn, así como el estadístico de máxima verosimilitud (LR), registran valores más favorables, comparados con los resultados del modelo probit.
 Estadístico de máxima verosimilitud (LR): el valor experimental obtenido y el teórico de este estadístico permite contrastar la hipótesis nula de no significatividad conjunta de los coeficientes de las variables explicativas del modelo. Los resultados de la estimación de estos estadísticos, sin excepción, sugieren que el modelo logit tiene un mayor grado de eficiencia para explicar el fenómeno analizado, en tanto que el coeficiente de determinación (R2 ) de McFadden, la suma de cuadrados residuales, el criterio de información de Akaike, y los criterios de Schwartz y Hannan-Quinn, así como el estadístico de máxima verosimilitud (LR), registran valores más favorables, comparados con los resultados del modelo probit.")
50
Ejemplo de aplicación De acuerdo al ejemplo anterior Hallar:
Ajuste un modelo de regresión logística para predecir la probabilidad de Adquirir una Tarjeta Premium basándose en los Gastos anuales y si Posee o no Tarjetas Adicionales para otros miembros de la familia.(modelo logit) Explique el significado de los coeficientes de regresión para el modelo ajustado. Prediga la probabilidad de que un cliente con Tarjeta Estandar que ha cargado S/. 36,000 el año anterior y que no posee tarjetas adicionales para los miembros de su familia, adquiera la Tarjeta Premium durante la campaña de comercialización. Al nivel de significación del 0.05, ¿existe evidencia de que un modelo logístico que utilice las variables indicadas anteriormente es un modelo bien ajustado? Al nivel de significación de 0.05 ¿existe evidencia de que cada una de las variables hace una contribución significativa al modelo de regresión?
 Explique el significado de los coeficientes de regresión para el modelo ajustado. Prediga la probabilidad de que un cliente con Tarjeta Estandar que ha cargado S/. 36,000 el año anterior y que no posee tarjetas adicionales para los miembros de su familia, adquiera la Tarjeta Premium durante la campaña de comercialización. Al nivel de significación del 0.05, ¿existe evidencia de que un modelo logístico que utilice las variables indicadas anteriormente es un modelo bien ajustado Al nivel de significación de 0.05 ¿existe evidencia de que cada una de las variables hace una contribución significativa al modelo de regresión")
51
Ajuste un modelo de regresión logística para predecir la probabilidad de Adquirir una Tarjeta Premium basándose en los Gastos anuales y si Posee o no Tarjetas Adicionales para otros miembros de la familia. Explique el significado de los coeficientes de regresión para el modelo ajustado. Prediga la probabilidad de que un cliente con Tarjeta Estandar que ha cargado S/. 36,000 el año anterior y que no posee tarjetas adicionales para los miembros de su familia, adquiera la Tarjeta Premium durante la campaña de comercialización. Al nivel de significación del 0.05, ¿existe evidencia de que un modelo logístico que utilice las variables indicadas anteriormente es un modelo bien ajustado? Al nivel de significación de 0.05 ¿existe evidencia de que cada una de las variables hace una contribución significativa al modelo de regresión? .

52
SOLUCION Según el modelo Probit: Quick - estimate equation, en el campo especification se elege BIARY- en el campo estimation method de se elige Probit……. aceptar

53
Buena significancia individual para los parámetros estimados , la significancia conjunta es muy alta porque el pv-del estadístico de la Razón de Verosimilitud es muy pequeño,El Pseudo R2 de McFadden, no se acerca a la unidad, los valores de los criterios de informacion de ( Akaike,Scharwz y Hannan-quinn) son adecuados porque son bajos y muy parecidos.
 son adecuados porque son bajos y muy parecidos.")
54
Otro criterio para medir la Bondad de Ajuste del modelo probit, es el Criterio de del porcentaje de predicciones correctas que consiste en observar el porcentaje de veces en que el valor de Yi observado que coincide con su predicción… Eview- Expectation Prediccion Table Aceptar

55
View – Descriptive statistics - individual samples
De la figura anterior se observa que el modelo predice adecuadamente el 80% de las observaciones ( se predicen mejor los unos ( la probabilidad de adquirir una tarjeta de crédito) con un 84.62% de aciertos frente a un 76.47% de no adquisición de tarjeta de crédito. Para cuantificar los efectos de las variables explicativas sobre la probabilidad de adquirir una tarjeta de crédito Calculamos los efectos para las observaciones medias, para ello calculamos las medias de las variables del modelo seleccionándolas: Open – as group View – Descriptive statistics - individual samples Se obtiene los datos siguientes
 con un 84.62% de aciertos frente a un 76.47% de no adquisición de tarjeta de crédito. Para cuantificar los efectos de las variables explicativas sobre la probabilidad de adquirir una tarjeta de crédito. Calculamos los efectos para las observaciones medias, para ello calculamos las medias de las variables del modelo seleccionándolas: Open – as group. View – Descriptive statistics - individual samples. Se obtiene los datos siguientes.")
57
Por lo tanto:

58
USAR EVIEWS Una vez ingresado las variables

59
Se marca modelo logit

61
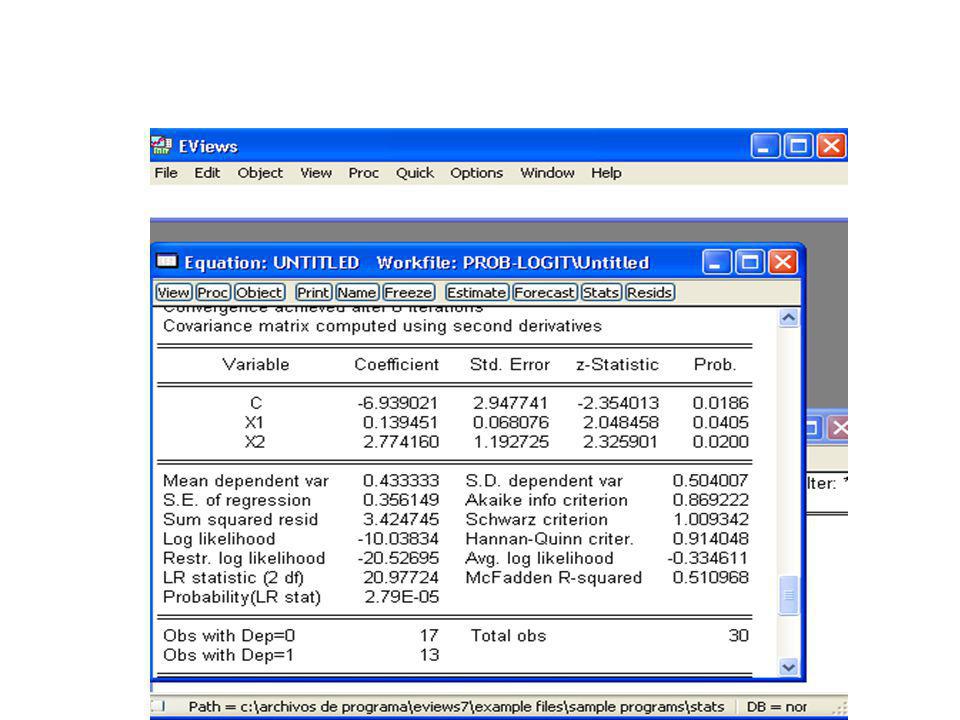
a) El modelo de regresión logística ajustado es:
b) Si el individuo pasa de 0 a 1, es decir pasa de no poseer a POSEER una Tarjeta de crédito adicional la probabilidad de adquirir la Tarjeta Premium se incrementa en 2.77%. Si el individuo incrementa su Gasto en 1 mil S/. La probabilidad de adquirir la tarjeta premium se incrementa en 0.139%. c) La probabilidad que adquiera la tarjeta premium es 69.80%
 Si el individuo pasa de 0 a 1, es decir pasa de no poseer a POSEER una Tarjeta de crédito adicional la probabilidad de adquirir la Tarjeta Premium se incrementa en 2.77%. Si el individuo incrementa su Gasto en 1 mil S/. La probabilidad de adquirir la tarjeta premium se incrementa en 0.139%. c) La probabilidad que adquiera la tarjeta premium es 69.80%")
62
d) La estadística de desviación sigue una distribución CHI2 con n-k-1 grados de libertad.
Las Hipótesis son: H0: EL modelo tiene buen ajuste H1: El modelo no tiene buen ajuste Si Desviación >CHI2 a, (n-k-1) Rechazar H0. Obsérvese que c20.05, (30-3-1)=38.89 Por tanto < No se rechaza H0. El modelo tiene buen ajuste
 Rechazar H0. Obsérvese que c20.05, (30-3-1)= Por tanto < No se rechaza H0. El modelo tiene buen ajuste.")
63
e) En el caso de la variable Gasto: para la significancia 0.05
Las hipótesis son: H0: El parámetro es cero (0) H1: El parámetro es diferente de cero (0) El p_valor del estadístico de Wald es 0.04 0.04<0.05 por tanto se rechaza la Hipótesis nula. Por tanto, la variable Gasto hace una contribución significativa al modelo. En el caso de la Variable POSEE tarjeta adicional, el p_valor del estadístico de Wald es 0.02 <0.05, con lo que se rechaza la H0. Por tanto la variable Posee Tarjeta de crédito adicional hace una contribución significativa al modelo.
 H1: El parámetro es diferente de cero (0) El p_valor del estadístico de Wald es <0.05 por tanto se rechaza la Hipótesis nula. Por tanto, la variable Gasto hace una contribución significativa al modelo. En el caso de la Variable POSEE tarjeta adicional, el p_valor del estadístico de Wald es 0.02 <0.05, con lo que se rechaza la H0. Por tanto la variable Posee Tarjeta de crédito adicional hace una contribución significativa al modelo.")
64
THE END

Presentaciones similares
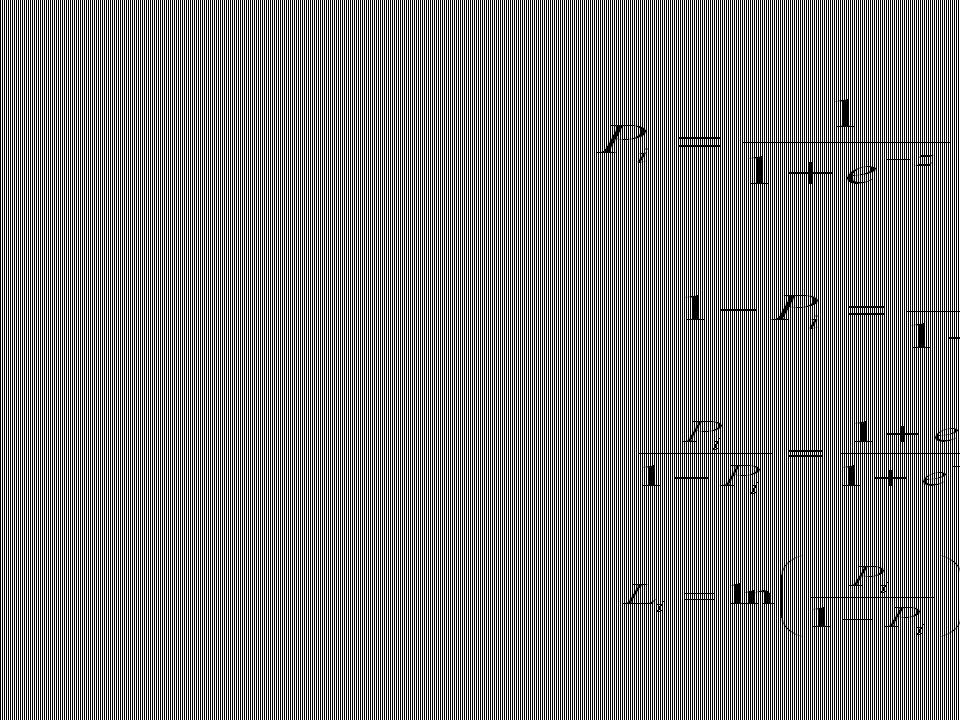





>")













