Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Procesamiento Post-traduccional
Tradicionalmente se piensa que los eventos en los que intervienen los ribosomas son los únicos responsable de la actividad de los péptidos sintetizados. Sin embargo, dicho péptido no es activo sino hasta que se pliega en su confromación correcta, o bien hasta que sufre cortes o modificaciones químicas. El conjunto de modificaciones a las que se somete un péptido/proteína se conocen como modificaciones postraduccionales.

2
1.Modificaciones de los extremos amino y carboxilo 2.Péptidos señal
3.Modificación de aa individuales 4.Unión de cadenas laterales de carbohidratos 5.Isoprenilación 6.Adición de grupos prostéticos 7.Procesamiento proteolítico 8.Formación de puentes S-S 1. Inicialmente los polipéptidos bacterianos comienzan con un residuo N-formilmetionina, mientras que los eucarióticos comienzan con metionina. Pero el grupo formil, la metionina amino terminal y a veces más residuos en este extremo son removidos enzimáticamente, razón por la que no figuran en la proteína activa final. Aproximadamente la mitad de las proteínas eucarióticas presentan N-acetilación del extremo amino después de la traducción. También existen modificaciones de los extremos carboxilo. 2. En algunas proteínas, los aa del extremo amino indican el destino final de la proteína, dichos péptidos señal son eliminados por acción enzimática. 3. Los hidroxilos de Ser, Thr y Tyr son enzimáticamente fosforilados por ATP lo que confiere carga negativa a los polipéptidos. Carboxilación de extremos amino ocurre por ejemplo en glutamato, dicha reacción es catalizada por una enzima que requiere vitamina K. Otra modificación que puede ocurrir es la metilación, que en el caso del carboxilo de glutamato permite eliminar la carga negativa. 4. En glicoproteínas, las cadenas laterales de carbohidratos se unen covalentemente ya sea a Asn, Ser, Thr. 5. Derivados del isopreno son agregados a ciertas proteínas, en las cysteínas con las cuales se forma un enlace tioeter. Isopreno deriva de intermediarios pirofosforilados del colesterol. 6. Unión covalente de un grupo prostético necesario para la actividad de algunas proteínas. Tal es el caso de la biotina en la carboxilasa de la acetil CoA. O el grupo heme del citocromo c. 7. Algunas proteínas son sintetizadas como precursores que requieren ser procesados proteolíticamente para producir la proteína activa. 8. Muchas proteínas que son exportadas por células eucarióticas forman puentes S-S intracatenarios o intercatenarios. Permiten a las proteínas mantener la conformación.

3
Plegamiento de proteínas

4
La existencia de las proteínas comienza como una cadena lineal de aa, enseguida y durante la síntesis, estos polipéptidos deben plegarse para adoptar sus configuraciones nativas. Cambios modestos en el ambiente de las proteínas pueden afectar su función.

5
10 Configuraciones posibles por residuo 10100 Posibles configuraciones
100 Residuos 10 Configuraciones posibles por residuo 10100 Posibles configuraciones Conversión entre configuraciones 13–13 s Tiempo estimado: 1085 s (1077 años) Tiempo observado: 10–1 a 103 s Si el plegamiento de las proteínas fuera un proceso al azar, consideremos que: Una bacteria sintetiza 100 aa en 5s, cada aa tiene 10 configuraciones posibles, por lo tanto los 10 aa tienen 10 a la 100 posibles configs. El menor tiempo para ensayar cada una de las posibles configs es de 10 a la menos 13 segs, tardaría 10 a la 77 años en probar todas las configs posibles. Sin embargo se ha observado que solo tardan 10 a la menos 1 a 10 a la 3 segs en plegarse adecuadamente.
 Tiempo observado: 10–1 a 103 s. Si el plegamiento de las proteínas fuera un proceso al azar, consideremos que: Una bacteria sintetiza 100 aa en 5s, cada aa tiene 10 configuraciones posibles, por lo tanto los 10 aa tienen 10 a la 100 posibles configs. El menor tiempo para ensayar cada una de las posibles configs es de 10 a la menos 13 segs, tardaría 10 a la 77 años en probar todas las configs posibles. Sin embargo se ha observado que solo tardan 10 a la menos 1 a 10 a la 3 segs en plegarse adecuadamente.")
6
Bovine pancreatic trypsin inhibitor
The polypeptide backbone and disulfide bonds of native bovine pancreatic trypsin inhibitor

7
↓ΔG Bovine pancreatic trypsin inhibitor
The renaturation pathway of BPTI showing the conformations of its polypeptide backbone as deduced from disulfide trapping experiments and NMR measurements. (note that these views of the protein differ from the picture by a slight rotation about the vertical axis). The fully reduced and native proteins are represented by R and N, respectively. The sequence numbers of the Cys residues involved in each disulfide bond are given in parentheses below the diagram representing each folding intermediate, Ia and IB, are in rapid equilibrium. the “+” between intermediates IIA and IIB indicates that both are formed directly from the one-disulfide intermediates, that both convert directly to the NSH2, and that either or both are intermediates in the rearrangement of IIC to NSH2. ↓ΔG 60% Bovine pancreatic trypsin inhibitor
. The fully reduced and native proteins are represented by R and N, respectively. The sequence numbers of the Cys residues involved in each disulfide bond are given in parentheses below the diagram representing each folding intermediate, Ia and IB, are in rapid equilibrium. the + between intermediates IIA and IIB indicates that both are formed directly from the one-disulfide intermediates, that both convert directly to the NSH2, and that either or both are intermediates in the rearrangement of IIC to NSH2. ↓ΔG. 60% Bovine pancreatic trypsin inhibitor.")
8
Hypothetical folding pathway of a dimeric protein
Hypothetical folding pathway of a dimeric protein. From top to bottom, the arrows correspond to the following steps: 1) the rapid irreversible formation of local secondary structures (folding nuclei); 2) formation of domains through the cooperative aggregation of folding nuclei; 3) assembly of the domains into a “molten globule”; 4) conformational adjustment of the monomer; 5) association of two monomers; and the dimeric protein to form the native structure
 the rapid irreversible formation of local secondary structures (folding nuclei); 2) formation of domains through the cooperative aggregation of folding nuclei; 3) assembly of the domains into a molten globule ; 4) conformational adjustment of the monomer; 5) association of two monomers; and the dimeric protein to form the native structure.")
9
(C) Mechanisms of accelerated folding
(C) Mechanisms of accelerated folding. Simple energy diagrams are shown for a protein that forms a kinetically trapped intermediate during spontaneous folding (left). In the iterative annealing model, this intermediate is thought to be actively unfolded by GroEL/GroES (69) and allowed to repartition (middle), whereas confinement of nonnative protein in the narrow, hydrophilic environment of the GroEL-GroES cage is suggested to result in a smoothing of the energy landscape (right), such that formation of certain trapped intermediates is avoided (67). Both proposed mechanisms would result in accelerated folding.
 Mechanisms of accelerated folding. Simple energy diagrams are shown for a protein that forms a kinetically trapped intermediate during spontaneous folding (left). In the iterative annealing model, this intermediate is thought to be actively unfolded by GroEL/GroES (69) and allowed to repartition (middle), whereas confinement of nonnative protein in the narrow, hydrophilic environment of the GroEL-GroES cage is suggested to result in a smoothing of the energy landscape (right), such that formation of certain trapped intermediates is avoided (67). Both proposed mechanisms would result in accelerated folding.")
11
Reacciones de isomerización son catalizadas por la PDI (protein disulfide isomerase) que cataliza los cambios e intercambios de enlaces disulfuro hasta que se alcanzan aquellos de la forma nativa. The X-ray structure of the E. coli Dsb A, a protein disulfide isomerase. a) A ribbon diagram in which those parts of the protein that structurally resemble thioredoxin are purple or green and the other parts are white The green helix contains the protein’s disulfide-linked sulfur atoms (yellow spheres) at its N-terminus. b) The molecular surface and charge distribution. The left view is oriented similarly to that in a) and the right view is related to that on the left by a 90 degree rotation about the vertical axis. The surface is colored according to charge: negative charged groups are red, positively charged groups are blue and uncharged groups are white. The one surface-exposed S atom in DsbA’s disulfide bond is denoted by “S”. Structural features that may be important for polypeptide binding are indicated. Part of groove 1 near the disulfide group is lined with hydrophobic residues
 A ribbon diagram in which those parts of the protein that structurally resemble thioredoxin are purple or green and the other parts are white The green helix contains the protein’s disulfide-linked sulfur atoms (yellow spheres) at its N-terminus. b) The molecular surface and charge distribution. The left view is oriented similarly to that in a) and the right view is related to that on the left by a 90 degree rotation about the vertical axis. The surface is colored according to charge: negative charged groups are red, positively charged groups are blue and uncharged groups are white. The one surface-exposed S atom in DsbA’s disulfide bond is denoted by S . Structural features that may be important for polypeptide binding are indicated. Part of groove 1 near the disulfide group is lined with hydrophobic residues.")
12
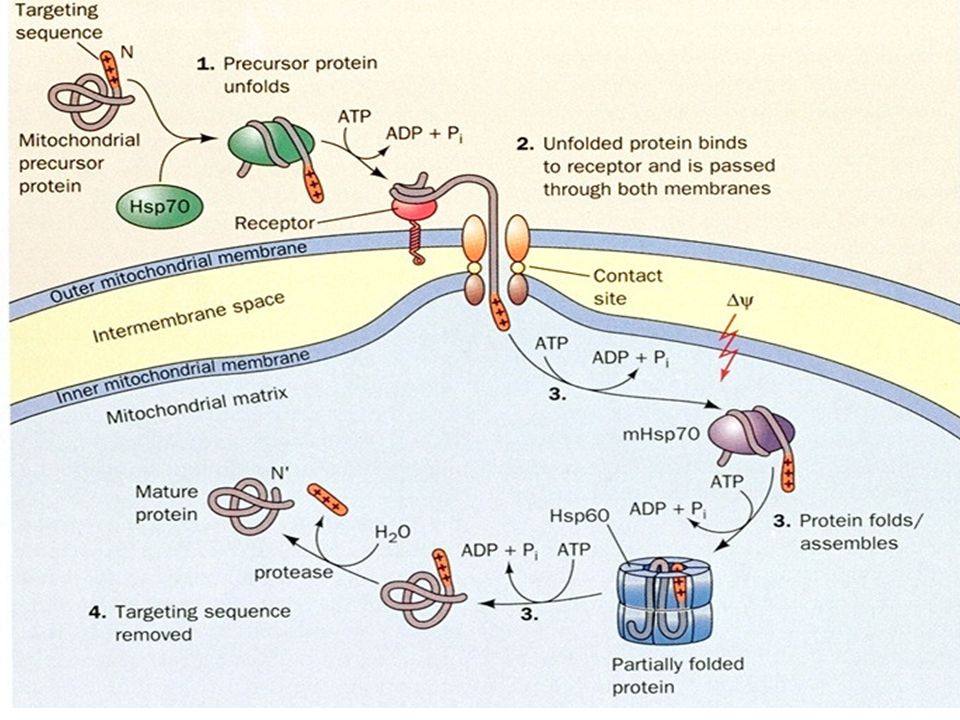
Las proteínas que no se pliegan espontáneamente lo hacen con la ayuda de proteínas especializadas. Estas son las chaperonas moleculares que interactúan con polipéptidos parcialmente o incorrectamente plegados, facilitando el plegamiento adecuado o bien proveyendo microambientes en los cuales el plegamiento puede llevarse a cabo. Dos clases de chaperonas moleculares han sido descritas, la primera es la familia de proteínas llamadas Hsp70. Esta proteína se une a polipéptidos mal plegados ricos en residuos hidrofóbicos, con lo que se impide plegamiento inadecuado. Hsp70 protege proteínas que han sido desnaturalizadas por calor, o péptidos que están siendo sintetizados, también mantiene no replegados péptidos que tienen que ser traslocados a través de membrana. Hsp40 es otra chaperona que participa con Hsp70 . Los equivalentes bacterianos de estas chaperonas son DnaJ y DnaK Models for the chaperone-assisted folding of newly synthesized polypeptides in the cytosol. (A) Eubacteria. TF, trigger factor; N, native protein. Nascent chains probably interact generally with TF, and most small proteins (~65 to 80% of total) fold rapidly upon synthesis without further assistance. Longer chains (10 to 20% of total) interact subsequently with DnaK and DnaJ and fold upon one or several cycles of ATP-dependent binding and release. About 10 to 15% of chains transit the chaperonin system--GroEL and GroES--for folding. GroEL does not bind to nascent chains and is thus likely to receive an appreciable fraction of its substrates after their interaction with DnaK. (B) Archaea. PFD, prefoldin; NAC, nascent chain-associated complex. Only some archaeal species contain DnaK/DnaJ. The existence of a ribosome-bound NAC homolog, as well as the interaction of PFD with nascent chains, has not yet been confirmed experimentally. (C) Eukarya--the example of the mammalian cytosol. Like TF, NAC probably interacts generally with nascent chains. The majority of small chains may fold upon ribosome release without further assistance. About 15 to 20% of chains reach their native states in a reaction assisted by Hsp70 and Hsp40, and a fraction of these must be transferred to Hsp90 for folding. About 10% of chains are co- or posttranslationally passed on to the chaperonin TRiC in a reaction mediated by PFD
 Eubacteria. TF, trigger factor; N, native protein. Nascent chains probably interact generally with TF, and most small proteins (~65 to 80% of total) fold rapidly upon synthesis without further assistance. Longer chains (10 to 20% of total) interact subsequently with DnaK and DnaJ and fold upon one or several cycles of ATP-dependent binding and release. About 10 to 15% of chains transit the chaperonin system--GroEL and GroES--for folding. GroEL does not bind to nascent chains and is thus likely to receive an appreciable fraction of its substrates after their interaction with DnaK. (B) Archaea. PFD, prefoldin; NAC, nascent chain-associated complex. Only some archaeal species contain DnaK/DnaJ. The existence of a ribosome-bound NAC homolog, as well as the interaction of PFD with nascent chains, has not yet been confirmed experimentally. (C) Eukarya--the example of the mammalian cytosol. Like TF, NAC probably interacts generally with nascent chains. The majority of small chains may fold upon ribosome release without further assistance. About 15 to 20% of chains reach their native states in a reaction assisted by Hsp70 and Hsp40, and a fraction of these must be transferred to Hsp90 for folding. About 10% of chains are co- or posttranslationally passed on to the chaperonin TRiC in a reaction mediated by PFD.")
13
Structure and function of chaperones with the ability to bind nascent chains. (A) (Top) Structures of the ATPase domain (40) and the peptide-binding domain (38) of Hsp70 shown representatively for E. coli DnaK, generated with the program MOLSCRIPT (87). The -helical latch of the peptide binding domain is shown in yellow and a ball-and-stick model of the extended peptide substrate in pink. ATP indicates the position of the nucleotide binding site. The amino acid sequence of the peptide is indicated in single-letter code (D, Asp; E, Glu; G, Gly; L, Leu; N, Asn; R, Arg; T, Thr; and V, Val). (Bottom) The interaction of prokaryotic and eukaryotic cofactors with Hsp70 is shown schematically. Residue numbers refer to human Hsp70. Only the Hsp70 proteins of the eukaryotic cytosol have the COOH-terminal sequence EEVD that is involved in binding of tetratricopeptide repeat (TPR) cofactors. (B) Simplified reaction cycle of the DnaK system with DnaK colored as in (A). J, DnaJ; E, GrpE; S, substrate peptide. GrpE is drawn to reflect the extended shape of the protein. Not all substrates are presented to DnaK by DnaJ. The intermediate DnaK-DnaJ-substrate-ATP is probably very transient, as this is the fastest step of the cycle. Chaperoninas es la segunda clase de chaperonas. Son complejos proteicos necesarios para el plegamiento de proteínas celulares incapaces de plegarse espontáneamente. El sistema de chaperoninas que permite el plegamiento es GroEL/GroES

14
Elmsistema de chaperoninas GroEL/GroES consiste de vastas bolsas en las que un gran número de proteínas pueden unirse. La bolsa está constituída por el complejo GroEL, la cubierta de dicha bolsa la forma GroES. GroEL sufre cambios sustanciales de estructura, repetidos ciclos de hidrólisis de ATP así como movimientos contínuos de la tapa GroES, estos movimientos favorecen el plegamiento de las proteínas contenidas en el saco. Los mecanismos permanecen no resueltos. The GroEL-GroES chaperonin system. (A) (Left) View of the asymmetric GroEL-GroES-(ADP)7 complex generated with the coordinates 1AON (61) and program Weblab ViewLite 4.0 (Molecular Simulations). The equatorial, intermediate, and apical domains of one subunit each in the cis and trans ring of GroEL are colored in pink, yellow, and dark blue, respectively, and one subunit of GroES is colored red. (Right) The accessible surface of the central cavity of the GroEL-GroES complex. Polar and charged side-chain atoms, blue; hydrophobic side-chain atoms, yellow; backbone atoms, white; and solvent-excluded surfaces at subunit interfaces, gray. [Reprinted from (61) with permission]
 (Left) View of the asymmetric GroEL-GroES-(ADP)7 complex generated with the coordinates 1AON (61) and program Weblab ViewLite 4.0 (Molecular Simulations). The equatorial, intermediate, and apical domains of one subunit each in the cis and trans ring of GroEL are colored in pink, yellow, and dark blue, respectively, and one subunit of GroES is colored red. (Right) The accessible surface of the central cavity of the GroEL-GroES complex. Polar and charged side-chain atoms, blue; hydrophobic side-chain atoms, yellow; backbone atoms, white; and solvent-excluded surfaces at subunit interfaces, gray. [Reprinted from (61) with permission]")
15
7 7 7 7 7 7 7 a) The reaction cycle of the E. coli chaperonins GroEL and GroES in protein folding: 1) GroEL in asymmetric complex with one heptameric ring of GroES and 14 ADP’s (one per GroEL subunit) binds an unfolded polypeptide in its central cavity in a process that releases all 14 ADP’s and the bound GroES. 2) GroEL binds 14 ATP’s thereby weakening the interaction between GroEL and the unfolded polypeptide and causing the rebinding of GroES to the opposite face of GroEL. 3) All 14 ATPs are simultaneously hydrolyzed, thereby releasing the bound polypeptide within GroEL. This permits the polypeptide, which is probably in its molten globule state, to fold in a protected microenvironment, out of contact with other partially folded polypeptides with which it would otherwise aggregate. 4) If the polypeptide has folded to its native conformation, it is released from GroEL. 5) However, the polypeptide has failed to fully attain its native fold, it remains bound to GroEL and reenters the reaction cycle at step 2 (note that in doing so, the diagrammed GroEL turns over by 180 degrees). GroES, which binds but does not hydrolyze ATP, presumably facilitates the binding of the ATPs to GroEL, coordinates their simultaneous hydrolysis, and prevents the escape of a partially folded polypeptide from the GroEL cavity. b) A model for the ATP-dependent release of an unfolded polypeptide from its multiple attachment sites in GroEL. ATP binding and hydrolysis conformationally mask the hydrophobic sites of GroEL (darker areas) that bind the unfolded polypeptide, thereby permitting it to fold in an isolated environment.
 The reaction cycle of the E. coli chaperonins GroEL and GroES in protein folding: 1) GroEL in asymmetric complex with one heptameric ring of GroES and 14 ADP’s (one per GroEL subunit) binds an unfolded polypeptide in its central cavity in a process that releases all 14 ADP’s and the bound GroES. 2) GroEL binds 14 ATP’s thereby weakening the interaction between GroEL and the unfolded polypeptide and causing the rebinding of GroES to the opposite face of GroEL. 3) All 14 ATPs are simultaneously hydrolyzed, thereby releasing the bound polypeptide within GroEL. This permits the polypeptide, which is probably in its molten globule state, to fold in a protected microenvironment, out of contact with other partially folded polypeptides with which it would otherwise aggregate. 4) If the polypeptide has folded to its native conformation, it is released from GroEL. 5) However, the polypeptide has failed to fully attain its native fold, it remains bound to GroEL and reenters the reaction cycle at step 2 (note that in doing so, the diagrammed GroEL turns over by 180 degrees). GroES, which binds but does not hydrolyze ATP, presumably facilitates the binding of the ATPs to GroEL, coordinates their simultaneous hydrolysis, and prevents the escape of a partially folded polypeptide from the GroEL cavity. b) A model for the ATP-dependent release of an unfolded polypeptide from its multiple attachment sites in GroEL. ATP binding and hydrolysis conformationally mask the hydrophobic sites of GroEL (darker areas) that bind the unfolded polypeptide, thereby permitting it to fold in an isolated environment.")
16
Secreción de proteínas

18
The N terminal sequences of some eukaryotic secretory preproteins
The N terminal sequences of some eukaryotic secretory preproteins. The hydrophobic cores (red) of most signal peptides are preceded by basic residues (blue).
 of most signal peptides are preceded by basic residues (blue).")
19
The ribosomal synthesis, membrane insertion and initial glycosylation of an integral membrane protein according to the signal hypothesis: 1) Protein synthesis is initiated at the N-terminus of the polypeptide, which consists of a 13- to 36-residue signal sequence. 2) A signal-recognition particle (SRP) binds to the ribosome as the signal sequence emerges from it, thereby arresting polypeptide synthesis. 3) The SRP is bound by the transmembrane SRP receptor, which causes resumption of polypeptide synthesis and facilitates the passage of the growing polypeptide through the membrane. The SRP.SRP receptor complex then releases the signal peptide and, in a process requiring GTP hydrolysis, dissociates. 4) Shortly after the entrance of the signal sequence into the lumen of the endoplasmic reticulum, it is proteolytically excised. 5) As the growing polypeptide chain is extruded into the lumen, it starts to fold into its native conformation, a process that is facilitated by its interaction with the chaperon protein Hsp70 (not shown). Simultaneously, enzymes initiate the polypeptide’s specific glycosylation. Once the protein has folded, it cannot be pulled out of the membrane. At a point determined by its sequence, the protein becomes stuck in the membrane (proteins destined for secretion pass completely into the ER lumen). 6) Once polypeptide synthesis is completed, the ribosome dissociates into its two subunits. For the sake of clarity, the ribosome is shown at ~1/50th of its actual size relative to the other cell components.
 A signal-recognition particle (SRP) binds to the ribosome as the signal sequence emerges from it, thereby arresting polypeptide synthesis. 3) The SRP is bound by the transmembrane SRP receptor, which causes resumption of polypeptide synthesis and facilitates the passage of the growing polypeptide through the membrane. The SRP.SRP receptor complex then releases the signal peptide and, in a process requiring GTP hydrolysis, dissociates. 4) Shortly after the entrance of the signal sequence into the lumen of the endoplasmic reticulum, it is proteolytically excised. 5) As the growing polypeptide chain is extruded into the lumen, it starts to fold into its native conformation, a process that is facilitated by its interaction with the chaperon protein Hsp70 (not shown). Simultaneously, enzymes initiate the polypeptide’s specific glycosylation. Once the protein has folded, it cannot be pulled out of the membrane. At a point determined by its sequence, the protein becomes stuck in the membrane (proteins destined for secretion pass completely into the ER lumen). 6) Once polypeptide synthesis is completed, the ribosome dissociates into its two subunits. For the sake of clarity, the ribosome is shown at ~1/50th of its actual size relative to the other cell components..")
20
The posttranslational processing of integral membrane proteins
The posttranslational processing of integral membrane proteins. 1) During their ribosomal synthesis,their glycosylation is initiated in the lumen of the endoplasmic reticulum. 2) After ribosomal synthesis is completed,coated vesicles containing the protein bud off from the endoplasmic reticulum and move to the Golgi apparatus where protein processing is completed. 3) Later, coated vesicles containing the mature protein bud off form the Golgi apparatus and fuse to the membrane for which the protein is targeted, here shown as the plasma membrane.
 During their ribosomal synthesis,their glycosylation is initiated in the lumen of the endoplasmic reticulum. 2) After ribosomal synthesis is completed,coated vesicles containing the protein bud off from the endoplasmic reticulum and move to the Golgi apparatus where protein processing is completed. 3) Later, coated vesicles containing the mature protein bud off form the Golgi apparatus and fuse to the membrane for which the protein is targeted, here shown as the plasma membrane.")
23
Procesamiento proteolítico
Incremento de diversidad Met aminopeptidasas Como mecanismo de activación Zimógenos Direccionamiento intracelular Translocación de proteínas

26
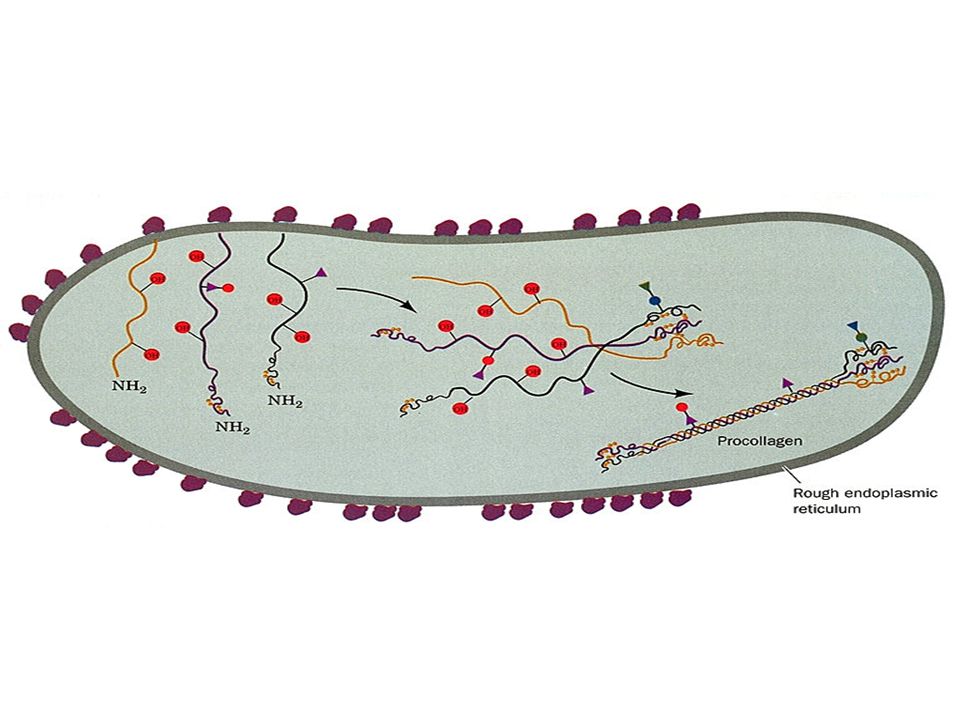
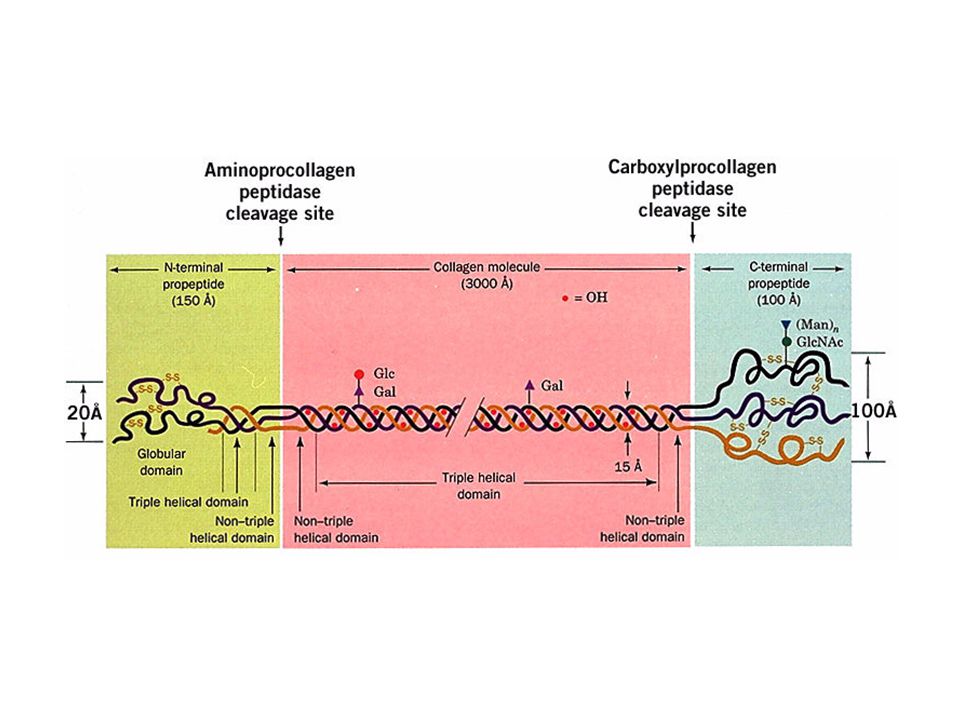
The amino acid sequence at the C-terminal end of the triple helical region of the bovine a1(I) collagen chain. Note the repeating triplets Gly_X-Y, where X is often Pro and Y is often Hpro. Here gly is shaded in purple, pro in tan, and hpro and 3hpro in brown.

27
Modificación covalente
Acetilaciones Glicosilaciones Hidroxilaciones Metilaciones Nucleotidilaciones Fosforilaciones ADP-ribosilaciones Etc.

28
co y post-traduccionales
Modificaciones co y post-traduccionales

29
Modificaciones post-traduccionales
Cuatro grandes grupos Plegamiento de la proteína Procesamiento proteolítico Modificaciones químicas Separación de inteínas

30
Procesamiento enzimático

31
Formación de puentes disulfuro

32
Modificaciones post-traduccionales
Cuatro grandes grupos Plegamiento de la proteína Procesamiento proteolítico Modificaciones químicas Separación de inteínas

33
MPT Función Fosforilación Señalización, activación Acetilación
Estabilidad, interacción DNA-prots Metilación Regulación génica Acilación, modif. por ácidos grasos Localización y señalización celular Glicosilación Proteínas excretadas, reconocimiento y señalización celular Anclas GPI Fijación de enzimas y receptores a membrana Puentes S-S Estabilidad de proteínas Ubiquitinación Señal de destrucción Sulfatación Modulador de interacciones

34
Nombre Sitio Modificación
Acetilación Terminal NH2- Replaced by CH3CONH- Miristilación Terminal NH2- Replaced by CH3(CH2)12CONH- Palmitoilación Terminal NH2- Replaced by CH3(CH2)14CONH- Amidación Terminal -COOH Replaced by -CONH2 Enlaces disulfuro 2 Cys -SH Replaced by -S-S- N-Glicosilación N-X-S/T O-Glicosilación S/T Sulfatación -OH of Y Replaced by -OSO3H Fosforilación -OH of Y/S/T Replaced by -OPO3H2 N-metilación -NH2 of K/R/H/Q Replaced by -NHCH3 O-metilesterificación -COOH of E/D Replaced by -COOCH3 Carboxilación -NH2 of E/D Replaced by -NHOCH3 Hidroxilación -NH2 of P/K/D Replaced by -NHOH
12CONH- Palmitoilación. Terminal NH2- Replaced by CH3(CH2)14CONH- Amidación. Terminal -COOH. Replaced by -CONH2. Enlaces disulfuro. 2 Cys -SH. Replaced by -S-S- N-Glicosilación. N-X-S/T. O-Glicosilación. S/T. Sulfatación. -OH of Y. Replaced by -OSO3H. Fosforilación. -OH of Y/S/T. Replaced by -OPO3H2. N-metilación. -NH2 of K/R/H/Q. Replaced by -NHCH3. O-metilesterificación. -COOH of E/D. Replaced by -COOCH3. Carboxilación. -NH2 of E/D. Replaced by -NHOCH3. Hidroxilación. -NH2 of P/K/D. Replaced by -NHOH.")
35
MPT Función Fosforilación Señalización, activación Acetilación
Estabilidad, interacción DNA-prots Metilación Regulación génica Acilación, modif. por ácidos grasos Localización y señalización celular Glicosilación Proteínas excretadas, reconocimiento y señalización celular Anclas GPI Fijación de enzimas y receptores a membrana Puentes S-S Estabilidad de proteínas Ubiquitinación Señal de destrucción Sulfatación Modulador de interacciones

36
y sus enlaces característicos
Glicosilación y sus enlaces característicos C-manosil Trp Man Ser GlcNAc-1-P Man-1-P Fuc-1-P Xyl-1-P Fosfo-glicosil Glipiación C-term EthN-6-P-Man

37
Ancla GPI

38
y sus enlaces característicos
Glicosilación y sus enlaces característicos O-glicosil Ser Glc FucNAc Xyl Gal Hyl Hyp GlcNAc Ara Tyr Thr Man Ser/Thr Pse GalNAc Fuc DiAcTridH N-glicosil Asn Arg GlcNAc GalNAc Glc Rha

39
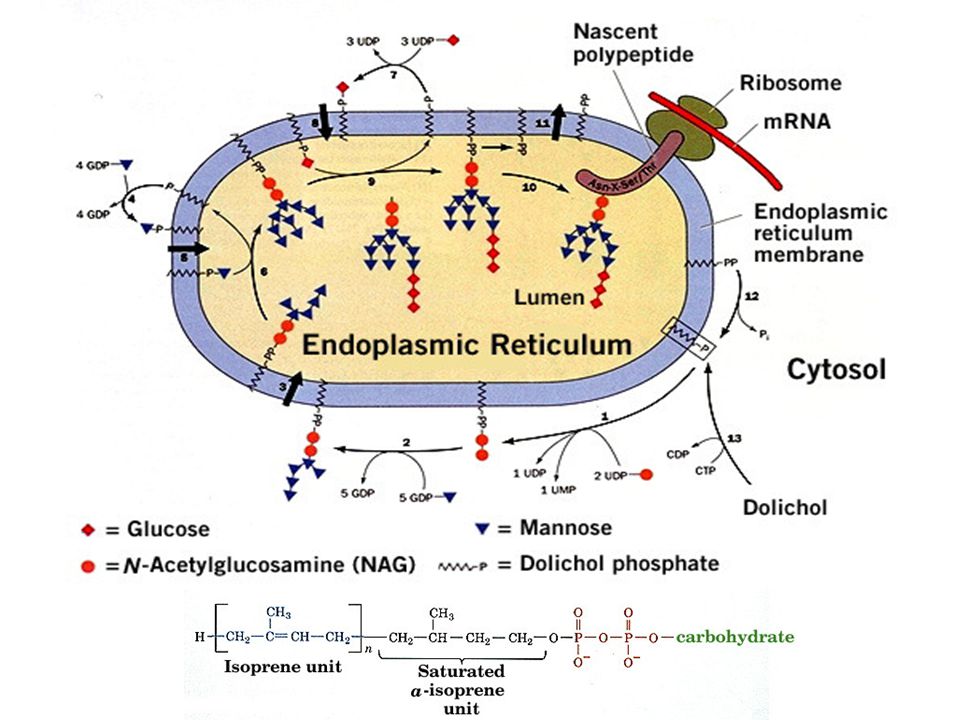
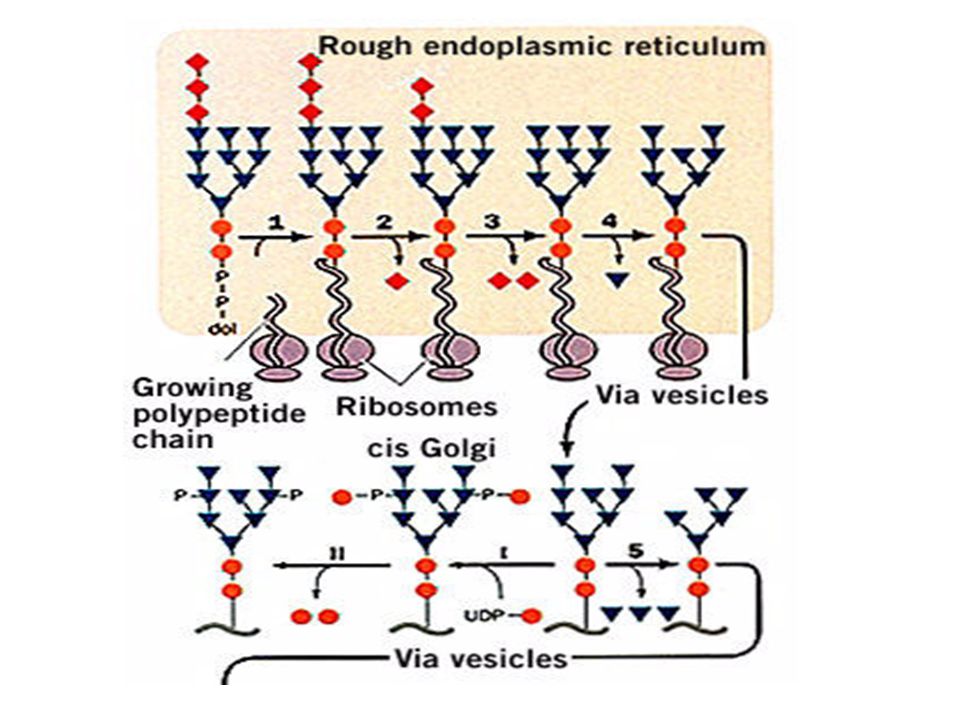
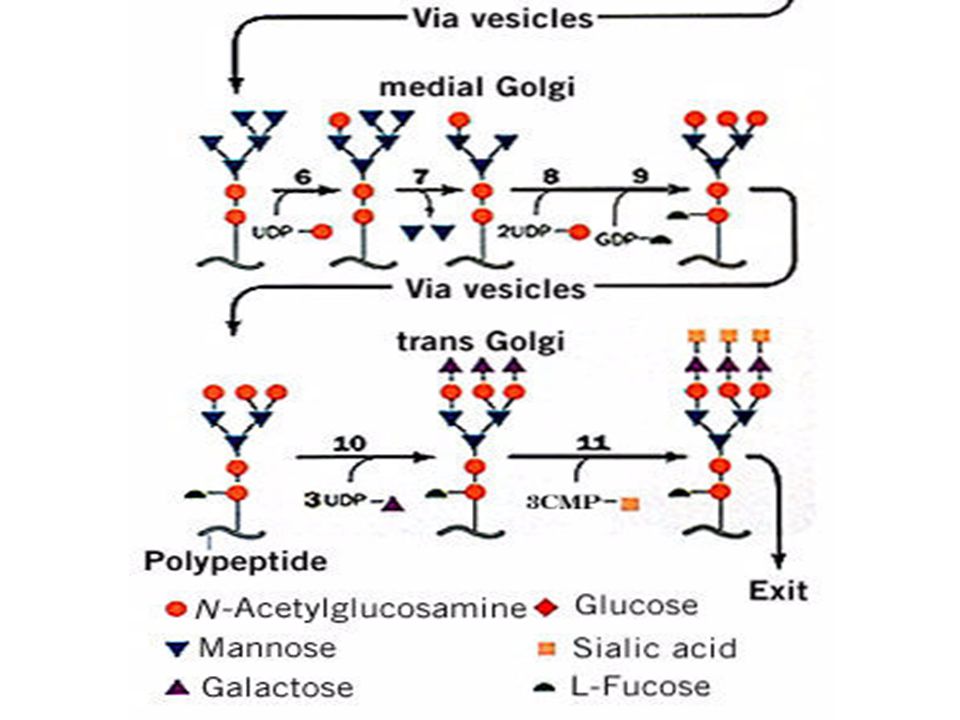
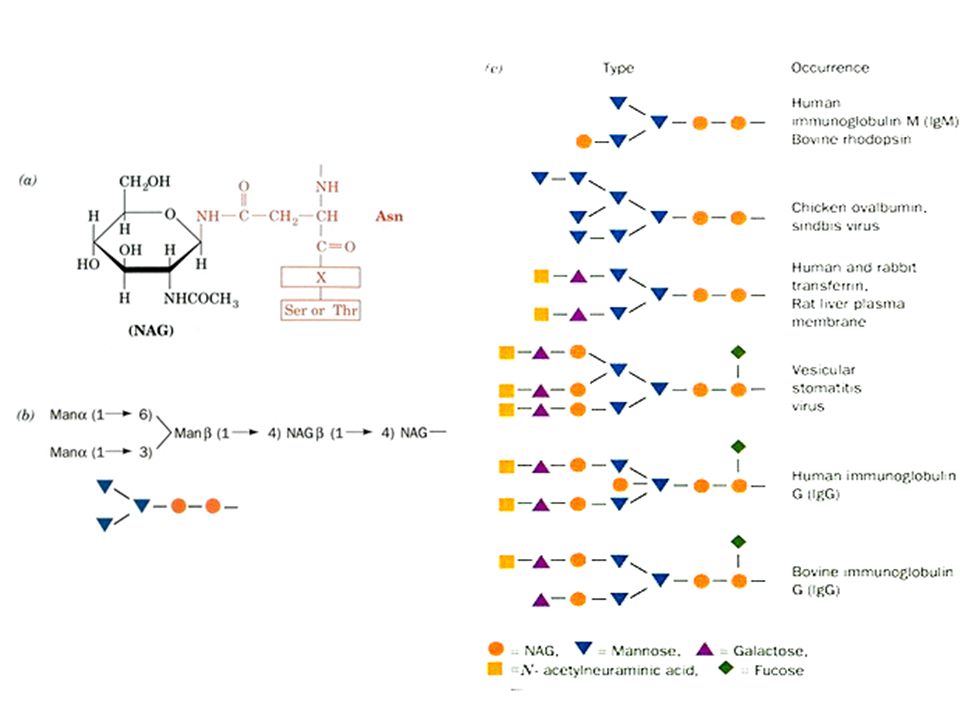
La N-glicosilación

40
Distribución filogenética
Enlace Eucariotas Arqueas Eubacterias N-glicosil + O-glicosil C-manosilación Fosfoglicosil Glipiación

41
Y la glicosilación, es frecuente
entre las proteínas? El 65% de las secuencias proteicas registradas en SWISS-PROT presentan consenso para N-glicosilación (NXS/T). Cada una de estas secuencias proteicas tendría 3.1 sitios de glicosilación. Apweiler et al., Biochim Biophys Acta. 1473:4-8.
. Cada una de estas secuencias proteicas tendría 3.1 sitios de glicosilación. Apweiler et al., Biochim Biophys Acta. 1473:4-8.")
42
La N-glicosilación Helenius, A. y Aebi, M Science. 291:

43
N-Glicosilación, un procesamiento
compartamentalizado

47
Membrane bound oligosaccharide-transferring enzyme
a-glucosidase I a-glucosidase II ER a-1,2 mannosidase Golgi a-mannosidase N-acetylglucosaminyltransferase I Golgi a-mannosidase II N-acetylglocosaminyltransferase II Fucosyltransferase Galactosyltransferase Sialyltransferase N-acetylglucosaminyl phosphotransferase N-acetylglucosamine-1-phosphodiester a-N-acetylglucosaminidase

51
Degradación de proteínas
Degradación inespecífica en lisosomas Degradación específica dependiente de ATP mediada por ubiquitina en proteosomas 26S

52
E1 ubiquitin activating enzyme
E2 ubiquitin-conjugating enzyme E3 ubiquitin-protein ligase

53
Proteasome/ Ubiquitination Proteasome/Ubiquitination
Attachment of ubiquitin to proteins targets them for proteolytic degradation by a complex cellular structure, the proteasome. Degradation of proteins by proteasomes removes denatured, damaged or improperly translated proteins from cells and regulates the level of proteins such as cyclins and some transcription factors. E1 and E2 enzymes prepare the ubiquitin chains that are then attached to proteins by the E3 enzyme. The core proteasome (20S proteasome) consists of four rings each with 14 subunits stacked on top of each other that are responsible for the proteolytic activity of the proteasome. The PA700 regulatory complex is stacked on the ends of the cylindrical core to form a 26S proteasome. Proteins that are tagged with ubiquitin are recognized and bound by the regulatory subunits, then unfolded in an ATP-dependent manner, and inserted into the core particle, where proteases degrade the protein, releasing small peptides and releasing the ubiquitin intact. The PA28 regulatory complex is an alternative regulatory complex that appears to play a role in antigen processing for presentation of peptides to immune cells in the major histocompatibility complex I (MHC I) complex.
 consists of four rings each with 14 subunits stacked on top of each other that are responsible for the proteolytic activity of the proteasome. The PA700 regulatory complex is stacked on the ends of the cylindrical core to form a 26S proteasome. Proteins that are tagged with ubiquitin are recognized and bound by the regulatory subunits, then unfolded in an ATP-dependent manner, and inserted into the core particle, where proteases degrade the protein, releasing small peptides and releasing the ubiquitin intact. The PA28 regulatory complex is an alternative regulatory complex that appears to play a role in antigen processing for presentation of peptides to immune cells in the major histocompatibility complex I (MHC I) complex.")
54
Ubiquitin-Proteasome Pathway
Intracellular proteolytic systems recognize and destroy misfolded or damaged proteins, unassembled polypeptide chains, and short-lived regulatory proteins. There are several mechanisms for protein degradation within cells. Two systems that play important roles in proteolysis resulting from cell stress are the calpain proteases and the ubiquitin-proteasome pathway. The ubiquitin-proteasome pathway functions widely in intracellular protein turnover. It plays a central role in degradation of short-lived and regulatory proteins important in a variety of basic cellular processes, including regulation of the cell cycle, modulation of cell surface receptors and ion channels, and antigen processing and presentation. The pathway employs an enzymatic cascade by which multiple ubiquitin molecules are covalently attached to the protein substrate. The polyubiquitin modification marks the protein for destruction and directs it to the 26S proteasome complex for degradation.

55
Vida media de algunas enzimas de higado de rata
Enzima Vida media (h) Ornitina descarboxilasa 0.2 RNA polimerasa I 1.3 Tirosina aminotransferasa 2.0 Serina deshidratasa 4.0 PEP carboxilasa 5.0 Aldolasa GAPDH Citocromo b LDH Citocromo c
 Ornitina descarboxilasa 0.2. RNA polimerasa I 1.3. Tirosina aminotransferasa 2.0. Serina deshidratasa 4.0. PEP carboxilasa 5.0. Aldolasa 118. GAPDH 130. Citocromo b 130. LDH 130. Citocromo c 150.")
56
Altamente desestabilizadores
Vida Media De Proteínas Citoplásmicas En Función De Sus Residuos N-terminales Reconocidos por E3 Residuo N-terminal Vida media Estabilizadores Met, Ser, Ala Thr, Val, Gly, Cis > 20 hrs Desestabilizadores Ile, Glu ~ 30 min Tyr, Gln ~ 10 min Altamente desestabilizadores Phe, Leu, Asp Lys, Arg ~ 2 min

57
Dos vistas del proteasoma de levadura
The structure of the 20S proteasome (yeast) has been resolved recently ( Groll M, Ditzel L, Lowe, J, Stock D, Bochtler M, Bartunik, HD. & Huber, R 1997 Nature 386: ) The active site residues are located in the subunits beta 1, 2 and 5. The active site trias consists of the residues Thr1, Lys33 and Ser129. Dos vistas del proteasoma de levadura
 has been resolved recently ( Groll M, Ditzel L, Lowe, J, Stock D, Bochtler M, Bartunik, HD. & Huber, R 1997 Nature 386: ) The active site residues are located in the subunits beta 1, 2 and 5. The active site trias consists of the residues Thr1, Lys33 and Ser129. Dos vistas del proteasoma de levadura.")
58
a single molecular complex
Structure of clathrin. a single molecular complex Isolated coated vesicles

59
Its extraordinary structure enables the protein to polymerize in a two-dimensional network consisting of numerous hexagons. Strictly speaking forms the aggregate no plane but a bent surface with a convex and a concave side. It is an open question whether the tendency to bend has intramolecular or intermolecular causes. Important is especially the fact that such networks fit with their concave side tightly to membranes, for example to the inner surface of the plasmalemma. The growing network provides the mechanical force to pull the membrane into a bud. This bud is finally pinched off: a clathrin-coated vesicle has been formed. Coated vesicles are known to exist in a range of plant and animal cells (E. H. NEWCOMB, 1980). They bring extracellular substances into the cell, a process called endocytosis. Depending on whether the vesicles cargo consists of particles or of liquid is it distinguished between phagocytosis and pinocytosis. Within the cell have coated vesicles the chance to fuse with other vesicles, for example with lysosomes. Their content is then digested by the lysosomal enzymes, the clathrin coat is dismantled and available for a new cycle. Vesícula recubierta de una reja de clatrina y adaptinas, la unidad básica de la jaula es un trisquelion
. They bring extracellular substances into the cell, a process called endocytosis. Depending on whether the vesicles cargo consists of particles or of liquid is it distinguished between phagocytosis and pinocytosis. Within the cell have coated vesicles the chance to fuse with other vesicles, for example with lysosomes. Their content is then digested by the lysosomal enzymes, the clathrin coat is dismantled and available for a new cycle. Vesícula recubierta de una reja de clatrina y adaptinas, la unidad básica de la jaula es un trisquelion.")
60
The common structure of signal peptides from various proteins is commonly described as a positively charged n-region, followed by a hydrophobic h-region and a neutral but polar c-region. The (-3,-1)-rule states that the residues at positions -3 and -1 (relative to the cleavage site) must be small and neutral for cleavage to occur correctly. In many instances the amino acids comprising the signal peptide are cleaved off the protein once its final destination has been reached. The cleavage is catalysed by enzymes known as signal peptidases.

61
Ubiquitin is a highly conserved, 76-residue (8
Ubiquitin is a highly conserved, 76-residue (8.5 kDa) polypeptide widespread in eukaryotes. The amino acid sequences of yeast and human are 53% identical. Proteins are condemned to degradation through ligation to ubiquitin.
 polypeptide widespread in eukaryotes. The amino acid sequences of yeast and human are 53% identical. Proteins are condemned to degradation through ligation to ubiquitin.")
62
Aggregation of nonnative protein chains as a side-reaction of productive folding in the crowded environment of the cell. Enhancement of aggregation and chain compaction by macromolecular crowding (red arrows). U, unfolded protein chain released from ribosome; I, partially folded intermediate; N, native, folded protein. Crowding is predicted to enhance the formation of amyloid fibrils, but this effect has not yet been demonstrated experimentally
. U, unfolded protein chain released from ribosome; I, partially folded intermediate; N, native, folded protein. Crowding is predicted to enhance the formation of amyloid fibrils, but this effect has not yet been demonstrated experimentally.")
63
The banded appearance of collagen fibrils in the electron microscope arises from the schematically represented staggered arrangement of collagen molecules (above) that results in a periodically indented surface. D, the distance between cross striations, is ~680 A, so the length of a 3000 A-long collagen molecule is 4.4D

Presentaciones similares





















 Sintetizado en vivo por la enzima NO-sintetasa>")
