Descargar la presentación
La descarga está en progreso. Por favor, espere

1
UNIVERSIDAD NACIONAL DE UCAYALI Facultad de Ing
UNIVERSIDAD NACIONAL DE UCAYALI Facultad de Ing. De Sistemas Escuela Pro. De Ing. De Sistemas Curso : Sistemas Distribuidos Capitulo : Servicios de Nombres Docente : Ing. Ind. Franklin Calle Zapata Grupo : 02 Integrantes : Lachi Cárdenas, Antony Martin(Líder) 95% Figueroa Muñoz, Amilkar 90% Tang Armas, Edward 90% Viviano Saré, Yojer 95% Fecha : 15/09/08
 95% Figueroa Muñoz, Amilkar 90% Tang Armas, Edward 90% Viviano Saré, Yojer 95% Fecha : 15/09/08.")
2
Sistemas Distribuidos
Servicios de Nombres

3
Contenido Introducción
Servicios de nombres y el Sistema de Nombres de Dominio Servicios de directorio y descubrimiento Estudio del caso del Servicio de Nombres Global Estudio del caso del Servicio de Directorio X.500 Resumen

4
Introducción Servicios de Nombres

5
Introducción En un sistema distribuido los nombres se utilizan para hacer referencia a una amplia variedad de recursos como computadores, servicios, objetos remotos y archivos. El dar nombres es una cuestión que puede ser fácilmente olvidada pero que es fundamental en el diseño de sistemas distribuidos. Los nombres facilitan al comunicación y la compartición de recursos. Se necesita un nombre para solicitar que un sistema computacional actué sobre un recurso especifico elegido entre muchos posibles; por ejemplo, se necesita un nombre en forma de URL para acceder a una pagina Web particular. Los procesos no pueden compartir recursos particulares gestionados por un sistema computacional a no ser que pueda nombrarlos de forma consistente. Los usuarios no pueden comunicarse entre ellos a través de un sistema distribuido a no ser que puedan nombrarse, por ejemplo mediante la dirección de correo electrónico.

6
Introducción Los nombres no constituyen el único medio útil de identificación: otro procedimiento son los atributos descriptivos. A veces los clientes no conocen los nombres de una entidad particular que están buscando, pero tienen información que la describe. O puede que el cliente necesite un servicio (en lugar de la entidad particular que la implementa) y conozca algunas de las características que debe tener el servicio que solicitan. Se presentan los servicios de nombres, los cuales proporcionan a los clientes datos sobre los objetos nombrados en sistemas distribuidos, también se presentan los conceptos relacionados sobre servicios de directorio y de descubrimiento, los cuales proporcionan datos sobre objetos que cumplen una cierta descripción. Describimos diferentes posibles aproximaciones en el diseño de implantación de esos servicios, utilizando el servicio de nombres de dominio (DNS), GNS y X500 como casos de estudio.
 y conozca algunas de las características que debe tener el servicio que solicitan. Se presentan los servicios de nombres, los cuales proporcionan a los clientes datos sobre los objetos nombrados en sistemas distribuidos, también se presentan los conceptos relacionados sobre servicios de directorio y de descubrimiento, los cuales proporcionan datos sobre objetos que cumplen una cierta descripción. Describimos diferentes posibles aproximaciones en el diseño de implantación de esos servicios, utilizando el servicio de nombres de dominio (DNS), GNS y X500 como casos de estudio.")
7
Introducción Nombres, Dirección y otros Atributos
Cualquier proceso que necesite acceder a un recurso específico debe poseer su nombre o un identificador. Ejemplo de nombres fácilmente legibles son nombres de archivos /etc/passwd, URL’s como y nombres de dominio de internet, como des.qmw.ac.uk. El término identificador se utiliza a veces para referirse a nombres que sólo se interpretan en los programas Las referencias a objetos remotos y administradores de archivos NFS son ejemplos de identificadores. Los identificadores se eligen por la eficiencia con la que puedan ser buscados y almacenados por el software.

8
Introducción Needham (1993) distingue entre nombre puro y otros. Los nombres puros son simplemente patrones de bits sin interpretar. Los nombres no puros contienen información acerca del objeto al que nombran. Los nombres puros siempre deben buscarse antes de poder ser utilizados. En el otro extremo de un nombre puro se sitúa la dirección de un objeto: un valor que identifica la ubicación del objeto en lugar del objeto en sí mismo. Las direcciones son eficaces para acceder a los objetos, pero los objetos cambian de localización, por lo que las direcciones no siempre resultan adecuadas como medio de identificación. Por ejemplo las direcciones de correo electrónico de los usuarios normalmente cambian cuando los usuarios se mueven entre organizaciones o entre proveedores de servicio a internet; nos son suficientes por ellas mismas para referirse a un individuo específico a lo largo del tiempo.
 distingue entre nombre puro y otros. Los nombres puros son simplemente patrones de bits sin interpretar. Los nombres no puros contienen información acerca del objeto al que nombran. Los nombres puros siempre deben buscarse antes de poder ser utilizados. En el otro extremo de un nombre puro se sitúa la dirección de un objeto: un valor que identifica la ubicación del objeto en lugar del objeto en sí mismo. Las direcciones son eficaces para acceder a los objetos, pero los objetos cambian de localización, por lo que las direcciones no siempre resultan adecuadas como medio de identificación. Por ejemplo las direcciones de correo electrónico de los usuarios normalmente cambian cuando los usuarios se mueven entre organizaciones o entre proveedores de servicio a internet; nos son suficientes por ellas mismas para referirse a un individuo específico a lo largo del tiempo.")
9
Introducción Decimos que un nombres esta resuelto cuando esta traducido a datos relacionados con el recurso u objeto nombrado, a menudo con el objetivo de realizar una acción de invocación sobre el. La asociación entre un nombre y un objeto se llama enlace. En general los nombres se enlazan a los atributos de los objetos nombrados en lugar de enlazarlos a la implementación de los propios objetos. Un atributo es el valor de una propiedad asociada con un objeto. Un atributo clave de una entidad que es normalmente relevante en un sistema distribuido en su dirección por ejemplo: DNS relaciona los nombres de dominio con los atributos de un cierto computador: su dirección IP, el tipo de entrada (por ejemplo una referencia a un servidor de correo o a otro tipo de nodo) y, por ejemplo, el periodo de tiempo durante el que la entrada del nodo será valida. Se puede utilizar el servicio de directorio X.500 para relacionar un nombre de persona sobre atributos que incluyen la dirección de correo electrónico y el número de teléfono.
 y, por ejemplo, el periodo de tiempo durante el que la entrada del nodo será valida. Se puede utilizar el servicio de directorio X.500 para relacionar un nombre de persona sobre atributos que incluyen la dirección de correo electrónico y el número de teléfono.")
10
Introducción Obsérvese que una dirección puede ser considerada a menudo simplemente como otro nombre que debe ser buscado o bien que puede contener dicho nombre. Cada dirección IP debe ser buscada para obtener una dirección de red, como una dirección Ethernet. De forma similar los navegadores web y clientes de correo electrónico utilizan DNS para interpretar los nombres de dominio de los URL y las direcciones de correo electrónico. La Figura 9.1 muestra la porción de nombres de dominio de un URL resuelto vía DNS para conseguir una dirección IP en primer lugar, y a continuación la dirección Ethernet del servidor web conseguida a través de ARP. La última parte del URL se resuelve en el sistema de archivos del servidor web para encontrar el archivo relevante.

11
Introducción Nombres y servicios
Muchos de los nombres utilizados en un sistema distribuido son es pecíficos de algún servicio particular. Un cliente utiliza dicho nombre al solicitar un servicio con objeto de realizar una operación sobre el objeto nombrado o sobre un recurso que éste maneja. Por ejemplo, al servicio de archivos se le proporciona un nombre de archivo cuando se solicita la eliminación de dicho archivo; al servicio de gestión de procesos se le proporciona un identificador de proceso cuando se solicita el envío de una señal a dicho proceso. Esos nombres sólo se utilizan en el contexto del servicio que gestiona los objetos nombrados, exceptuando cuando los clientes se comunican mediante objetos compartidos.

12
Introducción

13
Introducción Identificadores de Recurso Unificados Los URL presentan la importante propiedad de la escalabilidad, de modo que pueden hacer referencia aun conjunto de recursos Web sin límite, a la vez que apuntan de forma eficiente a los recursos. El acceder a un recurso es fácil, partiendo de la información en su URL (un nombre DNS de computador y un camino en esa maquina). Aunque debido a los URL son esencialmente direcciones de recursos Web, sufren el inconveniente de que si el recurso se borra o se reubica, por ejemplo de un sitio Web a otro, entonces habrá enlaces generalmente desconectados del recurso asociado al antiguo URL. Si un usuario trata de acceder a un enlace desconectado, el servidor Web responderá que el recurso no ha sido encontrado o, posiblemente peor, proporcionara un recurso diferente que actualmente ocupa la misma situación.
. Aunque debido a los URL son esencialmente direcciones de recursos Web, sufren el inconveniente de que si el recurso se borra o se reubica, por ejemplo de un sitio Web a otro, entonces habrá enlaces generalmente desconectados del recurso asociado al antiguo URL. Si un usuario trata de acceder a un enlace desconectado, el servidor Web responderá que el recurso no ha sido encontrado o, posiblemente peor, proporcionara un recurso diferente que actualmente ocupa la misma situación.")
14
Introducción Identificadores de Recurso Unificados
El otro tipo principal de URL es le nombre uniforme de recurso, los URN tratan de resolver el problema de los desconectados y proporcionan modos mas completos de encontrar recursos en el Web. La idea consiste en tener un URN permanente para un recurso en el Web, incluso si el recurso se recoloca. El propietario de un recurso registrara su nombre, junto con le URL actual, frente a un servicio de búsqueda URN que proporcionara el URL a partir del URN. El propietario debe anotar el nuevo URL si se traslada el recurso. Un URN tiene la forma urn: espacio Nombres: nombre especifico – espacio nombres. Por ejemplo. urn: ISBN: podría referirse al libro que lleva le nombre en el esquema de nombre estándar ISBN. El nombre (inventado) urn: doi: /music- pop 1234se refiere a la publicación llamada music- pop conocida en el esquema de nombres del editor como en el esquema de identificador de objetos. Las características de recurso uniformes son un subconjunto de los URN. Un URC es una descripción de un recurso Web que consta de atributos del recurso. Los URC sirven para describir recursos Web y para realizar búsquedas de recursos Web que cumplan con su especificación de atributos.
 urn: doi: /music- pop 1234se refiere a la publicación llamada music- pop conocida en el esquema de nombres del editor como en el esquema de identificador de objetos. Las características de recurso uniformes son un subconjunto de los URN. Un URC es una descripción de un recurso Web que consta de atributos del recurso. Los URC sirven para describir recursos Web y para realizar búsquedas de recursos Web que cumplan con su especificación de atributos.")
15
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
Servicio de Nombres

16
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
Un servicio de nombres almacena una colección de uno más contextos de nominación, es decir, conjunto de enlaces entre nombres textuales y atributos de objetos como usuarios, computadores, servicios y objetos remotos. La principal tarea que facilita un servicio de nombres es la resolución de un nombre, es decir, la búsqueda de atributos dado un cierto nombre. La gestión de nombres estará muy separa de los otros servicios en virtud del carácter abierto de los sistemas distribuidos, el motivo de esto se encuentra en: Unificación: a menudo es conveniente que los recursos que se gestionan desde diferentes servicios utilicen el mismo esquema de nomenclatura, los URL son un buen ejemplo. Integración: no es siempre posible predecir el ámbito de la compartición en un sistema distribuido, puede ser necesario compartir y por lo tanto nombrar recursos que fueron creados en diferentes dominios administrativos. Sin un servicio de nombres común podría ocurrir que los dominios administrativos utilizasen nomenclaturas completamente diferentes.

17
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
Requisitos de un servicio de nombres general En sus inicios, los servicios de nombres eran muy simples ya que se diseñaron para cubrir únicamente las necesidades de vincular nombres con direcciones en un único dominio de gestión, correspondiente a una única LAN O WAN. La interconexión de redes y el incremento de escala de los sistemas distribuidos han hecho que el problema de la correspondencia de nombres sea mucho más complejo. Grapevine (Virrey y otros 1982) fueron uno de los primeros servicios de nombres extensibles y multidominio, se diseño explícitamente para ser escalable por encima de, al menos, dos ordenes de magnitud el numero de nombres y el la carga de solicitudes que podría manejarse.
 fueron uno de los primeros servicios de nombres extensibles y multidominio, se diseño explícitamente para ser escalable por encima de, al menos, dos ordenes de magnitud el numero de nombres y el la carga de solicitudes que podría manejarse.")
18
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
Requisitos de un servicio de nombres general El servicio de nombres global, desarrollado en el centro de investigación de sistemas de digital Equipment Coporation (Lampson 1986), desciende de Grapevine aunque con objetivos más ambiciosos: Gestionar un numero arbitrario de nombres y servir un número arbitrario de organizaciones administrativas: por ejemplo, el sistema deberá ser capaz, entre otras cosas, de gestionar direcciones de correo electrónico para todos los usuarios de computadores del mundo. Tiempo de vida elevado: durante el tiempo de vida del servicio ocurrirán muchos cambios en la organización del conjunto de nombres y en los componentes que lo implementan. Alta disponibilidad: la mayor parte del resto del sistema dependerá del servicio de nombres y no podrá funcionar si este servicio no está disponible. Aislamiento de fallos: de forma que los fallos locales no provoquen el fallo del sistema completo. Tolerancia a la ausencia de autentificación: en un sistema abierto a gran escala no hay ningún componente que este autenticado por todos los clientes del sistema.
, desciende de Grapevine aunque con objetivos más ambiciosos: Gestionar un numero arbitrario de nombres y servir un número arbitrario de organizaciones administrativas: por ejemplo, el sistema deberá ser capaz, entre otras cosas, de gestionar direcciones de correo electrónico para todos los usuarios de computadores del mundo. Tiempo de vida elevado: durante el tiempo de vida del servicio ocurrirán muchos cambios en la organización del conjunto de nombres y en los componentes que lo implementan. Alta disponibilidad: la mayor parte del resto del sistema dependerá del servicio de nombres y no podrá funcionar si este servicio no está disponible. Aislamiento de fallos: de forma que los fallos locales no provoquen el fallo del sistema completo. Tolerancia a la ausencia de autentificación: en un sistema abierto a gran escala no hay ningún componente que este autenticado por todos los clientes del sistema.")
19
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
El sistema de nombres de dominio de Internet (DNS), es menos ambicioso en el numero de objetos que es capaz de manejar, peroné continua usándose de forma amplia. Para proporcionar un servicio satisfactorio, se basa en gran medida en la replicación y el almacenamiento en caché de los datos de nominación. El diseño DNS y de otros servicios de nombres parte de la suposición de que la consistencia caché no debe gestionarse estrictamente como en le caso de copias cache de archivos ya que las actualizaciones son menos frecuentes el uso de una copia sin actualizar, en una traducción de nombres, pueden detectarse generalmente en el software del cliente.
, es menos ambicioso en el numero de objetos que es capaz de manejar, peroné continua usándose de forma amplia. Para proporcionar un servicio satisfactorio, se basa en gran medida en la replicación y el almacenamiento en caché de los datos de nominación. El diseño DNS y de otros servicios de nombres parte de la suposición de que la consistencia caché no debe gestionarse estrictamente como en le caso de copias cache de archivos ya que las actualizaciones son menos frecuentes el uso de una copia sin actualizar, en una traducción de nombres, pueden detectarse generalmente en el software del cliente.")
20
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Un espacio de nombre es la colección de todos los nombres validos reconocidos por un servicio particular. Que un nombre sea valido significa que un servicio intentara su búsqueda incluso si ese nombre resulta no estar a asociado a ningún objeto, es decir, esta desvinculado. Los espacios de nombres requieren una definición sintáctica. Por ejemplo el nombre 2 posiblemente no se corresponda con un proceso UNIX, sin embargo el entero 2 seguramente si lo sea, de forma similar, el nombre <<…>>> no es aceptable como nombre DNS de un computador.

21
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Los nombres DNS tienen una estructura jerárquica: un nombre de dominio esta formado por una o mas cadenas, separadas por un delimitador << >>, llamadas componentes de nombres o etiquetas. No existe delimitador en el comienzo o en el final de un nombre de dominio, a pesar de que nos referimos mediante << >> a la raíz del espacio de nombres DNS con fines administrativos. Los componentes del nombres son cadenas imprimibles que no contienen << >>. En general, un prefijo de un nombre es una sección inicial del nombre que contiene únicamente cero o más componentes completos. Los servidores DNS no reconocen los nombres relativos: todos los nombres se refieren a la raíz global. Sin embargo, en la implementación practica, el software de cliente mantiene una lista de nombres de dominio que se añaden automáticamente a cualquier nombre de componente único antes de la resolución. Por ejemplo, el nombre bruno sobre el dominio dcs.qmw.ac.uk se refiere probablemente a bruno.dcs.qmw.ac.uk; el software de cliente añadirá el dominio por defecto dcs.qmw.ac.uk e intentara resolver el nombre resultante. Si esto falla, entonces se añadirán otros nombres de dominio por defecto; finalmente, el nombre (absoluto) bruno se presentara a la raíz para su resolución. Sin embargo, los nombres con más de un componente se presentan normalmente de forma intacta al DNS como nombres absolutos.
 bruno se presentara a la raíz para su resolución. Sin embargo, los nombres con más de un componente se presentan normalmente de forma intacta al DNS como nombres absolutos.")
22
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Alias. Desgraciadamente, los nombres con más de uno o más componentes son desagradables de teclear y recordar. En general, un alias es similar a los enlaces simbólicos de tipo UNIX. Permitiendo que un nombre practico sea sustituto de otro mas complicado. DNS permite alias, en los que se define un nombre de dominio para representar a otro. La razón para disponer de alias es para proporcionar transparencia. Por ejemplo, los alias se usan habitualmente para especificar los nombres de maquinas que ejecutan un servicio Web o un servicio FTP. El nombre es un alias de copper.dcs.qmw.ac.uk. esto tiene la ventaja de que los clientes pueden hacer referencia al servidor Web mediante un nombre genérico que n se refiere a una maquina particular, y si el servidor Web se mueve a otro computador, todo lo que hay que hacer es actualizar el alias en la base de datos DNS.

23
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Dominios de nombres. Un dominio de nombres es un espacio de nombres para el que existe una única autoridad administrativa global para asignar nombres. Esta autoridad ejerce, en conjunto, un control de los nombres que se pueden enlazar al dominio, aunque pueda delegar libremente esta tarea. Los dominios en DNS son colecciones de nombres de dominio; sintácticamente el nombre de un dominio es el sufijo común de los nombres de dominio que hay dentro de el, aunque por otra parte no se pueda distinguir, por ejemplo del nombre de un computador. Por ejemplo, qmw.ac.uk es un dominio que contiene dcs.qmw.ac.uk. observe que el termino nombre de dominio es potencialmente confusa que solo algunos nombres de dominios identifican dominios. Un computador puede llegar a tener el mismo nombre que un dominio: por ejemplo, yahoo.com es el nombre de un servidor Web en el dominio llamado yahoo.com.

24
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Combinación y personalización de los espacios de nombres. DNS proporciona un espacio de nombres global y homogéneo en el que un cierto nombre se refiere a la misma entidad. Independientemente de que proceso, en que computador busque dicho nombre. Por el contrario, algunos servicios de nombres permiten distintos espacios de nombres (algunas veces espacios de nombres heterogéneos) incluidos en ellos; también algunos servicios de nombres permiten personalizar el espacio de nombres para acomodarse a las necesidades de grupos individuales, usuarios e incluso procesos. Fusionado: el montado de sistemas de archivos UNIX y NFS es un ejemplo en el que una parte de un espacio de nombres se inserta cómodamente en otro. Pero, considérese como mezclar el sistema de archivos UNIX completo de dos (o más) computadores llamados rojo y azul. Cada computador tiene su propia raíz, con nombres de archivos que se solapan. Por ejemplo /etc/passwd se refiere a un archivo en rojo y a otro diferente en azul. La forma mas obvia de mezclar los sistemas de archivos de cada computador en esta súper raíz, sea por ejemplo /rojo y /azul. Los usuarios y los programas se referirían entonces a /rojo/etc/passwd y a /azul/etc/passwd. Sin embargo, la nueva asignación de nombres podría provocar que fallaran aquellos programas que todavía manejaran el nombre antiguo /etc/passwd. Una solución es dejar los contenidos de la raíz antigua en cada computador e insertar los sistemas de archivos /rojo y /azul en ambos computadores (asumiendo que esto no genera conflictos de nombres con los contenidos de la antigua raíz.)
 incluidos en ellos; también algunos servicios de nombres permiten personalizar el espacio de nombres para acomodarse a las necesidades de grupos individuales, usuarios e incluso procesos. Fusionado: el montado de sistemas de archivos UNIX y NFS es un ejemplo en el que una parte de un espacio de nombres se inserta cómodamente en otro. Pero, considérese como mezclar el sistema de archivos UNIX completo de dos (o más) computadores llamados rojo y azul. Cada computador tiene su propia raíz, con nombres de archivos que se solapan. Por ejemplo /etc/passwd se refiere a un archivo en rojo y a otro diferente en azul. La forma mas obvia de mezclar los sistemas de archivos de cada computador en esta súper raíz, sea por ejemplo /rojo y /azul. Los usuarios y los programas se referirían entonces a /rojo/etc/passwd y a /azul/etc/passwd. Sin embargo, la nueva asignación de nombres podría provocar que fallaran aquellos programas que todavía manejaran el nombre antiguo /etc/passwd. Una solución es dejar los contenidos de la raíz antigua en cada computador e insertar los sistemas de archivos /rojo y /azul en ambos computadores (asumiendo que esto no genera conflictos de nombres con los contenidos de la antigua raíz.)")
25
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Heterogeneidad: el espacio de nombres del entorno de computación distribuida (distributed computing environment, DCE) [OSF 1997] permiten incluir en su interior espacios de nombres heterogéneos. Los nombres DCE pueden contener uniones, similares a los puntos de montado de NFS y en UNIX, excepto por el hecho de que permiten montar espacios de nombres heterogéneos. Por ejemplo, sea el nombre completo DCE /…/dcs.qmw.ac.uk denota un contexto, denominado celda. El siguiente componente es una unión. Por ejemplo, la unión principals es un contexto que contiene los directores de seguridad donde puede buscarse el componente final jean.Dollimore. De forma similar, en /…/dcs.qmw.ac.uk/files/pub/reports/TR , la unión files es un contexto correspondiente a un directorio del sistema de archivos, en el que buscar el componente final pub/reports/ TR Los dos empalmes principals y files son las raíces de espacios de nombres heterogéneos, implementados mediante servicios de nombres heterogéneos.
 [OSF 1997] permiten incluir en su interior espacios de nombres heterogéneos. Los nombres DCE pueden contener uniones, similares a los puntos de montado de NFS y en UNIX, excepto por el hecho de que permiten montar espacios de nombres heterogéneos. Por ejemplo, sea el nombre completo DCE /…/dcs.qmw.ac.uk denota un contexto, denominado celda. El siguiente componente es una unión. Por ejemplo, la unión principals es un contexto que contiene los directores de seguridad donde puede buscarse el componente final jean.Dollimore. De forma similar, en /…/dcs.qmw.ac.uk/files/pub/reports/TR , la unión files es un contexto correspondiente a un directorio del sistema de archivos, en el que buscar el componente final pub/reports/ TR Los dos empalmes principals y files son las raíces de espacios de nombres heterogéneos, implementados mediante servicios de nombres heterogéneos.")
26
SERVICIOS DE NOMBRES Y EL SISTEMA DE NOMBRES DEL DOMINO
ESPACIOS DE NOMBRES Personalización: vimos en el ejemplo anterior, sobres sistemas de archivos empotrados montados en NFS, que a veces los usuarios prefieren construir sus espacios de nombres de forma independiente en lugar de compartir un espacio de nombres únicos. El montado de sistemas de archivos permite a los usuarios importar archivos que almacenados en los servidores y compartirlos, mientras que el resto de nombres continúan refiriéndose a archivos locales no compartidos y pueden ser administrados de forma autónoma. Sin embargo, incluso los mismos archivos, accedidos desde dos computadores diferentes pueden ser montadas en diferentes puntos y por lo tanto tener diferentes nombres. Debido a que no comparten el espacio de nombres completos, los usuarios deberán reducir los nombres entre computadores. Otro ejemplo que justifica la personalización en si el mismo nombre se refiere a diferentes archivos en diferentes computadores. Esta asociación de los mismos nombres sobre diferentes archivos hacen posible escribir scripts asociados a esos nombres que se ejecutan correctamente en todas las configuraciones de maquinas.

27
RESOLUCION DE NOMBRES En general, la resolución es un proceso iterativo en el que se presenta de forma repetitiva un nombre sobre los contextos de nominación. Un contexto de nominación puede asociar un cierto nombre sobre un conjunto de atributos básicos (como los de usuario) bien de forma directa o bien asociando el nombre sobre otro contexto de nominación y sobre otro nombre derivado para presentarse en ese contexto. Para resolver un nombre, en primer lugar se presenta sobre un contexto de nominación inicial; el proceso de resolución se reitera mientras se generen otros contextos y otros nombres derivados. Esto ilustro al principio con el ejemplo de /etc/passwd, en el que etc se presenta al contexto /, y a continuación passwd se presenta sobre el contexto /etc. Otro ejemplo de la naturaleza iterativa de la resolución es la utilización de alias. Por ejemplo, siempre que se pregunte q un servidor DNS para resolver un alias como el servidor primeramente resuelve el alias en otro nombre de dominio (en este caso copper.dcs.qmw.ac.uk), el cual deberá ser resuelto a continuación para producir la dirección IP.
 bien de forma directa o bien asociando el nombre sobre otro contexto de nominación y sobre otro nombre derivado para presentarse en ese contexto. Para resolver un nombre, en primer lugar se presenta sobre un contexto de nominación inicial; el proceso de resolución se reitera mientras se generen otros contextos y otros nombres derivados. Esto ilustro al principio con el ejemplo de /etc/passwd, en el que etc se presenta al contexto /, y a continuación passwd se presenta sobre el contexto /etc. Otro ejemplo de la naturaleza iterativa de la resolución es la utilización de alias. Por ejemplo, siempre que se pregunte q un servidor DNS para resolver un alias como el servidor primeramente resuelve el alias en otro nombre de dominio (en este caso copper.dcs.qmw.ac.uk), el cual deberá ser resuelto a continuación para producir la dirección IP.")
28
En general, la utilización de alias permite la presencia de ciclos en el espacio de nombres, en cuyo caso puede que la resolución no termine nunca. Existen dos soluciones, la primera consiste en abandonar el proceso de resolución si el numero de resoluciones supera un cierto umbral; y, la segunda, permitir a los administradores vetar cualquier alias que pueda inducir ciclos. SERVIDORES DE NOMBRES Y NAVEGACIÓN. Cualquier servicio de nombres, como DNS, que almacena una gran base de datos y es utilizado por una población grande no almacenara toda su información de nominación en un único computador servidor. Ese servidor seria un cuello de botella y un punto de fallo critico. Cualquier servicio de nominación seria fuertemente utilizado deberá usar replicación para conseguir la suficiente disponibilidad. Veremos que DNS especifica que cada subconjunto de bases de datos sea repicada en, al menos, dos servidores independientes. Hemos mencionado previamente que los datos que pertenecen a un dominio de nombres se almacenan normalmente en un servidor de nombres local gestionado por la autoridad responsable de ese dominio. A pesar de que, en algunos casos, un servidor de nombres puede almacenar datos relativos a más de un dominio, normalmente es correcto decir que los datos se reparten sobre los servidores de acuerdo a sus dominios. Veremos que en DNS, la mayor parte de las entradas se utilizan en las computadoras locales. Aun así, también hay servidores de nombres para dominios superiores, como yahoo.com y ac.uk, y para el dominio raíz.

29
La partición de los datos implica que el servidor de nombres local no podrá responder a todas las solicitudes sin al ayuda de otros servidores de nombres. Por ejemplo, el servidor en el dominio cs.purdue.edu a no ser que esa información este en la cache (por supuesto eso no ocurre la primera vez que se realiza la consulta). El proceso de localización de los datos con nombre entre más de un servidor de nombres, para resolver un nombre, se llama navegación. El software cliente de resolución de nombres realiza. fig 9.2 Un cliente contacta de forma iterativa con los servidores de nombres NS1-NS3 para resolver un nombre.

30
la navegación en nombre del cliente
la navegación en nombre del cliente. Se comunica con los servidores de nombres que sea necesario para resolver un nombre. Puede tomar la forma de una biblioteca de código que se enlaza a los clientes, por ejemplo en las implementaciones BIND de DNS o en Grapevine [birrel y otros 1982]. Al alternativa, utilizada con X500, es la de proporcionar la resolución de nombres como un proceso separado que se comparte por todos los procesos clientes de ese computador. DNS soporta el modelo conocido como navegación iterativa (fig. 9.2). Para resolver un nombre, un cliente lo presenta al servidor de nombres local, el cual intenta resolverlo. Si el servidor de nombres local tiene dicho nombre, devuelve el resultado inmediatamente. Si n lo tiene se lo enviara reenviándola hasta que el nombre sea localizado bien se descubra que no existe. Debido a que DNS esta diseñado para gestionar las entradas de millones de dominios y es accedido por un enorme numero de clientes, no seria factible hacer que todas las solicitudes comenzaran en un servidor raíz, incluso aunque este estuviera ampliamente replicado. La base de datos de DNS redivide entre servidores de forma que se permite que muchas de las solicitudes puedan satisfacerse localmente y otras que completen sin necesidad de resolver cada parte del nombre de formas separada.
. Para resolver un nombre, un cliente lo presenta al servidor de nombres local, el cual intenta resolverlo. Si el servidor de nombres local tiene dicho nombre, devuelve el resultado inmediatamente. Si n lo tiene se lo enviara reenviándola hasta que el nombre sea localizado bien se descubra que no existe. Debido a que DNS esta diseñado para gestionar las entradas de millones de dominios y es accedido por un enorme numero de clientes, no seria factible hacer que todas las solicitudes comenzaran en un servidor raíz, incluso aunque este estuviera ampliamente replicado. La base de datos de DNS redivide entre servidores de forma que se permite que muchas de las solicitudes puedan satisfacerse localmente y otras que completen sin necesidad de resolver cada parte del nombre de formas separada.")
31
NFS también utiliza navegación iterativa en la resolución de u nombre de archivo, implementándola componente a componente. Esto es así porque el servicio de archivos puede encontrarse un enlace simbólico cuando al resolver un nombre. Un enlace simbólico debe interpretarse en el espacio de nombres del sistema rearchivos del cliente porque puede apuntar a un archivo en un directorio almacenado en otro servidor. El computador cliente deberá determinar de qué servidor se trata, porque únicamente el cliente conoce sus puntos de montajes. En la navegación por mulltidifusion, cada cliente envía de forma simultánea el nombre resolver junto con el tipo de objeto requerido al grupo de servidores de nombres. Únicamente el servidor que almacena los atributos buscados responde a la solicitud. Sin embargo, si el nombre no se encuentra, entonces la solicitud no genera ninguna respuesta. Cheriton y Mann [1989] describen un esquema de navegación por multidifusion en el que cuando el nombre solicitado no haya podido resolverse, se incluye un servidor diferente en el grupo. La navegación por multidifusion también se utiliza en los servicios de descubrimiento. Otra alternativa al modelo de navegación iterativa es que un servidor de nombres coordine la resolución del nombre y devuelva los resultados al agente de usuario. Ma [1992] distingue entre navegación recursiva y no recursiva controlada por el servidor. En la navegación no recursiva controlada por el servidor, el cliente puede elegir cualquier servidor de nombres. El servidor, como si fuera un cliente, se comunica mediante multidifusión o de forma interactiva con sus parejas en la forma descrita previamente.

32
fig 9.3 En la navegación recursiva controlada por el servidor, una vez más el cliente contacta con un solo servidor. Si el nombre no esta en este servidor, el servidor contacta con un igual que almacene un prefijo (más largo) del nombre, el cual a su vez intenta una resolución. Este procedimiento continúa de forma recursiva hasta que resuelve el nombre.
 del nombre, el cual a su vez intenta una resolución. Este procedimiento continúa de forma recursiva hasta que resuelve el nombre.")
33
Si un servicio de nombres abarca diferentes dominios administrativos, entonces se puede prohibir que los clientes que se estén ejecutando en un cierto dominio administrativo accedan a los servidores de nombres pertenecientes a otro dominio. Además, incluso puede prohibirse que los servidores de nombres descubran de la disposición de datos de nominación sobre servidores de nombres en otros dominios administrativos. En este caso, tanto la navegación controlada por cliente como la no recursiva controlada por servidor son inapropiadas, y deberá utilizarse la navegación recursiva controlada por servidor. Los servidores de nombres autorizados solicitan datos de servicio nombres a los servidores designados por los diferentes administradores, los cuales devuelven los atributos sin revelar las zonas de los datos de nominación en lasque estaban almacenados. CACHÉ. En DNS y otros servicios de nombres, el software de resolución de nombres del cliente y los servidores mantienen una caché de resultados de resoluciones previas. Cuando un cliente solicita la búsqueda de un nombre, el software de resolución de nombres consulta cu caché. Si encuentra un resultado reciente de una búsqueda previa de dicho nombre, la devuelve al cliente: en otro caso se la envía al servidor. A su vez, dicho servidor puede devolver datos provenientes de otros servidores pero almacenados en su caché.

34
El almacenamiento de datas en caché es clave en las prestaciones de un servicio de nombres y ayuda en el mantenimiento de la disponibilidad tanto del servicio como de otros servicios que seguirán funcionando incluso después de que el servidor de nombres falle. La mejora en los tiempos de respuesta que generan gracias al ahorro en las comunicaciones con los servidores de nombres (por ejemplo, el servicio raíz) del camino de navegación, permitiendo que se realice la resolución a pesar del posible fallo de algún servidor. El uso de caché por parte de los sistemas de resolución renombres en los clientes esta ampliamente difundido en los servicios de nombres, y con mucho éxito ya que los datos de nominación raramente cambian. Por ejemplo, la información del tipo de dirección de computador o de servicio tiende a permanecer inalterada durante meses o años. Sin embargo, existe la posibilidad de que un servicio de nombres devuelva atributos caducados, por ejemplo una dirección obsoleta, durante el proceso de resolución.

35
EL SISTEMA DE NOMBRES DE DOMINIO.
El sistema de nombres de dominio es un diseño de servicio de nombre, y su base de datos principal se utiliza a .lo largo de Internet. fue ideado principalmente por Mockapetris (1987) con el objetivo de reemplazar el esquema de nombres original de Internet, en el que todos los nombres de host y las direcciones se mantenían en un único archivo maestro central y se descargaban vía FTP a todos los computadores que los necesitaban (Harrestien y otros 1985). Pronto se vio que este esquema inicial sufría de fuertes limitaciones: · No era escalable hasta u numero grande de computadores · Las organizaciones locales deseaban administrar sus propios sistemas de nombres. Se necesitaba un servicio de nombres general no uno que solo sirviera para buscar direcciones de computadores.
 con el objetivo de reemplazar el esquema de nombres original de Internet, en el que todos los nombres de host y las direcciones se mantenían en un único archivo maestro central y se descargaban vía FTP a todos los computadores que los necesitaban (Harrestien y otros 1985). Pronto se vio que este esquema inicial sufría de fuertes limitaciones: · No era escalable hasta u numero grande de computadores. · Las organizaciones locales deseaban administrar sus propios sistemas de nombres. Se necesitaba un servicio de nombres general no uno que solo sirviera para buscar direcciones de computadores.")
36
Los objetivos nombrados por DNS son, en primer lugar, computadores (para las cuales en su mayor parte los que se almacenan como atributos son sus direcciones IP) y lo que se denomina como dominios de nombres son llamados simplemente dominios en DNS.Sin embargo, en principio se pueden nombrar cualquier tipo de objeto, y su arquitectura tiene la capacidad suficiente para múltiples implementaciones. Las organizaciones y departamentos pueden manejar sus propios datos de nominación. En Internet hay millones de nombres enlazados mediante DNS, y se realizan búsquedas contra dicho sistema a lo largo de todo el mundo. Cualquier nombre puede ser resuelto por cualquier nombre. Esto se consigue mediante una participación jerárquica de la base de datos del nombre, mediante la replicación de los datos de nombres y mediante el uso de cachés. NOMBRES DE DOMINIO: DNS esta diseñado para uilizarse de varias formas, cada una de las cuales puede tener su propio espacio de nombres. Sin embargo, en la práctica solo uno se utiliza ampliamente, el usado para los nombres de Internet. El espacio de nombres DNS de Internet se divide de acuerdo a criterios de organización y geográficos. Los nombres se escriben con el dominio de mayor importancia en la derecha. Los dominios de organización de primer nivel (también llamados dominios genéricos) utilizados actualmente en Internet son:
 utilizados actualmente en Internet son:")
37
com – organizaciones comerciales
edu - universidades y otra instituciones educativas. gov – agencias de gobierno de los estados unidos (EE.UU.) mil – organizaciones militares de los EE.UU. net – principales centros de soporte de la red. org – otras organizaciones no mencionadas anteriormente. int – organizaciones internacionales. Además, cada país tiene sus propios dominios: Us – estados unidos Uk – reino unido Fr – Francia Los diferentes países, excepto los EE.UU. utilizan su propio dominio para distinguir sus organizaciones. El reino unido, por ejemplo tiene los dominios co.uk y ac.uk que corresponden a com y edu respectivamente.
 mil – organizaciones militares de los EE.UU. net – principales centros de soporte de la red. org – otras organizaciones no mencionadas anteriormente. int – organizaciones internacionales. Además, cada país tiene sus propios dominios: Us – estados unidos. Uk – reino unido. Fr – Francia. Los diferentes países, excepto los EE.UU. utilizan su propio dominio para distinguir sus organizaciones. El reino unido, por ejemplo tiene los dominios co.uk y ac.uk que corresponden a com y edu respectivamente.")
38
SOLICITUDES DNS DNS en Internet se utiliza, inicialmente como sistemas de resolución de nombres de host y para la búsqueda de host de correos electrónicos, como se explica a continuación: Resolución de nombres de host: en general las aplicaciones utilizan DNS para resolver nombres de host en direcciones IP. Los navegadores utilizan http para comunicarse con los servidores web en una dirección IP con un número de puerto reservado. Los servicios FTP y SMTP trabajan de forma similar. Localización de host de correo: el software de correo electrónico utilizan DNS para resolver nombres de dominio en la dirección IP de los host de correos (computadores que acepten correos para sus dominios). DNS puede devolver mas de un nombre de dominio de forma que el software de correo puede intentar diferentes alternativas si el host de correo principal es, por alguna razón inalcanzable. DNS devuelve un valor entero de preferencia para cada host de correo, indicando asi el orden en el que deben utilizarse los host de correos. Existen otros tipos de solicitudes que están implementadas en algunas instalaciones, pero se utilizan mucho menos que las explicadas anteriormente:
. DNS puede devolver mas de un nombre de dominio de forma que el software de correo puede intentar diferentes alternativas si el host de correo principal es, por alguna razón inalcanzable. DNS devuelve un valor entero de preferencia para cada host de correo, indicando asi el orden en el que deben utilizarse los host de correos. Existen otros tipos de solicitudes que están implementadas en algunas instalaciones, pero se utilizan mucho menos que las explicadas anteriormente:")
39
Resolución inversa: algunos programas necesitan obtener un nombre de dominio dada la dirección IP. Esto es justo los contrario a una solicitud normal e nombres de host, aunque el servidor de nombres que recibe la solicitud responde únicamente si la dirección IP esta en su propio dominio. Información de host: DNS puede almacenar el tipo de arquitectura y de S.O. de los nombres de dominio de los host. Servicios bien conocidos: a partir del nombre del dominio del computador puede obtenerse una lista de servicios en ejecución por ejemplo telnet, FTP, y el protocolo autorizado para acceder a ellos (es decir UDP o TCP en Internet), siempre que el servidor de nombres de soporte a esta información. En principio, DNS puede usarse para almacenar atributos arbitrarios. Una solicitud se especifica mediante un nombre de dominio, una clase y un tipo. Para los nombres de dominio en Internet la clase es IP. El tipo de las solicitudes especifica si se solicita una dirección IP, un host de correo, un servidor de nombre o algún otro tipo de información. El dominio especial in-atdr.arpa. existe para mantener las direcciones IP en las búsquedas inversas. La clase atributo se utiliza para distinguir por ejemplo, la base de datos de nombres de Internet de otras bases de datos experimentales de nominación DNS.
, siempre que el servidor de nombres de soporte a esta información. En principio, DNS puede usarse para almacenar atributos arbitrarios. Una solicitud se especifica mediante un nombre de dominio, una clase y un tipo. Para los nombres de dominio en Internet la clase es IP. El tipo de las solicitudes especifica si se solicita una dirección IP, un host de correo, un servidor de nombre o algún otro tipo de información. El dominio especial in-atdr.arpa. existe para mantener las direcciones IP en las búsquedas inversas. La clase atributo se utiliza para distinguir por ejemplo, la base de datos de nombres de Internet de otras bases de datos experimentales de nominación DNS.")
40
Servidores de nombres DNS: el problema de la escalabilidades trata mediante una combinación de particionando de la base de datos nombres y replicación y almacenamiento de caché de aquellas partes de la base de datos cercanos a los puntos donde se necesitan. La base de datos DNS se distribuye a lo largo de una red lógica y servidores. Cada servidor mantiene parte en la base de datos del nombre (principalmente datos para el dominio local). La mayor parte de las solicitudes se refiere a computadores en el dominio local y son satisfechos mediante servidores dentro de dicho dominio. Sin embargo, cada servidor almacena los nombres de dominios y direcciones de otros servidores de nombres, de forma que puedan satisfacerse las solicitudes referentes a objetos de fuera del dominio. Los datos de dominación de DNS se dividen en zonas. Una zona contiene los siguientes datos: Datos y atributos para nombres en el dominio, excepto los subdominios administrados por autoridades de menor nivel. Los nombres y direcciones de al menos dos servidores de nombres que proporcionan datos autorizados para la zona. Se trata de versiones de datos de zona para los que se puede confiar que estén razonablemente actualizados. Los nombres de servidores de nombres que mantienen datos autorizados para subdominios delegados; y datos de enlace que proporcionen las direcciones IP de esos servidores. Parámetros de gestión de zona, para, por ejemplo, gestionar la caché y la replicación de datos de zona.

41
Un servidor puede mantener datos autorizados para cero o más zonas
Un servidor puede mantener datos autorizados para cero o más zonas. Para que los datos de nombres estén disponibles incluso cuando el único servidor falla, la arquitectura DNS especifica que cada zona debe replicarse de forma autorizada en al menos dos servidores. Los administradores de sistema insertan los datos de una zona dentro de un archivo maestro, el cual es la fuente de datos autorizados para esa zona. Hay dos tipos de servidores a los que se permiten proporcionar datos autorizados. Un servidor maestro o primario lee los datos de zona directamente desde un archivo maestro local. Los servidores secundarios descargan los datos de zona desde un servido primario. Se comunican periódicamente con el servidor primario para comprobar que la versión que tienen almacenada coincide con la mantenida en el servidor primario. Si una copia secundaria ha caducado el primario envía la única versión. La frecuencia de comprobación de los secundarios se configura por los administradores con un parámetro de zona y su valor es generalmente de una o dos veces al día.

42
Cualquier servicio puede almacenar en su cache los datos provenientes de otros servidores para evitar tener que contactar con ellos cuando a resolución de nombres soliciten los mismos datos de nuevo; esto lo hace bajo la condición de que los clientes estén avisados de que dichos datos son no autorizados. Cada entrada en una zona tiene un valor tiempo de vida; cuando un servidor no autorizado almacena datos desde uno autorizado anótale tiempo de vida. No se proporcionara a los clientes datos por encima de dicho tiempo; cuando se le soliciten datos cuyo periodo de tiempo ha expirado, se vuelve a contactar con el servidor autorizado para comprobar los datos. Esta es una característica útil que minimiza el tráfico de red mientras se mantiene la flexibilidad para los administradores de sistema. Cuando se espera que los atributos cambien de forma esporádica se les puede asignar un tiempo de vida grande. Si un administrador sabe que los atributos cambiaran en breve puede reducir el tiempo de vida en la medida correspondiente. En la figura 9.4 se muestra la organización de una base de datos DNS. Nótese que en la práctica, los servidores raíz como a.root-servers.net mantienen entradas para diferentes entradas de dominios al igual que entradas para los nombres de dominio de primer nivel. Esto permite reducir el número de pasos de navegación al resolver nombres de dominio. Los servidores de nombre raíz mantiene entradas autorizadas de los servidores de nombres en los dominios de mayor nivel. También son servidores autorizados para los dominios de mayor nivel genéricos como com y edu.

43
fig 9.4

44
NAVEGACIÓN Y PROCESAMIENTO DE SOLICITUDES: los clientes DNS son conocidos como resolvedores. Aceptan solicitudes, las formatea y las inserta en mensajes validos del protocolo DNS y después se comunican con uno o más servidores de nombres para resolver las solicitudes. Se utiliza un protocolo simple de tipo petición-respuesta, normalmente a través de paquetes UDP sobre Internet (los servidores DNS utilizan un numero de puerto conocido). El revolvedor detecta un retardo excesivo y reenvía la solicitud, si es necesario. Además puede configurarse para contactar con una lista de servidores de nombres en orden de preferencia para el caso de que uno o más estén fuera de servicio. La arquitectura DNS permite la navegación recursiva al igual que la iterativa. El revolvedor especifica que tipo de navegación es la requerida cuando contacta un servidor de nombres. Sin embargo, los servidores de nombres no estan obligados a implementar la navegación recursiva. Para ahorrar comunicaciones de la red, el protocolo DNS permite empaquetar varias solicitudes en el mismo mensaje de petición, y permite que los servidores de nombres empaqueten varias respuestas en sus mensajes de contestación.

45
fig 9.5

46
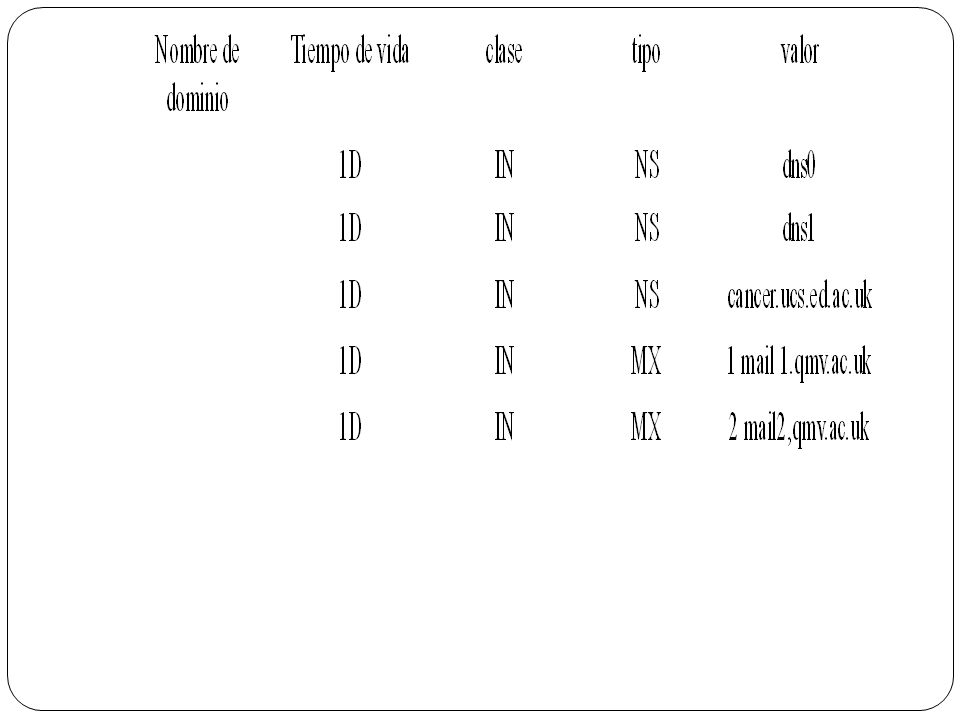
REGISTROS DE RECURSOS: los datos de zona se almacenan en los servidores de nombres en archivos que contienen datos de entre varios tipos fijos de registros de recurso. Para la base de datos de Internet estos tipos aparecen en la figura de arriba, cada registro se refiere a un nombre de dominio que no es mostrado. Las entradas de la tabla se refieren a ítems ya mencionados, excepto las entradas de txt, incluidas para permitir el almacenamiento, de otro tipo arbitrario de información asociada a los nombres de dominios. Los datos de una zona comienzan con registros de tipo soa, que contiene los parámetros de zona especificando, por ejemplo, el número de versión y la frecuencia con la que los secundarios deben refrescar sus propias copias. A continuación aparece una lista de registro de tipo NS que especifican los servidores de nombres para el dominio y una lista de registros de tipo MX que indica ,las preferencias y los nombres de dominio de los host de correos. Por ejemplo, la base de datos para el dominio dcs.qmw.ac.uk esta formada por los siguientes datos, con el tiempo de vida ID significa 1 día:

48
Los registros adicionales de tipo A en la base de datos proporcionan las direcciones IP de los dos servidores de nombres dns0 y dns1. las direcciones IP de lso host de correo y del tercer servidor de nombres se proporcionan en las bases de datos correspondientes en sus dominios. La mayor parte del resto de registros de una zona inferior como dcs.qmw.ac.uk serán de tipo A y enlazaran el nombre del dominio de un computador sobre su dirección IP. Pueden contener algunos alias para servicios conocidos.

49
Si el dominio tiene sus dominios, habrá registros adicionales de tipo dns especificando sus servidores de nombres, los cuales también tendrán entradas A individuales por ejemplo, la base de datos dcs.qmw.ac.uk contiene los siguientes registros para los servidores de nombres en su sub dominio dcs.qmw.ac.uk:

50
COMPARTIMENTO DE CARGA EN LOS SERVIDORES DE NOMBRES: en algunos puntos, servicios fuertemente utilizados como web y FTP pueden estar soportados por un grupo de computadores sobre la misma red. En este caso se utiliza el mismo nombre de dominio para cada miembro del grupo. Cuando un nombre de dominio se comparte por varios computadores, hay un registro para cada computador en el grupo, el cual proporciona sus direcciones IP. El servidor de nombres responde a las solicitudes que se refieren a múltiples registros con el mismo nombre devolviendo la dirección IP mediante una planificación roblin. Los clientes sucesivos tienen acceso a servidores diferentes de forma que los servidores puedan compartir la carga de trabajo. La caché puede potencialmente malograr este esquema, ya que un servidor de nombres no autorizado o un cliente pueden tener la dirección del servidor en su caché y continuar usándola. LA IMPLEMENTACIÓN BIND DE DNS. El dominio de nombres Internet de BIND es una implementación de DNS. Los programas cliente enlazan el revolvedor en las bibliotecas software. BIND soporta tres categorías de servicios de nombres: servidores primarios, servidores secundarios y servidores solo caché. Los servidores solo caché leen desde un archivo de configuración suficientes nombres y direcciones de servidores autorizados para resolver cualquier nombre por lo tanto únicamente almacenan esos datos y los que aprenden al resolver nombres de clientes.

51
Una organización típica esta formada por un servidor primario, con uno o más servidores secundarios que proporcionan servicios de nombres sobre diferentes redes de área local en el mismo sitio. Adicionalmente cada computador individual suele ejecutar sus servicios solo caché para reducir el trafico de red y acelerar aun mas los tiempos de respuesta. DISCUSIÓN SOBRE DNS. La implementación Internet de DNS consigue tiempos medios de respuestas en búsquedas relativamente cortos, teniendo en cuenta la cantidad de datos de nombres en la escala de las redes implicadas. Hemos visto que consigue estos resultados mediante una combinación de particionando, replicación y almacenamiento en caché de los datos de nombres. Los objetivos nombrados son principalmente, computadores, servidores de nombres y host de correos. La relación entre un nombre de computador (host) y una dirección IP raramente cambia al igual que los identificadores de los servidores de nombres y los host de correo, de forma que el almacenamiento en caché y la replicación se realizan en un entorno relativamente favorable. En un sistema DNS puede ocurrir que los datos de nominación se vuelvan inconsistentes. Es decir, si se cambian los datos de nominación puede que otros servidores proporcionen a los clientes datos obsoletos durante periodos que pueden ser del orden de días.
 y una dirección IP raramente cambia al igual que los identificadores de los servidores de nombres y los host de correo, de forma que el almacenamiento en caché y la replicación se realizan en un entorno relativamente favorable. En un sistema DNS puede ocurrir que los datos de nominación se vuelvan inconsistentes. Es decir, si se cambian los datos de nominación puede que otros servidores proporcionen a los clientes datos obsoletos durante periodos que pueden ser del orden de días.")
52
Además de computadores, DNS también implementan la denominación de un tipo particular de servicio: el correo, siempre en base a dominios. DNS asume que existe un solo servicio de correos por cada dominio direccionado, de forma que los usuarios no deben incluir el nombre de dicho servicio explícitamente en los nombres. Las aplicaciones de correo electrónico seleccionan de forma transparente este servicio utilizando el tipo de solicitud apropiado al contactar con los servidores DNS. En resumen, DNS almacena una variedad limitada de datos de nominación, pero hasta el momento ha sido suficiente ya que las aplicaciones como el correo electrónico imponen sus propios esquemas de nominación sobre los nombres de dominio. DNS no fue diseñado para ser el único servicio de nombres en Internet; coexiste con nombres locales y servicios de directorios que almacenan datos más oportunos para las necesidades locales.

53
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
Servicios de Nombres

54
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
X.500 es un servicio de directorio, puede ser utilizado de la misma forma que un servicio de nombres convencional, pero se usa principalmente para satisfacer solicitudes descriptivas, diseñadas para descubrir los nombres y atributos de otros usuarios o recursos del sistema. Los usuarios pueden tener múltiples requisitos para la búsqueda en un directorio de usuarios en red, organizaciones y recursos de sistema para obtener información acerca de las entidades contenidas en el directorio. Los posibles usos de este tipo de servicio pueden ser variados. Estos van desde la realización de consultas análogas a la utilización de directorios telefónicos, como accesos corrientes a las paginas blancas para obtener la dirección de correo electrónico de un usuario o una solicitud a las paginas amarillas con el objetivo, por ejemplo, de obtener los nombres y números telefónicos de garajes especializados en la reparación de un cierto tipo particular de coche, al uso del directorio para acceder a detalles personales, como puesto de trabajo, hábitos dieteticos o incluso imágenes fotográficas de los individuos. Este tipo de solicitudes pueden provenir de los usuarios, como el ejemplo de la consulta sobre garajes realizada en las páginas amarillas explicada previamente, o desde procesos, cuando pueden ser utilizados para la identificación de servicios que cumplen un cierto requisito funcional.

55
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
Los individuos y las organizaciones pueden utilizar un servicio de directorio para proporcionar una amplia cantidad de información sobre ellos mismos y sobre los recursos que ofrecen para ser utilizados desde la red. Los usuarios pueden realizar búsquedas sobre el directorio para encontrar información específica basándose únicamente en un conocimiento parcial de su nombre, estructura o contenido. Las organizaciones de estandarización ITU e ISO han definido el servicio de directorio x.500 [ITU/ISO 1997] como un servicio de red orientado al cumplimiento de dichos requisitos. El estándar lo describe como un servicio para el acceso a información de entidades del mundo real, pero puede utilizarse igualmente para el acceso a información sobre servicios y dispositivos hardware y software X.500 se especifica como un servicio de nivel de aplicación en el conjunto de estándares de Interconexión de Sistemas Abiertos (OSI) pero su diseño no depende de forma significativa de otros estándares OSI por lo que puede verse como el diseño de un servicio de directorio de propósito general. Esbozaremos a continuación el diseño del servicio de directorio X.500 y su implementación.
 pero su diseño no depende de forma significativa de otros estándares OSI por lo que puede verse como el diseño de un servicio de directorio de propósito general. Esbozaremos a continuación el diseño del servicio de directorio X.500 y su implementación.")
56
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
Los datos almacenados en los servidores X.500 se organizan en una estructura de árbol en la que los nodos tienen nombres, pero en X.500 es posible almacenar una gran cantidad de atributos en cada nodo del árbol y el acceso no se realiza simplemente por nombre sino que también se puede realizar búsquedas basadas en cualquier combinación de atributos. DUA DSA ARQUITECTURA DEL SERVICIO X.500

57
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
El árbol de nombres de X.500 se llama árbol de información de directorio (Directory Information Tree, DDT), y la estructura de directorio completa incluyendo los datos asociados se llama base de información de directorio (Directory Information Base, DIB). Esta pensado para tener único DIB integrado que contiene la información proporcionada por las organizaciones de todo el mundo, con porciones de DIB situadas en servidores X.500 individuales. Normalmente, una organización de tamaño medio o grande debería proporcionar al menos un servidor.
, y la estructura de directorio completa incluyendo los datos asociados se llama base de información de directorio (Directory Information Base, DIB). Esta pensado para tener único DIB integrado que contiene la información proporcionada por las organizaciones de todo el mundo, con porciones de DIB situadas en servidores X.500 individuales. Normalmente, una organización de tamaño medio o grande debería proporcionar al menos un servidor.")
58
Parte del Árbol de Información de Directorio X.500
Servidor X.500 (raiz) Francia(country) Gran Bretaña(country) Grecia(country) …BT Pic(organizacion) Universidad de Gormenghast(organizacion) ….Servicio de Computación (organizationalUnit) Departamento de Ciencia de Computadores (organizationalUnit) Departamento de Ingeniería (organizationalUnit) … Miembro del Departamento (organizationalUnit) Ely (applicationProcess) Estudiantes de Investigación (organizationalUnit) …Alicia Picapiedra (person) …Patricia Rey (person) …James Healey (person) Parte del Árbol de Información de Directorio X.500
 Francia(country) Gran Bretaña(country) Grecia(country) …BT Pic(organizacion) Universidad de Gormenghast(organizacion) ….Servicio de Computación (organizationalUnit) Departamento de Ciencia de Computadores (organizationalUnit) Departamento de Ingeniería (organizationalUnit) … Miembro del Departamento (organizationalUnit) Ely (applicationProcess) Estudiantes de Investigación (organizationalUnit) …Alicia Picapiedra (person) …Patricia Rey (person) …James Healey (person) Parte del Árbol de Información de Directorio X.500.")
59
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
Info Alicia Picapiedra, Miembro del Departamento, Departamento de Ciencia de los Computadores, Universidad de Gormenghast,GB. uid alf mail roomNumber Z42 UserClass Investigador . CommonName Alicia.L.Picapiedra Alice.Picapiedra Alice Picapiedra A.Picapiedra Surname Picapiedra TelephoneNumer Figura 12. Una entrada DIB en X.500

60
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
Los clientes acceden al directorio estableciendo una conexión al servidor y enviándole solicitudes de acceso. Los clientes pueden enviar una solicitud de información a cualquier servidor. Si los datos solicitados no están en el segmento de la DIB gestionado por el servidor sobre el que se ha contactado, este realizara una invocación a otros servidores para resolver la solicitud o bien redirigirá al cliente sobre otro servidor. Cada entrada en la DIB esta formada por un nombre y un conjunto de atributos. Al igual que en otros servidores de nombres, el nombre completo de una entrada se corresponde con un camino a través del DIT, desde la raíz del árbol hasta la entrada. Además de nombres completos o absolutos, un DUA puede establecer un contexto formado por un nodo base, y usar nombres relativos mas cortos que proporcionan el camino desde el nodo base hasta la entrada nombrada. La estructura de datos para las entradas en la DIB y en la DIT es muy flexible. Una entrada en la DIB esta formada por un conjunto de atributos en el que cada atributo tiene un tipo y uno o más valores.

61
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
El tipo de cada atributo distingue por un nombre de tipo, para cada tipo de distinto existe una definición de tipo, la cual incluye una descripción de tipo y una definición sintáctica en Notación ASN.1 definiendo representaciones para todos los valores permitidos del tipo.. Las entradas DIB se clasifican de forma similar a las estructuras de clases de objetos que aparecen en lenguajes de programación orientados a objetos. Cada entrada incluye un atributo objectClass, el cual determina la clase del objeto al que se refiere dicha entrada. La definición de una clase debe indicar que atributos son obligatorios y cuales son opcionales para las entradas en dicha clase.Las definiciones de clases se organizan en una jerarquía de herencias en la que todas las clases excepto una (llamada topClass) deben contener un atributo objectClass y el valor de dicho atributo debe ser el nombre de una o mas clases. El nombre de una entrada DIB se determina seleccionando como atributos distinguidos a uno o más de sus atributos. Los atributos seleccionados para este propósito son llamados Nombres Distinguidos (DN) de una entrada.Ahora podemos considerar los métodos utilizados para acceder a un directorio. Existen dos tipos principales de solicitudes de acceso:
 deben contener un atributo objectClass y el valor de dicho atributo debe ser el nombre de una o mas clases. El nombre de una entrada DIB se determina seleccionando como atributos distinguidos a uno o más de sus atributos. Los atributos seleccionados para este propósito son llamados Nombres Distinguidos (DN) de una entrada.Ahora podemos considerar los métodos utilizados para acceder a un directorio. Existen dos tipos principales de solicitudes de acceso:")
62
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
READ: Debe proporcionarse un nombre absoluto o relativo de una entrada, junto con una lista de atributos para ser leídos. El DSA localiza la entrada nombrada mediante la navegación en el DIT y enviado solicitudes a otros servidores DSA para aquellas partes del árbol que no mantenga. Obtiene los atributos requeridos y se los envía al cliente. SEARCH: Se trata de una solicitud de acceso basada en atributos. Se proporciona en forma de argumentos un nombre base y una expresión de filtro. El nombre base específica el nodo en el DIT desde el cual debe comenzar la búsqueda; la expresión de filtro es una expresión booleana que debe ser evaluada para cada no do que se encuentre por debajo del nodo base. El filtro especifica un criterio de búsqueda: una combinación lógica de test sobre los valores de cualquier atributo en una entrada.el mandato search devuelve una lista de nombres para todas aquellas entradas por debajo del nodo base para las que la evaluación del filtro haya resultado TRUE.

63
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
ADMINISTRACION Y ACTUALIZACION DE LA DIB. La interfaz DSA incluye operaciones para añadir, eliminar y modificar entradas. Se proporciona control de acceso tanto para solicitudes como para operaciones de actualización, de forma que el acceso a partes del DIT puede restringirse a ciertos usuarios o clases de usuarios. La DIB se divide bajo la suposición de que cada organización proporcionara como mínimo un servidor que gestione los detalles de las entidades en dicha organización. Se pueden replicar porciones de la DIB sobre diferentes servidores. Al ser X.500 un estándar no cuestiona la implementación. Sin embargo, resulta evidente que cualquier implementación sobre múltiples servidores en una red amplia se debe basar en una utilización extensiva de las técnicas de replicación y cache para reducir las redirecciones generadas en las solicitudes.

64
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
PROTOCOLO DE PESO LIGERO PARA EL ACCESO A DIRECTORIOS. La interfaz estandar de X.500 utiliza un protocolo que implica a los niveles superiores de la pila de protocolos ISO. En la universidad de Michigan se produso una aproximación de peso ligero llamada protocolo de peso Ligero para el Acceso aDirectorios (LDAP), en la DUA accede a un servicio de directorio X.500directamente utilizando TCP/IP. A pesar de que la especificación LDAP no lo necesita. Cualquier otro servidor de directorio que cumpla la especificación LDAP mas simple puede ser utilizado por una implementacion LDAP. Por ejemplo, el Servidor de directorio Activo de Microsoft proporciona una internaz LDAP.LDAP ah sido adoptado, sobre todo en servicios de directorios de intranet.
, en la DUA accede a un servicio de directorio X.500directamente utilizando TCP/IP. A pesar de que la especificación LDAP no lo necesita. Cualquier otro servidor de directorio que cumpla la especificación LDAP mas simple puede ser utilizado por una implementacion LDAP. Por ejemplo, el Servidor de directorio Activo de Microsoft proporciona una internaz LDAP.LDAP ah sido adoptado, sobre todo en servicios de directorios de intranet.")
65
ESTUDIO DEL CASO DEL SERVICIO DE DIRECTORIO X.500
DISCUSION DE X.500 X.500 especifica un modelo detallado para servicios de directorios que van desde el ámbito de organizaciones individuales hasta directorios globales, siendo por ello muy importantes. Su mayor impacto se ha producido a través de intranet, donde su influencia se a conseguido a través de software LDAP. El futuro de X.500 como estandar de directorio global no es claro. En primer lugar, el registro de un sistema de directorio global de existir en absoluto no esta claro, sobre todo a la vista de los problemas de privacidad que pueden llegar a existir sobre dicho directorio. Segundo, dicho sistema de directorio global necesitara integrarse con los estandares de nombres existentes en Internet, incluyendo nombres DNS y direcciones de correo. Finalmente, las decisiones sobre el ambito, de la información que debera ser proporcionada en los directorios debera ser tomada a nivel nacional e internacional para asegurar la uniformidad de las clases de objetos almacenados en la DIB.

66
RESUMEN. En este tema se ha descrito el diseño e implementacion de los servicios de nombres en sistemas distribuidos.Los servicios de nombres almacenan los atributos de objetos en un sistema distribuido y devuelven esos atributos cuando se realiza una busqueda sobre un cierto nombre de texto. Los principales requisitos que debe poseer un servicio de nombres son la habilidad para manejar un numero arbitrario de nombres; tiempo de vida grande; alta disponibilidad; aislamiento de los fallos; y tolerancia frente a la falta autenticación. Las principales cuestiones de diseño son, la estructura del espacio de nombres, es decir, las reglas sintacticas que gobiernan la formación de nombres. Una cuestion relacionada es el modelo de resolucion: las reglas mediante las que un nombre multi-componentes se resuelve en un conjunto de atributos. El conjunto de nombres enlazados debe ser gestionado. La mayor parte de los diseños dividen el espacio de nombres en dominios, asociados a cada uno de ellos una unica autoridad que controla el enlazado de nombres dentro del dominio.

67
RESUMEN. La implementación del servicio de nombres de dominio puede abarcar diferentes organizaciones y comunidades de usuarios. En otras palabras la colección de enlaces entre nombres y atributos, se almacena en varios servidores de nombres, cada uno de los cuales almacena al menos parte del conjunto de nombres del dominio de nombres. Se plantea así la cuestión de la navegación, es decir, el procedimiento utilizado para resolver un nombre cuando la información necesaria es almacenada en más de un punto. Los tipos de navegación soportados son la iterativa, la multidifusion, la recursiva controlada por el servidor y la no recursiva controlada por el servidor. También se han hablado los servicios de directorio y descubrimiento, que son, sistemas que buscan datos sobre objetos y servicios partiendo de información descriptiva basada en atributos proporcionada por los clientes X.500 es un servicio de directorio definido en forma de estándar por la CCITT y la ISO. Puede ser utilizado por directorios cuyo ámbito varia desde una intranet hasta Internet. Se ha descrito además el servicio de búsqueda en jini proporciona las interfaces para que los servicios se registren ellos mismos y para que los clientes descubran servicios que cumplan con sus requisitos.

68
Valor Agregado. http://ditec.um.es/ssdd/tema3.pdf
rchivos/index2.htm

Presentaciones similares


















:>")
