Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Tercera sesión

2
Fases en la construcción de un modelo de Estructura de covarianza
1. Especificación 2. Identificación 3. Selección de variables observadas. 4. Estimación del modelo 5. Valoración del ajuste del modelo 6. Re-especificación

3
Especificación del modelo
Previo al diseño de un modelo es necesario un conocimiento sustantivo del tema objeto de estudio que representaremos en el modelo. Etapas en la especificación del modelo - decidir las variable (observables o latentes) que intervendrán en el modelo. - clasificar las variables en exógenas (nunca les llegan flechas) y endógenas. - especificar las relaciones entre las variables
 que intervendrán en el modelo. - clasificar las variables en exógenas (nunca les llegan flechas) y endógenas. - especificar las relaciones entre las variables.")
4
Aspectos a tener en cuenta en la Especificación del modelo
1. Las variables que se van a considerar 2. Cuál va a ser la escala de dichas variables 3. El tipo de relación entre las variables 4. La dirección de la relación 5. Complejidad del modelo o identificación 6. Tamaño muestral

5
Identificación del modelo
En los modelos de estructura de covarianza se da el nombre de número de observaciones (que no hay que confundir con el tamaño de la muestra) al número de varianzas y covarianzas entre las variables observadas Nº Observaciones = nº varianzas + nº covarianzas. Nº varianzas = v (tantas como variables) Nº covarianzas = combinaciones de v elementos tomados de 2 en 2 = v(v-1)/2 nº varianzas + nº covarianzas = v + v(v-1)/2 = v(v+1)/2 v(v+1)/2 es el número de observaciones El número de parámetros a estimar no puede superar al número de observaciones
 al número de varianzas y covarianzas entre las variables observadas Nº Observaciones = nº varianzas + nº covarianzas. Nº varianzas = v (tantas como variables) Nº covarianzas = combinaciones de v elementos tomados de 2 en 2 = v(v-1)/2. nº varianzas + nº covarianzas = v + v(v-1)/2 = v(v+1)/2. v(v+1)/2 es el número de observaciones. El número de parámetros a estimar no puede superar al número de observaciones.")
6
Si el número de parámetros a estimar coincide con el número de observaciones se dice que tenemos un modelo identificado, también se le llama modelo saturado y la solución es única Si el número de parámetros a estimar es mayor al número de observaciones tenemos un modelo no identificado y para hacerle identificado se suelen poner restricciones a los parámetros. Para que el programa pueda realizar los cálculos que conducen al cálculo de los parámetros es necesario que el número de parámetros a estimar sea igual o menor que el número de observaciones

7
Grados de libertad Cuando el número de variables (V) (parámetros a estimar) es mayor que (>) el número de observaciones ( ecuaciones E), V > E significa que existen MULTIPLES soluciones al sistema de ecuaciones, es decir, se pueden elegir libremente la cantidad (V-E) de valores de variables y cada grupo de valores que se elija genera una solución distinta para las E variables que se decida calcular. Dado que se eligen libremente, este número de variables define el número de GRADOS DE LIBERTAD f=V-E
 de valores de variables y cada grupo de valores que se elija genera una solución distinta para las E variables que se decida calcular. Dado que se eligen libremente, este número de variables define el número de GRADOS DE LIBERTAD. f=V-E.")
8
Ajuste del modelo Para medir la consistencia entre los datos y el modelo propuesto, se estudia la semejanza entre la matriz de covarianzas de la población, que se suele representar como , obtenida mediante inferencia de la matriz de covarianzas de la muestra, que se suele representar por S y la matriz de covarianzas que el modelo predice para la población, que se suele representar por ().
.")
9
La hipótesis fundamental en la que se basa el desarrollo de los modelos causales de estructuras de covarianza se puede formalizar mediante la ecuación = (). Donde sigue siendo la matriz de covarianzas de la población y es un vector que contiene los parámetros del modelo, esto es los coeficientes que aparecen en las ecuaciones estructurales

10
Para resolver el sistema de ecuaciones el programa usa métodos iterativos. Después de cada iteración el programa calcula la función de discrepancia, que expresa la separación existente entre los datos observados y los datos que predice el modelo. Este proceso se repite hasta que ya no es posible mejorar los resultados. En ese momento se dice que se ha alcanzado la convergencia. A veces el programa no converge en un número razonable de iteraciones, lo que se interpreta como que algo intrínseco al modelo no es correcto. Será necesario realizar alguna modificación en el modelo o abandonarlo.

11
Clasificación de los métodos de estimación 1
Los programas pueden estimar los parámetros mediante diferentes métodos que se pueden clasificar en dos grupos 1 Basados en la teoría de la distribución Normal: A) LS. Mínimos cuadrados (ordinarios, generalizados, etc) tambien denominados regresión B) Máxima verosimilitud. Es el mas empleado para los SEM y el que aparece por defecto en los programas
 LS. Mínimos cuadrados (ordinarios, generalizados, etc) tambien denominados regresión. B) Máxima verosimilitud. Es el mas empleado para los SEM y el que aparece por defecto en los programas.")
12
Clasificación de los métodos de estimación 2
Basados en teorías de distribución no normales 1. ELS: Basados en la teoría de distribución elíptica para lo cual basta con que la distribución de las variables sea simétrica. Precisa como “input” los datos y requiere mayor tamaño muestral 2. ALS: Basados en la teoría de distribución arbitraria. Precisa como “input” los datos y requiere un tamaño muestral superior a 1000

13
Interpretación de los resultados
Al estimar un modelo se obtienen diversos estadísticos asociados a sus correspondientes hipótesis que habrá que interpretar. Hay de dos tipos 1. Parámetros: coeficientes de los caminos o efectos directos y Varianzas y covarianzas 2. Estadísticos de ajuste: de los parámetros y globales del ajuste del modelo

14
Para los estadísticos de ajuste de los caminos hay dos soluciones equivalentes estadísticamente, aunque con interpretaciones diferentes 1. Solución estandarizada: obtenida a partir de las variables estandarizadas (puntuaciones Z) 2. Solución no estandarizada obtenida a partir del valor real de las variables
 2. Solución no estandarizada obtenida a partir del valor real de las variables.")
15
Coeficientes estandarizados
Una de las ventajas de los coeficientes estandarizados es que se pueden establecer comparaciones entre ellos porque no dependen de la escala en la que se miden las variables. Como contrapartida es mas difícil saber si el efecto es grande, medio o pequeño. Se recomienda la siguiente regla: Coeficiente menor que 0’1 → efecto pequeño Coeficiente entre 0’1 y 0’5 → efecto medio Coeficiente mayor que 0’5 → efecto grande

16
Los coeficientes del camino o efectos directos permiten calcular los efectos indirectos ( los efectos que tiene una variable X sobre otra Y a través de variables endógenas intermedias). El efecto total es la suma de los efectos directos e indirectos. En la primera ecuación todos son efectos directos, pero en la segunda hay directos e indirectos. Esta posibilidad es una de las grandes aportaciones del análisis de caminos, respecto de la regresión. y1 = 11 x 12 x2 + 13 x3 + 1 y2 = 21 x 21 y1 + 23 x3 + 2

17
Ejemplo con los datos de la encuesta del CIS
Simpatía hacia los marroquíes, teniendo en cuenta las respuestas a las preguntas: ¿Le importa tener compañeros de trabajo de Marruecos? ¿Le importa tener vecinos de Marruecos? ¿Le importaría que su hijo/a se casara con un/a marroquí? Le importa que sus hijos/as compartan colegio con inmigrantes de Marruecos?

18
Ejemplos con variables observables

19
Puntuaciones estandarizadas

20
Puntuaciones no estandarizadas

21
Squared Multiple Correlations:
Estimate 0,292 Un 30% de la variación de la variable “simpatía hacia los marroquís” la explican las variables introducidas en el modelo.

22
Trabajo con grupos Podemos ajustar el mismo modelo, pero separando los sujetos según los grupos creados por una variable. (Ej.:Sexo, p32, separando hombres de mujeres) Hay que hacer dos cosas: 1. Abrir el rectángulo “Group number 1”, pulsando doble click en el boton izquierdo del ratón y se abrirá el cuadro de diálogo:“Manage Groups” y escribiremos los nombres de los grupos que vamos a crear 2. Abrir el icono con forma de hoja de cálculo “select data files”, con el que indicaremos la variable que crea los grupos y los valores que toma para cada grupo
 Hay que hacer dos cosas: 1. Abrir el rectángulo Group number 1 , pulsando doble click en el boton izquierdo del ratón y se abrirá el cuadro de diálogo: Manage Groups y escribiremos los nombres de los grupos que vamos a crear. 2. Abrir el icono con forma de hoja de cálculo select data files , con el que indicaremos la variable que crea los grupos y los valores que toma para cada grupo.")
23
Ejemplo del PIB x1= entradas laborales en millones por hombre-año
Goldberger A.S. (1964) en Econometric theory. New York. Wiley (pg. 187) presentó el ajuste del producto interior bruto en billones de dólares a partir de las variables x1= entradas laborales en millones por hombre-año X2= capital real en millones X3= periodo en años desde 1928 Los datos constan de 23 observaciones anuales para los EEUU durante los periodos de y
 en Econometric theory. New York. Wiley (pg. 187) presentó el ajuste del producto interior bruto en billones de dólares a partir de las variables. x1= entradas laborales en millones por hombre-año. X2= capital real en millones. X3= periodo en años desde Los datos constan de 23 observaciones anuales para los EEUU durante los periodos de y")
24
Ajuste del PIB

25
Datos del modelo del PIB
n ,00 23, , ,000 cov pib , cov trabajo ,016 52, cov capital , , ,447 . cov tiempo ,482 53, , ,747 mean ,435 45, , ,739 La matriz de correlaciones TIEMPO CAPITAL TRABAJO PIB 1,000 ,593 ,853 ,574 ,959 ,705 ,946

26
Ajuste sin estandarizar

27
Squared Multiple Correlations: (Group number 1 - Default model)
EstimatePIB= 0,997 El ajuste para el PIB a partir de las variables del modelo es casi perfecto

28
La variación del PIB la explica “totalmente” el modelo

29
La varianza del error (11,987) es muy pequeña en comparación con la varianza total del PIB que es superior a 1000. Las tres variables: trabajo, capital y tiempo dan cuenta de casi toda la varianza del PIB

30
Pesos de regresión, error estandar y razón crítica
Estimate S.E C.R. PIB<---TRABAJO 3, , ,998 PIB<---CAPITAL 0, , ,308 PIB<---TIEMPO 3, , ,845 La ecuación de regresión estimada: PIB=3,82* trabajo + 0,32*capital + 3,79 * tiempo Su interpretación será: si el trabajo se incrementa en una unidad, pero capital y tiempo permanecen sin cambiar, el incremento esperado para el PIB será de 3,82 unidades….

31
Estimate S.E C.R. PIB<---TRABAJO , , ,998 PIB<---CAPITAL , , ,308 PIB<---TIEMPO , , ,845 Los coeficientes de regresión van bajo “estimate” Los errores estandar de las estimaciones van bajo “S.E” Cada error estandar es una medida de la exactitud de la estimación del parámetro. Bajo C.R aparecen las razones críticas que son valores t y se calculan dividiendo ESTIMATE entre S.E. Cuando los valores de C.R. (t) son grandes, como en este caso se dice que el parámetro es significativo, y que podemos tener bastante confianza en que la variable correspondiente influye realmente en la variable dependiente PIB
 son grandes, como en este caso se dice que el parámetro es significativo, y que podemos tener bastante confianza en que la variable correspondiente influye realmente en la variable dependiente PIB.")
32
Ejemplo de Regresión Múltiple Divariada
Predicción notas El fichero de entrada son las puntuaciones de 15 estudiantes de primer curso de Universidad, en 5 mediciones educativas. Y1: media cursos obligatorios cursados Y2: media cursos optativos X1: Test cultura general X2: Coeficiente Inteligencia X3: nota de motivación educacional

33
FICHERO DE DATOS Caso y1 y2 x1 x2 x3 1 ,80 2,00 72,00 114,00 17,30
1 ,80 2,00 72,00 114,00 17,30 2 2,20 2,20 78,00 117,00 17,60 3 1,60 2,00 84,00 117,00 15,00 4 2,60 3,70 95,00 120,00 18,00 5 2,70 3,20 88,00 117,00 18,70 6 2,10 3,20 83,00 123,00 17,90 7 3,10 3,70 92,00 118,00 17,30 8 3,00 3,10 86,00 114,00 18,10 9 3,20 2,60 88,00 114,00 16,00 10 2,60 3,20 80,00 115,00 16,40 11 2,70 2,80 87,00 114,00 17,60 12 3,00 2,40 94,00 112,00 19,50 13 1,60 1,40 73,00 115,00 12,70 14 ,90 1,00 80,00 111,00 17,00 15 1,90 1,20 83,00 112,00 16,10

34
El gráfico del modelo

35
Pesos de regresión calculados por AMOS
Estimate S.E C.R P Y1<---X1 , , , *** Y1<---X2 , , , ,848 Y1<---X3 -, , , ,880 Y2<---X1 , , , ,040 Y2<---X2 , , , *** Y2<---X3 , , , ,187

36
Intercepts (términos independientes)
Estimate S.E C.R P Y , , , ,259 Y , , , ***

37
Estimaciones no estandarizadas

38
Estimaciones estandarizadas

39
Las ecuaciones de regresión
Media C. Obligatorios= -5, ’085 test cul general + 0´008 CI – 0’015 Motivación Media C. Optativos = -20, ,047 test cul general + 0,145 CI + 0,126 Motivación Pero teniendo en cuenta los C.R., sólo el test de cultura general (x1) es un predictor significativo de la Media Cursos obligatorios (y1) y sólo CI(x2) es un predictor significativo para la Media cursos optativos (y2), la motivación no parece significativo para ninguna de las dos variables, pero hay que tener en cuenta que el tamaño de la muestra es demasiado pequeño para obtener conclusiones con seguridad
 es un predictor significativo de la Media Cursos obligatorios (y1) y sólo CI(x2) es un predictor significativo para la Media cursos optativos (y2), la motivación no parece significativo para ninguna de las dos variables, pero hay que tener en cuenta que el tamaño de la muestra es demasiado pequeño para obtener conclusiones con seguridad.")
40
Chi-square = 8,886 Degrees of freedom = 1 Probability level = ,003 Por defecto AMOS asume que los términos de error no están correlacionados.

41
Squared Multiple Correlations: (Group number 1 - Default model)
Estimate Y ,568 Y ,685 El modelo explicaría el 57% de la varianza de Y1(media en los cursos obligatorios) y el 70 % de la de Y2 (media en los cursos optativos)
 y el 70 % de la de Y2 (media en los cursos optativos)")
42
Análisis de caminos Es una técnica que usó por primera vez el genetista Wright (1934) Se trata de calcular la contribución causal directa de unas variables en otras en una situación no experimental. En general el método sirve para calcular los coeficientes de un grupo de ecuaciones estructurales lineales, estando las relaciones causa efecto explicitadas por el investigador.

43
En el análisis de caminos intervienen:
1. Variables independientes o de causa: x 1, x2, … xp 2. Variables dependientes o de efecto: y 1, y2, … yq 3. Variables de error de las variables dependientes e1, e2, … eq En desarrollos posteriores se han incluido en estos modelos variables latentes, pero empezaremos con un ejemplo en el que intervienen solamente variables observables directamente.

44
La diferencia fundamental entre el análisis de caminos y la regresión lineal está en que de las variables dependientes pueden salir flechas que terminan en otras variables dependientes. El ejemplo que vamos a ver estudia el “sentimiento sindical de los trabadores del sector textil”. McDonald y Clelland (1984) analizaron datos sobre el sentimiento sindical en los trabajadores del sector textil no sindicalistas en el sur de los Estados Unidos.
 analizaron datos sobre el sentimiento sindical en los trabajadores del sector textil no sindicalistas en el sur de los Estados Unidos.")
45
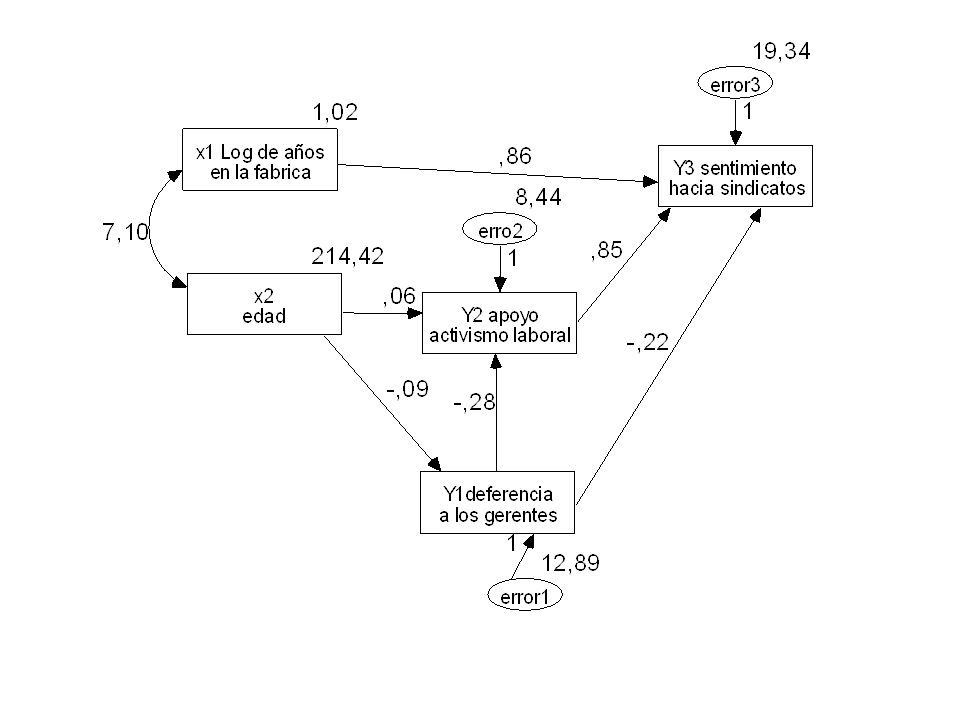
Después de transformar una variable (años de trabajo) en su logaritmo Bollen (1989) volvió a analizar un subconjunto de las variables según el modelo: Y1deferencia a los gerentes Y2 apoyo activismo laboral Y3 sentimiento hacia sindicatos x1 Log de años en la fabrica x2 edad error3 1 erro2 error1

46
La matriz de datos es: n n 173 173 173 173 cov y1 14,610
cov x1 -, , , ,021 cov x2 -18, , , , ,66

48
Chi-square = 1,251 Degrees of freedom = 3 Probability level = ,741 Squared Multiple Correlations: (Group number 1 - Default model) Estimate Y1 0,113 Y2 0,230 Y3 0,390 Las variables del modelo dan cuanta del 40% del sentimiento hacia los sindicatos Y3,

Presentaciones similares




>")














