Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Inferencia Bayesiana de Filogenias Moleculares Tania Hernández

2
Métodos de Verosimilitud

3
Joe Felsenstein Department of Genetics, University of Washington John Huelsenbeck Section of Ecology, Behavoir and Evolution, University of California, San Diego Ziheng Yang Department of Biology University College London Nick Goldman EBI. European Bioinformatics Institute Bruce Rannala Department Medical Genetics University of Alberta

4
… TODOS los métodos en sistemática molecular por necesidad, asumen un modelo de sustitución para las secuencias, pues hacen supuestos generales acerca del proceso evolutivo …

5
Métodos basados en verosimilitud - Tienen un modelo probabilistico explicito - Tienen importantes bases y soporte estadístico - Buscan parámetros para obtener la respuesta más probable

6
Maxima Verosimilitud (ML) También podria ser llamada Máxima Probabilidad Históricamente es el método más novedoso (ahora Bayesianos) Ha sido un método adoptado de manera muy lenta por la comunidad científica, lo cual tiene que ver con la dificultad de entender la base teórica y con la falta de software adecuado También resultaba impráctico por los tiempos computacionales al hacer los calculos para muchos datos Recientemente, el desarrollo de mejores computadoras, mejor software, mejores modelos y mayor dibulgación de la teoría hacen que ML se convierta en el método de elección. Popularizado principalmente por Joseph Felsenstein (Seattle, Washington)
.")
7
En general… La verosimilitud es la probabilidad de los datos dado un modelo. En sistemática se puede decir que el árbol es parte del modelo, entonces… La verosimilitud es la probabilidad de mis secuencias alineadas dado el modelo de sustitución postulado y el árbol Probabilidad de: dados:

8
Es decir, verosimilitud es… Pr ( D | H )
")
9
… es decir, se busca el modelo y las longitudes de ramas que maximicen la verosimilitud (probabilidad) de mis datos… Long. ramas

10
Verosimilitud en sistemática molecular > Diferentes tasas de evolución en diferentes linajes Los modelos toman en cuenta las diferentes longitudes de las ramas del árbol. > Los modelos son EXPLICITOS y no estan escondidos (falsabilidad) > Puedes buscar el modelo que ajuste mejor a tus datos. > Es un método eficiente y poderoso. Utiliza todos los datos considerando todas las posibilidades de cambio.
 > Puedes buscar el modelo que ajuste mejor a tus datos. > Es un método eficiente y poderoso. Utiliza todos los datos considerando todas las posibilidades de cambio..")
11
Verosimilitud… otras ventajas: - Gran facilidad para formular y probar hipótesis - Proveen de una manera de falsear los supuestos - Permiten estimar la confianza en las filogenias obtenidas y proveen herramientas para probar las hipótesis filogenéticas con solidas bases estadísticas - son métodos consistentes

12
ML permite la inferencia de árboles filogenéticos usando modelos evolutivos complejos - incluyendo la habilidad de estimar los parámetros del modelo y hacer inferencias de manera simultánea acerca de los patrones y procesos de evolución - y permite comparar diferentes modelos.

13
La construcción de un modelo puede hacerse : - empiricamente: propiedades calculadas a partir de comparaciones de un gran número de datos. Los parámetros son fijos y aplicables a todos los análisis. - parametricamente : propiedades químicas o biológicas de las moléculas. Permiten derivar los parámetros a partir de nuestros datos. Modelos de sustitucion

14
Modelos de sustitución Matrices de probabilidad de cambio Vector de frecuencias

15
¿por qué usar modelos? Recordar que... Solo hay cuatro caracteres ( A, T, G, C) Homopasia (Paralelismo, Convergencia, Reversiones) ¡¡ MULTIPLES SUSTITUCIONES !! A A T C A GA A T C A G T C Sustituciones C T A C C T A A C C A T A A C C A G
 Homopasia (Paralelismo, Convergencia, Reversiones) ¡¡ MULTIPLES SUSTITUCIONES !. A A T C A GA A T C A G T C Sustituciones C T A C C T A A C C A T A A C C A G.")
16
La mayoría de modelos asumen propiedades de modelos Markovianos: > Se asume independencia de evolución en cada sitio Para cada sitio existe la probabilidad P ij (T) de que la base i cambiará a j después del tiempo T Dada una variable estocástica x(t) que describe la evolución en tiempo t de un sitio en una secuencia, el supuesto de Markov es que: P ij (T) = Pr[x(s+T)=j x(s)=i] Considere tres diferentes tiempos t consecutivos: t 1 < t 2 < t 3. Se asume que el estado del nucleotido en t 3 depende solo de su estado en t 2 y no de t 1, si el estado de t 2 es conocido. Un proceso de Markov puede tener tres propiedades importantes: Homogeneidad : la matriz de cambio es independiente del tiempo Estacionaridad : las frec. de nucleotidos permanece constantes en t Reversibilidad : i P ij (t) = j P ji (t)
![La mayoría de modelos asumen propiedades de modelos Markovianos: > Se asume independencia de evolución en cada sitio Para cada sitio existe la probabilidad P ij (T) de que la base i cambiará a j después del tiempo T Dada una variable estocástica x(t) que describe la evolución en tiempo t de un sitio en una secuencia, el supuesto de Markov es que: P ij (T) = Pr[x(s+T)=j x(s)=i] Considere tres diferentes tiempos t consecutivos: t 1 < t 2 < t 3.](http://images.slideplayer.es/14/4320058/slides/slide_16.jpg "Se asume que el estado del nucleotido en t 3 depende solo de su estado en t 2 y no de t 1, si el estado de t 2 es conocido. Un proceso de Markov puede tener tres propiedades importantes: Homogeneidad : la matriz de cambio es independiente del tiempo Estacionaridad : las frec. de nucleotidos permanece constantes en t Reversibilidad : i P ij (t) = j P ji (t).")
17
Heterogeneidad de tasas Uno de los más importantes avances recientes en la reconstrucción filogenética es el reconocimiento de heterogeneidad de tasas entre sitios. > Modelos discretos ejem. Hasegawa, et al., 1985. Una fracción de sitios cambia a una tasa mientras que otros son invariantes. > Modelos continuos Basados en una distribución de tasas continua. Lo más usado es utilizar la distribución gamma: Se asume que la tasa de sustitución en cada sitio esta dada por una distribución gamma con parámetro de forma Si < 1 : gran cantidad de variación entre tasas. Muchos sitios evolucionan lentamente y otros rápidamente Si > 1 : menor variación. La mayoría de sitios con tasas similares. El rango de formas de distribución permite describir bien la variación encontrada en secuencias de DNA 0 < <

18
Heterogeneidad de tasas Distribucion gamma

19
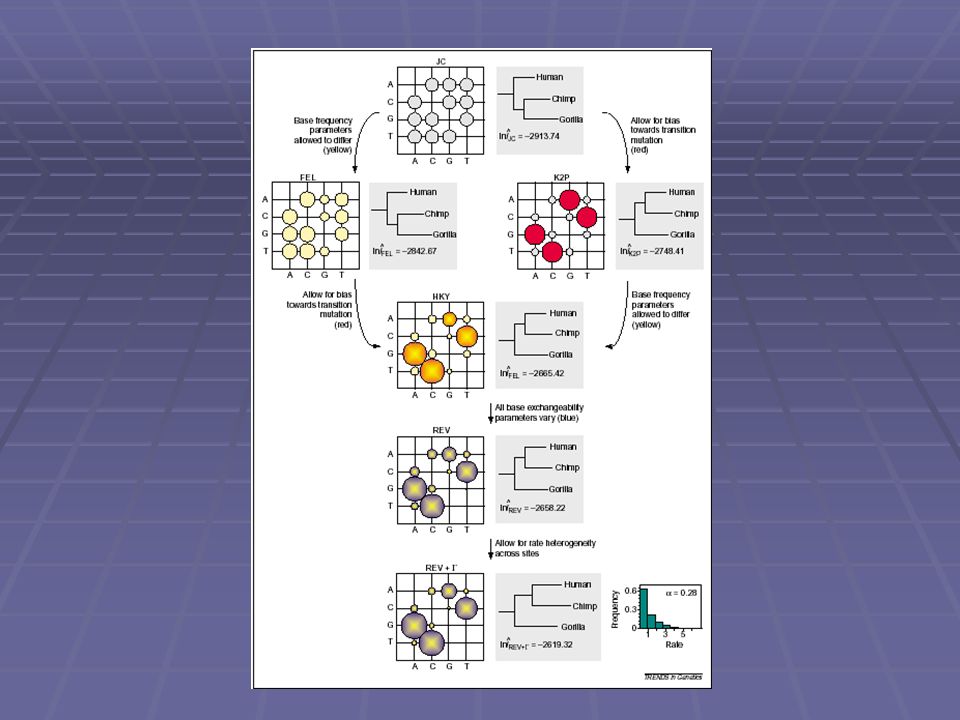
¿cambiar el modelo afecta el resultado? CLARO!!! Hay varios diferentes tipos de modelos: Jukes and Cantor (JC69): La tasa de cambio de una base a otra es igual en todos los casos. Todas las bases tienen igual frecuencia (0.25). Kimura 2-Parameter (K2P): Todas las bases tienen igual frecuencia (0.25 ), considera las diferencias en las frecuencias de transiciones y transversiones. Hasegawa-Kishino-Yano (HKY): Igual al K2P, pero las frecuencias de las bases varían. General Reversible en el Tiempo (GTR): Las frecuencia de las bases varíam. Todos los diferentes tipos de sustitución tienen diferente probabilidad. etc… Todos estos modelos pueden extenderse acomodando los parámetros adecuados para sitios invariantes y tasa de variación sitio por sitio y distribución gama.
: La tasa de cambio de una base a otra es igual en todos los casos. Todas las bases tienen igual frecuencia (0.25). Kimura 2-Parameter (K2P): Todas las bases tienen igual frecuencia (0.25 ), considera las diferencias en las frecuencias de transiciones y transversiones. Hasegawa-Kishino-Yano (HKY): Igual al K2P, pero las frecuencias de las bases varían. General Reversible en el Tiempo (GTR): Las frecuencia de las bases varíam. Todos los diferentes tipos de sustitución tienen diferente probabilidad. etc… Todos estos modelos pueden extenderse acomodando los parámetros adecuados para sitios invariantes y tasa de variación sitio por sitio y distribución gama..")
20
recordar que los modelos son descriptivos…

22
Métodos Bayesianos de Inferencia Filogenética

23
Maxima verosimilitud Busca el árbol que maximice la probabilidad de observar los datos P(datos | árbol+modelo) Inferencia Bayesiana Busca el árbol que maximice la probabilidad de observar el árbol (y modelo) dados los datos. P(árbol+modelo | datos)
.")
25
Se usa la regla de Bayes para obtener la probabilidad Posterior a partir de la verosimilitud y la dostribución (prob.) anterior. De acuerdo a la definición de prob. condicional… Pr (A,B) = Pr (A) Pr (B A) = Pr (B) Pr (A B) Dividiendo ambos lados por Pr (A): Pr (B A) = Pr (B) Pr (A B) --------------------- Pr (A) Donde B es la hipótesis y A los datos
 = Pr (A) Pr (B A) = Pr (B) Pr (A B) Dividiendo ambos lados por Pr (A): Pr (B A) = Pr (B) Pr (A B) Pr (A) Donde B es la hipótesis y A los datos.")
28
es decir… la distribución posterior en la cual se basa la inferencia bayesiana es directamente proporcional al producto de la distribución anterior y la verosimilitud

30
MCMC (Monte carlo Markov Chains) Una manera de ‘muestrear’ un espacio de soluciones e ir seleccionando segun la prob. posterior 1.- Sea una solución aleatoria N1 2.- Escogase otra solución aleatoria N2 3.- Si la posterior (N1<N2), entonces reemplazar N1 por N2 4.- ‘Guardar’ dicha solución 5.- Repetir el paso 2
, entonces reemplazar N1 por N2 4.- ‘Guardar’ dicha solución 5.- Repetir el paso 2.")
31
MCMC (Monte Carlo Markov Chains)
")
33
bootstrapprob. posterior

34
Suponga que se corre una cadena de Markov... En una muestra de 100 000 árboles Grupo X aparece como monofilético en 74 695 árboles. La probabilidad (ados los datos observados) de que el grupo X es monofilético es aproximadamente 0.74695, ya que la cadena de Markov visitó árboles de acuerdo a su probabilidad posterior.
 de que el grupo X es monofilético es aproximadamente , ya que la cadena de Markov visitó árboles de acuerdo a su probabilidad posterior..")
35
¿por que bayesianos y no verosimilitud? 1.- Velocidad 2.- La verosimilitud representa la probabilidad de los datos dada la hipótesis ??, pero los Bayesianos dan la probabilidad de la hipótesis dados los datos. Es decir, produce probabilidades para las hipótesis de interés 3.- Es posible obtener validas medidas de soporte en menos tiempo, que son conceptualmente mas fáciles de entender.

Presentaciones similares