Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Bioestadística Inferencia estadística y tamaño de muestra
Maricarmen Caamaño

2
Inferencia estadística
Población Seguridad (Significancia estadística) Muestra Experimento/medición Estimación (Intervalo de confianza) Resultados
 Muestra. Experimento/medición. Estimación. (Intervalo de confianza) Resultados.")
3
Inferencia estadística
¿Qué tan seguros estamos de que lo que encontramos aplica para la población que representamos? Es el proceso de tratar de conocer algo relativo a la regularidad estadística de alguna medición en una cierta población. Población Muestra

4
Inferencia estadística
La regularidad estadística que suponemos se puede representar con algún modelo de distribución de probabilidad como la distribución normal La inferencia estadística más simple y conocida es la estimación y prueba de hipótesis de una media Muestreo Muestra X s Población σ Inferencia

5
Inferencia estadística
Parámetro Poblacional Estadístico Media x Desviación estándar σ s Varianza σ2 s2 Tamaño N n

6
Teorema central del límite
En la realidad, no se conoce la media poblacional (µ) ni la varianza poblacional (σ2) que es la distribución teórica de la población, sino a partir de una muestra extraída al azar de la población que se desea estudiar se desease desea extrapolar los resultados obtenidos a la población de origen. Si tenemos el peso de una muestra n=100 individuos con una media (x) de 75Kg y una desviación estándar (s) de 12Kg y queremos estimar el valor medio real (µ) del peso en la población original. Para estimar este valor debemos basarnos en el teorema central del límite.
 ni la varianza poblacional (σ2) que es la distribución teórica de la población, sino a partir de una muestra extraída al azar de la población que se desea estudiar se desease desea extrapolar los resultados obtenidos a la población de origen. Si tenemos el peso de una muestra n=100 individuos con una media (x) de 75Kg y una desviación estándar (s) de 12Kg y queremos estimar el valor medio real (µ) del peso en la población original. Para estimar este valor debemos basarnos en el teorema central del límite.")
7
Teorema central del límite
El teorema central del límite dice que las medias de muestras aleatorias de cualquier variable siguen ellas mismas una distribución normal con igual media que la de la población y desviación estándar la de la población dividida por √n .

8
Teorema central del límite
Representación gráfica Distribución de medias de las n muestras Muestra1 x Muestra2 x Muestra3 Muestra4 x Error estándar de la media σ/√n Muestra N x

9
Teorema central del límite
En otras palabras, el teorema dice que si el tamaño de muestra es grande, entonces la regularidad estadística de la población de medias muestrales, es normal con la misma media poblacional µ, de la población original , y con una desviación estándar que es la desviación estándar original dividida entre la raíz cuadrada del tamaño de muestra. A esta desviación estándar de las medias se le llama error estándar. El error estándar señala el grado de error que se comete al tratar de conocer µ, con la media muestral.

10
Teorema central del límite
En el ejemplo del peso de los sujetos, la media muestral se estimaría utilizando el error estándar, entonces si queremos tener un 95% de probabilidad de que la media poblacional esté en un intervalo. . . Valor z en tablas para una probabilidad de 95%

11
Teorema central del límite
Ejercicio Tenemos evaluaciones de colesterol total de 252 mujeres obesas de 23 a 57 años donde, X=168mg/dL S=42mg/dL ¿Cuál es el intervalo en el que estaríamos 95% seguros de que incluye la media poblacional? Estamos 95% seguros de que la media poblacional de colesterol en mujeres obesas de 23 a 57 años está entre 164mg/dL y 173mg/dL

12
Teorema central del límite
PARA PROPORCIONES En una población de elementos a los que se mide una variable dicotómica. Con “1” para la presencia de algo y “ 0” para lo contrario. Si se extraen muchas muestras de tamaño n y se obtiene una distribución de proporciones. La distribución de estas proporciones es normal.

13
Teorema central del límite
Representación gráfica Distribución de proporciones de las n muestras Muestra1 Muestra2 Muestra3 Error estándar de la media P(1-P)/√n Muestra N
/√n. Muestra N.")
14
Teorema central del límite
Ejemplo de teorema central del límite para proporciones: Tenemos evaluaciones de colesterol total de 252 mujeres obesas de 23 a 57 años, se creó una variable discreta donde 1=Colesterol>200mg/dL y 0=Colesterol≤200mg/dL, entonces p=22% ¿Cuál es el intervalo en el que estaríamos 95% seguros de que incluye la media poblacional?

15
Pruebas de hipótesis Suponiendo que tenemos una muestra de 252 mujeres obesas y sabemos que su promedio de 168mg/dL y su desviación estándar es de 42: N=252 X=168mg/dL S=42mg/dL Conociendo que el nivel de colesterol en una población similar de mujeres sin sobrepeso es de 160mg/dL, ¿El rango del promedio estimado para la población de mujeres obesas será diferente a 160mg/dL? Planteando la hipótesis: Hipótesis nula: Ho: µ=µo Hipótesis alternativa Ho1: µ≠µo Donde µo =160mg/dL

16
Prueba de hipótesis Existen dos formas de contrastar la hipótesis nula: 1. Construyendo el intervalo de confianza, generalmente de 95%. 2. Evaluar la probabilidad de una discrepancia entre el promedio muestral y el poblacional según la hipótesis como la obtenida o mayor aun. El “Valor de P”. Si P es pequeña, menor a 5% ( 1%) , se rechaza
 , se rechaza.")
17
Construyendo el intervalo de confianza (Prueba de Z)
Fórmula: Es 95% probable que la MEDIA de concentración de colesterol en mujeres obesas está entre 164 y 173mg/dL. Ho: µ=160 95% Z= µ X=

18
Determinando la probabilidad
Se calcula el valor z para µ0 con la media y error estándar de la media de la muestra Buscando en tablas la probabilidad es Se rechaza H0 si Z calculada es≥1.96 = P0.975 de N(0,1) P=0.0013=0.13% 95% Z= µ …
 P=0.0013=0.13% 95% Z= µ 1.96 …")
19
Determinando la probabilidad
Enunciar la hipótesis nula (H0) y la alternativa (Ha ó H1) A partir de un nivel de confianza determinar : valor zα/2 para pruebas bilaterales ó valor zα para pruebas unilaterales
 y la alternativa (Ha ó H1) A partir de un nivel de confianza determinar : valor zα/2 para pruebas bilaterales. ó. valor zα para pruebas unilaterales.")
20
(Nivel de significancia)
Toma de decisión Para saber si rechazamos la hipótesis nula comparamos el valor Z calculado con su probabilidad en tablas o con los valores z críticos o correspondientes a la probabilidad que buscamos: Probabilidad (Nivel de significancia) Valor crítico de Z 0.05 1.96 0.01 2.58 0.001 3.29 La probabilidad = nivel de significancia = Error tipo I=Error alpha: Es la probabilidad de rechazar falsamente la hipótesis nula cuando es verdadera.
 Valor crítico de Z La probabilidad = nivel de significancia = Error tipo I=Error alpha: Es la probabilidad de rechazar falsamente la hipótesis nula cuando es verdadera.")
21
Repaso cálculo de intervalos de confianza
Formula para estimar una proporción Formula para estimar una media 𝑝±𝑧 𝑝(1−𝑝) 𝑛 𝑥 ±𝑧∗ 𝑠 𝑛 Valor Z correspondiente al rango del intervalo en tabla de distribución Z Error estándar de la media
 𝑛. 𝑥 ±𝑧∗ 𝑠 𝑛. Valor Z correspondiente al rango del intervalo en tabla de distribución Z. Error estándar de la media.")
22
Ejercicio Construye intervalos de confianza de 99 y 95% para Talla y para Peso Estima probabilidad de rechazar las siguientes hipótesis cuando son verdaderas: Estima probabilidad de rechazar las siguientes hipótesis cuando son verdaderas con una significancia del 5% y del 1%: Talla - H0=84.3 cm Peso - H0=12Kg Hb - H0=11.5 g/dL

23
Ejercicios para estimar intervalos de confianza
En una muestra de 400 niños elegidos aleatoriamente en una zona rural, se encontró que 300 tenían deficiencia de vitamina C. Construye el intervalo de confianza del 99% para la prevalencia de deficiencia de vitamina C de la población rural. Probar la hipótesis de que 80% de los niños tienen deficiencia de vitamina C en la población de dicha zona rural.

24
Ejercicios para estimar intervalos de confianza
En 120 niños se midieron las concentraciones del leptina, la media muestral fue de 15ng/mL y la desviación estándar fue de 11ng/mL. Calcular el intervalo de confianza del 95% para la población que representa. Probar la hipótesis de que la media poblacional de leptina es diferente a 16.

25
VARIABLE RESULTADO O DEPENDIENTE
Tipos de análisis VARIABLES PREDICTORAS O INDEPENDIENTES VARIABLE RESULTADO O DEPENDIENTE Categórica Continua Categóricas Chi Cuadrada Regresión Logística (Modelos probit, logit ) Prueba T Student (T-test) ANOVA (Analysis of Variance) Regresión lineal Continuas Linear regression Pearson correlation Mezcla de categóricas y contínuas Analysis de covarianza
 Prueba T Student (T-test) ANOVA (Analysis of Variance) Regresión lineal. Continuas. Linear regression. Pearson correlation. Mezcla de. categóricas y. contínuas. Analysis de covarianza.")
26
Distribución de la muestra vs distribución de la media muestral

27
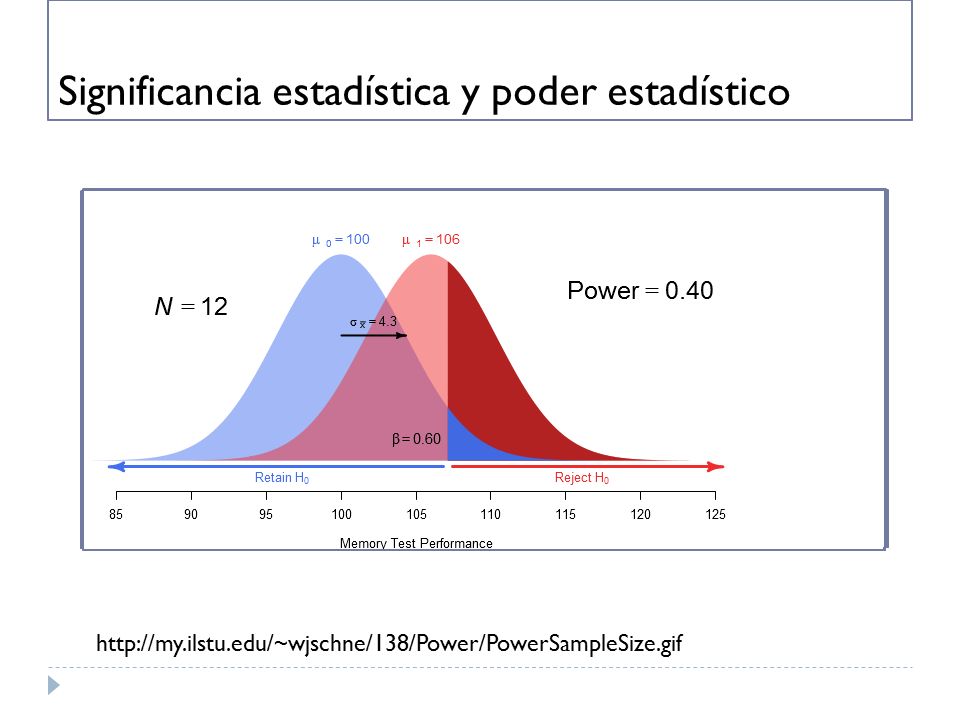
Significancia estadística y poder estadístico
Hipótesis Nula Ho – Las Medias son iguales / No hay asociación o correlación Alternativa H1 – Las medias no son iguales / Si hay asociación o correlación Error tipo I y error tipo II Significancia estadística: Probabilidad de rechazar la hipótesis nula cuando es verdadera A menor significancia mayor confiabilidad Poder estadístico: Probabilidad de rechazar la hipótesis nula cuando es realmente falsa A mayor tamaño de muestra, mayor poder estadístico

28
Significancia estadística y poder estadístico
Prueba estadística: Población: Ho = Verdadera Ho = Falsa No Error P = 1-α Error Tipo I P = α=Significancia (<.05) Error Tipo II P = β P =1-β=Poder estadístico (>.8)
 Error Tipo II. P = β. P =1-β=Poder estadístico (>.8)")
29
Significancia estadística y poder estadístico
30
Técnicas de muestreo Características de una muestra para inferencia estadística: Representativa – Debe reproducir las características del universo Aleatoria – Todos los sujetos que pertenecen a mi población de estudio tienen la misma probabilidad de ser escogidos. Tipos de muestreo aleatorio Sistemático Estratificado Aleatorio simple Conglomerados

31
Tamaño de muestra Cómo determinar un tamaño de muestra
Establecer ¿Cuál es mi población de estudio?´o ¿Hacia donde voy a generalizar mis resultados? ¿Qué análisis voy a utilizar para conocer mi resultado? – Objetivo o hipótesis Estimación de una media Comparación de dos o más medias Determinar prevalencia (%) Correlacionar variables
 Correlacionar variables.")
32
Tamaño de muestra Establecer: (Estimaciones)
Precisión o tolerancia o error aceptable de mi resultado Nivel de confianza - zα Variabilidad esperada de mis datos=(Desviación estándar esperada)2 – s2 Poder estadístico (en caso de comparación de medias) – zβ Estimar un porcentaje de posibles casos perdidos (Porcentaje de respuesta) 80% 90% 95% Z= Áreas bajo la curva normal
2 – s2. Poder estadístico (en caso de comparación de medias) – zβ. Estimar un porcentaje de posibles casos perdidos (Porcentaje de respuesta) 80% 90% 95% Z= Áreas bajo la curva normal.")
33
Tamaño de muestra Ejemplo 1. Estimar prevalencia
Deseamos saber cuál es la prevalencia de niños obesos de de 6 a 12 años en Querétaro. Determinar población: Niños que vivan en Querétaro Análisis: Estimar un porcentaje Precisión: Aceptamos un error de +/- 3% Nivel de confianza de 95% Proporción estimada. Cuando no se sabe es mejor usar 0.5 Fórmula: zα2 * p*q 1.962 * 0.5 * 0.5 n= = = ~ 1068 error2 .032

34
Tamaño de muestra Ejemplo 2. Estimar una media
Deseamos saber cuál es la media de concentración de colesterol en niños obesos de 6 a 12 años de la ciudad de Querétaro. Determinar población: Niños con percentil BMI>95 de 6 a 12 años que habiten en la ciudad de Qro. Análisis: Estimar media de Colesterol Precisión: Aceptamos un error de +/- 5mg Nivel de confianza de 95% Variabilidad ~ Mayor desviación estándar en otros estudios similares de 40mg Fórmula: zα2 * s2 (1.96)2 * 402 (1.96)2 * 402 n= = = = ~ 246 error2 52 52
2 * 402. (1.96)2 * 402. n= = = = ~ 246. error")
35
Tamaño de muestra Ejemplo 3. Estimar la diferencia entre dos medias
Deseamos saber si existe diferencia en concentraciónes de colesterol entre niños sin obesidad y niños con obesidad de la ciudad de Querétaro. Determinar población: Niños con percentil BMI>95 y con percentil BMI < 85 que habiten en la ciudad de Qro. Análisis: Comparar dos medias de Colesterol Diferencia práctica entre las dos medias aceptable como mínimo 15mg d Nivel de confianza de 95% zα Poder estadístico deseado - zβ Variabilidad ~ Mayor desviación estándar en otros estudios similares de 40mg s Fórmula: 2 2 (Zα + Zβ)s ( )40 ~ un estimado de 10% de casos perdidos = 247 n= = = d 15
s. ( ) ~ un estimado de 10% de casos perdidos = 247. n= = = d. 15.")
36
VARIABLE RESULTADO O DEPENDIENTE
Tipos de análisis VARIABLES PREDICTORAS O INDEPENDIENTES VARIABLE RESULTADO O DEPENDIENTE Categórica Continua Categóricas Chi Cuadrada Regresión Logística (Modelos probit, logit ) Prueba T Student (T-test) ANOVA (Analysis of Variance) Regresión lineal Continuas Linear regression Pearson correlation Mezcla de categóricas y contínuas Analysis de covarianza
 Prueba T Student (T-test) ANOVA (Analysis of Variance) Regresión lineal. Continuas. Linear regression. Pearson correlation. Mezcla de. categóricas y. contínuas. Analysis de covarianza.")
Presentaciones similares



















