Descargar la presentación
La descarga está en progreso. Por favor, espere

1
VARIABLE DEPENDIENTE DICOTOMICA

2
Hemos estudiados casos donde las variables dicotómicas actuaban como regresores, variables independientes o que explican. Pero también las variables dicotómicas pueden actuar como regresandos, es decir ser la variables dependientes. En consecuencia uno las variables dependiente adoptará dos posibles valores en la serie histórica, 0 o 1 (o en un macro mas general, puede adoptar valores tales como 1, 3 y 5, para por ejemplo un scoring).
..")
3
De esta manera, nosotros diremos que si el objeto de análisis tiene la propiedad, le ponemos un 1, y 0 viceversa. Corriendo la regresión para datos históricos, nos encontraremos con un modelo que, bajo el supuesto de un buen calce de ajuste, es capaz de predecir la probabilidad de poseer la propiedad de una nueva observación a partir de los datos explicativos que poseemos.

4
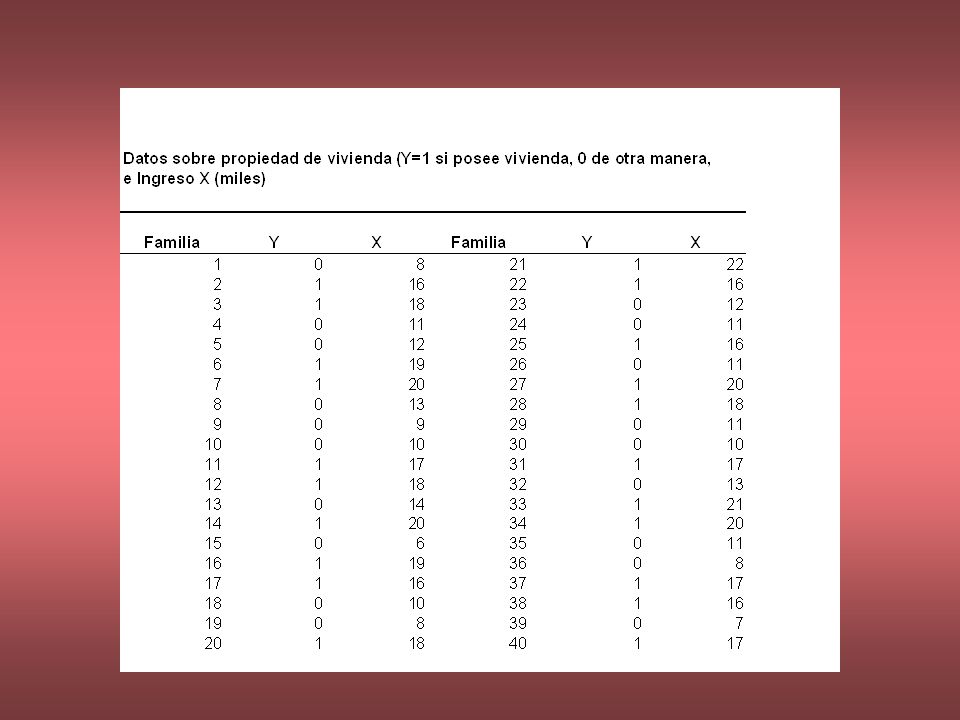
CASO – MODELO DE PROBABILIDAD LINEAL PROBABILIDAD QUE UNA FAMILIA POSEA VIVIENDA PROPIA La siguiente tabla presenta información sobre la propiedad de vivienda (Y = 1 si posee, Y=0 si no) y el ingreso familiar X (miles de $) para 40 familias.
 y el ingreso familiar X (miles de $) para 40 familias.")
6
Con base en estos datos, el MPL estimado por MCO es el siguiente Y e i = -0.9457 + 0.1021 X i (0.1228) (0.0082) t (-7.684) (12.515) R 2 = 0.8048
 (0.0082) t (-7.684) (12.515) R 2 =")
7
Primero interpretamos esta regresion. La intersección indica la probabilidad de que una familia con ingreso cero posea una casa. Puesto que este valor es negativo, y la probabilidad no puede ser negativa, tratamos este valor como cero (se puede interpretar el valor altamente negativo como probabilidad casi nula). El valor de la pendiente significa que un cambio unitario en el ingreso ($ 1000) incrementa la probabilidad de tener una casa en el valor del coeficiente.
. El valor de la pendiente significa que un cambio unitario en el ingreso ($ 1000) incrementa la probabilidad de tener una casa en el valor del coeficiente..")
8
Esta claro que dado un nivel especifico de ingreso nos permite estimar la probabilidad real de posee una casa con base en los datos. Por lo tanto para X = 12 (12.000), la probabilidad estimada de poseer una casa es: Y e i = -0.9457 + 0.1021 (12) = 0.2759 28%
, la probabilidad estimada de poseer una casa es: Y e i = (12) = 28%.")
9
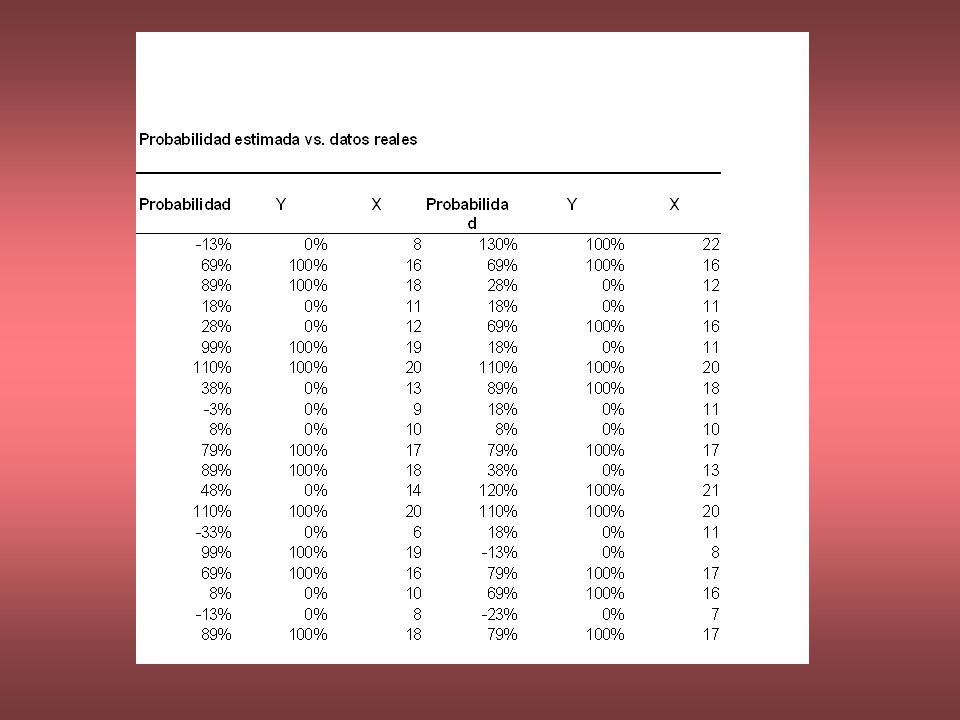
Esta claro que dado un nivel especifico de ingreso nos permite estimar la probabilidad real de posee una casa con base en los datos. Por lo tanto para X = 12 (12.000), la probabilidad estimada de poseer una casa es: Y e i = -0.9457 + 0.1021 (12) = 0.2759 28% Lo anterior implica que la probabilidad que una familia con ingreso de $ 12.000 posea una casa es aproximadamente 28%. La siguiente tabla muestra las probabilidades estimadas para los diferentes niveles de datos de ingreso.
, la probabilidad estimada de poseer una casa es: Y e i = (12) = 28% Lo anterior implica que la probabilidad que una familia con ingreso de $ posea una casa es aproximadamente 28%. La siguiente tabla muestra las probabilidades estimadas para los diferentes niveles de datos de ingreso..")
10
La caracteristica mas notable es que existen 6 valores menores que cero y 7 mayores que uno, demostrando claramente que los estimadores Y e i de E(Y i /X) no se encuentran necesariamente entre cero y uno, aunque los E() si deban encontrase en ese intervalo.
 no se encuentran necesariamente entre cero y uno, aunque los E() si deban encontrase en ese intervalo.")
12
CASO – MODELO DE PROBABILIDAD LINEAL PREDICCION DEL RATING DE UN BONO Con base en una combinacion de datos de serie de tiempo y corte transversal para 200 bonos Aa de alta calidad) y Baa (calidad intermedia), se estimo el siguiente modelo de valuacion de bonos: Y i = 1 + 2 X 2i 2 + 3 X 3i + 4 X 4i + 5 X 5i + u i,
 y Baa (calidad intermedia), se estimo el siguiente modelo de valuacion de bonos: Y i = 1 + 2 X 2i 2 + 3 X 3i + 4 X 4i + 5 X 5i + u i,")
13
donde Y i = 1 si la cotizacion el bono es Aa (rating de la firma Moody’s) = 0 si es Baa. X 2 = razon deuda a capital, como medida del endeudamiento=100 *Deuda LP/Capital X 3 = Tasa de Rentabilidad100 * EBI/Activos X 4 = Desviacion estandar de la tasa de rentabilidad, una medida de la volatilidad de los resultados. X 5 = Activos totales netos ($ ‘000) como medida del tamaño.
 como medida del tamaño..")
14
A priori se espera que 2 y 4 sean negativos (porque?) mientras que se espera que 3 5 sean positivos. Despues de corregir por heterocedasticidad y autocorrelacion de primer orden, se obtuvo el siguiente modelo de ajuste: Y e i = 0.6860 – 0.0179 X 2i 2 + 0.0486 X 3i + 0.0572 X 4i + 0.378(E-7) X 5i (0.1775)(0.0024) (0.0486)(0.0178) (0.039)(E-8)
 X 5i (0.1775)(0.0024) (0.0486)(0.0178) (0.039)(E-8).")
15
Todos, excepto el coeficiente de X 4 tienen los signos correctos. Queda a los estudiantes utilizar los conocimientos de finanzas y racionalizar los motivos de este signo, puesto que se esperaria que a mayor volatilidad de ganancias, menor sera la probabilidad que la firma Moody’s le asigne una calificacion buena. La interpretacion de la regresion es muy clara. Por ejemplo, el 0.0486 asociado a X 3 significa que, si las demas variables permanece iguales, un aumento del 1% en la tasa de rentabilidad producira en promedio un aumento aproximado de 5% en la probabilidad que un bono obtenga una calificacion Aa. En forma similar, cuanto mas alta sea la razon de endeudamiento, menor sera la probabilidad (en 2%) que un bono este clasificado como Aa.
 que un bono este clasificado como Aa..")
16
CASO –ANALISIS DE LA PROBABILIDAD DE FUSION/ADQUISICION DE UNA EMPRESA Para predecir la probabilidad que una empresa fuese objeto de una fusion o adquisicion, se utilizo el siguiente modelo donde Y = 1 si la empresa es un target de fusion/adquisicion, 0 en caso contario. Se asumio que la variable Y estaba relacionada linealmente con las siguientes variables

17
Y i = 1 + 2 pagos + 3 rotacion + 4 tamaño + 5 liquidez + 6 Volumen +error donde Y i = 1 si es objetivo de fusion, 0 si no; Pagos= razon de pagos a los accionistas (dividendos/ingresos); rotacion = rotacion de activos (ventas/total de activos); tamaño = valor de mercado del patrimonio; liquidez= tasa de endeudamiento o apalancamiento (deuda LP/Activos); volumen= volumen de transacciones en el año de adquisicion.
; rotacion = rotacion de activos (ventas/total de activos); tamaño = valor de mercado del patrimonio; liquidez= tasa de endeudamiento o apalancamiento (deuda LP/Activos); volumen= volumen de transacciones en el año de adquisicion.")
18
A priori se espera que 2, 4, y 5 sean negativos (porque?), 3 positivo o negativo, y 6 positivo. Con base en una muestra de 24 empresas fusionadas (Y=1) y 43 que no se fusionaron (Y=0), se obtuvieron los resultados que se observan en la siguiente tabla en base a un modelo LOGIT
 y 43 que no se fusionaron (Y=0), se obtuvieron los resultados que se observan en la siguiente tabla en base a un modelo LOGIT.")
19
Como se esperaba, los coeficientes estimados tienen los signos esperados a priori, y la mayoría son estadísticamente significativos a un nivel de por lo meses 10%. Los resultados indican por ejemplo que cuanto mas altos sea el nivel de rotacion de activos, y mayor el tamaño, menor sera la probabilidad que la empresa sea target de un “take over” o fusion (porque?). Por otras parte, cuanto mayor sea el numero de transacciones de sus acciones, mayor sera la probabilidad, debido a que las empresas que mueven altos volumenes se puede “tradear” mas facilmente, debido quiza a costos de transacción mas bajos. Con base a estos elementos, se concluye que :
. Por otras parte, cuanto mayor sea el numero de transacciones de sus acciones, mayor sera la probabilidad, debido a que las empresas que mueven altos volumenes se puede tradear mas facilmente, debido quiza a costos de transacción mas bajos. Con base a estos elementos, se concluye que :.")
20
“... un factor importante que afecta el atractivo de la empresa es la incapacidad que tiene la gerencia encargada de generar ventas por unidad de activo. Adicionalmente, una baja rotacion de activos debe estar acompañada por una combinacion de bajo nivel de dividendos, bajo nivel de apalancamiento financiero, alto volumen de transacciones y pequeño tamaño en el valor agregado de mercado para generar una alta probabilidad de fusion o adquisicion”.

Presentaciones similares


>")
















