Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Bioestadística Tema 7: Introducción a los contrastes de hipótesis

2
Objetivos del tema Conocer el proceso para contrastar hipótesis y su relación con el método científico. Diferenciar entre hipótesis nula y alternativa Nivel de significación Significación Toma de decisiones, tipos de error y cuantificación del error.

3
Contrastando una hipótesis Creo que la edad media es 40 años... Son demasiados... ¡Gran diferencia! Rechazo la hipótesis Muestra aleatoria

4
¿Qué es una hipótesis? Una creencia sobre la población, principalmente sus parámetros: –Media –Varianza –Proporción/Tasa OJO: Si queremos contrastarla, debe establecerse antes del análisis. Creo que el porcentaje de enfermos será el 5%

5
Identificación de hipótesis Hipótesis nula H o –La que contrastamos –Los datos pueden refutarla –No debería ser rechazada sin una buena razón. Hip. Alternativa H 1 –Niega a H 0 –Los datos pueden mostrar evidencia a favor –No debería ser aceptada sin una gran evidencia a favor.

6
¿Quién es H 0 ? Problema: ¿La osteoporosis está relacionada con el género? Solución: –Traducir a lenguaje estadístico: –Establecer su opuesto: –Seleccionar la hipótesis nula

7
¿Quién es H 0 ? Problema: ¿El colesterol medio para la dieta mediterránea es 6 mmol/l? Solución: –Traducir a lenguaje estadístico: –Establecer su opuesto: –Seleccionar la hipótesis nula

8
Razonamiento básico Si supongo que H 0 es cierta...... el resultado del experimento sería improbable. Sin embargo ocurrió. ¿qué hace un científico cuando su teoría no coincide con sus predicciones?

9
Razonamiento básico Si supongo que H 0 es cierta...... el resultado del experimento sería improbable. Sin embargo ocurrió. Rechazo que H 0 sea cierta.

10
Razonamiento básico Si supongo que H 0 es cierta...... el resultado del experimento es coherente. No hay evidencia contra H 0 No se rechaza H 0 El experimento no es concluyente El contraste no es significativo ¿Si una teoría hace predicciones con éxito, queda probado que es cierta?

11
Región crítica y nivel de significación Región crítica Valores ‘improbables’ si... Es conocida antes de realizar el experimento: resultados experimentales que refutarían H 0 Nivel de significación: Número pequeño: 1%, 5% Fijado de antemano por el investigador Es la probabilidad de rechazar H 0 cuando es cierta No rechazo H0 Reg. Crit. =5% =40

12
Contrastes: unilateral y bilateral La posición de la región crítica depende de la hipótesis alternativa Unilateral Bilateral H 1 : <40 H 1 : >40 H 1 : 40

13
Significación: p H 0 : =40

14
Significación: p No se rechaza H 0 : =40

15
Significación: p No se rechaza H 0 : =40 Es la probabilidad que tendría una región crítica que comenzase exactamente en el valor del estadístico obtenido de la muestra. Es la probabilidad de tener una muestra que discrepe aún más que la nuestra de H 0. Es la probabilidad de que por puro azar obtengamos una muestra “más extraña” que la obtenida. p es conocido después de realizar el experimento aleatorio El contraste es no significativo cuando p> P P

16
Significación : p Se rechaza H 0 : =40 Se acepta H 1 : >40

17
Significación : p P P Se rechaza H 0 : =40 Se acepta H 1 : >40 El contraste es estadísticamente significativo cuando p< Es decir, si el resultado experimental discrepa más de “lo tolerado” a priori.

18
Resumen: , p y criterio de rechazo Sobre –Es número pequeño, preelegido al diseñar el experimento –Conocido sabemos todo sobre la región crítica Sobre p –Es conocido tras realizar el experimento –Conocido p sabemos todo sobre el resultado del experimento Sobre el criterio de rechazo –Contraste significativo = p menor que

19
Resumen: , p y criterio de rechazo Sobre el criterio de rechazo –Contraste significativo = p menor que

20
Ejemplo Problema: ¿Está sesgada la moneda? Experimento: Lanzar la moneda repetidamente: P=50% P=25% P=12,5% P=6,25% P=3% P=1,5%

21
Ejemplo 1: Se juzga a un individuo por la presunta comisión de un delito H 0 : Hipótesis nula –E–Es inocente H 1 : Hipótesis alternativa –E–Es culpable Los datos pueden refutarla La que se acepta si las pruebas no indican lo contrario Rechazarla por error tiene graves consecuencias Riesgos al tomar decisiones No debería ser aceptada sin una gran evidencia a favor. Rechazarla por error tiene consecuencias consideradas menos graves que la anterior

22
Ejemplo 2: Se cree que un nuevo tratamiento ofrece buenos resultados Ejemplo 3: Parece que hay una incidencia de enfermedad más alta de lo normal H 0 : Hipótesis nula –(Ej.1) Es inocente –(Ej.2) El nuevo tratamiento no tiene efecto –(Ej.3) No hay nada que destacar H 1 : Hipótesis alternativa –(Ej.1) Es culpable –(Ej.2) El nuevo tratamiento es útil –(Ej. 3) Hay una situación anormal Riesgos al contrastar hipótesis No especulativa Especulativa
 Hay una situación anormal Riesgos al contrastar hipótesis No especulativa Especulativa.")
23
Tipos de error al tomar una decisión Realidad InocenteCulpable vere dicto Inocente OK Error Menos grave Culpable Error Muy grave OK

24
Tipos de error al contrastar hipótesis Realidad H 0 ciertaH 0 Falsa No Rechazo H 0 Correcto El tratamiento no tiene efecto y así se decide. Error de tipo II El tratamiento si tiene efecto pero no lo percibimos. Probabilidad β Rechazo H0 Acepto H 1 Error de tipo I El tratamiento no tiene efecto pero se decide que sí. Probabilidad α Correcto El tratamiento tiene efecto y el experimento lo confirma.

25
No se puede tener todo Para un tamaño muestral fijo, no se pueden reducir a la vez ambos tipos de error. Para reducir , hay que aumentar el tamaño muestral. Recordad lo que pasaba con sensiblidad y especificidad

26
Conclusiones Las hipótesis no se plantean después de observar los datos. En ciencia, las hipótesis nula y alternativa no tienen el mismo papel: –H 0 : Hipótesis científicamente más simple. –H 1 : El peso de la prueba recae en ella. α debe ser pequeño Rechazar una hipótesis consiste en observar si p<α Rechazar una hipótesis no prueba que sea falsa. Podemos cometer error de tipo I No rechazar una hipótesis no prueba que sea cierta. Podemos cometer error de tipo II Si decidimos rechazar una hipótesis debemos mostrar la probabilidad de equivocarnos.

27
¿Qué hemos visto? Hipótesis –Nula –Alternativa Nivel de significación –α –Probabilidad de error de tipo I Significación, p. –Criterio de aceptación/rechazo. Tipos de error –Tipo I –Tipo II

28
Análisis de identidad de dos distribuciones Test de t-Student: ¿Tienen dos distribuciones la misma media? Suposiciones: las muestras están derivadas de distribuciones gaussianas con la misma variancia. Por lo tanto, el test es paramétrico. Estrategia: medir el número de desviaciones estándar que las separa (err = σ/√N) Método: sean las muestras A ≡ {x i }, i=1,...,N A de media x A B ≡ {x i }, i=1,...,N B de media x B e igual variancia σ 2. Se definen s D y t La probabilidad de que t tome un valor así de grande o más viene dada por la distribución t-Student con n ≡ N A +N B grados de libertad, donde un valor pequeño significa que la diferencia es muy significante. Esta función está tabulada en los libros de estadística básica, y se puede encontrar codificada en la mayoría de las bibliotecas de programación. (Press et al., “Numerical Recipes”)
 Método: sean las muestras A ≡ {x i }, i=1,...,N A de media x A B ≡ {x i }, i=1,...,N B de media x B e igual variancia σ 2. Se definen s D y t La probabilidad de que t tome un valor así de grande o más viene dada por la distribución t-Student con n ≡ N A +N B grados de libertad, donde un valor pequeño significa que la diferencia es muy significante. Esta función está tabulada en los libros de estadística básica, y se puede encontrar codificada en la mayoría de las bibliotecas de programación. (Press et al., Numerical Recipes ).")
29
Análisis de identidad de dos distribuciones Variante del test de t-Student: ¿Tienen dos distribuciones la misma media? En el caso de que las variancias de las dos muestras sean diferentes, σ A 2 ≠ σ B 2, se definen t y n donde n no tiene por qué ser un número entero. La probabilidad de que t sea así de grande o más viene aproximadamente dada por la misma distribución P(t,n) anterior. (Press et al., “Numerical Recipes”)
 anterior. (Press et al., Numerical Recipes ).")
30
Análisis de identidad de dos distribuciones Test F: ¿Tienen dos distribuciones diferente variancia? Suposiciones: las distribuciones son gaussianas. El test es, por lo tanto, paramétrico. Estrategia: se analiza el cociente de las variancias y su desviación de la unidad. Método: sean las muestras A ≡ {x i }, i=1,...,N A de media x A y variancia σ A 2 B ≡ {x i }, i=1,...,N B de media x B y variancia σ B 2 Se define F ≡ σ A 2 /σ B 2, donde σ A >σ B. La significancia de que la variancia de la distribución A sea mayor que la de la distribución B viene dada por la distribución F con n A ≡ N A −1 y n B ≡ N B −1 grados de libertad en el numerador y denominador: donde La distribución F está tabulada en los libros de estadística básica, y se encuentra codificada en la mayoría de las bibliotecas de programación. (Press et al., “Numerical Recipes”)
.")
31
0 si x i <x 1 si x i ≥x Análisis de identidad de dos distribuciones Test Kolmogorov-Smirnov: ¿Son dos distribuciones diferentes? Suposiciones: las distribuciones son continuas. El test no es paramétrico, lo que lo hace muy eficaz. Es un test muy popular en Astronomía. Estrategia: medir la desviación máxima de las distribuciones acumuladas. Método: sean las muestras A ≡ {x i }, i=1,...,N A B ≡ {x i }, i=1,...,N B Se define la distribución acumulada S N (x) ≡ 1/N ∑ i f(x i ), donde f(x i ) ≡ { para cada muestra. La diferencia máxima entre ellas viene dada por D ≡ max |S A (x)−S B (x)| La significancia de que las dos distribuciones difieran viene dada aproximadamente por donde y N e =N A N B /(N A +N B ). La expresión es buena para N e ≥4 (Stephens 1970).
 ≡ 1/N ∑ i f(x i ), donde f(x i ) ≡ { para cada muestra. La diferencia máxima entre ellas viene dada por D ≡ max |S A (x)−S B (x)| La significancia de que las dos distribuciones difieran viene dada aproximadamente por donde y N e =N A N B /(N A +N B ). La expresión es buena para N e ≥4 (Stephens 1970)..")
32
Análisis de identidad de dos distribuciones El test de Kolmogorov-Smirnov no es muy sensible si la diferencia máxima entre las distribuciones acumuladas ocurre en los extremos de las mismas. Para solucionar este problema, se introdujo una variante del test. Test de Kuiper: ¿Son dos distribuciones diferentes? Suposiciones y estrategia: las mismas que K-S. Método: se definen las diferencias máximas por exceso, D +, y por defecto, D −, y la diferencia combinada D ≡ D + + D − = max [ S A (x) − S B (x) ] + max [ S B (x) − S A (x) ]. La significancia con la que las dos distribuciones difieren viene dada por P KP = 2 ∑ j (4j 2 λ 2 −1) exp(−2j 2 λ 2 ), donde λ ≡ [ √N e + 0.155 + 0.24 / √N e ] D y N e ≡ N A N B /(N A +N B ) Análisis de identidad de una distribución observada con una distribución teórica: tanto KS y KP se pueden aplicar a una sola distribución para estudiar si se deriva de una distribución teórica P(x). La estrategia es la misma, y las ecuaciones son válidas, substituyendo S B (x) por P(x) y haciendo N e =N A. (Press et al., “Numerical Recipes”)
 − S B (x) ] + max [ S B (x) − S A (x) ]. La significancia con la que las dos distribuciones difieren viene dada por P KP = 2 ∑ j (4j 2 λ 2 −1) exp(−2j 2 λ 2 ), donde λ ≡ [ √N e / √N e ] D y N e ≡ N A N B /(N A +N B ) Análisis de identidad de una distribución observada con una distribución teórica: tanto KS y KP se pueden aplicar a una sola distribución para estudiar si se deriva de una distribución teórica P(x). La estrategia es la misma, y las ecuaciones son válidas, substituyendo S B (x) por P(x) y haciendo N e =N A. (Press et al., Numerical Recipes ).")
33
QSOs: 85% RQ QSOs: 39% RL QSOs: 99.5% (Aragón-Salamanca et al. 1996, MNRAS, 281, 945) Ejemplo: distribución de galaxias débiles entorno a QSOs
 Ejemplo: distribución de galaxias débiles entorno a QSOs.")
34
Análisis de identidad de dos distribuciones Test Kolmogorov-Smirnov multidimensional: (Peacock 1983, MNRAS, 202, 615; Fasano & Franceschini 1987, MNRAS, 225, 155) Dificultad: en una dimensión, K-S es independiente de cómo se ordenan los datos, pero en N dimensiones, existe más de una forma de ordenarlos. Estrategia: se consideran las cuatro posibles acumulaciones de los n datos de una muestra siguiendo los ejes de coordenadas. En 2D, se considera el número de datos de la muestra que cae en cada cuadrante (x Y i ), (x>X i, y X i, y>Y i ), i=1,...,n, y se compara con la distribución padre o la distribución de comparación. Se define D BKS como la diferencia normalizada más grande de entre todos los cuadrantes y todos los puntos. En 3D, de igual manera, (x Z i ), (x Y i, z>Z i ), (x>X i, y X i, y Z i ), (x>X i, y>Y i, z>Z i ), i=1,...,n. Significancia: formalmente no existe una expresión rigurosa que dé la probabilidad de que las dos distribuciones difieran. Se han realizado diversos Monte Carlos con distribuciones en el plano y el espacio que presentan diferentes niveles de correlación. Fasano & Franceschini (1987) proveen de tablas y expresiones polinomiales para calcular la diferencia crítica Z n ≡ D BKS √N e que rechaza la identidad de las dos distribuciones, dados n, CC (coeficiente de correlación) y SL (el nivel de significancia).
, (x>X i, y X i, y>Y i ), i=1,...,n, y se compara con la distribución padre o la distribución de comparación. Se define D BKS como la diferencia normalizada más grande de entre todos los cuadrantes y todos los puntos. En 3D, de igual manera, (x Z i ), (x Y i, z>Z i ), (x>X i, y X i, y Z i ), (x>X i, y>Y i, z>Z i ), i=1,...,n. Significancia: formalmente no existe una expresión rigurosa que dé la probabilidad de que las dos distribuciones difieran. Se han realizado diversos Monte Carlos con distribuciones en el plano y el espacio que presentan diferentes niveles de correlación. Fasano & Franceschini (1987) proveen de tablas y expresiones polinomiales para calcular la diferencia crítica Z n ≡ D BKS √N e que rechaza la identidad de las dos distribuciones, dados n, CC (coeficiente de correlación) y SL (el nivel de significancia)..")
35
Análisis de identidad de dos distribuciones Cálculo de la dependencia de la diferencia crítica entre dos distribuciones 2D con el coeficiente de correlación de los puntos, el número de puntos y el nivel de confianza escogido para rechazar la hipótesis nula de identidad (Fasano & Franceschini 1987). Modelos de correlación entre los datos explorados

36
Análisis de identidad de dos distribuciones Aproximaciones polinomiales a las significancias encontradas en el Monte Carlo. Estos polinomios están codificados en varios paquetes de análisis estadístico (ejem. “Numerical Recipes”)
.")
37
(Wall J.V., 1996, Q. Jr. R. Astr. Soc., 37, 519)
")
38
Inferencia clásica frente a inferencia bayesiana (Loredo T. 1992, en “Statistical Challenges in Modern Astronomy”, ed. Feigelson & Babu, Springer, http://www.astro.cornell.edu/staff/loredo/bayes/tjl.html)http://www.astro.cornell.edu/staff/loredo/bayes/tjl.html Dos diferentes interpretaciones del término probabilidad: frecuentista: frecuencia con que un cierto resultado se obtiene en la repetición infinita de un proceso. bayesiana: plausibilidad de que una proposición (modelo) pueda dar cuenta de un conjunto de datos. En muchas situaciones se obtiene el mismo resultado utilizando las dos técnicas, pero existen excepciones notables (ejem. Kraft et al. 1991, ApJ, 374, 344). Los dos métodos son fundamentalmente diferentes. Parten de concepciones opuestas sobre cuál es la información fidedigna y por evaluar (modelo o datos). Los cálculos bayesianos discriminan entre hipótesis plausibles, mientras que los cálculos frecuentistas evalúan la validez del conjunto de datos dada una hipótesis que se toma como cierta. Teorema de Bayes:
 pueda dar cuenta de un conjunto de datos. En muchas situaciones se obtiene el mismo resultado utilizando las dos técnicas, pero existen excepciones notables (ejem. Kraft et al. 1991, ApJ, 374, 344). Los dos métodos son fundamentalmente diferentes. Parten de concepciones opuestas sobre cuál es la información fidedigna y por evaluar (modelo o datos). Los cálculos bayesianos discriminan entre hipótesis plausibles, mientras que los cálculos frecuentistas evalúan la validez del conjunto de datos dada una hipótesis que se toma como cierta. Teorema de Bayes:.")
39
Inferencia bayesiana Pasos a seguir en la inferencia Bayesiana: 1. Especificar el modelo, o hipótesis a evaluar: en general tendremos varias H i a comparar 2. Asignar las probabilidades: a priori o anterior P(H i ) anterior predictiva P(D) de muestreo P(D|H i ) 3. Calcular la probabilidad posterior mediante el teorema de Bayes. 4. Comparar los resultados entre los diferentes modelos, mediante el cociente de probabilidades posteriores P(H i |D)/P(H j |D), por ejemplo.
 anterior predictiva P(D) de muestreo P(D|H i ) 3. Calcular la probabilidad posterior mediante el teorema de Bayes. 4. Comparar los resultados entre los diferentes modelos, mediante el cociente de probabilidades posteriores P(H i |D)/P(H j |D), por ejemplo..")
40
Ejemplo: estimación de una media poissoniana Supongamos que hemos obtenido una medida de n eventos en un intervalo de tiempo T, y que deseamos inferir la frecuencia de eventos, r. 1.- Especificamos la hipótesis H, que el proceso es poissoniano con una frecuencia de eventos 0 r r max. 2.- Asignamos probabilidades: de muestreo: a priori (anterior):, que en este caso es una probabilidad no informativa anterior predictiva: 3.- Aplicamos el teorema de Bayes para calcular la probabilidad posterior: Si Tr max >> n, entonces la función incompleta gamma se puede aproximar por y la probabilidad posterior resulta Para el caso particular en el que se detectan 7 eventos en 1 segundo, la probabilidad de que el proceso tenga una media de 10 eventos por segundo es del 9%: (nota: compárese con la probabilidad frecuentista) P(10 | 7) (Loredo 1992)
:, que en este caso es una probabilidad no informativa anterior predictiva: 3.- Aplicamos el teorema de Bayes para calcular la probabilidad posterior: Si Tr max >> n, entonces la función incompleta gamma se puede aproximar por y la probabilidad posterior resulta Para el caso particular en el que se detectan 7 eventos en 1 segundo, la probabilidad de que el proceso tenga una media de 10 eventos por segundo es del 9%: (nota: compárese con la probabilidad frecuentista) P(10 | 7) (Loredo 1992).")
41
Ejemplo: estimación de una media poissoniana sobre un fondo Supongamos que hemos obtenido una medida de N on eventos en un intervalo de tiempo T on, y que deseamos inferir la frecuencia de eventos de la señal, s, sobre el fondo, b. Se supone que se puede estimar el fondo de una medida independiente de N off eventos en un intervalo T off. Como en el caso anterior Para la medida con señal y fondo conjuntamente: donde es la probabilidad de muestreo p(s|b) = p(s)= 1/s max p(b) = p(b | N off ) p(N on ) = 1/T on s max prob. anterior predictiva Para calcular la probabilidad posterior de la señal, hay que marginar el parámetro b, calculando p(s|N on ) = db p(sb|N on ). Realizando la expansión del término (s+b) N on se encuentra dan la probabilidad a priori } (Loredo 1992)
 = p(s)= 1/s max p(b) = p(b | N off ) p(N on ) = 1/T on s max prob. anterior predictiva Para calcular la probabilidad posterior de la señal, hay que marginar el parámetro b, calculando p(s|N on ) = db p(sb|N on ). Realizando la expansión del término (s+b) N on se encuentra dan la probabilidad a priori } (Loredo 1992).")
42
Se debe resaltar que éste es un cálculo ambiguo bajo la inferencia frecuentista, aunque hay algunas publicaciones con aproximaciones no libres de inconsistencias (O’Morgain, 1973, Nature, 241, 376; Cherry et al. 1980, ApJ, 242, 1257) ♦ Ejemplo: medida en la que b ≥ n (Kraft et al. 1991, ApJ, 374,344) — inconsistencias de los cálculos frecuentistas. Supóngase que b de conoce por un método alternativo con una gran precisión Cálculo frecuentista para constreñir s: Existen muchos métodos propuestos que no son correctos desde el punto de vista del planteamiento real del problema (véase Kraft et al.). Lo que sí es correcto, es calcular los límites de confianza (CL) de un s+b dado, con la función de probabilidad y substraer a estos el b previamente determinado. Cálculo bayesiano: No existe ninguna ambigüedad en el planteamiento del problema. Se deben calcular los CL de la densidad de la probabilidad posterior P(s| n,b) El intervalo de s para diferentes valores de CL, n, b se encuentra tabulado, aunque es simple calcularlo al resolver los CL con la expresión anterior.
 ♦ Ejemplo: medida en la que b ≥ n (Kraft et al. 1991, ApJ, 374,344) — inconsistencias de los cálculos frecuentistas. Supóngase que b de conoce por un método alternativo con una gran precisión Cálculo frecuentista para constreñir s: Existen muchos métodos propuestos que no son correctos desde el punto de vista del planteamiento real del problema (véase Kraft et al.). Lo que sí es correcto, es calcular los límites de confianza (CL) de un s+b dado, con la función de probabilidad y substraer a estos el b previamente determinado. Cálculo bayesiano: No existe ninguna ambigüedad en el planteamiento del problema. Se deben calcular los CL de la densidad de la probabilidad posterior P(s| n,b) El intervalo de s para diferentes valores de CL, n, b se encuentra tabulado, aunque es simple calcularlo al resolver los CL con la expresión anterior..")
43
(Kraft et al. 1991)
")
44
La comparación de ambos métodos indica que el cálculo frecuentista incurre en contradicciones cuando n<b, ya que los límites superiores de los CL llegan a ser negativos. Sin embargo, para casos en que b<n, los límites calculados son prácticamente iguales. frecuentista bayesiana frecuentista bayesiana

45
Nancy Lacourly FONDEF D99I1049 Tests de hipótesis

46
Se busca comprobar alguna información sobre la población a partir de los datos obtenidos sobre una muestra. Valverde tendrá más de 55% de los votos. Menos de 3% de las ampolletas del lote de 5000 duran menos de 1000 horas Las ampolletas duran más de 1000 horas en promedio.

47
¿Como elegir la muestra para responder? Depende de las alternativas de lo que se mide en la población

48
¿Porque en la elección municipal de Santiago (J. Lavin, M. Larrachea) se pudo decir temprano quíen iba a ser el ganador? ¿Porque en la última elección presidencial de Estados Unidos no se puede dar el nombre del ganador, siendo que faltan conocer 2000 votos? Es decir en el primer caso se puede usar una muestra, pero no en el segundo caso.
 se pudo decir temprano quíen iba a ser el ganador. ¿Porque en la última elección presidencial de Estados Unidos no se puede dar el nombre del ganador, siendo que faltan conocer 2000 votos. Es decir en el primer caso se puede usar una muestra, pero no en el segundo caso..")
49
La razón esta en la diferencia tan estrecha de los resultados. Es más fácil decir cual de los dos cuadrados es más obscuro: entre y que entre y

51
Tenemos 4 tasas con la leche puesta antes y 4 tasas con le leche puesta después del té. Una Dama Inglesa acierta reconociendo las tasa con la leche antes del té. ¿Es solamente suerte? NO. ¿Por qué?

52
Tenemos 4 tasas con la leche puesta antes y 4 tasas con le leche puesta después del té. Una Dama Inglesa acierta reconociendo las tasa con la leche antes del té. ¿Es solamente suerte? NO. ¿Por qué?

53
¿Cuantas repuestas posibles hay? Hay posibles. Hay un resultado correcto solamente. Suponiendo que alguien contesta al azar, hay una probabilidad de 1/70 de dar la repuesta correcta. ¡No es suerte!

54
¿Este dado esta cargado al 4? Lo que significaría que la probabilidad de sacar un 4 es mayor que 1/6. Tenemos dos alternativas: H o : = 1/6 y H 1 : > 1/6

55
Se hace un experimento: se lanza 120 veces el dado y se observa el número X de veces que se obtuvo un 4. X es un número aleatorio X es un número aleatorio Si fuera cierto que = 1/6, es decir el dado no cargado al 4, se podría dar la distribución de la variable aleatoria X.

56
X ~ Binomial(120, 1/6)
")
57
Si se encontro X=25, la probabilidad de encontrar X 25 es igual a

58
Si el suceso “obtener una proporción de 4 igual 25/120” ocurrío cuando tiene una pequña probabilidad de ocurrir si el dado no esta cargado, es que el dado efectivamente esta cargado a favor del 4.

59
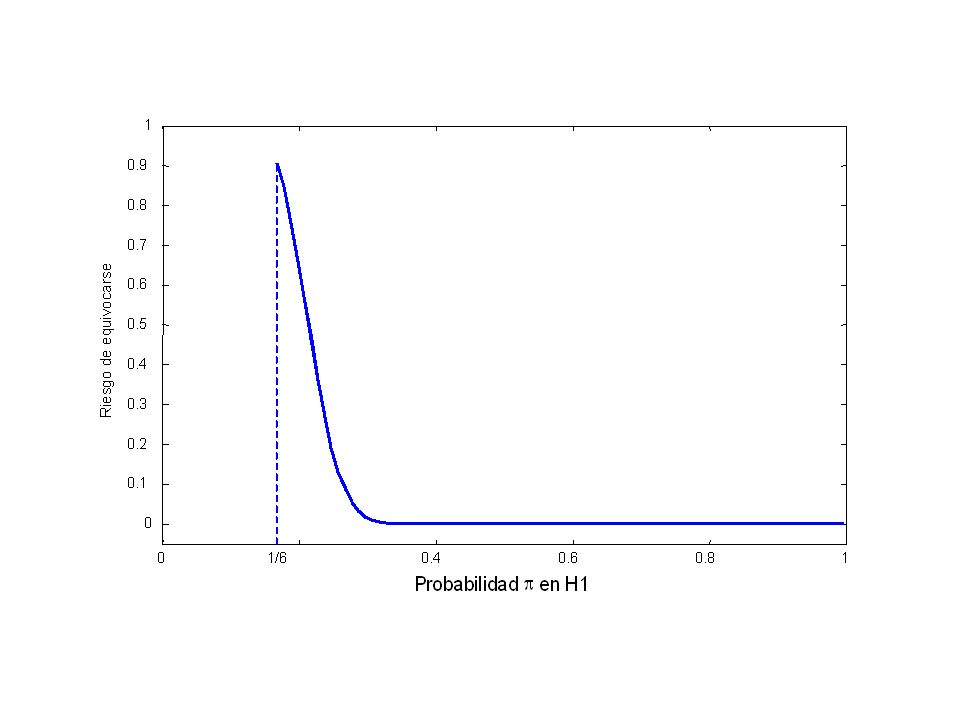
Si decidemos que el dado esta cargado, lo hacemos con un riesgo calculado: tenemos una probabilidad de 9% de equivocarnos. Obviamente si no queremos tomar un riesgo tan alto, tendremos que abstenernos de declarar que el dado cargado a favor del 4.

60
Pero si nos abstenemos de declarar que el dado esta cargado a favor del 4, sera ¿con que riesgo? Esto dependrá con que probabilidad comparamos.

61
Si comparamos = 1/6 a = 1/3, el error sera:

62
Si comparamos = 1/6 a = 1/4, el error sera:

63
Si comparamos = 1/6 a = 1/5, el error sera:

65
Sea ahora la comparación de dos grupos o dos poblaciones. Por ejemplo, ¿Las niñas tienen un mejor rendimiento escolar que los niños en Chile en 1º medio?

66
Si H y M son las medias de los rendimientos en1º medio de los niños y de las niñas, plateamos las dos alternativas: contra contra

67
Se toma una muetsra de 500 niñas y de 600 niños Sean y las medias en las muestras Son variables aleatorias:

68
Concuando

69
Si y

70
Entonces, se considera el valor de la probabilidad: para decidir:

71
Para calcular esta probabilidad, se considera las tablas de la variable aleatoria y el hecho que si entonces

72
Si decido, a partir de estas dos muestras, que los rendimientos son diferentes, esta decisión se hace con una probabilidad de 14% de equivocarse.

73
p * =0.65 95 % n=32: [0.485, 0.815] n=68: [0.537, 0.764] n=100: [0.556, 0.743]
![p * = % n=32: [0.485, 0.815] n=68: [0.537, 0.764] n=100: [0.556, 0.743]](http://images.slideplayer.es/14/4407344/slides/slide_73.jpg "p * = % n=32: [0.485, 0.815] n=68: [0.537, 0.764] n=100: [0.556, 0.743]")
Presentaciones similares