Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Licenciatura de Psicología:
Desarrollos actuales de la medición: Aplicaciones en evaluación psicológica. José Antonio Pérez Gil Dpto. de Psicología Experimental. Universidad de Sevilla. Tema I: Modelos de Medición: Desarrollos actuales, supuestos, ventajas e inconvenientes.

2
TEORÍA DE LOS TESTS Qué es? Para qué sirve? Cuáles hay ?

3
QUÉ ES UNA TEORÍA DE TESTS?
Una teoría de tests es una teoría que proporciona modelos para las puntuaciones de los tests, es decir, modeliza matrices de datos que contienen las respuestas que una muestra o grupo de sujetos han dado a cada uno de los elementos de un test. El análisis o modelado de estas matrices de datos da como resultado: la estimación del nivel en que poseen los sujetos la(s) característica(s)que mide el test (valores escalares de los sujetos) la estimación de los parámetros de los ítems (valores escalares de los ítems).
 característica(s)que mide el test (valores escalares de los sujetos) la estimación de los parámetros de los ítems (valores escalares de los ítems).")
4
El problema central de la teoría de los tests es la relación que existe entre:
el nivel del sujeto en la variable no observable que se desea estudiar y su puntuación observada en el test. Dicho de otro modo, el objetivo de cualquier teoría de tests es realizar inferencias sobre el nivel en que los sujetos poseen la característica o rasgo inobservable que mide el test, a partir de las respuestas que éstos han dado a los elementos que forman el mismo. Por tanto, para medir o, mejor dicho, estimar las características latentes de los sujetos es necesario relacionar éstas con la actuación observable en una prueba y esta relación debe de ser adecuadamente descrita por una función matemática.

5
Las distintas teorías de tests difieren justamente en la función que utilizan para relacionar la actuación observable en el test con el nivel del sujeto en la variable inobservable. En cualquier caso, esta función da siempre cuenta de la información contenida en la matriz de entrada a partir de: la(s) característica(s) de interés que supuestamente está midiendo el test y el error que de forma inevitable se introduce siempre en cualquier proceso de medición, ya sea de características físicas o psicológicas.
 característica(s) de interés que supuestamente está midiendo el test y. el error que de forma inevitable se introduce siempre en cualquier proceso de medición, ya sea de características físicas o psicológicas.")
6
TEORÍA DE LOS TESTS Qué es? Para qué sirve? Cuáles hay ?

7
PARA QUÉ SIRVE UNA TEORÍA DE TEST ?
Para saber hasta qué punto una medida obtenida en un momento determinado proporciona una estimación adecuada del nivel real en que posee el sujeto la característica psicológica que supuestamente se está evaluando. Por consiguiente, una teoría de los tests sirve para: dar cuenta del error de medida inherente a toda medición psicológica: estimación del error. Proporcionar una estimación del rasgo o característica evaluada: estimación de la característica de interés.

8
TEORÍA DE LOS TESTS Qué es? Para qué sirve? Cuáles hay ?

9
Teoría Clásica de los Tests Teoría de la Generalizabilidad
Las principales teorías de tests que han surgido en el campo de la psicometría son: Teoría Clásica de los Tests Teoría de la Generalizabilidad Teoría de Respuesta a los Ítems

10
Teoría Clásica de los Tests Teoría de la Generalizabilidad
Las principales teorías de tests que han surgido en el campo de la psicometría son: Teoría Clásica de los Tests Teoría de la Generalizabilidad Teoría de Respuesta a los Ítems

11
Teoría Clásica de los Tests (Spearman)
- Tesis central: desarrollo de un modelo estadístico que contemple los errores de medida. Asume X= V + error Propone el modelo lineal

12
Teoría Clásica de los Tests (Spearman)
X = V + error - Propone el modelo lineal X = + X

13
SUPUESTOS: El nivel real del sujeto en la característica de interés es la media de los valores que se obtendrían de forma empírica en caso de administrar el mismo test al sujeto en idénticas condiciones de medida un número infinito de veces. Naturaleza del error de medida:

14
SUPUESTOS: Independencia de las puntuaciones verdaderas y los errores de medida Independencia de los errores de medida cometidos con distintas formas del test

15
DEDUCCIONES: El valor esperado de la puntuación verdadera es igual al valor esperado de la puntuación empírica: La ecuación de regresión de la puntuación empírica sobre la puntuación verdadera es la ecuación lineal que pasa por el origen y que tienen el valor unidad como pendiente de la recta: La varianza de las puntuaciones empíricas en un test es igual a la suma de la varianza de las puntuaciones verdaderas más la varianza de los errores de medida:

16
DEDUCCIONES: La covarianza entre las puntuaciones empíricas y las puntuaciones verdaderas es igual a la varianza de las puntuaciones verdaderas: La razón de la varianza de las puntuaciones verdaderas con respecto a la varianza de las puntuaciones empíricas es igual al cuadrado del coeficiente de correlación entre las puntuaciones empíricas y sus correspondientes puntuaciones verdaderas:

17
DEDUCCIONES: La covarianza entre las puntuaciones empíricas y los errores de medida es igual a la varianza de los errores de medida: La razón de la varianza de los errores de medida con respecto a la varianza de las puntuaciones empíricas es igual al cuadrado del coeficiente de correlación entre las puntuaciones empíricas y sus correspondientes errores:

18
DEDUCCIONES: El cuadrado del coeficiente de correlación entre las puntuaciones empíricas y sus correspondientes puntuaciones verdaderas es igual a 1 menos el cuadrado del coeficiente de correlación entre las puntuaciones empíricas y sus correspondientes errores de medida:

19
El modelo así formulado, con sus supuestos y derivaciones, resulta inoperante, porque todos contienen elementos no observables. Spearman introduce el concepto de tests paralelos, que le permitirá operar empíricamente con las puntuaciones obtenidas por los sujetos en los tests.

20
Concepto de tests paralelos (Spearman)
Es posible X = V + e y X’ = V + e’ tal que X X’ y e e’ Siendo igual la puntuación verdadera: V = V

21
Para k tests paralelos:

22
Modelo de formas paralelas (Spearman)
x x’ X X’ x x’

23
Ello implica:

24
Según la teoría clásica de los tests, la puntuación empírica que obtiene un sujeto cuando se le administra un test -X- es función de: el nivel real o verdadero en que el sujeto posee la característica o rasgo que está evaluando dicho test: V y el error de medida que siempre se introduce en cualquier proceso de medición: E. Por tanto, desde este planteamiento, la relación entre el comportamiento observable en el test -X- y el nivel del sujeto en la variable no observable -V- es una relación lineal.

25
ESTIMACIÓN DE LA CARACTERÍSTICA DE INTERÉS
La característica que se desea medir o estimar al aplicar un test a un sujeto recibe la denominación de PUNTUACIÓN VERDADERA (V). Fórmula general para estimar V: V = E (X) Para determinar el valor de V y de E.máx. se dispone de tres estrategias: estimación mediante la desigualdad de Chebychev estimación basada en la distribución normal de los errores estimación según el modelo de regresión
. Fórmula general para estimar V: V = E (X) Para determinar el valor de V y de E.máx. se dispone de tres estrategias: estimación mediante la desigualdad de Chebychev. estimación basada en la distribución normal de los errores. estimación según el modelo de regresión.")
26
ESTIMACIÓN MEDIANTE LA DESIGUALDAD DE CHEBYCHEV

27
ESTIMACIÓN MEDIANTE LA DESIGUALDAD DE CHEBYCHEV
Por tanto,

28
ESTIMACIÓN BASADA EN LA DISTRIBUCIÓN NORMAL DE LOS ERRORES

29
ESTIMACIÓN BASADA EN LA DISTRIBUCIÓN NORMAL DE LOS ERRORES
Por tanto,

30
ESTIMACIÓN SEGÚN EL MODELO DE REGRESION

31
ESTIMACIÓN SEGÚN EL MODELO DE REGRESION
Por tanto,

32
Según la teoría clásica de los tests, la puntuación empírica que obtiene un sujeto cuando se le administra un test -X- es función de: el nivel real o verdadero en que el sujeto posee la característica o rasgo que está evaluando dicho test: V y el error de medida que siempre se introduce en cualquier proceso de medición: E. Por tanto, desde este planteamiento, la relación entre el comportamiento observable en el test -X- y el nivel del sujeto en la variable no observable -V- es una relación lineal.

33
ESTIMACIÓN DEL ERROR Error de medida: Donde, X = Puntuación observada
V=E(X)
")
34
Error de estimación de la puntuación verdadera:
Donde: Puntuación verdadera pronosticada a partir de la puntuación empírica mediante el modelo de regresión.

35
Error típico de medida:
Error típico de medida versus Error típico de estimación de la puntuación verdadera Error típico de medida: Error típico de estimación de la puntuación verdadera:

36
TEORÍA DE LOS TESTS Qué es? Para qué sirve? Cuáles hay ?

37
Teoría clásica de los test Teoría de la generalizabilidad
Las principales teorías de tests que han surgido en el campo de la psicometría son: Teoría clásica de los test Teoría de la generalizabilidad Teoría de respuesta a los items

38
TEORÍA DE LA GENERALIZABILIDAD:
ECUACIÓN BÁSICA PARA EL CASO MÁS SIMPLE: Donde: Es la puntuación del sujeto p en la condición i de medida Efecto o componente que refleja el nivel medio en la característica evaluada de la población de pertenencia del sujeto p

39
TEORÍA DE LA GENERALIZABILIDAD:
ECUACIÓN BÁSICA PARA EL CASO MÁS SIMPLE: Donde: Efecto de la característica evaluada por el test (en el sujeto p), o faceta de diferenciación Efecto de un factor o fuente de variación (en su condición i), o faceta de generalización.
, o faceta de diferenciación. Efecto de un factor o fuente de variación (en su condición i), o faceta de generalización.")
40
TEORÍA DE LA GENERALIZABILIDAD:
ECUACIÓN BÁSICA PARA EL CASO MÁS SIMPLE: Donde: Efecto de la interacción entre la faceta de diferenciación y la de generalización (del sujeto p en la condición i), confundido con error. Este modelo de medida incorpora portenciales fuentes de error: la(s) faceta(s) de generalización.
, confundido con error. Este modelo de medida incorpora portenciales fuentes de error: la(s) faceta(s) de generalización.")
41
TEORÍA DE LA GENERALIZABILIDAD:
Mediante un análisis de la varianza se estiman los componentes de la varianza asociada con cada fuente de variación del diseño, tanto las relativas a la faceta de diferenciación como a la(s) facetas de generalización. Se concluye que Xpi es una medida adecuada del rasgo o característica evaluada con el test cuando la variabilidad debida a la faceta de diferenciación es considerablemente mayor que la debida a la(s) faceta(s) de generalización.
 facetas de generalización. Se concluye que Xpi es una medida adecuada del rasgo o característica evaluada con el test cuando la variabilidad debida a la faceta de diferenciación es considerablemente mayor que la debida a la(s) faceta(s) de generalización.")
42
Coeficiente de generalizabilidad.
ESTIMACIÓN DE LA CARACTERÍSTICA DE INTERÉS La característica que se desea medir o estimar al aplicar un test a un sujeto recibe la denominación de PUNTUACIÓN UNIVERSO (U). Fórmula general para estimar U: Donde: Coeficiente de generalizabilidad.
. Fórmula general para estimar U: Donde: Coeficiente de generalizabilidad.")
43
ESTIMACIÓN DEL ERROR Error de medida: Donde,
X = Puntuación observadaen el sujeto en una determinada forma del test en unas determinadas condiciones. U=E(X) puntuación media que obtendría el sujeto en ese test en todos las condiciones posibles de medida incluidas en el universo de generalización
 puntuación media que obtendría el sujeto en ese test en todos las condiciones posibles de medida incluidas en el universo de generalización.")
44
Error típico de medida:
Donde, El valor estimado para las dos varianzas es función de: el tipo de diseño utilizado la finalidad del estudio de decisión

45
TEORÍA DE LOS TESTS Qué es? Para qué sirve? Cuáles hay ?

46
Teoría clásica de los test Teoría de la generalizabilidad
Las principales teorías de tests que han surgido en el campo de la psicometría son: Teoría clásica de los test Teoría de la generalizabilidad Teoría de respuesta a los items

47
Teoría de respuesta a los ítems (TRI)
- Tesis central: conseguir medidas invariantes respecto de los sujetos medidos y de los instrumentos utilizados. Asume X= V + error Propone un modelo no lineal

48
Teoría de respuesta a los ítems (TRI)
() = theta y representa el valor del sujeto en el rasgo latente (p.e. Habilidad cognitiva), P() representa la probabilidad de dar una respuesta positiva, D es una constante de escalamiento (normalización) igual a 1.702, y e es el número e (base de los logaritmos neperianos) - Propone el modelo logístico
 = theta y representa el valor del sujeto en el rasgo latente. (p.e. Habilidad cognitiva), P() representa la probabilidad de dar una respuesta positiva, D es una constante de escalamiento (normalización) igual a 1.702, y. e es el número e (base de los logaritmos neperianos) - Propone el modelo logístico.")
49
SUPUESTOS: Independencia local
Los principales supuestos de esta teoría son proposiciones referidas a la naturaleza del rasgo que se pretende medir y a las relaciones que se esperan entre las respuestas de los ítems. Unidimensionalidad Independencia local

50
SUPUESTOS: El supuesto de unidimensionalidad asume que la ejecución de los sujetos puede ser explicada con base a un espacio latente con rasgo único. Dimensionalidad del espacio latente: se refiere a la naturaleza del rasgo a medir, y en concreto, al espacio latente implicado en la medición, esto es, al número de componentes o variables latentes que es necesario tomar en consideración para describirlo adecuadamente. Hambleton y Swaminathan, (1985) señalan que en la práctica, la definición del espacio latente se limita a la exigencia de una “dimensión dominante”, es decir, basta que exista un rasgo principal que sea dominante o relevante para discriminar entre grupos de examinados.
 señalan que en la práctica, la definición del espacio latente se limita a la exigencia de una dimensión dominante , es decir, basta que exista un rasgo principal que sea dominante o relevante para discriminar entre grupos de examinados.")
51
SUPUESTOS: Unidimensionalidad del espacio latente Las respuestas de los sujetos está en función de su localización en el rasgo latente La distribución condicional de la puntuación de un ítem para un fijado es la misma para todas las poblaciones de interés.

52
SUPUESTOS: El supuesto de independencia local asume que las respuestas de diferentes sujetos j con un determinado nivel i en el rasgo (il , i2, , ij ) a un ítem son también estadísticamente independientes de las respuestas de esos sujetos a cualquier otro ítem, es decir, cada nueva respuesta es independiente de la respuesta anterior, y éstas sólo vienen determinadas por la probabilidad de acierto a ese ítem, que para sujetos con igual nivel de habilidad, es la misma para todo el grupo. La consecuencia inmediata de este supuesto así definido es que la probabilidad de un sujeto con aptitud , obtenga un determinado patrón de respuestas en un conjunto de items (i=1, 2, 3,...,n) es igual al producto de las probabilidades de respuesta a cada uno de los items condicionadas a ese nivel de aptitud; formalmente puede expresarse como sigue: donde Xi es la respuesta de un sujeto al ítem i.
 a un ítem son también estadísticamente independientes de las respuestas de esos sujetos a cualquier otro ítem, es decir, cada nueva respuesta es independiente de la respuesta anterior, y éstas sólo vienen determinadas por la probabilidad de acierto a ese ítem, que para sujetos con igual nivel de habilidad, es la misma para todo el grupo. La consecuencia inmediata de este supuesto así definido es que la probabilidad de un sujeto con aptitud , obtenga un determinado patrón de respuestas en un conjunto de items (i=1, 2, 3,...,n) es igual al producto de las probabilidades de respuesta a cada uno de los items condicionadas a ese nivel de aptitud; formalmente puede expresarse como sigue: donde Xi es la respuesta de un sujeto al ítem i.")
53
SUPUESTOS: Independencia local La información en que se basa la TRI para estimar los parámetros de los sujetos procede únicamente de los patrones de respuesta de los mismos. Las respuestas de los diferentes sujetos con un determinado nivel en el rasgo a un ítem son estadisticamente independientes de las respuestas de esos sujetos a cualquier otro ítem.

54
DEDUCCIONES: La mayoría de los modelos desarrollados bajo esta teoría asumen la unidimensionalidad del espacio latente. La probabilidad de que un sujeto con aptitud , obtenga un determinado patrón de respuestas en un conjunto de ítems (i=1,2,3,...,n) es igual al producto de las probabilidades de respuesta a cada uno de los ítems condicionadas a ese nivel de aptitud; formalmente se expresa:
 es igual al producto de las probabilidades de respuesta a cada uno de los ítems condicionadas a ese nivel de aptitud; formalmente se expresa:")
55
Otros supuestos: La naturaleza continua del espacio latente.
La probabilidad de dar la respuesta correcta a un ítem aumenta a medida que se incrementa el nivel de aptitud. Los tests utilizados para ajustar los diferentes modelos no deben ser administrados bajo condiciones de velocidad.

56
Naturaleza continua del espacio latente definido por el rasgo.
Los modelos en que se asume que el espacio latente definido por el rasgo es discreto se estudian bajo la Teoría de la Clase Latente, que junto con la TRI se enmarcan dentro de la Teoría del Rasgo Latente (Lazarfeld, 1950). El supuesto de monotonicidad simple: asume que la probabilidad de dar la respuesta correcta a un ítem aumenta a medida que se incremento el nivel de aptitud. Ausencia del factor velocidad o tiempo limitado en la ejecución del test: Hambleton y Swaminathan (1985) consideran que está implícita entre los supuestos de la TRI que los tests utilizados para ajustar los diferentes modelos no sean administrados bajo condiciones de velocidad (ligado al supuesto de unidimensionalidad).
. El supuesto de monotonicidad simple: asume que la probabilidad de dar la respuesta correcta a un ítem aumenta a medida que se incremento el nivel de aptitud. Ausencia del factor velocidad o tiempo limitado en la ejecución del test: Hambleton y Swaminathan (1985) consideran que está implícita entre los supuestos de la TRI que los tests utilizados para ajustar los diferentes modelos no sean administrados bajo condiciones de velocidad (ligado al supuesto de unidimensionalidad).")
57
En resumen: El conjunto de estos supuestos permite llevar a la práctica la idea central de la TRI, es decir, expresar la probabilidad de que una persona emita una determinada respuesta ante un ítem, generalmente la respuesta correcta o positiva, en función de la posición de la persona en el rasgo latente y de una o más características del ítem. Como expresan Hulin, Drasgow y Parsons (1983), los modelos de TRI proporcionan una estrategia probabilística para trabar o enlazar las respuestas de los sujetos -las variables observables- con los constructos teóricos contenidos en las teorías psicológicas -los rasgos latentes-. Las curvas características de los items constituyen el elemento de enlace como veremos a continuación.
, los modelos de TRI proporcionan una estrategia probabilística para trabar o enlazar las respuestas de los sujetos -las variables observables- con los constructos teóricos contenidos en las teorías psicológicas -los rasgos latentes-. Las curvas características de los items constituyen el elemento de enlace como veremos a continuación.")
58
Curva característica del ítem (CCI):
Un objetivo de la TRI sea establecer la mejor función que ajuste la relación funcional que existe entre los valores de la variable que miden los items y la probabilidad de acertar éstos, es decir, una función que de cuenta de la relación entre la probabilidad de acertar el ítem con la localización en el rasgo de los sujetos. Esta función de enlace recibe el nombre de Curva Característica del ítem (CCI), Huella del ítem o Función de Respuesta al Ítem (Lord y Stocking, 1988, Fischer, 1995). Cada ítem está caracterizado por una CCI particular y propia.
, Huella del ítem o Función de Respuesta al Ítem (Lord y Stocking, 1988, Fischer, 1995). Cada ítem está caracterizado por una CCI particular y propia.")
59
Curva característica del ítem (CCI):
Esa relación puede ser expresada mediante una función de regresión no lineal que une cada valor en el rasgo con la puntuación medida condicionada en el ítem, que, en el caso de ítems dicotómicos, coincide con la probabilidad condicionada al nivel de de acertar el ítem.

60
Curva característica del ítem (CCI):
La forma particular de cada CCI depende de los parámetros o características de cada ítem. Curva característica de un ítem en función de cuatro parámetros: a=1, b=1.5c=0.2 e Y=0.9

61
Curva característica del ítem (CCI):
Aunque las características de los ítems pueden ser numerosas, en particular son tres los parámetros que se suelen proponer para la obtención de las CCIs Parámetro a El parámetro a se le denomina índice de discriminación del ítem, y representa la magnitud del cambio en la probabilidad de acertar el ítem conforme varía el nivel de habilidad. Su valor es proporcional a la pendiente de la recta tangente a la CCI en el punto de inflexión de ésta. Parámetro b El parámetro b se corresponde con el valor en la abscisa (escala de habilidad ()) del punto de máxima pendiente de la CCI. Se le denomina índice de dificultad del ítem, y es un parámetro de localización del ítem que representa la posición de la CCI en relación al nivel de habilidad () necesario para obtener una probabilidad de acierto P()=(1+c)/2. Parámetro c El parámetro c es el índice de pseudo-azar del ítem, representa la probabilidad de acertar de los sujetos que desconocen la respuesta correcta, es decir, es el valor de P() cuando tiende a su valor mínimo (-).
) del punto de máxima pendiente de la CCI. Se le denomina índice de dificultad del ítem, y es un parámetro de localización del ítem que representa la posición de la CCI en relación al nivel de habilidad () necesario para obtener una probabilidad de acierto P()=(1+c)/2. Parámetro c. El parámetro c es el índice de pseudo-azar del ítem, representa la probabilidad de acertar de los sujetos que desconocen la respuesta correcta, es decir, es el valor de P() cuando tiende a su valor mínimo (-).")
62
Parámetros de la curva característica de un ítem:
Según el numero de parámetros que se tengan en cuenta se adoptaran funciones matemáticas diferentes. El tipo de respuesta y la dimensionalidad del espacio latente obtendremos diferentes modelos o tipos de CCI. ( N(0,1) y, a=0.8, b=1.5, c=0.2 e Y=.9)
 y, a=0.8, b=1.5, c=0.2 e Y=.9)")
63
Parámetro a : El parámetro a se le denomina índice de discriminación del ítem, representa la magnitud del cambio en la probabilidad de acertar el ítem conforme varía el nivel de habilidad. Su valor es proporcional a la pendiente de la recta tangente a la CCI en el punto de inflexión de ésta.

64
Teoría de respuesta a los ítems (TRI)
- Parámetro a :

65
Efecto del parámetro “a”

66
Efecto del parámetro “a”
“a” pequeño, discriminación pobre

67
Efecto del parámetro “a”
“a” grande, mejor discriminación

68
Parámetro b : El parámetro b se corresponde con el valor en la abscisa (escala de habilidad ()) del punto de máxima pendiente de la CCI. Se le denomina índice de dificultad del ítem, y es un parámetro de localización del ítem que representa la posición de la CCI en relación al nivel de habilidad () necesario para obtener una probabilidad de acierto P()=(1+c)/2.
 necesario para obtener una probabilidad de acierto P()=(1+c)/2.")
69
Teoría de respuesta a los ítems (TRI)
- Parámetros a y b :

70
Efecto del parámetro “b”

71
Efecto del parámetro “b”
“b” bajo, “ítem fácil ”

72
“b” alto, ítem de mayor dificultad
Efecto del parámetro “b” “b” alto, ítem de mayor dificultad “b” inversamente proporcional al ID de la TCT

73
Parámetro c : El parámetro c es el índice de pseudo-azar del ítem, representa la probabilidad de acertar de los sujetos que desconocen la respuesta correcta, es decir, es el valor de P() cuando tiende a su valor mínimo (-).
 cuando tiende a su valor mínimo (-).")
74
Teoría de respuesta a los ítems (TRI)
- Parámetros a, b y c :

75
Efecto del parámetro “c”

76
Efecto del parámetro “c”
c=0, asintótica al punto 0

77
Efecto del parámetro “c”
Sujetos con “baja habilidad” pueden responder correctamente

78
La CCI queda definida cuando se especifican estos tres parámetro y se adopta una determinada función matemática para conformar la curva. Recordando .... ( N(0,1) y, a=0.8, b=1.5, c=0.2 e Y=.9)
 y, a=0.8, b=1.5, c=0.2 e Y=.9)")
79
Ejemplo de CCI de 15 items de un test.

80
Función de información del item:
Expresa la cantidad de información que proporciona el item respecto al rasgo latente en un determinado nivel del mismo.

81
Ejemplo de funciones de informacion de tres de los items del test.
Función de información del item: Ejemplo de funciones de informacion de tres de los items del test.

82
Estimación de parámetros Ajuste del modelo.
Proceso de comprobación de los Modelos. “Comprobar que el modelo de TRI elegido es el adecuado constituye por razones obvias un aspecto central en la aplicación de los modelos” Fases: Estimación de parámetros Ajuste del modelo.

83
Estimación de parámetros
Los métodos de estimación de los parámetros de cualquier modelo TRI se basan fundamentalmente en : el principio de máxima verosimilitud: busca los valores que hacen más probable la obtención de los datos empíricos a partir del modelo criterios bayesianos: se basan en combinar la función de verosimilitud de los datos muéstrales con una distribución adicional, que se supone siguen los parámetros (distribución a priori), dando lugar a una distribución a posteriori. estrategias heurísticas: los métodos heurísticos se basan en la equivalencia que existe entre algunos modelos de TRI y ciertos estadísticos de la TCT (Urry, 1974, 1976). En la actualidad, estos métodos se utilizan únicamene para obtener los valores iniciales de los estimadores en algunos programas informáticos.
, dando lugar a una distribución a posteriori. estrategias heurísticas: los métodos heurísticos se basan en la equivalencia que existe entre algunos modelos de TRI y ciertos estadísticos de la TCT (Urry, 1974, 1976). En la actualidad, estos métodos se utilizan únicamene para obtener los valores iniciales de los estimadores en algunos programas informáticos.")
84
Estimación de parámetros
Esta estimación suele hacerse en dos situaciones diferentes : la estimación puede hacerse conjuntamente: Se desconocen tanto los parámetros de items como de los de los sujetos y ambos han de ser estimados simultáneamente a partir de las respuestas utilizando métodos de máxima verosimilitud conjunta (Lord, 1974, Birnbaum, 1968) o de máxima verosimilitud marginal (Bock y Liebennan, 1970; Bock y Aitkin, 1981). la estimación puede realizarse de manera condicional : Se conocen los parámetros de los items, pero se desconocen la los de los sujetos, estimándose éstos a partir de aquéllos y de las respuestas de los sujetos mediante el uso de métodos de máxima verosimilitud condicional que se emplean para estimar la habilidad de los sujetos, conocidos los valores de los parámetros (Lord, 1980).
 o de máxima verosimilitud marginal (Bock y Liebennan, 1970; Bock y Aitkin, 1981). la estimación puede realizarse de manera condicional : Se conocen los parámetros de los items, pero se desconocen la los de los sujetos, estimándose éstos a partir de aquéllos y de las respuestas de los sujetos mediante el uso de métodos de máxima verosimilitud condicional que se emplean para estimar la habilidad de los sujetos, conocidos los valores de los parámetros (Lord, 1980).")
85
Podemos encontrar una gran cantidad de programas para estimar los parámetros de casi todos los modelos: ANCILLES, OGIVA (Urry, 1974, 1976); ASCAL (Vale y Gialluca, 1985); BICAL (Wrigth y Mead, 1976); BIGSTEPS (Linacre y Wright, 1997); BILOG (Mislevy y Bock, 1990); BILOG-MG (Zimowski, Muraki, Mislevy y Bock (1996); BIMAIN (Muraki, Mislevy y Bock, 1987; Zimowski, Muraki, Mislevy, y Bock, 1993); LOGIST (Wingersky, Barton y Lord, 1982); METRIX (Renom, 1992b); MIRTE (Carlson, 1987); MULTILOG (Thissen, 1991); NOHARM (Fraser, 1988); PARSCALE (Muraki y Bock, 1996); PML (Gustaffson, 1980); QUEST (Adams y Khoo, 1995); RASCAL, (ASC, 1988); RIDA (Glass, 1990); RSP (Glass y Ellis, 1993); TESTAT (Stenson y Wilkinson, 1986); WINMIRA (van Davier, Smith, y Makov, 1995) XCALIBRE (ASC, 1988).
; ASCAL (Vale y Gialluca, 1985); BICAL (Wrigth y Mead, 1976); BIGSTEPS (Linacre y Wright, 1997); BILOG (Mislevy y Bock, 1990); BILOG-MG (Zimowski, Muraki, Mislevy y Bock (1996); BIMAIN (Muraki, Mislevy y Bock, 1987; Zimowski, Muraki, Mislevy, y Bock, 1993); LOGIST (Wingersky, Barton y Lord, 1982); METRIX (Renom, 1992b); MIRTE (Carlson, 1987); MULTILOG (Thissen, 1991); NOHARM (Fraser, 1988); PARSCALE (Muraki y Bock, 1996); PML (Gustaffson, 1980); QUEST (Adams y Khoo, 1995); RASCAL, (ASC, 1988); RIDA (Glass, 1990); RSP (Glass y Ellis, 1993); TESTAT (Stenson y Wilkinson, 1986); WINMIRA (van Davier, Smith, y Makov, 1995) XCALIBRE (ASC, 1988).")
86
Ajuste del Modelo Obtención de evidencias que permitan sostener que el modelo es apropiado y se ajusta a los datos. Evidencias que permitan hacer un juicio global de la adecuación del modelo (Hambleton y Rogers, 1991). Existen múltiples índices de ajuste, ninguno de ellos completamente satisfactorio, Los aspectos que hay que analizar son: el cumplimiento de los supuestos, la unidimensionalidad y la independencia local el ajuste del modelo análisis de residuales, índices basados en chi-cuadrado o la comparación de las distribuciones de puntuaciones predichas y observadas. las ventajas esperadas invarianza de los parámetros de los sujetos a través de diferentes grupos de items y la invarianza de los parámetros de los items en diferentes muestras de sujetos.
. Existen múltiples índices de ajuste, ninguno de ellos completamente satisfactorio, Los aspectos que hay que analizar son: el cumplimiento de los supuestos, la unidimensionalidad y la independencia local. el ajuste del modelo. análisis de residuales, índices basados en chi-cuadrado o. la comparación de las distribuciones de puntuaciones. predichas y observadas. las ventajas esperadas. invarianza de los parámetros de los sujetos a través de. diferentes grupos de items y la invarianza de los. parámetros de los items en diferentes muestras de sujetos.")
87
Una vez que se ha comprobado que el modelo propuesto presenta un ajuste adecuado a los datos, las estimaciones de los parámetros de los sujetos producidas por el modelo ofrecerán la medida de cada sujeto en el rasgo latente de interés. La precisión de estas medida suele representarse mediante la curva característica del test. Veamos a continuación estos concepto.

88
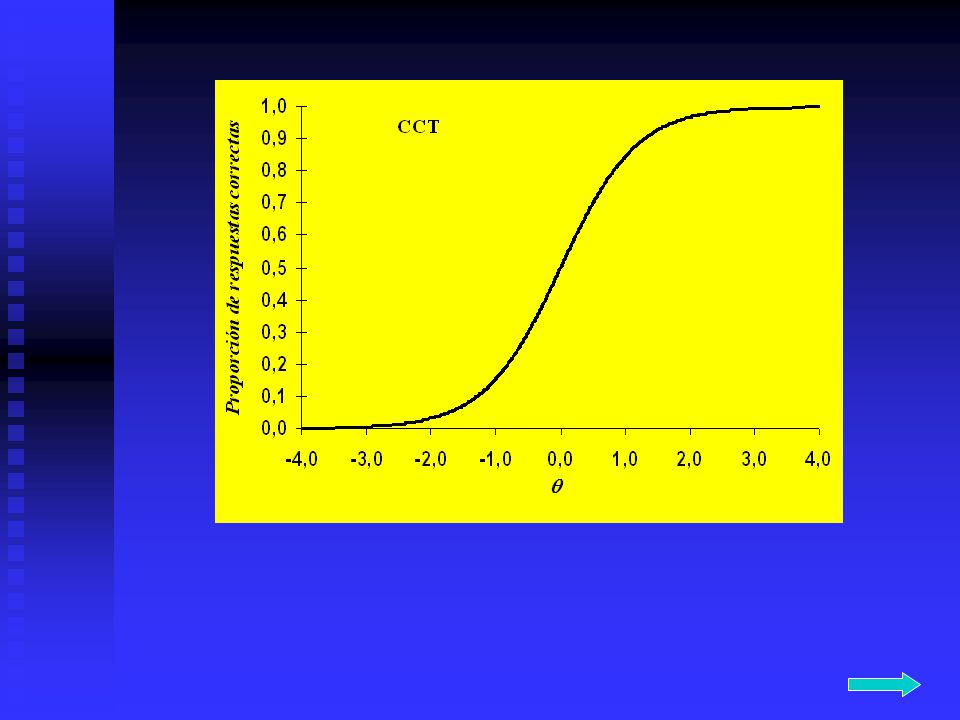
Curva Característica del Test (CCT).
El concepto de curva característica del test (CCT) es similar al concepto de CCI. Su interés principal se centra en que la CCT sirve de nexo entre la TRI y la TCT posibilitando, entre otras, la interpretación de los resultados y la equiparación de las puntuaciones de los sujetos. La curva característica del test es la suma de las curvas características de los items que componen el test, es decir, para obtener un determinado nivel de se suman los valores de P() de cada ítem del test para ese nivel. Formalmente puede expresarse como: siendo k el número de items Sus valores indican la relación que existe entre el nivel en el rasgo latente de un determinado sujeto y el patrón de respuesta esperado en el test.
 es similar al concepto de CCI. Su interés principal se centra en que la CCT sirve de nexo entre la TRI y la TCT posibilitando, entre otras, la interpretación de los resultados y la equiparación de las puntuaciones de los sujetos. La curva característica del test es la suma de las curvas características de los items que componen el test, es decir, para obtener un determinado nivel de se suman los valores de P() de cada ítem del test para ese nivel. Formalmente puede expresarse como: siendo k el número de items. Sus valores indican la relación que existe entre el nivel en el rasgo latente de un determinado sujeto y el patrón de respuesta esperado en el test.")
91
Al igual que en otras teorías o modelos de medida, la puntuación empírica que obtiene un sujeto cuando se le administra un test -X- es función de: el nivel real o verdadero en que el sujeto posee la característica o rasgo que está evaluando dicho test: V y el error de medida que siempre se introduce en cualquier proceso de medición: E.

92
ESTIMACIÓN DE LA CARACTERÍSTICA DE INTERÉS
Desde la TRI, al aplicar un test a un sujeto podemos estar interesados en medir tanto la PUNTUACIÓN VERDADERA, V(), como el NIVEL DE HABILIDAD, . Fórmula para estimar V(). : La puntuación verdadera en el test de un sujeto al que se ha estimado una determinada puntuación =j mediante un determinado modelo de TRI viene dada por las CCI que componen el test, es decir, se estima como la suma de las probabilidades P(j) de cada ítem: siendo k el número de items Como puede observarse, el valor de la puntuación verdadera se corresponde con el valor generado por la curva característica del test para =j .
, como el NIVEL DE HABILIDAD, . Fórmula para estimar V(). : La puntuación verdadera en el test de un sujeto al que se ha estimado una determinada puntuación =j mediante un determinado modelo de TRI viene dada por las CCI que componen el test, es decir, se estima como la suma de las probabilidades P(j) de cada ítem: siendo k el número de items. Como puede observarse, el valor de la puntuación verdadera se corresponde con el valor generado por la curva característica del test para =j .")
93
ESTIMACIÓN DE LA CARACTERÍSTICA DE INTERÉS
Fórmula para estimar el NIVEL DE HABILIDAD, : Como ya hemos referido, el nivel de habilidad de un sujeto se ha de estimar utilizando un determinado modelo de TRI que tenga en cuenta la/s característica/s de los ítems del test de manera que el valor estimado permita reproducir con criterios de máxima verosimilitud el patrón de respuestas realizado por el sujeto en cuestión. El valor obtenido está sujeto a errores de estimación producidos por el propio modelo. Para determinar el nivel real en que un sujeto posee la característica o rasgo latente que mide el test, se utiliza la siguiente formula general: donde E.máx= zce

94
ESTIMACIÓN DEL ERROR DE MEDIDA
Para estimar el error de medida, la TRI propone dos estimaciones diferentes, una a nivel de cada item del test y otra a nivel de test: estimación del error de medida a nivel del item: A nivel de cada ítem el error de medida se calcula como la diferencia entre la respuesta que el sujeto ha dado al ítem en cuestión ui y la probabilidad de responder correctamente a ese item, dado su nivel de habilidad . Formalmente, estimación del error de medida a nivel del test: A nivel del test, para determinar el error de medida se calcula como la diferencia entre la suma de las respuestas dadas por el sujeto a todos los items del test y la suma de las probabilidades de responder correctamente a todos los items del test, dado su nivel de habilidad j . Se utiliza la siguiente formula general:

95
Error de medida (a nivel del ítem):
ESTIMACIÓN DEL ERROR Error de medida (a nivel del ítem): Donde, u = respuesta dada al item en cuestion P(u=1/)= probabilidad de responder corectamente dado un nivel de habilidad
: Donde, u = respuesta dada al item en cuestion. P(u=1/)= probabilidad de responder corectamente dado un nivel de habilidad ")
96
Error de medida (a nivel del test):
ESTIMACIÓN DEL ERROR Error de medida (a nivel del test): Donde, X = respuesta dada a cada item en cuestion V()= puntuación verdadera del sujeto con nivel .
: Donde, X = respuesta dada a cada item en cuestion. V()= puntuación verdadera del sujeto con nivel .")
97
ESTIMACIÓN DEL ERROR DE MEDIDA EN LA ESTIMACIÓN DE :
donde E.máx= zce El error típico de medida e para un determinado nivel de = j puede calcularse como la raíz cuadrada de la varianza muestral de la estimación del parámetro ofrecida por el test: donde k es el número de items del test, Pi(j) es el valor de las CCI para =j y Qi (j) es igual a 1- P(j). A su vez, la inversa de la varianza muestral de la estimación del parámetro ofrecida por el test nos da información de la precisión de la medida y recibe el nombre de función de información del test.
 es el valor de las CCI. para =j y Qi (j) es igual a 1- P(j). A su vez, la inversa de la varianza muestral de la estimación del parámetro ofrecida por el test nos da información de la precisión de la medida y recibe el nombre de función de información del test.")
98
ESTIMACIÓN DEL ERROR Error de medida: e Donde,
I() = Función de información del test.
 = Función de información del test.")
99
Función de información del Test:
Expresa la cantidad de información que proporciona el test respecto al rasgo latente en un determinado nivel del mismo.

100
Función de información del Test:
Expresa la cantidad de información que proporciona el test respecto al rasgo latente en un determinado nivel del mismo. Y por tanto:

101
Función de información y error de medida del test de 15 ítems:

102
Recordando ..... La CCI queda definida cuando se especifican estos tres parámetro y se adopta una determinada función matemática para conformar la curva. Según el tipo de función matemática adoptada, el número de parámetros referidos al ítem considerados como relevantes, el tipo de respuesta y la dimensionalidad del espacio latente obtendremos diferentes modelos o tipos de CCI.

103
Modelos Básicos o funciones de enlace utilizadas:
El modelo logístico de Rasch o modelo de un parámetro. Mediante el uso de una constante adicional, (D=1.7) sus valores se aproximan notablemente a la curva normal acumulada, por lo que es frecuente encontrarla expresada como función logística normalizada.
 sus valores se aproximan notablemente a la curva normal acumulada, por lo que es frecuente encontrarla expresada como función logística normalizada.")
104
Modelos Básicos o funciones de enlace utilizadas:
La contribución de Birnbaum: los modelos logísticos. Modelo logístico de dos parámetros Modelo logístico normalizado de dos parámetros

105
Modelos Básicos o funciones de enlace utilizadas:
La contribución de Birnbaum: los modelos logísticos. Modelo logístico de tres parámetros Modelo logístico normalizado de tres parámetros

106
Modelos Básicos o funciones de enlace utilizadas:
La contribución de Birnbaum: los modelos logísticos. Modelo logístico generalizado (4 parámetros) Modelo logístico normalizado generalizado (4 parámetros) ci=0; Yi=1; ai=1 Modelo de 1 parametro ci=0; Yi=1; Modelo de 2 parametro Yi= Modelo de 3 parametro
 Modelo logístico normalizado generalizado (4 parámetros) ci=0; Yi=1; ai=1 Modelo de 1 parametro. ci=0; Yi=1; Modelo de 2 parametro. Yi=1 Modelo de 3 parametro.")
107
Desarrollo de los modelos básicos y su clasificación.
Tipo de Respuesta Autor RESPUESTA DICOTÓMICA: Modelo logístico de 1 parámetro Modelo logístico de 2 y 3 parámetros Modelo logístico de 4 parámetros Modelos normales Rasch (1960) Birnbaum (1968) McDonald (1967) Lord (1952,1953 a y b) RESPUESTA POLITÓMICA: Nominal: Modelo de respuesta nominal Modelo nominal modificado Modelo de elección múltiple Ordenada: Modelo de respuesta graduada Modelo de escala estimación Modelo de crédito parcial Modelo de crédito parcial generalizado Modelo secuencial Bock (1972) Samejima (1979) Thissen y Steinberg (1984) Samejima (1969) Andrich (1978) Masters (1982) Muraki (1992) Tutz (1990) RESPUESTA CONTINUA: Modelo de respuesta continua Modelo continuo de Rasch Samejima (1972) Müller (1987) Cuadro Clasificación de modelos según los criterios de Bejar (1983a). Tomado de Hontangas (1997).
 Birnbaum (1968) McDonald (1967) Lord (1952,1953 a y b) RESPUESTA POLITÓMICA: Nominal: Modelo de respuesta nominal. Modelo nominal modificado. Modelo de elección múltiple. Ordenada: Modelo de respuesta graduada. Modelo de escala estimación. Modelo de crédito parcial. Modelo de crédito parcial generalizado. Modelo secuencial. Bock (1972) Samejima (1979) Thissen y Steinberg (1984) Samejima (1969) Andrich (1978) Masters (1982) Muraki (1992) Tutz (1990) RESPUESTA CONTINUA: Modelo de respuesta continua. Modelo continuo de Rasch. Samejima (1972) Müller (1987) Cuadro Clasificación de modelos según los criterios de Bejar (1983a). Tomado de Hontangas (1997).")
108
Desarrollo de los modelos básicos y su clasificación.
Tipo de Respuesta Autor RESPUESTA DICOTÓMICA OJIVA NORMAL Modelos de 1, 2 y 3 parámetros OJIVA LOGÍSTICA Modelos de1, 2 y 3 parámetros Lord (1952,1953a,1953b) Birnbaum (1957,1958a,1958b,1968); Rasch, 1960; Lord, 1980; RESPUESTA POLITÓMICA Modelo de respuesta graduada Modelo de respuesta nominal Modelo de escala graduada Modelo de crédito parcial Modelo de elección múltiple Modelo secuencial Modelo politómico de Rasch Samejima (1969, 1995,1997) Bock (1972, 1997) Andrich (1978); Andersen, 1997) Masters, 1982; Masters y Wright, 1997; Muraki (1997); Verhelst, Glas y de Vries, (1997). Thissen y Steinberg (1986,1997) Tutz (1990, 1997) Andersen, (1995); Fischer, (1995); Glas y Verhelst, RESPUESTA CONTINUA Modelo de Samejima Modelo de Rasch Modelo de Mellenbergh Ferrando (1995)[1] Samejima (1972, 1973), (1995). Müeller, (1987) Mellenbergh (1993,1994) Cuadro Clasificación general de modelos TRI (Navas, 1997).
 Birnbaum (1957,1958a,1958b,1968); Rasch, 1960; Lord, 1980; RESPUESTA POLITÓMICA. Modelo de respuesta graduada. Modelo de respuesta nominal. Modelo de escala graduada. Modelo de crédito parcial. Modelo de elección múltiple. Modelo secuencial. Modelo politómico de Rasch. Samejima (1969, 1995,1997) Bock (1972, 1997) Andrich (1978); Andersen, 1997) Masters, 1982; Masters y Wright, 1997; Muraki (1997); Verhelst, Glas y de Vries, (1997). Thissen y Steinberg (1986,1997) Tutz (1990, 1997) Andersen, (1995); Fischer, (1995); Glas y Verhelst, RESPUESTA CONTINUA. Modelo de Samejima. Modelo de Rasch. Modelo de Mellenbergh. Ferrando (1995)[1] Samejima (1972, 1973), (1995). Müeller, (1987) Mellenbergh (1993,1994) Cuadro Clasificación general de modelos TRI (Navas, 1997).")
109
Desarrollo de los modelos básicos y su clasificación.
Tipo de Modelo Autor MODELOS POLITÓMICOS Modelo de respuesta nominal Modelo de elección múltiple Modelo de escala de estimación Modelo de respuesta graduada Modelo de crédito parcial Modelo de etapas Modelo secuencias ordenado Modelo de crédito parcial generalizado Bock Thissen y Steinberg Andersen Samejima Masters y Wright Verhelst, Glas y de Vries Tutz Muraki MODELOS PARA TIEMPO DE RESPUESTA O INTENTOS MÚLTIPLES Modelo de tiempo límite Modelo tiempo limite y velocidad Modelo de intentos múltiples Verheist, Verstralesn y Jansen Roskam Spray MODELOS DE COMPONENTES COGNITIVOS O HABILIDADES MÚLTIPLES Modelo logística lineal Modelo con predictores observados Modelo multidimensional normal Modelo multidimensional logística lineal Modelo multidimensional loglineal Modelo multicomponentes Fischer Zwinderman McDonald Reckase Keldennan Embretson Fischer y Seliger MODELOS NO PARAMÉTRICOS Modelo de Mokken dicotómico Modelo de Mokken politómico Modelo de análisis funcional Modelo de coseno hiperbólico Modelo de paralelogramo Mokken Molenaar Ramsay Andrich Hoijtink MODELOS CON SUPUESTOS ESPECIALES Modelo de grupos múltiples Modelo de logística mixto Modelo de conjuntiva Modelo de desajustes Bock y Zimowski Rost Jannarone Hutchinson Cuadro Modelos según la clasificación de van der Linden y Hambleton (1997). Tomada de Hontanga (1997).
. Tomada de Hontanga (1997).")
Presentaciones similares