Descargar la presentación
La descarga está en progreso. Por favor, espere

1
4. Distribuciones de Probabilidad
Probabilidad: Con una muestra aleatoria o experimento aleatorio, la probabilidad que una observación tome un valor en particular es la proporción de veces que el resultado ocurriría en una secuencia muy larga de observaciones. Generalmente corresponde a la proporción poblacional (y por lo tanto, cae entre 0 y 1) ya sea para una población real o conceptual.
 ya sea para una población real o conceptual.")
2
Reglas básicas de probabilidad
Sean A, B posibles resultados P(no A) = 1 – P(A) Para A y B, posibles resultados distintos P(A o B) = P(A) + P(B) P(A y B) = P(A)P(B dado A) Para resultados “independientes” P(B dado A) = P(B), entonces P(A y B) = P(A)P(B)
 = 1 – P(A) Para A y B, posibles resultados distintos. P(A o B) = P(A) + P(B) P(A y B) = P(A)P(B dado A) Para resultados independientes P(B dado A) = P(B), entonces. P(A y B) = P(A)P(B)")
3
Sea A = average income, B = very happy
Datos de GSS 2006 Happiness Income Very Pretty Not too Total Above Aver Average Below Aver Total Sea A = average income, B = very happy P(A) estimada por 1420/2955 = (“probabilidad marginal”), P(no A) = 1 – P(A) = 0.519 P(B dado A) estimada por 454/1420 = 0.320 (“probabilidad condicional ”) P(A y B) = P(A)P(B dado A) estimada por 0.481(0.320) = 0.154 (igual a 454/2955, “probabilidad conjunta”)
 estimada por 1420/2955 = ( probabilidad marginal ), P(no A) = 1 – P(A) = P(B dado A) estimada por 454/1420 = ( probabilidad condicional ) P(A y B) = P(A)P(B dado A) estimada por 0.481(0.320) = (igual a 454/2955, probabilidad conjunta )")
4
B1: una persona selec. aleatoriamente es “very happy”
B2: segunda persona selec. aleatoriamente es “very happy” P(B1), P(B2) estimada por 911/2955 = 0.308 P(B1 y B2) = P(B1)P(B2) estimada por (0.308)(0.308) = 0.095 Si, por otro lado, B2 se refiere a la pareja de la persona B1, B1 y B2 probablemente no son independientes y esta fórmula no es apropiada
, P(B2) estimada por 911/2955 = P(B1 y B2) = P(B1)P(B2) estimada por. (0.308)(0.308) = Si, por otro lado, B2 se refiere a la pareja de la persona B1, B1 y B2 probablemente no son independientes y esta fórmula no es apropiada.")
5
Distribución de probabilidad de una variable
Lista de los posibles resultados de una “variable aleatoria” y sus probabilidades Variable discreta: asigna probabilidades P(y) a valores individuales y, con
 a valores individuales y, con.")
6
Ejemplo Selecciona una muestra aleatoria de 3 personas y pregunta si están a favor (F) o en contra (C) de un sistema de salud público y = número a favor (0, 1, 2, ó 3) Para posibles muestras de tamaño n = 3, Muestra y Muestra y (C, C, C) (C, F, F) 2 (C, C, F) (F, C, F) 2 (C, F, C) (F, F, C) 2 (F, C, C) (F, F, F) 3
 Para posibles muestras de tamaño n = 3, Muestra y Muestra y. (C, C, C) 0 (C, F, F) 2. (C, C, F) 1 (F, C, F) 2. (C, F, C) 1 (F, F, C) 2. (F, C, C) 1 (F, F, F) 3.")
7
(Caso especial de la “distribución binomial”, en Cap. 6)
Si la población está igualmente dividida entre F y C, estas ocho muestras son igualmente posibles y la distribución de probabilidad de la variable aleatoria y (el número a favor) es y P(y) 0 1/8 1 3/8 2 3/8 3 1/8 (Caso especial de la “distribución binomial”, en Cap. 6) En la práctica, las distribuciones de probabilidad son estimadas de datos muestrales y entonces tienen una forma de distribuciones de frecuencias
 es. y P(y) 0 1/8. 1 3/8. 2 3/8. 3 1/8. (Caso especial de la distribución binomial , en Cap. 6) En la práctica, las distribuciones de probabilidad son estimadas de datos muestrales y entonces tienen una forma de distribuciones de frecuencias.")
8
Datos GSS Ejemplo: y = número de personas que conocen a alguien que se haya suicidado en los últimos 12 meses (variable “suiknew”). Distribución de probabilidad estimada es y P(y)
")
9
Media (valor esperado)
Como las distribuciones de frecuencias, distribuciones de probabilidad tienen medidas descriptivas tales como media y desviación estándar Media (valor esperado) µ = 0(0.895) + 1(0.084) + 2(0.015) + 3 (0.006) = representa un “resultado promedio de una secuencia larga” (media = moda = 0)
 µ = 0(0.895) + 1(0.084) + 2(0.015) + 3 (0.006) = 0.13 representa un resultado promedio de una secuencia larga (media = moda = 0)")
10
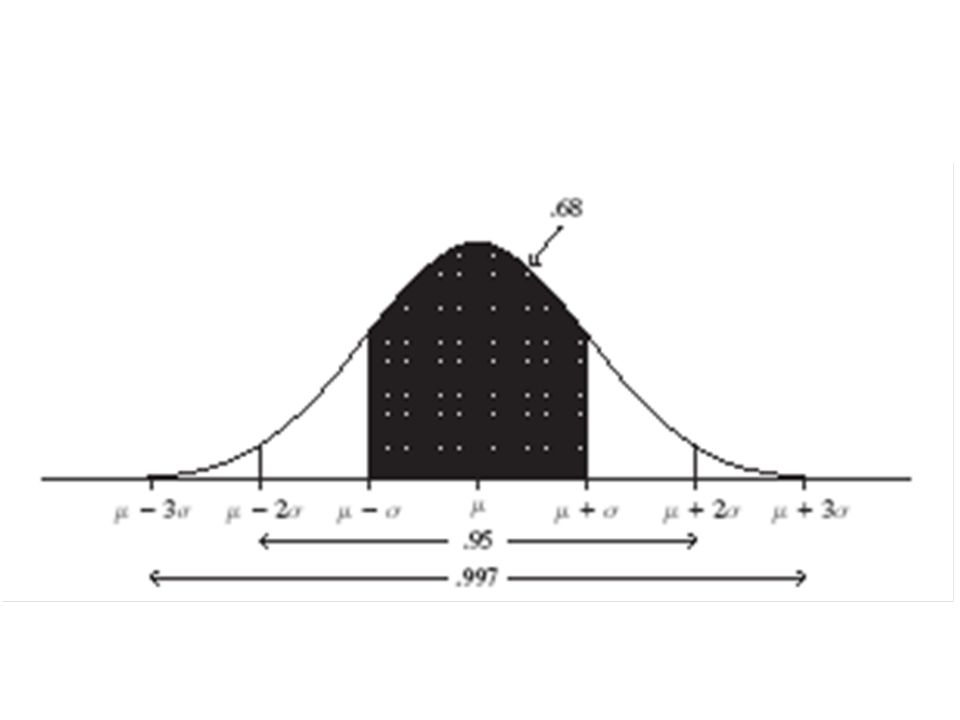
Desviación estándar Desviación estándar – medida de una distancia “típica” de un resultado de la media, denotada por (No vamos a necesitar calcular esta fórmula) Si una distribución tiene aprox. forma de campana, entonces: Toda o casi toda la distribución cae dentro del intervalo µ - 3σ y µ + 3σ Probabilidad del 0.68 cae dentro de µ - σ y µ + σ
 Si una distribución tiene aprox. forma de campana, entonces: Toda o casi toda la distribución cae dentro del intervalo µ - 3σ y µ + 3σ. Probabilidad del 0.68 cae dentro de µ - σ y µ + σ.")
11
Ejemplo De un resultado más adelante en el capítulo, si n personas son seleccionadas aleatoriamente de una población con proporción que favorece sistema de salud público (1- , se oponen), entonces y = número de personas en la muestra que está a favor, tiene una distribución de probabilidad con forma de campana con p. ej., con n = 1000, = 0.50, obtenemos µ = 500, σ = 16 Casi toda la distribución cae entre 500 – 3(16) = 452 y (16) = 548 Es decir, casi seguro entre 45% y 55% de la muestra dirá estar a favor de un sistema de salud pública
, entonces. y = número de personas en la muestra que está a favor, tiene una distribución de probabilidad con forma de campana con. p. ej., con n = 1000, = 0.50, obtenemos µ = 500, σ = 16. Casi toda la distribución cae entre. 500 – 3(16) = 452 y (16) = 548. Es decir, casi seguro entre 45% y 55% de la muestra dirá estar a favor de un sistema de salud pública.")
12
Variables continuas Variables continuas: probabilidades asignadas a intervalos de números Ejemplo: Cuano y toma muchos valores, como en el último ejemplo, se considera continua para términos prácticos. Entonces, si la distribución de probabilidad tiene aprox. forma de campana, La distribución de probabilidad más importante para variables continuas es la distribución normal

13
Distribución normal Es simétrica y con forma de campana (fórmula en Ejercicio 4.56) Se caracteriza por la media (m) y desviación estándar (s), representando el centro y la dispersión La probabilidad dentro de un número particular de desviaciones estándar de la media m es la misma para todas las distribuciones normales Una observación individual de una distribución aprox. normal tiene probabilidad 0.68 de caer a 1 desviación estándar de la media 0.95 de caer a 2 desviaciones estándar 0.997 de caer a 3 desviaciones estándar
 y desviación estándar (s), representando el centro y la dispersión. La probabilidad dentro de un número particular de desviaciones estándar de la media m es la misma para todas las distribuciones normales. Una observación individual de una distribución aprox. normal tiene probabilidad de caer a 1 desviación estándar de la media de caer a 2 desviaciones estándar de caer a 3 desviaciones estándar.")
15
Tabla A Tabla A da la probabilidad en la cola derecha arriba de µ + zσ para varios valores de z. Segundo decimal del valor de z z … ...

16
Ejemplo: ¿Cuál es la probabilidad de caer entre
µ σ y µ σ ? z = 1.50 tiene una prob. a la derecha = La prob. de la cola izq. = por simetría La prob. se las dos colas = 2(0.0668) = Prob. entre µ σ y µ σ = 1 – = 0.87 Ejemplo: z = 2.0 da Prob. de las dos colas = 2(0.0228) = 0.046 Probabilidad entre µ ± 2σ es = 0.954
 = Prob. entre µ σ y µ σ = 1 – = Ejemplo: z = 2.0 da. Prob. de las dos colas = 2(0.0228) = Probabilidad entre µ ± 2σ es =")
17
Ejemplo: ¿Qué valor-z corresponde al percentil-99
Ejemplo: ¿Qué valor-z corresponde al percentil-99? Es decir, ¿qué valor-z resulta en µ + zσ = percentil-99? Probabilidad de la cola derecha = 0.01 tiene z = 2.33 99% cae abajo de µ σ Ejemplo: Si el coeficiente intelectual (IQ) tiene µ = 100, σ = 16, entonces percentil-99% µ σ = (16) = 137 Nota: µ σ = 100 – 2.33(16) = 63 es el percentil-1% 0.98 = probabilidad que IQ caiga entre 63 y 137
 tiene µ = 100, σ = 16, entonces percentil-99% µ σ = (16) = 137. Nota: µ σ = 100 – 2.33(16) = 63 es el percentil-1% 0.98 = probabilidad que IQ caiga entre 63 y 137.")
18
Ejemplo ¿Qué valor de z hace que el intervalo µ ± zσ incluya exactamente el 95% de la curva normal? Probabilidad total en las dos colas = 0.05 Probabilidad en la cola derecha = 0.05/2 = 0.025 z = 1.96 µ ± 1.96σ contiene probabilidad 0.950 (µ ± 2σ contiene probabilidad 0.954) Ejercicio: Intenta para 99%, 90% (debes obtener 2.58, 1.64)
 Ejercicio: Intenta para 99%, 90% (debes obtener 2.58, 1.64)")
19
Ejemplo Minessota Multiphasic Personality Inventory (MMPI), basado en respuestas de 500 preguntas de verdadero/falso, provee calif. para varias escalas (p.ej., depresión, ansiedad, abuso de sustancias), con µ = 50, σ = 10. Si la distribución es normal y una calificación ≥ 65 es considerada muy alta, qué porcentaje es éste? z = ( )/10 = 1.50 Prob. de la cola derecha = (menos que 7%)
, basado en respuestas de 500 preguntas de verdadero/falso, provee calif. para varias escalas (p.ej., depresión, ansiedad, abuso de sustancias), con µ = 50, σ = 10. Si la distribución es normal y una calificación ≥ 65 es considerada muy alta, qué porcentaje es éste z = ( )/10 = Prob. de la cola derecha = (menos que 7%)")
20
Notas de valores-z Valor-z representa el número de desviaciones estándar que un valor está de la media de la distribución Un valor y está z = (y - µ)/σ desviaciones estándar de µ Ejemplo: y = 65, µ = 50, σ = 10 z = (y - µ)/σ = (65 – 50)/10 = 1.5 El valor-z es negativo cuando y está por debajo de µ (p.ej., y = 35 tiene z = -1.5)
/σ desviaciones estándar de µ. Ejemplo: y = 65, µ = 50, σ = 10. z = (y - µ)/σ = (65 – 50)/10 = 1.5. El valor-z es negativo cuando y está por debajo de µ (p.ej., y = 35 tiene z = -1.5)")
21
Distribución normal La distribución normal estándar es una distribución normal con µ = 0 y σ = 1 Por la distribución, z = (y - )/ = (y - 0)/1 = y Es decir, valor original = valor-z; µ + zσ = 0 + z(1) = z (usamos la normal estándar para inferencia estadístca empezando en Cap. 6, donde ciertas estadísticas son convertidas para tener una distribución normal estándar) Por qué es la distribución normal importante? Hoy aprenderemos que si estudios diferentes toman muestras aleatorias y calculan estadísticas (p.ej., media muestral) para estimar un parámetro (p.ej., media poblacional), la colección de los valores de las estadísticas de estos estudios usualmente tienen aprox. una distribución normal. (Y?)
/ = (y - 0)/1 = y. Es decir, valor original = valor-z; µ + zσ = 0 + z(1) = z. (usamos la normal estándar para inferencia estadístca empezando en Cap. 6, donde ciertas estadísticas son convertidas para tener una distribución normal estándar) Por qué es la distribución normal importante Hoy aprenderemos que si estudios diferentes toman muestras aleatorias y calculan estadísticas (p.ej., media muestral) para estimar un parámetro (p.ej., media poblacional), la colección de los valores de las estadísticas de estos estudios usualmente tienen aprox. una distribución normal. (Y )")
22
Distribución muestral
Una distribución muestral lista los posibles valores de la estadística (p.ej., media muestral y proporción muestral) y sus probabilidades Ejemplo: y = 1 si a favor del sistema público de salud y = 0 si se opone Para posibles muestras de tamaño n = 3, considera la media muestral Muestra Media Muestra Media (1, 1, 1) (1, 0, 0 ) 1/3 (1, 1, 0) / (0, 1, 0) 1/3 (1, 0, 1) / (0, 0, 1) 1/3 (0, 1, 1) / (0, 0, 0)
 y sus probabilidades. Ejemplo: y = 1 si a favor del sistema público de salud. y = 0 si se opone. Para posibles muestras de tamaño n = 3, considera la media muestral. Muestra Media Muestra Media. (1, 1, 1) 1.0 (1, 0, 0 ) 1/3. (1, 1, 0) 2/3 (0, 1, 0) 1/3. (1, 0, 1) 2/3 (0, 0, 1) 1/3. (0, 1, 1) 2/3 (0, 0, 0) 0.")
23
Para datos binarios (0, 1), media muestral es igual a proporción muestral de casos “1”. Para la población es la proporción poblacional de casos “1” (p.ej., a favor del sistema de salud pública) ¿Qué tan cerca está la media muestral de la media poblacional µ? Para responder esto, debemos poder responder, “¿Cuál es la distribución de probabilidad de la media muestral?”
 ¿Qué tan cerca está la media muestral de la media poblacional µ Para responder esto, debemos poder responder, ¿Cuál es la distribución de probabilidad de la media muestral")
24
Distribución muestral
Distribución muestral de una estadística es la distibución de probabilidad para los posibles valores de la estadística Ejemplo. Asume P(0) = P(1) = ½. Para una variable aleatoria de tamaño n = 3, cada uno de las 8 possible muestras son igualmente probables. La distribución muestral de la proporción muestral es Proporción muestral Probabilidad /8 1/ /8 2/ /8 / (Intenta para n = 4)
 = P(1) = ½. Para una variable aleatoria de tamaño n = 3, cada uno de las 8 possible muestras son igualmente probables. La distribución muestral de la proporción muestral es. Proporción muestral Probabilidad. 0 1/8. 1/3 3/8. 2/3 3/8. 1 1/8 (Intenta para n = 4)")
25
Distribución muestral de la media muestral
es una variable, sus valores varian de muestra a muestra alrededor de la media poblacional µ La desviación estándar de la distribución muestral de se llama error estándar de Para el muetreo aleatorio, la distribución muestral de tiene una media µ y error estándar

26
Ejemplo Para datos binarios (y =1 ó 0) con P(Y=1) = (con 0 < < 1), se puede mostrar que (Ej b, y caso especial de la fórmula anterior en p.11 de estas notas con n = 1) Cuando = 0.50, = 0.50, y el error estándar es n error estándar .289
 con P(Y=1) = (con 0 < < 1), se puede mostrar que (Ej. 4.55b, y caso especial de la fórmula anterior en p.11 de estas notas con n = 1) Cuando = 0.50, = 0.50, y el error estándar es. n error estándar")
27
Nota el error estándar decrece a medida que n crece (es decir, tiende a caer más cerca de µ)
Con n = 1000, error estándar = 0.016, así que si la distribución muestral tiene forma de campana, con una alta probabilidad, la proporción cae a 3(0.016) = de la proporción poblacional de 0.50 (es decir, entre and 0.55) Ejemplo: Número de veces y = 1 (es decir, número de personas a favor) es 1000×(proporción), así que la variable que “cuenta” el número de personas tiene media = 1000(0.50) = 500 y desv. est. 1000(0.016) = 16 (como en un ejemplo anterior en p. 11)
 = 0.05 de la proporción poblacional de 0.50 (es decir, entre 0.45 and 0.55) Ejemplo: Número de veces y = 1 (es decir, número de personas a favor) es 1000×(proporción), así que la variable que cuenta el número de personas tiene media = 1000(0.50) = 500 y desv. est. 1000(0.016) = 16 (como en un ejemplo anterior en p. 11)")
28
Consecuencia práctica: Este capítulo presenta resultados teóricos acerca de la dispersión (y forma) de las distribuciones muestrales, pero esto implica cómo, en la práctica, los diferentes estudios en el mismo tema pueden variar de estudio a estudio (y, por lo tanto, qué tan preciso cada estudio tiende a ser) Ejemplo: Tú planeas una muestra de 200 personas para estimar la proporción poblacional que está a favor de un sistema de salud público. Otros pueden estar haciendo lo mismo. Cómo variarán los resultados entre los estudios (y qué tan precisos son sus resultados)? La distribución muestral de la proporción muestral a favor del sistema de salud público tiene un error estándar que describe la variabilidad de estudio a estudio.
 La distribución muestral de la proporción muestral a favor del sistema de salud público tiene un error estándar que describe la variabilidad de estudio a estudio.")
29
Ejemplo Muchos estudiantes toman una muestra de n = 200 para estimar proporción poblacional Lanzar una moneda 200 veces simula el proceso cuando la proporción poblacional = 0.50. En teoría, hemos visto que la proporción muestral varía de estudio a estudio (es decir, de estudiante a estudiante) alrededor de 0.50 con un error estándar de 0.035 Evidencia empírica: Tomé los datos que ustedes generaron y calculé que el conjunto de todas las proporciones muestrales (0.515 = 103/200, = 94/200, etc.) tiene una media de y una desviación estándar de (OK, hice trampa y borré un outlier de 0.67) Forma? Parecida a forma de campana. Por qué?
 alrededor de 0.50 con un error estándar de Evidencia empírica: Tomé los datos que ustedes generaron y calculé que el conjunto de todas las proporciones muestrales (0.515 = 103/200, = 94/200, etc.) tiene una media de y una desviación estándar de (OK, hice trampa y borré un outlier de 0.67) Forma Parecida a forma de campana. Por qué")
30
Teorema Central del Límite
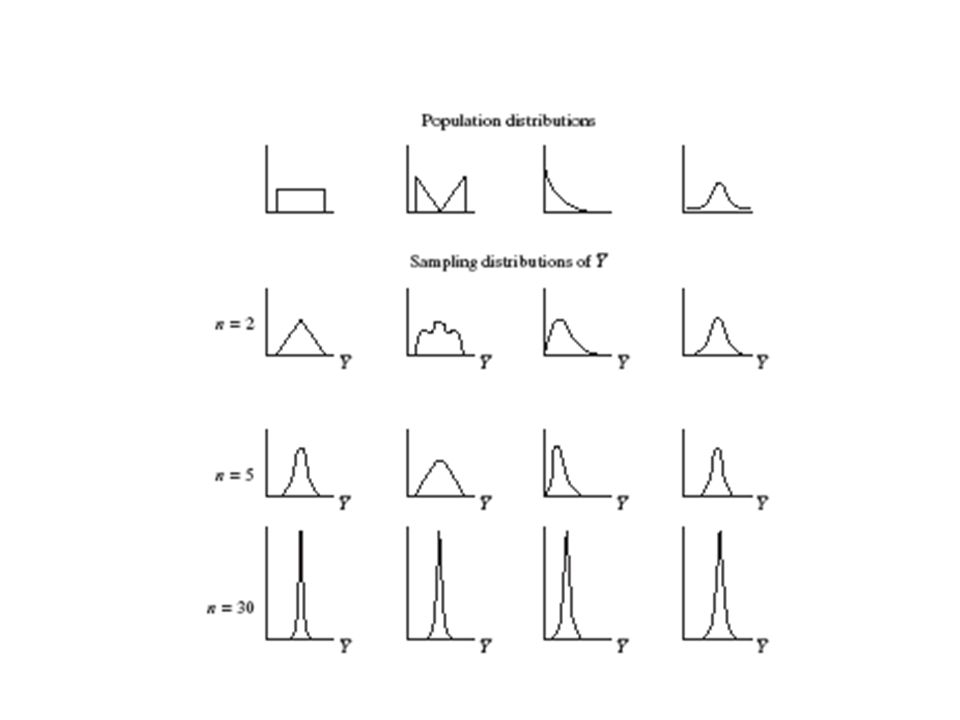
Teorema Central del Límite: Para muestreo aleatorio con n “grande”, la distribución muestral de la media muestral tiene aprox. una distribución normal Es aprox. normal sin importar la forma de la distribución poblacional Qué tan “grande” debe de ser n depende de qué tan asimétrica sea la distribución poblacional, pero usualmente n ≥ 30 es suficiente Puede verificarse empíricamente, haciendo simulaciones con el applet de “sampling distribution” en

32
Ejemplo Muestra aleatoria de 100 estudiantes seleccionados para estimar la proporción que han participado en actividad A. Encuentra la probabilidad de la proporción muestral caiga entre 0.04 de la proporción poblacional, si la proporción poblacional = 0.30 (es decir, entre 0.26 y 0.34) y = 1, sí y = 0, no µ = = 0.30 Por el TCL, distribución muestral de la media muestral (la proporción de “sí”) es aprox. normal con media = 0.30, error estándar =
 y = 1, sí y = 0, no. µ = = Por el TCL, distribución muestral de la media muestral (la proporción de sí ) es aprox. normal con. media = 0.30, error estándar =")
33
0.26 tiene valor-z = ( )/ = -0.87 0.34 tiene valor-z = ( )/ = 0.87 P(media muestral ≥ 0.34) = 0.19 P(media muestral ≤ 0.26) = 0.19 P(0.26 ≤ media muestral ≤ 0.34) = 1 – 2(0.19) = 0.62 La probabilidad es 0.62 que la proporción muestral caiga a 0.04 de la proporción poblacional
 = P(media muestral ≤ 0.26) = P(0.26 ≤ media muestral ≤ 0.34) = 1 – 2(0.19) = La probabilidad es 0.62 que la proporción muestral caiga a 0.04 de la proporción poblacional.")
34
Ejemplo Lanzamiento de monedas, n = 200 por estudiante
Si la probabilidad de águila = 0.50, entonces la proporción muestral de águilas en 200 lanzamientos varía de estudiante a estudiante de acuerdo a una distribución normal con media = 0.50, y error estándar (¿cómo?) Sería inusual que la proporción de águilas estuviera por debajo de 0.40 o por arriba de (por qué?) Cómo cambiaría el intervalo de valores factibles (0.40, 0.60) a medida que n crece? (p.ej., n = en una encuesta)
 Sería inusual que la proporción de águilas estuviera por debajo de 0.40 o por arriba de 0.60 (por qué ) Cómo cambiaría el intervalo de valores factibles (0.40, 0.60) a medida que n crece (p.ej., n = 1000 en una encuesta)")
35
No se dejen “engañar por aleatoriedad”
Hemos visto que algunas cosas son muy predecibles (es decir, qué tan cerca la media muestral cae de la media poblacional, para una n determinada) Pero, en el corto plazo, aleatoriedad no es “regular” como uno esperaría (Por lo general, yo puede predecir quién “falsificó” los lanzamientos de monedas En 200 lanzamientos de una moneda balanceada, P(la secuencia más larga de Caras consecutivas < 5) = 0.04 La distribución de probabilidad de Caras consecutivas tiene µ = 7 Implicaciones: deportes (ganar/perder, éxito/fracaso individual), mercado de acciones sube o baja día con día, …
 Pero, en el corto plazo, aleatoriedad no es regular como uno esperaría (Por lo general, yo puede predecir quién falsificó los lanzamientos de monedas. En 200 lanzamientos de una moneda balanceada, P(la secuencia más larga de Caras consecutivas < 5) = La distribución de probabilidad de Caras consecutivas tiene µ = 7. Implicaciones: deportes (ganar/perder, éxito/fracaso individual), mercado de acciones sube o baja día con día, …")
36
Algunos comentarios Consecuencia del TCL: Cuando el valor de una variable es resultado de promediar muchas influencias individuales, ninguna domina, la distribución es aprox. normal (p.ej., coef. intelectual, presión arterial) En la práctica, no conocemos µ, pero podemos usar la dispersión de la distribución muestral como base para la inferencia de parámetros desconocimos (veremos cómo en los próximos dos capítulos) Ahora podemos discutir tres tipos de distribuciones:
 En la práctica, no conocemos µ, pero podemos usar la dispersión de la distribución muestral como base para la inferencia de parámetros desconocimos. (veremos cómo en los próximos dos capítulos) Ahora podemos discutir tres tipos de distribuciones:")
37
(gráfico mostrando diferencias)
Distribución de la población – descrita por parámetros tales como µ, σ (generalmente desconocidos) Distribución de la muestra – descrita por estadísticas de la muestra tales como media muestral , desviación estándar s Distribución muestral de una estadística – distribuciones de la probabilidad de los posibles valores de la estadística muestral; determina la probabilidad que una estadística caiga dentro a cierta distancia del parámetro poblacional (gráfico mostrando diferencias)
 Distribución de la muestra – descrita por estadísticas de la muestra tales como. media muestral , desviación estándar s. Distribución muestral de una estadística – distribuciones de la probabilidad de los posibles valores de la estadística muestral; determina la probabilidad que una estadística caiga dentro a cierta distancia del parámetro poblacional. (gráfico mostrando diferencias)")
38
Ejemplo (categórica): Encuesta sobre sistema de salud
Estadística = proporción muestral que está a favor del plan de sistema de salud propuesto Cuál es (1) la distribución poblacional, (2) distribución de la muestra, (3) distribución muestral? Ejemplo (cuantitativa): Experimento sobre el impacto de uso de celular en tiempos de reacción Estadística =media muestral del tiempo de reacción Cuál es (1) la distribución poblacional, (2) distribución de la muestra, (3) distribución muestral?
 la distribución poblacional, (2) distribución de la muestra, (3) distribución muestral Ejemplo (cuantitativa): Experimento sobre el impacto de uso de celular en tiempos de reacción. Estadística =media muestral del tiempo de reacción. Cuál es (1) la distribución poblacional, (2) distribución de la muestra, (3) distribución muestral")
39
Por el Teorema Central del Límite (opción múltiple)
Todas las variables tienen aprox. distribuciones muestrales normales si una muestra aleatoria tiene al menos 30 observaciones Distribuciones poblacionales son normales cuando el tamaño de la población es grande (al menos 30 observ.) Para muestras grandes, la distribución muestral de la media muestral es aprox. normal, sin tomar en cuenta la forma de la distribución poblacional La distribución muestral se parece más a la distribución poblacional si el tamaño de muestra aumenta Todas las opciones anteriores
 Para muestras grandes, la distribución muestral de la media muestral es aprox. normal, sin tomar en cuenta la forma de la distribución poblacional. La distribución muestral se parece más a la distribución poblacional si el tamaño de muestra aumenta. Todas las opciones anteriores.")
Presentaciones similares