Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Bases Genética Molecular http://biologia. ucr. ac

2
Composición ADN Compuesto de 4 moléculas básicas: nucleótidos
Idénticas excepto en la base nitrogenada Cada nucleótido: grupo fosfato, azúcar desoxiribosa, 1 de 4 bases Bases: Adenina, Guanina, Citosina, Timina

3
Purinas y Pirimidinas Adenina y Guanina: Purinas
Citosina y Timina: Pirimidinas

4
Estructura del ADN %A = %T and %G = %C
Watson y Crick la descifraron en 1953 Basados en hallazgos de otras personas: Cristalografía de rayos X de Rosalind Franklin y Maurice Wilkins Datos de Chargaff %A = %T and %G = %C % Purina = % Pirimidina (A + G = C + T) antes de conocer estructura de doble hélice En humanos: A = 30.9% C = 19.8% T = 29.4% G = 19.9%
 antes de conocer estructura de doble hélice. En humanos: A = 30.9% C = 19.8% T = 29.4% G = 19.9%")
6
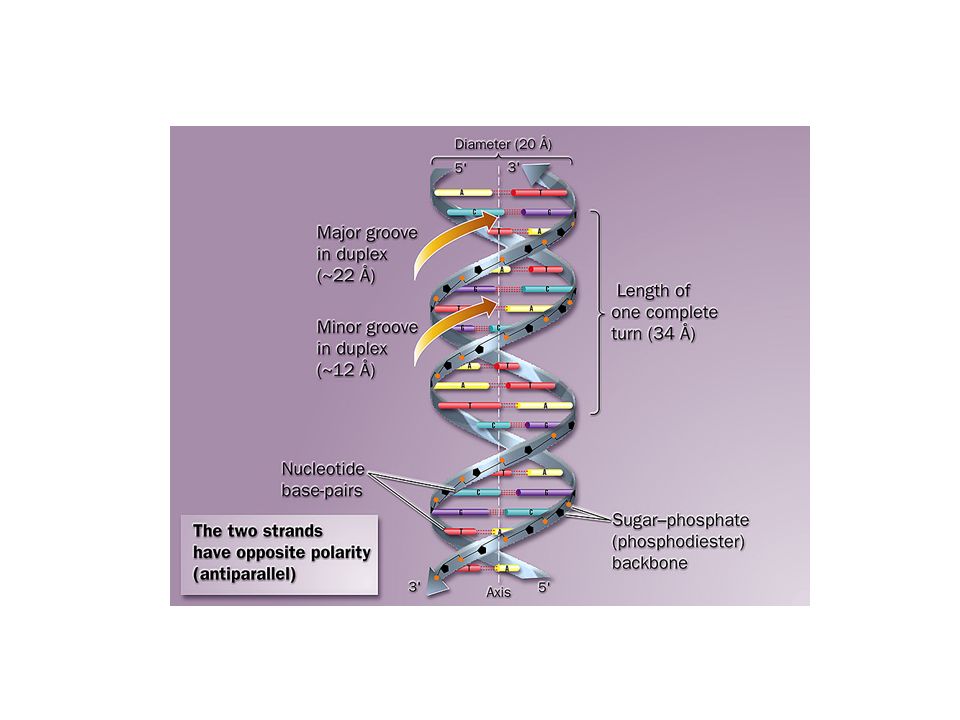
Doble hélice Enlace de Hidrógeno
Clave: poner azúcar y grupo fosfato en cadena lateral y las bases nitrogenadas hacia adentro Sólo unión purina-pirimidina podía explicar diámetro observado con rayos X Bases complementarias A-T G-C

7
Polaridad del ADN

8
Unión de las bases en el ADN
G C A T

9
Reconocimiento Premio Nobel 1962: Watson, Crick y Wilkins
Libro: „La doble hélice“ de James Watson James Watson y Francis Crick Maurice Wilkins Rosalind Franklin

10
Replicación Artículo en Nature: “No ha escapado a nuestra atención que el emparejamiento específico que hemos postulado sugiere de inmediato la posibilidad de un mecanismo de copia para el material genético“

11
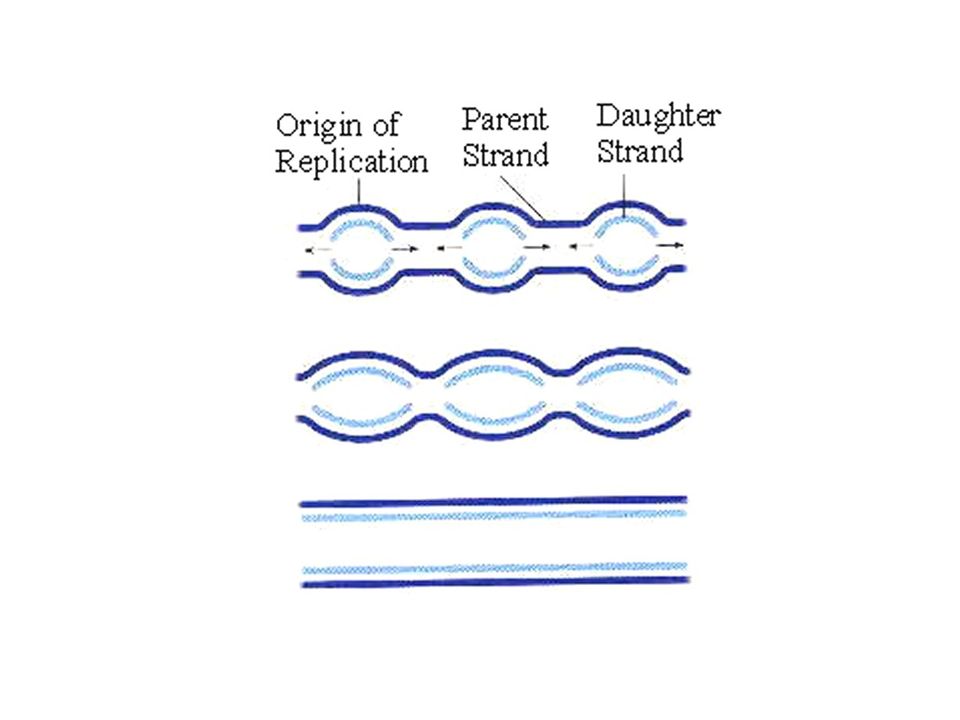
Replicación es semiconservativa

12
Replicación ADN polimerasa no puede iniciar síntesis de novo
Necesita cebador de ADN o ARN (sintetizado por primasa) Síntesis de nueva cadena: 5‘-3‘
 Síntesis de nueva cadena: 5‘-3‘")
13
Se agregan dNTPs al extremo 3’ de la cadena.
5’PPP 3’OH 3’ OH 5’ 3’ 5’ PP Choice of dNTPs: G-C ; A-T

14
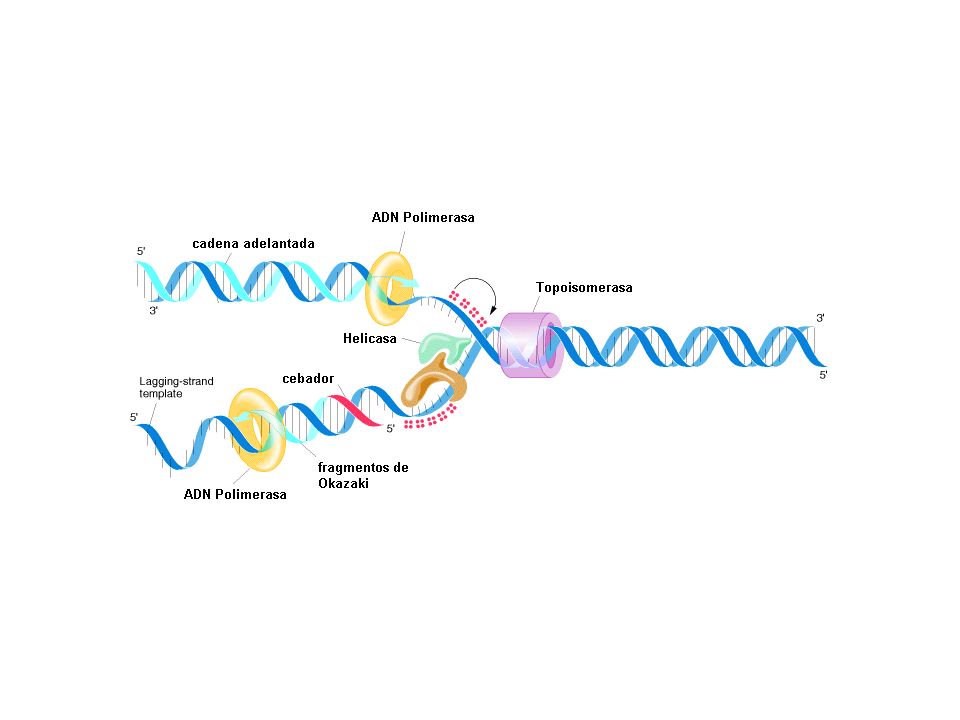
Horquilla de replicación
Fragmentos de Okasaki

16
Orígenes de Replicación
Replicación de ADN inicia en orígenes de replicación en procariotas y eucariotas Eucariotas hay múltiples orígenes: unos en el genoma humano Cada origen genera dos horquillas de replicación (que se mueven en direcciones opuestas)
")
18
Proofreading: función de corrección de las polimerasas
Algunas polimerasas (no todas) corrigen errores Cuando se detecta error en ADN recién sintetizado la polimerasa se devuelve un pb en dirección 3‘-5‘ La actividad exonucleasa de la enzima permite eliminar la base incorrecta Seguidamente la polimerasa reinserta la base correcta
 corrigen errores. Cuando se detecta error en ADN recién sintetizado la polimerasa se devuelve un pb en dirección 3‘-5‘ La actividad exonucleasa de la enzima permite eliminar la base incorrecta. Seguidamente la polimerasa reinserta la base correcta.")
19
Polimerasas en eucariotas y procariotas
5 en procariotas Por lo menos 15 en eucariotas

20
ADN polimerasas procariotas
Eliminar cebadores

21
ADN polimerasas eucariotas
(III) (II) Enzyme Location function Nuclear priming of both strands Nuclear elongation of both strands Nuclear repair & replication Nuclear repair Mitochondrial replication 3’-5’ exonuc. No Yes Yes No Yes relative activity 80% 10-15% 2-15% PRIMASE REPLICASE
 (II) Enzyme. Location. function. Nuclear. priming. of both. strands. Nuclear. elongation of both strands. Nuclear. repair & replication. Nuclear. repair. Mitochondrial. replication. 3’-5’ exonuc. No. Yes. Yes. No. Yes. relative activity. 80% 10-15% 2-15% PRIMASE. REPLICASE.")
22
Proofreading reduce drásticamente la cantidad de errores en la replicación
Enzyme Synthetic domain Proofreading domain Error rate - proof proof. DNA pol I aa N-terminal 10-5 5 x10-7 DNA pol III subunit subunit 7 x10-6 5 x10-9 T4 DNA pol C-terminal N-terminal 5 x10-5 10-7 Rev. transcrip. none 10-5

23
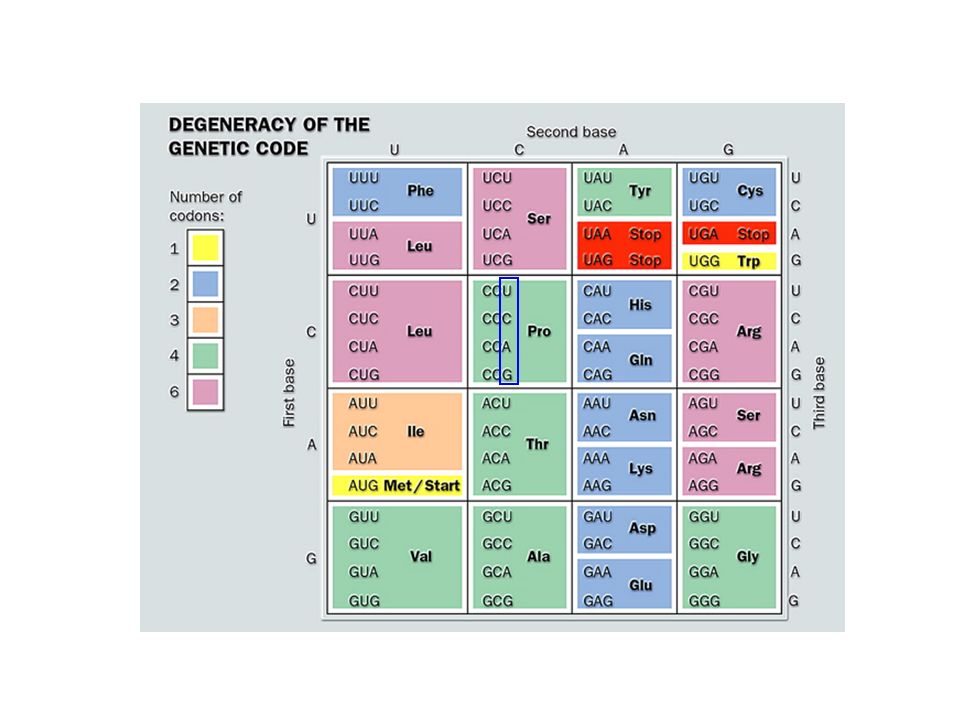
Código Genético En cuanto se determinó la estructura del ADN fue aparente que la estructura de las proteínas debe estar codificada en la secuencia de nucleótidos del ADN 20 aminoácidos codificados por los codones compuestos por combinaciones de 4 nucleótidos Posibilidades: Codón de 1 nucleótido: 4 posibles aminoácidos Codón de 2 nucleótidos: 16 posibles aminoácidos Codón de 3 nucleótidos: 64 posibles aminoácidos

24
Código Genético 2 El codón debe tener por lo menos 3 nucleótidos
En 1961 Francis Crick, Sidney Brenner y colaboradores demostraron experimentalmente que los codones consisten de tres nucleótidos Exceso de codones en relación con el número de aminoácidos El código es degenerado (redundante) : algunos aminoácidos están especificados por más de un codón Ej: ATT ATG Metionina ATC ATA Isoleucina
 : algunos aminoácidos están especificados por más de un codón. Ej: ATT ATG Metionina. ATC. ATA. Isoleucina.")
26
Código es universal Transferencia de información y codificación son prácticamente iguales en todos los organismos Excepción: ADN mitocondrial Algunos protozoarios El aparato de traducción es el mismo en un amplio rango de organismos (facilita técnicas de ADN recombinante)
")
27
Estructura base de aminoácidos
Secuencia de proteína va dirección amino-carboxilo

28
Aminoácidos

29
ARN Simple banda 3 de las bases son las mismas
En lugar de timina, tiene uracilo Azúcar es ribosa ARNm, ARNt, ARNr

30
Transcripción/Traducción

31
Dogma Central

32
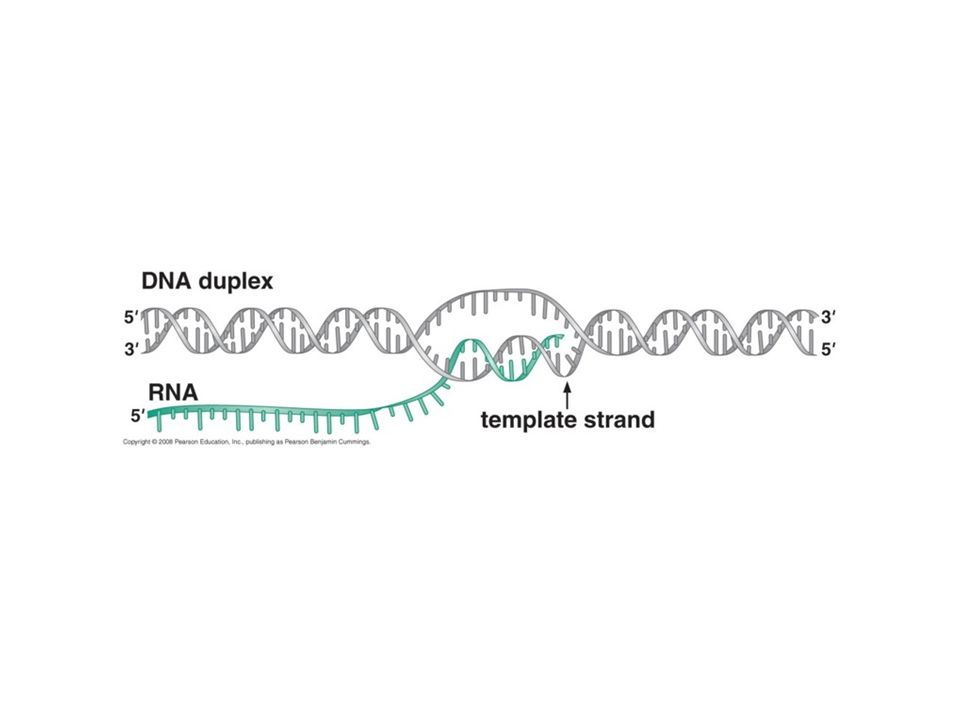
Templete, No-templete Secuencia templete de ADN va de 3’ a 5’
ARNm es complementario a secuencia templete Secuencia ARNm determina los aa (código genético) Secuencia ARNm corresponde a la secuencia no-templete Por convención se reporta en la literatura la secuencia no-templete de ADN (5’ a 3’) por ser la que corresponde al ARNm y por lo tanto a los aa
 Secuencia ARNm corresponde a la secuencia no-templete. Por convención se reporta en la literatura la secuencia no-templete de ADN (5’ a 3’) por ser la que corresponde al ARNm y por lo tanto a los aa.")
33
De ADN a Proteína AUG AAC CUG AAC CGG CUU GAC
3‘ TAC TTG GAC TTG GCC GAA CTG 5‘ ADN AUG AAC CUG AAC CGG CUU GAC ARNm Met Asp Leu Asn Arg Leu Asp Proteína Inserción AUG AAG CCU GAA CCG GCU UGA ARNm Met Lys Pro Glu Pro Ala Stop Proteína

34
Transcripción

36
Transcripción

37
Transcripción en procariotas y eucariotas
Procariotas Eucariotas Genes agrupados en operones Genes no agrupados en operones ARNm pueden ser policistrónicos ARNm monocistrónicos Transcripción y traducción están Transcripción y traducción no acopladas acopladas

38
Policistrónico/monocistrónico

39
ARNm humano típico * *

40
Pasos de gen a proteína Figure Summary of the steps leading from gene to protein in eucaryotes and bacteria. The final level of a protein in the cell depends on the efficiency of each step and on the rates of degradation of the RNA and protein molecules. (A) In eucaryotic cells the RNA molecule produced by transcription alone (sometimes referred to as the primary transcript) would contain both coding (exon) and noncoding (intron) sequences. Before it can be translated into protein, the two ends of the RNA are modified, the introns are removed by an enzymatically catalyzed RNA splicing reaction, and the resulting mRNA is transported from the nucleus to the cytoplasm. Although these steps are depicted as occurring one at a time, in a sequence, in reality they are coupled and different steps can occur simultaneously. For example, the RNA cap is added and splicing typically begins before transcription has been completed. Because of this coupling, complete primary RNA transcripts do not typically exist in the cell. (B) In procaryotes the production of mRNA molecules is much simpler. The 5 end of an mRNA molecule is produced by the initiation of transcription by RNA polymerase, and the 3 end is produced by the termination of transcription. Since procaryotic cells lack a nucleus, transcription and translation take place in a common compartment. In fact, translation of a bacterial mRNA often begins before its synthesis has been completed . 真核生物やバクテリアの遺伝子から蛋白への過程の要約 細胞内の蛋白の最終的なレベルは各段階の効率とRNAや蛋白の分解割合に依存している。(A)真核細胞では転写のみで作られるRNA分子は(時に、primary RNA, (第一次RNA)とよばれる)coding(アミノ酸になるコード(exon、エクソン)とnoncoding(アミノ酸のコードをもたない(intron,イントロン)の配列を含んでいる。蛋白に翻訳(translation)される前はこのRNAの両端は修飾され、イントロンは酵素的に触媒されたRNA-splicing(切断)反応により除去される。結果として出来たRNAは核から細胞質へ移動する。これらの段階は連なって一時に一つ起きるように描かれているが、実際はそれらは組み合わされ異なる段階が同時的に起きることができる。
 In eucaryotic cells the RNA molecule produced by transcription alone (sometimes referred to as the primary transcript) would contain both coding (exon) and noncoding (intron) sequences. Before it can be translated into protein, the two ends of the RNA are modified, the introns are removed by an enzymatically catalyzed RNA splicing reaction, and the resulting mRNA is transported from the nucleus to the cytoplasm. Although these steps are depicted as occurring one at a time, in a sequence, in reality they are coupled and different steps can occur simultaneously. For example, the RNA cap is added and splicing typically begins before transcription has been completed. Because of this coupling, complete primary RNA transcripts do not typically exist in the cell. (B) In procaryotes the production of mRNA molecules is much simpler. The 5 end of an mRNA molecule is produced by the initiation of transcription by RNA polymerase, and the 3 end is produced by the termination of transcription. Since procaryotic cells lack a nucleus, transcription and translation take place in a common compartment. In fact, translation of a bacterial mRNA often begins before its synthesis has been completed . 真核生物やバクテリアの遺伝子から蛋白への過程の要約. 細胞内の蛋白の最終的なレベルは各段階の効率とRNAや蛋白の分解割合に依存している。(A)真核細胞では転写のみで作られるRNA分子は(時に、primary RNA, (第一次RNA)とよばれる)coding(アミノ酸になるコード(exon、エクソン)とnoncoding(アミノ酸のコードをもたない(intron,イントロン)の配列を含んでいる。蛋白に翻訳(translation)される前はこのRNAの両端は修飾され、イントロンは酵素的に触媒されたRNA-splicing(切断)反応により除去される。結果として出来たRNAは核から細胞質へ移動する。これらの段階は連なって一時に一つ起きるように描かれているが、実際はそれらは組み合わされ異なる段階が同時的に起きることができる。")
41
ARN polimerasas Procariotas: sólo una Eucariotas tienen 3: I, II y III
Tipo II transcribe genes nucleares que codifican para proteínas Tipo I transcribe ARNr Tipo III para ARNt

42
Similitud ARN polimerasas
Figure The common origin of bacterial and eucaryotic RNA polymerases. Amino acid sequence similarities between the b' subunit of E. coliRNA polymerase and the largest subunit of eucaryotic RNA polymerase II are among the comparisons that reveal a common evolutionary origin for the bacterial and eucaryotic enzymes. The b' subunit is thought to bind to DNA. The regions of the sequence shown as green bars are more than 70% identical between yeast and Drosophila and more than 40% identical between Drosophila and E. coli. A uniquely eucaryotic sequence (of seven amino acid residues) is repeated 26 times at the carboxyl terminus of the yeast subunit and more than 40 times in the Drosophila subunit (indicated here by green circles); these repeats are phosphorylated as part of the process that starts an RNA chain in eucaryotes (see Figure9-30). (After A.L. Greenleaf et al., in RNA Polymerase and the Regulation of Transcription [W.S. Reznikoff et al., eds.], pp New York: Elsevier, 1987.) Origen evolutivo común
 is repeated 26 times at the carboxyl terminus of the yeast subunit and more than 40 times in the Drosophila subunit (indicated here by green circles); these repeats are phosphorylated as part of the process that starts an RNA chain in eucaryotes (see Figure9-30). (After A.L. Greenleaf et al., in RNA Polymerase and the Regulation of Transcription [W.S. Reznikoff et al., eds.], pp New York: Elsevier, 1987.) Origen evolutivo común.")
43
Promotor procariotas/eucariotas

44
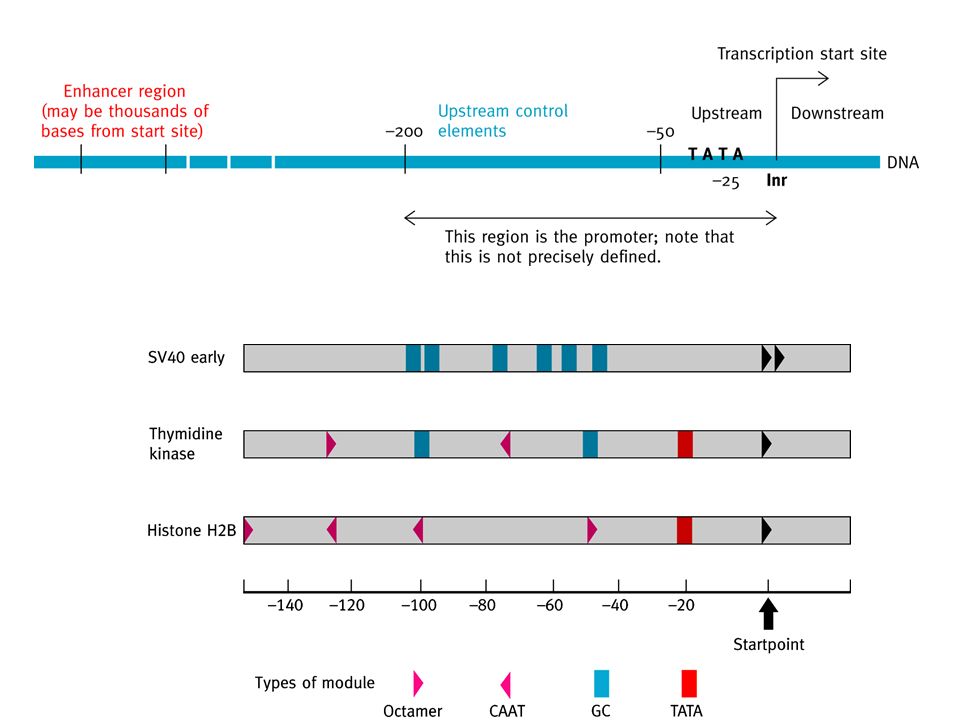
Promotores eucarióticos tipo II
Elementos basales: secuencia corta de pirimidinas (iniciador) y la caja TATA, posición alrededor de –25. Elementos de control corriente arriba entre –50 y –200. Incluyen caja CAAT y caja GC. Todos genes requieren por lo menos uno, pero no hay patrón común
 y la caja TATA, posición alrededor de –25. Elementos de control corriente arriba entre –50 y –200. Incluyen caja CAAT y caja GC. Todos genes requieren por lo menos uno, pero no hay patrón común.")
46
Pasos generales de transcripción

47
Principio y fin de transcripción en E.coli
Figure 6-4. Start and stop signals for RNA synthesis by a bacterial RNA polymerase. Here, the lower strand of DNA is the template strand, whereas the upper strand corresponds in sequence to the RNA that is made (note the substitution of U in RNA for T in DNA). (A) The polymerase begins transcribing at the start site. Two short sequences (shaded red), about -35 and -10 nucleotides from the start, determine where the polymerase binds; close relatives of these two hexanucleotide sequences, properly spaced from each other, specify the promoter for most E. coli genes. (B) A stop (termination) signal. The E. coliRNA polymerase stops when it synthesizes a run of U residues (shaded blue) from a complementary run of A residues on the template strand, provided that it has just synthesized a self-complementary RNA nucleotide sequence (shaded green), which rapidly forms a hairpin helix that is crucial for stopping transcription. The sequence of nucleotides in the self-complementary region can vary widely. Pribnow box:AT-rich region, about 7 bp long, central to prokaryotic promoters at about position –10 from the initiation site. Palindrome sequence: nucleotide sequence that is identical to its complementary strand when each is read in ths same (5-3) chemical direction aagctt ttcgaa UUUU Después de secuencia de ARN autocomplementaria que forma horquilla
. (A) The polymerase begins transcribing at the start site. Two short sequences (shaded red), about -35 and -10 nucleotides from the start, determine where the polymerase binds; close relatives of these two hexanucleotide sequences, properly spaced from each other, specify the promoter for most E. coli genes. (B) A stop (termination) signal. The E. coliRNA polymerase stops when it synthesizes a run of U residues (shaded blue) from a complementary run of A residues on the template strand, provided that it has just synthesized a self-complementary RNA nucleotide sequence (shaded green), which rapidly forms a hairpin helix that is crucial for stopping transcription. The sequence of nucleotides in the self-complementary region can vary widely. Pribnow box:AT-rich region, about 7 bp long, central to prokaryotic promoters at about position –10 from the initiation site. Palindrome sequence: nucleotide sequence that is identical to its complementary strand when each is read in ths same (5-3) chemical direction. aagctt. ttcgaa. UUUU. Después de secuencia de ARN autocomplementaria que forma horquilla.")
48
Concepto de fábrica de ARN para ARN polimerasa II de eucariotas
-Factores de “capping” Factores de “splicing” (no todas las enzimas pero inician proceso) Factores de poliadenilación Figure The "RNA factory" concept for eucaryotic RNA polymerase II. Not only does the polymerase transcribe DNA into RNA, but it also carries pre-mRNA-processing proteins on its tail, which are then transferred to the nascent RNA at the appropriate time. There are many RNA-processing enzymes, and not all travel with the polymerase. For RNA splicing, for example, only a few critical components are carried on the tail; once transferred to an RNA molecule, they serve as a nucleation site for the remaining components. The RNA-processing proteins first bind to the RNA polymerase tail when it is phosphorylated late in the process of transcription initiation (see Figure 6-16). Once RNA polymerase II finishes transcribing, it is released from DNA, the phosphates on its tail are removed by soluble phosphatases, and it can reinitiate transcription. Only this dephosphorylated form of RNA polymerase II is competent to start RNA synthesis at a promoter.
 Factores de poliadenilación. Figure The RNA factory concept for eucaryotic RNA polymerase II. Not only does the polymerase transcribe DNA into RNA, but it also carries pre-mRNA-processing proteins on its tail, which are then transferred to the nascent RNA at the appropriate time. There are many RNA-processing enzymes, and not all travel with the polymerase. For RNA splicing, for example, only a few critical components are carried on the tail; once transferred to an RNA molecule, they serve as a nucleation site for the remaining components. The RNA-processing proteins first bind to the RNA polymerase tail when it is phosphorylated late in the process of transcription initiation (see Figure 6-16). Once RNA polymerase II finishes transcribing, it is released from DNA, the phosphates on its tail are removed by soluble phosphatases, and it can reinitiate transcription. Only this dephosphorylated form of RNA polymerase II is competent to start RNA synthesis at a promoter.")
49
Regulación de la Transcripción
Factores de especificidad alteran especificidad de ARN polimerasa por un promotor Represores se unen a secuencias no codificantes en el ADN, impidiendo el progreso de la ARN polimerasa a lo largo del gen Activadores aumentan interacción entre ARN polimerasa y el promotor, facilitando expresión del gen. En procariotas, represores y activadores se unen a regiones llamadas operadores usualmente ubicados cerca del promotor

50
Regulación de la Transcripción
En eucariotas, regulación de la transcripción es por interacciones entre FT. Permite diff espaciales y temporales en expresión. Eucariotas usan también enhancers: regiones de ADN que hacen un loop de vuelta al promotor.

51
Splicing Editaje ARN Corte y Empalme

52
Genes divididos en eucariotas
Genes eucariotas presentan interrupciones Interrupciones: Intrones Segmentos que llegan a ser parte del ARNm (casi siempre codificantes): Exones
: Exones.")
53
“ Splicing“ El transcrito primario es procesado por splicing
Elimina los intrones y une los exones Ejempo: Gen de la distrofina tiene 74 intrones ARNm

54
Pasos “splicing”

55
Secuencia consenso

56
Conceptos Existen exones no codificantes (no traducidos). Error pensar que exon siempre es codificante Regiones no traducidas (5’, 3’, exones nc) son importantes para traducción eficiente Existen ARN completos nc
 son importantes para traducción eficiente. Existen ARN completos nc.")
57
“Splicing” alternativo
A partir del mismo transcrito inicial se obtienen diferentes ARNm 60% de genes humanos con splicing alternativo Explica bajo número de genes Consecuencias búsqueda de mutaciones

58
An example of alternative splicing
Figure Alternative splicing of the a-tropomyosin gene from rat. a-tropomyosin is a coiled-coil protein (see Figure 3-11) that regulates contraction in muscle cells. The primary transcript can be spliced in different ways, as indicated in the figure, to produce distinct mRNAs, which then give rise to variant proteins. Some of the splicing patterns are specific for certain types of cells. For example, the a-tropomyosin made in striated muscle is different from that made from the same gene in smooth muscle. The arrowheads in the top part of the figure demark the sites where cleavage and poly-A addition can occur.
 that regulates contraction in muscle cells. The primary transcript can be spliced in different ways, as indicated in the figure, to produce distinct mRNAs, which then give rise to variant proteins. Some of the splicing patterns are specific for certain types of cells. For example, the a-tropomyosin made in striated muscle is different from that made from the same gene in smooth muscle. The arrowheads in the top part of the figure demark the sites where cleavage and poly-A addition can occur.")
59
Control del “splicing” alternativo
Figure Negative and positive control of alternative RNA splicing. (A) Negative control, in which a repressor protein binds to the primary RNA transcript in tissue 2, thereby preventing the splicing machinery from removing an intron sequence. (B) Positive control, in which the splicing machinery is unable to efficiently remove a particular intron sequence without assistance from an activator protein.
 Negative control, in which a repressor protein binds to the primary RNA transcript in tissue 2, thereby preventing the splicing machinery from removing an intron sequence. (B) Positive control, in which the splicing machinery is unable to efficiently remove a particular intron sequence without assistance from an activator protein.")
60
Errores en “splicing“ como causantes de enfermedades

61
Traducción

62
Ribosomas en procariotas y eucariotas

63
Codón de iniciación

64
Codón de terminación

65
ARNm:5’-C G C -3’

66
Transfer RNA (tRNA)
")
67
Apareamiento “wobble” (balanceo/titubeo)
Bacterias: ARNt con diff anticodones Plantas y animales: 50 ARNt diff Pero hay 61 codones que codifican aa

68
Sitio de unión del ribosoma en E.coli
Figure The ribosome binding site for bacterial translation. In Escherichia coli, the ribosome binding site has the consensus sequence 5 -AGGAGGU-3 and is located between 3 and 10 nucleotides upstream of the initiation codon. Shine Dalgarno sequence The ribosome binding site upstream of an Escherichia coli gene Secuencia Shine Dalgarno

69
Iniciación de la traducción
Subunidad pequenna ribosoma y ARNt iniciador para iniciación

70
Elongación

71
Terminación traducción
Polipéptido se libera ARNt se separa Factor de liberación se une a sitio A Produce disociación de subunidades del ribosoma Cuando el ribosoma alcanza un codón de terminación (en este ejemplo UGA), el polipéptido se escinde del último tRNA y el tRNA se desprende del sitio P. El sitio A es ocupado por un factor de liberación que produce la disociación de las dos subunidades del ribosoma.
, el polipéptido se escinde del último tRNA y el tRNA se desprende del sitio P. El sitio A es ocupado por un factor de liberación que produce la disociación de las dos subunidades del ribosoma.")
72
Ensamblaje de subunidad pequeña ribosoma y el ARNt iniciador sobre el ARNm en eucariotas

73
Codon de iniciación se ubica escaneando corriente abajo del extremo 5’ del ARNm

74
Identificación codón de iniciación en eucariotas
Reconocimiento AUG iniciador gracias a secuencia de Kozak

75
Definición de gen Gen: la secuencia completa de ácidos nucleicos necearia para la síntesis de un producto génico funcional (proteína o ARN) Incluye todas las secuencias requeridas para la síntesis de un transcrito

Presentaciones similares



















>")