Descargar la presentación
La descarga está en progreso. Por favor, espere

1
PROCESOS DE DECISION DE MARKOV EN EL DISEÑO DE AGENTES INTELIGENTES GERMAN HERNANDEZ Ing. de Sistemas, Universidad Nacional-Bogota Http://dis.unal.edu.co/~hernandg ( PROGRAMACION DINAMICA ESTOCASTICA )
.")
2
INTRODUCCIÓN El objetivo fundamental de la charla es estudiar problemas de decisión secuencial, en los que los resultados de las decisiones o acciones, que se toman en cada paso, no son predecibles completamente; i.e., hay incertidumbre sobre los efectos de las acciones efectuadas. El objetivo en este tipo problemas es encontrar una políticas optima de acción.

3
Teoría de control Control optimo de sistemas dinámicos estocásticos. Teoría de la decisión, Inv. de operaciones, Ingeniería financiera Control de cadenas finitas de Markov. Inteligencia artificial Decisiones secuénciales “inteligentes” (agentes intligentes).
..")
4
Temario n Decisiones secuenciales bajo incertidumbre n Programación Dinámica Estocástica n Procesos de Decisión de Markov n Referencias

5
I. DESICIONES SECUENCIALES BAJO INCERTIDUMBRE La incertidumbre introduce dos características nuevas a un problemas de optimización Riesgo Obtención de información durante el proceso de decisión

6
(D,N,O,f,) D : conjunto de posibles acciones o decisiones. N : conjunto de estados de la naturaleza (índices de la incertidumbre en el problema). O : conjunto de salidas del problema. f: DNO función de salida. : relación de preferencia entre salidas. Problema de decisión bajo incertidumbre
. O : conjunto de salidas del problema. f: DNO función de salida. : relación de preferencia entre salidas. Problema de decisión bajo incertidumbre.")
7
Un agente que toma decisiones tiene una función de utilidad o recompensa R u : DN R u(a,y) es el pago obtenido al tomar la acción a en el estado y de la naturaleza. La naturaleza es modelada como un generador de estados aleatorios con una ley de probabilidad y ~P(). Los agentes se suponen maximixadores de la utilidad. Entonces la estrategia optima ( x ) es la mejor respuesta del agente a la selección aleatoria y de la naturaleza, con x la información disponible. “Una estrategia optima es la solución de equilibrio a un juego en contra de la naturaleza.”
. Los agentes se suponen maximixadores de la utilidad. Entonces la estrategia optima ( x ) es la mejor respuesta del agente a la selección aleatoria y de la naturaleza, con x la información disponible. Una estrategia optima es la solución de equilibrio a un juego en contra de la naturaleza. .")
9
Estrategias optimas Sin información Con información completa

10
Con información parcial

11
Desiciones secuenciales Sistemas dinámicos S utut wtwt ytyt F(u t,w t,x t ) x t+1 F(x t ) x t+1 Autónomo No autónomo +incertidumbre Parcialmente observado
 x t+1 F(x t ) x t+1 Autónomo No autónomo +incertidumbre Parcialmente observado")
12
Sistema dinámico (X,U,Y,W,F,S) X conjunto de estados internos U conjunto de entradas Y conjunto de salidas W conjunto de incertidumbre F: UWX X dinámica del sistema S: X Y función de salida sistema
 X conjunto de estados internos U conjunto de entradas Y conjunto de salidas W conjunto de incertidumbre F: UWX X dinámica del sistema S: X Y función de salida sistema")
13
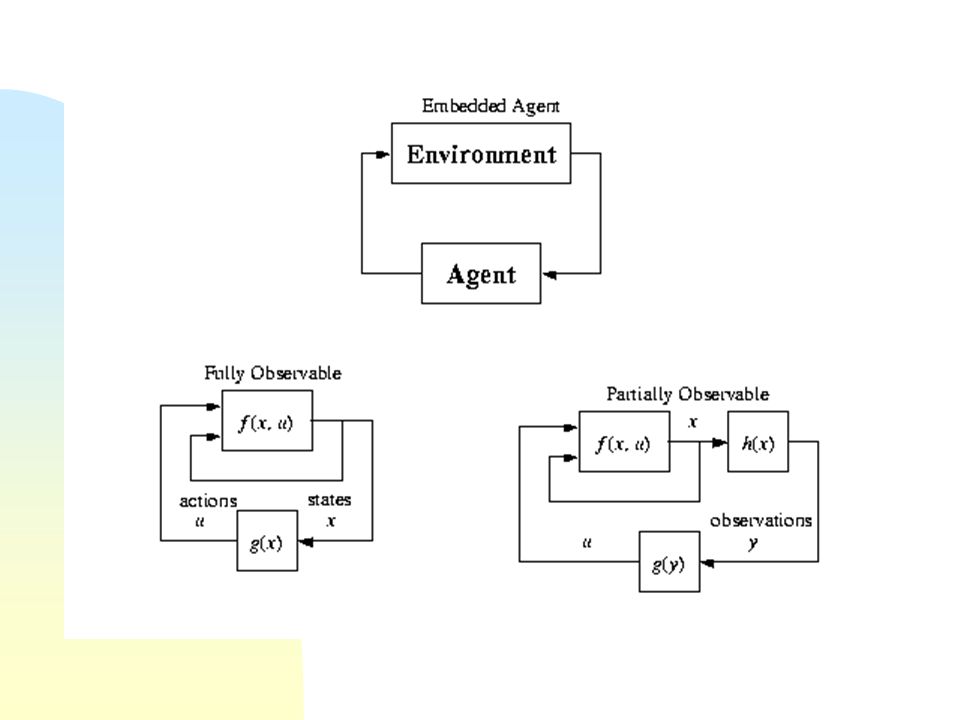
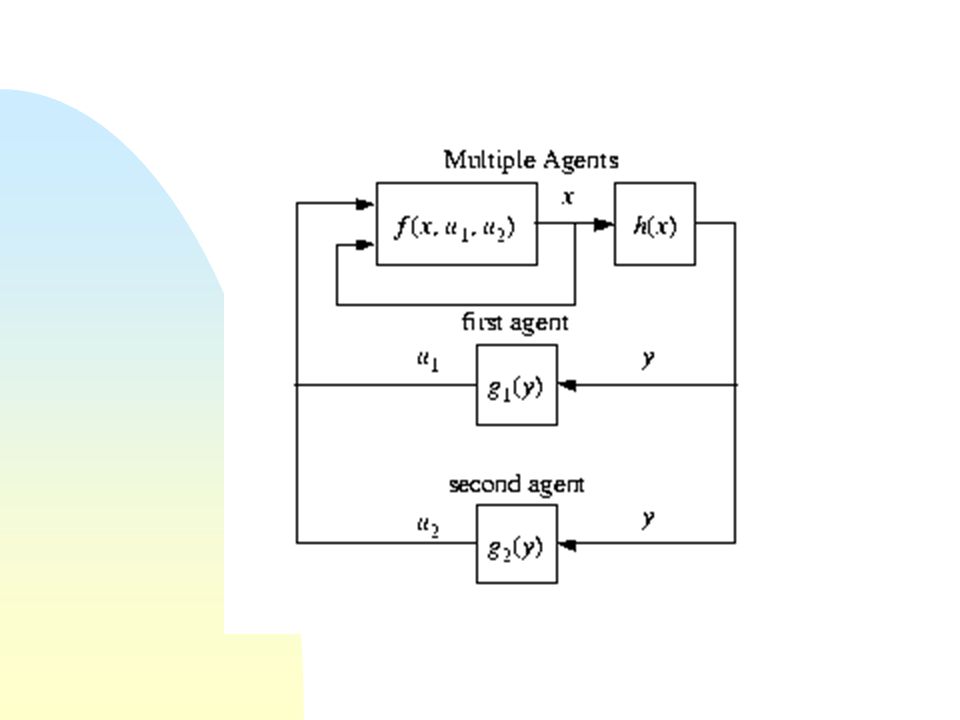
Ejemplos tomados de [1]
![Ejemplos tomados de [1]](http://images.slideplayer.es/2/5562957/slides/slide_13.jpg "Ejemplos tomados de [1]")
14
S utut wtwt xtxt F : Y U “control de realimentación” “política” “función de decisión” (y t ) ytyt ytyt Control
 ytyt ytyt Control")
15
D= conjunto de posibles controladores N=W O=(UWY) f: D N O (,w) (u,w,y) dados u 0,x 0 asociado con una función de utilidad R R : O T R, con T espacio de tiempo. Problema de decisión secuencial bajo incertidumbre D= conjunto de posibles controladores N=W O=(UWY) f: D N O (,w) (u,w,y) dados u 0,x 0 asociado con una función de utilidad R R : O T R, con T espacio de tiempo.
 f: D N O (,w) (u,w,y) dados u 0,x 0 asociado con una función de utilidad R R : O T R, con T espacio de tiempo..")
16
La política optima *, dada una estructura probabilistica sobre (u 0,x 0,w) que modela la incertidumbre, es la que maximiza el funcional de utilidad V = E w, u 0,x 0 [ R (u,w,y) ], i.e., V * = max V
![La política optima *, dada una estructura probabilistica sobre (u 0,x 0,w) que modela la incertidumbre, es la que maximiza el funcional de utilidad V = E w, u 0,x 0 [ R (u,w,y) ], i.e., V * = max V ](http://images.slideplayer.es/2/5562957/slides/slide_16.jpg "La política optima *, dada una estructura probabilistica sobre (u 0,x 0,w) que modela la incertidumbre, es la que maximiza el funcional de utilidad V = E w, u 0,x 0 [ R (u,w,y) ], i.e., V * = max V ")
17
Problemas de decisión secuencial de tiempo discreto Diagramas de influencia Howard y Matheson 1984[2]
![Problemas de decisión secuencial de tiempo discreto Diagramas de influencia Howard y Matheson 1984[2]](http://images.slideplayer.es/2/5562957/slides/slide_17.jpg "Problemas de decisión secuencial de tiempo discreto Diagramas de influencia Howard y Matheson 1984[2]")
18
Problemas de Decisión Secuencial Tiempo discreto T={0,1,2,...,N,} Utilidad Tiempo-separables (utilidad aditiva) R R t : XU R ( x t,a t ) R ( x t,a t ) R = R t I. PROG. DINAM. ESTOCASTICA

20
Principio de Optimalidad [Richard Bellman,1956 ] Una política optima tiene la propiedad de que sin importar la decisión y el estado inicial, las decisiones restantes deber ser optimas,con respecto al estado resultante de la decisión inicial en el estado inicial. “If you don't do the best with what you have happened to have got, you will never do the best with what you should have had.” [Rutherford Aris]
![Principio de Optimalidad [Richard Bellman,1956 ] Una política optima tiene la propiedad de que sin importar la decisión y el estado inicial, las decisiones restantes deber ser optimas,con respecto al estado resultante de la decisión inicial en el estado inicial.](http://images.slideplayer.es/2/5562957/slides/slide_20.jpg "If you don t do the best with what you have happened to have got, you will never do the best with what you should have had. [Rutherford Aris].")
21
Horizonte Finito Infinito Espacio de estados Discreto Finito Infinito Continuo Transiciones Determinísticas Probalísticas

22
Modelo de juego Cada jugada un jugador puede apostar cualquier cantidad menor o igual su fortuna presente y ganara o perdera esa cantidad con probabilidades p y q=p-1. Al jugador se le permite hacer n apuestas su objetivo es maximizar la esperanza del logaritmo de su fortuna final. Que estrategia debe seguir para conseguir esto?

23
Sea V n (x) la maxima ganacia esperada del juagor si tiene una fortuna presente x y se le permite n juegos más. con la condicion de frontera V 0 (x) = log(x) tenemos que
 = log(x) tenemos que.")
24
Tenemos entonces

25
Tenemos en general

26
I. MDP’s

30
Navegacion de robots Agentes financieros Inventarios Modelos Biologicos Agentes en la web Aplicaciones

31
Modelos de agentes tomados de [1]
![Modelos de agentes tomados de [1]](http://images.slideplayer.es/2/5562957/slides/slide_31.jpg "Modelos de agentes tomados de [1]")
35
Referencias [1] Dean T. Decision-Theoretic Planning and Markov Decision Porcesses [2] Dean T. Algerbaic Structure in Sequential Decision Processes) ttp://www.cs.brown.edu/people/tldttp://www.cs.brown.edu/people/tld [3] Bertsekas D.Dynamic Programing and Stochastic Control,Academic Press, 1987 [4] Ross Stochastic Dynamic Programming, John Wiley, [5] Putterman M.L. Markov Descion Processes in Handbook of IO and MS Vol2 Stochastic Models, Eds Heyman Sobel, 1990
![Referencias [1] Dean T. Decision-Theoretic Planning and Markov Decision Porcesses [2] Dean T.](http://images.slideplayer.es/2/5562957/slides/slide_35.jpg "Algerbaic Structure in Sequential Decision Processes) ttp:// [3] Bertsekas D.Dynamic Programing and Stochastic Control,Academic Press, 1987 [4] Ross Stochastic Dynamic Programming, John Wiley, [5] Putterman M.L. Markov Descion Processes in Handbook of IO and MS Vol2 Stochastic Models, Eds Heyman Sobel,")
Presentaciones similares









>")















