Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Programa de certificación de Green Belts
Seis Sigma Programa de certificación de Green Belts IV. Seis Sigma - Análisis P. Reyes / Octubre de 2007

2
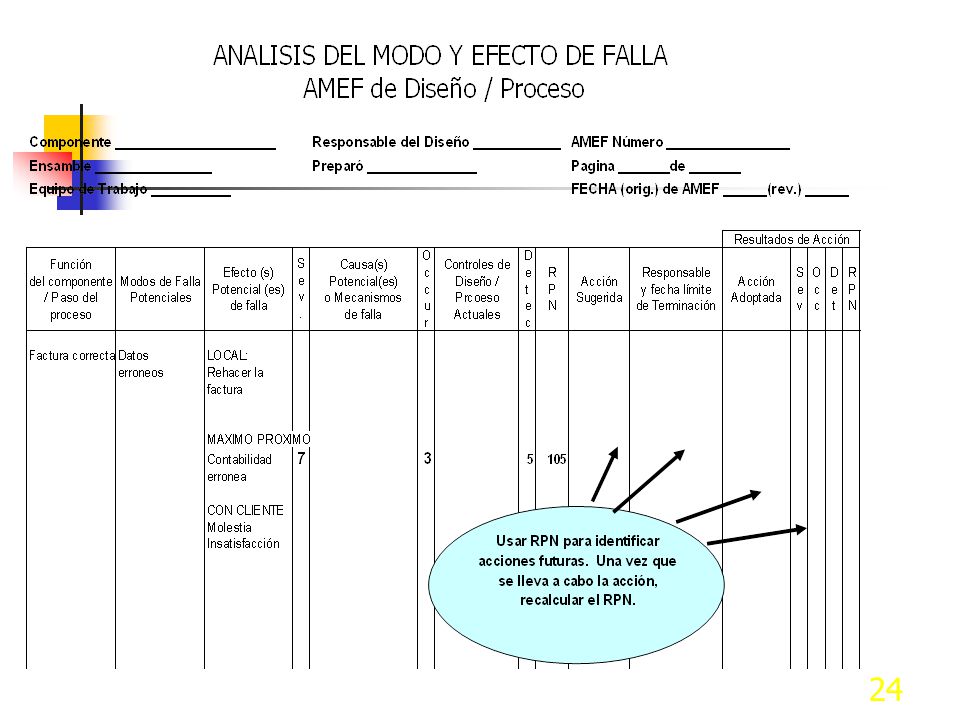
Llenar columnas del FMEA
Hasta sol. Propuesta y comprobar causas con Pruebas de Hipótesis

3
Seis Sigma - Análisis FMEA Identificación de causas potenciales
A. Análisis exploratorio de datos B. Pruebas de hipótesis

4
¿ Qué es el FMEA? El Análisis de del Modo y Efectos de Falla es un grupo sistematizado de actividades para: Reconocer y evaluar fallas potenciales y sus efectos. Identificar acciones que reduzcan o eliminen las probabilidades de falla. Documentar los procesos con los hallazgos del análisis. Existe el estándar MIL-STD-1629, Procedure for Performing a Failure Mode, Effects and Criticality Analysis

5
Tipos del FMEA AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA)
AMEF de concepto (CFMEA) A nivel de sistema, subsistema y componente AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA) AMEF de maquinaria (como aplicación del DFMEA)
 A nivel de sistema, subsistema y componente. AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA) AMEF de maquinaria (como aplicación del DFMEA)")
6
Tipos de FMEAs FMEA de Diseño (AMEFD), su propósito es analizar como afectan al sistema los modos de falla y minimizar los efectos de falla en el sistema. Se usan antes de la liberación de productos o servicios, para corregir las deficiencias de diseño. FMEA de Proceso (AMEFP), su propósito es analizar como afectan al proceso los modos de falla y minimizar los efectos de falla en el proceso. Se usan durante la planeación de calidad y como apoyo durante la producción o prestación del servicio.
, su propósito es analizar como afectan al sistema los modos de falla y minimizar los efectos de falla en el sistema. Se usan antes de la liberación de productos o servicios, para corregir las deficiencias de diseño. FMEA de Proceso (AMEFP), su propósito es analizar como afectan al proceso los modos de falla y minimizar los efectos de falla en el proceso. Se usan durante la planeación de calidad y como apoyo durante la producción o prestación del servicio.")
7
Salidas del FMEA de Proceso
Una lista de modos potenciales de falla Una lista de Caracteríticas críticas y/o significativas Una lista de características relacionadas con la seguridad del operador y con alto impacto Una lista de controles especiales recomendados para las Características Especiales designadas y consideradas en el Plan de control

8
Salidas del FMEA de Proceso
Una lista de procesos o acciones de proceso para reducir la Severidad, eliminar las causas de los modos de falla del producto o reducir su tasa de ocurrencia, y mejorar la tasa de Detección de defectos si no se puede mejorar la capacidad del proceso Cambios recomendados a las hojas de proceso y dibujos de ensamble

9
FMEA de Proceso - PFMEA

11
Modelo del PFMEA – Paso 1 Identificar todos los requerimientos funcionales dentro del alcance Identificar los modos de falla correspondientes Identificar un conjunto de efectos asociados para cada modo de falla Identificar la calificación de severidad para cada conjunto de efectos que de prioridad el modo de falla De ser posible, tomar acciones para eliminar modos de falla sin atender las “causas”

12
Modelo de PFMEA – Paso 1 Modos de falla potenciales No funciona
Funcionamiento parcial / Sobre función / Degradación en el tiempo Funcionamiento intermitente Función no intencionada Los modos de falla se pueden categorizar como sigue: Manufactura: Dimensional fuera de tolerancia Ensamble: Falta de componentes Recibo de materiales: Aceptar partes no conformes Inspección/Prueba: Aceptar partes equivocadas

13
Modelo de PFMEA - Paso 1 Efectos de las fallas potenciales (en usuario final) Ruido Operación errática Inoperable Inestable Apariencia mala Fugas Excesivo esfuerzo Retrabajos / reparaciones Insatisfacción del cliente

14
Efecto en Manufactura /Ensamble
CRITERIO DE EVALUACIÓN DE SEVERIDAD SUGERIDO PARA AMEFP Esta calificación resulta cuando un modo de falla potencial resulta en un defecto con un cliente final y/o una planta de manufactura / ensamble. El cliente final debe ser siempre considerado primero. Si ocurren ambos, use la mayor de las dos severidades Efecto Efecto en el cliente Efecto en Manufactura /Ensamble Calif. Peligroso sin aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, sin aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 10 Peligroso con aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 9 Muy alto El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor 8 Alto El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto 7 Modera do Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto 6 Bajo Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5 Muy bajo No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada 4 Menor No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación 3 Muy menor No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación 2 Ninguno Sin efecto perceptible Ligero inconveniente para la operación u operador, o sin efecto 1
 sin aviso. 10. Peligroso con aviso. Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso. Puede exponer al peligro al operador (máquina o ensamble) sin aviso. 9. Muy alto. El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor. 8. Alto. El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho. El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto. 7. Modera. do. Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho. Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto. 6. Bajo. Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos. El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5. Muy bajo. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes. El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada. 4. Menor. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes. El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación. 3. Muy menor. No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación. 2. Ninguno. Sin efecto perceptible. Ligero inconveniente para la operación u operador, o sin efecto. 1.")
15
Modelo de PFMEA – Paso 2 Paso 2 identificar:
Las causas asociadas (primer nivel y raíz) Su tasa de ocurrencia La designación apropiada de la característica indicada en ola columna de clasificación Acciones recomendadas para alta severidad y criticalidad (S x O) así como la Seguridad del operador (OS) y errores de proceso de alto impacto (HI)
 Su tasa de ocurrencia. La designación apropiada de la característica indicada en ola columna de clasificación. Acciones recomendadas para alta severidad y criticalidad (S x O) así como la Seguridad del operador (OS) y errores de proceso de alto impacto (HI)")
16
Modelo de PFMEA – Paso 2 Causa/Mecanismo potencial de falla
Describe la forma de cómo puede ocurrir la falla, descrito en términos de algo que puede ser corregido o controlado Se debe dar priorioridad a rangos de prioridad de 9 o 10

17
Efecto(s) Potencial(es) de falla
Evaluar 3 (tres) niveles de Efectos del Modo de Falla Efectos Locales Efectos en el Área Local Impactos Inmediatos Efectos Mayores Subsecuentes Entre Efectos Locales y Usuario Final Efectos Finales Efecto en el Usuario Final del producto o Servicio
 niveles de Efectos del Modo de Falla. Efectos Locales. Efectos en el Área Local. Impactos Inmediatos. Efectos Mayores Subsecuentes. Entre Efectos Locales y Usuario Final. Efectos Finales. Efecto en el Usuario Final del producto o Servicio.")
18
CRITERIO DE EVALUACIÓN DE OCURRENCIA SUGERIDO PARA AMEFP
Probabilidad Indices Posibles de falla ppk Calif. Muy alta: Fallas persistentes < 0.55 10 50 por mil piezas > 0.55 9 Alta: Fallas frecuentes 20 por mil piezas > 0.78 8 10 por mil piezas > 0.86 7 Moderada: Fallas ocasionales 5 por mil piezas > 0.94 6 2 por mil piezas > 1.00 5 1 por mil piezas > 1.10 4 Baja : Relativamente pocas fallas 0.5 por mil piezas > 1.20 3 0.1 por mil piezas > 1.30 2 Remota: La falla es improbable < por mil piezas > 1.67 1 100 por mil piezas

19
CRITERIO DE EVALUACIÓN DE DETECCION SUGERIDO PARA AMEFP
Detecciòn Criterio Tipos de Inspección Métodos de seguridad de Rangos de Detección Calif A B C Casi imposible Certeza absoluta de no detección X No se puede detectar o no es verificada 10 Muy remota Los controles probablemente no detectarán X El control es logrado solamente con verificaciones indirectas o al azar 9 Remota Los controles tienen poca oportunidad de detección X El control es logrado solamente con inspección visual 8 Muy baja Los controles tienen poca oportunidad de detección X El control es logrado solamente con doble inspección visual 7 Baja Los controles pueden detectar X X El control es logrado con métodos gráficos con el CEP 6 Moderada Los controles pueden detectar X El control se basa en mediciones por variables después de que las partes dejan la estación, o en dispositivos Pasa NO pasa realizado en el 100% de las partes después de que las partes han dejado la estación 5 Moderadamente Alta Los controles tienen una buena oportunidad para detectar X X Detección de error en operaciones subsiguientes, o medición realizada en el ajuste y verificación de primera pieza ( solo para causas de ajuste) 4 Alta Los controles tienen una buena oportunidad para detectar X X Detección del error en la estación o detección del error en operaciones subsiguientes por filtros multiples de aceptación: suministro, instalación, verificación. No puede aceptar parte discrepante 3 Muy Alta Controles casi seguros para detectar X X Detección del error en la estación (medición automática con dispositivo de paro automático). No puede pasar la parte discrepante 2 Muy Alta Controles seguros para detectar X No se pueden hacer partes discrepantes porque el item ha pasado a prueba de errores dado el diseño del proceso/producto 1 Tipos de inspección: A) A prueba de error B) Medición automatizada C) Inspección visual/manual
 4. Alta. Los controles tienen una buena oportunidad para detectar. X. X. Detección del error en la estación o detección del error en operaciones subsiguientes por filtros multiples de aceptación: suministro, instalación, verificación. No puede aceptar parte discrepante. 3. Muy Alta. Controles casi seguros para detectar. X. X. Detección del error en la estación (medición automática con dispositivo de paro automático). No puede pasar la parte discrepante. 2. Muy Alta. Controles seguros para detectar. X. No se pueden hacer partes discrepantes porque el item ha pasado a prueba de errores dado el diseño del proceso/producto. 1. Tipos de inspección: A) A prueba de error B) Medición automatizada C) Inspección visual/manual.")
20
Causas probables a atacar primero

21
Calcular RPN (Número de Prioridad de Riesgo)
Producto de Severidad, Ocurrencia, y Detección RPN / Gravedad usada para identificar principales CTQs Severidad mayor o igual a 8 RPN mayor a 150

22
Causas probables a atacar primero

23
Reducir el riesgo general del diseño
Planear Acciones Requeridas para todos los CTQs Listar todas las acciones sugeridas, qué persona es la responsable y fecha de terminación. Describir la acción adoptada y sus resultados. Recalcular número de prioridad de riesgo . Reducir el riesgo general del diseño

25
Ejemplo de AMEFP

26
Identificación de causas potenciales
Tormenta de ideas Diagrama de Ishikawa Diagrama de Relaciones Diagrama de Árbol Verificación de causas raíz

27
Tormenta de ideas Técnica para generar ideas creativas cuando la mejor solución no es obvia. Reunir a un equipo de trabajo (4 a 10 miembros) en un lugar adecuado El problema a analizar debe estar siempre visible Generar y registrar en el diagrama de Ishikawa un gran número de ideas, sin juzgarlas, ni criticarlas Motivar a que todos participen con la misma oportunidad
 en un lugar adecuado. El problema a analizar debe estar siempre visible. Generar y registrar en el diagrama de Ishikawa un gran número de ideas, sin juzgarlas, ni criticarlas. Motivar a que todos participen con la misma oportunidad.")
28
Tormenta de ideas Permite obtener ideas de los participantes

29
Diagrama de Ishikawa Anotar el problema en el cuadro de la derecha
Anotar en rotafolio las ideas sobre las posibles causas asignándolas a las ramas correspondientes a: Medio ambiente Mediciones Materia Prima Maquinaria Personal y Métodos o Las diferentes etapas del proceso de manufactura o servicio

30
Diagrama de causa efecto
Divide los problemas en partes más pequeñas Muestra las causas potenciales de manera gráfica También se llama diagrama de ishikawa o de las 4 o 6 M’s. Muestra como interactúan las diversas causas Sigue las reglas de la tormenta de ideas al generarlas

31
Diagrama de Ishikawa

32
TIPS PARA EL INSTRUCTOR
Diagrama de relaciones Programación deficiente Capacidad instalada desconocida Marketing no tiene en cuenta cap de p. Mala prog. De ordenes de compra Compras aprovecha ofertas Falta de com..... Entre las dif. áreas de la empresa Duplicidad de funciones Las un. Reciben ordenes de dos deptos diferentes Altos inventarios No hay control de inv..... En proc. Demasiados deptos de inv..... Y desarrollo Falta de prog. De la op. En base a los pedidos No hay com..... Entre las UN y la oper. Falta de coordinación al fincar pedidos entre marketing y la op. Falta de control de inventarios en compras Influencia de la situación econ del país No hay com..... Entre compras con la op. general No hay coordinación entre la operación y las unidades del negocio Falta de coordinación entre el enlace de compras de cada unidad con compras corporativo Influencia directa de marketing sobre Compra de material para el desarrollo de nuevos productos por parte inv..... Y desarrollo’’’ No hay flujo efectivo de mat. Por falta de programación de acuerdo a pedidos Perdida de mercado debido a la competencia Constantes cancelaciones de pedidos de marketing entre marketing operaciones Falta de comunicación entre las unidades NOTAS DEL INSTRUCTOR TIPS PARA EL INSTRUCTOR El instructor mostrará éste ejemplo de inventarios y pedirá a los participantes elaboren, si es que aplica, un diagrama de relaciones para su proyecto. Tomar 25 minutos para que trabajen los equipos y 5 minutos de plenaria. D-17

33
Dancer Taco generador del motor Poleas guías Presión del dancer Mal guiado Sensor de velocidad de línea Sensor circunferencial Bandas de transmisión Empaques de arrastre Presión de aire de trabajo Drive principal Voltaje del motor Ejes principales Poleas de transmisión ¿Que nos puede provocar Variación de Velocidad Durante el ciclo de cambio en la sección del Embobinadores? Causas a validar 13/0 2/4 0/4 1/2 5/1 1/4 2/1 1/1 0/3 5/2 4/1 1/5 Entradas Causa Salidas Efecto

34
¿Qué datos son necesarios para identificar las cuasas raíz?
Diagrama de Interrrelaciones Permite al equipo identificar y clasificar las relaciones de causa y efecto que existe entre las variables Communica- tion issues within the group External factors impact implemen- tation Means not clearly defined Plan not integrated Fast new product introductions stretch resources Lack of time and No strong commitment to the group Driver Planning approach not standardized Outcome Capacity may not meet needs In = 1 Out = 3 In = 3 Out = 2 In = 2 Out = 4 In = 1 Out = 2 In = 2 Out = 0 In = 0 Out = 5 In = 5 Out = 1 In = 0 Out = 2 In = 5 Out = 0

35
TIPS PARA EL INSTRUCTOR
Diagrama de árbol o sistemático NOTAS DEL INSTRUCTOR Meta Medio Segundo nivel Cuarto nivel Tercer nivel Primer nivel Meta u objetivo Medios o planes TIPS PARA EL INSTRUCTOR El instructor explicará que ésta es la forma que toma el diagrama sistemático, resaltando que una meta se convierte en un medio Es decir vamos dividiendo las grandes tareas en pequeñas tareas, que a su vez son más fáciles de solucionar y nos ayudan a alcanzar nuestro objetivo. D-20

36
Diagrama de Arbol- Aplicación Sistema SMED
¿Cómo? ¿Cuándo? Preparación para el SMED Filmar la preparación Mar-04 Analizar el video 10 y 17 –Mar-04 Describir las tareas 17- Mar-04 ¿Objetivo? Separar las tareas 17- Mar-04 Fase 1: Separación de la preparación interna de la externa Elaborar lista de chequeo 2- Mar-04 Implantar el Sistema SMED Producto DJ 2702 Realizar chequeo de funciones 24- Mar-04 Analizar el transporte de herramientas y materiales 24- Mar-04 ¿Qué? Analizar las funciones y propósito de c/operación 12 - Abr- 04 Fase 2: Conversión de preparación interna en externa Convertir tareas de prepa- ración interna a externas 15 –Abr - 04 Elaboramos un Diagrama de Arbol para poder analizar nuestro problema siguiendo el sistema SMED. Realización de operaciones en paralelo. 5 –May -04 Fase 3: Refinamiento de todos los aspectos de la preparación. Uso de sujeciones funcionales. 19– May -04 Eliminación de ajustes 12- May -04 19

37
Selección de posibles causas
El equipo discute la lista de causas de alta prioridad y decide cuáles son las más importantes (5 a 7). El equipo se cuestiona lo siguiente: ¿Es una causa? (¿no una solución?) ¿Podemos hacer algo respecto a la causa? ¿Estamos seguros que ésta cambiará el efecto? ¿Estamos de acuerdo? Causas 1. ________ 2. ________ 3. ________ 4. ________ 5. ________
. El equipo se cuestiona lo siguiente: ¿Es una causa (¿no una solución ) ¿Podemos hacer algo respecto a la causa ¿Estamos seguros que ésta cambiará el efecto ¿Estamos de acuerdo Causas. 1. ________. 2. ________. 3. ________. 4. ________. 5. ________.")
38
Verificación de posibles causas
Para cada causa probable , el equipo deberá por medio del diagrama 5Ws – 1H: Llevar a cabo una tormenta de ideas para verificar la causa. Seleccionar la manera que: represente la causa de forma efectiva, y sea fácil y rápida de aplicar.

39
Calendario de las actividades
¿qué? ¿por qué? ¿cómo? ¿cuándo? ¿dónde? ¿quién? 1 Tacogenerador de motor embobinador 1.1 Por variación de voltaje durante el ciclo de cambio 1.1.1 Tomar dimensiones de ensamble entre coples. 1.1.2 Verificar estado actual y especificaciones de escobillas. 1.1.3 tomar valores de voltaje de salida durante el ciclo de cambio. Abril ’04 1804 Embob. J. R. 2 Sensor circular y de velocidad de linea. 2.1 Por que nos genera una varión en la señal de referencia hacia el control de velocidad del motor embobinador 2.1.1 Tomar dimensiones de la distancia entre poleas y sensores. 2.1.2 Tomar valores de voltaje de salida de los sensores. 2.1.3 Verificar estado de rodamientos de poleas. 1804 Embob. U. P. 3 Ejes principales de transmisión. 3.1 Por vibración excesiva durante el ciclo de cambio 3.1.1 Tomar lecturas de vibración en alojamientos de rodamientos 3.1.2 Comparar valores de vibraciones con lecturas anteriores. 3.1.3 Analizar valor lecturas de vibración tomadas. Abril’04 F. F. 4 Poleas de transmisión de ejes embobinadores. 4.1 Puede generar vibración excesiva durante el ciclo de cambio. 4.1.1 Verificar alineación, entre poleas de ejes principales y polea de transmisión del motor. 4.1.2 Tomar dimensiones de poleas(dientes de transmisión). 4.1.3 Tomar dimensiones de bandas (dientes de transmisión) 4.1.4 Verificar valor de tensión de bandas.
 Tomar dimensiones de bandas (dientes de transmisión) Verificar valor de tensión de bandas.")
40
Verificación de posibles causas
Antes de invertir tiempo y dinero en la implementación de una mejora para “contrarrestar” una causa, asegurarse que la causa sea real. Estar completamente convencido que la causa es la verdadera culpable del efecto indeseable.

41
IV A 1. Estudios Multivari

42
Estudios Multivari La carta multivari permite analizar la variación dentro de la pieza, de pieza a pieza o de tiempo en tiempo Permite investigar la estabilidad de un proceso consiste de líneas verticales u otro esquema en función del tiempo. La longitud de la línea o del esquema representa el rango de valores encontrados en cada conjunto de muestras

43
Estudios Multivari La variación dentro de las muestras (cinco puntos en cada línea). La variación de muestra a muestra como posición vertical de las líneas. E S P O R Número de subgrupo
. La variación de muestra a muestra como posición vertical de las líneas. E. S. P. O. R. Número de subgrupo.")
44
Estudios Multivari Ejemplo de parte metálica Centro más grueso

45
Estudios Multivari Procedimiento de muestreo:
Seleccionar el proceso y la característica a investigar Seleccionar tamaño de muestra y frecuencia de muestreo Registrar en una hoja la hora y valores para conjunto de partes

46
Estudios Multivari Procedimiento de muestreo:
Realizar la carta Multivari Unir los valores observados con una línea Analizar la carta para variación dentro de la parte, de parte a parte y sobre el tiempo Puede ser necesario realizar estudios adicionales alrededor del área de máxima variación aparente Después de la acción de mejora comprobar con otro estudio Multivari

47
Cartas Multivari Su propósito fundamental es reducir el gran número de causas posibles de variación, a un conjunto pequeño de causas que realmente influyen en la variabilidad. Sirven para identificar el patrón principal de variación de entre tres patrones principales: Temporal: Variación de hora a hora; turno a turno; día a día; semana a semana; etc. Cíclico: Variación entre unidades de un mismo proceso; variación entre grupos de unidades; variación de lote a lote.

48
7A1. Cartas Multivari Posicional:
Variaciones dentro de una misma unidad (ejemplo: porosidad en un molde de metal) o a través de una sola unidad con múltiples partes (circuito impreso). Variaciones por la localización dentro de un proceso que produce múltiples unidades al mismo tiempo. Por ejemplo las diferentes cavidades de un molde Variaciones de máquina a máquina; operador a operador; ó planta a planta
 o a través de una sola unidad con múltiples partes (circuito impreso). Variaciones por la localización dentro de un proceso que produce múltiples unidades al mismo tiempo. Por ejemplo las diferentes cavidades de un molde. Variaciones de máquina a máquina; operador a operador; ó planta a planta.")
49
Cartas Multivari VARIACIÓN POSICIONAL DENTRO DE LA UNIDAD
Ejemplo: Se toman 3 a 5 unidades consecutivas, repitiendo el proceso tres o más veces a cierto intervalo de tiempo, hasta que al menos el 80% de la variación en el proceso se ha capturado. A VARIACIÓN POSICIONAL DENTRO DE LA UNIDAD

50
Cartas Multivari VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD
Ejemplo: (cont...) B VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD
 B VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD.")
51
Cartas Multivari VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO
Ejemplo: (cont...) C VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO
 C VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO.")
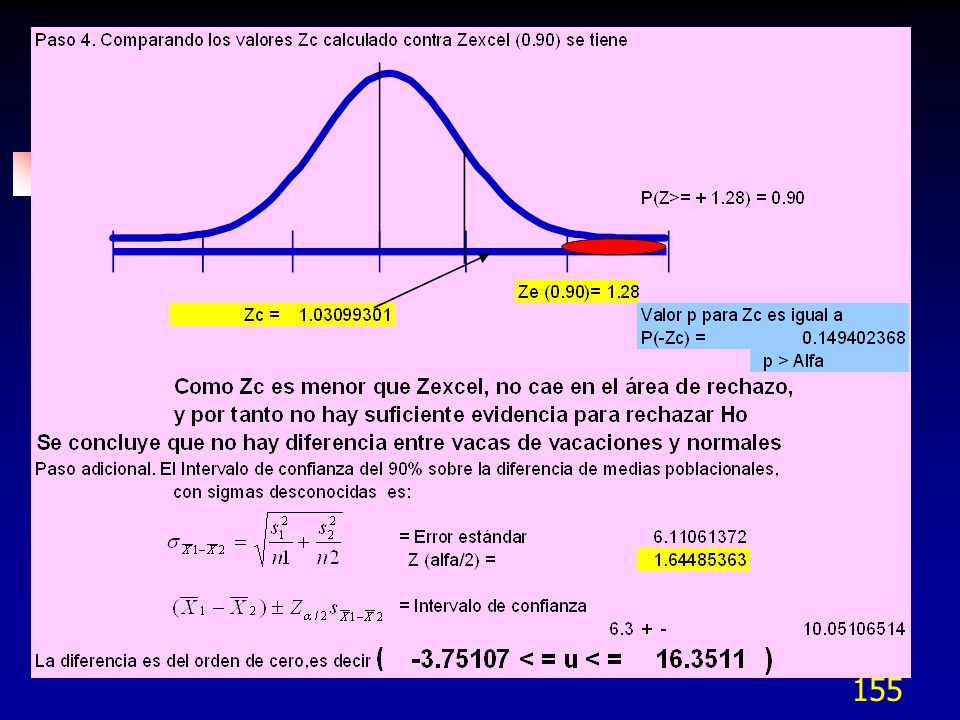
52
Cartas Multivari Ejemplo: Un proceso produce flecha cilíndricas, con un diámetro especificado de ” 0.001”. Sin embargo un estudio de capacidad muestra un Cp = 0.8 y una dispersión natural de ” (6 ) contra la permitida de ”. Se tiene pensado comprar un torno nuevo de US$70,000 para tolerancia de ”, i.e. Cpk = Se sugirió un estudio Multi Vari previo.
 contra la permitida de Se tiene pensado comprar un torno nuevo de US$70,000 para tolerancia de , i.e. Cpk = Se sugirió un estudio Multi Vari previo.")
53
Cartas Multivari Se tomaron cuatro lecturas en cada flecha, dos a cada lado. Estas muestran una disminución gradual desde el lado izquierdo al lado derecho de las flechas, además de excentricidad en cada lado de la flecha. La variación cíclica, de una flecha a la siguiente, se muestra mediante las líneas que concentran las cuatro lecturas de cada flecha. También se muestra la variación temporal.

54
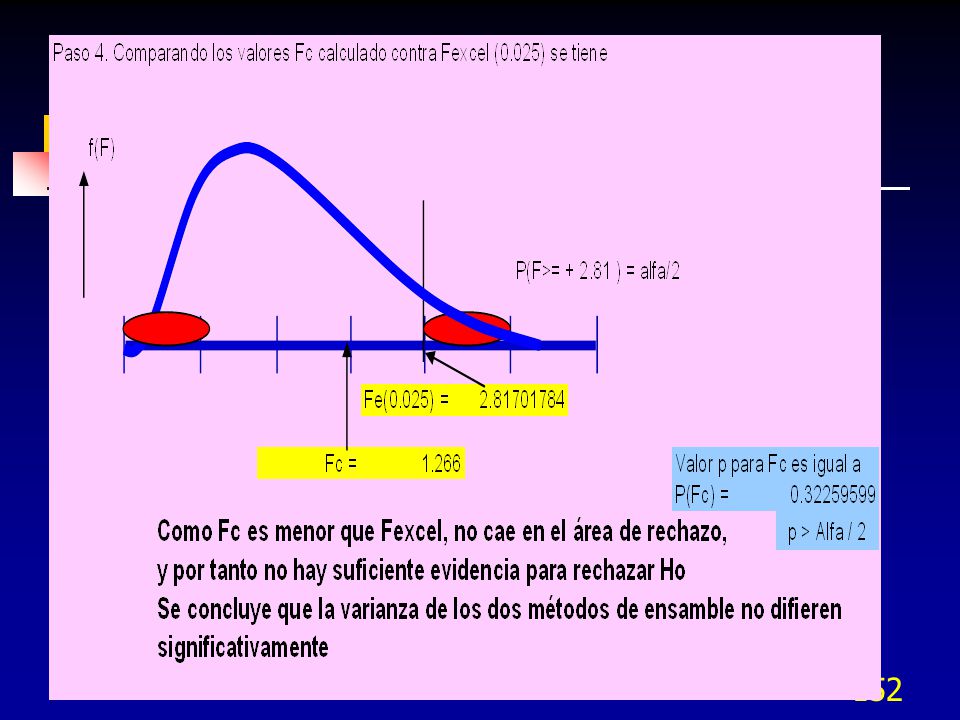
Cartas Multivari 8 AM 9 AM 10 AM 11 AM 12 AM .0.2510” 0.2500” 0.2490”
Izquierda Máximo Derecha Mínimo

55
Cartas Multivari Un análisis rápido revela que la mayor variación es temporal con un cambio mayor entre las 10 AM y las 11 AM. A las 10 AM se para el equipo para el almuerzo y se arranca a las 11 AM, con lecturas similares a las de las 8 AM. Conforme pasa el tiempo las lecturas tienden a decrecer más y más, hasta que se invierten a las 10 A.M. en forma drástica. Se investigó y se encontró que la temperatura tenía influencia en la variación. La variación en temperatura era causada por que la cantidad de refrigerante no era la adecuada, lo cual se notaba más cuando se paraba el equipo y se volvía a arrancar. Se adicionó, reduciendo la variación en 50% aproximadamente..

56
Cartas Multivari También se encontró que el acabado cónico era causado por que la herramienta de corte estaba mal alineada. Se ajustó, contribuyendo a otra reducción del 10% de la variabilidad. La excentricidad de las flechas se corrigió al cambiar un rodamiento excéntrico por desgaste en el torno. Se instaló un nuevo rodamiento eliminándose otro 30% de la variabilidad. La tabla siguiente muestra un resumen de los resultados.

57
Cartas Multivari Tipo de % var. Causas de Acción % de variación
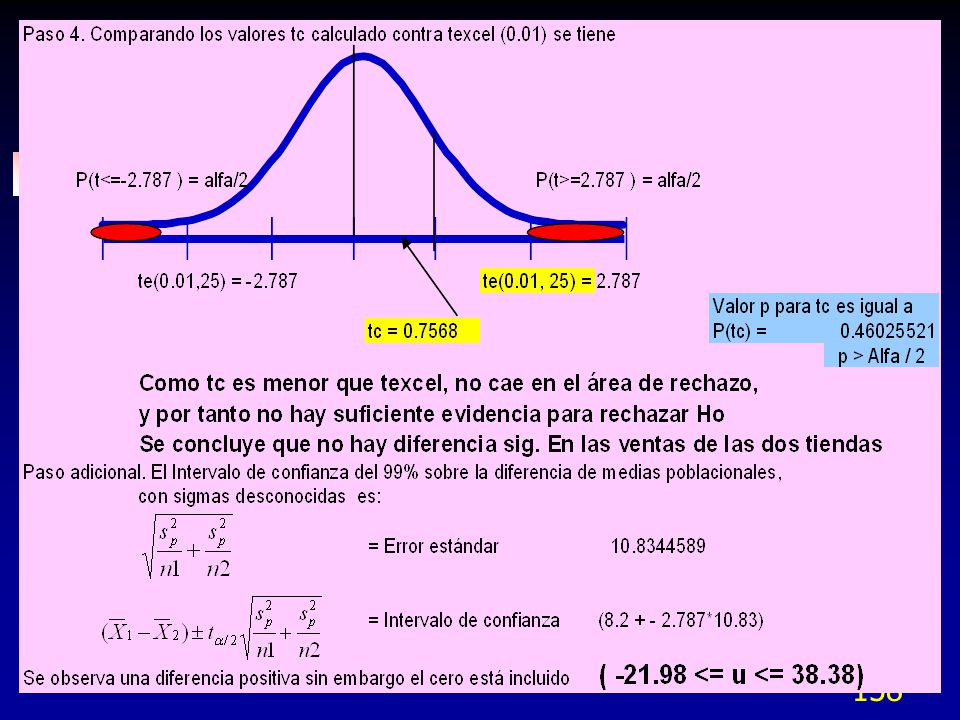
Variación Total Variación Correctiva Reducida Temporal 50 Bajo nivel de Adicionar Casi 50 Tiempo a tiempo Refrigerante refrigerante Dentro de 10 Ajuste no Ajuste de la Casi 10 la flecha no paralelo herramienta de corte Dentro de 30 Rodamiento Nuevo Casi 30 la flecha gastado rodamiento Flecha a ??? - - flecha

58
Cartas Multivari Resultados:
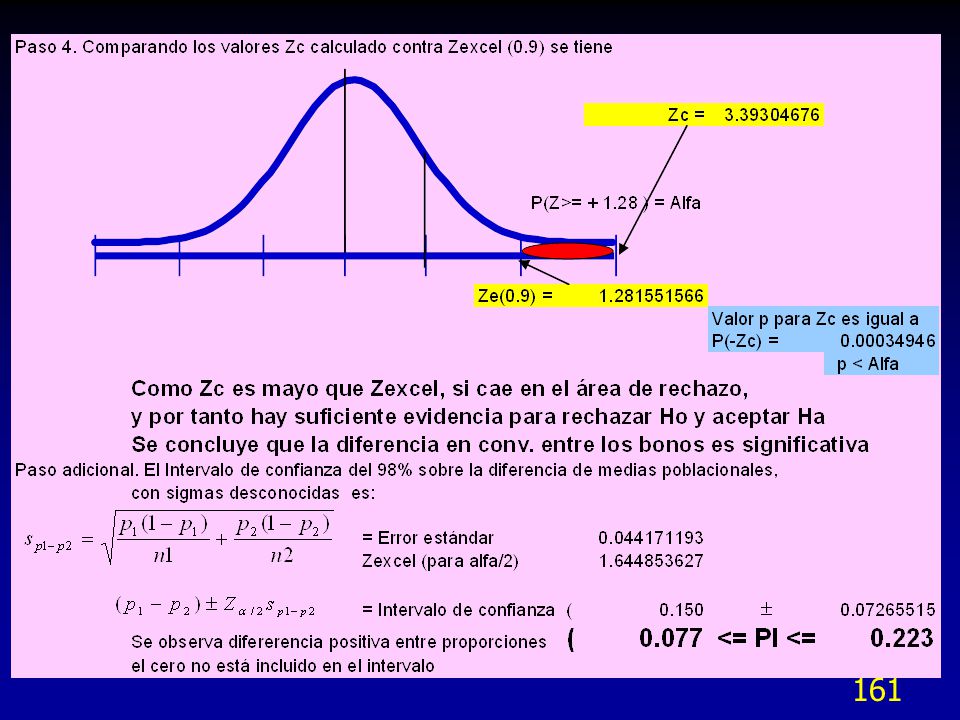
La variación total en la siguiente corrida de producción se redujo de ” a ” El nuevo Cp fue de / = 5.0 Como beneficios se redujo a cero el desperdicio y no hubo necesidad de adquirir una nueva máquina. Se observa que antes de cambiar equipo o máquinas, es conveniente realizar un estudio de variabilidad para identificar las fuentes de variación y tratar de eliminarlas.

59
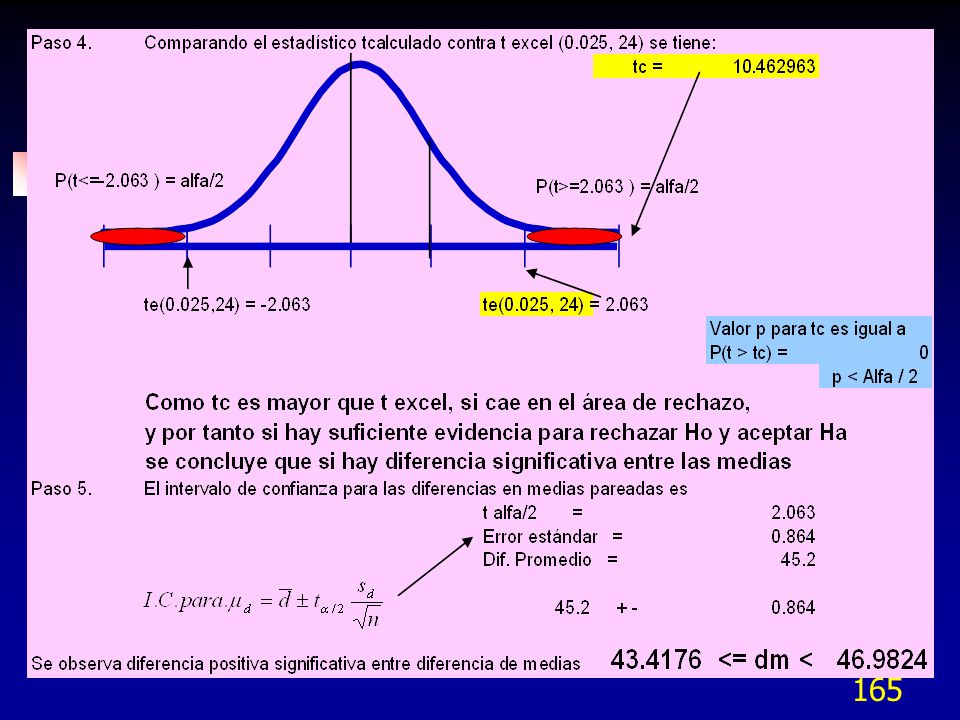
Cartas Multivari Diámetro de Flecha (0.150" +/- .002)
Ejemplo: Búsqueda de fuentes de variación con el diagrama sistemático. Diámetro de Flecha (0.150" +/- .002) Operador a operador Programa Máquina Accesorios
 Operador a operador. Programa. Máquina. Accesorios.")
60
Cartas Multivari Se Rechaza Ho: Oper1 = Oper2 = Oper3
Ejemplo (cont..): Al realizar la prueba de homogeneidad de varianza F, se encontró que había una diferencia significante entre los operadores. Se Rechaza Ho: Oper1 = Oper2 = Oper3 Para probar si existe diferencia significativa entre medias de operadores se hacen las siguientes comparaciones Ho: Oper1 = Oper2 Ho: Oper1 = Oper3 Ho: Oper2 = Oper3 Ha: Oper1 Oper2 Oper3
: Al realizar la prueba de homogeneidad de varianza F, se encontró que había una diferencia significante entre los operadores. Se Rechaza Ho: Oper1 = Oper2 = Oper3. Para probar si existe diferencia significativa entre medias de operadores se hacen las siguientes comparaciones. Ho: Oper1 = Oper2 Ho: Oper1 = Oper3. Ho: Oper2 = Oper3 Ha: Oper1 Oper2 Oper3.")
61
SinterTime MetalType Strength
Corrida en Minitab Se introducen los datos en varias columnas C1 a C3 incluyendo la respuesta (strenght) y los factores (time y Metal) SinterTime MetalType Strength
 y los factores (time y Metal) SinterTime MetalType Strength")
62
Corrida en Minitab Utilizar el achivo de ejemplo Sinter.mtw
Opción: Stat > Quality Tools > Multivari charts Indicar la columna de respuesta y las columnas de los factores En opciones se puede poner un título y conectar las líneas

63
Resultados

64
IV.A.2 Regresión lineal simple

65
Definiciones Correlación
Establece si existe una relación entre las variables y responde a la pregunta, ”¿Qué tan evidente es esta relación?" Regresión Describe con más detalle la relación entre las variables. Construye modelos de predicción a partir de información experimental u otra fuente disponible. Regresión lineal simple Regresión lineal múltiple Regresión no lineal cuadrática o cúbica

66
El 1er. paso es realizar una gráfica de la información.
Correlación Propósito: Estudiar la posible relación entre dos variables. • • • • Correlación positiva, posible • • • Accidentes laborales • • • • • • • • • • • • • • • • • • • Graphs are used to visualize relationships or associations between variables. Linear relationships between (primarily) continuous variables can be quantified using the Pearson product moment correlation coefficient (correlation for short) and regression. When might you use regression and correlation? To determine if a less expensive (or faster) procedure can be substituted for a procedure currently in use. As a first step in determining key input variables in a process (correlating input and out put variables). • • • Numero de órdenes urgentes El 1er. paso es realizar una gráfica de la información.
 continuous variables can be quantified using the Pearson product moment correlation coefficient (correlation for short) and regression. When might you use regression and correlation To determine if a less expensive (or faster) procedure can be substituted for a procedure currently in use. As a first step in determining key input variables in a process (correlating input and out put variables). • • • Numero de órdenes urgentes. El 1er. paso es realizar una gráfica de la información.")
67
Correlación de la información (R ) de las X y las Y
Correlación Positiva Evidente Correlación Negativa Evidente 25 25 20 20 15 15 Y 10 Y 10 5 5 Sin Correlación 5 10 15 20 25 5 10 15 20 25 X R=1 25 X R=-1 20 15 Correlación Positiva Y 10 Correlación Negativa 5 25 5 10 15 20 25 25 20 R=0 X 20 15 15 Y 10 Y 10 5 5 5 10 15 20 25 5 10 15 20 25 X R=>1 X R=>-1

68
Correlaciones (Pearson) Tabla de Correlación mínima
de confianza de confianza n % % de confianza de confianza Para un 95% de confianza, con una muestra de 10, el coeficiente (r) debe ser al menos .63
 debe ser al menos .63.")
69
Correlación La correlación puede usarse para información de atributos, variables normales y variables no normales. La correlación puede usarse con un “predictor” o más para una respuesta dada. La correlación es una prueba fácil y rápida para eliminar factores que no influyen en la predicción, para una respuesta dada.

70
Análisis de Regresión El análisis de regresión es un método estandarizado para localizar la correlación entre dos grupos de datos, y, quizá más importante, crear un modelo de predicción. Puede ser usado para analizar las relaciones entre: Una sola “X” predictora y una sola “Y” Múltiples predictores “X” y una sola “Y” Varios predictores “X” entre sí

71
Supuestos de la regresión lineal
Los principales supuestos que se hacen en el análisis de regresión lineal son los siguientes: La relación entre las variables Y y X es lineal, o al menos bien aproximada por una línea recta. El término de error tiene media cero. El término de error tiene varianza constante 2. Los errores no están correlacionados. Los errores están normalmente distribuidos.

72
Modelo de regresión lineal
Se aume que para cualquier valor de X el valor observado de Y varia en forma aleatoria y tiene una distribución de probabilidad normal El modelo general es: Y = Valor medio de Yi para Xi + error aleatorio

73
yi ei Regresión Lineal Simple y = b0 + b1x xi SSE = ei2 = yi - yi2
La línea de regresión se calcula por el método de mínimos cuadrados. Un residuo es la diferencia entre un punto de referencia en particular (xi, yi) y el modelo de predicción ( y = a + bx ). El modelo se define de tal manera que la suma de los cuadrados de los residuales es un mínimo. La suma residual de los cuadrados es llamada con frecuencia la suma de los cuadrados de los errores (SSE) acerca de la línea de regresión yi y = b0 + b1x ei • • • • • a y b son Estimados de 0 y 1 • • • • • • • • • • • • • • • • • • • • • • • • xi SSE = ei2 = yi - yi2
 y el modelo de predicción ( y = a + bx ). El modelo se define de tal manera que la suma de los cuadrados de los residuales es un mínimo. La suma residual de los cuadrados es llamada con frecuencia la suma de los cuadrados de los errores (SSE) acerca de la línea de regresión. yi. y = b0 + b1x. ei. • • • • • a y b son. Estimados de. 0 y 1. • • • • • • • • • • • • • • • • • • • • • • • • xi. SSE = ei2 = yi - yi2.")
74
Gráfica de la Línea de Ajuste
Recta de regresión Y= X R2 = .895 600 Retención 500 Regresión 95% Intervalo de confianza de predicción 400 0.18 0.19 0.20 Altura del muelle

75
Interpretación de los Resultados
La ecuación de regresión (Y = X) describe la relación entre la variable predictora X y la respuesta de predicción Y. R2 (coef. de determinación) es el porcentaje de variación explicado por la ecuación de regresión respecto a la variación total en el modelo El intervalo de confianza es una banda con un 95% de confianza de encontrar la Y media estimada para cada valor de X [Líneas rojas] El intervalo de predicción es el grado de certidumbre de la difusión de la Y estimada para puntos individuales X. En general, 95% de los puntos individuales (provenientes de la población sobre la que se basa la línea de regresión), se encontrarán dentro de la banda [Líneas azules]
 describe la relación entre la variable predictora X y la respuesta de predicción Y. R2 (coef. de determinación) es el porcentaje de variación explicado por la ecuación de regresión respecto a la variación total en el modelo. El intervalo de confianza es una banda con un 95% de confianza de encontrar la Y media estimada para cada valor de X [Líneas rojas] El intervalo de predicción es el grado de certidumbre de la difusión de la Y estimada para puntos individuales X. En general, 95% de los puntos individuales (provenientes de la población sobre la que se basa la línea de regresión), se encontrarán dentro de la banda [Líneas azules]")
76
Interpretación de los Resultados
Los valores “p” de la constante (intersección en Y) y las variables de predicción, se leen igual que en la prueba de hipótesis. Ho: El factor no es significativo en la predicción de la respuesta. Ha: El factor es significativo en la predicción de la respuesta. s es el “error estándar de la predicción” = desviación estándar del error con respecto a la línea de regresión. R2 (ajustada) es el porcentaje de variación explicado por la regresión, ajustado por el número de términos en el modelo y por el número de puntos de información. El valor “p” para la regresión se usa para ver si el modelo completo de regresión es significativo. Ho: El modelo no es significativo en la predicción de la respuesta. Ha: El modelo es significativo en la predicción de la respuesta.
 y las variables de predicción, se leen igual que en la prueba de hipótesis. Ho: El factor no es significativo en la predicción de la respuesta. Ha: El factor es significativo en la predicción de la respuesta. s es el error estándar de la predicción = desviación estándar del. error con respecto a la línea de regresión. R2 (ajustada) es el porcentaje de variación explicado por la regresión, ajustado por el número de términos en el modelo y por. el número de puntos de información. El valor p para la regresión se usa para ver si el modelo completo de regresión es significativo. Ho: El modelo no es significativo en la predicción de la respuesta. Ha: El modelo es significativo en la predicción de la respuesta.")
77
Errores residuales Los errores se denominan frecuentemente residuales. Podemos observar en la gráfica de regresión los errores indicados por segmentos verticales.

78
Ejemplo Considere el problema de predecir las ventas mensuales en función del costo de publicidad. Calcular el coeficiente de correlación, el de determinación y la recta. MES Publicidad Ventas

79
Riesgos de la regresión
Los modelos de regresión son válidos como ecuaciones de interpolación sobre el rango de las variables utilizadas en el modelo. No pueden ser válidas para extrapolación fuera de este rango. Mientras que todos los puntos tienen igual peso en la determinación de la recta, su pendiente está más influenciada por los valores extremos de X.

80
Riesgos de la regresión
Los outliers u observaciones aberrantes pueden distorsionar seriamente el ajuste de mínimos cuadrados. Si se encuentra que dos variables están relacionadas fuertemente, no implica que la relación sea casual, se debe investigar la relación causa – efecto entre ellas. Por ejemplo el número de enfermos mentales vs. número de licencias recibidas.

81
Ejercicio Calcular la recta de predicción con sus bandas de confianza, la correlación y la determinación para la respuesta de un Taxi, los datos se muestran a continuación: Distancia Tiempo

82
Regresión lineal múltiple

83
Regresión múltiple Cuando se usa más de una variable independiente para predecir los valores de una variable dependiente, el proceso se llama análisis de regresión múltiple, incluye el uso de ecuaciones lineales. Se asume que los errores u tienen las características siguientes: Tienen media cero y varianza común 2. Son estadísticamente independientes. Están distribuidos en forma normal.

84
Multicolinealidad Una prueba fácil de probar si hay multicolinealidad entre dos variables es que su coeficiente de correlación sea mayor a 0.7 Los elementos de la diagonal principal de la matriz X’X se denominan Factores de inflación de varianza (VIFs) y se usan como un diagnóstico importante de multicolinealidad. Para el componente j – ésimo se tiene: Si es mayor a 10 implica que se tienen serios problemas de multicolinealidad.
 y se usan como un diagnóstico importante de multicolinealidad. Para el componente j – ésimo se tiene: Si es mayor a 10 implica que se tienen serios problemas de multicolinealidad.")
85
HeatFlux Insolation East South North
Corrida en Minitab Se introducen los datos en varias columnas C1 a C5 incluyendo la respuesta Y (heatflux) y las variables predictoras X’s (North, South, East) HeatFlux Insolation East South North
 y las variables predictoras X’s (North, South, East) HeatFlux Insolation East South North")
86
Corrida en Minitab Utilzar el archivo de ejemplo Exh_regr.mtw
Opción: Stat > Regression > Regression Para regresión lineal indicar la columna de respuesta Y (Score2) y X (Score1) En Regresión lienal en opciones se puede poner un valor Xo para predecir la respuesta e intervalos. Las gráficas se obtienen Stat > Regression > Regression > Fitted line Plots Para regresión múltiple Y (heatflux) y las columnas de los predictores (north, south, east)
 y X (Score1) En Regresión lienal en opciones se puede poner un valor Xo para predecir la respuesta e intervalos. Las gráficas se obtienen Stat > Regression > Regression > Fitted line Plots. Para regresión múltiple Y (heatflux) y las columnas de los predictores (north, south, east)")
87
Resultados de la regresión lineal
The regression equation is Score2 = Score1 Predictor Coef SE Coef T P Constant Score S = R-Sq = 95.7% R-Sq(adj) = 95.1% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) New Obs Score1
 = 95.1% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Predicted Values for New Observations. New Obs Fit SE Fit 95.0% CI 95.0% PI ( , ) ( , ) New Obs Score")
88
Resultados de la regresión lineal

89
Resultados de la regresión Múltiple
The regression equation is HeatFlux = North South East Predictor Coef SE Coef T P Constant North South East S = R-Sq = 87.4% R-Sq(adj) = 85.9% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Source DF Seq SS North South East
 = 85.9% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Source DF Seq SS. North South East")
90
Resumen de la Regresión
La regresión sólo puede utilizarse con información de variables continuas. Los residuos deben distribuirse normalmente con media cero. Importancia práctica: (R2). Importancia estadística: (valores p) La regresión puede usarse con un “predictor” X o más, para una respuesta dada Reduzca el modelo de regresión cuando sea posible, sin perder mucha importancia práctica
. Importancia estadística: (valores p) La regresión puede usarse con un predictor X o más, para una respuesta dada. Reduzca el modelo de regresión cuando sea posible, sin perder mucha importancia práctica.")
91
IV.B Pruebas de hipótesis

92
IV.B. Pruebas de hipótesis
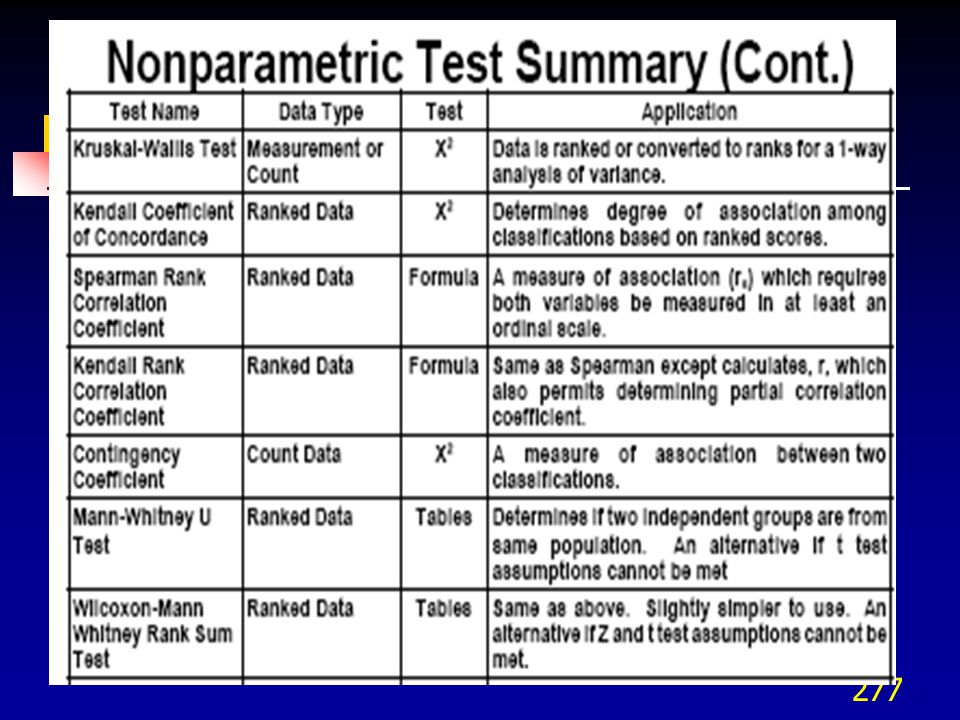
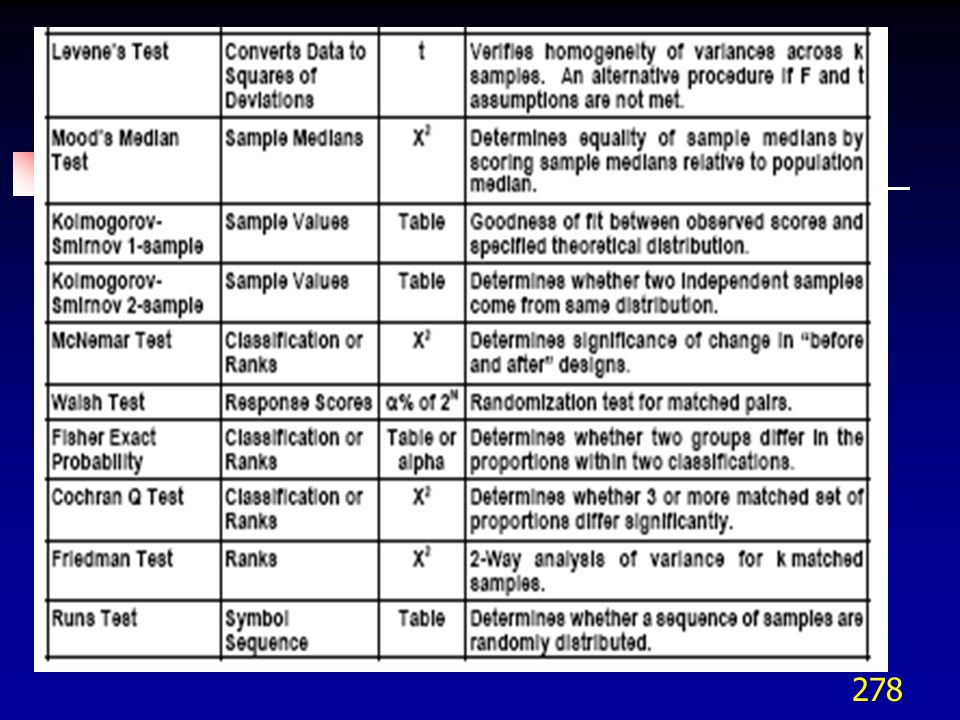
1. Conceptos fundamentales 2. Pruebas para medias, varianzas y proporciones 3. Pruebas pareadas de medias 4. Análisis de varianza (ANOVA) 5. Tablas de contingencia 6. Pruebas no paramétricas
 5. Tablas de contingencia. 6. Pruebas no paramétricas.")
93
IV.B.1 Conceptos fundamentales

94
Análisis Estadístico En CADA prueba estadística, se comparan algunos valores observados a algunos esperados u otro valor observado comparando estimaciones de parámetros (media, desviación estándar, varianza) Estas estimaciones de los VERDADEROS parámetros son obtenidos usando una muestra de datos y calculando los ESTADÏSTICOS... La capacidad para detectar un diferencia entre lo que es observado y lo que es esperado depende del desarrollo de la muestra de datos Incrementando el tamaño de la muestra mejora la estimación y tu confianza en las conclusiones estadísticas. La palabra parámetro es usada para cubrir la media, desviación estándar, kurtosis, skew - aquellos métricos usado para caracterizar la distribución subrayada Población - El total de posibilidades de todas las partes del proceso “Known but to God” => Media de la población xbar => Media de la población => Sigma de población hat => Sigma de la muestra Cuesta dinero y toma tiempo analizar la muestra. Se debe limitar a lo que es requerido
 Estas estimaciones de los VERDADEROS parámetros son obtenidos usando una muestra de datos y calculando los ESTADÏSTICOS... La capacidad para detectar un diferencia entre lo que es observado y lo que es esperado depende del desarrollo de la muestra de datos. Incrementando el tamaño de la muestra mejora la estimación y tu confianza en las conclusiones estadísticas. La palabra parámetro es usada para cubrir la media, desviación estándar, kurtosis, skew - aquellos métricos usado para caracterizar la distribución subrayada. Población - El total de posibilidades de todas las partes del proceso Known but to God => Media de la población. xbar => Media de la población. => Sigma de población. hat => Sigma de la muestra. Cuesta dinero y toma tiempo analizar la muestra. Se debe limitar a lo que es requerido.")
95
Conceptos fundamentales
Hipótesis nula Ho Es la hipótesis o afirmación a ser probada Puede ser por ejemplo , , , = 5 Sólo puede ser rechazada o no rechazada Hipótesis alterna Ha Es la hipótesis que se acepta como verdadera cuando se rechaza Ho, es su complemento Puede ser por ejemplo = 5 para prueba de dos colas < 5 para prueba de cola izquierda > 5 para prueba de cola derecha Esta hipótesis se acepta cuando se rechaza Ho

96
Conceptos fundamentales
Ejemplos: Se está investigando si una semilla modificada proporciona una mayor rendimiento por hectárea, la hipótesis nula de dos colas asumirá que los rendimientos no cambian Ho: Ya = Yb Se trata de probar si el promedio del proceso A es mayor que el promedio del proceso B. La hipótesis nula de cola derecha establecerá que el proceso A es <= Proceso B. O sea Ho: A <= B.

97
Conceptos fundamentales
Estadístico de prueba Para probar la hipótesis nula se calcula un estadístico de prueba con la información de la muestra el cual se compara a un valor crítico apropiado. De esta forma se toma una decisión sobre rechazar o no rechazar la Ho Error tipo I (alfa = nivel de significancia, normal=.05) Se comete al rechazar la Ho cuando en realidad es verdadera. También se denomina riesgo del productor Error tipo II (beta ) Se comete cuando no se rechaza la hipótesis nula siendo en realidad falsa. Es el riesgo del consumidor
 Se comete al rechazar la Ho cuando en realidad es verdadera. También se denomina riesgo del productor. Error tipo II (beta ) Se comete cuando no se rechaza la hipótesis nula siendo en realidad falsa. Es el riesgo del consumidor.")
98
Conceptos fundamentales
Tipos de errores Se asume que un valor pequeño para es deseable, sin embargo esto incrementa el riesgo . Para un mismo tamaño de muestra n ambos varían inversamente Incrementando el tamaño de muestra se pueden reducir ambos riesgos. Decisión realizada Ho en realidad es Verdadera Ho en realidad es falsa No hay evidencia para rechazar Ho p = 1- Decisión correcta p = Error tipo II Rechazar Ho p = Error tipo I p = 1 -

99
Conceptos fundamentales
Pruebas de dos colas Si la Ho: , , , = cte. que un valor poblacional, entonces el riesgo alfa se reparte en ambos extremos de la distribución. Por ejemplo si Ho = 10 se tiene:

100
Conceptos fundamentales
Pruebas de una cola Si la Ho: , , , >= Cte. que un valor poblacional, entonces el riesgo alfa se coloca en la cola izquierda de la distribución. Por ejemplo si Ho: >= 10 y Ha: < 10 se tiene una prueba de cola izquierda:

101
Conceptos fundamentales
Pruebas de una cola Si la Ho: , , , <= Cte. que un valor poblacional, entonces el riesgo alfa se coloca en la cola derecha de la distribución. Por ejemplo si Ho: <= 10 y Ha: > 10 se tiene una prueba de cola derecha:

102
Conceptos fundamentales
Tamaño de muestra requerido Normalmente se determina el error alfa y beta deseado y después se calcula el tamaño de muestra necesario para obtener el intervalo de confianza. El tamaño de muestra (n) necesario para la prueba de hipótesis depende de: El riesgo deseado tipo I alfa y tipo II Beta El valor mínimo a ser detectado entre las medias de la población (Mu – Mu0) La variación en la característica que se mide (S o sigma)
 necesario para la prueba de hipótesis depende de: El riesgo deseado tipo I alfa y tipo II Beta. El valor mínimo a ser detectado entre las medias de la población (Mu – Mu0) La variación en la característica que se mide (S o sigma)")
103
Conceptos fundamentales
El Tamaño de muestra requerido en función del error máximo E o Delta P intervalo proporcional esperado se determina como sigue:

104
Conceptos fundamentales
Ejemplo: ¿Cuál es el tamaño de muestra mínimo que al 95% de nivel de confianza (Z=1.96) confirma la significancia de una corrida en la media mayor a 4 toneladas/hora (E), si la desviación estándar (sigma) es de 20 toneladas? n = (1.96^2)(20^2)/(4)^2 = 96 Obtener 96 valores de rendimiento por hora y determinar el promedio, si se desvía por más de 4 toneladas, ya ha ocurrido un cambio significativo al 95% de nivel de confianza
 confirma la significancia de una corrida en la media mayor a 4 toneladas/hora (E), si la desviación estándar (sigma) es de 20 toneladas n = (1.96^2)(20^2)/(4)^2 = 96. Obtener 96 valores de rendimiento por hora y determinar el promedio, si se desvía por más de 4 toneladas, ya ha ocurrido un cambio significativo al 95% de nivel de confianza.")
105
Pruebas de Minitab Permite hacer las siguientes pruebas:
Prueba z de una muestra Prueba t de una muestra Prueba t de dos muestras Prueba de 1 proporción Prueba de 2 proporciones ANOVA Diseños factoriales de dos niveles Diseños de Packett Burman

106
Estimación puntual y por intervalo

107
7B2. Estimación puntual y por intervalo
Las medias o desviaciones estándar calculadas de una muestra se denominan ESTADÍSTICOS, podrían ser consideradas como un punto estimado de la media y desviación estándar real de población o de los PARAMETROS. ¿Qué pasa si no deseamos una estimación puntual como media basada en una muestra, qué otra cosa podríamos obtener como margen, algún tipo de error? “Un Intervalo de Confianza”

108
Intervalo de confianza
Error de estimación

109
Estimación puntual y por intervalo
¿Cómo obtenemos un intervalo de confianza? Estimación puntual + error de estimación ¿De dónde viene el error de estimación? Desv. estándar X multiplicador de nivel de confianza deseado Z/2 Por Ejemplo: Si la media de la muestra es 100 y la desviación estándar es 10, el intervalo de confianza al 95% donde se encuentra la media para una distribución normal es: 100 + (10) X 1.96 => (80.4, 119.6) = Z0.025
 X 1.96 => (80.4, 119.6) 1.96 = Z")
110
Estimación puntual y por intervalo
95% de Nivel de Confianza significa que sólo tenemos un 5% de oportunidad de obtener un punto fuera de ese intervalo. Esto es el 5% total, o 2.5% mayor o menor. Si vamos a la tabla Z veremos que para un área de 0.025, corresponde a una Z de C. I Multiplicador Z/2 Para tamaños de muestra >30, o conocida usar la distribución Normal Para muestras de menor tamaño, o desconocida usar la distribución t

111
Estimación puntual y por intervalo
; con n-1 gl.

112
Instrucciones con Minitab Intervalo de confianza para la media
Stat > Basic Statistics > 1-Sample Z, t Variable -- Indicar la columna de los datos o Summarized Data En caso de requerirse dar el valor de Sigma = dato En Options: Indicar el Confidence level -- 90, 95 o 99% OK

113
Instrucciones con Minitab Intervalo de confianza para proporción
Stat > Basic Statistics > 1-Proportion Seleccionar Summarized Data Number of trials = n tamaño de la muestra Number of events = D éxitos encontrados en la muestra En Options: Indicar el Confidence Interval -- 90, 95 o 99% Seleccionar Use test and interval based in normal distribution

114
Para n grande el IC es pequeño

115
Ejemplo Dadas las siguientes resistencias a la tensión: 28.7, 27.9, 29.2 y 26.5 psi Estimar la media puntual X media = con S = 1.02 Estimar el intervalo de confianza para un nivel de confianza del 95% (t = con n-1=3 grados de libertad) Xmedia±3.182*S/√n = 28.08±3.182*1.02/2=(26.46, 29.70)
 Xmedia±3.182*S/√n = 28.08±3.182*1.02/2=(26.46, 29.70)")
116
Ejemplos para la media con Distribución normal Z
Z 1. El peso promedio de una muestra de 50 bultos de productos Xmedia = Kgs., con S = Kgs. Determinar el intervalo de confianza al NC del 95% y al 99% donde se encuentra la media del proceso (poblacional). Alfa = 1 - NC 2. Un intervalo de confianza del 90% para estimar la ganancia promedio del peso de ratones de laboratorio oscila entre 0.93 y 1.73 onzas. ¿Cuál es el valor de Z?. latas de 16 onzas de salsa de tomate tienen una media de Xmedia = 15.2 onzas con una S = 0.96 onzas. ¿A un nivel de confianza del 95%, las latas parecen estar llenas con 16 onzas?. 4. Una muestra de 16 soluciones tienen un peso promedio de 16.6 onzas con S = Se rechaza la solución si el peso promedio de todo el lote no excede las 18 onzas. ¿Cuál es la decisión a un 90% de nivel de confianza?.
. Alfa = 1 - NC. 2. Un intervalo de confianza del 90% para estimar la ganancia promedio del peso de ratones de laboratorio oscila entre 0.93 y 1.73 onzas. ¿Cuál es el valor de Z latas de 16 onzas de salsa de tomate tienen una media de Xmedia = 15.2 onzas con una S = 0.96 onzas. ¿A un nivel de confianza del 95%, las latas parecen estar llenas con 16 onzas . 4. Una muestra de 16 soluciones tienen un peso promedio de 16.6 onzas con S = Se rechaza la solución si el peso promedio de todo el lote no excede las 18 onzas. ¿Cuál es la decisión a un 90% de nivel de confianza .")
117
Ejemplos para la media y varianza con Distribución t
t cajas de producto pesaron 102 grs. Con S = 8.5 grs. ¿Cuál es el intervalo donde se encuentra la media y varianza del lote para un 90% de nivel de confianza?. Grados libertad=20 -1 =19 6. Una muestra de 25 productos tienen un peso promedio de grs. Con una S = ¿Cuál es la estimación del intervalo de confianza para la media y varianza a un nivel de confianza del 95 y del 98% del peso de productos del lote completo?. 7. Los pesos de 25 paquetes enviados a través de UPS tuvieron una media de 3.7 libras y una desviación estándar de 1.2 libras. Hallar el intervalo de confianza del 95% para estimar el peso promedio y la varianza de todos los paquetes. Los pesos de los paquetes se distribuyen normalmente.

118
Ejemplos para proporciones con Distribución Z
Z 8. De 814 encuestados 562 contestaron en forma afirmativa. ¿Cuál es el intervalo de confianza para un 90% de nivel de confianza? 9. En una encuesta a 673 tiendas, 521 reportaron problemas de robo por los empleados ¿Se puede concluir con un 99% de nivel de confianza que el 78% se encuentra en el intervalo de confianza. ?

119
IV.B.2b Pruebas de hipótesis para media, varianza y proporción

120
Elementos de una Prueba de Hipótesis
Prueba Estadística- Procedimiento para decidir no rechazar Ho aceptando Ha o rechazar Ho. Hipótesis Nula (Ho) - Usualmente es una afirmación representando una situación “status quo”. Generalmente deseamos rechazar la hipótesis nula. Hipótesis Alterna (Ha) - Es lo que aceptamos si podemos rechazar la hipótesis nula. Ha es lo que queremos probar.
 - Usualmente es una afirmación representando una situación status quo . Generalmente deseamos rechazar la hipótesis nula. Hipótesis Alterna (Ha) - Es lo que aceptamos si podemos rechazar la hipótesis nula. Ha es lo que queremos probar.")
121
Elementos de una Prueba de Hipótesis
Estadístico de prueba: Calculado con datos de la muestra (Z, t, X2 or F). Región de Rechazo Indica los valores de la prueba estadística para que podamos rechazar la Hipótesis nula (Ho). Esta región esta basada en un riesgo deseado, normalmente 0.05 o 5%.
. Región de Rechazo Indica los valores de la prueba estadística para que podamos rechazar la Hipótesis nula (Ho). Esta región esta basada en un riesgo deseado, normalmente 0.05 o 5%.")
122
Pasos en la Prueba de Hipótesis
1. Definir el Problema - Problema Práctico 2. Señalar los Objetivos - Problema Estadístico 3. Determinar tipo de datos - Atributo o Variable 4. Si son datos Variables - Prueba de Normalidad

123
Pasos en la Prueba de Hipótesis
5. Establecer las Hipótesis - Hipótesis Nula (Ho) - Siempre tiene el signo =, , - Hipótesis Alterna (Ha) – Tiene signos , > o <. El signo de la hipótesis alterna indica el tipo de prueba a usar
 - Siempre tiene el signo =, , - Hipótesis Alterna (Ha) – Tiene signos , > o <. El signo de la hipótesis alterna indica el tipo de prueba a usar.")
124
Pasos en la Prueba de Hipótesis
6. Seleccionar el nivel de Alfa (normalmente 0.05 o 5%) o el nivel de confianza NC = 1 - alfa 7. Establecer el tamaño de la muestra, >= 10. 8.Desarrollar el Plan de Muestreo 9.Seleccionar Muestras y Obtener Datos 10. Decidir la prueba estadística apropiada y calcular el estadístico de prueba (Z, t, X2 or F) a partir de los datos.
 o el nivel de confianza NC = 1 - alfa. 7. Establecer el tamaño de la muestra, >= Desarrollar el Plan de Muestreo. 9.Seleccionar Muestras y Obtener Datos. 10. Decidir la prueba estadística apropiada y calcular el estadístico de prueba (Z, t, X2 or F) a partir de los datos.")
125
Estadísticos para medias, varianzas y proporciones

126
Estadísticos para medias, varianzas y proporciones
Para el caso de muestras pareadas se calculan las diferencias d individuales como sigue:

127
Pasos en la Prueba de Hipótesis
11. Obtener el estadístico correspondiente de tablas o Excel. 12.Determinar la probabilidad de que el estadístico de prueba calculado ocurre al azar. 13.Comparar el estadístico calculado con el de tablas y ver si cae en la región de rechazo o ver si la probabilidad es menor a alfa, rechaze Ho y acepte Ha. En caso contrario no rechaze Ho. 14.Con los resultados interprete una conclusión estadística para la solución práctica.

128
Prueba de Hipótesis Estadístico Calculado con Datos de la muestra
Pruebas de Hipótesis de dos colas: Ho: a = b Ha: a b Pruebas de Hipótesis de cola derecha: Ho: a b Ha: a > b Pruebas de Hipótesis cola izquierda: Ho: a b Ha: a < b Región de Rechazo Región de Rechazo -Z Z Región de Rechazo Z Región de Rechazo -Z Z

129
Prueba de hipótesis para la varianza
Las varianzas de la población se ditribuyen de acuerdo a la distribución Chi Cuadrada. Por tanto las inferencias acerca de la varianza poblacional se basarán en este estadístico La distribución Chi Cuadrada se utiliza en: Caso I. Comparación de varianzas cuando la varianza de la población es conocida Caso II. Comparando frecuencias observadas y esperadas de resultados de pruebas cuando no hay una varianza de la población definida (datos por atributos)
")
130
Prueba de hipótesis para la varianza
Las pruebas de hipótesis para comparar una varianza poblacional a un cierto valor constante 0, si la población sigue la distribución normal es: Con el estadístico Chi Cuadrada con n-1 grados de libertad

131
Prueba de hipótesis para la varianza
2.17 Ejemplo: ¿El material muestra una variación (sigma) en la resistencia a la tensión menor o igual a 15 psi con 95% de confianza?. En una muestra de 8 piezas se obtuvo una S = 8psi. X^2c =(7)(8)^2/(15)^2 = 1.99 Como La Chi calculada es menor a la Chi de Excel de 2.17 se debe rechazar la hipótesis nula. Si hay decremento en la resistencia
 en la resistencia a la tensión menor o igual a 15 psi con 95% de confianza . En una muestra de 8 piezas se obtuvo una S = 8psi. X^2c =(7)(8)^2/(15)^2 = Como La Chi calculada es menor a la Chi de Excel de 2.17 se debe rechazar la hipótesis nula. Si hay decremento en la resistencia.")
132
Prueba de hipótesis para atributos
Ejemplo: Un supervisor quiere evaluar la habilidad de 3 inspectores para detectar radios en el equipaje en un aeropuerto. ¿Hay diferencias significativas para un 95% de confianza? Valores observados O Inspector 1 Inspector 2 Inspector 3 Total por tratamiento Radios detectados 27 25 22 74 Radios no detectados 3 5 8 16 Total de la muestra 30 90

133
Prueba de hipótesis para atributos
Ho: p1 = p2 = p3 Ha: p1 p2 p3 Grados de libertad = (No. de columnas -1)*(No. renglones -1) Las frecuencias esperadas son: (Total columna x Total renglón) Valores esperados E Inspector 1 Inspector 2 Inspector 3 Total por tratamiento Radios detectados 24.67 74 Radios no detectados 5.33 16 Total de la muestra 30 90
*(No. renglones -1) Las frecuencias esperadas son: (Total columna x Total renglón) Valores esperados E. Inspector 1. Inspector 2. Inspector 3. Total por tratamiento. Radios detectados Radios no detectados Total de la muestra")
134
Prueba de hipótesis para atributos
El estadístico Chi Cuadrado en este caso es: El estadístico Chi Cuadrada de alfa = 0.05 para 4 grados de libertad es 5.99. El estadístico Chi Cuadrada calculada es menor que Chi de alfa, por lo que no se rechaza Ho y las habilidades son similares 5.99

135
Ejemplo de Prueba de hipótesis para la media
Para una muestra grande (n>30)probar la hipótesis de una media u 1.) Ho: 2.) Ha: 3.) Calcular el estadístico de prueba 4.) Establecer la región de rechazo Las regiones de rechazo para prueba de 2 colas: -Z y Z Zcalc= s n Región de Rechazo Región de Rechazo -Z Z Si el valor del estadístico de prueba cae en la región de rechazo rechazaremos Ho de otra manera no podemos rechazar Ho.
probar la hipótesis de una media u. 1.) Ho: 2.) Ha: 3.) Calcular el estadístico de prueba. 4.) Establecer la región de rechazo. Las regiones de rechazo para prueba de 2 colas: -Z y Z Zcalc= s. n. Región de. Rechazo. Región de. Rechazo. -Z Z Si el valor del estadístico de prueba cae en la región de rechazo rechazaremos Ho de otra manera no podemos rechazar Ho.")
136
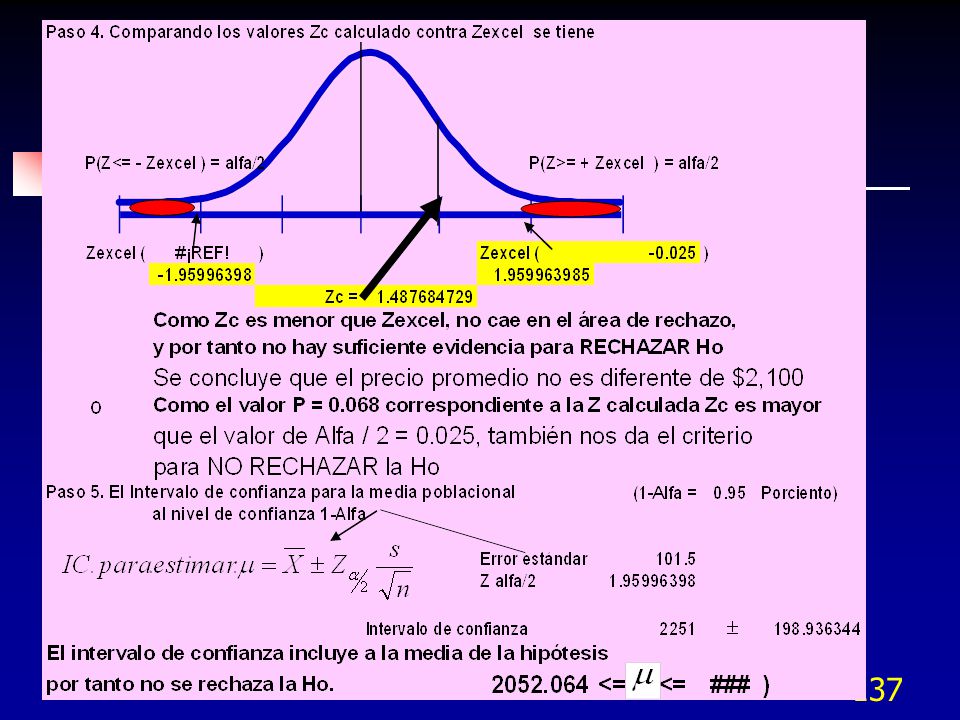
Prueba de hipótesis de una población para muestras grandes con Z

138
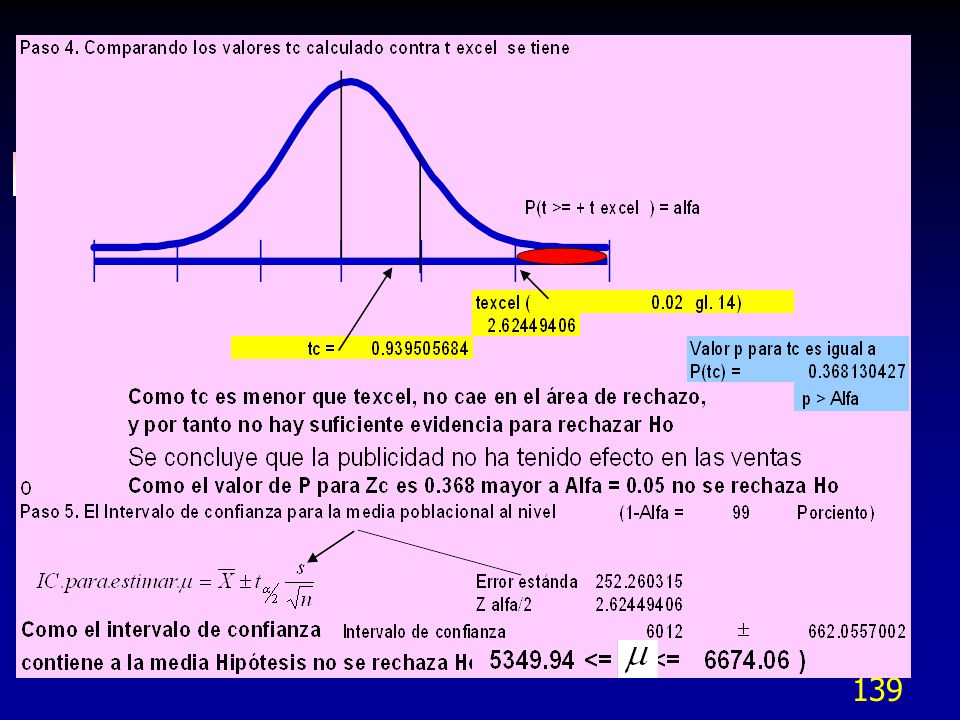
Prueba de hipótesis de una población para muestras pequeñas con t
Gl=14;

140
Instrucciones con Minitab para la prueba de hipótesis de una media
Stat > Basic Statistics > 1-Sample Z, t Variable -- Indicar la columna de los datos o Summarized Data En caso de requerirse dar el valor de Sigma = dato Proporcionar la Media de la hipótesis Test Mean En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than OK

141
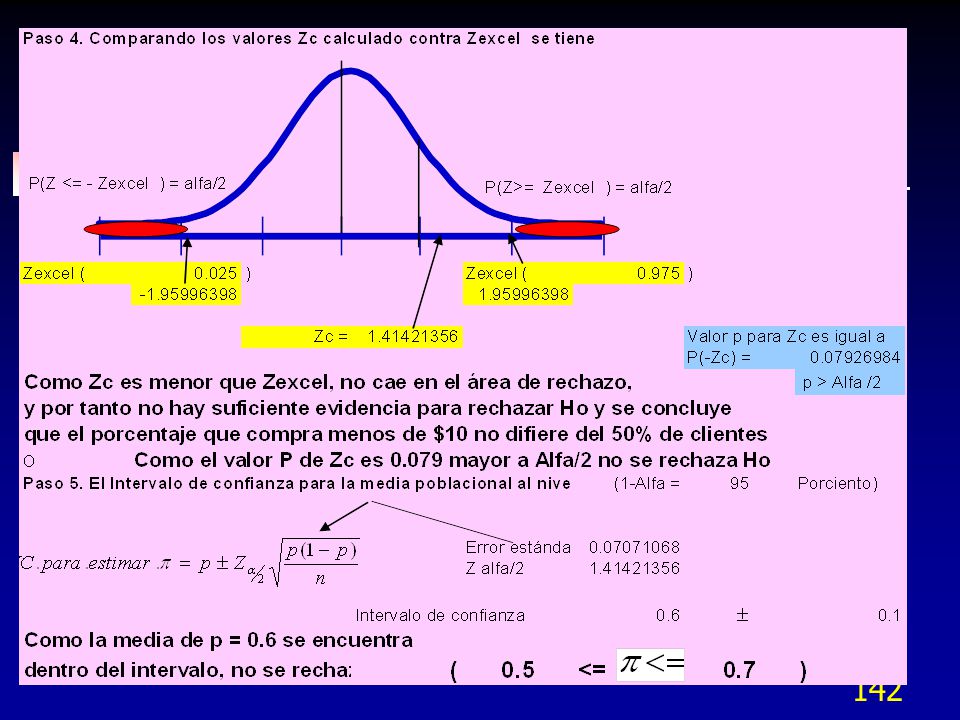
Prueba de hipótesis para una proporción con Z

143
Instrucciones con Minitab para la prueba de hipótesis de una proporción
Stat > Basic Statistics > 1-Proportion Seleccionar Summarized Data Number of trials = n tamaño de la muestra Number of events = D éxitos encontrados en la muestra En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la Test Proportion Proporción de la hipótesis Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than Seleccionar Use test and interval based in normal distribution OK

144
IV.B.2b Pruebas de hipótesis para comparación de varianzas, medias, y proporciones

145
Prueba de Hipótesis Supongamos que tenemos muestras de dos reactores que producen el mismo artículo. Se desea ver si hay diferencia significativa en el rendimiento de “Reactor a Reactor”. Reactor A Reactor B Estadísticas Descriptivas Variable Reactor N Media Desv.Std Rendimiento A B

146
Estaba mal hecha la traducción del
inglés al español Revisó M. Yris 4-Mar-99 Prueba de Hipótesis Pregunta Práctica: Existe diferencia entre los reactores? Pregunta estadística ¿La media del Reactor B (85.54) es significativamente diferente de la media del Reactor A (84.24)? O, su diferencia se da por casualidad en una variación de día a día. Ho: Hipótesis Estadística: No existe diferencia entre los Reactores Ha: Hipótesis Alterna: Las medias de los Reactores son diferentes. Se busca demostrar que los valores observados al parecer no corresponden al mismo proceso, se trata de rechazar Ho.
 es significativamente diferente de la media del Reactor A (84.24) O, su diferencia se da por casualidad en una variación de día a día. Ho: Hipótesis Estadística: No existe diferencia entre los Reactores. Ha: Hipótesis Alterna: Las medias de los Reactores son diferentes. Se busca demostrar que los valores observados al parecer no corresponden al mismo proceso, se trata de rechazar Ho.")
147
The Null Hypothesis is always stated as the thing we are trying to disprove. It states the status quo, that nothing has changed, that whatever you did had no effect. Prueba de Hipótesis Hipótesis Estadística: No existe diferencia entre los Reactores Esto se llama Hipótesis Nula (Ho) Hipótesis Alterna: Cuando las medias de Reactores son diferentes. A esto se le llama Hipótesis Alterna (Ha) Debemos demostrar que los valores que observamos al parecer no corresponden al mismo proceso, que la Ho debe estar equivocada
 Hipótesis Alterna: Cuando las medias de Reactores son diferentes. A esto se le llama Hipótesis Alterna (Ha) Debemos demostrar que los valores que observamos al parecer no corresponden al mismo proceso, que la Ho debe estar equivocada.")
148
¿Qué representa esto? Reactor A Reactor B
Gramática y ortografía estaban mal. Corregidas M. Yris 4-Mar-99 ¿Qué representa esto? Reactor A Reactor B A AA AAAA A A B B B B B BB B B B ¿Representan los reactores dos procesos diferentes? ¿Representan los reactores un proceso básico?

149
Prueba F de dos varianzas
Si se toman dos muestras de dos poblaciones normales con varianzas iguales, la razón de sus varianzas crea una distribución muestral F. Las hipótesis son las siguientes: El estadístico F se muestra a continuación donde S1 se acostumbra tomar como la mayor

150
Prueba F de dos varianzas
Sea S1 = 900 psi, n1 = 9, s2 = 300 psi, n2 = 7. A un 95% de nivel de confianza se puede concluir que hay menor variación? Ho: Varianza 1 <= Varianza H1: Varianza 1 > Varianza 2 Grados de libertad para Var1 = 8 y para var 2 = 6 Falfa = F(0.05, 8, 6) = 4.15 Fcalculada = (900^2)/(300^2) = 9 >> Falfa, se rechaza Ho. Hay evidencia suficiente para indicar que la variación ya se ha reducido
 = Fcalculada = (900^2)/(300^2) = 9 >> Falfa, se rechaza Ho. Hay evidencia suficiente para indicar que la variación ya se ha reducido.")
151
Prueba de hipótesis de dos pob. comparando varianzas con F

153
Instrucciones con Minitab para la comparación de dos varianzas
Stat > Basic Statistics > 2-variances Seleccionar samples in different columns o Summarized data First-- Indicar la columna de datos de la muestra 1 Second- Indicar la columna de datos de la muestra 2 En Options: Indicar el Confidence Interval -- 90, 95 o 99% OK

154
Prueba de hipótesis de dos pob. Comparando dos medias con Z

156
Prueba de dos medias muestras pequeñas
Sigmas descono- cidas e iguales Sigmas desconocidas y desiguales

157
Prueba de hipótesis de dos pob. Comparando dos medias con t

159
Instrucciones con Minitab para la comparación de dos medias
Stat > Basic Statistics > 2-Sample t Seleccionar samples in different columns o Summarized data First-- Indicar la columna de datos de la muestra 1 Second- Indicar la columna de datos de la muestra 2 Seleccionar o no seleccionar Assume equal variances de acuerdo a los resultados de la prueba de igualdad de varianzas En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la diferencia a probar Test Difference (normalmente 0) Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than En graphs seleccionar las graficas Boxplot e Individual value plot OK
 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than. En graphs seleccionar las graficas Boxplot e Individual value plot. OK.")
160
Prueba de hipótesis de dos pob. Comparando dos proporciones con Z

162
Instrucciones con Minitab para la prueba de hipótesis de dos proporciones
Stat > Basic Statistics > 2-Proportions Seleccionar Summarized Data Trials: Events: First: No. de elementos de la 1ª. Muestra y D1 éxitos encontrados Second: No. de elementos de la 2ª. Muestra y D2 éxitos encontrados En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la Test Difference Normalmente 0 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than Seleccionar Use pooled estimate of p for test OK

163
IV.B.3 Prueba de datos pareados

164
Prueba de hipótesis de dos pob. Comparando datos pareados con t
Grados de libertad = No. de pares - 1

166
Instrucciones con Minitab para la comparación de dos medias pareadas
Stat > Basic Statistics > Paired t Seleccionar samples in columns o Summarized data First sample Indicar la columna de datos de la muestra 1 Second sample - Indicar la columna de datos de la muestra 2 En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la diferencia a probar Test Mean (normalmente 0) Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than En graphs seleccionar las graficas Boxplot e Individual value plot OK
 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than. En graphs seleccionar las graficas Boxplot e Individual value plot. OK.")
167
Robustez Los procedimientos estadísticos se basan en supuestos acerca de su comportamiento teórico. Cuando los estadísticos obtenidos no son afectados por desviaciones moderadas de su expectativa teórica, se dice que son robustos.

168
Resumen

169
IV.B:4 ANOVA para un factor

170
Introducción Cuando es necesario comparar 2 o más medias poblacionales al mismo tiempo, para lo cual se usa ANOVA. El método ANOVA tiene los siguientes supuestos: La varianza es la misma para todos los tratamientos del factor en todos sus niveles Las mediciones indiviudales dentro de cada tratamiento se distribuyen normalmente El término de error tiene un efecto distribuido normalmente e independiente

171
Introducción Con el ANOVA las variaciones en la respuesta se dividen en componentes que reflejan los efectos de una o más variables independientes La variabilidad se representa como la suma de cuadrados total que es la suma de cuadrados de las desviaciones de mediciones individuales respecto a la gran media, se divide en: Suma de cuadrados de las medias de los tratamientos Suma de cuadrados del residuo o error experimental

172
ANOVA – Prueba de hipótesis para probar la igualdad de medias de varias poblaciones para un factor
Se trata de probar si el efecto de un factor o Tratamiento en la respuesta de un proceso o sistema es Significativo, al realizar experimentos variando Los niveles de ese factor (Temp. 1, Temp. 2, Temp.3, etc.)
")
173
ANOVA - Condiciones Todas las poblaciones son normales
Todas las poblaciones tiene la misma varianza Los errores son independientes con distribución normal de media cero La varianza se mantiene constante para todos los niveles del factor

174
ANOVA – Ejemplo de datos
Niveles del Factor Peso % de algodón y Resistencia de tela

175
ANOVA – Suma de cuadrados total
Xij Gran media Xij

176
ANOVA – Suma de cuadrados de renglones (a)-tratamientos
Media Trat. 1 Media Trat. a a renglones Gran media Media trat. 2

177
ANOVA – Suma de cuadrados del error
X2j X3j X1j Media X1. Media X3. Media X2. Muestra Muestra Muestra 3

178
ANOVA – Suma de cuadrados del error
X2j X3j X1j Media X1. Media X3. Media X2. Muestra Muestra Muestra 3

179
ANOVA – Grados de libertad: Totales, Tratamientos, Error

180
ANOVA – Cuadrados medios: Total, Tratamiento y Error

181
ANOVA – Cálculo del estadístico Fc y Fexcel

182
Tabla final de ANOVA

183
ANOVA – Toma de decisión
Distribución F Fexcel Alfa Zona de rechazo De Ho o aceptar Ha Zona de no rechazo de Ho O de no aceptar Ha Fc

184
ANOVA – Toma de decisión
Si Fc es mayor que Fexcel se rechaza Ho Aceptando Ha donde las medias son diferentes O si el valor de p correspondiente a Fc es menor de Alfa se rechaza Ho

185
ANOVA – Identificar las medias diferentes por Prueba de Tukey T
Para diseños balanceado (mismo número de columnas en los tratamientos) el valor de q se determina por medio de la tabla en el libro de texto
 el valor. de q se determina por medio de la tabla en el libro de texto.")
186
ANOVA – Identificar las medias diferentes por Prueba de Tukey T
Se calcula la diferencia Di entre cada par de Medias Xi’s: D1 = X1 – X D2 = X1 – X3 D3 = X2 – X3 etc. Cada una de las diferencias Di se comparan con el valor de T, si lo exceden entonces la diferencia es Significativa de otra forma se considera que las medias Son iguales

187
ANOVA – Identificar las medias diferentes por Prueba de Diferencia Mínima Significativa DMS
Para diseños balanceados (los tratamientos tienen igual no. De columnas), se calcula un factor DMS contra el que se comparan las diferencias Xi – Xi’. Significativas si lo exceden
, se calcula un factor DMS contra el que se comparan las diferencias Xi – Xi’. Significativas si lo exceden.")
188
Prueba DMS para Diseños no balanceados
Para diseños no balanceados (los tratamientos tienen diferente no. De columnas), se calcula un factor DMS Para cada una de las diferencias Xi – Xi’
, se calcula un factor DMS. Para cada una de las diferencias Xi – Xi’")
189
Ejemplo: Considerar un experimento de un factor (máquina) con tres niveles (máquinas A, B, C). Los datos se muestran a continuación y debe verificarse si existe diferencia significativa a un alfa = 0.05 Su ma Máquinas Datos Prom.
 con tres niveles (máquinas A, B, C). Los datos se muestran a continuación y debe verificarse si existe diferencia significativa a un alfa = Su. ma. Máquinas. Datos. Prom.")
190
Ejemplo: La tabla completa de ANOVA es la siguientes:
Fuentes De variación Cuadrado medio Máquinas Como el valor calculado de F(33.2) excede el valor crítico de F, se rechaza la Hipótesis nula Ho
 excede el valor crítico de F, se rechaza la Hipótesis nula Ho.")
191
Ejemplo: Con Minitab: Stat>ANOVA>One way unstacked
Responses (in separate columns) A B C Interpretar los resultados A B C 5 2 1 7 6 -2 -3
 A B C. Interpretar los resultados. A. B. C")
192
Ejemplo: One-way ANOVA: A, B, C Source DF SS MS F P
Factor Rechazo Ho Error Total S = R-Sq = 84.69% R-Sq(adj) = 82.14% Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev A (-----*----) B (----*-----) C (-----*----) Pooled StDev = 1.438
 = 82.14% Individual 95% CIs For Mean Based on. Pooled StDev. Level N Mean StDev A (-----*----) B (----*-----) C (-----*----) Pooled StDev =")
193
Corrida en Minitab Se introducen las respuestas en una columna C1
Se introducen los subíndices de los renglones en una columna C2 Durability Carpet 7.19 2 7.03 2

194
Corrida en Minitab Opción: stat>ANOVA – One Way (usar archivo Exh_aov) En Response indicar la col. De Respuesta (Durability) En factors indicar la columna de subíndices (carpet) En comparisons (Tukey) Pedir gráfica de Box Plot of data y residuales Normal Plot y vs fits y orden Si los datos estan en columnas pedir ANOVA – One Way (unstacked)
 En comparisons (Tukey) Pedir gráfica de Box Plot of data y residuales Normal Plot y vs fits y orden. Si los datos estan en columnas pedir ANOVA – One Way (unstacked)")
195
Resultados One-way ANOVA: Durability versus Carpet Source DF SS MS F P
Carpet > No hay diferencia entre las medias Error Total S = R-Sq = 39.85% R-Sq(adj) = 29.82% Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev ( * ) ( * ) Pooled StDev = 3.368 Tukey 95% Simultaneous Confidence Intervals All Pairwise Comparisons among Levels of Carpet Individual confidence level = 95.00% Carpet = 1 subtracted from: Carpet Lower Center Upper ( * )
 = 29.82% Individual 95% CIs For Mean Based on. Pooled StDev. Level N Mean StDev ( * ) ( * ) Pooled StDev = Tukey 95% Simultaneous Confidence Intervals. All Pairwise Comparisons among Levels of Carpet. Individual confidence level = 95.00% Carpet = 1 subtracted from: Carpet Lower Center Upper ( * )")
196
IV.B.5 Uso de Prueba Chi2 (2)
Revisado por Mónica Yris el 4 de Marzo de 1999. Se cambió el diseño, se revisó ortografía y parcialmente se cotejo la traducción. Inglés- Español. Si se hicieron algunos cambios en la traducción y en algunas partes donde no se había traducido porque lo dejaron en ingles. 1

197
¿Para qué se utiliza? 1. Para probar si una serie de datos observada, concuerda con el modelo (serie esperada) de la información. 2. Para probar las diferencias entre las proporciones de varios grupos (tabla de contingencia). Para todos los casos, Ho: No hay diferencia Ha: Hay diferencia Aún si no se ajusta la información al modelo esperado de la prueba chi2 . Debido a que su información es atribuida, usted no puede utilizar la distribución normal para el modelo. Se requiere un número muy grande de muestras para obtener una prueba significativa (>30). En la mayoría de los casos, la Hipótesis de Nulidad no “se Diferencia” y existe la Alternativa como “una diferencia existente”. En el acercamiento de Seis Sigma, podemos: Empezar con un Problema Práctico Convertir el Problema práctico a un Problema estadístico Resolver el Problema estadístico y obtener una Solución estadística Convertir nuevamente la solución estadística a una solución práctica. 2 3
. Para todos los casos, Ho: No hay diferencia. Ha: Hay diferencia. Aún si no se ajusta la información al modelo esperado de la prueba chi2 . Debido a que su información es atribuida, usted no puede utilizar la distribución normal para el modelo. Se requiere un número muy grande de muestras para obtener una prueba significativa (>30). En la mayoría de los casos, la Hipótesis de Nulidad no se Diferencia y existe la Alternativa como una diferencia existente . En el acercamiento de Seis Sigma, podemos: Empezar con un Problema Práctico. Convertir el Problema práctico a un Problema estadístico. Resolver el Problema estadístico y obtener una Solución estadística. Convertir nuevamente la solución estadística a una solución práctica. 2. 3.")
198
Ejemplo 1: Chi Cuadrada( 2 )
Se lanza una moneda al aire 100 veces y que obtenemos 63 águilas y 37 soles. ¿La proporción de águilas y soles sucede por casualidad? O, se concluye que la moneda está “cargada”? Pregunte a la clase ¿quién piensa que la moneda es “genuina” y por qué y qué nivel de confianza tienen para estar en lo correcto? Ahora, pregunte quién piensa que la moneda está “cargada”, por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón (“genuina” o “cargada”), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 “a mano”, siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. Ho: La moneda es buena Ha: La moneda “está cargada” 4
, hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 a mano , siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. Ho: La moneda es buena. Ha: La moneda está cargada 4.")
199
Ejemplo 1: Chi Cuadrada( 2 )
(fo - fe)2 Observada Esperada fe ( fo ) ( fe ) Aguilas 63 50 3.38 Soles 37 50 3.38 2 = 2 = 6.76 Estadístico Chi Cuadrada g Pregunte a la clase ¿quién piensa que la moneda es “genuina” y por qué y qué nivel de confianza tienen para estar en lo correcto? Ahora, pregunte quién piensa que la moneda está “cargada”, por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón (“genuina” o “cargada”), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 “a mano”, siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. fe (fo - fe)2 2 c= j = 1 4
2. Observada. Esperada. fe. ( fo ) ( fe ) Aguilas Soles 2 = 2 = Estadístico Chi Cuadrada. g. Pregunte a la clase ¿quién piensa que la moneda es genuina y por qué y qué nivel de confianza tienen para estar en lo correcto Ahora, pregunte quién piensa que la moneda está cargada , por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón ( genuina o cargada ), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 a mano , siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. fe. (fo - fe)2. 2. c= j =")
200
Ejemplo 1: Chi cuadrada Función de Distribución Acumulada Chi2 con 1 grado de libertad (d.f) 2c P(2c > x) p = = De tablas X2Crítica, (0.05, 1) = Ho: La moneda es buena. Ha: La moneda está “cargada”. Para un 95% de confianza antes de concluir que la moneda “está cargada”, se requiere que X2c > X2Crítica o que el valor de p sea 0.05. Como p 0.05, se puede concluir -con un 95% de confianza - que la moneda “está cargada”. 7
 = Ho: La moneda es buena. Ha: La moneda está cargada . Para un 95% de confianza antes de concluir que la moneda está cargada , se requiere que X2c > X2Crítica o que el valor de p sea Como p 0.05, se puede concluir -con un 95% de confianza - que la moneda está cargada . 7.")
201
Cálculo en Excel del estadístico Chi cuadrada
1. Posicionarse en una celda vacía 2. Accesar el menú de funciones con Fx 3. Seleccionar STATISTICAL o ESTADÍSTICAS, CHIINV. 4. Dar valores de probabilidad (0.05) y grados de libertad, normalmente (n - 1) para un parámetro o (# de renglones -1) * (# de columnas - 1) para el caso de tablas de proporciones. 7
 y grados de libertad, normalmente (n - 1) para un parámetro o (# de renglones -1) * (# de columnas - 1) para el caso de tablas de proporciones. 7.")
202
Tabla de contingencia Una tabla de clasificación de dos vías (filas y columnas) que contiene frecuencias originales, se puede analizar para determinar si las dos variables (clasificaciones) son independientes o tienen una asociación significativa. La prueba Chi Cuadrada probará si hay dependencia entre las dos clasificaciones. Además se puede calcular el coeficiente de contingencia (correlación) que en todo caso muestra la fuerza de la dependencia
 que contiene frecuencias originales, se puede analizar para determinar si las dos variables (clasificaciones) son independientes o tienen una asociación significativa. La prueba Chi Cuadrada probará si hay dependencia entre las dos clasificaciones. Además se puede calcular el coeficiente de contingencia (correlación) que en todo caso muestra la fuerza de la dependencia.")
203
Tabla de contingencia Para esta prueba se usa la prueba Chi Cuadrada donde: Entre mayor sea su valor, mayor será la diferencia de la discrepancia entre frecuencias observadas y teóricas. Esta prueba es similar a la de bondad de ajuste.

204
Tabla de contingencia Ejemplo: Cada una de las 15 celdas hace una contribución al estadístico Chi Cuadrado (una celda) Asumiendo Alfa = 0.1 y Gl= (reng – 1)*(Col – 1) = 4*2 = 8 Chi-Cuadrado de alfa = 20.09 Como Chi Cuadrada calculada >> Chi C. Alfa, se rechaza Ho de igualdad de resultados entre negocios
*(Col – 1) = 4*2 = 8 Chi-Cuadrado de alfa = Como Chi Cuadrada calculada >> Chi C. Alfa, se rechaza Ho de igualdad de resultados entre negocios.")
205
Ejemplo 2: Chi2 Para comparación de dos grupos; ¿son las mismas proporciones?)
Ho: No existen diferencias en los índices de defectos de las dos máquinas. Ha: Existen diferencias en los índices de defectos de las dos máquinas. Los valores observados (fo) son los siguientes: Partes buenas Partes defectuosas máquina fo = fo = Total = 534 máquina fo = fo = Total = 245 779 Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. Total El índice de defectos totales es 28 / 779 = 3.6% 9
 son los siguientes: Partes buenas. Partes defectuosas. máquina 1 fo = 517 fo = 17 Total = 534. máquina 2 fo = 234 fo = 11 Total = Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. Total El índice de defectos totales es 28 / 779 = 3.6% 9.")
206
Ejemplo 2: Chi2 Para comparación de dos grupos; ¿son las mismas proporciones?)
Cálculo de los valores esperados Partes buenas Partes defectuosas máquina fo = 751*534/ fo = 28*534/ Total = 534 máquina fo = 751*245/ fo = 28*245/ Total = 245 779 Basados en este índice, los valores esperados (fe) serían: Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. máquina Partes buenas máquina Partes defectuosas 9
 serían: Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. máquina Partes buenas. máquina Partes defectuosas. 9.")
207
Prueba de chi cuadrada:
Los conteos esperados están debajo de los conteos observados Partes buenas Partes Defectuosas Total Total Chi2 = = DF= 1; valor de p = 0.152 2 celdas con conteos esperados menores a 5.0 Nota: Chi cuadrada no podrá aplicarse en los casos donde los conteos seas menores a 5 en 20% de celdas. Si cualquiera de los conteos esperados en las celdas es menor a uno, no deberá usarse Chi2. Si algunas celdas tienen un conteo menor a los esperados, ya sea combinando u omitiendo renglones y/o columnas, las categorías pueden ser de utilidad.

208
Variación en familias a probar
Problema: Fugas Beneficios Potenciales: $10,000 de ahorro en retrabajos, y en la reducción de tiempo de ciclo. Variación en familias a probar Operador a operador Ho: No existe diferencia en los índices de defecto de los diferentes operadores Ha: Existe diferencia en los índices de defecto de los diferentes operadores Máquina a máquina Ho: No existe diferencia en los índices de defecto de las diferentes máquinas Ha: Existe diferencia en los índices de defecto de las diferentes máquinas Tamaño de la muestra: total de oportunidades (172 piezas) 22
 22.")
209
Prueba de chi2 (máquina a máquina)
Los conteos esperados están colocados debajo de los conteos observados Con fugas Sin fugas Total Total Chi2 = 0.000 = DF= (4-1)(2-1) = 3; valor P =
(2-1) = 3; valor P =")
210
Prueba de chi2 (operador a operador)
Los conteos esperados están colocados debajo de los conteos observados. Con gotera Sin gotera Total Total Chi2 = = DF= 5; valor P =

211
(en este caso, operador a operador y máquina a máquina)
¿Qué sucede si los grupos múltiples de variación son estadísticamente significativos? (en este caso, operador a operador y máquina a máquina) Se utiliza un procedimiento denominado “Coeficiente de Contingencia” como clave para determinar qué grupo de variación debe investigarse primero. Chi Cuadrada N Coeficiente de Contingencia x 100 Chi N CC Máquina Operador Controlador Mayor SI el tamaño de la muestra (N), es similar para los grupos. Al dividir entre N, probablemente, llevará a la misma ruta que hubiera alcanzado con sólo ver la estadística Chi2. Sin embargo, si N tiene una variación considerable, dependiendo del grupo de variación que se investiga, el coeficiente de contingencia puede ser una herramienta valiosa para determinar la prioridad sobre qué grupo debe investigarse primero. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. 14
 Se utiliza un procedimiento denominado Coeficiente de Contingencia como clave para determinar qué grupo de variación debe investigarse primero. Chi Cuadrada. N. Coeficiente de Contingencia. x 100. Chi2 N CC. Máquina Operador Controlador Mayor. SI el tamaño de la muestra (N), es similar para los grupos. Al dividir entre N, probablemente, llevará a la misma ruta que hubiera alcanzado con sólo ver la estadística Chi2. Sin embargo, si N tiene una variación considerable, dependiendo del grupo de variación que se investiga, el coeficiente de contingencia puede ser una herramienta valiosa para determinar la prioridad sobre qué grupo debe investigarse primero. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. 14.")
212
(Estos mismos operadores fueron quienes
¿Qué sucede si los grupos múltiples de variación son estadísticamente significativos? (en este caso, operador a operador y máquina a máquina) Ahora que la información nos ha llevado a investigar a los grupos de operador a operador. ¿Qué debemos hacer ahora? Encontremos cuál de los operadores estaban fuera del estándar. ¿Era alguno de ellos notablemente peor (o mejor) que el resto? Con gotera Sin gotera Total Mucho peor que lo esperado El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. Mucho mejor que lo esperado (Estos mismos operadores fueron quienes tuvieron los números más grandes de chi2) 14
 Ahora que la información nos ha llevado a investigar a los grupos de operador a operador. ¿Qué debemos hacer ahora Encontremos cuál de los operadores estaban fuera del estándar. ¿Era alguno de ellos notablemente peor (o mejor) que el resto Con gotera Sin gotera Total Mucho peor que. lo esperado. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. Mucho mejor que. lo esperado. (Estos mismos operadores fueron quienes. tuvieron los números más grandes de chi2) 14.")
213
Operador a operador: = 0.000 Rechace Ho y acepte Ha
(Existe una diferencia significativa entre los operadores) Los operadores 4 y 5 están fuera del estándar: El operador 4 es notablemente peor que el resto, El operador 5 es notablemente mejor que los demás ¿Cuál es el próximo paso? Hable con todos los operadores para averiguar qué diferencias pueden existen en sus técnicas. El operador 4 no tenía experiencia en este tipo de trabajo y apenas se estaba acostumbrado a soldar este producto en particular. El operador 5 encontró un modo de mejor de hacer el ensamble, con lo cual consiguió mejorar el trabajo de soldadura, aunque esto mostraba un grado de dificultad ergonómica. Se añadió un colocador para ensamblar la parte en forma segura. (Esto también redujo el tiempo que requerían los operadores para “acostumbrarse” a trabajar en esta forma)
 Los operadores 4 y 5 están fuera del estándar: El operador 4 es notablemente peor que el resto, El operador 5 es notablemente mejor que los demás. ¿Cuál es el próximo paso Hable con todos los operadores para averiguar qué diferencias pueden existen en sus técnicas. El operador 4 no tenía experiencia en este tipo de trabajo y apenas se estaba acostumbrado a soldar este producto en particular. El operador 5 encontró un modo de mejor de hacer el ensamble, con lo cual consiguió mejorar el trabajo de soldadura, aunque esto mostraba un grado de dificultad ergonómica. Se añadió un colocador para ensamblar la parte en forma segura. (Esto también redujo el tiempo que requerían los operadores para acostumbrarse a trabajar en esta forma)")
214
Ejercicios 1. Se quiere evaluar la habilidad de tres inspectores de rayos X en un aeropuerto para detectar artículos clave. Como prueba se pusieron radios de transistores en 90 maletas, cada inspector fue expuesto a 30 maletas conteniendo radios mezcladas entre otras que nos los contenían. Los resultados se resumen a continuación: Inspectores 1 2 3 Radios detectados Radios no detectados ¿Con un 95% de confianza, existe una diferencia entre los inspectores? Ho: p1 = p2 = p3; Ha: al menos una es diferente Grados de libertad = (columnas - 1) ( filas -1)
 ( filas -1)")
215
Ejercicios 2. Se quiere evaluar si hay preferencia por manejar en un carril de una autopista dependiendo de la hora del día. Los datos se resumen a continuación: Hora del día Carril 1:00 3:00 5:00 Izquierdo Central Derecho ¿Con un 95% de confianza, existe una diferencia entre las preferencias de los automovilistas dependiendo de la hora? Ho: P1 = P2 = P3; Ha: al menos una es diferente Grados de libertad = (columnas - 1) ( filas -1)
 ( filas -1)")
216
IV.B.6 Pruebas de Hipótesis no paramétricas

217
Pruebas no paramétricas
Las pruebas paramétricas asumen una distribución para la población, tal como la Normal Las pruebas no paramétricas no asumen una distribución específica de la población Bajo los mismos tamaños de muestra la Potencia o probabilidad de rechazar Ho cuando es falsa es mayor en las pruebas paramétricas que en las no paramétricas Una ventaja de las pruebas no paramétricas es que los resultados de la prueba son más robustos contra violación de los supuestos

218
Prueba de Hipótesis Atributo Variable No Normal Normal Varianza
Tablas de Contingencia de Varianza Medianas Correlación Correlación Homogeneidad de la Variación de Levene Prueba de signos Normal Wilcoxon Mann- Whitney Variancia Medias Kurskal- Wallis Pruebas de t Prueba-F Muestra-1 Residuos distribuidos normalmente Prueba de Mood Muestra-2 Homogeneidad de la Variación de Bartlett Friedman ANOVA Una vía Dos vías Correlación Regresión

219
Resumen de pruebas de Hipótesis
Datos Normales Datos No Normales Pruebas de Variancias X2 : Compara la variancia de una muestra con una variancia de un universo conocido. Prueba F : Compara dos varianzas de muestras. Homogeneidad de la variancia de Bartlett: Compara dos o más varianzas muestras de la misma población. Pruebas de Varianzas Homogeneidad de la varianza de Levene : Compara dos o más varianzas de muestras de la misma población.

220
Resumen de pruebas de Hipótesis
Datos Normales Datos No Normales Pruebas de los Promedios Prueba t de 1 muestra : Prueba si el promedio de la muestra es igual a un promedio conocido o meta conocida. Prueba t de 2 muestras : Prueba si los dos promedios de las muestras son iguales. ANOVA de un factor: Prueba si más de dos promedios de las muestras son iguales. ANOVA de dos factores : Prueba si los promedios de las muestras clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables. Regresión : Define la relación lineal entre una variable dependiente y una independiente. (Aquí la "normalidad" se aplica al valor residual de la regresión) Pruebas de la Mediana Prueba de signos o Prueba Wilcoxon : Prueba si la mediana de la muestra es igual a un valor conocido o a un valor a alcanzar. Prueba Mann-Whitney : Prueba si dos medianas de muestras son iguales. Prueba Kruskal-Wallis: Prueba si más de dos medianas de muestras son iguales. Asume que todas las distribuciones tienen la misma forma. Prueba de la mediana de Mood : Otra prueba para más de dos medianas. Prueba más firme para los valores atípicos contenidos en la información. Prueba Friedman : Prueba si las medianas de las muestras, clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables.
 Pruebas de la Mediana. Prueba de signos o Prueba Wilcoxon : Prueba si la mediana de la muestra es igual a un valor conocido o a un valor a alcanzar. Prueba Mann-Whitney : Prueba si dos medianas de muestras son iguales. Prueba Kruskal-Wallis: Prueba si más de dos medianas de muestras son iguales. Asume que todas las distribuciones tienen la misma forma. Prueba de la mediana de Mood : Otra prueba para más de dos medianas. Prueba más firme para los valores atípicos contenidos en la información. Prueba Friedman : Prueba si las medianas de las muestras, clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables.")
221
Acciones a tomar con datos No Normales
Revise y asegúrese de que los datos no siguen una distribución normal. Desarrollar una Prueba de normalidad (para verificar realmente lo anormal. Para la prueba de Bartlet el valor de p debe ser < 0.05) Desarrollar una Prueba de Corridas (para verificar que no existen sucesos no aleatorios que puedan haber distorsionado la información) Revisar la información para detectar errores (tipográficos, etc.). Investiguar los valores atípicos. Una muestra pequeña (n < 30) proveniente de un universo normal, se mostrará algunas veces como anormal. Intentar transformar los datos. Las transformaciones comunes incluyen: - Raíz cuadrada de todos los datos - Logaritmo de todos los datos - Cuadrado de todos los datos Si la información es todavía anormal, entonces usar las herramientas no paramétricas.
 Desarrollar una Prueba de Corridas (para verificar que no existen sucesos no aleatorios que puedan haber distorsionado la información) Revisar la información para detectar errores (tipográficos, etc.). Investiguar los valores atípicos. Una muestra pequeña (n < 30) proveniente de un universo normal, se mostrará algunas veces como anormal. Intentar transformar los datos. Las transformaciones comunes incluyen: - Raíz cuadrada de todos los datos. - Logaritmo de todos los datos. - Cuadrado de todos los datos. Si la información es todavía anormal, entonces usar las herramientas no paramétricas.")
222
Definiciones Promedio : Es la media aritmética de la información. Es la suma de todos los datos, dividida entre el número de datos de referencia. Mediana: Valor del punto medio de los datos, cuando se ordenan en forma ascendente (en caso de datos pares, obtener promedio). Moda : Valor que se repite con más frecuencia sobre el conjunto de datos. Ejemplo: Se cuestionó a veinte personas sobre cuánto tiempo les tomaba estar listas para ir a trabajar, en las mañanas. Sus respuestas (en minutos) se muestran más adelante. ¿Cuáles son el promedio y la mediana para esta muestra? 30, 37, 25, 35, 42, 35, 35, 47, 45, 60 39, 45, 30, 38, 35, 40, 44, 55, 47, 43 It is helpful to know the Mean, Median, and Mode of your data set. The mean (average) versus the median gives you an idea as to how skewed your data may be from Normal. As data becomes more Non-Normal (unless it’s bi-modal), the mean and median move farther apart. 5
. Moda : Valor que se repite con más frecuencia sobre el conjunto de datos. Ejemplo: Se cuestionó a veinte personas sobre cuánto tiempo les tomaba estar listas para ir a trabajar, en las mañanas. Sus respuestas (en minutos) se muestran más adelante. ¿Cuáles son el promedio y la mediana para esta muestra 30, 37, 25, 35, 42, 35, 35, 47, 45, , 45, 30, 38, 35, 40, 44, 55, 47, 43. It is helpful to know the Mean, Median, and Mode of your data set. The mean (average) versus the median gives you an idea as to how skewed your data may be from Normal. As data becomes more Non-Normal (unless it’s bi-modal), the mean and median move farther apart. 5.")
223
Un dibujo dice más que mil palabras
Promedio Mediana C1 Promedio = Mediana = 39.5 El promedio puede estar influenciado considerablemente por los valores atípicos porque, cuando se calcula un promedio, se incluyen los valores reales de estos valores. La mediana, por otra parte, asigna la misma importancia a todas las observaciones, independientemente de los valores reales de los valores atípicos, ya que es la que sencuentra en la posición media de los valores ordenados.

224
Pruebas Alternativas comúnmente usadas
Analogía con datos normales Prueba de Corridas (la misma prueba para ambos tipos de información) Prueba t de una muestra Prueba t de 2 muestras ANOVA de un factor Pruebas para datos No normales Prueba de Corridas : Calcula la probabilidad de que un X número de puntos de referencia, esté por encima o por debajo del promedio aleatoriamente. Prueba de signos, de 1 muestra : Prueba la probabilidad de que la mediana de la muestra, sea igual al valor hipotético. Prueba Mann-Whitney : Comprueba el rango de dos muestras, por la diferencia entre dos medianas del universo. Prueba de la Mediana de Mood : Prueba para más de dos medianas del universo. Más robusta para los valores atípicos o para los errores en la información.
 Prueba t de una muestra. Prueba t de 2 muestras. ANOVA de un factor. Pruebas para datos No normales. Prueba de Corridas : Calcula la probabilidad de que un X número de puntos de referencia, esté por encima o por debajo del promedio aleatoriamente. Prueba de signos, de 1 muestra : Prueba la probabilidad de que la mediana de la muestra, sea igual al valor hipotético. Prueba Mann-Whitney : Comprueba el rango de dos muestras, por la diferencia entre dos medianas del universo. Prueba de la Mediana de Mood : Prueba para más de dos medianas del universo. Más robusta para los valores atípicos o para los errores en la información.")
225
Prueba de Rachas Considere los siguientes datos (que se muestran aquí en orden cronológico): 325, 210, 400, 72, 150, 145, 110, 507, 56, 120, 99, 144, 110, 110, 320, 290, 101, 0, 80, 500, 201, 50, 140, 80, 220, 180, 240, 309, 80 Es importante tener los datos registrados en orden cronológico. Una representación gráfica de los datos se asemeja a esto: 600 Promedio 500 Primera "corrida" 400 300 200 100 Segunda ”racha" Racha: Un punto o una serie consecutiva de puntos que caen en un lado del promedio. Número total de Rachas: 12 Número total de puntos > al promedio: 11 Número total de puntos < al promedio: 18

226
Este es el valor p de las Prueba de Corridas
Prueba de Rachas Ho: Los datos son aleatorios Ha:Los datos NO so aleatorios Prueba de Rachas Promedio K = Número de rachas observado = 12 Número de rachas esperado = => No se rechaza Ho 11 observaciones por encima de K; 18 por debajo La prueba es significativa en p= No se puede rechazar Ho con valor alfa = 0.05 Promedio Este es el valor p de las Prueba de Corridas Ya que p > 0.05, no podemos rechazar la hipótesis nula. Los datos son aceptados, siendo aleatorios.

227
Cálculos de la Prueba de Rachas
El estadístico Z cuando n > 20 se calcula como: Z = (G - MediaG) / DesvStG Con MediaG = 1 + (2n1*n2) / (n1 + n2) DesvStG = Raiz [ (2n1*n2) (2n1*n2 - n1 -n2) / (n1 + n2)^2* (n1+n2 -1) Del ejemplo anterior G = 12; n1 = 11 n2 = 18 MediaG = DesStG = Z1 = ( ) / = P(Z1) = y para dos colas se tiene P(Z1) + P(Z2) = > Alfa crítico de 0.05, no rechazándose Ho Si las n1 y n2 son menores a 21, entonces se consulta la tabla de valores críticos para el número de Rachas G
 / DesvStG. Con MediaG = 1 + (2n1*n2) / (n1 + n2) DesvStG = Raiz [ (2n1*n2) (2n1*n2 - n1 -n2) / (n1 + n2)^2* (n1+n2 -1) Del ejemplo anterior G = 12; n1 = 11 n2 = 18. MediaG = DesStG = Z1 = ( ) / = P(Z1) = y para dos colas se tiene. P(Z1) + P(Z2) = > Alfa crítico de 0.05, no rechazándose Ho. Si las n1 y n2 son menores a 21, entonces se consulta la tabla de valores críticos para el número de Rachas G.")
228
Corrida con Minitab Runs Test: C1 Runs test for C1
Stat > Nonparametrics > Runs Test Variable C1, Above and below the mean Runs Test: C1 Runs test for C1 Runs above and below K = The observed number of runs = 12 The expected number of runs = 11 observations above K, 18 below P-value = 0.285 P > 0.05 No rechazar Ho

229
Prueba de Signos de la Mediana
Ho : La mediana de la muestra es igual a la mediana de la hipótesis Ha : Las medianas son diferentes Ejemplo (usando los datos del ejemplo anterior): Ho: Valor de la mediana = 115.0 Ha: Valor de la mediana diferente de 115.0 N DEBAJO IGUAL ENCIMA VALOR P MEDIANA Ya que p >0.05, no se puede rechazar la hipótesis nula. No se puede probar que la mediana real y la mediana hipotética son diferentes. En las páginas siguientes se muestra el detalle del cálculo.
: Ho: Valor de la mediana = Ha: Valor de la mediana diferente de N DEBAJO IGUAL ENCIMA VALOR P MEDIANA Ya que p >0.05, no se puede rechazar la hipótesis nula. No se puede probar que la mediana real y la mediana hipotética son diferentes. En las páginas siguientes se muestra el detalle del cálculo.")
230
Cálculos de la Prueba de Signos de la Mediana
Ejemplo: Con los datos del ejemplo anterior y ordenándo de menor a mayor se tiene: n = 29, Mediana de Ho = 115 No. Valor Signo No. Valor Signo No. Valor Signo Con la mediana en 144. Si el valor contra el cual se desea probar es 115, entonces hay 12 valores por debajo de el (-) y 17 valores por arriba (+).
 y 17 valores por arriba (+).")
231
Cálculos de la Prueba de Signos de la Mediana
El estadístico X es el el número de veces que ocurre el signo menos frecuente, en este caso el 12 (-). Cómo n 25, se calcula el estadístico Z para la prueba de signos con: Z = [ (Y + 0.5) - (0.5*n) ]/ 0.5 n En este caso Z1 = y P(Z1) = para la cola izquierda en forma similar P(Z2) para la cola derecha, por lo que la probabilidad total es >> 0.05 del criterio de rechazo. Si n hubiera sido < 25 entonces se hubiera consultado la tabla de valores críticos para la prueba de signo.
. Cómo n 25, se calcula el estadístico Z para la prueba de signos con: Z = [ (Y + 0.5) - (0.5*n) ]/ 0.5 n. En este caso Z1 = y P(Z1) = para la cola izquierda. en forma similar P(Z2) para la cola derecha, por lo que la. probabilidad total es >> 0.05 del criterio de rechazo. Si n hubiera sido < 25 entonces se hubiera consultado la tabla de valores críticos para la prueba de signo.")
232
Prueba de Signos de la Mediana
¿Es esto correcto?¿144 podría ser igual a 115? Bueno, veamos una gráfica de la información 100 200 300 400 500 115 144 Después de todo, tal vez esto SEA lo correcto.

233
Corrida en Minitab Sign Test for Median: Signos
Stat > Nonparametrics > 1-Sample sign Variable C1 Confidence interval 95% Test Median 115 Alternative Not equal Como P > 0.05 no se rechaza Ho y la mediana es 115 Sign Test for Median: Signos Sign test of median = versus not = 115.0 N Below Equal Above P Median Signos

234
Prueba de Signos de la Mediana Para observaciones pareadas
Calificaciones de amas de casa a dos limpiadores de ventanas: Ho: p = 0.5 no hay preferencia de A sobre B Ha: p<>0.5 Ama Limpiador B Casa A 1 10 7 2 5 3 8 4 6 9 ¿Hay evidencia que indique cierta preferencia de las amas de casa por lo limpiadores?

235
Prueba de Signos de la Mediana
Producto B Familia A 1 - + 2 3 4 5 6 7 8 9 10 11 Media = 0.5*n Desv. Estand.= 0.5*raiz(n) Zc = (Y – media) / Desv. Estánd. Rechazar Ho si Zc ><Zalfa/2 ¿Hay evidencia que indique cierta preferencia por un Producto A o B?
 Zc = (Y – media) / Desv. Estánd. Rechazar Ho si Zc ><Zalfa/2. ¿Hay evidencia que indique. cierta preferencia por un. Producto A o B")
236
Prueba de Signos de la Mediana
Desv. Estand.= 0.5*raiz(n) = 1.67 Para Zc = (8 – 5.5) / 1.67 = 1.497 Zexcel = 1.96 para alfa/2 = 0.025 Como Zc < Zexcel no se rechaza Ho o Como p value = > 0.025 No hay evidencia suficiente de que los Consumidores prefieran al producto B
 = Para Zc = (8 – 5.5) / 1.67 = Zexcel = 1.96 para alfa/2 = Como Zc < Zexcel no se rechaza Ho o. Como p value = > No hay evidencia suficiente de que los. Consumidores prefieran al producto B.")
237
Prueba rango con signo de Wilconox
Es la alternativa no paramétrica de la prueba paramétrica de muestras pareadas Ejemplo: HO: Las poblaciones son idénticas Ha: Caso contrario Trabajador Método 1 Método 2 Diferencias Abs(diferen.) Rango Rango c/signo 1 10.2 9.5 0.7 8 2 9.6 9.8 -0.2 0.2 -2 3 9.2 8.8 0.4 3.5 4 10.6 10.1 0.5 5.5 5 9.9 10.3 -0.4 -3.5 6 9.3 0.9 10 7 10.5 0.1 Eliminar 9 11.2 0.6 10.7 11 0.8 T = 44
 Rango. Rango c/signo Eliminar T = 44.")
238
Prueba rango con signo de Wilconox
Distribución muestral T para poblaciones idénticas Se aproxima a la distribución normal para n >= 10 En este caso n = pares eliminando las que son iguales con dif. = 0 para el trabajador 8. = raiz(10 x 11 x 21/6) = 19.62 Z = (T – )/ = 44/19.62 = 2.24 Z alfa/2 = Z0.025 = 1.96 Como Zc = 2.24 > Z0.025 se rechaza Ho, los métodos son diferentes
 = Z = (T – )/ = 44/19.62 = Z alfa/2 = Z0.025 = Como Zc = 2.24 > Z0.025 se rechaza Ho, los métodos son diferentes.")
239
Prueba en Minitab para prueba de mediana con Wilconox
File> Open worksheet > Exh_Stat Stat > Nonparametrics > 1-Sample Wilconox Variables C1 Test Median 77 Altenative Not equal Achievement 77 88 85 74 75 62 80 70 83 Wilcoxon Signed Rank Test: Achievement Test of median = versus median not = 77.00 for Wilcoxon Estimated N Test Statistic P Median Achievement Ho: Mediana = Ha: Mediana <> 77 Como P de >> alfa de 0.05 no se rechaza Ho

240
Prueba de Mann-Whitney
Se llevó a cabo un estudio que analiza la frecuencia del pulso en dos grupos de personas de edades diferentes, después de diez minutos de ejercicios aeróbicos. Los datos resultantes se muestran a continuación. Edad 40-44 C1 140 135 150 144 154 160 136 148 Edad 16-20 C2 130 166 128 126 132 124 ¿Tuvieron diferencias significativas las frecuencias de pulso de ambos grupos?

241
Prueba de Mann-Whitney
Ordenando los datos y asignándoles el (rango) de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Edad 40-44 C1 (7) 135 (8.5) 136 (11) 140 (11) 140 (13.5) 144 (15) 148 (16) 150 (17) 154 (18) 160 n1 = 10 Ta = 130.5 Edad 16-20 C2 (1) 124 (2) 126 (3.5) 128 (5) 130 (6) 132 (11)140 (15)166 n2 = 9 Tb = 55.5
 de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Edad C1. (7) 135. (8.5) 136. (11) 140. (11) 140. (13.5) 144. (15) 148. (16) 150. (17) 154. (18) 160. n1 = 10. Ta = Edad C2. (1) 124. (2) 126. (3.5) 128. (5) 130. (6) 132. (11)140. (15)166. n2 = 9. Tb =")
242
Prueba de Mann-Whitney
Ho: Las distribuciones de frecuencias relativas de las poblaciones A y B son iguales Ha: Las distribuciones de frecuencias relativas poblacionales no son idénticas Ho: 1 = 2 Ha: 1 2 1, 2 = Medianas de las poblaciones Ordenando los datos y asignándoles su posición relativa se tiene: Ua = n1*n2 + (n1) * (n1 + 1) /2 - Ta Ub = n1*n2 + (n2) * (n2 + 1) /2 - Tb Ua + Ub = n1 * n2 Ua = = P(Ua) = Ub = = 79.5 El menor de los dos es Ua. Para alfa = 0.05 el valor de Uo = 25 Como Ua < 25 se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.
 * (n1 + 1) /2 - Ta. Ub = n1*n2 + (n2) * (n2 + 1) /2 - Tb. Ua + Ub = n1 * n2. Ua = = 14.5 P(Ua) = Ub = = El menor de los dos es Ua. Para alfa = 0.05 el valor de Uo = 25. Como Ua < 25 se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.")
243
Prueba de Mann-Whitney
Ho: Las distribuciones de frecuencias relativas de las poblaciones A y B son iguales Ha: Las distribuciones de frecuencias relativas poblacionales no son idénticas Ua = Ub = 79.5 Utilizando el estadístico Z y la distribución normal se tiene: Z = [ (U - (n1* n2 / 2 ) / Raiz (n1 * n2 * (n1 + n2 + 1) / 12) Con Ua y Ub se tiene: Za = ( ) / = P(Z) = similar a la anterior Zb = ( ) / = 2.81 P(total) = 2 * = menor = 0.05 El valor crítico de Z para alfa por ser prueba de dos colas, es 1.96. Como Za > Zcrítico se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.
 / Raiz (n1 * n2 * (n1 + n2 + 1) / 12) Con Ua y Ub se tiene: Za = ( ) / = P(Z) = similar a la anterior. Zb = ( ) / = 2.81 P(total) = 2 * = menor = El valor crítico de Z para alfa por ser prueba de dos colas, es Como Za > Zcrítico se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.")
244
Prueba de Mann-Whitney 16-20 años de edad
Diferencias entre los encabezados de los renglones y las columnas De esta manera, se calcula la mediana de todas estas diferencias, denominada "punto estimado". Este punto estimado es una aproximación de la diferencia entre las medianas de los dos grupos (ETA1 y ETA2). Una vez ajustados los "enlaces" (eventos de un mismo valor en ambos grupos de información), Minitab usa este punto estimado para calcular el valor p.
. Una vez ajustados los enlaces (eventos de un mismo valor en ambos grupos de información), Minitab usa este punto estimado para calcular el valor p.")
245
Corrida en Minitab Mann-Whitney Test and CI: C1, C2 N Median P>0.05
Stat > Nonparametrics > Mann Whitney First Sample C1 Second Sample C2 Conf. Level 95% Alternative Not equal Mann-Whitney Test and CI: C1, C2 N Median P>0.05 C Se rechaza Ho C Point estimate for ETA1-ETA2 is 12.00 95.5 Percent CI for ETA1-ETA2 is (4.01,20.00) W = 130.5 Test of ETA1 = ETA2 vs ETA1 not = ETA2 is significant at The test is significant at (adjusted for ties)
 W = Test of ETA1 = ETA2 vs ETA1 not = ETA2 is significant at The test is significant at (adjusted for ties)")
246
Prueba de Kruskal Wallis
Ordenando los datos de ventas y asignándoles el (rango) de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Zona 1 (15.5) 147 (17.5) 17.5 (9) 128 (19) 162 (12) 135 (10) 132 (22) 181 (13) 138 n1 = 8 Ta = 118 Zona 2 (17.5) 160 (14) 140 (21) 173 (4) 113 (1) 85 (7) 120 (25) 285 (5) 117 (11) 133 (6) 119 n2 = 10 Tb = 111.5 Zona 3 (24) 215 (8) 127 (2) 98 (15.5) 127 (23) 184 (3) 109 (20) 169 n3 = 7 Tc = 95.5 N = n1 + n2 + n3 = 25
 de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Zona 1. (15.5) 147. (17.5) (9) 128. (19) 162. (12) 135. (10) 132. (22) 181. (13) 138. n1 = 8. Ta = 118. Zona 2. (17.5) 160. (14) 140. (21) 173. (4) 113. (1) 85. (7) 120. (25) 285. (5) 117. (11) 133. (6) 119. n2 = 10. Tb = Zona 3. (24) 215. (8) 127. (2) 98. (15.5) 127. (23) 184. (3) 109. (20) 169. n3 = 7. Tc = N = n1 + n2 + n3 = 25.")
247
Prueba de Kruskal Wallis
Ho: Las poblaciones A, B y C son iguales Ha: Las poblaciones no son iguales Ho: 1 = 2 = 3 Ha: 1 2 3 ; 1, 2, 3 = Medianas de las poblaciones Calculando el valor del estadístico H se tiene: H = [ 12 /( N* ( N + 1)) ] * [ Ta2 / n1 + Tb2 / n2 + Tc2 / n3 ] - 3 * ( N +1 ) H = * ( ) - 78 = 1.138 Se compara con el estadístico 2 para = 0.05 y G.l. = k - 1 = 3-1 = 1 (k muestras) 2 crítico = (válido siempre que las muestras tengan al menos 5 elementos) Como H < 2 crítico, no se rechaza la Hipótesis Ho: Afirmando que no hay diferencia entre las poblaciones 15
) ] * [ Ta2 / n1 + Tb2 / n2 + Tc2 / n3 ] - 3 * ( N +1 ) H = * ( ) - 78 = Se compara con el estadístico 2 para = 0.05 y G.l. = k - 1 = 3-1 = 1 (k muestras) 2 crítico = (válido siempre que las muestras tengan al menos 5 elementos) Como H < 2 crítico, no se rechaza la Hipótesis Ho: Afirmando que no hay diferencia entre las poblaciones. 15.")
248
Corrida en Minitab Kruskal-Wallis Test: Datos versus Factor
Stat > Nonparametrics > Kruskal Wallis Response C1 Factor C2 OK Kruskal-Wallis Test: Datos versus Factor Kruskal-Wallis Test on Datos Factor N Median Ave Rank Z Zona Zona Zona Overall P > 0.05 H = DF = 2 P = No se rechaza Ho H = DF = 2 P = (adjusted for ties)
")
249
Prueba de Medianas de Mood
Realiza prueba de hipótesis de igualdad de medias en un diseño de una vía. La prueba es robusta contra Outliers y errores en datos y es adecuada para análisis preliminares Determina si K grupos independientes han sido extraidas de la misma población con medianas iguales o poblaciones con formas similares Con base en la gran mediana, anotar un signo positivo si la observación excede la mediana o un signo menos si es menor. Los valores que coincidan se reparten en los grupos Hacer una tabla de contingencia K x 2 con las frecuencias de signos más y menos en cada grupo K

250
Prueba de Medianas de Mood
Se determina el estadístico Chi Cuadrada con: Probar Ho: Todas las medianas son iguales Ha: Al menos una mediana es diferente Se compara Chi Cuadrada calculada con Chi Cuadrada de alfa para 0.05 y (reng – 1)*(Col – 1) grados de libertad
*(Col – 1) grados de libertad.")
251
Corrida con Minitab Se les da a 179 participantes una conferencia con dibujos para ilustrar el tema. Después se les da la prueba OTIS que mide la habilidad intelectual. Los participantes se clasificaron por nivel educativo 0-No prof., 1-Prof., 2-Prepa Ho: h1 = h2 = h3 Ha: no todas las medianas son iguales File > Open Worksheet > Cartoon.mtw Stat > Nonparametrics > Mood’s Median Test Response Otis Factor ED Ok

252
Corrida con Minitab Mood Median Test: Otis versus ED
Mood median test for Otis P>0.05 Chi-Square = DF = 2 P = Se rechaza Ho Individual 95.0% CIs ED N<= N> Median Q3-Q (-----*-----) (------*------) (----*----) Overall median = 107.0
 (------*------) (----*----) Overall median =")
253
Diseños factoriales aleatorias bloqueados de Friedman
Esta prueba es una alternativa al ANOVA de dos vías, es una generalización de las pruebas pareadas con signo. La aditividad es requerida para para estimar los efectos de los tratamientos Ho: Los tratamientos no tienen un efecto significativo Ha: Algunos tratamientos tienen efecto significativo

254
Diseños factoriales aleatorias bloqueados de Friedman
Resultados de salida: Se muestra el estadístico de prueba con distribución Chi Cuadrada aproximada con gl = Tratamientos – 1. Si hay observaciones parecidas en uno o más bloques, se usa el rango promedio y se muestra el estadístico corregido La mediana estimada es la gran mediana más el efecto del tratamiento

255
Diseños factoriales aleatorias bloqueados de Friedman
Ejemplo: Se evalúa el efecto del tratamiento de una droga en la actividad enzimática con tres niveles, probado en cuatro animales Open the worksheet EXH_STAT.MTW. Stat > Nonparametrics > Friedman. Response, seleccionar EnzymeActivity. En Treatment, seleccionar Therapy. En Blocks, seleccionar Litter. Click OK.

256
Diseños factoriales aleatorias bloqueados de Friedman
EnzymeActivity Therapy Litter 0.15 1 0.26 2 0.23 3 0.99 4 0.55 -0.22 0.66 0.77 Datos:

257
Diseños factoriales aleatorias bloqueados de Friedman
Resultados: Friedman Test: EnzymeActivity versus Therapy blocked by Litter S = DF = 2 P = No rechazar Ho S = DF = 2 P = (adjusted for ties) Sum of Therapy N Est Median Ranks Grand median =
 Sum. of. Therapy N Est Median Ranks Grand median =")
258
Diseños factoriales aleatorias bloqueados de Friedman
Resultados: El estadístico de prueba S tiene un valor P de sin ajustar para observaciones en cero y para el valor ajustado. Por tanto no hay evidencia suficiente para rechazar Ho Las medianas estimadas asociadas con los tratamientos son la gran mediana más los efectos estimados de los tratamientos. El estadístico de prueba se determina con base a los rangos en cada bloque y totales

259
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

260
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

261
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

262
Prueba de igualdad de varianzas de Levene
Se usa para probar la hipótesis nula de que las varianzas de k múltiples poblacionales son iguales Las igualdad de varianzas en las muestras se denomina homogeneidad de varianzas La prueba de Levene es menos sensible que la prueba de Bartlett o la prueba F cuando se apartan de la normalidad La prueba de Bartlett tiene un mejor desempeño para la distribución normal o aproximadamente normal

263
Prueba de igualdad de varianzas de Levene
Para dos muestras el procedimiento es como sigue: Determinar la media Calcular la desviación de cada observación respecto a la media Z es el cuadrado de las desviaciones respecto a la media Aplicar la prueba t a las dos medias de los datos

264
Prueba de igualdad de Varianzas-Minitab
Rot Temp Oxygen 13 10 2 11 3 6 4 7 15 26 16 19 24 22 18 20 8 Prueba de igualdad de Varianzas-Minitab Se estudian tamaños de papa inyectando con bacterias y sujetas a diferentes temperaturas. Antes del ANOVA se verifica la igualdad de varianzas Stat > ANOVA > Test for equal variances Response Rot Factors Temp Oxigen Confidence level 95%

265
Resultados

266
Resultados Test for Equal Variances: Rot versus Temp, Oxygen
95% Bonferroni confidence intervals for standard deviations Temp Oxygen N Lower StDev Upper Bartlett's Test (normal distribution) Test statistic = 2.71, p-value = P>0.05 no rechazar Ho Levene's Test (any continuous distribution) Test statistic = 0.37, p-value = 0.858
 Test statistic = 2.71, p-value = P>0.05 no rechazar Ho. Levene s Test (any continuous distribution) Test statistic = 0.37, p-value =")
267
Prueba de la concordancia del Coeficiente de Kendall
El coeficiente expresa el grado de asociación entre las calificaciones múltiples realizadas por un evaluador Ho: Las variables son independientes Ha: Las variables están asociadas Kendall usa la información relacionada con las calificaciones relativas y es sensible a la seriedad de mala clasificación Por ejemplo para K = jueces N = Muestras = 10 Rango medio = 220 / S = Gl = n-1 = 9 Chi Cuadrada crítica = X2 0.01,9 = 21.67

268
Prueba de la concordancia del Coeficiente de Kendall
El Estadístico Chi Cuadrada calculado es: Como Chi Cuadrada de alfa es menor que la calculada, los cuatro jueces están asociados significativamente. Constituyen un panel uniforme. No quiere decir que estén en lo correcto, solo que responden de manera uniforme a los estímulos

269
El coeficiente de correlación de rangos de Spearman (rs)
El coeficiente de correlación es una medida de la asociación que requiere que ambas variables sean medidas en al menos una escala ordinal de manera que las muestras u observaciones a ser analizadas pueden ser clasificadas en rangos en dos series ordenadas Ho: Las variables son independientes Ha: Las variables están asociadas Para el ejemplo anterior si N = 10, el coeficiente es:

270
Coeficiente de correlación de rangos para monotonía de preferencias
Una persona interesada en adquirir un TV asigna rangos a modelos de cada uno de 8 fabricantes Preferencia Precio (rango) Fab. 1 7 (1) 2 4 (5) 3 (3) 6 (4) 5 (8) (7) 8 (2) (6) Di cuadrada Rango Di 6 36 -1 1 2 4 -7 49 -4 16 15
 Fab (1) (5) (3) (4) (8) (7) (2) (6) Di cuadrada. Rango. Di")
271
Coeficiente de correlación de rangos para monotonía de preferencias
Ho: No existe asociación entre los rangos Ha: Existe asociación entre los rangos o es positiva o negativa El coeficiente de correlación de rangos de Spearman es: Rs = 1 – 6*suma(di cuadrada) / (n(n cuadrada – 1)) En este caso: Rs = 1 – 6(144)/(8*(64-1) = R0 se determina de la tabla de Valores críticos del coeficiente de correlación del coeficiente de correlación de rangos de Spearman Rt = 0.686 Por tanto si hay asociación significativa en las preferencias 15
 / (n(n cuadrada – 1)) En este caso: Rs = 1 – 6(144)/(8*(64-1) = R0 se determina de la tabla de Valores críticos del coeficiente de correlación del coeficiente de correlación de rangos de Spearman. Rt = Por tanto si hay asociación significativa en las preferencias. 15.")
272
Tabla de constantes 15

273
Corrida con Minitab Correlations: Preferencia, Precio
Para la corrida en Minitab primero se deben determinar los rangos en forma manual para las variables X y Y. Stat > Basic statistics > Correlation Variables Preferencia Precio Fabricante Prefe-rencia Precio 1 7 449 2 4 5 525 3 479 6 499 8 580 549 469 532 Correlations: Preferencia, Precio Pearson correlation of Preferencia and Precio = P-Value = 0.047

274
Ejemplo con Minitab Correlations: Colageno, Proline
Se estudia la relación entre colágeno y Proline en pacientes con cirrosis Stat > Basic statistics > Correlation Variables Colágeno Proline Paciente Colágeno Proline 1 7.1 2.8 2 2.9 3 7.2 4 8.3 2.6 5 9.4 3.5 6 10.5 4.6 7 11.4 Correlations: Colageno, Proline Pearson correlation of Colageno and Proline = 0.935 P-Value = 0.002

275
Resumen de pruebas no paramétricas
Prueba de signos de 1 muestra: Prueba la igualdad de la mediana a un valor y determina el intervalo de confianza Prueba de Wilconox de 1 muestra: Prueba la igualdad de la mediana a un valor con rangos con signo y determina el intervalo de confianza Comparación de dos medianas poblacionales de Mann Whitney: Prueba la igualdad de las medianas y determina el intervalo de confianza

276
Resumen de pruebas no paramétricas
Comparación de igualdad de medianas poblacionales de Kruskal Wallis: Prueba la igualdad de las medianas en un diseño de una vía y determina el intervalo de confianza Comparación de medianas poblacionales de Mood: Prueba la igualdad de medianas con un diseño de una vía

279
Salidas de la Fase de Análisis
Causas raíz validadas Guía de oportunidades de mejora

280
Resumen de la validación de las causas
# de Causa Causas Resultados Causa Raíz 1 2 3 4 5 6 7 Ensamble de ojillos, bloques y contrapesos no adecuados en aspas. Amortiguadores dañados. Desgaste de bujes en los carretes. Fabricación y reemplazo de ejes y poleas no adecuados en ensamble de aspas. Desalineamiento de poleas y bandas de transmisión de aspas. Método de Balanceo no adecuado. Desalineación de pinolas en cuna. SI ES CAUSA RAIZ NO ES CAUSA RAIZ X

Presentaciones similares