Descargar la presentación
La descarga está en progreso. Por favor, espere

1
The CATH Domain Structure Database Ana Gabriela Murguía Carlos Villa Soto

2
Introducción Mutaciones dieron lugar a familias de proteínas (DAYHOFF) Las relaciones usando Algoritmos de programación dinámica. Datos estructurales< Datos secuencia (Debido a cuestiones técnicas) Actualmente discrepancias mayores a 2 ordenes de magnitud entre recursos de secuencia y de estructura. PDB 16000 entradas----------NCBI 12 000 000 entradas 1er cristal (1970) 1ra Clasificación estructural 1990s (SCOP, DALI y CATH)
 Actualmente discrepancias mayores a 2 ordenes de magnitud entre recursos de secuencia y de estructura. PDB entradas NCBI entradas 1er cristal (1970) 1ra Clasificación estructural 1990s (SCOP, DALI y CATH).")
3
2do DDBASE, 3DEE, DaliDD (3D) Reciente comparación entre SCOP, DALI y CATH (+80% de correspondencia) Debido a que gran proporción de la estructura del CORE (+50%) esta conservada, el alineamiento estructural es mucho mas exacto que el secuencial. SCOP y CATH contienen actual/ entre 950 – 1400 superfamilias de proteínas. Estas superfamilias contienen casi 1/3 de las secuencias no redundantes del Gen Bank.

4
Desarrollo Histórico: 1993 con menos de 3 000 estructuras de proteínas Una década después +/- 13 000 entradas del PDB, comprende 33 000 dominios estructurales 200 000 dominios extraídos del GenBank Dominio: Importante unidad evolutiva Debido a que los métodos de modelamiento por homología son más exitosos cuando se trabaja con dominios.

5
CATH inicialmente como una base de datos de dominios. CATH divide en clusters: Phonetically: Basado en Similaridad estructural Filogenéticamente: Basado en Aparente relación evolutiva Ambigüedades automáticas son validadas manualmente y el mayor cuello de botella en la clasificación corresponde a la detección de dominios limítrofes y la verificación de sus homólogos relacionados.

6
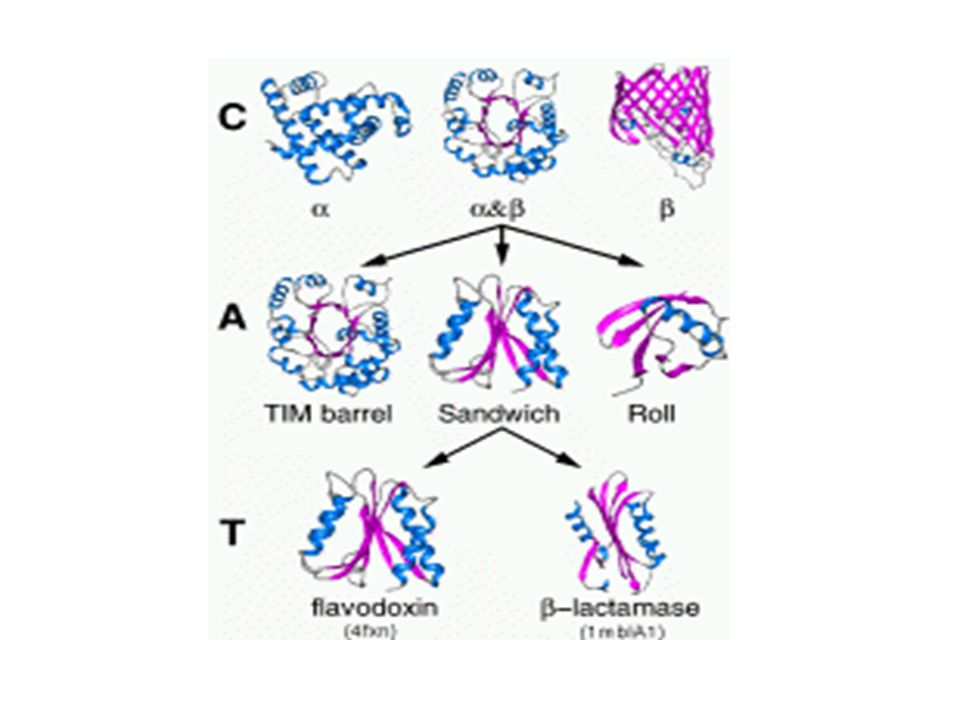
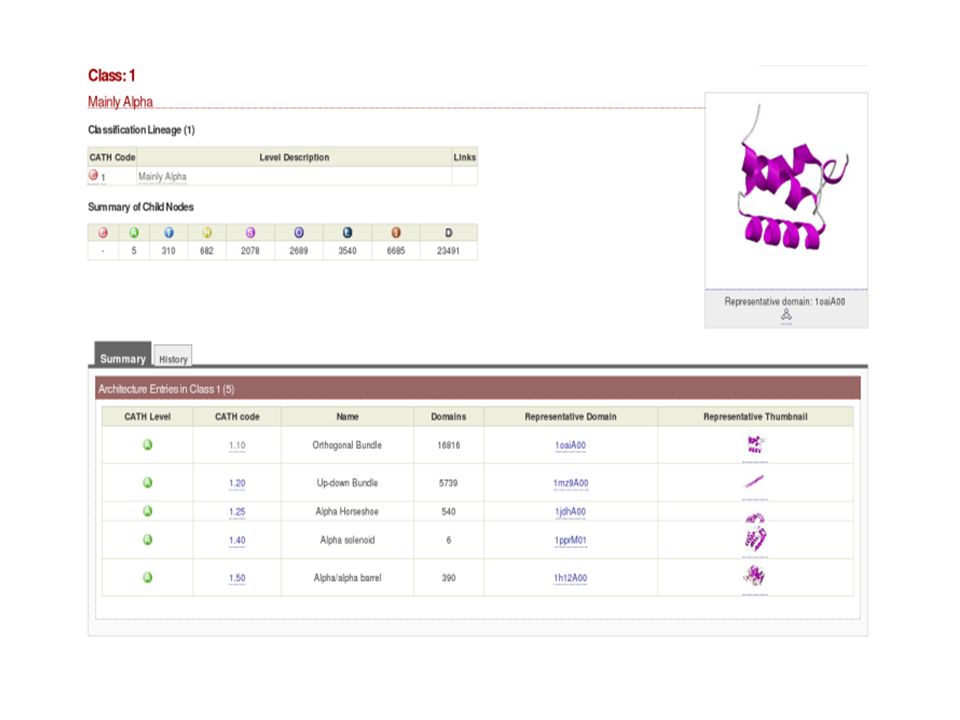
Niveles CATH Clase: estructura secundaria. Arquitectura: orientación de estructura secundaria en 3D. Topología: orientación estructural (folds) Homología: agrupadas según la evidencia (estructural, secuencia, similaridad funcional).
 Homología: agrupadas según la evidencia (estructural, secuencia, similaridad funcional)..")
7
Sequence identity >= 35%, overlap >= 60% of larger structure equivalent to smaller. SSAP score >= 80.0, sequence identity >= 20%, 60% of larger structure equivalent to smaller. SSAP score >= 70.0, 60% of larger structure equivalent to smaller, and domains which have related functions, which is informed by the literature and Pfam protein family database, (Bateman et al., 2004).
..")
10
Estrategia Método pairwise Perfil comparativo de secuencias y estructuras es usado para detectar mayores distancias. Examinación automática y manual para determinar dominios. Recomparación de dominios. Estructuras no clasificadas son manualmente asignadas.

12
SSAP Sequential Structure Aligment Program Adaptación de programación dinámica a 3D. Comparación de ambiente estructural de residuos entre proteínas. 2 niveles: –Superior: acumulación sobre pares equivalentes –Inferior: comparación entre ambiente estructural de residuos

13
GRATH Compara estructuras secundarias entre proteínas. Representación vectorial y son asociados con los “nudos” en un gráfico. Ángulos de inclinación y rotación para detectar motivos estructurales.

14
CORA Alineamiento progresivo estructura consenso alineamiento contra cada una. Se hace un template 3D. Reconoce homólogos distantes (estructural) Librería CORA. Más rápido, sensible y selectivo que el SSAP.
 Librería CORA. Más rápido, sensible y selectivo que el SSAP..")
15
Identificación de Dominios Algunas proteínas no se pueden clasificar. No definición cuantitativa de dominio. Cualitativa: unidad plegada compacta semindependiente. Protocolo DBS (PUU, DOMAK, DETECTIVE). Ambigüedades: Manualmente validadas. 17 % discordancia entre SCOP y CATH
. Ambigüedades: Manualmente validadas. 17 % discordancia entre SCOP y CATH.")
16
DHS Datos de: secuencia, estructura y función. Información sobre relación de pares de bases, E value, identidad de secuencias. PDB, Swiss prot, PROSITE, Gen ProtEC

17
GENE 3D Resource

18
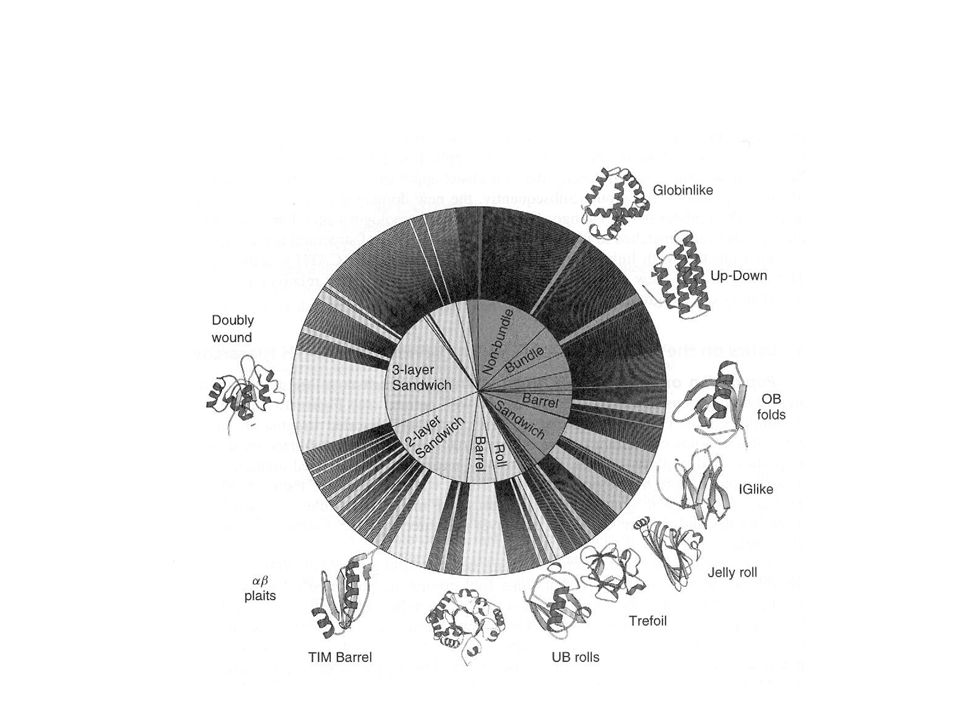
Estadística en Poblaciones Actualmente existen: –36 28 Bien definidas 8 Irregulares, Complejas, Poco estables. –6 estructuras características: α bundles 2 capas β sandwich Barriles β 2 capas de αβ sandwich 3 capas de αβ sandwich αβ barriles

19
Estadística en Poblaciones Algunos grupos de plegamientos son particularmente “Gregarios”. Sin embargo 15% de los Folds son distintos Estructuras que comparten el mismo FOLD pero que descienden de ancestro común: –Análogos

Presentaciones similares

















>")








