Descargar la presentación
La descarga está en progreso. Por favor, espere

1
OLAP, Data Mining y Data Warehousing

2
Contenidos Sistemas de ayuda a la toma de decisiones
Análisis de datos y Procesamiento analítico en línea (OnLine Analytical Processing – OLAP) Recopilación de datos Almacenamiento de datos Sistemas de recuperación de la información
 Recopilación de datos. Almacenamiento de datos. Sistemas de recuperación de la información.")
3
Introducción Los Sistemas de Bases de Datos son desarrollados con una aplicación específica en mente, con el objetivo de soportar las actividades de operación diaria en dicha aplicación. Los DBMS’s han sido diseñados para administrar las actividades operativas diarias a través del almacenamiento de los datos que requieren de una manera consistente basado en un modelo de datos, y optimizando sus operaciones de consulta y actualización para un performance de alto nivel. Debido a que dichas actividades diarias, son en efecto interactivas, este tipo de DBMS’s son llamados “on-line transaction processing systems ” (OLTP), o sistema de procesamiento de transacciones en línea.
, o sistema de procesamiento de transacciones en línea.")
4
Introducción El objetivo de los sistemas OLTP es soportar las decisiones del día-a-día a un gran número de usuarios operacionales. Sin embargo existe también la necesidad de soportar el análisis y toma de decisiones estratégicas de un número pequeño de usuarios gerenciales. Por ejemplo, después de una campaña de marketing, un gerente puede determinar su efectividad analizando el comportamiento de las ventas antes y después de la campaña.

5
Introducción Más allá, un ejecutivo puede analizar el comportamiento de las ventas para pronosticar las ventas de sus productos y planificarlas de acuerdo a los pedidos y capacidades de almacenamiento disponibles. Por ejemplo, identificando la temporada pre-escolar y las tendencias de los mercados locales, los gerentes de tiendas pueden ordenar y presentar en las vitrinas aquellos productos escolares que están siendo solicitados a los estudiantes y sus familias en las escuelas locales. La otra alternativa, ordenar masivamente todo tipo de productos y luego devolver aquellos que no son vendidos o rentables, parece poco eficiente frente a la anterior. Este tipo de procesos analíticos en línea - “on-line analytical processing” (OLAP) , pueden ser potenciados por herramientas de exploración de datos basadas en técnicas de “Data mining”.
 , pueden ser potenciados por herramientas de exploración de datos basadas en técnicas de Data mining .")
6
Introducción Las herramientas de Data Mining descubren nuevos patrones o reglas que no necesariamente pueden ser obtenidas a través del mero procesamiento de querys. Ellas utilizan técnicas de aprendizaje denominadas AI Machine learning techniques, que automáticamente clasifican los datos en diferentes grupos basados en diferentes criterios. Por ejemplo, es posible a partir de datos de ventas de productos, derivar una regla que identifique que el cliente que compra el Domingo antes de las 11 AM y compra leche, también comprará el diario y un chocolate. De esta forma, cuando un gerente de una tienda desea promover un chocolate en especial, puede utilizar la regla anterior y colocar los chocolates al lado del stand del diario.

7
Introducción OLAP y Data Mining NO involucran modificaciones a los datos, y requieren acceso ad-hoc a todos los datos de la organización, tanto actuales como históricos. Esto conlleva a la necesidad de nuevos modelos de datos para la organización y almacenamiento de datos históricos, modelos que optimizan el procesamiento de consultas en vez de transacciones. Los Data Warehouses extienden las tecnologías de bases de datos para integrar datos desde múltiples fuentes y organizarlos eficientemente para el procesamiento de querys y su presentación.

8
Base de Datos Operacional
Data Warehouse Datos Operacionales Datos del negocio para Información Orientado a la aplicación Orientado al sujeto Actual Actual + histórico Detallada Detallada + más resumida Cambia continuamente Estable

9
Qué es un Data Warehouse ?
Una de las mejores definiciones de Data warehouse fue propuesta por Inmon cuando él introdujo el término en 1992: Un data warehouse es una colección de datos para el soporte de decisiones estratégicas, orientado a la temática (subject-oriented), integrada, no-volátil, y variante en el tiempo (time-variant). Colección Orientada a la temática (subject-oriented): significa que la data es organizada alrededor de temáticas tales como clientes, productos, ventas, etc. En base de datos, en contraste, los datos son organizados alrededor de tareas. Por ejemplo, usamos una base de datos para el almacenamiento de ordenes de compra y adquisiciones de productos. Usamos un Data Warehouse para almacenar resúmenes de la información detallada basada en temáticas.
, integrada, no-volátil, y variante en el tiempo (time-variant). Colección Orientada a la temática (subject-oriented): significa que la data es organizada alrededor de temáticas tales como clientes, productos, ventas, etc. En base de datos, en contraste, los datos son organizados alrededor de tareas. Por ejemplo, usamos una base de datos para el almacenamiento de ordenes de compra y adquisiciones de productos. Usamos un Data Warehouse para almacenar resúmenes de la información detallada basada en temáticas.")
10
Qué es un Data Warehouse ?
Un resumen puede ser obtenido a través del uso de funciones agregadas combinadas con cláusulas GROUP BY. Por Ejemplo, un resumen alrededor de un producto pueden ser las ventas por producto: SELECT Producto, SUM(Total) FROM NotaVenta GROUP BY Producto Y un resumen en torno a una venta pueden ser las ventas diarias: SELECT Dia, SUM(Total) FROM OrdenCompra GROUP BY Dia
 FROM NotaVenta. GROUP BY Producto. Y un resumen en torno a una venta pueden ser las ventas diarias: SELECT Dia, SUM(Total) FROM OrdenCompra. GROUP BY Dia.")
11
Qué es un Data Warehouse ?
Colección Integrada: significa que un data warehouse integra y almacena datos desde múltiples fuentes, no todas necesariamente son bases de datos, una fuente de datos puede ser también un archivo de aplicación. Nótese que no hablamos de un sistema de integración que permite acceso a datos en bases de datos heterogeneas (multi-database system), sino que un datawarehouse almacena la información recolectada, después que esta es “limpiada” (cleaned), removiendo inconsistencias tales como formatos diferentes o valores erróneos. De esta forma, la data residente en el data warehouse es presentada a los usuarios con una vista unificada consistente.
, sino que un datawarehouse almacena la información recolectada, después que esta es limpiada (cleaned), removiendo inconsistencias tales como formatos diferentes o valores erróneos. De esta forma, la data residente en el data warehouse es presentada a los usuarios con una vista unificada consistente.")
12
Qué es un Data Warehouse ?
Colección no-volátil: significa que el data warehouse no es actualizado en tiempo real (en coordinación con las fuentes). Las actualizaciones en las fuentes son agrupadas y aplicadas por una transacción de mantenimiento. Las transacciones de mantenimiento se ejecutan periódicamente o en función de la demanda. Colección variante en el tiempo (time-variant): significa que los datos en un data warehouse son históricos y tienen validez temporal. Esto claramente muestra que un data warehouse debe soportar series de tiempo.
. Las actualizaciones en las fuentes son agrupadas y aplicadas por una transacción de mantenimiento. Las transacciones de mantenimiento se ejecutan periódicamente o en función de la demanda. Colección variante en el tiempo (time-variant): significa que los datos en un data warehouse son históricos y tienen validez temporal. Esto claramente muestra que un data warehouse debe soportar series de tiempo.")
13
Arquitectura de un Data warehouse

14
Modelamiento Multidimensional
El modelo relacional utilizado para estructurar bases de datos fue diseñado para el procesamiento de transacciones, aunque puede ser utilizado para soportar eficientemente el procesamiento de querys ad-hoc, no provee de una herramienta intuitiva de manipulación de los datos y reportes, según lo requerido por OLAP. Consideremos datos de series de tiempo. Una forma intuitiva de reportearlos sería plotearlos en un gráfico y guardarlos en una matriz de dos o más dimensiones. Este tipo de representación de los datos es llamada modelamiento multidimensional.

15
Modelamiento Multidimensional
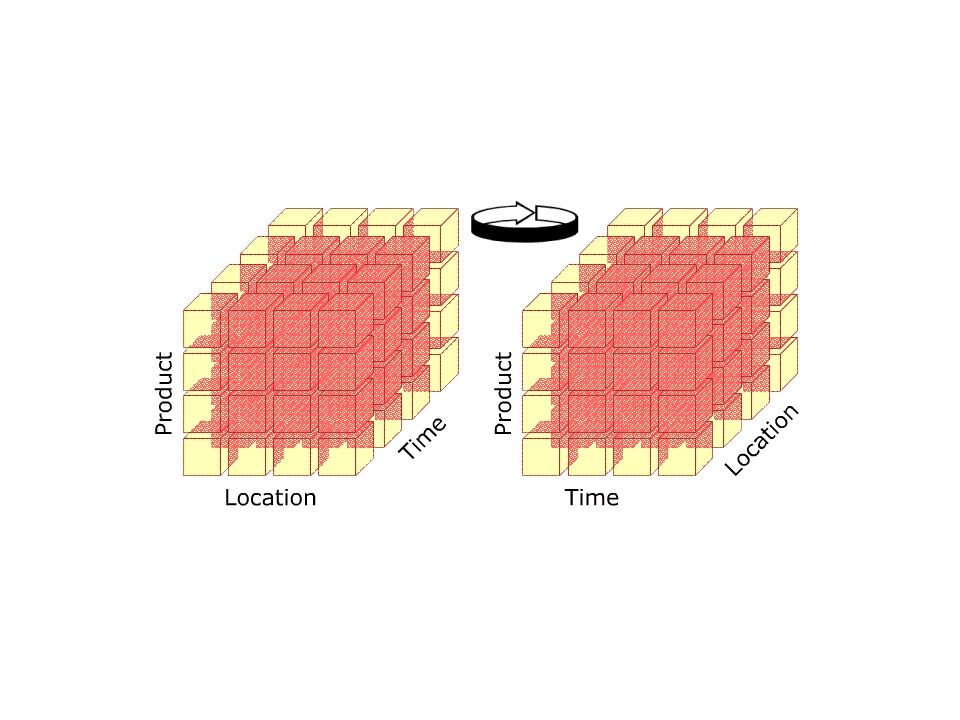
Los modelos multidimensionales almacenan los datos en matrices multidimensionales. Las matrices tri-dimensionales (3-d) son llamadas cubos de datos (data cubes), y las matrices con más de 3 dimensiones son llamadas hipercubos (hypercubes). Como ejemplo de un cubo, consideremos las dimensiones periodo, producto y región Como lo mencionamos anteriormente, podemos usar una matriz 2-d (planilla) para representar ventas regionales para un grupo de periodos: | R1 R2 R3 ... -----| > Region P1 | P2 | P3 | . | V Product
 son llamadas cubos de datos (data cubes), y las matrices con más de 3 dimensiones son llamadas hipercubos (hypercubes). Como ejemplo de un cubo, consideremos las dimensiones periodo, producto y región. Como lo mencionamos anteriormente, podemos usar una matriz 2-d (planilla) para representar ventas regionales para un grupo de periodos: | R1 R2 R | > Region. P1 | P2 | P3 | . | V. Product.")
16
Modelamiento Multidimensional
Esta planilla puede ser convertida a un cubo agregando la dimensión tiempo, como por ejemplo, intervalos mensuales:

17
Modelamiento Multidimensional
Visualizar un cubo de datos es tan fácil como usar un gráfico 3d o visualizar planillas en tablas 3d. Visualizar hipercubos es bastante complejo, por lo anterior estos normalmente son descompuestos en cubos al momento de visualizarlos. El procesamiento de querys en cubos o hipercubos es más rápido y eficiente que en un modelo relacional. Un query es básicamente transformado en una operación de lectura de elementos de una matriz. La data puede ser consultada directamente en cualquier combinación de dimensiones.

18
Cubos OLAP

19
Los cubos OLAP consisten de hechos (facts) llamados medidas categorizados por dimensiones (que pueden ser más de 3 dimensiones); las dimensiones son referidas desde la tabla de hechos por claves foráneas. Las medidas son derivadas de los registros en la Tabla de hechos(fact tables). Dimensiones son derivadas de las tablas de dimensiones. Los valores en las celdas son resúmenes (SUM, AVG, MAX, MIN, etc.)
. Dimensiones son derivadas de las tablas de dimensiones. Los valores en las celdas son resúmenes (SUM, AVG, MAX, MIN, etc.)")
20
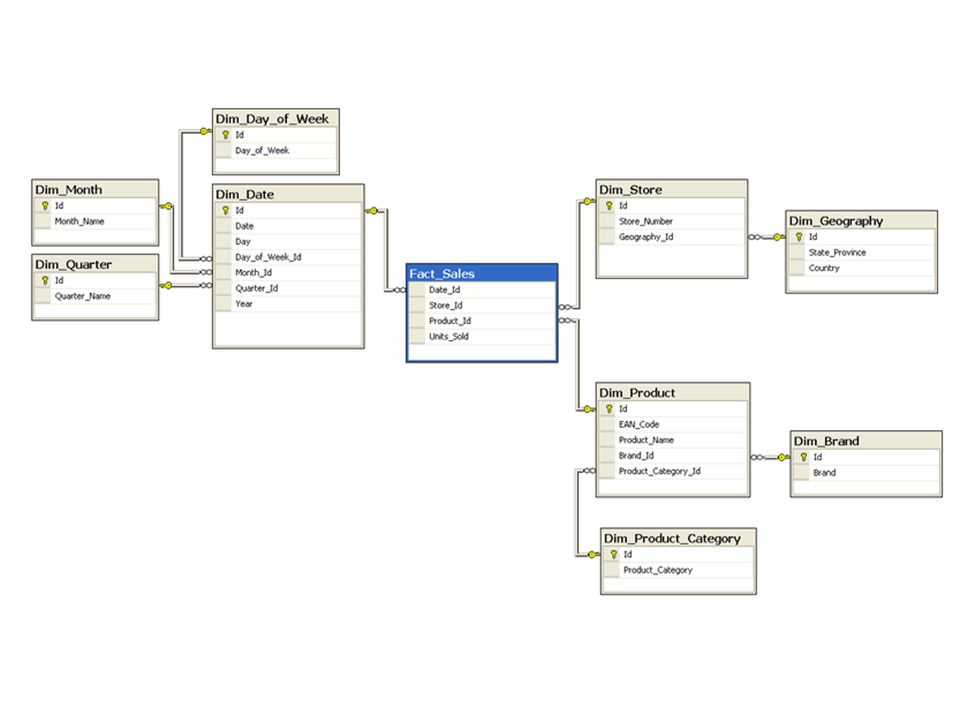
Esquemas de Copo de Nieve (snowflake)
")
22
SELECT B.Brand, G.Country, SUM(F.Units_Sold) FROM Fact_Sales F INNER JOIN Dim_Date D ON F.Date_Id = D.Id INNER JOIN Dim_Store S ON F.Store_Id = S.Id INNER JOIN Dim_Geography G ON S.Geography_Id = G.Id INNER JOIN Dim_Product P ON F.Product_Id = P.Id INNER JOIN Dim_Brand B ON P.Brand_Id = B.Id INNER JOIN Dim_Product_Category C ON P.Product_Category_Id = C.Id WHERE D.YEAR = 1997 AND C.Product_Category = 'tv' GROUP BY G.Country

23
Querys extendidos en un Data-Warehouse
Un data warehouse provee una vista conceptual multidimensional con un número ilimitado de dimensiones y niveles de agregación. Ofrecen varios operadores que facilitan tanto las operaciones de querys y la visualización de los datos en una vista multidimensional: Pivot-Rotation (Pivote – Rotación): los cubos pueden ser visualizados y reorientados en diferentes ejes. En el ejemplo anterior, producto y región están representados en el frente, usando rotación podemos traer tiempo y producto al frente, empujando región al eje posterior.
: los cubos pueden ser visualizados y reorientados en diferentes ejes. En el ejemplo anterior, producto y región están representados en el frente, usando rotación podemos traer tiempo y producto al frente, empujando región al eje posterior.")
25
Roll-Up Display: Puede ser usado para derivar resúmenes y agrupaciones de mayor agregación sobre una dimensión. Por ejemplo los meses pueden ser agrupados en años sobre la dimensión tiempo. Los productos pueden ser agrupados en categorías, etc. Drill-Down Display: Puede ser usado para derivar desagregaciones sobre una dimensión, por ejemplo, región puede ser desagregado en ciudades, los meses pueden ser desagregados en semanas o días, etc.

26
ROLL UP

27
ROLL UP

28
Slice and Dice: Puede ser utilizado para especificar proyecciones sobre las dimensiones, creando cubos más pequeños. Por ejemplo, recuperar todos lo productos juguetes en ciudades de Florida durante los meses de invierno.

29
Selección: Es similar al Select standard de SQL, puede ser utilizado para recuperar datos por valor o rango. Ordenamiento: Puede ser utilizado para especificar el orden de los datos sobre una dimensión. Atributos derivados: Permite la especificación de atributos que son computados desde atributos almacenados u otros atributos derivados

30
Modelo de Almacenamiento Multidimensional
Los Data warehouses soportan la sumarización provista por las operaciones drill-down y roll-up, ambas operaciones demandan en general mucho tiempo de proceso: Mantienen tablas de resumen que son recuperadas para desplegar una sumarización. Codifican los diferentes niveles sobre una dimensión (por ej. semanal, mensual, anual) sobre tablas existentes. Usando la codificación adecuada, una sumarización es computada desde los datos detallados cuando es necesario.
 sobre tablas existentes. Usando la codificación adecuada, una sumarización es computada desde los datos detallados cuando es necesario.")
31
Modelo de Almacenamiento Multidimensional
Las tablas en un Data warehouse son organizadas lógicamente en un esquema denominado star-schema (estrella). Un esquema estrella consiste en una tabla central “fact” que contiene los datos que pueden ser analizados en una variedad de formas, y una tabla “dimension” para cada dimensión, conteniendo datos referenciales. Los datos detallados son almacenados en las tablas de dimensiones y son referenciadas por llaves foráneas en la tabla fact.
. Un esquema estrella consiste en una tabla central fact que contiene los datos que pueden ser analizados en una variedad de formas, y una tabla dimension para cada dimensión, conteniendo datos referenciales. Los datos detallados son almacenados en las tablas de dimensiones y son referenciadas por llaves foráneas en la tabla fact.")
32
Modelo de Almacenamiento Multidimensional
Por ejemplo, un esquema estrella que pueda soportar el ejemplo consistiría de una tabla “fact”, rodeada de tres tablas “dimension”, una para productos, otra para ventas regionales, y otra para intervalos mensuales: Fact table: SALE SUMMARY (Product, Month, Region, Sales) Product -> PRODUCT(PID) Month -> MONTH_INTERVAL(Month) Region -> REGIONAL_SALES(RegionNo) Dimension tables: PRODUCT (PID, Pname, PCategory, PDescription) REGIONAL_SALES (Region, County, City) MONTH_INTERVAL (MonthNo, Month, Year)
 Product -> PRODUCT(PID) Month -> MONTH_INTERVAL(Month) Region -> REGIONAL_SALES(RegionNo) Dimension tables: PRODUCT (PID, Pname, PCategory, PDescription) REGIONAL_SALES (Region, County, City) MONTH_INTERVAL (MonthNo, Month, Year)")
33
Modelo de Almacenamiento Multidimensional
En el esquema estrella, las tablas de dimensión pueden no estar normalizadas, conteniendo datos redundantes. La motivación de esta redundancia es incrementar la eficiencia del procesamiento de querys a través de la eliminación de operaciones de join entre tablas. Por otra parte, una tabla desnormalizada puede crecer enormemente, causando un overhead que podría contrarrestar cualquier ganancia en el procesamiento de querys. En estos casos las tablas de dimensión pueden ser normalizadas y descompuestas en tablas más pequeñas, referenciándolas en la tabla de dimensión original. Esta descomposición lleva a un modelo de estrella jerárquico denominado Snowflake schema. Tal como en bases de datos, un Data warehouse utiliza diferentes formas de indexación para acceder más rápidamente a los datos, agregando la implementación de un manejo eficiente de matrices dinámicas.

34
Características y Categorías de Data Warehouses
Comparado con bases de datos, los Data warehouses son muy costosos de construir en términos de tiempo y dinero. Aún más, son muy costosos de mantener. Un Data warehouse tiene un tamaño gigantesco y crece con tasas enormes. Son al menos un orden de magnitud más grandes que la fuente. Sus tamaños oscilan entre cientos de gigabytes hasta varios terabytes o incluso petabytes. Resolver la semántica heterogénea entre diferentes fuentes, convertir diferentes formatos y cuerpos de datos desde las fuentes hacia el Data warehouse es un proceso complejo muy consumidor de tiempo y recursos. Este proceso no es ejecutado solo una vez, sino que se repite en el tiempo cada vez que el Data warehouse es sincronizado con las fuentes.

35
Características y Categorías de Data Warehouses
El proceso de limpieza de los datos para el aseguramiento de la calidad de la información es otro proceso complejo y costoso. De hecho ha sido identificado como una de las tareas más demandantes de trabajo en la construcción de un Data warehouse. Reconocer datos erróneos o incompletos es difícil de automatizar, al menos al comienzo, en algunos casos los errores siguen un patrón y pueden ser identificados y corregidos automáticamente. La decisión de qué resumir (sumarizar) y el cómo organizar es otro proceso crítico. Afecta tanto la utilidad del Data warehouse como su rendimiento. Los procesos de actualización y carga de datos son tareas bastante significativas y demandantes de tiempo, por este motivo el Data warehouse debe proveer capacidad de recuperación de cargas incompletas o actualizaciones erróneas.
 y el cómo organizar es otro proceso crítico. Afecta tanto la utilidad del Data warehouse como su rendimiento. Los procesos de actualización y carga de datos son tareas bastante significativas y demandantes de tiempo, por este motivo el Data warehouse debe proveer capacidad de recuperación de cargas incompletas o actualizaciones erróneas.")
36
Características y Categorías de Data Warehouses
Esta claro que la administración de los datos en un ambiente tan complejo requiere de herramientas de alto nivel y muchos recursos, en muchos casos organizaciones que han creado Data warehouses han requerido redestinar sus esfuerzos de administración hacia esta área. Con el objeto de reducir la severidad del impacto que causa lo anterior, dos nuevas alternativas han sido propuestas: Data Marts: estos son data warehouses pequeños y altamente focalizados al nivel de departamentos. Un Data warehouse corporativo puede ser construído formando una federación de Data Marts. Virtual Data Warehouses: Estas son colecciones persistentes de vistas de las bases de datos operacionales que son materializadas para un acceso eficiente y para el procesamiento de querys complejos.

37
Proceso de Descubrimiento de Conocimiento (Knowledge Discovery and Data Mining)
Selección de los datos. El subconjunto de datos objetivo y los atributos de interés se identifican examinando todo el conjunto de datos sin ninguna manipulación previa Limpieza de los datos. Se elimina el ruido y los datos fuera de rango, se transforman los valores de los campos a unidades comunes y se crean campos nuevos combinando campos ya existentes (desnormalización)
")
38
Proceso de Descubrimiento de Conocimiento (Knowledge Discovery and Data Mining)
Minería de datos. Se utilizan algoritmos de minería de datos para extraer las pautas interesantes. Evaluación. Se presentan las pautas a los usuarios finales de manera comprensible (visualización).
.")
39
RECUENTO DE APARICIONES CONJUNTAS
RECUENTO DE APARICIONES CONJUNTAS Recuento de los Artículos. Considérese el problema del recuento de los artículos que aparecen, cada carro de la compra es un conjunto de artículos adquiridos por un cliente en una sola transacción de cliente. Cada transacción consiste en una sola visita a la tienda (transacción del cliente). Un objetivo frecuente de los comerciantes es la identificación de los artículos que se compran de manera conjunta.
. Un objetivo frecuente de los comerciantes es la identificación de los artículos que se compran de manera conjunta.")
40
Recuento de Apariciones Conjuntas
Idtrans Idcli Fecha Artículo Cantidad 111 201 05/01/1999 Pluma 2 Tinta 1 Leche 3 Zumo 6 112 105 06/03/1999 113 106 05/10/1999 114 06/01/1999 4 Agua

41
Conjuntos de Artículos Frecuentes
Se puede considerar normalización. Observaciones: En el 75% de las transacciones se compran pluma y tinta. Lote es un conjunto de artículos. Lote {pluma, tinta} tiene 75% de soporte en Compras. Lote {leche, zumo} tiene soporte de 25%. Normalmente el conjunto de artículos que se compran simultáneamente con frecuencia es relativamente pequeño. Sopmin (soporte mínimo) 70%. Lotes frecuentes {pluma}, {tinta}, {leche}, {pluma, tinta}, {pluma, leche}. Propiedad a priori. Todo subconjunto de un lote frecuente es también un lote frecuente.
 70%. Lotes frecuentes {pluma}, {tinta}, {leche}, {pluma, tinta}, {pluma, leche}. Propiedad a priori. Todo subconjunto de un lote frecuente es también un lote frecuente.")
42
Conjuntos de Artículos Frecuentes
Foreach item //nivel 1 comprar si es un lote frecuente //si mayor sopmin k=1 Repeat para cada lote frecuente nuevo Lk con artículos k //nivel k+1 generar todos los lotes Lk+1 artículos, Lk C Lk+1 Examinar todas las transacciones una vez y comprobar si los k +1 lotes generados son frecuentes k = k + 1 until no se identifica ningún lote frecuente nuevo Se identifican primero los lotes frecuentes con un solo artículo. En cada iteración posterior se amplían los lotes frecuentes identificados en la iteración anterior para generar posibles lotes de mayor tamaño lo cual reduce el número de lotes frecuentes.

43
Conjuntos de Artículos Frecuentes
En la primera iteración (Nivel 1) se examina la relación Compras, se determina que todos los conjuntos de un solo artículo son lotes frecuentes: {pluma} {aparece en las cuatro transacciones} {tinta} {aparece en tres de las cuatro transacciones} {leche} {aparece en tres de las cuatro transacciones} En la segunda iteración (Nivel 2) se amplían todos los lotes frecuentes con artículo adicional y se generan los siguientes lotes posibles: {pluma, tinta} {pluma, leche} {pluma, zumo} {tinta, leche} {tinta, zumo} {leche, zumo} Al examinar nuevamente la relación compras {pluma, tinta} {pluma, leche} Aparecen en tres de las cuatro transacciones
 se examina la relación Compras, se determina que todos los conjuntos de un solo artículo son lotes frecuentes: {pluma} {aparece en las cuatro transacciones} {tinta} {aparece en tres de las cuatro transacciones} {leche} {aparece en tres de las cuatro transacciones} En la segunda iteración (Nivel 2) se amplían todos los lotes frecuentes con artículo adicional y se generan los siguientes lotes posibles: {pluma, tinta} {pluma, leche} {pluma, zumo} {tinta, leche} {tinta, zumo} {leche, zumo} Al examinar nuevamente la relación compras. {pluma, tinta} {pluma, leche} Aparecen en tres de las. cuatro transacciones.")
44
Conjuntos de Artículos Frecuentes
En la tercera iteración (Nivel 3) se amplían estos lotes con un artículo adicional: {pluma, tinta, leche} {pluma, tinta, zumo} {pluma, leche, zumo} No se genera {tinta, leche, zumo} por no ser frecuente La propiedad a priori implica que cada lote posible sólo puede ser frecuente si todos sus subconjuntos lo son. Para el ejemplo: con sopmin = 70% Nivel 1, lotes frecuentes tamaño 1: {pluma}.{tinta} y {leche}. Nivel 2 solo quedan: {pluma , tinta},{pluma, leche} y {tinta, leche} Pues {zumo} no es frecuente entonces{pluma, zumo} {tinta , zumo} y {leche, zumo} no son frecuentes y pueden eliminarse a priori. Nivel 3 {pluma, tinta, leche}
 se amplían estos lotes con un artículo adicional: {pluma, tinta, leche} {pluma, tinta, zumo} {pluma, leche, zumo} No se genera {tinta, leche, zumo} por no ser frecuente. La propiedad a priori implica que cada lote posible sólo puede ser frecuente si todos sus subconjuntos lo son. Para el ejemplo: con sopmin = 70% Nivel 1, lotes frecuentes tamaño 1: {pluma}.{tinta} y {leche}. Nivel 2 solo quedan: {pluma , tinta},{pluma, leche} y {tinta, leche} Pues {zumo} no es frecuente entonces{pluma, zumo} {tinta , zumo} y {leche, zumo} no son frecuentes y pueden eliminarse a priori. Nivel 3 {pluma, tinta, leche}")
45
Consultas Iceberg Considérese que se desea hallar parejas de clientes y artículos tales que el consumidor haya comprado ese artículos más de cinco veces. SELECT C.idcll, C.producto, Sum(C.cantidad) FROM Compras C GROUP BY C.idcli, C.producto HAVING SUM(C.cantidad) > 5 La consulta requiere de reglas de asociación. La consulta puede ser muy grande. El número de grupos es muy grande, pero la respuesta a la consulta – punta del iceberg – suele ser pequeña SELECT R.A1, R.A2,…,R.Ak, agree(R.B) FROM Relación R GROUP BY R.A1, …, R.Ak HAVING agree(R.B) >= constante
 FROM Compras C. GROUP BY C.idcli, C.producto. HAVING SUM(C.cantidad) > 5. La consulta requiere de reglas de asociación. La consulta puede ser muy grande. El número de grupos es muy grande, pero la respuesta a la consulta – punta del iceberg – suele ser pequeña. SELECT R.A1, R.A2,…,R.Ak, agree(R.B) FROM Relación R. GROUP BY R.A1, …, R.Ak. HAVING agree(R.B) >= constante.")
46
MINERÍA DE REGLAS REGLAS DE ASOCIACIÓN. {pluma} => {tinta}
Si en una transacción se compra una pluma, es probable que también se compre tinta en esa transacción, {izquierda} => {derecha} SOPORTE, el soporte de {izquierda} => {derecha} es Izq U Der Por ejemplo, para {pluma} {tinta}. El soporte de esta regla es el soporte del lote {pluma, tinta} que es 75% CONFIANZA, la confianza de {izq} => {der} es el porcentaje de esas transacciones que contienen también todos los artículos de Der sop(Izq) es el porcentaje de transacciones que contienen Izq. sop(Izq U Der) es el porcentaje de transacciones que contienen tanto Izq como Der Entonces Confianza de {izq} => {der} es sop(Izq U Der) / sop(Izq)
 es el porcentaje de transacciones que contienen Izq. sop(Izq U Der) es el porcentaje de transacciones que contienen tanto Izq como Der. Entonces Confianza de {izq} => {der} es sop(Izq U Der) / sop(Izq)")
Presentaciones similares









 Software (Software de Inteligencia Impresario)>")








>")
