Descargar la presentación
La descarga está en progreso. Por favor, espere

1
VIVIANA ACHURY S. ANGIE NATALIA GARCIA S.

2
En los últimos años, ha existido un gran crecimiento en nuestras capacidades de generar y colectar datos (Bajo costo de almacenamiento). INFORMACIÓN OCULTA El descubrimiento de esta información oculta es posible gracias a la Minería de Datos (DataMining)
.")
3
El valor real de los datos reside en la información que se puede extraer de ellos, información que ayude a tomar decisiones o mejorar nuestra comprensión de los fenómenos que nos rodean.

4
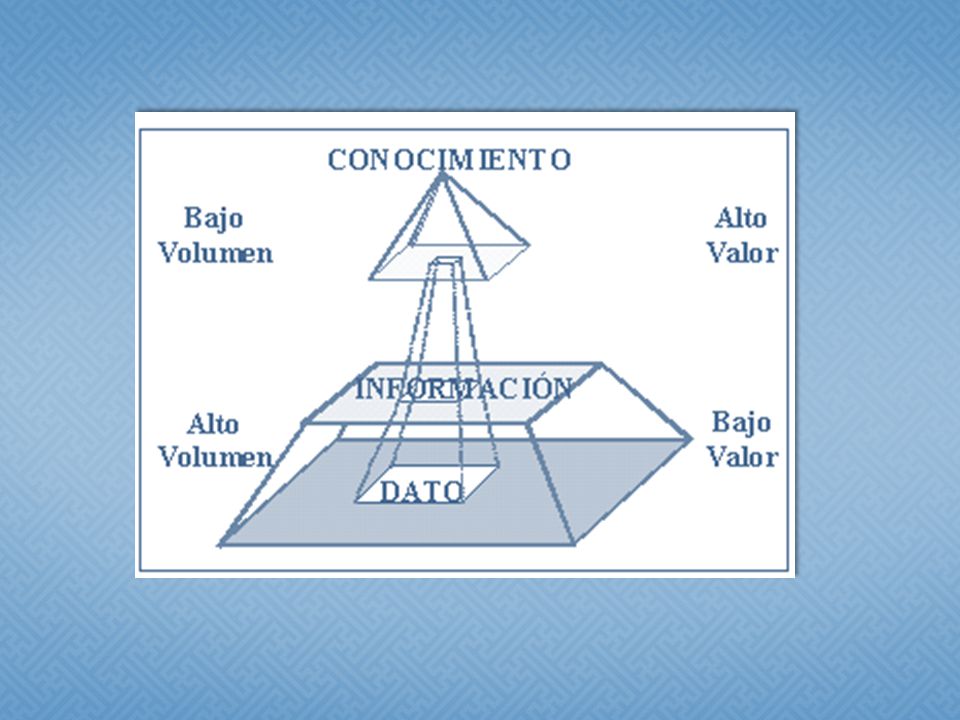
LOS DATOS SON LA MATERIA PRIMA BRUTA INFORMACIÓN ¿EN QUE MOMENTO?

5
Nos referimos al Conocimiento

7
4 4 4 4 4 4 4 Es un proceso de extracción no trivial para identificar patrones que sean validos, novedosos, potencialmente útiles y entendibles, a partir de los datos. Su objetivo principal es poder llegar a procesar automáticamente grandes cantidades de datos para encontrar conocimiento útil para un usuario y satisfacer sus metas.

8
Con las sentencias SQL se puede realizar un primer análisis, aproximadamente el 80% de la información se obtiene con estas técnicas. El 20% restante, que la mayoría de las veces, contiene la información más importante, requiere la utilización de técnicas más avanzadas. KDD, apunta a procesar automáticamente grandes cantidades de datos para encontrar conocimiento útil en ellos, de esta manera permitirá al usuario el uso de esta información valiosa para su conveniencia.

9
Procesar automáticamente grandes cantidades de datos crudos. Identificar los patrones más significativos y relevantes. Presentarlos como conocimiento apropiado para satisfacer las metas del usuario.

10
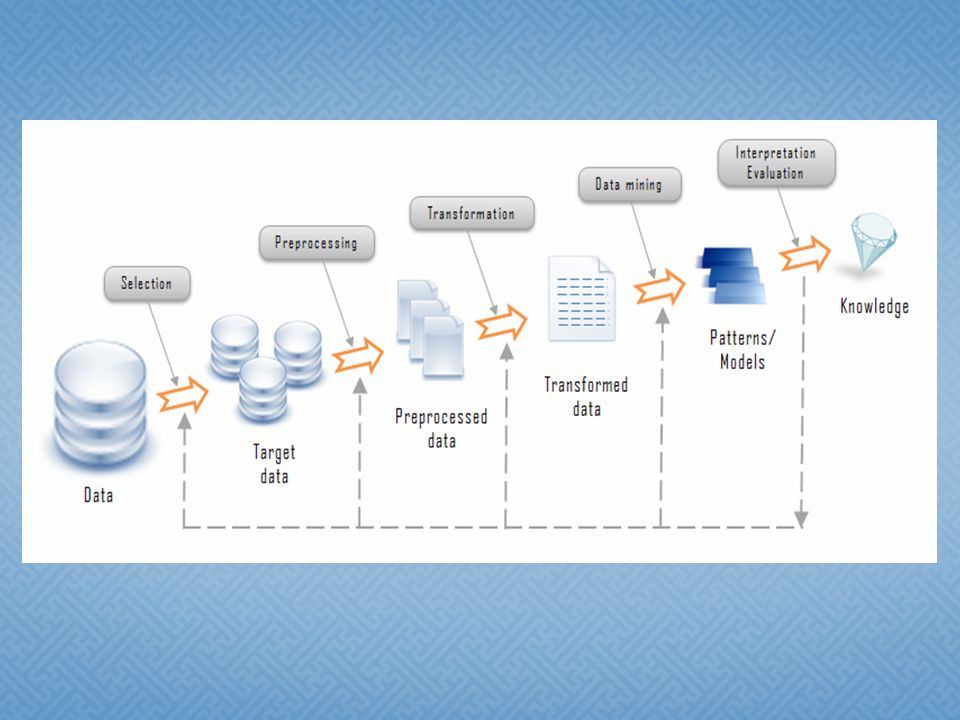
Determinar las fuentes de información Determinar las fuentes de información (que pueden ser útiles y dónde conseguirlas) Diseñar el esquema de un almacén de datos Diseñar el esquema de un almacén de datos (Data Warehouse): que consiga unificar de maner a operativa toda la información recogida. Implantación del almacén de datos Implantación del almacén de datos: que permita la navegación y visualización Previa de sus datos Previa de sus datos, para discernir qué aspectos puede interesar que sean estudiados.

11
Selección, limpieza y transformación de los datos Selección, limpieza y transformación de los datos que se van a analizar que se van a analizar Seleccionar y aplicar el método de minería de Seleccionar y aplicar el método de minería de datos apropiado. datos apropiado. Clasificación, agrupamiento o clustering Clasificación, agrupamiento o clustering La selección de él o de los algoritmos a utilizar; La selección de él o de los algoritmos a utilizar; Forma de representarlo (árboles de decisión, regl as, etc.) Forma de representarlo (árboles de decisión, regl as, etc.)
 Forma de representarlo (árboles de decisión, regl as, etc.).")
12
Evaluación, interpretación, trans formación y representación de l os patrones extraídos. Evaluación, interpretación, trans formación y representación de l os patrones extraídos. Difusión y uso del nuevo conoci miento. Difusión y uso del nuevo conoci miento.

14
Los algoritmos de aprendizaje son una parte integral de KDD. las técnicas de aprendizaje dirigidas disfrutan de un rango de éxito definido por la utilidad del descubrimiento del conocimiento. Estos algoritmos de aprendizaje son complejos y generalmente considerados como la parte más dificíl de cualquier técnica KDD.

15
Esta familia de técnicas KDD utiliza modelos de representación gráfica para comparar las diferentes representaciones del conocimiento. Estos modelos están basados en las probabilidades e independencias de los datos. Estos son útiles para aplicaciones que involucran incertidumbre y aplicaciones estructuradas tal que una probabilidad puede asignarse a cada uno de los resultados o pequeña cantidad del descubrimiento del conocimiento.

16
Las técnicas probabilísticas pueden usarse en los sistemas de diagnóstico, planeación y sistemas de control. Las herramientas del probabilidad automatizadas están disponibles en el dominio público y comercial

17
El método estadístico usa la regla del descubrimiento y se basa en las relaciones de los datos. El algoritmo de aprendizaje inductivo puede seleccionar automáticamente trayectorias útiles y atributos para construir las reglas de una base de datos con muchas relaciones. Este tipo de inducción es usado para generalizar los modelos en los datos y construir las reglas de los modelos nombrados.

18
El proceso analítico en línea (OLAP) es un ejemplo de un método orientado a la estadística. Las herramientas estadísticamente automatizadas están disponibles en el dominio público y comercial. Un ejemplo de una aplicación estadística es determinando que todas las transacciones en una base de datos de ventas que empiezan con una transacción de código especificada son las ventas en efectivo. El sistema notaría que todas las transacciones en la base de datos que sólo el 60% son las ventas en efectivo. Por consiguiente, el sistema podrá concluir con precisión que el 40% son artículos fuera de serie.

19
La clasificación es probablemente el método más antiguo y mayormente usado de todos los métodos de KDD. Este método agrupa los datos de acuerdo a similitudes o clases. Hay muchos tipos de clasificación de técnicas y numerosas herramientas disponible que son automatizadas.

20
método Bayesian El método Bayesian de KDD es un modelo gráfico que usa directamente los arcos exclusivamente para formar una gráfica acíclica'. Aunque el método Bayesian usa los medios probabilísticos y gráficos de representación, también es considerado un tipo de clasificación.

21
Se usan muy frecuentemente las las redes de Bayesian cuando la incertidumbre se asocia con un resultado puede expresarse en términos de una probabilidad. Este método cuenta con un dominio del conocimiento codificado y ha sido usado para los sistemas de diagnóstico. Otras aplicaciones de reconocimiento de patrones, incluyendo el Modelo Markov Oculto, puede ser modelado usando un método de Bayesian. Las herramientas automatizadas están disponibles en el dominio público y comercial.

22
Este es otro tipo de clasificación que sistemáticamente reduce una base de datos grande a unos cuantos archivos informativos. Si el dato es redundante y poco interesante se elimina, la tarea de descubrir los patrones en los datos se simplifica- da. Este método trabaja en la premisa de un dicho viejo, menos es más.

23
El descubrimiento de patrones y las técnicas de limpia de datos son útiles para reducir volúmenes Enormes de datos en las aplicaciones, tal como aquéllos encontrados al analizar las grabaciones de un sensor automatizado.

24
Una vez que las lecturas del sensor se reducen a un tamaño manejable usando la técnica de limpia de datos, pueden reconocerse con más facilidad los patrones de datos. Las herramientas automatizadas que usan estas técnicas están disponibles en el dominio público y comercial.

25
Usa las reglas de producción, construidas como figuras gráficas basado en datos premisos y clasificación de los datos según sus atributos. Este método requiere ese clases de los datos que son discretos y predefinidos. Según, el uso primario de este método es para predecir modelos que pueden ser apropiados para cualquier clasificación o técnicas de regresión. Las herramientas para el análisis de árbol de decisión están disponibles en el dominio público y comercial.

26
El método de detección por filtrado tiende ser importante como base para este método de KDD. Normalmente las técnicas de análisis y desviación son aplicadas temporalmente en las bases de datos Una buena aplicación para este tipo de KDD es el análisis de tráfico en las grandes redes de telecomunicaciones.

27
Las redes neuronales podrán usarse como método del descubrimiento del conocimiento. Las redes neuronales son particularmente útiles para el reconocimiento de patrones y algunas veces se agrupa con los métodos de clasificación. Hay herramientas disponible en el dominio público y comercial. Los algoritmos genéticos, también usados para la clasificación, son similares a las redes neuronal es aunque estas son consideradas más poderosos. Hay herramientas comerciales disponibles para el método genético.

28
Un método híbrido para KDD combina más de un método y también es llamado método multi-paradigmático. Aunque la implementación puede ser más difícil, las herramientas híbridas son capaces de combinar la potencia de varios métodos. Algunos de los métodos comúnmente usados combinan técnicas de visualización, inducción, redes neuronales y los sistemas basados en reglas para llevar a cabo el descubrimiento de conocimiento deseado. También se han usado bases de datos deductivas y algoritmos genéticos en los métodos híbridos. Hay herramientas híbridas disponible comercialmente y en el dominio público.

Presentaciones similares

















 Microsoft SQL Server 2008 R2 (2013) Suscribase a http://addkw.com/ o escríbanos.>")

