Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Manejo de Incertidumbre Sesión 13 Eduardo Morales / L. Enrique Sucar Sesión 13 Eduardo Morales / L. Enrique Sucar

2
Los sistemas basados en conocimiento deben ser capaces de representar y razonar con incertidumbre. Existen varias causas de incertidumbre que tienen que ver con la información, el conocimiento y la representación. Los sistemas basados en conocimiento deben ser capaces de representar y razonar con incertidumbre. Existen varias causas de incertidumbre que tienen que ver con la información, el conocimiento y la representación. Introducción

3
Incompleta Poco confiable Ruido, distorsión Incompleta Poco confiable Ruido, distorsión Información

4
Impreciso Contradictorio Impreciso Contradictorio Conocimiento

5
No adecuada Falta de poder descriptivo No adecuada Falta de poder descriptivo Representación

6
Diagnóstico médico Predicción financiera Exploración minera / petrolera Interpretación de imágenes (visión) Reconocimiento de voz Monitoreo / control de procesos industriales complejos Diagnóstico médico Predicción financiera Exploración minera / petrolera Interpretación de imágenes (visión) Reconocimiento de voz Monitoreo / control de procesos industriales complejos Ejemplos de dominios con incertidumbre
 Reconocimiento de voz Monitoreo / control de procesos industriales complejos Diagnóstico médico Predicción financiera Exploración minera / petrolera Interpretación de imágenes (visión) Reconocimiento de voz Monitoreo / control de procesos industriales complejos Ejemplos de dominios con incertidumbre")
7
Si pierden varias propiedades de los sistemas que no tienen incertidumbre, basados en lógicas o reglas, lo cual hace el manejo de incertidumbre más complejo. Las principales dos características que, en general, ya no aplican son: Si pierden varias propiedades de los sistemas que no tienen incertidumbre, basados en lógicas o reglas, lo cual hace el manejo de incertidumbre más complejo. Las principales dos características que, en general, ya no aplican son: Efectos de Incertidumbre 1. Modularidad 2. Monotonicidad 1. Modularidad 2. Monotonicidad

8
Un sistema de reglas es modular, ya que para saber la verdad de una regla sólo tiene que considerarla a ésta, sin importar el resto del conocimiento. Pero si hay incertidumbre ya no puedo considerar la regla por si sola, debo tomar en cuenta otras reglas Un sistema de reglas es modular, ya que para saber la verdad de una regla sólo tiene que considerarla a ésta, sin importar el resto del conocimiento. Pero si hay incertidumbre ya no puedo considerar la regla por si sola, debo tomar en cuenta otras reglas Modularidad

9
Un sistema es monotónico si al agregar nueva información a su base de datos, no se alteran las conclusiones que seguían de la base de datos original. Monotonicidad

10
Si hay incertidumbre ya no puedo considerar que la certeza en una hipótesis ya no puede cambiar, debo tomar en cuenta otras reglas que involucren a dicha hipótesis.

11
No-numéricas * Lógicas no-monotónicas * Sistemas de mantenimiento de verdad (TMS, ATMS) * Teoría de endosos No-numéricas * Lógicas no-monotónicas * Sistemas de mantenimiento de verdad (TMS, ATMS) * Teoría de endosos Técnicas
 * Teoría de endosos No-numéricas * Lógicas no-monotónicas * Sistemas de mantenimiento de verdad (TMS, ATMS) * Teoría de endosos Técnicas")
12
Numéricas * Empíricas (MYCIN, Prospector) * Métodos aproximados * Lógica difusa * Teoría de Dempster-Shafer * Redes Bayesianas Numéricas * Empíricas (MYCIN, Prospector) * Métodos aproximados * Lógica difusa * Teoría de Dempster-Shafer * Redes Bayesianas Técnicas
 * Métodos aproximados * Lógica difusa * Teoría de Dempster-Shafer * Redes Bayesianas Numéricas * Empíricas (MYCIN, Prospector) * Métodos aproximados * Lógica difusa * Teoría de Dempster-Shafer * Redes Bayesianas Técnicas")
13
Recordaremos algunos conceptos de probabilidad relevantes, en particular: Conceptos de Probabilidad Probabilidad Condicional Independencia Teorema de Bayes Probabilidad Condicional Independencia Teorema de Bayes

14
Para cada h,e con P(e) 0, la probabilidad condicional de h dado e o P(h e) ( probabilidad a posteriori ) es: Para cada h,e con P(e) 0, la probabilidad condicional de h dado e o P(h e) ( probabilidad a posteriori ) es: Probabilidad Condicional P(h e) = P(h e) P(e)
 0, la probabilidad condicional de h dado e o P(h e) ( probabilidad a posteriori ) es: Para cada h,e con P(e) 0, la probabilidad condicional de h dado e o P(h e) ( probabilidad a posteriori ) es: Probabilidad Condicional P(h e) = P(h e) P(e)")
15
En la práctica P(h e) no se obtiene fácilmente, sin embargo P(e h) sí. Para obtenerla utilizamos el Teorema de Bayes: En la práctica P(h e) no se obtiene fácilmente, sin embargo P(e h) sí. Para obtenerla utilizamos el Teorema de Bayes: Teorema de Bayes P(h e) = P(e h) P ( h ) P(e)
 no se obtiene fácilmente, sin embargo P(e h) sí. Para obtenerla utilizamos el Teorema de Bayes: Teorema de Bayes P(h e) = P(e h) P ( h ) P(e).")
16
Independencia marginal: P( h e)= P( h ). Independencia Los eventos e 1,…,e n son independientes si: Los eventos e 1,…,e n son condicionalmente independientes dado un evento h, si: P(e 1 ... e n )= P(e 1 ) … P(e n ) P(e 1 ... e n h )= P(e 1 h ) … P(e n h ) Independencia condicional: P( h k e)= P( h k ).
= P(e 1 ) … P(e n ) P(e 1 ... e n h )= P(e 1 h ) … P(e n h ) Independencia condicional: P( h k e)= P( h k )..")
17
Sean H ={ h 1,…,h n } el conjunto de n posibles hipótesis y E ={ e 1,…,e m }, m posibles evidencias. Si asuminos que la hipótesis y los eventos son T o F, lo que queremos encontrar es la h más probable dado e E. Probabilidad en Sistemas Expertos

18
Se tiene que calcular P(h e ) para cada subconjunto de h y seleccionar la de mayor probabilidad utilizando el teorema de Bayes.
 para cada subconjunto de h y seleccionar la de mayor probabilidad utilizando el teorema de Bayes.")
19
como Opción 1: Exhaustivo

20
A esto se le llama normalización ya que se toma como una constante que permite que los términos condicionales sumen 1. A esto se le llama normalización ya que se toma como una constante que permite que los términos condicionales sumen 1. 1 P(e) 1 P(e)
 1 P(e).")
21
En general: Generalización

22
Para aplicar Bayes, se requiere calcular las probabilidades condicionales P(e h i ) para cada combinación de evidencias (en general no se pueden calcular de sus componentes individuales). Esto implica que se tienen que conocer un número exponencial de probabilidades!! Para aplicar Bayes, se requiere calcular las probabilidades condicionales P(e h i ) para cada combinación de evidencias (en general no se pueden calcular de sus componentes individuales). Esto implica que se tienen que conocer un número exponencial de probabilidades!!
 para cada combinación de evidencias (en general no se pueden calcular de sus componentes individuales). Esto implica que se tienen que conocer un número exponencial de probabilidades!!.")
23
Las evidencias son condicionalmente independientes. Opción 2: independencia Con ésto, solo se requieren m x n probabilidades condicionales y n-1 probabilidades a priori.

24
En la opción 1 el sistema se vuelve demasiado complejo, mientras que la opción 2 puede no ser realista para muchas aplicaciones. Una altrenativa es buscar un compromiso entre ambos extremos, esto se logra mediante las redes Bayesianas. En la opción 1 el sistema se vuelve demasiado complejo, mientras que la opción 2 puede no ser realista para muchas aplicaciones. Una altrenativa es buscar un compromiso entre ambos extremos, esto se logra mediante las redes Bayesianas. Conclusión

25
Las primeras técnicas que surgen, cuando menos dentro del área de sistemas expertos, son técnicas empíricas o ad-hoc orientadas a resolver aplicaciones específicas y sin un fuerte fundamento teórico. Las más conocidas son las que corresponden a dos de los primeros sistemas expertos: Las primeras técnicas que surgen, cuando menos dentro del área de sistemas expertos, son técnicas empíricas o ad-hoc orientadas a resolver aplicaciones específicas y sin un fuerte fundamento teórico. Las más conocidas son las que corresponden a dos de los primeros sistemas expertos: Técnicas numéricas

26
PROSPECTOR (exploración minera) PROSPECTOR (exploración minera) MYCIN (diagnóstico de enfermedades infecciosas en la sangre) MYCIN (diagnóstico de enfermedades infecciosas en la sangre)
 PROSPECTOR (exploración minera) MYCIN (diagnóstico de enfermedades infecciosas en la sangre) MYCIN (diagnóstico de enfermedades infecciosas en la sangre)")
27
Sistemas basados en reglas En sistemas basados en reglas se tiene en general una estructura similar a la siguiente:

28
Si: se observa cierta evidencia E Entonces: se concluye cierta hipótesis H con probabilidad (certeza,...) P Si: se observa cierta evidencia E Entonces: se concluye cierta hipótesis H con probabilidad (certeza,...) P ¿Cómo obtener estas medidas? ¿Cómo combinar estas medidas? ¿Cómo interpretar estas medidas? ¿Cómo obtener estas medidas? ¿Cómo combinar estas medidas? ¿Cómo interpretar estas medidas? De aquí surgen varias interrogantes:

29
Las técnicas desarrolladas en MYCIN y Prospector son similares, ambas consideran sistemas basados en reglas a los que se les adicionan Factores de Certeza o Probabilidades Subjetivas, respectivamente. Veremos brevemente el método de MYCIN. Las técnicas desarrolladas en MYCIN y Prospector son similares, ambas consideran sistemas basados en reglas a los que se les adicionan Factores de Certeza o Probabilidades Subjetivas, respectivamente. Veremos brevemente el método de MYCIN. MYCIN

30
MYCIN define un Factor de Certeza que se asocia a cada regla y cada evidencia, y se definen un conjunto de reglas para combinar estos factores.

31
Reglas de combinación 1. Propagación (f prop ) o reglas en serie: 2. AND (conjunción), OR (disjunción) de evidencias ( f and, f or ): 2. AND (conjunción), OR (disjunción) de evidencias ( f and, f or ):
, OR (disjunción) de evidencias ( f and, f or ): 2. AND (conjunción), OR (disjunción) de evidencias ( f and, f or ):.")
32
3. Co-Conclusión (f co ) o reglas en paralelo:
 o reglas en paralelo:")
33
R1: IF A and (B or C) Then H cf 0.8 R2: If D and F Then B cf 0.6 R3: If F or G Then H cf 0.4 R4: If A Then D cf 0.75 R5: If I Then G cf 0.3 R1: IF A and (B or C) Then H cf 0.8 R2: If D and F Then B cf 0.6 R3: If F or G Then H cf 0.4 R4: If A Then D cf 0.75 R5: If I Then G cf 0.3 Ejemplo Se conoce: CF(A,Ev) = 1, CF(C,Ev) = 0.5, CF(F,Ev) = 0.7, CF(I,Ev) = -0.4 Se conoce: CF(A,Ev) = 1, CF(C,Ev) = 0.5, CF(F,Ev) = 0.7, CF(I,Ev) = -0.4
 Then H cf 0.8 R2: If D and F Then B cf 0.6 R3: If F or G Then H cf 0.4 R4: If A Then D cf 0.75 R5: If I Then G cf 0.3 R1: IF A and (B or C) Then H cf 0.8 R2: If D and F Then B cf 0.6 R3: If F or G Then H cf 0.4 R4: If A Then D cf 0.75 R5: If I Then G cf 0.3 Ejemplo Se conoce: CF(A,Ev) = 1, CF(C,Ev) = 0.5, CF(F,Ev) = 0.7, CF(I,Ev) = -0.4 Se conoce: CF(A,Ev) = 1, CF(C,Ev) = 0.5, CF(F,Ev) = 0.7, CF(I,Ev) = -0.4")
34
Aunque pretendía apartarse de probabilidad, se ha demostrado [Heckerman 86] que la técnica de MYCIN corresponde a un subconjunto de probabilidad con una serie de suposiciones implícitas: Desventajas:
![Aunque pretendía apartarse de probabilidad, se ha demostrado [Heckerman 86] que la técnica de MYCIN corresponde a un subconjunto de probabilidad con una serie de suposiciones implícitas: Desventajas:](http://images.slideplayer.es/12/3861332/slides/slide_34.jpg "Aunque pretendía apartarse de probabilidad, se ha demostrado [Heckerman 86] que la técnica de MYCIN corresponde a un subconjunto de probabilidad con una serie de suposiciones implícitas: Desventajas:")
35
La evidencia es condicionalmente independiente de la hipótesis y su negación. La red de inferencia debe corresponder a un árbol para que los resultados sean coherentes. Las fórmulas para conjunción y disjunción (min y max ) sólo son válidas si uno de los términos es subconjunto del otro. La evidencia es condicionalmente independiente de la hipótesis y su negación. La red de inferencia debe corresponder a un árbol para que los resultados sean coherentes. Las fórmulas para conjunción y disjunción (min y max ) sólo son válidas si uno de los términos es subconjunto del otro.
 sólo son válidas si uno de los términos es subconjunto del otro. La evidencia es condicionalmente independiente de la hipótesis y su negación. La red de inferencia debe corresponder a un árbol para que los resultados sean coherentes. Las fórmulas para conjunción y disjunción (min y max ) sólo son válidas si uno de los términos es subconjunto del otro..")
36
Estas suposiciones no son válidas en muchas aplicaciones por lo que el método de MYCIN no se puede generalizar.

37
Redes Bayesianas

38
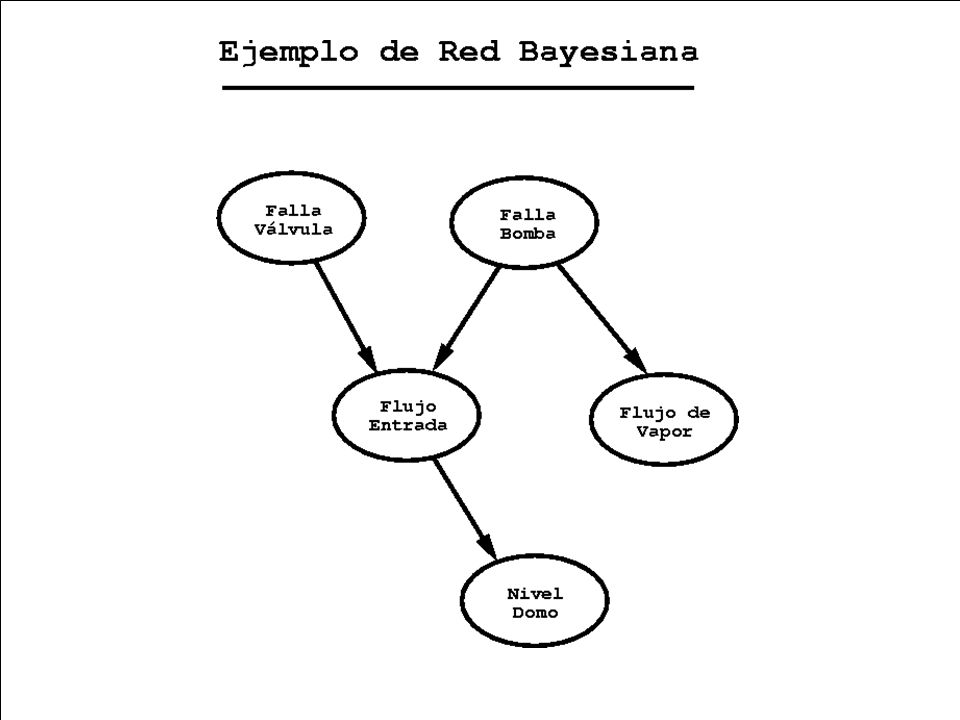
Las redes bayesianas o probabilísticas son una representación gráfica de dependencias para razonamiento probabilístico, en la cual los nodos y arcos representan: Introducción Nodo: Variable proposicional. Arcos: Dependencia probabilística. Nodo: Variable proposicional. Arcos: Dependencia probabilística.

39
Una red probabilística (RP) es un grafo acíclico dirigido (DAG) en la cual cada nodo representa una variable y cada arco una dependencia probabilística, en la cual se especifica la probabilidad condicional de cada variable dados sus padres. Definición: La variable a la que apunta el arco es dependiente (causa-efecto) de la que está en el origen de éste.
 de la que está en el origen de éste..")
41
Interpretación

42
1. Distribución de probabilidad: Representa la distribución de la probabilidad conjunta de las variables representadas en la red. 1. Distribución de probabilidad: Representa la distribución de la probabilidad conjunta de las variables representadas en la red. Podemos interpretar a una RP de dos formas: Por ejemplo:

43
2. Base de reglas: Cada arco representa un conjunto de reglas que asocian las variables involucradas, Por ejemplo: Si C, D entonces F 2. Base de reglas: Cada arco representa un conjunto de reglas que asocian las variables involucradas, Por ejemplo: Si C, D entonces F Dichas reglas están cuantificadas por las probabilidades respectivas.

44
La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables. La red también representa las independencias condicionales de una variable (o conjunto de variables) dada otra variable(s). La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables. La red también representa las independencias condicionales de una variable (o conjunto de variables) dada otra variable(s). Estructura
 dada otra variable(s). La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables. La red también representa las independencias condicionales de una variable (o conjunto de variables) dada otra variable(s). Estructura.")
45
Ej.: {E} es cond. indep. de {A,C,D,F,G} dado {B} Esto es: P(E | A,C,D,F,G,B)= P( E | B) Ej.: {E} es cond. indep. de {A,C,D,F,G} dado {B} Esto es: P(E | A,C,D,F,G,B)= P( E | B) Esto se representa gráficamente por el nodo B separando al nodo E del resto de las variables.
= P( E | B) Ej.: {E} es cond. indep. de {A,C,D,F,G} dado {B} Esto es: P(E | A,C,D,F,G,B)= P( E | B) Esto se representa gráficamente por el nodo B separando al nodo E del resto de las variables..")
46
En general, el conjunto de variables A es independiente del conjunto B dado C si al remover C hace que A y B se desconecten. Es decir, NO existe una trayectoria entre A y B en que las siguientes condiciones sean verdaderas. En general, el conjunto de variables A es independiente del conjunto B dado C si al remover C hace que A y B se desconecten. Es decir, NO existe una trayectoria entre A y B en que las siguientes condiciones sean verdaderas. Verificación de Independencia

47
1. Todos los nodos con flechas convergentes están o tiene descendientes en C. 2. Todos los demás nodos están fuera de C. 1. Todos los nodos con flechas convergentes están o tiene descendientes en C. 2. Todos los demás nodos están fuera de C. Esto se conoce como Separación-D.

48
En una RP todas la relaciones de independencia condicional representadas en el grafo corresponden a relaciones de independencia en la distribución de probabilidad. Dichas independencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades). En una RP todas la relaciones de independencia condicional representadas en el grafo corresponden a relaciones de independencia en la distribución de probabilidad. Dichas independencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades).
 y el razonamiento (propagación de las probabilidades). En una RP todas la relaciones de independencia condicional representadas en el grafo corresponden a relaciones de independencia en la distribución de probabilidad. Dichas independencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades)..")
49
Complementa la definición de una red bayesiana las probabilidades condicionales de cada variable dados sus padres. Nodos raíz: vector de probabilidades marginales Otros nodos: matriz de probabilidades condicionales dados sus padres Complementa la definición de una red bayesiana las probabilidades condicionales de cada variable dados sus padres. Nodos raíz: vector de probabilidades marginales Otros nodos: matriz de probabilidades condicionales dados sus padres Parámetros

50
El razonamiento probabilístico o propagación de probabilidades consiste en propagar de los efectos de la evidencia a través de la red para conocer la probabilidad a posteriori de las variables. El razonamiento probabilístico o propagación de probabilidades consiste en propagar de los efectos de la evidencia a través de la red para conocer la probabilidad a posteriori de las variables. Propagación de Probabilidades

51
La propagación consiste en darle valores a ciertas variables (evidencia), y obtener la probabilidad posterior de las demás variables dadas las variables conocidas (instanciadas).
, y obtener la probabilidad posterior de las demás variables dadas las variables conocidas (instanciadas).")
52
Los algoritmos de propagación dependen de la estructura de la red: Algoritmos Árboles Poliárboles Redes multiconectadas Árboles Poliárboles Redes multiconectadas

53
Cada nodo corresponde a una variable discreta, A={A 1,A 2,…,A n ) con su respectiva matriz de probabilidad condicional, P(B|A)=P(B j | A i ) Propagación en Árboles.
 con su respectiva matriz de probabilidad condicional, P(B|A)=P(B j | A i ) Propagación en Árboles.")
54
Dada cierta evidencia E --representada por la instanciación de ciertas variables-- la probabilidad posterior de cualquier variable B, por el teorema de Bayes: P( B i | E)=P( Bi ) P(E | B i ) / P( E )
=P( Bi ) P(E | B i ) / P( E )")
55
Ya que la estructura de la red es un árbol, el Nodo B la separa en dos subárboles, por lo que podemos dividir la evidencia en dos grupos: E-: Datos en el árbol que cuya raíz es B E+: Datos en el resto del árbol Ya que la estructura de la red es un árbol, el Nodo B la separa en dos subárboles, por lo que podemos dividir la evidencia en dos grupos: E-: Datos en el árbol que cuya raíz es B E+: Datos en el resto del árbol Evidencia

56
Entonces: P( B i | E ) = P ( B i ) P ( E -,E + | B i ) / P(E) Pero dado que ambos son independientes y aplicando nuevamente Bayes: Entonces: P( B i | E ) = P ( B i ) P ( E -,E + | B i ) / P(E) Pero dado que ambos son independientes y aplicando nuevamente Bayes: P( B i | E ) = P ( B i | E + ) P(E - | B i )
 = P ( B i ) P ( E -,E + | B i ) / P(E) Pero dado que ambos son independientes y aplicando nuevamente Bayes: Entonces: P( B i | E ) = P ( B i ) P ( E -,E + | B i ) / P(E) Pero dado que ambos son independientes y aplicando nuevamente Bayes: P( B i | E ) = P ( B i | E + ) P(E - | B i )")
57
Donde es una constante de normalización. Esto separa la evidencia para actualizar la probabilidad de B. Además vemos que no requerimos de la probabilidad a priori, excepto en el caso de la raíz donde: Donde es una constante de normalización. Esto separa la evidencia para actualizar la probabilidad de B. Además vemos que no requerimos de la probabilidad a priori, excepto en el caso de la raíz donde: P (A i | E + )=P( A i )
=P( A i ).")
58
Si definimos los siguientes términos: Definiciones: (B i )= P ( E - | B i ) Entonces: (B i )= P (B i | E + ) P(B i | E )= (B i ) (B i )
= P ( E - | B i ) Entonces: (B i )= P (B i | E + ) P(B i | E )= (B i ) (B i )")
59
Dado que los hijos son condicionalmente independientes dado el padre: Abajo hacia arriba (Lambda) Donde E k - corresponde a la evidencia que proviene del hijo k de B, denotado por S k.
 Donde E k - corresponde a la evidencia que proviene del hijo k de B, denotado por S k.")
60
Condicionando cada término en la ecuación anterior respecto a todos los posibles valores de cada nodo hijo, obtenemos:

61
Dado que B es condicionalmente de la evidencia bajo cada hijo dado éste y usando la definición de :

62
En forma análoga obtenemos una ecuación para . Arriba hacia abajo (PI) Primero la condicionamos sobre todos los posibles valores del padre:
 Primero la condicionamos sobre todos los posibles valores del padre:.")
63
Podemos eliminar E + del primer termino dada independencia condicional. El segundo término representa la probabilidad posterior de A sin contar la evidencia de subárbol de B, por lo que podemos expresarla usando la ecuación para P(B i |E) y la descomposición de. Donde k incluye a todos los hijos de A excepto B.
 y la descomposición de. Donde k incluye a todos los hijos de A excepto B..")
64
Mediante estas ecuaciones se integra un algoritmo de propagación de probabilidades en árboles. Cada nodo guarda los valores de los vectores y, así como las matrices de probabilidad P. Mediante estas ecuaciones se integra un algoritmo de propagación de probabilidades en árboles. Cada nodo guarda los valores de los vectores y, así como las matrices de probabilidad P. Algoritmo

65
La propagación se hace por un mecanismo de paso de mensajes, en donde cada nodo envía los mensajes correspondientes a su padre e hijos: Mensaje al padre (hacia arriba) -- nodo B a su padre A:
 -- nodo B a su padre A:")
66
Mensaje a los hijos (hacia abajo) -- nodo B a su hijo S k :
 -- nodo B a su hijo S k :")
67
Al instanciarse ciertos nodos, éstos envían mensajes a sus padres e hijos, y se propagan hasta a llegar a la raíz u hojas, o hasta encontrar un nodo instanciado. Así que la propagación se hace en un solo paso en un tiempo proporcional al diámetro de la red. Al instanciarse ciertos nodos, éstos envían mensajes a sus padres e hijos, y se propagan hasta a llegar a la raíz u hojas, o hasta encontrar un nodo instanciado. Así que la propagación se hace en un solo paso en un tiempo proporcional al diámetro de la red.

68
Esto se puede hacer en forma iterativa, instanciando ciertas variables y propagando su efecto; y luego instanciando otras y propagando la nueva información, combinando ambas evidencias.

69
Un poliárbol es una red en la que un nodo puede tener varios padres, pero sin existir múltiples trayectorias entre nodos (red conectada en forma sencilla - SCG ) Propagación en poliárboles
 Propagación en poliárboles")
70
La principal diferencia es que se requiere de la probabilidad conjunta de cada nodo dado todos sus padres: La principal diferencia es que se requiere de la probabilidad conjunta de cada nodo dado todos sus padres: P ( B i | A 1,....A n ) El algoritmo de propagación es muy similar al de árboles.
 El algoritmo de propagación es muy similar al de árboles.")
71
Una red multiconectada es un grafo no conectado en forma sencilla, es decir, en el que hay múltiples trayectorias entre nodos (MCG). En este tipo de RP los métodos anteriores ya no aplican, pero existen otras técnicas alternativas: Una red multiconectada es un grafo no conectado en forma sencilla, es decir, en el que hay múltiples trayectorias entre nodos (MCG). En este tipo de RP los métodos anteriores ya no aplican, pero existen otras técnicas alternativas: Propagación en Redes Multiconectadas Condicionamiento Simulación estocástica Agrupamiento Condicionamiento Simulación estocástica Agrupamiento
. En este tipo de RP los métodos anteriores ya no aplican, pero existen otras técnicas alternativas: Propagación en Redes Multiconectadas Condicionamiento Simulación estocástica Agrupamiento Condicionamiento Simulación estocástica Agrupamiento.")
72
Condicionamiento:

73
Si instanciamos una variable, ésta bloquea las trayectorias de propagación. Entonces asumiendo valores para un grupo seleccionado de variables podemos descomponer la gráfica en un conjunto de SCG. Propagamos para cada valor posible de dichas variables y luego promediamos las probabilidades ponderadas. Si instanciamos una variable, ésta bloquea las trayectorias de propagación. Entonces asumiendo valores para un grupo seleccionado de variables podemos descomponer la gráfica en un conjunto de SCG. Propagamos para cada valor posible de dichas variables y luego promediamos las probabilidades ponderadas.

74
Se asignan valores aleatorios a las variables no instanciadas, se calcula la distribución de probabilidad y se obtienen valores de cada variable dando una muestra. Se repite el procedimiento para obtener un número apreciable de muestras y en base al numero de ocurrencias de cada valor se determina la probabilidad de dicha variable. Se asignan valores aleatorios a las variables no instanciadas, se calcula la distribución de probabilidad y se obtienen valores de cada variable dando una muestra. Se repite el procedimiento para obtener un número apreciable de muestras y en base al numero de ocurrencias de cada valor se determina la probabilidad de dicha variable. Simulación Estocástica:

75
El método de agrupamiento consiste en transformar la estructura de la red para obtener un árbol, mediante agrupación de nodos usando la teoría de grafos [Lauritzen 88]. Agrupamiento:
![El método de agrupamiento consiste en transformar la estructura de la red para obtener un árbol, mediante agrupación de nodos usando la teoría de grafos [Lauritzen 88].](http://images.slideplayer.es/12/3861332/slides/slide_75.jpg "Agrupamiento:.")
76
En general, la propagación en una red probabilística con una estructura compleja es un problema de complejidad NP-duro [Cooper 90]; sin embargo, en muchas aplicaciones prácticas la estructura de la red no es tan compleja y los tiempos de propagación son razonables. Complejidad
![En general, la propagación en una red probabilística con una estructura compleja es un problema de complejidad NP-duro [Cooper 90]; sin embargo, en muchas aplicaciones prácticas la estructura de la red no es tan compleja y los tiempos de propagación son razonables.](http://images.slideplayer.es/12/3861332/slides/slide_76.jpg "Complejidad.")
77
Ejemplo de Propagación en Redes Bayesianas Demostración Ejemplo de Propagación en Redes Bayesianas Demostración

78
La redes bayesianas son un método adecuado para representar y razonar con incertidumbre. Conclusiones Se han desarrollado diversas aplicaciones basadas en redes bayesianas en áreas como diagnóstico médico e industrial, robótica, sistemas de soporte de decisiones, tutores inteligentes, etc.; e incluso los “ayudantes” de Office están en parte basados en redes bayesianas. Se han desarrollado diversas aplicaciones basadas en redes bayesianas en áreas como diagnóstico médico e industrial, robótica, sistemas de soporte de decisiones, tutores inteligentes, etc.; e incluso los “ayudantes” de Office están en parte basados en redes bayesianas.

79
Actualmente hay desarrollos en varios áreas, incluyendo la inclusión de aspectos temporales (redes dinámicas), manejo de variables continuas y aprendizaje.
, manejo de variables continuas y aprendizaje.")
80
Existen, básicamente, otras dos alternativas bien fundamentadas para el manejo de incertidumbre: teoría de Dempster-Shafer y Lógica Difusa. La teoría de Dempster-Shafer permite diferenciar entre ignorancia e iguales probabilidades, aunque para problemas grandes se vuelve demasiado compleja. Existen, básicamente, otras dos alternativas bien fundamentadas para el manejo de incertidumbre: teoría de Dempster-Shafer y Lógica Difusa. La teoría de Dempster-Shafer permite diferenciar entre ignorancia e iguales probabilidades, aunque para problemas grandes se vuelve demasiado compleja. Conclusiones

81
La lógica difusa teine la ventaja de que permite representar más facilmente ciertos conceptos no bien definidos y, en particular las reglas difusas, se asemeja a los sistemas basados en reglas. Sin embargo, tiene la dificultad de que falta de una semántica clara. La lógica difusa teine la ventaja de que permite representar más facilmente ciertos conceptos no bien definidos y, en particular las reglas difusas, se asemeja a los sistemas basados en reglas. Sin embargo, tiene la dificultad de que falta de una semántica clara.

82
Incertidumbre FIN

Presentaciones similares















 Microsoft SQL Server 2008 R2 Suscribase a o escríbanos a>")
>")


