Descargar la presentación
La descarga está en progreso. Por favor, espere

2
Un poco de historia Linux: Es un sistema operativo (asi como lo es Windows, Solaris, Mac OS X) y fue creado por Linus Torvalds en 1991 como una alternativa a los sistemas Unix de la época. Linux es, a simple vista, un Sistema Operativo. Es una implementación de libre distribución UNIX para computadoras personales (PC), servidores y estaciones de trabajo. Fue desarrollado para el i386 y ahora soporta los procesadores i486, Pentium, Pentium Pro y Pentium II, así como los clones AMD y Cyrix. También soporta máquinas basadas en SPARC, DEC Alpha, PowerPC/PowerMac y Mac/Amiga Motorola 680x0. El proyecto GNU, que se inició en 1983 por Richard Stallman;9 tiene como objetivo el desarrollo de un sistema operativo Unix completo y compuesto enteramente de software libre. La historia del núcleo Linux está fuertemente vinculada a la del proyecto GNU. En 1991 Linus Torvalds empezó a trabajar en un reemplazo no comercial para MINIX10 que más adelante acabaría siendo Linux. Cuando Torvalds liberó la primera versión de Linux, el proyecto GNU ya había producido varias de las herramientas fundamentales para el manejo del sistema operativo, incluyendo un intérprete de comandos, una biblioteca C y un compilador, pero como el proyecto contaba con una infraestructura para crear su propio núcleo (o kernel), el llamado Hurd, y este aún no era lo suficiente maduro para usarse, comenzaron a usar a Linux a modo de continuar desarrollando el proyecto GNU, siguiendo la tradicional filosofía de mantener cooperatividad entre desarrolladores. El día en que se estime que Hurd es suficiente maduro y estable, será llamado a reemplazar a Linux. Entonces, el núcleo creado por Linus Torvalds, quien se encontraba por entonces estudiando la carrera de Ingeniería Informática en la Universidad de Helsinki, llenó el "espacio" final que había en el sistema operativo de GNU
, servidores y estaciones de trabajo. Fue desarrollado para el i386 y ahora soporta los procesadores i486, Pentium, Pentium Pro y Pentium II, así como los clones AMD y Cyrix. También soporta máquinas basadas en SPARC, DEC Alpha, PowerPC/PowerMac y Mac/Amiga Motorola 680x0. El proyecto GNU, que se inició en 1983 por Richard Stallman;9 tiene como objetivo el desarrollo de un sistema operativo Unix completo y compuesto enteramente de software libre. La historia del núcleo Linux está fuertemente vinculada a la del proyecto GNU. En 1991 Linus Torvalds empezó a trabajar en un reemplazo no comercial para MINIX10 que más adelante acabaría siendo Linux. Cuando Torvalds liberó la primera versión de Linux, el proyecto GNU ya había producido varias de las herramientas fundamentales para el manejo del sistema operativo, incluyendo un intérprete de comandos, una biblioteca C y un compilador, pero como el proyecto contaba con una infraestructura para crear su propio núcleo (o kernel), el llamado Hurd, y este aún no era lo suficiente maduro para usarse, comenzaron a usar a Linux a modo de continuar desarrollando el proyecto GNU, siguiendo la tradicional filosofía de mantener cooperatividad entre desarrolladores. El día en que se estime que Hurd es suficiente maduro y estable, será llamado a reemplazar a Linux. Entonces, el núcleo creado por Linus Torvalds, quien se encontraba por entonces estudiando la carrera de Ingeniería Informática en la Universidad de Helsinki, llenó el espacio final que había en el sistema operativo de GNU.")
3
Y Unix? Unix (registrado oficialmente como UNIX®) es un sistema operativo portable, multitarea y multiusuario; desarrollado, en principio, en 1969, por un grupo de empleados de los laboratorios Bell de AT&T, entre los que figuran Ken Thompson, Dennis Ritchie y Douglas McIlroy.1 2 A finales de 1960, el Instituto Tecnológico de Massachusetts, los Laboratorios Bell de AT&T y General Electric trabajaban en un sistema operativo experimental llamado Multics (Multiplexed Information and Computing Service),4 desarrollado para ejecutarse en una computadora central (mainframe) modelo GE-645. El objetivo del proyecto era desarrollar un gran sistema operativo interactivo que contase con muchas innovaciones, entre ellas mejoras en las políticas de seguridad. El proyecto consiguió dar a luz versiones para producción, pero las primeras versiones contaban con un pobre rendimiento. Los laboratorios Bell de AT&T decidieron desvincularse y dedicar sus recursos a otros proyectos. sistema MULTICS castrado (pues eunuchs, en inglés, es un homófono de UNICS), se cambió el nombre a UNIX, dando origen al legado que llega hasta nuestros días.
 es un sistema operativo portable, multitarea y multiusuario; desarrollado, en principio, en 1969, por un grupo de empleados de los laboratorios Bell de AT&T, entre los que figuran Ken Thompson, Dennis Ritchie y Douglas McIlroy.1 2 A finales de 1960, el Instituto Tecnológico de Massachusetts, los Laboratorios Bell de AT&T y General Electric trabajaban en un sistema operativo experimental llamado Multics (Multiplexed Information and Computing Service),4 desarrollado para ejecutarse en una computadora central (mainframe) modelo GE-645. El objetivo del proyecto era desarrollar un gran sistema operativo interactivo que contase con muchas innovaciones, entre ellas mejoras en las políticas de seguridad. El proyecto consiguió dar a luz versiones para producción, pero las primeras versiones contaban con un pobre rendimiento. Los laboratorios Bell de AT&T decidieron desvincularse y dedicar sus recursos a otros proyectos. sistema MULTICS castrado (pues eunuchs, en inglés, es un homófono de UNICS), se cambió el nombre a UNIX, dando origen al legado que llega hasta nuestros días..")
4
Filosofía de uso de Software Libre Usado Copiado Modificado Redistribuirlo = Libertadad = Software Libre Peroooo: Libre NO significa Gratis.

5
El entorno de Linux

6
Sistema de Archivos Un sistema Linux reside bajo un árbol jerárquico de directorios muy similar a la estructura del sistema de archivos de plataformas Unix. Originariamente, en los inicios de Linux, este árbol de directorios no seguía un estándar cien por cien, es decir, podíamos encontrar diferencias en él de una distribución a otra. Todo esto hizo pensar a cierta gente* que, posteriormente, desarrollarían el proyecto FHS (Filesystem Hierarchy Standard, o lo que es lo mismo: Estándar de Jerarquía de Sistema de Ficheros) en otoño de 1993.
 en otoño de")
7
FHS FHS se define como un estándar que detalla los nombres, ubicaciones, contenidos y permisos de los archivos y directorios, es decir, un conjunto de reglas que especifican una distribución común de los directorios y archivos en sistemas Linux. Como se ha mencionado, se creo inicialmente para estandarizar la estructura del sistema de archivos para sistemas GNU/Linux y más tarde, en torno al año 1995, también para su aplicación en sistemas Unix. FHS no es más que un documento guía, es decir, cualquier fabricante de software independiente o cualquier persona que decida crear una nueva distribución GNU/Linux, podrá aplicarlo o no a la estructura del sistema de archivos, con la ventaja de que si lo integra en el sistema, el entorno de éste será mucho más compatible con la mayoría de las distribuciones. Es importante saber que el estándar FHS es en cierto modo flexible, es decir, existe cierta libertad en el momento de aplicar las normas. De ahí que existan en la actualidad leves diferencias entre distribuciones GNU/Linux. Objetivos principales de FHS

8
Presentar un sistema de archivos coherente y estandarizado. Facilidad para que el software prediga la localización de archivos y directorios instalados. Facilidad para que los usuarios prediga la localización de archivos y directorios instalados. Especificar los archivos y directorios mínimos requeridos. El estándar FHS está enfocado a Fabricantes de software independiente y creadores de sistemas operativos, para que establezcan una estructura de ficheros lo más compatible posible. Usuarios comunes, para que entiendan el significado y el contendido de cada uno de los elementos del sistema de archivos.

9
Archivos compartibles y no compartibles. Ficheros que son propios de un host determinado y, archivos que pueden compartirse entre diferentes host. Ejemplo: Archivos compartibles: los contenidos en /var/www/html (que es el DocumentRoot por defecto del servidor Web Apache. Donde se almacena inicialmente el index.html de bienvenida). Archivos no compartibles: los contenidos en /boot/grub/ (Subdirectorio donde se ubican los ficheros del gestor de arranque GRUB). Archivos estáticos y variables. Ficheros que no cambian sin la interacción de un administrador del sistema y, archivos que cambian sin la interacción de un administrador del sistema. Para comprender mejor estos dos tipos, imaginemos los ficheros log (archivos de bitácora) del sistema. Estos cambian sin la intervención del administrador; en consecuencia estos son del tipo variables. Los demás archivos son estáticos. No cambian su contenido ni tamaño a menos que lo autorice el administrador del sistema (o sea el propio quien lo modifique, por supuesto). o Archivos estáticos: /etc/password, /etc/shadow. o Archivos variables: /var/log/messages (log de mensajes generados por el kernel del sistema).
. Archivos no compartibles: los contenidos en /boot/grub/ (Subdirectorio donde se ubican los ficheros del gestor de arranque GRUB). Archivos estáticos y variables. Ficheros que no cambian sin la interacción de un administrador del sistema y, archivos que cambian sin la interacción de un administrador del sistema. Para comprender mejor estos dos tipos, imaginemos los ficheros log (archivos de bitácora) del sistema. Estos cambian sin la intervención del administrador; en consecuencia estos son del tipo variables. Los demás archivos son estáticos. No cambian su contenido ni tamaño a menos que lo autorice el administrador del sistema (o sea el propio quien lo modifique, por supuesto). o Archivos estáticos: /etc/password, /etc/shadow. o Archivos variables: /var/log/messages (log de mensajes generados por el kernel del sistema)..")
10
Archivos compartibles y no compartibles. Ficheros que son propios de un host determinado y, archivos que pueden compartirse entre diferentes host. Ejemplo: Archivos compartibles: los contenidos en /var/www/html (que es el DocumentRoot por defecto del servidor Web Apache. Donde se almacena inicialmente el index.html de bienvenida). Archivos no compartibles: los contenidos en /boot/grub/ (Subdirectorio donde se ubican los ficheros del gestor de arranque GRUB). Archivos estáticos y variables. Ficheros que no cambian sin la interacción de un administrador del sistema y, archivos que cambian sin la interacción de un administrador del sistema. Para comprender mejor estos dos tipos, imaginemos los ficheros log (archivos de bitácora) del sistema. Estos cambian sin la intervención del administrador; en consecuencia estos son del tipo variables. Los demás archivos son estáticos. No cambian su contenido ni tamaño a menos que lo autorice el administrador del sistema (o sea el propio quien lo modifique, por supuesto).
. Archivos no compartibles: los contenidos en /boot/grub/ (Subdirectorio donde se ubican los ficheros del gestor de arranque GRUB). Archivos estáticos y variables. Ficheros que no cambian sin la interacción de un administrador del sistema y, archivos que cambian sin la interacción de un administrador del sistema. Para comprender mejor estos dos tipos, imaginemos los ficheros log (archivos de bitácora) del sistema. Estos cambian sin la intervención del administrador; en consecuencia estos son del tipo variables. Los demás archivos son estáticos. No cambian su contenido ni tamaño a menos que lo autorice el administrador del sistema (o sea el propio quien lo modifique, por supuesto)..")
11
Todo en Linux es un archivo Cierto, todo en un sistema Linux es un archivo, tanto el Software como el Hardware. Desde el ratón, pasando por la impresora, el reproductor de DVD, el monitor, un directorio, un subdirectorio y un fichero de texto. De ahí vienen los conceptos de montar y desmontar por ejemplo un CDROM. El CDROM se monta como un subdirectorio en el sistema de archivos. En ese subdirectorio se ubicará el contenido del disco compacto cuando esté montado y, nada cuando esté desmontado. Para ver que tenemos montado en nuestra distribución GNU/Linux, podemos ejecutar el comando mount. Este concepto es muy importante para conocer como funciona Linux. En apartados posteriores, veremos donde ubica Linux los elementos Hardware del PC en el sistema de ficheros. NOTA: podemos acceder a los dispositivos Hardware como si fueran archivos. Realmente son ficheros para Linux; pero no son archivos normales, son archivos binarios (o.exe para los que vengan de Windows).
..")
12
La estructura del sistema de archivos en Linux La estructura del sistema de archivos en Linux _ Observatorio Tecnológico.htm La estructura del sistema de archivos en Linux _ Observatorio Tecnológico.htm

13
Aplicaciones mas Comunes Transferencia de archivos: SFTP,FTP Conexión Remota: SSH Editores de Texto: VI, Nano

14
Redes de datos Direcciones IP

15
Instalación avanzada ?=¡=)»»»#!»!#$$:s
»»»#!»!#$$:s")
16
El núcleo o kernel El kernel ó núcleo de linux se puede definir como el corazón de este sistema operativo. Es el encargado de que el software y el hardware de tu ordenador puedan trabajar juntos. Las funciones más importantes del mismo, aunque no las únicas, son: Administración de la memoria para todos los programas y procesos en ejecución. Administración del tiempo de procesador que los programas y procesos en ejecucion utilizan. Es el encargado de que podamos acceder a los periféricos/elementos de nuestro ordenador de una manera cómoda.

17
Herramientas de gestión de paquetes APT Advanced Packaging Tool (Herramienta Avanzada de Empaquetado), abreviado APT, es un sistema de gestión de paquetes creado por el proyecto Debian. APT simplifica en gran medida la instalación y eliminación de programas en los sistemas GNU/Linux. No existe un programa apt en sí mismo, sino que APT es una biblioteca de funciones C++ que se emplea por varios programas de línea de comandos para distribuir paquetes. En especial, apt-get y apt-cache. Existen también programas que proporcionan un frontispicio para APT, generalmente basados en apt-get, como aptitude con una interfaz de texto ncurses, Synaptic con una interfaz gráfica GTK+, o Adept con una interfaz gráfica Qt. Existe un repositorio central con más de ~25.000 paquetes apt utilizados por apt-get y programas derivados para descargar e instalar aplicaciones directamente desde Internet, conocida como una de las mejores cualidades de Debian. APT fue rápidamente utilizado para funcionar con paquetes.deb, en los sistemas Debian y distribuciones derivadas, pero desde entonces ha sido modificado para trabajar con paquetes RPM, con la herramienta apt-rpm, y para funcionar en otros sistemas operativos, como Mac OS X (Fink) y OpenSolaris (distribución Nexenta OS).
 y OpenSolaris (distribución Nexenta OS)..")
18
Herramientas de gestión de paquetes APTITUDE aptitude es una interfaz para APT. Muestra una lista de paquetes de software y permite al usuario elegir de modo interactivo cuáles desea instalar o eliminar. Dispone de un poderoso sistema de búsqueda que utiliza patrones de búsqueda flexibles, que facilitan al usuario entender las complejas relaciones de dependencia que puedan existir entre los paquetes. En un principio, se diseñó para distribuciones GNU/Linux Debian, pero hoy día también se puede utilizar en distribuciones basadas en paquetes RPM Aptitude update Aptitude upgrade

19
Comandos Avanzados Manual de consola Bash de Linux - Wikilibros.htm Manual de consola Bash de Linux - Wikilibros.htm

20
Administración de LINUX = Administrar Recursos Procesos, memoria, disco, conexiones, redundancia, disponibilidad,

21
LINUX Networking linux_ugbasicnet.html Directorios de primer nivel. Directorio del usuario.

22
Iptables Iptables es el nombre de la herramienta de espacio de usuario (User Space, es decir, área de memoria donde todas las aplicaciones, en modo de usuario, pueden ser intercambiadas hacia memoria virtual cuando sea necesario) a través de la cual los administradores crean reglas para cada filtrado de paquetes y módulos de NAT. Iptables es la herramienta estándar de todas las distribuciones modernas de GNU/Linux.I

23
Procedimientos. Cadenas. Las cadenas pueden ser para tráfico entrante (INPUT), tráfico saliente (OUTPUT) o tráfico reenviado (FORWARD). Reglas de destino. Las reglas de destino pueden ser aceptar conexiones (ACCEPT), descartar conexiones (DROP), rechazar conexiones (REJECT), encaminamiento posterior (POSTROUTING), encaminamiento previo (PREROUTING), SNAT, NAT, entre otras. Políticas por defecto. Establecen cual es la acción a tomar por defecto ante cualquier tipo de conexión. La opción -P cambia una política para una cadena. En el siguiente ejemplo se descartan (DROP) todas las conexiones que ingresen (INPUT), todas las conexiones que se reenvíen (FORWARD) y todas las conexiones que salgan (OUTPUT), es decir, se descarta todo el tráfico que entre desde una red pública y el que trate de salir desde la red local. iptables -P INPUT DROP iptables -P FORWARD DROP iptables -P OUTPUT ACCEPT Limpieza de reglas específicas. A fin de poder crear nuevas reglas, se deben borrar las existentes, para el tráfico entrante, tráfico reenviado y tráfico saliente así como el NAT. iptables -F INPUT iptables -F FORWARD iptables -F OUTPUT iptables -F -t nat Reglas específicas.
, tráfico saliente (OUTPUT) o tráfico reenviado (FORWARD). Reglas de destino. Las reglas de destino pueden ser aceptar conexiones (ACCEPT), descartar conexiones (DROP), rechazar conexiones (REJECT), encaminamiento posterior (POSTROUTING), encaminamiento previo (PREROUTING), SNAT, NAT, entre otras. Políticas por defecto. Establecen cual es la acción a tomar por defecto ante cualquier tipo de conexión. La opción -P cambia una política para una cadena. En el siguiente ejemplo se descartan (DROP) todas las conexiones que ingresen (INPUT), todas las conexiones que se reenvíen (FORWARD) y todas las conexiones que salgan (OUTPUT), es decir, se descarta todo el tráfico que entre desde una red pública y el que trate de salir desde la red local. iptables -P INPUT DROP iptables -P FORWARD DROP iptables -P OUTPUT ACCEPT Limpieza de reglas específicas. A fin de poder crear nuevas reglas, se deben borrar las existentes, para el tráfico entrante, tráfico reenviado y tráfico saliente así como el NAT. iptables -F INPUT iptables -F FORWARD iptables -F OUTPUT iptables -F -t nat Reglas específicas..")
24
Las opciones más comunes son: -A añade una cadena, la opción -i define una interfaz de tráfico entrante -o define una interfaz para trafico saliente -j establece una regla de destino del tráfico, que puede ser ACCEPT, DROP o REJECT. La -m define que se aplica la regla si hay una coincidencia específica --state define una lista separada por comas de distinto tipos de estados de las conexiones (INVALID, ESTABLISHED, NEW, RELATED). --to-source define que IP reportar al tráfico externo -s define trafico de origen -d define tráfico de destino --source-port define el puerto desde el que se origina la conexión --destination-port define el puerto hacia el que se dirige la conexión -t tabla a utilizar, pueden ser nat, filter, mangle o raw. Ejemplos de reglas. Reenvío de paquetes desde una interfaz de red local (eth1) hacia una interfaz de red pública (eth0): iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT Aceptar reenviar los paquetes que son parte de conexiones existentes (ESTABLISHED) o relacionadas de tráfico entrante desde la interfaz eth1 para tráfico saliente por la interfaz eth0: iptables -A FORWARD -i eth0 -o eth1 -m state --state ESTABLISHED,RELATED -j ACCEPT Permitir paquetes en el propio muro cortafuegos para tráfico saliente a través de la interfaz eth0 que son parte de conexiones existentes o relacionadas:
. --to-source define que IP reportar al tráfico externo -s define trafico de origen -d define tráfico de destino --source-port define el puerto desde el que se origina la conexión --destination-port define el puerto hacia el que se dirige la conexión -t tabla a utilizar, pueden ser nat, filter, mangle o raw. Ejemplos de reglas. Reenvío de paquetes desde una interfaz de red local (eth1) hacia una interfaz de red pública (eth0): iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT Aceptar reenviar los paquetes que son parte de conexiones existentes (ESTABLISHED) o relacionadas de tráfico entrante desde la interfaz eth1 para tráfico saliente por la interfaz eth0: iptables -A FORWARD -i eth0 -o eth1 -m state --state ESTABLISHED,RELATED -j ACCEPT Permitir paquetes en el propio muro cortafuegos para tráfico saliente a través de la interfaz eth0 que son parte de conexiones existentes o relacionadas:.")
25
iptables -A INPUT -i eth0 -m state --state ESTABLISHED,RELATED -j ACCEPT Permitir (ACCEPT) todo el tráfico entrante (INPUT) desde (-s) cualquier dirección (0/0) la red local (eth1) y desde el retorno del sistema (lo) hacia (-d) cualquier destino (0/0): iptables -A INPUT -i eth1 -s 0/0 -d 0/0 -j ACCEPT iptables -A INPUT -i lo -s 0/0 -d 0/0 -j ACCEPT
 todo el tráfico entrante (INPUT) desde (-s) cualquier dirección (0/0) la red local (eth1) y desde el retorno del sistema (lo) hacia (-d) cualquier destino (0/0): iptables -A INPUT -i eth1 -s 0/0 -d 0/0 -j ACCEPT iptables -A INPUT -i lo -s 0/0 -d 0/0 -j ACCEPT")
26
Seguridad del Servidor Scripts: Lusas boran.com/audit Tiger www.nongnu.org/tiger Distribuciones: Pentoo www.pentoo.ch/ BackTrack www.backtrack-linux.org/

27
Administración de Usuarios Administración de Sistemas de Archivos

28
Administración de Procesos ComandoDescripciónPágina del comando man ps, pgrep, prstat, pkillComprueba el estado de los procesos activos en un sistema y muestra información detallada sobre los procesos. ps(1)ps(1), pgrep(1) y prstat(1M)pgrep(1)prstat(1M) pkillFunciona de forma idéntica a pgrep, pero encuentra o señala procesos por nombre u otro atributo y termina el proceso. Cada proceso coincidente está señalado del mismo modo que si tuviera el comando kill, en lugar de tener impreso su ID de proceso. pgrep(1)pgrep(1) y pkill(1)kill(1)pkill(1)kill(1) pargs, preapAyuda con la depuración de procesos.pargs(1)pargs(1) y preap(1)preap(1) dispadminMuestra las directivas de programación de procesos predeterminadas. dispadmin(1M) priocntlAsigna procesos a una clase de prioridad y gestiona las prioridades del proceso. priocntl(1) niceCambia la prioridad de un proceso de tiempo compartido. nice(1) psrsetEnlaza grupos de procesos específicos a un grupo de procesadores, en lugar de un solo procesador. psrset(1M)
ps(1), pgrep(1) y prstat(1M)pgrep(1)prstat(1M) pkillFunciona de forma idéntica a pgrep, pero encuentra o señala procesos por nombre u otro atributo y termina el proceso. Cada proceso coincidente está señalado del mismo modo que si tuviera el comando kill, en lugar de tener impreso su ID de proceso. pgrep(1)pgrep(1) y pkill(1)kill(1)pkill(1)kill(1) pargs, preapAyuda con la depuración de procesos.pargs(1)pargs(1) y preap(1)preap(1) dispadminMuestra las directivas de programación de procesos predeterminadas. dispadmin(1M) priocntlAsigna procesos a una clase de prioridad y gestiona las prioridades del proceso. priocntl(1) niceCambia la prioridad de un proceso de tiempo compartido. nice(1) psrsetEnlaza grupos de procesos específicos a un grupo de procesadores, en lugar de un solo procesador. psrset(1M).")
29
Administración de la Red Nmap Tracertroute Netstad Ping Ifconfig Iptables

30
SSH SSH (Secure SHell, en español: intérprete de órdenes segura) es el nombre de un protocolo y del programa que lo implementa, y sirve para acceder a máquinas remotas a través de una red. Permite manejar por completo la computadora mediante un intérprete de comandos, y también puede redirigir el tráfico de X para poder ejecutar programas gráficos si tenemos un Servidor X (en sistemas Unix y Windows) corriendo.
 corriendo..")
31
Instalación y Administración de Apache Instalación y Administración Mysql

32
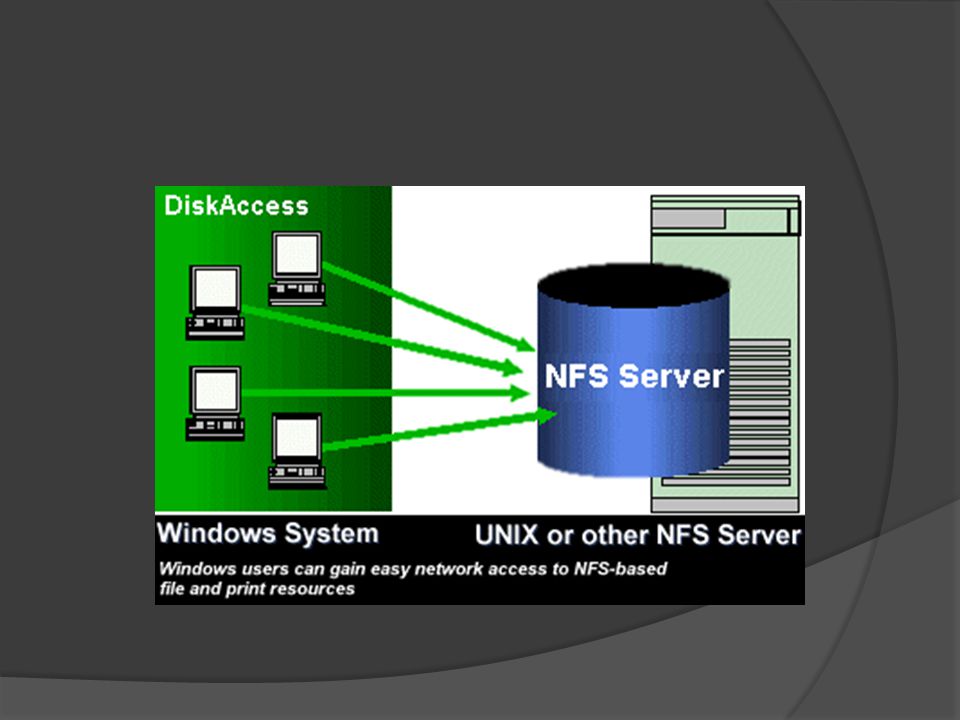
NFS El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión).1 El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
 y ONC RPC (sesión).1 El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux..")
33
El sistema NFS está dividido al menos en dos partes principales: un servidor y uno o más clientes. Los clientes acceden de forma remota a los datos que se encuentran almacenados en el servidor. Las estaciones de trabajo locales utilizan menos espacio de disco debido a que los datos se encuentran centralizados en un único lugar pero pueden ser accedidos y modificados por varios usuarios, de tal forma que no es necesario replicar la información. Los usuarios no necesitan disponer de un directorio “home” en cada una de las máquinas de la organización. Los directorios “home” pueden crearse en el servidor de NFS para posteriormente poder acceder a ellos desde cualquier máquina a través de la infraestructura de red. También se pueden compartir a través de la red dispositivos de almacenamiento como disqueteras, CD-ROM y unidades ZIP. Esto puede reducir la inversión en dichos dispositivos y mejorar el aprovechamiento del hardware existente en la organización.

35
El Sistema de Archivos Gluster, Gluster File System o GlusterFS, es un multiescalable sistema de archivos para NAS desarrollado inicialmente por Gluster Inc. Este permite agregar varios servidores de archivos sobre Ethernet o interconexines Infiniband RDMA en un gran entorno de archivos de red en paralelo. El diseño del GlusterFS se basa en la utilización del espacio de usuario y de esta manera no compromete el rendimiento. Se pueden encontrar siendo utilizado en una gran variedad de entornos y aplicaciones como computación en nube, ciencias biomédicas y almacenamiento de archivos. El GlusterFS está licenciado bajo la licencia GNU General Public License versión 3. Gluster FS

36
El GlusterFS se basa en la interacción de componentes cliente y servidor. Los servidores normalmente se implementan como almacenamiento en bloques, en cada servidor el proceso daemon glusterfsd exporta un sistema de archivos local como un volumen. El proceso cliente glusterfs, se conecta a los servidores a través de algún protocolo TCP/IP, InfiniBand o SDP, compone volúmenes compuestos virtuales a partir de los múltiples servidores remotos, mediante el uso de traductores. Por defecto, los archivos son almacenados enteros, pero también puede configurarse que se fragmente en múltiples porciones en cada servidor. Los volúmenes pueden ser montados en los equipos cliente mediante el modulo FUSE o acceder a través de la librería cliente libglusterfs sin incurrir en problemas con el sistema de archivos FUSE. La mayor parte de la funcionalidades del GlusterFS se implementa como traductores, incluyendo: Espejado y la replicación de archivos. Fragmentación de los archivos o Data striping. Balanceo de carga para la lectura y escritura de archivos. Volúmenes con tolerancia a fallos. Planificación de E/S y almacenamiento en caché de disco. Las cuotas de almacenamiento

37
GlusterFS.pdf GlusterFS.pdf

38
Cluster El término clúster (del inglés cluster, "grupo" o "racimo") se aplica a los conjuntos o conglomerados de computadoras construidos mediante la utilización de hardwares comunes y que se comportan como si fuesen una única computadora. Hoy en día desempeñan un papel importante en la solución de problemas de las ciencias, las ingenierías y del comercio moderno. La tecnología de clústeres ha evolucionado en apoyo de actividades que van desde aplicaciones de supercómputo y software de misiones críticas, servidores web y comercio electrónico, hasta bases de datos de alto rendimiento, entre otros usos. El cómputo con clústeres surge como resultado de la convergencia de varias tendencias actuales que incluyen la disponibilidad de microprocesadores económicos de alto rendimiento y redes de alta velocidad, el desarrollo de herramientas de software para cómputo distribuido de alto rendimiento, así como la creciente necesidad de potencia computacional para aplicaciones que la requieran. Simplemente, un clúster es un grupo de múltiples ordenadores unidos mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único ordenador, más potente que los comunes de escritorio.

39
Los clústeres son usualmente empleados para mejorar el rendimiento y/o la disponibilidad por encima de la que es provista por un solo computador típicamente siendo más económico que computadores individuales de rapidez y disponibilidad comparables. De un clúster se espera que presente combinaciones de los siguientes servicios: Alto rendimiento Alta disponibilidad Balanceo de carga Escalabilidad La construcción de los ordenadores del clúster es más fácil y económica debido a su flexibilidad: pueden tener todos la misma configuración de hardware y sistema operativo (clúster homogéneo), diferente rendimiento pero con arquitecturas y sistemas operativos similares (clúster semihomogéneo), o tener diferente hardware y sistema operativo (clúster heterogéneo), lo que hace más fácil y económica su construcción.
, diferente rendimiento pero con arquitecturas y sistemas operativos similares (clúster semihomogéneo), o tener diferente hardware y sistema operativo (clúster heterogéneo), lo que hace más fácil y económica su construcción..")
Presentaciones similares