Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Diplomado "Gestión de Negocios con Data Warehouse y Data Mining".
Clase 2 Técnicas y conceptos de modelamiento José Antonio Lipari A.

2
Tipos de problemas en Data Mining
Clasificación Regresión Agrupamiento Reglas de asociación Análisis correlacional Predictivos (supervisados) Descriptivos (no Supervisados) Problemas
 Descriptivos. (no Supervisados) Problemas.")
3
Tipos de problemas Predictivo (Supervisado) Descriptivo (No supervisado) Se sabe lo que se busca No se sabe lo que se busca Se utiliza información disponible en busca de recurrencias o similitudes Se utiliza información histórica para ajustar un modelo

4
Problemas Predictivos o Supervisados
Modelos de regresión Buscan predecir un valor continuo a partir de la información disponibles Modelos de Clasificación Buscan Predecir un clase a partir de la información disponible

5
Problemas Descriptivos no supervisados
Agrupamiento (clustering) Busca formar grupos que reúnen a elementos con características comunes Reglas de asociación Busca identificar reglas que involucran la ocurrencia de eventos simultáneos. Análisis correlacional Busca identificar correlaciones entre variables de interés
 Busca formar grupos que reúnen a elementos con características comunes. Reglas de asociación. Busca identificar reglas que involucran la ocurrencia de eventos simultáneos. Análisis correlacional. Busca identificar correlaciones entre variables de interés.")
6
Ejemplos: Se requiere saber con un mes de anticipación si un clientes renunciará a la compañía. Problema Predictivo de clasificación Se requiere conocer la demanda de yogurt de frutilla diaria en un supermercado Problema supervisado de regresión Se requiere segmentar la base de clientes de un banco para ofrecer productos diferenciados Problema no supervisado de agrupamiento

7
Ejemplos Se requiere saber que productos se venden juntos en un supermercado Problema descriptivo de reglas de asociación Se requiere saber que factores influyen en el riesgo de contraer cáncer al pulmón Modelo no supervisado de análisis correlacional

8
Método versus algoritmo
Un método es una forma de conceptualizar la resolución de un problema de Data Mining. Un método puede permitir la resolución de distintos problemas de Data Mining mediante el uso de distintos algoritmos

9
Concepto Método Realizar divisiones sucesivas al conjunto de datos disponible Árboles de decisión Utilizar una simulación matemática de las neuronas que permiten el aprendizaje humano Redes neuronales Estimar un conjunto de constantes que pertenecen a un polinimio de grado 1 Regresión lineal

10
Algoritmo Concepto Perceptron Multicapa ,utilizado en problemas supervisados Mapas auto-organizados de Kohonen, utilizado en problemas no supervisados Utilizar una simulación matemática de las neuronas que permiten el aprendizaje humano “REDES NEURONALES”

11
El problema de identificar un patrón
Un patrón puede tener cualquier forma y complejidad, la elección del método adecuado puede hacer la diferencia entre identificar un patrón o No (la detección de un patrón puede requerir la elección de un método adecuado). Por lo tanto, es importante entender en términos generales como funcionan los distintos métodos utilizados en Data Mining, y comprender sus ventajas y desventajas
. Por lo tanto, es importante entender en términos generales como funcionan los distintos métodos utilizados en Data Mining, y comprender sus ventajas y desventajas.")
12
Patrón discontinuo

13
Patrón Lineal

14
Patrón no lineal

15
Patrón en espiral

16
Conceptos importantes en la detección de patrones
Sobre ajuste: Situación en la que un modelo predictivo aprende con demasiada fidelidad el comportamiento de los datos perdiendo generalidad y por lo tanto disminuye la calidad de predicciones futuras Para enfrentar el sobre ajuste, por lo general, se dividen los datos disponibles en validación, entrenamiento y testeo, de esta formar se rescatan únicamente los patrones que aparecen en las bases de entrenamiento y validación, para finalmente evaluar el modelo con la base de testeo .

17
Conceptos importantes en la detección de patrones
Sobre Muestro: Técnica utilizada cuando la ocurrencia del fenómeno a predecir es muy baja, por ejemplo, la fuga de clientes es del orden de 0,5% contra un 99,5% de no fugados. En este caso se acostumbra modificar la proporción de fugados (sobremuestreo) hasta llegar a 50% fugados y 50% no fugados. Por lo general esta técnica facilita la detección de patrones y disminuye los tiempos de proceso.
 hasta llegar a 50% fugados y 50% no fugados. Por lo general esta técnica facilita la detección de patrones y disminuye los tiempos de proceso.")
18
Conceptos importantes en la detección de patrones
Outliers o datos fuera de rango: Se trata de registros que presentan valores que se alejan por mucho de los rangos de normalidad. Por ejemplo, clientes con edades de años Esta clase de registros pueden distorsionar mucho el ajuste de los modelos predictivos , por lo que generalmente son eliminados

19
Principales métodos y algoritmos utilizados en Data Mining
K-medias Árboles de decisión Regresión Lineal y Logística Redes Neuronales Reglas de Asociación Vector Suport Machine

20
Algoritmo K medias El algoritmo K medias, identifica los centros de un número datos de grupos o cluster ( C ) , a partir de los cuales es posible asignar un grado de pertenencia de cada elemento del conjunto a cada uno de los C cluster definidos. Este algoritmo es usado en problemas no supervisados de agrupamiento.
 , a partir de los cuales es posible asignar un grado de pertenencia de cada elemento del conjunto a cada uno de los C cluster definidos. Este algoritmo es usado en problemas no supervisados de agrupamiento.")
21
Concepto de lógica difusa o Fuzzy Logic
Este concepto da una definición “difusa” de pertenencia a un conjunto, a diferencia de la logica tradicional en que un elemento pertenece o no pertenece a un conjunto, en lógica difusa un elemento tiene distintos grados de pertenencia a todos los conjuntos.

22
Por ejemplo, si segmentamos la base clientes de un banco, según la edad.
Lógica tradicional Lógica difusa 24 años 365 días 25 años 18 30 Joven Adulto Joven Adulto 25 50% joven 50% adulto 49% joven 51% adulto

23
1. Determina una matriz U con ui,j [0,1; =1
Etapas del algoritmo K-medias 1. Determina una matriz U con ui,j [0,1; =1 2. Determina los centros de las clases: cj = 3. Actualiza los grados de pertenencia: ui,j = Uk = matriz en iteración k 4. Criterio para detener: Uk+1 - Uk <

24
C= 2 (2 clases) Iteración 0 Se cuenta con un conjunto de datos y se desea encontrar 2 clases o cluster

25
C= 2 (2 clases) Iteración 1 C1 C2
En la primera iteración se asignan aleatóriamente 2 centros de cada clase y se asocia cada elemento como perteneciente a la clase del centro mas cercano.

26
C= 2 (2 clases) Iteración 2 C1 C2
En la segunda iteración se reposicionan los centros en las coordenadas promedio de los elementos pertenecientes a su clase y luego se reasignan los elementos pertenecientes a cada clase.

27
C= 2 (2 clases) Iteración 3 C1 C2
En la tercera iteración se repite lo mismo que en la iteración anterior y se seguirá repitiendo hasta que se cumpla con la condición de salida

28
C= 2 (2 clases) Iteración 4 C1 C2 Finaliza el proceso iterativo porque los centros se mueven menos que un mínimo definido (condición salida)
 .")
29
Árboles de decisión El método consiste en realizar sucesivas particiones o “ramificaciones” sobre los datos con el objetivo de formar subconjuntos de datos o “hojas” en las que existan, idealmente, elementos de solo una clase Pueden ser usados en problemas supervisados tanto de regresión como de clasificación

30
Tronco Todos los datos Ramas Particiones Hojas Subconjuntos de clases puras idealmente

31
Principales características (árboles de decisión)
Son fáciles de entender Las reglas extraídas son fácilmente programables por lo que es fácil aplicar las predicciones Son poco intensivos en uso de recursos computacionales Pueden ser utilizados con muchas variables y gran cantidad de datos No se requieren datos muy depurados En muchos casos se utilizan para seleccionar las variables de mayor importancia para realizar una predicción

32
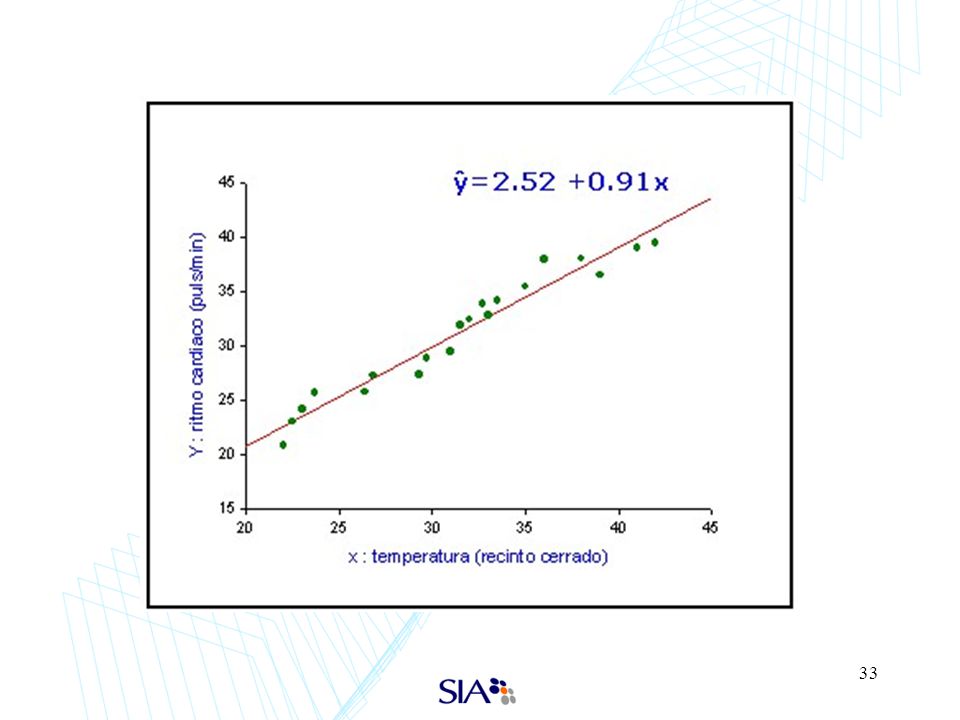
Regresión lineal El método consiste en ajustar un polinomio de grado 1 con los datos disponibles Puede ser usada en problemas supervisados de clasificación y regresión.

34
Principales características de la regresión lineal
Una vez identificadas las constantes del polinomio son fáciles de implementar Son bastante intensivas en uso de recursos computacionales Entregan información adicional sobre correlaciones entre las variables utilizadas, lo que resulta muy útil para entender el fenómeno a predecir

35
Redes Neuronales El método consiste en una simulación matemática del método de aprendizaje que ocurre en el cerebro humano Se utiliza normalmente en problemas supervisados de clasificación y regresión, además hay algunas aplicaciones en problemas no supervisados de agrupamiento.

36
Redes Neuronales å Conexiones con pesos Neurona Artificial Natural

37
Entrenamiento de una red neuronal
1 Se presentan los datos de un registro å Conexiones con pesos Neurona 2 Se evalúa la diferencia con variable objetivo 3 Se modifican los valores de la constantes 4 Se repiten los pasos 123 para el siguiente registro 5 Se repiten los pasos 1234 hasta que la diferencia del error entre validación y entrenamiento se mayor que un cierto límite

38
Principales características
Si se utiliza una topología de red adecuada una red neuronal es capaz de ajustarse a cualquier función no lineal por lo que potencialmente son capaces hacer muy buenas predicciones Son muy complejas de entender y no entregan información derivada para entender el problema Las predicciones realizadas con redes neuronales son difíciles de implementar sin uso de un software adecuado Son muy intensivas en uso de recursos Su uso requiere datos muy depurados

39
Reglas de asociación El método consiste en identificar un conjunto de reglas que se observan con cierta recurrencia en los datos, para seleccionar las reglas relevantes se utilizan dos conceptos que son la confianza y soporte. Este método se utiliza en problemas no supervisados de reglas de asociación.

40
Reglas de asociación “Confianza”: La regla X ==>Y tiene “confianza” c si c% de las transacciones en T con X también contienen Y. Ejemplo: Productos : {1, 2, 3, 4, 5} Transacciones : T = {(1, 3, 4), (2, 3, 5), (1, 2, 3, 5), (2, 5)} (2, 3) ==> (5) tiene “confianza” 100% (2 de 2 transacciones que contienen (2, 3) también contienen (5))
, (2, 3, 5), (1, 2, 3, 5), (2, 5)} (2, 3) ==> (5) tiene confianza 100% (2 de 2 transacciones que contienen (2, 3) también contienen (5))")
41
Reglas de asociación “Soporte”: La regla X==>Y tiene “soporte” s en el conjunto de transacciones D si s% de las transacciones en T contienen (X e Y). Ejemplo: Productos : {1, 2, 3, 4, 5} Transacciones : T = {(1, 3, 4), (2, 3, 5), (1, 2, 3, 5), (2, 5)} (2, 3) ==> (5) tiene “support” 50% (2 de 4 transacciones de T contienen (2, 3, 5))
. Ejemplo: Productos : {1, 2, 3, 4, 5} Transacciones : T = {(1, 3, 4), (2, 3, 5), (1, 2, 3, 5), (2, 5)} (2, 3) ==> (5) tiene support 50% (2 de 4 transacciones de T contienen (2, 3, 5))")
42
Reglas de asociación Podemos decir, entonces, que la Confianza nos indica que tan fiable es una regla y el Soporte nos indica cuan importante es esta regla dentro del total de transacciones. Utilizando estos 2 indicadores podemos seleccionar las reglas que nos interezará gestionar.

43
Principales características
Son fáciles de entender, verificar y demostrar económicamente. Son poco intensivas en uso de recursos No requieren datos muy depurados

44
Vector suport machine (maquinas de soporte vectorial) Este es un método busca mejorar lo realizado por los métodos mencionados antes, el objetivo es lograr la mejor clasificación consiguiendo además la mayor generalidad posible, es decir, minimizar el sobre ajuste. Es usado por general en problemas supervisados de clasificación

45
Árbol 1 Árbol 2 V2 Regresión 1 Regresión 2 ? V1

46
V2 Vector suport machine Máxima generalidad en la solución D V1

47
Principales características
Es intensivo en uso de recursos Las reglas encontradas son difíciles de entender Requiere datos depurados La predicción es difícil de aplicar sin uso de software apropiado Potencialmente es capaz de generar mejores modelos predictivos que los otros método estudiados

48
FIN

Presentaciones similares

















 Gastón Sabatelli (85523)>")

