Descargar la presentación
La descarga está en progreso. Por favor, espere

1
UD4: “Instalación y administración de servicios Web” Protocolo HTTP.
Jorge de Nova Segundo

2
Hypertext Transfer Protocol o HTTP (en español protocolo de transferencia de hipertexto) es el protocolo usado en cada transacción de la World Wide Web. HTTP fue desarrollado por el World Wide Web Consortium y la Internet Engineering Task Force, colaboración que culminó en 1999 con la publicación de una serie de RFC, el más importante de ellos es el RFC 2616 que especifica la versión 1.1. HTTP define la sintaxis y la semántica que utilizan los elementos de software de la arquitectura web (clientes, servidores, proxies) para comunicarse. Es un protocolo orientado a transacciones y sigue el esquema petición-respuesta entre un cliente y un servidor. Al cliente que efectúa la petición (un navegador web o un spider) se lo conoce como "user agent" (agente del usuario). A la información transmitida se la llama recurso y se la identifica mediante un localizador uniforme de recursos (URL). Los recursos pueden ser archivos, el resultado de la ejecución de un programa, una consulta a una base de datos, la traducción automática de un documento, etc. HTTP es un protocolo sin estado, es decir, que no guarda ninguna información sobre conexiones anteriores. El desarrollo de aplicaciones web necesita frecuentemente mantener estado. Para esto se usan las cookies, que es información que un servidor puede almacenar en el sistema cliente. Esto le permite a las aplicaciones web instituir la noción de "sesión", y también permite rastrear usuarios ya que las cookies pueden guardarse en el cliente por tiempo indeterminado.

3
Mensaje HTTP Un mensaje http consiste en una petición de un cliente al servidor y en la respuesta del servidor al cliente. Las peticiones y respuestas pueden ser simples o completas. La diferencia es que en las peticiones y respuestas completas se envían cabeceras y un contenido. Este contenido se pone después de las cabeceras dejando una línea vacía entre las cabeceras y el contenido. En el caso de peticiones simples, sólo se puede usar el método GET y no hay contenido. Si se trata de una respuesta simple, entonces ésta sólo consta de contenido. Esta diferenciación entre simples y completas se tiene para que el protocolo HTTP/1.0 pueda atender peticiones y enviar respuestas del protocolo HTTP/0.9.

4
Funcionamiento básico.
La comunicación entre el navegador y el servidor se lleva a cabo en dos etapas: El navegador realiza una solicitud HTTP El servidor procesa la solicitud y después envía una respuesta HTTP En realidad, la comunicación se realiza en más etapas si se considera el procesamiento de la solicitud en el servidor. Dado que sólo nos ocupamos del protocolo HTTP, no se explicará la parte del procesamiento en el servidor en esta sección del artículo. Si este tema les interesa, puede consultar el articulo sobre el tratamiento de CGI.

5
Una solicitud HTTP es un conjunto de líneas que el navegador envía al servidor. Incluye:
Una línea de solicitud: es una línea que especifica el tipo de documento solicitado, el método que se aplicará y la versión del protocolo utilizada. La línea está formada por tres elementos que deben estar separados por un espacio: el método la dirección URL la versión del protocolo utilizada por el cliente (por lo general, HTTP/1.0) Los campos del encabezado de solicitud: es un conjunto de líneas opcionales que permiten aportar información adicional sobre la solicitud y/o el cliente (navegador, sistema operativo, etc.). Cada una de estas líneas está formada por un nombre que describe el tipo de encabezado, seguido de dos puntos (:) y el valor del encabezado. El cuerpo de la solicitud: es un conjunto de líneas opcionales que deben estar separadas de las líneas precedentes por una línea en blanco y, por ejemplo, permiten que se envíen datos por un comando POST durante la transmisión de datos al servidor utilizando un formulario.
 Los campos del encabezado de solicitud: es un conjunto de líneas opcionales que permiten aportar información adicional sobre la solicitud y/o el cliente (navegador, sistema operativo, etc.). Cada una de estas líneas está formada por un nombre que describe el tipo de encabezado, seguido de dos puntos (:) y el valor del encabezado. El cuerpo de la solicitud: es un conjunto de líneas opcionales que deben estar separadas de las líneas precedentes por una línea en blanco y, por ejemplo, permiten que se envíen datos por un comando POST durante la transmisión de datos al servidor utilizando un formulario.")
8
Una respuesta HTTP es un conjunto de líneas que el servidor envía al navegador. Está constituida por: Incluye: Una línea de estado: es una línea que especifica la versión del protocolo utilizada y el estado de la solicitud en proceso mediante un texto explicativo y un código. La línea está compuesta por tres elementos que deben estar separados por un espacio: La línea está formada por tres elementos que deben estar separados por un espacio: la versión del protocolo utilizada el código de estado el significado del código Los campos del encabezado de respuesta: es un conjunto de líneas opcionales que permiten aportar información adicional sobre la respuesta y/o el servidor. Cada una de estas líneas está compuesta por un nombre que califica el tipo de encabezado, seguido por dos puntos (:) y por el valor del encabezado Cada una de estas líneas está formada por un nombre que describe el tipo de encabezado, seguido de dos puntos (:) y el valor del encabezado. El cuerpo de la respuesta: contiene el documento solicitado. Por lo tanto, una respuesta HTTP posee la siguiente sintaxis (<crlf> significa retorno de carro y avance de línea):
 y por el valor del encabezado Cada una de estas líneas está formada por un nombre que describe el tipo de encabezado, seguido de dos puntos (:) y el valor del encabezado. El cuerpo de la respuesta: contiene el documento solicitado. Por lo tanto, una respuesta HTTP posee la siguiente sintaxis (<crlf> significa retorno de carro y avance de línea):")
10
Nos podemos encontrar con varios tipos de mensajes:
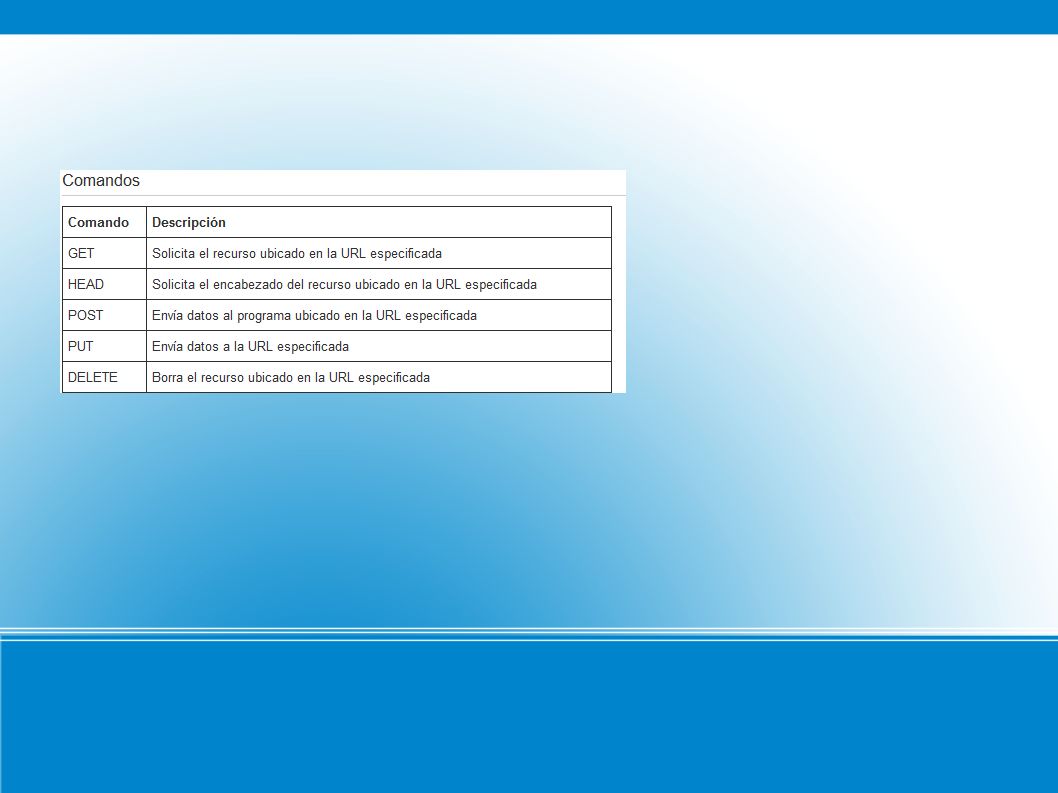
Petición Respuesta Métodos Método OPTIONS Método GET Método HEAD Método POST Método PUT Método DELETE Método TRACE Cabeceras generales Cabeceras de petición Cabeceras de respuesta Cabeceras de entidad

11
Un método se dice que es seguro si no provocan ninguna otra acción que no sea la de devolver algo (no produce efectos laterales). Estos métodos son el método GET y el método HEAD. Para realizar acciones inseguras (las que afectan a otras acciones) se pueden usar los métodos POST, PUT y DELETE. Aunque esto está definido así, no se puede asegurar que un método seguro no produzca efectos laterales, porque depende de la implementación del servidor. Un método es idempotente si los efectos laterales para N peticiones son los mismos que para una sola petición. Los métodos idempotentes son los métodos GET, HEAD, PUT y DELETE. Método GET El método GET requiere la devolución de información al cliente identificada por la URI. Si la URI se refiere a un proceso que produce información, se devuelve la información y no la fuente del proceso. El método GET pasa a ser un GET condicional si la petición incluye las cabeceras If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match o If-Range. Estas cabeceras hacen que el contenido de la respuesta se transmita sólo si se cumplen unas condiciones determinadas por esas cabeceras. Esto se hico para reducir el tráfico en las redes. También hay un método GET parcial, con el que se envía sólo parte del contenido del recurso requerido. Esto ocurre cuando la petición tiene una cabecera Range. Al igual que el método GET condicional, el método GET parcial se creó para reducir el tráfico en la red.

12
Método POST El método POST se usa para hacer peticiones en las que el servidor destino acepta el contenido de la petición como un nuevo subordinado del recurso pedido. El método POST se creó para cubrir funciones como la de enviar un mensaje a grupos de usuarios, dar un bloque de datos como resultado de un formulario a un proceso de datos, añadir nuevos datos a una base de datos, ... La función llevada a cabo por el método POST está determinada por el servidor y suele depender de la URI de la petición. El resultado de la acción realizada por el método POST puede ser un recurso que no sea identificable mediante una URI. Método HEAD El método HEAD es igual que el método GET, salvo que el servidor no tiene que devolver el contenido, sólo las cabeceras. Estas cabeceras que se devuelven en el método HEAD deberían ser las mismas que las que se devolverían si fuese una petición GET. Este método se puede usar para obtener información sobre el contenido que se va a devolver en respuesta a la petición. Se suele usar también para chequear la validez de links, accesibilidad y modificaciones recientes.

13
Método PUT El método PUT permite guardar el contenido de la petición en el servidor bajo la URI de la petición. Si esta URI ya existe, entonces el servidor considera que esta petición proporciona una versión actualizada del recurso. Si la URI indicada no existe y es válida para definir un nuevo recurso, el servidor puede crear el recurso con esa URI. Si se crea un nuevo recurso, debe responder con un código 201 (creado), si se modifica se contesta con un código 200 (OK) ó 204 (sin contenido). En caso de que no se pueda crear el recurso se devuelve un mensaje con el código de error apropiado. La principal diferencia entre POST y PUT se encuentra en el significado de la URI. En el caso del método POST, la URI identifica el recurso que va a manejar en contenido, mientras que en el PUT identifica el contenido. Un recurso puede tener distintas URI. Método DELETE Este método se usa para que el servidor borre el recurso indicado por la URI de la petición. No se garantiza al cliente que la operación se lleve a cabo aunque la respuesta sea satisfactoria. Método TRACE Este método se usa para saber si existe el receptor del mensaje y usar la información para hacer un diagnóstico. En las cabeceras el campo Via sirve para obtener la ruta que sigue el mensaje. Mediante el campo Max-Forwards se limita el número de pasos intermedios que puede tomar. Esto es útil para evitar bucles entre los proxy. La petición con el método TRACE no tiene contenido.
, si se modifica se contesta con un código 200 (OK) ó 204 (sin contenido). En caso de que no se pueda crear el recurso se devuelve un mensaje con el código de error apropiado. La principal diferencia entre POST y PUT se encuentra en el significado de la URI. En el caso del método POST, la URI identifica el recurso que va a manejar en contenido, mientras que en el PUT identifica el contenido. Un recurso puede tener distintas URI. Método DELETE. Este método se usa para que el servidor borre el recurso indicado por la URI de la petición. No se garantiza al cliente que la operación se lleve a cabo aunque la respuesta sea satisfactoria. Método TRACE. Este método se usa para saber si existe el receptor del mensaje y usar la información para hacer un diagnóstico. En las cabeceras el campo Via sirve para obtener la ruta que sigue el mensaje. Mediante el campo Max-Forwards se limita el número de pasos intermedios que puede tomar. Esto es útil para evitar bucles entre los proxy. La petición con el método TRACE no tiene contenido.")
14
Cabeceras generales Los campos de este tipo de cabeceras se aplican tanto a las peticiones como a las respuestas, pero no al contenido de los mensajes. Estas cabeceras son: Cache-Control son directivas que se han de tener en cuenta a la hora de mantener el contenido en una caché. Connection permite especificar opciones requeridas para una conexión. Date representa la fecha y la hora a la que se creó el mensaje. Pragma usado para incluir directivas de implementación. Transfer-Encoding indica la codificación aplicada al contenido. Upgrade permite al cliente especificar protocolos que soporta. Via usado por pasarelas y proxies para indicar los pasos seguidos.

15
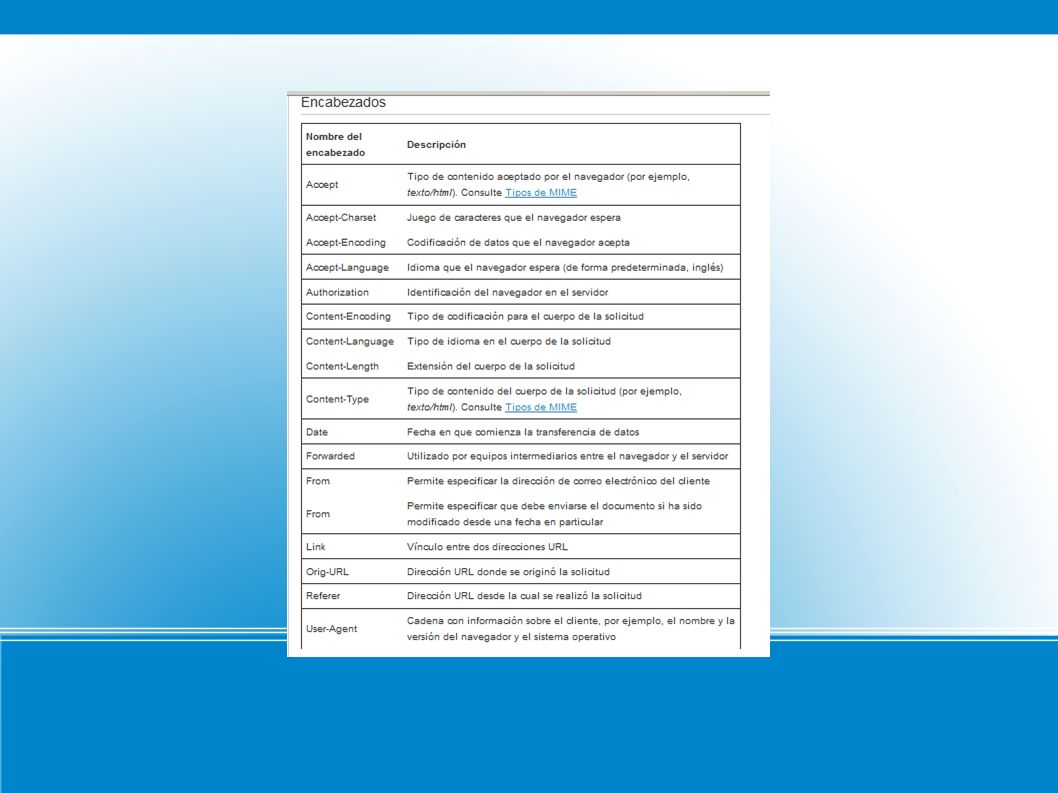
Cabeceras de petición Este tipo de cabeceras permite al cliente pasar información adicional al servidor sobre la petición y el propio cliente. Estas cabeceras son las siguientes: Accept indican el tipo de respuesta que acepta. Accept-Charset indica los conjuntos de caracteres que acepta. Accept-Encoding que tipo de codificación acepta. Accept-Language tipo de lenguaje de la respuesta que se prefiere. Authorization el agente de usuario quiere autentificarse con el servidor. From contiene la dirección de correo que controla en agente de usuario. Host especifica la máquina y el puerto del recurso pedido.

16
If-Modified-Since para el GET condicional. If-Match If-None-Match If-Range If-Unmodified-Since Max-Forwards indica el máximo número de elementos por los que pasa. Proxy-Authorization permite que el cliente se identifique a un proxy. Range establece un rango de bytes del contenido. Referer indica la dirección donde obtuvo la URI de la petición. User-Agent información sobre el agente que genera la petición.

17
Cabeceras de respuesta
Permiten al servidor pasar información adicional al cliente sobre la respuesta, el propio servidor y el recurso solicitado. Son los campos: Age estimación del tiempo transcurrido desde que se creó la respuesta. Location se usa par a redirigir la petición a otra URI. Proxy-Authenticate ante una respuesta con el código 407 (autentificación proxy requerida), indica el esquema de autentificación. Public da la lista de métodos soportados por el servidor. Retry-After ante un servicio no disponible da una fecha para volver a intentarlo. Server información sobre el servidor que maneja las peticiones. Vary indica que hay varias respuestas y el servidor ha escogido una. Warning usada para aportar información adicional sobre el estado de la respuesta. WWW-Authenticate indica el esquema de autentificación y los parámetros aplicables a la URI.
, indica el esquema de autentificación. Public. da la lista de métodos soportados por el servidor. Retry-After. ante un servicio no disponible da una fecha para volver a intentarlo. Server. información sobre el servidor que maneja las peticiones. Vary. indica que hay varias respuestas y el servidor ha escogido una. Warning. usada para aportar información adicional sobre el estado de la respuesta. WWW-Authenticate. indica el esquema de autentificación y los parámetros aplicables a la URI.")
18
Cabeceras de entidad Como su nombre indica, los campos de este tipo aportan información sobre el contenido del mensaje o si no hay contenido, sobre el recurso al que hace referencia la URI de la petición. Los campos de este tipo son: Allow da los métodos soportados por el recurso designadopor la URI. Content-Base indica la URI base para resolver las URI relativas. Content-Encoding indica una codificación adicional aplicada al contenido (a parte de la aplicada por el tipo). Content-Language describe el idioma del contenido. Content-Length indica el tamaño del contenido del mensaje. Content-Location da información sobre la localización del recurso que da el contenido del mensaje. Content-MD5 es un resumen en formato MD5 (RFC 1864) para chequear la integridad del contenido.
. Content-Language. describe el idioma del contenido. Content-Length. indica el tamaño del contenido del mensaje. Content-Location. da información sobre la localización del recurso que da el contenido del mensaje. Content-MD5. es un resumen en formato MD5 (RFC 1864) para chequear la integridad del contenido.")
19
Content-Range en un GET parcial, indica la posición del contenido. Content-Type indica el tipo de contenido que es. Etag define una marca para el contenido asociado. Expires indica la fecha a partir de la cual la respuesta deja de ser válida. Last-Modified indica la fecha de la última modificación.

20
Errores de servidor 500 Error interno Es un código comúnmente emitido por aplicaciones empotradas en servidores web, mismas que generan contenido dinámicamente, por ejemplo aplicaciones montadas en IIS o Tomcat, cuando se encuentran con situaciones de error ajenas a la naturaleza del servidor web. 501 No implementado 502 Pasarela incorrecta 503 Servicio no disponible 504 Tiempo de espera de la pasarela agotado 505 Versión de HTTP no soportada 506 Variante también negocia 507 Almacenamiento insuficiente 509 Límite de ancho de banda excedido Este código de estatus, a pesar de ser utilizado por muchos servidores, no es oficial. 510 No extendido

21
Errores del cliente 400 Solicitud incorrecta La solicitud contiene sintaxis errónea y no debería repetirse. 401 No autorizado Similar al 403 Forbidden, pero específicamente para su uso cuando la autentificación es posible pero ha fallado o aún no ha sido provista. Vea autentificación HTTP básica y Digest access authentication. 402 Pago requerido La intención original era que este código pudiese ser usado como parte de alguna forma o esquema de Dinero electrónico o micropagos, pero eso no sucedió, y este código nunca se utilizó. 403 Prohibido La solicitud fue legal, pero el servidor se rehúsa a responderla. En contraste a una respuesta 401 No autorizado, la autentificación no haría la diferencia. 404 No encontrado Recurso no encontrado. Se utiliza cuando el servidor web no encuentra la página o recurso solicitado. 405 Método no permitido Una petición fue hecha a una URI utilizando un método de solicitud no soportado por dicha URI; por ejemplo, cuando se utiliza GET en una forma que requiere que los datos sean presentados vía POST, o utilizando PUT en un recurso de sólo lectura.

22
406 No aceptable El servidor no es capaz de devolver los datos en ninguno de los formatos aceptados por el cliente, indicados por éste en la cabecera "Accept" de la petición. 407 Autenticación Proxy requerida 408 Tiempo de espera agotado El cliente falló al continuar la petición - excepto durante la ejecución de videos Adobe Flash cuando solo significa que el usuario cerró la ventana de video o se movió a otro. ref 409 Conflicto Indica que la solicitud no pudo ser procesada debido a un conflicto con el estado actual del recurso que esta identifica. 410 Ya no disponible Indica que el recurso solicitado ya no está disponible y no lo estará de nuevo. Debería ser utilizado cuando un recurso ha sido quitado de forma permanente. Si un cliente recibe este código no debería volver a solicitar el recurso en el futuro. Por ejemplo un buscador lo eliminará de sus índices y lo hará más rápidamente que utilizando un código 404. 411 Requiere longitud 412 Falló precondición 413 Solicitud demasiado larga 414 URI demasiado larga 415 Tipo de medio no soportado

23
416 Rango solicitado no disponible
El cliente ha preguntado por una parte de un archivo, pero el servidor no puede proporcionar esa parte, por ejemplo, si el cliente preguntó por una parte de un archivo que está más allá de los límites del fin del archivo. 417 Falló expectativa 421 Hay muchas conexiones desde esta dirección de internet 422 Entidad no procesable La solicitud está bien formada pero fue imposible seguirla debido a errores semánticos. 423 Bloqueado El recurso al que se está teniendo acceso está bloqueado. 424 Falló dependencia La solicitud falló debido a una falla en la solicitud previa. 425 Colección sin ordenar Definido en los drafts de WebDav Advanced Collections, pero no está presente en "Web Distributed Authoring and Versioning. 426 Actualización requerida El cliente debería cambiarse a TLS/1.0. 449 Reintente con Una extensión de Microsoft: La petición debería ser reintentada después de hacer la acción apropiada.

24
Código de estado 200 OK Respuesta estándar para peticiones correctas. 201 Creado La petición ha sido completada y ha resultado en la creación de un nuevo recurso. 202 Aceptada La petición ha sido aceptada para procesamiento, pero este no ha sido completado. La petición eventualmente pudiere no ser satisfecha, ya que podría ser no permitida o prohibida cuando el procesamiento tenga lugar. 203 Información no autoritativa (desde HTTP/1.1) 204 Sin contenido 205 Recargar contenido 206 Contenido parcial La petición servirá parcialmente el contenido solicitado. Esta característica es utilizada por herramientas de descarga como wget para continuar la transferencia de descargas anteriormente interrumpidas, o para dividir una descarga y procesar las partes simultáneamente. 207 Estado múltiple El cuerpo del mensaje que sigue es un mensaje XML y puede contener algún número de códigos de respuesta separados, dependiendo de cuántas sub-peticiones sean hechas.
 204 Sin contenido. 205 Recargar contenido. 206 Contenido parcial. La petición servirá parcialmente el contenido solicitado. Esta característica es utilizada por herramientas de descarga como wget para continuar la transferencia de descargas anteriormente interrumpidas, o para dividir una descarga y procesar las partes simultáneamente. 207 Estado múltiple. El cuerpo del mensaje que sigue es un mensaje XML y puede contener algún número de códigos de respuesta separados, dependiendo de cuántas sub-peticiones sean hechas.")
25
Almacenamiento en cache
Almacena documentos web (es decir, páginas, imágenes, etcétera) para reducir el ancho de banda consumido, la carga de los servidores y el retardo en la descarga. Un caché web almacena copias de los documentos que pasan por él, de forma que subsiguientes peticiones pueden ser respondidas por el propio caché, si se cumplen ciertas condiciones. Tipos: ◦ Cachés privados, las presentes en los navegadores web, que funcionan solo para un único usuario. ◦ Cachés compartidos. que sirvan páginas a varios usuarios. La cache compartida suele ser usados por los proveedores de servicios de Internet (ISP), universidades y empresas para ahorrar ancho de banda. ◦ Las cachés pasarela funcionan a cargo del propio servidor original, de forma que los clientes no distinguen unos de otros.
 para reducir el ancho de banda consumido, la carga de los servidores y el retardo en la descarga. Un caché web almacena copias de los documentos que pasan por él, de forma que subsiguientes peticiones pueden ser respondidas por el propio caché, si se cumplen ciertas condiciones. Tipos: ◦ Cachés privados, las presentes en los navegadores web, que funcionan solo para un único usuario. ◦ Cachés compartidos. que sirvan páginas a varios usuarios. La cache compartida suele ser usados por los proveedores de servicios de Internet (ISP), universidades y empresas para ahorrar ancho de banda. ◦ Las cachés pasarela funcionan a cargo del propio servidor original, de forma que los clientes no distinguen unos de otros.")
26
Redirecciones El cliente tiene que tomar una acción adicional para completar la petición. Esta clase de código de estado indica que una acción subsecuente necesita efectuarse por el agente de usuario para completar la petición. La acción requerida puede ser llevada a cabo por el agente de usuario sin interacción con el usuario si y sólo si el método utilizado en la segunda petición es GET o HEAD. El agente de usuario no debe redirigir automáticamente una petición más de 5 veces, dado que tal funcionamiento indica usualmente un Bucle infinito. 300 Múltiples opciones Indica opciones múltiples para el URI que el cliente podría seguir. Esto podría ser utilizado, por ejemplo, para presentar distintas opciones de formato para video, listar archivos con distintas extensiones o word sense disambiguation. 301 Movido permanentemente Esta y todas las peticiones futuras deberían ser dirigidas a la URI dada.

27
302 Movido temporalmente Este es el código de redirección más popular, pero también un ejemplo de las prácticas de la industria contradiciendo el estándar. La especificación HTTP/1.0 (RFC 1945) requería que el cliente realizara una redirección temporal (la frase descriptiva original fue "Moved Temporarily"), pero los navegadores populares lo implementaron como 303 See Other. Por tanto, HTTP/1.1 añadió códigos de estado 303 y 307 para eliminar la ambigüedad entre ambos comportamientos. Sin embargo, la mayoría de aplicaciones web y bibliotecas de desarrollo aún utilizan el código de respuesta 302 como si fuera el 303. 303 Vea otra (desde HTTP/1.1) La respuesta a la petición puede ser encontrada bajo otra URI utilizando el método GET. 304 No modificado Indica que la petición a la URL no ha sido modificada desde que fue requerida por última vez. Típicamente, el cliente HTTP provee un encabezado como If-Modified-Since para indicar una fecha y hora contra la cual el servidor pueda comparar. El uso de este encabezado ahorra ancho de banda y reprocesamiento tanto del servidor como del cliente.
 requería que el cliente realizara una redirección temporal (la frase descriptiva original fue Moved Temporarily ), pero los navegadores populares lo implementaron como 303 See Other. Por tanto, HTTP/1.1 añadió códigos de estado 303 y 307 para eliminar la ambigüedad entre ambos comportamientos. Sin embargo, la mayoría de aplicaciones web y bibliotecas de desarrollo aún utilizan el código de respuesta 302 como si fuera el Vea otra (desde HTTP/1.1) La respuesta a la petición puede ser encontrada bajo otra URI utilizando el método GET. 304 No modificado. Indica que la petición a la URL no ha sido modificada desde que fue requerida por última vez. Típicamente, el cliente HTTP provee un encabezado como If-Modified-Since para indicar una fecha y hora contra la cual el servidor pueda comparar. El uso de este encabezado ahorra ancho de banda y reprocesamiento tanto del servidor como del cliente.")
28
305 Utilice un proxy (desde HTTP/1.1)
Muchos clientes HTTP no se apegan al estándar al procesar respuestas con este código, principalmente por motivos de seguridad. 306 Cambie de proxy Esta respuesta está descontinuada. 307 Redirección temporal (desde HTTP/1.1) Se trata de una redirección que debería haber sido hecha con otra URI, sin embargo aún puede ser procesada con la URI proporcionada. En contraste con el código 303, el método de la petición no debería ser cambiado cuando el cliente repita la solicitud. Por ejemplo, una solicitud POST tiene que ser repetida utilizando otra petición POST.
 Se trata de una redirección que debería haber sido hecha con otra URI, sin embargo aún puede ser procesada con la URI proporcionada. En contraste con el código 303, el método de la petición no debería ser cambiado cuando el cliente repita la solicitud. Por ejemplo, una solicitud POST tiene que ser repetida utilizando otra petición POST.")
29
Comprensión La compresión HTTP es una capacidad que se puede construir en servidores web y clientes web para hacer un mejor uso del ancho de banda disponible, y ofrecer mayores velocidades de transmisión entre ambos. HTTP datos se comprimen antes de ser enviado desde el servidor: Los navegadores compatibles dará a conocer qué métodos se apoyan en el servidor antes de descargar el formato correcto; navegadores que no soportan el método de compresión compatible descargará datos sin comprimir. Los esquemas de compresión más comunes son gzip y deflate , sin embargo, una lista completa de los esquemas disponibles es mantenido por IANA . Además, los terceros el desarrollo de nuevos métodos y los incluyen en sus productos (por ejemplo, los de Google SDCH esquema implementado en Google Chrome navegador y utilizado en ciertos servidores de Google).
.")
30
Cookies Una cookie, también conocido como una cookie HTTP, galleta web, o navegador de galleta, es por lo general una pequeña cantidad de datos enviados desde un sitio web y almacenado en un usuario del navegador web mientras un usuario está navegando en una página web. Cuando el usuario navega por el mismo sitio web en el futuro, los datos almacenados en la cookie puede ser recuperada por el sitio web de notificar a la página web de la actividad anterior del usuario. Las cookies fueron diseñadas para ser un mecanismo confiable para sitios Web para recordar el estado de la página web o de la actividad que el usuario ha tomado en el pasado. Esto puede incluir clic en los botones específicos, accediendo , o un registro de las páginas que fueron visitadas por el usuario, incluso meses o años atrás. Aunque las cookies no pueden llevar virus , y no puede instalar software malicioso en el equipo host,cookies de seguimiento y sobre todo las cookies de terceros de seguimiento se utilizan como medios para compilar registros a largo plazo de las historias particulares de navegación - una gran preocupación por la privacidad que se le solicite Europea y los fabricantes estadounidenses de la ley para tomar medidas en 2011.

31
Autenticación En el contexto de una transacción HTTP, la autenticación de acceso básica es un método diseñado para permitir a un navegador web, u otro programa cliente, proveer credenciales en la forma de usuario y contraseña cuando se le solicita una página al servidor. Antes de la transmisión, al nombre de usuario se le añade un carácter de dos puntos (:) y luego es concatenado con la contraseña. La cadena resultante es codificada con el algoritmo Base64
 y luego es concatenado con la contraseña. La cadena resultante es codificada con el algoritmo Base64.")
32
Tipos de autenticación
Autenticación básica: La autenticación básica es un método muy utilizado de recopilación de información de nombre de usuario y contraseña. La autenticación básica envía y recibe información de usuario como caracteres de texto que se pueden leer. Aunque los nombres de usuario y las contraseñas se codifican, la autenticación básica no utiliza cifrado. Autenticación Digest: Es un método de la autenticación HTTP que mejora la Autenticación Básica proporcionando una manera de autenticar sin tener que transmitir la contraseña de manera clara a través de la red. Este método de autenticación tiene las siguientes características: Es soportado por los browsers más extendidos. Puede “pasar” a través de proxys y firewalls. Usa nonces (datos aleatorios) de cliente y servidor para limitar la capacidad de hacer ataques de replay y criptoanálisis de la clave enviada. No se envía la password en texto plano. Es vulnerable a ataques Man in the Middle
 de cliente y servidor para limitar la capacidad de hacer. ataques de replay y criptoanálisis de la clave enviada. No se envía la password en texto plano. Es vulnerable a ataques Man in the Middle.")
33
Autenticación integrada de Windows.
Se trata igualmente una forma segura de autenticación en la medida en que no se envían ni la contraseña ni el nombre de usuario a través de la Red. En su lugar, el navegador tiene que demostrarle al servidor que conoce la clave por medio de un corto intercambio de datos, pero sin revelar nunca la clave. No obstante, debido a los detalles de implantación, resulta incompatible con la autenticación por resúmenes, por lo que su uso se circunscribe a servidores NT. Funciona de la siguiente manera:

34
Conexiones persistentes(Keep-Alive) Antes de que esta característica existiese, se necesitaba una conexión TCP separada para cada petición. Cuando un documento utilizaba enlaces a otros ficheros externos, la transmisión era extremadamente ineficiente. HTTP en su última versión, proporciona la posibilidad de establecer sesiones de mayor duración de manera que se permiten múltiples peticiones sobre la misma conexión TCP. Esta característica llega a proporcionar en algunos casos hasta un 50 por cien de mejora en los tiempos de latencia entre documentos HTML. Los principales beneficios al usar conexiones persistentes son: Se abren menos conexiones TCP, lo que ahora recursos (CPU, memoria, etc.). Se pueden entubar (pipeline) peticiones y respuestas en una conexión. Esto permite al cliente hacer múltiples peticiones sin esperar a las respuestas. Se reduce la latencia en peticiones al utilizar varias veces un canal ya abierto. Con los clientes que soportan HTTP/1.0, las conexiones Keep-Alive sólo pueden ser utilizadas cuando son específicamente pedidas por el cliente, además están limitadas a documentos en los que se conoce la longitud de antemano2.10. Para clientes con soporte a HTTP/1.1, las conexiones son persistentes por defecto y existen métodos de envío de documentos de longitud no conocida.
. Se pueden entubar (pipeline) peticiones y respuestas en una conexión. Esto permite al cliente hacer múltiples peticiones sin esperar a las respuestas. Se reduce la latencia en peticiones al utilizar varias veces un canal ya abierto. Con los clientes que soportan HTTP/1.0, las conexiones Keep-Alive sólo pueden ser utilizadas cuando son específicamente pedidas por el cliente, además están limitadas a documentos en los que se conoce la longitud de antemano2.10. Para clientes con soporte a HTTP/1.1, las conexiones son persistentes por defecto y existen métodos de envío de documentos de longitud no conocida.")
Presentaciones similares
















 Pedro José López Javier Díaz>")



