Descargar la presentación
La descarga está en progreso. Por favor, espere

2
Problemas relacionados al manejo de materiales digitales
1. CALIDAD Y PERTINENCIA EN LA RECUPERACIÓN DE INFORMACIÓN 2. OPEN ACCESS Vs EDITORIALES 3. DISPARIDAD DE LA INFORMACIÓN

3
1.CALIDAD Y PERTINENCIA EN LA RECUPERACIÓN DE INFORMACIÓN
Existen más de 181,000,000 Sitios en el mundo (enero 2008) Más de 24,000,000,000 de páginas indexadas en el internet (Octubre 2008) ¡4 páginas por cada habitante del mundo! (16 páginas por cada usuario de Internet) Aproximadamente hay de páginas dentro del dominio registrados por Google A pesar de que Google utiliza algoritmos como Page Ranking ó Indización Semántica Latente para afinar sus búsquedas, aproximadamente el 80% de la información encontrada no coincidirá con nuestra necesidad de información (generalmente los primeros enlaces son de información publicitaria o empresas comerciales que aprovechan las formas de indización de estos buscadores para aparecer en las primeras posiciones).
 Más de 24,000,000,000 de páginas indexadas en el internet (Octubre 2008) ¡4 páginas por cada habitante del mundo! (16 páginas por cada usuario de Internet) Aproximadamente hay de páginas dentro del dominio registrados por Google. A pesar de que Google utiliza algoritmos como Page Ranking ó Indización Semántica Latente para afinar sus búsquedas, aproximadamente el 80% de la información encontrada no coincidirá con nuestra necesidad de información (generalmente los primeros enlaces son de información publicitaria o empresas comerciales que aprovechan las formas de indización de estos buscadores para aparecer en las primeras posiciones).")
5
Usted está aquí

6
Usted está aquí

7
2004 2005 2006 2007 1. britney spears 2. paris hilton
3. christina aguilera 4. pamela anderson 5. chat 6. games 7. carmen electra 8. orlando bloom 9. harry potter 10. mp3 1. Myspace 2. Ares 3. Baidu 4. wikipedia 5. orkut 6. iTunes 7. Sky News 8. World of Warcraft 9. Green Day 10. Leonardo da Vinci 1. bebo 2. myspace 3. world cup 4. metacafe 5. radioblog 6. wikipedia 7. video 8. rebelde 9. mininova 10. wiki 1. iphone 2. badoo 3. facebook 4. dailymotion 5. webkinz 6. youtube 7. ebuddy 8. second life 9. hi5 10. club penguin Fuente: Year-End Google Zeitgeist

8
Demora para encontrar la información pertinente
Puede ser que no recuperamos toda la información existente o la más relevante Los documentos encontrados contendrán información desarrollada sin ningún carácter científico o metodológico Aún se desconoce el gran poder de la web invisible o profunda, es la información que no puede recuperarse con los mecanismos de búsqueda comunes. Estos mecanismos tratan de abarcar toda la web, pero se calcula que los mayores motores de búsqueda alcanzan a indizar sólo entre un tercio y la mitad de los documentos disponibles. La web invisible no sólo es de mayor tamaño que la web visible o superficial sino que crece a mayor velocidad. Mucha información disponible en la web profunda, como la que se encuentra en bases de datos, tiene un alto valor potencial para el usuario. Parte de este problema se debe a la desorganización con la que fue creado Internet y la ausencia de un mecanismo de integración de metadatos normalizados junto a la información presentada en los documentos Web.

9
2. Open Access Vs Editoriales
Existe una contradicción entre el internet y las editoriales científicas Facilidades para la difusión y la accesibilidad de la información científica a través de Internet Barreras tanto económicas como de derechos de producción (copyright) impuestas por las grandes editoriales que controlan las mayoría del mercado de las publicaciones científicas (Melero, 2004).
 impuestas por las grandes editoriales que controlan las mayoría del mercado de las publicaciones científicas (Melero, 2004).")
10
Creador de información
Universidades $ $ $ Creador de información información Revisión por pares Investigación $ Bibliotecas Artículo $ Distribución Editor Impresión $ $ Editoriales

11
los creadores de información y conocimientos desean obtener de forma más fácil y en el menor tiempo posible, mayor prestigio y reconocimiento por sus investigaciones. «Los artículos que están libremente expuestos en la red, son mucho más citados que aquellos que están escondidos en los arcanos del papel impreso; estos artículos online son citados 4.5 veces más frecuentemente que los que no están en línea» (Lawrence, 2001).
.")
12
Intereses editoriales
Circulación libre de información Impacto científico Intereses editoriales Científicos, académicos y bibliotecólogos de todo el mundo se reunieron en el 2002 en Budapest, Hungría, y propusieron La iniciativa de acceso abierto de Budapest (Budapest Open Access Initiative),
,")
13
La literatura que debe ser accesible gratuitamente en la red es aquella que los científicos y estudiosos entregan al mundo sin esperar remuneración. En esta categoría se incluyen, sobre todo, los artículos publicados en revistas dotadas de comité de selección, pero también se debe incluir cualquier manuscrito inédito todavía no revisado, que sus autores podrían dejar disponible en la red en busca de comentarios, o para alertar a sus colegas sobre importantes descubrimientos logrados en una investigación. Existen distintas vías para ampliar y facilitar el acceso a esta literatura. Por acceso abierto a la literatura científica erudita, entendemos su disponibilidad gratuita en Internet, para que cualquier usuario la pueda leer, descargar, copiar, distribuir o imprimir, con la posibilidad de buscar o enlazar al texto completo del artículo, recorrerlo para una indexación exhaustiva, usarlo como datos para software, o utilizarlo para cualquier otro propósito legal, sin otras barreras financieras, legales o técnicas distintas de la fundamental de acceder a la propia Internet. El único límite a la reproducción y distribución de los artículos publicados, y la única función del copyright en este marco, no puede ser otra que garantizar a los autores el control sobre la integridad de su trabajo y el derecho a ser acreditados y citados. February 14, 2002 Budapest, Hungary

14
Actualmente muchas universidades iberoamericanas están haciendo esfuerzos, ayudados muchas veces por organizaciones internacionales, para colocar los contenidos en texto completo de sus publicaciones en línea y de libre acceso, logrando así un reconocimiento y mayor difusión internacional, más allá del simple interés económico de captar suscripciones.

15
3. Disparidad de la información
Los sistemas de información de organizaciones como bibliotecas, centros de documentación, archivos y otros, han sido pensados para atender necesidades particulares, No suelen seguirse normas o estándares comunes. Esto evita que se pueden interconectar y compartir su información plenamente. Existe un problema profundo a nivel interno de heterogenización de productos de hardware y software, además de la forma de ingreso de la información (niveles de catalogación).
.")
16
Base de datos centralizada
Institución A Base de datos centralizada COLECCIÓN A Institución B COLECCIÓN B Nodo principal Institución C COLECCIÓN A COLECCIÓN B COLECCIÓN C COLECCIÓN D COLECCIÓN C Institución D COLECCIÓN D

17
Base de datos centralizada
Institución A Base de datos centralizada COLECCIÓN A Institución B COLECCIÓN B Nodo principal Institución C COLECCIÓN A COLECCIÓN B COLECCIÓN C COLECCIÓN D COLECCIÓN C Ventajas: Velocidad de respuesta, ya que la información se encuentra en un mismo servidor. Facilidad de uso para las Instituciones participantes y para los usuarios. Institución D COLECCIÓN D

18
Base de datos centralizada
Institución A Base de datos centralizada Nodo principal COLECCIÓN A Objeto 1 Institución B COLECCIÓN A OBJETO 1 COLECCIÓN B OBJETO 2 COLECCIÓN C COLECCIÓN D OBJETO 3 Duplicidad COLECCIÓN B Objeto 2 Institución C Desventajas: Cualquier cambio al formato o tipo de documento implica volver a traducir. Es difícil evitar la duplicidad. Cada nodo nuevo requiere un nuevo traductor. COLECCIÓN C OBJETO 1 Institución D COLECCIÓN D Objeto 3

19
sistemas de información distribuidos
William E. Moen

20
sistemas de información distribuidos
William E. Moen

21
ZiNG, "Z39.50-International: Next Generation" Iniciativa que busca mantener las bondades del protocolo aprovechando las herramientas del Internet Z39.50 es un estándar pre internet No aprovecha las bondades de la “Autopista de la información” Search/Retrieve via URL Search/Retrieve Web service (SRW) Common Query Language Costoso y en proceso de desarrollo
 Common Query Language. Costoso y en proceso de desarrollo.")
23
Se pueden combinar los dos modelos anteriores:
base de datos centralizada sistemas de información distribuidos Existe una solución de integración e interoperabilidad de repositorios de información, para la creación de catálogos colectivos, mediante la utilización práctica de normas y estándares internacionales con una metodología de fácil uso y bajo costo de implementación, esto a través del proceso de recolección (cosecha de metadatos), en la cual periódicamente, los sistemas de información distribuidos se comunican y se actualizan entre sí de forma automática, y se genera un sistema centralizado para búsqueda y recuperación de información. Repositorios de información Normas y estándares internacionales Cosecha de metadatos
, en la cual periódicamente, los sistemas de información distribuidos se comunican y se actualizan entre sí de forma automática, y se genera un sistema centralizado para búsqueda y recuperación de información. Repositorios de información. Normas y estándares internacionales. Cosecha de metadatos.")
24
Repositorio de datos Metadatos Dublin Core y adicionales
(descriptivos y administrativos) Título Fecha Fuente Relación Otros Otros Autor P.Clave Contribuidor Otros Otros Otros Tema Formato Tipo Otros Otros Otros Derechos Cobertura Idioma Otros Otros Otros URL Descripción Audiencia Otros Otros Otros OD OD Objetos Digitales OD OD OD OD
 Título. Fecha. Fuente. Relación. Otros. Otros. Autor. P.Clave. Contribuidor. Otros. Otros. Otros. Tema. Formato. Tipo. Otros. Otros. Otros. Derechos. Cobertura. Idioma. Otros. Otros. Otros. URL. Descripción. Audiencia. Otros. Otros. Otros. OD. OD. Objetos Digitales. OD. OD. OD. OD.")
26
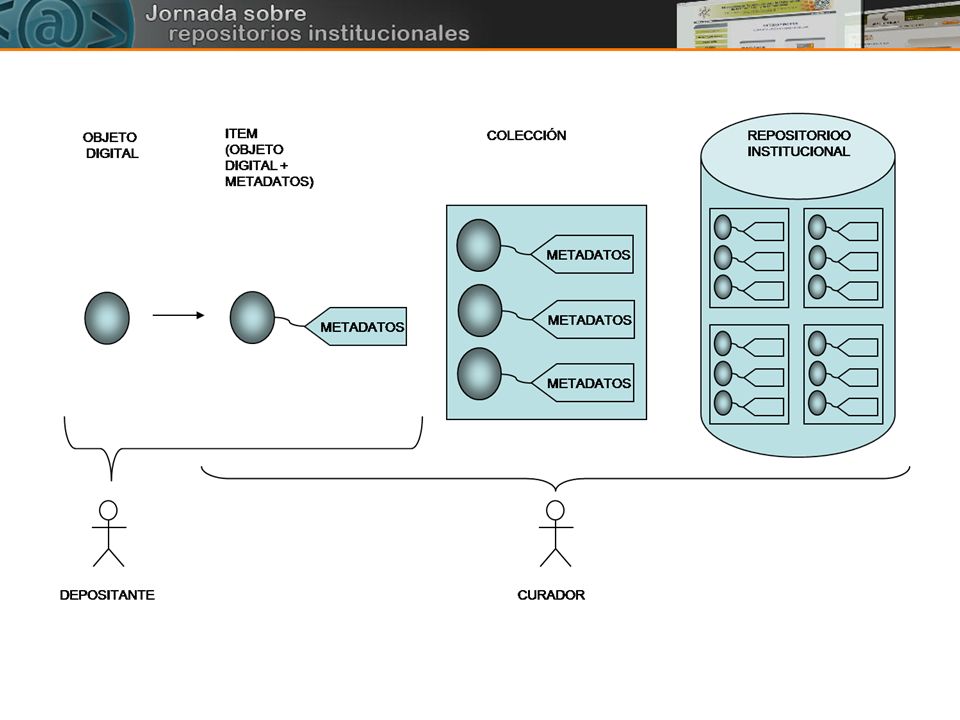
DEPOSITANTE CURADOR Autodepósito Depósito a través
REPOSITORIO INSTITUCIONAL DEPOSITANTE VALIDACIÓN CURADOR Autodepósito Depósito a través de un curador (editor)
")
27
Repositorio temático Los primeros repositorios se crearon para que los investigadores pudieran colocar sus artículos electrónicos en línea y para que otros investigadores del mismo campo pudieran acceder a ellos a través de las interfaces de búsqueda y recuperación. El motivo principal era poder compartir sus resultados de investigación de una forma más rápida, mejorando así la comunicación entre los investigadores. Adicionalmente, de esta forma se eliminaban las barreras económicas de acceso que existen para consultar los artículos en revistas académicas comerciales. (Harnard, 2001).
.")
28
Repositorio temático Repositorio Institucional Son organizados por una institución más que por áreas temáticas. El repositorio funciona como un tipo de vitrina para mostrar la producción académica de la institución que lo maneja. Están basados y apoyados en una institución académica y ofrecen material digital producido por sus miembros. Tanto el contenido del repositorio como las políticas de selección y almacenamiento de los materiales está definido institucionalmente (Johhson, 2002).
.")
29
Repositorio temático Repositorio Institucional Repositorio Universitario Es un depósito de contenidos digitales informativos, educativos y de investigación, con un conjunto de servicios en línea para su difusión, uso y visibilidad, producido y administrado por la comunidad académica de la universidad de forma institucional o grupal.

30
Repositorio Institucional Repositorio Universitario
Repositorio temático Repositorio Institucional Repositorio Universitario Contenido Artículos de investigación: Pre-prints sin publicar (no revisadas por pares), post-prints (borradores finales revisados por pares) y versiones publicadas Libros Traducciones Imágenes Mapas Publicaciones electrónicas (páginas Web, revistas) Monografías Memorias en congresos nacionales o internacionales Proyectos de investigación Reportes técnicos Manuales Programas de cómputo
, post-prints (borradores finales revisados por pares) y versiones publicadas. Libros. Traducciones. Imágenes. Mapas. Publicaciones electrónicas (páginas Web, revistas) Monografías. Memorias en congresos nacionales o internacionales. Proyectos de investigación. Reportes técnicos. Manuales. Programas de cómputo.")
31
Repositorio Institucional Repositorio Universitario
Repositorio temático Repositorio Institucional Repositorio Universitario Contenido Datasets (por ejemplo cadenas químicas o información georefernciada) Referencias Programas académicos Apuntes de cursos Multimedios (audio, videos, animaciones y publicaciones interactivas) Partituras Conferencias Ponencias Cursos Pósters y carteles Informes Documentos administrativos de proyectos Documentos administrativos de las dependencias Acontecimientos destacados
 Referencias. Programas académicos. Apuntes de cursos. Multimedios (audio, videos, animaciones y publicaciones interactivas) Partituras. Conferencias. Ponencias. Cursos. Pósters y carteles. Informes. Documentos administrativos de proyectos. Documentos administrativos de las dependencias. Acontecimientos destacados.")
32
Repositorio temático Repositorio Institucional Repositorio Universitario Contenido Medio Son repositorios definidos por el formato de los recursos, ya sea en su manifestación física o digital del recurso. Papel, ASCII, JPEG, TIFF, Shapefile, GRID, etc.

33
Repositorio Institucional Repositorio Universitario
Repositorio temático Repositorio Institucional Repositorio Universitario Contenido Medio Depósito El OA self-archiving Los autores publican en una revista de subscripción, haciendo además que sus artículos sean accesible libremente en línea, generalmente depositándolos en cualquier Repositorio Institucional. En el OA publishing los autores publican en las revistas de acceso abierto, que hacen disponibles los artículos en línea, inmediatamente desde la publicación.

34
¿Qué modelo usar? Que los datos hablen…

35
Vs Orden Caos

36
Los metadatos son datos que describen a otros datos.
En una biblioteca, donde los datos corresponden al contenido de los libros almacenados, los metadatos siempre van a incluir una descripción del contenido, el autor, la fecha de publicación y la localización física del libro. En el contexto de una cámara, en donde los datos son las imágenes fotográficas, los metadatos van a incluir la fecha en que la fotografía fue tomada y los detalles técnicos de la cámara. En el caso de un reproductor de música, en donde los datos son las canciones almacenadas, los metadatos van a contener el intérprete, el nombre del álbum, el nombre de la canción. Estos metadatos están incluidos en el archivo de música, y es lo que se utiliza para crear las listas de reproducción.

37
ID3 es un estándar de facto para incluir metadatos (etiquetas) en un contenedor multimedia, tales como álbum, título o artista. Se utiliza principalmente en archivos MP3. Interprete: Iggy Pop & Kate Pierson Título: Candy Album: A million in prizes Imagen:

38
Los metadatos se refieren a un grupo de datos llamado recurso.
Dan contexto a los datos o recursos Ayudan a ubicar datos o recursos en Internet

39
Los metadatos son útiles para varios campos de la informática como la recuperación de información o la web semántica La Web semántica (del inglés semantic web) se basa en la idea de añadir metadatos semánticos al Internet. Esas informaciones adicionales —describiendo el contenido, el significado y la relación de los datos— deben ser dadas de manera formal, para que así sea posible evaluarlas automáticamente por máquinas de procesamiento. El objetivo es mejorar Internet ampliando la interoperabilidad entre los sistemas informáticos y reducir la necesaria mediación de operadores humanos. Vannevar Bush
 se basa en la idea de añadir metadatos semánticos al Internet. Esas informaciones adicionales —describiendo el contenido, el significado y la relación de los datos— deben ser dadas de manera formal, para que así sea posible evaluarlas automáticamente por máquinas de procesamiento. El objetivo es mejorar Internet ampliando la interoperabilidad entre los sistemas informáticos y reducir la necesaria mediación de operadores humanos. Vannevar Bush.")
40
El uso de los metadatos mencionado más frecuentemente es la refinación de consultas a buscadores. Usando informaciones adicionales los resultados son más precisos, y el usuario se ahorra filtraciones manuales complementarias. El intervalo semántico plantea el problema de que el usuario y la computadora no se entiendan porque este último no comprenda el significado de los datos. Los metadatos posibilitan la comunicación declarando cómo están relacionados los datos.

41
Usted está aquí

42
Usted está aquí

43
Usted está aquí

44
Hay dos posibilidades para almacenar metadatos: depositarlos internamente, en el mismo documento que los datos, o depositarlos externamente, en su mismo recurso. Inicialmente, los metadatos se almacenaban internamente para facilitar la administración. Hoy, por lo general, se considera mejor opción la localización externa porque hace posible la concentración de metadatos para optimizar operaciones de busca. Por el contrario, existe el problema de cómo se liga un recurso con sus metadatos. La mayoría de los estándares usa URIs, la técnica de localizar documentos en la World Wide Web, pero este método propone otras preguntas, por ejemplo qué hacer con documentos que no tienen URI.

45
Ontologías Para garantizar la uniformidad y la compatibilidad de los metadatos, se debe usar un vocabulario controlado fijando los términos de un campo. Por ejemplo, en caso de sinónimos o interlenguaje hay que acordarse qué palabras se usan para evitar que el buscador localice «español» pero no «española». Una ontología además define las relaciones de los términos del vocabulario para que la computadora puede evaluarlas automáticamente. Así es posible presentar una página web sobre «Diego Rivera» aunque el usuario tecleó «pintores mexicanos»; usando una ontología adecuada el buscador comprende que Diego Rivera fue un pintor mexicano. Un concepto muy similar a las ontologías son las folksonomías. Las ontologías son definidas por expertos del campo que ordenan los términos, pero las folksonomías son definidas por los mismos usuarios.

46
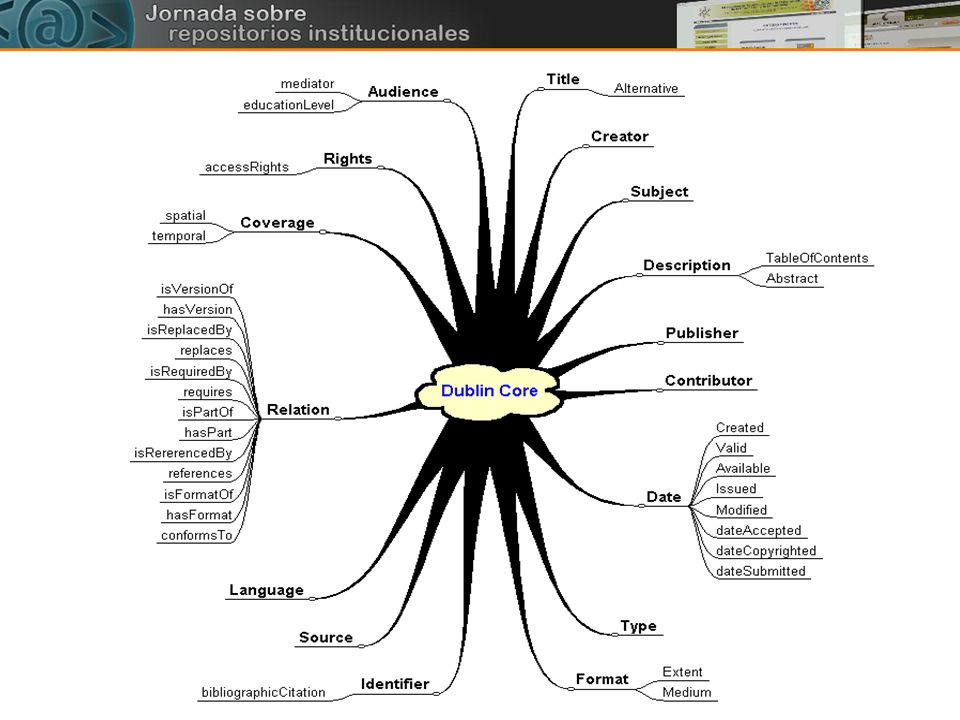
Dublin Core es un modelo de metadatos elaborado y auspiciado por la DCMI (Dublin Core Metadata Initiative), una organización dedicada a fomentar la adopción extensa de los estándares interoperables de los metadatos y a promover el desarrollo de los vocabularios especializados de metadatos para describir recursos para permitir sistemas más inteligentes del descubrimiento del recurso. El nombre viene por Dublín (Ohio, Estados Unidos), ciudad que en 1995 albergó la primera reunión a nivel mundial de muchos de los especialistas en metadatos y Web de la época.
, ciudad que en 1995 albergó la primera reunión a nivel mundial de muchos de los especialistas en metadatos y Web de la época.")
47
Dublin Core es un sistema de 15 definiciones semánticas descriptivas que pretenden transmitir un significado semántico a las mismas. Estas definiciones: Son opcionales Se pueden repetir Pueden aparecer en cualquier orden Este sistema de definiciones fue diseñado específicamente para proporcionar un vocabulario de características "base", capaces de proporcionar la información descriptiva básica sobre cualquier recurso, sin que importe el formato de origen, el área de especialización o el origen cultural.

48
En general, podemos clasificar estos elementos en tres grupos que indican la clase o el ámbito de la información que se guarda en ellos: Elementos relacionados principalmente con el contenido del recurso. Elementos relacionados principalmente con el recurso cuando es visto como una propiedad intelectual. Elementos relacionados principalmente con la instanciación del recurso.

49
- Título: el nombre dado a un recurso, habitualmente por el autor.
Etiqueta: DC.Title - Claves: los tópicos del recurso. Típicamente, Subject expresará las claves o frases que describen el título o el contenido del recurso. Se fomentará el uso de vocabularios controlados y de sistemas de clasificación formales. Etiqueta: DC.Subject - Descripción: una descripción textual del recurso. Puede ser un resumen en el caso de un documento o una descripción del contenido en el caso de un documento visual. Etiqueta: DC.Description - Fuente: secuencia de carácteres usados para identificar unívocamente un trabajo a partir del cual proviene el recurso actual. Etiqueta: DC.Source - Lengua: lengua/s del contenido intelectual del recurso. Etiqueta: DC.Language - Relación: es un identificador de un segundo recurso y su relación con el recurso actual. Este elemento permite enlazar los recursos relacionados y las descripciones de los recursos. Etiqueta: DC.Relation - Cobertura: es la característica de cobertura espacial y/o temporal del contenido intelectual del recurso. La cobertura espacial se refiere a una región física, utilizando por ejemplo coordenadas. La cobertura temporal se refiere al contenido del recurso, no a cuándo fue creado (que ya lo encontramos en el elemento Date). Etiqueta: DC.Coverage Contenido:
. Etiqueta: DC.Coverage. Contenido:")
50
Propiedad Intelectual:
- Autor o Creador: la persona o organización responsable de la creación del contenido intelectual del recurso. Por ejemplo, los autores en el caso de documentos escritos; artistas, fotógrafos e ilustradores en el caso de recursos visuales. Etiqueta: DC.Creator - Editor: la entidad responsable de hacer que el recurso se encuentre disponible en la red en su formato actual. Etiqueta: DC.Publisher - Otros Colaboradores: una persona u organización que haya tenido una contribución intelectual significativa, pero que esta sea secundaria en comparación con las de las personas u organizaciones especificadas en el elemento Creator. (por ejemplo: editor, ilustrador y traductor). Etiqueta: DC.Contributor - Derechos: son una referencia (por ejemplo, una URL) para una nota sobre derechos de autor, para un servicio de gestión de derechos o para un servicio que dará información sobre términos y condiciones de acceso a un recurso. Etiqueta: DC.Rights Propiedad Intelectual:
. Etiqueta: DC.Contributor. - Derechos: son una referencia (por ejemplo, una URL) para una nota sobre derechos de autor, para un servicio de gestión de derechos o para un servicio que dará información sobre términos y condiciones de acceso a un recurso. Etiqueta: DC.Rights. Propiedad Intelectual:")
51
Objeto: - Fecha: una fecha en la cual el recurso se puso a disposición del usuario en su forma actual. Esta fecha no se tiene que confundir con la que pertenece al elemento Coverage, que estaría asociada con el recurso en la medida que el contenido intelectual está de alguna manera relacionado con aquella fecha. Etiqueta: DC.Date - Tipo del Recurso: la categoría del recurso. Por ejemplo, página personal, romance, poema, diccionario, etc. Etiqueta: DC.Type - Formato: es el formato de datos de un recurso, usado para identificar el software y, posiblemente, el hardware que se necesitaría para mostrar el recurso. Etiqueta: DC.Format - Identificador del Recurso: secuencia de carácteres utilizados para identificar unívocamente un recurso. Ejemplos para recursos en línea pueden ser URLs i URNs. Para otros recursos pueden ser usados otros formatos de identificadores, como por ejemplo ISBN ("International Standard Book Number"). Etiqueta: DC.Identifier
. Etiqueta: DC.Identifier.")
53
Metadatos Geoespaciales.
Son un tipo de metadatos que se aplican a objetos que tienen una extensión geográfica, ya sea de manera explícita o implícita. Es decir que están asociados con una posición sobre la superficie del globo. Estos objetos pueden almacenarse en SIG o simplemente ser documentos, datos, imágenes u otros objetos, servicios o ítems relacionados, que tienen un ambiente natural, pero que sus características pueden ser apropiadas para describirse con metadatos geográficos.

54
Comité Federal de Datos Geográficos (FGDC)
1992 a 1994, desarrolló el Content Standard for Digital Geospatial Metadata (CSDGM) El CSDGM se diseñó para apoyar el desarrollo de la Infraestructura Nacional de Datos Espaciales de EU, pero, ha sido adoptado e implementado en Canadá, Reino Unido, África del Sur y en varios países de América Latina
 El CSDGM se diseñó para apoyar el desarrollo de la Infraestructura Nacional de Datos Espaciales de EU, pero, ha sido adoptado e implementado en Canadá, Reino Unido, África del Sur y en varios países de América Latina.")
56
ISO/TC211 y el Estándar 19115 En 1994, la Organización Internacional de Estandarización creó el Comité Técnico núm. 211 (ISO/TC211) como responsable de la generación de estándares sobre información geográfica/geomática. El Comité comprende, a la fecha, expertos de 29 naciones que trabajan de forma intensiva, organizados en cinco grupos de trabajo que tienen a su cargo unos 40 proyectos de estándares en la llamada serie 19000, uno de los cuales (el 19115, recientemente liberado) se refiere a metadatos. este estándar tiene mucho en común con el del FGDC, lo cual se ha dado en función de buscar la congruencia y compatibilidad entre ellos. Se puede tener acceso al Estándar de la ISO/TC211 con un costo, en la dirección
 como responsable de la generación de estándares. sobre información geográfica/geomática. El Comité comprende, a la fecha, expertos de 29 naciones que trabajan de forma intensiva, organizados. en cinco grupos de trabajo que tienen a su cargo unos 40 proyectos. de estándares en la llamada serie 19000, uno de los cuales (el 19115, recientemente liberado) se refiere a metadatos. este estándar tiene mucho en común con el del FGDC, lo cual se ha dado en función de buscar la congruencia y compatibilidad entre. ellos. Se puede tener acceso al Estándar de la ISO/TC211 con un. costo, en la dirección")
57
Metadatos de Biodiversidad Instituto Humboldt, Colombia

59
Proveedor de servicios (PS)
Proveedor de datos ó Repositorio (PD) Proveedor de servicios (PS) PD PS Utiliza el interfaz OAI de los Data Providers Recolecta y almacena los metadatos (nunca en tiempo real!) Puede seleccionar sólo un subconjunto de los datos contenidos en los Data Providers Ofrece servicios de valor añadido a partir de los metadatos Libre acceso a los metadatos No necesariamente libre acceso al texto completo Fácil de implementar
 Proveedor de servicios (PS) PD. PS. Utiliza el interfaz OAI de los Data Providers. Recolecta y almacena los metadatos (nunca en tiempo real!) Puede seleccionar sólo un subconjunto de los datos contenidos en los Data Providers. Ofrece servicios de valor añadido a partir de los metadatos. Libre acceso a los metadatos. No necesariamente libre acceso al texto completo. Fácil de implementar.")
60
Proveedor de servicios (PS)
Proveedor de datos ó Repositorio (PD) Proveedor de servicios (PS) PD PS Peticiones en HTML: Identify ListMetadataformats ListSets ListIdentifiers ListRecords GetRecord
 Proveedor de servicios (PS) PD. PS. Peticiones en HTML: Identify. ListMetadataformats. ListSets. ListIdentifiers. ListRecords. GetRecord.")
61
Proveedor de servicios (PS)
Proveedor de datos ó Repositorio (PD) Proveedor de servicios (PS) PD PS Respuestas en XML: General information Metadata formats Set structure Record identifier Metadata
 Proveedor de servicios (PS) PD. PS. Respuestas en XML: General information. Metadata formats. Set structure. Record identifier. Metadata.")
62
Proveedor de servicios
Usuario Proveedor de servicios (Servidor) Proveedor de datos (Cliente) Metadato Objeto 1 Metadato CGI Metadato Creación de Peticiones HTTP Análisis de Peticiones (parser) HTTP Metadato Módulo de Servicio Error Análisis de XML (parser) Creación de respuestas XML XML Metadato Objeto 2 Metadato Metadato Metadato
 Proveedor de datos. (Cliente) Metadato. Objeto Metadato. CGI. Metadato. Creación. de. Peticiones. HTTP. Análisis de. Peticiones. (parser) HTTP. Metadato. Módulo de. Servicio. Error. Análisis de. XML. (parser) Creación de. respuestas. XML. XML. Metadato. Objeto Metadato. Metadato. Metadato.")
63
“quiero todos los registros nuevos”
archive.org/oai?verb=ListRecords& metadataPrefix=oai_dc&from= Proveedor de servicios Proveedor de datos “tengo 267, pero te doy 100” 100 records + resumptionToken “anyID1” “dame más de estos” archive.org/oai?verb=ListRecords& resumptionToken=anyID1 “tengo 267, te doy otros 100” 100 records + resumptionToken “anyID2” Harvester Repository “dame más de estos” archive.org/oai?verb=ListRecords& resumptionToken=anyID2 “tengo 267, te doy mis últimos 67” 67 records + resumptionToken “”

64
<?xml version="1.0" encoding="UTF-8"?>
<OAI-PMH xmlns=" xmlns:xsi=" xsi:schemaLocation=" <responseDate> T14:57:01+01:00</responseDate> <request verb="GetRecord" metadataPrefix="oai_dc" identifier="oai:HUBerlin.de: "> <GetRecord> <record> <header> <identifier>oai:HUBerlin.de: </identifier> […] </header> <metadata> <oai_dc:dc xmlns:oai_dc=" xmlns:dc=" xmlns:xsi=" xsi:schemaLocation=" <dc:title>Einflugenetischer Variationen im Tumor Nekrose […]</dc:title> <dc:creator>Schfael, Antje</dc:creator> </metadata> </record> </GetRecord> </OAI-PMH>

65
PS PS PD PS PS PS PD PD PD PD PD PD PD PD

66
PS PS PD PS PS PS PD PD PD PD PD PD PD PD

67
PS PS PD PS PS PS PD PD PD PD PD PD PD PD

68
Repositorio centralizado
Concentra en un solo servidor los contenidos depositados y los servicios de acceso y preservación. Repositorio Institución Institución Institución Institución

69
Ventajas: Puede establecer un servicio de administración general que controle la totalidad de la estructura de las colecciones y los mecanismos de control de calidad sobre los metadatos. Tiene la posibilidad de supervisar y reponer rápidamente cualquier parte del sistema cuando se presente alguna falla. La infraestructura mínima requiere poco equipo pero de gran capacidad y alto rendimiento, esto hace más simple el mantenimiento y actualización tecnológica. La estructura es robusta y con un alto nivel de control respecto al resguardo y preservación. Requiere de poco personal pero con un grado mayor de especialización en la administración del sistema y en la organización del repositorio. Desventajas: El volumen de trabajo y de procesos implicados (validez y calidad de contenidos) son tareas más complejas que en otros modelos. Los costos generales son altos ya que recaen en la organización que implementa el repositorio y tienen que hacerse de una sola vez.
 son tareas más complejas que en otros modelos. Los costos generales son altos ya que recaen en la organización que implementa el repositorio y tienen que hacerse de una sola vez.")
70
Repositorio distribuido
Está constituido por los repositorios instalados en cada una de las organizaciones o dependencias que los administran, cuentan con su propia infraestructura técnica y se rigen por políticas administrativas y de preservación particulares. A nivel local cuentan con sus propios mecanismos de consulta y depósito, al mismo tiempo se integran una red en la cual por medio de un portal de búsqueda y recuperación ofrecen sus metadatos y recursos. Repositorio Repositorio Repositorio Repositorio Institución Institución Institución Institución

71
Ventajas: Este tipo de repositorio puede dar un mejor desempeño y en caso de alguna falla no se afecta la totalidad del sistema. Respecto a la infraestructura tecnológica requerida las inversiones iniciales pueden ser de bajo costo, pero se incrementan a largo plazo en lo que respecta el mantenimiento y operación de los distintos equipos de trabajo. Desventajas: La organización de este tipo de repositorio requiere de una mayor complejidad en los aspectos técnicos, de gestión y capacitación de los recursos humanos, ya que debe contar con distintos responsables en lo que respecta al área tecnológica y el área de contenidos y estructuración de sus colecciones, Conlleva también ciertas dificultades respecto a la estandarización en el control de los metadatos y la autentificación de usuarios y los procesos de provisión de recursos para su cosecha. Por otra parte el proceso de preservación y resguardo a largo plazo en este modelo platea un mayor costo y problemática, ya que difícilmente una sola dependencia podrá sostener una política de resguardo vigente, actualizada y consistente.

72
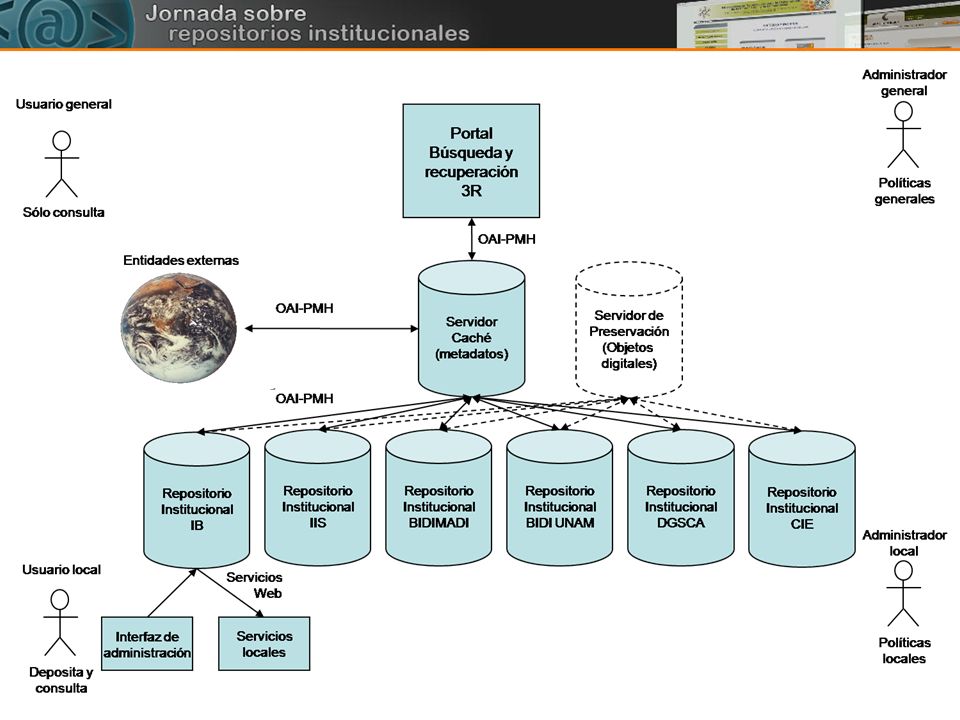
Repositorio híbrido El repositorio híbrido es una conjunción entre los dos modelos antes mencionados, es decir con una organización distribuida y un mecanismo de cosecha de metadatos y preservación centralizada. Repositorio Repositorio Repositorio Repositorio Repositorio Institución Institución Institución Institución

73
Ventajas: Pueden aplicarse políticas administrativas a dos niveles: local, en las dependencias de sus distintos repositorios y general, respecto al uso, consulta, depósito y derechos de los recursos propiedad de la universidad, esto les da a este tipo de repositorios funcionalidades distintas dentro de la dependencia que en el sistema general. La forma de acceso puede ser local o a través de un portal común que extrae sus datos de un servidor caché que los cosecha de los repositorios asociados. La preservación se hace más operativa y segura ya que el mismo sistema deposita respaldos de la información en un contenedor centralizado. Los costos se reducen debido a que se puede constituir un solo equipo de trabajo y soporte que responda a las contingencias que se pueden presentar en los distintos repositorios asociados. Desventajas Se deben constituir equipos independientes para administrar localmente los recursos y hacer un consejo general que regule la administración de todo el sistema. Tecnológicamente más complejos.

75
FEDORA Ventajas El software para repositorios FEDORA (Flexible Extensible Digital Object and Repository Arquitecture) fue desarrollado teniendo en cuenta que el contenido digital, resultado de la labor de investigación, no sólo son documentos de texto sino que existe una gran variedad de formatos que docentes e investigadores utilizan para difundir su trabajo. De manera general se puede dividir en dos el tipo de material que los administradores de repositorios tienen que gestionar: -Objetos convencionales: libros y otros objetos de tipo texto, datos geoespaciales, imágenes, mapas. -Objetos complejos y dinámicos: video, conjuntos de datos numéricos y sus códigos asociados, audio. FEDORA intenta dar respuesta a cuestiones que inquietan a los administradores de colecciones digitales (Jones et. al. 2006): ¿Cómo pueden interactuar las interfaces de usuario con colecciones heterogéneas de objetos complejos de una manera simple e interoperable? ¿Cómo se puede asociar servicios y herramientas con objetos para proporcionar diferentes presentaciones o transformaciones de los objetos contenidos? ¿Cómo se puede asociar políticas de acceso a objetos específicos o a grupos de objetos? ¿Cómo se puede facilitar la preservación y el manejo a largo plazo de los objetos?
 fue desarrollado teniendo en cuenta que el contenido digital, resultado de la labor de investigación, no sólo son documentos de texto sino que existe una gran variedad de formatos que docentes e investigadores utilizan para difundir su trabajo. De manera general se puede dividir en dos el tipo de material que los administradores de repositorios tienen que gestionar: -Objetos convencionales: libros y otros objetos de tipo texto, datos geoespaciales, imágenes, mapas. -Objetos complejos y dinámicos: video, conjuntos de datos numéricos y sus códigos asociados, audio. FEDORA intenta dar respuesta a cuestiones que inquietan a los administradores de colecciones digitales (Jones et. al. 2006): ¿Cómo pueden interactuar las interfaces de usuario con colecciones heterogéneas de objetos complejos de una manera simple e interoperable ¿Cómo se puede asociar servicios y herramientas con objetos para proporcionar diferentes presentaciones o transformaciones de los objetos contenidos ¿Cómo se puede asociar políticas de acceso a objetos específicos o a grupos de objetos ¿Cómo se puede facilitar la preservación y el manejo a largo plazo de los objetos")
76
FEDORA no hace diferencia en el tipo de material que maneja
FEDORA no hace diferencia en el tipo de material que maneja. Además es flexible en cuanto permite a los implementadotes del software diseñar sus propios modelos de contenido, para representar sus datos y sus requerimientos de presentación de la manera en que mejor les convenga o se adapte a sus necesidades esto por medio de los web services. Los objetos digitales y sus metadatos descriptores se ligan tratando a ambos elementos como un solo objeto compuesto; una facilidad que da FEDORA es que los metadatos de un objeto pueden estar almacenados localmente o en un servidor vía Web. Desventajas: Se encuentra aún en una etapa muy temprana Pocos usuarios Pocos desarrollos

77
DSpace Está escrito en el lenguaje de programación java y utiliza algunas herramientas extras al código principal de DSpace, para ampliar su funcionalidad y hacer sencilla su implementación y gestión. Entre las herramientas que utiliza DSpace para su funcionamiento están PostgreSQL (o algún otro sistema manejador de bases de datos relacionales), Apache y Tomcat (o algún otro servidor web y servidor de aplicaciones java). DSpace puede ejecutarse en cualquier plataforma que soporte JVM (Java Virtual Machine) incluyendo todas las variaciones de Unix y Linux, Mac OSX y Microsoft Windows. El sitio del proyecto DSpace en SourceForge.net proporciona todo el código fuente así como la documentación para poder instalar esta herramienta.
, Apache y Tomcat (o algún otro servidor web y servidor de aplicaciones java). DSpace puede ejecutarse en cualquier plataforma que soporte JVM (Java Virtual Machine) incluyendo todas las variaciones de Unix y Linux, Mac OSX y Microsoft Windows. El sitio del proyecto DSpace en SourceForge.net proporciona todo el código fuente así como la documentación para poder instalar esta herramienta.")
78
DSpace tiene como principales características funcionales (Jones et. al. 2006):
Depósito de contenido digital y sus metadatos (Dublin Core) asociados en el repositorio por parte de usuarios (investigadores y académicos universitarios) siguiendo un flujo de trabajo definido de manera particular para cada colección que el repositorio maneja de manera interna; flujo que permite tener un control en la manera en cómo se revisan y aprueban los contenidos que estarán almacenados en el repositorio. Gestión y manejo de los contenidos digitales del repositorio durante largos periodos de tiempo. Búsqueda/navegación y recuperación de contenidos digitales por medio de una interfaz Web sencilla, esto incluye algún tipo de soporte para búsquedas avanzadas en metadatos estructurados o a texto completo. Funciones de control de acceso que permiten restringir las personas que pueden alimentar al repositorio con nuevos objetos digitales; dichas funciones de permiten controlar el acceso a colecciones de objetos e incluso restringir el acceso a objetos individuales. Manejo de licencias individuales para cada ítem almacenado en el repositorio que garanticen a los administradores del repositorio permisos explícitos para administrar, preservar y diseminar los contenidos. Creciente comunidad de desarrolladores de software open source alrededor de todo el mundo que permite una mayor facilidad para encontrar soluciones a posibles problemas que se pueden presentar al implementar DSpace como software de repositorios.
 asociados en el repositorio por parte de usuarios (investigadores y académicos universitarios) siguiendo un flujo de trabajo definido de manera particular para cada colección que el repositorio maneja de manera interna; flujo que permite tener un control en la manera en cómo se revisan y aprueban los contenidos que estarán almacenados en el repositorio. Gestión y manejo de los contenidos digitales del repositorio durante largos periodos de tiempo. Búsqueda/navegación y recuperación de contenidos digitales por medio de una interfaz Web sencilla, esto incluye algún tipo de soporte para búsquedas avanzadas en metadatos estructurados o a texto completo. Funciones de control de acceso que permiten restringir las personas que pueden alimentar al repositorio con nuevos objetos digitales; dichas funciones de permiten controlar el acceso a colecciones de objetos e incluso restringir el acceso a objetos individuales. Manejo de licencias individuales para cada ítem almacenado en el repositorio que garanticen a los administradores del repositorio permisos explícitos para administrar, preservar y diseminar los contenidos. Creciente comunidad de desarrolladores de software open source alrededor de todo el mundo que permite una mayor facilidad para encontrar soluciones a posibles problemas que se pueden presentar al implementar DSpace como software de repositorios.")
80
Responsables: Clara López Guzmán – DGSCA (Coordinadora) Alberto Arriaga Arredondo - DGSCA Alberto Castro Thompson – DGB Isabel Galina Russell – DGSCA Fernando Gamboa Rodríguez – CCADET Joaquín Giménez Héau - Instituto de Biología Pablo Miranda Quevedo – DGSCA

81
El proyecto 3R-Red de Repositorios Universitarios de Recursos Digitales1, forma parte del Macroproyecto de Tecnologías para la Universidad de la Información y la Computación. Es un proyecto que consta de 4 etapas: Investigación, Modelo Conceptual, Desarrollo e Implementación. El objetivo del proyecto está encaminado a la creación del prototipo de una red de repositorios de la UNAM, que permita mayor uso y visibilidad de la producción intelectual de los miembros de la comunidad. El proyecto 3R, Red de Repositorios Universitarios de Recursos Universitarios, está encaminado a la creación de un prototipo para construir una red de repositorios de la UNAM, que permita dar una solución integral a la dispersión y gestión de recursos digitales, posibilitando una mayor difusión y visibilidad de la producción académica de los miembros de la Universidad. La integración de esta red de repositorios universitarios contempla la utilización de tecnología y estándares de clasificación y catalogación para el desarrollo de repositorios institucionales, y que estructure su funcionamiento acorde a las políticas de manejo de contenidos, requisitos y operación de las dependencias universitarias que la integren. Resulta conveniente aclarar que este proyecto no contempla la producción de contenidos digitales de ningún tipo, únicamente considerará repositorios ya conformados por las diversas entidades universitarias, que estén concentrando los recursos digitales que producen sus miembros.

82
Los repositorios universitarios que se integren a 3R:
Contendrán materiales digitales producto intelectual de por lo menos un miembro académico universitario. Los miembros académicos de la UNAM son los profesores, investigadores y técnicos académicos. Posteriormente, se podrá contemplar la opción de incluir estudiantes del posgrado Contendrán el recurso mismo y no solamente sus metadatos Contarán con un responsable académico y un responsable técnico avalados por la institución que implementa el repositorio. Deberán implementar el protocolo OAI-PMH para la interoperabilidad con otros repositorios universitarios. Esto incluye el estándar mínimo de metadatos de Dublin Core Utilizarán un software de aplicación específica, recomendado por 3R o compatible, para la creación y el manejo del repositorio Uno de los principales problemas que se busca resolver con la creación de una red de repositorios universitarios, es la detección y visibilidad de los recursos universitarios.

83
el análisis de navegación metódica no presentó los resultados esperados y no se detectaron repositorios universitarios; de manera complementaria se solicitó al comité de 3R, cuyos miembros cuentan con experiencia en la creación de recursos electrónicos, su asesoría para nombrar algunos repositorios candidatos, centrándose en algunos los candidatos de la propuesta original Colecciones existentes Heterogéneas Con apoyo institucional Usuarios tempranos

84
Instituto de Biología- UNIBIO La Unidad de Informática para la Biodiversidad y el Ambiente forma parte del Instituto de Biología y se encargan del desarrollo de herramientas tecnológicas para apoyar la investigación. La Biblioteca Digital de Materiales Didácticos, pertenece al macroproyecto de Tecnologías de Información, etc. y está formado por integrantes de varias dependencias de la UNAM. BIDI-UNAM La Biblioteca Digital de la UNAM reúne más de 70,000 recursos electrónicos y claramente es la colección de recursos digitales más grande de la universidad. La BIDI pertenece a la Dirección General de Bibliotecas. BIDI-UNAM da acceso a numerosos recursos gratuitos así como a los materiales suscritos, principalmente revistas electrónicas, bases de datos y libros. Instituto de Investigaciones Sociales (IIS) En la entrevista realizada se manifestó, por parte del ISS, el interés y disponibilidad para contar con un mecanismo de difusión del trabajo de investigación producido por el centro Colecciones mexicanas – DGSCA Es una base de datos en línea que se compone de tres fondos, Archivo Franciscano, Revistas Literarias del Siglo XIX y Españoles en México en el Siglo XIX. Este acervo fue implementado por DGSCA en 2003, El Centro de Investigaciones en Energía de la UNAM, localizado en Temixco, cuenta actualmente con 56 investigadores y 75 estudiantes de posgrado. Los temas principales de investigación son materiales solares, sistemas energéticos y termociencias.
 En la entrevista realizada se manifestó, por parte del ISS, el interés y disponibilidad para contar con un mecanismo de difusión del trabajo de investigación producido por el centro. Colecciones mexicanas – DGSCA Es una base de datos en línea que se compone de tres fondos, Archivo Franciscano, Revistas Literarias del Siglo XIX y Españoles en México en el Siglo XIX. Este acervo fue implementado por DGSCA en 2003, El Centro de Investigaciones en Energía de la UNAM, localizado en Temixco, cuenta actualmente con 56 investigadores y 75 estudiantes de posgrado. Los temas principales de investigación son materiales solares, sistemas energéticos y termociencias.")
85
Pasos básicos y necesarios que se deben seguir para implementar y operar un RU:
1. Conformación del grupo de trabajo 2. Establecimiento de políticas particulares 3. Adaptación de la infraestructura 4. Instalación de software 5. Pruebas 6. Poblamiento

86
Consideraciones generales
Para una mejor comprensión y aplicación de las políticas de 3R, deben tenerse las siguientes consideraciones: • El funcionamiento de los Repositorios Universitarios se apega a las funciones de docencia, investigación y difusión de la cultura decretadas en la Ley Orgánica de la Universidad Nacional Autónoma de México, en su Artículo primero. • Los Repositorios Universitarios promueven la filosofía del acceso abierto a los contenidos. Esto no implica acceso libre y gratuito pero sí conlleva una voluntad de difundir, compartir y reutilizar contenidos. • Los items que integran colecciones en los RU, deben ser producidos por miembros académicos (profesores, investigadores y técnicos) de las Dependencias de la UNAM. Y deben ser resultado de actividades de investigación, difusión o enseñanza. • Los items deberán contar con los datos básicos para su identificación y clasificación, estar completos y presentarse en formato digital; no tener problemas respecto a los derechos de propiedad intelectual y/o que estos no afecten a terceros.
 de las Dependencias de la UNAM. Y deben ser resultado de actividades de investigación, difusión o enseñanza. • Los items deberán contar con los datos básicos para su identificación y clasificación, estar completos y presentarse en formato digital; no tener problemas respecto a los derechos de propiedad intelectual y/o que estos no afecten a terceros.")
87
Políticas de depósito • En los RU podrán depositar publicaciones, documentos y otros tipos de recursos digitales, los profesores, investigadores y técnicos académicos, activos y avalados por las dependencias de la UNAM, que tengan un RU adscrito a 3R. • El autor podrá establecer y/o especificar las limitaciones y términos de uso en los se otorgue el acceso a sus items, de acuerdo a los derechos de propiedad intelectual establecidos para su trabajo. • La validez y autenticidad del contenido es responsabilidad del depositante. • La gestión y la validación de los items depositados está a cargo del responsable académico del RU.

88
Políticas de gestión y organización de colecciones
Sobre la creación del RU: • Los RU deben usar un software que cumpla con los requisitos del protocolo de transmisión de datos OAI-PMH que permita la interoperabilidad entre los distintos repositorios de la UNAM y otros externos. • Los RU creados a partir de 3R, deben contar con su dirección electrónica (URL) como: de la dependencia.unam.mx, en letras minúsculas. • Los RU deben adoptar la plantilla de la interfaz gráfica provista por 3R; a fin de mantener una usabilidad e identidad consistente en la red. • El sitio web de cada RU deben incluir metadatos descriptivos en el encabezado del código de sus páginas, al menos con los siguientes elementos: - nombre del repositorio - dependencia responsable - nombre del administrador(es) - temática - fechas de creación y actualización
 como: de la dependencia.unam.mx, en letras minúsculas. • Los RU deben adoptar la plantilla de la interfaz gráfica provista por 3R; a fin de mantener una usabilidad e identidad consistente en la red. • El sitio web de cada RU deben incluir metadatos descriptivos en el encabezado del código de sus páginas, al menos con los siguientes elementos: - nombre del repositorio. - dependencia responsable. - nombre del administrador(es) - temática. - fechas de creación y actualización.")
89
• Los RU deberán hacer explicitas sus políticas locales en la sección correspondiente de su sitio web. • Un repositorio de nueva creación no podrá ser liberado, si no logra integrar un conjunto de ítems representativo3. • Los RU deberán desarrollar y ofrecer servicios de valor agregado (listados, reportes de publicaciones, estadísticas de acceso y descarga, referencias, etc.) para los usuarios del repositorio, para fines informativos, de evaluación o administrativos. • Los RU contarán con un administrador técnico, encargado del mantenimiento y operación del sistema del repositorio; y un administrador académico, encargado de revisar y aprobar los ítems depositados. Estas figuras deberán ser nombradas por el director de la Dependencia que avale el RU. zzzzz
 para los usuarios del repositorio, para fines informativos, de evaluación o administrativos. • Los RU contarán con un administrador técnico, encargado del mantenimiento y operación del sistema del repositorio; y un administrador académico, encargado de revisar y aprobar los ítems depositados. Estas figuras deberán ser nombradas por el director de la Dependencia que avale el RU. zzzzz.")
90
Políticas de gestión y organización de colecciones
Sobre los ítems de los RU: • Los RU contendrán el recurso mismo y sus metadatos. • Los depositantes deberán proporcionar los metadatos básicos (para la identificación y clasificación de los ítems que depositan. • Cada RU definirá la estructura y organización de su colección, los tipos y formatos de los items que la integran; los procedimientos de revisión y aprobación para su depósito y las políticas de acceso a sus materiales. • Los RU son responsables de la calidad y validez de los contenidos de sus colecciones y tienen la facultad de aceptar, rechazar o retirar los ítems depositados de acuerdo a los requisitos exigidos para cada colección y sus ítems. • Si un RU detecta violaciones de derechos de autor en los ítems depositados, estos serán retirados inmediatamente. • Cada RU podrá definir sus políticas locales respecto a la gestión de sus temas y colecciones, asignación de permisos y procedimientos de depósito, administración y condiciones de uso de los materiales almacenados, siempre y cuando no se contravenga ninguno de los puntos anteriores.

91
Políticas de uso y derechos legales
• Los metadatos expuestos por cada RU pueden ser ligados o cosechados con propósitos no comerciales. • El acceso a los ítems puede ser: - libre a todo usuario -disponible sólo a usuarios y a grupos autorizados -circunscrito únicamente a la comunidad universitaria -disponible sólo su registro de metadatos • Los depositantes o el RU retienen el derecho de limitar el acceso al contenido, dependiendo de las restricciones de derechos de autor que posea cada ítem. • Los usuarios de 3R deberán aceptar los términos de un acuerdo para todos los contenidos depositados en el repositorio, en el que se compromete a respetar lo establecido respecto al buen uso de los materiales publicados. • El usuario puede descargar, almacenar o imprimir los ítems, resultados de búsqueda u otra información, sólo para uso personal, de investigación y docencia. • El uso de cada ítem está sujeto a lo que se disponga en el campo “derechos” de sus metadatos. • Los ítems no pueden ser cosechados externamente excepto para la indexación de sus metadatos o para la recopilación de referencias contenidos en los mismos. • El autor deberá poseer los derechos de propiedad intelectual de su trabajo y conceder a la Dependencia, 3R y/o la UNAM el derecho de preservar y dar acceso a su documento a través de los servicios de búsqueda y consulta del repositorio, exceptuando los que no sean posibles por limitaciones de derechos de autor u otras.

92
Establecer políticas particulares
3R establece un marco de políticas generales que definen y formalizan la operación y la organización de los RU en su gestión, depósito y uso de los contenidos. La planeación de políticas particulares desde un inicio facilita el trabajo a los usuarios y a administradores apegándose a las normativas de la institución, así como a la idiosincrasia de la comunidad que genera y utiliza los repositorios, por tal motivo, los RU tendrán la posibilidad de definir sus propios criterios respecto a la organización de sus colecciones, elegibilidad de los depositantes, procedimientos de ingreso y uso de los materiales a su cargo. En este punto los responsables del repositorio deben analizar las necesidades propias de su comunidad y de los ítems que se van a depositar, a partir de ello deberán determinar si las políticas generales cubren sus necesidades o si se requiere la inclusión de algunas políticas específicas, a fin de controlar y desarrollar adecuadamente su colecciones.

93
Hacia una adopción obligatoria del depósito en los RU
El éxito y estabilidad de los repositorios depende de manera decisiva de la operación de políticas que contribuyan gradualmente a promover la adhesión de nuevas comunidades, incrementar el número de usuarios (estimular el depósito) y aumentar el acervo de documentos. Paralelamente a las acciones de promoción y sensibilización sobre las ventajas de los RU se recomienda que progresivamente las Dependencias, Centros de Investigación y la propia UNAM en su conjunto adopten formalmente una política institucional que considere obligatorio el depósito de su producción intelectual en los repositorios universitarios y consideren incluir a las publicaciones electrónicas y los materiales depositados en los RU en los mecanismos de evaluación académica, con el mismo rango en que es considerada la producción escrita.
 y aumentar el acervo de documentos. Paralelamente a las acciones de promoción y sensibilización sobre las ventajas de los RU se recomienda que progresivamente las Dependencias, Centros de Investigación y la propia UNAM en su conjunto adopten formalmente una política institucional que considere obligatorio el depósito de su producción intelectual en los repositorios universitarios y consideren incluir a las publicaciones electrónicas y los materiales depositados en los RU en los mecanismos de evaluación académica, con el mismo rango en que es considerada la producción escrita.")
94
Resultados WS WS WS DiGIR FEDORA Consulta de ejemplares Repositorio
SERVIDOR DE MAPAS Consulta de ejemplares Repositorio Universitario UNIGEO 26

95
Resultados WS WS WS DiGIR FEDORA Consulta de ejemplares Repositorio
(Solo tipos) (Solo imágenes) MiniDiGIR Portal de Tipos de Insectos Acervo Digital del IB Irekani VIZUALIZADOR GEOGRÁFICO DE EJEMPLARES WS WS WS DiGIR FEDORA SERVIDOR DE MAPAS Consulta de ejemplares Repositorio Universitario UNIGEO 24
 (Solo imágenes) MiniDiGIR. Portal de Tipos de Insectos. Acervo Digital del IB. Irekani. VIZUALIZADOR GEOGRÁFICO DE EJEMPLARES. WS. WS. WS. DiGIR. FEDORA. SERVIDOR DE MAPAS. Consulta de. ejemplares. Repositorio. Universitario. UNIGEO. 24.")
96
IMPULSA SIBA UNIBIO

97
Colecciones en línea

98
Visualización en mapas provenientes del Instituto de Geografía…
…o en otros formatos como Google Earth

99
Registros por colección consultados a través de GBIF
Total de registros consultados: 3,255,870

100
El 97% de las consultas se han realizado desde México
El 3% desde el extranjero

101
Irekani, un buscador de imágenes de biodiversidad del Instituto de Biología
Ejemplares de herbario de la Estación de Biología Chamela 1,853 Fotocolectas de mamíferos en Oaxaca 1,024 Ejemplares tipo de Coleoptera 732 Ejemplares tipo de Lepidoptera 585 Familias de Angiospermas 301 Flora de Oaxaca 191 Triatominos de la Colección Nacional de Insectos 59 Colectas en las montañas que rodean el Valle de México 40 Briofitas de México 32 Ejemplares Tipo de Orthoptera Odonatos 18 Departamento de Zoología 11 Insectos Total 4,889

102
Hay imágenes de los ejemplares desde distintos ángulos y también de sus etiquetas y genitales.

103
Portal de tipos de insectos
Agathymus fieldi

Presentaciones similares
















 Sesión 6: Repositorios Complutenses: Archivo Institucional y Complumedia.>")










