Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Modelado – Árbol de Decisión
Mg. Samuel Oporto Díaz

2
Mapa del Curso Inteligencia de Negocios Metodología Kimball
Planeamiento del Proyecto Modelo del Negocio Modelado Dimensional Modelado Físico ETL Reportes Minería de Datos

3
Tabla de Contenido Inducción. Aprendizaje Automático. Clasificación
Procedimiento de Trabajo. Información, entropía y energía Árboles de decisión Construcción del árbol Condición de parada Poda del árbol

4
INDUCCIÓN

5
Inducción La inducción permite obtener la escencia de los objetos que nos rodean, la escencia es lo que define el objeto. La observación de la realidad proporciona un conjunto de relaciones. La inducción busca la generalización de los conceptos dados por estas relaciones. Va de lo particular a lo general.

6
Razonamiento Inductivo
El razonamiento inductivo permite obtener conclusiones generales a partir de premisas de datos particulares. Se obtienen conclusiones probables, más no absolutas.

7
Ejercicio 1 Cuál es el siguiente número de la secuencia:

8
Ejercicio 2 Sea la siguiente secuencia de números:
10, 7, 9, 6, 8, 5, 7, . . . Diga cuales son los siguientes tres números de la serie. Resolver por inducción.

9
Ejercicio 2 Observando la forma en que los números cambian de término a término. El primer término de la secuencia es 10. Le restas 3 para obtener el 2o término. Después le sumas 2 para obtener el 3er término. Continúas alternando entre restar 3 y sumar 2 para generar los términos restantes. Los siguientes tres términos son:

10
Inducción Formalmente la observación de la realidad se configura como un conjunto de pares, que definen una relación. [x, f(x)] Este par se denomina un par de entrenamiento (x, f(x)), donde x es la entrada y f(x) es la salida de la función aplicada a x.
] Este par se denomina un par de entrenamiento (x, f(x)), donde x es la entrada y f(x) es la salida de la función aplicada a x.")
11
Inducción La inducción es un proceso mediante el cual, dado un conjunto de ejemplos del par (x, f(x), se intenta encontrar una hipótesis que se aproxime a f. Se entiende que una hipótesis es una función que se debe validar mediante alguna prueba. La preferencia por alguna hipótesis es un desvio (bias). Todos los algoritmos tienen un grado de desvío dado que e hay un gran número de hipótesis consistentes posibles. El aprendizaje se logrará cuando se encuentre la función f que mejor explique los datos
, se intenta encontrar una hipótesis que se aproxime a f. Se entiende que una hipótesis es una función que se debe validar mediante alguna prueba. La preferencia por alguna hipótesis es un desvio (bias). Todos los algoritmos tienen un grado de desvío dado que e hay un gran número de hipótesis consistentes posibles. El aprendizaje se logrará cuando se encuentre la función f que mejor explique los datos.")
12
Inducción El proceso de aprendizaje es un compromiso entre:
¿la función deseada es representable en el lenguaje de representación usado? expresividad Inducción ¿será el problema de aprendizaje tratable para una elección dada del lenguaje de representación? eficiencia

13
Ejercicio 3 Para el ejercicio 1 encuentre una fórmula para expresar el número de la posición i ?. xi = g(i) En caso que no se pueda exprese la función recursivamente: xi = h(xi-1).
.")
14
Ejercicio 4 En la clase de física, el grupo de Rumi soltó una pelota desde diferentes alturas, se midió la altura del primer rebote y se registraron los siguientes datos: Se pide: Preparar al menos dos hipótesis (conjeturas) acerca de estos hallazgos. Aplicar una prueba para determinar cuál de las dos hipótesis es mejor. Calcular la altura del primer rebote para una caída de 280 cm.
 acerca de estos hallazgos. Aplicar una prueba para determinar cuál de las dos hipótesis es mejor. Calcular la altura del primer rebote para una caída de 280 cm.")
15
Ejercicio 4 Preparando el gráfico de dispersión de los datos y calculando el R2. Se observa comportamiento línea de los datos: R = f(A)
 .")
16
Ejercicio 4 Se necesita plantear algunas hipótesis para f, asumiendo que el comportamiento es lineal. f1: k1 = R/A R = A*k1 f2: k2 = (A - R) / A R = A*(1-k2) f3: k3 = (A - R) / R R = A*(1+k3) Intentando probar las hipótesis analíticamente: A R A-R (A-R)/A (A-R)/R R/A 120 90 30 25.00% 33.33% 75.00% 100 74 26 26.00% 35.14% 74.00% 160 122 38 23.75% 31.15% 76.25% 40 10 200 152 48 24.00% 31.58% 76.00% 80 59 21 26.25% 35.59% 73.75% STD = 1.01% 1.80%
 / A R = A*(1-k2) f3: k3 = (A - R) / R R = A*(1+k3) Intentando probar las hipótesis analíticamente: A. R. A-R. (A-R)/A. (A-R)/R. R/A % 33.33% 75.00% % 35.14% 74.00% % 31.15% 76.25% % 31.58% 76.00% % 35.59% 73.75% STD = 1.01% 1.80%")
17
APRENDIZAJE AUTOMÁTICO

18
Aprendizaje Automático
El aprendizaje automático es una disciplina de la Inteligencia Artificial que pretende desarrollar algoritmos para que aprendan desde la experiencia, mediante un proceso de inducción. Intenta crear algoritmos capaces de generalizar comportamientos a partir de una información no estructurada suministrada en forma de ejemplos. Los ejemplos (la experiencia) se presenta como n-tuplas. Es un proceso de inducción del conocimiento.
 se presenta como n-tuplas. Es un proceso de inducción del conocimiento.")
19
Aprendizaje Automático
Se solapa con la estadística, ya que se basan en el análisis de datos. Se centra en el estudio de la Complejidad Computacional de los problemas Muchos problemas de aprendizaje son intratables (NP-completo), por lo que el esfuerzo se centra en el diseño de soluciones factibles. La complejidad computacional es un indicador del tiempo necesario para que un algoritmo entregue una respuesta. Problema Indecible. No solucionables en forma algorítmica, se pueden describir, pero no se pueden representar o resolver. Problemas Decibles: Problemas intratables: Tiempo no polinómico O(kn) Problemas tratables. Tiempo polinómicos O(nk)
, por lo que el esfuerzo se centra en el diseño de soluciones factibles. La complejidad computacional es un indicador del tiempo necesario para que un algoritmo entregue una respuesta. Problema Indecible. No solucionables en forma algorítmica, se pueden describir, pero no se pueden representar o resolver. Problemas Decibles: Problemas intratables: Tiempo no polinómico O(kn) Problemas tratables. Tiempo polinómicos O(nk)")
20
Tipos de Algoritmos de Aprendizaje
Aprendizaje Supervisado Establece una correspondencia entre la entrada y la salida deseada (Clasificación, Regresión) [x, f(x)] Aprendizaje No-supervisado Todo el proceso de modelado se realiza sobre un conjunto de ejemplos donde se tiene solo las entradas [x] Aprendizaje por refuerzo El algoritmo re-aprende constantemente, en función a sus experiencias, refuerza el aprendizaje si tiene éxito (Feedback) [x, f(x)]
 [x, f(x)] Aprendizaje No-supervisado. Todo el proceso de modelado se realiza sobre un conjunto de ejemplos donde se tiene solo las entradas [x] Aprendizaje por refuerzo. El algoritmo re-aprende constantemente, en función a sus experiencias, refuerza el aprendizaje si tiene éxito (Feedback) [x, f(x)]")
21
Modelos de Aprendizaje
Una especie de profesor sugiere una categoría para cada conjunto de entrenamiento. Se busca reducir el error de entrenamiento. Supervisado Modelos de Aprendizaje No existe el profesor, el sistema realiza agrupamientos en forma natural sobre los patrones de entrada, para determinar la clase a la que pertenece. No Supervisado

22
CLASIFICACIÓN

23
Clasificación Intenta clasificar algunos objetos en un número finito de clases, en función a sus propiedades (características) Se intenta buscar un función de mapeo que permita separar la clase 1 de la clase 2 y esta de la clase 3… Las variables (atributos) pueden ser categóricas o numéricas. El modelo se construye con datos completos, cada registro tiene una clase predefinida. Busca formas de separar la data en clases pre-definidas Árboles de decisión. Redes Neuronales. Clasificador Bayesiano. Razonamiento basado en casos
 pueden ser categóricas o numéricas. El modelo se construye con datos completos, cada registro tiene una clase predefinida. Busca formas de separar la data en clases pre-definidas. Árboles de decisión. Redes Neuronales. Clasificador Bayesiano. Razonamiento basado en casos.")
24
Clasificación Atraer los clientes mas rentables. % ingresos % clientes
Clasificar a los clientes según la respuesta que se obtiene ente una campaña de mailing Gráfico de elevación: % clientes % ingresos Mail a 30% de los clientes para recibir el 60% de los ingresos La historias han demostrado como Data Mining a hecho la diferencia en su negocio. Por ejemplo usted podrán enfocar su correo directo a los clientes mas rentables de una forma mas efectiva reduciendo los costos de envio y materiales de promoción. En este ejemplo usted podrá enviar menos correos directos obteniendo casi el mismo nivel de respuesta que enviando una cantidad de correos masiva al azar.

25
Regresión Intenta determinar la función que mapea un conjunto de variables de entrada X (independiente), en una (o más) variables de salida Y (dependiente), . Es básicamente numérica. Está basada en supuestos estadísticos. Árboles de decisión. Redes Neuronales. Regresión Logística
, en una (o más) variables de salida Y (dependiente), . Es básicamente numérica. Está basada en supuestos estadísticos. Árboles de decisión. Redes Neuronales. Regresión Logística.")
26
Regresión Detectar efectivamente fraudes en el uso de servicios.
Valor de reclamo Valor de reclamo predecido La clave de detectar comportamientos fraudulentos se puede encontrar en sus datos. Por medio de clusters o perfiles de los diferentes tipos de comportamiento usted podrá descubrir posibles patrones o huellas de fraude. O como se muestra en la gráfica se podría modelar el comportamiento de la normal y enfocarse en los valores atípicos para detectar los posible fraudes

27
Clasificación Vs. Predicción
Intenta predecir las etiquetas de clases categóricas. Los datos se dividen en atributos y en una clase la que se pretende clasificar (categórica). Se clasifica los datos (construye un modelo) basado en un conjunto de entrenamiento y la clase a la que pertenece cada ocurrencia. Pronóstico: Intenta predecir funciones continuas. La entrada puede tener atributos continuos o categóricos.
. Se clasifica los datos (construye un modelo) basado en un conjunto de entrenamiento y la clase a la que pertenece cada ocurrencia. Pronóstico: Intenta predecir funciones continuas. La entrada puede tener atributos continuos o categóricos.")
28
PROCEDIMIENTO DE TRABAJO

29
Procedimiento de solución
Definir la arquitectura Parámetros Train Pre-procesamiento Inducción Entrenamiento Recolección de datos Reglas Test Prueba error

30
Procedimiento de solución
Recolección de datos: Recolectar los datos tanto de entrada como de salida en el número de muestras suficientes. Pre-procesamiento: Preparar los datos, para el proceso de aprendizaje (inductivo) Definir la arquitectura Definir el número de nivéles del árbol, el mínimo de ocurrencias por hoja, el error máximo de entrenamiento.
 Definir la arquitectura. Definir el número de nivéles del árbol, el mínimo de ocurrencias por hoja, el error máximo de entrenamiento.")
31
Procedimiento de solución
Entrenamiento: El conjunto de tuplas es el conjunto de entrenamiento. Cada ocurrencia (tupla) pertenece a una clase. El modelo es representado como reglas de clasificación, árboles de decisión, o fórmulas matemáticas. Uso de modelo: Para clasificar nuevos casos Estimando la exactitud del modelo. La etiqueta conocida del conjunto de entrenamiento es comparada con el resultado del clasificador La tasa de exactitud es el % correctamente clasificadas. Los datos de prueba independientes de los datos de entrenamiento.
 pertenece a una clase. El modelo es representado como reglas de clasificación, árboles de decisión, o fórmulas matemáticas. Uso de modelo: Para clasificar nuevos casos. Estimando la exactitud del modelo. La etiqueta conocida del conjunto de entrenamiento es comparada con el resultado del clasificador. La tasa de exactitud es el % correctamente clasificadas. Los datos de prueba independientes de los datos de entrenamiento.")
32
Construcción de modelo
Algoritmo de Clasificación Data de Entrenamiento Clasificador (Model) SI rango = ‘professor‘ o años > 6 entonces contratado = ‘yes‘
 SI rango = ‘professor‘ o años > 6. entonces contratado = ‘yes‘")
33
Uso del modelo Classificador (Godofredo, profesor, 4) Data de Prueba
Datos no usados (Godofredo, profesor, 4) ¿Contratado?
 ¿Contratado")
34
INFORMACIÓN, ENTROPÍA Y ENERGÍA

35
Información La información se mide en bits.
Un bit de información es suficiente para responder Verdadero/Falso a una pregunta cuya respuesta no se sabe (basado en la teoría de Shanon). La cantidad de información recibida respecto a la ocurrencia de un evento es inversamente proporcional a la probabilidad de ocurrencia de dicho evento. Alta probabilidad Mínima información Baja probabilidad Máxima información
. La cantidad de información recibida respecto a la ocurrencia de un evento es inversamente proporcional a la probabilidad de ocurrencia de dicho evento. Alta probabilidad Mínima información. Baja probabilidad Máxima información.")
36
Entropía La entropía mide el grado de incertidumbre asociado a una distribución de probabilidad. La entropía es la inversa de la cantidad de información. Se basa en la medida de la cantidad de información que da el atributo (basado en la teoría de Shanon).
.")
37
Entropía Para calcular la entropía de una variable se usa la siguiente fórmula. Donde S es un conjunto que se puede dividir en |C| clases, pi es la proporción de ocurrencias de la clase Ci en el conjunto S.

38
Ejercicio 10 Calcular la entropía para las siguientes variables discretas. E(1/2, 1/2) = 1.0000 E(1/3, 2/3) = 0.9183 E(1/5, 4/5) = 0.7219 E(1/9, 8/9) = 0.5033
 = E(1/9, 8/9) =")
39
Ejercicio 11 Calcular la entropía para las siguientes variables discretas. E(1/3, 1/3, 1/3) = 1.5850 E(1/7, 2/7, 4/7) = 1.3788 E(1/13, 4/13, 8/13) = 1.2389 E(1/25, 8/25, 16/25) = 1.1239
 = E(1/13, 4/13, 8/13) = E(1/25, 8/25, 16/25) =")
40
Función de Entropía

41
Entropía En una distribución con un solo pico en la que pi = 1 y pj =0, para i ≠ j la entropía es mínima lo cual indica mínima incertidumbre o máxima información. En una distribución uniforme, todos los valores son igualmente probables pi = 1/N y por tanto la entropía es máxima, lo cual indica máxima incertidumbre o mínima información.

42
Ganancia de Información
La ganancia de información (GI), permite decidir qué característica adicionar al árbol actual. Es una medida de cuánto ayuda el conocer el valor de cierta característica para conocer el verdadero valor de la clase a la que pertenece la clase asociada. Una ganancia de información alta implica que una característica permite reducir la incertidumbre de la clase a la que pertenece. La ganancia de información debe de tener su valor: máximo cuando el atributo sea perfecto (discrimine perfectamente ejemplos) mínimo cuando el atributo no sea relevante.
, permite decidir qué característica adicionar al árbol actual. Es una medida de cuánto ayuda el conocer el valor de cierta característica para conocer el verdadero valor de la clase a la que pertenece la clase asociada. Una ganancia de información alta implica que una característica permite reducir la incertidumbre de la clase a la que pertenece. La ganancia de información debe de tener su valor: máximo cuando el atributo sea perfecto (discrimine perfectamente ejemplos) mínimo cuando el atributo no sea relevante.")
43
Ganancia de Información
La ganancia de información se puede calcular restando a la entropía global, la media ponderada de las entropías asociadas a los valores que puede tomar una característica. Donde Sv, es el subconjunto de S, donde el atributo A toma el valor de v.

44
ÁRBOLES DE DECISIÓN

45
Árboles de decisión Un árbol de decisión es un conjunto de condicione (reglas) organizadas en una estructura jerárquica, de tal manera que la decisión final se puede determinar siguiendo las condiciones que se cumplen desde la raíz hasta alguna de sus hojas. Representación del conocimiento: Nodo internos Preguntas Nodos hoja Decisiones
 organizadas en una estructura jerárquica, de tal manera que la decisión final se puede determinar siguiendo las condiciones que se cumplen desde la raíz hasta alguna de sus hojas. Representación del conocimiento: Nodo internos Preguntas. Nodos hoja Decisiones.")
46
Ciclo de un árbol de decisión

47
Árbol de decisión para la compra de un computador
Ejemplo 20 age? overcast student? credit rating? no yes fair excellent <=30 >40 30..40 Árbol de decisión para la compra de un computador

48
Construcción de árboles de decisión
Consiste de tres etapas: Construir el árbol Al inicio todos los ejemplos de entrenamiento están a la raíz Partir los ejemplos en forma recursiva basado en los atributos seleccionados Detener la construcción. Podar de árbol Identificar y eliminar ramas que reflejen ruido o valores atípicos

49
Ejemplo Visual de Construcción de un DT
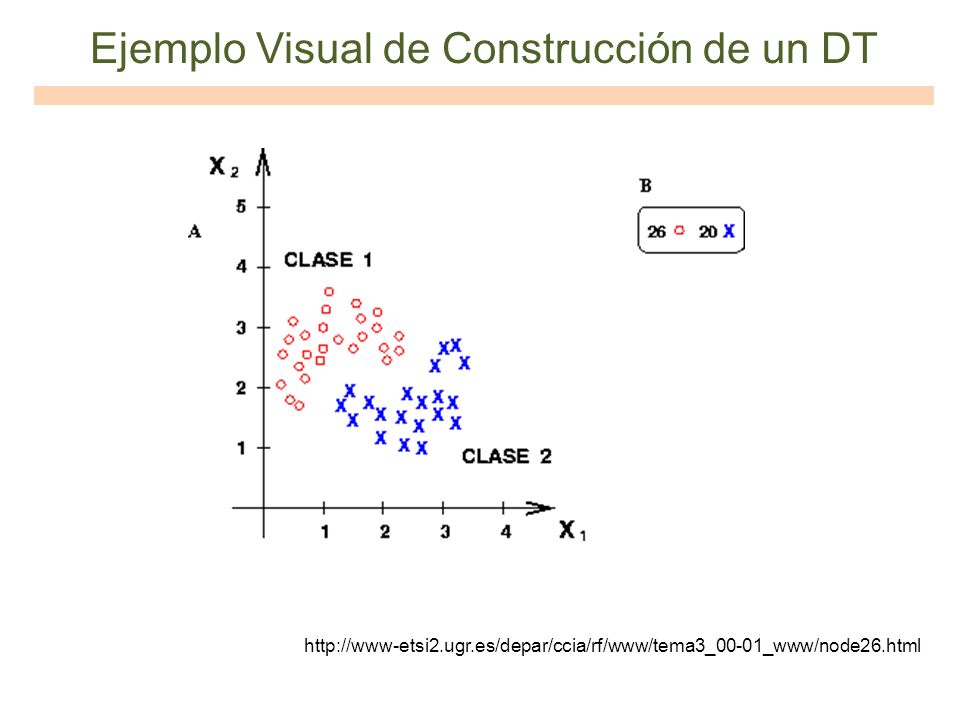
50
Ejemplo Visual de Construcción de un DT

51
Ejemplo Visual de Construcción de un DT

52
Construcción de árboles de decisión
Algoritmos TDIDT [Top-Down Induction on Decision Trees] Estrategia “divide y vencerás” para la construcción recursiva del árbol de decisión de forma descendente. Construcción del árbol. Reglas de división Detener la construcción. Reglas de parada Podar el árbol. Reglas de poda HOJA (etiquetada con la clase más común) Nodo puro No encontramos ninguna forma de seguir ramificando el árbol Se cumple alguna condición de parada (regla de parada) Conjunto vacío Información adicional (vg. C4.5 opta por la clase m´as frecuente en el nodo padre). NODO INTERNO: Cuando en el conjunto de entrenamiento hay casos de distintas clases, éste se divide en subconjuntos. Utilizando los casos de entrenamiento disponibles, hemos de seleccionar una pregunta para ramificar el ´arbol de decisión. Dicha pregunta, basada en los valores que toman los atributos predictivos en el conjunto de entrenamiento, ha de tener dos o más respuestas alternativas mutuamente excluyentes Ri. De todas las posibles alternativas, se selecciona una empleando una regla heur´ýstica a la que se denomina regla de división. El ´arbol de decisi´on resultante consiste en un nodo que identifica la pregunta realizada del cual cuelgan tantos hijos como respuestas alternativas existan. El mismo m´etodo utilizado para el nodo se utiliza recursivamente para construir los sub´arboles correspondientes a cada hijo del nodo, teniendo en cuenta que al hijo Hi se le asigna el subconjunto de casos de entrenamiento correspondientes a la alternativa Ri. Reglas de parada: Pureza del nodo, cota de profundidad, umbral de soporte Reglas de poda: Poda por coste-complejidad (CART), poda pesimista (C4.5) Justificación: La presencia de ruido ocasiona la generación de árboles de decisión que sobreajustan los datos del conjunto de entrenamiento.
 Nodo puro. No encontramos ninguna forma de seguir ramificando el árbol. Se cumple alguna condición de parada (regla de parada) Conjunto vacío Información adicional. (vg. C4.5 opta por la clase m´as frecuente en el nodo padre). NODO INTERNO: Cuando en el conjunto de entrenamiento hay casos de distintas clases, éste se divide en subconjuntos. Utilizando los casos de entrenamiento disponibles, hemos de seleccionar una pregunta para ramificar el ´arbol de decisión. Dicha pregunta, basada en los valores que toman los atributos predictivos en el conjunto de entrenamiento, ha de tener dos o más respuestas alternativas mutuamente excluyentes Ri. De todas las posibles alternativas, se selecciona una empleando una regla heur´ýstica a la que se denomina regla de división. El ´arbol de decisi´on resultante consiste en un nodo que identifica la pregunta realizada del cual cuelgan tantos hijos como respuestas alternativas existan. El mismo m´etodo utilizado para el nodo se utiliza recursivamente para construir los sub´arboles correspondientes a cada hijo del nodo, teniendo en cuenta que al hijo Hi se le asigna el subconjunto de casos de entrenamiento correspondientes a la alternativa Ri. Reglas de parada: Pureza del nodo, cota de profundidad, umbral de soporte. Reglas de poda: Poda por coste-complejidad (CART), poda pesimista (C4.5) Justificación: La presencia de ruido ocasiona la generación de árboles de decisión que sobreajustan los datos del conjunto de entrenamiento.")
53
1. Construcción del árbol
Algoritmo básico (un algoritmo codicioso) Los atributos deben ser categóricos (si son continuos ellos deben ser discretizados) El árbol es construido recursivamente de arriba hacia abajo con una visión de divide y conquista. Al inicio, todos los ejemplos de entrenamiento están en la raíz. Los ejemplos son particionados en forma recursiva basado en los atributos seleccionados Los atributos son seleccionados basado en una medida heurística o estadística (ganancia de información) La ganancia de información se calcula desde el nivel de entropía de los datos.
 Los atributos deben ser categóricos (si son continuos ellos deben ser discretizados) El árbol es construido recursivamente de arriba hacia abajo con una visión de divide y conquista. Al inicio, todos los ejemplos de entrenamiento están en la raíz. Los ejemplos son particionados en forma recursiva basado en los atributos seleccionados. Los atributos son seleccionados basado en una medida heurística o estadística (ganancia de información) La ganancia de información se calcula desde el nivel de entropía de los datos.")
54
Ejemplo 21 Construir un árbol de decisión para los siguientes datos:

55
Ejemplo 21

56
Ejemplo 21 saa Árbol de decisión para jugar Golf.

57
Otros Algoritmos Criterio de proporción de ganancia (C4.5)
Índice de diversidad de Gini (CART) Todos los atributos son continuos Se Asume que existen varias posibilidades de partir cada atributo Puede requerir otras herramientas para partir los datos (clustering) Puede ser modificado para datos categóricos
 Todos los atributos son continuos. Se Asume que existen varias posibilidades de partir cada atributo. Puede requerir otras herramientas para partir los datos (clustering) Puede ser modificado para datos categóricos.")
58
2. Condiciones de parada Condiciones para detener partición
Todas las muestras para un nodo dado pertenecen a la misma clase. No existe ningunos atributos restantes para ser particionados – el voto de la mayoría es empleada para clasificar la hoja. No existe más ejemplos para la hoja

59
3. Poda del árbol Identificar y eliminar ramas que reflejen ruido o valores atípicos

60
Bibliografía Data Mining: Practical Machine Learning Tools and Techniques. Ian H. Witten, Eibe Frank. Morgan Kaufmann; 2st edition (June 8, 2005). 560 pp. Data Mining with SQL Server ZhaoHui Tang, Jamie MacLennan. Wiley Publishing Inc. (2004). Data Mining: Concepts and Techniques, Jiawei Han, Micheline Kamber. Morgan Kaufmann; 1st edition (August, 2000), 500 pp. Introducción a la minería de datos. J. Hernández, J. Ramírez.
. 560 pp. Data Mining with SQL Server ZhaoHui Tang, Jamie MacLennan. Wiley Publishing Inc. (2004). Data Mining: Concepts and Techniques, Jiawei Han, Micheline Kamber. Morgan Kaufmann; 1st edition (August, 2000), 500 pp. Introducción a la minería de datos. J. Hernández, J. Ramírez.")
61
PREGUNTAS

62
soporto@wiphala.net http://www.wiphala.net/oporto
Mg. Samuel Oporto Díaz

Presentaciones similares

















 Microsoft SQL Server 2008 R2 Suscribase a o escríbanos a>")

