Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Técnicas de Biología Molecular aplicadas a Bioquímica Clínica
Química Biológica Patológica Técnicas de Biología Molecular aplicadas a Bioquímica Clínica 2014 Tema 1 Dra. Silvia Varas

2
Objetivos

3
Historia Local

4
10 años desde fin secuenciamiento ADN genómico humano
1989- PCR Premio Nobel a Kary Mullis ≈20-25 años 10 años desde fin secuenciamiento ADN genómico humano Cual es la realidad local? º termociclador Perkin Elmer UNSL:5-10 termocicladores; 1 tiempo real Otros: CSSL- Lab de Huellas Digitales

5
Usos? Usos? PCR Humanos: mutaciones, filiación? Microbiológicos
Virales? Plantas Hongos? Modelos animales: RT-PCR

6
Tema 1 Genoma Humano: constitución Proyecto Genoma Humano
Controversias Éticas Mutaciones mas comunes según Human Gene Mutation Database Deleciones y Mutaciones puntuales Estrategias de laboratorio

7
Genoma Humano Se llama genoma a la totalidad del material genético de un organismo. Su detallado conocimiento esta ligado al proyecto genoma humano En 1986 el Dpto de Energía y los Dptos de Salud de los EEUU lideró la iniciativa y puso en marcha el mayor proyecto biomédico de la historia. Oficialmente se inicia en octubre Hasta conseguir la secuenciación completa en 2005.

8
Objetivos: Identificación y localización (cartografía) de los genes en el genoma humano Mantenimiento de los bancos de datos de acceso publico Creación de herramientas para el análisis de datos Transferencia de tecnología relacionada al sector privado. Supervisión de temas éticos legales y sociales derivados del Proyecto Genoma HERRAMIENTAS DE CARTOGRAFIA Cartografía o mapeo genético: Mapas de ligamiento y mapas físicos SECUENCIACION: Método de secuenciación desarrollado por Frederick Sanger

9
Proyecto Genoma Humano
En 1990 se inició oficialmente. Un proyecto paralelo se realizó fuera del gobierno por parte de la Corporación Celera. La mayoría de la secuenciación se realizó en las universidades y centros de investigación de los EEUU, Canadá, Nueva Zelanda, Gran Bretaña y España. En el etapa de mayor actividad del programa se secuenciaba 1000 nt/seg. Francis Collins (director del CONSORCIO Proyecto Genoma Humano) y Craig Venter (gerente de Celera Genomics)
 y Craig Venter (gerente de Celera Genomics)")
10
Proyecto Genoma Humano: representación
Si cada par de nucleótidos se dibuja para abarcar 1 mm, entonces el genoma humano se extendería kilometros lo suficiente para cruzar la línea a través del centro de África (línea roja). A esta escala, habría, en promedio, un gen codificante para proteína cada 130 m. Un gen promedio se extendería por 30 m, pero las secuencias codificantes de este gen podría abarcar algo más de 1 metro.
. A esta escala, habría, en promedio, un gen codificante para proteína cada 130 m. Un gen promedio se extendería por 30 m, pero las secuencias codificantes de este gen podría abarcar algo más de 1 metro.")
11
Genoma Humano International Human Genome Sequencing Consortium (2001) Initial sequencing and analysis of the human genome. Nature 409, 860–933. International Human Genome Sequencing Consortium (2004) Finished: the euchromatic sequence of the human genome. Nature 431, 931–45.
 Finished: the euchromatic sequence of the human genome. Nature 431, 931–45.")
12
Genoma humano El genoma humano haploide consiste de 3200 millones pb de DNA Se suponía en un principio que el genoma humano podría tener unos a genes genes distribuidos en los 23 pares de cromosomas de la célula

13
Genoma humano: Historia
Si genes pueden producir una levadura, y a una mosca, ¿cuántos se necesitan para codificar un ser, una criatura compleja humano, curiosa y lo suficientemente inteligente como para estudiar su propio genoma? Hasta que los investigadores completaron el primer borrador de la secuencia del genoma humano, la estimación más citada fue Pero ¿de dónde esa cifra? ¿Y de donde sale la nueva estimación de sólo ?

14
Walter Gilbert, un físico convertido en biólogo y quien ganó el Premio Nobel por el desarrollo de técnicas de secuenciación de ADN, fue uno de los primeros en lanzar una estimación aproximada del número de genes humanos. A mediados de la década de 1980, Gilbert sugerido que los humanos podrían tener genes, una estimación basada en el tamaño medio de los pocos genes humanos conocidos en el momento (aproximadamente 3x104 pares de nucleótidos) y el tamaño de nuestro genoma (3x109 pares de nucleótidos). Hizo un cálculo que produjo un número con una redondez agradable tal, que terminó siendo citado ampliamente en artículos y libros de texto.
 y el tamaño de nuestro genoma (3x109 pares de nucleótidos). Hizo un cálculo que produjo un número con una redondez agradable tal, que terminó siendo citado ampliamente en artículos y libros de texto.")
15
Comparación de secuencias de nucleótidos de muchos vertebrados diferentes revela regiones de alta conservación La secuencia de nucleótidos examinado en este diagrama es de un pequeño segmento del gen humano para una proteína transportadora de membrana plasmática. La secuencia del exón se conserva en todas las especies, incluyendo el pollo y pescado. Tres bloques de la secuencia del intrón que se conservan en los mamíferos, pero no en la de pollo o pescado, se muestran en azul. las funciones de secuencias de intrones más conservadas en el genoma humano (incluyendo estos tres) no son conocidos.
 no son conocidos.")
16
Tipos de Secuencia

17
Altamente repetitiva: VNTR, STR
Mediamente repetitiva: LINEs, SINEs, transposones Copia Única Tipos de secuencia

18
La mayor parte del genoma humano está compuesto de no codificante y secuencias de nucleótidos repetitivos. Las LINEs, SINEs, transposones retroviral, y los transposones-ADN son elementos genéticos móviles que se han multiplicado en nuestro genoma mediante la replicación de sí mismos y la inserción de las nuevas copias en diferentes posiciones. Las repeticiones simples son secuencias de nucleótidos cortas (menos de 14 pares de nucleótidos) que se repiten una y otra vez durante largos períodos. Las duplicaciones de segmentos son bloques grandes del genoma ( pares de nucleótidos) que están presentes en dos o más lugares en el genoma. Las secuencias únicas que no son parte de ningún intrones o exones (verde oscuro) incluyen elementos reguladores de genes, así como las secuencias cuyas funciones no se conocen. Los bloques más altamente repetidas de ADN en la heterocromatina aún no se han secuenciado por completo; por lo tanto, cerca del 10% de las secuencias de ADN humano que no están representados en este diagrama
 que se repiten una y otra vez durante largos períodos. Las duplicaciones de segmentos son bloques grandes del genoma ( pares de nucleótidos) que están presentes en dos o más lugares en el genoma. Las secuencias únicas que no son parte de ningún intrones o exones (verde oscuro) incluyen elementos reguladores de genes, así como las secuencias cuyas funciones no se conocen. Los bloques más altamente repetidas de ADN en la heterocromatina aún no se han secuenciado por completo; por lo tanto, cerca del 10% de las secuencias de ADN humano que no están representados en este diagrama.")
19
Polimorfismos Repetitivos
VNTR (Variable number of tandem repeat), Ej: [CTGATCTATAGTAC]n STR, (Short tandem repeat), Ej: [ CG ] n Donde n= 20, 50 ó 70 veces
, Ej: [CTGATCTATAGTAC]n. STR, (Short tandem repeat), Ej: [ CG ] n. Donde n= 20, 50 ó 70 veces.")
20
Elementos repetitivos
SINE (Short Interspersed Nuclear Elements, elementos nucleares dispersos cortos): elementos Alu, nucleótidos, con unas copias. Los LINE (Long Interspersed Nuclear Elements, o elementos nucleares dispersos largos) constituyen un 20 por ciento del genoma humano. Son secuencias con un con un tamaño de varias kilobases Transposones ADN, retrovirales
: elementos Alu, nucleótidos, con unas copias. Los LINE (Long Interspersed Nuclear Elements, o elementos nucleares dispersos largos) constituyen un 20 por ciento del genoma humano. Son secuencias con un con un tamaño de varias kilobases. Transposones ADN, retrovirales.")
21
ADN copia única 48x106=1,5% A) El cromosoma 22, uno de los más pequeños cromosomas humanos, contiene 48 X 106 pares de nucleótidos y constituye aproximadamente el 1,5% de todo el genoma humano. La mayor parte del brazo izquierdo del cromosoma 22 se compone de secuencias cortas repetidas de ADN que son empacados en una forma particularmente compacta de la cromatina (heterocromatina). (B) una expansión de diez veces de una porción del cromosoma 22 muestra unos 40 genes. los de color marrón oscuro se conocen como genes y los rojos se predice genes. (C) una porción ampliada de (B) muestra toda la longitud de varios genes. (D) el arreglo intrón-exón de un gen típico se muestra después de una ampliación de diez veces más. cada exón (rojo) codifica para una porción de la proteína, mientras que la secuencia de ADN de los intrones (gris) es relativamente poco importante. (Adaptado de la Human Genome Sequencing Consortium International, Nature 409: , 2001
 El cromosoma 22, uno de los más pequeños cromosomas humanos, contiene 48 X 106 pares de nucleótidos y constituye aproximadamente el 1,5% de todo el genoma humano. La mayor parte del brazo izquierdo del cromosoma 22 se compone de secuencias cortas repetidas de ADN que son empacados en una forma particularmente compacta de la cromatina (heterocromatina). (B) una expansión de diez veces de una porción del cromosoma 22 muestra unos 40 genes. los de color marrón oscuro se conocen como genes y los rojos se predice genes. (C) una porción ampliada de (B) muestra toda la longitud de varios genes. (D) el arreglo intrón-exón de un gen típico se muestra después de una ampliación de diez veces más. cada exón (rojo) codifica para una porción de la proteína, mientras que la secuencia de ADN de los intrones (gris) es relativamente poco importante. (Adaptado de la Human Genome Sequencing Consortium International, Nature 409: ,")
22
Proyecto Genoma Humano: ESTADISTICAS
Se estima que el genoma humano contiene en torno a los genes. Alrededor de un 50 por ciento del genoma humano está constituido por ADN repetitivo. Se puede estimar que la densidad media de genes es de un gen cada 100 kb, aunque existen regiones ricas en genes (algunas zonas del cromosoma 19, por ejemplo) y otras regiones que son muy pobres en genes (como el cromosoma Y). Por tanto, se puede deducir una frecuencia media de 10 genes por cada Mb de secuencia. El tamaño promedio de un gen humano es de kb, aunque hay grandes diferencias de unos genes a otros. El número de exones que forman un gen es muy variable (desde genes que tienen un solo exón hasta algunos genes con 100 exones o más), pero podemos establecer un valor promedio de 7-8 exones por gen. El tamaño medio de un exón es de 150 nucleótidos. Por lo que respecta a los intrones, en cambio, existe una enorme variabilidad de tamaños, y no es infrecuente encontrar en casi todos los genes algún intrón de gran tamaño. El tamaño medio de un ARNm es de 1,8-2,2 kb incluyendo las regiones no-traducidas flanqueantes. La longitud media de una región codificante es de 1,4 kb.
 y otras regiones que son muy pobres en genes (como el cromosoma Y). Por tanto, se puede deducir una frecuencia media de 10 genes por cada Mb de secuencia. El tamaño promedio de un gen humano es de kb, aunque hay grandes diferencias de unos genes a otros. El número de exones que forman un gen es muy variable (desde genes que tienen un solo exón hasta algunos genes con 100 exones o más), pero podemos establecer un valor promedio de 7-8 exones por gen. El tamaño medio de un exón es de 150 nucleótidos. Por lo que respecta a los intrones, en cambio, existe una enorme variabilidad de tamaños, y no es infrecuente encontrar en casi todos los genes algún intrón de gran tamaño. El tamaño medio de un ARNm es de 1,8-2,2 kb incluyendo las regiones no-traducidas flanqueantes. La longitud media de una región codificante es de 1,4 kb.")
23
Proyecto Genoma Humano: HALLAZGOS
El rasgo más notable del genoma humano es el pequeño porcentaje que codifica para proteínas, RNAs estructurales y RNAs catalíticos. Casi la mitad del ADN restante se compone de elementos genéticos móviles que han colonizado nuestro largo genoma durante el tiempo evolutivo. Una segunda característica notable del genoma humano es el tamaño grande del promedio de los genes ( pares de nucleótidos). Sólo se requieren alrededor de pares de nucleótidos que codifica una proteína de tamaño medio (unos 430 aminoácidos en los seres humanos). La mayor parte del ADN que permanece en un gen consiste en largos tramos de ADN no codificante en los intrones y exones que codifican proteínas relativamente cortos Además de los intrones y exones, cada gen se asocia con secuencias de ADN reguladoras que aseguran que el gen se expresa en el nivel y el momento adecuado, y en el tipo apropiado de célula. En los seres humanos, estas secuencias de ADN reguladoras están normalmente distribuidos en decenas de miles de pares de nucleótidos, mucha de la cual parece ser ADN "espaciador". Los exones y secuencias reguladoras comprenden menos del 2% del genoma humano. Otra característica sorprendente del genoma humano es su número relativamente pequeño de genes. Las estimaciones anteriores habían sido de alrededor de Aunque el número exacto todavía no está claro, estimaciones revisadas indican que el número de genes humanos en alrededor de , nos compara al números de genes de animales multicelulares más simples, tales como Drosophila (14.000), C. elegans (19.000). .
. Sólo se requieren alrededor de pares de nucleótidos que codifica una proteína de tamaño medio (unos 430 aminoácidos en los seres humanos). La mayor parte del ADN que permanece en un gen consiste en largos tramos de ADN no codificante en los intrones y exones que codifican proteínas relativamente cortos Además de los intrones y exones, cada gen se asocia con secuencias de ADN reguladoras que aseguran que el gen se expresa en el nivel y el momento adecuado, y en el tipo apropiado de célula. En los seres humanos, estas secuencias de ADN reguladoras están normalmente distribuidos en decenas de miles de pares de nucleótidos, mucha de la cual parece ser ADN espaciador . Los exones y secuencias reguladoras comprenden menos del 2% del genoma humano. Otra característica sorprendente del genoma humano es su número relativamente pequeño de genes. Las estimaciones anteriores habían sido de alrededor de Aunque el número exacto todavía no está claro, estimaciones revisadas indican que el número de genes humanos en alrededor de , nos compara al números de genes de animales multicelulares más simples, tales como Drosophila (14.000), C. elegans (19.000). .")
24
Proyecto Genoma Humano: búsqueda del número de genes
En ADN genómico: cuando se busca en el recuento teórico del número de genes se tuvieron se buscaron el número de ORFs (open reading frames): secuencias de 100 codones comprendida entre un codón de inicio (AUG) de la traducción y un codón de terminación, descontando las secuencias que corresponden a los intrones en caso de haberlas. Se encuentra acotado por los UTRs, o secuencias no traducidas. Existen programas que son usados para la búsqueda de ORFs, los cuales se inician con el codón ATG, y terminan con un codón de terminación TAA, TAG, o TGA. El marco de lectura abierto quedará definido, por tanto, cuando el codón de inicio vaya seguido por un número suficiente de codones codificantes hasta llegar a un codón de parada.
: secuencias de 100 codones comprendida entre un codón de inicio (AUG) de la traducción y un codón de terminación, descontando las secuencias que corresponden a los intrones en caso de haberlas. Se encuentra acotado por los UTRs, o secuencias no traducidas. Existen programas que son usados para la búsqueda de ORFs, los cuales se inician con el codón ATG, y terminan con un codón de terminación TAA, TAG, o TGA. El marco de lectura abierto quedará definido, por tanto, cuando. el codón de inicio vaya seguido por un número suficiente de codones codificantes hasta llegar a un codón de parada.")
25
Proyecto Genoma Humano: Individualidad Genética
No hay 2 personas iguales (excepto gemelos) Cuando se compara la misma región del genoma en 2 personas difiere en 0,1% son ≈ 3 millones de diferencias en el genoma.
 Cuando se compara la misma región del genoma en 2 personas difiere en 0,1% son ≈ 3 millones de diferencias en el genoma.")
26
Variaciones Los Polimorfismos de un solo nucleótido (SNPs, pronunciado como snips) son secuencias en el genoma que difieren en un solo par de nucleótidos entre una porción de la población y otra. Existen duplicación y deleción de grandes blocks de DNA. Cuando el genoma de cualquier persona es comparada con el genoma de referencia estándar se observa al menos 100 diferencias que involucran grandes blocks de secuencia. Algunas de estas diferencias son muy comunes, sin embargo otras estas presentes en una pequeña minoría de la población. Una comparación entre dos genomas encontraron 297 variantes estructurales de segmentos de tamaño intermedio (8 kilobases): 139 inserciones, 102 deleciones y 56 inversiones. (SNP: single nucleotide polymorphisms)
 son secuencias en el genoma que difieren en un solo par de nucleótidos entre una porción de la población y otra. Existen duplicación y deleción de grandes blocks de DNA. Cuando el genoma de cualquier persona es comparada con el genoma de referencia estándar se observa al menos 100 diferencias que involucran grandes blocks de secuencia. Algunas de estas diferencias son muy comunes, sin embargo otras estas presentes en una pequeña minoría de la población. Una comparación entre dos genomas encontraron 297 variantes estructurales de segmentos de tamaño intermedio (8 kilobases): 139 inserciones, 102 deleciones y 56 inversiones. (SNP: single nucleotide polymorphisms)")
27
¿El genoma humano es patentable?
El 11 de Noviembre de 1997, la UNESCO aprobó la DECLARACIÓN UNIVERSAL SOBRE GENOMA HUMANO Y LOS DERECHOS DEL HOMBRE, fijando tres principios: La dignidad del individuo cualesquiera sean sus características genéticas. Rechazo al determinismo genético. El Genoma Humano es PATRIMONIO DE LA HUMANIDAD.

28
Controversias éticas El conocimiento del genoma humano tiene también diversas implicaciones éticas, jurídicas y sociales, estimulando un debate internacional sobre algunos aspectos: Patentar secuencias de genes humanos para uso comercial. Confidencialidad en la información obtenida, como por ejemplo, poner la información sobre genética humana a disposición de empresas de seguros. La libertad a no saber si se es o no portador de una enfermedad genética.

29
EN RESUMEN:

30
GENOMA HUMANO 25.000 Longitud del ADN 3,2x109 pb Número de genes
Gen mas largo 2,4 x106 pb Tamaño medio de gen pb Menor nº de exones /gen 1 Mayor nº de exones /gen 178 Nº medio de exones /gen 10,4 Tamaño del exón mas largo pb Tamaño medio de exon 145 pb Nº de pseudogenes Mas de % de la secuencia del DNA en los exones (secuencias que codifican proteínas 1,5% % de la secuencia del DNA en secuencias altamente conservadas* 3,5% % de DNA elementos altamente repetitivos 50% *: incluye DNa que codifica 5’ y 3’ UTRs (untranslated regions of mRNAs), genes de RNAs estructural y cataliticos, regiones regulatorias de ADN y regiones conservadas de función desconocidas.
, genes de RNAs estructural y cataliticos, regiones regulatorias de ADN y regiones conservadas de función desconocidas.")
31
Polimorfismo y Mutación
Cuando la frecuencia alelica, del alelo más raro es del uno por ciento o mayor, ese locus se llama locus polimórfico, y esa variación se denomina polimorfismo. Cuando la variación es menos frecuente es una mutación, es más grave y desencadenan una enfermedad

32
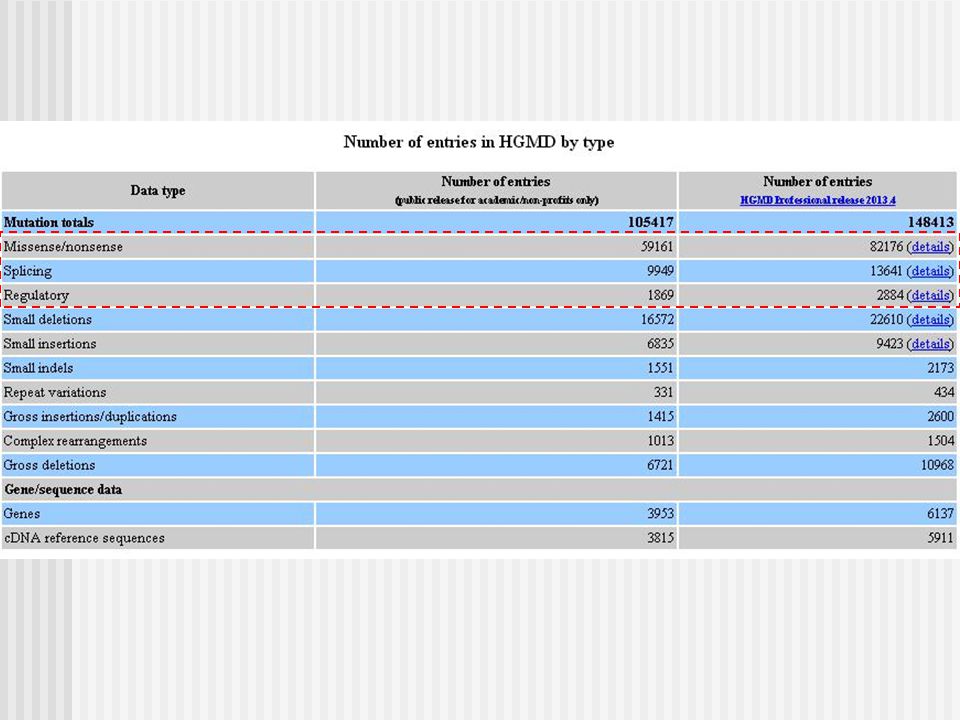
Human Gene Mutation Database (HGMD)

33
Número Total de Mutaciones
Total: mutaciones informadas

35
Espectro de diferentes tipos de mutaciones en genes humanos (Human Gene Mutation Database)
Single base pair substitutions Mutaciones sin sentido/con cambio de sentido

36
1º 2º 3º

37
1º 2º 3º 4º

38
MUTACIONES PUNTUALES En la región regulatoria En el splicing
Sin sentido (nonsense) Con cambio de sentido (missense)
 Con cambio de sentido (missense)")
39
Espectro de diferentes tipos de mutaciones en genes humanos (Human Gene Mutation Database)
Single base pair substitutions Mutaciones sin sentido/con cambio de sentido

40
DELECIONES DE GENES Las deleciones son responsables de mas 500 enfermedades hereditarias en humanos. Y estas deleciones pueden ser clasificadas en base a la longitud del ADN delecionado. Algunas deleciones consiste de solo unas pocas pares de bases hasta varias cientos de kilobases

41
DELECIONES DE GENES 2,5 a 5% de pacientes con hemofilia A son debidos a deleciones en el gen F8C (Factor VIII) con perdida de 26 exones de un longitud 186 Kb 84% de los pacientes con deficiencia sulfatasa esteroidal (STS), con perdida de 10 exones de una longitud de 146 kb de ADN genómico. Grandes deleciones son comunes en la distrofia muscular de Duchenne, GH, RLDL y el gen de 1-globina
 con perdida de 26 exones de un longitud 186 Kb. 84% de los pacientes con deficiencia sulfatasa esteroidal (STS), con perdida de 10 exones de una longitud de 146 kb de ADN genómico. Grandes deleciones son comunes en la distrofia muscular de Duchenne, GH, RLDL y el gen de 1-globina.")
42
PEQUEÑAS DELECIONES Existe un total de deleciones de genes causantes de enfermedadescon una longitud de 20 bp o menos

43
Estrategias en el laboratorio de Biología Molecular
Grandes Deleciones Southern Blotting GAP-PCR MAPH and MLPA Long-range PCR Mutaciones Puntuales y deleciones pequeñas RFLP-PCR(ER-PCR) Mutagenesis mediada por PCR Alelo-Específicas: MAS-PCR ARMS- MARMS DOT-ASO
 Mutagenesis mediada por PCR. Alelo-Específicas: MAS-PCR. ARMS- MARMS. DOT-ASO.")
44
Estrategias en el laboratorio de Biología Molecular II
Desconozco la mutación o polimorfismo SSCP (single strand conformation polymorphism) DGGE (Denaturing Gradient Gel Electrophoresis)
 DGGE. (Denaturing Gradient Gel Electrophoresis)")
45
SSCP SSCP (single strand conformation polymorphism) es un método simple y accesible para detectar alteraciones en la secuencia en un fragmento obtenido por PCR
 es un método simple y accesible para detectar alteraciones en la secuencia en un fragmento obtenido por PCR.")
46
Pasos Después de la amplificación de cualquier secuencia de ADN dada, los fragmentos de ADN amplificados se someten a la desnaturalización con calor o agentes químicos, tales como formamida. Posteriormente, los fragmentos de ADN desnaturalizados se someten a electroforesis a través de un gel de poliacrilamida nativo (no desnaturalizante).
.")
47
WT AA BB AB Delecion Inserción

48
DGGE (Denaturing Gradient Gel Electrophoresis)
simple complejo Los productos de PCR son cargados en un gel con un gradiente desnaturalizante Típicamente 20-80% formamida ADN doble cadena migra hasta encontrar su melting El melting es determinado por su secuencia y contenido de GC Las diferentes secuencias migran a diferentes distancias 20% 80%

49
DESNATURALIZACIÓN DEL DNA
1. Composición de bases 2. Longitud DNA doble 3. Presencia de agentes desnaturalizantes Agentes desnaturalizantes. Formamida: Baja la T° de melting a 0,72°C cada 1%

50
DGGE (Denaturing Gradient Gel Electrophoresis) II
Ventajas Puedo cortar las bandas y secuenciar Puedo detectar pequeñas diferencias en la secuencia de DNA Desventajas Puede haber complejidad en el chorreado de las muestras Requiere una aparatología específica

51
Extracción de ADN Todos los alumnos harán una extracción de muestra de sangre por punción venosa.

Presentaciones similares


.>")

















 fue un proyecto de investigación científica con el objetivo fundamental de determinar la secuencia de.>")