Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Cluster by mixtures

7
The Trace criteria (K-means)
")
8
Equal variances: The determinant

9
General situation:

11
Mixture estimation

15
The EM algorithm

25
Métodos de Proyección(*) Idea central: buscar direcciones de proyección que muestren la heterogeneidad de una muestra. Proyectar los datos y buscar grupos sobre las proyecciones “Cluster Identification using Projections” * Peña, D. y Prieto, J. (2001). “Cluster Identification using Projections” The Journal of American Statistical Association, 96, 456, 1433-1445, 2001
. Cluster Identification using Projections The Journal of American Statistical Association, 96, 456, ,")
26
Heterogeneidad ¿Cómo encontrar direcciones que muestren la heterogeneidad?

27
Heterogeneidad univariante Llamemos = A la variabilidad de una variable (la j) respecto a su media
 respecto a su media")
30
Kurtosis, para la normal =3 Coef. Kurtosis =12

31
Coef. Kurtosis= 1.38

32
Resultado principal Si los datos han sido generados por dos normales multivariantes con la misma matriz de varianzas, la dirección que minimiza la kurtosis es la dirección optima de Fisher para la discriminación cuando sabemos que hay dos poblaciones normales.

33
Puede demostrarse que si queremos alta separación en la proyeccion de dos distribuciones arbitrarias, medida por

34
Conclusión Si los datos han sido generados por dos normales multivariantes con la misma matriz de varianzas minimizando la kurtosis obtenemos la dirección optima de Fisher para la discriminación cuando sabemos que hay dos poblaciones normales.

35
Metodo de Proyeccion (PP)
")
37
Exploracion de las direcciones

41
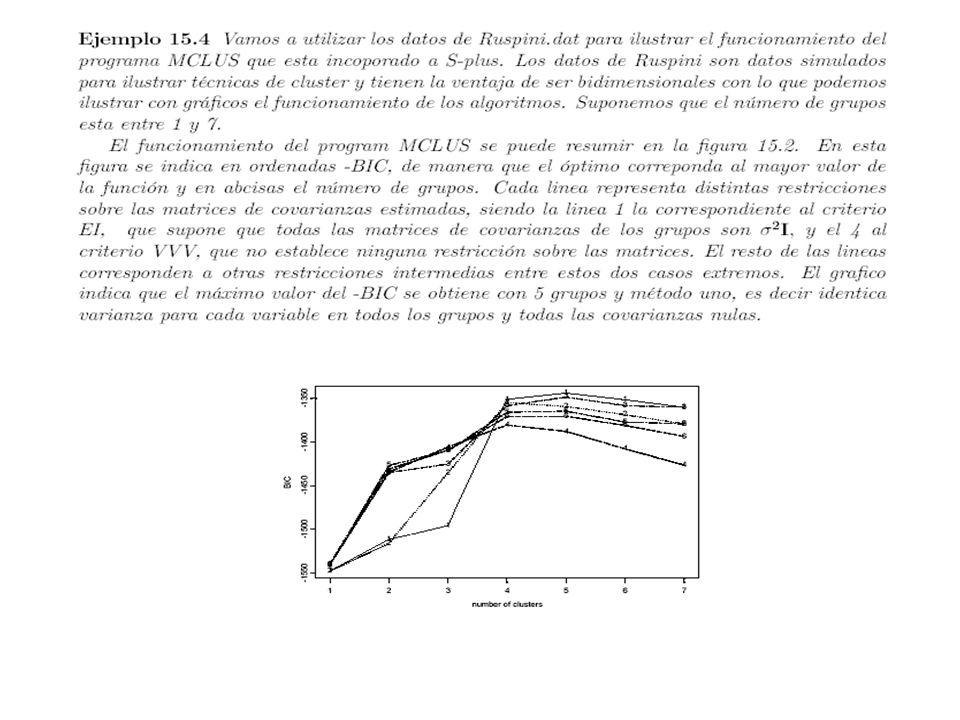
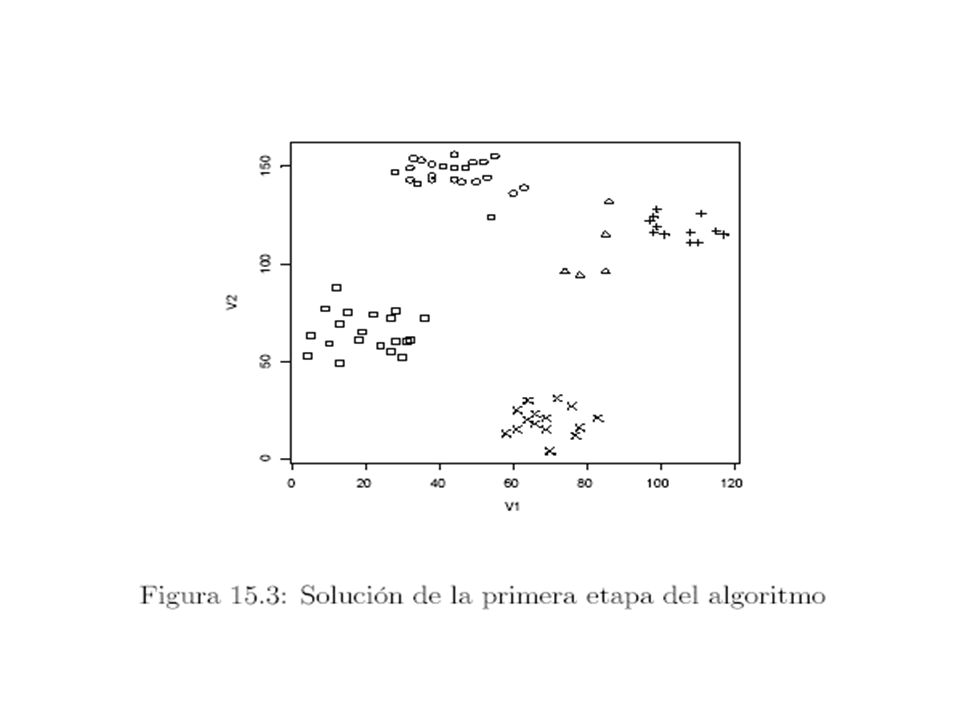
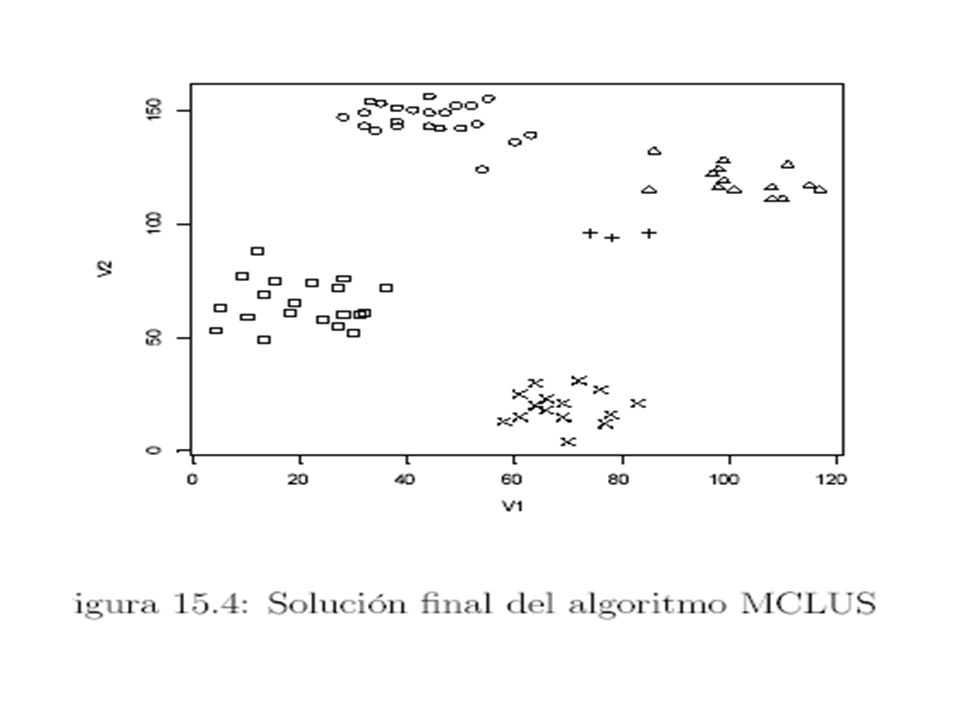
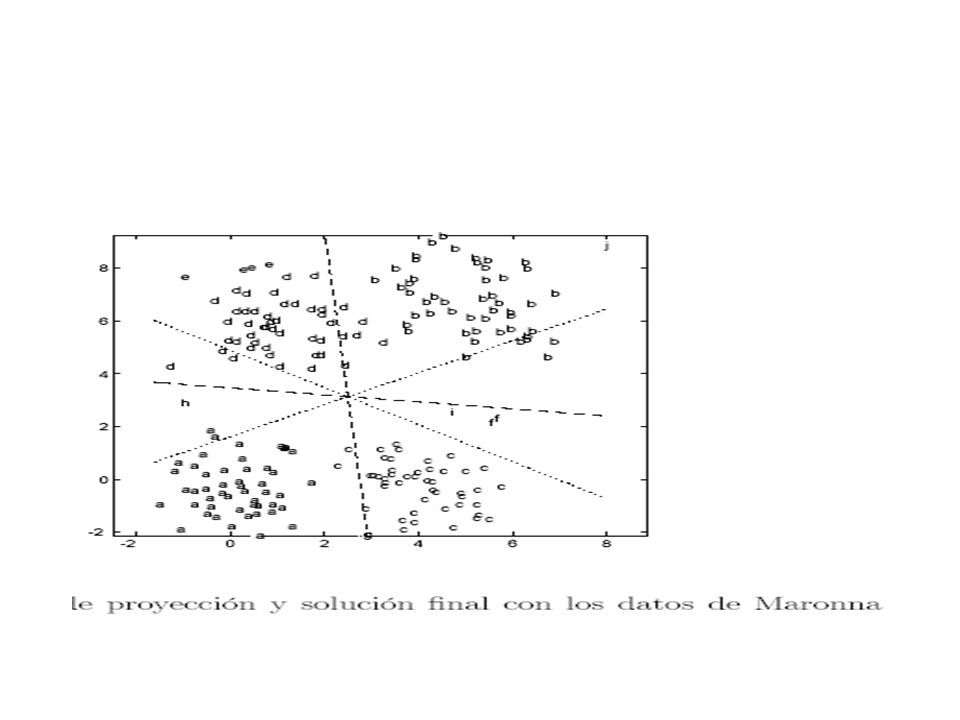
Ejemplo Ruspini

43
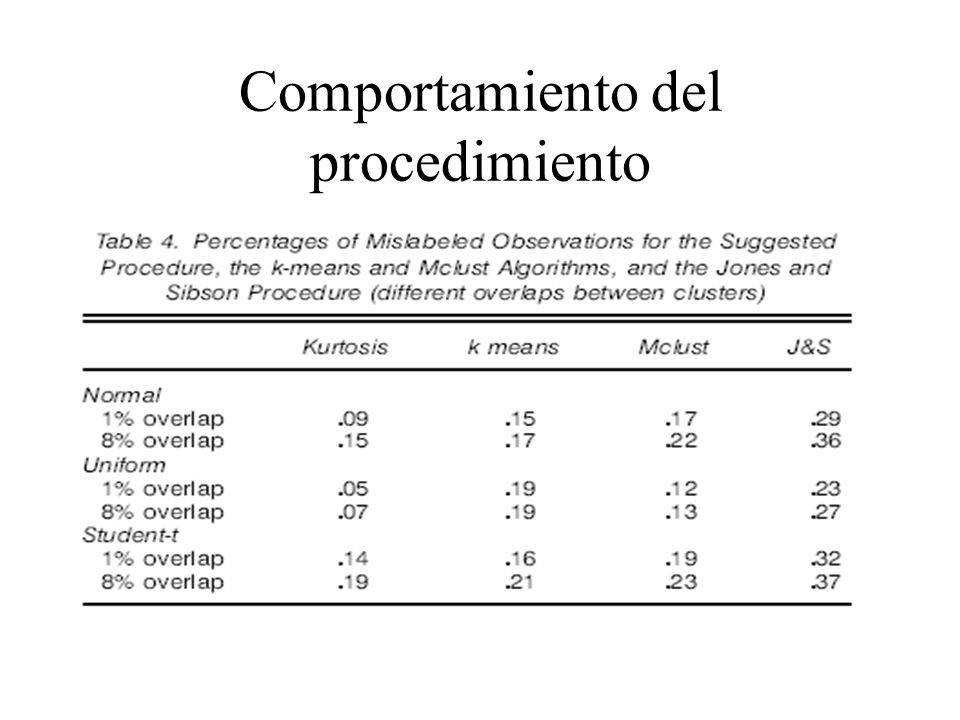
Comportamiento del procedimiento

45
Algunas conclusiones Buscar clusters en proyecciones 1.Evita la maldición de la dimensión 2.Es muy eficiente en dimensión alta 3.Es óptimo para mezclas de normales con la misma varianza 4.Asegura alta capacidad de separación lineal para cualquier distribución

46
Las direcciones mejores de separación son interesantes en si mismas para reducir el número de variables

47
Conclusiones generales Discriminación y cluster son problemas muy relacionados con la misma solución óptima en casos simples: La mejor direccion de discriminación, en el sentido de Fisher, es la mejor dirección para hacer clusters, en el sentido de minimizar la kurtosis de los datos proyectados

Presentaciones similares