Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Informática de gestión, Octubre de 2001
Qué es Data Mining 2 Informática de gestión, Octubre de 2001

2
Diferentes Formas de Conocimiento
Datos Superficiales (se descubren con SQL) Datos Multi-Dimensionales (se descubren con OLAP) Datos Escondidos (se descubren con KDD) Datos Profundos (se descubren sólo con pistas)
 Datos Multi-Dimensionales (se descubren con OLAP) Datos Escondidos. (se descubren con KDD) Datos Profundos (se descubren sólo con pistas)")
3
Minería de datos Un proceso analítico diseñado para explorar grandes cantidades de datos (generalmente relacionados a los negocios o mercadeo), búsqueda de modelos consistentes y/o las relaciones sistemáticas entre las variables validar los resultados aplicando los modelos descubiertos a los nuevos subconjuntos de datos. El proceso consiste así en tres fases básicas: exploración, construcción o definición del modelo, y validación/verificación Si la naturaleza de los datos disponibles permite, se repite iterativamente hasta identificar un modelo "robusto". Sin embargo, en la práctica de negocios las opciones para validar al modelo en la fase de análisis están generalmente limitadas y, así, los resultados iniciales tienen a menudo el estado de heurística que podría influir en el proceso de decisión Por ejemplo, Los datos parecen indicar que la probabilidad de probar píldoras para dormir aumenta más rápidamente con la edad en las mujeres que en los varones

4
Data Mining en la Web El DM es un proceso de descubrimiento de los patrones, perfiles y tendencias presentes y significativos a través del análisis de los datos del sitio web utilizando tecnologías de reconocimientos de patrones, como las redes neuronales, máquinas de aprendizaje y algoritmos genéticos. Es un proceso iterativo de extracción de patrones procedentes de las transacciones de negocios on-line (hacer clic sobre un enlace o sobre un banner, pedir información por , rellenar un formulario) con el fin de mejorar la coyuntura del sitio web de la empresa.
 con el fin de mejorar la coyuntura del sitio web de la empresa.")
5
Data Mining – Minado de Datos
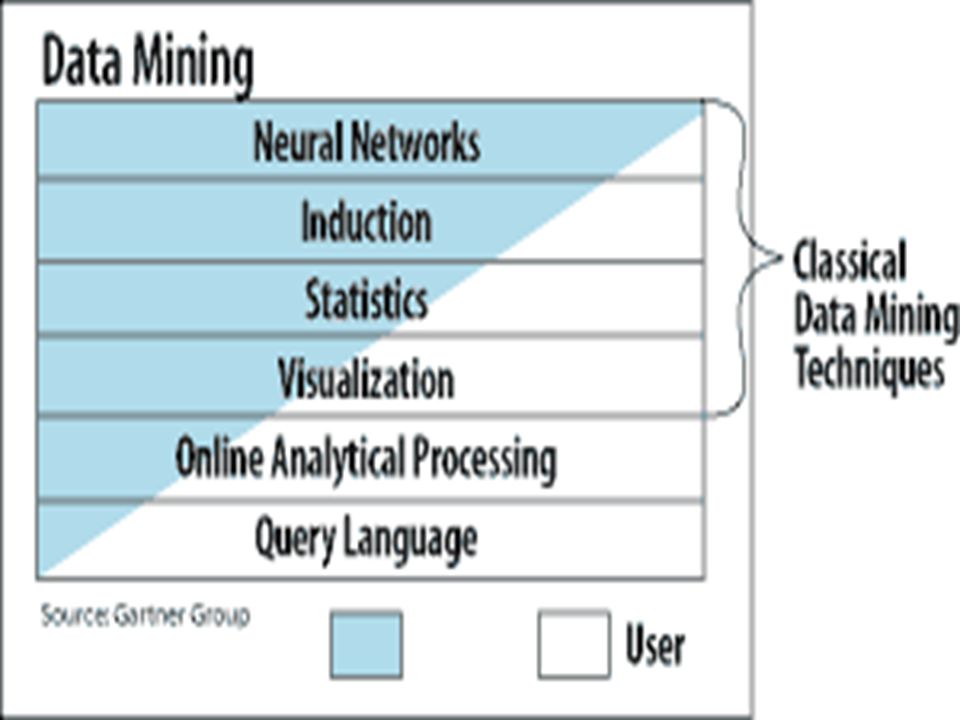
Hay tres áreas principales de trabajo: Ingeniería del conocimiento Clasificación Resolución de problemas Cada una de las técnicas de aprendizaje se ubica en este espacio tridimen-sional. No hay una técnica de aprendizaje o de reconocimiento de patrones que sea la mejor. Un ambiente KDD debe soportar estos tipos diferentes de técnicas. (ambiente híbrido) Ver cuadro de Selección de Algoritmos -
 Ver cuadro de Selección de Algoritmos -")
6
Diferentes Algoritmos de Aprendizaje Comparados con diferentes tipos de Tareas

7
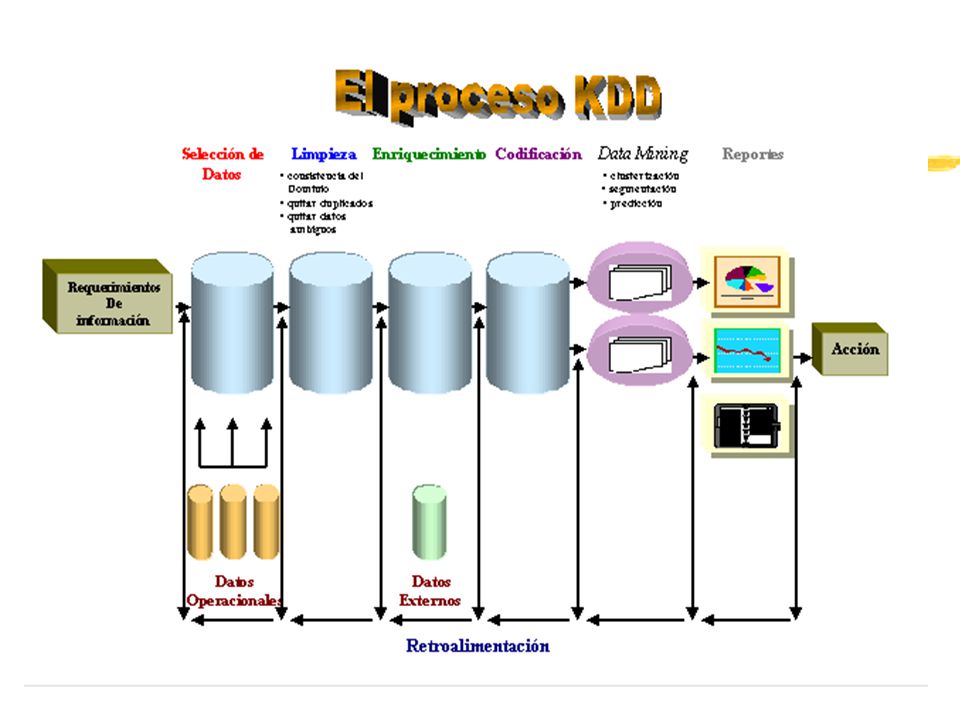
Reportes La etapa de reportes combina dos funciones diferentes:
Análisis de resultados de los algoritmos de reconocimiento de patrones. Aplicación de los resultados de los algoritmos de reconocimientos de patrones a los nuevos datos. Queremos inspeccionar qué hemos aprendido. Queremos aplicar la información de las clasificaciones y de segmentación obtenida. Se pueden usar las herramientas de consulta tradicionales para bases de datos. Nuevas técnicas de visualización de datos están emergiendo Desde simples diagramas de dos dimensiones a ambientes interactivos complejos dentro de los que se puede navegar en los diferentes entornos.

10
Selección de los datos Coleccionar y seleccionar los datos que se necesitan. Guardado de esos datos en bases de datos operacionales. Esto puede involucrar tareas de conversión de datos a bajo nivel. Los datos usados en diversas partes de la organización pueden variar en su calidad. Preparar la actividad KDD también es una inversión a largo plazo. Se necesitará transferir desde los datos operacionales con un criterio generalizado. Un Data Warehouse ayuda por su entorno estable y confiable

11
Preparación de un ambiente KDD (Knowledge Discovery in DataBases)
Las diferentes formas de Conocimiento. El Punto de Partida. Selección de los datos. Limpieza. Enriquecimiento. Codificación. Data Mining – Minado de los datos. Reportes. El ambiente KDD. Las 10 reglas de oro.

12
Limpieza No se está consciente de la polución existente en los datos que se poseen. Se deben examinar los datos (esto se complica a medida que los datos son mayores). Con bases de datos muy grandes (VLDB) es recomendable analizar algunos datos al azar. La mayoría de las bases de datos tienen el problema de la inconsistencia. Se deben limpiar los datos tanto como se pueda, en varios casos es posible hacerlo automáticamente. La polución en los datos puede ocurrir en varios niveles. Esta polución se produce por el método en que los datos son capturados e insertados en los campos.
. Con bases de datos muy grandes (VLDB) es recomendable analizar algunos datos al azar. La mayoría de las bases de datos tienen el problema de la inconsistencia. Se deben limpiar los datos tanto como se pueda, en varios casos es posible hacerlo automáticamente. La polución en los datos puede ocurrir en varios niveles. Esta polución se produce por el método en que los datos son capturados e insertados en los campos.")
13
Enriquecimiento Se puede acceder a bases de datos adicionales comercialmente. Temas variados: datos demográficos, precios promedio, índices económicos, tipos de seguros. Cooperación entre dos compañías para coordinar operaciones de marketing. Puede ser difícil hacer coincidir información de bases de datos compradas con las nuestras.

14
Codificación En SQL, podemos manipular datos para obtener una base objeto limpia. Algunas veces podemos limpiar los datos simplemente filtrando los registros que están sucios. Eliminar la información puede (o no) afectar el agrupamiento o los tipos de patrones que se buscan.
 afectar el agrupamiento o los tipos de patrones que se buscan.")
15
DM desde el punto de vista tecnológico

16
Proceso de minería de datos

17
Base de datos en una empresa
Una base de datos de una empresa puede tener cientos de campos, registrando los diferentes tipos de interacciones tanto on-line como off-line extraídos de distintos puntos de contacto, incluyendo el sitio web de una empresa: Campo Atributo del Cliente Campo 1 Fecha de comienzo de la cuenta Campo 2 Número de compras Campo 3 Código postal Campo 798 Número total de visitas Campo 799 Duración media de las visitas Campo 800 Tasa mensual de accesos

18
Modelo de fidelidad de cliente
Para construir un modelo de fidelidad de cliente, se deben descubrir dos aspectos clave dentro del fichero de datos: los atributos significativos y los intervalos significativos

19
Atributos Atributos. El descubrimiento de los atributos que representan las señales más importantes en la identificación de aquellos clientes que con la máxima probabilidad son los más rentables: ¿Es el código postal en el que residen? ¿Quizás podría ser la fecha de la creación de una cuenta? ¿Es su tasa de acceso mensual, su edad o su género? ¿Es una combinación de factores y, en tal caso, qué atributos son?

20
Intervalos Intervalos. El descubrimiento de los intervalos. Por ejemplo: ¿Después de qué fecha de creación de cuenta un cliente probablemente no fallará? ¿Qué rango de códigos postales? ¿Qué tasa de acceso al sitio web señala clientes de alta fidelidad o rentabilidad?

21
Propósitos de DM Una investigación reciente de la empresa META Group reveló que las 500 empresas del ranking Fortune utilizaban DM básicamente con 3 propósitos: 64% - para la planificación estratégica, 49% - para inteligencia competitiva, 46% - para aumentar su cuota de mercado.

22
Aplicaciones de Data Mining
Un estudio de este grupo de investigación, llamado "Data Mining: Tendencias, Tecnología e Imperativos de Implementación" (1998) pronosticó un crecimiento en el área del DM conducido por el marketing basado en bases de datos. Cita aplicaciones como: retención del cliente y gestión de los abandonos; venta cruzada (cross-selling) y up-selling; gestión de campañas; análisis del mercado, canal y precio; análisis de segmentación del cliente.
 pronosticó un crecimiento en el área del DM conducido por el marketing basado en bases de datos. Cita aplicaciones como: retención del cliente y gestión de los abandonos; venta cruzada (cross-selling) y up-selling; gestión de campañas; análisis del mercado, canal y precio; análisis de segmentación del cliente.")
23
- Situación IDEAL de los flujos de datos dentro de una empresa

24
Data Mining Versus Estadística
La diferencia decisiva entre DM y Estadística es la dirección de la búsqueda (query). En el DM, la interrogación de los datos se hace mediante algoritmos de Inteligencia Artificial (desde ahora, IA) o Redes Neuronales, en vez de a partir de la contribución del estadístico o del análisis de negocios. En otras palabras, el DM está dirigido por la naturaleza de los datos, en vez de estar dirigido por el usuario o por la verificación, como ocurre en la mayoría de los análisis estadísticos.
. En el DM, la interrogación de los datos se hace mediante algoritmos de Inteligencia Artificial (desde ahora, IA) o Redes Neuronales, en vez de a partir de la contribución del estadístico o del análisis de negocios. En otras palabras, el DM está dirigido por la naturaleza de los datos, en vez de estar dirigido por el usuario o por la verificación, como ocurre en la mayoría de los análisis estadísticos.")
25
Data Mining Versus Estadística
DM tiene también grandes ventajas sobre la Estadística cuando la escala de las bases de datos aumenta de tamaño, simplemente porque los enfoques manuales del análisis de datos se están haciendo impracticables. Por ejemplo, supongamos que hay 100 atributos a elegir de una base de datos, de los cuales no sabe cuáles son significativos. Incluso ante este pequeño problema, existen 100 x 99 = combinaciones de atributos a considerar. Si hubiesen 3 clases, como alta, media y baja, habría ahora 100 x 99 x 98 = combinaciones posibles.

26
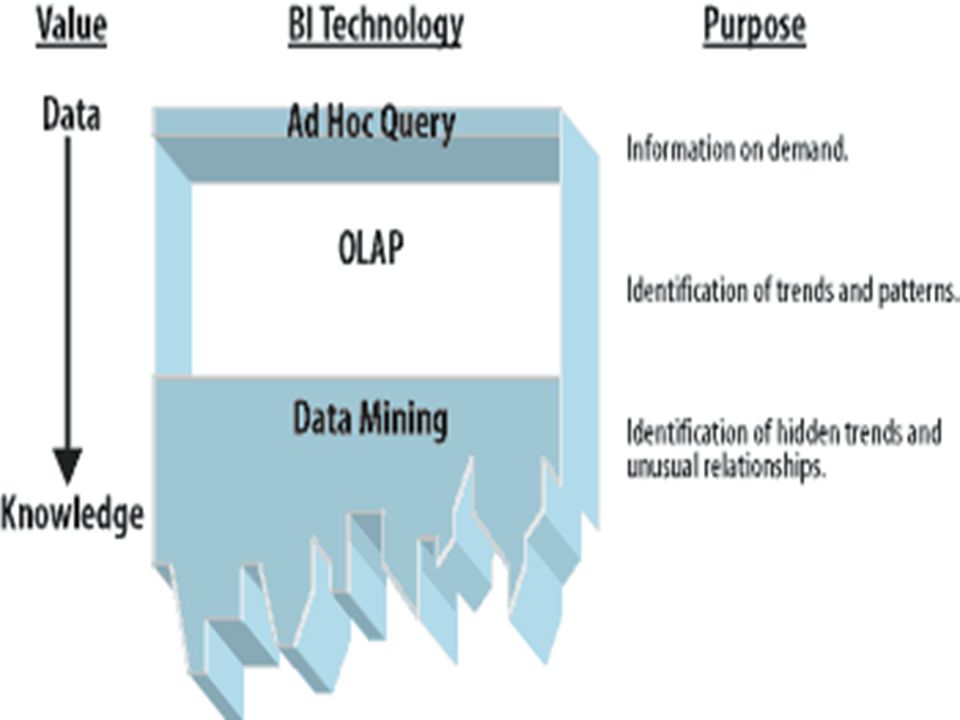
Data Mining Versus Olap
Las herramientas OLAP fueron diseñadas para permitir a los analistas de datos informes personalizados y en forma de "construcción de cubos". La estructura de datos OLAP es similar a un Cubo de Rubik de datos que un analista puede girar y visualizar diferentes formas de trabajar a través de informes multidimensionales y escenarios "what-would-happen"" (qué ocurriría). Las herramientas OLAP proporcionan fundamentalmente un análisis multidimensional de los datos, es decir, permiten resumir y segmentar los datos por líneas de producto y áreas mercantiles.
. Las herramientas OLAP proporcionan fundamentalmente un análisis multidimensional de los datos, es decir, permiten resumir y segmentar los datos por líneas de producto y áreas mercantiles.")
27
Data Mining Versus Olap
La diferencia básica entre OLAP y DM es que OLAP maneja agregados de datos, en tanto que DM maneja ratios (tasas). OLAP es adición, mientras que DM es división.
. OLAP es adición, mientras que DM es división.")
28
Data Mining Versus Olap
La metodología de DM incluye la extracción de información predictiva oculta procedente de grandes bases de datos. Con una definición tan amplia como ésta, se podría decir que un producto de procesamiento analítico on-line (OLAP) está cualificado como herramienta DM. Ese es el origen de esta tecnología, ya que para que se produzca un auténtico descubrimiento de conocimiento, una herramienta DM debería llegar automáticamente hasta esta información oculta.
 está cualificado como herramienta DM. Ese es el origen de esta tecnología, ya que para que se produzca un auténtico descubrimiento de conocimiento, una herramienta DM debería llegar automáticamente hasta esta información oculta.")
29
Data Mining Versus Olap
El OLAP manual podría basarse en hechos que se necesita conocer, como los informes regionales de ventas estratificados por el tipo de negocios, mientras que el DM automático se basa en la necesidad de descubrir los factores que influyen en estas ventas.

30
Data Mining Versus Olap
Una herramienta OLAP no es una herramienta DM, ya que la búsqueda se origina con el usuario. Las RN, la IAy los Algoritmos Genéticos, por otra parte, se consideran como verdaderas herramientas de DM automático, porque interrogan autónomamente a los datos, en búsqueda de patrones. Esto es lo que se conoce como Aprendizaje Supervisado, mientras que otra forma menos común de DM recibe el nombre de "clustering" o Aprendizaje No Supervisado. En ambos casos, el tratamiento ascendente del análisis de datos distingue el DM del OLAP.

31
Data Mining Versus Olap
Las herramientas autónomas de DM, sin embargo, basadas en las tecnologías de inteligencia artificial, son la únicas herramientas diseñadas para automatizar el proceso de descubrimiento del conocimiento y optimizar esto con sus características "hechas para el negocio": Robustez para manejar cualquier tipo de datos: ruidosos, omitidos, mezclados. Soluciones exportables en forma de reglas prácticas del negocio. Facilidad para entender los resultados por medio de árboles gráficos de decisión. Posibilidad de obtener resultados precisos, especialmente con ficheros de la vida real

32
Data Mining Versus Olap
El procesamiento analítico On-Line y la Estadística proporcionan análisis de- arriba-abajo, dirigidos por búsquedas, El DM proporciona análisis de-abajo- arriba , dirigido por los descubrimientos. El DM no requiere suposiciones. En su lugar, identifica hechos o conclusiones basados en los patrones descubiertos.

33
Data Mining Versus Olap
En otro ejemplo, una herramienta OLAP puede informar al vendedor sobre el número total de libros vendidos para una región determinada en un trimestre determinado. El DM, por otro lado, puede informar de los factores que influyen en las ventas de los libros.

Presentaciones similares










 Software (Software de Inteligencia Impresario)>")









