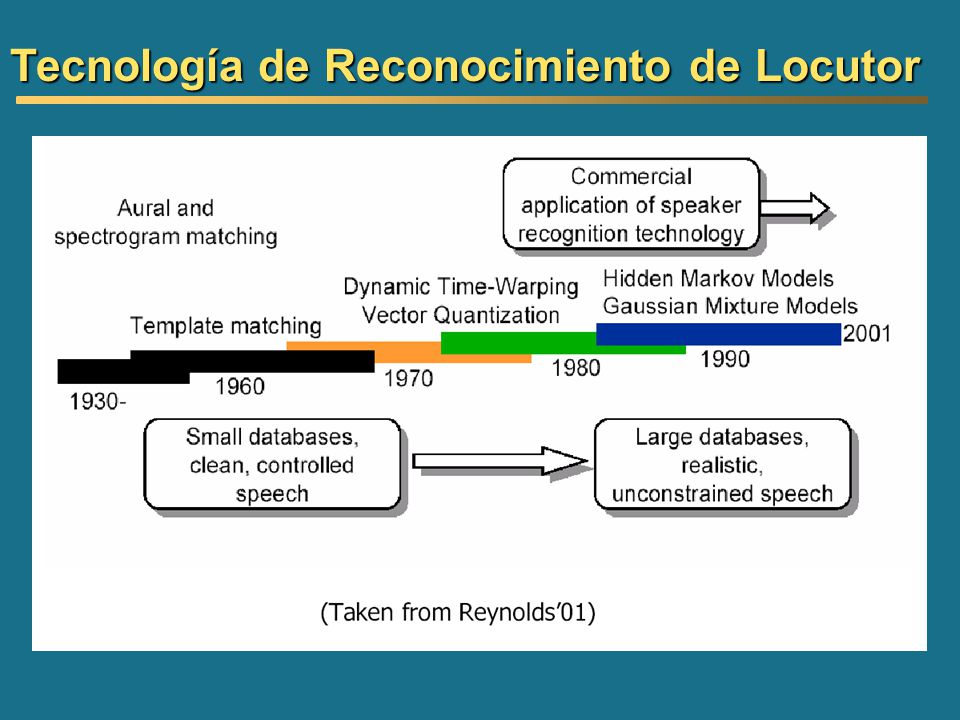
Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Logo del Departamento o Instituto Sistemas de Interacción Natural (4e) Luis Hernández Gómez luis@gaps.ssr.upm.es
 Luis Hernández Gómez")
2
SPEECH & LANGUAGE TECHNOLOGIES 4a: Speech production and analysis 4b: Speech perception 4c: Speech Analysis 4d: Text-to-Speech 4e: Speech Recognition 4f: Dialog Systems Digital Speech Processing Course Prof. Lawrence Rabiner http://www.caip.rutgers.edu/~lrr/

3
Tema 6: Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Tecnología de Reconocimiento de Locutor Tecnología de Reconocimiento de Habla Tratamiento Digital de Voz

4
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: ¿qué se dice? La variedad de locutores (¿quién lo dice?): “ruido” (Acentos, variedades dialectales, etc.) Reconocimiento de Locutor: ¿quién lo dice? La variedad de mensajes hablados (¿qué se dice?): “ruido” variación intra-locutor variación inter-locutores
: ruido (Acentos, variedades dialectales, etc.) Reconocimiento de Locutor: ¿quién lo dice. La variedad de mensajes hablados (¿qué se dice ): ruido variación intra-locutor variación inter-locutores.")
5
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: Características Dependiente / Independiente de Locutor Tamaño del Vocabulario “Tipos de Reconocimiento”: Habla aislada, palabras en contexto (word spotting), habla natural, lenguaje natural, habla espontánea,... Otros: Entorno de Ruido: móviles, cabinas, automóvil,... Sistema de comunicación: GSM, manos-libres, VoIP,... Prestaciones

6
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: Dependiente/Independiente del Locutor Dependiente de Locutor: por ejemplo, sistemas de dictado. Independiente de Locutor: aplicaciones telefónicas. Cada vez mayor importancia de las “Técnicas de Adaptación al Locutor” Reducción de la cantidad de voz para la adaptación. Adaptación supervisada / no-supervisada. Adaptación también al entorno de ruido. Adaptación a “habla espontánea”.

7
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: Tamaño del Vocabulario El vocabulario DEBE estar pre-fijado (en muchas ocasiones es muy importante la gestión dinámica de vocabularios : entradas variables) El diseño del vocabulario puede “olvidar” palabras: palabras fuera del vocabulario (OOV out-of-vocabulary). Cómo detectar e incorporar esas palabras es de gran importancia. Las prestaciones del Reconocedor son dependientes del tamaño del vocabulario: Pequeño ( 1000 -- 1M) PERO es muy importante (muchas veces más que el número de palabras): o El grado de similitud acústica entre palabras (ej.: teléfonos) o La GRAMÁTICA de reconocimiento. La gramática restringe la secuencia de palabras a reconocer.
 PERO es muy importante (muchas veces más que el número de palabras): o El grado de similitud acústica entre palabras (ej.: teléfonos) o La GRAMÁTICA de reconocimiento. La gramática restringe la secuencia de palabras a reconocer..")
8
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: ”Tipo” de Reconocimiento (terminología imprecisa) Habla aislada: lista de palabras (directorio de nombres) Palabras en contexto (word spotting): “con Juan Pérez por favor” Habla natural: “dictado natural,” u “órdenes naturales” (“quiero que me digas qué películas ponen hoy”) Lenguaje natural: suele asociarse a la identificación de entidades semánticas: quiero que me digas qué películas ponen hoy Habla espontánea: “disfluencias” : “..eh quiero que me des, que me diga.. digas qué... pone... las películas de hoy”

9
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Habla: Características Más otros.... Entorno de Ruido: móviles, cabinas, automóvil,... Sistema de comunicación: GSM, manos-libres, VoIP,... DIFICULTAD de medir “realmente” las prestaciones de un sistema de reconocimiento (en laboratorio en aplicaciones) Errores de Reconocimiento: Tasa de Error (Sustituciones / Inserciones / Elisiones (borrados)) Rechazo: Falsa Aceptación / Falso Rechazo => INFLUYE en la Tasa de Error. Ruidos Palabras OOV (fuera del vocabulario) Medidas de Confianza: “seguridad” del resultado de reconocimiento (ejemplo: Adaptación no-supervisada)
 Errores de Reconocimiento: Tasa de Error (Sustituciones / Inserciones / Elisiones (borrados)) Rechazo: Falsa Aceptación / Falso Rechazo => INFLUYE en la Tasa de Error. Ruidos Palabras OOV (fuera del vocabulario) Medidas de Confianza: seguridad del resultado de reconocimiento (ejemplo: Adaptación no-supervisada).")
10
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Locutor: Características Dependiente / Independiente de Texto Población cerrada / abierta “Modos de Funcionamiento”: VERIFICACIÓN IDENTIFICACIÓN (Detección; Autenticación) Otros: Entorno de Ruido..., Sistema de comunicaciones,... VARIABILIDAD ENTRE SESIONES Prestaciones

11
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Rec. de Locutor: Dependiente/Independiente de Texto Dependiente Texto: Texto fijo: locución pre-establecida (clave de acceso) Texto variable (vocabulario fijo): se pide que el locutor pronuncie una clave generada aleatoriamente (text prompted); objetivos: evitar grabaciones y “clave en voz alta” Independiente de Texto: el locutor puede emplear cualquier locución, sin restricciones (duración, riqueza fonética ? Imaginación ? => tipo de aplicación: Acústica Forense) Importancia de la estrategia de diálogo (factores humanos): preguntas sucesivas (nombre, apellidos, fecha de nacimiento,...) Reconocimiento de Locutor Sistemas de Verificación de Información Verbal (complementarios? Fases diferentes ?)
 Texto variable (vocabulario fijo): se pide que el locutor pronuncie una clave generada aleatoriamente (text prompted); objetivos: evitar grabaciones y clave en voz alta Independiente de Texto: el locutor puede emplear cualquier locución, sin restricciones (duración, riqueza fonética . Imaginación . => tipo de aplicación: Acústica Forense) Importancia de la estrategia de diálogo (factores humanos): preguntas sucesivas (nombre, apellidos, fecha de nacimiento,...) Reconocimiento de Locutor Sistemas de Verificación de Información Verbal (complementarios. Fases diferentes ).")
12
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Locutor: Población cerrada/abierta Población cerrada: reconocimiento entre un conjunto cerrado de usuarios; “el impostor está en casa”. Población abierta: reconocimiento “abierto” a impostores externos a los “locutores reconocibles”

13
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Locutor: Modos de funcionamiento VERIFICACIÓN: decidir si una persona es quien dice ser utilizando su “huella vocal” (ej.: tecleo mi password y el sistema me pide que hable para comprobar que soy yo: se contrasta la voz dubitada contra una sola “huella vocal” –la del password-) IDENTIFICACIÓN: decidir si la voz de una persona pertenece a algun locutor de una población de locutores identificados. (se compara la voz dubitada con todas las huellas vocales de la población “indubitada”) (DETECCIÓN: localización de un locutor en una grabación de audio – AUTENTICACIÓN: mediante verificación/identificación)
 (DETECCIÓN: localización de un locutor en una grabación de audio – AUTENTICACIÓN: mediante verificación/identificación).")
14
Reconocimiento de Voz Principios de Reconocimiento de Habla y de Locutor Reconocimiento de Locutor: Prestaciones Otros: Entorno de Ruido... Sistema de comunicación... VARIABILIDAD ENTRE SESIONES Errores de Reconocimiento: tasas de: Falsa Aceptación FA: un impostor vulnera el sistema Falso Rechazo FR: un usuario no es reconocido “Aciertos” de Reconocimiento: Rechazo correcta: un impostor es rechazado Aceptación correcta: un usuario es reconocido El coste de cada tipo de error depende de la aplicación (por ejemplo: mayor, menor seguridad) TAMBIÉN en aplicaciones reales: FTE Fail-to-enroll; imposibilidad de entrenarse en el sistema
 TAMBIÉN en aplicaciones reales: FTE Fail-to-enroll; imposibilidad de entrenarse en el sistema.")
15
Four conditional probabilities in speaker verification 0012-09 Input utterance Decision condition condition s n (customer) (impostor) S (accept) N (reject) P(S | s) P(S | n) P(N | s) P(N | n)
 (impostor) S (accept) N (reject) P(S | s) P(S | n) P(N | s) P(N | n)")
16
Relationship between error rate and decision criterion (threshold) in speaker verification 0012-10 Error rate Decision criterion (Threshold) 1 0 FR= P (N | s) FA= P (S | n) a c b Equal Error Rate EER
 in speaker verification Error rate Decision criterion (Threshold) 1 0 FR= P (N | s) FA= P (S | n) a c b Equal Error Rate EER")
17
Receiver operating characteristic (ROC) curves; performance examples of three speaker verification systems: A, B, and D 0012-11 1 1 0 P (S | n) P (S | s) A B D a b
 curves; performance examples of three speaker verification systems: A, B, and D P (S | n) P (S | s) A B D a b")
18
Reconocimiento de Voz Reconocimiento de Locutor: Prestaciones (http://www.nist.gov/speech)http://www.nist.gov/speech Curvas ROCCurvas DEC

19
Reconocimiento de Voz Reconocimiento de Locutor: Prestaciones (http://www.nist.gov/speech) We have found it useful in speech applications to use a variant of this which we call the DET (Detection Error Tradeoff) Curve, described below. In the DET curve we plot error rates on both axes, giving uniform treatment to both types of error, and use a scale for both axes which spreads out the plot and better distinguishes different well performing systems and usually produces plots that are close to linear.

20
Recognition error rates as a function of population size in speaker identification and verification 0103-23 20 10 5 2 1 0.5 0.2 0.1 2 5 10 20 50 100 Male Female Identification Verification Recognition error rate (%) Size of population
 Size of population")
21
Reconocimiento de Voz Reconocimiento de Locutor: Prestaciones (La Granja) SHEEP, GOATS, LAMBS and WOLVES A Statistical Analysis of Speaker Performance in the NIST 1998 Speaker Recognition Evaluation George Doddington 1,2,3,5, Walter Liggett 1, Alvin Martin 1, Mark Przybocki 1, Douglas Reynolds 3,4, 1 National Institute of Standards and Technology, 2 The Johns Hopkins University 3 U.S. Department of Defense, 4 MIT Lincoln Laboratory, 5 SRI International

22
Reconocimiento de Voz Reconocimiento de Locutor: Prestaciones (La Granja) Sheep (ovejas) – Sheep comprise our default speaker type. In our model, sheep dominate the population and systems perform nominally well for them. Goats (cabras) – Goats, in our model, are those speakers who are particularly difficult to recognize. Goats tend to adversely affect the performance of systems by accounting for a disproportionate share of the missed detections. The goat population can be an especially important problem for entry control systems, where it is important that all users be reliably accepted.
 – Goats, in our model, are those speakers who are particularly difficult to recognize. Goats tend to adversely affect the performance of systems by accounting for a disproportionate share of the missed detections. The goat population can be an especially important problem for entry control systems, where it is important that all users be reliably accepted..")
23
Reconocimiento de Voz Lambs (corderos) – Lambs, in our model, are those speakers who are particularly easy to imitate. That is, a randomly chosen speaker is exceptionally likely to be accepted as a lamb. Lambs tend to adversely affect the performance of systems by accounting for a disproportionate share of the false alarms. This represents a potential system weakness, if lambs can be identified, either through trial and error or through correlation with other directly observable characteristics. Wolves (lobos) – Wolves, in our model, are those speakers who are particularly successful at imitating other speakers. That is, their speech is exceptionally likely to be accepted as that of another speaker. Wolves tend to adversely affect the performance of systems by accounting for a disproportionate share of the false alarms. This represents a potential system weakness, if wolves can be identified and recruited to defeat systems.
 – Wolves, in our model, are those speakers who are particularly successful at imitating other speakers. That is, their speech is exceptionally likely to be accepted as that of another speaker. Wolves tend to adversely affect the performance of systems by accounting for a disproportionate share of the false alarms. This represents a potential system weakness, if wolves can be identified and recruited to defeat systems..")
24
Tecnología de Reconocimiento de Locutor Estructura de un Sistema de Reconocimiento de Locutor Tratamiento Digital de Voz Resultado Reconocimiento Señal de Voz Entrenamiento Reconocimiento Extracción De Características Modelos/Patrones de referencia para cada Locutor Comparación (Distancia) Speech Recognition Technology in the Ubiquitous/Wearable Computing Environment Sadaoki Furui http://www.furui.cs.titech.ac.jp/
 Speech Recognition Technology in the Ubiquitous/Wearable Computing Environment Sadaoki Furui")
25
Tecnología de Reconocimiento de Locutor Otros aspectos importantes: Tratamiento Digital de Voz Resultado Reconocimiento Señal de Voz Extracción De Características Modelos/Patrones de referencia para cada Locutor Comparación (Distancia) Detector de Actividad Cancelador De Ecos “Compensación” De Ruido
 Detector de Actividad Cancelador De Ecos Compensación De Ruido")
26
Identificación Tecnología de Reconocimiento de Locutor Similarity Reference template or model (Speaker #N) Reference template or model (Speaker #N) Reference template or model (Speaker #2) Reference template or model (Speaker #2) Reference template or model (Speaker #1) Reference template or model (Speaker #1) Feature extraction Feature extraction Maximum selection Maximum selection Speech wave Identification result (Speaker ID)
 Reference template or model (Speaker #N) Reference template or model (Speaker #2) Reference template or model (Speaker #2) Reference template or model (Speaker #1) Reference template or model (Speaker #1) Feature extraction Feature extraction Maximum selection Maximum selection Speech wave Identification result (Speaker ID)")
27
Verificación Tecnología de Reconocimiento de Locutor Speech wave Identification result (Accept / Reject) Speaker ID (#M) Similarity Reference template or model (Speaker #M) Reference template or model (Speaker #M) Feature extraction Feature extraction Decision Threshold
 Speaker ID (#M) Similarity Reference template or model (Speaker #M) Reference template or model (Speaker #M) Feature extraction Feature extraction Decision Threshold")
28
Decisión Tecnología de Reconocimiento de Locutor Distance Intra-speaker distance Inter-speaker distance DB DB Distribution

29
Objetivo: obtener un modelo del locutor Para discriminación, no para codificación ni síntesis Marco de Trabajo: Reconocimiento de Patrones El clasificador óptimo es el clasificador de Bayes Tecnología de Reconocimiento de Locutor

30
“Todo” lo necesario es conocer la función de probabilidad Tecnología de Reconocimiento de Locutor O RechazoClase 1Clase 2Clase 3Clase 2Rechazo

31
“Todo” lo necesario es conocer la función de probabilidad Tecnología de Reconocimiento de Locutor O............ Max Rechazo

32
PERO: la función de probabilidad “nunca” se conoce: forma paramétrica desconocida y cantidad de datos de estima (entrenamiento) limitados Tecnología de Reconocimiento de Locutor O............ Max Rechazo NO UN CLASIFICADOR ÚNICO Funciones de Discriminación

33
De una forma simplificada podemos considerar: Por la técnica de clasificación: Clasificadores no-paramétricos Clasificadores paramétricos (Discriminativos) Atendiendo al tipo de información empleada: Clasificadores a partir de información a largo plazo Clasificadores a partir de información a corto plazo Tecnología de Reconocimiento de Locutor
 Atendiendo al tipo de información empleada: Clasificadores a partir de información a largo plazo Clasificadores a partir de información a corto plazo Tecnología de Reconocimiento de Locutor")
34
0012-13 (b) short-term information based method Input speech Speaker identity Paterns Feature extraction Feature extraction Decision Accumulation Parametric or Non-Parametric Parametric or Non-Parametric (a) Long-term-statistics-based method Input speech Speaker identity Reference templates or models Feature extraction Feature extraction Decision Distance or similarity Distance or similarity Long-term statistics Long-term statistics Average, variance, correlation, MAR
 short-term information based method Input speech Speaker identity Paterns Feature extraction Feature extraction Decision Accumulation Parametric or Non-Parametric Parametric or Non-Parametric (a) Long-term-statistics-based method Input speech Speaker identity Reference templates or models Feature extraction Feature extraction Decision Distance or similarity Distance or similarity Long-term statistics Long-term statistics Average, variance, correlation, MAR")
35
Por la técnica de clasificación... Clasificadores no-paramétricos: No hacen ninguna hipótesis sobre el modelo de distribución de la voz del locutor Se basan completamente en los datos de entrenamiento Un ejemplo típico serían los sistemas de Reconocimiento Independientes del Locutor basados en Cuantificación Vectorial Tecnología de Reconocimiento de Locutor

36
Vector quantization (VQ)-based text-independent speaker recognition 0103-19 Spectral envelopes Speaker-specific codebook
-based text-independent speaker recognition Spectral envelopes Speaker-specific codebook")
37
Cuantificador Vectorial Tecnología de Reconocimiento de Locutor X Y Representa el conjunto de vectores de ENTRENAMIENTO X={x 1,x 2,... x N } por un número pequeño de representantes (centroides) Y={y 1, y 2,... y M } (M<N) Fase 1. Determinación de los representantes –Medida de distancia d( x i, y j ) Y –Entrenamiento: Codebook Y Fase 2. Asignación del centroide más próximo –Cuantificación de una observación o
 Y={y 1, y 2,... y M } (M<N) Fase 1. Determinación de los representantes –Medida de distancia d( x i, y j ) Y –Entrenamiento: Codebook Y Fase 2. Asignación del centroide más próximo –Cuantificación de una observación o.")
38
Entrenamiento CV algoritmo LBG Tecnología de Reconocimiento de Locutor Primer centroide D? N? Duplicación Asignación de vectores Cálculo de centroides SI NO

39
Cuantificación Asunción Moreno Universidad Politécnica de Cataluña

40
Entrenamiento x y

41
x y

42
x y

43
x y

44
x y

45
x y

46
x y

47
x y

48
x y

49
x y

50
x y

51
x y

52
Cuantificación x y

53
VQ Performance on Unseen Data Ramachandran & Mamone (eds) ‘Modern Methods of Speech Processing’ Kluer Academic, 1995
 ‘Modern Methods of Speech Processing’ Kluer Academic, 1995")
54
Reconocimiento de Voz Reconocimiento de Locutor: Prestaciones (La Granja) SHEEP, GOATS, LAMBS and WOLVES A Statistical Analysis of Speaker Performance in the NIST 1998 Speaker Recognition Evaluation George Doddington 1,2,3,5, Walter Liggett 1, Alvin Martin 1, Mark Przybocki 1, Douglas Reynolds 3,4, 1 National Institute of Standards and Technology, 2 The Johns Hopkins University 3 U.S. Department of Defense, 4 MIT Lincoln Laboratory, 5 SRI International

55
Tecnología de Reconocimiento de Locutor Input speech Speaker identity VQ codebooks Feature extraction Feature extraction Decision Accumulation VQ distortion Independencia de Texto Observaciones independientes

56
Reconocimiento de Locutor mediante CV El cuantificador vectorial “representa” la distribución estadística de los datos Otras técnicas de entrenamiento: Entrenamiento Discriminativo: el objetivo no es el minimizar el error de cuantificación sino el Error de CLASIFICACIÓN (técnicas de gradiente -> Redes Neuronales) Tecnología de Reconocimiento de Locutor
 Tecnología de Reconocimiento de Locutor")
57
Por la técnica de clasificación... Clasificadores paramétricos (I): Son los más utilizados en Reconocimiento Tecnología de Reconocimiento de Locutor
: Son los más utilizados en Reconocimiento Tecnología de Reconocimiento de Locutor.")
58
Por la técnica de clasificación... Clasificadores paramétricos (II): Utilizan una representación paramétrica explícita de la probabilidad acústica: X Los parámetros de se estiman a partir de los datos de entrenamiento X={x 1,x 2,... x N } Proporciona un formalismo matemático consistente para técnicas de adaptación a diferentes condiciones y entornos. Tecnología de Reconocimiento de Locutor
: Utilizan una representación paramétrica explícita de la probabilidad acústica: X Los parámetros de se estiman a partir de los datos de entrenamiento X={x 1,x 2,... x N } Proporciona un formalismo matemático consistente para técnicas de adaptación a diferentes condiciones y entornos. Tecnología de Reconocimiento de Locutor.")
60
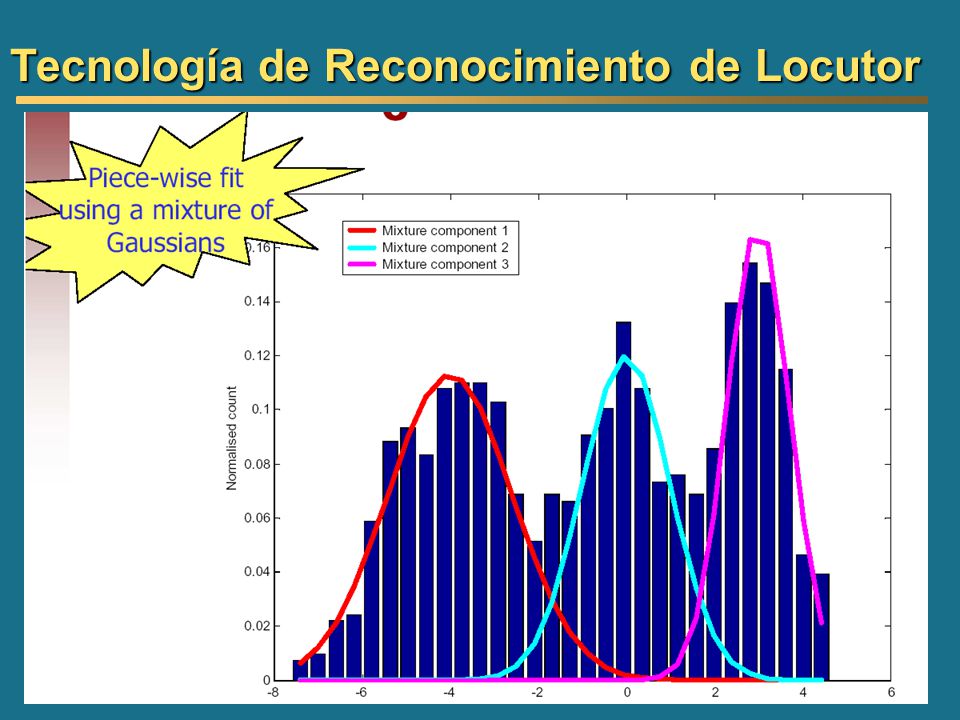
Clasificadores paramétricos: GMM (Gaussian Mixture Models) Representación paramétrica explícita de la probabilidad acústica como suma de fdp gaussianas: Tecnología de Reconocimiento de Locutor
 Representación paramétrica explícita de la probabilidad acústica como suma de fdp gaussianas: Tecnología de Reconocimiento de Locutor")
61
Clasificadores paramétricos: GMM (Gaussian Mixture Models) X Los parámetros de se estiman a partir de los datos de entrenamiento X={x 1,x 2,... x N } La combinación de gaussianas se aproxima a la distribución de los datos. Tecnología de Reconocimiento de Locutor

64
Identificación con GMMs Tecnología de Reconocimiento de Locutor Feature extraction Feature extraction Maximum selection Maximum selection Speech wave Identification result (Speaker ID)
")
65
Tecnología de Reconocimiento de Locutor Verificación con GMMs : Normalización Likelihood ratio log L(O) log p(O = c ) log p(O c ) c : identidad supuesta A posteriori probability log L(O) log p(O = c ) log p(O ) Ref : locutor de referencia o cohorte de locutores Modelo Universal log L(O) log p(O = c ) log p(O UBM ) UBM : Universal Background Model Likelihood ratio log L(O) log p(O = c ) log p(O c ) c : identidad supuesta A posteriori probability log L(O) log p(O = c ) log p(O ) Ref : locutor de referencia o cohorte de locutores Modelo Universal log L(O) log p(O = c ) log p(O UBM ) UBM : Universal Background Model S Ref
 log p(O = c ) log p(O c ) c : identidad supuesta A posteriori probability log L(O) log p(O = c ) log p(O ) Ref : locutor de referencia o cohorte de locutores Modelo Universal log L(O) log p(O = c ) log p(O UBM ) UBM : Universal Background Model Likelihood ratio log L(O) log p(O = c ) log p(O c ) c : identidad supuesta A posteriori probability log L(O) log p(O = c ) log p(O ) Ref : locutor de referencia o cohorte de locutores Modelo Universal log L(O) log p(O = c ) log p(O UBM ) UBM : Universal Background Model S Ref")
66
Tecnología de Reconocimiento de Locutor

67
Clasificadores paramétricos: GMM (Gaussian Mixture Models) X Los parámetros de se estiman a partir de los datos de entrenamiento X={x 1,x 2,... x N } ¡¡IMPORTANTE!!: Cantidad de datos de entrenamiento Número de Parámetros a estimar Técnicas de Entrenamiento: ML (Maximum Likelihood) MAP (Maximun a posteriori) Similares resultados si no hay información a priori, pero MAP válida para adaptación Tecnología de Reconocimiento de Locutor
 MAP (Maximun a posteriori) Similares resultados si no hay información a priori, pero MAP válida para adaptación Tecnología de Reconocimiento de Locutor.")
68
Entrenamiento ML Tecnología de Reconocimiento de Locutor

71
Reconocimiento de Locutor => Reconocimiento de Habla Hasta ahora: El orden de la secuencia de sonidos NO IMPORTABA => Independiente de Texto PERO: En Reconocimiento de Locutor dependiente de texto En Reconocimiento de Habla La secuencia de sonidos sí importa (“casa” “saca”) Primera Aproximación: Alineamiento Temporal + Medida de Distancia (DTW Dynamic Time Warping) Tratamiento Digital de Voz
 Primera Aproximación: Alineamiento Temporal + Medida de Distancia (DTW Dynamic Time Warping) Tratamiento Digital de Voz")
72
Reconocimiento de Locutor => Reconocimiento de Habla Primera Aproximación: Alineamiento Temporal + Medida de Distancia (DTW Dynamic Time Warping) Tratamiento Digital de Voz CASACASA ENVENTANADO V3V4V5V6 V2V2 V1V1 PATRÓN }{ ANÁLISIS
 Tratamiento Digital de Voz CASACASA ENVENTANADO V3V4V5V6 V2V2 V1V1 PATRÓN }{ ANÁLISIS")
73
Reconocimiento de Locutor => Reconocimiento de Habla DTW Dynamic Time Warping) ENTRENAMIENTO: se obtiene y almacena un patrón de refrencia (PRef) para cada una de las palabras del vocabulario RECONOCIMIENTO: se obtiene el patrón de la palabra a reconocer (PReco). La palabra reconocida será la correspondiente al patrón de referencia más parecido (menor distancia) al patrón a reconocer. Tratamiento Digital de Voz PROBLEMA: PRef TIENE DISTINTA DURACIÓN TEMPORAL QUE PReco SOLUCIÓN: DEFORMAR EL EJE DE TIEMPOS ESTIRÁNDOLO O ENCOGIÉNDOLO (TÉCNICAS DE PROGRAMACIÓN DINÁMICA)
 al patrón a reconocer. Tratamiento Digital de Voz PROBLEMA: PRef TIENE DISTINTA DURACIÓN TEMPORAL QUE PReco SOLUCIÓN: DEFORMAR EL EJE DE TIEMPOS ESTIRÁNDOLO O ENCOGIÉNDOLO (TÉCNICAS DE PROGRAMACIÓN DINÁMICA).")
74
Tratamiento Digital de Voz

75
Reconocimiento de Locutor => Reconocimiento de Habla DTW Dynamic Time Warping Tratamiento Digital de Voz Cálculo distancia acumulada g(i,j) según el “camino óptimo” (Programación Dinámica) g(i,j) = d(i,j) + min { g(i-1,j), g(i-1,j-1), g(i,j-1)} 1 < i < I ( nº tramas de Preco ) 1 < j < J ( nºtramas de Pref ) g(i,j) g(i,j-1)g(i-1,j-1) g(i-1,j) La distancia entrel el PRef y el PReco d(PRef, PReco) será: d(Preco, Pref) = g(I,J) / I+J
 según el camino óptimo (Programación Dinámica) g(i,j) = d(i,j) + min { g(i-1,j), g(i-1,j-1), g(i,j-1)} 1 < i < I ( nº tramas de Preco ) 1 < j < J ( nºtramas de Pref ) g(i,j) g(i,j-1)g(i-1,j-1) g(i-1,j) La distancia entrel el PRef y el PReco d(PRef, PReco) será: d(Preco, Pref) = g(I,J) / I+J")
76
Reconocimiento de Locutor => Reconocimiento de Habla DTW Dynamic Time Warping) Tratamiento Digital de Voz 15678432 5 4 3 2 1 PALABRA A RECONOCER (TIEMPO) PATRÓN DE REFERENCIA (TIEMPO)
 Tratamiento Digital de Voz PALABRA A RECONOCER (TIEMPO) PATRÓN DE REFERENCIA (TIEMPO)")
77
Tecnología Dominante: HMM (Hidden Markov Models) Clasificador Paramétrico: p(O/ con secuencia de sonidos, palabras, frases,... Primera Aproximación: Estados + GMMs por Estado Reconocimiento de Habla

78
HMM (Hidden Markov Models) IMPORTA la secuencia de sonidos DEFINICIÓN DE UN HMM : Topología (izquierda – derecha; saltos; no. estados) Probabilidades de transión entre estados a ij Probabilidades de comenzar en el estado i: i Probabilidades de observación de cada estado b i (O t ) Reconocimiento de Habla a55 a11 a22a33 a44 a24 a23a34a45 a13 a35 a12 Caso sencillo: HMM de una palabra L : L
 Probabilidades de transión entre estados a ij Probabilidades de comenzar en el estado i: i Probabilidades de observación de cada estado b i (O t ) Reconocimiento de Habla a55 a11 a22a33 a44 a24 a23a34a45 a13 a35 a12 Caso sencillo: HMM de una palabra L : L.")
79
HMM (Hidden Markov Models) Reconocimiento de Habla a55 a11 a22a33 a44 a24 a23a34a45 a13 a35 a12 Caso sencillo: HMM de una palabra i : i No. Estados: ¿no. sonidos ? ¿no. Medio de tramas / sonido? “lógica propia del modelado HMM” i = “siete” S1=/s/ S2=/i/ S3=/e/ S4=/t/ S5=/e/

80
HMM (Hidden Markov Models) Reconocimiento de Habla a55 a11 a22a33 a44 a24 a23a34a45 a13 a35 a12 Caso sencillo: HMM de una palabra L : L a ij : duración de los sonidos en cada estado (?) Probabilidad de comenzar en el estado i: i Izquierda – derecha: 1 =1 ; i =0 i != 0
 Reconocimiento de Habla a55 a11 a22a33 a44 a24 a23a34a45 a13 a35 a12 Caso sencillo: HMM de una palabra L : L a ij : duración de los sonidos en cada estado ( ) Probabilidad de comenzar en el estado i: i Izquierda – derecha: 1 =1 ; i =0 i != 0")
81
HMM (Hidden Markov Models) Reconocimiento de Habla Probabilidades de observación de cada estado b i (O t ): Continua (mezcla de gaussianas) Discreta (Cuantificador vectorial + probabilidades centroides) Semicontinua (gaussianas compartidas)
 Reconocimiento de Habla Probabilidades de observación de cada estado b i (O t ): Continua (mezcla de gaussianas) Discreta (Cuantificador vectorial + probabilidades centroides) Semicontinua (gaussianas compartidas)")
82
HMM (Hidden Markov Models) Reconocimiento de Habla Resultado DECISOR 11 3..................... LL RECONOCIMIENTO P(O/ 1 ) P(O/ ) P(O/ 3 ) P(O/ L ) MÁXIMO 22 Rechazo Confianza N-Best
 P(O/ ) P(O/ 3 ) P(O/ L ) MÁXIMO 22 Rechazo Confianza N-Best.")
83
Eduardo Lleida Solano Dpt. de Ingeniería Electrónica y Comunicaciones Universidad de Zaragoza

84
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Las Bases n Utilizando la fórmula de Bayes n P(W)... Probabilidad de que la secuencia de palabras W sea pronunciada n P(O|W)... Probabilidad de que cuando una persona pronuncia la secuencia de palabras W obtengamos la secuencia de medidas acústicas O n P(O)... Probabilidad de la secuencia de medidas acústicas O n Fórmula del Reconocedor Modelo AcústicoModelo de Lenguaje
... Probabilidad de que cuando una persona pronuncia la secuencia de palabras W obtengamos la secuencia de medidas acústicas O n P(O)... Probabilidad de la secuencia de medidas acústicas O n Fórmula del Reconocedor Modelo AcústicoModelo de Lenguaje.")
85
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza

86
Modelado de Lenguaje: Gramáticas de Dictado n n-gramas p( W ) = p( w 1 w 2...w N ) = p( w 1 ) p( w 2 / w 1 )... p( w N / w 1 w 2...w N-1 ) n Clases de palabras p( w i / w 1 w 2...w i-1 ) = p( w i / w i-n+1...w i-1 ) p( w i / w 1 w 2...w i-1 ) = p( w i / C(w i ) ) p( C(w i ) / C(w i-n+1 )...C (w i-1 ) ) n Punto de vista probabilístico volver n Dificultad de una tarea: número promedio de transiciones desde una palabra: Perplejidad generalmente: n = 2 : bigramas n = 3 : trigramas
 n Clases de palabras p( w i / w 1 w 2...w i-1 ) = p( w i / w i-n+1...w i-1 ) p( w i / w 1 w 2...w i-1 ) = p( w i / C(w i ) ) p( C(w i ) / C(w i-n+1 )...C (w i-1 ) ) n Punto de vista probabilístico volver n Dificultad de una tarea: número promedio de transiciones desde una palabra: Perplejidad generalmente: n = 2 : bigramas n = 3 : trigramas.")
87
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza

88
Modelos Ocultos de Markov Reconocimiento Dado un Modelo Oculto de Markov (HMM) Calcular la probabilidad de que dicho modelo genere la secuencia de medidas acústicas O={O 1, O 2, O 3,.... O T }

89
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza

91
Modelos Ocultos de Markov n Aproximación: secuencia más probable de estados n Algoritmo de Viterbi Inicialización 1 (i) = i b i (O 1 ) 1 (i) = 01 i N Estado observación 1 2 3 12T
 = i b i (O 1 ) 1 (i) = 01 i N Estado observación T")
92
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Recursión t (j) = max [ t-1 (i) a ij ] b j (O t ) 2 t T 1 i N t (j) = arg max [ t-1 (i) a ij ] 1 j N 1 i N Estado observación 1 2 3 12T t-1 (i) a ij t (j)
![Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Recursión t (j) = max [ t-1 (i) a ij ] b j (O t ) 2 t T 1 i N t (j) = arg max [ t-1 (i) a ij ] 1 j N 1 i N Estado observación T t-1 (i) a ij t (j)](http://images.slideplayer.es/13/4140706/slides/slide_92.jpg "Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Recursión t (j) = max [ t-1 (i) a ij ] b j (O t ) 2 t T 1 i N t (j) = arg max [ t-1 (i) a ij ] 1 j N 1 i N Estado observación T t-1 (i) a ij t (j)")
93
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Backtraking P* = max [ T (i)] 1 i N q T *=arg max [ T (i)] 1 i N q t * = t+1 ( q t+1 *)t = T-1, T-2,...1 Estado observación 1 2 3 12T
![Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Backtraking P* = max [ T (i)] 1 i N q T *=arg max [ T (i)] 1 i N q t * = t+1 ( q t+1 *)t = T-1, T-2,...1 Estado observación T](http://images.slideplayer.es/13/4140706/slides/slide_93.jpg "Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Algoritmo de Viterbi Backtraking P* = max [ T (i)] 1 i N q T *=arg max [ T (i)] 1 i N q t * = t+1 ( q t+1 *)t = T-1, T-2,...1 Estado observación T")
94
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza

95
Algoritmo de Reconocimiento Algoritmo de Reconocimiento voz Secuencia de palabras O W = w 1 w 2... w N Regla de búsqueda W = argmax { p( W/O ) } = argmax { p( O / W ) p( W ) } WW Modelo Acústico Modelo de Lenguaje
 } = argmax { p( O / W ) p( W ) } WW Modelo Acústico Modelo de Lenguaje.")
96
Grupo de Tecnologías de las Comunicaciones, Universidad de Zaragoza Word String Search n Maximization function W = argmax { p( W /O ) } = argmax { p( O / W ) p( W ) } WW p( O / W) = Σ p( O, s / W) = Σ Π p( O is / w i ) s i Acoustic model p( W ) = p( w 1 w 2...w N ) = p( w 1 ) Π p( w i / w i-1 ) i Language model i W= argmax { p( w 1 ) p( O 1s / w 1 ) Π p( O is / w i ) p( w i / w i-1 ) } W
 } = argmax { p( O / W ) p( W ) } WW p( O / W) = Σ p( O, s / W) = Σ Π p( O is / w i ) s i Acoustic model p( W ) = p( w 1 w 2...w N ) = p( w 1 ) Π p( w i / w i-1 ) i Language model i W= argmax { p( w 1 ) p( O 1s / w 1 ) Π p( O is / w i ) p( w i / w i-1 ) } W")
Presentaciones similares