Descargar la presentación
La descarga está en progreso. Por favor, espere

1
ARQUITECTURAS SIMD Clase Práctica No 6

2
1. Vector Processor M-M 1. Estime el tiempo de ejecución de una suma vectorial en un Vector Processor M-M basado en un cauce de 7 etapas que tiene un período de reloj de 200 ns y un tiempo de preparación de 20 ciclos, sabiendo que la operación se realiza sobre vectores de 128 elementos manteniendo ejecución en flujo continuo todo el tiempo.

3
1. Vector Processor M-M Recordemos Modelo tiempo de ejecución t v = t preparacion + t paso t v = t preparacion + k + (N-1) Reemplazando: t v = 20 + 7 + (N-1) 27+ N-1) t v = 27+ 127) = 154*200ns t v = 30,800ns = 30.8 s
 Reemplazando: t v = 20 + 7 + (N-1) 27+ N-1) t v = ) = 154*200ns t v = 30,800ns = 30.8 s.")
4
2. Vector Processor R-R Suponga que usted ejecuta dos operaciones vectoriales con dependencia de datos R-D en un VP R-R. La primera operación la realiza una unidad vectorial basada en un cauce de 5 etapas. La segunda, en otra unidad de 7 etapas. Todas las unidades tienen un período de reloj de 100 ns y un tiempo de preparación de 10 ciclos. sabiendo que las operaciones se realizan sobre vectores de 128 elementos, estime: Tiempo de ejecución total si las operaciones se ejecutan secuencialmente. Tiempo de ejecución total si se emplea encadenamiento de cauces.

5
2. Vector Processor R-R Caso secuencial: similar al anterior t total = [tprep 1 + k 1 +(N-1) ] + [tprep 2 + k 2 +(N-1) ] Con Encadenamiento: t total = tprep 1 + k 1 + k 2 +(N-1) tprep 1 + (k 1 +k 2 +N-1) t prep1 k1k1 (N-1) t prep2 k2k2 (N-1) t prep1 k1k1 t producción (N-1) t prep2 k2k2 (N-1)
 ] + [tprep 2 + k 2 +(N-1) ] Con Encadenamiento: t total = tprep 1 + k 1 + k 2 +(N-1) tprep 1 + (k 1 +k 2 +N-1) t prep1 k1k1 (N-1) t prep2 k2k2 (N-1) t prep1 k1k1 t producción (N-1) t prep2 k2k2 (N-1) .")
6
3. Array Processor: S(k) Explique el funcionamiento de un Array Processor para calcular Suma S(k) de las primeras k componentes de un vector A. Recuerde que esta arquitectura se basa en una red de EPs con UC central. Aproveche las operaciones de ruteo y enmascaramiento para calcular las sumas recursivamente.
 Explique el funcionamiento de un Array Processor para calcular Suma S(k) de las primeras k componentes de un vector A. Recuerde que esta arquitectura se basa en una red de EPs con UC central. Aproveche las operaciones de ruteo y enmascaramiento para calcular las sumas recursivamente..")
7
3. Array Processor: S(k) Se desea implementar operación S(k) o suma de las primeras k componentes de un vector A para todo k = 0,1,.......N-1, dado A= (A 0, A 1,......A N-1 ) Resulta un vector donde cada elemento vale S(K): la suma de las componentes inferiores o igual a la posición del elemento. Se puede calcular recursivamente realizando N-1 iteraciones definidas como: S(0) = A(0) S(k) = S(k-1) + A(k) para k = 1,2,...., N-1 En el ArrayProcessor esta operación requiere uso de N EPs y se ejecuta en [log 2 N] pasos. Por ejemplo, para N = 8 se usan 8 EP y se ejecuta en 3 pasos: [log 2 8]=3. Utiliza ruteo de datos y enmascaramiento de EP.
 Se desea implementar operación S(k) o suma de las primeras k componentes de un vector A para todo k = 0,1, N-1, dado A= (A 0, A 1,......A N-1 ) Resulta un vector donde cada elemento vale S(K): la suma de las componentes inferiores o igual a la posición del elemento. Se puede calcular recursivamente realizando N-1 iteraciones definidas como: S(0) = A(0) S(k) = S(k-1) + A(k) para k = 1,2,...., N-1 En el ArrayProcessor esta operación requiere uso de N EPs y se ejecuta en [log 2 N] pasos. Por ejemplo, para N = 8 se usan 8 EP y se ejecuta en 3 pasos: [log 2 8]=3. Utiliza ruteo de datos y enmascaramiento de EP..")
8
3. Array Processor: S(k) Preparación: Se copia cada elemento del vector al registro A de su EP correspondiente (ALU: A = A + D). Primer paso: i = 0 a N-2, enrutar el valor del registro A del EP (i) al registro D del EP (i+1) y la unidad de control envía: + Segundo paso: i = 0 a N-3, enrutar el valor del registro A del EP (i) al registro D del EP (i+2) y la unidad de control envía: + Tercer paso: i = 0 a N-5 enrutar el valor del registro A del EP (i) al registro D del EP (i+4) y la unidad de control envía: +
 Preparación: Se copia cada elemento del vector al registro A de su EP correspondiente (ALU: A = A + D). Primer paso: i = 0 a N-2, enrutar el valor del registro A del EP (i) al registro D del EP (i+1) y la unidad de control envía: + Segundo paso: i = 0 a N-3, enrutar el valor del registro A del EP (i) al registro D del EP (i+2) y la unidad de control envía: + Tercer paso: i = 0 a N-5 enrutar el valor del registro A del EP (i) al registro D del EP (i+4) y la unidad de control envía: +.")
9
3. Array Processor: S(k)
")
10
4. Array Processor: C[] = A[]+B[] Diseñe un Array Processor de 4x4 celdas. Recuerde que esta arquitectura se basa en una red de EPs con UC central. Explique la funcionalidad de cada EP para que pueda realizar suma matricial. Corra una suma matricial de 2 matrices de 4X4 en este procesador, explicando el proceso.
![4. Array Processor: C[] = A[]+B[] Diseñe un Array Processor de 4x4 celdas.](http://images.slideplayer.es/12/3885473/slides/slide_10.jpg "Recuerde que esta arquitectura se basa en una red de EPs con UC central. Explique la funcionalidad de cada EP para que pueda realizar suma matricial. Corra una suma matricial de 2 matrices de 4X4 en este procesador, explicando el proceso..")
11
4. Array Processor: C[] = A[]+B[] Esta operación es más simple y puede ser directa si N(RedEP) > N(A|B). Dado que es el caso: Preparación: Se cargan los elementos correspondientes de A[] y B[] a los registros A y D de los EP. Paso 1: Unidad de control instruye: + Guardar resultado: Se almacenan los elementos correspondientes de los registros A de los EP a C[]. Ejemplo en clase
 > N(A|B). Dado que es el caso: Preparación: Se cargan los elementos correspondientes de A[] y B[] a los registros A y D de los EP. Paso 1: Unidad de control instruye: + Guardar resultado: Se almacenan los elementos correspondientes de los registros A de los EP a C[]. Ejemplo en clase.")
12
5. WaveFront Processor: C[] = A[]*B[] Diseñe un WaveFront Processor de 2x2 celdas para multiplicar matrices. Recuerde que esta arquitectura se basa en una red de EPs con control distribuido en la red y los EPs con disparos de celdas y propagación de datos. Explique la funcionalidad de cada EP para que pueda realizar multiplicación matricial. Corra una multiplicación matricial 2x2 para verificar el funcionamiento del WFP. Carque las celdas de la periferia con vectores filas de la primera matriz en las entradas X y vectores columnas de la segunda matriz por las entradas Y. Verifique la multiplicación con una matriz diagonal (idéntico). Trate de derivar una expresión para determinar el desempeño del procesador en la multiplicación de matrices.
. Trate de derivar una expresión para determinar el desempeño del procesador en la multiplicación de matrices..")
13
5. WaveFront Processor: C[] = A[]*B[] Ejemplo de la clase. Solo resta: Aplicar la multiplicación con B[] como matriz diagonal. Derivar expresión del rendimiento: tiempo de ejecución. Calcular las olas que se requieren para diferentes tamaños de matrices Expresión general en base a N. Otras consideraciones: Definir un tiempo de disparo y de propagación. Considerar el tiempo medio de acceso de la memoria. No se puede basar en porque la red es asíncrona.
![5. WaveFront Processor: C[] = A[]*B[] Ejemplo de la clase.](http://images.slideplayer.es/12/3885473/slides/slide_13.jpg "Solo resta: Aplicar la multiplicación con B[] como matriz diagonal. Derivar expresión del rendimiento: tiempo de ejecución. Calcular las olas que se requieren para diferentes tamaños de matrices Expresión general en base a N. Otras consideraciones: Definir un tiempo de disparo y de propagación. Considerar el tiempo medio de acceso de la memoria. No se puede basar en porque la red es asíncrona..")
14
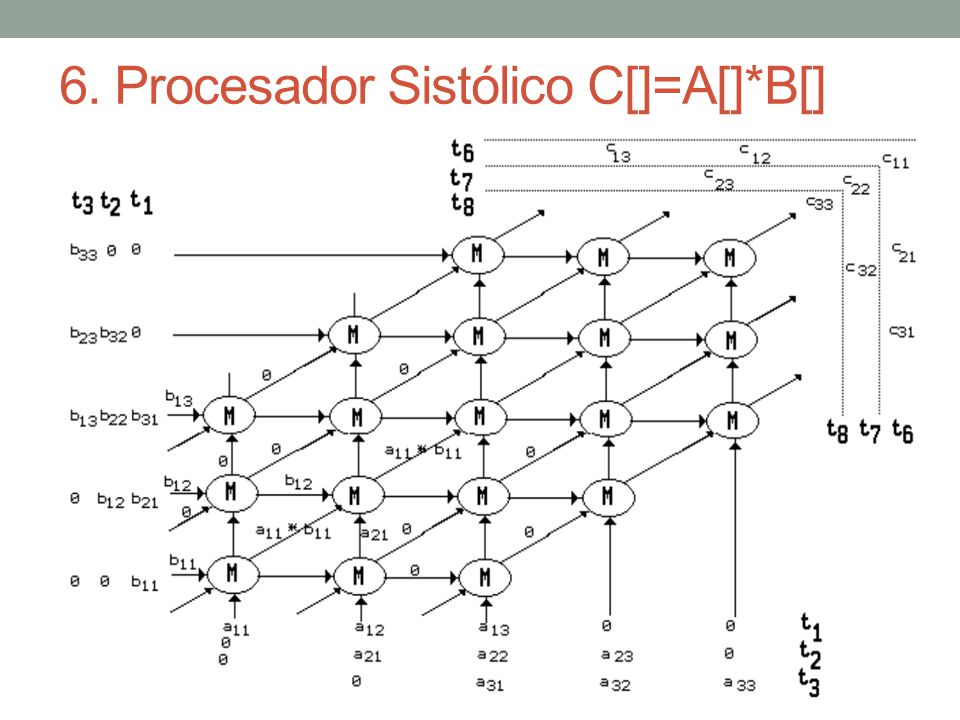
6. Procesador Sistólico C[]=A[]*B[] Diseñe un procesador sistólico para multiplicación de matrices 2x2. Recuerde que esta arquitectura se basa en una red de EPs con control distribuido en la red y los EPs. Explique la funcionalidad de cada EP para que pueda realizar multiplicación matricial. Derive una expresión para determinar el desempeño del procesador en la multiplicación de matrices.

15
6. Procesador Sistólico C[]=A[]*B[] Preparación: Configuración de las celdas (control distribuido) Celda Multiplicativa-Aditiva (similar a la del WFP) Se requerirá involucrar 3(N 2 - N) + 1 celdas o EP para la operación C[N] = A[N] * B[N]. Tiempo: Se requieren 3N-1 pasos para ejecutar la operación.
 Celda Multiplicativa-Aditiva (similar a la del WFP) Se requerirá involucrar 3(N 2 - N) + 1 celdas o EP para la operación C[N] = A[N] * B[N]. Tiempo: Se requieren 3N-1 pasos para ejecutar la operación..")
16
6. Procesador Sistólico C[]=A[]*B[]
![6. Procesador Sistólico C[]=A[]*B[]](http://images.slideplayer.es/12/3885473/slides/slide_16.jpg "6. Procesador Sistólico C[]=A[]*B[]")
18
7. Procesadores Asociativos Investigue el funcionamiento de una memoria asociativa, diferenciando los niveles bit serie-palabra paralelo y bit paralelo-palabra paralelo. Abordado en clase Consultar el Hwang o Internet.

Presentaciones similares








 Microsoft SQL Server 2008 R2 (Nov.2013) Suscribase a http://addkw.com/ o.>")




>")





