Descargar la presentación
La descarga está en progreso. Por favor, espere

1
ESMA 6835 Mineria de Datos CLASE 15:
Unsupervised classification, Clustering Dr. Edgar Acuna Departmento de Matematicas Universidad de Puerto Rico- Mayaguez math.uprrm.edu/~edgar

2
Introduccion La idea de analisis de conglomerados (“clustering” ) es agrupar muestras (filas) o features (columnas) o ambos a la vez, de acuerdo a la separación entre ellas determinada por una medida de distancia dada, llamada medida de dissimilaridad. Se supone que las clases a las que pertenecen las muestras no son conocidas. También es conocido con el nombre clasificacion no supervisado.
 es agrupar muestras (filas) o features (columnas) o ambos a la vez, de acuerdo a la separación entre ellas determinada por una medida de distancia dada, llamada medida de dissimilaridad. Se supone que las clases a las que pertenecen las muestras no son conocidas. También es conocido con el nombre clasificacion no supervisado.")
3
Cluster 4

4
Para cada muestra (fila) existe un vector de mediciones X=(X1,…XG).
El objetivo es identificar grupos de muestras similares basado en n mediciones observadas X1=x1,…., Xn=xn. Por ejemplo si las X’s representan niveles de expression obtenidos en microarreglos de tumores cancerosos uno podria identificar las caracteristicas de las personas que tienen distintos tipos de tumores.

5
Cuando el numero de columnas es bastantes grande se pueden formar tambien grupos de columnas con similar comportamiento y en consecuencia se puede reducir la dimensionalidad que es muy conveniente si se quiere usar luego un modelo para hacer predicciones. Pues es mucho mas conveniente predecir con 10 features que con 100. También se puede aplicar conglomerados simultaneamente a filas y columnas (Bi-clustering) (ver paper de Alon, et al, 1999, Getz et al , 2000 y Lazaeronni y Owen, 2000)
 (ver paper de Alon, et al, 1999, Getz et al , 2000 y Lazaeronni y Owen, 2000)")
6
Aspectos importantes en el analisis de conflomerados
i) Que features usar? , ii) Que medida de dissimilaridad usar?. iii) Qué método o algoritmo de conglomerado usar?. iv) Cuantos conglomerados se deben formar? v) Cómo asignar las filas (o columnas) a los conglomerados? vi) Cómo validar los conglomerados que se han formado?
 Que features usar , ii) Que medida de dissimilaridad usar . iii) Qué método o algoritmo de conglomerado usar . iv) Cuantos conglomerados se deben formar v) Cómo asignar las filas (o columnas) a los conglomerados vi) Cómo validar los conglomerados que se han formado")
7
Propiedades de medidas de dissimilaridad
No-negatividad: d(x,y) ≥ 0 La distancia de una instancia asi mismo es 0, d(x,x) = 0 Simetria: d(x,y) = d(y,x) Desigualdad Triangular: d(x,y) ≤ d(x,z) + d(z,y) x y z
 ≥ 0. La distancia de una instancia asi mismo es 0, d(x,x) = 0. Simetria: d(x,y) = d(y,x) Desigualdad Triangular: d(x,y) ≤ d(x,z) + d(z,y) x. y. z.")
8
Medidas de Dissimilaridad(variables continuas)
a) Distancia Minkowski o norma Lp. Caso particulares: Distancia Euclideana: p=2, Distancia Manhattan o City-Block: Distancia Chebychev, p=, La distancia ponderada Minkoswki, será:
 Distancia Minkowski o norma Lp. Caso particulares: Distancia Euclideana: p=2, Distancia Manhattan o City-Block: Distancia Chebychev, p=, La distancia ponderada Minkoswki, será:")
9
Medidas de Dissimilaridad (Cont)
b) Distancias basadas en formas cuadráticas. Q=(Qij) es una matriz cuadrada MxM definida positiva de pesos entonces la distancia cuadrática entre x y y está dada por: Si Q=V-1, V matríz de covarianza entre x y y se obtiene la distancia Mahalanobis. c) Distancia Camberra. Si xi y yi son ambos ceros entonces el i-ésimo término de la suma se considera como cero.
 Distancias basadas en formas cuadráticas. Q=(Qij) es una matriz cuadrada MxM definida positiva de. pesos entonces la distancia cuadrática entre x y y está dada por: Si Q=V-1, V matríz de covarianza entre x y y se obtiene la distancia Mahalanobis. c) Distancia Camberra. Si xi y yi son ambos ceros entonces el i-ésimo término de la suma se. considera como cero.")
10
Medidas de dissimilaridad (variables nominales)
Distancia Hamming. Sean x y y dos vectores de la misma dimension y con valores en ={0,1,2,……..k-1}, entonces la distancia Hamming (DH) entre ellos se define como el número de entradas diferentes que tienen los dos vectores. Por ejemplo si x=(1,1,0,0) y y=(0,1,0,1) entonces DH=2. Tambien se pueden usar para variables no binarias.Por ejemplo, si x=(0,1,3,2,1,0,1) y y=(1,1,2,2,3,0,2) entonces DH(x,y)=4 . En el caso de variables binarias , la distancia Hamming, la distancia L2 y la distancia L1 coinciden.
 entre ellos se define como el número de entradas diferentes que tienen los dos vectores. Por ejemplo si x=(1,1,0,0) y y=(0,1,0,1) entonces DH=2. Tambien se pueden usar para variables no binarias.Por ejemplo, si x=(0,1,3,2,1,0,1) y y=(1,1,2,2,3,0,2) entonces DH(x,y)=4 . En el caso de variables binarias , la distancia Hamming, la distancia L2 y la distancia L1 coinciden.")
11
Medidas de similaridad (Variables continuas))
a) Medida de correlación: Nota: 1-s(x,y) puede ser considerado como una medida de dissimilaridad b) Medida de Tanimoto. Se define por Tambien puede ser usada para variables nominales
 Medida de correlación: Nota: 1-s(x,y) puede ser considerado como una medida de dissimilaridad. b) Medida de Tanimoto. Se define por. Tambien puede ser usada para variables nominales.")
12
Medidas de similaridad (variables nominales)
i)La medida de Tanimoto. Sean X y Y dos vectors de longitud nx y ny respectivamente. Sea que representa la cardinalidad de , entonces la medida de Tanimoto se define por Es decir, la medida de Tanimono es la razón del número de elementos que los vectores tienen en común entre el número de elementos distintos. En el caso de variables binarias, la medida de Tanimoto se reduce a Donde a representa el número de posiciones donde los vectores X y Y coinciden en tomar el valor 0, d representa el número de coincidencias donde X y Y valen ambos 1. Mientras que c y b representan el número de no coincidencias.
La medida de Tanimoto. Sean X y Y dos vectors de longitud nx y ny respectivamente. Sea que representa la cardinalidad de , entonces la medida de Tanimoto se define por. Es decir, la medida de Tanimono es la razón del número de elementos que los vectores tienen en común entre el número de elementos distintos. En el caso de variables binarias, la medida de Tanimoto se reduce a. Donde a representa el número de posiciones donde los vectores X y Y coinciden en tomar el valor 0, d representa el número de coincidencias donde X y Y valen ambos 1. Mientras que c y b representan el número de no coincidencias.")
13
ii) El coeficientes de coincidencias simple. Definido por
El problema de esta medida es que incluye a a en el numerador, la cual indica ausencia de ambos factores. iii) La medida de Jaccard-Tanimoto. Definida por iv) La medida de Russel -Rao. v) La medida de Dice-Czekanowski. Similar a la de Jaccard pero asigna peso doble a las coincidencias. Es decir
 La medida de Jaccard-Tanimoto. Definida por. iv) La medida de Russel -Rao. v) La medida de Dice-Czekanowski. Similar a la de Jaccard pero asigna peso doble a las coincidencias. Es decir.")
14
Librerias y funciones en R para hallar distancias
La libreria stats de R tiene una funcion dist que calcula la matríz distancia de una matríz de datos usando las distancias Euclideana, Manhattan, Chebychev, Camberra, Mimkowski y binary.. Librería(stats) x =matrix(rnorm(100), nrow=5) dist(x) dist(x, method=”manhattan”,diag = TRUE) dist(x, method=”maximum”,upper = TRUE) # Ejemplo de distancia Camberra entre dos vectores x <- c(0, 0, 1, 1, 1, 1) y <- c(1, 0, 1, 1, 0, 1) dist(rbind(x,y), method="canberra")
 x =matrix(rnorm(100), nrow=5) dist(x) dist(x, method= manhattan ,diag = TRUE) dist(x, method= maximum ,upper = TRUE) # Ejemplo de distancia Camberra entre dos vectores. x <- c(0, 0, 1, 1, 1, 1) y <- c(1, 0, 1, 1, 0, 1) dist(rbind(x,y), method= canberra )")
15
La libreria cluster de R tiene una función daisy que calcula la
matriz distancia de una matriz de datos usando solamente las distancias euclideana y manhattan y considerando ademas distintos tipos de variables mediante el uso del coeficiente de Gower . La función cor de R calcula la matríz de correlaciones entre las columnas de una matríz y la función plot.cor de la librería sma permite hacer un “heatmap” de las correlaciones.

16
Plot de la matríz de corrrelaciones (sonar)
Sonar, tiene 60 columnas y 208 filas. La parte roja de la grafica indica que la correlación es bien alta y positiva, la parte verde indica que es bien alta pero negativa y la parte negra cerca de cero.

17
Distancias entre clusters
Despues de elegir la medida de similaridad se transforma la matriz n x p en una matriz distancia o de dissimilaridad D = (dij ) de orden n x n para las n muestras a ser agrupadas. Basado en esta matriz se debe determinar una medida de distancia entre dos conglomerados (clusters) cualesquiera. Entre estas medidas están: Linkage simple: (S,T)=min{xS,yT}d(x,y) Linkage completo: (S,T)=max{xS,yT}d(x,y) Linkage promedio: Donde |S|, y |T| representan la cardinalidad de S y T. Linkage centroide: (S,T)= Donde y representan los cenroides de S y T respectivamente
 de orden n x n para las n muestras a ser agrupadas. Basado en esta matriz se debe determinar una medida de distancia entre dos conglomerados (clusters) cualesquiera. Entre estas medidas están: Linkage simple: (S,T)=min{xS,yT}d(x,y) Linkage completo: (S,T)=max{xS,yT}d(x,y) Linkage promedio: Donde |S|, y |T| representan la cardinalidad de S y T. Linkage centroide: (S,T)= Donde y representan los cenroides de S y T respectivamente.")
18
Median linkage: (S,T)=median{xS,yT}d(x,y)
Linkage de Mc Quitty: Linkage de Ward: Aqui se junta el par de grupos que produce la varianza mas pequena en el grupo juntado.

19
Tipos de Algoritmos para Conglomerados (“Clustering”)
I. Métodos de particionamiento El conjunto de datos es particionado en un número pre-especificado de conglomerados K, y luego iterativamente se va reasignando las observaciones a los conglomerados hasta que algún criterio de parada (función a optimizar) se satisface (suma de cuadrados dentro de los conglomerados sea la más pequeña). Ejemplos: K-means, PAM, CLARA, SOM, Conglomerados basados en modelos de mezclas gausianas, Conglomerados difusos.
 se satisface (suma de cuadrados dentro de los conglomerados sea la más pequeña). Ejemplos: K-means, PAM, CLARA, SOM, Conglomerados basados en modelos de mezclas gausianas, Conglomerados difusos.")
20
II. Metodos Jerárquicos.
En estos algoritmos se generan sucesiones ordenadas (jerarquias) de conglomerados. Puede ser juntando cluster pequenos en mas grande o dividiendo grandes clusters en otros mas pequenos. La estructura jerárquica es representada en forma de un árbol y es llamada Dendograma. Se dividen en dos tipos: Algoritmos jerárquicos aglomerativos (bottom-up, inicialmente cada instancia es un cluster).AGNES Algoritmos jerárquicos divisivos (top-down, inicialmente todas las instancias estan en un solo cluster. DIANA.
 de conglomerados. Puede ser juntando cluster pequenos en mas grande o dividiendo grandes clusters en otros mas pequenos. La estructura jerárquica es representada en forma de un árbol y es llamada Dendograma. Se dividen en dos tipos: Algoritmos jerárquicos aglomerativos (bottom-up, inicialmente cada instancia es un cluster).AGNES. Algoritmos jerárquicos divisivos (top-down, inicialmente todas las instancias estan en un solo cluster. DIANA.")
21
1-Algoritmo k-means (MacQueen, 1967).
El objetivo es minimizar la dissimiliridad de los elementos dentro de cada cluster y maximizar la disimilaridad de los elementos que caen en diferentes clusters. INPUT: Un conjunto de datos S y k número de clusters a formar; OUTPUT: L una lista de los clusters en que caen las observaciones de S. Seleccionar los centroides iniciales de los K clusters: c1, c2, ..., cK. Asignar cada observación xi de S al cluster C(i) cuyo centroide c(i) está mas cerca de xi. Es decir, C(i)=argmin1kK||xi-ck|| Para cada uno de los clusters se recalcula su centroide basado en los elementos que están contenidos en el cluster y minimizando la suma de cuadrados dentro del cluster. Es decir, Ir al paso 2 hasta que se consiga convergencia.
 cuyo centroide c(i) está mas cerca de xi. Es decir, C(i)=argmin1kK||xi-ck|| Para cada uno de los clusters se recalcula su centroide basado en los elementos que están contenidos en el cluster y minimizando la suma de cuadrados dentro del cluster. Es decir, Ir al paso 2 hasta que se consiga convergencia.")
22
K-Means Actualizar los centroides
1 2 3 4 5 6 7 8 9 10 10 9 8 7 6 5 Actualizar los centroides 4 Asignar cada instancia al cluster mas cercano. 3 2 1 1 2 3 4 5 6 7 8 9 10 reasignar reasignar K=2 Escoger arbitrariamente K instances como los centroides Actualizar los centroides

23
Alternativas para los k centroides iniciales
Usando las primeras k bservaciones Eligiendo aleatoriamente k observaciones. Tomando cualquier partición al azar en k clusters y calculando sus centroides.

24
Características del Algoritmo k-means
No se satisface el criterio de optimizacion globalmente, solo produce un óptimo local. El algoritmo de k-means es computacionalmente rápida. Puede trabajar bien con datos faltantes (missing values). Es sensible a “outliers”.
. Es sensible a outliers .")
25
R y la función kmeans La librería mva de R tiene la función kmeans que ejecuta el algoritmo kmeans. Ejemplo: Consideremos conjunto de datos bupa (6 variables predictoras y 345 observaciones). > kmeans(bupa[,1:6],2) > kmeans(bupa[,1:6],3) > #K-means eligiendo como centros iniciales las observaciones10 y 100 de Bupa > medias<-bupa[c(10,100),1:6] > kmeans(bupa[,1:6],medias)
. > kmeans(bupa[,1:6],2) > kmeans(bupa[,1:6],3) > #K-means eligiendo como centros iniciales las observaciones10 y 100 de Bupa. > medias<-bupa[c(10,100),1:6] > kmeans(bupa[,1:6],medias)")
26
Particionamiento alrededor de medoides (PAM)
Introducido por Kauffman y Rousseauw, 1987. MEDOIDES, son instancias representativas de los clusters que se quieren formar. Para un pre-especificado número de clusters K, el procedimiento PAM está basado en la búsqueda de los K MEDOIDES, M = (m1, ,mK) de todas las observaciones a clasificar Para encontrar M hay que minimizar la suma de las distancias de las observaciones a su mas cercano Medoide. d es una medida de dissimilaridad
 de todas las observaciones a clasificar. Para encontrar M hay que minimizar la suma de las distancias de. las observaciones a su mas cercano Medoide. d es una medida de dissimilaridad.")
27
k-Medoides K=2 Hacer el loop hasta que no haya cambios Total Cost = 20
10 9 8 7 Arbitrariamente escoger k instances como medoides Asignar las instancias restantes a su mas cercano medoide. 6 5 4 3 2 1 1 2 3 4 5 6 7 8 9 10 K=2 Seleccionar al azar una instancia nonmedoide ,Oramdom Total Cost = 26 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Hacer el loop hasta que no haya cambios Calcular el costo total de swapping Swapping O y Oramdom Si se mejora la calidad

28
R y la función PAM La función pam de la librería cluster encuentra los
conglomerados usando el particionamiento alrededor de medoides. Aplicaremos PAM al conjunto de datos bupa. >pambupa=pam(bupa[,1:6],2,diss=F) Generalmente los resultados son un poco mejores que el de k- means.
 Generalmente los resultados son un poco mejores que el de. k- means.")
29
Mapas auto-organizados (Self-orgamizing Maps, SOM)(Kononen, 1988)
Son algoritmos de particionamiento que son restringidos al hecho que los clusters pueden ser representados en una estructura regular de dimensión baja, tal como un grid (los más usados son los SOM en una y dos dimensiones). Los clusters que son cercanos entre sí aparecen en celdas adyacentes del grid. O sea, SOM mapea el espacio de entrada de las muestras en un espacio de menor dimension en el cual la medida de similaridad entre las muestras es medida por la relación de cercanía de los vecinos. Cada uno de los K clusters es representado por un objeto prototipo Mi , i = 1,…K .
. Los clusters que son cercanos entre sí aparecen en celdas adyacentes del grid. O sea, SOM mapea el espacio de entrada de las muestras en un espacio de menor dimension en el cual la medida de similaridad entre las muestras es medida por la relación de cercanía de los vecinos. Cada uno de los K clusters es representado por un objeto prototipo Mi , i = 1,…K .")
30
Mapas auto-organizados (Self-orgamizing Maps, SOM)
En este método la posición de una observación en el espacio inicial de entradas influye de alguna manera en su asignación a un conglomerado. Se construye un plot en donde las observaciones similares son ploteadas cercanas entre sí. El algoritmo SOM es bastante similar a k-means Un SOM es entrenado como una red neural. El SOM puede ser considerado también como una técnica de reducción de dimensionalidad y guarda relación con la técnica conocida como escalamiento multidimensional (proceso de encontrar un conjunto de puntos en un espacio multidimensional que corresponda a medidas de similaridad entre objetos).
.")
31
El algoritmo SOM considerando un grid rectangular de dos dimensiones
Paso1-Seleccionar los numeros de filas (q1) y columnas (q2) en el grid. Luego habrá K=q1q2 clusters Paso2. Inicializar el tamaño del parámetro de actualizacion (la tasa de aprendizaje en terminos de redes neurales) ( =1) y el radio del grid (r=2) Paso3. Inicializar los vectores prototipos Mj, j (1,…,q1) x (1,….,q2) mediante la eleccion aleatoria de K instancias. Paso4. Para cada observacion del conjunto de datos hacer los siguiente: Identificar el vector índice j’ del prototipo Mj mas cercano a xi. Identificar un conjunto S de prototipos vecinos de Mj’. Es decir, S={j: distancia (j ,j’)<r} La distancia puede ser Euclideana o cualquiera otra Actualizar cada elemento de S moviendo el correspondiente prototipo hacia xi: MjMj +(xi-Mj) para todo j S Paso5. Disminuir el tamaño de y r en una cantidad predeterminada y continuar hasta alcanzar convergencia.
 y columnas (q2) en el grid. Luego habrá. K=q1q2 clusters. Paso2. Inicializar el tamaño del parámetro de actualizacion (la tasa de aprendizaje en. terminos de redes neurales) ( =1) y el radio del grid (r=2) Paso3. Inicializar los vectores prototipos Mj, j (1,…,q1) x (1,….,q2) mediante la. eleccion aleatoria de K instancias. Paso4. Para cada observacion del conjunto de datos hacer los siguiente: Identificar el vector índice j’ del prototipo Mj mas cercano a xi. Identificar un conjunto S de prototipos vecinos de Mj’. Es decir, S={j: distancia (j ,j’)<r} La distancia puede ser Euclideana o cualquiera otra. Actualizar cada elemento de S moviendo el correspondiente prototipo hacia xi: MjMj +(xi-Mj) para todo j S. Paso5. Disminuir el tamaño de y r en una cantidad predeterminada y continuar hasta alcanzar convergencia.")
32
R y la función SOM La función SOM de la librería class de B. Ripley construye un SOM, al igual que la libreria som. Aunque los resultados son solamente visuales. De cada centroide salen lineas que representan cada una de las variables Por ejemplo para el conjunto de datos bupa >bupgr=somgrid(2,3,topo="hexa") > sombupa=SOM(bupa[,1:6],bupgr) > plot(sombupa) > sombupa$codes Otros software: Somtoolbox en Matlab, Cluster por Eissen y Genecluster (MIT Center por Genome Research). Este ultimo muestra los elementos de cada cluster
 > sombupa=SOM(bupa[,1:6],bupgr) > plot(sombupa) > sombupa$codes. Otros software: Somtoolbox en Matlab, Cluster por Eissen y Genecluster (MIT Center por Genome Research). Este ultimo muestra los elementos de cada cluster.")
33
SOM usando la libreria SOM

34
Algoritmo jerárquicos
Estos algoritmos generan sucesiones anidadas de clusters que se pueden visualizar con una estructura de arbol llamado Dendrograma, En la figura se muestra el dendrograma del conjunto Bupa obtenido usando la función hclust para algoritmo jerarquico aglomerativo de la libreria mva. > a=hclust(dist(bupa)) > plot(a)
) > plot(a)")
35
Dendrogramas Los dendrogramas son fáciles de interpretar pero pueden conducir a falsas conclusiones por las siguientes razones: El dendograma correspondiente a un conglomerado jerárquico no es único, puesto que por cada junte de clusters (merge) uno necesita especificar que sub-árbol va a la derecha y cuál a la izquierda. Por default la función hclust de la librería cluster ordena los arboles de tal manera que los conglomerados más concentrados van a la izquierda. 2) La estructura jerárquica del Dendrograma no representa con certeza las verdaderas distancias entre los objetos distintos del conjunto de datos.
 uno necesita especificar que sub-árbol va a la derecha y cuál a la izquierda. Por default la función hclust de la librería cluster ordena los arboles de tal manera que los conglomerados más concentrados van a la izquierda. 2) La estructura jerárquica del Dendrograma no representa con certeza las verdaderas distancias entre los objetos distintos del conjunto de datos.")
36
disbupa=dist(bupa[,1:6]) hbupa=hclust(disbupa, method=”ave”)
El coeficiente de correlación cofenético puede ser usado para medir cuan bien la estructura jerárquica del dendrograma representa a las v erdaderas distancias. Se define como la correlación entre las n(n - 1)/2 pares de dissimilaridades y sus distancias cofenéticas del dendogramas. La función cophenetic en la libreria mva calcula la distancia cofenéticas. disbupa=dist(bupa[,1:6]) hbupa=hclust(disbupa, method=”ave”) denbupa=cophenetic(hbupa) cor(disbupa,denbupa) La distancia cofenética da
![disbupa=dist(bupa[,1:6]) hbupa=hclust(disbupa, method= ave )](http://slideplayer.es/slide/3775145/12/images/36/disbupa%3Ddist%28bupa%5B%2C1%3A6%5D%29+hbupa%3Dhclust%28disbupa%2C+method%3D+ave+%29.jpg "El coeficiente de correlación cofenético puede ser usado para medir cuan bien la estructura jerárquica del dendrograma representa a las v erdaderas distancias. Se define como la correlación entre las n(n - 1)/2 pares de dissimilaridades y sus distancias cofenéticas del dendogramas. La función cophenetic en la libreria mva calcula la distancia cofenéticas. disbupa=dist(bupa[,1:6]) hbupa=hclust(disbupa, method= ave ) denbupa=cophenetic(hbupa) cor(disbupa,denbupa) La distancia cofenética da")
37
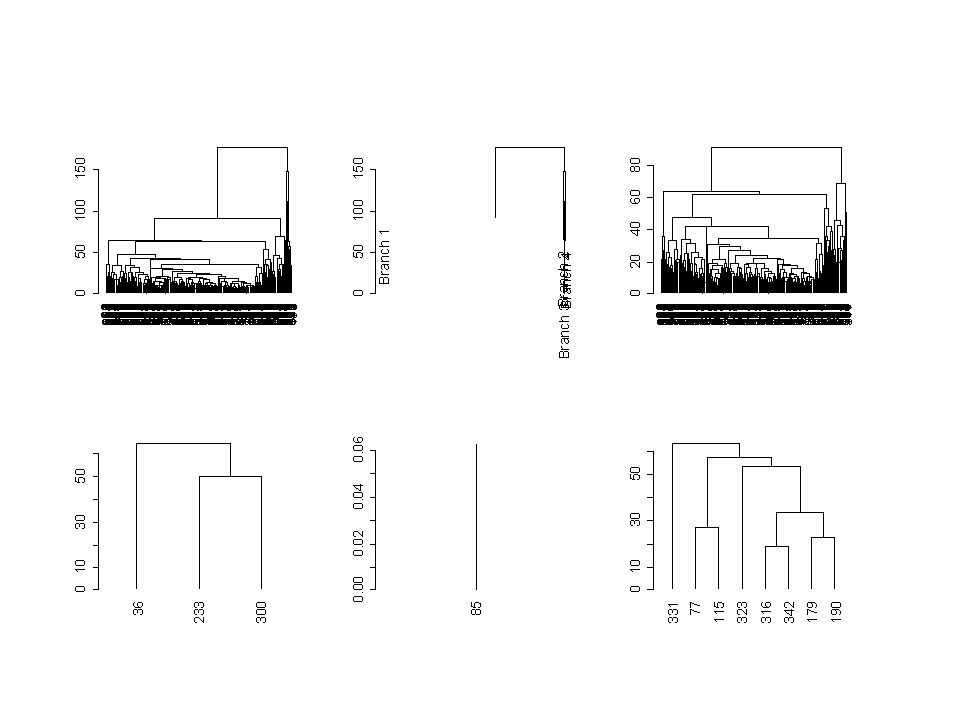
Ejemplo de un dendrograma y sus cortes
treebupa=as.dendrogram(hbupa) bupita=cut(treebupa,h=100) bupita=cut(treebupa, h=100) > bupita $upper `dendrogram' with 2 branches and 4 members total, at height $lower $lower[[1]] `dendrogram' with 2 branches and 333 members total, at height $lower[[2]] `dendrogram' with 2 branches and 3 members total, at height $lower[[3]] `dendrogram' leaf '85', at height 0 $lower[[4]] `dendrogram' with 2 branches and 8 members total, at height
 bupita=cut(treebupa,h=100) bupita=cut(treebupa, h=100) > bupita. $upper. `dendrogram with 2 branches and 4 members total, at height $lower. $lower[[1]] `dendrogram with 2 branches and 333 members total, at height $lower[[2]] `dendrogram with 2 branches and 3 members total, at height $lower[[3]] `dendrogram leaf 85 , at height 0. $lower[[4]] `dendrogram with 2 branches and 8 members total, at height")
39
Heatmaps. Son gráficas que muestran simultaneamente las
agrupaciones en conglomerados de columna y filas. La función heatmap de la libreria mva permite hacer heatmaps usando un gran número de tonalidades de colores.

40
Ejemplo de heatmaps para Iris
Notar que solo las variables 2 y 3 determinan claramente las 3 clases.

41
Algoritmo jerárquico aglomerativo
Suponiendo que tenemos una matriz de datos m x n. Se empieza con m conglomerados si se desea formar grupos de muestras (filas) o con n clusters si se quieren formar grupos de variables (columnas). En cada paso se juntan los cluster mas cercanos usando una medida de distancia entre clusters (linkage) Entre estas distancias están Linkage promedio: promedio de las distancias de las observaciones en cada cluster. Linkage simple: la menor distancia entre las observaciones de cada cluster Linkage completo: la mayor distancia entre las observaciones de cada cluster.
 o con n clusters si se quieren formar grupos. de variables (columnas). En cada paso se juntan los cluster mas cercanos usando una. medida de distancia entre clusters (linkage) Entre estas distancias están. Linkage promedio: promedio de las distancias de las. observaciones en cada cluster. Linkage simple: la menor distancia entre las observaciones. de cada cluster. Linkage completo: la mayor distancia entre las observaciones. de cada cluster.")
42
Ejemplo de Jerarquico Aglomerativo
En este caso usaremos la funcion agnes de la libreria cluster bupagl<-agnes(bupa[,1:6],metric="euclidean",method="ward") cutree(bupagl,k=2) > table(cutree(bupagl,k=2)) 1 2 62 283 > table(cutree(bupagl,k=3)) La función plot.agnes permite hacer un plot del dendrograma. Pero no tiene la misma flexibilidad de las funciones en mva.
 cutree(bupagl,k=2) > table(cutree(bupagl,k=2)) > table(cutree(bupagl,k=3)) La función plot.agnes permite hacer un plot del dendrograma. Pero no tiene la misma flexibilidad de las funciones en mva.")
43
Métodos jerárquicos divisivos
Empieza con un solo cluster, que es aquel que contiene a todas las muestras. En cada paso se divide los clusters en dos subgrupos. Son más lentos de calcular que los jeráquicos aglomerativos A continuacion se muestra un ejemplo del método jerarquico divisivo usando la función Diana de la libreria cluster. > bupadiv<-diana(bupa[,1:6],metric='euclidean') > plot(bupadiv,which=2) > bupadiv
 > plot(bupadiv,which=2) > bupadiv.")
44
Ejemplo usando Diana > bupadiv=diana(bupa[,1:6],metric=
'euclidean') > plot(bupadiv,which=2) > bupadiv > cutree(bupadiv,k=2) > table(cutree(bupadiv,k=2)) 1 2 33 312 > table(cutree(bupadiv,k=3))
![Ejemplo usando Diana > bupadiv=diana(bupa[,1:6],metric=](http://slideplayer.es/slide/3775145/12/images/44/Ejemplo+usando+Diana+%3E+bupadiv%3Ddiana%28bupa%5B%2C1%3A6%5D%2Cmetric%3D.jpg "euclidean ) > plot(bupadiv,which=2) > bupadiv. > cutree(bupadiv,k=2) > table(cutree(bupadiv,k=2)) > table(cutree(bupadiv,k=3))")
45
Comparación de métodos de particionamiento con los métodos jerárquicos.
Los métodos de particionamiento tienen la ventaja de que satisfacen un criterio de optimilidad aunque sea aproximadamente. Desventajas: Necesitan un valor inicial del número de clusters y toma mucho tiempo obtener los clusters. Por otro lados los métodos jerárquicos tienen la ventaja que son rápidos de calcular sobre todo el aglomerativo. Desventaja: La rigidez que le da la estructura de árbol ( el llamado factor de anidamiento). Es dificil corregir lo que se hizo antes.
. Es dificil corregir lo que se hizo antes.")
46
Determinación del número de clusters.
Indices Internos. Estadisticas basados en las sumas de cuadrados entre clusters y dentro de clusters. El número de clusters K es aquel que maximiza o minimiza uno de estos indices.(Milligan, GW& Cooper, MC). Entre los principales estan el indice de Dunn, el Indice de Davies-Bouldin. Ancho de silueta promedio. Métodos basado en modelos de mezclas gaussianas. Determinar el número de componentes de la mezcla es lo mismo que determinar el número de clusters. Se usan los criterios de AIC ( Criterio de Información de Akaike) y BIC ( Criterio de Información Bayesiano).
. Entre los principales estan el indice de Dunn, el Indice de Davies-Bouldin. Ancho de silueta promedio. Métodos basado en modelos de mezclas gaussianas. Determinar el número de componentes de la mezcla es lo mismo. que determinar el número de clusters. Se usan los criterios de AIC ( Criterio de Información de Akaike) y BIC ( Criterio de Información Bayesiano).")
47
Indice de Dunn (1974). La idea es identificar los clusteres que estan bien compactos y bien separados de los demas. Dada una particion de clusters donde ci representa el i-esimo cluster de la particion, se define el indice de Dunn por donde d(ci,cj) – es la distancia entre los clusters ci, y cj y d'(ck) representa la distancia intracluster del cluster ck. En numero optimo de clusters es aquel que maximiza D. La libreria fpc tiene una funcion cluster.stats que calcula el indice de Dunn.
 – es la distancia entre los clusters ci, y cj y d (ck) representa la distancia intracluster del cluster ck. En numero optimo de clusters es aquel que maximiza D. La libreria fpc tiene una funcion cluster.stats que calcula el indice de Dunn.")
48
Silhouette plots Los plots siluetas, (Rousseeuw 1987) pueden ser usados para: Seleccionar el número de clusters. Evaluar cuan bien han sido asignados las observaciones en los clusters. El ancho de la silueta (silhouette width) de la i-ésima observación es definida por: sili = (bi - ai)/ max(ai, bi) Donde, ai denota la distancia promedio entre la observación i y todas las otras que están en el mismo cluster de i, y bi denota la distancia promedio minima de i a las observaciones que están en otros clusters.
 de la i-ésima. observación es definida por: sili = (bi - ai)/ max(ai, bi) Donde, ai denota la distancia promedio entre la observación i y. todas las otras que están en el mismo cluster de i, y bi denota la. distancia promedio minima de i a las observaciones que están en. otros clusters.")
49
Características de los Silhouette plots
Las observaciones con ancho de silueta grande están bien agrupadas mientras aquellas con ancho de silueta baja tienden a estar ubicada en el medio de dos clusters. Para un número de clusters dado K, el ancho de silueta promedio de la configuracion de conglomerados será simplemente el promedio de sili sobre todas las observaciones. Es decir, Kaufman y Rousseeuw (1990) sugirieron estimar el número óptimo de cluster K para el cual el ancho de silueta promedio sea la mayor posible.
 sugirieron estimar el número óptimo de cluster K para el cual el ancho de silueta promedio sea la mayor posible.")
50
Ejemplo de los Silhouette plots
Ejemplo con el conjunto de datos Bupa y el metodo jerarquico aglomerativo > agbupa=agnes(dist(bupa[,1:6]),method=“ward”) >a=silohuette(cutree(agbupa,k=2),daisy(bupa[,1:6])) >b=silohuette(cutree(agbupa,k=3),daisy(bupa[,1:6])) >c=silohuette(cutree(agbupa,k=4),daisy(bupa[,1:6])) >par(mfrow=c(1,3)) >plot(a,”main=“”) >plot(b,”main=“”) >plot(c,”main=“”) Mirando el plot k=2 clusters es lo recomendado.
,method= ward ) >a=silohuette(cutree(agbupa,k=2),daisy(bupa[,1:6])) >b=silohuette(cutree(agbupa,k=3),daisy(bupa[,1:6])) >c=silohuette(cutree(agbupa,k=4),daisy(bupa[,1:6])) >par(mfrow=c(1,3)) >plot(a, main= ) >plot(b, main= ) >plot(c, main= ) Mirando el plot k=2 clusters es lo recomendado.")
51
PLOTS SILUETAS PARA CLUSTERING DE BUPA

52
Ejemplo de los Silhouette plots
Ejemplo con el conjunto de datos Bupa y el metodo PAM silicom=rep(0,9) for(i in 1:9){ silicom[i]=pam(vehicle[,1:18],i+1, diss=F,stand=T)$silinfo$avg.width} plot(2:10,silicom) plot(2:10,silicom,type="o",xla="clusters",main="plots de siluetas") Aqui tambien salen 2 clusters.
 for(i in 1:9){ silicom[i]=pam(vehicle[,1:18],i+1, diss=F,stand=T)$silinfo$avg.width} plot(2:10,silicom) plot(2:10,silicom,type= o ,xla= clusters ,main= plots de siluetas ) Aqui tambien salen 2 clusters.")
53
. Indices externos Supongamos que tenemos dos particiones de n objetos x1, ..., xn: la partición en R clases U = {u1, ..., uR} y la partición en C-clases = V={v1, ...,vC}, por lo general una de ellas conocida de antemano.. Los indices externos de concordancia entre las particiones pueden ser expresados en término de una tabla de contingencia con entradas nij que representa el número de objetos que están en ambos clusters ui and vj, i = 1,...,R, j = 1,...,C . Sean y . que denotan las sumas de filas y columnas de la tabla de contingencia. Sea

54
Dada las dos particiones U y V
a: numero de pares objetos que estan en el mismo cluster tanto en U como en V. c: numero de pares de objetos que estan en el mismo cluster en V pero no en U. b: numero de pares de objetos que estan en el mismo cluster en U pero no en V. d: numero de pares de objetos que estan en diferentes clusters tanto en U como en V. m1=a+b = numero de pares de objetos en el mismo cluster en U. m2=a+c= numero de pares de objetos en el mismo cluster en V.

55
Ejemplo a= 4, b =2, C=3, d=6, m1=6, m2=7, Z=14 5 5 1 4 4 2 1 2 3 6 3 6
Notar que M=a+b+c+d=

56
Rand(1971) Jaccard Fowlkes and Mallows
Un valor de Rand, Jaccard y FM cercano a 1 indica un buen agrupamiento.

57
La medida de Hubert y Arabie (1985)
Sean las variables aleatorias: X(i,j)=1 si los objetos i y j caen en el mismo cluster de la particion U e igual a 0 en otro caso. Y(i,j)=1 si los objetos i y j caen en el mismo cluster de la particion V e igual a 0 en otro caso. Se define la medida de Hubert como:
=1 si los objetos i y j caen en el mismo cluster de la particion U e igual a 0 en otro caso. Y(i,j)=1 si los objetos i y j caen en el mismo cluster de la particion V e igual a 0 en otro caso. Se define la medida de Hubert como:")
58
Para obtener valores de entre -1 y 1 se prefiere normalizarlo y se obtiene
Que es equivalente a:

59
Pero, usando el hecho que X y Y son binomiales, se tiene que
Que son las probabilidades de que los objetos i y j caigan en los mismos clusters de las particiones U y V respectivamente

60
Similarmente,

61
Finalmente,

62
Sustituyendo, en la forma de normalizada se tiene
Ahora usando las identidades y a= (z-n)/2, se tiene la siguiente formula simplificada de H
/2, se tiene la siguiente formula simplificada de H.")
64
>agbupa=agnes(dist(bupa[,1:6]),method="ward")
>a=cutree(agbupa,k=2) > mexter(bupa[,7],a) $rand [1] $jaccard [1] $fandm [1] $hubert [1]
![>agbupa=agnes(dist(bupa[,1:6]),method= ward )](http://slideplayer.es/slide/3775145/12/images/64/%3Eagbupa%3Dagnes%28dist%28bupa%5B%2C1%3A6%5D%29%2Cmethod%3D+ward+%29.jpg ">a=cutree(agbupa,k=2) > mexter(bupa[,7],a) $rand. [1] $jaccard. [1] $fandm. [1] $hubert. [1]")
65
> agbupa=agnes(dist(bupa[,1:6]),method="complete")
> c=cutree(agbupa,k=2) > mexter(bupa[,7],c) $rand [1] $jaccard [1] $fandm [1] $hubert [1] > table(c) c 1 2
![> agbupa=agnes(dist(bupa[,1:6]),method= complete )](http://slideplayer.es/slide/3775145/12/images/65/%3E+agbupa%3Dagnes%28dist%28bupa%5B%2C1%3A6%5D%29%2Cmethod%3D+complete+%29.jpg "> c=cutree(agbupa,k=2) > mexter(bupa[,7],c) $rand. [1] $jaccard. [1] $fandm. [1] $hubert. [1] > table(c) c")
66
FOM=Figure of Merit (Yeung and Ruzzo,2001)
The Gap Statistics (Tibshirani,2000). Clest (Dudoit & Fridlyand, 2002)
. Clest (Dudoit & Fridlyand, 2002)")
67
Algoritmo Clest (Dudoit & Fridlyand, 2002).
Estima el número de conglomerados basado en la precision de la prediccion. Para cada número de clusters k, se divide al azar B veces el conjunto de datos original en dos conjuntos que no se superponen. Uno de ellos Lb forma la muestra de entrenamiento y el otro, Tb forma la muestra de prueba , b = 1, , B. -Aplicar el algoritmo de conglomerados (se recomienda el PAM) a las observaciones en el conjunto de entrenamiento Lb. – Construir un clasificador ( puede ser LDA, k-nn, CART, etc) usando las etiquetas obtenidas del método de conglomerados. -Aplicar el clasificador al conjunto de prueba Tb. -Aplicar el algoritmo de conglomerados al conjunto de prueba Tb.
 a las. observaciones en el conjunto de entrenamiento Lb. – Construir un clasificador ( puede ser LDA, k-nn, CART, etc) usando las. etiquetas obtenidas del método de conglomerados. -Aplicar el clasificador al conjunto de prueba Tb. -Aplicar el algoritmo de conglomerados al conjunto de prueba Tb.")
68
-Calcular un score sk,b comparando las etiquetas del conjunto de prueba obtenidas por conglomerados y por predicción del clasificador. Estos scores se obtienen aplicando indices externos como RAND, Jaccard o Fowkles y Mallows (FM) -El score de similaridad para los k clusters es la mediana de los B scores de similaridad tk = median(sk,1, · · · , sk,B). -El número de clusters K es estimado comparando el score observado tk con su valor esperado asumiendo cierta distribución de Referencia.
. -El número de clusters K es estimado comparando el score observado tk con su valor esperado asumiendo cierta distribución de Referencia.")
69
El programa Machaon (2004) Nadia.Bolshakova (CS Department, Trinity College, UK) Cluster Validty Tool for gene Expression data
 Nadia.Bolshakova (CS Department, Trinity College, UK) Cluster Validty Tool for gene Expression data.")
70
Model-Based Clustering ( Fraley y Raftery, JASA 2002)
Cluster analysis is the automatic numerical grouping of objects into cohesive groups based on measured characteristics. It was invented in the late 1950s by Sokal, Sneath and others, and has developed mainly as a set of heuristic methods. More recently it has been found that basing cluster analysis on a probability model can be useful both for understanding when existing methods are likely to be successful, and for suggesting new and better methods. It also provides answers to several questions that often arise in practice but are hard to answer with heuristic methods: How many clusters are there? Which clustering method should be used? How should we deal with outliers?

73
Mixture Models

74
La distribucion Normal Multivariada

76
El criterio BIC (Bayesian Information Criiterio) para seleecionar el mejor modelo
 para seleecionar el mejor modelo")
77
Uso de Mclust Los siguientes modelos son comparados en 'Mclust':
"EII": spherical, equal volume "VII": spherical, unequal volume "EEI": diagonal, equal volume, equal shape "VVI": diagonal, varying volume, varying shape "EEE": ellipsoidal, equal volume, shape, and orientation "VVV": ellipsoidal, varying volume, shape, and orientation El comportamiendo de los modelos dependen de la descomposicion espectral de las matrices de covarianzas

78
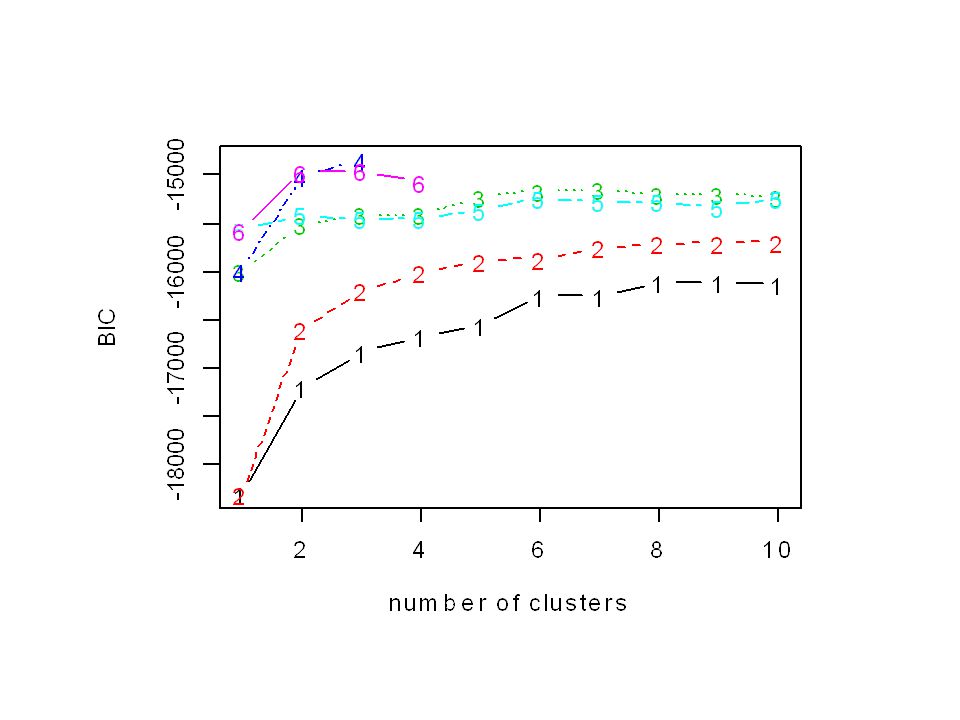
> a=Mclust(bupa[,1:6],1,10)
best model: diagonal, varying volume and shape with 3 groups averge/median classification uncertainty: / 0.021 > a$bic VVI,3 > table(a$class)
![> a=Mclust(bupa[,1:6],1,10)](http://slideplayer.es/slide/3775145/12/images/78/%3E+a%3DMclust%28bupa%5B%2C1%3A6%5D%2C1%2C10%29.jpg "best model: diagonal, varying volume and shape with 3 groups. averge/median classification uncertainty: / > a$bic. VVI, > table(a$class)")
79
> a$mu [1,] [2,] [3,] [4,] [5,] [6,] >
![> a$mu [1,] [2,]](http://slideplayer.es/slide/3775145/12/images/79/%3E+a%24mu+%5B1%2C%5D+%5B2%2C%5D.jpg "[3,] [4,] [5,] [6,] >")
80
> a$BIC EII VII EEI VVI EEE VVV NA NA NA NA NA NA NA NA NA NA NA NA NA

Presentaciones similares









 Gastón Sabatelli (85523)>")




 Gastón Sabatelli (85523)>")
>")







