Descargar la presentación
La descarga está en progreso. Por favor, espere

1
UNIVERSIDAD ANDINA NÉSTOR CÁCERES VELÁSQUEZ
Escuela de Postgrado Maestría en Ingeniería de Sistemas Mención Informática “SISTEMA DE BÚSQUEDAS EN ADN UTILIZANDO MINERÍA DE TEXTO” PRESENTADA POR: Mg. ROBERT ANTONIO, ROMERO FLORES JULIACA – PERÚ 2012

2
RESUMEN La presente tesis ilustra el desarrollo de un Sistema de Búsquedas en ADN al que se le ha denominado GAdn, aplicación del campo de la Bio Informática el mismo que ha sido desarrollado utilizando tecnología web y pretende difundir está área de investigación en nuestra región. El ADN (Acido Desoxiribonucleíco) es el componente biológico encargado de la transmisión genética de las especies (color de la piel, ojos, estatura, etc.) así como la transmisión de enfermedades hereditarias entender las características en el funcionamiento del ADN es un tema que actualmente tiene ocupada a la Ciencia debido a las bondades que podría aportar a la ciencia en el campo de la Ingeniería Genética como control de enfermedades y mejoramiento genético.
 es el componente biológico encargado de la transmisión genética de las especies (color de la piel, ojos, estatura, etc.) así como la transmisión de enfermedades hereditarias entender las características en el funcionamiento del ADN es un tema que actualmente tiene ocupada a la Ciencia debido a las bondades que podría aportar a la ciencia en el campo de la Ingeniería Genética como control de enfermedades y mejoramiento genético.")
3
RESUMEN Para realizar búsquedas de patrones en ADN se ha utilizado la minería de texto y una serie de algoritmos textuales como son: Boyer Moore, Knuth Morris Pratt y Aho Corasick en cuanto se refiere a la búsqueda exacta de patrones, en cuanto a la mutación o similitud del patrón se ha implementado los algoritmos de Levenshtein y Smith Waterman. El desarrollo del Sistema de Búsquedas en ADN tuvo por finalidad demostrar la viabilidad de desarrollar un software utilizando tecnología portable bajo una plataforma web de manera que el sistema pueda ser escalable y expandible para otras aplicaciones futuras como motores de búsqueda textuales y así impulsar el desarrollo de estas aplicaciones tecnológicas en nuestra región.

4
INTRODUCCIÓN Capítulo 1. Capítulo 2. Capítulo 3.
trata sobre el planteamiento del problema, donde se justifica del por qué se realiza la presente investigación y se formulan los respectivos problemas: general y específicos, los objetivos de la investigación: general y específicos. Capítulo 2. aborda sobre el marco teórico y conceptual de la investigación; considerando los antecedentes de investigación, se enfatizando temas como algoritmos de búsqueda textuales, metodología de desarrollo de software extrema (XP) y genética; así mismo, se consideran como antecedentes de la investigación importantes trabajos que incluyen el análisis de secuencias en ADN a nivel internacional, también incluye las hipótesis de la tesis así como la operacionalización de variables. Capítulo 3. Está referido a la conceptualización de los modelos de los sistemas y subsistemas identificados en los proyectos de mejoramiento de riego durante las diferentes fases que conforman el proyecto: elaboración de estudios, construcción de obras y gestión para sistemas de riego, como resultado de este capítulo se tienen los diagramas causa efecto del sistema de producción.
 y genética; así mismo, se consideran como antecedentes de la investigación importantes trabajos que incluyen el análisis de secuencias en ADN a nivel internacional, también incluye las hipótesis de la tesis así como la operacionalización de variables. Capítulo 3. Está referido a la conceptualización de los modelos de los sistemas y subsistemas identificados en los proyectos de mejoramiento de riego durante las diferentes fases que conforman el proyecto: elaboración de estudios, construcción de obras y gestión para sistemas de riego, como resultado de este capítulo se tienen los diagramas causa efecto del sistema de producción.")
5
INTRODUCCIÓN Capítulo 4. Conclusiones y Recomendaciones. Anexos.
desarrolla los resultados y discusión en el cual se detalla el desarrollo del sistema de búsquedas en ADN (GAdn) utilizando la metodología de desarrollo de software extrema (XP) mediante sus fases del juego de planificación, diseño, codificación y pruebas. Conclusiones y Recomendaciones. Anexos.
 utilizando la metodología de desarrollo de software extrema (XP) mediante sus fases del juego de planificación, diseño, codificación y pruebas. Conclusiones y Recomendaciones. Anexos.")
6
CAPÍTULO I EL PROBLEMA

7
1.1 ANÁLISIS DE LA SITUACIÓN PROBLEMÁTICA.
El ADN (Acido Desoxiribonucleíco) es el componente biológico encargado de la transmisión genética de las especies (color de la piel, ojos, estatura, etc.) así como la transmisión de enfermedades hereditarias entender las características en el funcionamiento del ADN es un tema que actualmente tiene ocupada a la Ciencia . EL ADN está conformada por cuatro bases nitrogenadas: Adenina (A), Guanina(G), Citosina(C) y Timina (T) y presenta una estructura de dos bandas en un doble hélice que si se representará a escala de 01 mm esta cadena llegaría al cielo, la estructura computacional para la representación de ADN se hace mediante archivos de texto (un archivo de texto para cada cromosoma) Estos archivos contienen la secuencia de nucleótidos. Cada nucleótido se representa con una letra A para Adenina, C para Citosina, G para Guananina y T para Timina, la representación genera cadenas de texto de gran tamaño que pueden llegar a tener un tamaño medido incluso en Gb (Giga bytes) por tanto la búsqueda y análisis de las características mediante procedimientos manuales sería un proceso tedioso que involucraría la asignación de varias personas con una alta tasa de ocurrencia de errores.
 es el componente biológico encargado de la transmisión genética de las especies (color de la piel, ojos, estatura, etc.) así como la transmisión de enfermedades hereditarias entender las características en el funcionamiento del ADN es un tema que actualmente tiene ocupada a la Ciencia . EL ADN está conformada por cuatro bases nitrogenadas: Adenina (A), Guanina(G), Citosina(C) y Timina (T) y presenta una estructura de dos bandas en un doble hélice que si se representará a escala de 01 mm esta cadena llegaría al cielo, la estructura computacional para la representación de ADN se hace mediante archivos de texto (un archivo de texto para cada cromosoma) Estos archivos contienen la secuencia de nucleótidos. Cada nucleótido se representa con una letra A para Adenina, C para Citosina, G para Guananina y T para Timina, la representación genera cadenas de texto de gran tamaño que pueden llegar a tener un tamaño medido incluso en Gb (Giga bytes) por tanto la búsqueda y análisis de las características mediante procedimientos manuales sería un proceso tedioso que involucraría la asignación de varias personas con una alta tasa de ocurrencia de errores.")
8
1.1. ANÁLISIS DE LA SITUACIÓN PROBLEMÁTICA
Utilizando diversas técnicas de minería de texto permitirá realizar la clasificación y diversos análisis de las secuencias de ADN como mutación, indización, etc.

9
1.2. PLANTEAMIENTO DEL PROBLEMA.
¿En qué medida la Implementación de un Sistema de Búsquedas de ADN utilizando minería de texto influye en la realización de búsquedas de secuencias genéticas en ADN?

10
1.2.1 PLANTEAMIENTO DE PROBLEMAS ESPECÍFICOS
¿Qué grado de satisfacción de requerimientos tiene el Sistema de Búsquedas en ADN? ¿Qué nivel de complejidad tiene el Sistema de Búsquedas en ADN? ¿El Sistema de Búsquedas en ADN tiene un nivel de usabilidad adecuado? ¿Cuál es el tiempo requerido para el mantenimiento del Sistema de Búsquedas en ADN? ¿Qué nivel de portabilidad tiene el Sistema de Búsquedas en ADN?

11
1.3. JUSTIFICACIÓN DE LA INVESTIGACIÓN
La representación computacional de los nucleótidos: Nucleótidos (A), Citosina (C), Guanina (G) y Timina (T) en un archivo de texto para cada cromosoma, para que se puedan realizar de manera eficiente búsquedas de repeticiones se debe implementar un sistema automatizado utilizando herramientas computacionales. Al realizar entrevistas con docentes de las Facultades de Agronomía y Medicina Veterinaria y Zootecnia de la Universidad Nacional del Altiplano se resalta que la región de Puno tiene especies de plantas como la quinua y especies animales como la Alpaca cuya riqueza genética está almacenada en Bancos de Germoplasma y cuya información no se encuentra automatizada, por tanto con el presente proyecto de investigación se brindará una herramienta importante a los expertos para realizar búsquedas y la correspondiente clasificación y análisis del ADN de estas importantes especies nativas además de aportar soluciones tecnológicas de origen regional que cuenten con un adecuado soporte, la presente investigación puede aplicarse en estudios posteriores para reconocimiento de imágenes, motores de búsquedas, etc.
, Citosina (C), Guanina (G) y Timina (T) en un archivo de texto para cada cromosoma, para que se puedan realizar de manera eficiente búsquedas de repeticiones se debe implementar un sistema automatizado utilizando herramientas computacionales. Al realizar entrevistas con docentes de las Facultades de Agronomía y Medicina Veterinaria y Zootecnia de la Universidad Nacional del Altiplano se resalta que la región de Puno tiene especies de plantas como la quinua y especies animales como la Alpaca cuya riqueza genética está almacenada en Bancos de Germoplasma y cuya información no se encuentra automatizada, por tanto con el presente proyecto de investigación se brindará una herramienta importante a los expertos para realizar búsquedas y la correspondiente clasificación y análisis del ADN de estas importantes especies nativas además de aportar soluciones tecnológicas de origen regional que cuenten con un adecuado soporte, la presente investigación puede aplicarse en estudios posteriores para reconocimiento de imágenes, motores de búsquedas, etc.")
12
1.3. JUSTIFICACIÓN DE LA INVESTIGACIÓN

13
1.4. OBJETIVOS DE LA INVESTIGACIÓN
Objetivo General. Desarrollar un sistema de búsquedas de secuencias genéticas en ADN utilizando minería de texto. Objetivos Específicos. Lograr un adecuado grado de satisfacción de requerimientos en el desarrollo del Sistema de Búsquedas en ADN. Determinar el nivel de complejidad e integridad del Sistema de Búsquedas en ADN. Desarrollar el Sistema de Búsquedas de manera que tenga un nivel de usabilidad adecuado.

14
Desarrollar el Sistema de Búsquedas de forma tal que permitan su adecuado mantenimiento.
Desarrollar el Sistema de Búsquedas en ADN de manera que sea portable.

15
CAPÍTULO II MARCO TEÓRICO CONCEPTUAL

16
2.1. ANTECEDENTES DE LA INVESTIGACIÓN
“Búsqueda de Repeticiones de ADN” Roberto A. Pava - Universidad Nacional de Colombia. El autor selecciona el cromosoma 21 del genoma humano pues considera que fue uno de los que presentó el secuenciamiento más completo. Roberto Pava como resultado de su investigación desarrolló un programa que procesa todo un genoma y emite un reporte del estado del secuenciamiento del genoma, el formato de los archivos leídos por el programa está en formato FASTA y muestra la cantidad de nucleótidos en el archivo del cromosoma procesado.

17
2.1. ANTECEDENTES DE LA INVESTIGACIÓN
2.1.2.“Una Nota Introductoria a La Clasificación Estadística De Poblaciones Basada En El Adn” Ana Reynoso , Javier García Fronti - Universidad de Buenos Aires. Los autores de la presente investigación relizan una comparación entre la propuesta de los autores Lewontin(1992) quien postula: “que los seres humanos de diferentes razas tienen diferencias genéticas ínfimas por lo que no tiene sentido pensar en una clasificación de la humanidad basada en ADN” situación que Edwards (2003) señalando que aunque las diferencias sean mínimas, son suficientes para clasificar los individuos en grupos. Mientras Lewontin se atiene a realizar únicamente un Análisis de Varianza para testear diferencias entre grupos.
 quien postula: que los seres humanos de diferentes razas tienen diferencias genéticas ínfimas por lo que no tiene sentido pensar en una clasificación de la humanidad basada en ADN situación que Edwards (2003) señalando que aunque las diferencias sean mínimas, son suficientes para clasificar los individuos en grupos. Mientras Lewontin se atiene a realizar únicamente un Análisis de Varianza para testear diferencias entre grupos.")
18
2.1. ANTECEDENTES DE LA INVESTIGACIÓN
“Algoritmo de Programación Dinámica para Segmentación en Texto Lineal” P. Fragkou, V. Petridis y. Kehagias. Los autores de la presente investigación abordan el problema de recuperación de información en segmentación de texto. La meta es dividir el texto en segmentos homogéneos, de tal forma que cada segmento concuerda con un sujeto en particular mientras segmentos continuos coinciden con sujetos diferentes. El algoritmo que presentan consultas que pueden que pueden ser realizadas de grandes bases de datos de una gran base de datos de texto sin formatear. En las conclusiones a las que llegan los autores mencionan: “el rendimiento del algoritmo es muy satisfactorio y para el futuro planean aplicar el algoritmo propuesto a un amplio espectro de tareas de textos grandes”.

19
2.2. BASES TEÓRICAS 2.2.1. Ácido Desoxirribonucleíco (ADN).
El ácido desoxirribonucleico (ADN y también DNA, del inglés Deoxyribo Nucleic Acid), se define como: “un tipo de ácido nucleico, una macromolécula que forma parte de todas las células y contiene la información genética usada en el desarrollo y el funcionamiento de los organismos vivos conocidos y de algunos virus, siendo el responsable de su transmisión hereditaria” (Micklos, Freyer, 2003, p. 50).
, se define como: un tipo de ácido nucleico, una macromolécula que forma parte de todas las células y contiene la información genética usada en el desarrollo y el funcionamiento de los organismos vivos conocidos y de algunos virus, siendo el responsable de su transmisión hereditaria (Micklos, Freyer, 2003, p. 50).")
20
2.2. BASES TEÓRICAS La molécula de ADN está compuesta por la misma cantidad de adenina(A) y timina(T) así como de citosina(C) y guanina (G). (la relación de A:T y C:G es igual a 1). Debido a su carácter de doble hélice la longitud del ADN se expresa en pares de bases (pb), donde cada par de base ocupa: - 1kb: 1000pb. - 1Mb: 1000Kb: pb. - 1Gb: 1000Mb: Kb: pb
 y timina(T) así como de citosina(C) y guanina (G). (la relación de A:T y C:G es igual a 1). Debido a su carácter de doble hélice la longitud del ADN se expresa en pares de bases (pb), donde cada par de base ocupa: - 1kb: 1000pb. - 1Mb: 1000Kb: pb. - 1Gb: 1000Mb: Kb: pb.")
21
2.2. BASE TEÓRICA Genética. Etimológicamente genética provienen del término griego “genéticos” derivado de "genetive" traducido es génesis u "origen" , la genética podemos conceptualizarla como: “una disciplina de la biología es la ciencia que estudia la herencia y sus variaciones en organismos vivos” (Posada, 2009, p. 27), las idea fundamental que seres vivos heredan propiedades de sus padres ha sido utilizado desde tiempos prehistóricos para mejorar cultivos de plantas y en la crianza de animales a través de procesos de selección; sin embargo la ciencia moderna de genética que investiga el proceso de herencia recién inicia con el trabajo de Gregor Mendel en la década de los 90 aunque nunca entendió las bases físicas de la herencia, Mendel sólo observaba “que los organismos heredaban características a través de unidades discretas de herencia a los que denomino genes” (Nickoloff, 2001, p. 41) .
, las idea fundamental que seres vivos heredan propiedades de sus padres ha sido utilizado desde tiempos prehistóricos para mejorar cultivos de plantas y en la crianza de animales a través de procesos de selección; sin embargo la ciencia moderna de genética que investiga el proceso de herencia recién inicia con el trabajo de Gregor Mendel en la década de los 90 aunque nunca entendió las bases físicas de la herencia, Mendel sólo observaba que los organismos heredaban características a través de unidades discretas de herencia a los que denomino genes (Nickoloff, 2001, p. 41) .")
22
2.2. BASE TEÓRICA. 2.2.3. Algoritmos de Búsquedas Textuales.
Los textos son un tema central en sistemas de “algoritmos textuales” o también conocido como "procesamiento de palabras", los algoritmos textuales proveen funcionalidades para la manipulación de texto. Tales sistemas usualmente procesan objetos que son de gran tamaño, por ejemplo un libro puede contener tranquilamente un millón de caracteres. Los algoritmos textuales se utilizan en muchas áreas de la Ciencia. Muchos editores de texto y lenguajes de programación tienen utilidades para procesamiento de texto. En biología los algoritmos textuales se utilizan en el campo de secuencias moleculares. El problema textual básico es conocido como (Crochemore, 1994, p. 75) “reconocimiento de patrones” el que es utilizado para acceder información en cadenas de texto, reconocimiento de patrones en este sentido son: “los algoritmos de ordenación o a las operaciones aritméticas básicas para lograr recuperar información”.
 reconocimiento de patrones el que es utilizado para acceder información en cadenas de texto, reconocimiento de patrones en este sentido son: los algoritmos de ordenación o a las operaciones aritméticas básicas para lograr recuperar información .")
23
El problema de reconocimiento de cadenas puede ser ampliado a (Crochemore, 1994, p. 86):
La estructura de los segmentos de un texto. Compresión de datos. Problemas de aproximación. Búsquedas de regularidades. Aplicaciones a imágenes de dos dimensiones. Extensiones a árboles. Implementaciones óptimas en tiempo y espacio. Implementaciones paralelas óptimas.

25
2.2. BASE TEÓRICA Aplicación de Algoritmos Textuales en Genética. . “El descubrimiento de técnicas de secuenciamiento hace 15 años ha permitido una rápida acumulación de secuencias de datos (mas de 10 millones de secuencias de nucleótidos). Desde la recolección de secuencias hasta el análisis implican muchos algoritmos textuales. Sin embargo sólo los algoritmos más rápidos pueden ser utilizados debido a la enorme cantidad de datos.
. Desde la recolección de secuencias hasta el análisis implican muchos algoritmos textuales. Sin embargo sólo los algoritmos más rápidos pueden ser utilizados debido a la enorme cantidad de datos.")
26
2.2. BASE TEÓRICA 2.2.5. Minería de Texto.
“se refiere al proceso de lograr información de alta calidad a partir de textos, la información de alta calidad por lo general se logra a través del descubrimiento de patrones y modas lo cual se conoce como aprendizaje estadístico de patrones. La minería de texto involucra el proceso de estructurar el texto de entrada (usualmente clasificar añadiendo algunas características lingüísticas y remover otras y posteriormente insertar la información en una base de datos), descubrir patrones dentro de los datos estructurados y finalmente evaluar e interpretar los resultados” (Jackson, 2007, p. 115). Categorización de texto. Agrupación de texto. Extracción de conceptos y entidades. Producción de taxonomías granulares. Análisis de sentimientos. Resúmenes de documentos. Modelamiento Entidad – Relación.
, descubrir patrones dentro de los datos estructurados y finalmente evaluar e interpretar los resultados (Jackson, 2007, p. 115). Categorización de texto. Agrupación de texto. Extracción de conceptos y entidades. Producción de taxonomías granulares. Análisis de sentimientos. Resúmenes de documentos. Modelamiento Entidad – Relación.")
27
2.2. BASE TEÓRICA Ingeniería de Software. “Ingeniería de software es la disciplina o área de la informática que ofrece métodos y técnicas para desarrollar y mantener software de calidad” (Pressman, 2007, p. 12).
.")
28
2.2. BASE TEÓRICA 2.2.7. Metodología de programación extrema.
La programación extrema o eXtreme Programming (XP) es una metodología de desarrollo de software ágil presentada por Kent Beck autor del primer libro sobre programación extrema titulado: “Programación Extrema Explicada: Abrazando el cambio” (Extreme Programming Explained: Embrace Change) (Beck Kent, 2004, p.1) La programación extrema es la metodología ágil de desarrollo de software más utilizada debido a las destacadas innovaciones e incremento en la productividad en la industria de software, esta metodología se diferencia de las metodologías de software tradicionales pues pone énfasis en la entrega de resultados (prototipos) más que en otros procesos como la documentación del software.
 es una metodología de desarrollo de software ágil presentada por Kent Beck autor del primer libro sobre programación extrema titulado: Programación Extrema Explicada: Abrazando el cambio (Extreme Programming Explained: Embrace Change) (Beck Kent, 2004, p.1) La programación extrema es la metodología ágil de desarrollo de software más utilizada debido a las destacadas innovaciones e incremento en la productividad en la industria de software, esta metodología se diferencia de las metodologías de software tradicionales pues pone énfasis en la entrega de resultados (prototipos) más que en otros procesos como la documentación del software.")
29
Steward Baird (Bair, 2002, p.21) Kent Beck conceptualiza la programación extrema de la siguiente forma: "La programación extrema comúnmente conocida como XP, es una disciplina del negocios de desarrollo de software que se enfoca en todo el equipo en común, metas razonables usando los valores y principios de la programación extrema, los equipos aplican apropiadamente practicas de XP en sus propios contextos, la práctica de XP es escogida por su valor para incrementar la creatividad humana, dar un mejor trato a los programadores, la programación extrema produce software de calidad y un ambiente sostenible" (Beck Kent, 2004, p.18)
")
30
2.2.7.1. Características Fundamentales de la Programación Extrema.
Desarrollo iterativo e incremental. Pruebas unitarias continuas, frecuentemente repetidas y automatizadas. Programación en parejas. Frecuente integración del equipo de programación con el cliente o usuario. Corrección de todos los errores antes de añadir nueva funcionalidad. Refactorización del código. Propiedad del código compartida. Simplicidad en el código.

31
2.2.7.2. Principios de la Programación Extrema.
Humanidad. Economía. Beneficio mutuo. Similitud. Mejora continua. Diversidad. Reflexión. Flujo. Oportunidades. Redundancia. Fracaso. Calidad. Pasos de Bebé. Responsabilidad Aceptada.

32
2.2.7.3. Prácticas de la Programación Extrema.
El juego de la planificación. Pequeñas Entregas. Metáfora. Diseño simple. Pruebas. Refactorización. Programación por parejas. Propiedad colectiva. Integración continua. Cuarenta horas semanales. Cliente en casa. Estándares de codificación.

33
2.2.7.5. Valores de la Programación Extrema.
Simplicidad. Comunicación. Retroalimentación. Coraje. Respeto.

34
Fases de Desarrollo Fases Principio Planificación El juego de la planificación Entregas pequeñas Metáfora Diseño Diseño simple. Codificación Refactorización. Programación en pares Propiedad colectiva Integración continua Semanas de 40 horas Cliente in situ Estándares de programación Pruebas Pruebas.

35
2.3. BASE TEÓRICA. 2.2.9. Árboles de Sufijos.
En Computación un árbol de sufijos es una estructura de datos que presenta los sufijos de una cadena de manera que permite realizar diferentes operaciones sobre cadenas (Baeza & Gonnet, 2007, p.78). El árbol de sufijos para una cadena S es un árbol cuyos bordes están etiquetados con cadenas de tal forma que cada sufijo de S corresponde a exactamente una camino desde la raíz del árbol a la hoja es denominado un árbol radix (usualmente llamados árboles patricia) para los sufijos de S.
. El árbol de sufijos para una cadena S es un árbol cuyos bordes están etiquetados con cadenas de tal forma que cada sufijo de S corresponde a exactamente una camino desde la raíz del árbol a la hoja es denominado un árbol radix (usualmente llamados árboles patricia) para los sufijos de S.")
36
2.3. MARCO CONCEPTUAL SECUENCIAS ALU “Son las secuencias móviles más abundantes del genoma humano. Derivan probablemente del gen 7SL ARN, que forma parte del complejo ribosomal. La aparición de las secuencias ALU se sitúa hace aproximadamente 65 millones de años, coincidiendo con el origen y expansión de los primates. Inserciones con esta secuencia han sido vinculadas con varias enfermedades heredables en humanos, incluyendo varias formas de cáncer. El estudio de las secuencias ALU es útil para investigar la diversidad del patrimonio genético de las poblaciones humanas y la evolución del orden primates” (Micklos, 2003, p. 34).
.")
37
2.3. MARCO CONCEPTUAL Cromosomas.
“una estructura organizada de ADN y proteínas que se encuentra en las células, es una pieza simple de ADN enrollado que contiene muchos genes, elementos regulatorios y otra secuencia de nucleótidos, los cromosomas también contienen proteínas de ADN conectadas, que sirven para el mismo ADN y para controlar sus funciones” (Grigorenko, 2001, p. 19). (Grigorenko, 2001). Gen “Un gen es una secuencia de nucleótidos organizada en la molécula de ADN, los genes contienen la información necesaria para la síntesis de una macromolécula con función celular especifica normalmente proteínas y también ARNm, ARNr y ARNt. El gen se considera como la unidad de almacenamiento de información genética y unidad de herencia al transmitir esa información a la descendencia, el conjunto de genes de una especie y los cromosomas que los componen se denomina genoma” (Grigorenko, 2001, p. 25).
. (Grigorenko, 2001). Gen. Un gen es una secuencia de nucleótidos organizada en la molécula de ADN, los genes contienen la información necesaria para la síntesis de una macromolécula con función celular especifica normalmente proteínas y también ARNm, ARNr y ARNt. El gen se considera como la unidad de almacenamiento de información genética y unidad de herencia al transmitir esa información a la descendencia, el conjunto de genes de una especie y los cromosomas que los componen se denomina genoma (Grigorenko, 2001, p. 25).")
38
2.3. MARCO CONCEPTUAL

39
2.3. MARCO CONCEPTUAL Telómeros.
Se define como: (Grigorenko, 2001, p. 93) “Región final de los cromosomas. Formado por secuencias de ADN repetitivas dispuestas en TANTEM (ADN mini satélite). Secuencias de TTAGGG (T2AG3) repetidas de 0.1 a 20kb”, entre las funciones de los telómeros tenemos: Permite la correcta replicación de las moléculas de ADN. Protege el cromosoma de daños producidos por los sistemas de reparación del ADN. Evita ser confundido con una cadena de ADN rota. Localización de los cromosomas dentro del núcleo.
 Región final de los cromosomas. Formado por secuencias de ADN repetitivas dispuestas en TANTEM (ADN mini satélite). Secuencias de TTAGGG (T2AG3) repetidas de 0.1 a 20kb , entre las funciones de los telómeros tenemos: Permite la correcta replicación de las moléculas de ADN. Protege el cromosoma de daños producidos por los sistemas de reparación del ADN. Evita ser confundido con una cadena de ADN rota. Localización de los cromosomas dentro del núcleo.")
40
2.4. HIPÓTESIS 2.4.1. Hipótesis General.
Es posible desarrollar un Sistema de Búsquedas en ADN utilizando minería de texto. Hipótesis Específicas. El grado de satisfacción de requerimientos en el desarrollo del Sistema de Búsquedas en ADN es el adecuado. El Sistema de Búsquedas en ADN tiene un nivel de complejidad adecuado. Se ha desarrollado el Sistema de Búsquedas en ADN con un nivel de usabilidad adecuado. El grado mantenibilidad del Sistema de Búsquedas en ADN es el apropiado. El Sistema de Búsquedas en ADN es portable.

41
2.5. ANÁLISIS DE VARIABLES E INDICADORES.
INDEPENDIENTE DIMENSIONES INDICADORES ITEMS SISTEMA DE BÚSQUEDAS Satisfacción de los Requerimientos Grado de satisfacción de los requerimientos. Número de requerimientos identificados Número de requerimientos desarrollados satisfactoriamente Complejidad del sistema de Búsquedas en ADN. Nivel de complejidad. Número de líneas de código fuente Longitud del Programa (N) Volumen del Programa (V)
 Volumen del Programa (V)")
42
2.5. ANÁLISIS DE VARIABLES E INDICADORES.
INDEPENDIENTE DIMENSIONES INDICADORES ITEMS SISTEMA DE BÚSQUEDAS Usabilidad del Sistema de Búsquedas en ADN Nivel de usabilidad del sistema. Esfuerzo necesario para la formación en el uso del programa. Facilidad de operación Mantenibilidad del Sistema de Búsquedas en ADN Grado de Mantenibilidad del sistema Índice de madurez del software Portabilidad del Sistema de Búsquedas en ADN Grado de portabilidad del sistema. Independencia del hardware Independencia del sistema operativo Generalidad

43
2.5. ANÁLISIS DE VARIABLES E INDICADORES.
DEPENDIENTE DIMENSIONES INDICADORES ITEMS BUSQUEDAS EN ADN Eficiencia. Tiempo de Respuesta Tiempo Uso de Recursos Cantidad de Recursos Fiabilidad. Exactitud de las operaciones Errores Detectados

44
CAPÍTULO III MÉTODO DE INVESTIGACIÓN

45
3.1. MÉTODO DE INVESTIGACIÓN
En la presente investigación se usó el método científico para probar los resultados de la investigación. Analítico. Sintético. Cuantitativo (variables e indicadores). Cualitativo (interpretación del significado de los resultados).
. Cualitativo (interpretación del significado de los resultados).")
46
3.2. DISEÑO DE LA INVESTIGACIÓN
El diseño para nuestro tema de investigación “Sistema de Búsquedas en ADN” responde a un diseño experimental debido a que el investigador desea comprobar los efectos de una intervención específica, en este caso el investigador tiene un papel activo pues puede provocar cambios en las variables que intervienen en la investigación. Su diseño más específico es cuasiexperimental pues no se asignan al azar los sujetos que forman parte del grupo de control y experimental, ni son emparejados pues los grupos de trabajo ya están formados es decir ya existen previamente al experimento.

47
3.2. DISEÑO DE LA INVESTIGACIÓN
TIPO DE INVESTIGACIÓN. El tipo de investigación es investigación aplicada pues tienen propósitos prácticos bien definidos es decir se plantea la presente investigación para transformar un determinado sector de la realidad como es el campo de la genética. NIVEL DE INVESTIGACIÓN. El nivel de investigación es experimental pues por su concepción pretendemos responder ¿Cuál es la eficiencia del nuevo Sistema de búsquedas en ADN?, este tipo de investigación se realiza luego de conocer las características del fenómeno o hecho que se investiga, es decir conociendo los factores que han dado origen al problema entonces se le puede dar un tratamiento metodológico.

48
3.3. POBLACIÓN Y MUESTRA La población está definida para el caso por los usuarios que deben validar la operatividad del sistema, para la presente investigación hemos considerado a los estudiantes de décimo semestre (semestre 2012-I) de la Escuela Profesional de Ciencias Biológicas de la Universidad Nacional del Altiplano, por tanto: N = 41 Siendo el tamaño de la población pequeño se ha decidido trabajar con el total de la población por tanto el tamaño de la muestra. n = 41
 de la Escuela Profesional de Ciencias Biológicas de la Universidad Nacional del Altiplano, por tanto: N = 41. Siendo el tamaño de la población pequeño se ha decidido trabajar con el total de la población por tanto el tamaño de la muestra. n = 41.")
49
3.4. TÉCNICAS E INSTRUMENTOS DE INVESTIGACIÓN
TRABAJO DE CAMPO. GABINETE. INSTRUMENTOS DE MEDICIÓN. Entrevistas. Observación. Análisis de contenidos. Estudio de casos. MATERIALES Y EQUIPOS. Documentación de algoritmos textuales. Manuales de Lenguajes de Programación. Cuestionarios. Guías de Entrevistas. Reportes del Sistema de Búsquedas. Lenguajes de Programación (ANSI C++, JavaScript, Phyton, Java.) Computador.
 Computador.")
50
3.5. DISEÑO DE CONTRASTACIÓN DE HIPÓTESIS
Según los criterios estadísticos, el valor estándar para el margen de error es del 5% (0.05) equivalente a la tabla T students a 1.65, para los diseños cuasi experimentales tenemos la siguiente fórmula [13]:
 equivalente a la tabla T students a 1.65, para los diseños cuasi experimentales tenemos la siguiente fórmula [13]:")
51
CAPÍTULO IV RESULTADOS Y DISCUSIÓN

52
4.1. FASES DEL DESARROLLO DEL PROYECTO
4.1.1 El Juego de Planificación. Las responsabilidades durante el escenario de la planificación son: Cliente. Desarrollador. Responsabilidades del negocios. Responsabilidades técnicas. Metáfora. “Sistema de Búsquedas en ADN que permite buscar secuencias de ADN y extraer las principales características como estadísticas de repeticiones y repeticiones en TANDEM”.

53
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 1 Nombre: Búsquedas de Secuencias Usuario: Estudiante Modificación de Historia Número: Iteración Asignada: 0 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: Debe realizar búsqueda de determinas secuencias de ADN; principalmente conocidas como satélites, micro satélites y mini satélites; así como la frecuencia de cada uno en el ADN con longitudes variables. Una característica importante es verificar las repeticiones en TANDEM. Observaciones:
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: Debe realizar búsqueda de determinas secuencias de ADN; principalmente conocidas como satélites, micro satélites y mini satélites; así como la frecuencia de cada uno en el ADN con longitudes variables. Una característica importante es verificar las repeticiones en TANDEM. Observaciones:")
54
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 2 Nombre: Comparación de Secuencias Usuario: Estudiante Modificación de Historia Número: Iteración Asignada: 0 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: El sistema debe determinar la similitud que existe entre dos secuencias de ADN lo cual se conoce como mutaciones Observaciones:
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: El sistema debe determinar la similitud que existe entre dos secuencias de ADN lo cual se conoce como mutaciones. Observaciones:")
55
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 3 Nombre: Visualización de ADN Usuario: Estudiante Modificación de Historia Número: Iteración Asignada: 1 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 8 Riesgo en desarrollo: Baja Puntos reales: 8 Descripción: El sistema debe mostrar la secuencia de ADN de manera que se pueda marcar de manera manual la aparición de sub secuencias que se determinen como importantes. Observaciones:
 Puntos estimados: 8. Riesgo en desarrollo: Baja. Puntos reales: 8. Descripción: El sistema debe mostrar la secuencia de ADN de manera que se pueda marcar de manera manual la aparición de sub secuencias que se determinen como importantes. Observaciones:")
56
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 4 Nombre: Lenguaje de Programación Usuario: Programador Modificación de Historia Número: Iteración Asignada: 1 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: Para garantizar la eficiencia del sistema y lograr una ventaja comparativa en relación a otros Sistemas de Búsquedas en ADN se considera la utilización del lenguaje de programación de nivel intermedio C++. Observaciones: según recopilación de información al respecto C++ se utiliza para sistemas de “performance crítico” de forma que pueda extenderse el uso del programa a otras aplicaciones, C++ al ser orientado a objetos permite garantizar el “mantenimiento” del sistema.
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: Para garantizar la eficiencia del sistema y lograr una ventaja comparativa en relación a otros Sistemas de Búsquedas en ADN se considera la utilización del lenguaje de programación de nivel intermedio C++. Observaciones: según recopilación de información al respecto C++ se utiliza para sistemas de performance crítico de forma que pueda extenderse el uso del programa a otras aplicaciones, C++ al ser orientado a objetos permite garantizar el mantenimiento del sistema.")
57
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 5 Nombre: Entorno de usuario web servidor Usuario: Programador Modificación de Historia Número: Iteración Asignada: 1 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: Para garantizar una adecuada interfaz de usuario y el mayor acceso a los datos para mayor cantidad de usuarios se debe desarrollar utilizando tecnología web: cgi (compilados en C++) y tecnología XAMP (Servidor Web Apache, Gestor de Base de Datos MySQL y PHP) del lado del servidor. Observaciones: La decisión de la plataforma también es conducente a lograr la portabilidad del sistema
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: Para garantizar una adecuada interfaz de usuario y el mayor acceso a los datos para mayor cantidad de usuarios se debe desarrollar utilizando tecnología web: cgi (compilados en C++) y tecnología XAMP (Servidor Web Apache, Gestor de Base de Datos MySQL y PHP) del lado del servidor. Observaciones: La decisión de la plataforma también es conducente a lograr la portabilidad del sistema.")
58
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 6 Nombre: Entorno de usuario web Usuario: Programador Modificación de Historia Número: Iteración Asignada: 1 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: Para garantizar una adecuada interfaz de usuario y el óptimo uso de recursos como tráfico de red y tiempo de ejecución, del lado del cliente se deben desarrollador rutinas en javascript Observaciones: La decisión de la plataforma también es conducente a lograr la “usabilidad” del sistema
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: Para garantizar una adecuada interfaz de usuario y el óptimo uso de recursos como tráfico de red y tiempo de ejecución, del lado del cliente se deben desarrollador rutinas en javascript. Observaciones: La decisión de la plataforma también es conducente a lograr la usabilidad del sistema.")
59
4.1.1.2. Definición de Historias de Usuario
Historia de Usuario Número 7 Nombre: Optimización de transacciones. Usuario: Programador Modificación de Historia Número: Iteración Asignada: 1 Prioridad en el Negocios: Alta (Alta / Media /Baja) Puntos estimados: 10 Riesgo en desarrollo: Baja Puntos reales: 10 Descripción: En las múltiples funciones desarrolladas se debe tomar en cuenta técnicas para la optimización de transacciones a nivel de presentación de datos ( Ejm: paginación), acceso a memoria, rendimiento en bases de datos (optimizar consultas, índices, etc.) Observaciones: También es conducente a lograr la escalabilidad del sistema considerando el gran tamaño de los archivos que contienen la información de ADN.
 Puntos estimados: 10. Riesgo en desarrollo: Baja. Puntos reales: 10. Descripción: En las múltiples funciones desarrolladas se debe tomar en cuenta técnicas para la optimización de transacciones a nivel de presentación de datos ( Ejm: paginación), acceso a memoria, rendimiento en bases de datos (optimizar consultas, índices, etc.) Observaciones: También es conducente a lograr la escalabilidad del sistema considerando el gran tamaño de los archivos que contienen la información de ADN.")
60
Planificación

61
Plan de Entregas Historia Esfuerzo Iteración 0 Iteración 1
Búsquedas de Secuencias 3 X Comparación de Secuencias 2 Visualización de ADN

62
DISEÑO El principio que rige esta fase de XP es el diseño simple, lo cual implica: Ejecutar todas las pruebas. Eliminar código duplicado. Mantener la mínima cantidad de clases y métodos. Instruir a los programadores codificar lo más claramente posible. El sistema de búsqueda en ADN se desarrolla en base a una arquitectura WEB, utilizando para ello un Servidor WEB (tecnología XAMP) configurado para ejecutar módulos desarrollados en C++, se ha elegido esta tecnología debido a que el presente proyecto posteriormente puede ser modificado y utilizado como motor de búsquedas textuales (tipo Google, Yahoo, etc.). De la misma forma se elige el lenguaje de programación ANSI C++ debido a que es un lenguaje portable, soportado por múltiples arquitecturas de hardware y software y el más rápido junto con el lenguaje de programación C (Anon., 2011) además que aporta características orientadas a objeto. La tecnología AJAX se utiliza para ejecutar rutinas de usuario en el cliente de manera que se aligere el trabajo del servidor con lo cual tenemos una arquitectura cliente – servidor en dos capas.
 configurado para ejecutar módulos desarrollados en C++, se ha elegido esta tecnología debido a que el presente proyecto posteriormente puede ser modificado y utilizado como motor de búsquedas textuales (tipo Google, Yahoo, etc.). De la misma forma se elige el lenguaje de programación ANSI C++ debido a que es un lenguaje portable, soportado por múltiples arquitecturas de hardware y software y el más rápido junto con el lenguaje de programación C (Anon., 2011) además que aporta características orientadas a objeto. La tecnología AJAX se utiliza para ejecutar rutinas de usuario en el cliente de manera que se aligere el trabajo del servidor con lo cual tenemos una arquitectura cliente – servidor en dos capas.")
65
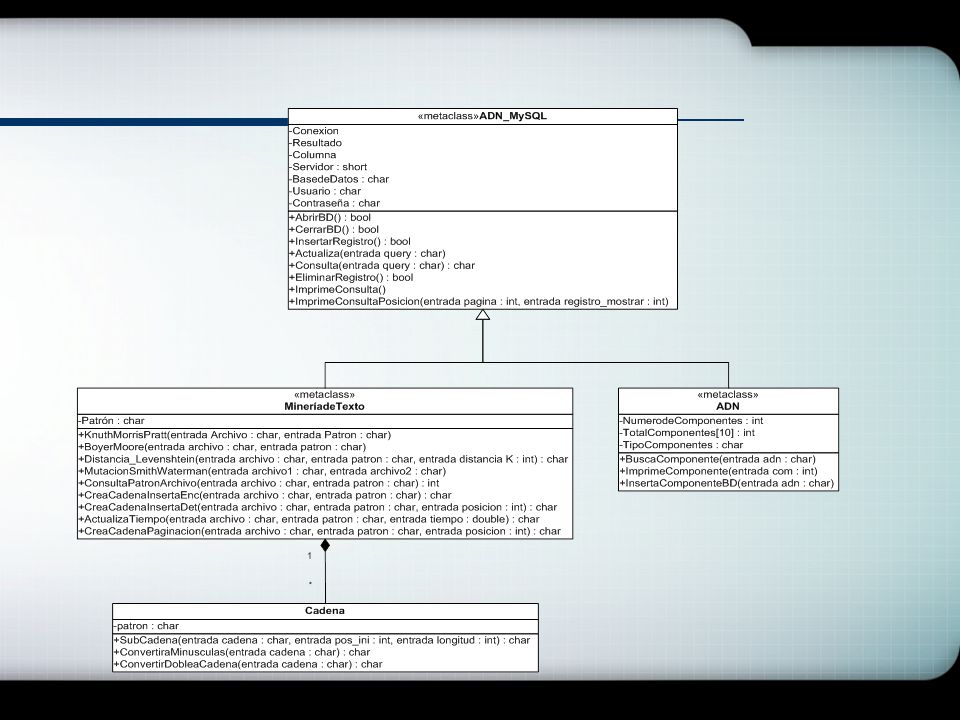
Tarjetas Clase, Responsabilidad y Colaboración
ADN_MySQL Realizar las conexiones del CGI con el Servidor de base de datos MySQL. Interfaz de las operaciones de inserción. actualización y eliminación en las tablas de la base de datos. Mostrar el resultado de las consultas a la BD

66
Tarjetas Clase, Responsabilidad y Colaboración
MineriadeTexto Implementa las funciones de búsqueda de patrones en los archivos de texto que contienen información de ADN. Verifica si la consulta ya ha sido realizada con fines de no duplicar las búsquedas. Crea las cadenas para actulizar la base de datos que serán enviadas a la clase ADN_MySQL ADN_MySQL

67
Tarjetas Clase, Responsabilidad y Colaboración
ADN Implementar las funciones para llevar a cabo conteo de componetes de ADN (A,C,G,T,U,R,P,K,N y X) y similares Mostrar el resultado de las consultas a la BD. ADN_MySQL
 y similares. Mostrar el resultado de las consultas a la BD. ADN_MySQL.")
68
Tarjetas Clase, Responsabilidad y Colaboración
Trie Implementa el árbol para la búsqueda mediante el algoritmo Aho Corasick Nodo Implementa las operaciones sobre nodos del árbol de la clase Trie, también se utiliza para la búsqueda mediante el algoritmo Aho Corasick Trie

69
4.1.2.2. Arquitectura del Sistema.

70
Diagrama de Despliegue

71
Codificación. La etapa de codificación se basan en los principios enumerados en el Capítulo 3 del presente documento, los estándares de programación son definidos de acuerdo al documento “Estándares de Código para C++” (C++ Coding Standard) (Todd, 2008) y el “Manual de Estilo de Programación” elaborado por Alexander Hristov (Hristov, ), los estándares de código y estilo abordan los siguientes temas: Nombres. Documentación. Administración de la complejidad. Clases. Procesos. Formateo. Excepciones. Plantillas (templates). Espacios de nombres (namespaces). Portabilidad. ANSI C++., G++ (compilador C++). Consideraciones especiales.
 (Todd, 2008) y el Manual de Estilo de Programación elaborado por Alexander Hristov (Hristov, ), los estándares de código y estilo abordan los siguientes temas: Nombres. Documentación. Administración de la complejidad. Clases. Procesos. Formateo. Excepciones. Plantillas (templates). Espacios de nombres (namespaces). Portabilidad. ANSI C++., G++ (compilador C++). Consideraciones especiales.")
72
4.1.3.1. Diseño e Implementación de Pruebas.
Pruebas sobre las funciones miembro de la clase ADN_MySQL. El listado de las pruebas es el siguiente cuyo diseño se muestra en el anexo C: Evalua_AbrirBD Evalua_CerrarBD. Evalua_InsertarRegistro. Evalua_Actualiza. Evalua_Consulta. Evalua_EliminarRegistro. Evalua_ImprimeConsultaPosicion.

73
4.1.3.2. Implementación de los Módulos.
g++ archivo.c libmysql.a –o archiv.cgi

74
Pantalla Principal del Sistema de Búsquedas en ADN

75
Resultados de la Búsqueda del Patrón

76
Reporte de Apariciones en Tandem de la Secuencia CATG

77
Resultados de los Componentes del Cromosoma 4

78
Búsquedas de Múltiples Secuencias Utilizando el Algortimo Aho Corasick

79
Resultado de Múltiples Búsquedas Utilizando el Algoritmo de Aho Corasick

80
Búsqueda de Expresiones Regulares Utilizando el Algoritmo de Aho Corasick

81
Resultado de Búsquedas de Expresiones Regulares Utilizando el Algoritmo Aho Corasick

82
Alineación de Secuencias de ADN Utilizando el Algoritmo Smith Waterman

83
Resultados de Alineación de Secuencias Utilizando el Algoritmo Smith Waterman

84
Información de los patrones de búsqueda insertados en MySQL

85
Implementación de Clases
class ADN_MySQL{ // Tipos de Mysql.h MYSQL *conexion; MYSQL_RES *R; MYSQL_ROW COL; // Variables String para conexion, opcionales char *servidor; //"localhost" por defecto char *usuario; // = "root"; usuario por defecto char *clave; // = "********"; contraseña char *db; // = "unap"; base de datos public: ADN_MySQL(); ~ADN_MySQL(); //realiza una consulta añadiendo los resultados a *R void Consulta(char *query); //Actualiza según el query enviado void Actualiza(char *query); void ImprimeConsulta(); void ImprimeConsultaPosicion(char *patron, char *archivo, char *tip_bus, int k,int pagina, int registrom, int total_registros); int NumeroRegistros(); void InsertaRegistros(string tabla, char *valores); void EliminaPatronPosicion(); };//fin implementación de la clase
; ~ADN_MySQL(); //realiza una consulta añadiendo los resultados a *R. void Consulta(char *query); //Actualiza según el query enviado. void Actualiza(char *query); void ImprimeConsulta(); void ImprimeConsultaPosicion(char *patron, char *archivo, char *tip_bus, int k,int pagina, int registrom, int total_registros); int NumeroRegistros(); void InsertaRegistros(string tabla, char *valores); void EliminaPatronPosicion(); };//fin implementación de la clase.")
86
Implementación de Clases
class MineriadeTexto : public ADN_MySQL{ char *patron; //utilizado para preprocesamiento en busquedas KnuthMorissPratt int siguienteKMP[256]; Cadena oCadena; public: MineriadeTexto(char *patron_recibido); int BoyerMooreTodos(char *archivo, char* texto, char* patron, int long_texto, int long_patron); int BoyerMoorePrimero(char* texto, char* patron, int long_texto, int long_patron); void KnuthMorrisPrattPreproceso(char* patron); int KnuthMorrisPrattTodos(char *archivo, char* texto, char* patron);
; int BoyerMooreTodos(char *archivo, char* texto, char* patron, int long_texto, int long_patron); int BoyerMoorePrimero(char* texto, char* patron, int long_texto, int long_patron); void KnuthMorrisPrattPreproceso(char* patron); int KnuthMorrisPrattTodos(char *archivo, char* texto, char* patron);")
87
Implementación de Clases
class Nodo { public: Nodo() { Contenido = ' '; Marcador = false; } ~Nodo() {} char MuestraContenido() { return Contenido; } void ActualizaContenido(char c) { Contenido = c; } bool MuestraMarcador() { return Marcador; } void ActualizaMarcador() { Marcador = true; } Nodo* EncontrarNodo(char c); Nodo* EncontrarNodoExpresion(char c); void AnadirNodo(Nodo* hijo) { Hijos.push_back(hijo); } vector<Nodo*> RetornaHijos() { return Hijos; } private: char Contenido; bool Marcador; vector<Nodo*> Hijos; };
 { Contenido = ; Marcador = false; } ~Nodo() {} char MuestraContenido() { return Contenido; } void ActualizaContenido(char c) { Contenido = c; } bool MuestraMarcador() { return Marcador; } void ActualizaMarcador() { Marcador = true; } Nodo* EncontrarNodo(char c); Nodo* EncontrarNodoExpresion(char c); void AnadirNodo(Nodo* hijo) { Hijos.push_back(hijo); } vector<Nodo*> RetornaHijos() { return Hijos; } private: char Contenido; bool Marcador; vector<Nodo*> Hijos; };")
88
Implementación de Clases
class Trie { public: Trie(); ~Trie(); void AnadePalabra(string palabra); bool BuscaPalabra(string palabra); int BuscaPalabraBuf(string palabra, int inicio); int BuscaPalabraBuffer(char *palabra, int inicio, int long_palabra); int BuscaPalabraBufferExpresion(char *palabra, int inicio, int long_palabra); void EliminaPalabra(string palabra); private: Nodo* root; };//fin clase Trie
; ~Trie(); void AnadePalabra(string palabra); bool BuscaPalabra(string palabra); int BuscaPalabraBuf(string palabra, int inicio); int BuscaPalabraBuffer(char *palabra, int inicio, int long_palabra); int BuscaPalabraBufferExpresion(char *palabra, int inicio, int long_palabra); void EliminaPalabra(string palabra); private: Nodo* root; };//fin clase Trie")
89
4.1.4. Pruebas Búsquedas en ADN Código: P001 Historia de usuario
Búsqueda de Secuencias(01): Nombre: Prueba de Búsquedas en ADN Descripción: Determinar si el conteo de componentes y búsqueda de patrones se realiza satisfactoriamente y estos deben ser almacenados adecuadamente. Condiciones de ejecución: en entorno web con el cgi compilado de C++, los datos deben ser subidos a memoria para fines de eficiencia. Entrada / Pasos de ejecución: Ingreso de parámetros archivo, patrón, tipo de búsqueda (Boyer Moore, Knuth Morris Prat y Aho Corasick). Si la búsqueda ya existe (archivo, patrón) no realizarla nuevamente solo mostrar los datos Búsqueda utilizando punteros. Inserción de los datos en tablas MySQL Resultado Esperado: Numero de componentes, posiciones de los patrones dentro del archivo, existencia de repeticiones en TANDEM, datos correctamente insertados en la Base de Datos. Evaluación de la prueba: Prueba desarrollada satisfactoriamente mostrando gran eficiencia en el resultado de los datos
: Nombre: Prueba de Búsquedas en ADN. Descripción: Determinar si el conteo de componentes y búsqueda de patrones se realiza satisfactoriamente y estos deben ser almacenados adecuadamente. Condiciones de ejecución: en entorno web con el cgi compilado de C++, los datos deben ser subidos a memoria para fines de eficiencia. Entrada / Pasos de ejecución: Ingreso de parámetros archivo, patrón, tipo de búsqueda (Boyer Moore, Knuth Morris Prat y Aho Corasick). Si la búsqueda ya existe (archivo, patrón) no realizarla nuevamente solo mostrar los datos. Búsqueda utilizando punteros. Inserción de los datos en tablas MySQL. Resultado Esperado: Numero de componentes, posiciones de los patrones dentro del archivo, existencia de repeticiones en TANDEM, datos correctamente insertados en la Base de Datos. Evaluación de la prueba: Prueba desarrollada satisfactoriamente mostrando gran eficiencia en el resultado de los datos.")
90
4.1.4. Pruebas Búsquedas en ADN Código: P002 Historia de usuario
Comparación de Secuencias(02): Nombre: Prueba de Comparación de Secuencias en ADN Descripción: Determinar la existencia de cadenas similares a una distancia k y la similitud entre dos archivos de ADN. Condiciones de ejecución: en entorno web con el cgi compilado de C++, los datos deben ser subidos a memoria para fines de eficiencia. Entrada / Pasos de ejecución: Ingreso de parámetros archivo, patrón, tipo de búsqueda, distancia K (Levenshtein). Ingreso de parámetros archivo1, archivo2 (Smith Waterman). Si la búsqueda ya existe (archivo, patrón) no realizarla nuevamente solo mostrar los datos Búsqueda utilizando punteros. Inserción de los datos en tablas MySQL Resultado Esperado: Patrones que son similares al original en una distancia k Distancia entre el archivo1 y archivo2 Datos correctamente insertados en la Base de Datos. Evaluación de la prueba: Prueba desarrollada satisfactoriamente mostrando gran eficiencia en el resultado de los datos
: Nombre: Prueba de Comparación de Secuencias en ADN. Descripción: Determinar la existencia de cadenas similares a una distancia k y la similitud entre dos archivos de ADN. Condiciones de ejecución: en entorno web con el cgi compilado de C++, los datos deben ser subidos a memoria para fines de eficiencia. Entrada / Pasos de ejecución: Ingreso de parámetros archivo, patrón, tipo de búsqueda, distancia K (Levenshtein). Ingreso de parámetros archivo1, archivo2 (Smith Waterman). Si la búsqueda ya existe (archivo, patrón) no realizarla nuevamente solo mostrar los datos. Búsqueda utilizando punteros. Inserción de los datos en tablas MySQL. Resultado Esperado: Patrones que son similares al original en una distancia k. Distancia entre el archivo1 y archivo2. Datos correctamente insertados en la Base de Datos. Evaluación de la prueba: Prueba desarrollada satisfactoriamente mostrando gran eficiencia en el resultado de los datos.")
91
4.1.4. Pruebas Visualización Código: P003 Historia de usuario
Nombre: Prueba de Visualización de Reportes en ADN Descripción: Mostrar en el navegador el reporte de los resultados de las búsquedas ejecutadas en otros módulos. Condiciones de ejecución: en entorno web con el cgi compilado de C++, los datos deben ser presentados usando técnicas de paginación para optimizar el tráfico en la red. La interfaz debe ser amigable e intuitiva Entrada / Pasos de ejecución: Ingreso de parámetros archivo, patrón, tipo de búsqueda, distancia K, tabla. Ejecución de la consulta según parámetros. Impresión de los datos por página y número de registros. Impresión de comandos de navegación para indicar el número de página a consultar. El usuario puede insertar anotaciones en los registros de su elección. Resultado Esperado: Reporte “impreso” en la interfaz web Evaluación de la prueba: Prueba desarrollada satisfactoriamente mostrando gran eficiencia en el resultado de los datos

92
CONCLUSIONES Ha sido factible desarrollar el sistema de búsquedas de secuencias genéticas en ADN utilizando minería de texto, para lo cual se ha utilizado la metodología de desarrollo de software programación extrema, las múltiples fases de desarrollo se muestran en la Capítulo 4 de la presente Tesis, lo cual también se confirma con la prueba de hipótesis desarrollada en el anexo A en el cual se confirma la Hipótesis Alternativa que indica que los promedios de los tiempos de respuesta experimentales utilizando el sistema desarrollado (GAdn) son menores que los promedios de los tiempos de respuesta de control . Todos los requerimiento identificados en la sección 4.1 mediante historias de usuario han sido desarrollados mostrando resultados satisfactorios en la fase de pruebas, los requerimientos funcionales y no funcionales en total son 7 y los 7 han sido desarrollados.
 son menores que los promedios de los tiempos de respuesta de control . Todos los requerimiento identificados en la sección 4.1 mediante historias de usuario han sido desarrollados mostrando resultados satisfactorios en la fase de pruebas, los requerimientos funcionales y no funcionales en total son 7 y los 7 han sido desarrollados.")
93
CONCLUSIONES El número de líneas de código del Sistemas de Búsquedas en ADN es de 3701 en el lenguaje de programación C++, según los expertos un software ha logrado un grado de complejidad adecuado a partir de las 1000 líneas de código. Como se puede observar en el Anexo E el cálculo de la métrica de longitud N es igual 789,105 y el cálculo de volumen V es igual a ,00 que indica el volumen de información en bits requerido para especificar un programa. El sistema según las encuestas desarrolladas en cuanto al aspecto de formación los usuarios han manifestado que el sistema es fácil de aprender en un 95%, en cuanto al entendimiento de las interfaces de entrada y reportes estos se entienden al 100%, en cuanto a la facilidad de uso indican que es 100% fácil de usar, el diseño de la interfaz indican que es adecuada en un 85%; por tanto, se ha logrado desarrollar un sistema con alto grado de usabilidad.

94
CONCLUSIONES La mantenibilidad del sistema según el cálculo de índice de madurez (IMS) es de 73.46% según el anexo G; por tanto, el sistema de búsqueda ha logrado un grado de mantenibilidad adecuado. En cuanto a la portabilidad, desde el análisis de requerimientos no funcionales se ha elegido herramientas que faciliten que el sistema sea independiente del hardware y software, al respecto para el lenguaje de programación C++ se ha utilizado el compilador MinGw (Minimalist GNU for Windows) que es la versión del compilador g++ para Unix según las referencias el compilador es soportado por 65 plataformas (alpha-dec-osf5.1, amd64-solaris2.10, arm-eabi, avr, Blackfin, DOS, freebsd, etc.) información extraida del portal de GNU. El gestor de Base de Datos MySQL es soportada por 15 plataformas (Oracle Linux, Oracle Solaris, Suse, Debian, Microsoft, etc), esta información ha sido extraida del portal de MySQL. El servidor web Apache es soportado por 10 sistemas operativos (Unix, FreeBSD, Solaris, Novell, etc.), esta información ha sido extraida del portal de Apache.
 es de 73.46% según el anexo G; por tanto, el sistema de búsqueda ha logrado un grado de mantenibilidad adecuado. En cuanto a la portabilidad, desde el análisis de requerimientos no funcionales se ha elegido herramientas que faciliten que el sistema sea independiente del hardware y software, al respecto para el lenguaje de programación C++ se ha utilizado el compilador MinGw (Minimalist GNU for Windows) que es la versión del compilador g++ para Unix según las referencias el compilador es soportado por 65 plataformas (alpha-dec-osf5.1, amd64-solaris2.10, arm-eabi, avr, Blackfin, DOS, freebsd, etc.) información extraida del portal de GNU. El gestor de Base de Datos MySQL es soportada por 15 plataformas (Oracle Linux, Oracle Solaris, Suse, Debian, Microsoft, etc), esta información ha sido extraida del portal de MySQL. El servidor web Apache es soportado por 10 sistemas operativos (Unix, FreeBSD, Solaris, Novell, etc.), esta información ha sido extraida del portal de Apache.")
95
CONCLUSIONES http://gcc.gnu.org/install/specific.html

96
RECOMENDACIONES Perú es un país con una importante riqueza biológica; por lo que es importante que esta sea adecuadamente sistematizada utilizando tecnologías de información. El análisis de secuencias de ADN es importante para comprender el funcionamiento y características de los seres vivos de forma que se pueda desarrollar tecnología para el tratamiento de enfermedades, mejoramiento de productividad, etc.; por lo que se recomienda que más profesionales de ciencias médicas, biológicas, ingeniería de sistemas, computación entre otras profesiones puedan dedicar esfuerzos a este campo de investigación pues ya se cuenta con herramientas como la desarrollada en la presente tesis que hacen más fácil su tratamiento. En cuanto al desarrollo de software es importante que la calidad de este sea determinada por métricas para cada una de las fases de su desarrollo.

97
RECOMENDACIONES La portabilidad del software es importante para que este pueda ser utilizado en múltiples plataformas de hardware y software sin necesidad de reescribir código y de esta forma se puede desarrollar tecnología propia que pueda ser expandible y escalable como el caso de buscadores de texto (Google, Yahoo, etc.) y así contribuir de manera eficiente con desarrollo tecnológico del país.
 y así contribuir de manera eficiente con desarrollo tecnológico del país.")
98
PRUEBA DE HIPÓTESIS Los criterios para contrastación de hipótesis se han definido en la sección 3.5 de la presente tesis; según los criterios estadísticos, el valor estándar para el margen de error es del 5% (0.05) equivalente a la tabla T students a 1.65, para los diseños cuasi experimentales tenemos la siguiente fórmula: Sean las Hipótesis Nula y Alternativa respectivamente: Ho : H1 :
 equivalente a la tabla T students a 1.65, para los diseños cuasi experimentales tenemos la siguiente fórmula: Sean las Hipótesis Nula y Alternativa respectivamente: Ho : H1 :")
99
PRUEBA DE HIPÓTESIS Reemplazando Valores
Según la curva de control el Tc Calculado (-8.72) cae en la región de rechazo
 cae en la región de rechazo.")
100
MUCHAS GRACIAS POR SU ATENCIÓN

Presentaciones similares










>")










