Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Interfaces de usuario usando clustering Expositor : Randall Mora Jiménez Carne : 942349

2
Introducción

3
Motivación Los mecanismos convencionales de una búsqueda están plagados de baja precisión. Un problema común con esto es que los usuarios deben navegar a través de muchos documentos irrelevantes antes de encontrar el tipo de documento que le interesa.

4
Motivación Aún algoritmos avanzados de ranking, no puede saber de antemano que tipo de documentos el usuario prefiere. Por ejemplo: Query = Computer Documentos retornados tratan de: hardware o software Interfases Gráficas basadas en Clustering pueden ayudar al usuario a encontrar más fácilmente lo que busca.

5
Objetivo Presentar una herramienta de búsqueda de texto con nuevas formas de visualizar los resultados, que permitan una mejor navegación de los documentos retornados.

6
Objectivos especificos Contribuir a la visualización y Browsing de un conjunto de documentos retornados. Utilización Keywords representativos que permitan el agrupamiento de documentos.

7
Criterios de selección para Keywords Potencialmente de interés general. Específicos para el conjunto de documentos retornados. Poder discriminativo en este conjunto.

8
Espectativas de los Keywords Los keywords deben ayudar para usuario en varias formas: Informando acerca de temas relacionados con el query. Mejorar el query con keywords sugeridos.

9
Metodología Los métodos están basados en identificar Keywords que permitan relacionar el contenido de un documento con el de otro. Estos Keywords son usados para obtener una representación de cada documento y calcular los cluster usando una variante del algoritmo de BuckShot

10
Metodología Los clusters se usan para agrupar los documentos retornados en un query y presentarlos visualmente. Diferentes formas de visualizar los resultados son presentados de acuerdo a las necesidades del usuario.

11
Marco Teórico

12
Calculo de Keywords En lugar de utilizar el idf para calcular el peso de los Keywords, se sugiere utilizar la siguiente formula: wj = hj / dj * hj * log( |H| /hj ) Donde: |H| es el número total de documentos retornados hj es el número de documentos en H que contienen la palabra j dj es el número de documentos en toda la colección D que contienen la palabra j
 Donde: |H| es el número total de documentos retornados hj es el número de documentos en H que contienen la palabra j dj es el número de documentos en toda la colección D que contienen la palabra j")
13
Representación del documento Para cada documento i retornado de un query se crea un vector Vi de k dimensiones, cuyo componente Vij es una función del numero de ocurrencias (tij) del keyword j rankeado en el documento i: Vij = log 2 (1 + tij ) * log( | D | / dj ) Cada vector vi se normaliza produciendo un vector ui que representa al documento i.
 del keyword j rankeado en el documento i: Vij = log 2 (1 + tij ) * log( | D | / dj ) Cada vector vi se normaliza produciendo un vector ui que representa al documento i.")
14
Representación del documento Para calcular la similaridad entre dos documentos a y b se calcula el producto escalar de los vectores u a * u b. U puede ser vista como una representación matricial de los documentos, donde las filas del vector ui son una representación k-dimensional del documento i, y uij es la importancia de la palabra j documento en el documento i. En particular uij es = 0, si y solo si la palabra j no esta contenida en el documento i.

15
Agrupamiento de documentos Se aplica una variante del algoritmo de Buckshot [2] a la matriz u ij. Se obtiene una representación de jerárquica de clusters. Cada cluster tiene cierto numero de vectores de documentos. Jerarquía coherente con el ranking de los documentos retornados.
![Agrupamiento de documentos Se aplica una variante del algoritmo de Buckshot [2] a la matriz u ij.](http://images.slideplayer.es/2/168314/slides/slide_15.jpg "Se obtiene una representación de jerárquica de clusters. Cada cluster tiene cierto numero de vectores de documentos. Jerarquía coherente con el ranking de los documentos retornados..")
16
Pasos para aplicar el Algoritmo: Cree una matriz de similaridad doc-doc Cada documento empieza en un cluster de tamaños 1 Do Until solo halla un cluster: Combine los dos cluster con similaridad más grande. Actualize la matriz de doc-doc

17
Ejemplo Considere A, B, C, D, E como documentos con las siguientes similaridades: A B C D E A - 2 7 9 4 B 2 - 9 11 14 C 7 9 - 4 8 D 9 11 4 - 2 E 4 14 8 2 - Par con similaridad mayor: E-B = 14

18
Se agrupan E y B Obteniendo la siguiente estructura: BE A C D E B

19
Update de la matriz DOC-DOC A BE C D A - 2 7 9 BE 2 - 8 2 C 7 8 - 4 D 9 2 4 - Calculo de BE SC (A, B) = 2 y SC (A, E) = 4 SC(A,BE) = 4 single link (take max) SC(A,BE) = 2 complete linkage (take min) SC(A,BE) = 3 group average (take average)
 = 2 y SC (A, E) = 4 SC(A,BE) = 4 single link (take max) SC(A,BE) = 2 complete linkage (take min) SC(A,BE) = 3 group average (take average)")
20
Se agrupa BE y C Obteniendo la siguiente estructura: BCE BE C A D E B

21
Update de la matriz DOC-DOC A BCE D A - 2 9 BCE 2 - 2 D 9 2 - Cálculo de SC(A, BCE): SC (A, BE) = 2 y SC (A, C) = 7 SC(A,BCE) = 2 Cálculo de SC(D,BCE) SC(D, BE) = 2 y SC(D, C) = 4 SC(D, BCE) = 2
: SC (A, BE) = 2 y SC (A, C) = 7 SC(A,BCE) = 2 Cálculo de SC(D,BCE) SC(D, BE) = 2 y SC(D, C) = 4 SC(D, BCE) = 2")
22
Se agrupa A y D. ABCDE BCE AD BE C A D E B

23
Tiempo de procesamiento Algoritmo consume una cantidad de tiempo lineal entre el número de documentos retornados y el número de cluster generados. En promedio 1000 documentos pueden ser procesados en menos de un segundo con un PC estándar de 500 MHz.

24
Desarrollo

25
Nuevos paradigmas en visualización de información Sammon Cluster View Tree-Map Visualization Radial Interactive Visualization

26
Sammon Cluster View Utiliza Sammon map, para generar una localización en dos dimensiones de los clusters. Este mapa se calcula usando un búsqueda de gradiante iterativo (Ver [3]).
..")
28
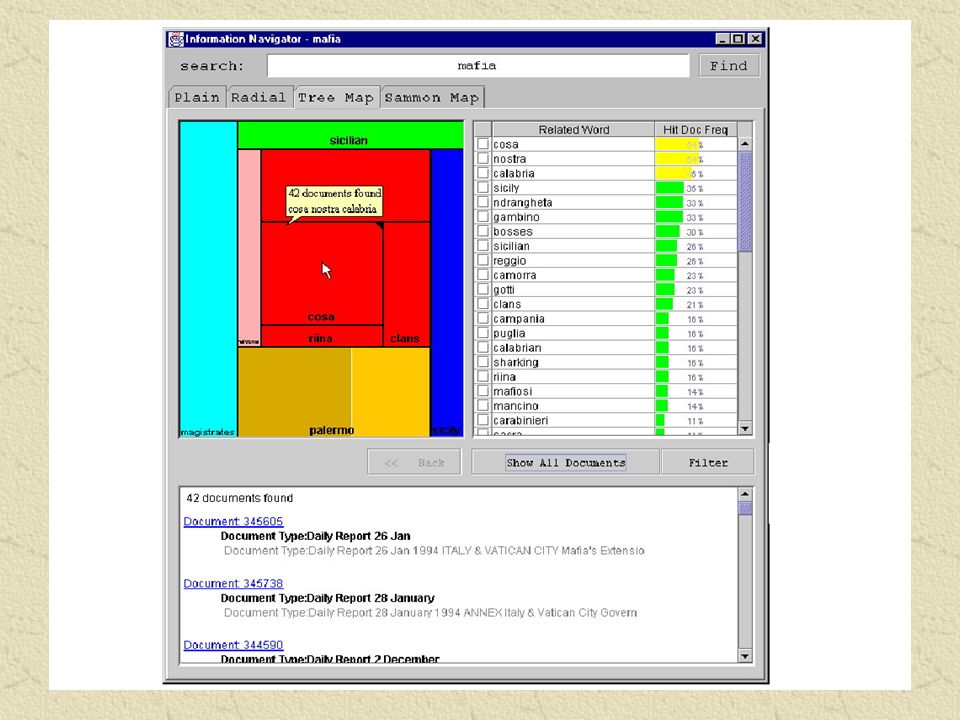
Tree-Map Visualization Representación jerárquica de los cluster. Los cluster se visualizan mediante rectángulos. Clusters similares se agrupan en Súper Clusters (Ver 4).
..")
29
A B C D EF Tree-Map Construction NodeWeight A10 B1 C4 D5 E2 F3

30
B: 1 A: 10 C: 4 D: 5 E: 2F: 3 Tree-Map Construction A B C D EF

31
A B C D EF A

32
A B C D EF BCD

33
A B C D EF BCD

35
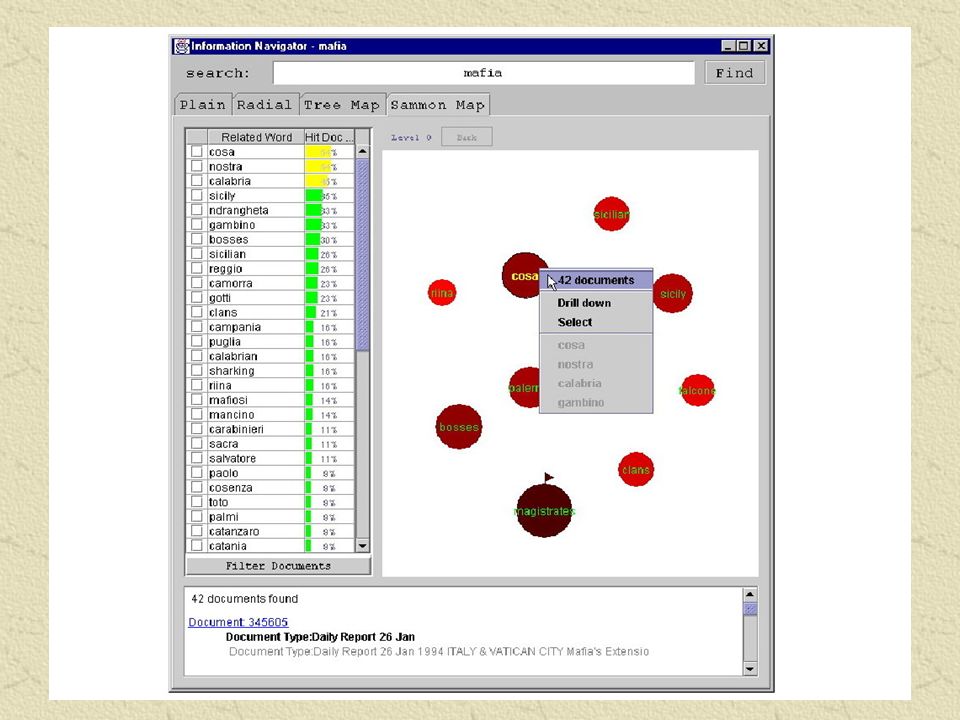
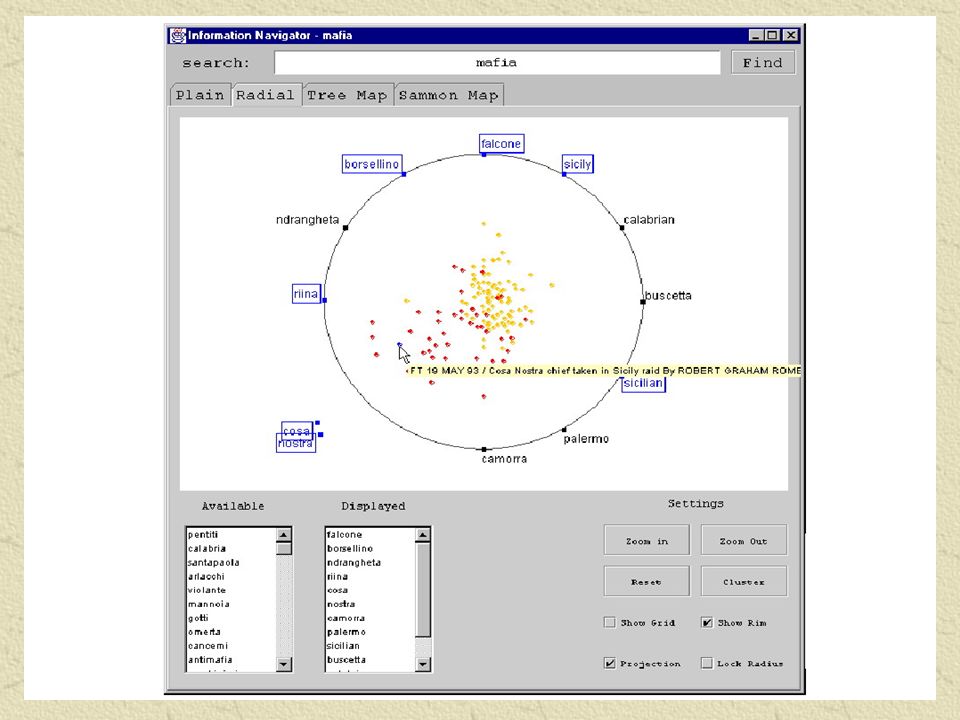
Radial Interactive Visualization Nodos con Keywords son colocados alrededor de un círculo. Documentos representados por puntos en el interior del círculo. Entre mas relacionado un documento con un Keyword más cercano estará de este (Ver 5, 6 y 7).
..")
36
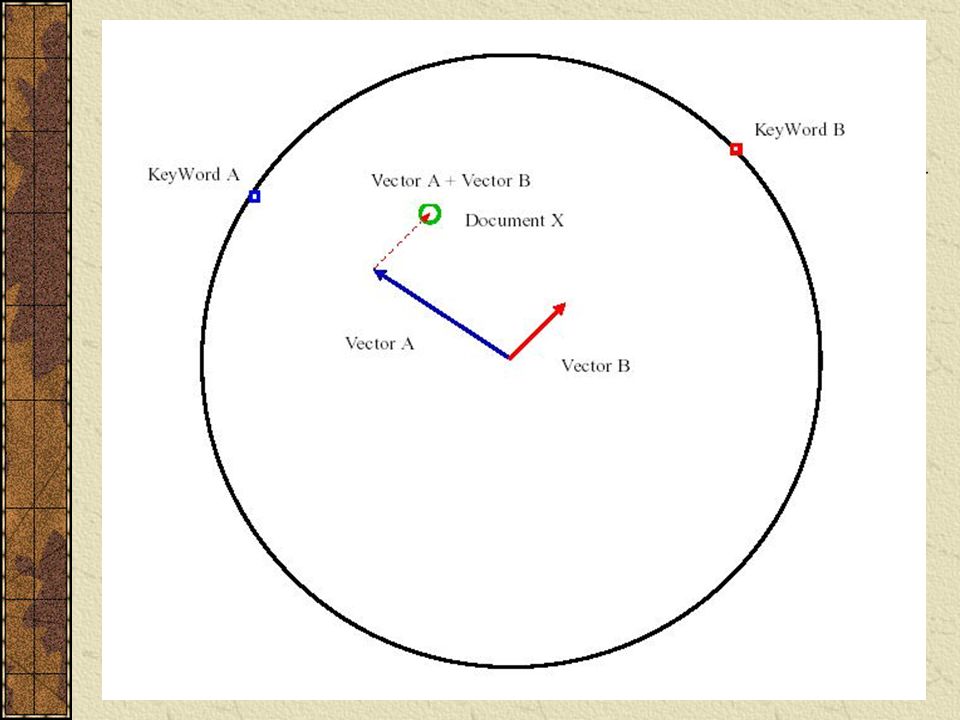
Ejemplo de Algoritmo Radial Sea P1 la posición del Keyword A en el círculo. Sea P2 la posición del Keyword B en el círculo. Se utiliza la matriz de pesos de Keyword para cada documento. ( P1 * wij, P2 * wij)
.")
39
Experimentos de clustering Se realizaron experimentos de agrupamiento con 548,948 documentos principalmente de US. Estos documentos se tomaron de los CDs vol 4 y 5 de TREC (ver http://trec.nist.gov) Las Fuentes de estos artículos pertenecen a Los Angeles Times, the Financial Times, the Federal Register, Congress Records, etc.

40
Calidad de clusters Basado en el análisis brindado por expertos, acerca de documentos relevantes y no relevantes. 100 queries enfocados en encontrar concentraciones altas y bajas de documentos relevantes en los clusters.

41
Resultados Los resultados compilan evidencia que valida la Hipótesis de Clustering en bajas dimensiones para la representación de documentos [8]
![Resultados Los resultados compilan evidencia que valida la Hipótesis de Clustering en bajas dimensiones para la representación de documentos [8]](http://images.slideplayer.es/2/168314/slides/slide_41.jpg "Resultados Los resultados compilan evidencia que valida la Hipótesis de Clustering en bajas dimensiones para la representación de documentos [8]")
42
Resultados Generales Una palabra candidata aparece por lo menos en 3 documentos. Una palabra candidata no aparece en más del 33% de todos los documentos. Vocabulario resultante 222,872 Keywords. Un promedio de 200 Keywords por documento.

43
Encuesta Las personas llenaban un cuestionario antes de usar la aplicación. Después utilizaban la aplicación para realizar una serie de queries en una colección de documentos.

44
Encuesta Los queries se diseñaron para que aunque la información estubiera en la colleccion, no fuese obvia su localización. Finalmente un cuestionario post uso, con preguntas acerca de la aplicación y otras áreas más abiertas.

45
Carácteriscas Comparativas Visualizaciones basadas en clusters dan un panorama más amplio del conjunto de resultados. Visualización Radial permite enfocarse en formar subconjuntos de Keywords

46
Carácteriscas Comparativas Sammon Map se enfoca más en la relación que existe en un cluster y otro. TreeMap es más explicito en cuanto al tamaño de los cluster y su estructura jerárquica.

47
Facilidades de cada interfaz Sammon Map guía en el análisis, permite reagrupar subconjuntos, y gradualmente acercar al tipo de documentos de interés. TreeMap permite enfocarse en Keywords que de ciertos documentos que de interés, para formular una búsqueda más productiva. Radial apropiado si el usuario esta familiarizado con los Keywords del area de su interes.

48
Conclusiones Contribuye a la visualización y Browsing de un conjunto de documentos retornados mediante: Identificación de features relevantes en un conjunto de documentos (Keywords) Desechar rápidamente clusters irrelevantes. Operaciones de Drill Down en cluster relevantes. Construcción de grupos personalizado usando Radial.

49
Posibles Mejoras Uso de Tesauros para realizar el agrupamiento de Keywords.

Presentaciones similares









>")




. Función DESREF y Otras>")



>")
