Descargar la presentación
La descarga está en progreso. Por favor, espere

1
REGRESION LINEAL SIMPLE
Jorge Galbiati Riesco

2
Se dispone de una muestra de observaciones formadas por pares de variables: (x1, y1)
.. (xn, yn)
")
3
A través de esta muestra, se desea estudiar la relación existente entre las dos variables X e Y.
Es posible representar estas observaciones mediante un gráfico de dispersión, como el anterior. También se puede expresar el grado de asociación mediante algunos indicadores, que se verán a continuación.

4
MEDIDAS DE ASOCIACION DE VARIABLES
Covarianza entre las variables X e Y. Es una medida de la variación conjunta. Se define como Puede tomar valores positivos o negativos.

5
Covarianza positiva, significa que ambas variables tienden a variar de la misma forma, hay una asociación positiva. Negativa, significa que si una aumenta, la otra tiende a disminuir, y vice versa. Covarianza cercana a cero indica que no hay asociación entre las variables.

6
Ejemplo 1

7
Calcularemos de la covarianza entre estas dos variables.

8
Coeficiente de correlación lineal.
La covariaza tiene el inconveniente de que su valor no es acotado, por lo que, a partir de él es dificil juzgar si es grande o pequeña. Se define la correlación, que es una medida de asociación lineal independiente de las unidades de medida. Es igual a la covarianza dividida por las desviaciones standard:

9
Coeficiente de correlación lineal.
La covariaza tiene el inconveniente de que su valor no es acotado, por lo que, a partir de él es dificil juzgar si es grande o pequeña. Se define la correlación, que es una medida de asociación lineal independiente de las unidades de medida: Es igual a la covarianza dividida por las desviaciones estandar:

10
El valor de la correlación entre cualquier par de variables es un número entre -1 y 1. n valor alto de correlación no indica que existe alguna relación de causa-efecto entre las variables.

11
Ejemplo (continuación)
")
12
El siguiente es un gráfico de dispersión que muestra estos datos.

13
La interpretación del coeficiente de correlación puede ilustrarse mediante los siguientes gráficos.

14
REGRESION LINEAL SIMPLE
Ahora asumiremos que si hay una relación de causalidad de la variable X (causa) hacia la variable Y (efecto). Además, se sabe que esa relación es de tipo lineal, dentro del rango de los datos. Estableceremos un modelo para explicar la causa (Y) en términos del efecto (X), del tipo siguiente:
 hacia la variable Y (efecto). Además, se sabe que esa relación es de tipo lineal, dentro del rango de los datos. Estableceremos un modelo para explicar la causa (Y) en términos del efecto (X), del tipo siguiente:")
15
para i = 1,2,..., n en que a y b son dos cantidades fijas (parámetros del modelo) y los ei son cantidades aleatorias que representan las diferencias entre lo que postula el modelo y lo que realmente se observa, y. Por esa razón a los e los llamaremos "errores" o "errores aleatorios". Se asume que tienen valor esperado 0 y desviación estándar común .
 y los ei son cantidades aleatorias que representan las diferencias entre lo que postula el modelo y lo que realmente se observa, y. Por esa razón a los e los llamaremos errores o errores aleatorios . Se asume que tienen valor esperado 0 y desviación estándar común .")
16
Ejemplo 2

17
Representación de los datos en un gráfico de dispersión:

18
Se puede apreciar la relación lineal existente entre ambas variables observadas.
Nuestro problema es estimar los parámetros a, b y para poder identificar el modelo. Para estimar a y b se utiliza el método de Mínimos cuadrados, que consiste en encontrar aquellos valores de a y de b que hagan mínima la suma de los cuadrados de las desviaciones de las observaciones respecto de la recta que representa el modelo, en el sentido vertical.

19
En la figura, son los cuadrados de los segmentos verticales cuya suma de cuadrados se debe minimizar, para determinar a y b. Estos segmentos representan los errores e del modelo. b se llama pendiente de la recta que representa los datos y a se llama intercepto sobre el eje vertical.

20
La solución está dada por las siguientes fórmulas:

21
Ejemplo 2 (continuación)
Calculamos los promedios de ambas variables y se las restamos a los valores.

22
El modelo, para estos datos, es
para i=1,2,.. 15 Representa una recta, cuyo intercepto con el eje vertical es -0.96, y su pendiente es 3.18, o sea, si el porcentaje de comisión X aumenta en 1%, la ganancia neta Y aumenta en 3.18 Millones de pesos.

23
Gráfico de los datos:

24
VALORES AJUSTADOS AL MODELO.
El modelo de regresión lineal se puede utilizar para obtener valores de Y ajustados al modelo. Los valores puntuales se obtienen mediante la fórmula en que a y b son los valores estimados por el procedimiento indicado anteriormente, y Xi toma los valores de la muestra. Los puntos que representan estos valores en el gráfico de dispersión, yacen sobre la recta.

25
Ejemplo 2 (continuación)
La tabla siguiente contiene los valores de Y ajustados , para cada valor de X, además de los valores de Y observados, a modo de comparación. Los ajustados se obtienen por la fórmula.

26
Se puede observar que el promedio de los valores ajustados es igual al promedio de los valores observados, y que el promedio de las diferencias es cero. La raíz cuadrada del promedio de los cuadrados de las diferencias entre los valores observados y ajustados, es una estimación de la varianza del error, s . En el ejemplo, la suma de las diferencias al cuadrado es 19.8, luego la estimación de la desviación estándar del error es igual a Millones de pesos

27
Coeficiente de determinación.
Es una medida de bondad de ajuste del modelos de regresión lineal a los datos. Es deseable que los valores de Y ajustados al modelo, sean lo más parecidos posible a los valores observados. Una medida de lo parecido que son, es el coeficiente de correlación. Se define el coeficiente de determinación, R2, como el cuadrado del coeficiente de correlación entre los valores de Y observados y los valores de Y ajustados.

28
Sin embargo se puede demostrar que es igual a la siguiente expresión:
El rango de R2 es entre 0, cero ajuste, hasta 1, ajuste perfecto (cuando los puntos aparecen en un línea recta).
.")
29
Ejemplo 2 (continuación)
Más arriba se calcularos las sumas de cuadrados y de productos, y dieron los siguientes valores: Sxx = 39.6 , Syy = , Sxy = 126.1 Entonces el coeficiente de determinación es que señala que el ajuste del modelo a los datos es bueno.

30
Ejemplo 3 Los datos siguientes corresponde al Indice de Producción Física de la Industria Manufacturera, por agrupación, de los meses de mayo de 2002 y mayo de 2003, entregado por el Instituto Nacional de Estadísticas.

31
Es un índice cuya base 100 es el promedio de producción de cada agrupación, en el año 1989.
El gráfico de dispersión es el siguiente:

32
Cálculos parciales, en que X es el índice mayo 2002, Y el índice mayo 2003:
Estimación de los parámetros del modelo:

33
Bondad de ajuste: que indica un muy buen ajuste. El siguiente gráfico muestra de recta de regresión estimada:

34
Predicción por bandas de confianza.
Se pueden hacer predicciones de valores Y para valores X que no están en el conjunto de observaciones, dentro o fuera de su rango, utilizando la fórmula de la regresión lineal, con los parámetros a y b estimados. También se pueden hacer predicciones por intervalos de confianza verticales, que tienen la ventaja de proporcionar una cuantificación del error de predicción. Los intervalos tienen la propiedad de ser de diferente ancho, según el valor de X, siendo más angostos cuando X es igual al promedio, ensanchándose a medida que nos alejamos del promedio.

35
Cuando se sale del rango de los datos, se ensanchan más fuertemente.
Esto significa que mientras más nos alejamos del centro de los valores de la variable X, más imprecisas serán nuestras estimaciones del valor de la variable Y, lo que parece razonable.

36
Si unimos los extremos superiores (o los inferiores) de todos los intervalos de confianza, se obtienen dos curvas con forma de hipérbola, como se muestra en la figura:
 de todos los intervalos de confianza, se obtienen dos curvas con forma de hipérbola, como se muestra en la figura:")
37
El gráfico siguiente muestra las bandas de confianza de coeficiente 95%, para el ejemplo de la producción física manufacturera. Mientras mayor es el coeficiente de determinación R2, más angostas son las bandas de confianza; lo mismo mientras mayor es la desviación estándar de las X, y lo mismo si el tamaño muestral aumenta. Y a medida que nos alejamos del promedio de las X, se ensanchan las bandas.

38
Relación entre población y número de nacimientos.
ESTUDIO DE CASO Relación entre población y número de nacimientos.

39
El objetivo del estudio es explorar el valor predictivo de la población de cada uno de los tramos etarios sobre el número de nacimientos, de las comunas. En particular, determinar cuál tramo etario (su población) tiene mayor poder predictivo sobre el número de nacimientos.
 tiene mayor poder predictivo sobre el número de nacimientos.")
40
Se tiene una muestra de 40 comunas comunas elegidas al azar, en que se midieron las siguientes variables : Población por tramo etario (del censo de 2002): 1 menos de 1 año 2 entre 1 y 4 años 3 entre 5 y 9 años 4 entre 19 y 19 años 5 entre 20 y 44 años 6 entre 45 y 64 años 7 entre 65 y 79 años 8 80 años o más 9 Nacimientos en el año (correspondientes a 2006)
: 1 menos de 1 año. 2 entre 1 y 4 años. 3 entre 5 y 9 años. 4 entre 19 y 19 años. 5 entre 20 y 44 años. 6 entre 45 y 64 años. 7 entre 65 y 79 años años o más. 9 Nacimientos en el año (correspondientes a 2006)")
41
Comuna menos 1 e 1 - 4 e 5-9 e 10-19 e 20-44 e 45-64 e 65-79 mas 80 Nacimientos 1 Huasco 116 486 677 1,501 2735 1802 624 124 101 2 Las Cabras 305 1,299 1,794 3,872 7995 4661 1639 378 1066 3 El Monte 508 2,079 2,634 5,634 11082 5467 1700 464 392 4 Alto Biobío 140 544 617 1,108 4146 2038 387 74 176 5 San Nicolás 132 538 761 1,736 3684 2216 779 165 118 6 San Fernando 960 4,090 5,756 12,911 25627 14007 4446 1098 965 7 Aisén 427 1,682 2,121 4,790 9951 4535 1234 271 409 8 Llanquihue 280 1,155 1,581 3,327 6619 3446 1078 234 218 9 Victoria 471 1,760 2,547 6,500 11768 6995 2751 707 462 10 Arauco 613 2,678 3,573 7,521 15147 7119 2140 517 528 11 El Bosque 2,655 10,647 13,257 31,249 66602 35983 11795 2547 2573 12 San Vicente 568 1,392 3,462 7,955 15458 9518 3202 785 561 13 Yerbas Buenas 244 978 1,362 3,189 6265 3512 1050 240 216 14 Pemuco 507 794 1,692 3295 1844 691 153 90 15 Chiguayante 1,537 6,152 8,612 20,445 39650 20500 5239 1552 1145 16 Porvenir 67 366 994 2275 1157 382 77 80 17 Combarbalá 161 661 934 2,010 4225 2962 1521 395 168 18 Conchalí 1,686 6,676 8,286 18,977 44767 25540 11377 2842 1958 19 Tucapel 190 745 1,058 2,391 4609 2787 1205 175 20 Camarones 100 255 546 346 106 26

42
Comuna menos 1 e 1 - 4 e 5-9 e 10-19 e 20-44 e 45-64 e 65-79 mas 80 Nacimientos 21 Quinta de Tilcoco 160 635 894 2,179 4279 2556 813 203 162 22 Ovalle 1,661 6,712 9,140 20,281 38840 20843 7750 1833 1653 23 Pica 75 304 354 746 7218 2487 338 100 59 24 Ninhue 60 310 455 939 1738 1272 550 134 49 25 Taltal 177 735 950 1,939 4075 2336 655 143 199 26 Molina 538 2,297 3,224 7,218 15539 8832 2803 666 521 27 Arica 2,842 11,630 15,545 33,775 67981 38405 12487 2767 3079 28 Navidad 54 263 369 752 1658 1396 709 184 45 29 Graneros 429 1,757 2,406 5,480 10809 5659 1634 217 86 30 Coronel 1,471 6,248 8,681 20,287 39860 20784 5792 1130 1509 31 Caldera 249 966 1,266 2,941 5512 2810 837 138 264 32 Mejillones 682 830 1,836 3954 1943 408 81 139 33 Colchane 101 120 620 347 140 47 14 34 Chillán 2,283 9,549 13,437 30,848 66475 35890 11216 2527 2479 35 Lago Verde 13 53 68 390 258 69 12 36 Futrono 278 1,150 1,541 3,211 5420 2886 976 208 214 37 Máfil 111 368 1,516 2472 1436 569 38 Canela 121 515 716 1,437 2818 1986 1101 261 103 39 Freire 402 1,667 2,337 5,134 9525 5416 2093 542 311 40 Valdivia 2,173 8,470 11,336 28,184 59713 30986 10176 2539 2192

43
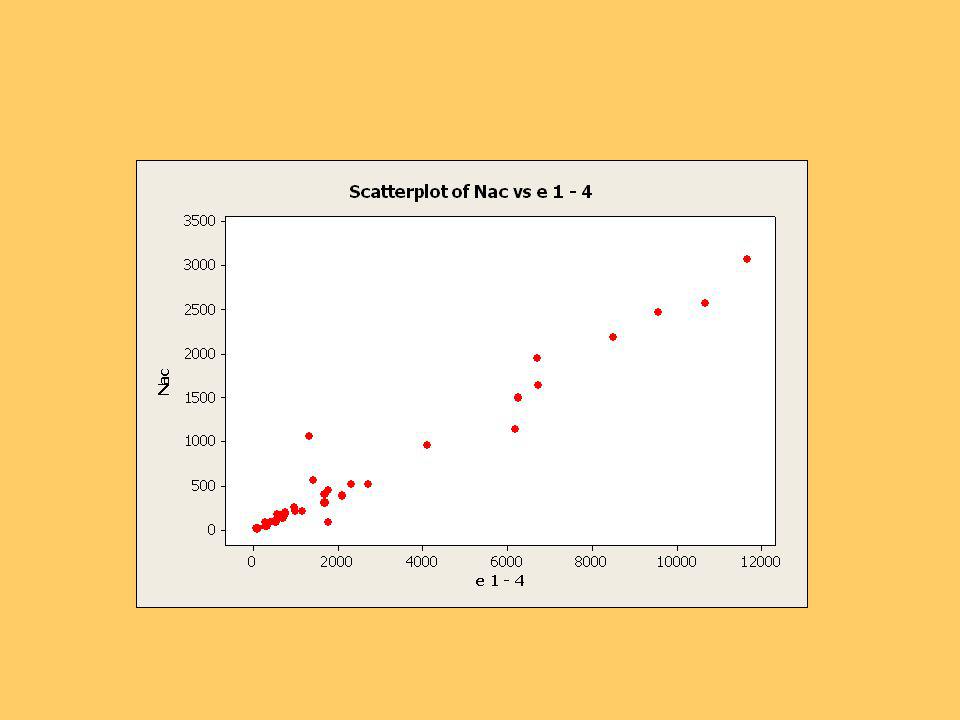
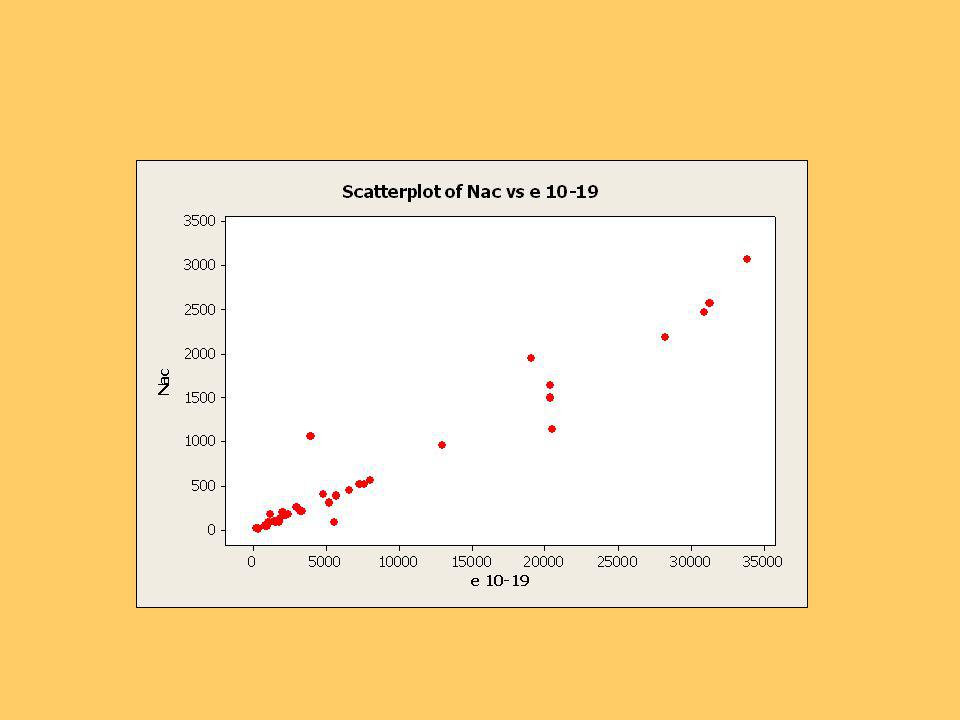
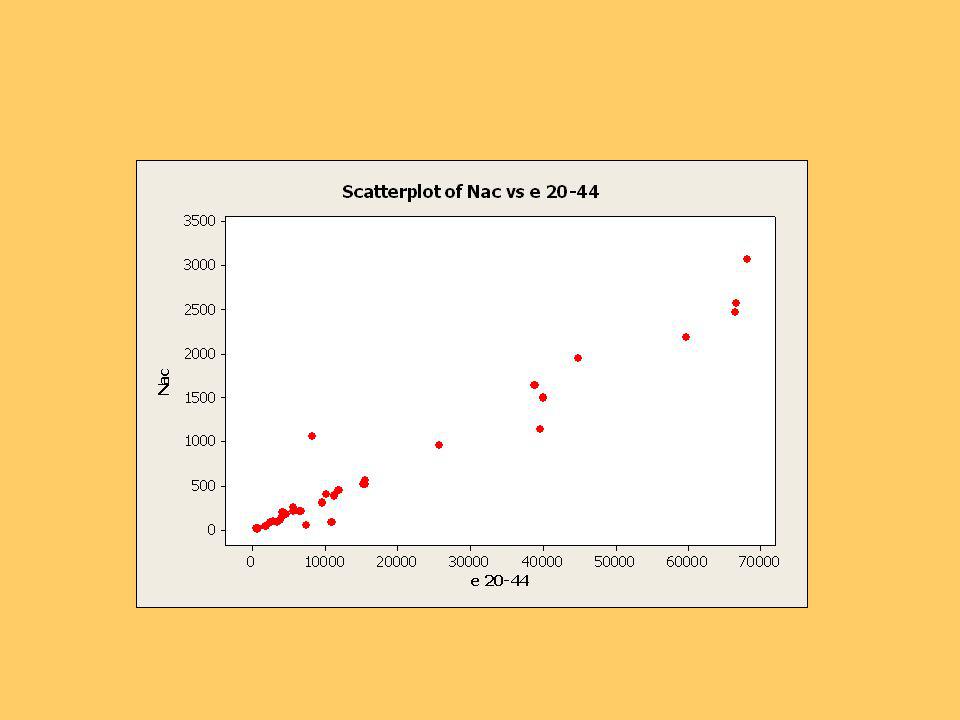
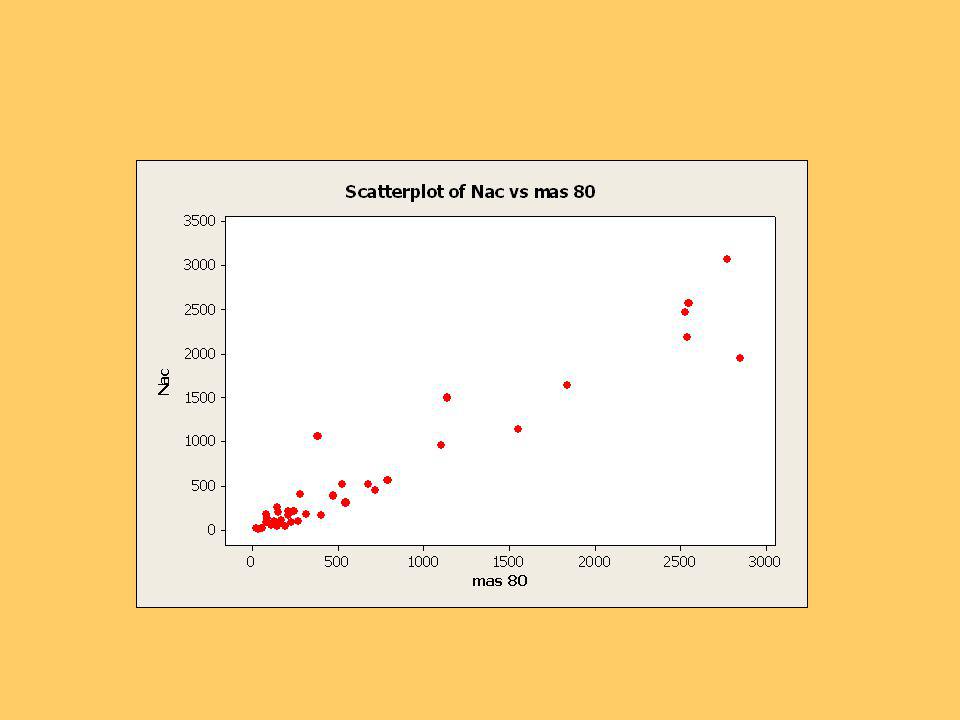
Se presentan los gráficos de los nacimientos versus población, de cada tramo.

51
Se observa que persistentemente una comuna tiene un número de nacimientos mayor que el resto, según su población, en todos los tramos. Es la Comuna de Las Cabras. Las comunas con ambos números más grandes son Arica, El Bosque y Chillán. Para los gráficos y los cálculos siguientes se usó el software MINITAB.,

52
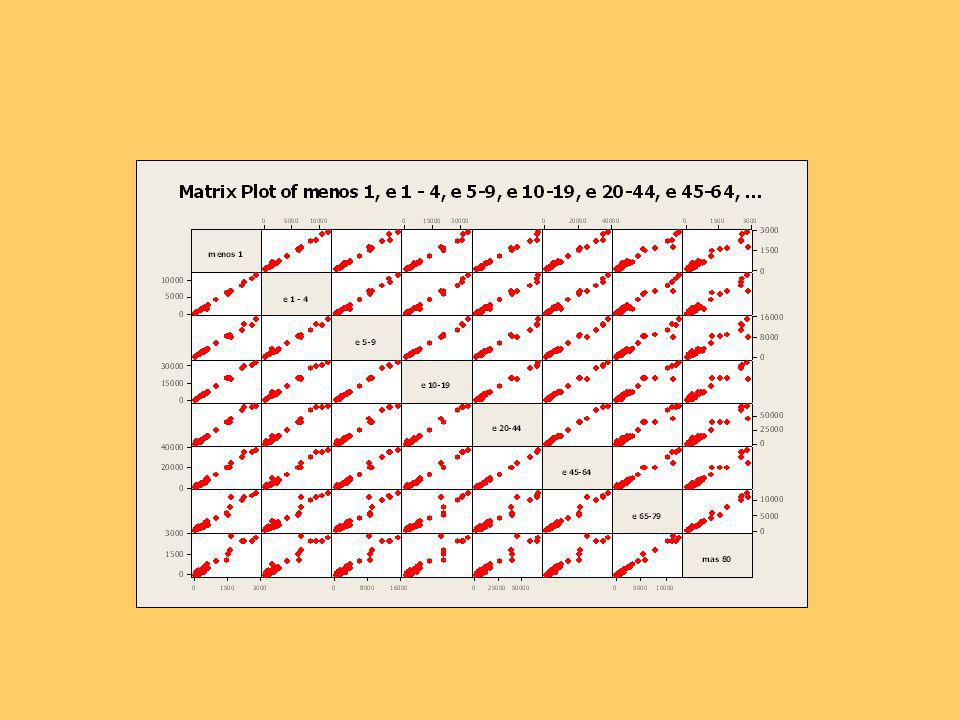
Hay una correlación muy fuerte entre las poblaciones de los distintos tramos de edad, siendo un poco menos entre el tramo “más de 80” y las demás. Esto se puede apreciar en la siguiente figura, en que grafican las variables de a pares.

54
Se ajustaron modelos de regresión lineal simple a los nacimientos, con la población de cada uno de los tramos etarios, como regresor. La respuesta (y) siempre fue el número de nacimientos. La salida de MINITAB es la siguiente (en el primer caso):
 siempre fue el número de nacimientos. La salida de MINITAB es la siguiente (en el primer caso):")
55
Regression Analysis: Nac versus menos 1
The regression equation is Nac = (menos 1) Predictor Coef SE Coef T P Constant menos
 Predictor Coef SE Coef T P. Constant menos")
56
(cont.) S = R-Sq = 96.0% R-Sq(adj) = 95.9% Analysis of Variance Source DF SS MS F P Regression Residual Error Total

57
De las pruebas t de hipótesis, se concluye que el intercepto
a = no es significativo, mientras que la pendiente b = 1.03 si lo es. Por lo tanto la relación entre nacimientos y el tamaño de la población de menores de 1 año es Nac = 1.03 (menos 1)
")
58
Relaciones similares se puede obtener para las otras variables poblacionales y su efecto sobre el número de nacimientos. Eso queda para el lector.

59
FIN

Presentaciones similares

















>")




