Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Programa de certificación de Black Belts CFE
Seis Sigma Programa de certificación de Black Belts CFE VI. Seis Sigma - Análisis P. Reyes / Abril de 2009

2
Fase de Análisis Propósitos: Salidas:
Establecer hipótesis sobre las posibles Causas Raíz Refinar, rechazar, o confirmar la Causa Raíz Seleccionar las Causas Raíz más importantes: Las pocas Xs vitales Salidas: Causas raíz validadas Factores de variabilidad identificados

3
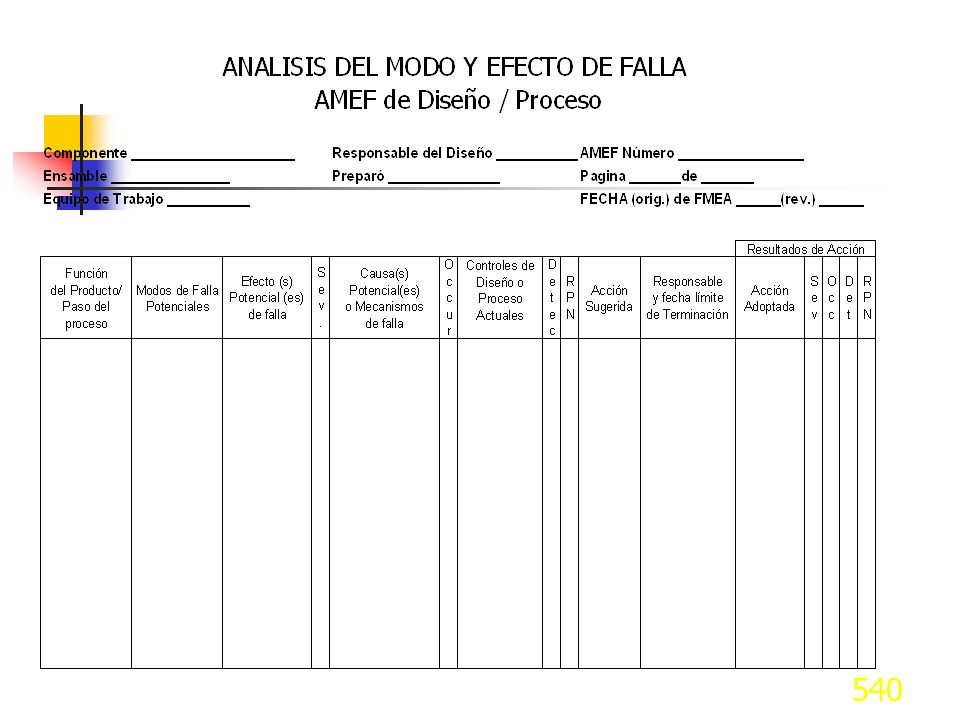
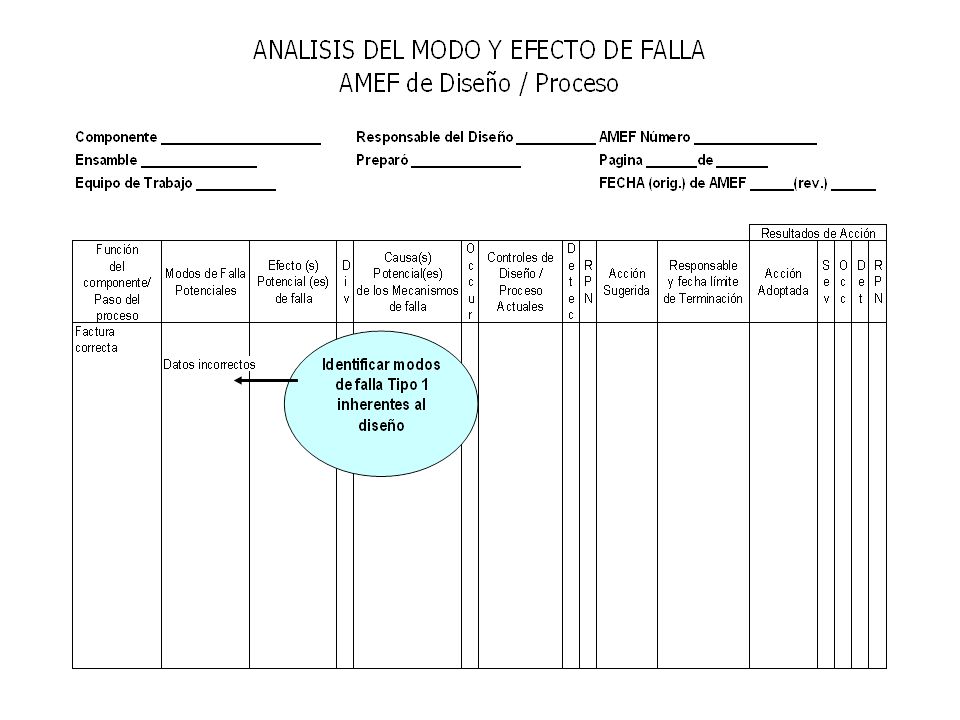
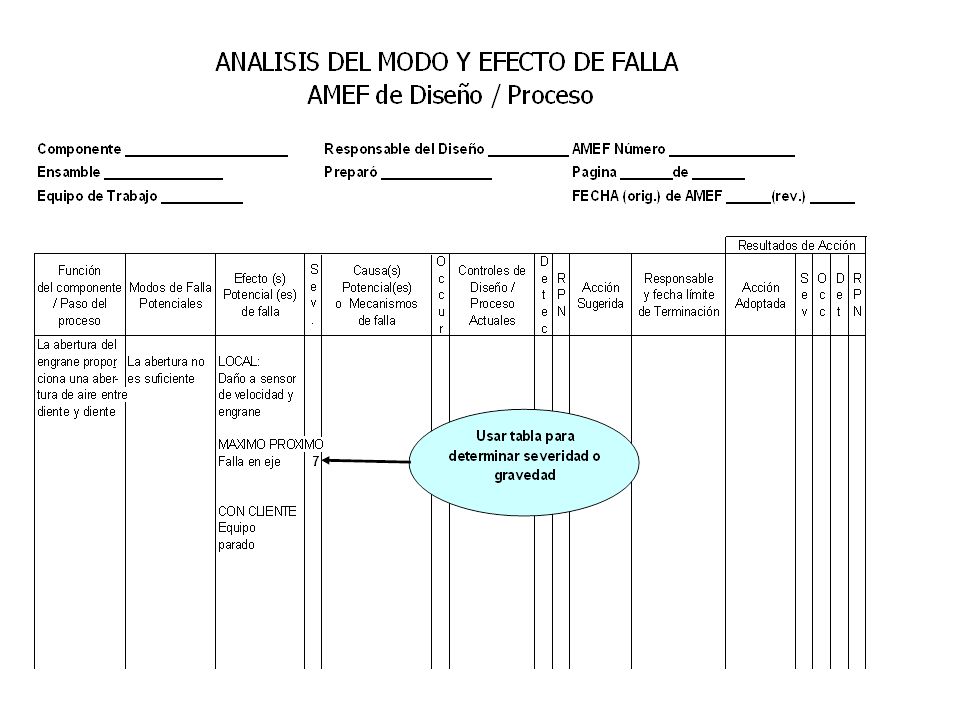
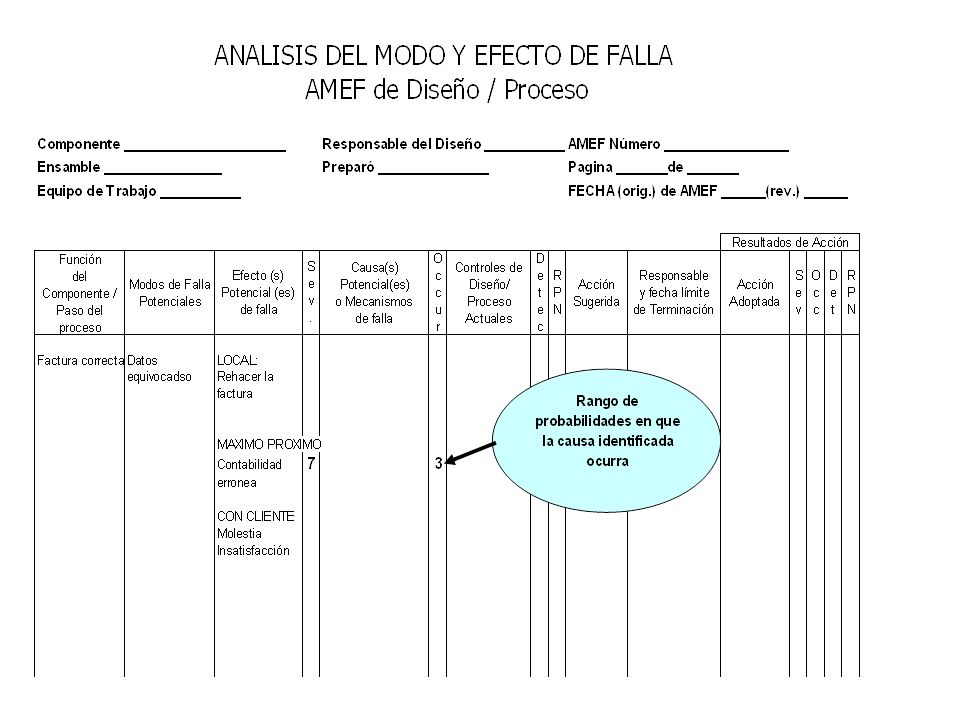
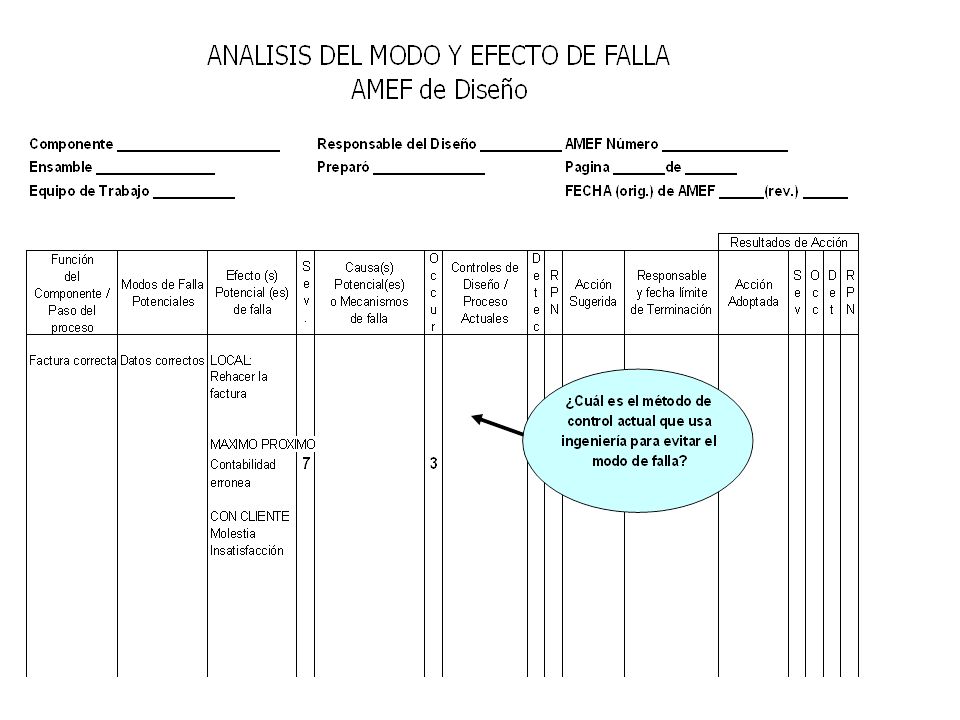
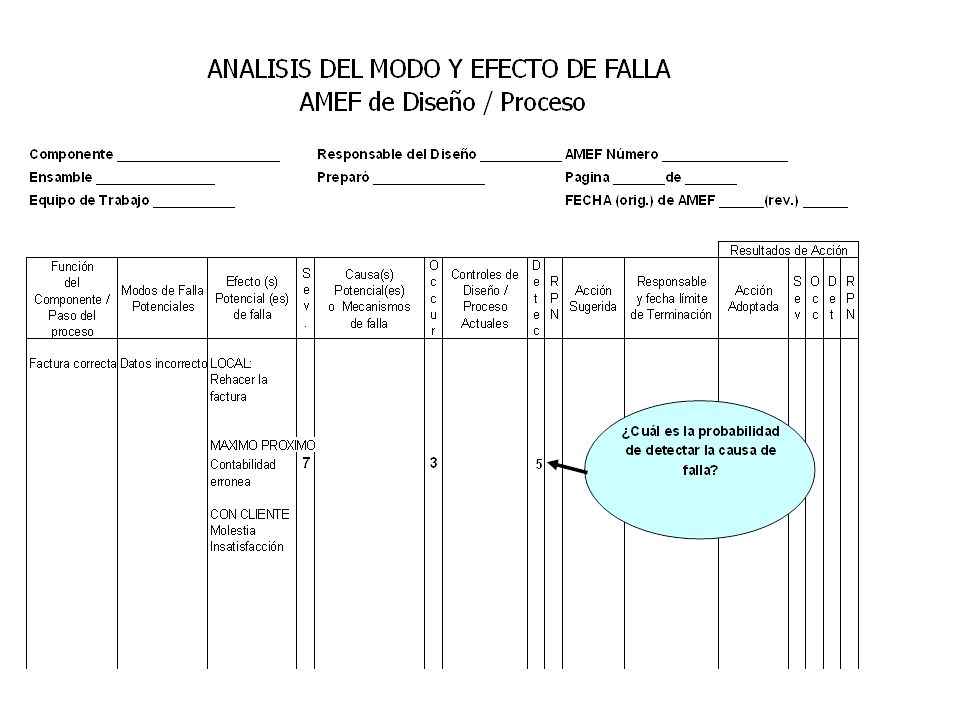
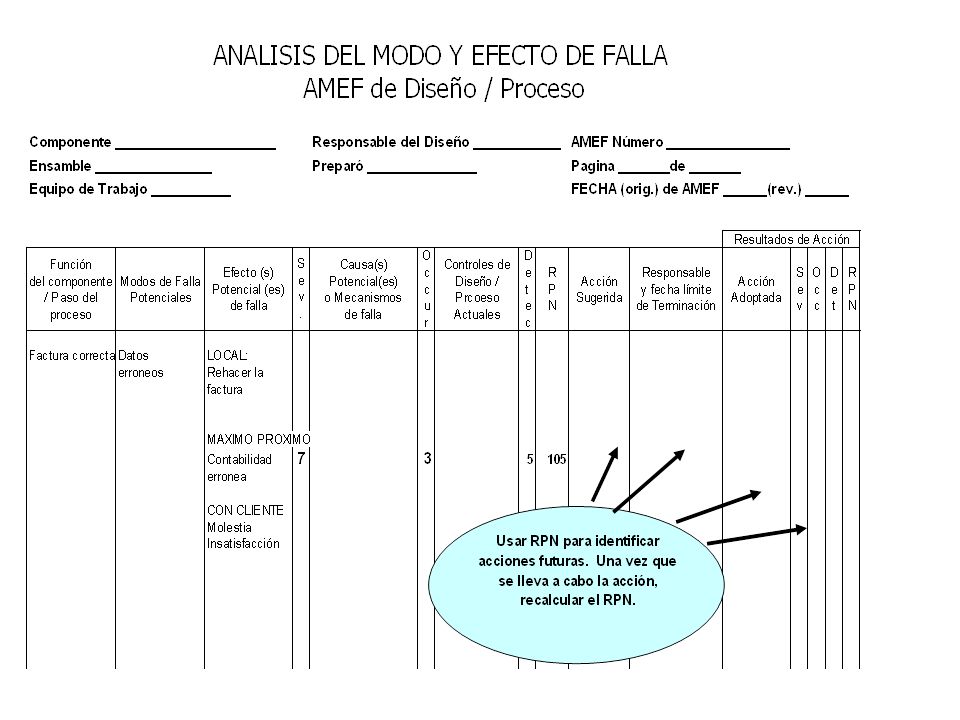
Llenar columnas del FMEA
Hasta sol. Propuesta y comprobar causas con Pruebas de Hipótesis

4
VI. Análisis A. Medición y modelaje de relación entre variables
B: Pruebas de hipótesis C. Análisis del modo y efecto de falla (AMEF) D. Métodos adicionales de análisis
 D. Métodos adicionales de análisis.")
5
A. Medición y modelaje de relación entre variables

6
A. Medición y modelaje de relación entre variables
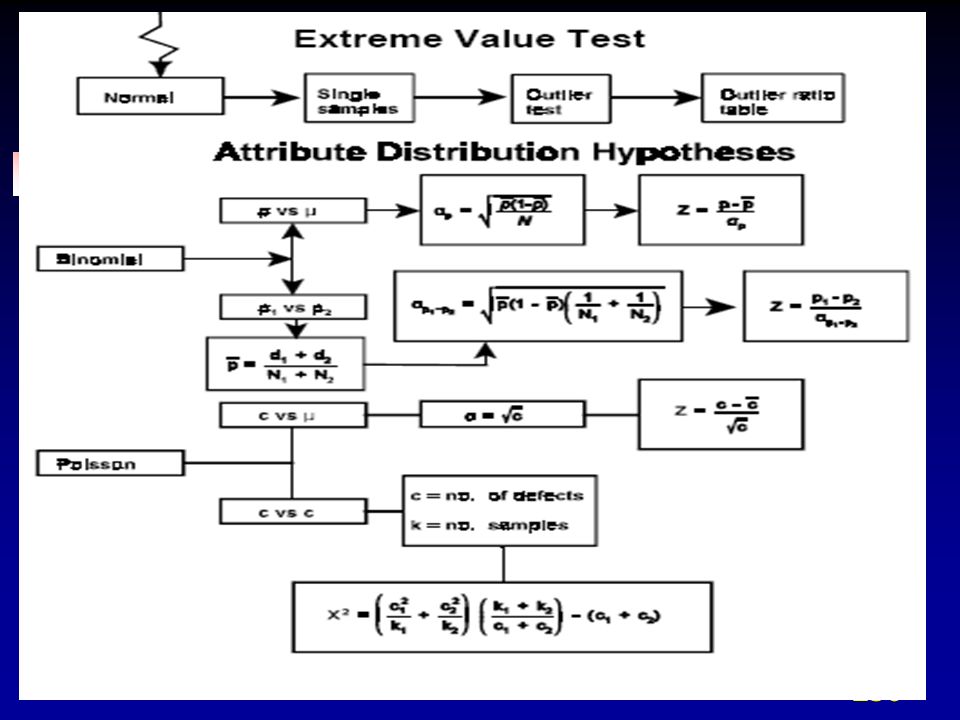
1. Coeficiente de correlación 2. Regresión 3. Herramientas Multivariadas 4. Estudios Multivari 5. Análisis de datos por atributos

7
VI.A.1 Coeficiente de correlación

8
Definiciones Correlación
Establece si existe una relación entre las variables y responde a la pregunta, ”¿Qué tan evidente es esta relación?" Regresión Describe con más detalle la relación entre las variables. Construye modelos de predicción a partir de información experimental u otra fuente disponible. Regresión lineal simple Regresión lineal múltiple Regresión no lineal cuadrática o cúbica

9
El 1er. paso es realizar una gráfica de la información.
Correlación Propósito: Estudiar la posible relación entre dos variables. • • • • Correlación positiva, posible • • • Accidentes laborales • • • • • • • • • • • • • • • • • • • Graphs are used to visualize relationships or associations between variables. Linear relationships between (primarily) continuous variables can be quantified using the Pearson product moment correlation coefficient (correlation for short) and regression. When might you use regression and correlation? To determine if a less expensive (or faster) procedure can be substituted for a procedure currently in use. As a first step in determining key input variables in a process (correlating input and out put variables). • • • Numero de órdenes urgentes El 1er. paso es realizar una gráfica de la información.
 continuous variables can be quantified using the Pearson product moment correlation coefficient (correlation for short) and regression. When might you use regression and correlation To determine if a less expensive (or faster) procedure can be substituted for a procedure currently in use. As a first step in determining key input variables in a process (correlating input and out put variables). • • • Numero de órdenes urgentes. El 1er. paso es realizar una gráfica de la información.")
10
Coeficiente de correlación (r )
Mide la fuerza de la relación lineal entre las variables X y Y en una muestra. El coeficiente de correlación muestral de Pearson rx,y con valores entre -1 y +1 es:

11
Correlación de la información (R ) de las X y las Y
Correlación Positiva Evidente Correlación Negativa Evidente 25 25 20 20 15 15 Y 10 Y 10 5 5 Sin Correlación 5 10 15 20 25 5 10 15 20 25 X R=1 25 X R=-1 20 15 Correlación Positiva Y 10 Correlación Negativa 5 25 5 10 15 20 25 25 20 R=0 X 20 15 15 Y 10 Y 10 5 5 5 10 15 20 25 5 10 15 20 25 X R=>1 X R=>-1

12
Coeficiente de correlación
El coeficiente de correlación r asume el mismo signo de la pendiente de la recta 1 siendo cero cuando 1 =0 Un valor positivo de r implica que la pendiente de la línea es ascendente hacia la derecha Un valor negativo de r implica que la pendiente de la línea es descendente hacia la derecha Si r=0 no hay correlación lineal, aunque puede haber correlación curvilínea

13
Coeficiente de correlación
Reglas empíricas Coeficiente de correlación 0.8 < r < 1.0 0.3 < r < 0.8 -0.3 < r < 0.3 -0.8 < r < -0.3 -1.0 < r < -0.8 Relación Fuerte, positiva Débil, positiva No existe Débil, negativa Fuerte, negativa

14
Correlaciones (Pearson) Tabla de Correlación mínima
de confianza de confianza n % % de confianza de confianza Para un 95% de confianza, con una muestra de 10, el coeficiente (r) debe ser al menos .63
 debe ser al menos .63.")
15
Correlación La correlación puede usarse para información de atributos, variables normales y variables no normales. La correlación puede usarse con un “predictor” o más para una respuesta dada. La correlación es una prueba fácil y rápida para eliminar factores que no influyen en la predicción, para una respuesta dada.

16
Coeficiente de Correlación
Para determinar que tanto se acercan los datos predichos por el modelo a los datos observados aplicando el coeficiente de correlación de Pearson (ver tabla anterior para identificar la significancia) r = S(yeyo) S(yeye) S(yoyo) S(yeye) = Syei2 - (Syei)2 n S(yoyo) = Syoi2 - (Syoi)2 S(yeyo) = Syei yoi - (Syei)(Syoi) ye = Respuesta esperada yo = Respuesta observada r = Coeficiente de correlación
 r = S(yeyo) S(yeye) S(yoyo) S(yeye) = Syei2 - (Syei)2. n. S(yoyo) = Syoi2 - (Syoi)2. S(yeyo) = Syei yoi - (Syei)(Syoi) ye = Respuesta esperada. yo = Respuesta observada. r = Coeficiente de correlación.")
17
Coeficiente de Correlación ajustado
Otra forma para no consultar la tabla de coeficiente de correlación de Pearson es la r ajustada R2(Adj) = 1 – (1 – r2) (n-1) (n-p) Criterios en función a la R2(Adj) > 90% = Correlación Fuerte 80% - 90% = Buena correlación 60% - 80% = Correlación media 40% - 60% = Correlación débil < 40% = No existe correlación Donde : R2(Adj) = Coeficiente de correlación ajustado r = Coeficiente de correlación de Pearson n = Número de datos p = Núm. términos en el modelo (Incluyendo la constante)
 = 1 – (1 – r2) (n-1) (n-p) Criterios en función a la R2(Adj) > 90% = Correlación Fuerte. 80% - 90% = Buena correlación. 60% - 80% = Correlación media. 40% - 60% = Correlación débil. < 40% = No existe correlación. Donde : R2(Adj) = Coeficiente de correlación ajustado. r = Coeficiente de correlación de Pearson. n = Número de datos. p = Núm. términos en el modelo. (Incluyendo la constante)")
18
Coeficiente de Determinación (R2)
El coeficiente de determinación es la proporción de la variación total explicada por la regresión, R2 se encuentra en el rango de valores de 0 a 1.

19
Correlación vs causación
Tener cuidado de no tener variables colineales, por ejemplo peso de un coche y peso de las personas que transporta, o que no la relación no tenga sentido, como si lavo mi coche, llueve.

20
VI.A.2 Regresión

21
Análisis de Regresión El análisis de regresión es un método estandarizado para localizar la correlación entre dos grupos de datos, y, quizá más importante, crear un modelo de predicción. Puede ser usado para analizar las relaciones entre: Una sola “X” predictora y una sola “Y” Múltiples predictores “X” y una sola “Y” Varios predictores “X” entre sí

22
Supuestos de la regresión lineal
Los principales supuestos que se hacen en el análisis de regresión lineal son los siguientes: La relación entre las variables Y y X es lineal, o al menos bien aproximada por una línea recta. El término de error tiene media cero. El término de error tiene varianza constante 2. Los errores no están correlacionados. Los errores están normalmente distribuidos.

23
Modelo de regresión lineal
Se aume que para cualquier valor de X el valor observado de Y varia en forma aleatoria y tiene una distribución de probabilidad normal El modelo general es: Y = Valor medio de Yi para Xi + error aleatorio

24
yi ei Regresión Lineal Simple y = b0 + b1x xi SSE = ei2 = yi - yi2
La línea de regresión se calcula por el método de mínimos cuadrados. Un residuo es la diferencia entre un punto de referencia en particular (xi, yi) y el modelo de predicción ( y = a + bx ). El modelo se define de tal manera que la suma de los cuadrados de los residuales es un mínimo. La suma residual de los cuadrados es llamada con frecuencia la suma de los cuadrados de los errores (SSE) acerca de la línea de regresión yi y = b0 + b1x ei • • • • • a y b son Estimados de 0 y 1 • • • • • • • • • • • • • • • • • • • • • • • • xi SSE = ei2 = yi - yi2
 y el modelo de predicción ( y = a + bx ). El modelo se define de tal manera que la suma de los cuadrados de los residuales es un mínimo. La suma residual de los cuadrados es llamada con frecuencia la suma de los cuadrados de los errores (SSE) acerca de la línea de regresión. yi. y = b0 + b1x. ei. • • • • • a y b son. Estimados de. 0 y 1. • • • • • • • • • • • • • • • • • • • • • • • • xi. SSE = ei2 = yi - yi2.")
25
Gráfica de la Línea de Ajuste
Recta de regresión Y= X R2 = .895 600 Retención 500 Regresión 95% Intervalo de confianza de predicción 400 0.18 0.19 0.20 Altura del muelle

26
Interpretación de los Resultados
La ecuación de regresión (Y = X) describe la relación entre la variable predictora X y la respuesta de predicción Y. R2 (coef. de determinación) es el porcentaje de variación explicado por la ecuación de regresión respecto a la variación total en el modelo El intervalo de confianza es una banda con un 95% de confianza de encontrar la Y media estimada para cada valor de X [Líneas rojas] El intervalo de predicción es el grado de certidumbre de la difusión de la Y estimada para puntos individuales X. En general, 95% de los puntos individuales (provenientes de la población sobre la que se basa la línea de regresión), se encontrarán dentro de la banda [Líneas azules]
 describe la relación entre la variable predictora X y la respuesta de predicción Y. R2 (coef. de determinación) es el porcentaje de variación explicado por la ecuación de regresión respecto a la variación total en el modelo. El intervalo de confianza es una banda con un 95% de confianza de encontrar la Y media estimada para cada valor de X [Líneas rojas] El intervalo de predicción es el grado de certidumbre de la difusión de la Y estimada para puntos individuales X. En general, 95% de los puntos individuales (provenientes de la población sobre la que se basa la línea de regresión), se encontrarán dentro de la banda [Líneas azules]")
27
Interpretación de los Resultados
Los valores “p” de la constante (intersección en Y) y las variables de predicción, se leen igual que en la prueba de hipótesis. Ho: El factor no es significativo en la predicción de la respuesta. Ha: El factor es significativo en la predicción de la respuesta. s es el “error estándar de la predicción” = desviación estándar del error con respecto a la línea de regresión. R2 (ajustada) es el porcentaje de variación explicado por la regresión, ajustado por el número de términos en el modelo y por el número de puntos de información. El valor “p” para la regresión se usa para ver si el modelo completo de regresión es significativo. Ho: El modelo no es significativo en la predicción de la respuesta. Ha: El modelo es significativo en la predicción de la respuesta.
 y las variables de predicción, se leen igual que en la prueba de hipótesis. Ho: El factor no es significativo en la predicción de la respuesta. Ha: El factor es significativo en la predicción de la respuesta. s es el error estándar de la predicción = desviación estándar del. error con respecto a la línea de regresión. R2 (ajustada) es el porcentaje de variación explicado por la regresión, ajustado por el número de términos en el modelo y por. el número de puntos de información. El valor p para la regresión se usa para ver si el modelo completo de regresión es significativo. Ho: El modelo no es significativo en la predicción de la respuesta. Ha: El modelo es significativo en la predicción de la respuesta.")
28
Errores residuales Los errores se denominan frecuentemente residuales. Podemos observar en la gráfica de regresión los errores indicados por segmentos verticales.

29
Errores residuales Los residuos pueden ser graficados para:
Checar normalidad. Checar el efecto del tiempo si su orden es conocido en los datos. Checar la constancia de la varianza y la posible necesidad de transformar los datos en Y. Checar la curvatura de más alto orden que ajusta en las X’s. A veces es preferible trabajar con residuos estandarizados o estudentizados:

30
Errores residuales Análisis de los errores o residuales

31
Ejemplo Considere el problema de predecir las ventas mensuales en función del costo de publicidad. Calcular el coeficiente de correlación, el de determinación y la recta. MES Publicidad Ventas

32
Cálculo manual Calcular columnas para Suma X, Suma Y, Xi2, XiYi y Yi2
MES Publicidad Ventas Xi2 XiYi Yi2 SUMA ,569

33
Método de mínimos cuadrados
Donde: Yest = Valor predicho de para un valor particular de x. b0 = Estimador puntual de .(ordenada al origen) b1= Estimador puntual de (pendiente) Para el cálculo de b0 y b1 se utilizamos las siguientes fórmulas:
 b1= Estimador puntual de (pendiente) Para el cálculo de b0 y b1 se utilizamos las siguientes fórmulas:")
34
Análisis de varianza en la regresión
La desviación estándar S corresponde a la raíz cuadrada del valor de MSE o cuadrado medio residual. Los residuos son:

35
Análisis de varianza en la regresión
Las conclusiones son como sigue: Intervalos de confianza para Beta 0 y Beta 1

36
Análisis de varianza en la regresión
El intervalo de confianza para la desviación estándar es: Intervalos de confianza para la Y estimada promedio Intervalo de predicción para un valor particular de Y estimado

37
Análisis de varianza en la regresión
Prueba de Hipótesis para Beta 1: Ho: 1 = 0 contra H1:1 0 Si el coeficiente Beta 1 es significativo

38
Análisis de varianza en la regresión
Coeficiente de correlación r: Coeficiente de determinación: r2 R2 mide la proporción de la variación total respecto a la media que es explicada por la regresión. Se expresa en porcentaje.

39
Análisis de varianza en la regresión
Prueba de hipótesis para el Coeficiente de correlación r: H0: = 0 contra H1: 0 Si se rechaza la hipótesis Ho, indicando que existe una correlación significativa

40
Riesgos de la regresión
Los modelos de regresión son válidos como ecuaciones de interpolación sobre el rango de las variables utilizadas en el modelo. No pueden ser válidas para extrapolación fuera de este rango. Mientras que todos los puntos tienen igual peso en la determinación de la recta, su pendiente está más influenciada por los valores extremos de X.

41
Riesgos de la regresión
Los outliers u observaciones aberrantes pueden distorsionar seriamente el ajuste de mínimos cuadrados. Si se encuentra que dos variables están relacionadas fuertemente, no implica que la relación sea casual, se debe investigar la relación causa – efecto entre ellas. Por ejemplo el número de enfermos mentales vs. número de licencias recibidas.

42
Cálculo manual (cont..) Cálculo de la recta de regresión lineal:
Sxx = (9.4)^2/10 = 0.444 Sxy = (9.4)(959) / 10 = 23.34 Ymedia = 959 / 10 = 95.9 Xmedia = 9.4 / 10 = 0.94 b1 = Sxy / Sxx = / = 52.57 b0 = Ymedia - b1*Xmedia = ( )(0.94) = 46.49 Yest. = * X
^2/10 = Sxy = (9.4)(959) / 10 = Ymedia = 959 / 10 = 95.9 Xmedia = 9.4 / 10 = b1 = Sxy / Sxx = / = b0 = Ymedia - b1*Xmedia = ( )(0.94) = Yest. = * X.")
43
Ejemplo (cont..) Cálculo de S2 estimador de
S2 = SSE / (n - 2) = Syy - (Sxy)^2/Sxx Syy = 93,569 - (959)^2 / 10 = SSE = Syy - b1*Sxy = (52.567)(23.34) = S2 = SSE / (n - 2) = / 8 = 46.75 S = 6.84 El intervalo de confianza donde caerán el 95% de los puntos es el rango de 1.96S = o sea a de la línea.
 = Syy - (Sxy)^2/Sxx. Syy = 93,569 - (959)^2 / 10 = SSE = Syy - b1*Sxy = (52.567)(23.34) = S2 = SSE / (n - 2) = / 8 = S = El intervalo de confianza donde caerán el 95% de los puntos es el rango de 1.96S = o sea a de la línea.")
44
Ejemplo (cont..) Inferencias respecto a la pendiente de la línea b1:
Se usa el estadístico t = b1 / (S / Sxx) El término del denominador es el error estándar de la pendiente. Para probar la hipótesis nula Ho: 1 = 0 En este caso tc = / (6.84 / 0.444) = 5.12 El valor crítico tcrit. para alfa/2 = con (n-2) = 8 grados de libertad es Como tc > tcrítico se rechaza la hipótesis de que b1 = 0 existiendo la regresión.
 El término del denominador es el error estándar de la pendiente. Para probar la hipótesis nula Ho: 1 = 0. En este caso tc = / (6.84 / 0.444) = El valor crítico tcrit. para alfa/2 = con (n-2) = 8 grados de libertad es Como tc > tcrítico se rechaza la hipótesis de que b1 = 0 existiendo la regresión.")
45
Ejemplo (cont..) Estableciendo un 95% de confianza para la pendiente de la recta b1. Usando la fórmula b1 t0.025 (S / Sxx) se tiene: 52.57 * 6.84 / = Por tanto una unidad de incremento en publicidad, hará que el volumen de ventas se encuentre entre $28.9 a $76.2.

46
Ejemplo (cont..) Cálculo del coeficiente de Correlación: ________
r = Sxy / (SxxSyy) ____________ r = / 0.444* = 0.88 Como r es positivo, la pendiente de la recta apunta hacia arriba y a la derecha. El coeficiente de determinación r^2 = 1 - SSE/Syy r^2 = ( Syy - SSE ) / Syy = 0.774
 ____________. r = / 0.444* = Como r es positivo, la pendiente de la recta apunta hacia arriba y a la derecha. El coeficiente de determinación r^2 = 1 - SSE/Syy. r^2 = ( Syy - SSE ) / Syy =")
47
Análisis de Regresión El coeficiente de correlación r = 0.875442
1. Teclear los datos para Xi y Yi 2. Llamar a TOOLS o HERRAMIENTAS, DATA ANALYSIS o ANALISIS DE DATOS, CORRELATION o CORRELACIÓN 3. Dar INPUT RANGE (rango de datos), OUTPUT RANGE (para los resultados) y obtener los resultados Column 1 Column 2 Column Column El coeficiente de correlación r =
, OUTPUT RANGE (para los resultados) y obtener los resultados. Column 1 Column 2. Column Column El coeficiente de correlación r =")
48
Cálculo con Excel) 4. Llamar a TOOLS o HERRAMIENTAS, DATA ANALYSIS o ANALISIS DE DATOS, REGRESION o REGRESIÓN 3. Dar INPUT RANGE Y (rango de datos Yi), INPUT RANGE X (rango de datos Xi), CONFIDENCE INTERVAL 95%, OUTPUT RANGE (para los resultados), RESIDUAL PLOTS o GRAFICAS DE RESIDUALES y obtener una tabla de resultados como los que se muestran en las páginas siguientes. NOTAS: a) La gráfica de probabilidad normal debe mostrar puntos fácilmente aproximables por una línea recta, indicando normalidad. B) La gráfica de residuos estandarizados se deben distribuir en forma aleatoria alrededor de la línea media igual a cero.
, INPUT RANGE X (rango de datos Xi), CONFIDENCE INTERVAL 95%, OUTPUT RANGE (para los resultados), RESIDUAL PLOTS o GRAFICAS DE RESIDUALES y obtener una tabla de resultados como los que se muestran en las páginas siguientes. NOTAS: a) La gráfica de probabilidad normal debe mostrar puntos fácilmente aproximables por una línea recta, indicando normalidad. B) La gráfica de residuos estandarizados se deben distribuir en forma aleatoria alrededor de la línea media igual a cero.")
49
Resultados de Excel SUMMARY OUTPUT Regression Statistics Multiple R R Square Adjusted R Square Standard Error Observations 10 ANOVA df SS MS F Significance F Regression Residual Total Confidence 95% Coefficients Standard Error t Stat P-value Lower Upper Intercept X Variable La ecuación de la recta es Yest = X Como los valores p para los coeficientes son menores a 0.05, ambos son significativos

50
Gráfica normal de Excel

51
Gráfica de Residuos vs. X de Excel

52
Ejercicio Calcular la recta de predicción con sus bandas de confianza, la correlación y la determinación para la respuesta de un Taxi, los datos se muestran a continuación: Distancia Tiempo

53
Relaciones no Lineales
¿Qué pasa si existe una relación causal, no lineal? ¿Cómo describiría esta relación? El siguiente es un conjunto de datos experimentales codificados, sobre resistencia a la compresión de una aleación especial: Resistencia a Concentración la Compresión x y (ref. Walpole & Myers, 1985)
")
54
Resultados del Análisis de Regresión - Modelo Cuadrático
Y = X E-02X**2 R2 = 0.614 Análisis de Variancia FUENTE DF SS MS F p Regresión E-03 Error Total FUENTE DF Seq SS F p Lineal E-03 Cuadrática E-02

55
Regresión cuadrática

56
Regresión cuadrática

57
Regresión cuadrática Los residuos No son normales Se deben transformar
Las variables

58
Otros Patrones No Lineales
A veces es posible transformar una o ambas variables, para mostrar mejor la relación entre ambas. La meta es identificar la relación matemática entre las variables, para que con la variable transformada se obtenga una línea más recta. Algunas transformaciones comunes incluyen: x’ = 1/x x’ = Raíz cuadrada de (x) Funciones trigonométricas: x’ = Seno de x x’ = log x
 Funciones trigonométricas: x’ = Seno. de x. x’ = log x.")
59
Trasformación de funciones
Ejemplo: sea se transforma como

60
Transformación de variables del ejemplo de regresión cuadrática
Transformando la variable X’ = 1/X se tiene, utilizando Minitab

61
Transformación de variables del ejemplo de regresión cuadrática
Transformando la variable X’ = 1/X se tiene, utilizando Minitab

62
Transformación de variables del ejemplo de regresión cuadrática
Los residuos ahora ya se muestran normales

63
Transformación para homoestacidad de la varianza
Algunas transformaciones para estabilizar la varianza

64
Transformación para homoestacidad de la varianza
Ejemplo: Se hizo un estudio entre la demanda (Y) y la energía eléctrica utilizada (X) durante un cierto periodo de tiempo
 y la energía eléctrica utilizada (X) durante un cierto periodo de tiempo.")
65
Transformación para homoestacidad de la varianza
Ejemplo: Se hizo un estudio entre la demanda (Y) y la energía eléctrica utilizada (X) durante un cierto periodo de tiempo
 y la energía eléctrica utilizada (X) durante un cierto periodo de tiempo.")
66
Transformación para homoestacidad de la varianza
Se observa que la varianza se incrementa conforme aumenta X

67
Transformación para homoestacidad de la varianza
Se observa que la varianza se incrementa conforme aumenta X

68
Transformación para homoestacidad de la varianza
Transformando a X por su raíz cuadrada se tiene:

69
Transformación para homoestacidad de la varianza
Transformando a X por su raíz cuadrada se tiene:

70
Transformación para homoestacidad de la varianza
Transformando a X por su raíz cuadrada se tiene:

71
Regresión lineal múltiple

72
Regresión múltiple Cuando se usa más de una variable independiente para predecir los valores de una variable dependiente, el proceso se llama análisis de regresión múltiple, incluye el uso de ecuaciones lineales. Se asume que los errores u tienen las características siguientes: Tienen media cero y varianza común 2. Son estadísticamente independientes. Están distribuidos en forma normal.

73
Regresión múltiple Estimación de los parámetros del modelo
Se trata de minimizar los errores cuadráticos en: El modelo de regresión múltiple en forma matricial es: Y = X + = [1 : D] + Y es un vector N x 1. X es una matriz de orden N x (k + 1), donde la 1ª. columna es 1’s. es un vector de orden (k + 1) x 1. es un vector de orden N x 1. D es la matriz de Xij con i = 1, 2, ..., N; j = 1, 2, , k
, donde la 1ª. columna es 1’s. es un vector de orden (k + 1) x 1. es un vector de orden N x 1. D es la matriz de Xij con i = 1, 2, ..., N; j = 1, 2, , k.")
74
Regresión múltiple Estimación de los parámetros del modelo:
b = (X’X)-1 X’Y El vector de valores ajustados se puede expresar como: La varianza del modelo se estima como:
-1 X’Y. El vector de valores ajustados se puede expresar como: La varianza del modelo se estima como:")
75
Tamaño de muestra Tomar 5 observaciones para cada una de las variables independientes, si esta razón es menor de5 a 1, se tiene el riesgo de “sobreajustar” el modelo Un mejor nivel deseable es tomar 15 a 20 observaciones por cada variable independiente

76
Ejemplo de regresión múltiple
Un embotellador está analizando las rutas de servicio de máquinas dispensadoras, está interesado en predecir la cantidad de tiempo requerida por el chofer para surtir las máquinas en el local (Y). La actividad de servicio incluye llenar la máquina con refrescos y un mantenimiento menor. Se tienen como variables el número de envases con que llena la máquina (X1) y la distancia que tiene que caminar (X2).
. La actividad de servicio incluye llenar la máquina con refrescos y un mantenimiento menor. Se tienen como variables el número de envases con que llena la máquina (X1) y la distancia que tiene que caminar (X2).")
77
Ejemplo de regresión múltiple

78
Ejemplo de regresión múltiple Solución matricial

79
Ejemplo de regresión múltiple Solución matricial

80
Ejemplo de regresión múltiple Solución matricial

81
Ejemplo de regresión múltiple Solución matricial
Intervalo de confianza para Beta 1 Por tanto el intervalo de confianza para el 95% es: 1

82
Ejemplo de regresión múltiple Solución matricial
El embotellador desea construir un intervalo de confianza sobre el tiempo medio de entrega para un local requiriendo: X1 = 8 envases y cuya distancia es X2 = 275 pies. La varianza de la Y0 estimada es (tomando M8=inv(X’X) :
 :")
83
Ejemplo de regresión múltiple Solución matricial
El intervalo de confianza sobre el tiempo medio de entrega para un local requiriendo es para 95% de nivel de confianza: Que se reduce a: Y0

84
Ejemplo de regresión múltiple Solución matricial
El análisis de varianza es:

85
Ejemplo de regresión múltiple Solución matricial
El comportamiento de los residuos es como sigue:

86
Multicolinealidad La multicolinealidad implica una dependencia cercana entre regresores (columnas de la matriz X ), de tal forma que si hay una dependencia lineal exacta hará que la matriz X’X sea singular. La presencia de dependencias cercanamente lineales impactan dramáticamente en la habilidad para estimar los coeficientes de regresión. La varianza de los coeficientes de la regresión son inflados debido a la multicolinealidad. Es evidente por los valores diferentes de cero que no están en la diagonal principal de X’X. Que son correlaciones simples entre los regresores.
, de tal forma que si hay una dependencia lineal exacta hará que la matriz X’X sea singular. La presencia de dependencias cercanamente lineales impactan dramáticamente en la habilidad para estimar los coeficientes de regresión. La varianza de los coeficientes de la regresión son inflados debido a la multicolinealidad. Es evidente por los valores diferentes de cero que no están en la diagonal principal de X’X. Que son correlaciones simples entre los regresores.")
87
Multicolinealidad Una prueba fácil de probar si hay multicolinealidad entre dos variables es que su coeficiente de correlación sea mayor a 0.7 Los elementos de la diagonal principal de la matriz X’X se denominan Factores de inflación de varianza (VIFs) y se usan como un diagnóstico importante de multicolinealidad. Para el componente j – ésimo se tiene: Si es mayor a 10 implica que se tienen serios problemas de multicolinealidad.
 y se usan como un diagnóstico importante de multicolinealidad. Para el componente j – ésimo se tiene: Si es mayor a 10 implica que se tienen serios problemas de multicolinealidad.")
88
Análisis de los residuos
Los residuos graficados vs la Y estimada, pueden mostrar diferentes patrones indicando adecuación o no adecuación del modelo: Gráfica de residuos aleatorios cuya suma es cero (null plot) indica modelo adecuado Gráfica de residuos mostrando una no linealidad curvilínea indica necesidad de transformar las variables Si los residuos se van abriendo indica que la varianza muestra heteroestacidad y se requiere transformar las variables. Se puede probar con la prueba de Levene de homogeneidad de varianzas
 indica modelo adecuado. Gráfica de residuos mostrando una no linealidad curvilínea indica necesidad de transformar las variables. Si los residuos se van abriendo indica que la varianza muestra heteroestacidad y se requiere transformar las variables. Se puede probar con la prueba de Levene de homogeneidad de varianzas.")
89
Escalamiento de residuos
En algunos casos es difícil hacer comparaciones directas entre los coeficientes de la regresión debido a que la magnitud de bj refleja las unidades de medición del regresor Xj. Por ejemplo: Para facilitarla visualización de residuos ante grandes diferencias en los coeficientes, se sugiere estandarizar o estudentizar los residuos

90
Escalamiento de residuos
Residuos estandarizados Se obtienen dividiendo cada residuo entre la desviación estándar de los residuos Después de la estandarización, los residuos tienen una media de 0 y desviación estándar de 1 Con más de 50 datos siguen a la distribución t, de manera que si exceden a 1.96 (límite para alfa 0.05) indica significancia estadística y son “outliers”
 indica significancia estadística y son outliers")
91
Escalamiento de residuos
Residuos estudentizados Son similares a los residuos donde se elimina una observación y se predice su valor, pero además se elimina la i-ésima observación en el cálculo de la desviación estándar usada para estandarizar la í-ésima observación Puede identificar observaciones que tienen una gran influencia pero que no son detectadas por los residuos estandarizados H = X (X’X)-1X’ es la matriz sombrero o “hat matriz”.
-1X’ es la matriz sombrero o hat matriz .")
92
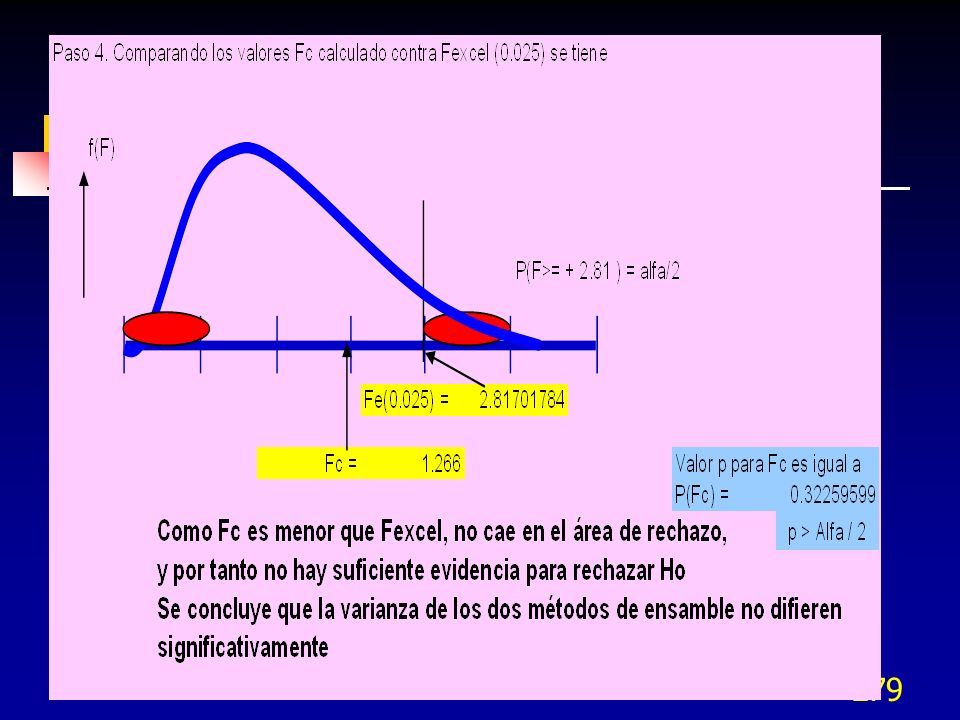
Escalamiento de residuos
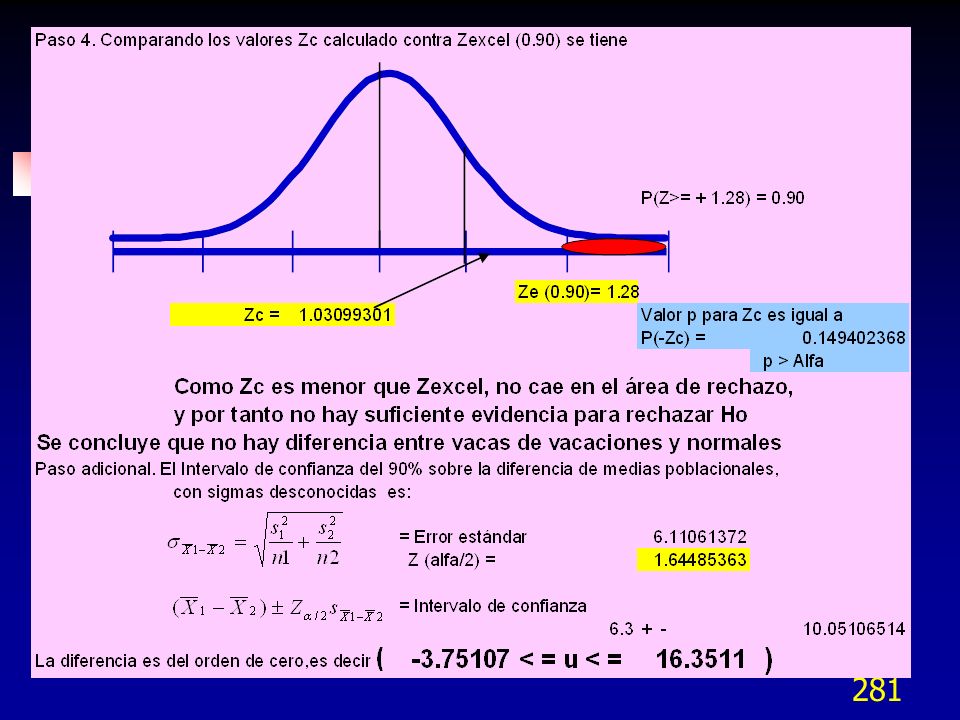
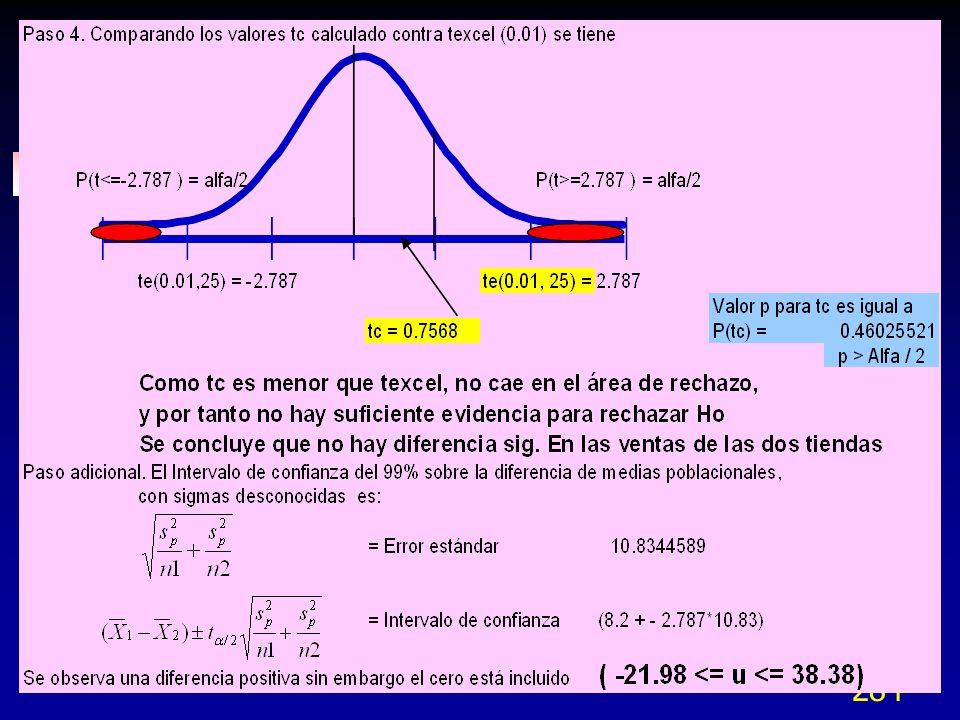
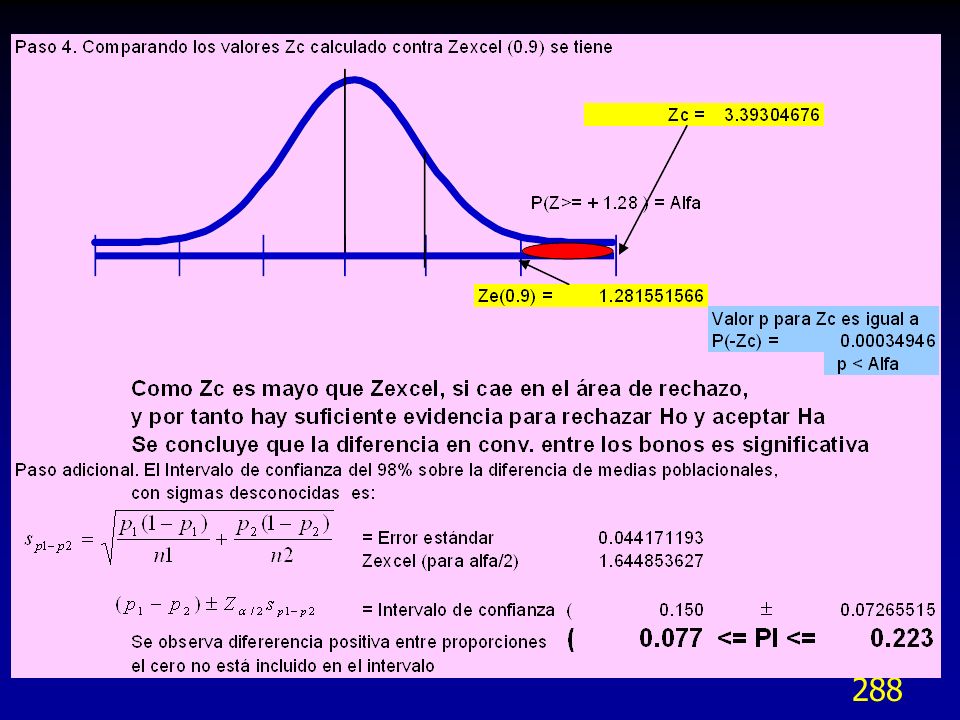
El estadístico PRESS (Prediction Error Sum of Squares) es una medida similar a la R2 en la regresión. Difiere en que se estiman n-1 modelos de regresión. En cada modelo se omite una observación en la estimación del modelo de regresión y entonces se predice el valor de la observación omitida con el modelo estimado. El residuo iésimo será: El residuo PRESS es la suma al cuadrado de los residuos individuales e indica una medida de la capacidad de predicción
 es una medida similar a la R2 en la regresión. Difiere en que se estiman n-1 modelos de regresión. En cada modelo se omite una observación en la estimación del modelo de regresión y entonces se predice el valor de la observación omitida con el modelo estimado. El residuo iésimo será: El residuo PRESS es la suma al cuadrado de los residuos individuales e indica una medida de la capacidad de predicción.")
93
Gráficas parciales de regresión
Para mostrar el impacto de casos individuales es más efectiva la gráfica de regresión parcial. Un caso “outlier” impacta en la pendiente de la ecuación de regresión (y su coeficiente). Una comparación visual de la gráfica de regresión parcial con y sin la observación muestra la influencia de la observación El coeficiente de correlación parcial es la correlación de la variable independiente Xi la variable dependiente Y cuando se han eliminado de ambos Xi y Y La correlación semiparcial refleja la correlación entre las variables independiente y dependiente removiendo el efecto Xi
. Una comparación visual de la gráfica de regresión parcial con y sin la observación muestra la influencia de la observación. El coeficiente de correlación parcial es la correlación de la variable independiente Xi la variable dependiente Y cuando se han eliminado de ambos Xi y Y. La correlación semiparcial refleja la correlación entre las variables independiente y dependiente removiendo el efecto Xi.")
94
Matriz sombrero Los puntos de influencia son observaciones substancialmente diferentes de las observaciones remanentes en una o más variables independientes Contiene valores (sombrero en su diagonal) para cada observación que representa influencia. Representa los efectos combinados de todos las variables independientes para cada caso
 para cada observación que representa influencia. Representa los efectos combinados de todos las variables independientes para cada caso.")
95
Matriz sombrero Los valores en la diagonal de la matriz sombrero miden dos aspectos: Para cada observación miden la distancia de la observación al centro de la media de todas las observaciones de las variables independientes Valores altos en la diagonal indica que la observación tiene mucho peso para la predicción del valor de la variable dependiente, minimizando su residuo El rango de valores es de 0 a 1, con media p/n, p es el número de predictores y n es el tamaño de muestra. Valores límite se encuentran en 2p/n y 3p/n

96
Distancia de Mahalanobis
D2 es una medida comparable a los valores sombrero (hat values) que considera sólo la distancia de una observación del valor medio de las variables independientes. Es otra forma de identificar “outliers” La significancia estadística de la distancia de Malahanobis se puede hacer a partir de tablas del texto: Barnett, V., Outliers in Statistical Data, 2nd. Edition, Nueva York, Wiley, 2984
 que considera sólo la distancia de una observación del valor medio de las variables independientes. Es otra forma de identificar outliers La significancia estadística de la distancia de Malahanobis se puede hacer a partir de tablas del texto: Barnett, V., Outliers in Statistical Data, 2nd. Edition, Nueva York, Wiley,")
97
Influencia en coeficientes individuales
El impacto de eliminar una observación simple en cada uno de los coeficientes de la regresión múltiple se muestra con la DFBETA y su versión estandarizada SDFBETA. Se sugiere aplicar como límites ±1.0 o ±2 para tamaños de muestra pequeños y ±√n para muestras medias y grandes La distancia de Cook (Di) captura el impacto de una observación: La dimensión del cambio en los valores pronosticados cuando se omite la observación y la distancia de las otras observaciones, el límite es 1 o 4/(n-k-1)
 captura el impacto de una observación: La dimensión del cambio en los valores pronosticados cuando se omite la observación y la distancia de las otras observaciones, el límite es 1 o 4/(n-k-1)")
98
Influencia en coeficientes individuales
La medida COVRATIO estima el efecto de la observación en la eficiencia del proceso, en sus errores estándar de los coeficientes de la regresión. Considera a todos los coeficientes colectivamente. El límite puede ser establecido en 1 ±3p/n, los valores mayores al límite hacen el proceso más eficiente y los menores más ineficiente La medida SDFFIT es el grado en que cambian los valores ajustados o pronosticados cuando el caso se elimina. El valor límite es 2*raíz((k+1)/(n-k-1))
/(n-k-1))")
99
Ejemplo de regresión múltiple Solución con Excel y Minitab

100
Ejemplo de Regresión Múltiple
Cat. (US News) GMAT Salario Inicial ($) % Aceptación Stanford Harvard Penn (Wharton) MIT (Sloan) Chicago Northwestern Columbia Dartmouth Duke Berkeley Virginia Michigan NYU Carnegie Mellon Yale U.N.C UCLA Texas-Austin Indiana Cornell Rochester Ohio State Emory Purdue Maryland
 GMAT Salario Inicial ($) % Aceptación. Stanford Harvard Penn (Wharton) MIT (Sloan) Chicago Northwestern Columbia Dartmouth Duke Berkeley Virginia Michigan NYU Carnegie Mellon Yale U.N.C UCLA Texas-Austin Indiana Cornell Rochester Ohio State Emory Purdue Maryland")
101
Interpretación de Resultados de Excel- Regresión Multiple
SUMMARY OUTPUT Regression Statistics Multiple R R Square Adjusted R Square Standard Error Observations 25 ANOVA df SS MS F Significance F Regression E E-07 Residual E Total E+09 Coefficients Standard t Stat P-value Lower 95% U pper 95% Error Intercept X Variable X Variable X Variable

102
Resultados de Excel- Regresión sólo con sólo X1
SUMMARY OUTPUT Regression Statistics Multiple R R Square Adjusted R Square Standard Error Observations 25 ANOVA df SS MS F Significance F Regression E E E-08 Residual E Total E+09 Coefficients Standard Error t Stat P-value Lower 95% Upper 95% Intercept E X Variable E Con sólo X1, el Modelo se simplifica enormemente poca importancia práctica se pierde en R2 (ajustada)
")
103
El Modelo se simplifica enormemente..…poca
Reducción del Modelo Vuelva a correr la regresión usando la categoría US News, como el único agente de predicción (“predictor”) La ecuación de regresión es: y = x “Predictor” Coef Desv. Estándar T p Constante x S = R2 = 73.3% R2 (ajustada) = 72.1% Análisis de Variancia Fuente DF SS MS F p Regresión Error Total El Modelo se simplifica enormemente..…poca importancia práctica se pierde en R2 (ajustada)
 La ecuación de regresión es: y = x. Predictor Coef Desv. Estándar T p. Constante x S = 4133 R2 = 73.3% R2 (ajustada) = 72.1% Análisis de Variancia. Fuente DF SS MS F p. Regresión Error Total El Modelo se simplifica enormemente..…poca. importancia práctica se pierde en R2 (ajustada)")
104
HeatFlux Insolation East South North
Corrida en Minitab Se introducen los datos en varias columnas C1 a C5 incluyendo la respuesta Y (heatflux) y las variables predictoras X’s (North, South, East) HeatFlux Insolation East South North
 y las variables predictoras X’s (North, South, East) HeatFlux Insolation East South North")
105
Corrida en Minitab Utilzar el archivo de ejemplo Exh_regr.mtw
Opción: Stat > Regression > Regression Para regresión lineal indicar la columna de respuesta Y (Score2) y X (Score1) En Regresión lienal en opciones se puede poner un valor Xo para predecir la respuesta e intervalos. Las gráficas se obtienen Stat > Regression > Regression > Fitted line Plots Para regresión múltiple Y (heatflux) y las columnas de los predictores (north, south, east)
 y X (Score1) En Regresión lienal en opciones se puede poner un valor Xo para predecir la respuesta e intervalos. Las gráficas se obtienen Stat > Regression > Regression > Fitted line Plots. Para regresión múltiple Y (heatflux) y las columnas de los predictores (north, south, east)")
106
Resultados de la regresión lineal
The regression equation is Score2 = Score1 Predictor Coef SE Coef T P Constant Score S = R-Sq = 95.7% R-Sq(adj) = 95.1% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) New Obs Score1
 = 95.1% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Predicted Values for New Observations. New Obs Fit SE Fit 95.0% CI 95.0% PI ( , ) ( , ) New Obs Score")
107
Resultados de la regresión lineal

108
Resultados de la regresión Múltiple
The regression equation is HeatFlux = North South East Predictor Coef SE Coef T P Constant North South East S = R-Sq = 87.4% R-Sq(adj) = 85.9% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Source DF Seq SS North South East
 = 85.9% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Source DF Seq SS. North South East")
109
Resumen de la Regresión
La regresión sólo puede utilizarse con información de variables continuas. Los residuos deben distribuirse normalmente con media cero. Importancia práctica: (R2). Importancia estadística: (valores p) La regresión puede usarse con un “predictor” X o más, para una respuesta dada Reduzca el modelo de regresión cuando sea posible, sin perder mucha importancia práctica
. Importancia estadística: (valores p) La regresión puede usarse con un predictor X o más, para una respuesta dada. Reduzca el modelo de regresión cuando sea posible, sin perder mucha importancia práctica.")
110
VI.A.4 Herramientas multivariadas

111
Herramientas multivariadas
1. Introducción 2. Análisis de componentes principales 3. Análisis factorial 4. Análisis discriminante 5. MANOVA

112
Introducción En el análisis multivariado se incluyen dos o más variables dependientes Y1, Y2, etc. Consideradas simultáneamente para las variables independientes X1, X2, …., Xn Normalmente se resuelven con herramientas computacionales tales como Minitab y SPSS. Entre las herramientas principales se encuentran: Componentes principales, análisis factorial, análisis discriminante, análisis de conglomerados, análisis canónico, MANOVA

113
Análisis de componentes principales
El análisis (PCA) y el análisis factorial (FA) se usan para encontrar patrones de correlación entre muchas variables posibles y subconjuntos de datos Busca reducirlas a un menor número de componentes o factores que representen la mayor parte de la varianza. Normalmente se requieren al menos cinco observaciones por variable
 y el análisis factorial (FA) se usan para encontrar patrones de correlación entre muchas variables posibles y subconjuntos de datos. Busca reducirlas a un menor número de componentes o factores que representen la mayor parte de la varianza. Normalmente se requieren al menos cinco observaciones por variable.")
114
Análisis de componentes principales
Pasos de análisis en Minitab Se usa una matriz de correlación para determinar la relación entre componentes Las matrices definen cantidades como eigenvalores y eigenvectores Se suman los eigenvalores y se calculan las proporciones de cada componente Se identifican los PC1, PC2, … que explican la mayor parte de la varianza Se puede hacer un diagrama de Pareto como apoyo

115
Ejemplo: Alimentos en Europa

116
Corrida en Minitab 2 Stat > Multivariate > Principal components
3 En Variables, X1, X2, X3, X4, X6, X7, X8, X9 4 En Number of factors to extract, 3. Seleccionar Correlation Matrix 5 Click Graphs y seleccionar Scree Plot, Score plot for first 2 components Loading plot for first 2 components 8 Click Storage e indicar las columnas donde se guarden los coeficientes y los valores Z (scores) Coef1 Coef 2 y Z1 Z2 9. Click OK en cada uno de los cuadros de diálogo
 Coef1 Coef 2 y Z1 Z2. 9. Click OK en cada uno de los cuadros de diálogo.")
117
Ejemplo: Alimentos en Europa
Dos componentes exceden El eigenvalor de ref. de 1

118
Ejemplo: Alimentos en Europa

119
Análisis factorial Es una técnica de reducción de variables para identificar factores que expliquen la variación, aunque se reiere un juicio subjetivo. Las variables de salida están relacionadas linealmente con las variables de entrada. Las variables deben ser medibles y simétricas. Debe haber cuatro o más factores de entrada para cada variable independiente

120
Análisis factorial Se especifican un cierto número de factores comunes
El análisis factorial se hace en dos etapas: Extracción de factores, para identificar los factores principales para un estudio posterior Rotación de factores, para hacerlos más significativos

121
Corrida con Minitab 2 Stat > Multivariate > Factor Analysis.
3 En Variables, X1, X2, X3, X4, X6, X7, X8, X9 4 En Number of factors to extract, 4. En Method of Extraction, seleccionar Principal components 6 En Type of Rotation, seleccionar Varimax. 7 Click Graphs y seleccionar Loading plot for first 2 factors y Scree Plot. Click Results y seleccionar Sort loadings. Seleccionar Storage e indicar columnas para ponderaciones, coeficientes, Z’s, eigenvalores, etc. Click OK en cada uno de los cuadros de d

122
Ejemplo

123
Ejemplo:

124
Análisis discriminante
Si se tiene una muestra con grupos conocidos, el análisis discriminante clasifica las observaciones o atributos en dos o más grupos Puede utilizarse como herramienta predictiva o descriptiva Las variables deben ser multivariadamente normales, con la misma varianza y covarianza poblacional entre variables dependientes, y las muestras exhiben independencia

125
Ejemplo de actividades en países

126
Corrida con Minitab 2 Stat > Multivariate > Discriminant Analysis. 3 En Groups, poner SalmonOrigin. 4 En Predictors, poner Freshwater Marine. Click OK.

127
Corrida con Minitab

128
Análisis de conglomerados

129
Análisis de conglomerados
Se usa para determinar agrupaciones o clasificaciones de un conjunto de datos Las personas se pueden agrupar por IQ, padres, hábitos de estudio, etc. Se trata de dar sentido a grandes cantidades de datos de cuestionarios, ecnuestas, etc.

130
Ejemplo Suponer que un estudio de mercado trata de determinar segmentos de mercado en base a los patrones de lealtad de marcas (V1) y tiendas (V2), medidas del 0 al 10 en 7 personas (A-G). Variables V1 V2 A 3 2 B 4 5 C 7 D E 6 F G
 y tiendas (V2), medidas del 0 al 10 en 7 personas (A-G). Variables. V1. V2. A B C. 7. D. E. 6. F. G.")
131
Corrida en Minitab Stat > Multivariate Análisis > Cluster Observations Distance Measured Euclidean Seleccionar Show Dendogram OK

132
Análisis de correlación canónico
Prueba la hipótesis de que los efectos pueden tener causas múltiples y de que las causas pueden tener efectos múltiples (Hotelling 1935) Es como una regresión múltiple para determinar la correlación entre dos conjuntos de combinaciones lieneales, cada conjunto puede tener varias variables relacionadas. La relación de un conjunto de variables dependientes a un conjunto de variables independientes forma combinaciones lineales
 Es como una regresión múltiple para determinar la correlación entre dos conjuntos de combinaciones lieneales, cada conjunto puede tener varias variables relacionadas. La relación de un conjunto de variables dependientes a un conjunto de variables independientes forma combinaciones lineales.")
133
Análisis de correlación canónico
Se usan los más altos valores de correlación para los conjuntos. Los pares de combinaciones lineales se denominan variates canónicas con correlaciones canónicas (Rc con valor mayor a 0.3) Por ejemplo se quiere determinar si hay una correlación entre las características de un ingeniero industrial y las habilidades requeridas en la descripción de puesto del mismo ingeniero.
 Por ejemplo se quiere determinar si hay una correlación entre las características de un ingeniero industrial y las habilidades requeridas en la descripción de puesto del mismo ingeniero.")
134
MANOVA (Análisis de varianza múltiple)
Es un modelo para analizar la relación entre una o más variables independientes y dos o más variables dependientes Prueba si hay diferencias significativas en las medias de grupos de una combinanción de respuestas Y. Los datos deben ser normales, con covarianza homogenea y observaciones independientes

135
MANOVA (Análisis de varianza múltiple)
")
136
Diferencias de ANOVA y MANOVA

137
Ejemplo: Extrusión de película plástica
Se realiza un estudio para determinar las condiciones óptimas para extruir película plástica. Se miden tres respuestas – Tear, gloss y opacity – cinco veces en cada combinación de dos factores – tasa de extrusión y cantidad de aditivo – cada grupo se pone en niveles bajos y altos. Se utiliza el MANOVA balanceado para probar la igualdad de las medias.

138
Ejemplo: Extrusión de película plástica

139
Ejemplo: Extrusión de película plástica
1 Abrir el archivo EXH_MVAR.MTW. 2 Seleccionar Stat > ANOVA > Balanced MANOVA. 3 En Responses, poner Tear Gloss Opacity. 4 En Model, poner Extrusion | Additive. 5 Click Results. En Display of Results, seleccionar Matrices (hypothesis, error, partial correlations) y Eigen analysis. 6 Click OK en cada cuadro de diálogo.
 y Eigen analysis. 6 Click OK en cada cuadro de diálogo.")
140
Ejemplo

141
Ejemplo: Extrusión de película plástica
Las matrices SSCP evalúan la contribución a la variabilidad de manera similar a la suma de cuadrados en la ANOVA univariada. Las correlaciones parciales entre Tear y Gloss son pequeñas. Como la estructura de las correlaciones es débil, se pueden realizar análisis univariados de ANOVA para cada una de las respuestas.

142
VI.A.4 Estudios Multivari

143
Estudios Multivari La carta multivari permite analizar la variación dentro de la pieza, de pieza a pieza o de tiempo en tiempo Permite investigar la estabilidad de un proceso consiste de líneas verticales u otro esquema en función del tiempo. La longitud de la línea o del esquema representa el rango de valores encontrados en cada conjunto de muestras

144
Estudios Multivari La variación dentro de las muestras (cinco puntos en cada línea). La variación de muestra a muestra como posición vertical de las líneas. E S P O R Número de subgrupo
. La variación de muestra a muestra como posición vertical de las líneas. E. S. P. O. R. Número de subgrupo.")
145
Estudios Multivari Ejemplo de parte metálica Centro más grueso

146
Estudios Multivari Procedimiento de muestreo:
Seleccionar el proceso y la característica a investigar Seleccionar tamaño de muestra y frecuencia de muestreo Registrar en una hoja la hora y valores para conjunto de partes

147
Estudios Multivari Procedimiento de muestreo:
Realizar la carta Multivari Unir los valores observados con una línea Analizar la carta para variación dentro de la parte, de parte a parte y sobre el tiempo Puede ser necesario realizar estudios adicionales alrededor del área de máxima variación aparente Después de la acción de mejora comprobar con otro estudio Multivari

148
Cartas Multivari Su propósito fundamental es reducir el gran número de causas posibles de variación, a un conjunto pequeño de causas que realmente influyen en la variabilidad. Sirven para identificar el patrón principal de variación de entre tres patrones principales: Temporal: Variación de hora a hora; turno a turno; día a día; semana a semana; etc. Cíclico: Variación entre unidades de un mismo proceso; variación entre grupos de unidades; variación de lote a lote.

149
Cartas Multivari Posicional:
Variaciones dentro de una misma unidad (ejemplo: porosidad en un molde de metal) o a través de una sola unidad con múltiples partes (circuito impreso). Variaciones por la localización dentro de un proceso que produce múltiples unidades al mismo tiempo. Por ejemplo las diferentes cavidades de un molde Variaciones de máquina a máquina; operador a operador; ó planta a planta
 o a través de una sola unidad con múltiples partes (circuito impreso). Variaciones por la localización dentro de un proceso que produce múltiples unidades al mismo tiempo. Por ejemplo las diferentes cavidades de un molde. Variaciones de máquina a máquina; operador a operador; ó planta a planta.")
150
Cartas Multivari VARIACIÓN POSICIONAL DENTRO DE LA UNIDAD
Ejemplo: Se toman 3 a 5 unidades consecutivas, repitiendo el proceso tres o más veces a cierto intervalo de tiempo, hasta que al menos el 80% de la variación en el proceso se ha capturado. A VARIACIÓN POSICIONAL DENTRO DE LA UNIDAD

151
Cartas Multivari VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD
Ejemplo: (cont...) B VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD
 B VARIACIÓN CÍCLICA DE UNIDAD A UNIDAD.")
152
Cartas Multivari VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO
Ejemplo: (cont...) C VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO
 C VARIACIÓN TEMPORAL DE TIEMPO A TIEMPO.")
153
Cartas Multivari Ejemplo: Un proceso produce flecha cilíndricas, con un diámetro especificado de ” 0.001”. Sin embargo un estudio de capacidad muestra un Cp = 0.8 y una dispersión natural de ” (6 ) contra la permitida de ”. Se tiene pensado comprar un torno nuevo de US$70,000 para tolerancia de ”, i.e. Cpk = Se sugirió un estudio Multi Vari previo.
 contra la permitida de Se tiene pensado comprar un torno nuevo de US$70,000 para tolerancia de , i.e. Cpk = Se sugirió un estudio Multi Vari previo.")
154
Cartas Multivari Se tomaron cuatro lecturas en cada flecha, dos a cada lado. Estas muestran una disminución gradual desde el lado izquierdo al lado derecho de las flechas, además de excentricidad en cada lado de la flecha. La variación cíclica, de una flecha a la siguiente, se muestra mediante las líneas que concentran las cuatro lecturas de cada flecha. También se muestra la variación temporal.

155
Cartas Multivari 8 AM 9 AM 10 AM 11 AM 12 AM .0.2510” 0.2500” 0.2490”
Izquierda Máximo Derecha Mínimo

156
Cartas Multivari Un análisis rápido revela que la mayor variación es temporal con un cambio mayor entre las 10 AM y las 11 AM. A las 10 AM se para el equipo para el almuerzo y se arranca a las 11 AM, con lecturas similares a las de las 8 AM. Conforme pasa el tiempo las lecturas tienden a decrecer más y más, hasta que se invierten a las 10 A.M. en forma drástica. Se investigó y se encontró que la temperatura tenía influencia en la variación. La variación en temperatura era causada por que la cantidad de refrigerante no era la adecuada, lo cual se notaba más cuando se paraba el equipo y se volvía a arrancar. Se adicionó, reduciendo la variación en 50% aproximadamente..

157
Cartas Multivari También se encontró que el acabado cónico era causado por que la herramienta de corte estaba mal alineada. Se ajustó, contribuyendo a otra reducción del 10% de la variabilidad. La excentricidad de las flechas se corrigió al cambiar un rodamiento excéntrico por desgaste en el torno. Se instaló un nuevo rodamiento eliminándose otro 30% de la variabilidad. La tabla siguiente muestra un resumen de los resultados.

158
Cartas Multivari Tipo de % var. Causas de Acción % de variación
Variación Total Variación Correctiva Reducida Temporal 50 Bajo nivel de Adicionar Casi 50 Tiempo a tiempo Refrigerante refrigerante Dentro de 10 Ajuste no Ajuste de la Casi 10 la flecha no paralelo herramienta de corte Dentro de 30 Rodamiento Nuevo Casi 30 la flecha gastado rodamiento Flecha a ??? - - flecha

159
Cartas Multivari Resultados:
La variación total en la siguiente corrida de producción se redujo de ” a ” El nuevo Cp fue de / = 5.0 Como beneficios se redujo a cero el desperdicio y no hubo necesidad de adquirir una nueva máquina. Se observa que antes de cambiar equipo o máquinas, es conveniente realizar un estudio de variabilidad para identificar las fuentes de variación y tratar de eliminarlas.

160
Cartas Multivari Diámetro de Flecha (0.150" +/- .002)
Ejemplo: Búsqueda de fuentes de variación con el diagrama sistemático. Diámetro de Flecha (0.150" +/- .002) Operador a operador Programa Máquina Accesorios
 Operador a operador. Programa. Máquina. Accesorios.")
161
Cartas Multivari Se Rechaza Ho: Oper1 = Oper2 = Oper3
Ejemplo (cont..): Al realizar la prueba de homogeneidad de varianza F, se encontró que había una diferencia significante entre los operadores. Se Rechaza Ho: Oper1 = Oper2 = Oper3 Para probar si existe diferencia significativa entre medias de operadores se hacen las siguientes comparaciones Ho: Oper1 = Oper2 Ho: Oper1 = Oper3 Ho: Oper2 = Oper3 Ha: Oper1 Oper2 Oper3
: Al realizar la prueba de homogeneidad de varianza F, se encontró que había una diferencia significante entre los operadores. Se Rechaza Ho: Oper1 = Oper2 = Oper3. Para probar si existe diferencia significativa entre medias de operadores se hacen las siguientes comparaciones. Ho: Oper1 = Oper2 Ho: Oper1 = Oper3. Ho: Oper2 = Oper3 Ha: Oper1 Oper2 Oper3.")
162
SinterTime MetalType Strength
Corrida en Minitab Se introducen los datos en varias columnas C1 a C3 incluyendo la respuesta (strenght) y los factores (time y Metal) SinterTime MetalType Strength
 y los factores (time y Metal) SinterTime MetalType Strength")
163
Corrida en Minitab Utilizar el achivo de ejemplo Sinter.mtw
Opción: Stat > Quality Tools > Multivari charts Indicar la columna de respuesta y las columnas de los factores En opciones se puede poner un título y conectar las líneas

164
Resultados

165
VI.A.5 Análisis de datos por atributos

166
Análisis de datos por atributos
Si los CTQ’s son variables continuas, se usa la regresión, dependiendo de la naturaleza de la característica crítica para el cliente (CTS’s) como éste la expresa: CTS HERRAMIENTA Nominal (Verde, Rojo, azul) Regresión Logística Nominal Atributo (Pasa/No pasa) Regresión Logística Binaria Ordinal (1, 2, 3, 4, 5) Regresión Logística Ordinal
 como éste la expresa: CTS HERRAMIENTA. Nominal (Verde, Rojo, azul) Regresión Logística Nominal. Atributo (Pasa/No pasa) Regresión Logística Binaria. Ordinal (1, 2, 3, 4, 5) Regresión Logística Ordinal.")
167
Análisis de datos por atributos
El análisis de datos por atributos se organiza en valores, categorías o grupos dicotómicos Las decisiones incluyen: si / no, pasa / no pasa, bueno / malo, pobre/justo/bueno/superior/excelente, etc. Entre los modelos no lineales de regresión usados se tienen: regresión logística, regresión logit y regresión probit

168
Análisis de datos por atributos
Regresión logística Relaciona variables independientes categóricas a una variable dependiente (Y). Minitab incluye los modelos binario, ordinal y nominal Regresión logit Es subconjunto del modelo log-lineal. Tiene solo una variable dependiente, usa determinaciones de probabilidad o tasa de probabilidad
. Minitab incluye los modelos binario, ordinal y nominal. Regresión logit. Es subconjunto del modelo log-lineal. Tiene solo una variable dependiente, usa determinaciones de probabilidad o tasa de probabilidad.")
169
Análisis de datos por atributos
Regresión probit Es similar a la prueba de vida acelerada, la unidad se somete a esfuerzo con la respuesta pasa/falla, bueno o malo. Es una respuesta binaria en un tiempo de falla futuro

170
Regresión logística o binaria
En caso de información cualitativa es necesario traducir las preferencias del cliente expresadas como atributos a un intervalo de valores aceptables de variables (Especificaciones).
.")
171
Regresión logística o binaria
Es similar a la regresión múltiple excepto que la respuesta es binaria (si/no, bueno/malo, etc.) Sus coeficientes se determinan por el método de máxima verosimilitud Su función tiene forma de “S”, con valores máximos de Cero y Uno. Yi = 0, 1
 Sus coeficientes se determinan por el método de máxima verosimilitud. Su función tiene forma de S , con valores máximos de Cero y Uno. Yi = 0, 1.")
172
Regresión logística o binaria
La probabilidad de que el resultado esté en cierta categoría es: El método de cálculo del coeficiente b es diferente que en la regresión lineal Los coeficientes se determinan con la relación sig.:

173
Regresión logística Condiciones:
Hay solo dos resultados posibles Hay solo un resultado por evento Los resultados son independientes estadísticamente Todos los predictores relevantes están en el modelo Es mutuamente exclusivo y colectivamente exhaustivo Los tamaños de muestra son mayores que para la regresión múltiple Los efectos positivos se obtienen con b1>1 y los negativos con b1 e 0 a 1

174
Regresión logística Relación con ajuste pobre Relación con buen ajuste

175
Regresión logística - Procedimiento
Definir el atributo a “traducir” (“y”) Definir la variable apropiada para el atributo (“x”) Definir el modelo matemático a probar Determinar los defectos que está dispuesto a aceptar Recolecte información de “x” vs “y”. Asigne 1 si falla y 0 si es aceptable. Analice la información mediante Regresión Logística Binaria
 Definir la variable apropiada para el atributo ( x ) Definir el modelo matemático a probar. Determinar los defectos que está dispuesto a aceptar. Recolecte información de x vs y . Asigne 1 si falla y 0 si es aceptable. Analice la información mediante Regresión Logística Binaria.")
176
Regresión logística- Procedimiento

177
Regresión logística - Procedimiento
Coeficientes del modelo P-Value de Deviance Observe el P-Value de “Deviance” en la Sesión, debe de ser grande (P >0.10) Obtenga los coeficientes del modelo (De la Sesión)
 Obtenga los coeficientes del modelo (De la Sesión)")
178
Regresión logística - Procedimiento
Construya el modelo de regresión para la probabilidad de falla estará dado por : Identifique el(los) valor(es) de “x” que le generarán como máximo la cantidad de defectos que usted está dispuesto a aceptar [4] Donde : b0, b1, ... = Coeficientes del modelo P(Falla) = b0+b1x1+.... e 1 + e
 valor(es) de x que le generarán como máximo la cantidad de defectos que usted está dispuesto a aceptar [4] Donde : b0, b1, ... = Coeficientes del modelo. P(Falla) = b0+b1x e. 1 + e.")
179
Ejemplo de riesgo de paro cardiaco
Para Fuma, el coeficiente negativo de y la tasa de posibilidades de 0.30, indica que quien fuma, tiende a tener una tasa de pulso más alta que los sujetos que no fuman. Si los sujetos tienen el mismo peso, las posibilidades de que los fumadores tengan un pulso bajo sea sólo del 30% de las posibilidades de que los no fumadores tengan un pulso bajo.

180
Regresión logística ordinal
Cuando la respuesta ó CTS es de tipo ordinal (Varias categorías de respuesta como “totalmente de acuerdo”, “de acuerdo”, “en desacuerdo” y “totalmente en desacuerdo”) y el Factor ó CTQ es de naturaleza continua, entonces, para definir Especificaciones, la herramienta a utilizar es la Regresión Logística Ordinal.
 y el Factor ó CTQ es de naturaleza continua, entonces, para definir Especificaciones, la herramienta a utilizar es la Regresión Logística Ordinal.")
181
Regresión logística ordinal - Procedimiento
Defina la variable de respuesta a “traducir” (“y” ó CTS) Defina el CTQ (“x”) ó variable a relacionar con el CTS Defina el modelo matemático a probar Determine los defectos que está dispuesto a aceptar en la categoría de interés Recolecte información de “x” vs “y” Analice la información mediante Regresión Logística Ordinal
 Defina el CTQ ( x ) ó variable a relacionar con el CTS. Defina el modelo matemático a probar. Determine los defectos que está dispuesto a aceptar en la categoría de interés. Recolecte información de x vs y Analice la información mediante Regresión Logística Ordinal.")
182
Regresión logística ordinal - Procedimiento
Stat > Regression > Ordinal Logistic Regression Seleccione la respuesta (“y”) Seleccione los términos que estima tiene el modelo [3] Constantes y Coeficientes del modelo
 Seleccione los términos que estima tiene el modelo [3] Constantes y Coeficientes del modelo.")
183
Regresión logística ordinal - Procedimiento
Observe el P-Value de “Deviance” en la Sesión, debe de ser grande (P >0.10) Obtenga las constantes y coeficientes del modelo (De la Sesión) Construya los modelos de regresión para la probabilidad acumulada por categoría
 Obtenga las constantes y coeficientes del modelo (De la Sesión) Construya los modelos de regresión para la probabilidad acumulada por categoría.")
184
Regresión logística ordinal - Procedimiento
Donde : Ki = Constante de la categoría i b1, b2, ... = Coeficientes del modelo acumulada hasta categoría i Ki+b1x1+ b2x2.... = P Constantes y Coeficientes del modelo Identifique el(los) valor(es) de “x” que le generarán como máximo la cantidad de defectos que usted está dispuesto a aceptar en la categoría de interés [4]
 valor(es) de x que le generarán como máximo la. cantidad de defectos que usted está dispuesto a aceptar en la. categoría de interés [4]")
185
Regresión logística ordinal - Procedimiento
Una vez que se tienen establecidos los CTQs con los que se medirá el desempeño del producto, es necesario indicar las Especificaciones de los mismos Producto (General) Usuarios Finales Clientes Expectativas (CTS’s) Tipo Importan. (Específico) Parámetros de Diseño (DPs) Matriz de Diseño CTQs Especificaciones LIE LSE Otra
 Usuarios. Finales. Clientes. Expectativas. (CTS’s) Tipo. Importan. (Específico) Parámetros. de Diseño. (DPs) Matriz de. Diseño. CTQs. Especificaciones. LIE. LSE. Otra.")
186
Análisis Logit Usa razones para determinar que tanta posibilidad tiene una observación de pernecer a un grupo que a otro. Una posibilidad de 0.8 de estar en el grupo A se puede expresar como una tasa de posibilidades de 4:1 ( que es p/(1-p)), cuyo logaritmo es el logit. La probabilidad para un valor L está dado por la ecuación
), cuyo logaritmo es el logit. La probabilidad para un valor L está dado por la ecuación.")
187
Análisis Logit - ejemplo
50 estudiantes tomaron un examen, donde solo 27 pasaron. ¿Cuáles son las posibilidades de pasar? Posibilidades = P/(1-P) = 0.54/0.46 = 1.17 o 1.71:1 Un estudiante que estudia 80 horas tiene un 54.5% de pasar, ¿cuáles son las posibilidades? Posibilidades = 0.545/( ) = o 1.198:1 Logit = ln(p/(1-p)) = ln(1.189) = y despejando al Exp(b1) = exp(0.1082) = 1.11 que es la tasa de pasar a otro nivel
 = 0.54/0.46 = 1.17 o 1.71:1. Un estudiante que estudia 80 horas tiene un 54.5% de pasar, ¿cuáles son las posibilidades Posibilidades = 0.545/( ) = o 1.198:1. Logit = ln(p/(1-p)) = ln(1.189) = y despejando al. Exp(b1) = exp(0.1082) = 1.11 que es la tasa de pasar a otro nivel.")
188
Análisis Probit Es similar a las pruebas de vida acelerada y análisis de sobrevivencia. Un artículo sujeto a esfuerzo puede fallar o sobrevivir. El modelo probit tiene un valor esperado de 0 y una varianza de 1. Requiere tamaños de muestra muy grandes para diferenciarse del modelo logit Los coeficientes b del modelo logit difieren del probit en con: bl = bp

189
VI.B Pruebas de hipótesis

190
VI.B Pruebas de hipótesis
1. Conceptos fundamentales 2. Estimación puntual y por intervalo 3. Pruebas para medias, varianzas y proporciones 4. Pruebas comparativas para varianzas, medias y prop. 5. Bondad de ajustes 6. Análisis de varianza (ANOVA) 7. Tablas de contingencia 8. Pruebas no paramétricas
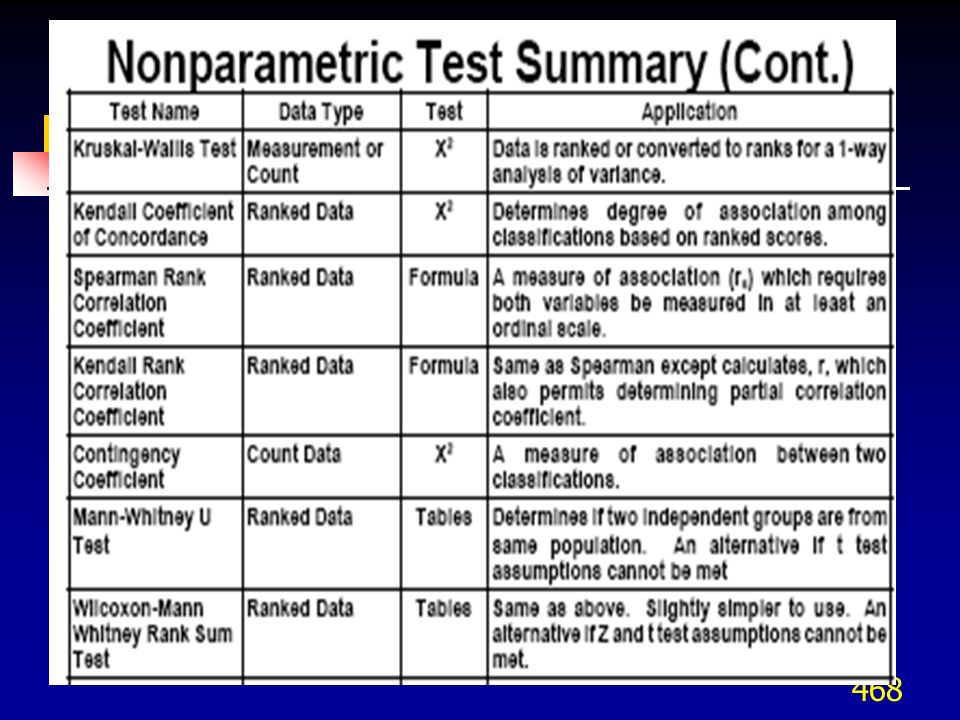
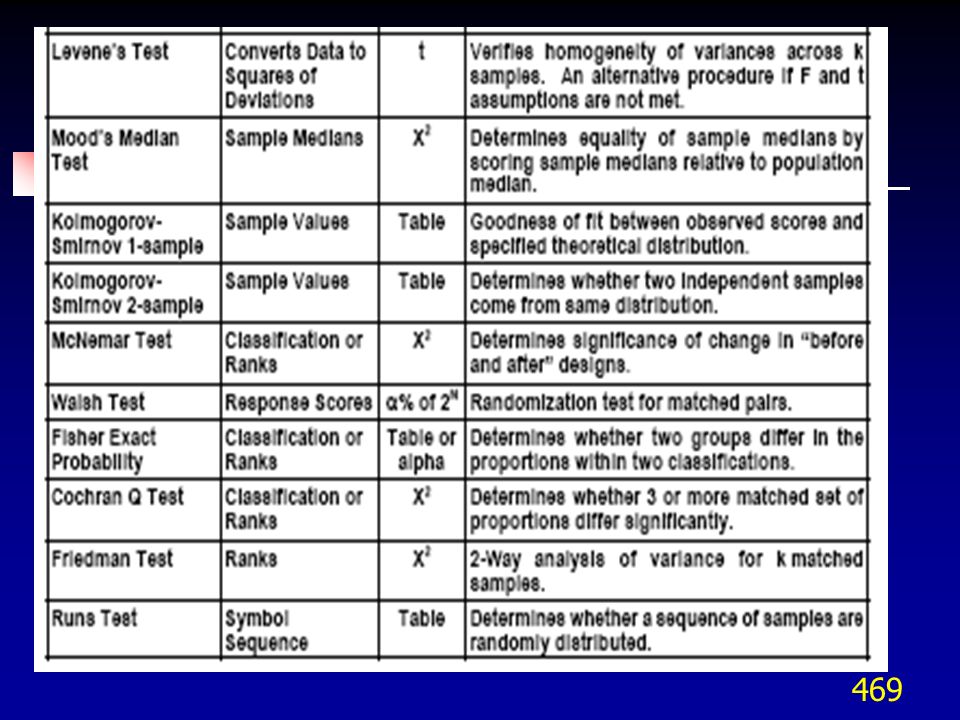
 7. Tablas de contingencia. 8. Pruebas no paramétricas.")
191
VI.B.1 Conceptos fundamentales

192
Análisis Estadístico En CADA prueba estadística, se comparan algunos valores observados a algunos esperados u otro valor observado comparando estimaciones de parámetros (media, desviación estándar, varianza) Estas estimaciones de los VERDADEROS parámetros son obtenidos usando una muestra de datos y calculando los ESTADÏSTICOS... La capacidad para detectar un diferencia entre lo que es observado y lo que es esperado depende del desarrollo de la muestra de datos Incrementando el tamaño de la muestra mejora la estimación y tu confianza en las conclusiones estadísticas. La palabra parámetro es usada para cubrir la media, desviación estándar, kurtosis, skew - aquellos métricos usado para caracterizar la distribución subrayada Población - El total de posibilidades de todas las partes del proceso “Known but to God” => Media de la población xbar => Media de la población => Sigma de población hat => Sigma de la muestra Cuesta dinero y toma tiempo analizar la muestra. Se debe limitar a lo que es requerido
 Estas estimaciones de los VERDADEROS parámetros son obtenidos usando una muestra de datos y calculando los ESTADÏSTICOS... La capacidad para detectar un diferencia entre lo que es observado y lo que es esperado depende del desarrollo de la muestra de datos. Incrementando el tamaño de la muestra mejora la estimación y tu confianza en las conclusiones estadísticas. La palabra parámetro es usada para cubrir la media, desviación estándar, kurtosis, skew - aquellos métricos usado para caracterizar la distribución subrayada. Población - El total de posibilidades de todas las partes del proceso Known but to God => Media de la población. xbar => Media de la población. => Sigma de población. hat => Sigma de la muestra. Cuesta dinero y toma tiempo analizar la muestra. Se debe limitar a lo que es requerido.")
193
Conceptos fundamentales
Hipótesis nula Ho Es la hipótesis o afirmación a ser probada Puede ser por ejemplo , , , = 5 Sólo puede ser rechazada o no rechazada Hipótesis alterna Ha Es la hipótesis que se acepta como verdadera cuando se rechaza Ho, es su complemento Puede ser por ejemplo = 5 para prueba de dos colas < 5 para prueba de cola izquierda > 5 para prueba de cola derecha Esta hipótesis se acepta cuando se rechaza Ho

194
Conceptos fundamentales
Ejemplos: Se está investigando si una semilla modificada proporciona una mayor rendimiento por hectárea, la hipótesis nula de dos colas asumirá que los rendimientos no cambian Ho: Ya = Yb Se trata de probar si el promedio del proceso A es mayor que el promedio del proceso B. La hipótesis nula de cola derecha establecerá que el proceso A es <= Proceso B. O sea Ho: A <= B.

195
Conceptos fundamentales
Estadístico de prueba Para probar la hipótesis nula se calcula un estadístico de prueba con la información de la muestra el cual se compara a un valor crítico apropiado. De esta forma se toma una decisión sobre rechazar o no rechazar la Ho Error tipo I (alfa = nivel de significancia, normal=.05) Se comete al rechazar la Ho cuando en realidad es verdadera. También se denomina riesgo del productor Error tipo II (beta ) Se comete cuando no se rechaza la hipótesis nula siendo en realidad falsa. Es el riesgo del consumidor
 Se comete al rechazar la Ho cuando en realidad es verdadera. También se denomina riesgo del productor. Error tipo II (beta ) Se comete cuando no se rechaza la hipótesis nula siendo en realidad falsa. Es el riesgo del consumidor.")
196
Conceptos fundamentales
Tipos de errores Se asume que un valor pequeño para es deseable, sin embargo esto incrementa el riesgo . Para un mismo tamaño de muestra n ambos varían inversamente Incrementando el tamaño de muestra se pueden reducir ambos riesgos. Decisión realizada Ho en realidad es Verdadera Ho en realidad es falsa No hay evidencia para rechazar Ho p = 1- Decisión correcta p = Error tipo II Rechazar Ho p = Error tipo I p = 1 -

197
Conceptos fundamentales
Pruebas de dos colas Si la Ho: , , , = cte. que un valor poblacional, entonces el riesgo alfa se reparte en ambos extremos de la distribución. Por ejemplo si Ho = 10 se tiene:

198
Conceptos fundamentales
Pruebas de una cola Si la Ho: , , , >= Cte. que un valor poblacional, entonces el riesgo alfa se coloca en la cola izquierda de la distribución. Por ejemplo si Ho: >= 10 y Ha: < 10 se tiene una prueba de cola izquierda:

199
Conceptos fundamentales
Pruebas de una cola Si la Ho: , , , <= Cte. que un valor poblacional, entonces el riesgo alfa se coloca en la cola derecha de la distribución. Por ejemplo si Ho: <= 10 y Ha: > 10 se tiene una prueba de cola derecha:

200
Conceptos fundamentales
Tamaño de muestra requerido Normalmente se determina el error alfa y beta deseado y después se calcula el tamaño de muestra necesario para obtener el intervalo de confianza. El tamaño de muestra (n) necesario para la prueba de hipótesis depende de: El riesgo deseado tipo I alfa y tipo II Beta El valor mínimo a ser detectado entre las medias de la población (Mu – Mu0) La variación en la característica que se mide (S o sigma)
 necesario para la prueba de hipótesis depende de: El riesgo deseado tipo I alfa y tipo II Beta. El valor mínimo a ser detectado entre las medias de la población (Mu – Mu0) La variación en la característica que se mide (S o sigma)")
201
Conceptos fundamentales
El Tamaño de muestra requerido en función del error máximo E o Delta P intervalo proporcional esperado se determina como sigue:

202
Conceptos fundamentales
Ejemplo: ¿Cuál es el tamaño de muestra mínimo que al 95% de nivel de confianza (Z=1.96) confirma la significancia de una corrida en la media mayor a 4 toneladas/hora (E), si la desviación estándar (sigma) es de 20 toneladas? n = (1.96^2)(20^2)/(4)^2 = 96 Obtener 96 valores de rendimiento por hora y determinar el promedio, si se desvía por más de 4 toneladas, ya ha ocurrido un cambio significativo al 95% de nivel de confianza
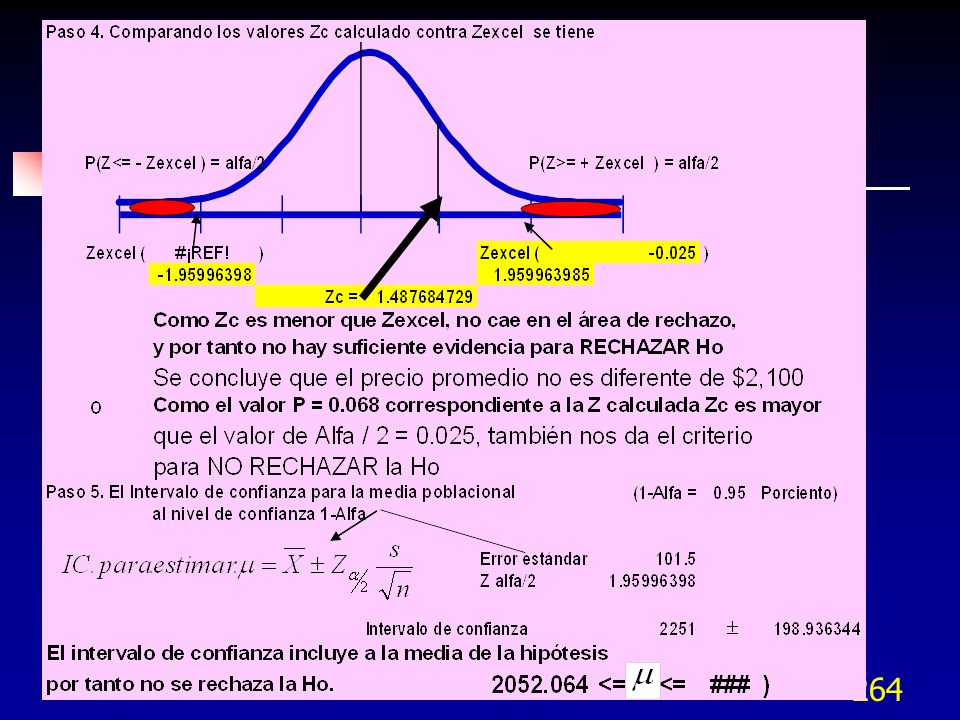
 confirma la significancia de una corrida en la media mayor a 4 toneladas/hora (E), si la desviación estándar (sigma) es de 20 toneladas n = (1.96^2)(20^2)/(4)^2 = 96. Obtener 96 valores de rendimiento por hora y determinar el promedio, si se desvía por más de 4 toneladas, ya ha ocurrido un cambio significativo al 95% de nivel de confianza.")
203
Efecto del tamaño de muestra

204
Efecto del tamaño de muestra

205
Efecto del tamaño de muestra

206
Efecto del tamaño de muestra

207
Potencia de la prueba La potencia de una prueba estadística es su habilidad para detectar una diferencia crítica Si Beta = 0.1 la potencia es del 90% Delta se puede normalizar dividiéndolo entre la desviación estándar y se expresa en un cierto número de (1 , 1.5 )
")
208
Potencia de la prueba La potencia de la prueba es la probabilidad de de rechazar correctamente la hipótesis nula siendo que en realidad es falsa. El análisis de potencia puede ayudar a contestar preguntas como: ¿Cuántas muestras se deben tomar para el análisis? ¿Es suficiente el tamaño de muestra? ¿Qué tan grande es la diferencia que la prueba puede detectar? ¿Son realmente valiosos los resultados de la prueba?

209
Potencia de la prueba Para estimar la potencia, Minitab requiere de dos de los siguientes parámetros: Tamaños de muestra Diferencias - un corrimiento significativo de la media que se desea detectar Valores de potencia - La probabilidad deseada de rechazar Ho cuando es falsa

210
Considerando la potencia de prueba

211
VI.2 Significancia estadística vs práctica

212
Estimación de riesgos

213
Pruebas de Minitab Permite hacer las siguientes pruebas:
Prueba z de una muestra Prueba t de una muestra Prueba t de dos muestras Prueba de 1 proporción Prueba de 2 proporciones ANOVA Diseños factoriales de dos niveles Diseños de Packett Burman

214
Calculo manual

215
Calculo manual

216
VI.3 Tamaño de muestra

217
Calculo manual de tamaño de muestra

218
Calculo manual de tamaño de muestra – Pruebas de una cola

219
Calculo manual de tamaño de muestra – Pruebas de una cola

220
Ejemplo con prueba de una media t
Ejemplo: Se tiene una población normal con media de 365 y límites de especificación de 360 y 370. Si la media se desplaza 2.5 gramos por arriba de la media, el número de defectos sería inaceptable, la desviación estándar histórica es de 2.403:

221
Ejemplo con prueba de una media t

222
Ejemplo con prueba de una media t

223
Ejemplo con prueba de una media t

224
Ejemplo con prueba de 2 medias t

225
Ejemplo con prueba de 1 proporción

226
Ejemplo con prueba de 1 proporción

227
Ejercicios Calcular los tamaños de muestra necesarios para los siguientes escenarios (usar pruebas de dos colas): a. 1-muestra Z à a=0.05, b=0.1 y 0.2, d = 1.5s b. 1-muestra t à a=0.05, b=0.1 y 0.2, d = 1.5s c. 1-muestra t à a=0.01, b=0.05, d = 0.5s y 1.0s d. 2-muestras t à a=0.05, b=0.1, d = 1.5s y 2.0s 2. Calcular la potencia de la prueba para los siguientes escenarios (usar pruebas de dos colas): a. 1-muestra Z à a=0.05, d = 0.5s, n = 25, 35 b. 1-muestra t à a=0.05, d = 1.0s, n = 10, 20 c. 1-muestra t à a=0.01, d = 1.0s, n = 10, 25 d. 2-muestras t à a=0.05, d = 0.5s, n = 10, 25, 50, 75, 100
: a. 1-muestra Z à a=0.05, d = 0.5s, n = 25, 35. b. 1-muestra t à a=0.05, d = 1.0s, n = 10, 20. c. 1-muestra t à a=0.01, d = 1.0s, n = 10, 25. d. 2-muestras t à a=0.05, d = 0.5s, n = 10, 25, 50, 75, 100.")
228
Ejercicios Calcular el tamaño de muestra requerido para los siguientes
escenarios (usar pruebas de dos colas): a. 1-proporción à a=0.05, b=0.1 & 0.2, P0 = 0.5, PA = 0.6 b. 1-proporción à a=0.01, b=0.1 & 0.2, P0 = 0.8, PA = 0.9 c. 2-proporción à a=0.05, b=0.1, P0 = 0.5, PA = 0.6, 0.8 d. 2-proporciones à a=0.01, b=0.1, P0 = 0.8, PA = 0.85, 0.95 2. Calcular la potencia de la prueba para los siguientes escenarios (usar pruebas de dos colas): a. 1-proporción à a=0.05, P0 = 0.5, PA = 0.6, n = 250, 350 b. 1-proporción à a=0.01, P0 = 0.9, PA = 0.95, n = 400, 500 c. 2-proporciones à a=0.05, P0 = 0.5, PA = 0.6, n = 250, 350 d. 2-proporciones à a=0.01, P0 = 0.9, PA = 0.95, n = =400, 500
: a. 1-proporción à a=0.05, b=0.1 & 0.2, P0 = 0.5, PA = 0.6. b. 1-proporción à a=0.01, b=0.1 & 0.2, P0 = 0.8, PA = 0.9. c. 2-proporción à a=0.05, b=0.1, P0 = 0.5, PA = 0.6, 0.8. d. 2-proporciones à a=0.01, b=0.1, P0 = 0.8, PA = 0.85, Calcular la potencia de la prueba para los siguientes escenarios. (usar pruebas de dos colas): a. 1-proporción à a=0.05, P0 = 0.5, PA = 0.6, n = 250, 350. b. 1-proporción à a=0.01, P0 = 0.9, PA = 0.95, n = 400, 500. c. 2-proporciones à a=0.05, P0 = 0.5, PA = 0.6, n = 250, 350. d. 2-proporciones à a=0.01, P0 = 0.9, PA = 0.95, n = =400, 500.")
231
VI.B.4 Estimación puntual y por intervalo

232
Estimación puntual y por intervalo
Las medias o desviaciones estándar calculadas de una muestra se denominan ESTADÍSTICOS, podrían ser consideradas como un punto estimado de la media y desviación estándar real de población o de los PARAMETROS. ¿Qué pasa si no deseamos una estimación puntual como media basada en una muestra, qué otra cosa podríamos obtener como margen, algún tipo de error? “Un Intervalo de Confianza”

233
Intervalo de confianza
Error de estimación

234
Estimación puntual y por intervalo
¿Cómo obtenemos un intervalo de confianza? Estimación puntual + error de estimación ¿De dónde viene el error de estimación? Desv. estándar X multiplicador de nivel de confianza deseado Z/2 Por Ejemplo: Si la media de la muestra es 100 y la desviación estándar es 10, el intervalo de confianza al 95% donde se encuentra la media para una distribución normal es: 100 + (10) X 1.96 => (80.4, 119.6) = Z0.025
 X 1.96 => (80.4, 119.6) 1.96 = Z")
235
Estimación puntual y por intervalo
95% de Nivel de Confianza significa que sólo tenemos un 5% de oportunidad de obtener un punto fuera de ese intervalo. Esto es el 5% total, o 2.5% mayor o menor. Si vamos a la tabla Z veremos que para un área de 0.025, corresponde a una Z de C. I Multiplicador Z/2 Para tamaños de muestra >30, o conocida usar la distribución Normal Para muestras de menor tamaño, o desconocida usar la distribución t

236
Estimación puntual y por intervalo
; con n-1 gl.

237
Para n grande el IC es pequeño

238
Para n grande el IC es pequeño

239
Ejemplo Dadas las siguientes resistencias a la tensión: 28.7, 27.9, 29.2 y 26.5 psi Estimar la media puntual X media = con S = 1.02 Estimar el intervalo de confianza para un nivel de confianza del 95% (t = con n-1=3 grados de libertad) Xmedia±3.182*S/√n = 28.08±3.182*1.02/2=(26.46, 29.70)
 Xmedia±3.182*S/√n = 28.08±3.182*1.02/2=(26.46, 29.70)")
240
Ejemplos para la media con Distribución normal Z
Z 1. El peso promedio de una muestra de 50 bultos de productos Xmedia = Kgs., con S = Kgs. Determinar el intervalo de confianza al NC del 95% y al 99% donde se encuentra la media del proceso (poblacional). Alfa = 1 - NC 2. Un intervalo de confianza del 90% para estimar la ganancia promedio del peso de ratones de laboratorio oscila entre 0.93 y 1.73 onzas. ¿Cuál es el valor de Z?. latas de 16 onzas de salsa de tomate tienen una media de Xmedia = 15.2 onzas con una S = 0.96 onzas. ¿A un nivel de confianza del 95%, las latas parecen estar llenas con 16 onzas?. 4. Una muestra de 16 soluciones tienen un peso promedio de 16.6 onzas con S = Se rechaza la solución si el peso promedio de todo el lote no excede las 18 onzas. ¿Cuál es la decisión a un 90% de nivel de confianza?.
. Alfa = 1 - NC. 2. Un intervalo de confianza del 90% para estimar la ganancia promedio del peso de ratones de laboratorio oscila entre 0.93 y 1.73 onzas. ¿Cuál es el valor de Z latas de 16 onzas de salsa de tomate tienen una media de Xmedia = 15.2 onzas con una S = 0.96 onzas. ¿A un nivel de confianza del 95%, las latas parecen estar llenas con 16 onzas . 4. Una muestra de 16 soluciones tienen un peso promedio de 16.6 onzas con S = Se rechaza la solución si el peso promedio de todo el lote no excede las 18 onzas. ¿Cuál es la decisión a un 90% de nivel de confianza .")
241
Ejemplos para la media y varianza con Distribución t
t cajas de producto pesaron 102 grs. Con S = 8.5 grs. ¿Cuál es el intervalo donde se encuentra la media y varianza del lote para un 90% de nivel de confianza?. Grados libertad=20 -1 =19 6. Una muestra de 25 productos tienen un peso promedio de grs. Con una S = ¿Cuál es la estimación del intervalo de confianza para la media y varianza a un nivel de confianza del 95 y del 98% del peso de productos del lote completo?. 7. Los pesos de 25 paquetes enviados a través de UPS tuvieron una media de 3.7 libras y una desviación estándar de 1.2 libras. Hallar el intervalo de confianza del 95% para estimar el peso promedio y la varianza de todos los paquetes. Los pesos de los paquetes se distribuyen normalmente.

242
Ejemplos para proporciones con Distribución Z
Z 8. De 814 encuestados 562 contestaron en forma afirmativa. ¿Cuál es el intervalo de confianza para un 90% de nivel de confianza? 9. En una encuesta a 673 tiendas, 521 reportaron problemas de robo por los empleados ¿Se puede concluir con un 99% de nivel de confianza que el 78% se encuentra en el intervalo de confianza. ?

243
Instrucciones con Minitab Intervalo de confianza para la media
Stat > Basic Statistics > 1-Sample Z, t Variable -- Indicar la columna de los datos o Summarized Data En caso de requerirse dar el valor de Sigma = dato En Options: Indicar el Confidence level -- 90, 95 o 99% OK

244
Instrucciones con Minitab Intervalo de confianza para proporción
Stat > Basic Statistics > 1-Proportion Seleccionar Summarized Data Number of trials = n tamaño de la muestra Number of events = D éxitos encontrados en la muestra En Options: Indicar el Confidence Interval -- 90, 95 o 99% Seleccionar Use test and interval based in normal distribution

245
VI.B.5 Pruebas de hipótesis para medias, varianzas y proporciones

246
Elementos de una Prueba de Hipótesis
Prueba Estadística- Procedimiento para decidir no rechazar Ho aceptando Ha o rechazar Ho. Hipótesis Nula (Ho) - Usualmente es una afirmación representando una situación “status quo”. Generalmente deseamos rechazar la hipótesis nula. Hipótesis Alterna (Ha) - Es lo que aceptamos si podemos rechazar la hipótesis nula. Ha es lo que queremos probar.
 - Usualmente es una afirmación representando una situación status quo . Generalmente deseamos rechazar la hipótesis nula. Hipótesis Alterna (Ha) - Es lo que aceptamos si podemos rechazar la hipótesis nula. Ha es lo que queremos probar.")
247
Elementos de una Prueba de Hipótesis
Estadístico de prueba: Calculado con datos de la muestra (Z, t, X2 or F). Región de Rechazo Indica los valores de la prueba estadística para que podamos rechazar la Hipótesis nula (Ho). Esta región esta basada en un riesgo deseado, normalmente 0.05 o 5%.
. Región de Rechazo Indica los valores de la prueba estadística para que podamos rechazar la Hipótesis nula (Ho). Esta región esta basada en un riesgo deseado, normalmente 0.05 o 5%.")
248
Pasos en la Prueba de Hipótesis
1. Definir el Problema - Problema Práctico 2. Señalar los Objetivos - Problema Estadístico 3. Determinar tipo de datos - Atributo o Variable 4. Si son datos Variables - Prueba de Normalidad

249
Pasos en la Prueba de Hipótesis
5. Establecer las Hipótesis - Hipótesis Nula (Ho) - Siempre tiene el signo =, , - Hipótesis Alterna (Ha) – Tiene signos , > o <. El signo de la hipótesis alterna indica el tipo de prueba a usar
 - Siempre tiene el signo =, , - Hipótesis Alterna (Ha) – Tiene signos , > o <. El signo de la hipótesis alterna indica el tipo de prueba a usar.")
250
Elementos de una Prueba de Hipótesis
Pruebas de Hipótesis de dos colas: Ho: a = b Ha: a b Pruebas de Hipótesis de cola derecha: Ho: a b Ha: a > b Pruebas de Hipótesis cola izquierda: Ho: a b Ha: a < b Región de Rechazo Región de Rechazo -Z Z Región de Rechazo Z Región de Rechazo -Z Z

251
Pasos en la Prueba de Hipótesis
6. Seleccionar el nivel de Alfa (normalmente 0.05 o 5%) o el nivel de confianza NC = 1 - alfa 7. Establecer el tamaño de la muestra, >= 10. 8.Desarrollar el Plan de Muestreo 9.Seleccionar Muestras y Obtener Datos 10. Decidir la prueba estadística apropiada y calcular el estadístico de prueba (Z, t, X2 or F) a partir de los datos.
 o el nivel de confianza NC = 1 - alfa. 7. Establecer el tamaño de la muestra, >= Desarrollar el Plan de Muestreo. 9.Seleccionar Muestras y Obtener Datos. 10. Decidir la prueba estadística apropiada y calcular el estadístico de prueba (Z, t, X2 or F) a partir de los datos.")
252
Estadísticos para medias, varianzas y proporciones

253
Estadísticos para medias, varianzas y proporciones
Para el caso de muestras pareadas se calculan las diferencias d individuales como sigue:

254
Pasos en la Prueba de Hipótesis
11. Obtener el estadístico correspondiente de tablas o Excel. 12.Determinar la probabilidad de que el estadístico de prueba calculado ocurre al azar. 13.Comparar el estadístico calculado con el de tablas y ver si cae en la región de rechazo o ver si la probabilidad es menor a alfa, rechaze Ho y acepte Ha. En caso contrario no rechaze Ho. 14.Con los resultados interprete una conclusión estadística para la solución práctica.

255
Prueba de Hipótesis Estadístico Calculado con Datos de la muestra
Pruebas de Hipótesis de dos colas: Ho: a = b Ha: a b Pruebas de Hipótesis de cola derecha: Ho: a b Ha: a > b Pruebas de Hipótesis cola izquierda: Ho: a b Ha: a < b Región de Rechazo Región de Rechazo -Z Z Región de Rechazo Z Región de Rechazo -Z Z

256
Prueba de hipótesis para la varianza
Las varianzas de la población se ditribuyen de acuerdo a la distribución Chi Cuadrada. Por tanto las inferencias acerca de la varianza poblacional se basarán en este estadístico La distribución Chi Cuadrada se utiliza en: Caso I. Comparación de varianzas cuando la varianza de la población es conocida Caso II. Comparando frecuencias observadas y esperadas de resultados de pruebas cuando no hay una varianza de la población definida (datos por atributos)
")
257
Prueba de hipótesis para la varianza
Las pruebas de hipótesis para comparar una varianza poblacional a un cierto valor constante 0, si la población sigue la distribución normal es: Con el estadístico Chi Cuadrada con n-1 grados de libertad

258
Prueba de hipótesis para la varianza
2.17 Ejemplo: ¿El material muestra una variación (sigma) en la resistencia a la tensión menor o igual a 15 psi con 95% de confianza?. En una muestra de 8 piezas se obtuvo una S = 8psi. X^2c =(7)(8)^2/(15)^2 = 1.99 Como La Chi calculada es menor a la Chi de Excel de 2.17 se debe rechazar la hipótesis nula. Si hay decremento en la resistencia
 en la resistencia a la tensión menor o igual a 15 psi con 95% de confianza . En una muestra de 8 piezas se obtuvo una S = 8psi. X^2c =(7)(8)^2/(15)^2 = Como La Chi calculada es menor a la Chi de Excel de 2.17 se debe rechazar la hipótesis nula. Si hay decremento en la resistencia.")
259
Prueba de hipótesis para atributos
Ejemplo: Un supervisor quiere evaluar la habilidad de 3 inspectores para detectar radios en el equipaje en un aeropuerto. ¿Hay diferencias significativas para un 95% de confianza? Valores observados O Inspector 1 Inspector 2 Inspector 3 Total por tratamiento Radios detectados 27 25 22 74 Radios no detectados 3 5 8 16 Total de la muestra 30 90

260
Prueba de hipótesis para atributos
Ho: p1 = p2 = p3 Ha: p1 p2 p3 Grados de libertad = (No. de columnas -1)*(No. renglones -1) Las frecuencias esperadas son: (Total columna x Total renglón) Valores esperados E Inspector 1 Inspector 2 Inspector 3 Total por tratamiento Radios detectados 24.67 74 Radios no detectados 5.33 16 Total de la muestra 30 90
*(No. renglones -1) Las frecuencias esperadas son: (Total columna x Total renglón) Valores esperados E. Inspector 1. Inspector 2. Inspector 3. Total por tratamiento. Radios detectados Radios no detectados Total de la muestra")
261
Prueba de hipótesis para atributos
El estadístico Chi Cuadrado en este caso es: El estadístico Chi Cuadrada de alfa = 0.05 para 4 grados de libertad es 5.99. El estadístico Chi Cuadrada calculada es menor que Chi de alfa, por lo que no se rechaza Ho y las habilidades son similares 5.99

262
Ejemplo de Prueba de hipótesis para la media
Para una muestra grande (n>30)probar la hipótesis de una media u 1.) Ho: 2.) Ha: 3.) Calcular el estadístico de prueba 4.) Establecer la región de rechazo Las regiones de rechazo para prueba de 2 colas: -Z y Z Zcalc= s n Región de Rechazo Región de Rechazo -Z Z Si el valor del estadístico de prueba cae en la región de rechazo rechazaremos Ho de otra manera no podemos rechazar Ho.
probar la hipótesis de una media u. 1.) Ho: 2.) Ha: 3.) Calcular el estadístico de prueba. 4.) Establecer la región de rechazo. Las regiones de rechazo para prueba de 2 colas: -Z y Z Zcalc= s. n. Región de. Rechazo. Región de. Rechazo. -Z Z Si el valor del estadístico de prueba cae en la región de rechazo rechazaremos Ho de otra manera no podemos rechazar Ho.")
263
Prueba de hipótesis de una población para muestras grandes con Z

265
Prueba de hipótesis de una población para muestras pequeñas con t
Gl=14;

267
Prueba de hipótesis para una proporción con Z

269
Instrucciones con Minitab para la prueba de hipótesis de una media
Stat > Basic Statistics > 1-Sample Z, t Variable -- Indicar la columna de los datos o Summarized Data En caso de requerirse dar el valor de Sigma = dato Proporcionar la Media de la hipótesis Test Mean En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than OK

270
Instrucciones con Minitab para la prueba de hipótesis de una proporción
Stat > Basic Statistics > 1-Proportion Seleccionar Summarized Data Number of trials = n tamaño de la muestra Number of events = D éxitos encontrados en la muestra En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la Test Proportion Proporción de la hipótesis Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than Seleccionar Use test and interval based in normal distribution OK

271
Pruebas de hipótesis para comparación de varianzas, medias, y proporciones

272
Prueba de Hipótesis Supongamos que tenemos muestras de dos reactores que producen el mismo artículo. Se desea ver si hay diferencia significativa en el rendimiento de “Reactor a Reactor”. Reactor A Reactor B Estadísticas Descriptivas Variable Reactor N Media Desv.Std Rendimiento A B

273
Estaba mal hecha la traducción del
inglés al español Revisó M. Yris 4-Mar-99 Prueba de Hipótesis Pregunta Práctica: Existe diferencia entre los reactores? Pregunta estadística ¿La media del Reactor B (85.54) es significativamente diferente de la media del Reactor A (84.24)? O, su diferencia se da por casualidad en una variación de día a día. Ho: Hipótesis Estadística: No existe diferencia entre los Reactores Ha: Hipótesis Alterna: Las medias de los Reactores son diferentes. Se busca demostrar que los valores observados al parecer no corresponden al mismo proceso, se trata de rechazar Ho.
 es significativamente diferente de la media del Reactor A (84.24) O, su diferencia se da por casualidad en una variación de día a día. Ho: Hipótesis Estadística: No existe diferencia entre los Reactores. Ha: Hipótesis Alterna: Las medias de los Reactores son diferentes. Se busca demostrar que los valores observados al parecer no corresponden al mismo proceso, se trata de rechazar Ho.")
274
The Null Hypothesis is always stated as the thing we are trying to disprove. It states the status quo, that nothing has changed, that whatever you did had no effect. Prueba de Hipótesis Hipótesis Estadística: No existe diferencia entre los Reactores Esto se llama Hipótesis Nula (Ho) Hipótesis Alterna: Cuando las medias de Reactores son diferentes. A esto se le llama Hipótesis Alterna (Ha) Debemos demostrar que los valores que observamos al parecer no corresponden al mismo proceso, que la Ho debe estar equivocada
 Hipótesis Alterna: Cuando las medias de Reactores son diferentes. A esto se le llama Hipótesis Alterna (Ha) Debemos demostrar que los valores que observamos al parecer no corresponden al mismo proceso, que la Ho debe estar equivocada.")
275
¿Qué representa esto? Reactor A Reactor B
Gramática y ortografía estaban mal. Corregidas M. Yris 4-Mar-99 ¿Qué representa esto? Reactor A Reactor B A AA AAAA A A B B B B B BB B B B ¿Representan los reactores dos procesos diferentes? ¿Representan los reactores un proceso básico?

276
Prueba F de dos varianzas
Si se toman dos muestras de dos poblaciones normales con varianzas iguales, la razón de sus varianzas crea una distribución muestral F. Las hipótesis son las siguientes: El estadístico F se muestra a continuación donde S1 se acostumbra tomar como la mayor

277
Prueba F de dos varianzas
Sea S1 = 900 psi, n1 = 9, s2 = 300 psi, n2 = 7. A un 95% de nivel de confianza se puede concluir que hay menor variación? Ho: Varianza 1 <= Varianza H1: Varianza 1 > Varianza 2 Grados de libertad para Var1 = 8 y para var 2 = 6 Falfa = F(0.05, 8, 6) = 4.15 Fcalculada = (900^2)/(300^2) = 9 >> Falfa, se rechaza Ho. Hay evidencia suficiente para indicar que la variación ya se ha reducido
 = Fcalculada = (900^2)/(300^2) = 9 >> Falfa, se rechaza Ho. Hay evidencia suficiente para indicar que la variación ya se ha reducido.")
278
Prueba de hipótesis de dos pob. comparando varianzas con F

280
Prueba de hipótesis de dos pob. Comparando dos medias con Z

282
Prueba de dos medias muestras pequeñas
Sigmas descono- cidas e iguales Sigmas desconocidas y desiguales

283
Prueba de hipótesis de dos pob. Comparando dos medias con t

285
Prueba de hipótesis de dos pob. Comparando datos pareados con t
Grados de libertad = No. de pares - 1

287
Prueba de hipótesis de dos pob. Comparando dos proporciones con Z

289
Robustez Los procedimientos estadísticos se basan en supuestos acerca de su comportamiento teórico. Cuando los estadísticos obtenidos no son afectados por desviaciones moderadas de su expectativa teórica, se dice que son robustos.

290
Resumen

291
Instrucciones con Minitab para la comparación de dos varianzas
Stat > Basic Statistics > 2-variances Seleccionar samples in different columns o Summarized data First-- Indicar la columna de datos de la muestra 1 Second- Indicar la columna de datos de la muestra 2 En Options: Indicar el Confidence Interval -- 90, 95 o 99% OK

292
Instrucciones con Minitab para la comparación de dos medias
Stat > Basic Statistics > 2-Sample t Seleccionar samples in different columns o Summarized data First-- Indicar la columna de datos de la muestra 1 Second- Indicar la columna de datos de la muestra 2 Seleccionar o no seleccionar Assume equal variances de acuerdo a los resultados de la prueba de igualdad de varianzas En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la diferencia a probar Test Difference (normalmente 0) Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than En graphs seleccionar las graficas Boxplot e Individual value plot OK
 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than. En graphs seleccionar las graficas Boxplot e Individual value plot. OK.")
293
Instrucciones con Minitab para la comparación de dos medias pareadas
Stat > Basic Statistics > Paired t Seleccionar samples in columns o Summarized data First sample Indicar la columna de datos de la muestra 1 Second sample - Indicar la columna de datos de la muestra 2 En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la diferencia a probar Test Mean (normalmente 0) Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than En graphs seleccionar las graficas Boxplot e Individual value plot OK
 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than. En graphs seleccionar las graficas Boxplot e Individual value plot. OK.")
294
Instrucciones con Minitab para la prueba de hipótesis de dos proporciones
Stat > Basic Statistics > 2-Proportions Seleccionar Summarized Data Trials: Events: First: No. de elementos de la 1ª. Muestra y D1 éxitos encontrados Second: No. de elementos de la 2ª. Muestra y D2 éxitos encontrados En Options: Indicar el Confidence Interval -- 90, 95 o 99% Indicar la Test Difference Normalmente 0 Indicar el signo de la hipótesis alterna: Less Than, Not equal, Greater than Seleccionar Use pooled estimate of p for test OK

295
VI.B.7 Pruebas de bondad de ajuste

296
Bondad de ajuste

297
Bondad de ajuste

298
Prueba de Bondad de ajuste para la distribución de Poisson
1. Plantear la hipótesis nula y alterna Ho: La población tiene una distribución de prob. De Poisson Ha: Caso contrario 2. Tomar una muestra aleatoria, anotar la frecuencia observada fi y calcular la media de ocurrencias 3. Calcular la frecuencia esperada de ocurrencias ei. Multiplicar el tamaño de muestra con la prob. de Poisson para cada valor de la variable aleatoria. Si hay menos de 5 combinar las categorías 4. Calcular el estadístico de prueba 5. Rechazar Ho si o si p < alfa. Con gl=k-p-1 y alfa nivel de significancia

299
Ejemplo: Distribución de Poisson =5
Ho: No. de clientes que llega en intervalos de 5 min. tiene una distribución de Poisson Ha: No se sigue una distribución de Poisson Clientes Frec. observada f(x) de Poisson 128*f(x) cantidad esperada 2 0.0067 0.8576 1 8 0.0337 4.3136 10 0.0842 3 12 0.1404 4 18 0.1755 5 22 6 0.1462 7 16 0.1044 0.0653 8.3584 9 0.0363 4.6464 10 o más 0.0318 4.0704
 de Poisson. 128*f(x) cantidad esperada o más")
300
Ejemplo: Distribución de Poisson =5
Combinando X=0,1 y X=9, 10 o más para que la frecuencia observada sea mayor a 5 y se pueda aplicar la distribución Chi Cuadrada se tiene Clientes Frec. Observada (fi) f(x) de Poisson 128*f(x) frecuencia esperada (ei) 0 o 1 10 5.1712 2 0.0842 3 12 0.1404 4 18 0.1755 5 22 6 0.1462 7 16 0.1044 8 0.0653 8.3584 9 o más 8.7168
 f(x) de Poisson. 128*f(x) frecuencia esperada (ei) 0 o o más")
301
Estadístico y conclusión
Con los datos anteriores se calcula el estadístico Chi cuadrada que se compara con Chi Cuadrada de alfa para k-p-1 grados de libertad (K – categorías: 9, p – parámetros a estimar: 1 media). Ho se rechaza si o si p es mayor que alfa. El valor de Chi Cuadrada calculado es de y el valor Chi Cuadrada de alfa 0.05 con 2 gl. Es de no se rechaza Ho En este caso p = 0.14 > 0.05 por tanto no se rechaza Ho y se concluye que los datos siguen una distribución de Poisson
. Ho se rechaza si o si p es mayor que alfa. El valor de Chi Cuadrada calculado es de y el valor Chi Cuadrada de alfa 0.05 con 2 gl. Es de no se rechaza Ho. En este caso p = 0.14 > 0.05 por tanto no se rechaza Ho y se concluye que los datos siguen una distribución de Poisson.")
302
Prueba de Bondad de ajuste para la distribución Normal
1. Plantear la hipótesis nula y alterna Ho: La población tiene una distribución de prob. Normal Ha: Caso contrario 2. Tomar una muestra aleatoria, calcular la media y la desviación estándar 3. Definir K intervalos de valores de forma que la frecuencia esperada sea 5 cuando menos para cada uno (intervalos de igual probabilidad). Anotar la frecuencia observada de los valores de datos fi, en cada intervalo
. Anotar la frecuencia observada de los valores de datos fi, en cada intervalo.")
303
Prueba de Bondad de ajuste para la distribución Normal
4. Calcular el número de ocurrencias esperado ei, para cada intervalo de valores. Multiplicar el tamaño de muestra por la probabilidad de que una variable aleatoria esté en el intervalo. 5. Calcular el estadístico de prueba 6. Rechazar Ho si o si p < alfa. Con gl=k-p-1 y alfa nivel de significancia

304
Prueba de Bondad de ajuste para la distribución Normal
Ejemplo: datos de calificaciones: Media = 68.42; S = 10.41 Calificaciones 71 66 61 65 54 93 60 86 70 73 55 63 56 62 76 82 79 68 53 58 85 80 64 90 69 77 74 84

305
Prueba de Bondad de ajuste para la distribución Normal
Ho: la población tiene una distribución normal con media y S= Ha: Caso contrario Para una muestra de 50 con una frecuencia mínima esperada de 5 se tiene el 10% al menos por cada celda La primera celda correspondiente al 10% está en Z = con X = (Media - Z*S) = 55.10 Para el área del 20%, Z = y X = 59.68 y así sucesivamente
 = Para el área del 20%, Z = y X = y así sucesivamente.")
306
Prueba de Bondad de ajuste para la distribución Normal
Intervalo Frecuencia observada (fi) Frecuencia esperada (ei) Menos de 55.10 5 55.10 a 59.68 59.68 a 63.01 9 63.01 a 65.82 6 65.82 a 68.42 2 68.42 a 71.02 71.02 a 73.83 73.83 a 77.16 77.16 a 81.74 81.74 o más 50 Se registran las frecuencias de los datos tomados de las calificaciones
 Frecuencia esperada (ei) Menos de a a a a a a a a o más. 50. Se registran las frecuencias de los datos. tomados de las. calificaciones.")
307
Prueba de Bondad de ajuste para la distribución Normal
Se determina el estadístico Chi Cuadrado = 7.2 El Valor de Chi Cuadrado de alfa = 0.10 para k – p – 1 grados de libertad. K = 10 categorías, p = 2 parámetros. Gl = 7. Chi Cuadrado es Como no se puede rechazar la hipótesis nula de normalidad de las calificaciones

308
Prueba de Bondad de ajuste para la distribución Multinomial
1. Enunciar la hipótesis nula y alternativa Ho: La población sigue una distribución de probabilidad multinomial con probabilidades especificadas para cada una de las K categorías Ha: Caso contrario 2. Tomar una muestra aleatoria y anotar las frecuencias observadas fi para cada categoría 3. Suponiendo que Ho es cierta, determinar la frecuencia esperada ei, en cada categoría multiplicando la probabilidad de la categoría por el tamaño de muestra

309
Prueba de Bondad de ajuste para la distribución Multinomial
4. Se determina el estadístico Chi Cuadrado de prueba 5. Regla de rechazo: Si no se puede rechazar la hipótesis nula Rechazar si el valor p es menor a alfa Con alfa nivel de significancia y los grados de libertad son k-1

310
Prueba de Bondad de ajuste para la distribución Multinomial
Ejemplo: El año pasado la participación de mercado para la empresa A fue del 30%, 50% para la empresa B y 20% para la empresa C. La empresa C hace una prueba con un nuevo producto para estimar su impacto en las preferencias del mercado. Se tomó una muestra de 200 clientes resultando preferencias de compra de: 48 para A, 98 para B y 54 para C. De acuerdo a las probabilidades esperadas, en los 200 clientes las preferencias esperadas son: A=200*0.3=60, B=200*0.5=100, C=200*0.2=40

311
Prueba de Bondad de ajuste para la distribución Multinomial
Datos para calcular el estadístico de prueba Chi Cuadrado Categoría Proporción hipotética Frecuencia observada Frecuencia esperada Empresa A 0.3 48 60 Empresa B 0.5 98 100 Empresa C 0.2 54 40

312
Prueba de Bondad de ajuste para la distribución Multinomial
Chi Cuadrado calculado = 7.34 Chi cuadrado de alfa = 0.05 con k – 1 = 2 grados de libertad = 2 es de El valor p correspondiente es de Como 7.34 es mayor a 5.99 o el valor p de es menor a alfa de 0.05 se rechaza la hipótesis nula Ho y se concluye que el nuevo producto modificará las preferencias del mercado actuales La participación de la empresa C aumenta con el nuevo producto

313
Prueba de Bondad de ajuste en Minitab
La columna C1 – Observadas contiene las frecuencias observadas y la C2 – esperadas las frecuencias esperadas Calc > Calculator > Store result in variable ChiCuadrada Teclear en el cuadro de expresión sum((Observadas-Esperadas)**2/Esperadas) Calc > Probability distributions > Chi Square Seleccionar Cummulative probability Degrees of freedom 2 Input column ChiCuadrada; Optional Storage CumProb OK Calc > Calculator > Store results in variable p En el cuadro Expression teclear 1-CumProb OK
**2/Esperadas) Calc > Probability distributions > Chi Square. Seleccionar Cummulative probability. Degrees of freedom 2. Input column ChiCuadrada; Optional Storage CumProb OK. Calc > Calculator > Store results in variable p. En el cuadro Expression teclear 1-CumProb. OK.")
314
Prueba de Bondad de ajuste en Minitab
Ejemplo: investigación de mercado Observadas Esperadas ChiCuadrada CumProb p 48 60 7.34 98 100 54 40

315
Prueba de Bondad de ajuste en Excel
Ejemplo: investigación de mercado 1. Calcular el estadístico Chi Cuadrada con =(A2-B2)^2/B2 y Suma Chi cuadrada = 7.34 2. El valor P es =distr.chi(7.34, 2) 3. El estadístico Chi Cuadrada de alfa es: =prueba.chi.inv(0.05,2) = 5.99 4. Como p es menor a alfa de 0.05 se rechaza la Ho
^2/B2 y Suma. Chi cuadrada = El valor P es =distr.chi(7.34, 2) 3. El estadístico Chi Cuadrada de alfa es: =prueba.chi.inv(0.05,2) = Como p es menor a alfa de 0.05 se rechaza la Ho.")
316
VI.B.6 ANOVA para un factor principal y una o más variables de bloqueo

317
Introducción Cuando es necesario comparar 2 o más medias poblacionales al mismo tiempo, para lo cual se usa ANOVA. El método ANOVA tiene los siguientes supuestos: La varianza es la misma para todos los tratamientos del factor en todos sus niveles Las mediciones indiviudales dentro de cada tratamiento se distribuyen normalmente El término de error tiene un efecto distribuido normalmente e independiente

318
Contenido ANOVA de un factor o dirección
ANOVA de un factor y una variable de bloqueo ANOVA de un factor y dos variables de bloqueo – CUADRADO LATINO ANOVA de un factor y tres variables de bloqueo – CUADRADO GRECOLATINO

319
ANOVA de un factor o dirección

320
Introducción Con el ANOVA las variaciones en la respuesta se dividen en componentes que reflejan los efectos de una o más variables independientes La variabilidad se representa como la suma de cuadrados total que es la suma de cuadrados de las desviaciones de mediciones individuales respecto a la gran media, se divide en: Suma de cuadrados de las medias de los tratamientos Suma de cuadrados del residuo o error experimental

321
ANOVA – Prueba de hipótesis para probar la igualdad de medias de varias poblaciones para un factor
Se trata de probar si el efecto de un factor o Tratamiento en la respuesta de un proceso o sistema es Significativo, al realizar experimentos variando Los niveles de ese factor (Temp. 1, Temp. 2, Temp.3, etc.)
")
322
ANOVA - Condiciones Todas las poblaciones son normales
Todas las poblaciones tiene la misma varianza Los errores son independientes con distribución normal de media cero La varianza se mantiene constante para todos los niveles del factor

323
ANOVA – Ejemplo de datos
Niveles del Factor Peso % de algodón y Resistencia de tela

324
ANOVA – Suma de cuadrados total
Xij Gran media Xij

325
ANOVA – Suma de cuadrados de renglones (a)-tratamientos
Media Trat. 1 Media Trat. a a renglones Gran media Media trat. 2

326
ANOVA – Suma de cuadrados del error
X2j X3j X1j Media X1. Media X3. Media X2. Muestra Muestra Muestra 3

327
ANOVA – Suma de cuadrados del error
X2j X3j X1j Media X1. Media X3. Media X2. Muestra Muestra Muestra 3

328
ANOVA – Grados de libertad: Totales, Tratamientos, Error

329
ANOVA – Cuadrados medios: Total, Tratamiento y Error

330
ANOVA – Cálculo del estadístico Fc y Fexcel

331
Tabla final de ANOVA

332
ANOVA – Toma de decisión
Distribución F Fexcel Alfa Zona de rechazo De Ho o aceptar Ha Zona de no rechazo de Ho O de no aceptar Ha Fc

333
ANOVA – Toma de decisión
Si Fc es mayor que Fexcel se rechaza Ho Aceptando Ha donde las medias son diferentes O si el valor de p correspondiente a Fc es menor de Alfa se rechaza Ho

334
ANOVA – Identificar las medias diferentes por Prueba de Tukey T
Para diseños balanceado (mismo número de columnas en los tratamientos) el valor de q se determina por medio de la tabla en el libro de texto
 el valor. de q se determina por medio de la tabla en el libro de texto.")
335
ANOVA – Identificar las medias diferentes por Prueba de Tukey T
Se calcula la diferencia Di entre cada par de Medias Xi’s: D1 = X1 – X D2 = X1 – X3 D3 = X2 – X3 etc. Cada una de las diferencias Di se comparan con el valor de T, si lo exceden entonces la diferencia es Significativa de otra forma se considera que las medias Son iguales

336
ANOVA – Identificar las medias diferentes por Prueba de Diferencia Mínima Significativa DMS
Para diseños balanceados (los tratamientos tienen igual no. De columnas), se calcula un factor DMS contra el que se comparan las diferencias Xi – Xi’. Significativas si lo exceden
, se calcula un factor DMS contra el que se comparan las diferencias Xi – Xi’. Significativas si lo exceden.")
337
Prueba DMS para Diseños no balanceados
Para diseños no balanceados (los tratamientos tienen diferente no. De columnas), se calcula un factor DMS Para cada una de las diferencias Xi – Xi’
, se calcula un factor DMS. Para cada una de las diferencias Xi – Xi’")
338
Ejemplo: Considerar un experimento de un factor (máquina) con tres niveles (máquinas A, B, C). Los datos se muestran a continuación y debe verificarse si existe diferencia significativa a un alfa = 0.05 Su ma Máquinas Datos Prom.
 con tres niveles (máquinas A, B, C). Los datos se muestran a continuación y debe verificarse si existe diferencia significativa a un alfa = Su. ma. Máquinas. Datos. Prom.")
339
Ejemplo: La tabla completa de ANOVA es la siguientes:
Fuentes De variación Cuadrado medio Máquinas Como el valor calculado de F(33.2) excede el valor crítico de F, se rechaza la Hipótesis nula Ho
 excede el valor crítico de F, se rechaza la Hipótesis nula Ho.")
340
Ejemplo: Con Minitab: Stat>ANOVA>One way unstacked
Responses (in separate columns) A B C Interpretar los resultados A B C 5 2 1 7 6 -2 -3
 A B C. Interpretar los resultados. A. B. C")
341
Ejemplo: One-way ANOVA: A, B, C Source DF SS MS F P
Factor Rechazo Ho Error Total S = R-Sq = 84.69% R-Sq(adj) = 82.14% Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev A (-----*----) B (----*-----) C (-----*----) Pooled StDev = 1.438
 = 82.14% Individual 95% CIs For Mean Based on. Pooled StDev. Level N Mean StDev A (-----*----) B (----*-----) C (-----*----) Pooled StDev =")
342
Corrida en Minitab Se introducen las respuestas en una columna C1
Se introducen los subíndices de los renglones en una columna C2 Durability Carpet 7.19 2 7.03 2

343
Corrida en Minitab Opción: stat>ANOVA – One Way (usar archivo Exh_aov) En Response indicar la col. De Respuesta (Durability) En factors indicar la columna de subíndices (carpet) En comparisons (Tukey) Pedir gráfica de Box Plot of data y residuales Normal Plot y vs fits y orden Si los datos estan en columnas pedir ANOVA – One Way (unstacked)
 En comparisons (Tukey) Pedir gráfica de Box Plot of data y residuales Normal Plot y vs fits y orden. Si los datos estan en columnas pedir ANOVA – One Way (unstacked)")
344
Results for: Exh_aov.MTW One-way ANOVA: Durability versus Carpet
Analysis of Variance for Durabili Source DF SS MS F P Carpet Error Total Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev ( * ) ( * ) ( * ) ( * ) Pooled StDev = Tukey's pairwise comparisons Family error rate = Individual error rate = Critical value = 4.20 Resultados
 ( * ) ( * ) ( * ) Pooled StDev = Tukey s pairwise comparisons. Family error rate = Individual error rate = Critical value = Resultados.")
345
ANOVA de dos vías un factor principal y una variable de bloqueo

346
ANOVA de 2 vías Este es un procedimiento extensión de los patrones del ANOVA de una vía con tres fuentes de variación: Tratamiento del factor A (columnas), Tratamiento del factor B (renglones) y Error experimental.
, Tratamiento del factor B (renglones) y Error experimental.")
347
ANOVA – Prueba de hipótesis para probar la igualdad de medias de varias poblaciones con dos vías
Se trata de probar si el efecto de un factor o Tratamiento en la respuesta de un proceso o sistema es Significativo, al realizar experimentos variando Los niveles de ese factor (Temp.1, Temp.2, etc.) POR RENGLON Y Considerando los niveles de otro factor que se piensa Que tiene influencia en la prueba – FACTOR DE BLOQUEO POR COLUMNA
 POR RENGLON. Y. Considerando los niveles de otro factor que se piensa. Que tiene influencia en la prueba – FACTOR DE BLOQUEO. POR COLUMNA.")
348
ANOVA – 2 vías Para el tratamiento – en renglones
Para el factor de bloqueo – en columnas

349
ANOVA 2 vías - Ejemplo

350
ANOVA – Dos vías o direcciones
La SCT y SCTr (renlgones) se determina de la misma forma que para la ANOVA de una dirección o factor En forma adicional se determina la suma de cuadrados del factor de bloqueo (columnas) de forma similar a la de los renglones La SCE = SCT – SCTr - SCBl
 se determina de la misma forma que para la ANOVA de una dirección o factor. En forma adicional se determina la suma de cuadrados del factor de bloqueo (columnas) de forma similar a la de los renglones. La SCE = SCT – SCTr - SCBl.")
351
ANOVA de 2 vías

352
ANOVA de 2 vías

353
ANOVA –Estadístico Fc y Fexcel

354
ANOVA – Estadístico Fb

355
Tabla final ANOVA 2 vías

356
ANOVA – 2 vías: Toma de decisión
Distribución F Fexcel Alfa Zona de rechazo De Ho o aceptar Ha Zona de no rechazo de Ho O de no aceptar Ha Fc Tr o Bl

357
ANOVA – 2 vías: Toma de decisión
Si Fc (Tr o Bl) es mayor que Fexcel se rechaza Ho Aceptando Ha donde las medias son diferentes O si el valor de p correspondiente a Fc (Tr o Bl) es menor de Alfa se rechaza Ho
 es mayor que Fexcel se rechaza Ho Aceptando Ha donde las medias son diferentes. O si el valor de p correspondiente a Fc (Tr o Bl) es menor de Alfa se rechaza Ho.")
358
Cálculo de los residuales
Y estimada Error o residuo Error estándar Factor de comparación Si la diferencia de medias excede a Rk es significativa

359
Adecuación del modelo Los residuales deben seguir una recta en la gráfica normal Deben mostrar patrones aleatorios en las gráficas de los residuos contra el orden de las Yij, contra los valores estimados y contra los valores reales Yij

360
Corrida en Minitab Se introducen las respuestas en una columna C3 y los subíndices de renglones en columna C4 y de columnas en C5 Plantas Suplemento Lago 34 1 Rose 43 57 Dennison 40 85 2 68 67 53 41 3 24 42 52

361
Corrida en Minitab Opción: stat>ANOVA – Two Way (usar archivo Exh_aov) En Response indicar la col. De Respuesta (Plantas) En Row factor y Column Factor indicar las columnas de subíndices de renglones y columnas (suplemento y lago) y Display Means para ambos casos Pedir gráfica residuales Normal Plot y vs fits y orden
 y Display Means para ambos casos. Pedir gráfica residuales Normal Plot y vs fits y orden.")
362
Two-way ANOVA: Zooplankton versus Supplement, Lake
Analysis of Variance for Zooplank Source DF SS MS F P Suppleme Lake Interaction Error Total Individual 95% CI Suppleme Mean ( * ) ( * ) ( * ) Lake Mean Dennison ( * ) Rose ( * ) Resultados
 ( * ) ( * ) Lake Mean Dennison 51.8 ( * ) Rose 49.2 ( * ) Resultados.")
363
ANOVA de un factor y dos o tres variables de bloqueo
CUADRADO LATINO Y GRECOLATINO

364
ANOVA – 3 y 4 factores El diseño de Cuadrado latino utiliza dos factores de bloqueo adicionales al de Tratamiento EL diseño de Cuadrado Grecolatino utiliza tres factores adicionales al del Tratamiento El cálculo de suma de cuadrados para renglones y para columnas es similar al de ANOVA de un factor principal y otro de bloqueo

365
Cuadrado Latino

366
ANOVA – Cuadrado Latino: Factor principal (A,B,C,D)
")
367
ANOVA – Cuadrado Latino: Cálculo del error

368
ANOVA – Cálculo del estadístico Fc y Fexcel

369
ANOVA – Cuadrado Latino Reng / Col

370
Tabla final ANOVA 2 Factores

371
Cuadrado latino en Minitab
Se introducen las respuestas en una columna C1 Se introducen los subíndices de los renglones en una columna C2 Se introducen los subíndices de las columnas en una columna C3 Se introducen las letras mayúsculas que indican el nivel del factor (A, B, C, D, etc.) correspondientes a cada respuesta en la columna C4
 correspondientes a cada respuesta en la columna C4.")
372
Cuadrado latino en Minitab
Opción: stat> ANOVA – General linear model En Response indicar la col. De Respuesta, En Model indicar las columnas de los factores y En Random factors indicar los factores adicionales al del efecto principal a probar (A, B, C, D). Se pueden pedir interacciones entre factores x – y con Cx*Cy Pedir gráfica de residuales Normal y vs fits y orden
. Se pueden pedir interacciones entre factores x – y con Cx*Cy. Pedir gráfica de residuales Normal y vs fits y orden.")
373
Cuadrado Greco Latino

374
Cuadrado Greco latino en Minitab
Se introducen las respuestas en una columna C1 Se introducen los subíndices de los renglones en una columna C2 Se introducen los subíndices de las columnas en una columna C3 Introducir los subíndices del factor adicional de letras griegas con letras latinas minúsculas (a,b,c,d,e) en C4 Se introducen las letras mayúsculas que indican el nivel del factor (A, B, C, D, etc.) correspondientes a cada respuesta en la columna C5
 en C4. Se introducen las letras mayúsculas que indican el nivel del factor (A, B, C, D, etc.) correspondientes a cada respuesta en la columna C5.")
375
Cuadrado Greco latino en Minitab
Opción: ANOVA – General linear model En Response indicar la col. De Respuesta, En Model indicar las columnas de los factores y En Random factors indicar los factores adicionales al del efecto principal a probar (A, B, C, D). También se pueden indicar interacciones entre factores x-y con Cx * Cy Pedir gráfica de residuales Normal y vs fits y orden
. También se pueden indicar interacciones entre factores x-y con Cx * Cy. Pedir gráfica de residuales Normal y vs fits y orden.")
376
ANOVA – Cuadrado Grecolatino

377
ANOVA de 2 factores – Suma de cuadrados, gl
ANOVA de 2 factores – Suma de cuadrados, gl. y Cuadrado medio para el error

378
ANOVA – Cálculo del estadístico Fc y Fexcel

379
ANOVA – Cuadrado Grecolatino

380
Tabla final ANOVA 2 Factores

381
ANOVA para diseño factorial AxB
En un experimento factorial involucrando el factor A con (a) niveles y un factor B con (b) niveles, la suma de cuadrados se puede dividir en: SST = SS(A) + SS(B) + SS(AB) + SSE
 niveles y un factor B con (b) niveles, la suma de cuadrados se puede dividir en: SST = SS(A) + SS(B) + SS(AB) + SSE.")
382
VI.B.8 Tablas de contingencia
Prueba Chi2 (2) Revisado por Mónica Yris el 4 de Marzo de 1999. Se cambió el diseño, se revisó ortografía y parcialmente se cotejo la traducción. Inglés- Español. Si se hicieron algunos cambios en la traducción y en algunas partes donde no se había traducido porque lo dejaron en ingles. 1
 Revisado por Mónica Yris el 4 de Marzo de Se cambió el diseño, se revisó ortografía y parcialmente se cotejo la traducción. Inglés- Español. Si se hicieron algunos cambios en la traducción y en algunas partes donde no se había traducido porque lo dejaron en ingles. 1.")
383
¿Para qué se utiliza? 1. Para probar si una serie de datos observada, concuerda con el modelo (serie esperada) de la información. 2. Para probar las diferencias entre las proporciones de varios grupos (tabla de contingencia). Para todos los casos, Ho: No hay diferencia Ha: Hay diferencia Aún si no se ajusta la información al modelo esperado de la prueba chi2 . Debido a que su información es atribuida, usted no puede utilizar la distribución normal para el modelo. Se requiere un número muy grande de muestras para obtener una prueba significativa (>30). En la mayoría de los casos, la Hipótesis de Nulidad no “se Diferencia” y existe la Alternativa como “una diferencia existente”. En el acercamiento de Seis Sigma, podemos: Empezar con un Problema Práctico Convertir el Problema práctico a un Problema estadístico Resolver el Problema estadístico y obtener una Solución estadística Convertir nuevamente la solución estadística a una solución práctica. 2 3
. Para todos los casos, Ho: No hay diferencia. Ha: Hay diferencia. Aún si no se ajusta la información al modelo esperado de la prueba chi2 . Debido a que su información es atribuida, usted no puede utilizar la distribución normal para el modelo. Se requiere un número muy grande de muestras para obtener una prueba significativa (>30). En la mayoría de los casos, la Hipótesis de Nulidad no se Diferencia y existe la Alternativa como una diferencia existente . En el acercamiento de Seis Sigma, podemos: Empezar con un Problema Práctico. Convertir el Problema práctico a un Problema estadístico. Resolver el Problema estadístico y obtener una Solución estadística. Convertir nuevamente la solución estadística a una solución práctica. 2. 3.")
384
Ejemplo 1: Chi Cuadrada( 2 )
Se lanza una moneda al aire 100 veces y que obtenemos 63 águilas y 37 soles. ¿La proporción de águilas y soles sucede por casualidad? O, se concluye que la moneda está “cargada”? Pregunte a la clase ¿quién piensa que la moneda es “genuina” y por qué y qué nivel de confianza tienen para estar en lo correcto? Ahora, pregunte quién piensa que la moneda está “cargada”, por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón (“genuina” o “cargada”), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 “a mano”, siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. Ho: La moneda es buena Ha: La moneda “está cargada” 4
, hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 a mano , siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. Ho: La moneda es buena. Ha: La moneda está cargada 4.")
385
Ejemplo 1: Chi Cuadrada( 2 )
(fo - fe)2 Observada Esperada fe ( fo ) ( fe ) Aguilas 63 50 3.38 Soles 37 50 3.38 2 = 2 = 6.76 Estadístico Chi Cuadrada g Pregunte a la clase ¿quién piensa que la moneda es “genuina” y por qué y qué nivel de confianza tienen para estar en lo correcto? Ahora, pregunte quién piensa que la moneda está “cargada”, por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón (“genuina” o “cargada”), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 “a mano”, siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. fe (fo - fe)2 2 c= j = 1 4
2. Observada. Esperada. fe. ( fo ) ( fe ) Aguilas Soles 2 = 2 = Estadístico Chi Cuadrada. g. Pregunte a la clase ¿quién piensa que la moneda es genuina y por qué y qué nivel de confianza tienen para estar en lo correcto Ahora, pregunte quién piensa que la moneda está cargada , por qué y que tan confiados están en su respuesta. El punto es que no tenemos una confianza en nuestra eleccíón ( genuina o cargada ), hasta que hagamos uso de las estadísitcas. En este ejemplo, realizamos los cálculos para Chi 2 a mano , siguiendo las siguientes ecuaciones estadísticas. Si aparecen valores conocidos, esta sería una forma de calcular Chi2. fe. (fo - fe)2. 2. c= j =")
386
Ejemplo 1: Chi cuadrada Función de Distribución Acumulada Chi2 con 1 grado de libertad (d.f) 2c P(2c > x) p = = De tablas X2Crítica, (0.05, 1) = Ho: La moneda es buena. Ha: La moneda está “cargada”. Para un 95% de confianza antes de concluir que la moneda “está cargada”, se requiere que X2c > X2Crítica o que el valor de p sea 0.05. Como p 0.05, se puede concluir -con un 95% de confianza - que la moneda “está cargada”. 7
 = Ho: La moneda es buena. Ha: La moneda está cargada . Para un 95% de confianza antes de concluir que la moneda está cargada , se requiere que X2c > X2Crítica o que el valor de p sea Como p 0.05, se puede concluir -con un 95% de confianza - que la moneda está cargada . 7.")
387
Cálculo en Excel del estadístico Chi cuadrada
1. Posicionarse en una celda vacía 2. Accesar el menú de funciones con Fx 3. Seleccionar STATISTICAL o ESTADÍSTICAS, CHIINV. 4. Dar valores de probabilidad (0.05) y grados de libertad, normalmente (n - 1) para un parámetro o (# de renglones -1) * (# de columnas - 1) para el caso de tablas de proporciones. 7
 y grados de libertad, normalmente (n - 1) para un parámetro o (# de renglones -1) * (# de columnas - 1) para el caso de tablas de proporciones. 7.")
388
Tabla de Valores Críticos Seleccionados de Chi2

389
Tabla de contingencia Una tabla de clasificación de dos vías (filas y columnas) que contiene frecuencias originales, se puede analizar para determinar si las dos variables (clasificaciones) son independientes o tienen una asociación significativa. La prueba Chi Cuadrada probará si hay dependencia entre las dos clasificaciones. Además se puede calcular el coeficiente de contingencia (correlación) que en todo caso muestra la fuerza de la dependencia
 que contiene frecuencias originales, se puede analizar para determinar si las dos variables (clasificaciones) son independientes o tienen una asociación significativa. La prueba Chi Cuadrada probará si hay dependencia entre las dos clasificaciones. Además se puede calcular el coeficiente de contingencia (correlación) que en todo caso muestra la fuerza de la dependencia.")
390
Tabla de contingencia Para esta prueba se usa la prueba Chi Cuadrada donde: Entre mayor sea su valor, mayor será la diferencia de la discrepancia entre frecuencias observadas y teóricas. Esta prueba es similar a la de bondad de ajuste.

391
Tabla de contingencia Ejemplo: Cada una de las 15 celdas hace una contribución al estadístico Chi Cuadrado (una celda) Asumiendo Alfa = 0.1 y Gl= (reng – 1)*(Col – 1) = 4*2 = 8 Chi-Cuadrado de alfa = 20.09 Como Chi Cuadrada calculada >> Chi C. Alfa, se rechaza Ho de igualdad de resultados entre negocios
*(Col – 1) = 4*2 = 8 Chi-Cuadrado de alfa = Como Chi Cuadrada calculada >> Chi C. Alfa, se rechaza Ho de igualdad de resultados entre negocios.")
392
Ejemplo 2: Chi2 Para comparación de dos grupos; ¿son las mismas proporciones?)
Ho: No existen diferencias en los índices de defectos de las dos máquinas. Ha: Existen diferencias en los índices de defectos de las dos máquinas. Los valores observados (fo) son los siguientes: Partes buenas Partes defectuosas máquina fo = fo = Total = 534 máquina fo = fo = Total = 245 779 Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. Total El índice de defectos totales es 28 / 779 = 3.6% 9
 son los siguientes: Partes buenas. Partes defectuosas. máquina 1 fo = 517 fo = 17 Total = 534. máquina 2 fo = 234 fo = 11 Total = Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. Total El índice de defectos totales es 28 / 779 = 3.6% 9.")
393
Ejemplo 2: Chi2 Para comparación de dos grupos; ¿son las mismas proporciones?)
Cálculo de los valores esperados Partes buenas Partes defectuosas máquina fo = 751*534/ fo = 28*534/ Total = 534 máquina fo = 751*245/ fo = 28*245/ Total = 245 779 Basados en este índice, los valores esperados (fe) serían: Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. máquina Partes buenas máquina Partes defectuosas 9
 serían: Este es un ejemplo fácil para mostrarle cómo calcular el valor esperado cuando usted tiene un modelo más complejo y no supiera cuál es la probabilidad. máquina Partes buenas. máquina Partes defectuosas. 9.")
394
Prueba de chi cuadrada:
Los conteos esperados están debajo de los conteos observados Partes buenas Partes Defectuosas Total Total Chi2 = = DF= 1; valor de p = 0.152 2 celdas con conteos esperados menores a 5.0 Nota: Chi cuadrada no podrá aplicarse en los casos donde los conteos seas menores a 5 en 20% de celdas. Si cualquiera de los conteos esperados en las celdas es menor a uno, no deberá usarse Chi2. Si algunas celdas tienen un conteo menor a los esperados, ya sea combinando u omitiendo renglones y/o columnas, las categorías pueden ser de utilidad.

395
Tabla de Chi2 . Tabla de valores críticos seleccionados para Chi2 DF
.250 .100 .050 .025 .010 .005 .001 1 1.323 2.706 3.841 5.024 6.635 7.879 10.828 2 2.773 4.605 5.991 7.378 9.210 10.597 13.816 3 4.108 6.251 7.815 9.348 11.345 12.838 16.266 4 5.385 7.779 9.488 11.143 13.277 14.860 18.467 5 6.626 9.236 11.070 12.832 15.086 16.750 20.515 6 7.841 10.645 12.592 14.449 16.812 18.548 22.458 7 9.037 12.017 14.067 16.013 18.475 20.278 24.322 8 10.219 13.362 15.507 17.535 20.090 21.955 26.125 9 11.389 14.684 16.919 19.023 21.666 23.589 27.877 10 12.549 15.987 18.307 20.483 23.209 25.188 29.588 11 13.701 17.275 19.675 21.920 24.725 26.757 31.264 12 14.845 18.549 21.026 23.337 26.217 28.300 32.909 13 15.984 19.812 22.362 24.736 27.688 29.819 34.528 14 17.117 21.064 23.685 26.119 29.141 31.319 36.123 15 18.245 22.307 24.996 27.488 30.578 32.801 37.697 16 19.369 23.542 26.296 28.845 32.000 34.267 39.252 17 20.489 24.769 27.587 30.191 33.409 35.718 40.790 18 21.605 25.989 28.869 31.526 34.805 37.156 43.312 19 22.718 27.204 30.144 32.852 36.191 38.582 43.820 20 23.828 28.412 31.410 34.170 37.566 39.997 45.315 .
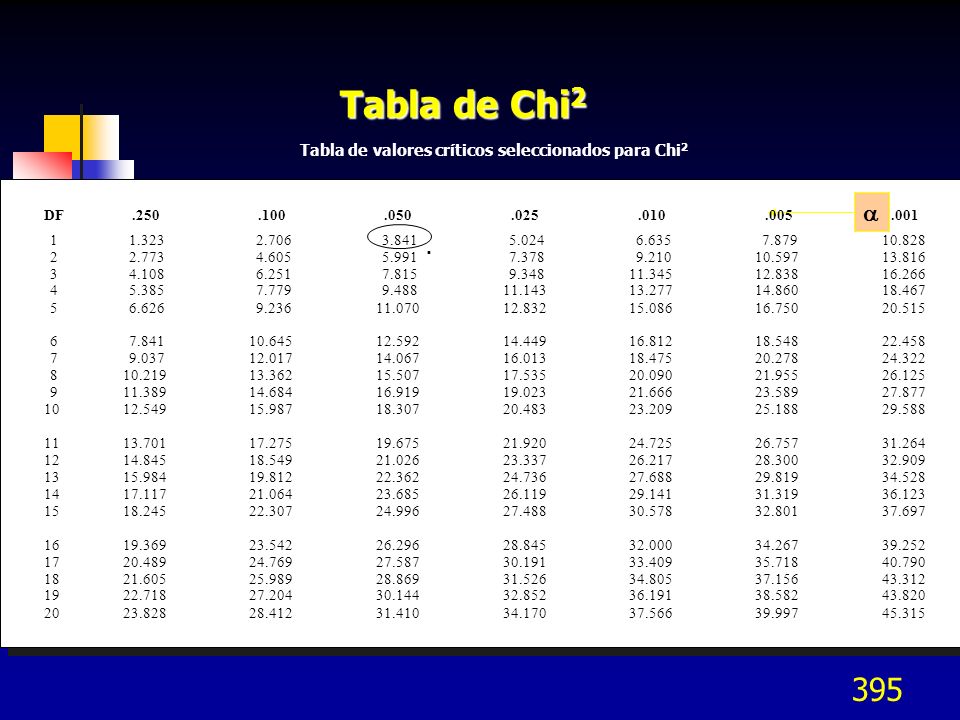
396
Variación en familias a probar
Problema: Fugas Beneficios Potenciales: $10,000 de ahorro en retrabajos, y en la reducción de tiempo de ciclo. Variación en familias a probar Operador a operador Ho: No existe diferencia en los índices de defecto de los diferentes operadores Ha: Existe diferencia en los índices de defecto de los diferentes operadores Máquina a máquina Ho: No existe diferencia en los índices de defecto de las diferentes máquinas Ha: Existe diferencia en los índices de defecto de las diferentes máquinas Tamaño de la muestra: total de oportunidades (172 piezas) 22
 22.")
397
Prueba de chi2 (máquina a máquina)
Los conteos esperados están colocados debajo de los conteos observados Con fugas Sin fugas Total Total Chi2 = 0.000 = DF= (4-1)(2-1) = 3; valor P =
(2-1) = 3; valor P =")
398
Prueba de chi2 (operador a operador)
Los conteos esperados están colocados debajo de los conteos observados. Con gotera Sin gotera Total Total Chi2 = = DF= 5; valor P =

399
(en este caso, operador a operador y máquina a máquina)
¿Qué sucede si los grupos múltiples de variación son estadísticamente significativos? (en este caso, operador a operador y máquina a máquina) Se utiliza un procedimiento denominado “Coeficiente de Contingencia” como clave para determinar qué grupo de variación debe investigarse primero. Chi Cuadrada N Coeficiente de Contingencia x 100 Chi N CC Máquina Operador Controlador Mayor SI el tamaño de la muestra (N), es similar para los grupos. Al dividir entre N, probablemente, llevará a la misma ruta que hubiera alcanzado con sólo ver la estadística Chi2. Sin embargo, si N tiene una variación considerable, dependiendo del grupo de variación que se investiga, el coeficiente de contingencia puede ser una herramienta valiosa para determinar la prioridad sobre qué grupo debe investigarse primero. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. 14
 Se utiliza un procedimiento denominado Coeficiente de Contingencia como clave para determinar qué grupo de variación debe investigarse primero. Chi Cuadrada. N. Coeficiente de Contingencia. x 100. Chi2 N CC. Máquina Operador Controlador Mayor. SI el tamaño de la muestra (N), es similar para los grupos. Al dividir entre N, probablemente, llevará a la misma ruta que hubiera alcanzado con sólo ver la estadística Chi2. Sin embargo, si N tiene una variación considerable, dependiendo del grupo de variación que se investiga, el coeficiente de contingencia puede ser una herramienta valiosa para determinar la prioridad sobre qué grupo debe investigarse primero. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. 14.")
400
(Estos mismos operadores fueron quienes
¿Qué sucede si los grupos múltiples de variación son estadísticamente significativos? (en este caso, operador a operador y máquina a máquina) Ahora que la información nos ha llevado a investigar a los grupos de operador a operador. ¿Qué debemos hacer ahora? Encontremos cuál de los operadores estaban fuera del estándar. ¿Era alguno de ellos notablemente peor (o mejor) que el resto? Con gotera Sin gotera Total Mucho peor que lo esperado El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. Mucho mejor que lo esperado (Estos mismos operadores fueron quienes tuvieron los números más grandes de chi2) 14
 Ahora que la información nos ha llevado a investigar a los grupos de operador a operador. ¿Qué debemos hacer ahora Encontremos cuál de los operadores estaban fuera del estándar. ¿Era alguno de ellos notablemente peor (o mejor) que el resto Con gotera Sin gotera Total Mucho peor que. lo esperado. El coeficiente de contingencia (también llamado, en ocasiones, R cuadrada o contribución de porcentaje) ayuda a determinar en donde enfocarse primero si tiene dos familias que son estadísticamente significativas. Si un valor p ha determinado una de las familias como no estadísticamente significativa, entonces no es necesario calcular el CC. Para usar efectivamente esto, el tamaño de sus muestras deberá ser el mismo para todas sus familias de variación. Además, a menos que sea SS de un ANOVA, los CC no sumarán 100%. Mucho mejor que. lo esperado. (Estos mismos operadores fueron quienes. tuvieron los números más grandes de chi2) 14.")
401
Operador a operador: = 0.000 Rechace Ho y acepte Ha
(Existe una diferencia significativa entre los operadores) Los operadores 4 y 5 están fuera del estándar: El operador 4 es notablemente peor que el resto, El operador 5 es notablemente mejor que los demás ¿Cuál es el próximo paso? Hable con todos los operadores para averiguar qué diferencias pueden existen en sus técnicas. El operador 4 no tenía experiencia en este tipo de trabajo y apenas se estaba acostumbrado a soldar este producto en particular. El operador 5 encontró un modo de mejor de hacer el ensamble, con lo cual consiguió mejorar el trabajo de soldadura, aunque esto mostraba un grado de dificultad ergonómica. Se añadió un colocador para ensamblar la parte en forma segura. (Esto también redujo el tiempo que requerían los operadores para “acostumbrarse” a trabajar en esta forma)
 Los operadores 4 y 5 están fuera del estándar: El operador 4 es notablemente peor que el resto, El operador 5 es notablemente mejor que los demás. ¿Cuál es el próximo paso Hable con todos los operadores para averiguar qué diferencias pueden existen en sus técnicas. El operador 4 no tenía experiencia en este tipo de trabajo y apenas se estaba acostumbrado a soldar este producto en particular. El operador 5 encontró un modo de mejor de hacer el ensamble, con lo cual consiguió mejorar el trabajo de soldadura, aunque esto mostraba un grado de dificultad ergonómica. Se añadió un colocador para ensamblar la parte en forma segura. (Esto también redujo el tiempo que requerían los operadores para acostumbrarse a trabajar en esta forma)")
402
Ejercicios 1. Se quiere evaluar la habilidad de tres inspectores de rayos X en un aeropuerto para detectar artículos clave. Como prueba se pusieron radios de transistores en 90 maletas, cada inspector fue expuesto a 30 maletas conteniendo radios mezcladas entre otras que nos los contenían. Los resultados se resumen a continuación: Inspectores 1 2 3 Radios detectados Radios no detectados ¿Con un 95% de confianza, existe una diferencia entre los inspectores? Ho: p1 = p2 = p3; Ha: al menos una es diferente Grados de libertad = (columnas - 1) ( filas -1)
 ( filas -1)")
403
Ejercicios 1. Se quiere evaluar si hay preferencia por manejar en un carril de una autopista dependiendo de la hora del día. Los datos se resumen a continuación: Hora del día Carril 1:00 3:00 5:00 Izquierdo Central Derecho ¿Con un 95% de confianza, existe una diferencia entre las preferencias de los automovilistas dependiendo de la hora? Ho: P1 = P2 = P3; Ha: al menos una es diferente Grados de libertad = (columnas - 1) ( filas -1)
 ( filas -1)")
404
Coeficiente de Contingencia
Coeficiente de contingencia es el grado de relación o dependencia de las clasificaciones en la tabla de contingencias es: Donde N es la frecuencia total y X es el estadístico Chi Cuadrado calculado

405
Coeficiente de Contingencia
Para los datos del ejemplo anterior se tiene: El valor máximo de C se obtiene de:

406
Correlación de atributos
Para tablas de orden k * k, el coeficiente de correlación, r, es : Donde 0<= r <= 1

407
VI.B.9 Pruebas de Hipótesis no paramétricas

408
Pruebas no paramétricas
Las pruebas paramétricas asumen una distribución para la población, tal como la Normal Las pruebas no paramétricas no asumen una distribución específica de la población Bajo los mismos tamaños de muestra la Potencia o probabilidad de rechazar Ho cuando es falsa es mayor en las pruebas paramétricas que en las no paramétricas Una ventaja de las pruebas no paramétricas es que los resultados de la prueba son más robustos contra violación de los supuestos

409
Prueba de Hipótesis Atributo Variable No Normal Normal Varianza
Tablas de Contingencia de Varianza Medianas Correlación Correlación Homogeneidad de la Variación de Levene Prueba de signos Normal Wilcoxon Mann- Whitney Variancia Medias Kurskal- Wallis Pruebas de t Prueba-F Muestra-1 Residuos distribuidos normalmente Prueba de Mood Muestra-2 Homogeneidad de la Variación de Bartlett Friedman ANOVA Una vía Dos vías Correlación Regresión

410
Resumen de pruebas de Hipótesis
Datos Normales Datos No Normales Pruebas de Variancias X2 : Compara la variancia de una muestra con una variancia de un universo conocido. Prueba F : Compara dos varianzas de muestras. Homogeneidad de la variancia de Bartlett: Compara dos o más varianzas muestras de la misma población. Pruebas de Varianzas Homogeneidad de la varianza de Levene : Compara dos o más varianzas de muestras de la misma población.

411
Resumen de pruebas de Hipótesis
Datos Normales Datos No Normales Pruebas de los Promedios Prueba t de 1 muestra : Prueba si el promedio de la muestra es igual a un promedio conocido o meta conocida. Prueba t de 2 muestras : Prueba si los dos promedios de las muestras son iguales. ANOVA de un factor: Prueba si más de dos promedios de las muestras son iguales. ANOVA de dos factores : Prueba si los promedios de las muestras clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables. Regresión : Define la relación lineal entre una variable dependiente y una independiente. (Aquí la "normalidad" se aplica al valor residual de la regresión) Pruebas de la Mediana Prueba de signos o Prueba Wilcoxon : Prueba si la mediana de la muestra es igual a un valor conocido o a un valor a alcanzar. Prueba Mann-Whitney : Prueba si dos medianas de muestras son iguales. Prueba Kruskal-Wallis: Prueba si más de dos medianas de muestras son iguales. Asume que todas las distribuciones tienen la misma forma. Prueba de la mediana de Mood : Otra prueba para más de dos medianas. Prueba más firme para los valores atípicos contenidos en la información. Prueba Friedman : Prueba si las medianas de las muestras, clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables.
 Pruebas de la Mediana. Prueba de signos o Prueba Wilcoxon : Prueba si la mediana de la muestra es igual a un valor conocido o a un valor a alcanzar. Prueba Mann-Whitney : Prueba si dos medianas de muestras son iguales. Prueba Kruskal-Wallis: Prueba si más de dos medianas de muestras son iguales. Asume que todas las distribuciones tienen la misma forma. Prueba de la mediana de Mood : Otra prueba para más de dos medianas. Prueba más firme para los valores atípicos contenidos en la información. Prueba Friedman : Prueba si las medianas de las muestras, clasificadas bajo dos categorías, son iguales. Correlación : Prueba la relación lineal entre dos variables.")
412
Acciones a tomar con datos No Normales
Revise y asegúrese de que los datos no siguen una distribución normal. Desarrollar una Prueba de normalidad (para verificar realmente lo anormal. Para la prueba de Bartlet el valor de p debe ser < 0.05) Desarrollar una Prueba de Corridas (para verificar que no existen sucesos no aleatorios que puedan haber distorsionado la información) Revisar la información para detectar errores (tipográficos, etc.). Investiguar los valores atípicos. Una muestra pequeña (n < 30) proveniente de un universo normal, se mostrará algunas veces como anormal. Intentar transformar los datos. Las transformaciones comunes incluyen: - Raíz cuadrada de todos los datos - Logaritmo de todos los datos - Cuadrado de todos los datos Si la información es todavía anormal, entonces usar las herramientas no paramétricas.
 Desarrollar una Prueba de Corridas (para verificar que no existen sucesos no aleatorios que puedan haber distorsionado la información) Revisar la información para detectar errores (tipográficos, etc.). Investiguar los valores atípicos. Una muestra pequeña (n < 30) proveniente de un universo normal, se mostrará algunas veces como anormal. Intentar transformar los datos. Las transformaciones comunes incluyen: - Raíz cuadrada de todos los datos. - Logaritmo de todos los datos. - Cuadrado de todos los datos. Si la información es todavía anormal, entonces usar las herramientas no paramétricas.")
413
7B8. Definiciones Promedio : Es la media aritmética de la información. Es la suma de todos los datos, dividida entre el número de datos de referencia. Mediana: Valor del punto medio de los datos, cuando se ordenan en forma ascendente (en caso de datos pares, obtener promedio). Moda : Valor que se repite con más frecuencia sobre el conjunto de datos. Ejemplo: Se cuestionó a veinte personas sobre cuánto tiempo les tomaba estar listas para ir a trabajar, en las mañanas. Sus respuestas (en minutos) se muestran más adelante. ¿Cuáles son el promedio y la mediana para esta muestra? 30, 37, 25, 35, 42, 35, 35, 47, 45, 60 39, 45, 30, 38, 35, 40, 44, 55, 47, 43 It is helpful to know the Mean, Median, and Mode of your data set. The mean (average) versus the median gives you an idea as to how skewed your data may be from Normal. As data becomes more Non-Normal (unless it’s bi-modal), the mean and median move farther apart. 5
. Moda : Valor que se repite con más frecuencia sobre el conjunto de datos. Ejemplo: Se cuestionó a veinte personas sobre cuánto tiempo les tomaba estar listas para ir a trabajar, en las mañanas. Sus respuestas (en minutos) se muestran más adelante. ¿Cuáles son el promedio y la mediana para esta muestra 30, 37, 25, 35, 42, 35, 35, 47, 45, , 45, 30, 38, 35, 40, 44, 55, 47, 43. It is helpful to know the Mean, Median, and Mode of your data set. The mean (average) versus the median gives you an idea as to how skewed your data may be from Normal. As data becomes more Non-Normal (unless it’s bi-modal), the mean and median move farther apart. 5.")
414
Un dibujo dice más que mil palabras
Promedio Mediana C1 Promedio = Mediana = 39.5 El promedio puede estar influenciado considerablemente por los valores atípicos porque, cuando se calcula un promedio, se incluyen los valores reales de estos valores. La mediana, por otra parte, asigna la misma importancia a todas las observaciones, independientemente de los valores reales de los valores atípicos, ya que es la que sencuentra en la posición media de los valores ordenados.

415
Pruebas Alternativas comúnmente usadas
Analogía con datos normales Prueba de Corridas (la misma prueba para ambos tipos de información) Prueba t de una muestra Prueba t de 2 muestras ANOVA de un factor Pruebas para datos No normales Prueba de Corridas : Calcula la probabilidad de que un X número de puntos de referencia, esté por encima o por debajo del promedio aleatoriamente. Prueba de signos, de 1 muestra : Prueba la probabilidad de que la mediana de la muestra, sea igual al valor hipotético. Prueba Mann-Whitney : Comprueba el rango de dos muestras, por la diferencia entre dos medianas del universo. Prueba de la Mediana de Mood : Prueba para más de dos medianas del universo. Más robusta para los valores atípicos o para los errores en la información.
 Prueba t de una muestra. Prueba t de 2 muestras. ANOVA de un factor. Pruebas para datos No normales. Prueba de Corridas : Calcula la probabilidad de que un X número de puntos de referencia, esté por encima o por debajo del promedio aleatoriamente. Prueba de signos, de 1 muestra : Prueba la probabilidad de que la mediana de la muestra, sea igual al valor hipotético. Prueba Mann-Whitney : Comprueba el rango de dos muestras, por la diferencia entre dos medianas del universo. Prueba de la Mediana de Mood : Prueba para más de dos medianas del universo. Más robusta para los valores atípicos o para los errores en la información.")
416
Prueba de Rachas Considere los siguientes datos (que se muestran aquí en orden cronológico): 325, 210, 400, 72, 150, 145, 110, 507, 56, 120, 99, 144, 110, 110, 320, 290, 101, 0, 80, 500, 201, 50, 140, 80, 220, 180, 240, 309, 80 Es importante tener los datos registrados en orden cronológico. Una representación gráfica de los datos se asemeja a esto: 600 Promedio 500 Primera "corrida" 400 300 200 100 Segunda ”racha" Racha: Un punto o una serie consecutiva de puntos que caen en un lado del promedio. Número total de Rachas: 12 Número total de puntos > al promedio: 11 Número total de puntos < al promedio: 18

417
Este es el valor p de las Prueba de Corridas
Prueba de Rachas Ho: Los datos son aleatorios Ha:Los datos NO so aleatorios Prueba de Rachas Promedio K = Número de rachas observado = 12 Número de rachas esperado = => No se rechaza Ho 11 observaciones por encima de K; 18 por debajo La prueba es significativa en p= No se puede rechazar Ho con valor alfa = 0.05 Promedio Este es el valor p de las Prueba de Corridas Ya que p > 0.05, no podemos rechazar la hipótesis nula. Los datos son aceptados, siendo aleatorios.

418
Cálculos de la Prueba de Rachas
El estadístico Z cuando n > 20 se calcula como: Z = (G - MediaG) / DesvStG Con MediaG = 1 + (2n1*n2) / (n1 + n2) DesvStG = Raiz [ (2n1*n2) (2n1*n2 - n1 -n2) / (n1 + n2)^2* (n1+n2 -1) Del ejemplo anterior G = 12; n1 = 11 n2 = 18 MediaG = DesStG = Z1 = ( ) / = P(Z1) = y para dos colas se tiene P(Z1) + P(Z2) = > Alfa crítico de 0.05, no rechazándose Ho Si las n1 y n2 son menores a 21, entonces se consulta la tabla de valores críticos para el número de Rachas G
 / DesvStG. Con MediaG = 1 + (2n1*n2) / (n1 + n2) DesvStG = Raiz [ (2n1*n2) (2n1*n2 - n1 -n2) / (n1 + n2)^2* (n1+n2 -1) Del ejemplo anterior G = 12; n1 = 11 n2 = 18. MediaG = DesStG = Z1 = ( ) / = P(Z1) = y para dos colas se tiene. P(Z1) + P(Z2) = > Alfa crítico de 0.05, no rechazándose Ho. Si las n1 y n2 son menores a 21, entonces se consulta la tabla de valores críticos para el número de Rachas G.")
419
Corrida con Minitab Runs Test: C1 Runs test for C1
Stat > Nonparametrics > Runs Test Variable C1, Above and below the mean Runs Test: C1 Runs test for C1 Runs above and below K = The observed number of runs = 12 The expected number of runs = 11 observations above K, 18 below P-value = 0.285 P > 0.05 No rechazar Ho

420
Prueba de Signos de la Mediana
Ho : La mediana de la muestra es igual a la mediana de la hipótesis Ha : Las medianas son diferentes Ejemplo (usando los datos del ejemplo anterior): Ho: Valor de la mediana = 115.0 Ha: Valor de la mediana diferente de 115.0 N DEBAJO IGUAL ENCIMA VALOR P MEDIANA Ya que p >0.05, no se puede rechazar la hipótesis nula. No se puede probar que la mediana real y la mediana hipotética son diferentes. En las páginas siguientes se muestra el detalle del cálculo.
: Ho: Valor de la mediana = Ha: Valor de la mediana diferente de N DEBAJO IGUAL ENCIMA VALOR P MEDIANA Ya que p >0.05, no se puede rechazar la hipótesis nula. No se puede probar que la mediana real y la mediana hipotética son diferentes. En las páginas siguientes se muestra el detalle del cálculo.")
421
Cálculos de la Prueba de Signos de la Mediana
Ejemplo: Con los datos del ejemplo anterior y ordenándo de menor a mayor se tiene: n = 29, Mediana de Ho = 115 No. Valor Signo No. Valor Signo No. Valor Signo Con la mediana en 144. Si el valor contra el cual se desea probar es 115, entonces hay 12 valores por debajo de el (-) y 17 valores por arriba (+).
 y 17 valores por arriba (+).")
422
Cálculos de la Prueba de Signos de la Mediana
El estadístico X es el el número de veces que ocurre el signo menos frecuente, en este caso el 12 (-). Cómo n 25, se calcula el estadístico Z para la prueba de signos con: Z = [ (Y + 0.5) - (0.5*n) ]/ 0.5 n En este caso Z1 = y P(Z1) = para la cola izquierda en forma similar P(Z2) para la cola derecha, por lo que la probabilidad total es >> 0.05 del criterio de rechazo. Si n hubiera sido < 25 entonces se hubiera consultado la tabla de valores críticos para la prueba de signo.
. Cómo n 25, se calcula el estadístico Z para la prueba de signos con: Z = [ (Y + 0.5) - (0.5*n) ]/ 0.5 n. En este caso Z1 = y P(Z1) = para la cola izquierda. en forma similar P(Z2) para la cola derecha, por lo que la. probabilidad total es >> 0.05 del criterio de rechazo. Si n hubiera sido < 25 entonces se hubiera consultado la tabla de valores críticos para la prueba de signo.")
423
Prueba de Signos de la Mediana
¿Es esto correcto?¿144 podría ser igual a 115? Bueno, veamos una gráfica de la información 100 200 300 400 500 115 144 Después de todo, tal vez esto SEA lo correcto.

424
Corrida en Minitab Sign Test for Median: Signos
Stat > Nonparametrics > 1-Sample sign Variable C1 Confidence interval 95% Test Median 115 Alternative Not equal Como P > 0.05 no se rechaza Ho y la mediana es 115 Sign Test for Median: Signos Sign test of median = versus not = 115.0 N Below Equal Above P Median Signos

425
Prueba de Signos de la Mediana Para observaciones pareadas
Calificaciones de amas de casa a dos limpiadores de ventanas: Ho: p = 0.5 no hay preferencia de A sobre B Ha: p<>0.5 Ama Limpiador B Casa A 1 10 7 2 5 3 8 4 6 9 ¿Hay evidencia que indique cierta preferencia de las amas de casa por lo limpiadores?

426
Prueba de Signos de la Mediana
Producto B Familia A 1 - + 2 3 4 5 6 7 8 9 10 11 Media = 0.5*n Desv. Estand.= 0.5*raiz(n) Zc = (Y – media) / Desv. Estánd. Rechazar Ho si Zc ><Zalfa/2 ¿Hay evidencia que indique cierta preferencia por un Producto A o B?
 Zc = (Y – media) / Desv. Estánd. Rechazar Ho si Zc ><Zalfa/2. ¿Hay evidencia que indique. cierta preferencia por un. Producto A o B")
427
Prueba de Signos de la Mediana
Desv. Estand.= 0.5*raiz(n) = 1.67 Para Zc = (8 – 5.5) / 1.67 = 1.497 Zexcel = 1.96 para alfa/2 = 0.025 Como Zc < Zexcel no se rechaza Ho o Como p value = > 0.025 No hay evidencia suficiente de que los Consumidores prefieran al producto B
 = Para Zc = (8 – 5.5) / 1.67 = Zexcel = 1.96 para alfa/2 = Como Zc < Zexcel no se rechaza Ho o. Como p value = > No hay evidencia suficiente de que los. Consumidores prefieran al producto B.")
428
Prueba rango con signo de Wilconox
Es la alternativa no paramétrica de la prueba paramétrica de muestras pareadas Ejemplo: HO: Las poblaciones son idénticas Ha: Caso contrario Trabajador Método 1 Método 2 Diferencias Abs(diferen.) Rango Rango c/signo 1 10.2 9.5 0.7 8 2 9.6 9.8 -0.2 0.2 -2 3 9.2 8.8 0.4 3.5 4 10.6 10.1 0.5 5.5 5 9.9 10.3 -0.4 -3.5 6 9.3 0.9 10 7 10.5 0.1 Eliminar 9 11.2 0.6 10.7 11 0.8 T = 44
 Rango. Rango c/signo Eliminar T = 44.")
429
Prueba rango con signo de Wilconox
Distribución muestral T para poblaciones idénticas Se aproxima a la distribución normal para n >= 10 En este caso n = pares eliminando las que son iguales con dif. = 0 para el trabajador 8. = raiz(10 x 11 x 21/6) = 19.62 Z = (T – )/ = 44/19.62 = 2.24 Z alfa/2 = Z0.025 = 1.96 Como Zc = 2.24 > Z0.025 se rechaza Ho, los métodos son diferentes
 = Z = (T – )/ = 44/19.62 = Z alfa/2 = Z0.025 = Como Zc = 2.24 > Z0.025 se rechaza Ho, los métodos son diferentes.")
430
Prueba en Minitab para prueba de mediana con Wilconox
File> Open worksheet > Exh_Stat Stat > Nonparametrics > 1-Sample Wilconox Variables C1 Test Median 77 Altenative Not equal Achievement 77 88 85 74 75 62 80 70 83 Wilcoxon Signed Rank Test: Achievement Test of median = versus median not = 77.00 for Wilcoxon Estimated N Test Statistic P Median Achievement Ho: Mediana = Ha: Mediana <> 77 Como P de >> alfa de 0.05 no se rechaza Ho

431
Prueba de Mann-Whitney
Se llevó a cabo un estudio que analiza la frecuencia del pulso en dos grupos de personas de edades diferentes, después de diez minutos de ejercicios aeróbicos. Los datos resultantes se muestran a continuación. Edad 40-44 C1 140 135 150 144 154 160 136 148 Edad 16-20 C2 130 166 128 126 132 124 ¿Tuvieron diferencias significativas las frecuencias de pulso de ambos grupos?

432
Prueba de Mann-Whitney
Ordenando los datos y asignándoles el (rango) de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Edad 40-44 C1 (7) 135 (8.5) 136 (11) 140 (11) 140 (13.5) 144 (15) 148 (16) 150 (17) 154 (18) 160 n1 = 10 Ta = 130.5 Edad 16-20 C2 (1) 124 (2) 126 (3.5) 128 (5) 130 (6) 132 (11)140 (15)166 n2 = 9 Tb = 55.5
 de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Edad C1. (7) 135. (8.5) 136. (11) 140. (11) 140. (13.5) 144. (15) 148. (16) 150. (17) 154. (18) 160. n1 = 10. Ta = Edad C2. (1) 124. (2) 126. (3.5) 128. (5) 130. (6) 132. (11)140. (15)166. n2 = 9. Tb =")
433
Prueba de Mann-Whitney
Ho: Las distribuciones de frecuencias relativas de las poblaciones A y B son iguales Ha: Las distribuciones de frecuencias relativas poblacionales no son idénticas Ho: 1 = 2 Ha: 1 2 1, 2 = Medianas de las poblaciones Ordenando los datos y asignándoles su posición relativa se tiene: Ua = n1*n2 + (n1) * (n1 + 1) /2 - Ta Ub = n1*n2 + (n2) * (n2 + 1) /2 - Tb Ua + Ub = n1 * n2 Ua = = P(Ua) = Ub = = 79.5 El menor de los dos es Ua. Para alfa = 0.05 el valor de Uo = 25 Como Ua < 25 se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.
 * (n1 + 1) /2 - Ta. Ub = n1*n2 + (n2) * (n2 + 1) /2 - Tb. Ua + Ub = n1 * n2. Ua = = 14.5 P(Ua) = Ub = = El menor de los dos es Ua. Para alfa = 0.05 el valor de Uo = 25. Como Ua < 25 se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.")
434
Prueba de Mann-Whitney
Ho: Las distribuciones de frecuencias relativas de las poblaciones A y B son iguales Ha: Las distribuciones de frecuencias relativas poblacionales no son idénticas Ua = Ub = 79.5 Utilizando el estadístico Z y la distribución normal se tiene: Z = [ (U - (n1* n2 / 2 ) / Raiz (n1 * n2 * (n1 + n2 + 1) / 12) Con Ua y Ub se tiene: Za = ( ) / = P(Z) = similar a la anterior Zb = ( ) / = 2.81 P(total) = 2 * = menor = 0.05 El valor crítico de Z para alfa por ser prueba de dos colas, es 1.96. Como Za > Zcrítico se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.
 / Raiz (n1 * n2 * (n1 + n2 + 1) / 12) Con Ua y Ub se tiene: Za = ( ) / = P(Z) = similar a la anterior. Zb = ( ) / = 2.81 P(total) = 2 * = menor = El valor crítico de Z para alfa por ser prueba de dos colas, es Como Za > Zcrítico se rechaza la Hipótesis Ho de que las medianas son iguales. Dado que p < 0.05, rechazamos la hipótesis nula. Estadísticamente existe una diferencia significativa entre los dos grupos de edad.")
435
Prueba de Mann-Whitney 16-20 años de edad
Diferencias entre los encabezados de los renglones y las columnas De esta manera, se calcula la mediana de todas estas diferencias, denominada "punto estimado". Este punto estimado es una aproximación de la diferencia entre las medianas de los dos grupos (ETA1 y ETA2). Una vez ajustados los "enlaces" (eventos de un mismo valor en ambos grupos de información), Minitab usa este punto estimado para calcular el valor p.
. Una vez ajustados los enlaces (eventos de un mismo valor en ambos grupos de información), Minitab usa este punto estimado para calcular el valor p.")
436
Corrida en Minitab Mann-Whitney Test and CI: C1, C2 N Median P>0.05
Stat > Nonparametrics > Mann Whitney First Sample C1 Second Sample C2 Conf. Level 95% Alternative Not equal Mann-Whitney Test and CI: C1, C2 N Median P>0.05 C Se rechaza Ho C Point estimate for ETA1-ETA2 is 12.00 95.5 Percent CI for ETA1-ETA2 is (4.01,20.00) W = 130.5 Test of ETA1 = ETA2 vs ETA1 not = ETA2 is significant at The test is significant at (adjusted for ties)
 W = Test of ETA1 = ETA2 vs ETA1 not = ETA2 is significant at The test is significant at (adjusted for ties)")
437
Prueba de Kruskal Wallis
Ordenando los datos de ventas y asignándoles el (rango) de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Zona 1 (15.5) 147 (17.5) 17.5 (9) 128 (19) 162 (12) 135 (10) 132 (22) 181 (13) 138 n1 = 8 Ta = 118 Zona 2 (17.5) 160 (14) 140 (21) 173 (4) 113 (1) 85 (7) 120 (25) 285 (5) 117 (11) 133 (6) 119 n2 = 10 Tb = 111.5 Zona 3 (24) 215 (8) 127 (2) 98 (15.5) 127 (23) 184 (3) 109 (20) 169 n3 = 7 Tc = 95.5 N = n1 + n2 + n3 = 25
 de su posición relativa se tiene (promediando posiciones para el caso de que sean iguales): Zona 1. (15.5) 147. (17.5) (9) 128. (19) 162. (12) 135. (10) 132. (22) 181. (13) 138. n1 = 8. Ta = 118. Zona 2. (17.5) 160. (14) 140. (21) 173. (4) 113. (1) 85. (7) 120. (25) 285. (5) 117. (11) 133. (6) 119. n2 = 10. Tb = Zona 3. (24) 215. (8) 127. (2) 98. (15.5) 127. (23) 184. (3) 109. (20) 169. n3 = 7. Tc = N = n1 + n2 + n3 = 25.")
438
Prueba de Kruskal Wallis
Ho: Las poblaciones A, B y C son iguales Ha: Las poblaciones no son iguales Ho: 1 = 2 = 3 Ha: 1 2 3 ; 1, 2, 3 = Medianas de las poblaciones Calculando el valor del estadístico H se tiene: H = [ 12 /( N* ( N + 1)) ] * [ Ta2 / n1 + Tb2 / n2 + Tc2 / n3 ] - 3 * ( N +1 ) H = * ( ) - 78 = 1.138 Se compara con el estadístico 2 para = 0.05 y G.l. = k - 1 = 3-1 = 1 (k muestras) 2 crítico = (válido siempre que las muestras tengan al menos 5 elementos) Como H < 2 crítico, no se rechaza la Hipótesis Ho: Afirmando que no hay diferencia entre las poblaciones 15
) ] * [ Ta2 / n1 + Tb2 / n2 + Tc2 / n3 ] - 3 * ( N +1 ) H = * ( ) - 78 = Se compara con el estadístico 2 para = 0.05 y G.l. = k - 1 = 3-1 = 1 (k muestras) 2 crítico = (válido siempre que las muestras tengan al menos 5 elementos) Como H < 2 crítico, no se rechaza la Hipótesis Ho: Afirmando que no hay diferencia entre las poblaciones. 15.")
439
Corrida en Minitab Kruskal-Wallis Test: Datos versus Factor
Stat > Nonparametrics > Kruskal Wallis Response C1 Factor C2 OK Kruskal-Wallis Test: Datos versus Factor Kruskal-Wallis Test on Datos Factor N Median Ave Rank Z Zona Zona Zona Overall P > 0.05 H = DF = 2 P = No se rechaza Ho H = DF = 2 P = (adjusted for ties)
")
440
Prueba de Medianas de Mood
Realiza prueba de hipótesis de igualdad de medias en un diseño de una vía. La prueba es robusta contra Outliers y errores en datos y es adecuada para análisis preliminares Determina si K grupos independientes han sido extraidas de la misma población con medianas iguales o poblaciones con formas similares Con base en la gran mediana, anotar un signo positivo si la observación excede la mediana o un signo menos si es menor. Los valores que coincidan se reparten en los grupos Hacer una tabla de contingencia K x 2 con las frecuencias de signos más y menos en cada grupo K

441
Prueba de Medianas de Mood
Se determina el estadístico Chi Cuadrada con: Probar Ho: Todas las medianas son iguales Ha: Al menos una mediana es diferente Se compara Chi Cuadrada calculada con Chi Cuadrada de alfa para 0.05 y (reng – 1)*(Col – 1) grados de libertad
*(Col – 1) grados de libertad.")
442
Corrida con Minitab Se les da a 179 participantes una conferencia con dibujos para ilustrar el tema. Después se les da la prueba OTIS que mide la habilidad intelectual. Los participantes se clasificaron por nivel educativo 0-No prof., 1-Prof., 2-Prepa Ho: h1 = h2 = h3 Ha: no todas las medianas son iguales File > Open Worksheet > Cartoon.mtw Stat > Nonparametrics > Mood’s Median Test Response Otis Factor ED Ok

443
Corrida con Minitab Mood Median Test: Otis versus ED
Mood median test for Otis P>0.05 Chi-Square = DF = 2 P = Se rechaza Ho Individual 95.0% CIs ED N<= N> Median Q3-Q (-----*-----) (------*------) (----*----) Overall median = 107.0
 (------*------) (----*----) Overall median =")
444
Diseños factoriales aleatorias bloqueados de Friedman
Esta prueba es una alternativa al ANOVA de dos vías, es una generalización de las pruebas pareadas con signo. La aditividad es requerida para para estimar los efectos de los tratamientos Ho: Los tratamientos no tienen un efecto significativo Ha: Algunos tratamientos tienen efecto significativo

445
Diseños factoriales aleatorias bloqueados de Friedman
Resultados de salida: Se muestra el estadístico de prueba con distribución Chi Cuadrada aproximada con gl = Tratamientos – 1. Si hay observaciones parecidas en uno o más bloques, se usa el rango promedio y se muestra el estadístico corregido La mediana estimada es la gran mediana más el efecto del tratamiento

446
Diseños factoriales aleatorias bloqueados de Friedman
Ejemplo: Se evalúa el efecto del tratamiento de una droga en la actividad enzimática con tres niveles, probado en cuatro animales Open the worksheet EXH_STAT.MTW. Stat > Nonparametrics > Friedman. Response, seleccionar EnzymeActivity. En Treatment, seleccionar Therapy. En Blocks, seleccionar Litter. Click OK.

447
Diseños factoriales aleatorias bloqueados de Friedman
EnzymeActivity Therapy Litter 0.15 1 0.26 2 0.23 3 0.99 4 0.55 -0.22 0.66 0.77 Datos:

448
Diseños factoriales aleatorias bloqueados de Friedman
Resultados: Friedman Test: EnzymeActivity versus Therapy blocked by Litter S = DF = 2 P = No rechazar Ho S = DF = 2 P = (adjusted for ties) Sum of Therapy N Est Median Ranks Grand median =
 Sum. of. Therapy N Est Median Ranks Grand median =")
449
Diseños factoriales aleatorias bloqueados de Friedman
Resultados: El estadístico de prueba S tiene un valor P de sin ajustar para observaciones en cero y para el valor ajustado. Por tanto no hay evidencia suficiente para rechazar Ho Las medianas estimadas asociadas con los tratamientos son la gran mediana más los efectos estimados de los tratamientos. El estadístico de prueba se determina con base a los rangos en cada bloque y totales

450
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

451
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

452
Diseños factoriales aleatorias bloqueados de Friedman
Resultados:

453
Prueba de igualdad de varianzas de Levene
Se usa para probar la hipótesis nula de que las varianzas de k múltiples poblacionales son iguales Las igualdad de varianzas en las muestras se denomina homogeneidad de varianzas La prueba de Levene es menos sensible que la prueba de Bartlett o la prueba F cuando se apartan de la normalidad La prueba de Bartlett tiene un mejor desempeño para la distribución normal o aproximadamente normal

454
Prueba de igualdad de varianzas de Levene
Para dos muestras el procedimiento es como sigue: Determinar la media Calcular la desviación de cada observación respecto a la media Z es el cuadrado de las desviaciones respecto a la media Aplicar la prueba t a las dos medias de los datos

455
Prueba de igualdad de Varianzas-Minitab
Rot Temp Oxygen 13 10 2 11 3 6 4 7 15 26 16 19 24 22 18 20 8 Prueba de igualdad de Varianzas-Minitab Se estudian tamaños de papa inyectando con bacterias y sujetas a diferentes temperaturas. Antes del ANOVA se verifica la igualdad de varianzas Stat > ANOVA > Test for equal variances Response Rot Factors Temp Oxigen Confidence level 95%

456
Resultados

457
Resultados Test for Equal Variances: Rot versus Temp, Oxygen
95% Bonferroni confidence intervals for standard deviations Temp Oxygen N Lower StDev Upper Bartlett's Test (normal distribution) Test statistic = 2.71, p-value = P>0.05 no rechazar Ho Levene's Test (any continuous distribution) Test statistic = 0.37, p-value = 0.858
 Test statistic = 2.71, p-value = P>0.05 no rechazar Ho. Levene s Test (any continuous distribution) Test statistic = 0.37, p-value =")
458
Prueba de la concordancia del Coeficiente de Kendall
El coeficiente expresa el grado de asociación entre las calificaciones múltiples realizadas por un evaluador Ho: Las variables son independientes Ha: Las variables están asociadas Kendall usa la información relacionada con las calificaciones relativas y es sensible a la seriedad de mala clasificación Por ejemplo para K = jueces N = Muestras = 10 Rango medio = 220 / S = Gl = n-1 = 9 Chi Cuadrada crítica = X2 0.01,9 = 21.67

459
Prueba de la concordancia del Coeficiente de Kendall
El Estadístico Chi Cuadrada calculado es: Como Chi Cuadrada de alfa es menor que la calculada, los cuatro jueces están asociados significativamente. Constituyen un panel uniforme. No quiere decir que estén en lo correcto, solo que responden de manera uniforme a los estímulos

460
El coeficiente de correlación de rangos de Spearman (rs)
El coeficiente de correlación es una medida de la asociación que requiere que ambas variables sean medidas en al menos una escala ordinal de manera que las muestras u observaciones a ser analizadas pueden ser clasificadas en rangos en dos series ordenadas Ho: Las variables son independientes Ha: Las variables están asociadas Para el ejemplo anterior si N = 10, el coeficiente es:

461
Coeficiente de correlación de rangos para monotonía de preferencias
Una persona interesada en adquirir un TV asigna rangos a modelos de cada uno de 8 fabricantes Preferencia Precio (rango) Fab. 1 7 (1) 2 4 (5) 3 (3) 6 (4) 5 (8) (7) 8 (2) (6) Di cuadrada Rango Di 6 36 -1 1 2 4 -7 49 -4 16 15
 Fab (1) (5) (3) (4) (8) (7) (2) (6) Di cuadrada. Rango. Di")
462
Coeficiente de correlación de rangos para monotonía de preferencias
Ho: No existe asociación entre los rangos Ha: Existe asociación entre los rangos o es positiva o negativa El coeficiente de correlación de rangos de Spearman es: Rs = 1 – 6*suma(di cuadrada) / (n(n cuadrada – 1)) En este caso: Rs = 1 – 6(144)/(8*(64-1) = R0 se determina de la tabla de Valores críticos del coeficiente de correlación del coeficiente de correlación de rangos de Spearman Rt = 0.686 Por tanto si hay asociación significativa en las preferencias 15
 / (n(n cuadrada – 1)) En este caso: Rs = 1 – 6(144)/(8*(64-1) = R0 se determina de la tabla de Valores críticos del coeficiente de correlación del coeficiente de correlación de rangos de Spearman. Rt = Por tanto si hay asociación significativa en las preferencias. 15.")
463
Tabla de constantes 15

464
Corrida con Minitab Correlations: Preferencia, Precio
Para la corrida en Minitab primero se deben determinar los rangos en forma manual para las variables X y Y. Stat > Basic statistics > Correlation Variables Preferencia Precio Fabricante Prefe-rencia Precio 1 7 449 2 4 5 525 3 479 6 499 8 580 549 469 532 Correlations: Preferencia, Precio Pearson correlation of Preferencia and Precio = P-Value = 0.047

465
Ejemplo con Minitab Correlations: Colageno, Proline
Se estudia la relación entre colágeno y Proline en pacientes con cirrosis Stat > Basic statistics > Correlation Variables Colágeno Proline Paciente Colágeno Proline 1 7.1 2.8 2 2.9 3 7.2 4 8.3 2.6 5 9.4 3.5 6 10.5 4.6 7 11.4 Correlations: Colageno, Proline Pearson correlation of Colageno and Proline = 0.935 P-Value = 0.002

466
Resumen de pruebas no paramétricas
Prueba de signos de 1 muestra: Prueba la igualdad de la mediana a un valor y determina el intervalo de confianza Prueba de Wilconox de 1 muestra: Prueba la igualdad de la mediana a un valor con rangos con signo y determina el intervalo de confianza Comparación de dos medianas poblacionales de Mann Whitney: Prueba la igualdad de las medianas y determina el intervalo de confianza

467
Resumen de pruebas no paramétricas
Comparación de igualdad de medianas poblacionales de Kruskal Wallis: Prueba la igualdad de las medianas en un diseño de una vía y determina el intervalo de confianza Comparación de medianas poblacionales de Mood: Prueba la igualdad de medianas con un diseño de una vía

470
VI.C Análisis del Modo y Efecto de Falla (FMEA)
")
471
¿ Qué es el FMEA? El Análisis de del Modo y Efectos de Falla es un grupo sistematizado de actividades para: Reconocer y evaluar fallas potenciales y sus efectos. Identificar acciones que reduzcan o eliminen las probabilidades de falla. Documentar los procesos con los hallazgos del análisis. Existe el estándar MIL-STD-1629, Procedure for Performing a Failure Mode, Effects and Criticality Analysis

472
Propósitos del FMEA Mejorar la calidad, confiabilidad y seguridad de los productos y procesos evaluados Reducir el tiempo y costo de re-desarrollo del producto Documenta y da seguimiento a acciones tomadas para reducir el riesgo Soporta el desarrollo de planes de control robustos

473
Propósitos del FMEA Soporta el desarrollo de planes de verificación del desarrollo de diseño robusto Apoya a priorizar y enfocarse en eliminar/reducir problemas de proceso y producto y/o previene la ocurrencia de problemas Mejora la satisfacción del cliente/consumidor

474
Tipos del FMEA AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA)
AMEF de concepto (CFMEA) A nivel de sistema, subsistema y componente AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA) AMEF de maquinaria (como aplicación del DFMEA)
 A nivel de sistema, subsistema y componente. AMEF de diseño (DFMEA) AMEF de Proceso (PFMEA) AMEF de maquinaria (como aplicación del DFMEA)")
475
Tipos de FMEAs FMEA de Diseño (AMEFD), su propósito es analizar como afectan al sistema los modos de falla y minimizar los efectos de falla en el sistema. Se usan antes de la liberación de productos o servicios, para corregir las deficiencias de diseño. FMEA de Proceso (AMEFP), su propósito es analizar como afectan al proceso los modos de falla y minimizar los efectos de falla en el proceso. Se usan durante la planeación de calidad y como apoyo durante la producción o prestación del servicio.
, su propósito es analizar como afectan al sistema los modos de falla y minimizar los efectos de falla en el sistema. Se usan antes de la liberación de productos o servicios, para corregir las deficiencias de diseño. FMEA de Proceso (AMEFP), su propósito es analizar como afectan al proceso los modos de falla y minimizar los efectos de falla en el proceso. Se usan durante la planeación de calidad y como apoyo durante la producción o prestación del servicio.")
476
PFMEA o AMEF de Proceso Fecha límite:
Concepto Prototipo Pre-producción /Producción FMEAD FMEAP FMEAD FMEAP Característica de Diseño Paso de Proceso Falla Forma en que el Forma en que el proceso falla producto o servicio falla al producir el requerimiento que se pretende Controles Técnicas de Diseño de Controles de Proceso Verificación/Validación

477
Flujo del FMEA y su rol en evitar el Modo de Falla
DFMEA Es un análisis detallado de los modos de falla potenciales relacionados con las funciones primarias y de interfases del sistema. Es el documento primario para demostrar que se han evitado errores e identifica los controles y acciones para reducir los riesgos asociados

478
Beneficios de los tipos de FMEA FMEA de Diseño
Soporta el proceso de diseño al reducir el riesgo de fallas (incluyendo las salidas no intencionadas) por: Soporta la evaluación objetiva de diseño, incluyendo requerimientos funcionales y alternativas de diseño Evaluar los diseños iniciales sobre requerimientos de manufactura, ensamble, servicio y reciclado Incrementar la probabilidad de que los modos de falla potencial y sus efectos en el sistema y operación del producto se han considerado en el procesos de diseño/desarrollo
 por: Soporta la evaluación objetiva de diseño, incluyendo requerimientos funcionales y alternativas de diseño. Evaluar los diseños iniciales sobre requerimientos de manufactura, ensamble, servicio y reciclado. Incrementar la probabilidad de que los modos de falla potencial y sus efectos en el sistema y operación del producto se han considerado en el procesos de diseño/desarrollo.")
479
Beneficios de los tipos de FMEA FMEA de Diseño
Proporcionar información adicional como apoyo en la planeación exhaustiva de programas de diseño eficiente, desarrollo y validación Desarrollo de una lista priorizada de modos de falla potenciales de acuerdo a su efecto en el “cliente” estableciendo un sistema de prioridades para mejoras al diseño, desarrollo, validación, prueba y análisis Proporcionar un formato de problemas pendientes para recomendar y dar seguimiento de acciones que reduzcan el riesgo

480
Beneficios de los tipos de FMEA FMEA de Proceso
Los beneficios de un FMEA de proceso incluyen: Identifica las funciones y requerimientos del proceso Identifica modos de falla potenciales relacionados con el producto y proceso Evalúa los efectos de las fallas potenciales con el cliente Identifica las causas potenciales en el proceso de manufactura Identifica las variables de proceso en las cuales hay que enfocarse para reducir las fallas muy lejanas

481
Beneficios de los tipos de FMEA FMEA de Proceso
Los beneficios de un FMEA de proceso incluyen: Identificar las variables del proceso centrandose en la ocurrencia Reducción o detección de las condiciones de falla Identificar variables del proceso a las cuales enfocar el control Desarrollar una lista ordenada clasificada de modos de falla estandarizados para establecer un sistema de prioridades

482
Beneficios de los tipos de FMEA FMEA de Proceso
Sistema del prioridad del riesgo para consideraciones de acciones preventivas y correctivas Documentar los resultados del proceso de manufactura o proceso de ensamble Documenta los resultados del proceso de manufactura o ensamble Identifica deficiencias del proceso para orientar a establecer controles para reducir la ocurrencia de productos no conformes o en métodos para mejorar su detección

483
Beneficios de los tipos de FMEA FMEA de Proceso
Identifica características críticas y/o significativas confirmadas Apoya en el desarrollo de Planes de Control a través de todo el proceso de manufactura Identifica aspectos de preocupación en relación con la seguridad del operador Retroalimenta información sobre cambios de diseño requeridos y factibilidad de manufactura a las áreas de diseño

484
Beneficios de los tipos de FMEA FMEA de Proceso
Se enfoca a modos de falla potenciales del producto causados por deficiencias de manufactura o ensamble Confirma la necesidad de controles especiales en manufactura y confirma las “Características Especiales” designadas en el DFMEA Identifica modos de falla del proceso que pudieran violar las reglamentaciones del gobierno o comprometer la seguridad del personal, identificando otras “Características especiales” – de Seguridad del operador (OS) y con alto impacto (HI)
 y con alto impacto (HI)")
485
Salidas del FMEA de Proceso
Una lista de modos potenciales de falla Una lista de Caracteríticas críticas y/o significativas Una lista de características relacionadas con la seguridad del operador y con alto impacto Una lista de controles especiales recomendados para las Características Especiales designadas y consideradas en el Plan de control

486
Salidas del FMEA de Proceso
Una lista de procesos o acciones de proceso para reducir la Severidad, eliminar las causas de los modos de falla del producto o reducir su tasa de ocurrencia, y mejorar la tasa de Detección de defectos si no se puede mejorar la capacidad del proceso Cambios recomendados a las hojas de proceso y dibujos de ensamble

487
Modos de fallas vs Mecanismos de falla
El modo de falla es el síntoma real de la falla (altos costos del servicio; tiempo de entrega excedido). Mecanismos de falla son las razones simples o diversas que causas el modo de falla (métodos no claros; cansancio; formatos ilegibles) o cualquier otra razón que cause el modo de falla
. Mecanismos de falla son las razones simples o diversas que causas el modo de falla (métodos no claros; cansancio; formatos ilegibles) o cualquier otra razón que cause el modo de falla.")
488
Definiciones Modo de Falla
- La forma en que un producto o proceso puede fallar para cumplir con las especificaciones o requerimientos. - Normalmente se asocia con un Defecto, falla o error. Diseño Proceso Alcance insuficiente Omisiones Recursos inadecuados Monto equivocado Servicio no adecuado Tiempo de respuesta excesivo

489
Definiciones Efecto - El impacto en el Cliente cuando el Modo de Falla no se previene ni corrige. - El cliente o el siguiente proceso puede ser afectado. Ejemplos: Diseño Proceso Serv. incompleto Servicio deficiente Operación errática Claridad insuficiente Causa - Una deficiencia que genera el Modo de Falla. - Las causas son fuentes de Variabilidad asociada con variables de Entrada Claves Ejemplos: Diseño Proceso Material incorrecto Error en servicio Demasiado esfuerzo No cumple requerimientos

490
Preparación del AMEF Se recomienda que sea un equipo multidisciplinario El responsable del sistema, producto o proceso dirige el equipo, así como representantes de las áreas involucradas y otros expertos en la materia que sea conveniente.

491
¿Cuando iniciar un FMEA?
Al diseñar los sistemas, productos y procesos nuevos. Al cambiar los diseños o procesos existentes o que serán usados en aplicaciones o ambientes nuevos. Después de completar la Solución de Problemas (con el fin de evitar la incidencia del problema). El AMEF de diseño, después de definir las funciones del producto, antes de que el diseño sea aprobado y entregado para su manufactura o servicio. El AMEF de proceso, cuando los documentos preliminares del producto y sus especificaciones están disponibles.
. El AMEF de diseño, después de definir las funciones del producto, antes de que el diseño sea aprobado y entregado para su manufactura o servicio. El AMEF de proceso, cuando los documentos preliminares del producto y sus especificaciones están disponibles.")
492
FMEA de Diseño - DFMEA

493
AMEF de Diseño El DFMEA es una técnica analítica utilizada por el equipo de diseño para asegurar que los modos de falla potenciales y sus causas/mecanismos asociados, se han considerado y atendido

494
AMEF de Diseño El proceso inicia con un listado de lo que se espera del diseño (intención) y que no hará el diseño Las necesidades y expectativas de los clientes de determinan de fuentes tales como el QFD, requerimientos de diseño del producto, y/o requerimientos de manufactura/ensamble/servicio. Entre mejor se definan las características deseadas, será más fácil identificar Modos de de falla potenciales para toma de acciones correctivas / preventivas.

495
Equipo de trabajo El equipo se divide en dos secciones:
El equipo central (“core”) que participa en todas las fases del FMEA y el equipo de soporte que apoya conforme es requerido El apoyo de la alta dirección es crucial para el éxito
 que participa en todas las fases del FMEA y el equipo de soporte que apoya conforme es requerido. El apoyo de la alta dirección es crucial para el éxito.")
496
Alcance del DMEA El alcance se establece en el Diagrama de límites (Boundary Diagram) por medio de consenso con el equipo de: ¿Qué se va incluir? ¿Qué se va a excluir? Establecer los límites adecuados antes de hacer el DFMEA evitará entrar en áreas que no se están revisando o creando, para asegurar que el equipo adecuado realice el análisis

497
Alcance del DMEA Para determinar la amplitud del alcance, se deben hacer las decisiones siguientes: Determinar la estabilidad del diseño o desarrollo del proceso, a lo mejor primero se deben aclarar y resolver asuntos pendientes antes del DMFEA, ¿está finalizado o es un punto de control? ¿Cuántos atributos o características están todavía bajo discusión o la necesidad debe determinarse? ¿Qué tan avanzado va el diseño o proceso para su terminación? Tendrá cambios

498
Entradas al DFMEA Herramientas de robustez
Su propósito es reducir la probabilidad de campañas de calidad, mejorar la imagen, reducir reclamaciones de calidad e incrementar la satisfacción del cliente Se generan del diagrama P que identifica los cinco factores de ruido, para ser atendidos a tiempo haciendo al diseño insensible al ruido

499
Modelo DFMEA – Paso 1 Funciones
Identificar todas las funciones en el alcance Identificar como cada una de las funciones puede fallar (Modos de falla) Identificar un grupo de efectos asociados para cada modo de falla Identificar el rango de severidad para cada uno de los grupos de efectos que prioriza los modos de falla Si es posible recomendar acciones para eliminar los modos de falla sin atender las “causas” Completar pasos 2 y 3
 Identificar un grupo de efectos asociados para cada modo de falla. Identificar el rango de severidad para cada uno de los grupos de efectos que prioriza los modos de falla. Si es posible recomendar acciones para eliminar los modos de falla sin atender las causas Completar pasos 2 y 3.")
500
Modelo DFMEA – Paso 1 Funciones
La función da respuesta a ¿Qué se supone que hace este artículo? Las funciones son intenciones del diseño o especs. de ing. y: Se escriben en forma de verbo/nombre/caract. medible La característica Medible o SDS: Puede ser verificada/validada; incluye parámetros adicionales o parámetros de diseño como especificaciones de servicio, condiciones especiales, peso, tamaño, localización y accesibilidad o requerimientos de estándares (v. gr. EMVSS)
")
501
Modelo DFMEA – Paso 1 Funciones
Las funciones representan las expectativas, necesidades y requerimientos tanto explícitos como no explícitos de los clientes y sistemas Las funciones no pueden “fallar” si no son medibles o especificadas Ejemplos: Almacenar fluido, X litros sin fugas Controlar el flujo, X centímetros cúbicos por segundo Abrir con X fuerza Mantener la calidad del fluido durante X años bajo condiciones de operación

502
Modelo DFMEA – Paso 1 Modos de falla potenciales
Son las formas en las cuales un componente, subsistema o sistema pueden potencialmente no cumplir o proporcionar la función intencionada, pueden ser también las causas El Modo de falla en un sistema mayor puede ser el efecto de un componente de menor nivel Listar cada uno de los modos de falla potenciales asociados con el artículo en particular y con su función (revisar el historial de garantías y fallas o hacer tormenta de ideas También se deben considerar modos de falla potenciales que pudieran ocurrir sólo bajo ciertas condiciones (vg. Calor, frío, humedad, polvo, etc)
")
503
Modelo DFMEA – Paso 1 Tipos de Modos de falla potenciales
No funciona Funciona parcialmente / sobre función / degradación con el tiempo Función intermitente A veces causado por los factores ambientales Función no intencionada Los limpiadores operan sin haber actuado el switch El coche va hacia atrás aún con la palanca en Drive

504
Modelo DFMEA – Paso 1 Preguntas para Modos Potenciales de falla
¿De que manera puede fallar este artículo para realizar su función intencionada? ¿Qué puede salir mal (go wrong), a pesar de que el artículo se fabrica de acuerdo al dibujo? ¿Cuándo se prueba la función, como se debería reconocer su modo de falla? ¿Dónde y cómo operará el diseño?
, a pesar de que el artículo se fabrica de acuerdo al dibujo ¿Cuándo se prueba la función, como se debería reconocer su modo de falla ¿Dónde y cómo operará el diseño")
505
Modelo DFMEA – Paso 1 Preguntas para Modos Potenciales de falla
¿Bajo que condiciones ambientales operará? ¿El artículo será usado en ensambles de más alto nivel? ¿Cómo interactúa/interfase con otros niveles del diseño? No introducir modos de fallas triviales que no pueden o no ocurrirán Asumiendo la función: Almacenar fluido, X litros, 0 fugas, durante 10 años Sus modos de falla son: Almacenar < X, presenta fugas

506
Modelo DFMEA – Paso 1 Efectos Potenciales de falla
Se definen como los efectos del modo de falla en la función percibida por el cliente. Qué puede notar o experimentar ya sea interno o final Establecer claramente si la función podría impactar a la seguridad, o no cumplimiento de reglamentaciones Los efectos se establecen en términos de sisemas específicos, subsistemas o componentes conforme sean analizados La intención es analizar los efectos de falla al nivel de experiecia y conocimiento del equipo.

507
Modelo DFMEA – Paso 1 Efectos Potenciales de falla
Describir las consecuencias de cada uno de los modos de falla identificados en: Partes o componentes Ensambles del siguiente nivel Sistemas Clientes Reglamentaciones NOTA. Todos los estados de error del diagrama P deben ser incluidos en la columna de Modos de falla o efectos del DMFEA

508
Modelo DFMEA – Paso 1 Ejemplos de Efectos Potenciales de falla
Ruidos Operación errática – no operable Apariencia pobre – olores desagradables Operación inestable Operación intermitente Fugas Ruido de radiofrecuencia (EMC)
")
509
Modelo DFMEA – Paso 1 Severidad
Es la evaluación asociada con el efecto más serio de la columna anterior. Habrá sólo una severidad para cada modo de falla Para reducir la severidad es necesario hacer un cambio de diseño La severidad se estima de la tabla siguiente

510
Rangos de Severidad (AMEFD)
Efecto Rango Criterio No 1 Sin efecto Muy poco 2 Cliente no molesto. Poco efecto en el desempeño del componente o servicio. Poco 3 Cliente algo molesto. Poco efecto en el desempeño del comp. o servicio. Menor 4 El cliente se siente un poco fastidiado. Efecto menor en el desempeño del componente o servicio. Moderado 5 El cliente se siente algo insatisfecho. Efecto moderado en el desempeño del componente o servicio. Significativo 6 El cliente se siente algo inconforme. El desempeño del comp. o servicio se ve afectado, pero es operable y está a salvo. Falla parcial, pero operable. Mayor 7 El cliente está insatisfecho. El desempeño del servicio se ve seriamente afectado, pero es funcional y está a salvo. Sistema afectado. Extremo 8 Cliente muy insatisfecho. Servicio inadecuado, pero a salvo. Sistema inoperable. Serio 9 Efecto de peligro potencial. Capaz de descontinuar el uso sin perder tiempo, dependiendo de la falla. Se cumple con el reglamento del gobierno en materia de riesgo. Peligro 10 Efecto peligroso. Seguridad relacionada - falla repentina Incumplimiento con reglamento del gobierno.

511
Modelo DFMEA – Paso 1 Clasificación
Cuando un modo de falla tiene un rango de severidad de 9 o 10, existe una característica crítica, se identifica como “YC” y se inicia un FMEA de proceso Estas características del producto afectan su función segura y/o cumplimiento de reglamentaciones gubernamentales y pueden requerir condiciones especiales de manufactura, ensamble, abastecimiento, embarque, monitoreo y/o acciones de inspección o controles

512
Modelo DFMEA – Paso 1 Acciones recomendadas
Eliminar el Modo de falla Mitigar el efecto Es necesario un énfasis especial en acciones posibles cuando la severidad es 9 o 10. Para valores menores también se pueden considerar acciones Para eliminar el modo de falla considerar la acción: Cambiar el diseño (vg. Geometría, material) si está relaionado a una característica del producto
 si está relaionado a una característica del producto.")
513
Modelo DFMEA – Paso 2 Identificar:
Las Causas asociadas (primer nivel y raíz) Su tasa de ocurrencia estimada La designación de la característica adecuada (si existe) a ser indicada en la columna de clasificación Acciones recomendadas para Severidad y Criticalidad alta (S x O)
 Su tasa de ocurrencia estimada. La designación de la característica adecuada (si existe) a ser indicada en la columna de clasificación. Acciones recomendadas para Severidad y Criticalidad alta (S x O)")
514
Model DFMEA – Paso 2 Causa potencial o mecanismo de falla
La causa potencial de falla se define como un indicador de debilidad del diseño cuya consecuencia es el modo de falla Listar como sea posible, cada causa de falla y/o mecanismo de falla para cada uno de los modos de falla. El detalle de la descripción permitirá enfocar los esfuerzos para atacar la causa pertinente

515
Model DFMEA – Paso 2 Causa potencial o mecanismo de falla
Se puede emplear un diagrama de Ishikawa o un Árbol de falla (FTA), preguntarse: ¿Qué circunstancia pudo causar que fallara el artículo para su fúnción? ¿Cómo podría fallar el artículo para cumplir con las especificaciones? ¿Cómo pueden ser incompatibles artículos que interactúan? ¿Qué información desarrollada en los diagramas P y Matriz de Interfase pueden identificar causas potenciales? ¿Qué puede causar que el artículo no de la función intencionada? ¿Qué información en el Diagrama de límites pudo haberse pasado que pueda causar este modo de falla? ¿En que puede contribuir el historial de 8Ds y FMEAs a las causas potenciales?
, preguntarse: ¿Qué circunstancia pudo causar que fallara el artículo para su fúnción ¿Cómo podría fallar el artículo para cumplir con las especificaciones ¿Cómo pueden ser incompatibles artículos que interactúan ¿Qué información desarrollada en los diagramas P y Matriz de Interfase pueden identificar causas potenciales ¿Qué puede causar que el artículo no de la función intencionada ¿Qué información en el Diagrama de límites pudo haberse pasado que pueda causar este modo de falla ¿En que puede contribuir el historial de 8Ds y FMEAs a las causas potenciales")
516
Model DFMEA – Paso 2 Causa potencial o mecanismo de falla
Supuesto 1: El artículo se fabricó de acuerdo a especificaciones, ejemplos de causas de falla: La especificación de Porosidad del material es muy alta La dureza del material especificada es muy baja El lubricante especificado es muy viscoso Torque especificado demasiado bajo Supuesto de confiabilidad inadecuada Degradación de parámetro del Componente Calor excesivo

517
Model DFMEA – Paso 2 Causa potencial o mecanismo de falla
Supuesto 2: El artículo puede incluir una deficiencia que causa variabilidad introducida en el proceso de ensamble o manufactura: Especificar un diseño simétrico que permita que la parte se pueda instalar desde atrás o de arriba a abajo Torque incorrecto debido a que el hoyo está diseñado fuera de posición Cinturón equivocado debido a que el diseño es similar a otro que es estándar también en uso

518
Modelo DFMEA – Paso 2 Causa potencial o mecanismo de falla
Precauciones: El DFMA no confía en los controles del proceso para subsanar debilidades del diseño, pero toma en cuenta sus limitaciones El objetivo es identificar las deficiencias del diseño que peuden causar variación inaceptable en el proceso de manufactura o ensamble a través de un equipo multidisciplinario Las causas de variación que no sean el resultado de directo de deficiencias de diseño pueden identificarse en el DFMEA y ser atendidas en el FMEA de Proceso Otro objetivo es identificar las características que mejoren la robustez del diseño que pueda compensar variaciones en proceso

519
Modelo DFMEA – Paso 2 Ocurrencia
Ocurrencia es la probabilidad de que una causa/mecanismo (listado en la columna previa) ocurra durante la vida del diseño El rango de ocurrencia tiene un significado relativo más que sea absoluto La prevención o control de las Causas / Mecanismos del modo de falla se realiza a través de cambios de diseño o cambios de diseño del proceso para reducir la ocurrencia
 ocurra durante la vida del diseño. El rango de ocurrencia tiene un significado relativo más que sea absoluto. La prevención o control de las Causas / Mecanismos del modo de falla se realiza a través de cambios de diseño o cambios de diseño del proceso para reducir la ocurrencia.")
520
Modelo DFMEA – Paso 2 Estimación de la Ocurrencia
¿Cuál es el historial de servicio y campo experimentado con artículos similares? ¿El artículo es similar al utilizado en niveles anteriores de subsistemas? ¿El componente es radicalmente diferente de los anteriores? ¿Ha cambiado la aplicación del componente? ¿Se han instalado controles preventivos en el proceso? ¿Cuáles son los cambios en el ambiente? ¿Se ha realizado un análisis análítico de la predicción de confiabilidad para estimar la tasa de ocurrencia?

521
Rangos de Ocurrencia (AMEFD)
Ocurrencia Criterios Remota Falla improbable. No existen fallas asociadas con este producto o con un producto / Servicio casi idéntico Muy Poca Sólo fallas aisladas asociadas con este producto / Servicio casi idéntico Poca Fallas aisladas asociadas con productos / Servicios similares Moderada Este producto / Servicio ha tenido fallas ocasionales Alta Este producto / Servicio ha fallado a menudo Muy alta La falla es casi inevitable Rango Probabilidad de Falla 1 <1 en 1,500,000 Zlt > 5 2 1 en 150,000 Zlt > 4.5 3 1 en 30, Zlt > 4 4 1 en 4,500 Zlt > en 800 Zlt > en 150 Zlt > 2.5 7 1 en 50 Zlt > en 15 Zlt > 1.5 9 1 en 6 Zlt > >1 en 3 Zlt < 1 Nota: El criterio se basa en la probabilidad de ocurrencia de la causa/mecanismo. Se puede basar en el desempeño de un diseño similar en una aplicación similar.

522
Clasificación Cuando el Modo de falla/causa tien una severidad de 5 a 8 y una ocurrencia de 4 o mayor, entonces se tiene una caracterítica significativa crítica potencial que se identifica con “YS” y se inicia el FMEA de proceso Estas características del producto afectan la función del producto y/o son importantes para la satisfacción del cliente y pueden requerir condiciones especiales de manufactura, ensamble, embarque, monitoreo y/o inspección

523
Modelo DFMEA Paso 3 Si las causas no se pueden eliminar en paso 1 o 2, Identificar Controles actuales de prevención usados para establecer la ocurrencia Controles actuales de detección (vg. Pruebas) usadas para establecer la Detección Determinar la efectividad de los controles de Detección en escala de 1 a 10 El RPN inicial (Risk Priority Number). Acciones Recomendadas (Prevenciónn and Detección). Cuando ya se hayan implementado las acciones recomenddas, se revisa el formato DFMEA en relación a la Severidad, Ocurrencia, Detección y RPN
 usadas para establecer la Detección. Determinar la efectividad de los controles de Detección en escala de 1 a 10. El RPN inicial (Risk Priority Number). Acciones Recomendadas (Prevenciónn and Detección). Cuando ya se hayan implementado las acciones recomenddas, se revisa el formato DFMEA en relación a la Severidad, Ocurrencia, Detección y RPN.")
524
Modelo DFMEA – Paso 3 Controles de diseño actuales
Listar las actividades terminadas para prevención, vaidación/verificación del diseño (DV), u otras actividades que aseguran la adecuación del diseño para el modo de falla y/o causa / mecanismo bajo consideración Controles actuales (vg. Diseños falla/seguro como válvulas de alivio, revisiones de factibilidad, CAE, Confianilidad y robustez analítica) son los que han sido o estan usándose con los mismos diseños o similares. El equipo siempre debe enfocarse a mejorar los controles de diseño, por ejemplo la creación de nuevos sistemas de prueba en el laboratorio, o la creación de muevos algoritmos de modelado, etc.
, u otras actividades que aseguran la adecuación del diseño para el modo de falla y/o causa / mecanismo bajo consideración. Controles actuales (vg. Diseños falla/seguro como válvulas de alivio, revisiones de factibilidad, CAE, Confianilidad y robustez analítica) son los que han sido o estan usándose con los mismos diseños o similares. El equipo siempre debe enfocarse a mejorar los controles de diseño, por ejemplo la creación de nuevos sistemas de prueba en el laboratorio, o la creación de muevos algoritmos de modelado, etc.")
525
Modelo DFMEA – Paso 3 Controles de diseño actuales
Hay dos tipos de controles de diseño: Prevención y detección De prevención: Previenen la ocurrencia de la causa/mecanismo o Modo de falla/efecto reduciendo la tasa de Ocurrencia De detección: Detectan la causa/mecanismo o Modo de falla/efecto ya sea por métodos analíticos o físicos antes que el artículo se libere para Poducción Si solo se usa una columna indicarlos con P o D

526
Modelo DFMEA – Paso 3 Controles de diseño actuales
Identificación de controles de diseño Si una causa potencial no fue analizada, el producto con deficiencia de diseño pasará a Producción. Una forma de detectarlo es con su Modo de falla resultante. Se debe tomar acción correctiva Identificar controles de diseño como sigue: Identificar y listar los métodos que puedan ser utilizados para detectar el modo de falla, como: FMEA anteriores, Planes de DV anteriores, Lista de verificáción de robustez, Acciones de 8Ds

527
Modelo DFMEA – Paso 3 Controles de diseño actuales
2. Listar todos los controles de diseño históricos que puedan ser suados para causas de primer nivel listadas. Revisar reportes históricos de pruebas 3. Identificar otros métodos posibles preguntando: ¿De que manera puede la causa de este modo de falla ser reconocida? ¿Cómo puedo descubrir que esta causa ha ocurrido? ¿De que manera este modo de falla puede ser reconocido? ¿Cómo puedo descubrir que este modo de falla ha ocurrido?

528
Modelo DFMEA – Paso 3 Detección
Cuando se estima una tasa de Detección, considerar solo los controles que serán usados para detectar los Modos de Falla o sus Causas. Los controles intencionados para prevenir o reducir la Ocurrencia de una Causa o Modo de falla son considerados al estimar la tasa de Ocurrencia Si los controles de prevención no detectan deben ser calificadas con 10 Solo se deben considerar los métodos que son usados antes de la liberación a Producción para estimar la tasa de Detección Los programas de verificación de diseño deben basarse en la efectividad de los controles de diseño

529
Modelo DFMEA – Paso 3 Detección
Para evaluar la efectividad de cada control de diseño considerar las siguientes categorías (de mayor a menor): Métodos de análisis de diseño Modelado y simulación probada (vg. Análisis de elementos finitos) Estudios de tolerancias (vg. Tolerancias deométricas dimensionales) Estudios de compatibilidad de materiales (vg. Expansión térmica, corrosión) Revisión de diseño subjetiva Métodos de desarrollo de pruebas: Diseño de experimentos/ experimentos de peor caso (vg. Ruido)
: Métodos de análisis de diseño. Modelado y simulación probada (vg. Análisis de elementos finitos) Estudios de tolerancias (vg. Tolerancias deométricas dimensionales) Estudios de compatibilidad de materiales (vg. Expansión térmica, corrosión) Revisión de diseño subjetiva. Métodos de desarrollo de pruebas: Diseño de experimentos/ experimentos de peor caso (vg. Ruido)")
530
Modelo DFMEA – Paso 3 Detección
Métodos de desarrollo de pruebas (cont…): Pruebas en muestras de pre-producción o prototipo Maquetas usando partes similares Pruebas de durabilidad (verificación de diseño) Número de muestras a ser probadas Muestra significativa estadísticamente Cantidad pequeña, no significativa estadísticamente Oportunidad de la aplicación de control de diseño Desde la etapa de diseño del concepto (vg. Decisión del tema) Al tener prototipos de ingeneiría Justo antes de liberarse a Producción
: Pruebas en muestras de pre-producción o prototipo. Maquetas usando partes similares. Pruebas de durabilidad (verificación de diseño) Número de muestras a ser probadas. Muestra significativa estadísticamente. Cantidad pequeña, no significativa estadísticamente. Oportunidad de la aplicación de control de diseño. Desde la etapa de diseño del concepto (vg. Decisión del tema) Al tener prototipos de ingeneiría. Justo antes de liberarse a Producción.")
531
Rangos de Detección (AMEFD)
Rango de Probabilidad de Detección basado en la efectividad del Sistema de Control Actual; basado en el cumplimiento oportuno con el Plazo Fijado 1 Detectado antes del prototipo o prueba piloto 2 - 3 Detectado antes de entregar el diseño 4 - 5 Detectado antes del lanzamiento del servicio 6 - 7 Detectado antes de la prestación del servicio 8 Detectado antes de prestar el servicio 9 Detectado en campo, pero antes de que ocurra la falla o error 10 No detectable hasta que ocurra la falla o error en campo

532
DFMEA – Cálculo del riesgo
El número de prioridad del rieso (RPN) es el producto de Severidad (S), Ocurrencia (O) y Detección (D) RPN = (S) x (O) x (D) con valores entre 1 y 1000 Puede usarse como en un Pareto para priorizar riesgos potenciales con efectos que tengan las tasas más altas de severidad Atender los aspectos con Severidad 9 o 10 y después los efectos con Severidad alta; los de criticalidad alta (S x O) y al final los que tienen RPNs más altos
 es el producto de Severidad (S), Ocurrencia (O) y Detección (D) RPN = (S) x (O) x (D) con valores entre 1 y Puede usarse como en un Pareto para priorizar riesgos potenciales con efectos que tengan las tasas más altas de severidad. Atender los aspectos con Severidad 9 o 10 y después los efectos con Severidad alta; los de criticalidad alta (S x O) y al final los que tienen RPNs más altos.")
533
DFMEA – Acciones recomendadas
Considerar acciones como las siguientes: Revisión del diseño de la Geometría y/o tolerancias Revisión de especificación de materiales Diseños de experimentos (con múltiples causas interactuando) u otras técnicas de solución de problemas Revisión de planes de prueba Sistemas redundantes – dispositivos de aviso – estados de falla (ON y OFF) El objetivo primario de las acciones recomendadas es reducir riesgos e incrementar la satisfacción del cliente al mejorar el diseño. Para reducir la severidad es necesario un cambio de diseño
 u otras técnicas de solución de problemas. Revisión de planes de prueba. Sistemas redundantes – dispositivos de aviso – estados de falla (ON y OFF) El objetivo primario de las acciones recomendadas es reducir riesgos e incrementar la satisfacción del cliente al mejorar el diseño. Para reducir la severidad es necesario un cambio de diseño.")
534
DFMEA – Acciones tomadas
Se identifica la organización y persona responsable para las acciones recomendadas y la fecha de terminación Dar seguimiento: Desarrollar una lista de características especiales parasu consideración en el DFMEA Dar seguimiento a todas las acciones recomendadas y actualizar las acciones del DFMEA Después de que se implementa una acción, anotar una descripción breve y la fecha de efectividad

535
DFMEA – Nivel de riesgo RPN
Después de haber implementado las acciones preventivas/correctivas, registrar la nueva Severidad, Ocurrencia y Detección Calcular el nuevo RPN Si no se tomaron acciones en algunos aspectos, dejarlos en blanco

536
DFMEA – Lista de verificación de robustez
Es una salida del proceso integrado de robustez: Resume los atributos de robustez clave y controles de diseño Enlaza el DFMEA y los 5 factores de ruido del diseño al Plan de verificación de diseño (DVP); vg., esta lista es una entrada al DVP Debe ser un documento clave a revisar como parte del proceso de revisión de diseño
; vg., esta lista es una entrada al DVP. Debe ser un documento clave a revisar como parte del proceso de revisión de diseño.")
537
FMEA de Proceso - PFMEA

538
PFMEA Equipo Se inicia por el Ing. responsable de la actividad, en conjunto con un equipo de personas expertas además de incluir personas de apoyo Alcance Define que es incluido y que es excluido

539
Entradas al PFMEA Diagrama de flujo del proceso
El equipo debe desarrollar el flujo del proceso, preguntando ¿Qué se supone que hace el proceso?; ¿Cuál es su propósito?; ¿Cuál es su función? El Diagrama P es una entrada opcional al PFMEA

541
Modelo del PFMEA – Paso 1 Identificar todos los requerimientos funcionales dentro del alcance Identificar los modos de falla correspondientes Identificar un conjunto de efectos asociados para cada modo de falla Identificar la calificación de severidad para cada conjunto de efectos que de prioridad el modo de falla De ser posible, tomar acciones para eliminar modos de falla sin atender las “causas”

542
Modelo de PFMEA – Paso 1 Requerimientos de la función del proceso
Contiene características de ambos el producto y el proceso Ejemplos Operación No. 20: Hacer perforación de tamaño X de cierta profundidad Operación No. 22: Realizar el subensamble X al ensamble Y

543
Pasos del proceso Del diagrama de flujo

544
Modelo de PFMEA – Paso 1 Modos de falla potenciales No funciona
Funcionamiento parcial / Sobre función / Degradación en el tiempo Funcionamiento intermitente Función no intencionada Los modos de falla se pueden categorizar como sigue: Manufactura: Dimensional fuera de tolerancia Ensamble: Falta de componentes Recibo de materiales: Aceptar partes no conformes Inspección/Prueba: Aceptar partes equivocadas

546
Modelo de PFMEA – Paso 1 Efectos de las fallas potenciales (consecuencias en) Seguridad del operador Siguiente usuario Usuarios siguientes Máquinas / equipos Operación del producto final Cliente último Cumplimiento de reglamentaciones gubernamentales

547
Modelo de PFMEA - Paso 1 Efectos de las fallas potenciales (en usuario final) Ruido Operación errática Inoperable Inestable Apariencia mala Fugas Excesivo esfuerzo Retrabajos / reparaciones Insatisfacción del cliente

548
Modelo de PFMEA –Paso 1 Efectos de las fallas potenciales (en siguiente operación) No se puede sujetar No se puede tapar No se puede montar Pone en riesgo al operador No se ajusta No conecta Daña al equipo Causa excesivo desgaste de herramentales

549
CTQs del QFD o Matriz de Causa Efecto

550
Efecto en Manufactura /Ensamble
CRITERIO DE EVALUACIÓN DE SEVERIDAD SUGERIDO PARA AMEFP Esta calificación resulta cuando un modo de falla potencial resulta en un defecto con un cliente final y/o una planta de manufactura / ensamble. El cliente final debe ser siempre considerado primero. Si ocurren ambos, use la mayor de las dos severidades Efecto Efecto en el cliente Efecto en Manufactura /Ensamble Calif. Peligroso sin aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, sin aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 10 Peligroso con aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 9 Muy alto El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor 8 Alto El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto 7 Modera do Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto 6 Bajo Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5 Muy bajo No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada 4 Menor No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación 3 Muy menor No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación 2 Ninguno Sin efecto perceptible Ligero inconveniente para la operación u operador, o sin efecto 1
 sin aviso. 10. Peligroso con aviso. Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso. Puede exponer al peligro al operador (máquina o ensamble) sin aviso. 9. Muy alto. El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor. 8. Alto. El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho. El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto. 7. Modera. do. Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho. Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto. 6. Bajo. Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos. El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5. Muy bajo. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes. El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada. 4. Menor. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes. El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación. 3. Muy menor. No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación. 2. Ninguno. Sin efecto perceptible. Ligero inconveniente para la operación u operador, o sin efecto. 1.")
551
Efecto en Manufactura /Ensamble
CRITERIO DE EVALUACIÓN DE SEVERIDAD SUGERIDO PARA PFMEA Esta calificación resulta cuando un modo de falla potencial resulta en un defecto con un cliente final y/o una planta de manufactura / ensamble. El cliente final debe ser siempre considerado primero. Si ocurren ambos, use la mayor de las dos severidades Efecto Efecto en el cliente Efecto en Manufactura /Ensamble Calif. Peligroso sin aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, sin aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 10 Peligroso con aviso Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso Puede exponer al peligro al operador (máquina o ensamble) sin aviso 9 Muy alto El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor 8 Alto El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto 7 Modera do Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto 6 Bajo Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5 Muy bajo No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada 4 Menor No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación 3 Muy menor No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación 2 Ninguno Sin efecto perceptible Ligero inconveniente para la operación u operador, o sin efecto 1
 sin aviso. 10. Peligroso con aviso. Calificación de severidad muy alta cuando un modo potencial de falla afecta la operación segura del producto y/o involucra un no cumplimiento con alguna regulación gubernamental, con aviso. Puede exponer al peligro al operador (máquina o ensamble) sin aviso. 9. Muy alto. El producto / item es inoperable ( pérdida de la función primaria) El 100% del producto puede tener que ser desechado op reparado con un tiempo o costo infinitamente mayor. 8. Alto. El producto / item es operable pero con un reducido nivel de desempeño. Cliente muy insatisfecho. El producto tiene que ser seleccionado y un parte desechada o reparada en un tiempo y costo muy alto. 7. Modera. do. Producto / item operable, pero un item de confort/conveniencia es inoperable. Cliente insatisfecho. Una parte del producto puede tener que ser desechado sin selección o reparado con un tiempo y costo alto. 6. Bajo. Producto / item operable, pero un item de confort/conveniencia son operables a niveles de desempeño bajos. El 100% del producto puede tener que ser retrabajado o reparado fuera de línea pero no necesariamente va al àrea de retrabajo . 5. Muy bajo. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 75% de los clientes. El producto puede tener que ser seleccionado, sin desecho, y una parte retrabajada. 4. Menor. No se cumple con el ajuste, acabado o presenta ruidos y rechinidos. Defecto notado por el 50% de los clientes. El producto puede tener que ser retrabajada, sin desecho, en línea, pero fuera de la estación. 3. Muy menor. No se cumple con el ajuste, acabado o presenta ruidos, y rechinidos. Defecto notado por clientes muy críticos (menos del 25%) El producto puede tener que ser retrabajado, sin desecho en la línea, en la estación. 2. Ninguno. Sin efecto perceptible. Ligero inconveniente para la operación u operador, o sin efecto. 1.")
552
Modelo de PFMEA – Paso 2 Paso 2 identificar:
Las causas asociadas (primer nivel y raíz) Su tasa de ocurrencia La designación apropiada de la característica indicada en ola columna de clasificación Acciones recomendadas para alta severidad y criticalidad (S x O) así como la Seguridad del operador (OS) y errores de proceso de alto impacto (HI)
 Su tasa de ocurrencia. La designación apropiada de la característica indicada en ola columna de clasificación. Acciones recomendadas para alta severidad y criticalidad (S x O) así como la Seguridad del operador (OS) y errores de proceso de alto impacto (HI)")
553
Modelo de PFMEA – Paso 2 Causa/Mecanismo potencial de falla
Describe la forma de cómo puede ocurrir la falla, descrito en términos de algo que puede ser corregido o controlado Se debe dar priorioridad a rangos de prioridad de 9 o 10 Ejemplos, especificar claramente: Torque inadecuado (bajo o alto) Soldadura iandecuada (corriente, tiempo, presión) Lubricación inadecuada
 Soldadura iandecuada (corriente, tiempo, presión) Lubricación inadecuada.")
554
Efecto(s) Potencial(es) de falla
Evaluar 3 (tres) niveles de Efectos del Modo de Falla Efectos Locales Efectos en el Área Local Impactos Inmediatos Efectos Mayores Subsecuentes Entre Efectos Locales y Usuario Final Efectos Finales Efecto en el Usuario Final del producto o Servicio
 niveles de Efectos del Modo de Falla. Efectos Locales. Efectos en el Área Local. Impactos Inmediatos. Efectos Mayores Subsecuentes. Entre Efectos Locales y Usuario Final. Efectos Finales. Efecto en el Usuario Final del producto o Servicio.")
555
Modelo de PFMEA – Paso 2 Suposición 1: Los materiales para la operación son correctos Ajuste de herramentales a la profundidad equivocada Desgaste de herramentales Temperatura del horno muy alta Tiempo de curado muy corto Presión de aire muy baja Velocidad del transportador no es constante Jets de lavadora desconectados

556
Modelo de PFMEA – Paso 2 Suposición 2: Los materiales para la operación tienen variación Material demasiado duro / suave / quebradizo La Dimensión no cumple especificaciones El acabado superficial de la operación 10 no cumple especificaciones El localizador de perforación fuera de posición correcta

557
Modelo de PFMEA – Paso 2 Ocurrencia:
Es la probabilidad de que una causa/mecanismo ocurra Se puede reducir o controlar solo a través de un cambio de diseño Si la ocurrencia de la causa no puede ser estimada, entonces estimar la tasa de falla posible

558
CRITERIO DE EVALUACIÓN DE OCURRENCIA SUGERIDO PARA AMEFP
Probabilidad Indices Posibles de falla ppk Calif. Muy alta: Fallas persistentes < 0.55 10 50 por mil piezas > 0.55 9 Alta: Fallas frecuentes 20 por mil piezas > 0.78 8 10 por mil piezas > 0.86 7 Moderada: Fallas ocasionales 5 por mil piezas > 0.94 6 2 por mil piezas > 1.00 5 1 por mil piezas > 1.10 4 Baja : Relativamente pocas fallas 0.5 por mil piezas > 1.20 3 0.1 por mil piezas > 1.30 2 Remota: La falla es improbable < por mil piezas > 1.67 1 100 por mil piezas

559
Modelo de PFMEA – Paso 2 Clasificación de características especiales si: Afectan la función del producto final, cumplimiento con reglamentaciones gubernamentales, seguridad de los operadores, o la satisfacción del cliente, y Requieren controles especiales de manufactura, ensamble, proveedores, embarques, monitoreo y/o inspección o seguridad

562
Modelo de PFMEA – Paso 3 En el paso 3 identificar:
Controles actuales de prevención del proceso (con acciones de diseño o proceso) usados para establecer la ocurrencia Controles actuales de detección (vg. Inspección) usados para establecer la tasa de detección Efectividad de los controles de detección del proceso en una escala de 1 a 10 El factor de riesgo RPN inicial Acciones recomendadas (Prevención y Detección)
 usados para establecer la ocurrencia. Controles actuales de detección (vg. Inspección) usados para establecer la tasa de detección. Efectividad de los controles de detección del proceso en una escala de 1 a 10. El factor de riesgo RPN inicial. Acciones recomendadas (Prevención y Detección)")
563
Identificar Causa(s) Potencial(es) de la Falla
Causas relacionadas con el diseño - Características del servicio o Pasos del proceso Diseño de formatos Asignación de recursos Equipos planeados Causas que no pueden ser Entradas de Diseño, tales como: Ambiente, Clima, Fenómenos naturales Mecanismos de Falla Rendimiento, tiempo de entrega, información completa

564
Causas potenciales De Diagrama de Ishikawa Diagrama de árbol o Diagrama de relaciones

565
Modelo de PFMEA – Paso 3 Controles de proceso actuales:
Son una descripción de los controles ya sea para prevenir o para detectar la ocurrencia de los Modos/causas de falla Consideraciones Incrementar la probabilidad de detección es costosa y no efectiva A veces se requiere un cambio en el diseño para apoyar la detección El incremento del control de calidad o frecuencia de inspección sólo debe utilizarse como medida temporal Se debe hacer énfasis en la prevención de los defectos

566
Identificar Controles de Diseño o de Proceso Actuales
Verificación/ Validación de actividades de Diseño o control de proceso usadas para evitar la causa, detectar falla anticipadamente, y/o reducir impacto: Cálculos, Análisis, Prototipo de Prueba, Pruebas piloto Poka Yokes, planes de control, listas de verificación Primera Línea de Defensa - Evitar o eliminar causas de falla o error Segunda Línea de Defensa - Identificar o detectar fallas o errores Anticipadamente Tercera Línea de Defensa - Reducir impactos/consecuencias de falla o errores

568
Modelo de PFMEA – Paso 3 Seleccionar un rango en la tabla de detección
Si se usa inspección automática al 100% considerar: La condición del gages La calibración del gage La variación del sistema de medición del gage Probabilidad de falla del gage Probabilidad de que el sistema del gage sea punteado Si se usa inspección visual al 100% considerar: Es efectiva entre un 80 a 100% dependiendo del proc. El número de personas que pueden observar el modo de falla potencialmente La naturaleza del modo de falla - ¿es claro o confuso?

569
CRITERIO DE EVALUACIÓN DE DETECCION SUGERIDO PARA AMEFP
Detecciòn Criterio Tipos de Inspección Métodos de seguridad de Rangos de Detección Calif A B C Casi imposible Certeza absoluta de no detección X No se puede detectar o no es verificada 10 Muy remota Los controles probablemente no detectarán X El control es logrado solamente con verificaciones indirectas o al azar 9 Remota Los controles tienen poca oportunidad de detección X El control es logrado solamente con inspección visual 8 Muy baja Los controles tienen poca oportunidad de detección X El control es logrado solamente con doble inspección visual 7 Baja Los controles pueden detectar X X El control es logrado con métodos gráficos con el CEP 6 Moderada Los controles pueden detectar X El control se basa en mediciones por variables después de que las partes dejan la estación, o en dispositivos Pasa NO pasa realizado en el 100% de las partes después de que las partes han dejado la estación 5 Moderadamente Alta Los controles tienen una buena oportunidad para detectar X X Detección de error en operaciones subsiguientes, o medición realizada en el ajuste y verificación de primera pieza ( solo para causas de ajuste) 4 Alta Los controles tienen una buena oportunidad para detectar X X Detección del error en la estación o detección del error en operaciones subsiguientes por filtros multiples de aceptación: suministro, instalación, verificación. No puede aceptar parte discrepante 3 Muy Alta Controles casi seguros para detectar X X Detección del error en la estación (medición automática con dispositivo de paro automático). No puede pasar la parte discrepante 2 Muy Alta Controles seguros para detectar X No se pueden hacer partes discrepantes porque el item ha pasado a prueba de errores dado el diseño del proceso/producto 1 Tipos de inspección: A) A prueba de error B) Medición automatizada C) Inspección visual/manual
 4. Alta. Los controles tienen una buena oportunidad para detectar. X. X. Detección del error en la estación o detección del error en operaciones subsiguientes por filtros multiples de aceptación: suministro, instalación, verificación. No puede aceptar parte discrepante. 3. Muy Alta. Controles casi seguros para detectar. X. X. Detección del error en la estación (medición automática con dispositivo de paro automático). No puede pasar la parte discrepante. 2. Muy Alta. Controles seguros para detectar. X. No se pueden hacer partes discrepantes porque el item ha pasado a prueba de errores dado el diseño del proceso/producto. 1. Tipos de inspección: A) A prueba de error B) Medición automatizada C) Inspección visual/manual.")
571
Modelo de PFMEA – Paso 3 Número de prioridad de riesgo
Se calcula como RPN = (S) x (O) x (D) Acciones recomendadas Se deben dirigir primero a las de valores altos de Severidad (9 o 10) o RPNs, después continuar con las demás Las acciones se deben orientar a prevenir los defectos a través de la eliminación o reducción de las causas o modos de falla
 x (O) x (D) Acciones recomendadas. Se deben dirigir primero a las de valores altos de Severidad (9 o 10) o RPNs, después continuar con las demás. Las acciones se deben orientar a prevenir los defectos a través de la eliminación o reducción de las causas o modos de falla.")
572
Calcular RPN (Número de Prioridad de Riesgo)
Producto de Severidad, Ocurrencia, y Detección RPN / Gravedad usada para identificar principales CTQs Severidad mayor o igual a 8 RPN mayor a 150

573
Reducir el riesgo general del diseño
Planear Acciones Requeridas para todos los CTQs Listar todas las acciones sugeridas, qué persona es la responsable y fecha de terminación. Describir la acción adoptada y sus resultados. Recalcular número de prioridad de riesgo . Reducir el riesgo general del diseño

574
Modelo de PFMEA – Paso 3 Acciones tomadas
Identificar al responsable de las acciones recomendadas y la fecha estimada de terminación Después de terminar una acción, dar una descripción breve de la acción real y fecha de efectividad Responsabilidad y fechas de terminación Desarrollar una lista de características especiales proporcionándola al diseñador para modificar el DFMEA Dar seguimiento a las acciones recomendadas y actualizar las últimas columnas del FMEA

575
Modelo de PFMEA – Paso 3 RPN resultante Salidas del PFMEA
Después de implementadas las acciones recomendadas, estimar de nuevo los rangos de Severidad, Ocurrencia y Detección y calcular el nuevo RPN. Si no se tomaron acciones dejarlo en blanco. Salidas del PFMEA Hay una relación directa del PFMEA a el Plan de Control del proceso

576
Causas probables a atacar primero

578
Herramientas para el FMEA

579
Herramientas Diagramas de límites Diagramas de flujo de proceso
Matriz de características Tormenta de ideas Árboles de funciones Lista de efectos: FMEA de diseño Lista de efectos: FMEA de proceso Diagrama de Ishikawa Tecnica de preguntas

580
Herramientas Análisis de árbol de fallas (FTA)
Análisis del modo de falla (FMA) Diseño de experimentos (DOE) Proceso de solución de problemas de 8Ds Planes de Control Planeación dinámica de control (DCP) Despliegue de la función de calidad (QFD) Análisis de valor/ Ingeniería del valor (VA/VE) REDPEPR FMEA Express FMEA del software
 Diseño de experimentos (DOE) Proceso de solución de problemas de 8Ds. Planes de Control. Planeación dinámica de control (DCP) Despliegue de la función de calidad (QFD) Análisis de valor/ Ingeniería del valor (VA/VE) REDPEPR. FMEA Express. FMEA del software.")
581
Diagrama de límites Diagramas de límites de funciones
Salida del análisis de funciones para la fase de concepto CFMEA, ilustran funciones en vez de partes Diagramas de límites Hardware/funcional Dividen al sistema en elementos más pequeños desde un punto de vista funcional. Muestran relaciones físicas, se usan en los DFMEAs.

582
Nombres de verbos útiles

583
Tormenta de ideas Seleccionar el problema a tratar.
Pedir a todos los miembros del equipo generen ideas para la solución del problema, las cuales se anotan en el pizarrón sin importar que tan buenas o malas sean estas. Ninguna idea es evaluada o criticada antes de considerar todos los pensamientos concernientes al problema. Aliente todo tipo de ideas, ya que al hacerlo pueden surgir cosas muy interesantes, que motivan a los participantes a generar más ideas. Apruebe la naturalidad y el buen humor con informalidad, en este punto el objetivo es tener mayor cantidad de ideas Se les otorga a los participantes la facultad de modificar o mejorar las sugerencias de otros. Una vez que se tengan un gran número de ideas el facilitador procede a agrupar y seleccionar las mejores ideas por medio del consenso del grupo Las mejores ideas son discutidas y analizadas con el fin del proponer una solución.

584
Herramientas para el FMEA
Árbol de funciones Ayuda a que los requerimientos del cliente no expresados explícitamente sobre el producto o proceso se cumplan Es conveniente describir las funciones de un producto o proceso por un verbo – pronombre medible, por ejemplo: Calentar el interior a XºC Enfriar a los ocupantes a XºC Eliminar la niebla del parabrisas en X segundos

585
Técnica de preguntas MODO DE FALLA: No ajustan los faros delanteros
Hacer una oración con el modo de falla, causa y efecto y ver si la oración tiene sentido. Un modo de falla es debido a una causa, el modo de falla podría resultar en efectos, por ejemplo: MODO DE FALLA: No ajustan los faros delanteros P: ¿Qué podría ocasionar esta falla? R: La luz desalineada -> Efecto P: ¿A que se puede deber esta falla? R: Cuerda grande en tornillo de ajuste -> Causa El “No ajuste de faros delanteros” se debe a “Cuerda grande en tornillo de ajuste”. El “desajuste de los faros” ocasiona “haces de luz desalineados”

586
Técnica de preguntas Paso 3 Paso 1 ¿Qué lo causa? Paso 2 Modo de falla
¿Qué efecto tiene?

587
Análisis de árbol de fallas (FTA)
Es una técnica analítica deductiva que usa un árbol para mostrar las relaciones causa efecto entre un evento indeseable (falla) y las diversas causas que contribuyen. Se usan símbolos lógicos para interconectar las ramas Después de hacer el FTA e identificadas las causas raíz, se pueden determinar las acciones preventivas o los controles necesarios Otra aplicación es determinar las probabilidades de las causas que contribuyen a la falla y propagarlas hacia adelante
 y las diversas causas que contribuyen. Se usan símbolos lógicos para interconectar las ramas. Después de hacer el FTA e identificadas las causas raíz, se pueden determinar las acciones preventivas o los controles necesarios. Otra aplicación es determinar las probabilidades de las causas que contribuyen a la falla y propagarlas hacia adelante.")
588
Análisis del Modo de Falla (FMA)
Es un enfoque sistemático disciplinado para cuantificar el modo de falla, tasa de falla, y causa raíz de fallas o tasas de reparación conocidas (el FMEA para las desconocidas) Se basa en información histórica de garantías, datos de campo, datos de servicios, y/o datos de procesos Se usa para identificar la operación, modos de falla, tasas de falla y parámetros críticos de diseño de hardware o procesos. También permite identificar acciones correctivas para causas raíz actuales
 Se basa en información histórica de garantías, datos de campo, datos de servicios, y/o datos de procesos. Se usa para identificar la operación, modos de falla, tasas de falla y parámetros críticos de diseño de hardware o procesos. También permite identificar acciones correctivas para causas raíz actuales.")
589
Diseño de experimentos (DOE)
Es un método para definir los arreglos en cuales se puedas realizar experimentos, donde se cambian de manera controlada las variables independientes de acuerdo a un plan definido y se determinan los efectos Para pruebas de confiabilidad el DOE usa un enfoque estadístico para diseñar pruebas para identificar los factores primarios que causas eventos indeseables Se usan para identificar causas raíz de modos de falla, cuando varios factores pueden estar contribuyendo o cuando estos factores están interrelacionados y se desean conocer los efectos de sus interacciones

590
Método de 8 disciplinas (8Ds)
Es un método de solución de problemas orientado a equipos de trabajo, las disciplinas o pasos son: Preparar el proceso Establecer el equipo Describir el problema Desarrollar las acciones de contención o contingentes Diagnosticar el problema (definir y verificar causa raíz) Seleccionar y verificar acciones correctivas permanentes (PCAs) para causas raíz y puntos de escape Implementar y validar PCAs Reconocer contribuciones del equipo y los miembros
 Seleccionar y verificar acciones correctivas permanentes (PCAs) para causas raíz y puntos de escape. Implementar y validar PCAs. Reconocer contribuciones del equipo y los miembros.")
591
Planes de control Es una descripción escrita del sistema para controlar el proceso de producción Lista todos los parámetros del proceso y características de las partes características de las partes que requiere acciones específicas de calidad El plan de control contiene todaslas características críticas y significativas Hay planes de control a nivel de manufactura de: Prototipos, producción piloto (capacidad de procesos) y de producción
 y de producción.")
592
Planeación dinámica de control (DCP)
Es un procesos que liga las herramientas de calidad para construir planes de control robustos a través de un equipo Lanzamiento – definir los requerimientos de recursos Estructura del equipo central y de soporte Bitácora de preguntas

593
Planeación dinámica de control (DCP)
4. Información de soporte (ES, DFMEAs, DVP&R, PFMEA, etc.) 5. Diagrama de flujo y carácterísticas de enlace 6. Pre lanzamiento o controles preliminares 7. PFMEA 8. Plan de control 9. Desarrollar ilustraciones e instrucciones 10. Implementar y mantener
 5. Diagrama de flujo y carácterísticas de enlace. 6. Pre lanzamiento o controles preliminares. 7. PFMEA. 8. Plan de control. 9. Desarrollar ilustraciones e instrucciones. 10. Implementar y mantener.")
594
Despliegue de la función de calidad (QFD)
El QFD es un método estructurado en el cual los requerimientos del cliente son traducidos en requerimientos técnicos para cada una de las etapas del desarrollo del producto y producción El QFD es entrada al FMEA de diseño o al FMEA de concepto. Los datos se anotan en el FMEA como medidas en la columna de función La necesidad de obtener datos de QFD pueden ser también una salida del FMEA de concepto

595
Análisis del valor / Ingeniería del valor (VA/VE)
Son metodologías usadas comúnmente para despliegue del valor. La Ingeniería del valor se realiza antes de comprometer el herramental. El análisis del valor (VA) se realiza después del herramentado. Ambas técnicas usan la fórmula: Valor = Función (primaria o secundaria) / Costo Los datos de VA/VE pueden ser entradas al FMEA de diseño o de proceso en columna de Función como funciones primaria y secundaria. También pueden ser causas, controles o acciones recomendadas La metodología VA debe ser incluida en la revisión de FMEAs actuales como apoyo para evaluar riesgos y beneficios cuando se analizan varias propuestas
 se realiza después del herramentado. Ambas técnicas usan la fórmula: Valor = Función (primaria o secundaria) / Costo. Los datos de VA/VE pueden ser entradas al FMEA de diseño o de proceso en columna de Función como funciones primaria y secundaria. También pueden ser causas, controles o acciones recomendadas. La metodología VA debe ser incluida en la revisión de FMEAs actuales como apoyo para evaluar riesgos y beneficios cuando se analizan varias propuestas.")
596
REDPEPR (Robust Engineering Design Product Enhacement Process)
Es una herramienta que proporciona a los equipos de Diseño: Un proceso paso a paso para aplicar el RED Las herramientas necesarias para completar el diagrama P, listas de verificación de confiabilidad y robustez (RRCL) y la matriz de demostración de confiabilidad y robustez (RRDM) Preguntas y tips para guiar al equipo en el proceso Capacidad para generar reportes en Excel Un proceso para mejorar la comunicación con el equipo de ingeneiría El Web site donde se encuentra el software es
 y la matriz de demostración de confiabilidad y robustez (RRDM) Preguntas y tips para guiar al equipo en el proceso. Capacidad para generar reportes en Excel. Un proceso para mejorar la comunicación con el equipo de ingeneiría. El Web site donde se encuentra el software es")
597
Express Ambiental De máquinas
Aplicaciones del FMEA Express Ambiental De máquinas

598
FMEA Express Es un proceso que aplica técnicas de FMEA simultaneamente tanto a los aspectos de diseño como a los de manufactura de un proyecto: Consiste de cuatro fases: Preparación: Se forma un equipo directivo para definir el alcance del proyecto, equipo de trabajo multidisciplinario, colección de información y documentos de modos de falla conocidos, causas, efectos y controles

599
FMEA Express Desarrollo del FMEA: El equipo de trabajo multidisciplianrio completa el FMEA utilizando formatos y definiciones estándar Posterior a la tarea: El facilitador y el equipo directivo generan un reporte final y un plan de seguimiento. El líder del equipo de FMEA es responsable de monitorear el avance Auditoría de calidad: Después de una verificación de calidad, se proporciona un certificado de cumplimiento Software para el FMEA:

600
E-FMEA ambiental

601
E-FMEA ambiental

602
Matriz de requerimientos ambientales con criterios múltiples
Para cada alternativa de diseño resumir la siguiente información Uso de substancias prohibidas o de uso restringido Tipo y cantidad de residuos (refleja el nivel de materiales utilizados) Consumo de energía por componente Consumo de agua por componente Otros objetivos ambientales
 Consumo de energía por componente. Consumo de agua por componente. Otros objetivos ambientales.")
603
E-FMEA Ejemplos de acciones recomendadas (hacer una revisión previa de efectos secundarios en la vida del producto): Sistemas de conexión alternos Reciclar Rutas alternas de disposición de residuos Uso de materiales naturales Revisar rutas de transporte Reducir trayectorias de proceso Optimizar el consumo de agua y energía

604
E-FMEA Salidas del FMEA ambiental: Recomendaciones de materiales
Recomendaciones de diseño (vg. Tipo de enlace) Recomendaciones de proceso (vg. Potencial de ahorro de energía) Recomendación para rutas de disposición
 Recomendaciones de proceso (vg. Potencial de ahorro de energía) Recomendación para rutas de disposición.")
605
MFMEA – FMEA de maquinaria

606
FMEA de maquinaria Su propósito es que a través de un equipo se asegure que los modos de falla y sus causas/mecanismos asociados se hayan atendido Soporta el proceso de diseño en: Apoyar en la evaluación objetiva de las funciones del equipo, requerimientos de diseño y alternativas de diseño Incrementar la probabilidad de que los modos de falla y sus efectos en la maquinaria se han considerado en el proceso de diseño y desarrollo

607
FMEA de maquinaria Proporcionar información adicional como apoyo a la planeación de todos los programas de diseño, prueba y desarrollo Desarrollar una lista de modos de falla potenciales en base a su efecto con el cliente, estableciendo prioridades para mejoras al diseño y desarrollo Proporcionar documentación para referencia futura para el análisis de problemas de campo, evaluando cambios de diseño y desarrollo de maquinaria.

608
FMEA de maquinaria Ejemplos de descripción de funciones
Proceso de partes – 120 tareas / hora Cabezal del índice – MTBF > 200 Hrs Control del flujo hidráulico – 8p cl/seg. Sistema de posición – Ángulo de rotación de 30º Hacer un barreno – Rendimiento a la primera 99.9%

609
FMEA de maquinaria Efectos potenciales como consecuencias de falla de subsistemas en relación a seguridad y “Las 7 grandes pérdidas” Falla – pérdidas resultado de una pérdida funcional o reducción de la función sobre una parte del equipo requiriendo intervención de mantenimiento Preparación y ajustes – pérdidas que son resultado de procedimientos de preparación tal como herramentado, cambio de modelo o cambio de molde. Los ajustes incluyen el tiempo muerto usado para ajustar el equipo para evitar defectos y bajo rendimiento, requiriendo intervención del operador o ajustador

610
FMEA de maquinaria Tiempo de espera y paros menores – pérdidas resultado de interrupciones menores al flujo del proceso (como atoramiento de microswitch) requiriendo intervención del operador. El tiempo de espera sólo se puede resolver revisando el sistema / línea completa Capacidad reducida – pérdidas que resultan de la diferencia entre el ciclo de tiempo ideal del equipo y su tiempo de ciclo real. El tiempo de ciclo ideal se determina por: a) velocidad original; b) condiciones óptimas y c) tiempo máximo de ciclo logrado con maquinaria similar
 requiriendo intervención del operador. El tiempo de espera sólo se puede resolver revisando el sistema / línea completa. Capacidad reducida – pérdidas que resultan de la diferencia entre el ciclo de tiempo ideal del equipo y su tiempo de ciclo real. El tiempo de ciclo ideal se determina por: a) velocidad original; b) condiciones óptimas y c) tiempo máximo de ciclo logrado con maquinaria similar.")
611
FMEA de maquinaria Pérdidas en el arranque – pérdidas que ocurren durante los primeros pasos del proceso productivo después de paros largos (fines de semana, días de azueto, o entre turnos), resultando en rendimiento reducido o incremento de desperdicio y rechazos Partes defectivas – pérdidas que resultan de la generación de defectos que producen retrabajo, reaparaciones, y/o partes no útiles Herramentales – pérdidas que resultan de fallas en el herramental, rotura, deterioración o desgaste (vg. Herramientas de corte, tips de soldadura, etc.)
, resultando en rendimiento reducido o incremento de desperdicio y rechazos. Partes defectivas – pérdidas que resultan de la generación de defectos que producen retrabajo, reaparaciones, y/o partes no útiles. Herramentales – pérdidas que resultan de fallas en el herramental, rotura, deterioración o desgaste (vg. Herramientas de corte, tips de soldadura, etc.)")
612
FMEA de maquinaria Criterios de Severidad

613
FMEA de maquinaria Causas potenciales, se asume que la maquinaria se fabricó, instaló, usó, y se dispuso de acuerdo a sus especificaciones, preguntarse para identificar causas potenciales lo siguiente: ¿Cuáles son las circunstancias que pueden orientar al componente, subsistema y sistema a no cumplir sus requerimientos funcionales / de desempeño? ¿A qué grado pueden los componentes, subsistemas y sistemas que interactúan ser compatibles? ¿Qué especificaciones garantizan compatibilidad?

614
FMEA de maquinaria Criterios de Ocurrencia

615
FMEA de maquinaria Criterios de Detección

616
Herramientas de la Fase de Análisis
Identificación de causas potenciales Cartas Multivari y Análisis de Regresión Intervalos de confianza y Pruebas de Hipótesis

617
Identificación de causas potenciales
Tormenta de ideas Diagrama de Ishikawa Diagrama de Relaciones Diagrama de Árbol Verificación de causas raíz

618
Tormenta de ideas Técnica para generar ideas creativas cuando la mejor solución no es obvia. Reunir a un equipo de trabajo (4 a 10 miembros) en un lugar adecuado El problema a analizar debe estar siempre visible Generar y registrar en el diagrama de Ishikawa un gran número de ideas, sin juzgarlas, ni criticarlas Motivar a que todos participen con la misma oportunidad
 en un lugar adecuado. El problema a analizar debe estar siempre visible. Generar y registrar en el diagrama de Ishikawa un gran número de ideas, sin juzgarlas, ni criticarlas. Motivar a que todos participen con la misma oportunidad.")
619
Tormenta de ideas Permite obtener ideas de los participantes

620
Diagrama de Ishikawa Anotar el problema en el cuadro de la derecha
Anotar en rotafolio las ideas sobre las posibles causas asignándolas a las ramas correspondientes a: Medio ambiente Mediciones Materia Prima Maquinaria Personal y Métodos o Las diferentes etapas del proceso de manufactura o servicio

621
Diagrama de Ishikawa

622
TIPS PARA EL INSTRUCTOR
Diagrama de relaciones Programación deficiente Capacidad instalada desconocida Marketing no tiene en cuenta cap de p. Mala prog. De ordenes de compra Compras aprovecha ofertas Falta de com..... Entre las dif. áreas de la empresa Duplicidad de funciones Las un. Reciben ordenes de dos deptos diferentes Altos inventarios No hay control de inv..... En proc. Demasiados deptos de inv..... Y desarrollo Falta de prog. De la op. En base a los pedidos No hay com..... Entre las UN y la oper. Falta de coordinación al fincar pedidos entre marketing y la op. Falta de control de inventarios en compras Influencia de la situación econ del país No hay com..... Entre compras con la op. general No hay coordinación entre la operación y las unidades del negocio Falta de coordinación entre el enlace de compras de cada unidad con compras corporativo Influencia directa de marketing sobre Compra de material para el desarrollo de nuevos productos por parte inv..... Y desarrollo’’’ No hay flujo efectivo de mat. Por falta de programación de acuerdo a pedidos Perdida de mercado debido a la competencia Constantes cancelaciones de pedidos de marketing entre marketing operaciones Falta de comunicación entre las unidades NOTAS DEL INSTRUCTOR TIPS PARA EL INSTRUCTOR El instructor mostrará éste ejemplo de inventarios y pedirá a los participantes elaboren, si es que aplica, un diagrama de relaciones para su proyecto. Tomar 25 minutos para que trabajen los equipos y 5 minutos de plenaria. D-17

623
Dancer Taco generador del motor Poleas guías Presión del dancer Mal guiado Sensor de velocidad de línea Sensor circunferencial Bandas de transmisión Empaques de arrastre Presión de aire de trabajo Drive principal Voltaje del motor Ejes principales Poleas de transmisión ¿Que nos puede provocar Variación de Velocidad Durante el ciclo de cambio en la sección del Embobinadores? Causas a validar 13/0 2/4 0/4 1/2 5/1 1/4 2/1 1/1 0/3 5/2 4/1 1/5 Entradas Causa Salidas Efecto

624
Interrelationship Diagraph Business Planning Process
What Data Needs to be Collected to understand the sources of variation in a key measure ? Interrelationship Diagraph Allows a team to identify & classify the cause and effect relationships that exist among variables Business Planning Process Communica- tion issues within the group External factors impact implemen- tation Means not clearly defined Plan not integrated Fast new product introductions stretch resources Lack of time and No strong commitment to the group Driver Planning approach not standardized Outcome Capacity may not meet needs In = 1 Out = 3 In = 3 Out = 2 In = 2 Out = 4 In = 1 Out = 2 In = 2 Out = 0 In = 0 Out = 5 In = 5 Out = 1 In = 0 Out = 2 In = 5 Out = 0

625
TIPS PARA EL INSTRUCTOR
Diagrama de árbol o sistemático NOTAS DEL INSTRUCTOR Meta Medio Segundo nivel Cuarto nivel Tercer nivel Primer nivel Meta u objetivo Medios o planes TIPS PARA EL INSTRUCTOR El instructor explicará que ésta es la forma que toma el diagrama sistemático, resaltando que una meta se convierte en un medio Es decir vamos dividiendo las grandes tareas en pequeñas tareas, que a su vez son más fáciles de solucionar y nos ayudan a alcanzar nuestro objetivo. D-20

626
Diagrama de Arbol- Aplicación Sistema SMED
¿Cómo? ¿Cuándo? Preparación para el SMED Filmar la preparación Mar-04 Analizar el video 10 y 17 –Mar-04 Describir las tareas 17- Mar-04 ¿Objetivo? Separar las tareas 17- Mar-04 Fase 1: Separación de la preparación interna de la externa Elaborar lista de chequeo 2- Mar-04 Implantar el Sistema SMED Producto DJ 2702 Realizar chequeo de funciones 24- Mar-04 Analizar el transporte de herramientas y materiales 24- Mar-04 ¿Qué? Analizar las funciones y propósito de c/operación 12 - Abr- 04 Fase 2: Conversión de preparación interna en externa Convertir tareas de prepa- ración interna a externas 15 –Abr - 04 Elaboramos un Diagrama de Arbol para poder analizar nuestro problema siguiendo el sistema SMED. Realización de operaciones en paralelo. 5 –May -04 Fase 3: Refinamiento de todos los aspectos de la preparación. Uso de sujeciones funcionales. 19– May -04 Eliminación de ajustes 12- May -04 19

627
Verificación de posibles causas
Para cada causa probable , el equipo deberá por medio del diagrama 5Ws – 1H: Llevar a cabo una tormenta de ideas para verificar la causa. Seleccionar la manera que: represente la causa de forma efectiva, y sea fácil y rápida de aplicar.

628
Calendario de las actividades
¿qué? ¿por qué? ¿cómo? ¿cuándo? ¿dónde? ¿quién? 1 Tacogenerador de motor embobinador 1.1 Por variación de voltaje durante el ciclo de cambio 1.1.1 Tomar dimensiones de ensamble entre coples. 1.1.2 Verificar estado actual y especificaciones de escobillas. 1.1.3 tomar valores de voltaje de salida durante el ciclo de cambio. Abril ’04 1804 Embob. J. R. 2 Sensor circular y de velocidad de linea. 2.1 Por que nos genera una varión en la señal de referencia hacia el control de velocidad del motor embobinador 2.1.1 Tomar dimensiones de la distancia entre poleas y sensores. 2.1.2 Tomar valores de voltaje de salida de los sensores. 2.1.3 Verificar estado de rodamientos de poleas. 1804 Embob. U. P. 3 Ejes principales de transmisión. 3.1 Por vibración excesiva durante el ciclo de cambio 3.1.1 Tomar lecturas de vibración en alojamientos de rodamientos 3.1.2 Comparar valores de vibraciones con lecturas anteriores. 3.1.3 Analizar valor lecturas de vibración tomadas. Abril’04 F. F. 4 Poleas de transmisión de ejes embobinadores. 4.1 Puede generar vibración excesiva durante el ciclo de cambio. 4.1.1 Verificar alineación, entre poleas de ejes principales y polea de transmisión del motor. 4.1.2 Tomar dimensiones de poleas(dientes de transmisión). 4.1.3 Tomar dimensiones de bandas (dientes de transmisión) 4.1.4 Verificar valor de tensión de bandas.
 Tomar dimensiones de bandas (dientes de transmisión) Verificar valor de tensión de bandas.")
629
Resumen de la validación de las causas
# de Causa Causas Resultados Causa Raíz 1 2 3 4 5 6 7 Ensamble de ojillos, bloques y contrapesos no adecuados en aspas. Amortiguadores dañados. Desgaste de bujes en los carretes. Fabricación y reemplazo de ejes y poleas no adecuados en ensamble de aspas. Desalineamiento de poleas y bandas de transmisión de aspas. Método de Balanceo no adecuado. Desalineación de pinolas en cuna. SI ES CAUSA RAIZ NO ES CAUSA RAIZ X

630
VI.D Métodos de análisis adicionales

631
Métodos adicionales de análisis
1. Análisis de brecha 2. Análisis de causa raíz 3. Análisis del Muda

632
VI.D.1 Análisis de brecha

633
El análisis de brecha (Gap Analysis) es una herramienta de evaluación para comparar el desempeño actual de la organización, a un desempeño potencial deseado. Identifica la diferencia de lo que es y lo que debería ser

634
Análisis de brecha Se pueden redirigir los esfuerzos a objetivos como:
Permanecer en el negocio Mantener o incrementar la participación del mercado Mejorar el clima laboral Igualar o exceder a Benchmarks Igualar o exceder a la competencia Reducir tiempos de ciclo Lograr certificaciones Mejorar la productividad Mejorar los niveles de calidad

635
Análisis de brecha Se requieren tres categorías de información
¿Dónde estamos? ¿Dónde queremos ir? ¿Cómo vamos a medir los resultados?

636
Planeación de escenarios
Al elaborar planes estratégicos, los directivos pueden confiarse o ser orgullosos de aceptar cambios. Por lo que se sugiere considerar escenarios del mejor y del peor caso, para evitar errores en la toma de decisiones Los escenarios permiten imaginar el desempeño futuro de la organización ante riesgos, para tomar las mejores decisiones y atender estos eventos. Aunque algunos elementos sean desconocidos

637
Planeación de escenarios
El proceso de planeación es como sigue: Seleccionar al personal que pueda dar muchas perspectivas Desarrollar una lista de cambios percibidos, sociales, técnicos y económicos Agrupar estas percepciones en patrones relacionados Desarrollar una lista de las mejores percepciones (prioridades)
")
638
Planeación de escenarios
El proceso de planeación es como sigue: Desarrollar un escenario grueso del futuro basado en estas prioridades Determinar como afectan los escenarios a la organización Determinar los cursos de acción potenciales a tomar Monitorear, evaluar, y revisar los escenarios

639
Planeación de escenarios
Por lo común se perciben de 6 – 10 amenazas u oportunidades en 2 o 3 escenarios desarrollados. Evitar las siguientes trampas: No utilizar un facilitador experimentado Considerar escenarios como pronósticos Hacer escenarios simplistas Limitar el impacto global de los escenarios

640
Planeación de escenarios
Evitar las siguientes trampas…..: No incluir a un equipo directivo en el proceso Tratar los escenarios solo como actividad informativa Limitar el estímulo imaginativo en el diseño del escenario No desarrollar escenarios para área de impacto clave del negocio

641
Planeación Hoshin Es una herramienta de ejecución, usada para organizar y desplegar planes estratégicos Hoshin traduce la visión de la empresa en resultados medibles dramáticos y rupturas estratégicas Hoshin se enfoca a identificar los pocos logros vitales de ruptura

642
Planeación Hoshin Tiene seis objetivos:
Alinear las metas organizacionales Enfocarse en las pocas brechas vitales estratégicas Trabajar con otros para cerrar las brechas Especificar los métodos para lograr los objetivos Hacer visible el enlace entre planes locales Mejora continua del proceso de planeación

643
Otras técnicas de análisis clave
Benchmarking Análisis FODA Análisis PEST Las cinco fuerzas competitivas de Porter

644
Evaluación organizacional
Análisis funcional con datos de colección: Entrevistas cara a cara Selección de muestra apropiada Entradas de grupo de enfoque Observaciones de visitas a la planta Datos colectados de fuentes de la industria Se divide a la organización en áreas funcionales clave Liderazgo, prácticas de negocio, análisis financiero, mercadotecnia, gestión de la calidad, diseño y desarrollo, manufactura, salud y seguridad, etc…

645
Evaluación organizacional
Se deben analizar los resultados y presentarlos a la dirección, quien debe promover e implementar planes de acción claros Normalmente el consultor colecta y resume la información en categorías principales para su revisión por la dirección. Quienes deben generar e implementar las soluciones y guiar al éxito

646
Métricas organizacionales
Se establecen metas de desempeño organizacional y sus métricas en las áreas de: Utilidades Tiempos de ciclo Recursos Respuestas del mercado Por cada meta organizacional mayor deben desarrollarse métricas, con unidades y métodos de medición.

647
Métricas organizacionales
Para los anteriores, las métricas pueden ser: Utilidades a corto y largo plazo Valor de acciones, inversión de capital, costos personales, comparaciones competitivas, ROI, ventas$ Tiempos de ciclo Tiempos de ciclo actuales Benchmarks internos Benchmarks externos Reducción en tiempos de ciclo

648
Métricas organizacionales
Recursos No. De proyectos de mejora, ROI de proyectos, estudios de capacidad de procesos, reducciones de variabilidad, costos de calidad con relación a una base, porcentaje de defectos con relación a alguna base Respuestas del mercado Encuestas con clientes Análisis de devoluciones Desarrollo de nuevos productos Retención de clientes Pérdidas con clientes Tasas de cortesías e instalaciones

649
Métricas organizacionales
Las métricas permiten medir los avances en relación a las metas organizacionales De acuerdo a Juran se debe tomar en cuenta lo siguiente: Las métricas deben tener un significado estándar Deben apoyar el proceso de toma de decisiones Deben proporcionar información valiosa Debe ser fácil de instalar Si son valiosas, deben usarse en todo Las métricas se basan en la retroalimentación con base en clientes, proveedores, o internas

650
VI.D.2 Análisis de causa raíz

651
Análisis de causa raíz Un equipo tiene la responsabilidad de determinar la causa raíz de una deficiencia y corregirla. Pueden tomar varios pasos: Situación (presa con fuga) Acción inmediata (desahogarla) Acción intermedia (reparar la presa) Acción en la causa raíz (identificar que causó la fuga para evitar su recurrencia y reconstruir la presa)
 Acción inmediata (desahogarla) Acción intermedia (reparar la presa) Acción en la causa raíz (identificar que causó la fuga para evitar su recurrencia y reconstruir la presa)")
652
Análisis de causa raíz Se pueden utilizar las siguientes herramientas:
Herramientas subjetivas: Preguntar por qué cinco veces, tormenta de ideas, análisis de flujo de proceso, PHVA, grupo nominal, observación de operación, diagrama de causa efecto, técnicas de consenso, seis sombreros de pensamiento, equipos de trabajo, FMEA, FTA

653
Análisis de causa raíz Se pueden utilizar las siguientes herramientas:
Herramientas analíticas: Colección y análisis de datos Análisis de Pareto, análisis de regresión, hoja de verificación Análisis de matriz de datos Análisis de capacidad de procesos, división de variación Subgrupos de datos, experimentos simples, DOE Pruebas analíticas, cartas de control

654
Análisis de causa raíz Ante una acción correctiva permanente, la dirección debe determinar si: El análisis de causa raíz ha identificado el impacto completo del problema La acción correctiva es efectiva para eliminar o prevenir la recurrencia La acción correctiva es realista y sostenible

655
Los 5 Por qués Se hace la pregunta ¿Por qué? Cinco veces
¿Por qué? Nos faltaron partes por máquina dañada ¿Por qué? La máquina no ha tenido mantenimiento en los últimos 3 meses ¿Por qué? El departamento de mantenimiento se ha reducido a 6 personas de 8 ¿Por qué? Se pasó del presupuesto, les quitaron el tiempo extra y dos personas ¿Por qué? La empresa no ha tenido los resultados esperados y el director ha hecho recortes para salvar la situación, teme por su puesto

656
5Ws y 1H El método de las 5Ws y 1H se resume al preguntar ¿quién?, ¿qué?, ¿cuándo?, ¿dónde?, ¿por qué? Y ¿cómo?. Pueden usarse las ramas del diagrama de causa efecto

657
Diagrama de causa efecto
Rompe el problema en partes más pequeñas Muestra muchas causas potenciales gráficamente Muestra como interactúan las causas Sigue las reglas de la tormenta de ideas Las sesiones tienen tres partes: Tormenta de ideas Dar prioridades (identificar las tres causas principales) Desarrollo de un plan de acción
 Desarrollo de un plan de acción.")
658
Diagrama de Pareto Sirve para identificar problemas u oportunidades prioritarias o mayores De acuerdo a Juran permite identificar “los pocos vitales” de los “muchos triviales” El principio de Pareto sugiere que unas cuantas categorías de problemas (20% aprox.) presentan la mayor oportunidad para la mejora (80% aprox.)
 presentan la mayor oportunidad para la mejora (80% aprox.)")
659
Método de las 8 disciplinas - Ford
El método de Ford para el análisis de causa raíz es: D1. Establecer el equipo D2. Describir el problema D3. Desarrollar una acción de contención D4. Identificar la causa raíz D5. Desarrollar alternativas de solución D6. Implementar una acción correctiva permanente D7. Prevenir la recurrencia D8. Reconocer al equipo y las contribuciones individuales

660
Análisis de árbol de falla - FTA
FTA es un método sistemático deductivo, para definir un evento singular específico e indeseable, y determinar todas las posibles razones (fallas) que pueden hacer que ocurra el evento Se utiliza el las primeras fases del diseño como herramienta para impulsar modificaciones iniciales de diseño.
 que pueden hacer que ocurra el evento. Se utiliza el las primeras fases del diseño como herramienta para impulsar modificaciones iniciales de diseño.")
661
Análisis de árbol de falla - FTA
Otras áreas de su aplicación son: Análisis funcional de sistemas complejos Evaluación de requerimientos de seguridad, confiabilidad, defectos de diseño, riesgos de peligro, acciones correctivas, simplificación de mantenimiento y detección de falla, eliminación lógica de causas de falla

662
Análisis de árbol de falla - FTA
Se prefiere el FTA en vez del FMEA cuando: La seguridad el personal es importante Se pueden identificar un número pequeño de eventos superiores Hay alto potencial de falla El problema es cuantificar la evaluación del riesgo La funcionalidad del producto es altamente compleja El producto no es reaprables

663
Análisis de árbol de falla - FTA
Se prefiere el FMEA en vez del FTA cuando: Los eventos superiores no se pueden definir explícitamente Son factibles múltiples perfiles potencialmente exitosos La identificación de todos los modos de falla es importante La funcionalidad del producto tiene poca intervención externa

664
Análisis de árbol de falla - FTA
Símbolos de compuertas lógicas para determinar la confiabilidad del sistema. Hay símbolos de eventos y símbolos de compuertas Símbolos de eventos Evento superior, falla a nivel sistema o evento indeseable Evento básico, evento falla de más bajo nivel a estudiar Evento de falla, evento de falla de bajo nivel. Puede recibir entradas o proporcionar salidas a una compuerta lógica

665
Análisis de árbol de falla - FTA
Símbolos de compuertas lógicas “AND”. El evento de salida ocurre solo Si ocurren todos los eventos de entrada Simultaneamente “OR”. El evento de salida ocurre si Ocurre alguno de los eventos de La entrada

666
Análisis de árbol de falla - FTA
Ejemplo: se asume que falla el sistema superior

667
Análisis de árbol de falla - FTA
La probabilidad de falla del sistema es 5.02%. Se indica que el teclado es prioritario (0.20), después la CPU (0.015) y el monitor (0.015)
, después la CPU (0.015) y el monitor (0.015)")
668
VI.D.3 Análisis del Muda

669
Análisis de Muda Las actividades que no agregan valor se clasifican como Muda, de acuerdo a Imai son: Sobreproducción Inventarios Reparaciones / rechazos Movimientos Transportes Re – Procesos Esperas

670
Sobreproducción Se produce más en cierto momento, por:
Producir más de lo necesario por el siguiente proceso Producir antes de lo requerido por el siguiente proceso Producir más rápido de lo requerido por el siguiente proceso Sus consecuencias son: Espacio extra en las instalaciones del cliente Materias primas adicionales en uso Utilización de energéticos y transportes adicionales Costos de programación adicionales

671
Inventario en exceso Las partes, materias primas, inventario en proceso, refacciones y productos terminados forman el inventario, el inventario es Muda ya que requiere: Espacio en piso, Transporte, Montacargas Sistemas de transportadores Interés sobre el costo de los materiales Puede verse afectado por: El polvo, deterioro, obsolescencia Humedad (oxidación), daño durante el manejo
, daño durante el manejo.")
672
Inventario en exceso Las partes, materias primas, inventario en proceso, refacciones y productos terminados forman el inventario, el inventario es Muda ya que requiere: Espacio en piso, Transporte, Montacargas Sistemas de transportadores Interés sobre el costo de los materiales Puede verse afectado por: El polvo, deterioro, obsolescencia Humedad (oxidación), daño durante el manejo
, daño durante el manejo.")
673
Reparaciones / defectos
Las reparaciones o el retrabajo de partes defectivas significa un segundo intento de producirlas bien. Se rompe el Takt Time Puede haber desperdicio de materiales o productos no recuperable Si hay defectos, no puede implementarse el flujo de una pieza Los cambios de diseño también son Muda

674
Movimientos Los movimientos adicionales del personal son Muda. Caminar mucho, cargar pesado, agacharse, estirarse mucho, repetir movimientos, etc. El lugar de trabajo debe diseñarse ergonómicamente, analizando cada estación de trabajo La ergonomía puede causar daños y producción perdida

675
Movimientos Algunas reglas de la ergonomía incluyen:
Enfatizar la seguridad todas las veces Adecuar el empelado a la tarea Cambiar el lugar de trabajo para que se adecue al empleado Mantener posiciones neutrales del cuerpo Rediseñar las herramientas para reducir esfuerzo y daños Variar las tareas con rotación de puestos Hacer que la máquina sirva al ser humano

676
Reprocesos Consiste de pasos adicionales en el proceso de manufactura, por ejemplo: Remoción de rebabas Maquinado de partes mal moldeadas Agregar procesos de manejo adicionales Realizar procesos de inspección Repetir cambios al producto innecesarios Mantener copias adicionales de información

677
Transportes Todo transporte es Muda excepto la entrega al cliente. Incluye: Uso de montacargas Uso de transportadores Uso de movedores de pallets y camiones Puede ser causado por: Deficiente distribución de planta o de celdas Tiempos de espera largos, áreas grandes de almacenaje, o problemas de programación

678
Esperas Ocurre cuando un operador está listo para realizar su operación, pero permanece ocioso, por falla de máquina, falta de partes, paros de línea, etc. El Muda de espera puede ser por: Operadores ociosos Fallas de maquinaria Tiempos de ajuste y preparación largos Tareas no programadas a tiempo Flujo de materiales en lotes Juntas largas e innecesarias

679
Mudas adicionales Otros mudas adicionales a los 7 desperdicios son:
Recursos mal utilizados Recursos poco utilizados Actividades de conteo Búsqueda de herramientas o partes Sistemas múltiples Manos múltiples Aprobaciones innecesarias Fallas de máquinas Envío de producto defectivo al cliente o mal servicio

680
Salidas de la Fase de Análisis
Causas raíz validadas Guía de oportunidades de mejora

681
Preguntas ejemplo 1. En un sentido amplio, cuantas de las siguientes causas de variación en estudios multi vari pueden incluir elementos de proceso relacionados con el tiempo: I. Posicional II. Cilíndrica III. Temporal a. I y II c. II y III b. I y III d. I, II y III 2. En un estudio de análisis de regresión con dos variables, ¿que representa el término Beta 1?: a. La pendiente de la línea b. La interacción de la medición c. La intersección en el eje X d. La intersección en el eje Y 3. Se hace un estudio entre la velocidad de coches y su consumo de gasolina. El coeficiente de correlación es de Después se encontró que el velocímetro está equivocado y debió haber marcado 5 km. De más. Se recalcula el coeficiente de correlación, que debe dar: a b c d

682
Preguntas ejemplo 4. La siguiente ecuación es:
a. La covarianza de X y Y b. El coeficiente de correlación de X y Y c. El coeficiente de determinación de X y Y d. La varianza del producto de X y Y 5. Según la figura, ¿Cuál de las afirmaciones siguientes es falsa? I. El coeficiente de correlación es negativo II. El coeficiente de determinación es positivo III. El coeficiente de determinación es menor que el coeficiente de correlación a. Sólo I c. Sólo III b. Sólo II d. II y III

683
Preguntas ejemplo 6. Un problema de correlación:
a. Se resuelve estimado el valor de la variable dependiente para varios valores de la variable independiente b. Considera la variación conjunta de las dos mediciones, ninguna de las cuales es restringida por el experimentador c. Es un caso donde la distribución relevante debe ser geométrica d. Se resuelve al asumir que las variables son normales e independientemente distribuidas con media cero y varianza “s”

684
Preguntas ejemplo 7. Una muestra aleatoria de tamaño n se toma de una gran población con desviación estándar de 1.0”. El tamaño de muestra se determina de manera que haya un 0.05 de probabilidad de riesgo de exceder 0.1” de error de tolerancia al usar la media de la muestra para estimar la Mu. ¿Cuál de los siguientes valores es el más cercano al tamaño de muestra requerido? a. 365 b. 40 c d. 100 8. La diferencia entre poner alfa de 0.05 y alfa igual a 0.01 en una prueba de hipótesis es: a. Con alfa de 0.05 se tiene mayor tendencia a cometer un error tipo I b. Con alfa de 0.05 se tiene más posibilidad de riesgo de cometer un error tipo II c. Con alfa de 0.05 es una prueba más “conservadora” de la hipótesis nula Ho d. Con alfa de 0.05 se tiene menos posibilidad de cometer un error tipo I 9. Si un tamaño de muestra de 16 tiene un promedio de 12 y una desviación estándar de 3, estimar el intervalo de confianza para un nivel de confianza del 95% para la población (asumir una distribución normal)
")
685
Preguntas ejemplo 10. En una muestra aleatoria de 900 vehículos, 80% tienen frenos ABS. ¿Cuál es el intervalo del 95% para el porcentaje de vehículos con frenos ABS? a – c – 0.964 b – d – 0.826 11. Determinar si los siguientes dos tipos de misiles tienen diferencias significativas en sus varianzas a un nivel del 5%: Misil A: 61 lecturas Varianza = km2. Misil B: 31 lecturas Varianza = km2. a. Hay diferencia significativa ya que Fcalc < Ftablas b. No hay diferencia significativa por que Fcalc < Ftablas c. Hay diferencia significativa por que Fcalc > Ftablas d. No hay diferencia significativa pro que Facla > Ftablas 12. El valor crítico para t, cuando se hace una prueba t de dos colas, con muestras de 13 y alfa de 0.05 es: a c b d

686
Preguntas ejemplo 13. Tres personas en entrenamiento se les proporciona el mismo lote de 50 piezas y se les pide que las clasifiquen como buenas o defectuosas, con los resultados siguientes: Persona Para determinar si hay o no hay diferencia en la habilidad de las tres personas para clasificar adecuadamente las partes, ¿cuál de los siguiente es (son) verdadero? I. El valor calculado de Chi cuadrada es de 6.9 II. Para un nivel de significancia de 0.05, el valor crítico de Chi cuadrada es de 5.99 III. Como el valor calaculado de Chi cuadrada en mayor a 5.99, se rechaza la hipótesis nula a. Sólo I c. Sólo II b. I y II d. I, II y III 14. Un análisis de varianza de dos vías tiene r niveles para una variable y c niveles para la otra, con dos obseraciones por celda. Los grados de libertad para la interacción son: a. 2 (r ) (c ) b. (r-1) (c-1) c. rc – 1 d. 2 (r -1) (c – 1)
 verdadero I. El valor calculado de Chi cuadrada es de 6.9. II. Para un nivel de significancia de 0.05, el valor crítico de Chi cuadrada es de III. Como el valor calaculado de Chi cuadrada en mayor a 5.99, se rechaza la hipótesis nula. a. Sólo I c. Sólo II. b. I y II d. I, II y III. 14. Un análisis de varianza de dos vías tiene r niveles para una variable y c niveles para la otra, con dos obseraciones por celda. Los grados de libertad para la interacción son: a. 2 (r ) (c ) b. (r-1) (c-1) c. rc – 1 d. 2 (r -1) (c – 1)")
687
Preguntas ejemplo 15. Los supuestos básicos del análisis de varianza oncluyen: I. Las observaciones vienen de poblaciones normales II. Las observaciones vienen de poblaciones con vaianzas iguales III. Las observaciones vienen de poblaciones con medias iguales a. I y II c. II y III b. I y III d. I, II y III 16. El valor teórico esperado para una celda en la tabla de contingencia se calcula como:

688
Preguntas ejemplo 17. ¿Cuál de las siguientes afirmaciones son verdaderas en relación a las pruebas no paramétricas? I. Tienen mayor eficiencia que sus equivalentes pruebas paramétricas II. Pueden ser aplicadas a estudios de correlación III. Requieren supuestos acerca de la forma oi naturaleza de las poblaciones involucradas IV. Requieren cálculos que son más difíciles que sus equivalentes pruebas paramétricas a. Sólo II c. II y IV b. I y III d. I, II y III

Presentaciones similares