Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Data Mining, OLAP y Data Warehousing

2
Contenidos Sistemas de ayuda a la toma de decisiones
Análisis de datos y Procesamiento analítico en línea (OnLine Analytical Processing – OLAP) Recopilación de datos Almacenamiento de datos Sistemas de recuperación de la información
 Recopilación de datos. Almacenamiento de datos. Sistemas de recuperación de la información.")
3
Introducción Los Sistemas de Bases de Datos son desarrollados con una aplicación específica en mente, con el objetivo de soportar las actividades de operación diaria en dicha aplicación. Los DBMS’s han sido diseñados para administrar las actividades operativas diarias a través del almacenamiento de los datos que requieren de una manera consistente basado en un modelo de datos, y optimizando sus operaciones de consulta y actualización para un performance de alto nivel. Debido a que dichas actividades diarias, son en efecto interactivas, este tipo de DBMS’s son llamados “on-line transaction processing systems ” (OLTP), o sistema de procesamiento de transacciones en línea.
, o sistema de procesamiento de transacciones en línea.")
4
Introducción El objetivo de los sistemas OLTP es soportar las decisiones del día-a-día a un gran número de usuarios operacionales. Sin embargo existe también la necesidad de soportar el análisis y toma de decisiones estratégicas de un número pequeño de usuarios gerenciales. Por ejemplo, después de una campaña de marketing, un gerente puede determinar su efectividad analizando el comportamiento de las ventas antes y después de la campaña.

5
Introducción Más allá, un ejecutivo puede analizar el comportamiento de las ventas para pronosticar las ventas de sus productos y planificarlas de acuerdo a los pedidos y capacidades de almacenamiento disponibles. Por ejemplo, identificando la temporada pre-escolar y las tendencias de los mercados locales, los gerentes de tiendas pueden ordenar y presentar en las vitrinas aquellos productos escolares que están siendo solicitados a los estudiantes y sus familias en las escuelas locales. La otra alternativa, ordenar masivamente todo tipo de productos y luego devolver aquellos que no son vendidos o rentables, parece poco eficiente frente a la anterior. Este tipo de procesos analíticos en línea - “on-line analytical processing” (OLAP) , pueden ser potenciados por herramientas de exploración de datos basadas en técnicas de “Data mining”.
 , pueden ser potenciados por herramientas de exploración de datos basadas en técnicas de Data mining .")
6
Introducción Las herramientas de Data Mining descubren nuevos patrones o reglas que no necesariamente pueden ser obtenidas a través del mero procesamiento de querys. Ellas utilizan técnicas de aprendizaje denominadas AI Machine learning techniques, que automáticamente clasifican los datos en diferentes grupos basados en diferentes criterios. Por ejemplo, es posible a partir de datos de ventas de productos, derivar una regla que identifique que el cliente que compra el Domingo antes de las 11 AM y compra leche, también comprará el diario y un chocolate. De esta forma, cuando un gerente de una tienda desea promover un chocolate en especial, puede utilizar la regla anterior y colocar los chocolates al lado del stand del diario.

7
Introducción OLAP y Data Mining NO involucran modificaciones a los datos, y requieren acceso ad-hoc a todos los datos de la organización, tanto actuales como históricos. Esto conlleva a la necesidad de nuevos modelos de datos para la organización y almacenamiento de datos históricos, modelos que optimizan el procesamiento de consultas en vez de transacciones. Los Data Warehouses extienden las tecnologías de bases de datos para integrar datos desde múltiples fuentes y organizarlos eficientemente para el procesamiento de querys y su presentación.

8
Definiciones de Minería de Datos
Es la exploración automática o semiautomática de grandes cantidades de datos para el descubrimiento de reglas y patrones. Proceso iterativo de detección y extracción de patrones a partir de grandes bases de datos, modelo de reconocimiento. Es el análisis de un conjunto de datos para encontrar relaciones desconocidas y resumir los datos de nuevas formas entendibles para el minero. Es el proceso analítico, por medio del cual se extrae información oculta de grandes cantidades de datos siendo muy útil para predecir futuros comportamientos y tendencias.

9
ETAPAS DE LA MINERÍA DE DATOS
Determinación de los objetivos. Trata de la delimitación de los objetivos que el cliente desea bajo la orientación del especialista en data mining. Preprocesamiento de los datos. Se refiere a la selección, la limpieza, el enriquecimiento, la reducción y la transformación de las bases de datos. Esta etapa consume generalmente alrededor del setenta por ciento del tiempo total de un proyecto de data mining. Determinación del modelo. Se comienza realizando unos análisis estadísticos de los datos, y después se lleva a cabo una visualización gráfica de los mismos para tener una primera aproximación. Según los objetivos planteados y la tarea que debe llevarse a cabo, pueden utilizarse algoritmos desarrollados en diferentes áreas de la Inteligencia Artificial. Análisis de los resultados. Verifica si los resultados obtenidos son coherentes y los coteja con los obtenidos por los análisis estadísticos y de visualización gráfica. El cliente determina si son novedosos y si le aportan un nuevo conocimiento que le permita considerar sus decisiones.

10
Aplicaciones de la Minería de Datos
Sistemas automáticos de control de calidad que discriminan los productos defectuosos con un alto grado de precisión. El control de calidad no sólo se debe hacer al final del proceso, no resulta fácil medir las variables que determinen calidad, es necesario utilizar técnicas de minería de datos para descubrir relaciones que permitan detectar fallos.

11
Aplicaciones de la Minería de Datos
Resistencia de materiales. Programas de mantenimiento predictivo (calendario de reparaciones). Campañas de mercadero, es posible llegar a una mayor cantidad de clientes. Fidelización de clientes, conseguir uno nuevo o recuperar un cliente es más costoso.
. Campañas de mercadero, es posible llegar a una mayor cantidad de clientes. Fidelización de clientes, conseguir uno nuevo o recuperar un cliente es más costoso.")
12
Aplicaciones de la Minería de Datos
Id Salario Automóvil Hijos Casado Casa Propia Antigüedad Sexo Llamadas de Atención 1 500 Si 3 M No 2 700 V 800 4 450 5 6 .. … Grupo 1: con hijos, casados, con casa propia mayoritariamente mujeres, no tienen llamadas de atención Grupo 2: con salario relativamente alto, no tiene casa propia, hombres con auto, tienen llamadas de atención. La empresa puede decidir contratar sólo mujeres para cargos que demanden mayor responsabilidad

13
Aplicaciones de la Minería de Datos
De acuerdo a las ventas del año pasado se puede armar un modelo predictivo para mantener stock del presente año. Servicios de mercadeo como ubicación de productos.

14
Aplicaciones de la Minería de Datos
Para el FBI analizar las bases de datos comerciales para detectar terroristas. Departamento de Justicia debe introducirse en la vasta cantidad de datos comerciales referentes a los hábitos y preferencias de compra de los consumidores, con el fin de descubrir potenciales terroristas antes de que ejecuten una acción. Algunos expertos aseguran que, con esta información, el FBI uniría todas las bases de datos y permitirá saber si una persona fuma, qué talla y tipo de ropa usa, su registro de arrestos, su salario, las revistas a las que está suscrito, su altura y peso, sus contribuciones a la Iglesia, grupos políticos u organizaciones no gubernamentales, sus enfermedades crónicas (como diabetes o asma), los libros que lee, los productos de supermercado que compra
, los libros que lee, los productos de supermercado que compra.")
15
Aplicaciones de la Minería de Datos
En la empresa Detección de fraudes en las tarjetas de crédito. Examinar transacciones, propietarios de tarjetas y datos financieros para detectar y mitigar fraudes. En un principio para detectar fraudes en tarjetas de crédito, luego incorporar las tarjetas comerciales, de combustibles y de débito. Descubriendo el porqué de la deserción de clientes de una compañía operadora de telefonía móvil. Este estudio fue desarrollado en una operadora española que básicamente situó sus objetivos en dos puntos: el análisis del perfil de los clientes que se dan de baja y la predicción del comportamiento de sus nuevos clientes. los clientes que abandonaban la operadora generaban ganancias para la empresa; sin embargo, una de las conclusiones más importantes radicó en el hecho de que los clientes que se daban de baja recibían pocas promociones y registraban un mayor número de incidencias respecto a la media.

16
Aplicaciones de la Minería de Datos
En la Universidad Conociendo si los recien titulados de una universidad llevan a cabo actividades profesionales relacionadas con sus estudios. Se hizo un estudio sobre los recién titulados de la carrera de Ingeniería en Sistemas Computacionales del Instituto Tecnológico de Chihuahua II. El objetivo era saber si con los planes de estudio de la universidad y el aprovechamiento del alumno se hacía una buena inserción laboral o si existían otras variables que participaban en el proceso. Mediante la aplicación de conjuntos aproximados se descubrió que existían cuatro variables que determinaban la adecuada inserción laboral, que son citadas de acuerdo con su importancia: zona económica donde habitaba el estudiante, colegio de dónde provenía, nota al ingresar y promedio final al salir de la carrera. A partir de estos resultados, la universidad tendrá que hacer un estudio socioeconómico sobre grupos de alumnos que pertenecían a las clases económicas bajas para dar posibles soluciones, debido a que tres de las cuatro variables no dependían de la universidad.

17
Aplicaciones de la Minería de Datos
El AC de Milan utiliza un sistema inteligente para prevenir lesiones. El club usa redes neuronales para prevenir lesiones y optimizar el acondicionamiento de cada atleta. Esto ayudará a seleccionar el fichaje de un posible jugador o a alertar al médico del equipo de una posible lesión. El sistema, creado por Computer Associates International, es alimentado por datos de cada jugador, relacionados con su rendimiento, alimentación y respuesta a estímulos externos, que se obtienen y analizan cada quince días. El jugador lleva a cabo determinadas actividades que son monitoreadas por veinticuatro sensores conectados al cuerpo y que transmiten señales de radio que posteriormente son almacenadas en una base de datos. Actualmente el sistema dispone de casos registrados que permiten predecir alguna posible lesión. Con ello, el club intenta ahorrar dinero evitando comprar jugadores que presenten una alta probabilidad de lesión, lo que haría incluso renegociar su contrato.

18
Aplicaciones de la Minería de Datos
Los equipos de la NBA utilizan aplicaciones inteligentes para apoyar a su cuerpo de entrenadores. El Advanced Scout es un software que emplea técnicas de data mining y que han desarrollado investigadores de IBM para detectar patrones estadísticos y eventos raros. Tiene una interfaz gráfica muy amigable orientada a un objetivo muy específico: analizar el juego de los equipos de la National Basketball Association (NBA). El software utiliza todos los registros guardados de cada evento en cada juego: pases, encestes, rebotes y doble marcaje (doublé team) a un jugador por el equipo contrario, entre otros. El objetivo es ayudar a los entrenadores a aislar eventos que no detectan cuando observan el juego en vivo o en película.
. El software utiliza todos los registros guardados de cada evento en cada juego: pases, encestes, rebotes y doble marcaje (doublé team) a un jugador por el equipo contrario, entre otros. El objetivo es ayudar a los entrenadores a aislar eventos que no detectan cuando observan el juego en vivo o en película.")
19
Aplicaciones de la Minería de Datos
Genética En el estudio de la genética humana, el objetivo principal es entender la relación cartográfica entre las partes y la variación individual en las secuencias del ADN humano y la variabilidad en la susceptibilidad a las enfermedades. En términos más llanos, se trata de saber cómo los cambios en la secuencia de ADN de un individuo afectan al riesgo de desarrollar enfermedades comunes (como por ejemplo el cáncer). Esto es muy importante para ayudar a mejorar el diagnóstico, prevención y tratamiento de las enfermedades. La técnica de minería de datos que se utiliza para realizar esta tarea se conoce como "reducción de dimensionalidad multifactorial"
. Esto es muy importante para ayudar a mejorar el diagnóstico, prevención y tratamiento de las enfermedades. La técnica de minería de datos que se utiliza para realizar esta tarea se conoce como reducción de dimensionalidad multifactorial")
20
Fases de Descubrimiento de Conocimiento
Limpieza de datos Integración de datos Bases de Datos Datos Preprocesados Conocimiento Tareas Relevantes Transformación de datos Selección Data Mining Interpretación del Conocimiento

21
Proceso de KDD Ejemplo: Web Log
Selección: Seleccionar los archivos log data (fechas y ubicaciones). Preprocesamiento: Borrar URLs de identificación Borrar log de error Transformación: Ordenar y agrupar. Data Mining: Identificar y contar patrones. Construir estructura de datos. Interpretación/Evaluación: Identificar y mostrar secuencias de acceso frecuentes. Aplicaciones Potenciales para el usuario: Predicciones de Cache Personalización.
. Preprocesamiento: Borrar URLs de identificación. Borrar log de error. Transformación: Ordenar y agrupar. Data Mining: Identificar y contar patrones. Construir estructura de datos. Interpretación/Evaluación: Identificar y mostrar secuencias de acceso frecuentes. Aplicaciones Potenciales para el usuario: Predicciones de Cache. Personalización.")
22
Modelo Relacional SQL Algoritmos y Reglas de Asociación Data Warehousing Técnicas de Escalabilidad Medidas de Similitud Clustering Jerárquico Consultas Imprecisas Datos Textuales Motores de Búsqueda Web Bayes Análisis de Regresión Algoritmo EM K-Means Series de Tiempos DATA MINING Técnicas de Diseño de Algoritmos Análisis de Algoritmos Estructuras de Datos Redes Neuronales Ärboles de Decisión

23
Se estima que la extracción de patrones (minería) de los datos ocupa solo el 15% - 20% del esfuerzo total del proceso de KDD. El proceso de descubrimiento de conocimiento en bases de datos involucra varios pasos: Determinar las fuentes de información: que pueden ser útiles y dónde conseguirlas. Diseñar el esquema de un almacén de datos (Data Warehouse): que consiga unificar de manera operativa toda la información recogida. Implantación del almacén de datos: que permita la navegación y visualización previa de sus datos, para discernir qué aspectos puede interesar que sean estudiados. Esta es la etapa que puede llegar a consumir el mayor tiempo. Selección, limpieza y transformación de los datos que se van a analizar: la selección incluye tanto una criba o fusión horizontal (filas) como vertical (atributos).La limpieza y preprocesamiento de datos se logra diseñando una estrategia adecuada para manejar ruido, valores incompletos, secuencias de tiempo, casos extremos (si es necesario), etc.
: que consiga unificar de manera operativa toda la información recogida. Implantación del almacén de datos: que permita la navegación y visualización previa de sus datos, para discernir qué aspectos puede interesar que sean estudiados. Esta es la etapa que puede llegar a consumir el mayor tiempo. Selección, limpieza y transformación de los datos que se van a analizar: la selección incluye tanto una criba o fusión horizontal (filas) como vertical (atributos).La limpieza y preprocesamiento de datos se logra diseñando una estrategia adecuada para manejar ruido, valores incompletos, secuencias de tiempo, casos extremos (si es necesario), etc.")
24
Seleccionar y aplicar el método de minería de datos apropiado: esto incluye la selección de la tarea de descubrimiento a realizar, por ejemplo, clasificación, agrupamiento o clustering, regresión, etc. La selección de él o de los algoritmos a utilizar. La transformación de los datos al formato requerido por el algoritmo específico de minería de datos. Y llevar a cabo el proceso de minería de datos, se buscan patrones que puedan expresarse como un modelo o simplemente que expresen dependencias de los datos, el modelo encontrado depende de su función (clasificación) y de su forma de representarlo (árboles de decisión, reglas, etc.), se tiene que especificar un criterio de preferencia para seleccionar un modelo dentro de un conjunto posible de modelos, se tiene que especificar la estrategia de búsqueda a utilizar (normalmente está predeterminada en el algoritmo de minería).
 y de su forma de representarlo (árboles de decisión, reglas, etc.), se tiene que especificar un criterio de preferencia para seleccionar un modelo dentro de un conjunto posible de modelos, se tiene que especificar la estrategia de búsqueda a utilizar (normalmente está predeterminada en el algoritmo de minería)..")
25
Evaluación, interpretación, transformación y representación de los patrones extraídos:
Interpretar los resultados y posiblemente regresar a los pasos anteriores. Esto puede involucrar repetir el proceso, quizás con otros datos, otros algoritmos, otras metas y otras estrategias. Este es un paso crucial en donde se requiere tener conocimiento del dominio. La interpretación puede beneficiarse de procesos de visualización, y sirve también para borrar patrones redundantes irrelevantes. Difusión y uso del nuevo conocimiento. Incorporar el conocimiento descubierto al sistema (normalmente para mejorarlo) lo cual puede incluir resolver conflictos potenciales con el conocimiento existente. El conocimiento se obtiene para realizar acciones, ya sea incorporándolo dentro de un sistema de desempeño o simplemente para almacenarlo y reportarlo a las personas interesadas. En este sentido, KDD implica un proceso interactivo e iterativo involucrando la aplicación de varios algoritmos de minería de datos.
 lo cual puede incluir resolver conflictos potenciales con el conocimiento existente. El conocimiento se obtiene para realizar acciones, ya sea incorporándolo dentro de un sistema de desempeño o simplemente para almacenarlo y reportarlo a las personas interesadas. En este sentido, KDD implica un proceso interactivo e iterativo involucrando la aplicación de varios algoritmos de minería de datos.")
26
Disciplinas Relacionadas
La estadística, junto con el aprendizaje computacional es considerada como el corazón de la minería de datos; proporciona métodos relacionados con la toma, organización, recopilación, presentación y presentación de datos: análisis de varianza, series de tiempo, prueba chi cuadrado, análisis discriminante, media, moda, desviación estándar, mediana, etc. Aprendizaje computacional: redes neuronales, algoritmos genéticos, árboles de inducción, etc. Bases de Datos y Almacenes de Datos (dataware house): bases de datos, archivos excel, imágenes, etc. Sistemas de soporte a la toma de decisiones.
: bases de datos, archivos excel, imágenes, etc. Sistemas de soporte a la toma de decisiones.")
27
Minería de datos Inteligencia Artificial (“Machine Estadística
Learning”) Estadística Minería de datos Bases de Datos (VLDB) Ciencias de la información Graficación y visualización Otras disciplinas
 Estadística. Minería de datos. Bases de. Datos. (VLDB) Ciencias de. la información. Graficación y. visualización. Otras. disciplinas.")
28
Mineria de Datos como Subconjunto de la Inteligencia de Negocios

29
Conceptos Relacionados
Clasificación: incluye los procesos de minería de datos que buscan reglas para definir si un ítem o un evento pertenecen a un subset particular o a una clase de datos. Esta técnica, probablemente la más utilizada, incluye dos subprocesos: la construcción de un modelo la predicción. En términos generales, los métodos de clasificación desarrollan un modelo compuesto por reglas IF-THEN y se aplican perfectamente, por ejemplo, para encontrar patrones de compra en las bases de datos de los clientes y construir mapas que vinculan los atributos de los clientes con los productos comprados.

30
Conceptos Relacionados
Asociación: incluye técnicas conocidas como linkage analysis, utilizadas para buscar patrones que tienen una probabilidad alta de repetición, como ocurre al analizar una canasta en la búsqueda de productos afines. Se desarrolla un algoritmo asociativo que incluye las reglas que van a correlacionar un conjunto de eventos con otro. Por ejemplo, un supermercado podría necesitar información sobre hábitos de compra de sus clientes. Secuencia: los métodos de análisis de series de tiempo son usados para relacionar los eventos con el tiempo. Como resultado de este tipo de modelo se puede aprender que las personas que alquilan una película de video tienden a adquirir los productos promocionales durante las siguientes dos semanas; o bien, que la adquisición de un horno de microondas se produce frecuentemente luego de determinadas compras previas.

31
Cluster: Muchas veces resulta difícil o imposible definir los parámetros de una clase de datos. En ese caso, los métodos de clustering pueden usarse para crear particiones, de forma tal que los miembros de cada una de ellas resulten similares entre sí, según alguna métrica o conjunto de métricas. El análisis de clusters podría utilizarse, entre otras aplicaciones, al estudiar las compras con tarjetas de crédito, para descubrir—digamos—que los alimentos comprados con una tarjeta dorada de uso empresarial son adquiridos durante los días de semana y tienen un valor promedio de ticket de 152 pesos, mientras que el mismo tipo de compra, pero realizado con una tarjeta platino personal, ocurre predominantemente durante los fines de semana, por un valor menor, pero incluye una botella de vino más del 65 % de las veces

32
Grupos de Técnicas Principales
Visualización. - Ayudas para el descubrimiento manual de información. - Se muestran tendencias, agrupamientos de datos, etc. - Funcionamiento semi-automático.

33
Verificación. Se conoce de antemano un modelo y se desea saber si los datos disponibles se ajustan a él. Se establecen medidas de ajuste al modelo.

34
Descubrimiento. - Se busca un modelo desconocido de antemano. - Descubrimiento descriptivo: se busca modelo legible. - Descubrimiento predictivo: no importa que el modelo no sea legible.

35
Sea como sea la presentación del problema, una de las características presente en cualquier tipo de aprendizaje y en cualquier tipo de técnica de Minería de Datos es su carácter hipotético, es decir, lo aprendido puede, en cualquier momento, ser refutado por evidencia futura. En muchos casos, los modelos no aspiran a ser modelos perfectos, sino modelos aproximados. En cualquier caso, al estar trabajando con hipótesis, es necesario realizar una evaluación de los patrones obtenidos, con el objetivo de estimar su validez y poder compararlos con otros. Por tanto, la Minería de Datos, más que verificar patrones hipotéticos, usa los datos para encontrar estos patrones. Por lo tanto, es un proceso inductivo.

36
PREPROCESAMIENTO DE DATOS
Las organizaciones manejan gran variedad de información las cuales están llenas de datos erróneos, faltantes, en diversos formatos, etc. Los que se convierte en un problema para realizar un buen análisis. De este problema se deriva el concepto “calidad de datos”. El preprocesamiento de datos suele ser una necesidad para aplicaciones reales, engloba a todas aquellas ténicas de análisis que permiten mejorar la calidad de un conjunto de datos de modo que las técnicas de extracción de conocimiento puedan obtener mayor y mejor información. El objetivo es transformar el conjunto de datos haciendo que la información sea más accesible y coherente

37
RECOLECCIÓN E INTEGRACIÓN
MODELOS DE DATOS MULTIDIMENSIONALES

38
Base de Datos Operacional
Data Warehouse Datos Operacionales Datos del negocio para Información Orientado a la aplicación Orientado al sujeto Actual Actual + histórico Detallada Detallada + más resumida Cambia continuamente Estable Transacciones simples Consultas complejas Se enfoca en los datos Se enfoca en la información Lectura/Escritura Principalmente Lectura Indexación Exploración por lotes Miles de Registros Millones de Registros 100 Mb a Gb 100 Gb a Tb Transacciones Tiempos de respuesta

39
Qué es un Data Warehouse ?
Una de las mejores definiciones de Data warehouse fue propuesta por Inmon cuando él introdujo el término en 1992: Un data warehouse es una colección de datos para el soporte de decisiones estratégicas, orientado a la temática (subject-oriented), integrada, no-volátil, y variante en el tiempo (time-variant). Colección Orientada a la temática (subject-oriented): significa que la data es organizada alrededor de temáticas tales como clientes, productos, ventas, etc. En base de datos, en contraste, los datos son organizados alrededor de tareas. Por ejemplo, usamos una base de datos para el almacenamiento de ordenes de compra y adquisiciones de productos. Usamos un Data Warehouse para almacenar resúmenes de la información detallada basada en temáticas.
, integrada, no-volátil, y variante en el tiempo (time-variant). Colección Orientada a la temática (subject-oriented): significa que la data es organizada alrededor de temáticas tales como clientes, productos, ventas, etc. En base de datos, en contraste, los datos son organizados alrededor de tareas. Por ejemplo, usamos una base de datos para el almacenamiento de ordenes de compra y adquisiciones de productos. Usamos un Data Warehouse para almacenar resúmenes de la información detallada basada en temáticas.")
40
Qué es un Data Warehouse ?
Un resumen puede ser obtenido a través del uso de funciones agregadas combinadas con cláusulas GROUP BY. Por Ejemplo, un resumen alrededor de un producto pueden ser las ventas por producto: SELECT Producto, SUM(Total) FROM NotaVenta GROUP BY Producto Y un resumen en torno a una venta pueden ser las ventas diarias: SELECT Dia, SUM(Total) FROM OrdenCompra GROUP BY Dia
 FROM NotaVenta. GROUP BY Producto. Y un resumen en torno a una venta pueden ser las ventas diarias: SELECT Dia, SUM(Total) FROM OrdenCompra. GROUP BY Dia.")
41
Qué es un Data Warehouse ?
Colección Integrada: significa que un data warehouse integra y almacena datos desde múltiples fuentes, no todas necesariamente son bases de datos, una fuente de datos puede ser también un archivo de aplicación. Nótese que no hablamos de un sistema de integración que permite acceso a datos en bases de datos heterogeneas (multi-database system), sino que un datawarehouse almacena la información recolectada, después que esta es “limpiada” (cleaned), removiendo inconsistencias tales como formatos diferentes o valores erróneos. De esta forma, la data residente en el data warehouse es presentada a los usuarios con una vista unificada consistente.
, sino que un datawarehouse almacena la información recolectada, después que esta es limpiada (cleaned), removiendo inconsistencias tales como formatos diferentes o valores erróneos. De esta forma, la data residente en el data warehouse es presentada a los usuarios con una vista unificada consistente.")
42
Qué es un Data Warehouse ?
Colección no-volátil: significa que el data warehouse no es actualizado en tiempo real (en coordinación con las fuentes). Las actualizaciones en las fuentes son agrupadas y aplicadas por una transacción de mantenimiento. Las transacciones de mantenimiento se ejecutan periódicamente o en función de la demanda. Colección variante en el tiempo (time-variant): significa que los datos en un data warehouse son históricos y tienen validez temporal. Esto claramente muestra que un data warehouse debe soportar series de tiempo.
. Las actualizaciones en las fuentes son agrupadas y aplicadas por una transacción de mantenimiento. Las transacciones de mantenimiento se ejecutan periódicamente o en función de la demanda. Colección variante en el tiempo (time-variant): significa que los datos en un data warehouse son históricos y tienen validez temporal. Esto claramente muestra que un data warehouse debe soportar series de tiempo.")
43
Arquitectura de un Data warehouse

44
Modelamiento Multidimensional
El modelo relacional utilizado para estructurar bases de datos fue diseñado para el procesamiento de transacciones, aunque puede ser utilizado para soportar eficientemente el procesamiento de querys ad-hoc, no provee de una herramienta intuitiva de manipulación de los datos y reportes, según lo requerido por OLAP. Consideremos datos de series de tiempo. Una forma intuitiva de reportearlos sería plotearlos en un gráfico y guardarlos en una matriz de dos o más dimensiones. Este tipo de representación de los datos es llamada modelamiento multidimensional.

45
Modelamiento Multidimensional
Los modelos multidimensionales almacenan los datos en matrices multidimensionales. Las matrices tri-dimensionales (3-d) son llamadas cubos de datos (data cubes), y las matrices con más de 3 dimensiones son llamadas hipercubos (hypercubes). Como ejemplo de un cubo, consideremos las dimensiones periodo, producto y región Como lo mencionamos anteriormente, podemos usar una matriz 2-d (planilla) para representar ventas regionales para un grupo de periodos: | R1 R2 R3 ... -----| > Region P1 | P2 | P3 | . | V Product
 son llamadas cubos de datos (data cubes), y las matrices con más de 3 dimensiones son llamadas hipercubos (hypercubes). Como ejemplo de un cubo, consideremos las dimensiones periodo, producto y región. Como lo mencionamos anteriormente, podemos usar una matriz 2-d (planilla) para representar ventas regionales para un grupo de periodos: | R1 R2 R | > Region. P1 | P2 | P3 | . | V. Product.")
46
Modelamiento Multidimensional
Esta planilla puede ser convertida a un cubo agregando la dimensión tiempo, como por ejemplo, intervalos mensuales:

47
Modelamiento Multidimensional
Visualizar un cubo de datos es tan fácil como usar un gráfico 3d o visualizar planillas en tablas 3d. Visualizar hipercubos es bastante complejo, por lo anterior estos normalmente son descompuestos en cubos al momento de visualizarlos. El procesamiento de querys en cubos o hipercubos es más rápido y eficiente que en un modelo relacional. Un query es básicamente transformado en una operación de lectura de elementos de una matriz. La data puede ser consultada directamente en cualquier combinación de dimensiones.

48
Arquitectura de un Almacén de Datos
Componentes: Sistema ETL (Extraction, Transformation, Load): realiza las funciones de extracción de las fuentes de datos (transaccionales o externas), transformación (limpieza, consolidación, ...) y la carga del AD, realizando: extracción de los datos. filtrado de los datos: limpieza, consolidación, etc. carga inicial del almacén: ordenación, agregaciones, etc. refresco del almacén: operación periódica que propaga los cambios de las fuentes externas al almacén de datos Repositorio Propio de Datos: información relevante, metadatos. Interfaces y Gestores de Consulta: permiten acceder a los datos ys sobre ellos se conectan herramientas más sofisticadas (OLAP, EIS, minería de datos). Sistemas de Integridad y Seguridad: se encargan de un mantenimiento global, copias de seguridad, ...
: realiza las funciones de extracción de las fuentes de datos (transaccionales o externas), transformación (limpieza, consolidación, ...) y la carga del AD, realizando: extracción de los datos. filtrado de los datos: limpieza, consolidación, etc. carga inicial del almacén: ordenación, agregaciones, etc. refresco del almacén: operación periódica que propaga los cambios de las fuentes externas al almacén de datos. Repositorio Propio de Datos: información relevante, metadatos. Interfaces y Gestores de Consulta: permiten acceder a los datos ys sobre ellos se conectan herramientas más sofisticadas (OLAP, EIS, minería de datos). Sistemas de Integridad y Seguridad: se encargan de un mantenimiento global, copias de seguridad, ...")
49
Arquitectura de un Almacén de Datos
Tiempo Día Mes Semana Año Trimestre Producto Departamento Nro_producto Categoría Marca Tipo Descripción Ventas importe unidades Almacén Ciudad Región Tipo

50
Arquitectura de un Almacén de Datos
Dimensiones (puntos de vista) desde los que se puede analizar la actividad. Almacén Producto Tiempo Marca Descripción Semana Categoría Ventas importe unidades Departamento Mes Trimestre Nro_producto Día Tipo Año Actividad que es objeto de análisis con los indicadores que interesa analizar Almacén Ciudad Tipo Región
 desde los que se puede analizar la actividad. Almacén. Producto. Tiempo. Marca. Descripción. Semana. Categoría. Ventas. importe. unidades. Departamento. Mes. Trimestre. Nro_producto. Día. Tipo. Año. Actividad que es objeto de análisis con los indicadores que interesa analizar. Almacén. Ciudad. Tipo. Región.")
51
Arquitectura de un Almacén de Datos
Tiempo Día Mes Semana Año Trimestre Producto Departamento Nro_producto Categoría Marca Tipo Descripción hecho medidas Ventas importe unidades dimensión atributos Almacén Ciudad Tipo Almacén Región

52
Arquitectura de un Almacén de Datos
Producto nro. producto categoría departamento Almacén ciudad región almacén tipo Tiempo día mes trimestre año semana

53
Arquitectura de un Almacén de Datos
Este esquema multidimensional recibe varios nombres: estrella: si la jerarquía de dimensiones es lineal proyecto tiempo PERSONAL equipo estrella jerárquica o copo de nieve: si la jerarquía no es lineal. tiempo producto VENTAS lugar

54
Almacén formado por 4 datamarts.
Arquitectura de un Almacén de Datos ¿Se puede recopilar toda la información necesaria en un único esquema estrella o copo de nieve? NO : necesidad de varios esquemas. Cada uno de estos esquemas se denomina datamart. producto proveedor producto tiempo VENTAS lugar Almacén formado por 4 datamarts. PRODUCCIÓN lugar tiempo tiempo lugar PERSONAL proyecto equipo tiempo CAMPAÑA producto

55
Arquitectura de un Almacén de Datos
El almacén de datos puede estar formado por varios datamarts y, opcionalmente, por tablas adicionales. subconjunto de un almacén de datos, generalmente en forma de estrella o copo de nieve. Data mart se definen para satisfacer las necesidades de un departamento o sección de la organización. contiene menos información de detalle y más información agregada.

56
Herramientas OLAP una consulta a un almacén de datos consiste generalmente en la obtención de medidas sobre los hechos parametrizadas por atributos de las dimensiones y restringidas por condiciones impuestas sobre las dimensiones medida hecho ¿ “Importe total de las ventas durante este año de los productos del departamento Bebidas, por trimestre y por categoría” ?. Restricciones: productos del departamento Bebidas, ventas durante este año Parámetros de la consulta: por categoría de producto y por trimestre

57
“Bebidas” Marca Tiempo Día de la semana Producto Categoría Ventas importe unidades Mes Departamento Nro_producto Día “2002” Año Trimestre Tipo Almacén “Importe total de ventas en este año, del departamento de “Bebidas”, por categoría y trimestre” Ciudad Tipo Almacén Región

58
trimestre categoría importe

59
Categoría Trimestre Ventas Presentación tabular (relacional) de los datos seleccionados Refrescos T1 Refrescos T2 Refrescos T3 Refrescos T4 T1 Zumos Zumos T2 Se asumen dos categorías en el departamento de Bebidas: Refrescos y Zumos. T3 Zumos Zumos T4

60
trimestre Presentación matricial (multidimensional) de los datos seleccionados T1 T2 T3 T4 categoría Refrescos Zumos Los parámetros de la consulta (“por trimestre” y “por categoría”) determinan los criterios de agrupación de los datos seleccionados (ventas de productos del departamento Bebidas durante este año). La agrupación se realiza sobre dos dimensiones (Producto, Tiempo).
 determinan los criterios de agrupación de los datos seleccionados (ventas de productos del departamento Bebidas durante este año). La agrupación se realiza sobre dos dimensiones (Producto, Tiempo).")
61
Cubos OLAP

62
Los cubos OLAP consisten de hechos (facts) llamados medidas categorizados por dimensiones (que pueden ser más de 3 dimensiones); las dimensiones son referidas desde la tabla de hechos por claves foráneas. Las medidas son derivadas de los registros en la Tabla de hechos(fact tables). Dimensiones son derivadas de las tablas de dimensiones. Los valores en las celdas son resúmenes (SUM, AVG, MAX, MIN, etc.)
. Dimensiones son derivadas de las tablas de dimensiones. Los valores en las celdas son resúmenes (SUM, AVG, MAX, MIN, etc.)")
63
Esquemas de Copo de Nieve (snowflake)
")
65
SELECT B.Brand, G.Country, SUM(F.Units_Sold) FROM Fact_Sales F INNER JOIN Dim_Date D ON F.Date_Id = D.Id INNER JOIN Dim_Store S ON F.Store_Id = S.Id INNER JOIN Dim_Geography G ON S.Geography_Id = G.Id INNER JOIN Dim_Product P ON F.Product_Id = P.Id INNER JOIN Dim_Brand B ON P.Brand_Id = B.Id INNER JOIN Dim_Product_Category C ON P.Product_Category_Id = C.Id WHERE D.YEAR = 1997 AND C.Product_Category = 'tv' GROUP BY G.Country

66
Querys extendidos en un Data-Warehouse
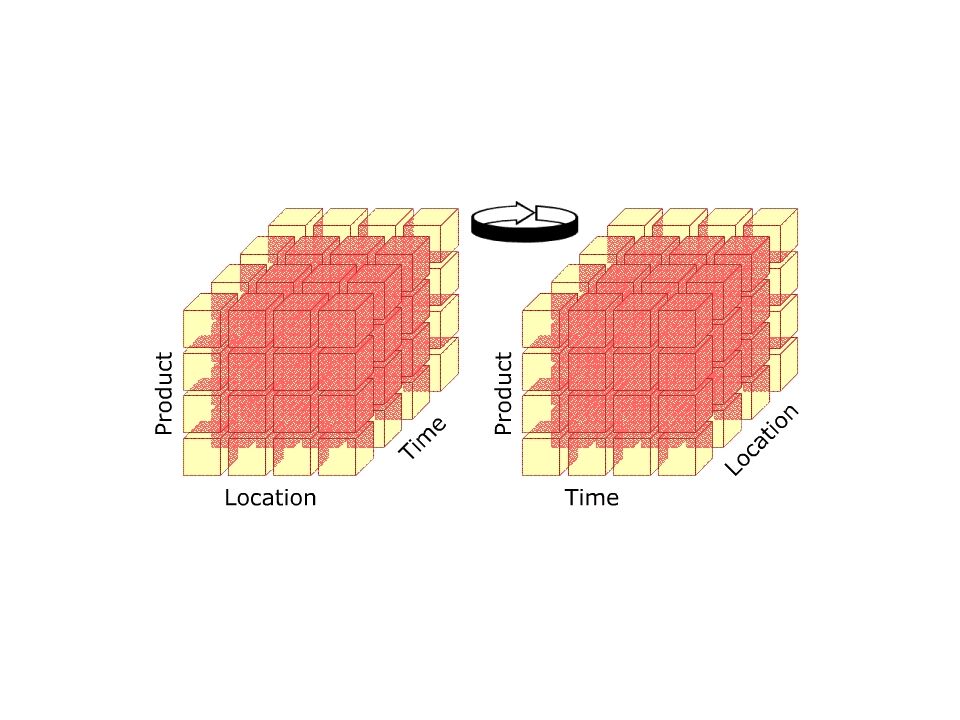
Un data warehouse provee una vista conceptual multidimensional con un número ilimitado de dimensiones y niveles de agregación. Ofrecen varios operadores que facilitan tanto las operaciones de querys y la visualización de los datos en una vista multidimensional: Pivot-Rotation (Pivote – Rotación): los cubos pueden ser visualizados y reorientados en diferentes ejes. En el ejemplo anterior, producto y región están representados en el frente, usando rotación podemos traer tiempo y producto al frente, empujando región al eje posterior.
: los cubos pueden ser visualizados y reorientados en diferentes ejes. En el ejemplo anterior, producto y región están representados en el frente, usando rotación podemos traer tiempo y producto al frente, empujando región al eje posterior.")
68
Ventas Ventas PIVOT Productos Productos Store1 Store2 Q1 Q2
Electronics Toys Clothing Cosmetics $5,2 $1,9 $2,3 $1,1 $5,6 $1,4 $2,6 $1,1 Electronics Toys Clothing Cosmetics $5,2 $1,9 $2,3 $1,1 $8,9 $0,75 $4,6 $1,5 Q1 Store 1 Electronics Toys Clothing Cosmetics $8,9 $0,75 $4,6 $1,5 $7,2 $0,4 $4,6 $0,5 Electronics Toys Clothing Cosmetics $5,6 $1,4 $2,6 $1,1 $7,2 $0,4 $4,6 $0,5 PIVOT Q2 Store 2

69
El carácter agregado de las consultas en el Análisis de Datos, aconseja la definición de nuevos operadores que faciliten la agregación (consolidación) y la disgregación (división) de los datos: agregación (roll): permite eliminar un criterio de agrupación en el análisis, agregando los grupos actuales. disgregación (drill): permite introducir un nuevo criterio de agrupación en el análisis, disgregando los grupos actuales.
: permite eliminar un criterio de agrupación en el análisis, agregando los grupos actuales. disgregación (drill): permite introducir un nuevo criterio de agrupación en el análisis, disgregando los grupos actuales.")
70
Roll-Up Display: Puede ser usado para derivar resúmenes y agrupaciones de mayor agregación sobre una dimensión. Por ejemplo los meses pueden ser agrupados en años sobre la dimensión tiempo. Los productos pueden ser agrupados en categorías, etc. Drill-Down Display: Puede ser usado para derivar desagregaciones sobre una dimensión, por ejemplo, región puede ser desagregado en ciudades, los meses pueden ser desagregados en semanas o días, etc.

71
ROLL UP

72
ROLL UP

73
drill-across T1 T2 T3 T4 T1 T2 T3 T4 T1 T1 T2 T2
Categoría Trimestre Ventas Categoría Trimestre Ciudad Ventas Refrescos T1 Valencia Refrescos T1 Refrescos León T1 T2 Refrescos Refrescos T2 Valencia 400000 Refrescos T2 León 700000 Refrescos T3 drill-across Refrescos T4 Cada grupo (categoría-trimestre) de la consulta original se disgrega en dos nuevos grupos (categoría-trimestre-ciudad) para las ciudades de León y Valencia. T1 Zumos Zumos T2 T3 Zumos Zumos T4
 de la consulta original se disgrega en dos nuevos grupos (categoría-trimestre-ciudad) para las ciudades de León y Valencia. T1. Zumos Zumos. T T3. Zumos Zumos. T")
74
Presentación matricial de los datos seleccionados.
León Valencia Zumos 300000 500000 200000 Refrescos 400000 100000 500000 Presentación matricial de los datos seleccionados.

75
Si se desea eliminar el criterio de agrupación sobre la dimensión Tiempo en la consulta original:
¿ “Importe total de las ventas durante este año de los productos del departamento Bebidas, por categorías” ? Categoría Trimestre Ventas Refrescos T1 Refrescos T2 Refrescos T3 Categoría Ventas Refrescos Refrescos T4 roll-across T1 Zumos Zumos Zumos T2 T3 Zumos Zumos T4

76
drill-down T1 T2 T3 T4 T1 T2 T3 T4 T1 T1 T1
Categoría Trimestre Ventas Categoría Trimestre Mes Ventas Refrescos T1 Enero Refrescos T1 Refrescos Febrero 500000 T1 T2 Refrescos Refrescos T1 Marzo 500000 drill-down Refrescos T3 Refrescos T4 Cada grupo (categoría-trimestre) de la consulta original se disgrega en dos nuevos grupos (categoría-trimestre-mes). T1 Zumos Zumos T2 T3 Zumos Zumos T4
 de la consulta original se disgrega en dos nuevos grupos (categoría-trimestre-mes). T1. Zumos Zumos. T T3. Zumos Zumos. T")
77
Slice and Dice: Puede ser utilizado para especificar proyecciones sobre las dimensiones, creando cubos más pequeños. Por ejemplo, recuperar todos lo productos juguetes en ciudades de Florida durante los meses de invierno.

78
Ventas Ventas Productos Productos SLICE & DICE Store1 Store2
Electronics Toys Clothing Cosmetics $5,2 $1,9 $2,3 $1,1 $5,6 $1,4 $2,6 $1,1 Productos Store1 Q1 Electronics Toys $5,2 $1,9 Q1 Electronics Toys Clothing Cosmetics $8,9 $0,75 $4,6 $1,5 $7,2 $0,4 $4,6 $0,5 Electronics Toys $8,9 $0,75 Q2 Q2 SLICE & DICE

79
Selección: Es similar al Select standard de SQL, puede ser utilizado para recuperar datos por valor o rango. Ordenamiento: Puede ser utilizado para especificar el orden de los datos sobre una dimensión. Atributos derivados: Permite la especificación de atributos que son computados desde atributos almacenados u otros atributos derivados

80
Modelo de Almacenamiento Multidimensional
Los Data warehouses soportan la sumarización provista por las operaciones drill-down y roll-up, ambas operaciones demandan en general mucho tiempo de proceso: Mantienen tablas de resumen que son recuperadas para desplegar una sumarización. Codifican los diferentes niveles sobre una dimensión (por ej. semanal, mensual, anual) sobre tablas existentes. Usando la codificación adecuada, una sumarización es computada desde los datos detallados cuando es necesario.
 sobre tablas existentes. Usando la codificación adecuada, una sumarización es computada desde los datos detallados cuando es necesario.")
81
Modelo de Almacenamiento Multidimensional
Las tablas en un Data warehouse son organizadas lógicamente en un esquema denominado star-schema (estrella). Un esquema estrella consiste en una tabla central “fact” que contiene los datos que pueden ser analizados en una variedad de formas, y una tabla “dimension” para cada dimensión, conteniendo datos referenciales. Los datos detallados son almacenados en las tablas de dimensiones y son referenciadas por llaves foráneas en la tabla fact.
. Un esquema estrella consiste en una tabla central fact que contiene los datos que pueden ser analizados en una variedad de formas, y una tabla dimension para cada dimensión, conteniendo datos referenciales. Los datos detallados son almacenados en las tablas de dimensiones y son referenciadas por llaves foráneas en la tabla fact.")
82
Modelo de Almacenamiento Multidimensional
Por ejemplo, un esquema estrella que pueda soportar el ejemplo consistiría de una tabla “fact”, rodeada de tres tablas “dimension”, una para productos, otra para ventas regionales, y otra para intervalos mensuales: Fact table: SALE SUMMARY (Product, Month, Region, Sales) Product -> PRODUCT(PID) Month -> MONTH_INTERVAL(Month) Region -> REGIONAL_SALES(RegionNo) Dimension tables: PRODUCT (PID, Pname, PCategory, PDescription) REGIONAL_SALES (Region, County, City) MONTH_INTERVAL (MonthNo, Month, Year)
 Product -> PRODUCT(PID) Month -> MONTH_INTERVAL(Month) Region -> REGIONAL_SALES(RegionNo) Dimension tables: PRODUCT (PID, Pname, PCategory, PDescription) REGIONAL_SALES (Region, County, City) MONTH_INTERVAL (MonthNo, Month, Year)")
83
Modelo de Almacenamiento Multidimensional
En el esquema estrella, las tablas de dimensión pueden no estar normalizadas, conteniendo datos redundantes. La motivación de esta redundancia es incrementar la eficiencia del procesamiento de querys a través de la eliminación de operaciones de join entre tablas. Por otra parte, una tabla desnormalizada puede crecer enormemente, causando un overhead que podría contrarrestar cualquier ganancia en el procesamiento de querys. En estos casos las tablas de dimensión pueden ser normalizadas y descompuestas en tablas más pequeñas, referenciándolas en la tabla de dimensión original. Esta descomposición lleva a un modelo de estrella jerárquico denominado Snowflake schema. Tal como en bases de datos, un Data warehouse utiliza diferentes formas de indexación para acceder más rápidamente a los datos, agregando la implementación de un manejo eficiente de matrices dinámicas.

84
Características y Categorías de Data Warehouses
Comparado con bases de datos, los Data warehouses son muy costosos de construir en términos de tiempo y dinero. Aún más, son muy costosos de mantener. Un Data warehouse tiene un tamaño gigantesco y crece con tasas enormes. Son al menos un orden de magnitud más grandes que la fuente. Sus tamaños oscilan entre cientos de gigabytes hasta varios terabytes o incluso petabytes. Resolver la semántica heterogénea entre diferentes fuentes, convertir diferentes formatos y cuerpos de datos desde las fuentes hacia el Data warehouse es un proceso complejo muy consumidor de tiempo y recursos. Este proceso no es ejecutado solo una vez, sino que se repite en el tiempo cada vez que el Data warehouse es sincronizado con las fuentes.

85
Características y Categorías de Data Warehouses
El proceso de limpieza de los datos para el aseguramiento de la calidad de la información es otro proceso complejo y costoso. De hecho ha sido identificado como una de las tareas más demandantes de trabajo en la construcción de un Data warehouse. Reconocer datos erróneos o incompletos es difícil de automatizar, al menos al comienzo, en algunos casos los errores siguen un patrón y pueden ser identificados y corregidos automáticamente. La decisión de qué resumir (sumarizar) y el cómo organizar es otro proceso crítico. Afecta tanto la utilidad del Data warehouse como su rendimiento. Los procesos de actualización y carga de datos son tareas bastante significativas y demandantes de tiempo, por este motivo el Data warehouse debe proveer capacidad de recuperación de cargas incompletas o actualizaciones erróneas.
 y el cómo organizar es otro proceso crítico. Afecta tanto la utilidad del Data warehouse como su rendimiento. Los procesos de actualización y carga de datos son tareas bastante significativas y demandantes de tiempo, por este motivo el Data warehouse debe proveer capacidad de recuperación de cargas incompletas o actualizaciones erróneas.")
86
Características y Categorías de Data Warehouses
Esta claro que la administración de los datos en un ambiente tan complejo requiere de herramientas de alto nivel y muchos recursos, en muchos casos organizaciones que han creado Data warehouses han requerido redestinar sus esfuerzos de administración hacia esta área. Con el objeto de reducir la severidad del impacto que causa lo anterior, dos nuevas alternativas han sido propuestas: Data Marts: estos son data warehouses pequeños y altamente focalizados al nivel de departamentos. Un Data warehouse corporativo puede ser construído formando una federación de Data Marts. Virtual Data Warehouses: Estas son colecciones persistentes de vistas de las bases de datos operacionales que son materializadas para un acceso eficiente y para el procesamiento de querys complejos.

87
MOLAP Y ROLAP El Almacén de Datos y las herramientas OLAP se pueden basar físicamente en varias organizaciones: Sistemas ROLAP se implementan sobre tecnología relacional, pero disponen de algunas facilidades para mejorar el rendimiento (índices de mapas de bits, índices de JOIN). Sistemas MOLAP disponen de estructuras de almacenamiento específicas (arrays) y técnicas de compactación de datos que favorecen el rendimiento del almacén. Sistemas HOLAP sistemas híbridos entre ambos.
. Sistemas MOLAP. disponen de estructuras de almacenamiento específicas (arrays) y técnicas de compactación de datos que favorecen el rendimiento del almacén. Sistemas HOLAP. sistemas híbridos entre ambos.")
88
MOLAP Y ROLAP Sistemas ROLAP:
El almacén de datos se construye sobre un SGBD Relacional. Los fabricantes de SGBD relacionales ofrecen extensiones y herramientas para poder utilizar el SGBDR como un Sistema Gestor de Almacenes de Datos.

89
MOLAP Y ROLAP Sistemas ROLAP: Extensiones de los SGBD relacionales:
índices de mapa de bits índices de JOIN técnicas de particionamiento de los datos optimizadores de consultas extensiones del SQL (operador CUBE, roll-up)
")
90
MOLAP Y ROLAP Sistemas MOLAP. Sistema de propósito específico:
estructuras de datos (arrays) técnicas de compactación. El objetivo de los sistemas MOLAP es almacenar físicamente los datos en estructuras multidimensionales de forma que la representación externa y la representación interna coincidan.
 técnicas de compactación. El objetivo de los sistemas MOLAP es almacenar físicamente los datos en estructuras multidimensionales de forma que la representación externa y la representación interna coincidan.")
91
Estructuras multidimensionales
MOLAP Y ROLAP Estructuras multidimensionales Herramienta OLAP El servidor MOLAP construye y almacena datos en estructuras multidimensionales. La herramienta de OLAP presenta estas estructuras multidimensionales. Servidor MOLAP Warehouse

92
Estructuras multidimensionales
MOLAP Y ROLAP Estructuras multidimensionales Herramienta OLAP MOLAP: Datos Arrays Extraídos del almacén de datos almacenamiento y procesos eficientes la complejidad de la BD se oculta a los usuarios el análisis se hace sobre datos agregados y métricas o indicadores precalculados. Servidor MOLAP Warehouse

93
Servidor Multidimensional
MOLAP Y ROLAP ROLAP MOLAP Desktop Herramienta OLAP Cliente Herramienta OLAP Servidor Multidimensional Servidor Relacional Servidor Warehouse

94
MOLAP Y ROLAP ROLAP/MOLAP: Ventajas e Inconvenientes: ROLAP MOLAP:
pueden aprovechar la tecnología relacional. pueden utilizarse sistemas relacionales genéricos (más baratos o incluso gratuitos). el diseño lógico corresponde al físico si se utiliza el diseño de Kimball. MOLAP: generalmente más eficientes que los ROLAP. el coste de los cambios en la visión de los datos. la construcción de las estructuras multidimensionales.
. el diseño lógico corresponde al físico si se utiliza el diseño de Kimball. MOLAP: generalmente más eficientes que los ROLAP. el coste de los cambios en la visión de los datos. la construcción de las estructuras multidimensionales.")
95
Proceso de Descubrimiento de Conocimiento (Knowledge Discovery and Data Mining)
Selección de los datos. El subconjunto de datos objetivo y los atributos de interés se identifican examinando todo el conjunto de datos sin ninguna manipulación previa Limpieza de los datos. Se elimina el ruido y los datos fuera de rango, se transforman los valores de los campos a unidades comunes y se crean campos nuevos combinando campos ya existentes (desnormalización)
")
96
Proceso de Descubrimiento de Conocimiento (Knowledge Discovery and Data Mining)
Minería de datos. Se utilizan algoritmos de minería de datos para extraer las pautas interesantes. Evaluación. Se presentan las pautas a los usuarios finales de manera comprensible (visualización).
.")
97
TAREAS DE LA MINERÍA DE DATOS

98
DESCRIPCIÓN DE CLASES Descripción de clases
Sumarizacion/ caracterización de la colección de datos - Tendencias. - Reportes. Aplicaciones: - Supermercados (Canasta de mercado) - Contratos de Mantenimiento (Que debe hacer el almacén para potenciar las ventas de contratos de mantenimiento) ‡98% de la gente que compra llantas y accesorios de autos también obtiene servicios de mantenimiento - Recomendaciones de páginas Web (URL1 & URL3 -> URL5) ‡60% de usuarios de la Web quien visita la Página A y B compra el ítem T1
 - Contratos de Mantenimiento (Que debe hacer el almacén para potenciar las ventas de contratos de mantenimiento) ‡98% de la gente que compra llantas y accesorios de autos también obtiene servicios de mantenimiento. - Recomendaciones de páginas Web (URL1 & URL3 -> URL5) ‡60% de usuarios de la. Web quien visita la Página A y B compra el ítem T1.")
99
ENCONTRAR ASOCIACIONES

100
ENCONTRAR ASOCIACIONES RECUENTO DE APARICIONES CONJUNTAS
ENCONTRAR ASOCIACIONES RECUENTO DE APARICIONES CONJUNTAS Aplicaciones. - Aprobación de créditos - Diagnóstico médico - Clasificación de documentos de texto (text mining) - Recomendación de páginas Web automáticamente - Seguridad Recuento de los Artículos. Considérese el problema del recuento de los artículos que aparecen, cada carro de la compra es un conjunto de artículos adquiridos por un cliente en una sola transacción de cliente. Cada transacción consiste en una sola visita a la tienda (transacción del cliente). Un objetivo frecuente de los comerciantes es la identificación de los artículos que se compran de manera conjunta.
 - Recomendación de páginas Web automáticamente. - Seguridad. Recuento de los Artículos. Considérese el problema del recuento de los artículos que aparecen, cada carro de la compra es un conjunto de artículos adquiridos por un cliente en una sola transacción de cliente. Cada transacción consiste en una sola visita a la tienda (transacción del cliente). Un objetivo frecuente de los comerciantes es la identificación de los artículos que se compran de manera conjunta.")
101
Recuento de Apariciones Conjuntas
Idtrans Idcli Fecha Artículo Cantidad 111 201 05/01/1999 Pluma 2 Tinta 1 Leche 3 Zumo 6 112 105 06/03/1999 113 106 05/10/1999 114 06/01/1999 4 Agua

102
Conjuntos de Artículos Frecuentes
Se puede considerar normalización. Observaciones: En el 75% de las transacciones se compran pluma y tinta. Lote es un conjunto de artículos. Lote {pluma, tinta} tiene 75% de soporte en Compras. Lote {leche, zumo} tiene soporte de 25%. Normalmente el conjunto de artículos que se compran simultáneamente con frecuencia es relativamente pequeño. Sopmin (soporte mínimo) 70%. Lotes frecuentes {pluma}, {tinta}, {leche}, {pluma, tinta}, {pluma, leche}. Propiedad a priori. Todo subconjunto de un lote frecuente es también un lote frecuente.
 70%. Lotes frecuentes {pluma}, {tinta}, {leche}, {pluma, tinta}, {pluma, leche}. Propiedad a priori. Todo subconjunto de un lote frecuente es también un lote frecuente.")
103
Conjuntos de Artículos Frecuentes
Foreach item //nivel 1 comprar si es un lote frecuente //si mayor sopmin k=1 Repeat para cada lote frecuente nuevo Lk con artículos k //nivel k+1 generar todos los lotes Lk+1 artículos, Lk C Lk+1 Examinar todas las transacciones una vez y comprobar si los k +1 lotes generados son frecuentes k = k + 1 until no se identifica ningún lote frecuente nuevo Se identifican primero los lotes frecuentes con un solo artículo. En cada iteración posterior se amplían los lotes frecuentes identificados en la iteración anterior para generar posibles lotes de mayor tamaño lo cual reduce el número de lotes frecuentes.

104
Conjuntos de Artículos Frecuentes
En la primera iteración (Nivel 1) se examina la relación Compras, se determina que todos los conjuntos de un solo artículo son lotes frecuentes: {pluma} {aparece en las cuatro transacciones} {tinta} {aparece en tres de las cuatro transacciones} {leche} {aparece en tres de las cuatro transacciones} En la segunda iteración (Nivel 2) se amplían todos los lotes frecuentes con artículo adicional y se generan los siguientes lotes posibles: {pluma, tinta} {pluma, leche} {pluma, zumo} {tinta, leche} {tinta, zumo} {leche, zumo} Al examinar nuevamente la relación compras {pluma, tinta} {pluma, leche} Aparecen en tres de las cuatro transacciones
 se examina la relación Compras, se determina que todos los conjuntos de un solo artículo son lotes frecuentes: {pluma} {aparece en las cuatro transacciones} {tinta} {aparece en tres de las cuatro transacciones} {leche} {aparece en tres de las cuatro transacciones} En la segunda iteración (Nivel 2) se amplían todos los lotes frecuentes con artículo adicional y se generan los siguientes lotes posibles: {pluma, tinta} {pluma, leche} {pluma, zumo} {tinta, leche} {tinta, zumo} {leche, zumo} Al examinar nuevamente la relación compras. {pluma, tinta} {pluma, leche} Aparecen en tres de las. cuatro transacciones.")
105
Conjuntos de Artículos Frecuentes
En la tercera iteración (Nivel 3) se amplían estos lotes con un artículo adicional: {pluma, tinta, leche} {pluma, tinta, zumo} {pluma, leche, zumo} No se genera {tinta, leche, zumo} por no ser frecuente La propiedad a priori implica que cada lote posible sólo puede ser frecuente si todos sus subconjuntos lo son. Para el ejemplo: con sopmin = 70% Nivel 1, lotes frecuentes tamaño 1: {pluma}.{tinta} y {leche}. Nivel 2 solo quedan: {pluma , tinta},{pluma, leche} y {tinta, leche} Pues {zumo} no es frecuente entonces{pluma, zumo} {tinta , zumo} y {leche, zumo} no son frecuentes y pueden eliminarse a priori. Nivel 3 {pluma, tinta, leche}
 se amplían estos lotes con un artículo adicional: {pluma, tinta, leche} {pluma, tinta, zumo} {pluma, leche, zumo} No se genera {tinta, leche, zumo} por no ser frecuente. La propiedad a priori implica que cada lote posible sólo puede ser frecuente si todos sus subconjuntos lo son. Para el ejemplo: con sopmin = 70% Nivel 1, lotes frecuentes tamaño 1: {pluma}.{tinta} y {leche}. Nivel 2 solo quedan: {pluma , tinta},{pluma, leche} y {tinta, leche} Pues {zumo} no es frecuente entonces{pluma, zumo} {tinta , zumo} y {leche, zumo} no son frecuentes y pueden eliminarse a priori. Nivel 3 {pluma, tinta, leche}")
106
CLASIFICACIÓN Y PREDICCIÓN
Clasificación: Construir un modelo por cada clase de dato etiquetado usado en el entrenamiento del modelo. Basado en sus características y usado para clasificar futuros datos Predicción: Predecir valores posibles de datos/atributos basados en similar objetos. Paso 1: Construcción del model.

107
CLASIFICACIÓN Y PREDICCIÓN
Uso del modelo en la predicción.

108
CLASIFICACIÓN Y PREDICCIÓN (ÁRBOLES DE DECISIÓN)
")
109
EVALUACIÓN DEL MODELO

110
Aplicaciones: Procesamiento de Imágenes (segmentar imágenes a color en regiones) Indexamiento de texto e imágenes WWW Clasificación de paginas Web (usados por motores de búsqueda -Google) Agrupar web log para descubrir grupos de patrones de acceso similares (web usage profiles) Seguridad: Descubriendo patrones de acceso a redes (Detección de intrusos).
 Agrupar web log para descubrir grupos de patrones de acceso similares (web usage profiles) Seguridad: Descubriendo patrones de acceso a redes (Detección de intrusos).")
111
Regresion Predicción de una variable real (no categórica )
- Variable real -> regresión - Variable categórica -> clasificación. Series de tiempo Predecir valores futuros de acuerdo al tiempo. Agrupacion Dividir datos sin etiqueta en grupos (clusters) de tal forma que datos que pertenecen al mismo grupo son similares, y datos que pertenecen a diferentes grupos son diferentes
 de tal forma que datos que pertenecen al mismo grupo son similares, y datos que pertenecen a diferentes grupos son diferentes.")
112
Consultas Iceberg Considérese que se desea hallar parejas de clientes y artículos tales que el consumidor haya comprado ese artículos más de cinco veces. SELECT C.idcll, C.producto, Sum(C.cantidad) FROM Compras C GROUP BY C.idcli, C.producto HAVING SUM(C.cantidad) > 5 La consulta requiere de reglas de asociación. La consulta puede ser muy grande. El número de grupos es muy grande, pero la respuesta a la consulta – punta del iceberg – suele ser pequeña SELECT R.A1, R.A2,…,R.Ak, agree(R.B) FROM Relación R GROUP BY R.A1, …, R.Ak HAVING agree(R.B) >= constante
 FROM Compras C. GROUP BY C.idcli, C.producto. HAVING SUM(C.cantidad) > 5. La consulta requiere de reglas de asociación. La consulta puede ser muy grande. El número de grupos es muy grande, pero la respuesta a la consulta – punta del iceberg – suele ser pequeña. SELECT R.A1, R.A2,…,R.Ak, agree(R.B) FROM Relación R. GROUP BY R.A1, …, R.Ak. HAVING agree(R.B) >= constante.")
113
MINERÍA DE REGLAS REGLAS DE ASOCIACIÓN. {pluma} => {tinta}
Si en una transacción se compra una pluma, es probable que también se compre tinta en esa transacción, {izquierda} => {derecha} SOPORTE, el soporte de {izquierda} => {derecha} es Izq U Der Por ejemplo, para {pluma} {tinta}. El soporte de esta regla es el soporte del lote {pluma, tinta} que es 75% CONFIANZA, la confianza de {izq} => {der} es el porcentaje de esas transacciones que contienen también todos los artículos de Der sop(Izq) es el porcentaje de transacciones que contienen Izq. sop(Izq U Der) es el porcentaje de transacciones que contienen tanto Izq como Der Entonces Confianza de {izq} => {der} es sop(Izq U Der) / sop(Izq)
 es el porcentaje de transacciones que contienen Izq. sop(Izq U Der) es el porcentaje de transacciones que contienen tanto Izq como Der. Entonces Confianza de {izq} => {der} es sop(Izq U Der) / sop(Izq)")
Presentaciones similares












 Software (Software de Inteligencia Impresario)>")







