Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Programa de certificación de Black Belts
Lean Seis Sigma Programa de certificación de Black Belts V. Seis Sigma – Medición Parte B P. Reyes / Abril 2010

2
V. Seis Sigma - Medición D. Estadística básica 1. Términos básicos
2. Teorema del límite central 3. Estadística descriptiva Medidas de tendencia central Medidas de dispersión Funciones de densidad de probabilidad Distribuciones de frecuencia y Funciones acumulativas de distribución 4. Métodos gráficos 5. Conclusiones estadísticas válidas

3
V. Seis Sigma - Medición E. Probabilidad
1. Distribuciones de probabilidad 2. Distribuciones de probabilidad discretas Hipergeométrica, Binomial, Poisson 3. Distribución normal 4. Distribuciones muestrales Chi Cuadrada, t de Student, F 5. Otras Distribuciones de probabilidad Bivariada, Exponencial, Lognormal, Weibull

4
V. Seis Sigma - Medición F. Capacidad de procesos
1. Índices de capacidad de procesos 2. Índices de desempeño de procesos 3. Capacidad a corto y a largo plazo 4. Capacidad de proceso de datos no normales 5. Capacidad de proceso para datos por atributos 6. Capacidad de procesos bajo Seis Sigma

5
V.D Estadística básica

6
V.D Estadística básica 1. Términos básicos
2. Teorema del límite central 3. Estadística descriptiva 4. Métodos gráficos 5. Conclusiones estadísticas válidas

7
V.D.1 Términos básicos

8
Estadística “La estadística descriptiva nos proporciona métodos para organizar y resumir información, la estadística inferencial se usa para obtener conclusiones a partir de una muestra” Por ejemplo, sí deseamos saber el promedio de peso de las personas en una población tenemos dos opciones: Pesar a todas y cada una de las personas, anotar y organizar los datos, y calcular la media. Pesar solo una porción o subconjunto de la población (muestra). Registrar y organizar los datos y calcular la media de la muestra, tomándola para pronosticar o Inferir la media de toda la población.
. Registrar y organizar los datos y calcular la media de la muestra, tomándola para pronosticar o Inferir la media de toda la población.")
9
Población y muestra Población: Es la colección de todos los elementos (piezas, personas, etc.). En nuestro caso sería un número infinito de mediciones de la característica del proceso bajo estudio. Muestra: Es una parte o subconjunto representativo de la población, o sea un grupo de mediciones de las características.
. En nuestro caso sería un número infinito de mediciones de la característica del proceso bajo estudio. Muestra: Es una parte o subconjunto representativo de la población, o sea un grupo de mediciones de las características.")
10
Estadísticos y parámetros
Estadístico: Es una medición tomada en una muestra que sirve para hacer inferencias en relación con una población (media de la muestra, desviación estándar de la muestra se indican con letras latinas X, s, p). Normalmente es una variable aleatoria y tiene asociada una distribución. Parámetro: Es el valor verdadero en una población (media, desviación estándar, se indican con letras griegas , , )
. Normalmente es una variable aleatoria y tiene asociada una distribución. Parámetro: Es el valor verdadero en una población (media, desviación estándar, se indican con letras griegas , , )")
11
Tipos de datos Distribución continua Una distribución con un número infinito de puntos de datos (variables) que pueden mostrarse en una escala de medición continua. Por ejemplo: Distribuciones normal, uniforme, exponencial y Webull Distribución discreta: Una distribución que resulta de datos contables (discretos) con un número finito de valores posibles. Por ejemplo: Distribuciones binomial, Poisson, hipergeométrica.
 que pueden mostrarse en una escala de medición continua. Por ejemplo: Distribuciones normal, uniforme, exponencial y Webull. Distribución discreta: Una distribución que resulta de datos contables (discretos) con un número finito de valores posibles. Por ejemplo: Distribuciones binomial, Poisson, hipergeométrica.")
12
V.D.2 Teorema del límite central

13
Teorema del límite central
La distribución de las medias de las muestras tiende a la normalidad independientemente de la forma de la distribución poblacional de la que sean obtenidas. Es la base de las cartas de control X-R.

14
Teorema del límite central
Por lo anterior la dispersión de las medias es menor que para los datos individuales Para las medias muestrales, el error estándar de la media se relaciona con la desviación estándar de la población como sigue:

15
Aplicación del teorema del límite central

16
Teorema del Límite Central
La distribución de las medias de las muestras tienden a distribuirse en forma normal Por ejemplo los 300 datos (cuyo valor se encuentra entre 1 a 9) pueden estar distribuidos como sigue:
 pueden estar distribuidos como sigue:")
17
Teorema del Límite Central
Población con media y desviación estándar y cualquier distribución. Seleccionando muestras de tamaño n y calculando la X-media o promedio en cada una X-media X-media X-media 3 Conforme el tamaño de muestra se incrementa las muestras se distribuyen normalmente con media de medias y desviación estándar de las medias de las muestras / n. También se denomina Error estándar de la media.

18
Teorema del Límite Central
La distribución de las medias de las muestras tienden a distribuirse en forma normal Tomando de muestras de 10 datos, calculando su promedio y graficando estos promedios se tiene:

19
TIPS PARA EL INSTRUCTOR
Cartas de Control NOTAS DEL INSTRUCTOR Causa especial Causas normales o comunes TIPS PARA EL INSTRUCTOR El instructor explicará cuales son los usos y la definición de las cartas de control, tomando como base las paginas 43 y 49 /130 del manual. Utilizar el ejemplo de ventas. DEFINICION Es una ayuda gráfica para el control de las variaciones de los procesos administrativos y de manufactura. C-14

20
Variación observada en una Carta de Control
Una Carta de control es simplemente un registro de datos en el tiempo con límites de control superior e inferior, diferentes a los límites de especificación. El patrón normal de un proceso se llama causas de variación comunes. El patrón anormal debido a eventos especiales se llama causa especial de variación.

21
Variación – Causas comunes
Límite inf. de especs. Límite sup. de especs. Objetivo

22
Variación – Causas especiales
Límite inf. de especs. Límite sup. de especs. Objetivo

23
Aplicación en la carta de control
“Escuche la Voz del Proceso” Región de control, captura la variación natural del proceso original M E D I A S C L LSC LIC Tendencia del proceso El proceso ha cambiado Causa Especial identifcada TIEMPO

24
Patrones Fuera de Control
Corridas 7 puntos consecutivos de un lado de X-media. Puntos fuera de control 1 punto fuera de los límites de control a 3 sigmas en cualquier dirección (arriba o abajo). Tendencia ascendente o descendente 7 puntos consecutivos aumentando o disminuyendo. Adhesión a la media 15 puntos consecutivos dentro de la banda de 1 sigma del centro. Otros 2 de 3 puntos fuera de los límites a dos sigma
. Tendencia ascendente o descendente. 7 puntos consecutivos aumentando o disminuyendo. Adhesión a la media. 15 puntos consecutivos dentro de la banda de 1 sigma del centro. Otros. 2 de 3 puntos fuera de los límites a dos sigma.")
25
en Control Estadístico
Patrón de Carta en Control Estadístico Proceso en Control estadístico Sucede cuando no se tienen situaciones anormales y aproximadamente el 68% (dos tercios) de los puntos de la carta se encuentran dentro del 1 de las medias en la carta de control. Lo anterior equivale a tener el 68% de los puntos dentro del tercio medio de la carta de control.
 de los puntos de la carta se encuentran dentro del 1 de las medias en la carta de control. Lo anterior equivale a tener el 68% de los puntos dentro del tercio medio de la carta de control.")
26
Aplicación en Intervalos de confianza
Intervalo de confianza para la media: A) Sigma conocida y n>30 (n es tamaño de muestra) B) Sigma desconocida y n<30, los grados de libertad son gl = n-1.
 Sigma conocida y n>30 (n es tamaño de muestra) B) Sigma desconocida y n<30, los grados de libertad son gl = n-1.")
27
Aplicación en Intervalos de confianza
Intervalo de confianza para proporciones y varianza: Para proporciones, p es la proporción y n>30 Para la varianza

28
V.D.3 Estadística descriptiva

29
Estadística Descriptiva
No existen en la naturaleza dos cosas exactamente iguales, ni siquiera los gemelos, por tanto la variación es inevitable y es analizada por la Estadística

30
Estadística descriptiva
La estadística descriptiva incluye: Medidas de tendencia central Medidas de dispersión Funciones de densidad de probabilidad Distribuciones de frecuencia y Funciones acumulativas de distribución

31
Estadística descriptiva
Medidas de tendencia central Representan las diferentes formas de caracterizar el valor central de un conjunto de datos Media muestral poblacional

32
Estadística descriptiva
Medidas de tendencia central Mediana: es el valor medio cuando los datos se arreglan en orden ascendente o descendente, en el caso de n par, la mediana es la media entre los valores intermedios

33
Estadística descriptiva
Medidas de tendencia central Moda: Valor que más se repite, puede haber más de una Media acotada (Truncated Mean): Se elimina cierto porcentaje de los valores más altos y bajos de un conjunto dado de datos (tomando números enteros), para los valores restantes se calcula la media.
: Se elimina cierto porcentaje de los valores más altos y bajos de un conjunto dado de datos (tomando números enteros), para los valores restantes se calcula la media.")
34
Estadística descriptiva
Medidas de tendencia central

35
Estadística descriptiva

36
Estadística descriptiva
Medidas de dispersión: Rango: Es el valor mayor menos el valor menor de un conjunto de datos

37
Estadística descriptiva
Medidas de dispersión: Varianza: es el promedio de las desviaciones al cuadrado respecto a la media (n para población y n-1 para muestra para eliminar el sesgo)
")
38
Estadística descriptiva
Medidas de dispersión: Coeficiente de variación: es igual a la desviación estándar dividida por la media y se expresa en porcentaje

39
Medidas de Dispersión- Rango, CV
Rango: Valor Mayor – Valor menor Coeficiente de variación: (Desv. Estándar / Media )*100%, Se usa para comparar datos en diferentes niveles de media o tipo. Por ejemplo: Material No. de Media Desviación Coeficiente Observaciones Aritmética Estándar de Variación n s Srel A ,204 B ,250 El Material A tiene una menor variabilidad relativa relativa que el material B Error estándar de la Media: Es la desviación estándar de las medias de las muestras de mediciones, se representa como la desviación estándar de la población entre la raíz de n = número de mediciones por muestra.
*100%, Se usa para comparar datos en diferentes niveles de media o tipo. Por ejemplo: Material No. de Media Desviación Coeficiente. Observaciones Aritmética Estándar de Variación. n s Srel. A ,204. B ,250. El Material A tiene una menor variabilidad relativa relativa que el material B. Error estándar de la Media: Es la desviación estándar de las medias de las muestras de mediciones, se representa como la desviación estándar de la población entre la raíz de n = número de mediciones por muestra.")
40
Estadística descriptiva
Función de densidad de probabilidad El área bajo la curva de densidad de probabilidad a la izquierda de un valor dado x, es igual a la probabilidad de la variable aleatoria en el eje x para X<= x Para distribuciones continuas Para distribuciones discretas

41
Estadística descriptiva
Función de densidad de probabilidad

42
Estadística descriptiva
Función de distribución acumulada Función de densidad Función de distribución acumulada

43
V.D.4 Métodos gráficos

44
Métodos gráficos Se incluyen los métodos siguientes: Diagramas de caja
Diagramas de tallo y hojas Diagramas de dispersión Análisis de patrones y tendencias Histogramas Distribuciones de probabilidad normales Distribuciones de Weibull

45
Diagrama de caja PERCENTILES, DECILES Y QUARTILES
Cada conjunto de datos ordenado tiene tres cuartiles que lo dividen en cuatro partes iguales. El primer cuartil es ese valor debajo del cual clasifica el 25% de las observaciones y sobre el cual se encuentra el 75% restante. El segundo cuartil divide a los datos a la mitad similar a la mediana. El tercer cuartil es el valor debajo del cual se encuentra el 75% de las observaciones. Los deciles separan un conjunto de datos ordenado en 10 subconjuntos iguales y los percentiles en 100 partes

46
Diagrama de caja PERCENTILES, DECILES Y QUARTILES
La ubicación de un percentil se encuentra en: Donde: Lp es el sitio del percentil deseado en una serie ordenada n es el número de observaciones P es el percentil deseado

47
Diagrama de caja Por ejemplo para los datos siguientes: 3 10 19 27 34 38 48 56 67 74 4 12 20 29 39 59 7 14 21 31 36 43 52 62 69 76 9 15 25 37 45 53 63 72 79 17 47 64 73 80

48
Diagrama de caja La localización del percentil 35 se halla en:
O sea que el percentil 35 está al 85% del trayecto comprendido entre la observación 17 que es 29 y la observación 18 que es 31 o sea L35 = 29 + (0.85)(31-29) = Por tanto el 35% de las observaciones están por debajo de 30.7 y el 65% restante por encima de 30.7. De la misma forma los percentiles 25, 50 y 75 proporcionan la localización de los cuartiles Q1, Q2 y Q3 respectivamente. Q1: es el número que representa al percentil 25 Q2 o Mediana: es el número que representa al percentil 50 Q3: es el número que representa al percentil 75 (hay 75% de los datos por debajo de este). Rango o Recorrido intercuartílico: es la diferencia entre Q1 y Q3.
(31-29) = Por tanto el 35% de las observaciones están por debajo de 30.7 y el 65% restante por encima de De la misma forma los percentiles 25, 50 y 75 proporcionan la localización de los cuartiles Q1, Q2 y Q3 respectivamente. Q1: es el número que representa al percentil 25. Q2 o Mediana: es el número que representa al percentil 50. Q3: es el número que representa al percentil 75 (hay 75% de los datos por debajo de este). Rango o Recorrido intercuartílico: es la diferencia entre Q1 y Q3.")
49
Gráficas de caja Permite identificar la distribución de los datos, muestra la mediana, bases y extremos. Mediana = dato intermedio entre un grupo de datos ordenados en forma ascendente Primer cuartil Tercer cuartil Mediana Valor mínimo Valor máximo DEFINICION: Es una ayuda gráfica para ver la variabilidad de los datos.

50
Métodos gráficos Diagramas de caja
Representan un resumen de los datos. La línea media es la mediana, los lados son el primer y tercer cuartil. El máximo y el mínimo se dibuja como puntos al final de las líneas (bigotes)
")
51
Métodos gráficos Diagramas de tallo y hojas
El diagrama consiste del agrupamiento de los datos por intervalos de clase, como tallos y los incrementos de datos más pequeños como hojas. Hojas Tallos

52
Métodos gráficos Diagramas de dispersión
Es una gráfica de muchos puntos coordenados X-Y que representan la relación entre dos variables. También se denomina carta de correlación. Se puede tomar la variable dependiente para el eje Y y la dependiente en el eje X. La correlación tiene las siguientes fuentes: Una relación de causa efecto Una relación entre dos causas Una relación entre una causa y dos o más causas

53
Relaciones no lineales
Métodos gráficos Diagramas de dispersión Positiva débil Positiva fuerte Sin correlación Negativa fuerte Relaciones no lineales

54
Métodos gráficos Coeficiente de correlación
El coeficiente de correlación “r” determina el grado de asociación entre dos variables X y Y

55
Métodos gráficos Análisis de correlación
Busca descubrir relaciones, aplicar el sentido común La línea de “mejor ajuste” es la línea de regresión, sin embargo un análisis visual debiera ser suficiente para identificar si hay o no hay relación Los diagramas de dispersión deben ser analizados antes de tomar decisiones sobre correlación estadística

56
Métodos gráficos Análisis de patrones y tendencias
Para visualizar el comportamiento de los datos en el tiempo Tendencia creciente Tendencia decreciente Corrida de proceso Valores anormales Ciclos Variabilidad creciente

57
Métodos gráficos Análisis de patrones y tendencias
Para visualizar el comportamiento de los datos en el tiempo Tendencia creciente

58
Histogramas

59
TIPS PARA EL INSTRUCTOR
Métodos gráficos NOTAS DEL INSTRUCTOR Histogramas Son gráficas de columnas de frecuencia que muestran una imagen estática del comportamiento del proceso y requieren un mínimo de 50 a 100 puntos La frecuencia en cada barra o intervalo es el número de puntos que caen dentro de ese intervalo Un proceso estable muestra un histograma con forma de campana unimodal, es predecible TIPS PARA EL INSTRUCTOR El instructor se auxiliará de las pags /130 del manual. Utilizar dos ejemplos uno planta y otro ventas. C-13

60
TIPS PARA EL INSTRUCTOR
Métodos gráficos NOTAS DEL INSTRUCTOR Histogramas Un proceso inestable muestra un histograma que no tiene una forma acampanada. Sin embargo los procesos que siguen una distribución exponencial, lognormal, gamma, beta, Weibull, Poisson, binomial, hipergeométrica, geométrica, etc. existen como procesos estables Cuando la distribución es acampanada, la variación alrededor de la media es aleatoria, otras variaciones son debidas a causas especiales o asignables. TIPS PARA EL INSTRUCTOR El instructor se auxiliará de las pags /130 del manual. Utilizar dos ejemplos uno planta y otro ventas. C-13

61
TIPS PARA EL INSTRUCTOR
Métodos gráficos NOTAS DEL INSTRUCTOR Permite ver la distribución que tienen los procesos de manufactura y administrativos vs. especificaciones Permiten ver la frecuencia con la que ocurren las cosas. La variabilidad del proceso se representa por el ancho del histograma, se mide en desviaciones estándar o . Un rango de ± 3 cubre el 99.73%. TIPS PARA EL INSTRUCTOR El instructor se auxiliará de las pags /130 del manual. Utilizar dos ejemplos uno planta y otro ventas. DEFINICION Un Histograma es la organización de un número de datos muestra que nos permite visualizar al proceso de manera objetiva. C-13

62
Histograma de Frecuencia
Media TAMAÑO TAMAÑO TAMAÑO En un proceso estable las mediciones se distribuyen normalmente, a la derecha y a la izquierda de la media adoptando la forma de una campana. M E D I C O N S TAMAÑO TAMAÑO

63
Histograma de Frecuencia
Permite ver la distribución de la frecuencia con la que ocurren las cosas en los procesos de manufactura y administrativos. La variabilidad del proceso se representa por el ancho del histograma, se mide en desviaciones estándar o , ± 3 cubre el 99.73%. LIE LSE DEFINICION Un Histograma es la organización de un número de datos muestra que nos permite visualizar al proceso de manera objetiva.

64
Las distribuciones pueden variar en:
POSICIÓN AMPLITUD FORMA … O TENER CUALQUIER COMBINACION

65
Ejemplos de histogramas:

66
Histogramas con Datos agrupados
El Histograma es una gráfica de las frecuencias que presenta los diferentes datos o valores de mediciones agrupados en celdas y su frecuencia. Una tabla de frecuencias lista las categorías o clases de valores con sus frecuencias correspondientes, por ejemplo: CLASE FRECUENCIA

67
Definiciones - datos agrupados
Límite inferior y superior de clase Son los numeros más pequeños y más grandes de las clases (del ejemplo, 1 y 5; 6 y 10; 11 y 15; 16 y 20; 21 y 25; 26 y 30) Marcas de clase Son los puntos medios de las clases (del ejemplo 3, 8, 13, 18, 23 y 28) Fronteras de clase Se obtienen al incrementar los límites superiores de clase y al decrementar los inferiores en una cantidad igual a la media de la diferencia entre un límite superior de clase y el siguiente límite inferior de clase (en el ejemplo, las fronteras de clase son 0.5, 5.5, 10.5, 15.5, 20.5, 25.5 y 30.5) Ancho de clase Es la diferencia entre dos límites de clase inferiores consecutivas(en el ejemplo, es 5).
 Marcas de clase. Son los puntos medios de las clases (del ejemplo 3, 8, 13, 18, 23 y 28) Fronteras de clase. Se obtienen al incrementar los límites superiores de clase y al decrementar los inferiores en una cantidad igual a la media de la diferencia entre un límite superior de clase y el siguiente límite inferior de clase (en el ejemplo, las fronteras de clase son 0.5, 5.5, 10.5, 15.5, 20.5, 25.5 y 30.5) Ancho de clase. Es la diferencia entre dos límites de clase inferiores consecutivas(en el ejemplo, es 5).")
68
Construcción del histograma - datos agrupados
Paso 1. Contar los datos (N) Paso 2. Calcular el rango de los datos R = (Valor mayor- valor menor) Paso 3. Seleccionar el número de columnas o celdas del histograma (K). Como referencia si N = 1 a 50, K = 5 a 7; si N = ; K = También se utiliza el criterio K = Raíz (N) Paso 4. Dividir el rango por K para obtener el ancho de clase Paso 5. Identificar el límite inferior de clase más conveniente y sumarle el ancho de clase para formar todas las celdas necesarias Paso 6. Tabular los datos dentro de las celdas de clase Paso 7. Graficar el histograma y observar si tiene una forma normal
 Paso 2. Calcular el rango de los datos R = (Valor mayor- valor menor) Paso 3. Seleccionar el número de columnas o celdas del histograma (K). Como referencia si N = 1 a 50, K = 5 a 7; si N = ; K = También se utiliza el criterio K = Raíz (N) Paso 4. Dividir el rango por K para obtener el ancho de clase. Paso 5. Identificar el límite inferior de clase más conveniente y sumarle el ancho de clase para formar todas las celdas necesarias. Paso 6. Tabular los datos dentro de las celdas de clase. Paso 7. Graficar el histograma y observar si tiene una forma normal.")
69
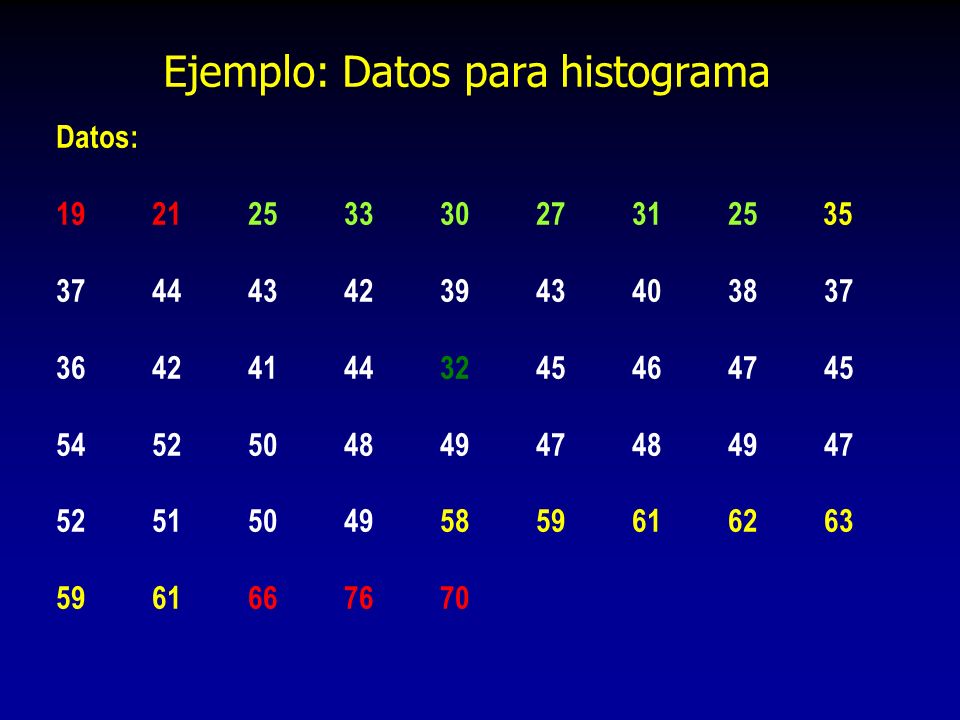
Ejemplo: Datos para histograma
70
Ejemplo: Construcción del histograma
Paso 1. Número de datos N = 50 Paso 2. Rango R = = 60 Paso 3. Número de celdas K = 6; Paso 4. Ancho de clase = 60 / 6 = 10 Paso 5. Lím. de clase: , , , , , 65-74, 75-94 Paso 6. Número de datos: Marcas de clase Paso 7. Graficar el histograma y observar si tiene una forma normal

71
Histograma en Excel Accesar el menu de análisis de datos con HERRAMIENTAS, ANALISIS DE DATOS, HISTOGRAMAS Marcar los datos de entrada en RANGO DE ENTRADA, marcar el rango de los límites superiores de clase en RANGO DE CLASES, indicar GRAFICA, marcar el área de resultados con RANGO DE SALIDA y obtener resultados y gráfica NOTA: Los datos deben estar en forma no agrupada, Excel forma los grupos en forma automática o se le pueden proporcionar los límites de las celdas.

72
Construcción del histograma

73
Otras medidas de Dispersión- Rango, CV
Rango: Valor Mayor – Valor menor Coeficiente de variación: (Desv. Estándar / Media *100% Se usa para comparar datos en diferentes niveles de media o tipo. Por ejemplo: Material No. de Media Desviación Coeficiente Observaciones Aritmética Estándar de Variación n s Srel A ,204 B ,250 El Material A tiene una menor variabilidad relativa relativa que el material B

74
Cálculo de la media - datos agrupados
Media - Promedio numérico o centro de gravedad del histograma Donde, Fi = Frecuencia de cada observación xi = Valor de cada marca de clase - Usa todos los datos - Le afectan los extremos La media aritmética (También llamada la Media) es el promedio de los datos. A esto también se le llama medición de tendencia central. Se calcula sumando todas las observaciones de los datos y luego dividiendo entre el número de observaciones. Sirve como punto de equilibrio. Ej..( =15/5=3) ( =60/5=12) La Mediana es el valor medio de una secuencia ordenada de datos. Si no hay empates, la mitad de las observaciones serán menores y la otra mitad serán mayores. La mediana no es afectada por observaciones extremas de datos. Por lo tanto, siempre que esté presente una observación extrema es más apropiado usar la mediana que la media. La Moda es el valor que aparece con más frecuencia en una serie de datos. Mediana - Es el valor que se encuentra en medio de los datos Moda - Es el valor que más se repite
 es el promedio de los datos. A esto también se le llama medición de tendencia central. Se calcula sumando todas las observaciones de los datos y luego dividiendo entre el número de observaciones. Sirve como punto de equilibrio. Ej..( =15/5=3) ( =60/5=12) La Mediana es el valor medio de una secuencia ordenada de datos. Si no hay empates, la mitad de las observaciones serán menores y la otra mitad serán mayores. La mediana no es afectada por observaciones extremas de datos. Por lo tanto, siempre que esté presente una observación extrema es más apropiado usar la mediana que la media. La Moda es el valor que aparece con más frecuencia en una serie de datos. Mediana - Es el valor que se encuentra en medio de los datos. Moda - Es el valor que más se repite.")
75
Desviación Estándar - Datos agrupados
S es usada cuando los datos corresponden a una muestra de la población Nota: Cada Xi representa la marca de clase típicamente es usada si se está considerando a toda la población NOTA: Para lo cálculos con Excel, se puede utilizar el mismo método que para datos no agrupados, tomando como Xi los valores de las marcas de clase.

76
Ejercicio de Histogramas
Datos:

77
V.D.5 Conclusiones estadísticas válidas

78
Estadística descriptiva e inferencial
Estudios descriptivos enumerativos : Los datos enumerativos son los que pueden ser contados. Para Deming: En un Estudio enumerativo la acción se toma en el universo. En un estudio analítico la acción será tomada en un proceso para mejorar su desempeño futuro

79
Obteniendo conclusiones válidas
Obtención de conclusiones estadísticas válidas El objetivo de la estadística inferencial es obtener conclusiones acerca de las características de la población (parámetros , , ) con base en la información obtenida de muestras (estadísticos X, s, r) Los pasos de la estadística inferencial son: La inferencia La evaluación de su validez
 con base en la información obtenida de muestras (estadísticos X, s, r) Los pasos de la estadística inferencial son: La inferencia. La evaluación de su validez.")
80
Obteniendo conclusiones válidas
Los pasos de la estadística inferencial son: Definir el objetivo del problema en forma precisa Decidir si el problema se evaluará con una o dos colas Formular una hipótesis nula y la alterna Seleccionar una distribución de prueba y un valor crítico del estadístico reflejado el grado de incertidumbre que puede ser tolerado (alfa, riesgo)
")
81
Obteniendo conclusiones válidas
Los pasos de la estadística inferencial son: Calcular el valor del estadístico de prueba con la información de la muestra Comparar el valor del estadístico calculado vs su valor crítico y tomar una decisión de rechazar o no rechazar la hipótesis nula Comunicar los hallazgos a las partes interesadas

82
Obteniendo conclusiones válidas
Hipótesis nula a ser probada (Ho) y alterna (Ha) La hipótesis nula puede ser rechazada o no ser rechazada no puede ser aceptada La hipótesis alterna incluye todas las posibilidades que no están en la nula y se designa con H1 o Ha. Ho: Ya = Yb Ha: Ya Yb Prueba de dos colas Ho: A B Ha: A<B Prueba de cola izquierda
 y alterna (Ha) La hipótesis nula puede ser rechazada o no ser rechazada no puede ser aceptada. La hipótesis alterna incluye todas las posibilidades que no están en la nula y se designa con H1 o Ha. Ho: Ya = Yb Ha: Ya Yb Prueba de dos colas. Ho: A B Ha: A<B Prueba de cola izquierda.")
83
Obteniendo conclusiones válidas
Estadístico de prueba: Para probar la hipótesis nula sobre un parámetro poblacional, se debe calcular un estadístico de prueba de la información de la muestra El estadístico de prueba se compara con un valor crítico apropiado Se toma una decisión de rechazar o no rechazar la hipótesis nula

84
Obteniendo conclusiones válidas
Tipos de errores: Error tipo I: resulta cuando se rechaza Ho siendo verdadera, se denomina como alfa o riesgo del productor Error tipo II: resulta cuando no se rechaza Ho siendo que es falsa, es denominado beta o riesgo del consumidor Incrementando el tamaño de muestra se reducen alfa y beta. Alfa es normalmente 5%. Alfa y beta son inversamente relativos

85
Obteniendo conclusiones válidas
Estudios enumerativos y analíticos: Los datos enumerativos pueden ser contados. Las pruebas de hipótesis utilizadas son la Chi cuadrada, binomial y de Poisson. Deming: en los estudios enumerativos las acciones se toman en el universo. Deming: en los estudios analíticos se toma acción en un proceso para mejorar su desempeño futuro

86
V.E Probabilidad

87
V. E Probabilidad 1. Conceptos básicos 2. Distribuciones utilizadas normalmente 3. Otras distribuciones

88
V.E.1 Conceptos básicos

89
Conceptos básicos Introducción:
Diferencia entre experimento deterministico y aleatorio (estocastico). Deterministico. Se obtienen el mismo resultado, con condiciones experimentales similares La caída de un cuerpo Aleatorio. Se obtienen distintos resultados , aunque se repitan en condiciones similares. Tiempo de vida de un componente eléctrico
. Deterministico. Se obtienen el mismo resultado, con condiciones experimentales similares. La caída de un cuerpo. Aleatorio. Se obtienen distintos resultados , aunque se repitan en condiciones similares. Tiempo de vida de un componente eléctrico.")
90
Conceptos relacionados a experimentos aleatorios:
Variable aleatoria. Es el nombre Que se le da a la característica (s) de interés observada en un experimento. Dicha variable es denotada por letras mayúsculas. Pueden ser Continuas o Discretas. Espacio muestra. Es el conjunto de todos los posibles valores Que toma una variable aleatoria en un experimento. Puede ser finito o infinito. Evento. Puede ser uno o una combinación de los valores Que toma una variable aleatoria
 de interés observada en un experimento. Dicha variable es denotada por letras mayúsculas. Pueden ser Continuas o Discretas. Espacio muestra. Es el conjunto de todos los posibles valores Que toma una variable aleatoria en un experimento. Puede ser finito o infinito. Evento. Puede ser uno o una combinación de los valores Que toma una variable aleatoria.")
91
Espacio Muestral Consiste en todos los posibles resultados de un experimento. Para el lanzamiento de una moneda es (A,S).
.")
92
Probabilidad histórica o frecuentista.
Una forma de conocer algo acerca del comportamiento de una variable aleatoria es conociendo como se comporto en el pasado. Note Que si un experimento se realizo un gran numero de veces, N, y la se observo Que en n veces sucedía el evento A, entonces n/N es un estimación razonable de la proporción de tiempos Que el evento A sucederá en el futuro. Para un gran numero de experimentos N, se puede interpretar dicha proporción como la probabilidad de del evento A.

93
Ejemplo en los 1900-s , Karl Pearson lanzo una moneda 24,000 veces y obtuvo 12,012 caras, dando una proporción de 1 .5 probabilidad de caras 500 1000 n

94
Definición Clásica de Probabilidad.
La probabilidad de un evento A, puede ser calculada mediante la relación de el numero de respuestas en favor de A, y el numero total de resultados posibles en un experimento. Note Que para las dos definiciones dadas de probabilidad esta será un numero entre 0 y 1. Ejemplo 1. Se observa si 3 artículos tienen defecto o no , con defecto (m) o sin defecto (v). S={vvv,mvv,vmv,vvm,vmm,mvm,mmv,mmm} es el espacio muestral . Asociada a este espacio muestral se puede definir la variable aleatoria X=# de defectos, la cual toma los valores {0,1,2,3}
 o sin defecto (v). S={vvv,mvv,vmv,vvm,vmm,mvm,mmv,mmm} es el espacio muestral . Asociada a este espacio muestral se puede definir la variable aleatoria X=# de defectos, la cual toma los valores {0,1,2,3}")
95
Conceptos básicos Principios básicos:
La probabilidad de un evento varia entre 0 y 1 (éxito) Un evento simple no puede descomponerse El conjunto de resultados posibles del experimento se denomina espacio muestral La suma de las probabilidades en el espacio muestra es 1 Si se repite un experimento un gran número de veces N y el evento E es observado nE veces, la probabilidad de E es aproximadamente:
 Un evento simple no puede descomponerse. El conjunto de resultados posibles del experimento se denomina espacio muestral. La suma de las probabilidades en el espacio muestra es 1. Si se repite un experimento un gran número de veces N y el evento E es observado nE veces, la probabilidad de E es aproximadamente:")
96
Conceptos básicos Eventos compuestos (conjunto de dos o más eventos):
La unión de A o B contiene elementos de A o de B La intersección de A y B contiene elementos comunes que se localizan al mismo tiempo en A y en B

97
Leyes de probabilidades
1. En un experimento, si P(A) e la probabilidad de un evento A, entonces la probabilidad de Que no suceda A es: 2. En un experimento, si A y B son dos eventos mutuamente excluyentes entonces la probabilidad de Que ocurra A o el evento B es Para el caso de dos eventos A y B Que no son mutuamente excluyentes. A las dos ecuaciones se les conoce como Leyes de adición de probabilidad
 e la probabilidad de un evento A, entonces la probabilidad de Que no suceda A es: 2. En un experimento, si A y B son dos eventos mutuamente excluyentes entonces la probabilidad de Que ocurra A o el evento B es. Para el caso de dos eventos A y B Que no son mutuamente excluyentes. A las dos ecuaciones se les conoce como. Leyes de adición de probabilidad.")
98
Reglas de la probabilidad
Ley de la Adición Si 2 eventos A y B no son mutuamente excluyentes, entonces la probabilidad que el evento A o el evento B ocurra es: Ley de la Multiplicación probabilidad que ambos A y B ocurran es (A y B dependientes) Cuando los eventos A y B son independientes, entonces P(A|B) = P(A) y
 Cuando los eventos A y B son independientes, entonces P(A|B) = P(A) y.")
100
Permutaciones Definición.
Un arreglo ordenado de r objetos diferentes es llamado una permutación . El numero resultante de ordenar n objetos diferentes tomando r a la vez será representado por el símbolo Antes revisemos el concepto de factorial !!!!!! Considere el siguiente caso: Hay 3 libros: Uno de Historia (H), Uno de Física (F), Otro de Matemáticas (M). Note Que existen 6 formas de acomodar dichos libros. { HFM, HMF, FHM, FMH, MHF, MFH } Aquí importa el orden 3*2*1=6
, Uno de Física (F), Otro de Matemáticas (M). Note Que existen 6 formas de acomodar dichos libros. { HFM, HMF, FHM, FMH, MHF, MFH } Aquí importa el orden. 3*2*1=6.")
101
Diagramas de árbol 12 tratamientos
En casos simples resultan útiles los diagramas de árbol para enumerar objetos en forma sistemática. Ejemplo: Se desea conocer todas las formas posibles de hacer un experimento que consiste en 4 componentes de auto a {L1, L2, L3, L4}, entonces cada componente es sometido a tres diferentes temperaturas de {A1, A2, A3} hasta que se obtiene una falla. A1 A2 L1 A3 A1 L2 A2 A3 12 tratamientos A1 L3 A2 A3 L4 A1 A2 A3

102
n! se lee como n factorial
El numero de formas de ordenar n objetos distintos en n lugares diferentes es : n! se lee como n factorial ¿ Que pasa cuando tenemos solo r lugares para acomodar n objetos, tal Que n es mayor o igual que r? En este caso el numero de arreglos resulta ser:

103
10 intensidades (i1,i2,…,i10 ) y 2 aplicaciones.
Ejemplo: Suponga que a un grupo de motores se les aplicara un tratamiento que consiste en dos aplicaciones de diferentes intensidades de presión. Hay 10 diferentes intensidades y el orden de administrar las intensidades es importante, ¿ cuantos motores se ocupan si cada tratamiento se tiene que llevar a cabo?. 10 intensidades (i1,i2,…,i10 ) y 2 aplicaciones. Nos interesa contar los pares (i1,12),(i1,i3),…..
 y 2 aplicaciones. Nos interesa contar los pares (i1,12),(i1,i3),…..")
104
!! En este caso no es importante el orden de los objetos !!
Combinaciones Una combinación es un arreglo de distintos elementos , en donde una combinación difiere de otra solamente si el contenido del arreglo es distinto. !! En este caso no es importante el orden de los objetos !! Definición. (Combinaciones). El numero de combinaciones de n objetos tomando r a la vez es el numero de maneras de formar un subconjunto de tamaño r de los n objetos. Esto se denota como:
. El numero de combinaciones de n objetos tomando r a la vez es el numero de maneras de formar un subconjunto de tamaño r de los n objetos. Esto se denota como:")
105
Teorema 2. Ejemplo: En un lote de producción 100 chips de computadora, un comprador desea adquirir 10 chips, ¿ de cuantas formas se pueden seleccionar 10 chips de ese lote?.

106
V.E.2 Distribuciones de probabilidad

107
Distribuciones usadas por los Black Belts
1. Distribuciones de probabilidad 2. Distribuciones de probabilidad discretas Hipergeométrica, Binomial, Poisson 3. Distribución normal 4. Distribuciones muestrales Chi Cuadrada, t de Student, F 5. Otras Distribuciones de probabilidad Exponencial, Lognormal, Weibull

108
1. Distribuciones de probabilidad

109
Tipos de variables aleatorias
Variable aleatoria: Es aquella función que a cada resultado posible de un experimento le asocia un numero real. Se denotan con letras Mayúsculas: X,Y,Z,etc.... Tipos de variables aleatorias Discretas Continuas

110
Variables aleatorias discretas
Es aquella variable que únicamente toma valores susceptibles de contarse. Ejemplo 1: Considere el experimento de tomar al azar una ficha de asistencia de un numero de empleados. Sea X la variable numero de ausencias al año de un empleado. Note que X toma valores 0,1,2,...,250. Ejemplo 2: Considere un experimento que consiste en medir el numero de artículos defectos de un lote de producto. Si Y es la variable numero de defectos , toma valores 0,1,2,...

111
Distribuciones y funciones de probabilidad
Toda variable aleatoria tiene asociada una función de probabilidades Ejemplo : Se lanzan dos monedas y observamos el numero Y de caras. Espacio muestral:{a, as, sa, ss} Y toma valores 0,1,2.

112
Función de probabilidades para Y.
0.51 0.46 0.41 Gráfica p P(Y=y) 0.36 0.31 0.26 -0.2 0.3 0.8 1.3 1.8 y Y
 y. Y.")
113
Formula para la distribución de probabilidades de la tabla anterior
La distribución de probabilidades puede ser una Tabla, una Gráfica o una formula.

114
Requisitos para una distribución de probabilidad discreta
En algunas ocasiones la notación usada es:

115
Funciones de distribución acumulativa
La función de distribución de probabilidades acumulativa es calcula sumando las probabilidades obtenidas hasta un determinado valor de la variable aleatoria. Esta función tiene propiedades.

116
Función de distribución acumulativa para Y=#de caras
0.9 0.7 F(x) 0.5 0.3 -0.2 0.3 0.8 1 1.3 1.8 2 y
 y.")
117
Valor Esperado o Media de una variable aleatoria discreta
La media o valor esperado de una variable aleatoria discreta X , denotada como o E(X), es La media es el centro de la masa del rango de los valores de X.
, es. La media es el centro de la masa del rango de los valores de X.")
118
Calculo de la media para la variable de No. De defectos
En este caso note que esta media no toma un valor entero como X

119
Media

120
Ejercicio: La demanda de un producto es -1,0,1,2 por dia (-1 significa devolución). Con probabilidades dadas por 1/5,1/10,2/5,3/10. Calcular la demanda esperada.
. Con probabilidades dadas por 1/5,1/10,2/5,3/10. Calcular la demanda esperada.")
121
Varianza de una variable aleatoria
Sea Y una variable aleatoria discreta con distribución de probabilidades P(X=x). Entonces , la varianza de Y es: Medida de dispersión
. Entonces , la varianza de Y es: Medida de dispersión.")
123
La desviación estándar de una variable aleatoria es simplemente la raíz cuadrada de la varianza

124
2. Distribuciones de probabilidad discretas

125
Distribuciones Discretas
Uniforme discreta. La variable aleatoria toma un numero finito de n valores , cada uno con igual probabilidad.

126
Uniforme discreta con n=10

127
La media y varianza de la distribución Uniforme discreta son:
Aplicaciones

128
Distribución hipergeométrica
Se aplica cuando la muestra (n) es una porporción relativamente grande en relación con la población (n > 0.1N). El muestreo se hace sin reemplazo P(x,N,n,D) es la probabilidad de exactamente x éxitos en una muestra de n elementos tomados de una población de tamaño N que contiene D éxitos. La función de densidad de distribución hipergeométrica:
 es una porporción relativamente grande en relación con la población (n > 0.1N). El muestreo se hace sin reemplazo. P(x,N,n,D) es la probabilidad de exactamente x éxitos en una muestra de n elementos tomados de una población de tamaño N que contiene D éxitos. La función de densidad de distribución hipergeométrica:")
129
Distribución hipergeométrica
La media y la varianza de la distribución hipergeométrica son:

130
Distribución hipergeométrica
Ejemplo: De un grupo de 20 productos, 10 se seleccionan al azar para prueba. ¿Cuál es la probabilidad de que 10 productos seleccionados contengan 5 productos buenos? Los productos defectivos son 5 en el lote. N = 20, n = 10, D = 5, (N-D) = 15, x = 5 P(x=5) = = 1.83%
 = 15, x = 5. P(x=5) = = 1.83%")
131
Distribución Binomial
Ensayo Bernoulli. Es un experimento aleatorio que solo tiene dos resultados. Éxito o fracaso. Donde la probabilidad de éxito se denota por p Suponga se realizan n experimentos Bernoulli independientes. Suponga que la variable X de interés es el numero de éxitos. X toma valores 0,1,2,...,n

132
Distribución binomial
Se utiliza para modelar datos discretos y se aplica para poblaciones grandes (N>50) y muestras pequeñas (n<0.1N). El muestreo binomial es con reemplazamiento. Es apropiada cuando la proporción defectiva es mayor o igual a 0.1. La binomial es una aproximación de la hipergeométrica La distribución normal se paroxima a la binomial cuando np > 5
 y muestras pequeñas (n<0.1N). El muestreo binomial es con reemplazamiento. Es apropiada cuando la proporción defectiva es mayor o igual a 0.1. La binomial es una aproximación de la hipergeométrica. La distribución normal se paroxima a la binomial cuando np > 5.")
133
La variable aleatoria X tiene una distribución binomial
Tiene media y varianza.

134
Distribución de Poisson
Se utiliza para modelar datos discretos Se aproxima a la binomial cuando p es igual o menor a 0.1, y el tamaño de muestra es grande (n > 16) por tanto np < 5
 por tanto np < 5.")
135
Distribución de Poisson
Una Variable aleatoria X tiene distribución Poisson si toma probabilidades con.

136
3. La Distribución Normal

137
IMPORTANCIA DE LA DISTRIBUCIÓN NORMAL
Abraham Simon de Carl Francis de Moivre Laplace Gauss Galton Los primeros industriales frecuentemente se basaban en el conocimiento de limites normales para clasificar artículos o procesos como correctos o de otro modo. Por ejemplo, el colesterol arriba de 250 mg/dl es ampliamente conocido que incrementa el riesgo de un paro cardiaco. Una determinación precisa - pudiera ser asunto de vida o muerte. Sin embargo , no todas las variables son normales. Por ejemplo: urea y ph

138
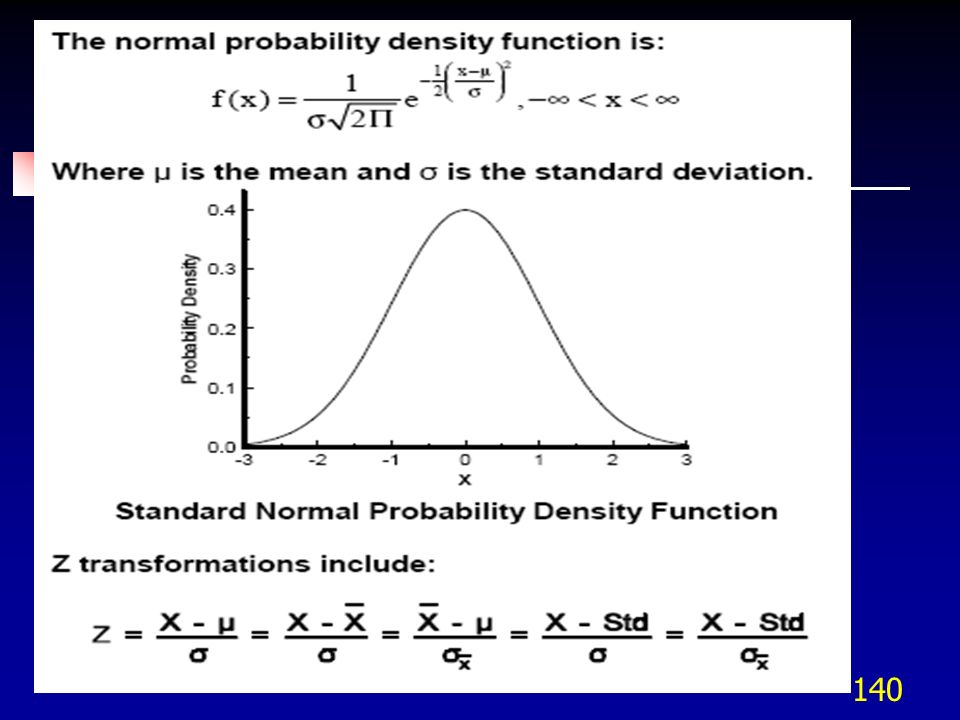
CARACTERISTICAS DE UNA DISTRIBUCIÓN NORMAL
La curva normal es acampanada y tiene un solo pico en toda la distribución. La media, mediana, y moda de la distribución son las mismas y están localizadas en el pico. La mitad del área de la curva esta arriba del punto central (pico), y la otra mitad esta abajo. La distribución normal es simétrica alrededor de su media. Es asintotica - la curva se acerca a eje x pero nunca lo toca.
, y la otra mitad esta abajo. La distribución normal es simétrica alrededor de su media. Es asintotica - la curva se acerca a eje x pero nunca lo toca.")
139
CARACTERISTICAS DE UNA DISTRIBUCION NORMAL
La Normal is simétrica Cola Cola Teóricamente, la curva se extiende a + infinito Teóricamente, la curva se extiende a - infinito Media, mediana, y moda son iguales

141
Distribución Normal Distribución de la Función Normal
Función de Densidad de Probabilidad Normal = 500 = 30 = 50 = 70 0.0000 0.0020 0.0040 0.0060 0.0080 0.0100 0.0120 0.0140 200 400 600 800 1000 Tiempo f(t)
")
142
Curvas Normales con Medias iguales pero Desviaciones estándar diferentes

143
Desviaciones estándar diferentes
Normales con Medias y Desviaciones estándar diferentes m = 5, s = 3 m = 9, s = 6 m = 14, s = 10

144
La distribución Normal estándar
La distribución normal estándar es una distribución de probabilidad que tiene media 0 y desviación estándar de 1. El área bajo la curva o la probabilidad desde menos infinito a más infinito vale 1. La distribución normal es simétrica, es decir cada mitad de curva tiene un área de 0.5. La escala horizontal de la curva se mide en desviaciones estándar, su número se describe con Z. Para cada valor Z se asigna una probabilidad o área bajo la curva mostrada en la Tabla de distribución normal

145
Las distribuciones pueden variar en:
POSICIÓN AMPLITUD FORMA … O TENER CUALQUIER COMBINACION

146
La Distribución Normal
Para la población - se incluyen TODOS los datos Para la muestra X m-3s m-2s m-s m m+s m+2s m+3s x-3s x-2s x-s x x+s x+2s x+3s

147
La Distribución Normal Estándar
La desviación estándar sigma representa la distancia de la media al punto de inflexión de la curva normal X x-3s x-2s x-s x x+s x+2s x+s3 z 1 2 3 -1 -2 -3

148
AREA BAJO LA CURVA NORMAL
Alrededor de 68 % del area bajo la curva normal está entre más una y menos una desviación estándar de la media. Esto puede ser escrito como: m ± 1s. Cerca del 95 % del área bajo la normal está entre más y menos 2 desviaciones estándar de la media, m ± 2s. Prácticamente toda (99.74 %) el área bajo la normal esta entre 3 desviaciones de la media m ± 3s.
 el área bajo la normal esta entre 3 desviaciones de la media m ± 3s.")
149
Cálculos con Excel – Dist. Normal Estándar
Distribución normal estándar con media = 0 y desviación estándar = 1: Para Z = (X - Xmedia )/ s 1. Área desde menos infinito a un valor de Z se obtiene como sigue: - Colocarse en una celda vacía Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.ESTAND, dar valor de Z y obtener el área requerida Z Area 2. Un valor de Z específico para una cierta área (por ejemplo 0.05) se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, o DISTR.NORM.ESTAND.INV, dar valor del área y se obtiene la Z
/ s. 1. Área desde menos infinito a un valor de Z se obtiene como sigue: - Colocarse en una celda vacía. Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.ESTAND, dar valor de Z y obtener el área requerida. Z. Area. 2. Un valor de Z específico para una cierta área (por ejemplo 0.05) se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, o DISTR.NORM.ESTAND.INV, dar valor del área y se obtiene la Z.")
150
Entre: % % % m+3s m-2s m-1s m m+1s m+2s m+3s

151
Características de la Distribución Normal
68% 34% 34% +1s 95% +2s 99.73% +3s

152
El valor de Z Determina el número de desviaciones estándar entre algún valor x y la media de la población, mu Donde sigma es la desviación estándar de la población. En Excel usar Fx, ESTADISTICAS, NORMALIZACIÓN, para calcular el valor de Z z = x - m s (p..390) Se usa para hacer inferencias estádisticas acerca de la media cuando Sigma es conocida. Está basada en el teorema de límite central, la distribución de muestreo de la media deberia tener una distribución normal y la estádistica de prueba Z seria. El numerador es una medida de qué tan lejos la media de muestra observada, X, se encuentra de la media supuesta, m x . El denominador es el error estándar de la media, de modo que Z representa cuántos errores estándar X esta de m. x.
 Se usa para hacer inferencias estádisticas acerca de la media cuando Sigma es conocida. Está basada en el teorema de límite central, la distribución de muestreo de la media deberia tener una distribución normal y la estádistica de prueba Z seria. El numerador es una medida de qué tan lejos la media de muestra observada, X, se encuentra de la media supuesta, m x . El denominador es el error estándar de la media, de modo que Z representa cuántos errores estándar X esta de m. x.")
153
y desviación estándar = 10
Proceso con media =100 y desviación estándar = 10 68% 34% 34% 68% 95% 2.356% 68% 2.356% 99.73%

154
Áreas bajo la curva normal

155
Cálculos con Excel – Dist. Normal Estándar
Distribución normal estándar con media = 0 y desviación estándar = 1: Para Z = (X - Xmedia )/ s 1. Área desde menos infinito a un valor de Z se obtiene como sigue: - Colocarse en una celda vacía Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.ESTAND, dar valor de Z y obtener el área requerida Z Area 2. Un valor de Z específico para una cierta área (por ejemplo 0.05) se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, o DISTR.NORM.ESTAND.INV, dar valor del área y se obtiene la Z
/ s. 1. Área desde menos infinito a un valor de Z se obtiene como sigue: - Colocarse en una celda vacía. Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.ESTAND, dar valor de Z y obtener el área requerida. Z. Area. 2. Un valor de Z específico para una cierta área (por ejemplo 0.05) se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, o DISTR.NORM.ESTAND.INV, dar valor del área y se obtiene la Z.")
156
Cálculos con Excel – Distr. Normal
Distribución normal, dadas una media y desviación estándar: 1. Área desde menos infinito a X se obtiene como sigue: - Colocarse en una celda vacía - Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM, dar el valor de X, Media, Desviación Estándar s, VERDADERO y se obtendrá el área requerida X Area 2. Un valor de X específico para una cierta área (por ejemplo 0.05) se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.INV, dar el valor del área, Media y Desviación Estándar y se obtendrá el valor de la X
 se obtiene como sigue: - Accesar el menú de funciones con Fx, ESTADÍSTICAS, DISTR.NORM.INV, dar el valor del área, Media y Desviación Estándar y se obtendrá el valor de la X.")
157
Calculo de Probabilidades normales
1. Identificar la variable de interés. 2. Identificar los parámetros de la variable (su media y desv. estándar). 3. ¿Cual es la pregunta área bajo la curva de probabilidad normal? 4. Convertir los valores a la distribución normal estándar (estandarización Z = (X-Media)/S) . 5. Encuentre la probabilidad en tabla de la normal estándar o por Excel.
. 3. ¿Cual es la pregunta área bajo la curva de probabilidad normal 4. Convertir los valores a la distribución normal estándar (estandarización Z = (X-Media)/S) . 5. Encuentre la probabilidad en tabla de la normal estándar o por Excel.")
158
Ejemplo El agua usada diariamente por persona en México está distribuida normalmente con media 20 litros y una desviación de 5 lts.. ¿Entre que valores cae cerca del 68% el agua usada por una persona en Mexico? m ± 1s = 20 ± 1(5). Esto es, cerca del 68% de la cantidad usada por persona cae entre 15 lts. y 25 lts.. De manera similar para 95% y 99%, el intervalo será de 10 lts a 30 lts y 5 lts a 35 lts.
. Esto es, cerca del 68% de la cantidad usada por persona cae entre 15 lts. y 25 lts.. De manera similar para 95% y 99%, el intervalo será de 10 lts a 30 lts y 5 lts a 35 lts.")
159
Ejemplo El agua usada diariamente por persona en México es distribuida normalmente con media 20 litros y una desviación de 5 lts. Sea X el uso diario de agua. Cual es la probabilidad que una persona seleccionada al azar use menos de 20 lts./dia? El valor z asociado es z = ( )/5 = 0. entonces, P(X < 20) = P(z < 0) = 0.5.
/5 = 0. entonces, P(X < 20) = P(z < 0) = 0.5.")
160
Ejemplo Que porciento usa entre 20 y 24 lts?
El value z asociado con X = 20 es z = 0 y con X = 24, z = ( )/5 = 0.8. Entonces, P(20 < X < 24) = P(0 < z < 0.8) = P(0.8) - P(0) = = o 28.81%. ¿Que porciento usa entre 16 y 20 lts? El valor z1 para X = 16 es z1 = ( )/5 = -0.8, y para X = 20, z2 = 0. Entonces, P(16 < X < 20) = P(-0.8 < z < 0) = P(0) - P(-0.8) = = = 28.81%.
/5 = 0.8. Entonces, P(20 < X < 24) = P(0 < z < 0.8) = P(0.8) - P(0) = = o 28.81%. ¿Que porciento usa entre 16 y 20 lts El valor z1 para X = 16 es z1 = ( )/5 = -0.8, y para X = 20, z2 = 0. Entonces, P(16 < X < 20) = P(-0.8 < z < 0) = P(0) - P(-0.8) = = = 28.81%.")
161
P(0 < z < 0.8) = 0.8
 =")
162
Ejemplo Cual es la probabilidad que una persona seleccionada al azar use mas de 28 lts? El valor z asociado a X = 28 es z = ( )/5 = Ahora, P(X > 28) = P(z > 1.6) = 1 - P(z < 1.6) = =
/5 = 1.6. Ahora, P(X > 28) = P(z > 1.6) = 1 - P(z < 1.6) = =")
163
P(z > 1.6) = = 0.0548 Area = z 1.6
 = = Area = z 1.6")
164
Ejemplo ¿Que porcentaje usa entre 18 y 26 lts?
El valor z asociado con X = 18 es z = ( )/5 = -0.4, y para X = 26, z = ( )/5 = entonces, P(18 < X < 26)= P(-0.4 < z < 1.2) = F(1.2) - F(-0.4)= =
/5 = -0.4, y para X = 26, z = ( )/5 = 1.2. entonces, P(18 < X < 26)= P(-0.4 < z < 1.2) = F(1.2) - F(-0.4)= =")
165
Ejemplos El tiempo de vida de las baterías del conejito tiene una distribución aproximada a la normal con una media de horas y una desviación estándar de 3.77 horas. ¿Qué porcentaje de las baterías se espera que duren 80 horas o menos? ¿Cuál es la probabilidad de que una batería dure entre 86.0 y 87.0 horas? ¿Cuál es la probabilidad de que una batería dure más de 87 horas?

166
Área bajo la curva normal
¿Que porcentaje de las baterías se espera que duren 80 horas o menos? Z = (x-mu) / s Z = ( )/(3.77)= / 3.77 = -1.42 80 85.36 -1.42
 / s. Z = ( )/(3.77)= / 3.77 =")
167
Área bajo la curva normal
¿Cuál es la probabilidad de que una batería dure entre 86.0 y 87.0 horas? 85.36 86 87 1

168
Área bajo la curva normal
¿Cuál es la probabilidad de que una batería dure más de 87 horas? 85.36 87 1.67 = .33 ó 33% de las veces una batería durará más de 87 horas

169
Ejercicios Considere una media de peso de estudiantes de 75 Kgs. con una desviación estándar de 10Kgs. Contestar lo siguiente: ¿Cuál es la probabilidad de que un estudiante pese más de 85Kgs.? 2. ¿Cuál es la probabilidad de que un estudiante pese menos de 50Kgs.? 3. ¿Cuál es la probabilidad de que pese entre 60 y 80 Kgs.?. 4. ¿Cuál es la probabilidad de que pese entre 55 y 70 Kgs.? 5. ¿Cuál es la probabilidad de que pese entre 85 y 100Kgs.?

170
4. Distribuciones muestrales

171
Distribuciones muestrales
1. Introducción a las distribuciones muestrales 2. Distribución Chi cuadrada 3. Distribución t de student 4. Distribución F

172
A las distribuciones de los estadísticas muestrales se les llama distribuciones muestrales.
POBLACION

173
Distribuciones Derivadas del muestreo de Poblaciones Normales
Muestra Aparecen distribuciones muestrales: Normal, Chi-cuadrada, t-student, F Población

174
Distribución de la Media:
Si es una muestra aleatoria de una Poblacion (X) con distribución normal Entonces se distribuye normal con media y varianza
 con distribución normal .Entonces se. distribuye normal con media y varianza.")
175
Distribución Chi Cuadrada
Esta distribución se forma al sumar los cuadrados de las variables aleatorias normales estándar. Si Z es una variable aleatoria normal, entonces el estadístico Y siguiente es una variable aleatoria Chi cuadrada con n grados de libertad.

176
Distribución de la varianza.
Repaso de la distribución ji-cuadrada. La función de densidad de probabilidad con k grados de libertad y la función gama Γ es: k=grados de libertad. (1,2,...)
")
177
Gráficas de la distribución ji-cuadrada
K=1 K=5 K=50 K=25 Con k grande ji-cuadrada se hace normal

178
Media y varianza de una ji-cuadrada.
E(X)=k V(X)=2k Calculo de puntos críticos usando las tablas de ji-cuadrada
=k. V(X)=2k. Calculo de puntos críticos usando las tablas de ji-cuadrada.")
179
Ejemplo: Calcule el valor critico que satisface
De tablas de ji-cuadrada con alfa=.05 y k=20

180
Resultado: Si es una muestra aleatoria de una Poblacion (X) con distribución normal Entonces se distribuye ji-cuadrada con k= n-1 grados de libertad. Donde S cuadrada es la varianza muestral.
 con distribución normal .Entonces se. distribuye ji-cuadrada con k= n-1 grados de libertad. Donde S cuadrada es la varianza muestral.")
181
Distribución t-student
Si es una muestra aleatoria de una Población (X) con distribución normal Entonces se distribuye t-student con n-1 grados de libertad. Se utiliza en vez de la distribución normal cuando sigma es desconocida (que la aproxima con n > 100)
 con distribución normal . Entonces se distribuye. t-student con n-1 grados de libertad. Se utiliza en vez de la distribución normal cuando sigma es desconocida (que la aproxima con n > 100)")
182
Función de Distribución t-student
K=1 K=10 K=100

183
Función de Distribución t-student

184
Distribución t de Student
La media y la varianza de la distribución t son: De una muestra aleatoria de n artículos, la probabilidad de que Caiga entre dos valores especificados es igual al área bajo la distribución de probabilidad t de Student con los valores correspondientes en el eje X, con n-1 grados de libertad

185
Distribución t de Student
Ejemplo: La resistencia de 15 sellos seleccionados aleatoriamente son: 480, 489, 491, 508, 501, 500, 486, 499, 479, 496, 499, 504, 501, 496, 498 ¿Cuál es la probabilidad de que la resistencia promedio de los sellos sea mayor a 500?. La media es y la desviación estándar es de t = y el área es

186
Distribución F Surge de dividir dos ji-cuadradas independientes
F=(W/u)/(Y/v) W se distribuye ji-cuadrada con u g.l. Y se distribuye ji-cuadrada con v g.l. El uso de esta distribución es para comparar varianzas (Recuerde el análisis de varianza)
/(Y/v) W se distribuye ji-cuadrada con u g.l. Y se distribuye ji-cuadrada con v g.l. El uso de esta distribución es para comparar varianzas (Recuerde el análisis de varianza)")
187
Función de densidad de la Distribución F
v=5 u=20 v=20

188
Función de densidad de la Distribución F

189
Distribución F Para determinar la otra cola de la distribución F se determina con la expresión. Falfa, k1, k2 = 1 / F(1-alfa), k2, k1 Dado K1 = 8 y K2 = 10, F0.05 = 3.07, encontrar el valor de F0.05 con K1 = 10 y K2 = 8 F0.05,10,8 = 1/ F0.95,8,10 = 1/ 3.07 = 0.326

190
Distribución F. Función de densidad de la Distribución F

191
V.E.3 Otras distribuciones de probabilidad

192
Otras distribuciones de probabilidad
1. Distribución bivariada 2. Distribución exponencial 3. Distribución Lognormal 4. Distribución de Weibull

193
Distribución Bivariada
La distribución conjunta de dos variables es llamada una distribución bivariada. El coeficiente de correlación es :

194
Distribución Exponencial
Se usa para modelar artículos con una tasa de falla constante y está relacionada con la distribución de Poisson. Si una variable aleatoria x se distribuye exponencialmente, entonces el recíproco de x, y = 1/x sigue una distribución de Poisson y viceversa. La función de densidad de probabilidad exponencial es: Para x >= 0

195
Distribución Exponencial
Donde Lambda es la tasa de falla y theta es la media La función de densidad de la distribución exponencial

196
Distribución Exponencial
Es usada como el modelo, para la parte de vida útil de la curva de la bañera, i.e., la tasa de falla es constante Los sistemas complejos con muchos componentes y múltiples modos de falla tendrán tiempos de falla que tiendan a la distribución exponencial Desde una perspectiva de confiabilidad, es la distribución más conservadora para predicción. La forma de la exponencial siempre es la misma

197
Distribución Exponencial
El modelo exponencial, con un solo parámetro, es el más simple de todo los modelos de distribución del tiempo de vida. Las ecuaciones clave para la exponencial se muestran: CDF : F ( t ) = 1 - e - l t CONFIABILI DAD : R ( t ) = e - l t PDF : f ( t ) = l e - l t = 0.003, MEDIA = 333 1 = 0.002, MEDIA = 500 MEDIA : m = l = 0.001, MEDIA = 1,000 ln 2 . 693 MEDIANA : @ l l 1 VARIANZA : l 2 TASA DE FALLA : h ( t ) = l
 = 1. - e. - l. t. CONFIABILI. DAD. : R. ( t. ) = e. - l. t. PDF. : f. ( t. ) = l. e. - l. t. = 0.003, MEDIA = = 0.002, MEDIA = 500. MEDIA. : m. = l. = 0.001, MEDIA = 1,000. ln MEDIANA. l. l. 1. VARIANZA. : l. 2. TASA. DE. FALLA. : h. ( t. ) = l.")
198
Distribución Exponencial
R(t) = e(-t) (Confiabilidad) = 0.001, MTBF = 1,000 = 0.002, MTBF = 500 = 0.003, MTBF = 333
 = e(-t) (Confiabilidad) = 0.001, MTBF = 1,000. = 0.002, MTBF = 500. = 0.003, MTBF = 333.")
199
Distribución Exponencial
h(t) = MEDIA(Velocidad de Falla) Note que la tasa de falla tiende a ser una constante l para cualquier tiempo. La distribución exponencial es la única que tiene una velocidad de falla constante = 0.003, MTBF = 333 = 0.002, MTBF = 500 = 0.001, MTBF = 1,000
 = MEDIA(Velocidad de Falla) Note que la tasa de falla tiende a ser una constante l para cualquier tiempo. La distribución exponencial es la única que tiene una velocidad de falla constante. = 0.003, MTBF = 333. = 0.002, MTBF = 500. = 0.001, MTBF = 1,000.")
200
Distribución Lognormal
La transformación más común se hace tomando el logaritmo natural, pero también se puede hacer con los logaritmos base 2 y base 10. Y = x1 x2 x3 Ln y = ln x1 + ln x2 + ln x3 La función de densidad de probabilidad lognormal es con Y = ln(t):
:")
201
Distribución Lognormal
La media y la varianza de la distribución lognormal son las siguientes:

202
Distribución Lognormal
Un tiempo de falla se distribuye según una Lognormal si el logaritmo del tiempo de falla está normalmente distribuido. La Distribución Lognormal es una distribución sesgada hacia la derecha. La PDF comienza en cero, aumenta hasta su moda y diminuye después.

203
Distribución Lognormal
Si un tiempo t está distribuido Lognormal, t~LN(t, t) y si Y = ln(t) entonces Y~N(y, y) t y = ln(t) PDF CDF MEDIA MEDIANA VARIANZA F(z) es la CDF de la Normal estándar
 y si Y = ln(t) entonces Y~N(y, y) t. y = ln(t) PDF. CDF. MEDIA. MEDIANA. VARIANZA. F(z) es la CDF de la Normal estándar.")
204
Distribución Lognormal
La Distribución de vida Lognormal, como la Weibull, es un modelo muy flexible que puede empíricamente ajustar a muchos tipos de datos de falla. En su forma de dos parámetros tiene los parámetros sln(t) = sy parámetro de forma, y T50 = la mediana (un parámetro de escala) Si el tiempo para la falla t, tiene una distribución Lognormal, entonces el logaritmo natural del tiempo de falla (y =ln(t)) tiene una distribución normal con media my = ln T50 y desviación estándar sy.
 = sy parámetro de forma, y T50 = la mediana (un parámetro de escala) Si el tiempo para la falla t, tiene una distribución Lognormal, entonces el logaritmo natural del tiempo de falla (y =ln(t)) tiene una distribución normal con media my = ln T50 y desviación estándar sy.")
205
Distribución Lognormal
Esto hace a los datos lognormales convenientes para trabajarlos así: Determine los logaritmos naturales de todos los tiempos de falla y de los tiempos censurados (y = ln(t)) y analice los datos normales resultantes. Posteriormente, haga la conversión a tiempo real y a los parámetros lognormales usando sy como la forma lognormal y T50 = exp(my) como (mediana) el parámetro de escala.
) y analice los datos normales resultantes. Posteriormente, haga la conversión a tiempo real y a los parámetros lognormales usando sy como la forma lognormal y T50 = exp(my) como (mediana) el parámetro de escala.")
206
Distribución Lognormal
Ejemplo: Dado t~LN(25,4), encuentre P(t<18) Calculemos los valores que nos permiten usar la tabla normal estándar Para poder usar las Tablas de la Normal Estándar: P(t<18) = P{Z<[ln(t/ T50)]/ y] = P{Z<[ln(18/24.7)]/0.159} = P(Z<-1.99) = 0.023
, encuentre P(t<18) Calculemos los valores que nos permiten usar la tabla normal estándar. Para poder usar las Tablas de la Normal Estándar: P(t<18) = P{Z<[ln(t/ T50)]/ y] = P{Z<[ln(18/24.7)]/0.159} = P(Z<-1.99) =")
207
Distribución Lognormal
Función de Distribución Lognormal donde y son funciones de ln’s = 0 = 0.5 = 0 = 1 = 1 = 0.5 = 1 = 1

208
Distribución Lognormal
Función de Distribución Lognormal donde z[ln(t)] = [ln(t)-/] (z) = normal estandarizada normal pdf = 1 = 0.5 = 1 = 1 = 0 = 1 = 0 = 0.5
] = [ln(t)-/] (z) = normal estandarizada normal pdf. = 1. = 0.5. = 1. = 1. = 0. = 1. = 0. = 0.5.")
209
Distribución Lognormal
f ( t ) Función de Distribución Lognormal h ( t ) = R ( t ) = 0 = 0.5 = 1 = 0.5 = 1 = 1 = 0 = 1
 Función de Distribución Lognormal. h. ( t. ) = R. ( t. ) = 0. = 0.5. = 1. = 0.5. = 1. = 1. = 0. = 1.")
210
Distribución Lognormal
Número de ciclos de falla en la fatiga de los metales y partes metálicas, en niveles de tensión mucho menores que sus límites Representa bien el tiempo de falla de los dispositivos mecánicos, especialmente en el caso de uso La resistencia de materiales frecuentemente sigue una distribución Lognormal Las variables de peso son frecuentemente bien representadas con una distribución Lognormal Es una buena distribución para cualquier variable La medida de cualquier resultado el cual es el resultado de una proporción o efecto multiplicativo es Lognormal

211
Distribución de Weibull
La distribución de Weibull es una de las más utilizadas en confiabilidad y estadística. La versión de dos parámetros forma y escala (que representa la vida característica) no incluye el parámetro de localización es cero. La versión de tres parámetros tiene una parámetro de localización cuando hay un tiempo de falla diferente de cero para la primera falla
 no incluye el parámetro de localización es cero. La versión de tres parámetros tiene una parámetro de localización cuando hay un tiempo de falla diferente de cero para la primera falla.")
212
Distribución de Weibull
La función de densidad de probabilidad de Weibull de 3 parámetros es: Para x es el parámetro de forma es el parámetro de escala es el parámetro de localización

213
Distribución de Weibull
La función de densidad de probabilidad de Weibull de 3 parámetros también se puede expresar como: Para t 0 es el parámetro de forma es el parámetro de escala es el parámetro de localización diferente de cero También es la vida característica si el parámetro de localización es cero, de otra forma será +

214
Distribución de Weibull
La media y la varianza de la distribución de Weibull es:

215
Distribución de Weibull
Efecto del parámetro de forma Beta con Theta = 100 y Delta = 0

216
Distribución de Weibull
Efecto del parámetro de escala Theta

217
Distribución de Weibull
Efecto del parámetro de escala Delta

218
El Modelo Weibull En muchas aplicaciones de confiabilidad, el supuesto de tasa de riesgo constante no es apropiado. Los artículos mecánicos tienen Failure Rate Creciente. Otros artículos pueden ser Failure Rate Decreciente. Failure Rate Creciente Failure Rate Decreciente Failure Rate Constante

219
Modelo Weibull Un modelo que puede representar un amplio espectro de comportamientos es el modelo Weibull. La densidad del modelo Weibull puede tomar muchas y diferentes formas. Note que si = 1 entonces se tiene el modelo exponencial como caso particular del modelo Weibull. = 3 = 0.5 = 1 = 2

220
Modelo Weibull El modelo Weibull es FRC si = 1 FRI si > 1
FRD si < 1 Entonces el parámetro muestra la forma de la función de riesgo. = 3 FRD FRI = 0.5 FRC = 1

221
Modelo Weibull Que es ? Entonces presenta la escala de h(t). = 3
= 2 = 1

222
Modelo Weibull Los momentos de la distribución Weibull son:

223
Modelo Weibull El tiempo de vida (sobre horas) de cierto tipo de resorte usado continuamente bajo condiciones de funcionamiento, es sabido que tiene una distribución de Weibull con parámetro de forma y de escala 1.28. Cuál es el tiempo medio de falla? Cuál es la probabilidad de que un resorte funcionará por 500 horas? Cuál es la probabilidad que un resorte que ha funcionado por 200 horas funcione por otras 500 horas?
 de cierto tipo de resorte usado continuamente bajo condiciones de funcionamiento, es sabido que tiene una distribución de Weibull con parámetro de forma y de escala Cuál es el tiempo medio de falla Cuál es la probabilidad de que un resorte funcionará por 500 horas Cuál es la probabilidad que un resorte que ha funcionado por 200 horas funcione por otras 500 horas")
224
Modelo Weibull Se tiene un sistema de n componentes.
Los componentes son independientes e idénticamente distribuidos de acuerdo a una distribución Weibull. Cual es la distribución del tiempo de vida del sistema? Se sabe que Entonces

225
Distribución Weibull La distribución de Weibull es un modelo de distribución de vida útil muy flexible, para el caso de 2 parámetros: Donde h (etha) es un parámetro de escala (la vida característica) y beta se conoce como el parámetro de forma (pendiente) y G es la función Gamma con G(N)=(N-1)! para N entero
 es un parámetro de escala (la vida característica) y beta se conoce como el parámetro de forma (pendiente) y G es la función Gamma con G(N)=(N-1)! para N entero.")
226
Distribución Weibull Una forma más general de 3 parámetros de la Weibull incluye un parámetro de tiempo de espera localización ó desplazamiento). Las fórmulas se obtienen reemplazando t por (t-g). No puede ocurrir una falla antes de g horas, el tiempo comienza en g no en 0.
. No puede ocurrir una falla antes de g horas, el tiempo comienza en g no en 0.")
227
Distribución Weibull Función de Distribución Weibull = 0.5 = 1000
= 1.0 = 1000 = 3.4 = 1000

228
Distribución Weibull Funciones de Distribución Weibull = 3.4
= 1000 = 1.0 = 1000 = 0.5 = 1000

229
Distribución Weibull Funciones de Distribución Weibull b æ t ö h ( t )
- 1 b æ t ö h ( t ) = Funciones de Distribución Weibull ç ÷ h è h ø = 3.4 = 1000 = 0.5 = 1000 = 1.0 = 1000
 = Funciones de Distribución Weibull. ç. ÷ h. è. h. ø. = 3.4. = = 0.5. = = 1.0. =")
230
Distribución Weibull Distribución Weibull
La función pdf de la distribución exponencial modela la característica de vida de los sistemas, la Weibull modela la característica de vida de los componentes y partes Modela fatiga y ciclos de falla de los sólidos Es el traje correcto para datos de vida La función de distribución Weibull pdf es una distribución de la confiabilidad de los elementos de una muestra Muy flexible y puede tomar diferentes formas

231
Distribución Weibull Tiene usted una Distribución Weibull con b=2 y h=2, ¿Cuál es la media y la varianza? 1 Archivo Weibull.xls 2 3

232
Distribución Weibull Las tres porciones de la curva de tina de la bañera tienen diferentes índices de falla. Las fallas tempranas se caracterizan por un índice de falla decreciente, la vida útil por un índice de falla constante y el desgaste se caracteriza por un índice de falla creciente. La distribución de Weibull puede modelar matemáticamente estas tres situaciones. tiempo Índice de falla Tiempo de vida útil Fallas tempranas Desgaste decreciente < 1 constante = 1 creciente > 1 < 1 disminuye la tasa de riesgo, implica mortalidad infantil = 1 tasa de riesgo constante, fallas aleatorias 1< < 4 aumenta la tasa de riesgo, fallas por corrosión, erosión > 4 aumenta rápidamente la tasa de riesgo, implica fallas por desgaste y envejecimiento

233
La Distribución Weibull - Interpretación
= 1 (Tasa de riesgo constante) Implica fallas aleatorias(Distribución Exponencial) Una parte vieja es tan buena como una nueva Si esto ocurre: Mezcla de modos de falla Las fallas pueden deberse a eventos externos, como:luminosidad o errores humanos Fundido y removido antes de su desgaste < 1 (Tasa de riesgo decreciente) Implica mortalidad infantil Si esto ocurre, puede existir: Carga, inspección o prueba inadecuada Problemas de Manufactura Problemas de reparación Si un componente sobrevive la mortalidad infantil , la resistencia a fallar mejora con la edad. 1 <4 (Tasa de Riesgo creciente) Si esto ocurre La mayoría de los baleros y engranes fallan Corrosión o Erosión El reemplazo programado puede ser efectivo en costo =3.44aprox. Normal, =2Rayleigh 4 (La tasa de riesgo crece rápidamente) Implica edad avanzada y rápido desgaste Si esto ocurre, sospeche de: Propiedades del material Materiales frágiles como la cerámica Variabilidad pequeña en manufactura o material
 Implica fallas aleatorias(Distribución Exponencial) Una parte vieja es tan buena como una nueva. Si esto ocurre: Mezcla de modos de falla. Las fallas pueden deberse a eventos externos, como:luminosidad o errores humanos. Fundido y removido antes de su desgaste. < 1 (Tasa de riesgo decreciente) Implica mortalidad infantil. Si esto ocurre, puede existir: Carga, inspección o prueba inadecuada. Problemas de Manufactura. Problemas de reparación. Si un componente sobrevive la mortalidad infantil , la resistencia a fallar mejora con la edad. 1 <4 (Tasa de Riesgo creciente) Si esto ocurre. La mayoría de los baleros y engranes fallan. Corrosión o Erosión. El reemplazo programado puede ser efectivo en costo. =3.44aprox. Normal, =2Rayleigh. 4 (La tasa de riesgo crece rápidamente) Implica edad avanzada y rápido desgaste. Si esto ocurre, sospeche de: Propiedades del material. Materiales frágiles como la cerámica. Variabilidad pequeña en manufactura o material.")
234
Distribución Weibull Cuando = 2.5 la Weibull se aproxima a la distribución Lognormal(estas distribuciones son tan cercanas que se requieren tamaños de muestra mayores a 50 para distinguirlas). Cuando se modela el tiempo que se necesita para que ocurran reacciones químicas, se ha mostrado que la distribución Lognormal usualmente proporciona un mejor ajuste que la Weibull. Cuando = 5 la Weibull se aproxima a una Normal puntiaguda.
. Cuando se modela el tiempo que se necesita para que ocurran reacciones químicas, se ha mostrado que la distribución Lognormal usualmente proporciona un mejor ajuste que la Weibull. Cuando = 5 la Weibull se aproxima a una Normal puntiaguda.")
235
Distribución Weibull Debido a su flexibilidad,hay pocas tasas de falla observadas que no pueden modelarse adecuadamente mediante la Weibull. Algunos ejemplos son. 1.La resistencia a la ruptura de componentes o el esfuerzo requerido para la fatiga de metales. 2.El tiempo de falla de componentes electrónicos. 3.El tiempo de falla para artículos que se desgastan, tales como las llantas de un automóvil. 4.Sistemas que fallan cuando falla el componente más débil del sistema(la distribución Weibull representa una distribución de valor extremo).
.")
236
Distribución Weibull ¿Qué pasa en una distribución Weibull si el tiempo tiene el valor de la vida característica, t = h? Al llegar al tiempo de vida igual a la vida característica el 63.2% de los elementos habrá fallado. Este hecho se usa en las gráficas para identificar el valor de h (eta) Este mismo resultado se obtiene para el caso exponencial, recordando que la Weibull se puede reducir a una exponencial cuando b = 1.
 Este mismo resultado se obtiene para el caso exponencial, recordando que la Weibull se puede reducir a una exponencial cuando b = 1.")
237
V.F Capacidad de procesos

238
V.F Capacidad de procesos
1. Índices de capacidad de procesos 2. Índices de desempeño de procesos 3. Capacidad a corto y a largo plazo 4. Capacidad de proceso de datos no normales 5. Capacidad de proceso para datos por atributos 6. Capacidad de procesos bajo Seis Sigma

239
V.F.1 Índices de capacidad del proceso

240
Teoría del camión y el túnel
El túnel tiene 9' de ancho (especificación). El camión tiene 10’ y el chofer es perfecto (variación del proceso). ¿Pasaría el camión? NO, la variabilidad del proceso es mayor que la especificación. Centrar es hacer que el promedio del proceso sea igual al centro de la especificación. Si el camión tiene 8 pies de ancho ¿pasará el camión?, Si. Si el chofer puede mantener el centro del camión en el centro del túnel. De otra forma chocará con las paredes del túnel y no pasará a pesar de ser más angosto. El proceso debe estar en control, tener capacidad y estar centrado Ancho 9´ Nigel´s Trucking Co.
. El camión tiene 10’ y el chofer es perfecto. (variación del proceso). ¿Pasaría el camión NO, la variabilidad del proceso es mayor. que la especificación. Centrar es hacer que el promedio del proceso sea igual al centro de la. especificación. Si el camión tiene 8 pies de ancho ¿pasará el camión , Si. Si. el chofer puede mantener el centro del camión en el centro del túnel. De otra forma. chocará con las paredes del túnel y no pasará a pesar de ser más angosto. El proceso debe estar en control, tener capacidad y estar centrado. Ancho 9´ Nigel´s Trucking Co.")
241
Objetivos de la capacidad del proceso
1. Predecir que tanto el proceso cumple especificaciones 2. Apoyar a diseñadores de producto o proceso en sus modificaciones 3. Especificar requerimientos de desempeño para el equipo nuevo 4. Seleccionar proveedores 5. Reducir la variabilidad en el proceso de manufactura 6. Planear la secuencia de producción cuando hay un efecto interactivo de los procesos en las tolerancias

242
Análisis de la capacidad de proceso – Estudios de capacidad
La capacidad del proceso es un patrón predecible de comportamiento estadístico estable donde las causas de variación se comparan con las especificaciones.

243
Análisis de la capacidad de proceso – Estudios de capacidad
LIE Especificación inferior LSE Especificación superior Z s _ X xi p = porcentaje de partes fuera de Especificaciones

244
¿Cómo vamos a mejorar esto?
Podemos reducir la desviación estándar... Podemos cambiar la media... O (lo ideal sería, por supuesto) que podríamos cambiar ambas Cualquiera que sea la mejora que lleve a cabo, asegúrarse que se mantenga
 que podríamos cambiar ambas. Cualquiera que sea la mejora que lleve a cabo, asegúrarse que se mantenga.")
245
Procedimiento 1. Seleccionar una máquina donde realizar el estudio
2. Seleccionar las condiciones de operación del proceso 3. Seleccionar un operador entrenado 4. El sistema de medición debe tener habilidad (error R&R < 10%) 5. Cuidadosamente colectar la información 6. Construir un histograma de frecuencia con los datos 7. Calcular la media y desviación estándar del proceso
 5. Cuidadosamente colectar la información. 6. Construir un histograma de frecuencia con los datos. 7. Calcular la media y desviación estándar del proceso.")
246
Análisis de la capacidad de proceso – Estudios de capacidad
Objetivos: Establecer un estado de control sobre el proceso de manufactura mantenerlo en el tiempo. Al comparar el proceso vs los límites de especificación pueden ocurrir los siguientes eventos: No hacer nada Cambiar las especificaciones Centrar el proceso+ Reducir la variabilidad Aceptar las pérdidas

247
Análisis de la capacidad de proceso – Estudios de capacidad
Identificación de características: Deben ser indicativas de un factor clave en la calidad del producto o proceso Debería ser posible ajustar el valor de la característica como factor de control Las condiciones de operación que afecten la característica medida deben ser identificadas y controladas El PPAP indica la evaluación una inicial de la capacidad

248
Estimación de la desviación estándar con el proceso normal o en control
La desviación estándar del proceso cuando se encuentra en control se determina como sigue con base en una carta de control X-R siempre que esté bajo control estadístico: Rango medio Desv. Est. st (Within) = Constante d2 de acuerdo al tamaño de subgrupo en X-R D2 = para carta I-MR con n=2 D2= para carta X-R con n=5
 = Constante d2 de acuerdo al. tamaño de subgrupo en X-R. D2 = para carta I-MR con n=2. D2= para carta X-R con n=5.")
249
Límites de tolerancia natural del proceso
LTNS = Media + 3*sigma LTNI = Media – 3*sigma Si los límites de especificación son: LIE y LSE El Cp = (LSE – LIE) / (LTNS – LTNI) debe ser mayor a 1
 / (LTNS – LTNI) debe ser mayor a 1.")
250
Capacidad del proceso Z’s y P(Z’s) Fracción defectiva
Los valores de Z inferior y Z superior se calculan de acuerdo a las fórmulas siguientes: LIE - promedio del proceso LSE - Promedio del proceso Zi Zs = = Desviación Estándar - st Desviación Estándar - st La fracción defectiva se calcula con la distribución normal estándar: P(Zi) = Área en tabla (-Z) P(Zs) = 1 – Área corresp. a Zs en tabla (+Z) Fracción defectiva = P(Zi) + P(Zs)
 = Área en tabla (-Z) P(Zs) = 1 – Área corresp. a Zs en tabla (+Z) Fracción defectiva = P(Zi) + P(Zs)")
251
Índices de Capacidad Potencial del proceso en control – Corto plazo
El índice de capacidad potencial del Proceso (Cp) mide la variación del proceso en relación con el rango de Especificación. Tolerancia LSE - LIE Cp = = Variación del proceso 6 Desviaciones Estándar - st La relación de capacidad (CR) es la inversa del cálculo de Cp. Este índice le indica que porcentaje de la especificación está siendo usado por la variación del proceso. Rango del proceso 6 desviaciones estándar - st CR = = Tolerancia LSE - LIE Otro índice que toma en cuenta el centrado del proceso vs Media de Especificaciones M es:
 mide la. variación del proceso en relación con el rango de Especificación. Tolerancia. LSE - LIE. Cp. = = Variación del proceso. 6 Desviaciones Estándar - st. La relación de capacidad (CR) es la inversa del cálculo de Cp. Este índice le. indica que porcentaje de la especificación está siendo usado por la variación del. proceso. Rango del proceso. 6 desviaciones estándar - st. CR. = = Tolerancia. LSE - LIE. Otro índice que toma en cuenta. el centrado del proceso vs. Media de Especificaciones M es:")
252
Índice de capacidad real del proceso en control estadístico – corto plazo
Cpk es una medida de la capacidad real del proceso en función de la posición de la media del proceso (X) en relación con con los límites de especificación. Con límites bilaterales da una indicación del centrado. Es el menor de: LSE - promedio del proceso Promedio del proceso - LIE Cpk = y 3 desviaciones Est. - st 3 desviaciones Estándar - st
 en relación con con los límites de especificación. Con límites bilaterales da una indicación del centrado. Es el menor de: LSE - promedio del proceso. Promedio del proceso - LIE. Cpk. = y. 3 desviaciones Est. - st. 3 desviaciones Estándar - st.")
253
Cálculo de la capacidad del proceso
Habilidad o capacidad potencial Cp = (LSE - LIE ) / 6 st Debe ser 1.33, si está entre 1 – 1.33 requiere mucho control, <1 inac. para tener el potencial de cumplir con especificaciones (LIE, LSE) Habilidad o capacidad real Cpk = Menor | ZI y ZS | / 3 El Cpk debe ser 1.33 para que el proceso cumpla especificaciones, entre 1 y 1.33 requiere control, <1 inac.
 / 6 st. Debe ser 1.33, si está entre 1 – 1.33 requiere mucho control, <1 inac. para tener el potencial de. cumplir con especificaciones (LIE, LSE) Habilidad o capacidad real Cpk = Menor | ZI y ZS | / 3. El Cpk debe ser 1.33 para que el. proceso cumpla especificaciones, entre 1 y 1.33 requiere control, <1 inac.")
254
Tasa de falla vs Cp

255
Tasa de capacidad Tasa de capacidad l Cp = 6 st/ (LSE - LIE )
Debe ser <= 0.75 si está entre 0.75 y 1 requiere mucho control, >1 inac. para tener el potencial de cumplir con especificaciones (LIE, LSE) Índice Cpm basado en el índice de Taguchi, equivale al Cp tomando en cuenta el centrado: T = valor objetivo
 Índice Cpm basado en el índice de Taguchi, equivale al Cp tomando en cuenta el centrado: T = valor objetivo.")
256
Capacidad del proceso Z’s y P(Z’s) Fracción defectiva
Los valores de Z inferior y Z superior se calculan de acuerdo a las fórmulas siguientes: LIE - promedio del proceso LSE - Promedio del proceso Zi Zs = = Desviación Estándar - st Desviación Estándar - st La fracción defectiva se calcula con la distribución normal estándar: P(Zi) = Área en tabla (-Z) P(Zs) = 1 – Área corresp. a Zs en tabla (+Z) Fracción defectiva = P(Zi) + P(Zs)
 = Área en tabla (-Z) P(Zs) = 1 – Área corresp. a Zs en tabla (+Z) Fracción defectiva = P(Zi) + P(Zs)")
257
Capacidad de proceso a partir de Histogramas y Distribución normal

258
Ejemplo Se tomaron los datos siguientes:
251

259
Ejemplo (cont…) Agrupando los datos en celdas se tiene:
Intervalo Marca Frecuencia Frecuencia de clase de clase Frecuencia Relativa Absoluta

260
Ejemplo (cont…) El histograma es el siguiente (se observa con forma normal):
 El histograma es el siguiente (se observa con forma normal):")
261
Ejemplo (cont…) Calculando la media y la desviación estándar se tiene:
X-media = s = 32.02 La variabilidad del proceso se encuentra en 6 = Si las especificaciones fueran LIE = 200 y LSE = 330 Cp = ( ) / < 1 no es hábil el proceso Zi = ( ) / Zs = ( ) / 32.02 Cpk = menor de Zi y Zs < 1 el proceso no cumple especificaciones
 / < 1 no es hábil el proceso. Zi = ( ) / Zs = ( ) / Cpk = menor de Zi y Zs < 1 el proceso no cumple especificaciones.")
262
Ejercicio Calcular la capacidad del proceso con la distribución de frecuencias siguiente considerando LIE = 530 y LSE = 580: Intervalo Frecuencia Frecuencia de clase Marca de clase Frecuencia Relativa Absoluta

263
Ejemplo de capacidad de proceso

264
Interpretación de salida Minitab
Desviación estándar “Within” se determina con R / d2, se usa para determinar los índices de capacidad a corto plazo Cp, Cpk y PPM “Within” Desviación estándar “Overall” det. Con la desviación estándar de los datos S/C4, donde C4=4(n–1)/(4n-3)), se usa para determinar los índices de Desempeño Pp, Ppk y PPM “Overall” El “Observed Perfomance” se determina comparando los datos de la muestra con las especificaciones
/(4n-3)), se usa para determinar los índices de Desempeño Pp, Ppk y PPM Overall El Observed Perfomance se determina comparando los datos de la muestra con las especificaciones.")
265
Capacidad a partir de cartas de control

266
? ? ? ? ? ? ? EN CASOS ESPECIALES COMO ESTOS
DONDE LAS VARIACIONES PRESENTES SON TOTALMENTE INESPERADAS TENEMOSUN PROCESO INESTABLE o “IMPREDECIBLE”. ? ? ? ? ? ? ?

267
Bases del CEP SI LAS VARIACIONES PRESENTES SON IGUALES,
SE DICE QUE SE TIENE UN PROCESO “ESTABLE”. LA DISTRIBUCION SERA “PREDECIBLE” EN EL TIEMPO Predicción Tiempo

268
Control y Capacidad de Proceso
Control de Proceso: Cuando la única fuente de variación es normal o de causa común, se dice que el proceso esta operando en “CONTROL”. Capacidad de Proceso: Medición estadística de las variaciones de causa común que son demostradas por un proceso. Un proceso es capaz cuando la causa común de variación cae dentro de las especificaciones del cliente. La capacidad no se puede determinar a menos que el proceso se encuentre en Control y Estable.

269
x Proceso en Control Estadístico
La distribución de la mayoría de las características medidas forman una curva en forma de campana o normal, si no hay causas especiales presentes, que alteren la normalidad . ¿cuales son las causas comunes?| x Area entre 0 y 1s -Probabilidad de Ocurrencia Distribución del Proceso _ x= media 34% 34% s= sigma; es la desviación estándar; medida de la variación del proceso. 14 % 14 % -3s s s x s s s 2% 99.73% 2%

270
Ejemplo de carta de control X-R

271
Estudios de capacidad Desviación estándar:
Si el proceso sigue una distribución normal y está en control estadístico, entonces la desviación estándar puede ser estimada de: Para procesos nuevos, se puede estimar la capacidad del proceso de una producción piloto

272
= R o = S d2 c4 Desviación Estándar del proceso Donde,
= Desviación estándar de la población d2 = Factor que depende del tamaño del subgrupo en la carta de control X - R C4 = Idem al anterior para una carta X - S NOTA: En una carta por individuales, d2 se toma para n = 2 y Rango Medio= Suma rangos / (n -1)
")
273
Capacidad de proceso Cpk C p
Cuando las causas comunes son la única variación: C p El índice de capacidad potencial del proceso compara la amplitud del proceso con la amplitud especificada. Cp = (LSE - LIE) / 6 Cpk El índice de capacidad real del proceso compara la media real con el límite de especificaciones más cercano (LE) a esta. Cpk = LE – Xmedia Cpk = menor |Z1 ; Z2| / 3 3
 / 6 Cpk. El índice de capacidad real del proceso compara la media. real con el límite de especificaciones más cercano (LE) a esta. Cpk = LE – Xmedia Cpk = menor |Z1 ; Z2| / 3. 3 ")
274
Ejemplo (carta X - R) De una carta de control X - R (con subgrupo n = 5) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes: Xmedia de medias = Rmedio = 77.3 Por tanto estimando los parámetros del proceso se tiene: = X media de medias = Rmedio / d2 =77.3 / = 33.23 [ d2 para n = 5 tiene el valor ] Si el límite de especificación es: LIE = 200. El Cpk = ( ) / (77.3) (3) = 0.64 por tanto el proceso no cumple con las especificaciones
 se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes: Xmedia de medias = Rmedio = Por tanto estimando los parámetros del proceso se tiene: = X media de medias = Rmedio / d2 =77.3 / = [ d2 para n = 5 tiene el valor 2.326] Si el límite de especificación es: LIE = 200. El Cpk = ( ) / (77.3) (3) = 0.64 por tanto el proceso no cumple con las especificaciones.")
275
Ejemplo (carta X - S) De una carta de control X - S (con subgrupo n = 5) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes: Xmedia de medias = 100 Smedio = 1.05 Por tanto estimando los parámetros del proceso se tiene: = X media de medias = Smedio / C4 = 1.05 / 0.94 = [ C4 para n = 5 tiene el valor ] Si el límite de especificación es: LIE = 85 y el LSE = 105. El Cpk = ( ) / (1.117 ) (3) = El Cp = ( ) / 6 (1.117 ) = 2.984 por tanto el proceso es capaz de cumplir con especificaciones
 se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes: Xmedia de medias = 100 Smedio = Por tanto estimando los parámetros del proceso se tiene: = X media de medias = Smedio / C4 = 1.05 / 0.94 = [ C4 para n = 5 tiene el valor 0.94 ] Si el límite de especificación es: LIE = 85 y el LSE = 105. El Cpk = ( ) / (1.117 ) (3) = El Cp = ( ) / 6 (1.117 ) = por tanto el proceso es capaz de cumplir con especificaciones.")
276
Ejercicios 1) De una carta de control X - R (con subgrupo n = 8) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes (LIE = 36, LSE = 46): Xmedia de medias = 40 Rmedio = 5 2) De una carta de control X - S (con subgrupo n = 6) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes (LIE = 15, LSE = 23): Xmedia de medias = 20 Smedio = 1.5
 De una carta de control X - R (con subgrupo n = 8) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes (LIE = 36, LSE = 46): Xmedia de medias = 40 Rmedio = 5. 2) De una carta de control X - S (con subgrupo n = 6) se obtuvo lo siguiente, después de que el proceso se estabilizó quedando sólo con causas comunes (LIE = 15, LSE = 23): Xmedia de medias = 20 Smedio = 1.5.")
277
V.F.2 Índices de desempeño del proceso

278
Estimación de la desviación estándar con el proceso a largo plazo
Se toman todos los datos del proceso históricos, no importa que el proceso no esté en control o no sea normal. Desv. Est. lt (Overall) =
 =")
279
Índices de desempeño Potencial del proceso – Largo plazo
El índice de desempeño potencial del Proceso (Pp) mide la variación del proceso en relación con el rango de Especificación. Tolerancia LSE - LIE Pp = = Variación del proceso 6 Desviaciones Estándar - lt La relación de capacidad (CR) es la inversa del cálculo de Cp. Este índice le indica que porcentaje de la especificación está siendo usado por la variación del proceso. Rango del proceso 6 desviaciones Est. - lt CR = = Tolerancia LSE - LIE
 mide la. variación del proceso en relación con el rango de Especificación. Tolerancia. LSE - LIE. Pp. = = Variación del proceso. 6 Desviaciones Estándar - lt. La relación de capacidad (CR) es la inversa del cálculo de Cp. Este índice le. indica que porcentaje de la especificación está siendo usado por la variación del. proceso. Rango del proceso. 6 desviaciones Est. - lt. CR. = = Tolerancia. LSE - LIE.")
280
Índice de desempeño real del proceso – largo plazo
Ppk es una medida del desempeño real del proceso en función de la posición de la media del proceso (X) en relación con con los límites de especificación. Con límites bilaterales da una indicación del centrado. Es el menor de: LSE - promedio del proceso Promedio del proceso - LIE Ppk = y 3 desviaciones est. - lt 3 desviaciones Estándar - lt
 en relación con con los límites de especificación. Con límites bilaterales da una indicación del centrado. Es el menor de: LSE - promedio del proceso. Promedio del proceso - LIE. Ppk. = y. 3 desviaciones est. - lt. 3 desviaciones Estándar - lt.")
281
Cálculo del desempeño del
proceso a lago plazo Índice de desempeño potencial Pp = (LSE - LIE ) / 6 lt Debe ser 1 de preferencia >1.33 para tener el potencial de cumplir con especificaciones (LIE, LSE) Índice de desempeño real Ppk = Menor | ZI y ZS | / 3 El Ppk debe ser 1 para que el proceso cumpla especificaciones de preferencia > 1.33
 / 6 lt. Debe ser 1 de preferencia >1.33. para tener el potencial de. cumplir con especificaciones (LIE, LSE) Índice de desempeño real Ppk = Menor | ZI y ZS | / 3. El Ppk debe ser 1 para que el. proceso cumpla especificaciones. de preferencia >")
282
IIIF.3 Capacidad a corto y a largo plazo

283
Corto y largo plazos Corto plazo:
Es un periodo corto de tiempo en el cual no hay cambios significativos en el proceso en relación a las 6M’s (personal, materiales, métodos, medio ambiente, mediciones, máquinas) Largo Plazo Es el periodo de tiempo en el cual ya han ocurrido todos los cambios posibles en el proceso, se trata de información histórica
 Largo Plazo. Es el periodo de tiempo en el cual ya han ocurrido todos los cambios posibles en el proceso, se trata de información histórica.")
284
Carta de corridas cortas
Se puede utilizar una carta X-R modificada para corridas cortas, con base en subgrupos de 3 a 10 piezas. Inicialmente se utilizan A2 y D4 para calcular los límites de control que se modifican al tomar más puntos El Cpk calcualdo de esta forma se considera preliminar

285
Corto y largo plazos Los índices de capacidad del proceso Cp y Cpk se consideran a corto plazo, cuando no se presentan cambios en el proceso (en las 6 M’s) Los índices de desempeño Pp y Ppk se consideran a largo plazo con datos históricos cuando ya han sucedido todos los cambios en el proceso
 Los índices de desempeño Pp y Ppk se consideran a largo plazo con datos históricos cuando ya han sucedido todos los cambios en el proceso.")
286
V.F.4 Análisis de la Capacidad de procesos no normales

287
Procesos no normales Los datos no siempre se ajustan a la distribución normal. Se tienen dos estrategias para transformar los datos no normales para lograr un comportamiento normal, la de Box Cox y Johnson

288
Transformación de Box Cox
Minitab encuentra una transformación óptima (W = Y**Lamda) Está limitada a datos positivos . Asume que los datos están en subgrupos para permitir un análisis “dentro del subgrupo” La transformación de potencia de Box-Cox dada por:
 Está limitada a datos positivos . Asume que los datos están en subgrupos para permitir un análisis dentro del subgrupo La transformación de potencia de Box-Cox dada por:")
289
Procesos no normales Dadas las observaciones X1, X2, X3,….., Xn, seleccionar la potencia que maximice el logaritmo de la función de máxima verosimilitud Con la media aritmética de los datos transformados dada por:

290
Capacidad de procesos no normales transformando datos con Box - Cox
Con archivo de Minitab TILES.MTW, lamda = 0.5

291
Capacidad de procesos no normales transformando datos con Box - Cox
Con la raíz cuadrada de los datos y de los límites de especificaciones se tiene:

292
Transformación de Johnson
Minitab selecciona la función de transformación de tres tipos de funciones (SB, SL y SU), para tener muchas opciones
, para tener muchas opciones.")
293
Transformación de Johnson
Con archivo Tiles.mtw Warping Transf Etc.

294
Capacidad con distribuciones diferentes a la normal
Se pueden utilizar otras distribuciones que ajusten a los datos no normales para determinar el Pp y el Ppk

295
Capacidad de procesos no normales usando la distribución de Weibull
Con archivo de Minitab TILES.MTW

296
Capacidad de procesos por Pearson
Independientemente de si los datos siguen una distribución normal o no, se pueden calcular los índices de capacidad y habilidad de proceso determinando los valores de los “Percentiles” o “límites de control” equivalentes a un área bajo la curva de 0.135% de cada lado de la misma. Este método ha sido propuesto por Clements (1989) con base en las curvas de Karl Pearson (1893), para ello, es necesario caracterizar la curva de distribución de acuerdo a su posición (Media), dispersión (Desviación Estándar) y forma (Grado de asimetría mediante el Sesgo y grado de “achatamiento” o Kurtosis).
 con base en las curvas de Karl Pearson (1893), para ello, es necesario caracterizar la curva de distribución de acuerdo a su posición (Media), dispersión (Desviación Estándar) y forma (Grado de asimetría mediante el Sesgo y grado de achatamiento o Kurtosis).")
297
Capacidad de procesos por Pearson
Procedimiento : Identificar los límites de especificación de la variable de interés (LSE, LIE) Calcular la Media (Y). Calcular la Desviación estándar (s ó s) Calcular el coeficiente de sesgo (a3) Calcular el coeficiente de Kurtosis Pi’ se determina de la tabla 1ª y Ps’ de la 1b
 Calcular la Media (Y). Calcular la Desviación estándar (s ó s) Calcular el coeficiente de sesgo (a3) Calcular el coeficiente de Kurtosis. Pi’ se determina de la tabla 1ª y Ps’ de la 1b.")
298
Capacidad de procesos por Pearson
Cálculo del sesgo: Donde : momento 3 = m3 = (S(yi – y)3)/n a3 = n (n-1)(n-2) S i=1 n ( ) yi – y s 3 O bien : a3 > 0 a3 < 0 a3 = 0
3)/n. a3 = n . (n-1)(n-2) S. i=1. n. ( ) yi – y. s. 3. O bien : a3 > 0. a3 < 0. a3 = 0.")
299
Capacidad de procesos por Pearson
Calcular el coeficiente de curtosis (a4 -3) a4 = m4 / s4 Donde : momento 4 = m4 = (S(yi – y)4)/n O bien : { ( } ) n 4 n (n+1) . (n-1)(n-2)(n-3) S yi – y s a4-3 = - 3 (n-1)2 . (n-2)(n-3) i=1 Curva Leptocúrtica : a4 > 3 Curva Mesocúrtica : a4 = 3 Curva Platicúrtica : a4 < 3
 a4 = m4 / s4. Donde : momento 4 = m4 = (S(yi – y)4)/n. O bien : { ( } ) n. 4. n (n+1) . (n-1)(n-2)(n-3) S. yi – y. s. a4-3 = - 3 (n-1)2 . (n-2)(n-3) i=1. Curva Leptocúrtica : a4 > 3. Curva Mesocúrtica : a4 = 3. Curva Platicúrtica : a4 < 3.")
300
Con Minitab Stat > Basic Statistics > Display descriptive statistics >> Graphs... >> Graphical Summary

301
Con Minitab PI = y – s * PI’ PS = y + s * PS’ M = y + s * M’
De la tabla 2 de las curvas de Pearson obtenga la Mediana estandarizada (M’) : Para coeficiente de sesgo positivo cambie el signo a M’. Para coeficiente de sesgo negativo deje el signo de M’. Calcular el percentil estimado (PI) : PI = y – s * PI’ Calcular percentil estimado (PS) : PS = y + s * PS’ Calcular la Mediana estimada (M) : M = y + s * M’
 : Para coeficiente de sesgo positivo cambie el signo a M’. Para coeficiente de sesgo negativo deje el signo de M’. Calcular el percentil estimado (PI) : PI = y – s * PI’ Calcular percentil estimado (PS) : PS = y + s * PS’ Calcular la Mediana estimada (M) : M = y + s * M’")
302
Con Minitab LSE - LIE Pp = PS - PI M - LIE Ppi = M - PI LSE – M Pps =
Calcular el índice de capacidad potencial de proceso (Pp). LSE - LIE PS - PI Pp = Calcular el índice de habilidad del proceso (Ppk) M - LIE M - PI Ppi = LSE – M PS - M Pps = Ppk = min {Ppi, Pps}
. LSE - LIE. PS - PI. Pp = Calcular el índice de habilidad del proceso (Ppk) M - LIE. M - PI. Ppi = LSE – M. PS - M. Pps = Ppk = min {Ppi, Pps}")
303
Tabla 1a de Pearson

304
Tabla 1b de Pearson

305
Tabla 2 de Pearson

306
Índices de desemepeño Procedimiento :
Obtener el índice de capacidad potencial de proceso a corto plazo (Cp) y el índice de capacidad real de proceso a largo plazo (Ppk). Calcular el índice de desempeño potencial de proceso (Zcp). Zst = 3 Cp (P/especif. Bilaterales) Zst = 3 Cpk (P/especif. Unilaterales) Calcular el índice de desempeño real de proceso (Zlp): Zlt = 3 Ppk Calcule el índice de desempeño entre grupos (Zshift): Zshift = Zst - Zlt
 y el índice de capacidad real de proceso a largo plazo (Ppk). Calcular el índice de desempeño potencial de proceso (Zcp). Zst = 3 Cp (P/especif. Bilaterales) Zst = 3 Cpk (P/especif. Unilaterales) Calcular el índice de desempeño real de proceso (Zlp): Zlt = 3 Ppk. Calcule el índice de desempeño entre grupos (Zshift): Zshift = Zst - Zlt.")
307
Pobre control y pobre capacidad
Índices de desempeño Analice la información; se consideran como valores aceptables los siguientes: Zlt > 3 ; Zst > 4 ; Zshift < 1.5 3.0 3.0 Malo Zlp =-1 Pobre control y pobre capacidad Pobre control Zlp =0 Zshift 2.0 Zshift 2.0 Control Zlp =1 Control Zlp =2 Zlp =3 1.0 1.0 Pobre capacidad Estado deseado Zlp = 4 Zlp =5 Bueno 0.0 0.0 0.0 2.0 4.0 6.0 0.0 2.0 4.0 6.0 Zst Malo Zst Bueno Capacidad/Diseño/Tecnología Capacidad/Diseño/Tecnología

308
V.F.5 Capacidad de procesos por atributos

309
Capacidad de proceso para datos por atributos
En este caso la capacidad del proceso es la proporción media de producto no conforme Para cartas p y np, la capacidad del proceso es la p media de fracción no conforme. Se puede usar 1 – p. Para cartas c, la capacidad del proceso es el promedio de las no conformidades, c media, para una muestra fija de tamaño n. Para cartas u, la capacidad del proceso es el promedio de las no conformidades por unidad, u media

310
V.E.6 Capacidad de procesos bajo Seis Sigma

311
Capacidad de procesos bajo Seis Sigma
Motorola notó que muchas operaciones en productos complejos tendían a desplazarse 1.5 sobre el tiempo, por tanto un proceso de 6 a la larga tendrá 4.5 hacia uno de los límites de especificación, generando 3.4 DPMOs (defectos por millón de oportunidades)
")
312
Variación a Corto Plazo (periodo durante el cual no se presenta ningún cambio en el proceso)
Zst = Zlt + 1.5 Variación a largo plazo (periodo en el cual ya se han presentado todos los cambios posibles en el proceso) - Zlt Variación Global - Zbench.
 - Zlt. Variación Global - Zbench.")
313
Variabilidad combinada
Capacidad en el corto y largo plazo LIE LSE Capacidad a Corto Plazo 3.5 2.5 Salida 1.5 Mes E F M A M J J A S O N D E F M A M J J A S O N D Capacidad a Largo Plazo Variabilidad Total (Natural) = Variabilidad “entre subgrupos” + Variabilidad combinada “dentro del subgrupo”
 = Variabilidad. entre subgrupos + Variabilidad combinada. dentro del subgrupo")
314
Rendimiento de la capacidad real
Recibo de partes del proveedor 95.5% de rendimiento 1,000,000 unidades Después de la inspección de recepción 97% de rendimiento 45,000 Unidades desperdiciadas De las operaciones de Maquinado 94.4% de rendimiento 28,650 Unidades desperdiciadas En los puestos de prueba - 1er intento 51,876 Unidades desperdiciadas YRT = .955*.97*.944 = 87.4% Correcto la primera vez 125,526 unidades desperdiciadas por millón de oportunidades

315
Ejemplos de defectos / unidad
Determinar DPU en la producción de 100 unidades DPU = D/U = ( )/100=0.46 Si cada unidad tiene 6 oportunidades para defecto (características A, B, C, D, E y F), calcular DPO y DPMO DPO = DPU / O = 0.46/6 = DPMO = 78,333 Defectos 20 10 12 4 Unidades 70 6
/100=0.46. Si cada unidad tiene 6 oportunidades para defecto (características A, B, C, D, E y F), calcular DPO y DPMO. DPO = DPU / O = 0.46/6 = DPMO = 78,333. Defectos Unidades")
316
Relaciones de sigmas La probabilidad de uno o más defectos es:
P(d) = 1- Yrt = 1 – FPY o P(d) = 1 – Yrt para varios procesos Si se tiene FPY = 95% P(d) = 0.05 Entonces la Z a largo plazo se encuentra en tablas como Zlt = sigma y por tanto la Zst a corto plazo es: Zst = (corrimiento) = 3.145
 = 1- Yrt = 1 – FPY o P(d) = 1 – Yrt para varios procesos. Si se tiene FPY = 95% P(d) = Entonces la Z a largo plazo se encuentra en tablas como Zlt = sigma y por tanto la Zst a corto plazo es: Zst = (corrimiento) =")
317
¿Como calcular la capacidad Seis Sigma para un proceso (equivale a la Zst de corto plazo)?
¿Qué proceso se considera? Facturación y CxC ¿Cuántas unidades tiene el proceso? 1,283 ¿Cuántas están libres de defectos? 1,138 Calcular el desempeño del proceso 1138/1283=0.887 Calcular la tasa de defectos = 0.113 Determinar el número de oportunidades que pueden ocasionar un defecto (CTQs) 24 Calcular la tasa de defecto por caract. CTQ / 24 = Calcular los defectos x millón de oportunidades DPMO = 4,709 Calcular #sigmas con tabla de conversión de sigma 4.1
 24. Calcular la tasa de defecto por caract. CTQ / 24 = Calcular los defectos x millón de oportunidades DPMO = 4,709. Calcular #sigmas con tabla de conversión de sigma 4.1.")
318
Planta escondida Y1=0.90 Y2=0.90 Y3=0.90 100 90 81 73 66 10 9 8 7 100
$1/Unit 100 10 Rework

319
La eficiencia rolada p n YRT = Yi = i=1
100 100 100 $1/Unit $1/Unit $1/Unit 100 $1/Unit 100 10 10 10 10 Reproceso Reproceso Reproceso Reproceso YRT = p i=1 n Yi = 0.9 x 0.9 x 0.9 x 0.9 = 0.94 = 66/100 = 0.66 = 66% Aproximando de Binomial a Poisson : YRT = e- DPU = e- (40/100) = e- 0.4 = 0.67 = 67% 1 – YRT = Probabilidad de un defecto/unidad = 1 – 0.67 = 0.33 = 33% 1 + (1 – YRT) = Numero de unidades equivalentes iniciadas para producir una unidad buena = 1 + ( ) = 1.33
 = e- 0.4 = 0.67 = 67% 1 – YRT = Probabilidad de un defecto/unidad = 1 – 0.67 = 0.33 = 33% 1 + (1 – YRT) = Numero de unidades equivalentes iniciadas para producir una unidad buena = 1 + ( ) =")
320
Costos de pobre calidad
$1/Unit 100 10 Rework Considerando : No existe scrap ni costos de inventarios Precio de Ventas = $5.00/Unidad Por lo tanto : Como el número de unidades equivalentes iniciadas para producir una unidad buena = 1.33 Costo de producir una unidad buena = 1.33*$4 = $5.32 Utilidades = $ $5.32 = -$0.32/Unidad COPQ = ($5.32-$4.00)/$5.00 = 26.4% de las ventas
/$5.00 = 26.4% de las ventas.")
321
Eficiencias y DPMOs PPMs
El desempeño de un proceso también puede ser expresado en términos de eficiencia. Las 3 eficiencias más usadas son : Eficiencia de primer paso (bien a la primera vez), eficiencia final (Yfinal) o “First Time Yield” (YFT) Eficiencia rolada o “Rolled-Throughput Yield” (YRT) Eficiencia Normalizada (Ynorm)
, eficiencia final (Yfinal) o First Time Yield (YFT) Eficiencia rolada o Rolled-Throughput Yield (YRT) Eficiencia Normalizada (Ynorm)")
322
Eficiencias y DPMOs PPMs
Eficiencia de primer paso (bien a la primera vez), eficiencia final (Yfinal) o “First Time Yield” (YFT) Yfinal = Número de unidades buenas antes de retrabajo Número de unidades probadas ó evaluadas
, eficiencia final (Yfinal) o First Time Yield (YFT) Yfinal = Número de unidades buenas antes de retrabajo. Número de unidades probadas ó evaluadas.")
323
Eficiencias y DPMOs PPMs
Eficiencia rolada o “Rolled-Throughput Yield” (YRT) Y1=S1/E Y2=S2/S1 Y3=S3/S2 Yn=Sn/Sn-1 ..... E S1 S2 S3 Sn-1 Sn Donde : e = m = Número de oportunidades por unidad Para datos continuos : YRT = p i=1 n Yi = Y1 x Y2 x Y3 x....x Yn Para datos discretos (Aproximación de Binomial a Poisson) : YRT = e-TDPU YRT = e-(DPO) m Donde : Y1, Y2, Y3,...., Yn son “first time Yield” de los pasos 1, 2, 3,...,n
 Y1=S1/E. Y2=S2/S1. Y3=S3/S2. Yn=Sn/Sn E. S1. S2. S3. Sn-1. Sn. Donde : e = m = Número de oportunidades por unidad. Para datos continuos : YRT = p. i=1. n. Yi = Y1 x Y2 x Y3 x....x Yn. Para datos discretos (Aproximación de Binomial a Poisson) : YRT = e-TDPU. YRT = e-(DPO) m. Donde : Y1, Y2, Y3,...., Yn son first time Yield de los pasos 1, 2, 3,...,n.")
324
Eficiencias y DPMOs PPMs
Cálculo de la Eficiencia Normalizada (Ynorm) : Eficiencia Normalizada (Ynorm) Ynorm = (YRT)1/k Cálculo de DPU a partir de la Eficiencia : DPU = 1 - Y Eficiencia a partir de PPM’s : Y = 1 – (PPM/1’000,000)
 : Eficiencia Normalizada (Ynorm) Ynorm = (YRT)1/k. Cálculo de DPU a partir de la Eficiencia : DPU = 1 - Y. Eficiencia a partir de PPM’s : Y = 1 – (PPM/1’000,000)")
325
Relaciones con el rendimiento Y
La probabilidad de encontrar X defectos con la distribución de Poisson es: X es un entero y DPU > 0 Para el caso de que X sea cero se tiene Rendimiento o FRC = P(X=0) = Exp(-DPU)
 = Exp(-DPU)")
326
Fórmulas de desempeño

327
Rolled Troughput Yield (Yrt)
Yrt es el cálculo acumulativo del índice de defectos a lo largo de procesos múltiples La probabilidad de un defecto es 1 – P(Yrt) = 0.05
 =")
328
Tablero de control de variable discreta
Se utiliza cuando se va a evaluar el desempeño de un CTQ, pero hay desempeños parciales en el tiempo. Defina el defecto, la unidad y el número de oportunidades por unidad Defina que es un corto plazo Evalúe el desempeño en DPMO y Z del CTQ en varios (k) cortos plazos
 cortos plazos.")
329
Tablero de control de variable discreta
Evalúe el desempeño en DPMO del largo plazo, considerando lo siguiente Dlt = S Dsti i = 1 k TotOplt = S [Ui*(Op/U)i ] DPMOlt = Dlt . TotOplt * 106 Donde : Dlt = Defectos de largo plazo Dst = Defectos de corto plazo U = Número de unidades Op/U = Oportunidades por unidad TotOp = Total de oportunidades DPMOlt = Defectos por Millón de Oportunidades k = Número total de características críticas
i ] DPMOlt = Dlt . TotOplt. * 106. Donde : Dlt = Defectos de largo plazo. Dst = Defectos de corto plazo. U = Número de unidades. Op/U = Oportunidades por unidad. TotOp = Total de oportunidades. DPMOlt = Defectos por Millón de Oportunidades. k = Número total de características críticas.")
330
Tablero de control de variable discreta
Con los DPMOlt evalúe la Zlt Identifique la Z de corto plazo más pequeña y ésta será la Zst Calcule la Zshift considerando que : Zshift = Zst - Zlt

331
Tablero de control de variable continua
Se utiliza cuando se va a evaluar el desempeño de un CTQ, pero hay desempeños parciales en el tiempo. Determine la variable y los Límites de Especificación Defina que es un periodo de tiempo Recolecte datos de cada periodo y calcule la desviación estándar de Corto plazo (Sst) y las PPM’s de cada periodo de tiempo Calcule la Zst y Zlt de cada periodo de tiempo
 y las PPM’s de cada periodo de tiempo. Calcule la Zst y Zlt de cada periodo de tiempo.")
332
Tablero de control de variable discreta
Calcule la Sst total del CTQ mediante: Calcule la Zst total del CTQ Calcule los PPM’s totales mediante un promedio ponderado g å (nj-1) sj2 j=1 (n-g) sst = Donde : n = Número Total de Datos nj = Número de datos del grupo j sj = Desviación Estándar del grupo j g = Número de grupos
 sj2. j=1. (n-g) sst = Donde : n = Número Total de Datos. nj = Número de datos del grupo j. sj = Desviación Estándar del grupo j. g = Número de grupos.")
333
Tablero de control de variable discreta
Con los PPM’s totales obtenga Zlt total del CTQ Calcule la Zshift considerando que : Donde : PPM = PPM Totales PPMj = PPM’s del periodo i ni = Número de datos del periodo i N = Número total de datos PPM = S PPMi ni N i = 1 k

334
Tablero de control de variable discreta
Con los DPMOlt evalúe la Zlt Identifique la Z de corto plazo más pequeña y ésta será la Zst Calcule la Zshift considerando que : Zshift = Zst - Zlt

335
Tablero de control de variable múltiple
Se utiliza cuando se va a evaluar el desempeño de un Producto, Proceso ó Sistema a partir del desempeño de varios CTS’s, CTQ’s ó CTP’s Defina el Producto, Proceso ó Sistema a evaluar Identifique los CTS’s, CTQ’s ó CTP’s del Sistema a evaluar Evalúe de forma individual cada CTS, CTQ ó CTP en términos de DPMOlt

336
Tablero de control de variable múltiple
Calcule la eficiencia (Yftlt) de cada CTS, CTQ ó CTP considerando que: Evalúe desempeño potencial de cada característica crítica expresado en DPMOst, el cual se puede obtener a partir de la Zst ó los menores DPMO que el proceso ha demostrado generar a corto plazo. yftlti = 1 – Donde : yftlti = Eficiencia de la característica crítica i DPMOlti = Defectos por Millón de Op. de la caract. i DPMOlti 106
 de cada CTS, CTQ ó CTP considerando que: Evalúe desempeño potencial de cada característica crítica expresado en DPMOst, el cual se puede obtener a partir de la Zst ó los menores DPMO que el proceso ha demostrado generar a corto plazo. yftlti = 1 – Donde : yftlti = Eficiencia de la característica crítica i. DPMOlti = Defectos por Millón de Op. de la caract. i. DPMOlti")
337
Tablero de control de variable múltiple
Calcule la eficiencia (yftst) de cada CTS, CTQ ó CTP considerando que : DPMOsti 106 yftsti = 1 – Calcule las eficiencias roladas (YRT) de Corto (st) y largo plazo (lt) del Producto, Proceso ó Sistema mediante : Donde : YRTlt = Eficiencia rolada total del sistema YRTst = Eficiencia rolada potencial del sistema yftlti = Eficiencia de la característica crítica i yftsti = Eficiencia potencial de la característica crítica i k = Número total de características k YRTlt = P yftlti i = 1 k YRTst = P yftsti i = 1
 de cada CTS, CTQ ó CTP considerando que : DPMOsti yftsti = 1 – Calcule las eficiencias roladas (YRT) de Corto (st) y largo plazo (lt) del Producto, Proceso ó Sistema mediante : Donde : YRTlt = Eficiencia rolada total del sistema. YRTst = Eficiencia rolada potencial del sistema. yftlti = Eficiencia de la característica crítica i. yftsti = Eficiencia potencial de la característica crítica i. k = Número total de características. k. YRTlt = P yftlti. i = 1. k. YRTst = P yftsti. i = 1.")
338
Tablero de control de variable múltiple
Calcule la Eficiencia Normalizada (ynorm) de corto (st) y largo plazo (lt) : Ynormst = (YRTst)1/k Ynormlt = (YRTlt)1/k En caso de que cada Característica Crítica tenga un diferente nivel de importancia, entonces la Eficiencia Normalizada se puede obtener ponderando las eficiencias de cada Característica usando la siguiente fórmula : Ynorm = (d1I1) x (d2I2) x … x (dnIn) (1/SIi) I es la importancia. La característica crítica con mayor valor de I es ponderado con mayor peso al calcular el valor total compuesto Y
 de corto (st) y largo plazo (lt) : Ynormst = (YRTst)1/k. Ynormlt = (YRTlt)1/k. En caso de que cada Característica Crítica tenga un diferente nivel de importancia, entonces la Eficiencia Normalizada se puede obtener ponderando las eficiencias de cada Característica usando la siguiente fórmula : Ynorm = (d1I1) x (d2I2) x … x (dnIn) (1/SIi) I es la importancia. La característica crítica con mayor valor de I es ponderado con mayor peso al calcular el valor total compuesto Y.")
339
Tablero de control de variable múltiple
Calcule los DPMO totales del sistema mediante: Con los DPMOst obtenga la Zst, con los DPMOlt obtenga la Zlt Calcule la Zshift del sistema mediante : DPMOst = (1 – Ynormst)*106 DPMOlt = (1 – Ynormlt)*106 Zshift = Zst - Zlt
*106. DPMOlt = (1 – Ynormlt)*106. Zshift = Zst - Zlt.")
Presentaciones similares