Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Optativa II Carlos Quilumbaqui

2
¿Qué es Big Data? Big Data son grandes en cantidad, se capturan a un índice rápido, y son estructurados o no estructurados, o la combinación de los dos. Estos factores hacen que los Big Data sean difíciles de capturar, extraer, y gestionar usando métodos tradicionales. A partir del año 2012, los clústers ‘grandes’ oscilan el rango de 100 Petabyte.

3
Las bases de datos relacionales tradicionales, como Informix y DB2, proporcionan soluciones comprobadas para datos estructurados. A través de la extensibilidad, también gestionan datos no estructurados. La tecnología Hadoop trae técnicas de programación nuevas y más accesibles para trabajar en almacenamientos de datos masivos con datos tanto estructurados como no estructurados.

4
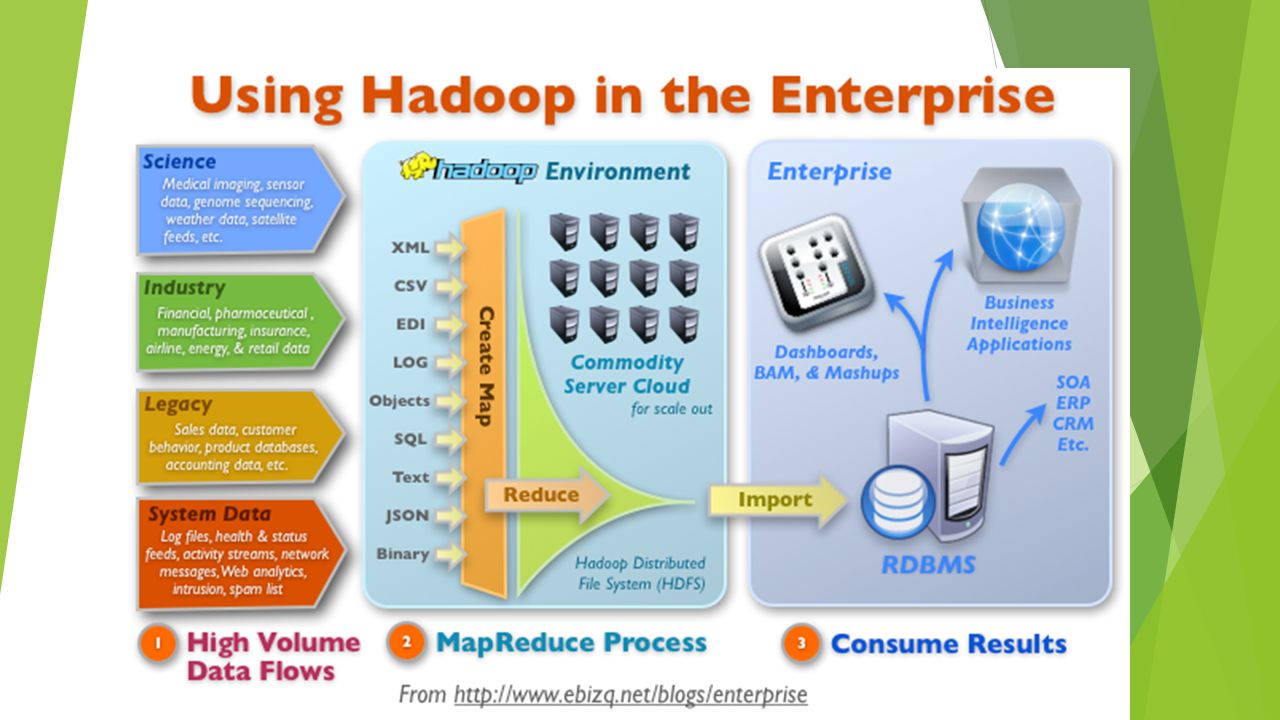
¿Qué es Hadoop? Apache ™ Hadoop ® es un proyecto de software de código abierto que permite el procesamiento distribuido de grandes conjuntos de datos a través de clusters de servidores estandar. Está diseñado para escalar desde un único servidor a miles de máquinas, con un alto grado de tolerancia a fallos. En lugar de confiar en el hardware de gama alta, la resistencia de estos clusters proviene de la capacidad del software para detectar y controlar los errores en la capa de aplicación.

5
Apache Hadoop tiene dos sub-proyectos principales: MapReduce - El framework que entiende y asigna el trabajo a los nodos de un clúster.MapReduce HDFS - Un sistema de archivos que se extiende por todos los nodos en un cluster Hadoop para el almacenamiento de datos. Se conectan entre sí los sistemas de archivos en muchos nodos locales para convertirlos en un sistema de archivos grandes. HDFS asume nodos fallosos, lo que logra fiabilidad por la replicación de datos a través de múltiples nodosHDFS Hadoop se complementa con un entorno de proyectos de Apache, como cerdo, Colmena yZookeeper, que extienden el valor de Hadoop y mejora su usabilidad.cerdoColmenaZookeeper

6
Hadoop cambia la economía y la dinámica de computación a gran escala. Su impacto se puede reducir a cuatro características sobresalientes. Hadoop permite una solución informática que es: Escalable - Los nuevos nodos se pueden agregar según sea necesario, y ha añadido sin necesidad de cambiar formatos de datos, cómo se cargan los datos, cómo se escriben empleos, o las aplicaciones en la parte superior. Rentable - Hadoop trae masiva computación paralela para servidores básicos. El resultado es una disminución considerable en el costo por terabyte de almacenamiento, que a su vez hace que sea asequible para modelar todos sus datos.

7
Flexible - Hadoop es esquema-menos, y puede absorber cualquier tipo de datos, estructurados o no, de cualquier número de fuentes. Los datos procedentes de múltiples fuentes se pueden unir y se agregan de manera arbitraria que permite realizar análisis más profundos que cualquier sistema puede proporcionar. Tolerante de fallas - Cuando se pierde un nodo, el sistema vuelve a dirigir el trabajo a otro lugar de los datos y seguir con el procesamiento sin perder el ritmo. Facilita el almacenamiento de información y permite hacer consultas complejas sobre las bases de datos existentes, resolviéndolas con rapidez.

8
El 80% de los datos del mundo no es estructurado, y la mayoría de las empresas ni siquiera tratan de utilizar estos datos en beneficio propio. Imagínese si usted podría permitirse el lujo de mantener todos los datos generados por su negocio? Imagínese si usted tenía una manera de analizar los datos? Quienes lo utilizan?? Lo utiliza el buscador de Yahoo.com, companias de Internet como Facebook, Ebay o Twitter.

Presentaciones similares













>")
 Software (Software de Inteligencia Impresario)>")




