Descargar la presentación
La descarga está en progreso. Por favor, espere

1
EL PROCESAMIENTO DISTRIBUIDO Y SU APLICACIÓN AL TRATAMIENTO DE IMÁGENES

2
INTRODUCCIÓN ESTADO DE LA TÉCNICA PROCESAMIENTO DISTRIBUIDO CON MPI PROCESAMIETNO DISTRIBUIDO DE IMÁGENES GENÉRICO CON VTK PROCESAMIENTO DISTRIBUIDO DE IMÁGENES GENÉRICO CON MATLAB PROCESAMIENTO DISTRIBUIDO DE IMÁGENES GENÉRICO CON PARAVIEW RENDERIZACIÓN DE UNA NEURONA PROCESAMIENTO DISTRIBUIDO CON C++ CONCLUSIONES Y LÍNEAS DE MEJORA

3
CAPÍTULO 1: INTRODUCCIÓN

4
OBJETIVOS QUE PERSIGUE EL PROYECTO
Dar una visión más en profundidad de lo que entendemos por procesamiento distribuido: el conocimiento y manejo de las implementaciones existentes a la hora de realizar este procesamiento distribuido, como pueden ser MPI y MatlabMPI La aplicación de estas diversas técnicas de procesamiento distribuido al tratamiento y procesado de imágenes Dar una introducción a las implementaciones existentes para desarrollar el procesamiento distribuido en otros lenguajes, como es el lenguaje C++: PVM y CORBA.

5
CAPÍTULO 2: ESTADO DE LA TÉCNICA

6
¿QUÉ ES UN SISTEMA DISTRIBUIDO?
Un sistema distribuido es un conjunto de computadoras conectadas en red de forma que le da la sensación al usuario de ser una sola computadora. Los sistemas de procesamiento distribuidos brindan una buena relación precio-desempeño y pueden aumentar su tamaño de manera gradual al aumentar la carga de trabajo. VENTAJAS DESVENTAJAS ECONOMÍA COMPLEJIDAD DE VELOCIDAD IMPLEMENTACIÓN ALTA DISPONIBILIDAD ESCALABILIDAD SISTEMA DE FICHEROS DE RAÍZ ÚNICA COMUNICACIÓN ENTRE PROCESOS INTERCAMBIO DE DATOS UNIVERSAL

7
LOS CLUSTERS De forma genérica, podemos definir un cluster como un conjunto de máquinas unidas por una red de comunicación trabajando por un objetivo conjunto. Según el tipo puede ser dar alta disponibilidad, alto rendimiento etc... Podemos resumir las características de un cluster en las siguientes: Un cluster consta de 2 o más nodos. Los nodos necesitan estar conectados para llevar a cabo su misión. Los nodos de un cluster están conectados entre sí por un canal de comunicación funcional. Los clusters necesitan software especializado. Existen varios tipos de software que pueden conformar un cluster: software a nivel de aplicación y software a nivel de sistema. Acoplamiento del software: entendemos por acoplamiento del software a la integración que tengan todos los elementos software que existan en cada nodo: acoplamiento fuerte, acoplamiento medio y acoplamiento débil.

8
Cluster a nivel de sistema y a nivel de aplicación
Podemos catalogar los clusters según una serie de consideraciones: Acoplamiento: fuerte, medio, débil Control: centralizado o descentralizado Homogeneidad: homogéneos o heterogéneos Seguridad

9
Según lo visto anteriormente, podemos catalogar los clusters en tres tipos diferentes:
CLUSTERS DE ALTO RENDIMIENTO (HP): Los clusters de alto rendimiento han sido creados para compartir el recurso más valioso de un ordenador, es decir, el tiempo de proceso. La misión de este tipo de clusters es mejorar el rendimiento en la obtención de la solución de un problema. CLUSTERS DE ALTA DISPONIBILIDAD (HA): Los clusters de alta disponibilidad han sido diseñados para que proporcionen la máxima disponibilidad sobre los servicios que presenta el cluster. La mayoría de los problemas que tratan de resolver este tipo de clusters están ligados a la necesidad de dar servicio continuado de cualquier tipo a una serie de clientes de manera ininterrumpida. CLUSTERS DE ALTA CONFIABILIDAD (HR): Estos clusters tratan de aportar la máxima confiabilidad en un entorno en el cual se necesite saber que el sistema se va a comportar de una manera determinada.
: Los clusters de alto rendimiento han sido creados para compartir el recurso más valioso de un ordenador, es decir, el tiempo de proceso. La misión de este tipo de clusters es mejorar el rendimiento en la obtención de la solución de un problema. CLUSTERS DE ALTA DISPONIBILIDAD (HA): Los clusters de alta disponibilidad han sido diseñados para que proporcionen la máxima disponibilidad sobre los servicios que presenta el cluster. La mayoría de los problemas que tratan de resolver este tipo de clusters están ligados a la necesidad de dar servicio continuado de cualquier tipo a una serie de clientes de manera ininterrumpida. CLUSTERS DE ALTA CONFIABILIDAD (HR): Estos clusters tratan de aportar la máxima confiabilidad en un entorno en el cual se necesite saber que el sistema se va a comportar de una manera determinada.")
10
CAPÍTULO 3: PROCESAMIENTO DISTRIBUIDO CON MPI

11
MPI MPI (Message Passing Interface) es un interfaz estandarizado para la implementación de aplicaciones paralelas basadas en paso de mensajes OBJETIVOS DE MPI Entorno de programación único para asegurar la portabilidad de las aplicaciones paralelas. Definir el interfaz de programación sin especificar cómo debe ser la implementación del mismo. Favorecer la extensión del estándar.

12
LIMITACIONES DE MPI No existe un mecanismo estandarizado de entrada/salida paralela. MPI asume un número de procesos constante, que es establecido al arrancar la aplicación. El modelo de comunicación estandarizado por MPI sólo tiene en cuenta el paso de mensajes. Desarrollo de bindings para otros lenguajes: C++ y ADA. Soporte para las aplicaciones de tiempo real. No se define ningún aspecto relacionado con la interacción mediante GUIs con una aplicación paralela.

13
ubicación de MPI en el proceso de programación de aplicaciones paralelas

14
ESTRÚCTURA BÁSICA DE LOS PROGRAMAS MPI
# include "mpi.h" main (int argc, char **argv) { int nproc; /* Número de procesos */ int yo; /* Mi dirección: 0<=yo<= (nproc-1) */ MPI_Init (&argc, &argv); /* Inicio aplicación paralela */ MPI_Comm_size (MPI_COMM_WORLD, &nproc); MPI_Comm_rank (MPI_COMM_WORLD, &yo); /* CUERPO DEL PROGRAMA */ MPI_Finalize (); } para que cada proceso averigüe su dirección (identificador) dentro del conjunto de diferentes procesos que componen la aplicación para averiguar el número de procesos que toman parte en la aplicación en cuestión para dar por finalizada la aplicación
 { int nproc; /* Número de procesos */ int yo; /* Mi dirección: 0<=yo<= (nproc-1) */ MPI_Init (&argc, &argv); /* Inicio aplicación paralela */ MPI_Comm_size (MPI_COMM_WORLD, &nproc); MPI_Comm_rank (MPI_COMM_WORLD, &yo); /* CUERPO DEL PROGRAMA */ MPI_Finalize (); } para que cada proceso averigüe su dirección (identificador) dentro del conjunto de diferentes procesos que componen la aplicación. para averiguar el número de procesos que toman parte en la aplicación en cuestión. para dar por finalizada la aplicación.")
15
COMUNICACIÓN A TRAVÉS DE MPI: COMUNICACIÓN PUNTO A PUNTO
MODELOS DE COMUNICACIÓN Modelo de comunicación bloqueante (blocking) Modelo de comunicación no bloqueante (non-blocking) MODELOS DE ENVÍO EN MPI BÁSICO (BASIC): dependiente de la implementación CON BUFFER (BUFFERED): una copia del mensaje que se envía se guarda en el buffer SÍNCRONO (SYNCHRONOUS): la operación se da por terminada cuando el mensaje es recibido en el destino LISTO (READY): sólo se puede realizar si antes el receptor está preparado
 Modelo de comunicación no bloqueante (non-blocking) MODELOS DE ENVÍO EN MPI. BÁSICO (BASIC): dependiente de la implementación. CON BUFFER (BUFFERED): una copia del mensaje que se envía se guarda en el buffer. SÍNCRONO (SYNCHRONOUS): la operación se da por terminada cuando el mensaje es recibido en el destino. LISTO (READY): sólo se puede realizar si antes el receptor está preparado.")
16
OPERACIONES COLECTIVAS CON MPI
BARRERAS DE SINCRONIZACIÓN: (MPI_Barrier ()) BROADCAST (DIFUSIÓN): (MPI_Broadcast ())
) BROADCAST (DIFUSIÓN): (MPI_Broadcast ())")
17
GATHER (RECOLECCIÓN): (MPI_Gather ())
SCATTER (DISTRIBUCIÓN): (MPI_Scatter ()) REDUCCIÓN COMUNICACIÓN CON TODOS LOS NODOS: (MPI_Alltoall ())
: (MPI_Scatter ()) REDUCCIÓN. COMUNICACIÓN CON TODOS LOS NODOS: (MPI_Alltoall ())")
18
MODULARIDAD MPI permite definir grupos de procesos. Un grupo de procesos es una colección de procesos, y define un espacio de direcciones (desde 0 hasta el tamaño del grupo menos 1). Un comunicador consiste en un grupo de procesos, y un contexto de comunicación. Entre las funciones más comunes sobre comunicadores podemos encontrar las siguientes: MPI_Comm_size () MPI_Comm_rank () MPI_Comm_dup () MPI_Comm_free () MPI_Comm_split ()
. Un comunicador consiste en un grupo de procesos, y un contexto de comunicación. Entre las funciones más comunes sobre comunicadores podemos encontrar las siguientes: MPI_Comm_size () MPI_Comm_rank () MPI_Comm_dup () MPI_Comm_free () MPI_Comm_split ()")
19
CAPÍTULO 4: PROCESAMIENTO DISTRIBUIDO DE IMÁGENES GENÉRICO CON VTK

20
ARQUITECTURA BÁSICA DE VTK
VTK (Visualization ToolKit) son un conjunto de librerías que se utilizan para la visualización y el procesamiento de imágenes y objetos gráficos 2D y 3D. Constan de código abierto y software orientado a objetos ARQUITECTURA BÁSICA DE VTK VTK consta de dos partes fundamentales: Un núcleo compilado (implementado en C++): Las estructuras de datos, los algoritmos y las funciones de sistema de tiempo crítico están implementadas en el núcleo de C++ Una capa de interpretación generada automáticamente: Mientras el núcleo nos proporciona velocidad y eficiencia, la capa de interpretación nos ofrece flexibilidad y extensibilidad
 son un conjunto de librerías que se utilizan para la visualización y el procesamiento de imágenes y objetos gráficos 2D y 3D. Constan de código abierto y software orientado a objetos. ARQUITECTURA BÁSICA DE VTK. VTK consta de dos partes fundamentales: Un núcleo compilado (implementado en C++): Las estructuras de datos, los algoritmos y las funciones de sistema de tiempo crítico están implementadas en el núcleo de C++ Una capa de interpretación generada automáticamente: Mientras el núcleo nos proporciona velocidad y eficiencia, la capa de interpretación nos ofrece flexibilidad y extensibilidad.")
21
SUBSISTEMAS DE VTK VTK está constituido por dos grandes subsistemas: Graphics Model y Visualization Model GRAPHICS MODEL El graphics model forma una capa abstracta por encima del lenguaje de los gráficos (por ejemplo, OpenGL) para asegurar la portabilidad entre las diferentes plataformas. Los conceptos de gráficos abstractos y capas independientes de los dispositivos crearon el modelo gráfico. Los objetos principales que componen el Graphics Model son: vtkActor, vtkActor2D, vtkVolume vtkLight vtkCamera vtkProperty, vtkProperty2D vtkMapper, vtkMapper2D vtkTransform vtkLookupTable, vtkColorTransferFunction vtkRenderer vtkRenderWindow vtkRenderWindowInteractor
 para asegurar la portabilidad entre las diferentes plataformas. Los conceptos de gráficos abstractos y capas independientes de los dispositivos crearon el modelo gráfico. Los objetos principales que componen el Graphics Model son: vtkActor, vtkActor2D, vtkVolume. vtkLight. vtkCamera. vtkProperty, vtkProperty2D. vtkMapper, vtkMapper2D. vtkTransform. vtkLookupTable, vtkColorTransferFunction. vtkRenderer. vtkRenderWindow. vtkRenderWindowInteractor.")
22
VISUALIZATION MODEL: El pipeline de procesamiento de datos de VTK transforma los datos de forma que puedan ser visualizados en los subsistemas gráficos descritos con anterioridad. El modelo Visualization Model es el encargado de construir la representación geométrica que será renderizada por el pipeline gráfico. Los objetos principales que componen el Visualization Model son los siguientes: vtkDataObject: Los “data objects” representan datos de varios tipos. La clase vtkDataObject puede interpretarse como un conjunto genérico de datos. A los datos que tienen una estructura formal se les llama “dataset” (de la clase vtkDataSet). vtkProcessObject: Los “process objects”, también llamados filtros, operan en los data objects para generar nuevos data objects. Representan los algoritmos del sistema. Process y data objects se conectan para formar los pipelines de visualización.
. vtkProcessObject: Los process objects , también llamados filtros, operan en los data objects para generar nuevos data objects. Representan los algoritmos del sistema. Process y data objects se conectan para formar los pipelines de visualización.")
23
Objetos dataset en VTK

24
PROCESAMIENTO DE LAS IMÁGENES CON VTK
VTK tiene un extenso número de métodos para el procesamiento de imágenes y renderización de volúmenes. Los datos de imágenes 2D y 3D vienen dados por la clase vtkImageData. En un dataset de imagen los datos son ordenados en un vector regular alineado con los ejes. Mapas de bits y mapas de píxeles son ejemplos de datasets de imágenes 2D, y volúmenes (pilas de imágenes 2D) lo son de datasets de imágenes 3D. Los process objects en un pipeline de imagen siempre tienen como entradas y salidas data objects de imagen. Debido a la naturaleza regular y simple de los datos, el pipeline de imagen tiene otros rasgos importantes. La renderización de volumen se usa para visualizar objetos 3D de la clase vtkImageData, y visores especiales de imágenes se usan para ver objetos 2D. Los filtros detectan de forma automática el número disponible de procesos en el sistema y crean el mismo número de uniones durante la ejecución; igualmente separan automáticamente los datos en partes que fluyen a través del pipeline.
 lo son de datasets de imágenes 3D. Los process objects en un pipeline de imagen siempre tienen como entradas y salidas data objects de imagen. Debido a la naturaleza regular y simple de los datos, el pipeline de imagen tiene otros rasgos importantes. La renderización de volumen se usa para visualizar objetos 3D de la clase vtkImageData, y visores especiales de imágenes se usan para ver objetos 2D. Los filtros detectan de forma automática el número disponible de procesos en el sistema y crean el mismo número de uniones durante la ejecución; igualmente separan automáticamente los datos en partes que fluyen a través del pipeline.")
25
CREACIÓN DE UNA APLICACIÓN GRÁFICA CON VTK
Los pasos a seguir para crear una aplicación gráfica con VTK son: Construcción de un pipeline de datos para procesar los datos: es decir, conectar fuentes (crear datos), filtros (procesar datos) y mappers (transformar datos en gráficos). Creamos los objetos gráficos necesarios para poder interpretar estos datos. Los pasos para crear estos objetos gráficos son: Crear una ventana de renderización Crear un render Crear un interactor Crear uno o más actores Renderizar
, filtros (procesar datos) y mappers (transformar datos en gráficos). Creamos los objetos gráficos necesarios para poder interpretar estos datos. Los pasos para crear estos objetos gráficos son: Crear una ventana de renderización. Crear un render. Crear un interactor. Crear uno o más actores. Renderizar.")
26
UTILIZACIÓN DE VTK CON MPI
VTK dispone de una serie de clases preparadas para su aplicación en el procesamiento en paralelo. Estas clases hacen uso de la librería MPI. Entre las más destacadas se encuentran las siguientes: vtkMPIController vtkMPIEventLog vtkMPICommunicator vtkMultiProcessController vtkMPIGroup El uso de comunicadores definidos por el usuario se realiza a través de vtkMPICommunicator y vtkMPIGroup. Las funciones que más se utilizan de esta clase son las siguientes: Inicialize (int *argc, char ***argv) GetNumberOfProcesses () GetLocalProcessId () Finalize ()
 GetNumberOfProcesses () GetLocalProcessId () Finalize ()")
27
Un ejemplo de la visualización lograda a través del empleo de VTK

28
CAPÍTULO 5: PROCESAMIENTO DISTRIBUIDO DE IMÁGENES GENÉRICO CON MATLAB

29
MATLAB MPI MATLAB es el lenguaje de programación predominante y más extendido para la implementación de cómputos numéricos, desarrollo e implementación de algoritmos, simulación, reducción de datos, comprobación y evaluación de sistemas. MATLAB MPI es una implementación para MATLAB de MPI que permite que cualquier programa creado bajo MATLAB pueda ser ejecutado en múltiples procesadores. Consiste en un conjunto de instrucciones de MATLAB que implementan un subconjunto de MPI, permitiendo que cualquier programa de MATLAB pueda ser ejecutado en una computadora paralela.

30
CARÁCTERÍSTICAS DE MATLAB MPI REQUISITOS DEL SISTEMA
Implementación extremadamente compacta (aproximadamente 100 líneas de código). Implementación muy pura. La implementación funcionará en cualquier punto en donde MATLAB también funcione. MATLAB MPI puede igualar el ancho de banda de comunicación del lenguaje C basado en MPI en el envío de mensajes de gran tamaño. REQUISITOS DEL SISTEMA Sistemas de memoria compartida: una única licencia de MATLAB Sistemas de memoria distribuida: una licencia de MATLAB por máquina
. Implementación muy pura. La implementación funcionará en cualquier punto en donde MATLAB también funcione. MATLAB MPI puede igualar el ancho de banda de comunicación del lenguaje C. basado en MPI en el envío de mensajes de gran tamaño. REQUISITOS DEL SISTEMA. Sistemas de memoria compartida: una única licencia de MATLAB. Sistemas de memoria distribuida: una licencia de MATLAB por máquina.")
31
PROGRAMA EJEMPLO DE INTERCAMBIO DE MENSAJES A TRAVÉS DE MATLABMPI
MPI_Init; % Inicia MPI. comm = MPI_COMM_WORLD; % Crea el comunicador comm_size = MPI_Comm_size(comm); % Nº procesadores my_rank = MPI_Comm_rank(comm); % Rango procesador source = 0; % Identifica la fuente dest = 1; % Identifica el destino tag = 1; % Etiqueta del mensaje if(comm_size == 2) % Check nº procesadores if (my_rank == source) % Si source data = 1:10; % Crea dato a enviar MPI_Send(dest,tag,comm,data); % Envía dato end if (my_rank == dest) % Si destino. data=MPI_Recv(source,tag,comm); % Recive dato MPI_Finalize; % Finaliza MatlabMPI. exit; % Sale de Matlab
; % Nº procesadores. my_rank = MPI_Comm_rank(comm); % Rango procesador. source = 0; % Identifica la fuente. dest = 1; % Identifica el destino. tag = 1; % Etiqueta del mensaje. if(comm_size == 2) % Check nº procesadores. if (my_rank == source) % Si source. data = 1:10; % Crea dato a enviar. MPI_Send(dest,tag,comm,data); % Envía dato. end. if (my_rank == dest) % Si destino. data=MPI_Recv(source,tag,comm); % Recive dato. MPI_Finalize; % Finaliza MatlabMPI. exit; % Sale de Matlab.")
32
ANCHO DE BANDA Y RESULTADO DE LAS PRUEBAS REALIZADAS
Ancho de banda. Ancho de banda en función del tamaño del mensaje probado en el SGI ORIGIN MATLAB MPI iguala la implementación en lenguaje C en mensajes de gran tamaño.

33
Ancho de banda en un cluster de LINUX.
velocidad de la memoria paralela compartida velocidad paralela compartida/distribuida

34
Productividad vs rendimiento
Productividad vs rendimiento. Las línea de código como función del máximo rendimiento alcanzado (medido en unidades de pico de procesador) para diferentes implementaciones para la misma aplicación de filtrado de imagen
 para diferentes implementaciones para la misma aplicación de filtrado de imagen.")
35
Futura arquitectura en forma de capas: diseño de unas herramientas paralelas de Matlab las cuales crearán una estructura de datos distribuida y objetos dataflow construidos en la cima de MatlabMPI

36
CAPÍTULO 6: PROCESAMIENTO DISTRIBUIDO DE IMÁGENES GENÉRICO CON PARAVIEW

37
CARACTERÍSTICAS GENERALES DE PARAVIEW
ParaView es una aplicación que se utiliza para visualizar datos en 2D o 3D. Puede ser utilizada en un solo puesto de trabajo o también en un cluster de ordenadores, lo que permite a ParaView ejecutar grandes cadenas de datos mediante la utilización de procesamiento distribuido. CARACTERÍSTICAS GENERALES DE PARAVIEW Es una aplicación de visualización multiplataforma de libre distribución. Soporta procesamiento distribuido para procesar grandes cantidades de datos. Dispone de una flexible e intuitiva interfaz de usuario. Desarrolla una extensible arquitectura basada en estándares abiertos.

38
FICHEROS SOPORTADOS POR PARAVIEW
OBJETIVO DE PARAVIEW El objetivo de ParaView es desarrollar una herramienta paralela escalable que realice procesamiento distribuido de memoria FICHEROS SOPORTADOS POR PARAVIEW ParaView Files, VTK Files Parallel VTK files Legacy VTK Files Parallel legacy VTK EnSight Files PLOT3D Files Stereo Lithography BYU Files POP Ocean Files Protein Data Bank Files Xmol Files XDMF Files

39
TIPOS DE DATOS ADMITIDOS POR PARAVIEW

40
COMANDOS DE PARAVIEW Distinguiremos cuatro categorías: General Paralelo start-empty, -e use-rendering-group, -p disable-registry, -dr group-file, -gf play-demo, -pd use-tiled-display, -td batch, -b tile-dimensions-x, -tdx Stereo tile-dimensions-y, -tdy use-offscreen-rendering, -os render-module help Client/Server Mesa client, -c use-software-rendering, -r server, -v use-satellite-software, -s host

41
C:\temp\mpirun –np 4 –localroot C:\ParaView\bin\debug\ParaView
PARAVIEW CON MPI Para lanzar ParaView en paralelo con MPI hay que realizarlo de igual modo que cualquier otra aplicación MPI, es decir, en la línea de comandos habrá que poner algo como: C:\temp\mpirun –np 4 –localroot C:\ParaView\bin\debug\ParaView Una vez realizado lo anterior se abrirá la pantalla de ParaView (solo en el nodo raíz) y podremos realizar las operaciones que queramos interactuando con los menús.
 y podremos realizar las operaciones que queramos interactuando con los menús.")
42
CAPÍTULO 7: RENDERIZACIÓN DE UNA NEURONA

43
RENDERIZACIÓN Denominamos Renderización al proceso mediante el cual una estructura poligonal (tridimensional) digital más o menos básica obtiene una definición mucho mayor con juegos de luces, texturas y acentuado y mejorado de los polígonos, simulando ambientes y estructuras físicas. Algunos métodos de Render son: Wireframe: es un algoritmo de renderización del que resulta una imagen semitransparente. Sólido: es un algoritmo de renderización algo más complejo que el Wireframe. Sombreado Goraud: interpola los valores de iluminación en los vértices del polígono teniendo en cuenta la superficie curva mediante la malla. Sombreado Phong: se caracteriza por crear precisos brillos especulares. A cada píxel se le da un color basado en el modelo de iluminación aplicado al punto. Radiosidad: En este algoritmo calculamos las interacciones entre la luz y el color de los objetos más o menos próximos.
 digital más o menos básica obtiene una definición mucho mayor con juegos de luces, texturas y acentuado y mejorado de los polígonos, simulando ambientes y estructuras físicas. Algunos métodos de Render son: Wireframe: es un algoritmo de renderización del que resulta una imagen semitransparente. Sólido: es un algoritmo de renderización algo más complejo que el Wireframe. Sombreado Goraud: interpola los valores de iluminación en los vértices del polígono teniendo en cuenta la superficie curva mediante la malla. Sombreado Phong: se caracteriza por crear precisos brillos especulares. A cada píxel se le da un color basado en el modelo de iluminación aplicado al punto. Radiosidad: En este algoritmo calculamos las interacciones entre la luz y el color de los objetos más o menos próximos.")
44
PARALELISMO EN EL PROCESO DE RENDERIZACIÓN
Existen diferentes tipos de paralelismo aplicables al proceso de renderización; entre ellos destacan por su importancia: El paralelismo Funcional: Consiste en dividir el proceso de renderización en una serie de etapas que pueden aplicarse de forma sucesiva a un conjunto de datos. El paralelismo de Datos: En lugar de aplicarse una secuencia de operaciones consecutivas a un único flujo de datos, existe la posibilidad de dividir los datos en múltiples flujos y operar con ellos en unidades de procesamiento independientes. El paralelismo Temporal: En este caso el paralelismo puede obtenerse de forma casi inmediata dividiendo el número de imágenes entre los procesadores disponibles, de modo que la unidad de trabajo sea una imagen completa. Métodos híbridos: Es posible integrar varias formas de paralelismo en un mismo sistema.

45
CONCEPTOS ALGORÍTMICOS
La mayor parte de algoritmos paralelos introducen una serie de sobrecargas que no están presentes en sus equivalentes secuenciales. Las causas de dichas sobrecargas pueden ser las siguientes: Comunicación entre procesos Desvíos en el balanceo de la carga Computación redundante Mayor espacio de almacenamiento requerido, debido a estructuras de datos replicadas o auxiliares.

46
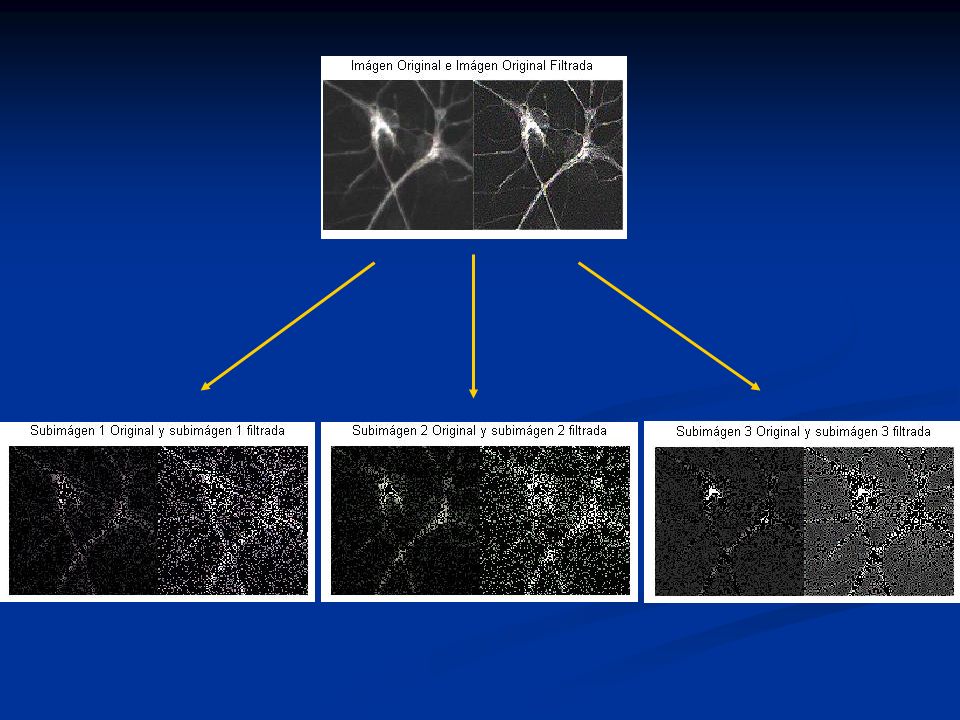
RENDERIZACIÓN DE UNA NEURONA
Partimos del código fuente AbrirPic.m. A través de este script lo que hacemos es abrir la imagen de una neurona segmentada en 76 rodajas (slices), con el nombre NUEVO1.PIC. A continuación reducimos las dimensiones de la imagen original (512 x 512 x 3), para reducir el tiempo computacional (128 x 128x 3). A continuación dividimos la imagen abierta en tres subimágenes distintas para llevar a cabo la renderización por separado de cada una de las subimágenes. Una vez realizada la segmentación seleccionamos el algoritmo de filtrado a utilizar (Average, Disk, Gaussian, Motion, Prewitt, Sobel, Unsharp). Después realizamos la visualización conjunta de la imagen y subimágenes originales y de la imagen y subimágenes filtradas. A continuación realizamos la reconstrucción 3D de la imagen filtrada y de las subimágenes.
, con el nombre NUEVO1.PIC. A continuación reducimos las dimensiones de la imagen original (512 x 512 x 3), para reducir el tiempo computacional (128 x 128x 3). A continuación dividimos la imagen abierta en tres subimágenes distintas para llevar a cabo la renderización por separado de cada una de las subimágenes. Una vez realizada la segmentación seleccionamos el algoritmo de filtrado a utilizar (Average, Disk, Gaussian, Motion, Prewitt, Sobel, Unsharp). Después realizamos la visualización conjunta de la imagen y subimágenes originales y de la imagen y subimágenes filtradas. A continuación realizamos la reconstrucción 3D de la imagen filtrada y de las subimágenes.")
48
reconstrucción 3D de la imagen

49
CAPÍTULO 8: PROCESAMIENTO DISTRIBUIDO CON C++

50
INTRODUCCIÓN A C++ El lenguaje C++ proviene del lenguaje C. El lenguaje C nació en los laboratorios Bell de AT&T en los años 70. Su eficiencia y claridad, y la posibilidad de realizar tanto acciones de bajo como de alto nivel han hecho de este lenguaje el principal tanto en el mundo del desarrollo de sistemas operativos como de aplicaciones tanto industriales como de ofimática. Dentro de esta estandarización se incluye un conjunto de clases, algoritmos y plantillas que constituyen la librería estandar de C++. Esta librería introduce facilidades para manejar las entradas y salidas del programa, para la gestión de listas, pilas, colas, vectores, para tareas de búsqueda y ordenación de elementos, para el manejo de operaciones matemáticas complejas, gestión de cadenas de caracteres, tipos de datos genéricos, etc. A este conjunto de algoritmos, contenedores y plantillas, se los denomina habitualmente por las siglas STL (Standard Template Library).
.")
51
ESTÁNDARES PARA LA PROGRAMACIÓN PARALELA EN C++
El lenguaje C++ no incluye ninguna primitiva para poder realizar la implementación de aplicaciones paralelas. No existe ninguna manera a través del lenguaje C++ para especificar que dos o más instrucciones deberían ser ejecutadas de forma paralela. Para poder llevar a cabo la implementación de capacidades paralelas en C++, debemos recurrir a estándares externos que suplen esta función. Los tres estándares que vamos a estudiar van a ser: El estándar MPI El estándar PVM El estándar CORBA

52
EL ESTÁNDAR MPI MPI es la implementación estándar para llevar a cabo la comunicación basándose en el intercambio de mensajes. MPI fue desarrollado para su ejecución tanto en máquinas paralelas como en clusters de estaciones de trabajo. Para trabajar con MPI utilizamos la implementación MPICH. MPICH es una implementación de MPI libre y portable. MPICH proporciona al programador de C++ un conjunto de APIs y librerías que soportan programación paralela. MPI es especialmente útil para la programación SPMD (Single Program Multiple Data) y MPMD (Multiple Program Multiple Data).
 y MPMD (Multiple Program Multiple Data).")
53
EL ESTÁNDAR PVM PVM significa “Parallel Virtual Machine”. Es un software que permite ejecutar aplicaciones paralelas distribuidas en redes de ordenadores heterogéneos. PVM es un paquete de software que permite a una colección heterogénea de computadoras conectarse mutuamente a través de una red para ser utilizadas como una gran computadora paralela. El objetivo de un sistema PVM es permitir que una colección de computadoras puedan ser utilizadas para la computación paralela. PVM es, junto con MPI, uno de los paquetes de software más utilizados para implementar aplicaciones paralelas. La librería PVM es especialmente útil para sistemas de varios procesadores que pueden ser conectados juntos para formal un procesador virtual paralelo.

54
PVM soporta: Heterogeneidad en términos de máquinas, redes y aplicaciones Modelos de pase de mensajes explícitos Computación basada en procesos Soporte multiprocesador (MPP, SMP) Acceso al hardware: las aplicaciones bien pueden ignorar o aprovechar las diferencias entre el hardware Lista de host configurable dinámicamente: los procesadores pueden ser añadidos o eliminados y se pueden incluir procesadores mixtos
 Acceso al hardware: las aplicaciones bien pueden ignorar o aprovechar las diferencias entre el hardware. Lista de host configurable dinámicamente: los procesadores pueden ser añadidos o eliminados y se pueden incluir procesadores mixtos.")
55
Esquemas Maestro-Esclavo
Un programa paralelo en PVM, generalmente, constará de un proceso maestro y varios procesos esclavos, realizando cada esclavo una parte del trabajo global. Esquemas Maestro-Esclavo

56
VENTAJAS Y DESVENTAJAS DEL USO DE PVM
Algunas de las ventajas que presenta la utilización de PVM son: Fiabilidad Reduce el "wall clock execution time" Fácil instalación y uso Extensión Flexibilidad Tolerancia a fallos Precio Heterogeneidad Disponibilidad Las desventajas que presenta la utilización de PVM son, principalmente: El paralelismo fuertemente acoplado La abstracción de la máquina virtual, la independencia del hardware y la independencia de la codificación tienen un coste

57
FUNCIONES DE PVM Funciones de Control de Procesos. Funciones de Información. Funciones de Configuración de grupos. Funciones de Empaquetamiento de datos y control de Buffers. Funciones de Envío de Mensajes. Funciones de Recepción de mensajes.

58
EL ESTÁNDAR CORBA En computación, Common Object Request Broker Architecture (CORBA) es un estándar que establece una plataforma de desarrollo de sistemas distribuidos facilitando la invocación de métodos remotos bajo un paradigma orientado a objetos. CORBA utiliza un lenguaje de definición de interfaces (IDL) para especificar los interfaces con los servicios que los objetos ofrecerán. CORBA puede especificar a partir de este IDL la interfaz a un lenguaje determinado, describiendo cómo los tipos de dato CORBA deben ser utilizados en las implementaciones del cliente y del servidor. Implementaciones estándar existen para Ada, C, C++, Smalltalk, Java y Python. Hay también implementaciones para Perl y TCL.
 es un estándar que establece una plataforma de desarrollo de sistemas distribuidos facilitando la invocación de métodos remotos bajo un paradigma orientado a objetos. CORBA utiliza un lenguaje de definición de interfaces (IDL) para especificar los interfaces con los servicios que los objetos ofrecerán. CORBA puede especificar a partir de este IDL la interfaz a un lenguaje determinado, describiendo cómo los tipos de dato CORBA deben ser utilizados en las implementaciones del cliente y del servidor. Implementaciones estándar existen para Ada, C, C++, Smalltalk, Java y Python. Hay también implementaciones para Perl y TCL.")
59
CORBA se encarga habitualmente de los siguientes aspectos en los sistemas distribuidos:
Registro de objetos Localización de objetos Activación de objetos Gestión de errores Multiplexación y desultiplexación de invocaciones Aplanado y desaplanado de datos

60
Los tipos de componentes de los que consta CORBA son, generalmente:
Objects Services Common Facilities Domain Interfaces Application Interfaces

61
Descripción de la arquitectura CORBA

62
Descripción de interfaces y objetos

63
Estructura cliente de CORBA
Estructura servidor de CORBA

64
CAPÍTULO 9: CONCLUSIONES Y LÍNEAS DE MEJORA

65
CONCLUSIONES SOBRE MPI
Gracias a MPI conseguimos portabilidad, proveyendo una librería de paso de mensajes estándar independiente de la plataforma y de dominio público. La especificación de esta librería está en una forma independiente del lenguaje y proporciona funciones para ser usadas con C, C++ y Fortran. Abstrae los sistemas operativos y el hardware. El usuario en MPI tiene que crear la máquina virtual decidiendo qué nodos del cluster usar para poner en funcionamiento sus aplicaciones cada vez que las arranca. La implementación del cluster es sencilla, pero resulta conveniente que todos los nodos que lo forman sean similares en cuanto a potencia y prestaciones, para facilitar la función de paralelización de los programas.

66
MPI CON VTK Y PARAVIEW VTK (Visualization Toolkit) son un conjunto de librerías destinadas a la visualización y el procesado de imágenes. Incluyen código abierto y software orientado a objetos. Son muy amplias y complejas, pero aún así, están diseñadas para ser sencillas de usar con cualquier lenguaje de programación orientado a objetos, como son C++, Java, Tcl, etc. Paraview es una aplicación que se utiliza para visualizar datos en dos o tres dimensiones. Esta aplicación puede ser utilizada en un solo puesto de trabajo o también en un cluster de ordenadores. Esto último permite a paraview ejecutar grandes cadenas de datos mediante la utilización de procesamiento distribuido.
 son un conjunto de librerías destinadas a la visualización y el procesado de imágenes. Incluyen código abierto y software orientado a objetos. Son muy amplias y complejas, pero aún así, están diseñadas para ser sencillas de usar con cualquier lenguaje de programación orientado a objetos, como son C++, Java, Tcl, etc. Paraview es una aplicación que se utiliza para visualizar datos en dos o tres dimensiones. Esta aplicación puede ser utilizada en un solo puesto de trabajo o también en un cluster de ordenadores. Esto último permite a paraview ejecutar grandes cadenas de datos mediante la utilización de procesamiento distribuido.")
67
PROCESAMIENTO DISTRIBUIDO CON MATLAB
MatlabMPI es una implementación para Matlab de MPI (Message Passing Interface) que permite que cualquier programa creado bajo Matlab pueda ser ejecutado en múltiples procesadores. MatlabMPI consiste en un conjunto de instrucciones de Matlab que implementan un subconjunto de MPI, permitiendo que cualquier programa de Matlab pueda ser ejecutado en una computadora paralela. Además, MatlabMPI podrá ejecutarse en cualquier sistema de computadoras que soporten Matlab. La simplicidad y funcionalidad de MATLAB MPI lo hace una elección muy aconsejable para programadores que quieran acelerar sus códigos MATLAB en computadoras paralelas. El trabajo para el futuro será el de crear objetos de mayor rango (como, por ejemplo, matrices distribuidas). El resultado será la construcción de una capa de comunicaciones dentro de MATLAB MPI, que permita a un usuario lograr un aceptable desarrollo paralelo sin un aumento de las líneas de código.
 que permite que cualquier programa creado bajo Matlab pueda ser ejecutado en múltiples procesadores. MatlabMPI consiste en un conjunto de instrucciones de Matlab que implementan un subconjunto de MPI, permitiendo que cualquier programa de Matlab pueda ser ejecutado en una computadora paralela. Además, MatlabMPI podrá ejecutarse en cualquier sistema de computadoras que soporten Matlab. La simplicidad y funcionalidad de MATLAB MPI lo hace una elección muy aconsejable para programadores que quieran acelerar sus códigos MATLAB en computadoras paralelas. El trabajo para el futuro será el de crear objetos de mayor rango (como, por ejemplo, matrices distribuidas). El resultado será la construcción de una capa de comunicaciones dentro de MATLAB MPI, que permita a un usuario lograr un aceptable desarrollo paralelo sin un aumento de las líneas de código.")
68
PROCESAMIENTO DISTRIBUIDO CON C++
En este capítulo hemos visto una visión aproximada de tres de las implementaciones existentes para implementar el procesamiento distribuido en C++: MPI, PVM y CORBA. La implementación con MPI está más desarrollada. Sin embargo, las otras dos implementaciones existentes, PVM y CORBA, no son tan conocidas y desarrolladas. Faltaría como conclusión el desarrollo más en profundidad de estas implementaciones, así como el desarrollo de diversos ejemplos.

69
LÍNEAS DE MEJORA Realización e implementación de un cluster basado en el sistema operativo Linux. Utilización de otra implementación de MPI como puede ser LAM-MPI. Profundizar más en la utilización de MPI con Matlab, en especial en lo que se refiere a la hora del envío de datos entre procesadores, en especial de realización e implementación de un cluster basado en el sistema operativo Linux. Profundizar más en la utilización de MPI con Matlab, en especial en lo que se refiere a la hora del envío de datos entre procesadores, en especial de

70
FIN

Presentaciones similares

 clasificación:>")











>")
.>")




