Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Propuesta de Investigación Grupo Data Mining- KDDPeru2005 Curso-Taller Investigación en Inteligencia Artificial MODELO DIFUSO DE LAS PREFERENCIAS DE CLIENTES DE UNA BASE DE DATOS: APLICACIÓN A LA SELECCIÓN DEL OBJETIVO EN MARKETING DIRECTO 23 Julio 2005

2
Responsables Iván Aquino Morales –Estudiante de Ing. de Sistemas-UNI –6to ciclo –i.aquino@computer.orgi.aquino@computer.org Karina Chávez Cuzcano –Estudiante de Ing. De Sistemas –6to ciclo –karinajcc@ieee.orgkarinajcc@ieee.org Cesar Pérez Pinche –Estudiante de Ing. de Sistemas-UNI –6to ciclo –cesaruni24@yahoo.com.mxcesaruni24@yahoo.com.mx

3
PROPUESTA DE LA INVESTIGACIÓN

4
Título MODELO DIFUSO DE LAS PREFERENCIAS DE CLIENTES DE UNA BASE DE DATOS: APLICACIÓN A LA SELECCIÓN DEL OBJETIVO EN MARKETING DIRECTO

5
Problema ¿Hacia que clientes debemos dirigir una campaña de Marketing directo relacionado a un producto? ¿Qué productos ofrecer a cada cliente? ¿Cómo reducir costos en campañas de marketing sin provocar disminución en las ventas ?

6
Objetivo GENERAL Elaborar un Sistema Difuso de Selección Objetivo para mejorar la eficiencia, en ventas, de una campaña de Marketing Directo. ESPECIFICOS –Determinar la Data a ser usada por el Modelo propuesto. –Determinar las características influyentes en la clasificación de los clientes (respondedores positivos, no respondedores). –Determinar las reglas para la selección de clientes a quienes será dirigida una campaña de marketing.
. –Determinar las reglas para la selección de clientes a quienes será dirigida una campaña de marketing..")
8
DISEÑO DEL EXPERIMENTO

9
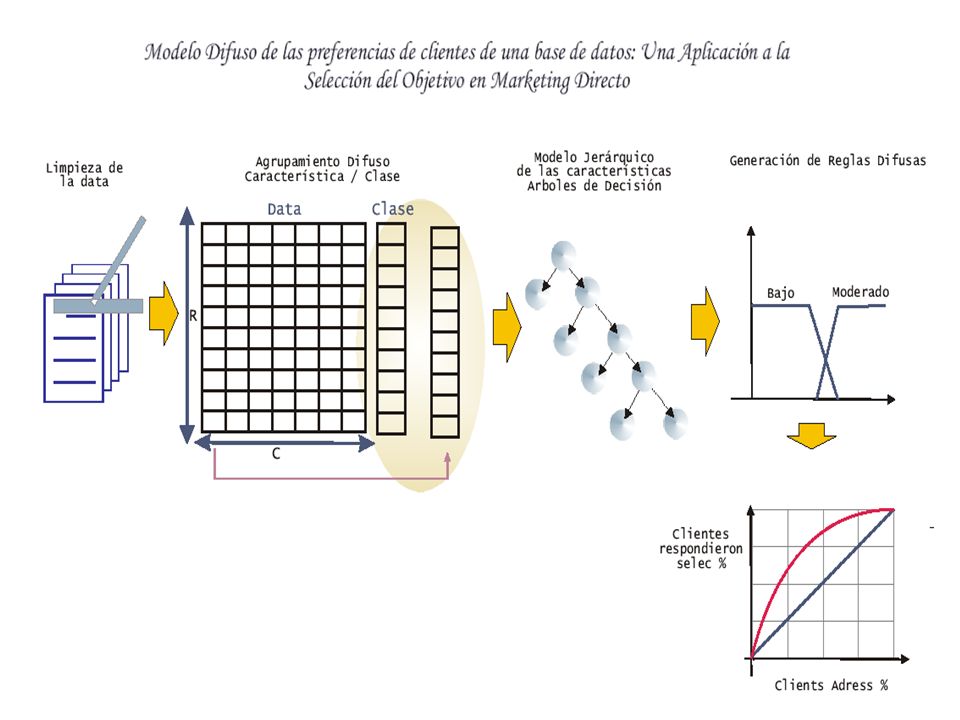
Diseño del Experimento Se limpia la Data, eliminando valores nulos. –Esto se hace mediante la el método de Conjuntos Difusos.

10
Diseño del Experimento Se realiza el agrupamiento difuso por cada característica de la data –Esto se hace mediante el algoritmo del Fuzzy c-means extendido

11
Diseño del Experimento Se realiza un modelo jerárquico de las características –Esto se hace mediante un árbol de decisión, con la características mas relevante en la raiz, y la menos relevante en el ultimo nodo

12
Diseño del Experimento Se determina las reglas lingüísticas difusas para selección de clientes objetivos teniendo como entrada los clusters. –Esto se hace mediante un motor de inferencia difuso La eficiencia del Modelo se determina mediante gain-charts.

13
Hipótesis Ho.La eficiencia, en ventas, de una campaña de Marketing aumenta con el uso de un Modelo Difuso sobre un modelo estadístico.

14
Antecedentes David J. Stracuzzi y Paul E.Utgoff (2004), Desarrollaron modelo para la selección de características relevantes a un determinado proceso de aprendizaje usando una red neuronal perceptron. Huan Liu (2005), propuso un avance de un metalgoritmo para la elección de algoritmos de selección de características de acuerdo al modelo que se quiere ajustar la data.
, Desarrollaron modelo para la selección de características relevantes a un determinado proceso de aprendizaje usando una red neuronal perceptron. Huan Liu (2005), propuso un avance de un metalgoritmo para la elección de algoritmos de selección de características de acuerdo al modelo que se quiere ajustar la data..")
15
ANÁLISIS DE FACTIBILIDAD

16
Fuente de Datos La data a usar es del KDDCUP98 obtenida de Internet; –La data es de una organización sin fines de lucro cuyo fin es la ayuda a los americanos con enfermedades de parálisis o problemas de la medula ósea. –La data posee una columna TARGET_B que vale 1 si es que el cliente respondió a la campaña de mail, y 0 si no.

17
Recursos Tiempo. –Dedicación de 3 horas diarias (7:00 PM – 10:00 PM) Bibliografía. –Se requiere acceso a la BD de la IEEE, ACM. Ingles. –Lectura de textos en ingles al 95% Equipos. –Se requiere 3 PC Pentium IV, en todo momento. –Internet. –Se requiere acceso a Internet en todo momento. Herramientas de Software. –Se requiere MatLab, Látex, Clementine, SPSS, Java. Conocimientos. –Análisis de Cluster difusos, Árboles de decisión, K-fold, Diseño experimentos, Sistemas de inferencia Difuso.

18
Plan de Trabajo S1 3 S4 6 S7 9 S10 12 S13 15 S16 18 S19 21 S21 23 S25 27 Revisión Bibliográfica Preparación del Plan de Trabajo Limpieza de la data Diseño del modelo de solución Diseño del prototipo Pruebas y Corridas Análisis de los resultados Redacción del documento final

19
MARCO TEORICO

20
Análisis de Grupos Difusos El agrupamiento de datos de manera difusa se basa en la teoría de conjuntos difusos. Esta teoría plantea que un objeto puede pertenecer a una clase con un determinado grado de pertenencia. Permite construir reglas lingüísticas comprensibles por el experto. Las reglas de inferencia difusa se construyen a partir de conjuntos difusos. La teoría de conjuntos difusos maneja un mayor grado de abstracción de la realidad.

21
Conjuntos Difusos Es aquel conjunto cuyos elementos pueden pertenecer total o parcialmente a el.

22
CONCLUSIONES Y BIBLIOGRAFIA

23
Conclusiones Se pretende desarrollar un experimento para determinar la eficiencia del Modelo Difuso de Selección del Objetivo en Marketing Directo. Se pretende comparar los resultados con resultados arrojados por herramientas estadísticas como el Chaid

24
Bibliografía [1] M. Setnes and U. Kaymak. Fuzzy modeling of client preference from large data sets: An application to target selection in direct marketing. IEEE Transactions on Fuzzy Systems, 2001; 153(1). [2] Lucio Soibelman, Hyunjoo Kim. Data Preparation Process for Construccion Knowledge Generation through Knowdledge Discovery in DataBases Journal of Computing in Civil Engineering January 2002 ; 40(3). 3 Feature Selection for Unsupervised Learning, Technical Report for the Northeastern University, Jennifer G.Dy, Carla E. Brodley 4 H. Liu and R. Setiono, "Feature Selection and Classification-A Probabilistic Wrapper Approach," Proc. Ninth Int'l Conf. Industrial and Eng. Applications of AI and ES, T. Tanaka, S. Ohsuga, and M. Ali, eds., pp. 419-424, 1996. [5] K.S. Ng and H. Liu, "Customer Retention via Data Mining," AI Rev., vol. 14, no. 6, pp. 569-590, 2000. [6] "Adaptive Intrusión Detection. A data Mining Approach". AI rev, vol 14, no. 6, pp. 533-567, 2000. [7] "Feature Selection for High-Dimensional Genomic Microarray Data". Proc 15th Int'l Conf. Machina Learning, pp.601- 608, 2001. [8] "Redundancy Bases Feature Selection for Microarray Data". Proc. 10th ACM SIGKDD Conf. Knowledge Discovery and Data Mining, 2004. [9] "Text Classification from Labeled data and Unlabeled Documents using EM", Machine Learning, vol. 39, 103-134, 2000. [10] "Efficient Content-Based Image Retrieval Using Automatic Feature Selection". IEEE Int'l Symp. Computer Vision, pp. 85-90, 1995. [11] Y. Rui, T.S. Huang, and S. Chang, "Image Retrieval: Current Techniques, Promising Directions and Open Issues," Visual Comm. and Image Representation, vol. 10, no. 4, pp. 39-62, 1999. [12] N.Wyse, R. Dubes, and A. K. Jain. A critical evaluation of intrinsec dimensionality algorithms, In E.Gelsema and L.N.Kanal, editors, Pattern Recognition, pages 415-425. Morgan Kaufmann, 1980 [13] Huan Liu, Lei Yu, Toward Integrating Feature Selection Algoritms for Classification and Clustering IEEE Transactions on Knowledge and Data Engeneering Vol 17, No 4, April 2005. [14] H.Liu and H.Motorola, Feature Selection for Knowledge Discovery and Data Mining. Boston: Kluwer Academy, 1998. [15] David J. Stracuzzi, Paul E. Utgoff, Randomized Variable Elimination, Journal of Machine Learning Research 5 (2004) 1331–1362
![Bibliografía [1] M. Setnes and U. Kaymak.](http://images.slideplayer.es/1/92211/slides/slide_24.jpg "Fuzzy modeling of client preference from large data sets: An application to target selection in direct marketing. IEEE Transactions on Fuzzy Systems, 2001; 153(1). [2] Lucio Soibelman, Hyunjoo Kim. Data Preparation Process for Construccion Knowledge Generation through Knowdledge Discovery in DataBases Journal of Computing in Civil Engineering January 2002 ; 40(3). 3 Feature Selection for Unsupervised Learning, Technical Report for the Northeastern University, Jennifer G.Dy, Carla E. Brodley 4 H. Liu and R. Setiono, Feature Selection and Classification-A Probabilistic Wrapper Approach, Proc. Ninth Int l Conf. Industrial and Eng. Applications of AI and ES, T. Tanaka, S. Ohsuga, and M. Ali, eds., pp , [5] K.S. Ng and H. Liu, Customer Retention via Data Mining, AI Rev., vol. 14, no. 6, pp , [6] Adaptive Intrusión Detection. A data Mining Approach . AI rev, vol 14, no. 6, pp , [7] Feature Selection for High-Dimensional Genomic Microarray Data . Proc 15th Int l Conf. Machina Learning, pp , [8] Redundancy Bases Feature Selection for Microarray Data . Proc. 10th ACM SIGKDD Conf. Knowledge Discovery and Data Mining, [9] Text Classification from Labeled data and Unlabeled Documents using EM , Machine Learning, vol. 39, , [10] Efficient Content-Based Image Retrieval Using Automatic Feature Selection . IEEE Int l Symp. Computer Vision, pp , [11] Y. Rui, T.S. Huang, and S. Chang, Image Retrieval: Current Techniques, Promising Directions and Open Issues, Visual Comm. and Image Representation, vol. 10, no. 4, pp , [12] N.Wyse, R. Dubes, and A. K. Jain. A critical evaluation of intrinsec dimensionality algorithms, In E.Gelsema and L.N.Kanal, editors, Pattern Recognition, pages Morgan Kaufmann, 1980 [13] Huan Liu, Lei Yu, Toward Integrating Feature Selection Algoritms for Classification and Clustering IEEE Transactions on Knowledge and Data Engeneering Vol 17, No 4, April [14] H.Liu and H.Motorola, Feature Selection for Knowledge Discovery and Data Mining. Boston: Kluwer Academy, [15] David J. Stracuzzi, Paul E. Utgoff, Randomized Variable Elimination, Journal of Machine Learning Research 5 (2004) 1331–1362.")
Presentaciones similares

 el sujeto de la investigación –B) el objeto de la investigación –C) el nexo de unión entre el sujeto.>")











 Maestría en Ingeniería de Sistemas y Computación.>")





