Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Supuestos en el análisis de regresión
Parte 1. Supuestos para distribuciones univariadas Miles , J. & Shervin, M. (2011). Applyng regression & correlation. A guide for students and researchers. London: Sage. Chap. 4.
. Applyng regression & correlation. A guide for students and researchers. London: Sage. Chap. 4.")
2
Introducción En realidad, ¿qué nos dicen los datos?
¿La técnica de análisis es la más apropiada a la luz de nuestro propósito? Ver críticamente el análisis y considerar las ocasiones en que los resultados pueden ser erróneos. ¿Cuáles son los supuestos que subyacen al análisis de regresión? ¿Por qué es necesario cumplirlos? ¿Qué ocurre cuando se violan?

3
Supuestos en el análisis de regresión
I. Supuestos sobre el nivel de medición II. Supuestos sobre los datos A. En distribuciones univariadas 1. Distribución normal Puntajes extremos (outliers) Sesgo y curtosis 2. Detección de la no-normalidad 2.1 Métodos gráficos Histogramas Cajas y bigotes Gráficas de probabilidad 2.2 Métodos numéricos Sesgo y curtosis Puntajes extremos (outliers) Puntajes Z Estadísticos de influencia Estadísticos de influencia estandarizados 3. Tratamiento de la no-normalidad Efectos del sesgo y de la curtosis Transformaciones del sesgo y la curtosis B. En distribuciones multivariadas
 Sesgo y curtosis. 2. Detección de la no-normalidad. 2.1 Métodos gráficos. Histogramas. Cajas y bigotes. Gráficas de probabilidad. 2.2 Métodos numéricos. Sesgo y curtosis. Puntajes extremos (outliers) Puntajes Z. Estadísticos de influencia. Estadísticos de influencia estandarizados. 3. Tratamiento de la no-normalidad. Efectos del sesgo y de la curtosis. Transformaciones del sesgo y la curtosis. B. En distribuciones multivariadas.")
4
I. Supuestos sobre el nivel de medición

5
I. Supuestos sobre el nivel de medición
Escalas de medición: ¿Qué significa el número asignado a una persona respecto de un atributo? Las unidades con cero absoluto Datos continuos, cuantitativos o cardinales El número de unidades El orden o rango que le corresponde en un grupo La categoría o grupo al que pertenece Datos categóricos

6
I. Supuestos sobre el nivel de medición
En el contexto de regresión (conservador): La variable independiente debe ser medida en una escala de intervalo o de razón, aunque es posible recodificarla para convertirla en una escala categórica. La variable dependiente debe ser medida en una escala de intervalo o de razón.
: La variable independiente debe ser medida en una escala de intervalo o de razón, aunque es posible recodificarla para convertirla en una escala categórica. La variable dependiente debe ser medida en una escala de intervalo o de razón.")
7
I. Supuestos sobre el nivel de medición
En el contexto de regresión (liberal): 1. En psicología es muy difícil lograr el nivel de medición intervalar y casi imposible el de razón. 2. En lugar de preguntar: ¿La variable está medida en una escala intervalar? Mientras más opciones de respuesta se tengan, más similar será el tamaño de las unidades. Sugerencia: 7 opciones …se debería preguntar: ¿Qué tan cercana se encuentra la variable a una escala intervalar?
: 1. En psicología es muy difícil lograr el nivel de medición intervalar y casi imposible el de razón. 2. En lugar de preguntar: ¿La variable está medida en una escala intervalar Mientras más opciones de respuesta se tengan, más similar será el tamaño de las unidades. Sugerencia: 7 opciones. …se debería preguntar: ¿Qué tan cercana se encuentra la variable a una escala intervalar")
8
II. Supuestos sobre los datos A. En distribuciones univariadas

9
II. Supuestos sobre los datos
Supuestos sobre la distribución de la variable independiente y de los residuos Si no se satisfacen, las conclusiones serán incorrectas. La distribución normal es una fundamental en estadística. Debe haber una distribución normal para el cálculo de la desviación estándar y el error estándar.

10
II. Supuestos sobre los datos

11
Distribución normal El análisis de regresión asume que los residuales están distribuidos normalmente. La media es un modelo razonable. Con la media y su error estándar ya se tiene una aproximación. No es una distribución normal cuando… Los datos incluyen algunos puntajes extremos (altos y bajos) comparados con el resto: outliers. La forma de la distribución no parece curva normal.
 comparados con el resto: outliers. La forma de la distribución no parece curva normal.")
12
Outliers Elemento de los datos que es significativamente diferente a los otros datos del grupo, o un elemento que parece implicar un patrón que es inconsistente con el grueso de la evidencia de datos. Afecta la media.

13
Valores atípicos y la media
Los outliers son calificaciones que caen fuera del rango de datos de calificaciones que se esperaría tener. En el caso de tener un outlier en un conjunto de datos, la media podría no ser un buen modelo. Ejemplo: Columna1 Columna2 Persona Salario Técnico 10 400 11 300 12 900 Profesor 1 13 200 Profesor 2 14 600 Profesor 3 15 800 Profesor4 15 500 Profesor 5 Profesor 17 000 Profesor titular 22 700 23 500 24 600 Jefe de departamento 28 900 35 500 Columna1 Columna2 Persona Salario Técnico 10 400 11 300 12 900 Profesor 1 13 200 Profesor 2 14 600 Profesor 3 15 800 Profesor 4 15 500 Profesor 5 16 100 Profesor 17 000 Profesor titular 22 700 23 500 24 600 Jefe de departamento 28 900 17 400 Outlier

14
Sesgo y curtosis Aún sin outliers, la distribución se puede alejar de la normalidad de dos formas: 1) Sesgo 2) Curtosis
 Curtosis.")
15
Sesgo El sesgo ocurre si los datos no están distribuidos normalmente.
Suele ocurrir cuando hay un “efecto de piso” o un “efecto de techo”. Efecto de techo: no es posible puntuar más allá de cierto límite superior (sesgo negativo). Efecto de piso: hay un valor mínimo en los datos (sesgo positivo).
. Efecto de piso: hay un valor mínimo. en los datos. (sesgo positivo).")
16
Curtosis Si la distribución es simétrica, pero no tiene la forma de una distribución normal, exhibe curtosis. Con curtosis hay menos problema para la estimación de la regresión. Tres tipos de distribución: Normal Leptocúrtica (curtosis positiva) Platicúrtica (curtosis negativa)
 Platicúrtica (curtosis negativa)")
17
Detección de la no-normalidad Métodos gráficos

18
Detección de la no-normalidad Histograma
Un histograma es la forma más fácil de definir una distribución normal. Puede ser dibujado por un gráfico de barras o de líneas. Es fácil detectar el sesgo, la curtosis y los outliers en los histogramas.

19
Cuando se tienen histogramas de poblaciones pequeñas es difícil determinar si éstas siguen una distribución normal, por eso existen otros métodos. n = 20

20
Detección de la no-normalidad Cajas y bigotes

21
Debido a que el diagrama de caja resume la información y remueve algunos obstáculos es mas fácil utilizar un diagrama de caja que un histograma.

22
Una ventaja sobre el histograma es cuando se tienen muestras pequeñas, ya que permite ver con mayor claridad la normalidad de los datos. n = 20

23
Detección de la no-normalidad Gráfico de probabilidad
Es un método más matemático para comparar los datos con una distribución normal. Se sabe (por cálculos o por tablas) el tipo de puntajes que se esperarían si los datos estuvieran distribuidos normalmente. Es posible utilizar esta información para comparar los datos obtenidos. SPSS: Analizar →Estadísticos descriptivos → Gráficos PP
 el tipo de puntajes que se esperarían si los datos estuvieran distribuidos normalmente. Es posible utilizar esta información para comparar los datos obtenidos. SPSS: Analizar. →Estadísticos descriptivos. → Gráficos PP.")
24
Gráfico de probabilidad
Si los datos obtenidos igualan a la distribución calculada de datos, entonces se distribuyen de forma normal. En ese caso, los puntos deberán caer a lo largo de una línea recta. Si la distribución no es normal, los puntos caerán fuera de la diagonal.

25
Gráfico de probabilidad

26
Detección de la no-normalidad Métodos numéricos

27
Detección de sesgo y curtosis
Sesgo y curtosis normales = 0; fuera de la normalidad: valores por arriba o debajo de 0. Métodos: Fisher (SPSS) y Pearson (STATA) . Error estándar del sesgo y la curtosis: evalúa si difieren significativamente de la población. La distribución en cuestión difiere de una distribución normal cuando el índice es dos veces mayor que el error estándar. Influye el tamaño de la muestra. Precaución: no estamos interesados en saber si la distribución difiere significativamente de una distribución normal, sino en saber qué tan sesgada se encuentra.
 y Pearson (STATA) . Error estándar del sesgo y la curtosis: evalúa si difieren significativamente de la población. La distribución en cuestión difiere de una distribución normal cuando el índice es dos veces mayor que el error estándar. Influye el tamaño de la muestra. Precaución: no estamos interesados en saber si la distribución difiere significativamente de una distribución normal, sino en saber qué tan sesgada se encuentra.")
28
Sesgo < 1.0 → poco problema.
Sesgo > 1.0 < 2.0 → puede haber un efecto en los parámetros calculados, pero es adecuado. Sesgo > 2.0 → considerarse de cuidado.

29
El sesgo y la curtosis no detectan outliers.
Detección de outliers El sesgo y la curtosis no detectan outliers. Puntajes Z

30
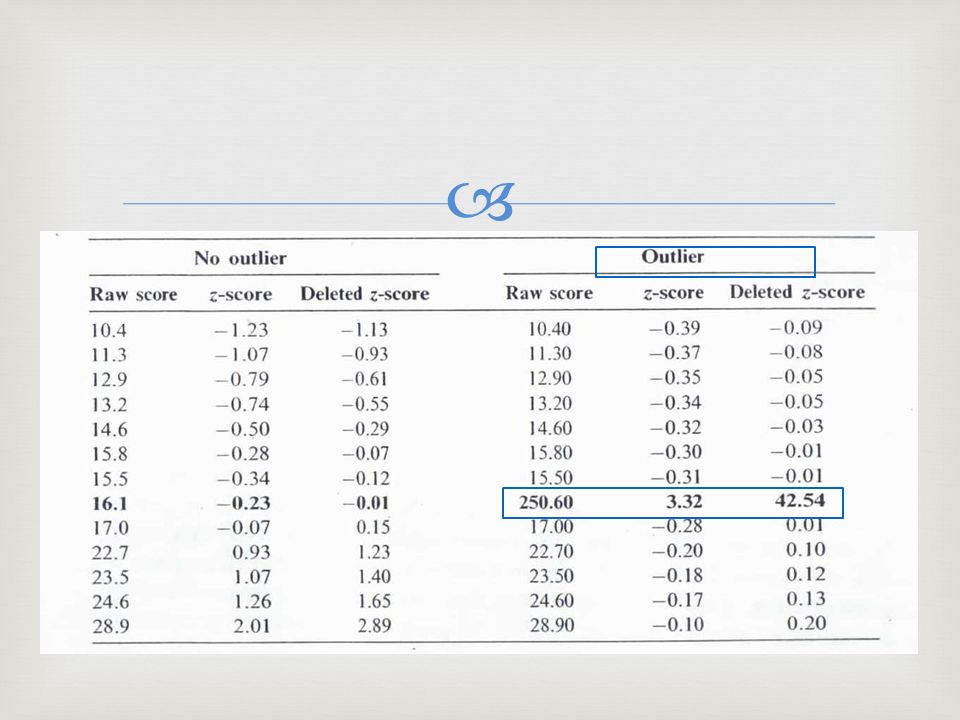
En una distribución normal es raro encontrar puntajes Z > 3.

31
Detección de outliers Puntaje Z eliminado
La media es afectada porque considera los outliers en su cálculo. Alternativa: utilizar la media y la desviación estándar de cada uno de los datos, eliminado el puntaje en cuestión. Una vez calculados la desviación estándar y la media, se calcula Z para el puntaje de interés. Se repite el proceso con cada uno de los valores.

33
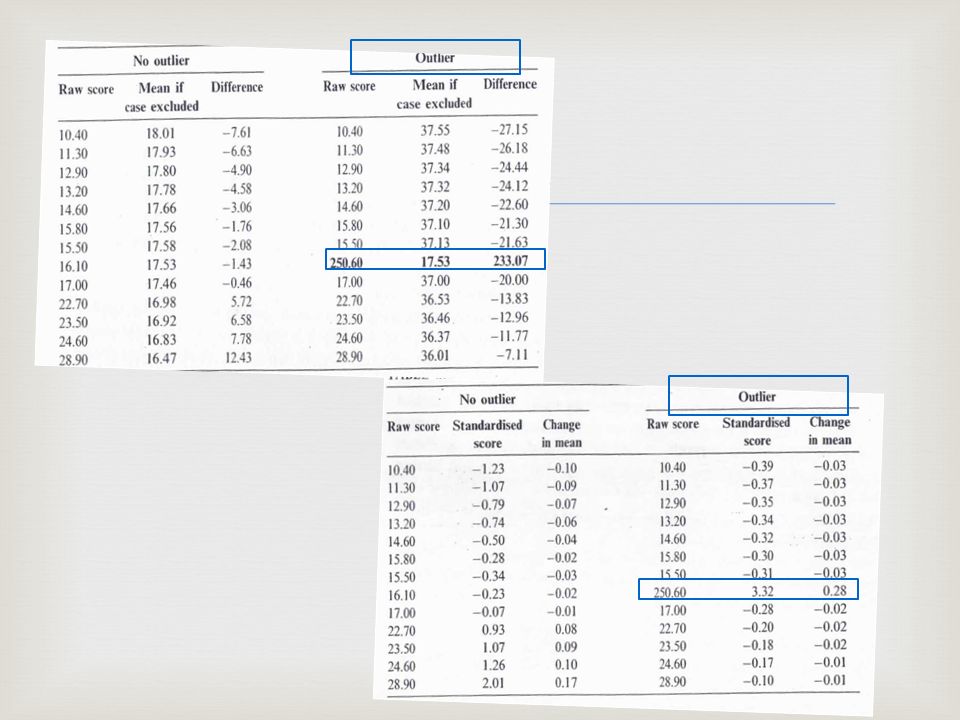
Detección de outliers Estadístico de influencia
Rara vez se usa en distribuciones univariadas para detectar un outlier. Se usa para evaluar el efecto de un dato particular sobre el modelo (la media).
.")
34
Detección de outliers Cálculo del estadístico de influencia
Calcular el parámetro, tomando en cuenta todos los datos, por ej., la media. Recalcularlo quietando el outlier. Calcular las diferencias entre los resultados con y sin el outlier.

35
Detección de outliers Estadístico de influencia estandarizados
Permite hacer comparaciones, sin el problema de la métrica empleada. Permite interpretar de forma mas fácil el cambio esperado.

36
Detección de outliers Estadístico de influencia estandarizados
Calcular el parámetro, por ej., la media. Calcular puntajes Z Recalcularlo quietando el outlier. Calcular las diferencias entre los resultados con y sin el outlier.

38
Tratamiento de la no-normalidad

39
Efectos de la no-normalidad
Si la distribución no es normal, el método de mínimos de cuadrados será inexacto. El modelo de regresión no tiene una prueba no paramétrica alterna. Se puede tratar de adecuar la información para su análisis.

40
Ouliers Outliers: ¿por qué? ¿errores de captura?
Arte: saber si quitarlos o no, pero TODO debe reportarse. Regresar y revisar la teoría y los instrumentos de medición, para ver si son apropiadas. Si son parte del proceso no se deben quitar. Puede deberse a un error en el equipo de medición, de captura –regresar y verificar; si no se puede encontrar el valor, eliminarlo y continuar.

41
Ouliers Quedan dos opciones, no del todo satisfactorias
Correr el análisis con el outlier siendo conscientes de sus efectos en los parámetros estimados. Eliminar el outlier, cuantos sean necesarios (modelar la mayoría de los datos) Analizar dos veces la información, una vez con los outliers y otra sin ellos, presentando un reporte con los aspectos principales de los resultados.
 Analizar dos veces la información, una vez con los outliers y otra sin ellos, presentando un reporte con los aspectos principales de los resultados.")
42
Sesgo y curtosis Efectos de sesgo
La media podría ser un estimador parcial, debido a la distancia de los puntos respecto de la media. En una distribución con sesgo negativo hay un sesgo hacia abajo. En una distribución con sesgo positivo hay un sesgo hacia arriba. El sesgo positivo es más común (hay límites bajos, no así altos; v. gr., depresión, tiempo).
.")
43
Sesgo y curtosis Efectos de la curtosis
Puede haber un error estándar de la media muy pequeño o muy grande; sólo es correcto cuando la distribución es normal. 1er. efecto: el estimado parece no ser tan adecuado (error tipo II); el error estándar será muy grande. 2° efecto: el error estándar puede ser muy pequeño y parecer que los estimados son significativos cuando no lo son (error tipo I).
; el error estándar será muy grande. 2° efecto: el error estándar puede ser muy pequeño y parecer que los estimados son significativos cuando no lo son (error tipo I).")
44
Transformaciones Alternativa:
Realizar transformaciones, transformar una distribución que no está distribuida normalmente para hacerla ajustarse a una distribución normal. Una transformación es un cálculo que se hace para todos los valores al mismo tiempo. Transformación logarítmica: Se utiliza comúnmente para cambiar el sesgo positivo.

45
Transformaciones Se toma el logaritmo de cada valor y se utiliza el resultado (los logaritmos de la datos originales) como una nueva variable en el nuevo cálculo. Se genera un nuevo histograma. Tanto el gráfico como la tabla muestran que los datos tienen una distribución más simétrica. La media se calcula a partir de los logaritmos de los puntajes crudos. Por lo que es necesario transformar este valor al puntaje crudo de la escala. Si la distribución está sesgada negativamente, cada valor puede elevarse al cuadrado.
 como una nueva variable en el nuevo cálculo. Se genera un nuevo histograma. Tanto el gráfico como la tabla muestran que los datos tienen una distribución más simétrica. La media se calcula a partir de los logaritmos de los puntajes crudos. Por lo que es necesario transformar este valor al puntaje crudo de la escala. Si la distribución está sesgada negativamente, cada valor puede elevarse al cuadrado.")
Presentaciones similares