Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Varianza intra grupo Varianza entre grupos Análisis de Varianza

2
ANOVA La técnica denominada Análisis de la varianza (ANOVA: Analysis of variance) sirve para determinar si las diferencias que existen entre las medias de tres o más grupos son estadísticamente significativas. Las técnicas de Anova se basan en la partición de la varianza para establecer si la varianza explicada por los grupos formados es suficientemente mayor que la varianza residual o no explicada. Hipótesis: de diferencia entre más de dos grupos. La hipótesis de investigación propone que los grupos difieren significativamente entre sí y la hipótesis nula propone que los grupos no difieren significativamente.
 sirve para determinar si las diferencias que existen entre las medias de tres o más grupos son estadísticamente significativas. Las técnicas de Anova se basan en la partición de la varianza para establecer si la varianza explicada por los grupos formados es suficientemente mayor que la varianza residual o no explicada. Hipótesis: de diferencia entre más de dos grupos. La hipótesis de investigación propone que los grupos difieren significativamente entre sí y la hipótesis nula propone que los grupos no difieren significativamente.")
3
Por qué utilizar un ANOVA en lugar de comparar los grupos con múltiples pruebas t?
Cada vez que se realiza una prueba t existe la posibilidad de que se de un error de tipo 1. Este error es generalmente del 5%. Mediante la ejecución de dos pruebas t en los mismos datos, se aumentaría la probabilidad de "cometer el error" al 10%, con tres pruebas t sería del 15% (en realidad, 14,3%) y así sucesivamente. Estos son errores inaceptables. Un ANOVA controla esta situación para que el error tipo 1 se mantenga en 5% y usted puede estar más seguros de que cualquier resultado significativo encontrado no se deba a la casualidad. una prueba estadística basada en todos los datos utilizados simultáneamente, es más estable que una prueba que parcializa los datos y no los examina todos juntos. El error típico es menor cuando el número de sujetos es mayor, como sucede cuando se analizan todos los datos de todos los grupos simultáneamente. En principio es preferible utilizar un método de análisis global que abarque todos los datos que se quieren examinar Por lo general, un error de tipo I se denomina "falso positivo" y es el proceso de rechazar incorrectamente la hipótesis nula en favor de la alternativa.
 y así sucesivamente. Estos son errores inaceptables. Un ANOVA controla esta situación para que el error tipo 1 se mantenga en 5% y usted puede estar más seguros de que cualquier resultado significativo encontrado no se deba a la casualidad. una prueba estadística basada en todos los datos utilizados simultáneamente, es más estable que una prueba que parcializa los datos y no los examina todos juntos. El error típico es menor cuando el número de sujetos es mayor, como sucede cuando se analizan todos los datos de todos los grupos simultáneamente. En principio es preferible utilizar un método de análisis global que abarque todos los datos que se quieren examinar. Por lo general, un error de tipo I se denomina falso positivo y es el proceso de rechazar incorrectamente la hipótesis nula en favor de la alternativa.")
4
Requisitos previos para utilizar el análisis de varianza
En los modelos teóricos en los que se basa el análisis de varianza se hacen tres suposiciones, pero estas tres suposiciones son de importancia muy desigual. La primera suposición es que utilizamos escalas de intervalo en la variable dependiente (en la que medimos a los sujetos) , Variables Nivel de medición Aclaratoria Variable independiente Categórica El hecho de que la variable independiente sea categórica significa que es posible formar grupos diferentes. Puede ser una variable nominal, ordinal, por intervalos o de razón (pero en estos últimos dos casos la variable debe reducirse a categorías). Por ejemplo: religión, nivel socio económico (muy alto, alto, medio, bajo y muy bajo), raza, etc. Variable dependiente Intervalos o razón Aunque se supone que la variable dependiente se mide en una escala de intervalo, la verdad es que esto no suele ser lo habitual en los instrumentos de medición educacional y psicológica (tests, escalas de diverso tipo, preguntas con respuestas graduadas, etc.). Los métodos habituales de obtención de datos (como escalas tipo-Likert, etc.) se aproximan suficientemente a las escalas de intervalo y las distorsiones que se pueden introducir son pequeñas; es más lo que se gana que lo se pierde con estos métodos
 , Variables. Nivel de medición. Aclaratoria. Variable independiente. Categórica. El hecho de que la variable independiente sea categórica significa que es posible formar grupos diferentes. Puede ser una variable nominal, ordinal, por intervalos o de razón (pero en estos últimos dos casos la variable debe reducirse a categorías). Por ejemplo: religión, nivel socio económico (muy alto, alto, medio, bajo y muy bajo), raza, etc. Variable dependiente. Intervalos o razón. Aunque se supone que la variable dependiente se mide en una escala de intervalo, la verdad es que esto no suele ser lo habitual en los instrumentos de medición educacional y psicológica (tests, escalas de diverso tipo, preguntas con respuestas graduadas, etc.). Los métodos habituales de obtención de datos (como escalas tipo-Likert, etc.) se aproximan suficientemente a las escalas de intervalo y las distorsiones que se pueden introducir son pequeñas; es más lo que se gana que lo se pierde con estos métodos.")
5
La variable dependiente sigue la distribución normal
La variable dependiente sigue la distribución normal. Sobre el presupuesto de normalidad en la variable dependiente (la que medimos),una abundante investigación confirma que en general la violación de estos presupuestos no invalida de manera apreciable los resultados del análisis de varianza. La violación dela normalidad es menos importante (prácticamente irrelevante, Glass y Stanley,1974), como está confirmado por numerosos estudios; de hecho las medias tienden a la distribución normal aunque las poblaciones de donde proceden no sean normales(Guilford y Fruchter, 1973). Se puede comprobar el supuesto de Normalidad: Test de Kolmogorov-Smirnov y Shapiro-Wilks
,una abundante investigación confirma que en general la violación de estos presupuestos no invalida de manera apreciable los resultados del análisis de varianza. La violación dela normalidad es menos importante (prácticamente irrelevante, Glass y Stanley,1974), como está confirmado por numerosos estudios; de hecho las medias tienden a la distribución normal aunque las poblaciones de donde proceden no sean normales(Guilford y Fruchter, 1973). Se puede comprobar el supuesto de Normalidad: Test de Kolmogorov-Smirnov y Shapiro-Wilks.")
6
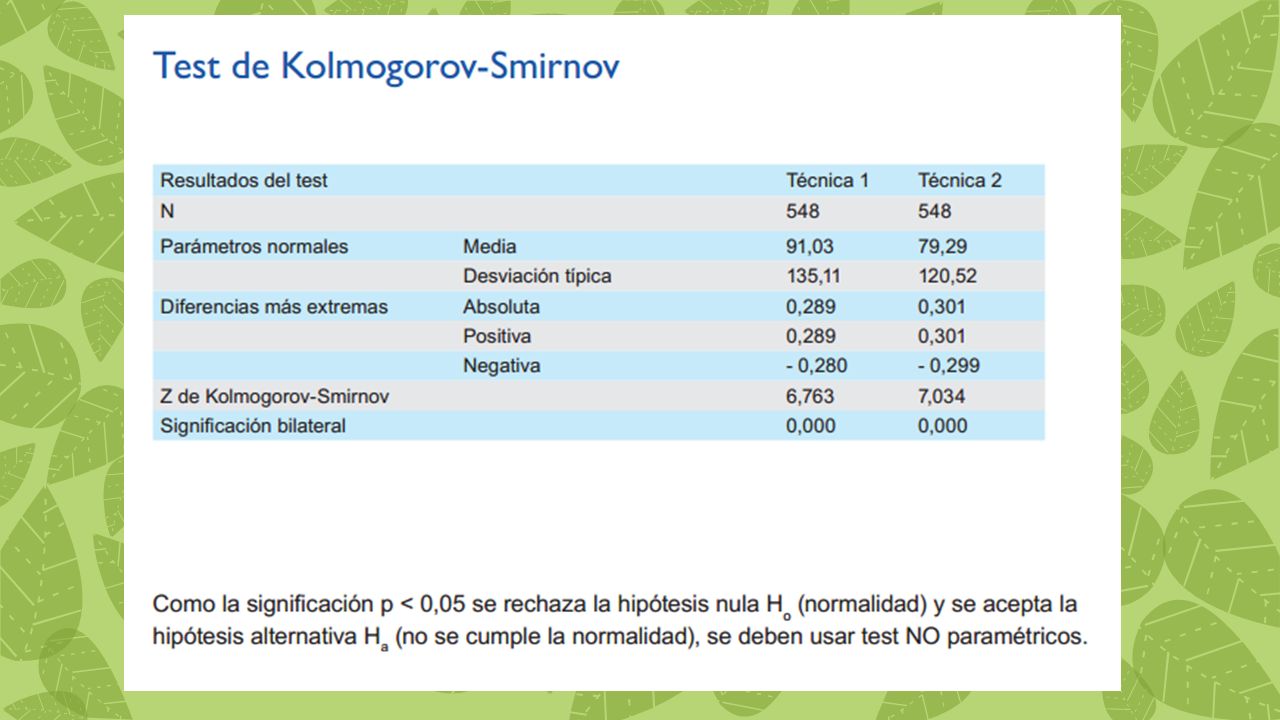
Test de Kolmogorov-Smirnov
Es el test de normalidad más difundido en los programas estadísticos. se recomienda el test de Kolmogorov-Smirnov para muestras mayores de 30 casos). Se basa en la idea de comparar la función de distribución acumulada de los datos observados con la de una DISTRIBUCIÓN NORMAL, midiendo la máxima distancia entre ambas curvas. Como en todos los tests de contraste de hipótesis, la hipótesis nula (Ho) se rechaza cuando el valor del estadístico calculado supera un cierto valor crítico (tabulado) que se obtiene de una tabla de cálculo de probabilidades. p > 0,05 se acepta la Ho (se cumple la normalidad), se pueden usar test paramétricos. p < 0,05 se acepta la Ha (no se cumple la normalidad), se deben usar test NO paramétricos.
. Se basa en la idea de comparar la función de distribución acumulada de los datos observados con la de una DISTRIBUCIÓN NORMAL, midiendo la máxima distancia entre ambas curvas. Como en todos los tests de contraste de hipótesis, la hipótesis nula (Ho) se rechaza cuando el valor del estadístico calculado supera un cierto valor crítico (tabulado) que se obtiene de una tabla de cálculo de probabilidades. p > 0,05 se acepta la Ho (se cumple la normalidad), se pueden usar test paramétricos. p < 0,05 se acepta la Ha (no se cumple la normalidad), se deben usar test NO paramétricos.")
8
¿Qué sucede cuando las varianzas son muy desiguales?.
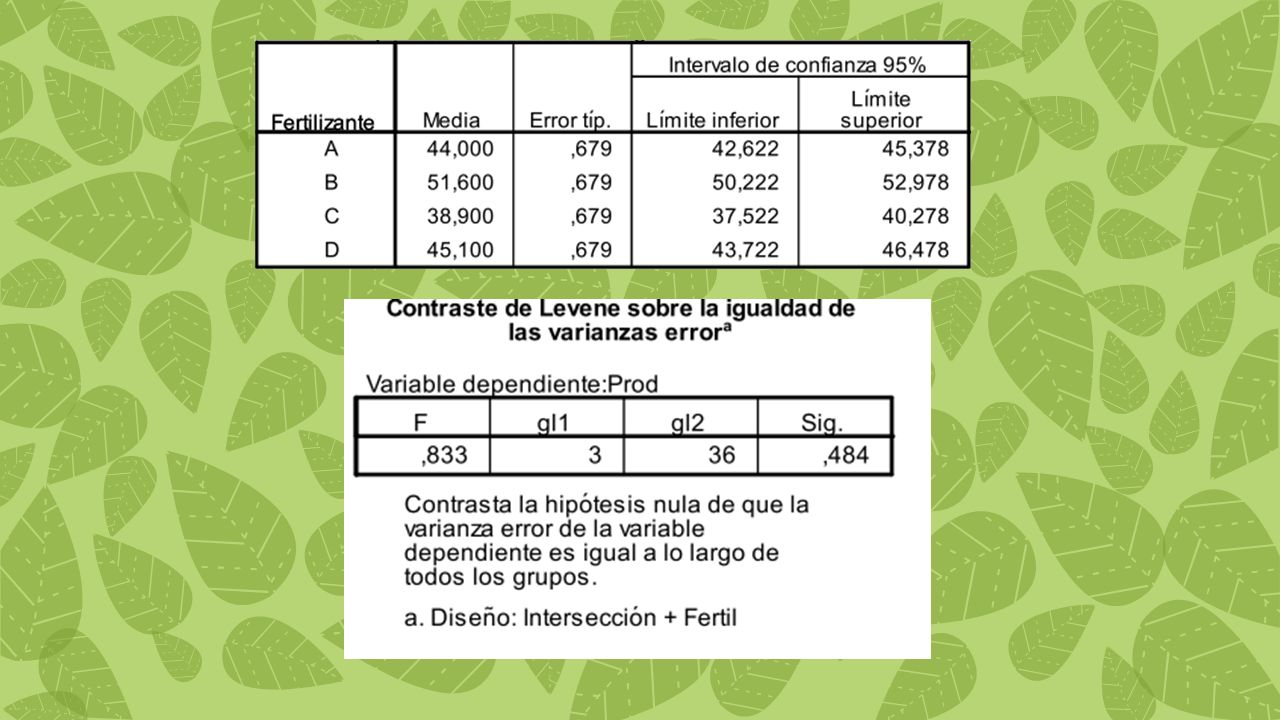
3. homogeneidad de varianzas (denominada homoestacidad). El supuesto de que las varianzas de las distintas poblaciones representadas en las muestras no difieren significativamente entre sí, sin duda es la más importante de las condiciones previas ¿Qué sucede cuando las varianzas son muy desiguales?. Las probabilidades que señalan las tablas de la F no son las reales Existen contrastes para detectar heterocedasticidad: Conover y cols (1981) mencionan existencia de 56 pruebas para comprobar la igualdad de varianza y las clasifica en varios grupos . Aquí se colocan las que son más populares Grupo 1: las que trabajan bajo el supuesto de normalidad como la prueba de Barlett y la prueba de Hartley Grupo 2: las que emplean como estimador la kurtosis, tales como la prueba de Box Grupo 3: las que son modificaciones de la prueba F como la prueba de Levene
. El supuesto de que las varianzas de las distintas poblaciones representadas en las muestras no difieren significativamente entre sí, sin duda es la más importante de las condiciones previas. ¿Qué sucede cuando las varianzas son muy desiguales . Las probabilidades que señalan las tablas de la F no son las reales. Existen contrastes para detectar heterocedasticidad: Conover y cols (1981) mencionan existencia de 56 pruebas para comprobar la igualdad de varianza y las clasifica en varios grupos . Aquí se colocan las que son más populares. Grupo 1: las que trabajan bajo el supuesto de normalidad como la prueba de Barlett y la prueba de Hartley. Grupo 2: las que emplean como estimador la kurtosis, tales como la prueba de Box. Grupo 3: las que son modificaciones de la prueba F como la prueba de Levene.")
9
En el caso de que las muestras no sean homocedásticas, no se puede, en principio, realizar el análisis de la varianza. Existen, sin embargo, soluciones alternativas: Sokal y Rohlf describen una prueba aproximada, basada en unas modificaciones de las fórmulas originales.

10
suponiendo varianzas desiguales conviene tener en cuenta estas orientaciones.
Las varianzas desiguales no deben preocuparnos si las muestras son de idéntico tamaño; por varianzas desiguales podemos entender que la mayor no es más de tres veces mayor que la varianza más pequeña. Tampoco deben preocuparnos las varianzas desiguales si las muestras son de distinto tamaño con tal de que los tamaños de las muestras no difieran mucho y las muestras no tengan menos de 20 sujetos En algunos casos de varianzas muy desiguales podemos examinar si en alguna muestra hay sujetos atípicos con puntuaciones muy extremas (outliers). Si hay sujetos muy atípicos, podemos considerar el eliminar de la muestra a estos sujetos (responsables de una varianza mucho mayor). En estos casos habrá que comprobar si estos sujetos tienen alguna característica común para no generalizar los resultados a ese tipo de sujetos. Por ejemplo, podemos encontrarnos conque un subgrupo de sujetos con puntuaciones muy atípicas tienen también una edad muy distinta a la de la mayoría, o una procedencia distinta, etc. Cuando las varianzas son notablemente distintas, y sobre todo si los grupos son de tamaño distinto, hay otras alternativas al análisis de varianza menos conocidas. Con grupos pequeños, de tamaño desigual y con varianzas muy distintas, siempre tenemos las alternativas no paramétricas.
. Si hay sujetos muy atípicos, podemos considerar el eliminar de la muestra a estos sujetos (responsables de una varianza mucho mayor). En estos casos habrá que comprobar si estos sujetos tienen alguna característica común para no generalizar los resultados a ese tipo de sujetos. Por ejemplo, podemos encontrarnos conque un subgrupo de sujetos con puntuaciones muy atípicas tienen también una edad muy distinta a la de la mayoría, o una procedencia distinta, etc. Cuando las varianzas son notablemente distintas, y sobre todo si los grupos son de tamaño distinto, hay otras alternativas al análisis de varianza menos conocidas. Con grupos pequeños, de tamaño desigual y con varianzas muy distintas, siempre tenemos las alternativas no paramétricas.")
11
Modelo sin interacción
Cuando se trabaja con ANOVA, es frecuente el uso de la palabra: “factor” Los factores son las variables independientes de la investigación. Un factor puede tener varios niveles o modalidades Anova Anova doble (Two ways) Modelo aditivo Sin interacción Modelo sin interacción Anova simple (one way) Imaginemos que estamos comparando el peso de un tipo de insecto en tres localidades distintas: La VD es el peso La VI o el factor es la localidad y la VI tiene 3 modalidades (3 modalidades) porque se trata de tres localidades distintas Factor localidad Localidad 1 Localidad 2 Localidad 3 3.7 3.9 3.2 3.8 3.6 4.1 3.4 3.5
 Modelo aditivo. Sin interacción. Modelo sin interacción. Anova simple. (one way) Imaginemos que estamos comparando el peso de un tipo de insecto en tres localidades distintas: La VD es el peso. La VI o el factor es la localidad. y la VI tiene 3 modalidades (3 modalidades) porque se trata de tres localidades distintas. Factor localidad. Localidad 1. Localidad 2. Localidad")
12
La varianza expresa variación, y si podemos descomponer la varianza, podemos aislar fuentes de variación. Cuando de los sujetos tenemos varios tipos de información, el análisis de varianza nos va a responder a esta pregunta ¿De dónde vienen las diferencias? Varianza total Entre grupos Variabilidad del Factor A Variabilidad del Factor B Variabilidad de la interacción AxB Dentro del grupo la varianza total puede descomponerse en dos varianzas: 1) Una varianza que indica la variabilidad dentro de los grupos y otra varianza que expresa la variabilidad (diferencias) entre los grupos (entre las medias).
 Una varianza que indica la variabilidad dentro de los grupos y otra varianza que expresa la variabilidad (diferencias) entre los grupos (entre las medias).")
13
ANOVA de dos vías o de dos factores
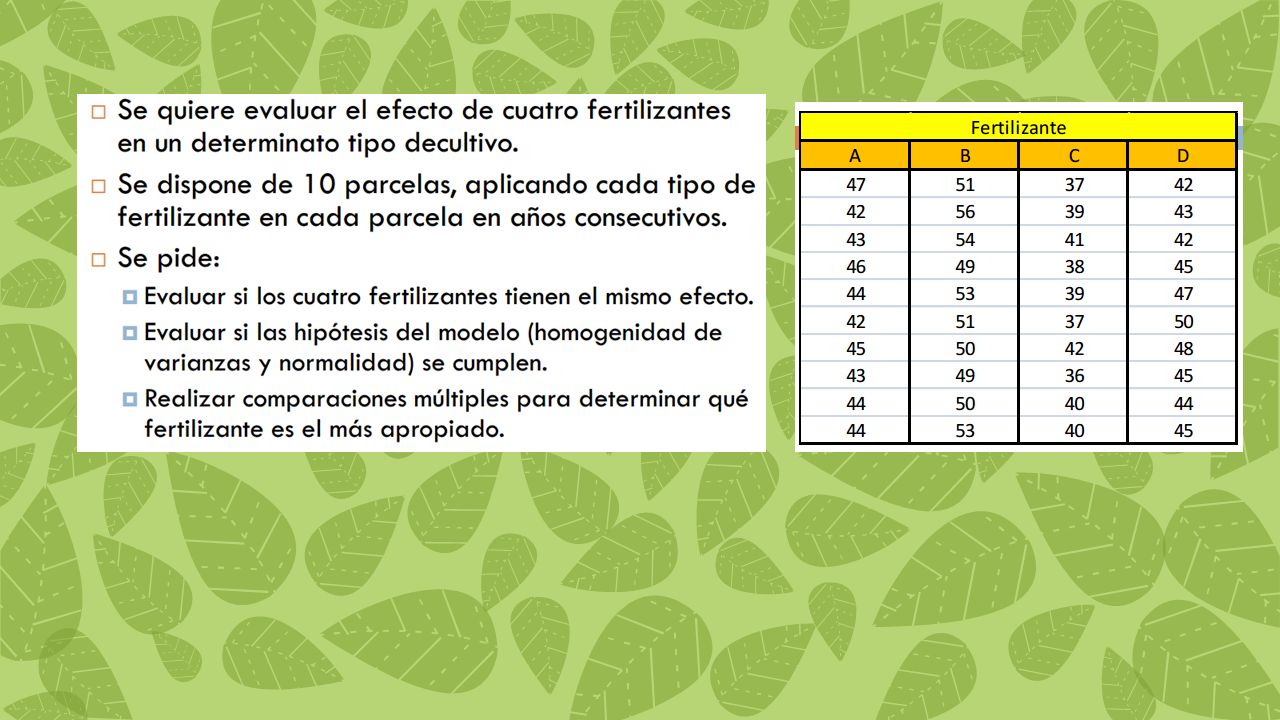
ANOVA de una vía o de un factor Caso 1: Un médico quiere comparar la efectividad de tres tratamientos para reducir el colesterol de pacientes con altos niveles de colesterol sanguíneo. Se asignan aleatoriamente 60 individuos a los tres tratamientos (20 en cada uno) y se registra la reducción de colesterol de cada paciente. La Vd es el nivel de colesterol La VI (o factor) es el tipo de tratamiento, y esta tiene 3 modalidades distintas (3 niveles) Caso 2: Una ecóloga está interesada en comparar la concentración de cadmio en 5 ríos. Recolecta 50 muestras de agua (10 muestras en cada río) y mide la concentración de cadmio. La VD es el nivel de contaminación La VI (o factor) es el río, con 5 modalidades distintas ANOVA de dos vías o de dos factores Caso 1: Se quiere evaluar la eficacia de distintas dosis (5) de un fármaco contra la hipertensión arterial. se podría plantear que, quizás, la evolución de la misma fuera diferente para los hombres y las mujeres. La VD: nivel de tensión arterial La VI 1 (factor 1) distintas dosis del medicamento con 5 modalidades (niveles) distintas La VI 2 (factor 2) sexo con dos modalidades (niveles) diferentes
 y se registra la reducción de colesterol de cada paciente. La Vd es el nivel de colesterol. La VI (o factor) es el tipo de tratamiento, y esta tiene 3 modalidades distintas (3 niveles) Caso 2: Una ecóloga está interesada en comparar la concentración de cadmio en 5 ríos. Recolecta 50 muestras de agua (10 muestras en cada río) y mide la concentración de cadmio. La VD es el nivel de contaminación. La VI (o factor) es el río, con 5 modalidades distintas. ANOVA de dos vías o de dos factores. Caso 1: Se quiere evaluar la eficacia de distintas dosis (5) de un fármaco contra la hipertensión arterial. se podría plantear que, quizás, la evolución de la misma fuera diferente para los hombres y las mujeres. La VD: nivel de tensión arterial. La VI 1 (factor 1) distintas dosis del medicamento con 5 modalidades (niveles) distintas. La VI 2 (factor 2) sexo con dos modalidades (niveles) diferentes.")
14
Ejemplo para la comprensión de la situación
Supongamos una población de la notas de un universo de 9 alumnos de tres grupos distintos, así: Grupo 1 Grupo 2 Grupo 3 5 Evidentemente en este caso la media global es 5 y la de cada grupo también. Yi= µ Cada valor es igual a la media general. Por lo tanto se puede afirmar que NO HAY DIFERENCIA ENTRE GRUPOS, NI DENTRO DE CADA UNO DE LOS GRUPOS

15
Ejemplo para la comprensión de la situación
Supongamos que aplicamos un método de enseñanza (factor) que afecta: subiendo las notas del grupo 1 en 1 punto, las del grupo 2 en dos puntos y no modificando las del grupo 3. así: Grupo 1 Grupo 2 Grupo 3 5+1=6 5+2=7 5+0=5 Ahora la nota del alumno sería Yi=µ+αi, en los que α son 1, 2, 0. Parece claro que EL FACTOR INFLUYE EN ESTABLECER DIFERENCIAS ENTRE GRUPOS, PERO NO DENTRO
 que afecta: subiendo las notas del grupo 1 en 1 punto, las del grupo 2 en dos puntos y no modificando las del grupo 3. así: Grupo 1. Grupo 2. Grupo =6. 5+2=7. 5+0=5. Ahora la nota del alumno sería Yi=µ+αi, en los que α son 1, 2, 0. Parece claro que EL FACTOR INFLUYE EN ESTABLECER DIFERENCIAS ENTRE GRUPOS, PERO NO DENTRO.")
16
Ejemplo para la comprensión de la situación
Lo más habitual es que haya alumnos que rindan más que otros (por diversas razones aleatorias que en principio no dependen de un factor) son por tanto comportamientos aleatorios individuales que denominamos ε. En nuestro ejemplo, sería Los efectos aleatorios serían -1,-2,0,2,0,1,3,4,0 que fomentan la variabilidad INTRA-GRUPOS Grupo 1 Grupo 2 Grupo 3 5+1-1=5 5+2+2=9 5+0+3=8 5+1-2=4 5+2+0=7 5+0+4=9 5+1+0=6 5+2+1=8 5+0+0=5 Por lo tanto tenemos dos tipos de variabilidad: la que se da entre grupos (debida al factor) y la que se da intragrupos (debida a la aleatoriedad). Para poder afirmar que el factor produce efectos, la variabilidad ENTRE LOS GRUPOS ha de ser significativamente GRANDE respecto a la INTRA GRUPOS
 son por tanto comportamientos aleatorios individuales que denominamos ε. En nuestro ejemplo, sería. Los efectos aleatorios serían -1,-2,0,2,0,1,3,4,0 que fomentan la variabilidad INTRA-GRUPOS. Grupo 1. Grupo 2. Grupo = = = = = = = = =5. Por lo tanto tenemos dos tipos de variabilidad: la que se da entre grupos (debida al factor) y la que se da intragrupos (debida a la aleatoriedad). Para poder afirmar que el factor produce efectos, la variabilidad ENTRE LOS GRUPOS ha de ser significativamente GRANDE respecto a la INTRA GRUPOS.")
17
Descomponiendo la varianza
La hipótesis que pone a prueba el ANOVA es que las medias de las VD de los distintos grupos son iguales. Estos son los resultados de los puntajes obtenidos en un examen de estadística (VD) por estudiantes. Cada grupo ve la materia con un profesor distinto (la VI o factor sería el profesor) Para entender el procedimiento de análisis de varianza consideraremos que todos los sujetos hipotéticamente pertenecen a una única muestra porque es esta varianza del grupo total la que vamos a analizar o descomponer. ¿De dónde vienen las diferencias en este grupo total formado por las muestras A y B? ¿De que los sujetos son muy distintos entre sí dentro de cada grupo? No, en este ejemplo los sujetos dentro de cada grupo tienen un grado semejante de homogeneidad o variabilidad. Si las medias difieren entre sí, más que los sujetos entre sí, concluiremos que esas diferencias se deben al tipo de profesor
 por estudiantes. Cada grupo ve la materia con un profesor distinto (la VI o factor sería el profesor) Para entender el procedimiento de análisis de varianza consideraremos que todos los sujetos hipotéticamente pertenecen a una única muestra porque es esta varianza del grupo total la que vamos a analizar o descomponer. ¿De dónde vienen las diferencias en este grupo total formado por las muestras A y B ¿De que los sujetos son muy distintos entre sí dentro de cada grupo No, en este ejemplo los sujetos dentro de cada grupo tienen un grado semejante de homogeneidad o variabilidad. Si las medias difieren entre sí, más que los sujetos entre sí, concluiremos que esas diferencias se deben al tipo de profesor.")
18
Otro caso: Uniendo ambos grupos, podríamos calcular la varianza total, y preguntarnos de nuevo: ¿De dónde viene esa varianza (esas diferencias)? ¿De que los grupos son distintos, con media distinta, como en el caso anterior? ¿O las diferencias en el grupo total vienen simplemente de que los sujetos dentro de cada grupo son distintos? . En este caso las diferencias no vienen de diferencias entre los grupos, que tienen idéntica media, sino de que los sujetos dentro de cada grupo son muy distintos. Supongamos que tenemos dos grupos, uno de enanos y otro de gigantes: Cada grupo tiene su media en altura; la media de los gigantes es mayor que la media de los enanos. Dentro de cada grupo hay también diferencias; no todos los enanos son igualmente bajitos ni todos los gigantes son igualmente altos. Pero ¿cuál sería nuestra conclusión si comprobamos que la diferencia entre las medias de los gigantes y de los enanos es más o menos igual a las diferencias que podemos encontrar entre los sujetos dentro de cada grupo?… Pues sencillamente que no tenemos ni enanos, ni gigantes, la hipótesis es falsa, y por lo que respecta a estatura, podemos considerar que todos pertenecen al mismo grupo (o hablando con más propiedad, que todos pertenecen a la misma población por lo que respecta a la altura). Estos ejemplos reflejan una situación sencilla porque se trata solamente de dos grupos; los grupos podrían ser tres o más.
 ¿De que los grupos son distintos, con media distinta, como en el caso anterior ¿O las diferencias en el grupo total vienen simplemente de que los sujetos dentro de cada grupo son distintos . En este caso las diferencias no vienen de diferencias entre los grupos, que tienen idéntica media, sino de que los sujetos dentro de cada grupo son muy distintos. Supongamos que tenemos dos grupos, uno de enanos y otro de gigantes: Cada grupo tiene su media en altura; la media de los gigantes es mayor que la media de los enanos. Dentro de cada grupo hay también diferencias; no todos los enanos son igualmente bajitos ni todos los gigantes son igualmente altos. Pero ¿cuál sería nuestra conclusión si comprobamos que la diferencia entre las medias de los gigantes y de los enanos es más o menos igual a las diferencias que podemos encontrar entre los sujetos dentro de cada grupo … Pues sencillamente que no tenemos ni enanos, ni gigantes, la hipótesis es falsa, y por lo que respecta a estatura, podemos considerar que todos pertenecen al mismo grupo (o hablando con más propiedad, que todos pertenecen a la misma población por lo que respecta a la altura). Estos ejemplos reflejan una situación sencilla porque se trata solamente de dos grupos; los grupos podrían ser tres o más.")
19
Estadístico F La estrategia para poner a prueba la hipótesis de la igualdad de medias es obtener un estadístico llamado F que refleja el grado de parecido entre las medias que se están comparando. Intuitivamente: si la hipótesis nula es cierta, es decir si no hay diferencias entre los grupos, el denominador y el numerador deben ser aproximadamente iguales. Por lo tanto, cuanto más cercano a 1 este el cociente F, más nos acercamos a aceptar la hipótesis nula. Al contrario conforme el coeficiente crece nos inclinaremos más a rechazar la hipótesis nula y a aceptar la alternativa, de que existen diferencias entre las medias de los grupos como resultado de la intervención (VI), porque indica más diferencias entre grupos, que dentro de cada grupo
, porque indica más diferencias entre grupos, que dentro de cada grupo.")
20
Ojo: vas a encontrar que a la fuente de variación dentro de los grupos (intragrupal)
también se le llama efecto del error

21
Cálculo de Anova Procedimiento

22
(18,36) =337.0896 94 - 75,64 = 18,36 Fuente de variación
Suma de cuadrados Grados de libertad Cuadrados Medios F Tratamiento SST - SSE K-1 MST= (SST-SSE)/(k-1) MST/MSE Error n-k MSE=SSE/(n-k) Total N-1 Fuente de variación Suma de cuadrados Grados de libertad Cuadrados Medios F Tratamiento Error Total 1485 21 Eran 22 sujetos Grados de libertad=N-1 22-1=21 (18,36) = ,64 = 18,36
/(k-1) MST/MSE. Error. n-k. MSE=SSE/(n-k) Total. N-1. Fuente de variación. Suma de cuadrados. Grados de libertad. Cuadrados Medios. F. Tratamiento. Error. Total Eran 22 sujetos. Grados de libertad=N =21. (18,36) = ,64 = 18,36.")
23
SST - SSE 1485, ,41= 890,68 K-1 4-1=3 Fuente de variación Suma de cuadrados Grados de libertad Cuadrados Medios F Tratamiento SST - SSE K-1 MST= (SST-SSE)/(k-1) MST/MSE Error n-k MSE=SSE/(n-k) Total N-1 Fuente de variación Suma de cuadrados Grados de libertad Cuadrados Medios F Tratamiento 890.68 3 Error 594.41 18 Total 1485 21 n-k n=22 sujetos K=4 grupos 22- 4 = 18 ,25 = 6.75 ( 6,75) = 45,56
/(k-1) MST/MSE. Error. n-k. MSE=SSE/(n-k) Total. N-1. Fuente de variación. Suma de cuadrados. Grados de libertad. Cuadrados Medios. F. Tratamiento Error Total n-k. n=22 sujetos K=4 grupos = ,25 = ( 6,75) = 45,56.")
24
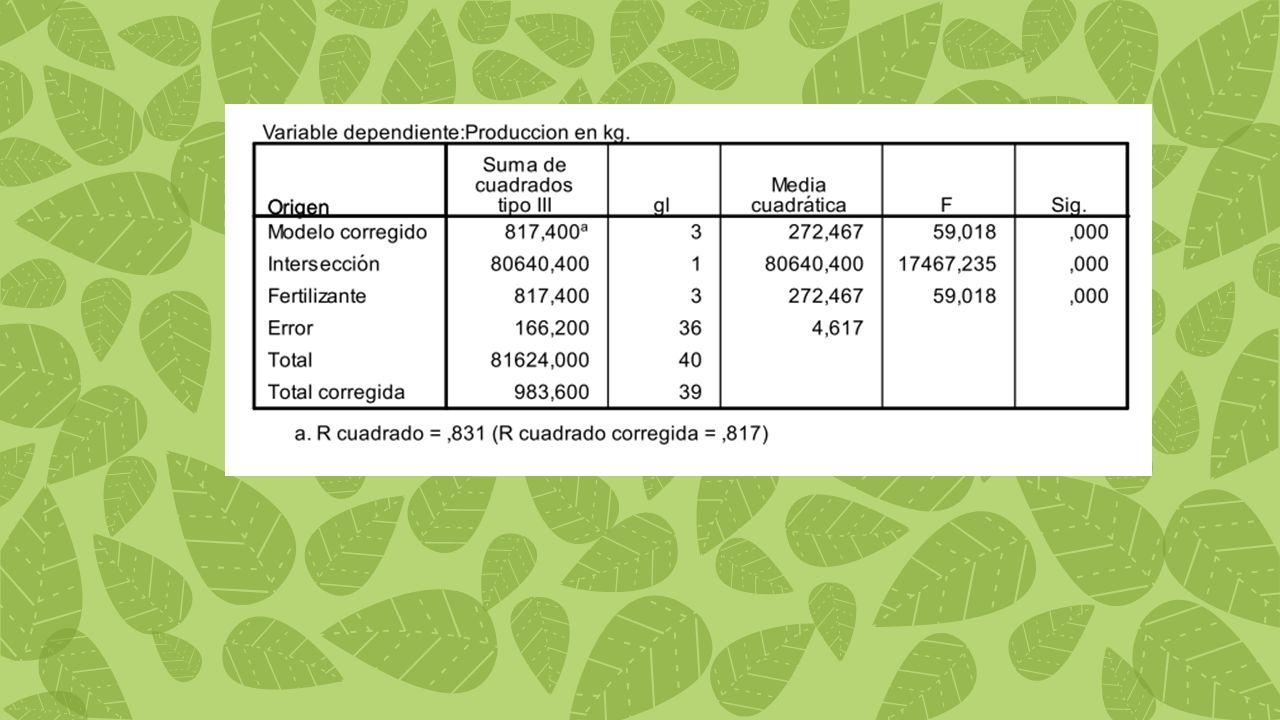
MST/MSE 296,89 / = 8.99 Debemos buscar en la tabla de F, ese valor ,para determinar si es o no significativo SST – SSE / (K-1) 890,68 / 3 = 296,89 Recuerda que hay 2 formas de establecer la regla de decisión: 1: comparas el valor F calculado con el F teórico. Si el valor de F calculado es mayor o igual que el teórico, rechazas la Ho 2. Comparas los valores de significación: de manera previa estableces un nivel de significación, por ejemplo (.05), si el software o a través de tu calculo manual arroja un valor menor al nivel de significación establecido, debes rechazar Ho Fuente de variación Suma de cuadrados Grados de libertad Cuadrados Medios F Tratamiento 890.68 3 296.89 8.99 Error 594.41 18 33.02 Total 1485 21 SSE/(n-k) 594,41 / 18 = 33.02
 890,68 / 3 = 296,89. Recuerda que hay 2 formas de establecer la regla de decisión: 1: comparas el valor F calculado con el F teórico. Si el valor de F calculado es mayor o igual que el teórico, rechazas la Ho. 2. Comparas los valores de significación: de manera previa estableces un nivel de significación, por ejemplo (.05), si el software o a través de tu calculo manual arroja un valor menor al nivel de significación establecido, debes rechazar Ho. Fuente de variación. Suma de cuadrados. Grados de libertad. Cuadrados Medios. F. Tratamiento Error Total SSE/(n-k) 594,41 / 18 =")
25
Otro resultado

26
Otro Resultado

27
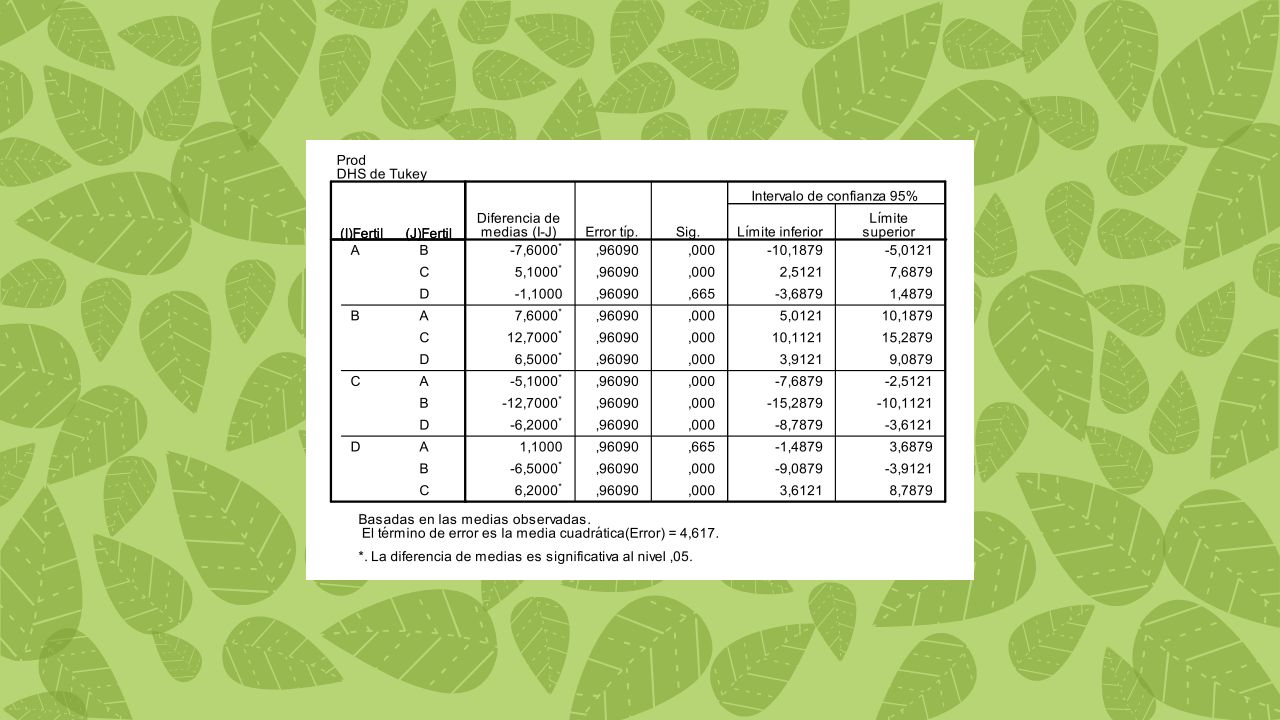
Y después del ANOVA qué? El estadístico F del ANOVA únicamente nos permite contrastar la hipótesis general de que las medias comparadas son iguales. Al rechazar esta hipótesis sabemos que las medias comparadas no son iguales, pero no sabemos en concreto dónde se encuentran la diferencias: son diferentes entre sí todas las medias?, hay sólo una media que difiere de las demás? Para saber qué media difiere de qué otra debemos utilizar un tipo particular de contraste comparaciones múltiples post hoc o comparaciones a posteriori. No existe consenso sobre cuál es la mejor prueba, pero algunas de las más comunes son la prueba de Duncan la prueba de Student-Newman-Keuls (o prueba SNK) la prueba de Tukey (o prueba de diferencia significativa honesta de Tukey) la prueba de Scheffé la prueba de Dunnett la prueba de la diferencia mínima significativa y la prueba de Bonferroni.
 la prueba de Tukey (o prueba de diferencia significativa honesta de Tukey) la prueba de Scheffé. la prueba de Dunnett. la prueba de la diferencia mínima significativa y. la prueba de Bonferroni.")
28
Contrastes entre medias
Contrastes entre medias dependiendo del nivel de complejidad contrastes simples (cuando involucran únicamente dos medias) contrastes complejos (cuando involucran tres o más medias). Contrastes entre medias dependiendo del momento en que se plantean "a priori" (cuando se plantean antes de analizar los datos) "a posteriori" (cuando se plantean una vez vistos los datos), A priori A posteriori Contraste simple Tukey Contrate complejo Bonferroni Scheffé
 contrastes complejos. (cuando involucran tres o más medias). Contrastes entre medias dependiendo del momento en que se plantean. a priori (cuando se plantean antes de analizar los datos) a posteriori (cuando se plantean una vez vistos los datos), A priori. A posteriori. Contraste simple. Tukey. Contrate complejo. Bonferroni. Scheffé.")
33
La salida de SPSS para una prueba de Scheffé (de otro ejemplo)
")
34
La salida de SPSS para una prueba de Bonferroni (de otro ejemplo)
")
Presentaciones similares





: un y dos factores completamente.>")


>")




>")





