Descargar la presentación
La descarga está en progreso. Por favor, espere

1
To Cloud or not Cloud, That is the Question
To Cloud or not Cloud, That is the Question! 22 Noviembre de 2010, 9:00-14:00 Bizkaia Enpresa Digitala, Parque Tecnológico de Zamudio. Edificio ESI, #204 Dr. Diego Lz. de Ipiña Glz. de Artaza

2
Agenda Introducción a Cloud Computing (30’)
Concepto y campos relacionados Diferentes manifestaciones (SaaS, PaaS e IaaS) Ejemplos de servicios, infraestructura y aplicaciones en la nube Ejemplo de IaaS: Amazon Web Services (AWS) (90’ + 60’) Introducción Amazon Elastic Cloud (EC2) Amazon Simple Storage Service (S3) y CloudFront Amazon Simple DB y RDS Desarrollo de una aplicación de ejemplo sobre AWS
 Ejemplos de servicios, infraestructura y aplicaciones en la nube. Ejemplo de IaaS: Amazon Web Services (AWS) (90’ + 60’) Introducción. Amazon Elastic Cloud (EC2) Amazon Simple Storage Service (S3) y CloudFront. Amazon Simple DB y RDS. Desarrollo de una aplicación de ejemplo sobre AWS.")
3
Agenda Ejemplo de PaaS: Google App Engine (60’ + 90’) Introducción DataStore API y GQL Memcache y Cron Versiones Python y Java de Google App Engine Desarrollo de una aplicación de ejemplo sobre GoogleApp Conclusiones (30’) Comparativa AWS, Google App Engine y Azure Patrones de diseño Cuándo y cómo adoptaré Cloud Computing en mi empresa Ejemplos en:
 Comparativa AWS, Google App Engine y Azure. Patrones de diseño. Cuándo y cómo adoptaré Cloud Computing en mi empresa. Ejemplos en:")
4
Misión de la Future Internet (FI)
Ofrecer a todos los usuarios un entorno seguro, eficiente, confiable y robusto, que: Permita un acceso abierto, dinámico y descentralizado a la red y a su información y Sea escalable, flexible y adapte su rendimiento a las necesidades de los usuarios y su contexto

5
Arquitectura de la Internet del Futuro

6
Internet de los Servicios
Una multitud de servicios IT conectados, que son ofrecidos, comprados, vendidos, utilizados, adaptados y compuestos por una red universal de proveedores, consumidores y agregadores de servicios o brokers - resultando en - una nueva manera de ofrecer, utilizar, y organizar funcionalidad soportada por IT Message: The future consists of services (the boxes on the ring) and users of services (the others). All interaction is free without central control Standards are needed for the interactions Is there a need for a platform / infrastructure to coordinate interactions? SAP Services mantra: Services will become tradable, composed from services of different providers, be offered, delivered & executed automatically & supported by IT The Internet of Services will offer customized & personalized services community involvement to improve services, both for providers & consumers of services seamless & smooth adaptation and integration of services into the user environment These network infrastructures need to support an Internet of dynamically combined services with worldwide service delivery platforms and flexibly enable the creation of opportunities for new market entrant. The 'third party generated service' is emerging as a trend supporting the move towards user-centric services, as shown by the advances in Service-Oriented-Architectures and in service front-ends as the interface to users and communities. Virtualisation of resources remains an important research driver enabling the delivery of networked services independently from the underlying platform, an important issue for service providers. Advances in these domains also require breakthroughs in software engineering methods and architectures addressing complexity in distributed, heterogeneous and dynamically composed environments, as well as non-functional requirements. Adapted from SAP Research, 2008, and SEEKDA, 2008 6
 and users of services (the others). All interaction is free without central control. Standards are needed for the interactions. Is there a need for a platform / infrastructure to coordinate interactions SAP Services mantra: Services will become tradable, composed from services of different providers, be offered, delivered & executed automatically & supported by IT. The Internet of Services will offer. customized & personalized services. community involvement to improve services, both for providers & consumers of services. seamless & smooth adaptation and integration of services into the user environment. These network infrastructures need to support an Internet of dynamically combined services with worldwide service delivery platforms and flexibly enable the creation of opportunities for new market entrant. The third party generated service is emerging as a trend supporting the move towards user-centric services, as shown by the advances in Service-Oriented-Architectures and in service front-ends as the interface to users and communities. Virtualisation of resources remains an important research driver enabling the delivery of networked services independently from the underlying platform, an important issue for service providers. Advances in these domains also require breakthroughs in software engineering methods and architectures addressing complexity in distributed, heterogeneous and dynamically composed environments, as well as non-functional requirements. Adapted from SAP Research, 2008, and SEEKDA,")
7
Campos de Actuación de la Internet de los Servicios
Cloud computing: virtualización de servicios y optimización de recursos tanto en capacidad de procesamiento como almacenamiento Open service platforms: modularidad de servicios para facilitar su integración por usuarios finales Autonomic computing: sistemas autogestionados Green IT: optimización del consumo energético

8
El Futuro del Desarrollo Software

9
Infraestructura Virtualizada: Cloud Computing
Un paradigma de computación emergente donde los datos y servicios residen en centros de datos muy escalables que pueden ser accedidos ubicuamente desde cualquier dispositivo conectado a Internet1 Merrill Lynch: Cloud computing market opportunity by 2011 = $95bn in business and productivity apps + $65bn in online advertising = $160bn Message: Big opportunities in cloud computing “Traditional” association with resources/infrastructure blurring. Where exactly is the opportunity? (1) Source: IBM
 Source: IBM.")
10
Cloud Computing es … … capacidad computacional y almacenamiento virtualizada expuesta mediante infraestructura agnóstica a la plataforma y accedida por Internet Recursos IT compartidos en demanda, creados y eliminados eficientemente y de modo escalable a través de una variedad de interfaces programáticos facturados en base a su uso

11
Forrester Research “A pool of abstracted, highly scalable, and managed compute infrastructure capable of hosting end-customer applications and billed by consumption1” 1- “Is Cloud Computing Ready for The Enterprise?” Forrester Research, Inc.

12
The “Cloud” = 10X Improvement
Fácil de usar: hazlo tu mismo remotamente de cualquier lugar en cualquier momento Escalable: controla tu infraestructura con tu aplicación Riesgo: nada que comprar, cancela inmediatamente Robustez: basado en gran hardware empresarial Coste: paga sólo por lo que uses

13
Evolución hacia Cloud Computing
La coexistencia y limitaciones de cluster computing y supercomputing dieron lugar a grid computing De grid computing progresamos hacia utility computing, i.e. Servicios computacionales empaquetados como agua, electricidad, etc. Esto derivó en Cloud Computing, es decir, todo como servicio (XaaS) : Plataforma como Servicio Software como Servicio Infraestructura como Servicio
 : Plataforma como Servicio. Software como Servicio. Infraestructura como Servicio.")
14
Múltiples Descripciones Gráficas de la “Cloud”

15
Múltiples Descripciones Gráficas de la “Cloud”

16
Arquitectura Cloud Computing

17
Características de Cloud
Tipos de despliegue Manifestaciones Cloud privada Propiedad de o alquilada por una empresa (centros de datos,…) Cloud comunitaria Infraestructura compartida por una comunidad específica Cloud pública Vendida al público, gran escala (ec2, S3,…) Cloud híbrida Composición de dos o más clouds Cloud Software as a Service (SaaS) Uso de la aplicación del proveedor sobre la red, e.j., Salesforce.com,… Cloud Platform as a Service (PaaS) Despliega aplicaciones creadas por los clientes a la nube, e.j. Google App Engine, Microsoft Azure, … Cloud Infrastructure as a Service (IaaS) Alquilar procesamiento, almacenamiento, capacidad de red y otros recursos computacionales e.j., EC2 – Elastic Compute Cloud, S3 – Simple Storage Service, Simple DB,…
 Cloud comunitaria. Infraestructura compartida por una comunidad específica. Cloud pública. Vendida al público, gran escala (ec2, S3,…) Cloud híbrida. Composición de dos o más clouds. Cloud Software as a Service (SaaS) Uso de la aplicación del proveedor sobre la red, e.j., Salesforce.com,… Cloud Platform as a Service (PaaS) Despliega aplicaciones creadas por los clientes a la nube, e.j. Google App Engine, Microsoft Azure, … Cloud Infrastructure as a Service (IaaS) Alquilar procesamiento, almacenamiento, capacidad de red y otros recursos computacionales e.j., EC2 – Elastic Compute Cloud, S3 – Simple Storage Service, Simple DB,…")
18
Diferentes Manifestaciones

19
Cloud Computing vs. Centros de Datos Tradicionales

20
Componentes de Cloud Computing

21
Taxonomía de Cloud Computing

22
Evolución de Tecnologías de Cloud Computing
Maduración de tecnología de virtualización La virtualización permite nubes de computación Las nubes de computación demandan nubes de almacenamiento Las nubes de almacenamiento y computación crean infraestructura cloud La infraestructura cloud da lugar a plataformas y aplicaciones cloud Diferentes tipos de cloud dan lugar a Cloud Aggregators Nichos de requisitos dan lugar a Cloud Extenders

23
Aplicaciones Cloud Corresponden con lo que se denomina como SaaS
Manifestación de cloud más popular Ejemplos: SalesForce, Gmail, Yahoo! Mail, rememberthemilk, doodle, Google Docs, DropBox, picnik, Panda Cloud Antivirus, scribd, slideshare Ventajas: Libre, Fácil, Adopción de consumo Desventajas: funcionalidad limitada, no hay control de acceso a la tecnología subyacente

24
Plataformas Cloud Contenedores de aplicaciones Entornos cerrados
Ejemplos: Google App Engine, Heroku, Mosso, Engine Yard, Joyent o Force.com (SalesForce Dev Platform) Ventajas: buenas para desarrolladores, más control que en las aplicaciones cloud, configuradas estrechamente Desventajas: restringidas a lo que está disponible, otras dependencias, dependencia tecnológica
 Ventajas: buenas para desarrolladores, más control que en las aplicaciones cloud, configuradas estrechamente. Desventajas: restringidas a lo que está disponible, otras dependencias, dependencia tecnológica.")
25
Infraestructura Cloud
Proveen nubes de computación y almacenamiento Ofrecen capas de virtualización (hardware/software) Ejemplos: Amazon EC2, GoGrid, Amazon S3, Nirvanix, Linode, Arsys Cloud Flexible, EyeOS Ventajas: control completo del entorno y la infraestructura Desventajas: precio premium, competencia limitada
 Ejemplos: Amazon EC2, GoGrid, Amazon S3, Nirvanix, Linode, Arsys Cloud Flexible, EyeOS. Ventajas: control completo del entorno y la infraestructura. Desventajas: precio premium, competencia limitada.")
26
Extensores de la Cloud Proveen extensiones a infraestructura y plataformas cloud con funcionalidad básica Ejemplos: Amazon SimpleDB, Amazon SQS, Google BigTable Ventajas: extienden la funcionalidad de las nubes de computación y almacenamiento para integrar sistemas heredados u otras cloud Desventajas: a veces requieren el uso de plataformas o infraestructura específica

27
Agregadores Cloud Se apoyan en varias infraestructuras cloud para su gestión Ejemplos: RightScale, Appistry Ventajas: proveen más opciones para entornos cloud Desventajas: dependientes de proveedores de cloud

28
¿Qué framework o plataforma usar para mis aplicaciones Cloud?

29
Amazon Web Services (AWS)
AWS proporciona una infraestructura de servicios elástica donde alojar computación, almacenamiento o sistemas empresariales Amazon Elastic Cloud (EC2) – permite configurar y ejecutar un Amazon Machine Instance (AMI) – servidores en demanda Amazon Simple Storage Service (S3) – permite guardar y recuperar datos en la nube Amazon SimpleDB – proporciona la funcionalidad de una base de datos sobre S3 – basada en pares clave-valor Amazon Simple Queue Service (SQS) – servicio de mensajería para encolar tareas y mensajes Amazon Relational Database Service (RDS) – servicio web para crear, operar y escalar una base de datos en la nube Amazon CloudFront – copias de tus objetos más populares son cacheados en una red de nodos alrededor del mundo … Documentación:
 – permite configurar y ejecutar un Amazon Machine Instance (AMI) – servidores en demanda. Amazon Simple Storage Service (S3) – permite guardar y recuperar datos en la nube. Amazon SimpleDB – proporciona la funcionalidad de una base de datos sobre S3 – basada en pares clave-valor. Amazon Simple Queue Service (SQS) – servicio de mensajería para encolar tareas y mensajes. Amazon Relational Database Service (RDS) – servicio web para crear, operar y escalar una base de datos en la nube. Amazon CloudFront – copias de tus objetos más populares son cacheados en una red de nodos alrededor del mundo. … Documentación:")
30
Amazon Web Services (AWS)
")
31
Amazon Web Services (AWS)
")
32
Amazon Elastic Compute Cloud: EC2
Permite ejecutar varios servidores Linux o Windows virtuales en demanda, facilitando tantos ordenadores como necesites para procesar tus datos o ejecutar una aplicación Otorga acceso root al sistema operativo de cada servidor, un cortafuegos para gestionar el acceso a la red y la libertad para instalar cualquier software Una vez configurado un servidor adecuadamente, se guarda como Amazon Machine Image (AMI) que puede ser lanzada para crear máquinas virtuales en demanda La EC2 API (Query o SOAP) ofrece funcionalidad para empezar y parar instancias de servidor, aplicar permisos de acceso y red o gestionar tus imágenes de servidor. Cada servidor individual se gestiona usando herramientas Linux o Windows sobre una sesión de shell segura. Se factura en función de los recursos consumidos : CPU y datos transferidos Más información en:
 que puede ser lanzada para crear máquinas virtuales en demanda. La EC2 API (Query o SOAP) ofrece funcionalidad para empezar y parar instancias de servidor, aplicar permisos de acceso y red o gestionar tus imágenes de servidor. Cada servidor individual se gestiona usando herramientas Linux o Windows sobre una sesión de shell segura. Se factura en función de los recursos consumidos : CPU y datos transferidos. Más información en:")
33
Conceptos EC2 AMI (Amazon Machine Instance)
Basadas en XEN Instancia: AMI en ejecución Es necesario crear instancias EBS si queremos pararlas y reiniciarlas Dos IPs: IP pública e IP elástica Volúmenes EBS (Elastic Block Storage): almacenamiento para las instancias Conceptos de credenciales: Access Key ID y Secret Access Key X.509 certificate y clave privada (SOAP y EC2 Tools) IP Elástica – asociada a tu cuenta no una instancia, te permite controlar la a qué instancia o instancias apunta (útil por robustez). Conceptos y herramientas para usar EC2 en:
: almacenamiento para las instancias. Conceptos de credenciales: Access Key ID y Secret Access Key. X.509 certificate y clave privada (SOAP y EC2 Tools) IP Elástica – asociada a tu cuenta no una instancia, te permite controlar la a qué instancia o instancias apunta (útil por robustez). Conceptos y herramientas para usar EC2 en:")
34
EC2: Regiones y Zonas de Disponibilidad
Las instancias en EC2 se pueden colocar en diferentes localizaciones: Las regiones están dispersas geográficamente (ver tabla debajo) Las zonas de disponibilidad son localizaciones diferentes dentro de una Región que están aisladas de fallos en otras zonas y facilitan conectividad de red económica, de baja latencia a otras zonas de disponibilidad dentro de la Región Region Endpoint US-East (Northern Virginia) Region ec2.us-east-1.amazonaws.com US-West (Northern California) Region ec2.us-west-1.amazonaws.com EU (Ireland) Region ec2.eu-west-1.amazonaws.com Asia Pacific (Singapore) Region ec2.ap-southeast-1.amazonaws.com
 Las zonas de disponibilidad son localizaciones diferentes dentro de una Región que están aisladas de fallos en otras zonas y facilitan conectividad de red económica, de baja latencia a otras zonas de disponibilidad dentro de la Región. Region. Endpoint. US-East (Northern Virginia) Region. ec2.us-east-1.amazonaws.com. US-West (Northern California) Region. ec2.us-west-1.amazonaws.com. EU (Ireland) Region. ec2.eu-west-1.amazonaws.com. Asia Pacific (Singapore) Region. ec2.ap-southeast-1.amazonaws.com.")
35
CloudWatch Amazon CloudWatch es un servicio que proporciona monitorización para recursos gestionados por AWS Muestra utilización de recursos como CPU, lecturas y escrituras de disco o tráfico de red Elastic Load Balancing distribuye automáticamente el tráfico de aplicación entrante entre varias instancias EC2 Auto Scaling permite escalar automáticamente hacia arriba o abajo tu capacidad EC2 en función de triggers que defines

36
CloudWatch en Funcionamiento

37
CloudWatch en Funcionamiento

38
Elastic Load Balancing en Funcionamiento

39
Autoscaling en Funcionamiento

40
Amazon Simple Storage Service: S3
Ofrece espacio de almacenamiento seguro para cualquier tipo de datos en los data centers de Amazon Es una alternativa a construir, mantener y utilizar tus propios sistemas de almacenamiento No tiene límites sobre cuánta información, por cuánto tiempo y con qué ancho de banda puede transferirse. Ofrece una simple API agnóstica a la información a guardar Depende de ti qué datos y qué representación interna tienen El modelo de datos interno consta de dos tipos de recursos de almacenamiento: Objects: guardan datos y metadatos Buckets: contenedores que pueden contener infinidad de objetos Incorpora mecanismos de control de acceso (ACL) que pueden aplicarse a objetos y buckets
 que pueden aplicarse a objetos y buckets.")
41
Amazon Simple Storage Service: S3
Los recursos en S3 se identifican mediante URIs: Ejemplo: Algunas características de su arquitectura son: Los objetos S3 no pueden ser manipulados como ficheros estándar Los cambios sobre ellos tardan en propagarse Las peticiones a objetos pueden fallar ocasionalmente Permite guardar versiones Se deben resolver las direcciones IP de los nombres DNS de S3 periódicamente Se pueden guardar infinitos objetos de hasta 5GB en tamaño Se paga por almacenamiento, transferencia y operaciones Algunos posibles usos de S3: Compartir grandes ficheros Como repositorio de back-up de tus ficheros Sistema de ficheros mapeado sobre S3 (ElasticDrive) Más información en:
 Más información en:")
42
Amazon CloudFront Mientras que en Amazon S3 se guardan contenidos (ficheros) con CloudFront se garantiza que tus objetos en S3 buckets son servidos rápidamente. Lo hace copiando los ficheros en buckets S3 a diferentes edge locations que sirven contenidos a los usuarios finales. Tales edge locations se distribuyen por el planeta asegurándose que los contenidos son servidos del servidor Amazon más cercano Es ventajoso porque el 80-90% del tiempo invertido esperando a una respuesta web se debe a la descarga de los componentes de la página: imágenes, hojas de estilo, scripts, Flash, etc. La clave es colocar la parte estática de nuestra web en una red de distribución de contenidos como Akamai. Con CloudFront hay que pagar las transferencias desde S3 a las localizaciones de los bordes. Más información en:
 con CloudFront se garantiza que tus objetos en S3 buckets son servidos rápidamente. Lo hace copiando los ficheros en buckets S3 a diferentes edge locations que sirven contenidos a los usuarios finales. Tales edge locations se distribuyen por el planeta asegurándose que los contenidos son servidos del servidor Amazon más cercano. Es ventajoso porque el 80-90% del tiempo invertido esperando a una respuesta web se debe a la descarga de los componentes de la página: imágenes, hojas de estilo, scripts, Flash, etc. La clave es colocar la parte estática de nuestra web en una red de distribución de contenidos como Akamai. Con CloudFront hay que pagar las transferencias desde S3 a las localizaciones de los bordes. Más información en:")
43
¿Cómo usar CloudFront? Las redes de distribución de contenidos tienen servidores distribuidos por Internet y determinan la ruta más rápida y corta entre el servidor que aloja el contenido y el usuario final Los 4 sencillos pasos que hay que seguir para utilizar CloudFront han sido extraídos del artículo: Get the S3 Fox add-on for Firefox and log-in to your Amazon S3 account. Now right-click your S3 bucket and select "Manage Distributions.“ Next we’ll associate a CNAME (some easy to remember sub-domain name) with our S3 bucket so it become easy to link to the files from our web pages. In this example, I use the web address "cache.labnol.org" and then click Create Distribution. The status will change from "In Progress" to "Deployed". Now copy the resource URL to the clipboard which is of the format xyz.cloudfront.net Log in to your account on your web hosting service’s website, and go to the DNS management page. Create a new CNAME record as shown in the screenshot.
 with our S3 bucket so it become easy to link to the files from our web pages. In this example, I use the web address cache.labnol.org and then click Create Distribution. The status will change from In Progress to Deployed . Now copy the resource URL to the clipboard which is of the format xyz.cloudfront.net. Log in to your account on your web hosting service’s website, and go to the DNS management page. Create a new CNAME record as shown in the screenshot.")
44
Amazon SimpleDB Almacén de claves/valor: trabaja con los conceptos domain, item y attribute Diseñado para minimizar la complejidad y el coste de mantenimiento de tus datos Guarda pequeñas piezas de información textual en una estructura de base de datos sencilla simple de gestionar, modificar y buscar Ofrece su propio lenguaje de consultas de datos Ejemplos de consultas sencillas: ['Date' > ' ' and Not 'Date' starts-with ' '] ['Suburb' = 'Newtown'] or['Price' < '100000'] intersection ['Bedrooms' = '3'] Si tus aplicaciones están basadas en bases de datos simples, este servicio puede reemplazar a tu RDBMS dejándote con una pieza de infraestructura menos que comprar y mantener No exige la especificación de un schema previo, tú puedes modificar la estructura y contenidos de tu base de datos cuando quieras Indexa cada pieza almacenada Guarda tu información de modo seguro, y redundante en la red de data centers de Amazon Pagas por almacenamiento, datos transferidos y operaciones Más información en:

45
Amazon SimpleDB Ofrece tres recursos principales:
Dominios: nombre de un contenedor con información relacionada (similar a base de datos) Solamente se procesan consultas dentro de un dominio Elementos: es una colección con nombre de los atributos que representan un objeto de datos Atributos: es una categoría individual de información guardada dentro de un elemento. Identificado por un nombre contiene una colección de valores de tipo string, obligatorio que tenga al menos un valor. Es una base de datos sencilla, no un RDBMS: Los elementos se guardan en una estructura jerárquica, no una tabla Todos los datos se guardan como texto Capacidades de consulta limitadas La consistencia de la información depende de retardos de propagación Los valores de atributos pueden ser colecciones y alcanzar hasta 1024 bytes SimpleDB está concebido para usarse en conjunción con S3
 Solamente se procesan consultas dentro de un dominio. Elementos: es una colección con nombre de los atributos que representan un objeto de datos. Atributos: es una categoría individual de información guardada dentro de un elemento. Identificado por un nombre contiene una colección de valores de tipo string, obligatorio que tenga al menos un valor. Es una base de datos sencilla, no un RDBMS: Los elementos se guardan en una estructura jerárquica, no una tabla. Todos los datos se guardan como texto. Capacidades de consulta limitadas. La consistencia de la información depende de retardos de propagación. Los valores de atributos pueden ser colecciones y alcanzar hasta 1024 bytes. SimpleDB está concebido para usarse en conjunción con S3.")
46
Amazon SimpleDB

47
Example DataSet con SimpleDB
Item Name Title Author Year Number of Pages Keywords Rating The Sirens of Titan Kurt Vonnegut 1959 00336 Book Paperback ***** 5 stars Excellent Tropic of Cancer Henry Miller 1934 00318 **** The Right Stuff Tom Wolfe 1979 00304 Hardcover American 4 stars B000T9886K In Between Paul Van Dyk 2007 CD Trance B00005JPLW 300 Zack Snyder DVD Action Frank Miller *** 3 stars Not bad B000SF3NGK Heaven's Gonna Burn Your Eyes Thievery Corporation 2002

48
Ejemplos de Consultas Query Expression Description Result Set
select * from mydomain where Title = 'The Right Stuff' Retrieves all items where the attribute "Title" equals "The Right Stuff." select * from mydomain where Year > '1985' Retrieves all items where "Year" is greater than "1985." Although this looks like a numerical comparison, it is lexicographical. Because the calendar won't change to five digits for nearly 8,000 years, "Year" is not zero padded. B000T9886K, B00005JPLW, B000SF3NGK select * from mydomain where Rating like '****%' Retrieves all items that have at least a 4 star (****) rating. The prefix comparison is case-sensitive and exact and does not match attributes that only have the "4 star" value, such as item B000T9886K. Note: The like operator is similar to starts-with and only supports % at the end of the string. , , , B000SF3NGK select * from mydomain where Pages < '00320' Retrieves all items that have less than 320 pages. This attribute is zero padded in the data set and the select expression, which allows for proper lexicographical comparison between the strings. Items without this attribute are not considered. , ,
 rating. The prefix comparison is case-sensitive and exact and does not match attributes that only have the 4 star value, such as item B000T9886K. Note: The like operator is similar to starts-with and only supports % at the end of the string , , , B000SF3NGK. select * from mydomain where Pages < Retrieves all items that have less than 320 pages. This attribute is zero padded in the data set and the select expression, which allows for proper lexicographical comparison between the strings. Items without this attribute are not considered , ,")
49
Amazon Relational Database Service (Amazon RDS)
Es un servicio web que facilita la instalación, operación y escalabilidad de una base de datos relacional en la nube Te da completo acceso a las capacidades de una base de datos MySQL Las aplicaciones que ya funcionan con MySQL también lo harán con Amazon RDS Amazon RDS modifica el software MySQL para programar la creación de back-ups o garantizar la escalabilidad, todo ello controlado a través de una API sencilla. Solamente se paga por los recursos utilizados. Más información en: Herramienta: Amazon RDS Command Line Toolkit Tutorial en:

50
AWS Free User Tier La condiciones de uso son las siguientes:
AWS Free Usage Tier (Per Month): 750 hours of Amazon EC2 Linux Micro Instance usage (613 MB of memory and 32-bit and 64-bit platform support) – enough hours to run continuously each month* 750 hours of an Elastic Load Balancer plus 15 GB data processing* 10 GB of Amazon Elastic Block Storage, plus 1 million I/Os, 1 GB of snapshot storage, 10,000 snapshot Get Requests and 1,000 snapshot Put Requests* 5 GB of Amazon S3 storage, 20,000 Get Requests, and 2,000 Put Requests* 30 GB per of internet data transfer (15 GB of data transfer “in” and 15 GB of data transfer “out” across all services except Amazon CloudFront)* 25 Amazon SimpleDB Machine Hours and 1 GB of Storage** 100,000 Requests of Amazon Simple Queue Service** 100,000 Requests, 100,000 HTTP notifications and 1,000 notifications for Amazon Simple Notification Service** In addition to these services, the AWS Management Console is available at no charge to help you build and manage your application on AWS.
: 750 hours of Amazon EC2 Linux Micro Instance usage (613 MB of memory and 32-bit and 64-bit platform support) – enough hours to run continuously each month* 750 hours of an Elastic Load Balancer plus 15 GB data processing* 10 GB of Amazon Elastic Block Storage, plus 1 million I/Os, 1 GB of snapshot storage, 10,000 snapshot Get Requests and 1,000 snapshot Put Requests* 5 GB of Amazon S3 storage, 20,000 Get Requests, and 2,000 Put Requests* 30 GB per of internet data transfer (15 GB of data transfer in and 15 GB of data transfer out across all services except Amazon CloudFront)* 25 Amazon SimpleDB Machine Hours and 1 GB of Storage** 100,000 Requests of Amazon Simple Queue Service** 100,000 Requests, 100,000 HTTP notifications and 1,000 notifications for Amazon Simple Notification Service** In addition to these services, the AWS Management Console is available at no charge to help you build and manage your application on AWS.")
51
Amazon SQS Implementa el servicio de mensajería basado en colas
Los mensajes son siempre strings Útil para crear trabajos asíncronos y descargar de actividad a un web server Se paga por mensajes y datos transferidos Más información en:

52
Registro y Documentación
Se puede ver en detalle cómo acceder a AWS: (Free usage tier)
")
53
Proceso para usar AWS EC2
Vamos a seguir el siguiente workflow para aprender a usar EC2, crear instancias y conectarnos a ellas, tanto desde Windows como UNIX.

54
Fase 1: Registro en AWS Para utilizar Amazon EC2, necesitas una cuenta Amazon AWS Ir a hacer click en Sign Up for Amazon EC2. Seguir las instrucciones de pantalla Pasarás a estar suscrito también a Amazon Simple Storage and Amazon Virtual Private Cloud Recibirás una llamada donde introducir el PIN que te asignan vía web

55
Fase 1: Registro en AWS

56
Fase 1: Registro en AWS

57
Fase 1: Registro en AWS

58
Fase 1: Registro en AWS

59
Fase 1: Registro en AWS

60
Fase 1: Obteniendo los Identificadores de Acceso
Vete a logueate, haz click en Security Credentials y recupera: Access Key ID y Access Key, pestaña Access Keys Account number se ve en la parte derecha, superior de la página de Security Credentials X.509 Private Key File (pestaña X.509 Certificates) X.509 Certificate File (pestaña KeyPairs) Los siguientes pantallazos muestran cómo obtener estos datos Guárdalos en ficheros para luego usarlos en tus aplicaciones
 X.509 Certificate File (pestaña KeyPairs) Los siguientes pantallazos muestran cómo obtener estos datos. Guárdalos en ficheros para luego usarlos en tus aplicaciones.")
61
Fase 1: Obteniendo los Identificadores de Acceso

62
Fase 1: Obteniendo los Identificadores de Acceso

63
Fase 1: Registrarse para EC2 y S3
Acceder a la consola de administración de AWS en: Logearse o Registrarse Durante el registro se solicitan los datos de cargo bancario Recibirás un de confirmación tanto para EC2 como S3 Alternativamente puedes registrarte individualmente en los diferentes productos yendo al enlace Products y seleccionando el servicio concreto en:

64
Fase 1: Registrarse para EC2 y S3

65
Fase 1: Registrarse para EC2 y S3

66
Fase 2: Lanzar una Instancia de EC2
Iniciar el “dashboard”, panel de control de AWS Console y realizar los siguientes pasos: Pulsar el botón de nueva instancia Seleccionar una instancia concreta Fedora LAMP Web Server para ejemplo completo Instancia AMI de Windows básica Instancia AMI de UNIX básica Generar o reutilizar un par de claves Guardar las claves Configurar el firewall Revisar los detalles de la instancia desplegada Lanzar la instancia y comprobar que está en ejecución

67
Paso 2.1: Lanzar una Nueva Instancia

68
Paso 2.2: Seleccionar la instancia

69
Paso 2.3: Configurar la Instancia

70
Paso 2.4: Asignar Par de Claves

71
Paso 2.5: Configurar el Firewall

72
Paso 2.6: Revisar los Detalles de la Instancia Configurada

73
Paso 2.7: Lanzar la Instancia y Operar sobre Ella

74
Detalles de la Instancia Creada

75
Fase 2: Lanzando Otras Instancias
Vamos a lanzar otra instancia en Windows y otra en UNIX con soporte EBS: Accede a AWS Management Console: y regístrate Desde EC2 Console Dashboard, haz click en Launch Instance Elige un AMI, vamos a trabajar bien con Fedora 8 Core o Microsoft Windows Server 2008 Selecciona y acepta los detalles de la instancia Crea un par de claves, que es un credencial utilizado para conectarse a una instancia Crea un grupo de seguridad que define reglas de firewall para tu instancia Revisa tus configuraciones y pulsa el botón Launch

76
Fase 3: Accediendo a la instancia vía web (Servidor LAMP Fedora)
")
77
Fase 3: Modificando la Página por Defecto
Pasos a seguir en cliente UNIX: Logeo en el servidor remoto: ssh -i <instancia> ssh –i ami-f04f6484 Vamos al directorio htdocs cd /home/webuser/helloworld/htdocs Modificamos la página index.php (ver contenido siguiente trasparencia)
")
78
Fase 3: Ejemplo de contenido para index.php
<html> <head> <title>Nuestro propio Servidor Web</title> <meta http-equiv="Content-Type" content="text/html; charset-ISO "> </head> <body> <Nuestro propio Servidor Web ejecutándose en AWS</h1> <p>Una demostración del curso To Cloud or not To Cloud. That is the question! en Enpresa Digitala.</p> <p>Ejemplo adaptado de <a href=" </a> </p> </body> </html>

79
Fase 3: Herramientas para Conectarse a Instancia UNIX desde Windows
Software necesario (cygwin también valdría): Putty – Putty es un terminal cliente de SSH, descargable de: PuttyGen – programa que convierte la clave privada de Amazon al formato PPK usado por putty Se descarga de la misma página que putty WinSCP – cliente de SFTP y SSH para Windows que permite la transferencia segura de ficheros entre ordenadores. Soporta los protocols SSH, FTP y SCP. Se descarga desde: Tutorial detallado en:
: Putty – Putty es un terminal cliente de SSH, descargable de: PuttyGen – programa que convierte la clave privada de Amazon al formato PPK usado por putty. Se descarga de la misma página que putty. WinSCP – cliente de SFTP y SSH para Windows que permite la transferencia segura de ficheros entre ordenadores. Soporta los protocols SSH, FTP y SCP. Se descarga desde: Tutorial detallado en:")
80
Fase 3: Conectándose a UNIX AMI desde Windows – Conversión de Clave para putty
Cargar el fichero LAMPServerFedora.pem y pulsar en Save Private Key que guardará un fichero con extensión ppk que usa putty

81
Fase 3: Conectándose a UNIX AMI desde Windows – Logeo en Windows con putty
Arrancar putty Introducir el nombre público DNS del servidor (ec eu-west-1.compute.amazonaws.com) Ir a al menú ssh->Auth->Browse y cargar clave privada LAMPServerFedora.ppk Loguéate como root
 Ir a al menú ssh->Auth->Browse y cargar clave privada LAMPServerFedora.ppk. Loguéate como root.")
82
Fase 3: Accediendo a ficheros en UNIX AMI desde Windows – Edición de index.php con WinSCP

83
Página Final en Instancia EC2

84
Fase 3: Conectándose a una Instancia de Windows
Obteniendo la contraseña Haz click con el botón derecho del ratón sobre la instancia Windows y selecciona “Get Windows Password” Aparece el diálogo Retrieve Default Windows Administrator Password, pega ahí la private key obtenida antes, parte del fichero de claves entre BEGIN RSA PRIVATE KEY y END RSA PRIVATE KEY Selecciona descrifrar clave Conectarse a la instancia usando Remote Desktop Connection Start All Programs Accessories Introduce el nombre DNS de la instancia Logéate como Administrator/<password-recuperada>

85
Fase 4: Terminar Instancia
No es lo mismo “parar” (stop) que “terminar” (terminate) en AWS Cuando terminas una instancia no la puedes reiniciar, ¡dejas de pagar! Sólo la puedes parar si tiene un EBS asociado Para terminar una instancia en la AWS Console, haz click con el botón derecho del ratón y selecciona terminate
 que terminar (terminate) en AWS. Cuando terminas una instancia no la puedes reiniciar, ¡dejas de pagar! Sólo la puedes parar si tiene un EBS asociado. Para terminar una instancia en la AWS Console, haz click con el botón derecho del ratón y selecciona terminate.")
86
Probando S3

87
Probando SimpleDB Scratchpad for SimpleDB es una aplicación web que permite usar Amazon SimpleDB sin necesidad de realizar programación Te permite: Crear dominios Poblarlos con datos Consultarlos Modificarlos Borrar el dominio

88
Probando SimpleDB

89
Probando RDS Para utilizarlo hay que seguir los siguientes pasos:
Ir a registrarte con Amazon RDS Lanzar la instancia y rellenar los datos de tamaño, tipo de base de datos, nombre y clave de usuario Asignar accesos a la instancia de la base de datos, se utiliza CIDR (Classless Inter-Domain Routing) para indicar sólo una dirección IP o un conjunto de direcciones desde las que se permite la conexión Acceso total: /0 Conectarse a la instancia usando la herramienta mysql, en la descripción de la instancia en AWS Console aparecerá el string de conexión mysql -h <nombre-host-amazon-rds> -u <username> -p Terminar la instancia para que dejen de facturarnos por su uso
 para indicar sólo una dirección IP o un conjunto de direcciones desde las que se permite la conexión. Acceso total: /0. Conectarse a la instancia usando la herramienta mysql, en la descripción de la instancia en AWS Console aparecerá el string de conexión. mysql -h <nombre-host-amazon-rds> -u <username> -p. Terminar la instancia para que dejen de facturarnos por su uso.")
90
Probando SQS El Simple Queue Service (SQS) puede probarse con una sencilla herramienta: JavaScript Scratchpad for Amazon SQS

91
Probando CloudFront Ejemplo de uso desde consola de administración de Amazon

92
Desregistro de un Servicio
Para cancelar un servicio: Firma en AWS Haz click en Your Account y luego en Account Activity. Selecciona View/Edit Service debajo del servicio que quieres cancelar Haz click en el enlace cancel this service.

93
Calculadora de Costes en Amazon
La siguiente herramienta te permite estimar costes de consumo de servicios en Amazon: Además, desde la página se puede acceder al menú “Account Activity” que ilustra el gasto actual incurrido.

94
APIs web: SOAP vs. REST SOAP: Simple Object Access Protocol
Define cómo dos objetos en diferentes procesos pueden comunicarse por medio de intercambio de datos XML. Deriva de un protocolo creado por David Winer en 1998, llamado XML-RPC. Fue creado por Microsoft, IBM, y otros y actualmente se encuentra bajo el auspicio de la W3C. Su arquitectura consiste en varias capas de especificaciones para formato de mensajes: Message Exchange Patterns (MEP) Protocolos de transporte (SMTP y HTTP/S) Modelos de procesado de mensajes Protocolo de extensibilidad WS-* REST: Represantional State Transfer Estilo de arquitectura software para sistemas de hypermedia distribuidos como la WWW. Introducido en la tésis doctoral de Roy Fielding en el año 2000. Se refiere a una colección de principios de arquitectura de red, que marcan cómo definir e invocar los recursos. El término se usa a veces para describir una simple interfaz que transmite datos de un dominio específico por HTTP sin capas adicionales como SOAP o uso de cookies. Los sistemas que cumplen los principios marcados por Fielding suelen ser referidos como sistemas RESTful.
 Protocolos de transporte (SMTP y HTTP/S) Modelos de procesado de mensajes. Protocolo de extensibilidad. WS-* REST: Represantional State Transfer. Estilo de arquitectura software para sistemas de hypermedia distribuidos como la WWW. Introducido en la tésis doctoral de Roy Fielding en el año Se refiere a una colección de principios de arquitectura de red, que marcan cómo definir e invocar los recursos. El término se usa a veces para describir una simple interfaz que transmite datos de un dominio específico por HTTP sin capas adicionales como SOAP o uso de cookies. Los sistemas que cumplen los principios marcados por Fielding suelen ser referidos como sistemas RESTful.")
95
Programación en AWS Interfaces REST: Interfaces Query: Interfaces SOAP
Utilizan componentes estándar de peticiones HTTP para representar la acción de la API a ejecutar: Métodos HTTP: describen la acción a ejecutar por la petición Universal Resource Identifier (URI): identifican el recurso sobre el que se va a ejecutar la acción Cabeceras de petición: ofrecen más metadatos sobre la petición o el peticionario Cuerpo de la petición: transfieren los datos que nutrirán la acción a ejecutar por el servicio Interfaces Query: También hacen uso del protocolo HTTP para representar acciones de la API, pero lo hacen a través de parámetros (pares nombre valor) que indican la acción y los datos que nutrirán tal acción. Se suelen indicar en la URI de una petición GET o el cuerpo de un POST Esta interfaz es considerada como REST-like no RESTful, no es un enfoque puro de REST sino que explota HTTP Interfaces SOAP
: identifican el recurso sobre el que se va a ejecutar la acción. Cabeceras de petición: ofrecen más metadatos sobre la petición o el peticionario. Cuerpo de la petición: transfieren los datos que nutrirán la acción a ejecutar por el servicio. Interfaces Query: También hacen uso del protocolo HTTP para representar acciones de la API, pero lo hacen a través de parámetros (pares nombre valor) que indican la acción y los datos que nutrirán tal acción. Se suelen indicar en la URI de una petición GET o el cuerpo de un POST. Esta interfaz es considerada como REST-like no RESTful, no es un enfoque puro de REST sino que explota HTTP. Interfaces SOAP.")
96
APIs Disponibles por Servicio AWS
Service REST API Query API SOAP API S3 Yes No EC2 SQS FPS SimpleDB RDS

97
Revisión APIs de los Principales Servicios
EC2: (mirar quick reference card) S3: SimpleDB: SQS Documentation: RDS
 S3: WorkingWithS3.html. SimpleDB: SQS Documentation: RDS.")
98
Invocación de Servicios Web AWS
Recetas para el uso de la API SOAP desde Java: Recipe 27.5 Getting Set Up with Amazon's Web Services API Recipe 27.6 Creating a JavaBean to Connect with Amazon Recipe 27.7 Using a Servlet to Connect with Amazon

99
AWS SDK for Java Ofrece una API basada en Java para acceder a los servicios de infraestructura de AWS, haciendo sencillo el desarrollo de aplicaciones que usan las características de la nube AWS: eficiente en costes, escalable y robusta Descargar de: incluye: AWS Java Library Ejemplos de código Soporte para Eclipse Soporta los siguientes servicios: Amazon Elastic Compute Cloud (EC2), Amazon Simple Storage Service (S3), Amazon Virtual Private Cloud, Amazon SimpleDB, Amazon Relational Database Service, Amazon Simple Notification Service, Amazon Simple Queue Service, Amazon Elastic MapReduce, Amazon CloudWatch, Elastic Load Balancing, Auto Scaling Documentación:
, Amazon Simple Storage Service (S3), Amazon Virtual Private Cloud, Amazon SimpleDB, Amazon Relational Database Service, Amazon Simple Notification Service, Amazon Simple Queue Service, Amazon Elastic MapReduce, Amazon CloudWatch, Elastic Load Balancing, Auto Scaling Documentación: externalID= externalID=848&categoryID=152.")
100
Usando AWS SDK for Java Revisar ejemplos en carpeta examples/aws
Se puede obtener documentación detallada en: Antes de empezar, debes registrarte en cada servicio que quieras utilizar. Necesitas obtener tus credenciales de seguridad de: Previamente puede que tengas que firmar en Los credenciales son un par de claves públicas y privadas que contienen: Access Key ID Secret Access Key Revisar ejemplos en carpeta examples/aws

101
Herramientas para Usar Amazon
ScratchPad for SimpleDB y SQS ElasticDrive – ElasticFox – S3 Fox – plugin para Firefox, Amazon EC2 API Tools Programas de línea de comandos para intermediar con Amazon EC2 Sirven para registrar, lanzar instancias, manipular grupos de seguridad y más

102
Caso práctico de Álbum de Fotos
Álbum de fotos que permite subir fotos, organizarlas y visualizarlas Arquitectura tradicional:

103
Caso práctico de Álbum de Fotos
Solución Cloud con: S3, SDB, SQS y CloudFront Ejemplo descrito en:

104
Caso práctico de Álbum de Fotos

105
Despliegue de Django en EC2
Seguir los pasos indicados en:

106
Soporte para Otros Lenguajes
Existe soporte para otros lenguajes como Python, Ruby, PHP o .NET PHP: Tarzan AWS ( Más información en:

107
Ejemplo Plataforma Cloud: Google App Engine
Google App Engine es una herramienta para el alojamiento de aplicaciones web escalables sobre la infraestructura de Google Su misión es permitir al desarrollador web crear fácilmente aplicaciones web escalables sin ser un experto en sistemas Aporta las siguientes características a los desarrolladores: Limita la responsabilidad del programador al desarrollo y primer despliegue – Google App Engine provee recursos computacionales dinámicamente según son necesarios Toma control de los picos de tráfico – si nuestro portal crece en popularidad no es necesario actualizar nuestra infraestructura (servidores, BBDD) Ofrece replicación y balanceo de carga automática apoyado en componentes como Bigtable Fácilmente integrable con otros servicios de Google – los desarrolladores pueden hacer uso de componentes existentes y la librería de APIs de Google ( , autenticación, pagos, etc.)
 Ofrece replicación y balanceo de carga automática apoyado en componentes como Bigtable. Fácilmente integrable con otros servicios de Google – los desarrolladores pueden hacer uso de componentes existentes y la librería de APIs de Google ( , autenticación, pagos, etc.)")
108
Google App Engine: Características
Ofrece una plataforma completa para el alojamiento y escalado automático de aplicaciones, consistiendo en: Servidores de aplicaciones Python y Java La base de datos BigTable El sistema de ficheros GFS Como desarrollador simplemente tienes que subir tu código Python o Java compilado a Google, lanzar la aplicación y monitorizar el uso y otras métricas Google App Engine incluye la librería estándar de Python 2.5 y soporta Java 1.6 No todas las acciones se permiten (acceso a ficheros, llamadas al SO, algunas llamadas de red) Se ejecuta en un entorno restringido para permitir que las aplicaciones escalen Ejemplo:
 Se ejecuta en un entorno restringido para permitir que las aplicaciones escalen. Ejemplo:")
109
Facturación Google App Engine
Hasta 10 aplicaciones con 500 MB de almacenamiento y 5 millones de visitas al mes cada una Página de presupuestado y facturación de recursos: Detalles sobre las cuotas en: Recurso Unidad Coste de la unidad Ancho de banda de salida gigabytes 0,12 dólares Ancho de banda de entrada 0,10 dólares Tiempo de CPU horas de CPU Datos almacenados gigabytes al mes 0,15 dólares Destinatarios de mensajes de correo electrónico destinatarios 0,0001 dólares

111
Google App Engine: Python y Java
Vamos a revisar primero (brevemente) cómo realizar aplicaciones con Python Luego nos centraremos en cómo hacerlo desde Java en mayor grado de detalle
 cómo realizar aplicaciones con Python. Luego nos centraremos en cómo hacerlo desde Java en mayor grado de detalle.")
112
GAE for Python: Instalación
Descargar Google App Engine SDK para Python de: Herramientas de la SDK para Python: dev_appserver.py, el servidor web de desarrollo appcfg.py, sirve para subir tu aplicación a App Engine Herramienta de descarga de datos – es una herramienta sencilla que te permite subir datos en ficheros CSV al almacen de datos de appengine

113
Principios Una aplicación de App Engine se comunica con el servidor que la aloja a través de CGI Cuando recibe una petición el servidor lee de la entrada estándar y de las variables de entorno Cuando genera una respuesta escribe a la salida estándar

114
Mi primera aplicación Crear el directorio helloworld
Crea el fichero helloworld.py dentro de él con el siguiente contenido, que corresponde a una respuesta HTTP: print 'Content-Type: text/plain' print '' print 'Hello, world!‘ Crea el fichero de configuración requerido por toda aplicación App Engine denominado app.yaml, en formato YAML ( application: helloworld version: 1 runtime: python api_version: 1 handlers: - url: /.* script: helloworld.py Arranca el servidor con el comando: dev_appserver.py helloworld/ El switch --help da más indicaciones sobre las opciones aceptadas por el servidor Vete a la siguiente URL para probarlo:

115
Ejecutando Hola Mundo en Google App Engine

116
Opciones Avanzadas para GAE for Python
Framework webapp que soporta el estándar WSGI Acceso a datos de usuarios mediante la Users API DataStore API Plantillas en Google App Engine

117
Usando el Almacén de Datos de Google App Engine
Guardar datos en una aplicación web escalable puede ser difícil La infraestructura de App Engine se encarga de la distribución, replicación y balanceo de carga de los datos detrás de una API sencilla que también ofrece un motor de consultas y transacciones App Engine incluye una API de modelado de datos para Python Se asemeja a la API de Django pero utiliza el servidor de datos escalable BigTable por detrás. No es relacional, todas las entidades de un mismo tipo tienen las mismas propiedades Una propiedad puede tener uno o varios valores El siguiente import nos da acceso a la base de datos de Google App Engine: from google.appengine.ext import db Para más detalles sobre el DataStore API ir a:

118
La API del DataStore Incluye una API de modelado de datos y un lenguaje similar a SQL que NO permite JOINs y que se llama GQL, haciendo el desarrollo de aplicaciones escalables basadas en datos muy sencillo. from google.appengine.ext import db from google.appengine.api import users class Pet(db.Model): name = db.StringProperty(required=True) type = db.StringProperty(required=True, choices=set(["cat", "dog", "bird"])) birthdate = db.DateProperty() weight_in_pounds = db.IntegerProperty() spayed_or_neutered = db.BooleanProperty() owner = db.UserProperty() pet = Pet(name="Fluffy", type="cat", owner=users.get_current_user()) pet.weight_in_pounds = 24 pet.put()
: name = db.StringProperty(required=True) type = db.StringProperty(required=True, choices=set([ cat , dog , bird ])) birthdate = db.DateProperty() weight_in_pounds = db.IntegerProperty() spayed_or_neutered = db.BooleanProperty() owner = db.UserProperty() pet = Pet(name= Fluffy , type= cat , owner=users.get_current_user()) pet.weight_in_pounds = 24 pet.put()")
119
GQL Query Language Para limpiar la base de datos creada: dev_appserver.py --clear_datastore helloworld/ Ejemplo GQL: if users.get_current_user(): user_pets = db.GqlQuery("SELECT * FROM Pet WHERE pet.owner = :1“, users.get_current_user()) for pet in user_pets: pet.spayed_or_neutered = True db.put(user_pets)
: user_pets = db.GqlQuery( SELECT * FROM Pet WHERE pet.owner = :1 , users.get_current_user()) for pet in user_pets: pet.spayed_or_neutered = True. db.put(user_pets)")
120
Usando plantillas en Google App Engine
Empotrar HTML en código es algo lioso y difícil de mantener. Los sistemas de plantillas están diseñados para mantener HTML aparte en otro fichero donde elementos con sintaxis especial indican dónde deberían aparecer los datos de la aplicación Dentro de App Engine puede utilizarse cualquier motor de plantillas empaquetándolo con el código de tu aplicación, webapp incluye el mecanismo de plantillas de Django, donde se pueden pasar objetos del modelo datos Para utilizarlo hay que incluir los dos siguientes imports: import os from google.appengine.ext.webapp import template Además reemplazar las sentencias self.response.out.write por la sentencia template.render(path, template_values), que toma como parámetros de entrada: El camino al fichero de la plantilla Un diccionario de valores Y retorna: El texto a renderizar
, que toma como parámetros de entrada: El camino al fichero de la plantilla. Un diccionario de valores. Y retorna: El texto a renderizar.")
121
Registrando la aplicación

122
Verificación de tu cuenta

123
Verificación de tu Cuenta

124
Registrando la aplicación en appengine.google.com

125
Registrando la applicación

126
Subiendo la aplicación
Es necesario realizar los siguientes pasos: Editar el fichero app.yaml file y cambiar el valor de la aplicación: de helloworld al nombre de id de aplicación (enpresadigitala) Ejecutar el siguiente comando: appcfg.py update helloworld/ Acceder a la aplicación en por ejemplo en
 Ejecutar el siguiente comando: appcfg.py update helloworld/ Acceder a la aplicación en por ejemplo en")
127
Subiendo la aplicación

128
Accediendo a la aplicación

129
Programando Google App Engine con Django
Google App Engine y Django tienen la habilidad de usar el estándar WSGI para ejecutar aplicaciones Como consecuencia podemos utilizar la pila de Django en Google App Engine, incluso su parte de middleware Lo único que tenemos que hacer es cambiar los modelos de datos de Django para que usen la DataStore API de Google App Engine Como ambas APIs son muy similares, tenemos la misma flexibilidad usando la potencia de BigTable, es trivial adaptar un modelo Django a Google App Engine Además como Google App Engine ya incluye Django, solamente hay que importar los módulos que utilizarías normalmente Para usar el gestor WSGI tenemos que realizar los siguientes pasos: Importar util de google.appengine.ext.webapp Importar WSGI handler de Django [OPCIONAL] Redirigir los logs a la Admin Console de Google App Engine Es conveniente cambiar las siguientes configuraciones en Django: Dejar vacías las variables DATABASE_* de settings.py Deshabilitar el middleware de session y autenticación que hace uso de los modelos Django Más info en: Revisar ejemplo de encuestas programado en Django para AppEngine en: examples/googleappengine/python/djangosolopsiteappengine

130
Ejemplo Django Compleja sobre App Engine

131
App Engine para Java Crea aplicaciones web a través de tecnologías estándar de Java y las ejecuta en la infraestructura escalable Google Usa JVM Java 6, interfaz de servlets Java y la compatibilidad de interfaces estándar como JDO, JPA, JavaMail y JCache App Engine utiliza el estándar Java Servlet para aplicaciones web JVM se ejecuta en un entorno seguro de la "zona de pruebas" para aislar tu aplicación por servicio y seguridad. Una aplicación en GAE sólo pueda realizar acciones que no interfieran con el rendimiento ni con la escalabilidad de otras aplicaciones.

132
Funcionalidad de AppEngine for Java
App Engine proporciona un conjunto de servicios escalables que pueden utilizar las aplicaciones para: Almacenar datos persistentes. En Java, el almacén de datos admite 2 interfaces Java estándar: los objetos de datos Java (JDO) 2.3 y el API de persistencia de Java (JPA) 1.0. Acceder a recursos en la red. A través de la URL Fectch API. Cachear información. Memcache de App Engine proporciona un almacenamiento en caché distribuido, transitorio y rápido de los resultados de cálculos y consultas de almacén de datos. La interfaz Java implementa JCache (JSR 107). Enviar . Da soporte de JavaMail para el envío de correos Procesar imágenes. A través de la Images Java API, permite a las aplicaciones transformar y manipular datos de imágenes en varios formatos. Gestionar usuarios. A través de la Users Java API permite utilizar Cuentas de Google para la autenticación del usuario. Lanzar tareas planificadas o en background. Mediante la Task Queue Java API y la gestión de tareas por Cron.
 2.3 y el API de persistencia de Java (JPA) 1.0. Acceder a recursos en la red. A través de la URL Fectch API. Cachear información. Memcache de App Engine proporciona un almacenamiento en caché distribuido, transitorio y rápido de los resultados de cálculos y consultas de almacén de datos. La interfaz Java implementa JCache (JSR 107). Enviar . Da soporte de JavaMail para el envío de correos. Procesar imágenes. A través de la Images Java API, permite a las aplicaciones transformar y manipular datos de imágenes en varios formatos. Gestionar usuarios. A través de la Users Java API permite utilizar Cuentas de Google para la autenticación del usuario. Lanzar tareas planificadas o en background. Mediante la Task Queue Java API y la gestión de tareas por Cron.")
133
Instalación de AppEngine for Java
Descargar el fichero de: Descomprimir el fichero .zip Crear una variable de entorno APPENGINE_JAVA_SDK que apunte al directorio raíz de instalación de la SDK Incluir el directorio %APPENGINE_JAVA_SDK%\bin en la variable de entorno PATH

134
Pasos para crear una Aplicación con Google App Engine para Java
Crear el proyecto de la aplicación Crear la clase servlet Crear el fichero de despliegue de la aplicación: web.xml Crear el archivo appengine-web.xml Ejecutar el proyecto Probar el proyecto: Subir la aplicación al dominio appspot.com

135
Configuración del Entorno
Instalar java Descomprimir la distribución de GAE for Java a una carpeta de tu disco duro Modificar la variable de entorno APPENGINE_JAVA_SDK para que apunte a ese directorio Modificar la variable de entorno PATH para que apunte a %APPENGINE_JAVA_SDK%\bin Descomprimir el fichero downloads\apache-ant bin.zip Modificar la variable de entorno PATH para que apunte a <ANT_DIR>\bin cd examples\googleappengine\java\guestbook ant

136
Paso 1: Creando la estructura del proyecto
Dos opciones: Usar el plug-in para Eclipse: Usar la plantilla de proyecto disponible en %APP_ENGINE_HOME%\demos\new_project_template Las aplicaciones Java de App Engine utilizan el API Java Servlet para interactuar con el servidor web. Un servlet HTTP es una clase de aplicación que puede procesar y responder solicitudes web. Esta clase amplía la clase javax.servlet.GenericServlet o a la clase javax.servlet.http.HttpServlet. La estructura del directorio de trabajo será la siguiente: Guestbook/ src/ ...Java source code... META-INF/ ...other configuration... war/ ...JSPs, images, data files... WEB-INF/ ...app configuration... classes/ ...compiled classes... lib/ ...JARs for libraries...

137
Paso 2: Creando la clase Servlet
Crear en el directorio src/guestbook/ un fichero denominado GuestbookServlet.java con el siguiente contenido: package guestbook; import java.io.IOException; import javax.servlet.http.*; public class GuestbookServlet extends HttpServlet { public void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { resp.setContentType("text/plain"); resp.getWriter().println("Hello, world"); } }
 throws IOException { resp.setContentType( text/plain ); resp.getWriter().println( Hello, world ); } }")
138
Paso 3: Creando el fichero de despliegue – web.xml
Cuando el servidor web recibe una solicitud, decide qué clase de servlet ejecutar mediante un archivo de configuración conocido como "descriptor de implementación de la aplicación web". Este archivo se denomina web.xml y se ubica en el directorio war/WEB-INF/ del directorio que contiene los ficheros de una aplicación web en Java <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" " <web-app xmlns=" version="2.5"> <servlet> <servlet-name>guestbook</servlet-name> <servlet-class>guestbook.GuestbookServlet</servlet-class> </servlet> <servlet-mapping> <url-pattern>/guestbook</url-pattern> </servlet-mapping> <welcome-file-list> <welcome-file>index.html</welcome-file> </welcome-file-list> </web-app>

139
Paso 4: Crear el fichero de configuración de aplicación GAE: appengine-web.xml
App Engine necesita un archivo de configuración adicional para poder desarrollar y ejecutar la aplicación, denominado appengine-web.xml Se ubica en WEB-INF/ junto a web.xml. Incluye la ID registrada de la aplicación, el número de versión de la aplicación y listas de archivos que se deben tratar como archivos estáticos (por ejemplo, imágenes y CSS) y archivos de recursos (por ejemplo, JSP y otros datos de aplicación). El directorio war/WEB-INF/ incluye un archivo denominado appengine-web.xml que contiene lo siguiente: <?xml version="1.0" encoding="utf-8"?> <appengine-web-app xmlns=" <application>librocitas</application> <version>1</version> </appengine-web-app>
 y archivos de recursos (por ejemplo, JSP y otros datos de aplicación). El directorio war/WEB-INF/ incluye un archivo denominado appengine-web.xml que contiene lo siguiente: < xml version= 1.0 encoding= utf-8 > <appengine-web-app xmlns= > <application>librocitas</application> <version>1</version> </appengine-web-app>")
140
Paso 5: Ejecución del Proyecto
El SDK de App Engine incluye un servidor web de pruebas para depurar tu aplicación. El servidor simula los servicios y el entorno App Engine, que incluyen restricciones en la zona de pruebas, el almacén de datos y los servicios. Con el fichero ant ejecuta: ant runserver Puedes detenerlo con Ctrl-C

141
Paso 6: Subiendo la aplicación
Puedes crear y administrar aplicaciones web App Engine con la consola de administración de App Engine a través de la siguiente URL: Para crear una nueva aplicación, haz clic en el botón "Create an Application" (Crear aplicación) Edita el archivo appengine-web.xml y, a continuación, cambia el valor del elemento <application> para que sea la ID registrada de tu aplicación (librocitas). Ejecuta el siguiente comando en línea de comandos para subir la aplicación: $ appcfg update www Vete a:
 Edita el archivo appengine-web.xml y, a continuación, cambia el valor del elemento <application> para que sea la ID registrada de tu aplicación (librocitas). Ejecuta el siguiente comando en línea de comandos para subir la aplicación: $ appcfg update www. Vete a:")
142
El fichero de Ant Apache Ant facilita la administración de tu proyecto desde la línea de comandos o desde otros entornos de desarrollo integrados (IDE) compatibles con Ant. El SDK de Java incluye un conjunto de macros de Ant para realizar tareas de desarrollo de App Engine, entre las que se incluyen: El inicio del servidor de desarrollo y La subida de la aplicación a App Engine Algunos problemas con el build.xml suministrado por new-project-template Fichero adaptado en examples/guestbook/build.xml: Hay que definir variable de entorno APP_ENGINE_SDK para desligar build.xml de su localización en disco Introducir tarea para copiar jars con dependencias
 compatibles con Ant. El SDK de Java incluye un conjunto de macros de Ant para realizar tareas de desarrollo de App Engine, entre las que se incluyen: El inicio del servidor de desarrollo y. La subida de la aplicación a App Engine. Algunos problemas con el build.xml suministrado por new-project-template. Fichero adaptado en examples/guestbook/build.xml: Hay que definir variable de entorno APP_ENGINE_SDK para desligar build.xml de su localización en disco. Introducir tarea para copiar jars con dependencias.")
143
Usando el Servicio de Usuarios
Google App Engine ofrece varios servicios útiles basados en la infraestructura de Google a los que se puede acceder a través de aplicaciones utilizando una serie de bibliotecas incluidas en el kit de desarrollo de software (SDK) Por ejemplo, el servicio de usuarios te permite integrar tu aplicación con cuentas de usuarios de Google package guestbook; import java.io.IOException; import javax.servlet.http.*; import com.google.appengine.api.users.User; import com.google.appengine.api.users.UserService; import com.google.appengine.api.users.UserServiceFactory; public class GuestbookServlet extends HttpServlet { public void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { UserService userService = UserServiceFactory.getUserService(); User user = userService.getCurrentUser(); if (user != null) { resp.setContentType("text/plain"); resp.getWriter().println("Hello, " + user.getNickname()); } else { resp.sendRedirect(userService.createLoginURL(req.getRequestURI())); } } }
 Por ejemplo, el servicio de usuarios te permite integrar tu aplicación con cuentas de usuarios de Google. package guestbook; import java.io.IOException; import javax.servlet.http.*; import com.google.appengine.api.users.User; import com.google.appengine.api.users.UserService; import com.google.appengine.api.users.UserServiceFactory; public class GuestbookServlet extends HttpServlet { public void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { UserService userService = UserServiceFactory.getUserService(); User user = userService.getCurrentUser(); if (user != null) { resp.setContentType( text/plain ); resp.getWriter().println( Hello, + user.getNickname()); } else { resp.sendRedirect(userService.createLoginURL(req.getRequestURI())); } } }")
144
Uso de un JSP Aunque podríamos generar el código HTML para la interfaz de usuario directamente a partir del código Java del servlet, no sería algo fácil de mantener, ya que el código HTML se complica Es más conveniente utilizar un sistema de plantillas, en el que la interfaz de usuario esté diseñada e implementada en archivos independientes con marcadores y lógica para insertar datos proporcionados por la aplicación. Pasos: En el directorio war/, crea un archivo llamado guestbook.jsp con el contenido de la siguiente transparencia Modificar el fichero web.xml para que el welcome-file apunte a guestbook.jsp Acceder a la ruta: o Al cargar una JSP por primera vez, el servidor de desarrollo lo convierte en código fuente Java y, a continuación, compila este código en código de bytes de Java Al subir la aplicación a App Engine, el SDK compila todas las JSP en código de bytes y únicamente sube el código de bytes.

145
Uso de un JSP page contentType="text/html;charset=UTF-8" language="java" %> page import="com.google.appengine.api.users.User" %> page import="com.google.appengine.api.users.UserService" %> page import="com.google.appengine.api.users.UserServiceFactory" %> <html> <body><% UserService userService = UserServiceFactory.getUserService(); User user = userService.getCurrentUser(); if (user != null) {%> <p>Hello, <%= user.getNickname() %>! (You can<a href="<%= userService.createLogoutURL(request.getRequestURI()) %>">sign out</a>.)</p><% } else {%> <p>Hello!<a href="<%= userService.createLoginURL(request.getRequestURI()) %>">Sign in</a>to include your name with greetings you post.</p><% }%> </body>
; User user = userService.getCurrentUser(); if (user != null) {%> <p>Hello, <%= user.getNickname() %>! (You can<a href= <%= userService.createLogoutURL(request.getRequestURI()) %> >sign out</a>.)</p><% } else {%> <p>Hello!<a href= <%= userService.createLoginURL(request.getRequestURI()) %> >Sign in</a>to include your name with greetings you post.</p><% }%> </body>")
146
Formulario Libro Invitados
La aplicación de libro de invitados necesita un formulario web para que el usuario publique un nuevo saludo, así como una forma de procesar ese formulario El código HTML del formulario se inserta en la JSP guestbook.jsp: <form action="/sign" method="post"> <div><textarea name="content" rows="3" cols="60"></textarea></div> <div><input type="submit" value="Post Greeting" /></div> </form> El destino del formulario es una nueva URL, /sign, controlada por una nueva clase de servlet,SignGuestbookServlet que procesa el formulario y redirige a: /guestbook.jsp Es necesario modificar web.xml para crear una nueva entrada para este servlet, con los siguientes datos: <servlet> <servlet-name>sign</servlet-name> <servlet-class>guestbook.SignGuestbookServlet</servlet-class> </servlet> <servlet-mapping> <url-pattern>/sign</url-pattern> </servlet-mapping>

147
El Servlet que Procesa una Nueva Entrada en Libro
package guestbook; import java.io.IOException; import java.util.logging.Logger; import javax.servlet.http.*; import com.google.appengine.api.users.User; import com.google.appengine.api.users.UserService; import com.google.appengine.api.users.UserServiceFactory; public class SignGuestbookServlet extends HttpServlet { private static final Logger log = Logger.getLogger(SignGuestbookServlet.class.getName()); public void doPost(HttpServletRequest req, HttpServletResponse resp) throws IOException { UserService userService = UserServiceFactory.getUserService(); User user = userService.getCurrentUser(); String content = req.getParameter("content"); if (content == null) { content = "(No greeting)"; } if (user != null) { log.info("Greeting posted by user " + user.getNickname() + ": " + content); } else { log.info("Greeting posted anonymously: " + content); resp.sendRedirect("guestbook.jsp");
); public void doPost(HttpServletRequest req, HttpServletResponse resp) throws IOException { UserService userService = UserServiceFactory.getUserService(); User user = userService.getCurrentUser(); String content = req.getParameter( content ); if (content == null) { content = (No greeting) ; } if (user != null) { log.info( Greeting posted by user + user.getNickname() + : + content); } else { log.info( Greeting posted anonymously: + content); resp.sendRedirect( guestbook.jsp );")
148
Logeo de Información con App Engine
El nuevo servlet utiliza la clase java.util.logging.Logger para escribir mensajes en el registro. Puedes controlar el comportamiento de esta clase a través de un archivo logging.properties y de un conjunto de propiedades del sistema en el archivo appengine-web.xml de la aplicación. Copia el archivo de ejemplo del SDK appengine-java-sdk/config/user/logging.properties en el directorio war/WEB-INF/ de la aplicación Para modificar el nivel de registro de todas las clases del paquete guestbook, edita el archivo logging.properties y añade una entrada para guestbook.level, como se muestra a continuación: .level = WARNING guestbook.level = INFO A continuación edita el archivo war/WEB-INF/appengine-web.xml de la aplicación como se indica: <appengine-web-app xmlns=" ... <system-properties> <property name="java.util.logging.config.file" value="WEB-INF/logging.properties"/> </system-properties> </appengine-web-app> Los ficheros de logeo se descargan con la consola de administración o la aplicación appcfg de App Engine:

149
Uso del Almacen de Datos JDO
La infraestructura de App Engine se encarga de todas las tareas de distribución, replicación y balanceo de carga de los datos de un API sencilla, además de ofrecer un potente motor de consulta y transacciones. Ofrece dos API: un API estándar y otra de nivel inferior. App Engine for Java permite el uso de dos estándares de API diferentes para el almacén de datos: Objetos de datos Java (JDO) y API de persistencia Java (JPA). Estas interfaces las proporciona DataNucleus Access Platform, una implementación de software libre de varios estándares de persistencia Java, con un adaptador para Google DataStore Utilizaremos la interfaz JDO para la recuperación y la publicación de los mensajes de los usuarios en el almacén de datos de App Engine. Access Platform necesita un archivo de configuración que le indique que debe utilizar el almacén de datos de App Engine como servidor para la implementación de JDO: META-INF/jdoconfig.xml Documentación detallada de JDO puede encontrarse en:
 y API de persistencia Java (JPA). Estas interfaces las proporciona DataNucleus Access Platform, una implementación de software libre de varios estándares de persistencia Java, con un adaptador para Google DataStore. Utilizaremos la interfaz JDO para la recuperación y la publicación de los mensajes de los usuarios en el almacén de datos de App Engine. Access Platform necesita un archivo de configuración que le indique que debe utilizar el almacén de datos de App Engine como servidor para la implementación de JDO: META-INF/jdoconfig.xml. Documentación detallada de JDO puede encontrarse en:")
150
Funcionamiento de JDO Al crear clases JDO, debes utilizar anotaciones Java para describir cómo se deben guardar las instancias en el almacén de datos y cómo se deben volver a crear al recuperarlas de dicho almacén. Access Platform conecta las clases de datos a la implementación mediante un paso de procesamiento posterior a la compilación, que DataNucleus denomina "mejora" de las clases. JDO permite almacenar objetos Java (a veces denominados "objetos Java antiguos y simples" o POJO) en cualquier almacén de datos con un adaptador compatible con JDO, como DataNucleus Access Platform El complemento Access Platform para el almacén de datos de App Engine permite almacenar instancias de clases definidas en el almacén de datos de App Engine Ejemplo: la clase Greeting representará mensajes individuales publicados en el libro de invitados de nuestra aplicación
 en cualquier almacén de datos con un adaptador compatible con JDO, como DataNucleus Access Platform. El complemento Access Platform para el almacén de datos de App Engine permite almacenar instancias de clases definidas en el almacén de datos de App Engine. Ejemplo: la clase Greeting representará mensajes individuales publicados en el libro de invitados de nuestra aplicación.")
151
La Clase de Persistencia Greeting
package guestbook; import java.util.Date; import javax.jdo.annotations.IdGeneratorStrategy; import javax.jdo.annotations.IdentityType; import javax.jdo.annotations.PersistenceCapable; import javax.jdo.annotations.Persistent; import javax.jdo.annotations.PrimaryKey; import = IdentityType.APPLICATION) public class = IdGeneratorStrategy.IDENTITY) private Long private User author; private String content; private Date date; public Greeting(User author, String content, Date date) { this.author = author; this.content = content; this.date = date; } ...
 public class = IdGeneratorStrategy.IDENTITY) private Long private User author; private String content; private Date date; public Greeting(User author, String content, Date date) { this.author = author; this.content = content; this.date = date; } ...")
152
La Clase de Persistencia Greeting
Esta sencilla clase define tres propiedades para un saludo: author, content y date Estos tres campos privados presentan la que indica a DataNucleus que debe almacenarlos como propiedades de objetos en el almacén de datos de App Engine. La clase también define un campo llamado id, una clave Long que presenta dos El almacén de datos de App Engine tiene una noción de las claves de entidades y puede representar las claves de varias formas en un objeto. Más información sobre cómo definir modelos de datos puede encontrarse en:

153
Serializando datos con JDO
Cada solicitud que utiliza el almacén de datos crea una nueva instancia de la clase PersistenceManager que se obtiene a través de PersistenceManagerFactory Una instancia de PersistenceManagerFactory tarda algún tiempo en inicializarse Afortunadamente, sólo se necesita una instancia para cada aplicación Creamos la clase singleton PMF para resolverlo: package guestbook; import javax.jdo.JDOHelper; import javax.jdo.PersistenceManagerFactory; public final class PMF { private static final PersistenceManagerFactory pmfInstance = JDOHelper.getPersistenceManagerFactory("transactions-optional"); private PMF() {} public static PersistenceManagerFactory get() { return pmfInstance; } Para usarlo creamos una nueva instancia de Greeting mediante la ejecución del constructor. Para guardar la instancia en el almacén de datos, crea una clase PersistenceManager a través de PMF.get() e invocamos sobre él makePersistent()
; private PMF() {} public static PersistenceManagerFactory get() { return pmfInstance; } Para usarlo creamos una nueva instancia de Greeting mediante la ejecución del constructor. Para guardar la instancia en el almacén de datos, crea una clase PersistenceManager a través de PMF.get() e invocamos sobre él makePersistent()")
154
Serializando datos con JDO
Dentro del fichero SignGuestBookServlet introduciríamos los siguientes cambios para serializar los saludos en App Engine DataStore, a través de JDO: String content = req.getParameter("content"); Date date = new Date(); Greeting greeting = new Greeting(user, content, date); PersistenceManager pm = PMF.get().getPersistenceManager(); try { pm.makePersistent(greeting); } finally { pm.close(); }
; Date date = new Date(); Greeting greeting = new Greeting(user, content, date); PersistenceManager pm = PMF.get().getPersistenceManager(); try { pm.makePersistent(greeting); } finally { pm.close(); }")
155
Consultando datos con JDO
El estándar JDO define un mecanismo para consultas de objetos persistentes denominado JDOQL. Modificaremos guestbook.jsp para realizar la consulta introduciendo los siguientes cambios: page import="java.util.List" page import="javax.jdo.PersistenceManager" page import="guestbook.Greeting" page import="guestbook.PMF" %> … <% PersistenceManager pm = PMF.get().getPersistenceManager(); String query = "select from " + Greeting.class.getName() + " order by date desc range 0,5"; List<Greeting> greetings = (List<Greeting>) pm.newQuery(query).execute(); if (greetings.isEmpty()) { %> <p>The guestbook has no messages.</p> <% } else { for (Greeting g : greetings) { if (g.getAuthor() == null) { %> <p>An anonymous person wrote:</p> <% } else { %> <p><b><%= g.getAuthor().getNickname() %></b> wrote:</p> <% } %> <blockquote><%= g.getContent() %></blockquote> <% } pm.close(); %>
.getPersistenceManager(); String query = select from + Greeting.class.getName() + order by date desc range 0,5 ; List<Greeting> greetings = (List<Greeting>) pm.newQuery(query).execute(); if (greetings.isEmpty()) { %> <p>The guestbook has no messages.</p> <% } else { for (Greeting g : greetings) { if (g.getAuthor() == null) { %> <p>An anonymous person wrote:</p> <% } else { %> <p><b><%= g.getAuthor().getNickname() %></b> wrote:</p> <% } %> <blockquote><%= g.getContent() %></blockquote> <% } pm.close(); %>")
156
Usando Ficheros Estáticos
Hay muchos casos en los que querrás mostrar los archivos estáticos directamente en el navegador web: imágenes, vídeos Para una mayor eficiencia, App Engine muestra los archivos estáticos desde servidores independientes en lugar de los que ejecutan servlets. App Engine considera todos los archivos del directorio WAR como archivos estáticos, salvo JSP y los archivos de WEB-INF/ Cualquier solicitud de una URL cuya ruta coincida con un archivo estático lo muestra Puedes configurar los archivos que quieres que App Engine considere como archivos estáticos a través del archivo appengine-web.xml La siguiente página da más información al respecto: Para este ejemplo: Crear main.css con el siguiente contenido: body { font-family: Verdana, Helvetica, sans-serif; background-color: #FFFFCC; } Añadir a guestbook.jsp lo siguiente: <head> <link type="text/css" rel="stylesheet" href="/stylesheets/main.css" /> </head>

157
Creando de Objetos y Claves
Para almacenar un objeto de datos sencillo en el almacén de datos, ejecuta el método makePersistent() del PersistenceManager y transfiérelo a la instancia. PersistenceManager pm = PMF.get().getPersistenceManager(); Employee e = new Employee("Alfred", "Smith", new Date()); try { pm.makePersistent(e); } finally { pm.close(); } Las claves más sencillas están basadas en los tipos Long o String, pero también se pueden crear con la clase Key. import com.google.appengine.api.datastore.Key; import com.google.appengine.api.datastore.KeyFactory; // ... Key k = KeyFactory.createKey(Employee.class.getSimpleName(), Para recuperar un elemento por clave podemos usar lo siguiente, se puede pasar como segundo argumento una clave, un entero o un string: Employee e = pm.getObjectById(Employee.class,
 del PersistenceManager y transfiérelo a la instancia. PersistenceManager pm = PMF.get().getPersistenceManager(); Employee e = new Employee( Alfred , Smith , new Date()); try { pm.makePersistent(e); } finally { pm.close(); } Las claves más sencillas están basadas en los tipos Long o String, pero también se pueden crear con la clase Key. import com.google.appengine.api.datastore.Key; import com.google.appengine.api.datastore.KeyFactory; // ... Key k = KeyFactory.createKey(Employee.class.getSimpleName(), ); Para recuperar un elemento por clave podemos usar lo siguiente, se puede pasar como segundo argumento una clave, un entero o un string: Employee e = pm.getObjectById(Employee.class, );")
158
Actualización y Borrado de Objetos
El siguiente código muestra cómo actualizar un objeto persistente: public void updateEmployeeTitle(User user, String newTitle) { PersistenceManager pm = PMF.get().getPersistenceManager(); try { Employee e = pm.getObjectById(Employee.class, user.get ()); if (titleChangeIsAuthorized(e, newTitle) { e.setTitle(newTitle); } else { throw new UnauthorizedTitleChangeException(e, newTitle); } } finally { pm.close(); } } El siguiente ejemplo muestra cómo borrar un objeto: pm.deletePersistent(e);
 { PersistenceManager pm = PMF.get().getPersistenceManager(); try { Employee e = pm.getObjectById(Employee.class, user.get ()); if (titleChangeIsAuthorized(e, newTitle) { e.setTitle(newTitle); } else { throw new UnauthorizedTitleChangeException(e, newTitle); } } finally { pm.close(); } } El siguiente ejemplo muestra cómo borrar un objeto: pm.deletePersistent(e);")
159
Realizando Consultas con JDO
JDOQL es similar a SQL, aunque es más adecuado para bases de datos relacionadas con objetos, como, por ejemplo, el almacén de datos de App Engine. Dos usos diferentes: Puedes especificar parte o la totalidad de la consulta mediante métodos de ejecución en el objeto de consulta import java.util.List; import javax.jdo.Query; // ... Query query = pm.newQuery(Employee.class); query.setFilter("lastName == lastNameParam"); query.setOrdering("hireDate desc"); query.declareParameters("String lastNameParam"); try { List<Employee> results = (List<Employee>) query.execute("Smith"); if (results.iterator().hasNext()) { for (Employee e : results) { } } else { // ... no results ... } finally { query.closeAll();
; query.setFilter( lastName == lastNameParam ); query.setOrdering( hireDate desc ); query.declareParameters( String lastNameParam ); try { List<Employee> results = (List<Employee>) query.execute( Smith ); if (results.iterator().hasNext()) { for (Employee e : results) { } } else { // ... no results ... } finally { query.closeAll();")
160
Realizando Consultas con JDO
Puedes especificar una consulta completa en una cadena mediante la sintaxis de cadena JDOQL: Query query = pm.newQuery("select from Employee " + "where lastName == lastNameParam " + "order by hireDate desc " + "parameters String lastNameParam"); List<Employee> results = (List<Employee>) query.execute("Smith"); Otro modo: Query query = pm.newQuery(Employee.class, "lastName == lastNameParam order by hireDate desc"); query.declareParameters("String lastNameParam"); Query query = pm.newQuery(Employee.class, "lastName == 'Smith' order by hireDate desc");
; List<Employee> results = (List<Employee>) query.execute( Smith ); Otro modo: Query query = pm.newQuery(Employee.class, lastName == lastNameParam order by hireDate desc ); query.declareParameters( String lastNameParam ); Query query = pm.newQuery(Employee.class, lastName == Smith order by hireDate desc );")
161
Filtros y Restricciones en Consultas JDO sobre App Engine
Algunos ejemplos de filtros son: query.setFilter("lastName == 'Smith' && hireDate > hireDateMinimum"); query.declareParameters("Date hireDateMinimum"); Query query = pm.newQuery(Employee.class, "(lastName == 'Smith' || lastName == 'Jones')" + " && firstName == 'Harold'"); ATENCIÓN: importantes restricciones en las consultas, revisar: Ejemplo: Los filtros de desigualdad sólo están permitidos en una propiedad
; query.declareParameters( Date hireDateMinimum ); Query query = pm.newQuery(Employee.class, (lastName == Smith || lastName == Jones ) + && firstName == Harold ); ATENCIÓN: importantes restricciones en las consultas, revisar: Ejemplo: Los filtros de desigualdad sólo están permitidos en una propiedad.")
162
Ejemplo Objeto Serializable
La siguiente clase define un objeto que puede serializarse en JDO: import java.io.Serializable; public class DownloadableFile implements Serializable { private byte[] content; private String filename; private String mimeType; // ... accessors ... } La siguiente clase define cómo usarlo: import javax.jdo.annotations.Persistent; import DownloadableFile; // ... @Persistent(serialized = "true"); private DownloadableFile file;
; private DownloadableFile file;")
163
Ejemplo Relación 1 a 1 entre Entidades
import com.google.appengine.api.datastore.Key; // ... imports public class = IdGeneratorStrategy.IDENTITY) private Key private String streetAddress; private String city; private String stateOrProvince; private String zipCode; // ... accessors ... } import ContactInfo; public class Employee { private ContactInfo myContactInfo;
 private Key private String streetAddress; private String city; private String stateOrProvince; private String zipCode; // ... accessors ... } import ContactInfo; public class Employee { private ContactInfo myContactInfo;")
164
Relaciones Uno a Varios
Ejemplo de relación bidireccional uno a varios: // Employee.java import java.util.List; // ... @Persistent private List<ContactInfo> contactInfoSets; // ContactInfo.java import Employee; private Employee employee;

165
Relaciones Varios a Varios
Ejemplo de relación varios a varios, sólo se puede hacer guardando colecciones de claves en ambas relaciones implicadas: //Person.java import java.util.Set; import com.google.appengine.api.datastore.Key; // ... @Persistent private Set<Key> favoriteFoods; //Food.java private Set<Key> foodFans; // Album.java public void addFavoriteFood(Food food) { favoriteFoods.add(food.getKey()); food.getFoodFans().add(getKey()); } public void removeFavoriteFood(Food food) { favoriteFoods.remove(food.getKey()); food.getFoodFans().remove(getKey());
 { favoriteFoods.add(food.getKey()); food.getFoodFans().add(getKey()); } public void removeFavoriteFood(Food food) { favoriteFoods.remove(food.getKey()); food.getFoodFans().remove(getKey());")
166
Características Avanzadas de Google App Engine
Planificación de tareas con Cron for Java Memcache Java API URL Fech Java API Envío de mensajes instantáneos con XMPP e Colas de tareas – permite ejecutar asíncronamente tareas

167
Planificación de Tareas con Cron
El servicio App Engine Cron Service permite planificar tareas que se ejecutan en un momento o periodos determinados. Los trabajos cron (cron jobs) son ejecutados por App Engine Cron Service Algunos ejemplos de uso serían: Envío de con informe diario Actualización de tu caché de datos cada 10 minutos Documentación en: Formato de las planificaciones: ("every"|ordinal) (days) ["of" (monthspec)] (time)
 son ejecutados por App Engine Cron Service. Algunos ejemplos de uso serían: Envío de con informe diario. Actualización de tu caché de datos cada 10 minutos. Documentación en: Formato de las planificaciones: ( every |ordinal) (days) [ of (monthspec)] (time)")
168
Planificación de Tareas con Cron
El fichero WEB-INF\cron.xml controla cron para tu aplicación: <?xml version="1.0" encoding="UTF-8"?> <cronentries> <cron> <url>/recache</url> <description>Repopulate the cache every 2 minutes</description> <schedule>every 2 minutes</schedule> </cron> <cron> <url>/weeklyreport</url> <description>Mail out a weekly report</description> <schedule>every monday 08:30</schedule> <timezone>America/New_York</timezone> </cron> </cronentries>

169
Memcache Java API Las aplicaciones web escalables de alto rendimiento utilizan a menudo una caché distribuida de datos integrados en memoria delante o en lugar de un sistema de almacenamiento complejo permanente para algunas tareas App Engine incluye un servicio de memoria caché El API Java de Memcache implementa la interfaz JCache (javax.cache), un estándar en formato borrador descrito en JSR 107 JCache proporciona una interfaz en forma de mapa para recopilar datos Puedes almacenar y recuperar valores de la memoria caché mediante las claves Controlar cuándo los valores vencen en la memoria caché Inspeccionar el contenido de la memoria caché y obtener estadísticas sobre ella Utilizar "funciones de escucha" para añadir un comportamiento personalizado al establecer y borrar valores.
, un estándar en formato borrador descrito en JSR 107. JCache proporciona una interfaz en forma de mapa para recopilar datos. Puedes almacenar y recuperar valores de la memoria caché mediante las claves. Controlar cuándo los valores vencen en la memoria caché. Inspeccionar el contenido de la memoria caché y obtener estadísticas sobre ella. Utilizar funciones de escucha para añadir un comportamiento personalizado al establecer y borrar valores.")
170
Pasos para Hacer uso de Memcache
Obtención y configuración de una instancia de Cache, para ello hay que configurar los parámetros del método createCache import javax.cache.Cache; import javax.cache.CacheException; import javax.cache.CacheFactory; // ... Cache cache; try { Map props = new Map; props.put(GCacheFactory.EXPIRATION_DELTA, 3600); props.put(MemcacheService.SetPolicy.ADD_ONLY_IF_NOT_PRESENT, true); CacheFactory cacheFactory = CacheManager.getInstance().getCacheFactory(); // cache = cacheFactory.createCache(Collections.emptyMap()); cache = cacheFactory.createCache(props); } catch (CacheException e) { // ... } Establecimiento y obtención de valores. Se comporta como un mapa Puedes almacenar claves y valores a través del método put() y recuperar valores con el método get() Otros métodos de interés son: remove(), clear(), containsKey(), isEmpty() y size() Más documentación en:
; props.put(MemcacheService.SetPolicy.ADD_ONLY_IF_NOT_PRESENT, true); CacheFactory cacheFactory = CacheManager.getInstance().getCacheFactory(); // cache = cacheFactory.createCache(Collections.emptyMap()); cache = cacheFactory.createCache(props); } catch (CacheException e) { // ... } Establecimiento y obtención de valores. Se comporta como un mapa. Puedes almacenar claves y valores a través del método put() y recuperar valores con el método get() Otros métodos de interés son: remove(), clear(), containsKey(), isEmpty() y size() Más documentación en:")
171
URL Fetch Java API GAE permite realizar conexiones HTTP y HTTPS a través del servicio URL Fetch, que en el caso de GAE for Java se implementa mediante la clase java.net.URLConnection La funcionalidad que da es: Acceso sencillo a los contenidos de una página mediante java.net.URL y el método openStream() El método openConnection() de java.net.URL devuelve una instancia de HttpURLConnection, sobre la que se puede hacer getInputStream() y getOutputStream() Se pueden cambiar propiedades de la conexión como: Añadir cabeceras: connection.setRequestProperty("X-MyApp-Version", "2.7.3"); Modificar el hecho de que las peticiones se redirijan directamente: connection.setRequestProperty("X-MyApp-Version", "2.7.3"); Más detalles en:
 El método openConnection() de java.net.URL devuelve una instancia de HttpURLConnection, sobre la que se puede hacer getInputStream() y getOutputStream() Se pueden cambiar propiedades de la conexión como: Añadir cabeceras: connection.setRequestProperty( X-MyApp-Version , ); Modificar el hecho de que las peticiones se redirijan directamente: connection.setRequestProperty( X-MyApp-Version , ); Más detalles en:")
172
Mail Java API Una aplicación en App Engine puede enviar mensajes en representación del administrador de la página o de usuarios autorizados con cuentas Google La Mail Service Java API hace uso de javax.mail Se puede configurar tu aplicación para recibir mensajes en una dirección con el formato Cuando una aplicación se ejecuta en el servidor de desarrollo, el mensaje enviado se imprime en el log, no se envía

173
Enviando un Mensaje ... import java.util.Properties; import javax.mail.Message; import javax.mail.MessagingException; import javax.mail.Session; import javax.mail.Transport; import javax.mail.internet.AddressException; import javax.mail.internet.InternetAddress; import javax.mail.internet.MimeMessage; // ... Properties props = new Properties(); Session session = Session.getDefaultInstance(props, null); String msgBody = "...“; try { Message msg = new MimeMessage(session); msg.setFrom(new "Example.com Admin")); msg.addRecipient(Message.RecipientType.TO, new "Mr. User")); msg.setSubject("Your Example.com account has been activated"); msg.setText(msgBody); Transport.send(msg); } catch (AddressException e) { } catch (MessagingException e) { }
; Session session = Session.getDefaultInstance(props, null); String msgBody = ... ; try { Message msg = new MimeMessage(session); msg.setFrom(new InternetAddress( , Example.com Admin )); msg.addRecipient(Message.RecipientType.TO, new InternetAddress( , Mr. User )); msg.setSubject( Your Example.com account has been activated ); msg.setText(msgBody); Transport.send(msg); } catch (AddressException e) { } catch (MessagingException e) { }")
174
Recibiendo un Mensaje Los pasos a seguir son:
Configurar tu aplicación para ser receptora de en la dirección: Modificando el fichero appengine-web.xml: <inbound-services> <service>mail</service> </inbound-services> Modificando el fichero web.xml, que recibirá mensajes en la siguiente dirección: /_ah/mail/<address> <servlet> <servlet-name>mailhandler</servlet-name> <servlet-class>MailHandlerServlet</servlet-class> </servlet> <servlet-mapping> <url-pattern>/_ah/mail/*</url-pattern> </servlet-mapping> <security-constraint> <web-resource-collection> </web-resource-collection> <auth-constraint> <role-name>admin</role-name> </auth-constraint> </security-constraint>

175
Recibiendo un Mensaje Los pasos a seguir son:
Crear un servlet que reciba los mensajes import java.io.IOException; import java.util.Properties; import javax.mail.Session; import javax.mail.internet.MimeMessage; import javax.servlet.http.*; public class MailHandlerServlet extends HttpServlet { public void doPost(HttpServletRequest req, HttpServletResponse resp) throws IOException { Properties props = new Properties(); Session session = Session.getDefaultInstance(props, null); MimeMessage message = new MimeMessage(session, req.getInputStream()); … }
 throws IOException { Properties props = new Properties(); Session session = Session.getDefaultInstance(props, null); MimeMessage message = new MimeMessage(session, req.getInputStream()); … }")
176
Task Queue API Una aplicación Java puede crear una cola configurada en el fichero de configuración WEB-INF/queue.xml Para encolar una tarea, hay que obtener una instancia de Queue usando una QueueFactory y luego invocar el método add() Puedes obtener una cola por nombre declarada en el fichero queue.xml o la cola por defecto con el método getDefaultQueue() Se puede añadir una tarea a la cola pasando una instancia de TaskOptions al método add() Se invocará un servlet que será quien ejecute la tarea encolada (ver ejemplo siguiente trasparencia) Espacio de nombres en versión beta: com.google.appengine.api.labs.taskqueue
 Puedes obtener una cola por nombre declarada en el fichero queue.xml o la cola por defecto con el método getDefaultQueue() Se puede añadir una tarea a la cola pasando una instancia de TaskOptions al método add() Se invocará un servlet que será quien ejecute la tarea encolada (ver ejemplo siguiente trasparencia) Espacio de nombres en versión beta: com.google.appengine.api.labs.taskqueue.")
177
Ejemplo de Task Queue API
El siguiente ejemplo muestra cómo añadir una tarea a una cola: import com.google.appengine.api.labs.taskqueue.Queue; import com.google.appengine.api.labs.taskqueue.QueueFactory; import static com.google.appengine.api.labs.taskqueue.TaskOptions.Builder.*; // ... Queue queue = QueueFactory.getDefaultQueue(); queue.add(url("/worker").param("key", key));
; queue.add(url( /worker ).param( key , key));")
178
Ejemplo de Task Queue API
Ejemplo de queue.xml, donde s indica segundos, m minutos, h horas y d días, es decir, la frecuencia con la que las tareas encoladas serían procesadas: <queue-entries> <queue> <name>default</name> <rate>1/s</rate> </queue> <queue> <name>mail-queue</name> <rate>2000/d</rate> <bucket-size>10</bucket-size> </queue> <queue> <name>background-processing</name> <rate>5/s</rate> </queue> </queue-entries>

179
Combinando Struts2 y GAE
Revisar ejemplo: struts2tutorial Modificaciones a realizar en la distribución de struts2tutorial: Reimplementar la clase freemarker.core.TextBlock Inicializar a null el SecurityManager de OgnlRuntime Explicación de cómo hacerlo en:

180
Plugin for Eclipse for Java
Instrucciones en: Descarga Eclipse Galileo for Java Developers de:

181
Importación y Exportación de Datos
Se pueden acceder a datos detrás de tu Intranet desde una aplicación de Google App Engine, con Google Secure Data Connector y el servicio urlfetch (com.google.appengine.api.urlfetch.*) Se pueden importar y exportar datos del datastore en forma de ficheros CSV Solamente disponible en Python de momento:
 Se pueden importar y exportar datos del datastore en forma de ficheros CSV. Solamente disponible en Python de momento:")
182
Google App Engine for Business
Las aplicaciones generadas con App Engine for Business usan las APIs de Java y Python, pero permiten acceder al desarrollador a capacidades especiales (premium): Acceso a SSL y SQL Tendrán un coste adicional Mas información en:
: Acceso a SSL y SQL. Tendrán un coste adicional. Mas información en:")
183
Limitaciones Google App Engine
El servicio tiene varias limitaciones: Solo hasta recientemente no todo el mundo podía acceder a él Es gratis durante el periodo de pruebas, pero con límites de uso: 500 MB de almacenamiento, 200 millones de megaciclos/día y 10 Gb de ancho de banda Google cobra para webs que requieren alta escalabilidad Existen escasas aplicaciones comerciales desarrolladas en esta plataforma Repositorio de ejemplos: VOSAO CMS - Limitaciones técnicas originales parcialmente resueltas: Los desarrolladores solamente tienen acceso de lectura al sistema de ficheros de App Engine Solamente se puede ejecutar código a partir de una petición HTTP Solamente se puede subir código puramente Python (resuelto con soporte Java) No se puede descargar o ejecutar scripts en su base de datos (remote_api) Las aplicaciones deben ser escritas en Python o Java Guido van Rosum, creador de Python está detrás de Google App Engine
 No se puede descargar o ejecutar scripts en su base de datos (remote_api) Las aplicaciones deben ser escritas en Python o Java. Guido van Rosum, creador de Python está detrás de Google App Engine.")
184
Google App Engine vs. Amazon Web Services
A primera vista Google App Engine es un competidor a la suite de servicios web ofrecida por Amazon: S3 para almacenamiento EC2 para la creación de servidores virtuales SimpleDB como base de datos Pero … Google App Engine es una plataforma mucho más acoplada y menos flexible Si quieres hacer uso de BigTable tienes que escribir y desplegar un script de Python a su servidor de aplicaciones ofreciendo una interfaz web accesible a BigTable (resuelto parcialmente)
")
185
Google App Engine vs. Amazon Web Services

186
Microsoft’s Windows Azure Platform
Windows Azure es un servicio utilizado para ejecutar aplicaciones y guardar datos en máquinas de Microsoft accesibles vía Internet Proporciona tres componentes: El servicio Compute ejecuta aplicaciones con web role y worker role El servicio Storage permite guarda datos como blobs, tables y queues El Windows Azure Fabric proporciona una API para gestionar y monitorizar aplicaciones que usan la plataforma Azure Más información en:

187
Microsoft’s Windows Azure Platform

188
Comparativa AWS, GAE y Azure
AWS es IaaS pero cada vez con más características de PaaS GAE y Azure son PaaS que permiten la creación de aplicaciones (GAE sólo web) en la infraestructura Cloud de Google y Microsoft, respectivamente AWS te permite usar tus herramientas favoritas, aunque recomienda su uso de servicios escalables de almacenamiento, bases de datos o mensajes a través de interfaces REST GAE es muy sencillo pero exige el uso de las APIs exclusivas provistas por Google, aunque están basadas en estándares de facto de la industria Azure no limita el uso de .NET para las aplicaciones desplegadas aunque lo promociona Comparativa detallada en:
 en la infraestructura Cloud de Google y Microsoft, respectivamente. AWS te permite usar tus herramientas favoritas, aunque recomienda su uso de servicios escalables de almacenamiento, bases de datos o mensajes a través de interfaces REST. GAE es muy sencillo pero exige el uso de las APIs exclusivas provistas por Google, aunque están basadas en estándares de facto de la industria. Azure no limita el uso de .NET para las aplicaciones desplegadas aunque lo promociona. Comparativa detallada en:")
189
Patrones de Diseño en Cloud Computing
Fuente: Usar la nube para el escalado Usar en cada momento sólo los recursos necesarios Dos mecanismos: Passive listener model Active worker model Compartir la nube entre varios usuarios

190
Patrones de Diseño en Cloud Computing
Usar la nube para batch processing Usar la nube para almacenamiento Usar la nube para comunicación

191
Ventajas de Cloud Computing
Ahorros de costes en IT empresariales Ordenadores de bajo coste para los usuarios Costes más bajos en infraestructura IT Costes de software más bajos Mejora del rendimiento global Elasticidad para conseguir una escalabilidad superior Menos problemas en mantenimiento Actualizaciones inmediatas de software Capacidad de almacenamiento ilimitada Incremento de la seguridad de los datos (safety)
")
192
Desventajas de Cloud Computing
Requiere una conexión a Internet continua y rápida Puede ofrecer bastante latencia Características disponibles todavía limitadas Falta de confianza Los datos guardados pueden ser accedidos por otros Nuestros datos ya no están en la empresa Problemas legales (LODP): Safe Harbor Dependencia tecnológica en otras compañías ajenas Si la nube pierde los datos, ¡estás perdido!
: Safe Harbor. Dependencia tecnológica en otras compañías ajenas. Si la nube pierde los datos, ¡estás perdido!")
193
Conclusiones Cloud Computing nos ofrece un nuevo paradigma para alojar nuestros sistemas de información, aplicaciones y datos en la nube de Internet Son muchas las ventajas potenciales de este enfoque Ahorro de costes, pago por uso Escalabilidad exponencial PERO también muchos los riesgos para su implantación global inmediata Falta de control sobre nuestros datos y sistemas Relativa baja madurez de los productos que hacen posible Cloud Computing Ahora están surgiendo las herramientas y plataformas, pero tenemos que trabajar en patrones de diseño para asegurarnos buenas prácticas en Cloud Computing El futuro inmediato de los sistemas de información empresarial combinará los enfoques tradicionales, donde los sistemas y datos se ejecutan en infraestructura propia, con un paulatino e incremental despliegue de datos y aplicaciones a la nube.

194
Referencias Cloud Computing – Disruptive Innovation & Enabling Technology Cloud Computing and Amazon Web Services Architecting for the Cloud: Best Practices Are You Ready for Computing in the Cloud? Is Cloud Computing Ready for the Enterprise?

195
Referencias Amazon Web Services
Developing With Amazon Web Services - Highly Scalable Services that are Someone Else's Headache to Maintain and Develop How to Setup Amazon S3 with CloudFront as a Content Delivery Network Google App Engine Microsoft Windows Azure Platform

196
To Cloud or not Cloud, That is the Question
To Cloud or not Cloud, That is the Question! 22 Noviembre de 2010, 9:00-14:00 Bizkaia Enpresa Digitala, Parque Tecnológico de Zamudio Edificio ESI, #204 Dr. Diego Lz. de Ipiña Glz. de Artaza

Presentaciones similares
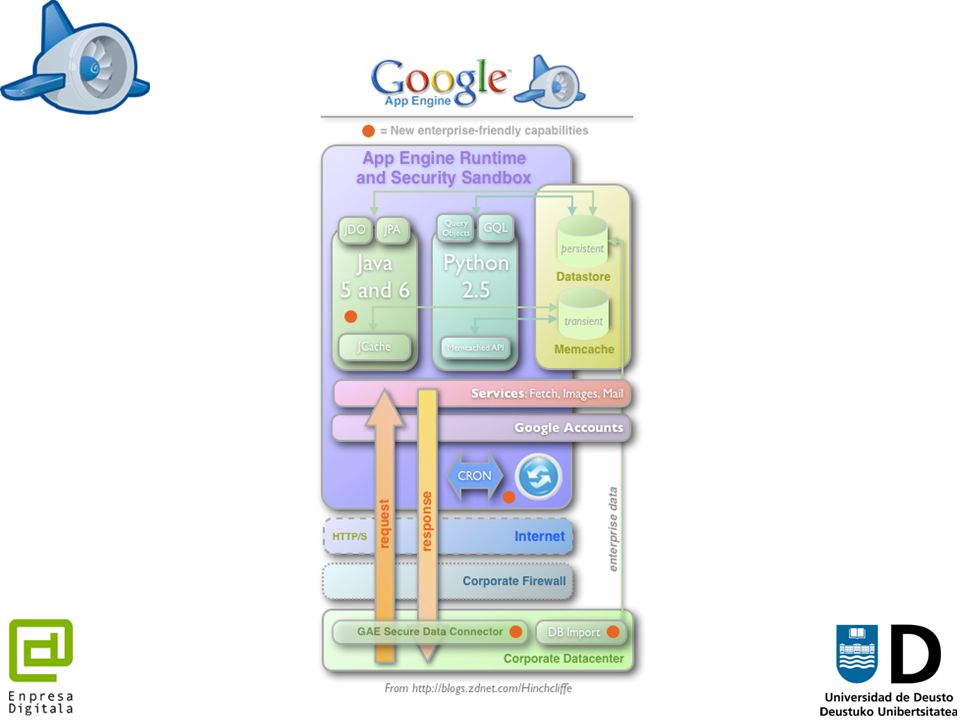
 Encriptación.>")









 Trucos, opciones y personalización de Excel Índice: 1 Vínculos absolutos y relativos, conectando datos de Excel con.>")








