Descargar la presentación
La descarga está en progreso. Por favor, espere

1
PostgreSQL: Parte 1 Integrantes: Álvaro Marciales Claudio Torrez

2
Puntos a Tratar Introducción a PostgreSQL Arquitectura del SMBD
Arquitectura Básica Arquitectura Avanzada Manejo de memoria Storage Manager Operación Vacuum Como configurar el uso de la memoria Índices Tipos de índices. Creación de índices en PostgreSQL. Concurrencia MVCC: Multiversion Concurrency Control Recuperación Backups de Bases de datos y de logs

5
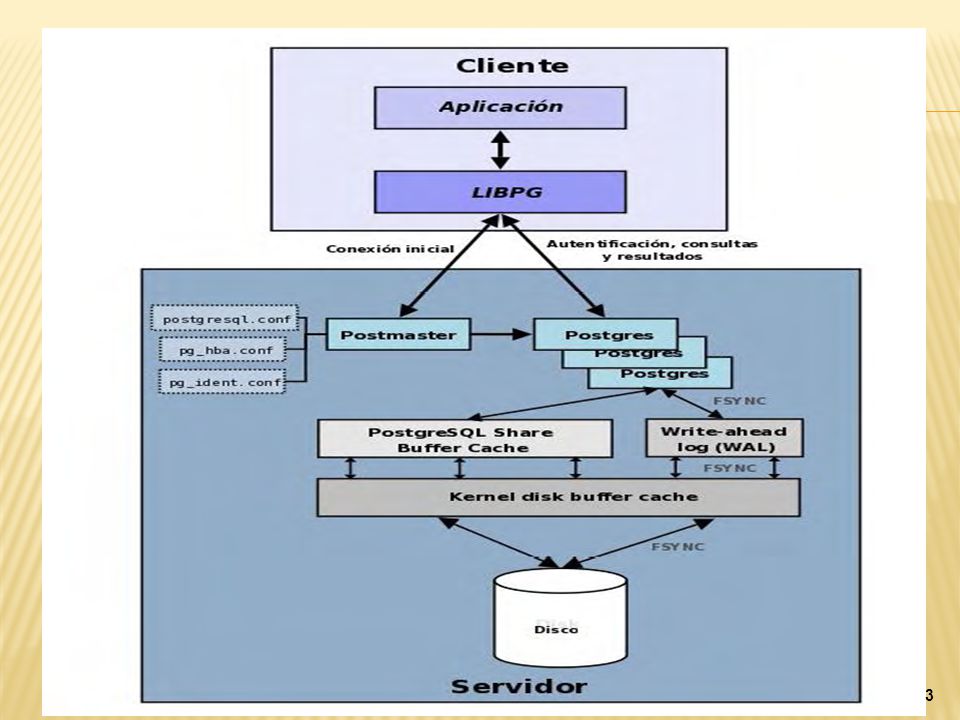
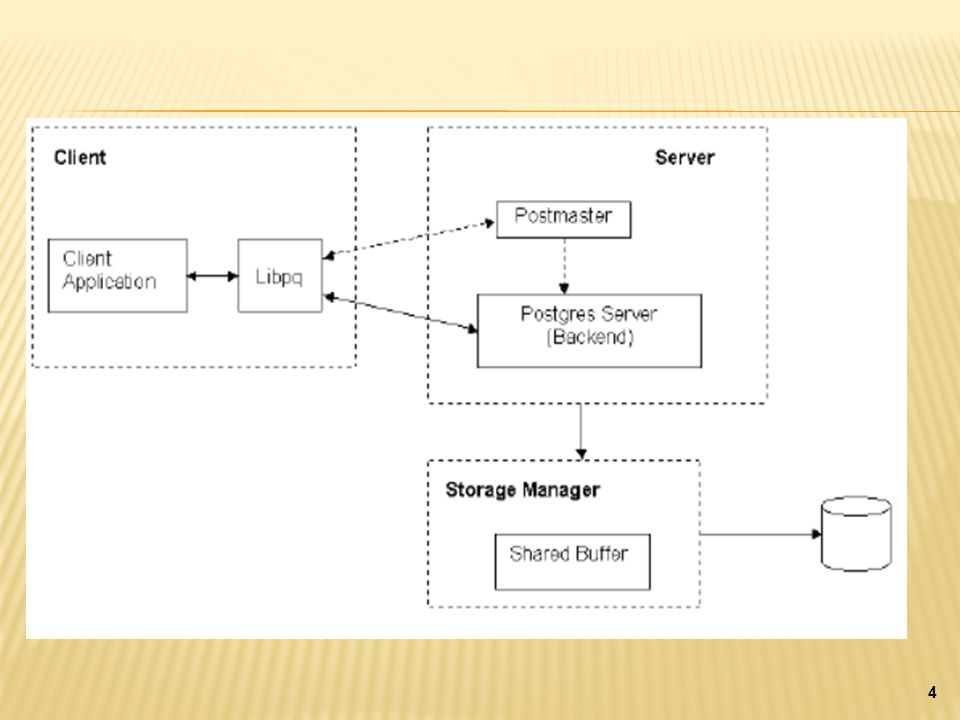
Arquitectura Básica del SMBD
PostgreSQL está basado en una arquitectura cliente-servidor. El programa servidor: postgres. Clientes: pgaccess y psql. Storage Manager: gestiona transacciones, memoria, concurrencia, es el responsable de la administración general de almacenamiento de datos y controla la consistencia de la información. Cuáles otras cosas importantes? Fotos de los módulos , es esta la arquitectura básica? PostgreSQL está basado en una arquitectura cliente-servidor. El programa servidor se llama postgres y entre los muchos programas cliente tenemos, por ejemplo, pgaccess (un cliente gráfico) y psql (un cliente en modo texto). (EXPLICACION IMAGEN) Un proceso servidor postgres puede atender exclusivamente a un solo cliente; es decir, hacen falta tantos procesos servidor postgres como clientes haya. El proceso postmaster es el encargado de ejecutar un nuevo servidor para cada cliente que solicite una conexión. PostgreSQL también cuenta con otro modulo muy importante llamado STORAGE MANAGER
 y psql (un cliente en modo texto). (EXPLICACION IMAGEN) Un proceso servidor postgres puede atender exclusivamente a un solo cliente; es decir, hacen falta tantos procesos servidor postgres como clientes haya. El proceso postmaster es el encargado de ejecutar un nuevo servidor para cada cliente que solicite una conexión. PostgreSQL también cuenta con otro modulo muy importante llamado STORAGE MANAGER.")
6
Almacenamiento y organización de datos
Almacena los datos en bloques del disco llamados "páginas" Mínimo 8 KB Máximo 32 KB Páginas 1.Al igual que cualquier DBMS se almacena la data en pequeños bloques de disco llamadas “páginas”, estas se almacena de manera dispersa en distintos sectores del disco. 2. Tamaño Mínimo de una pagina es de 8KB, el cual es el utilizado por defecto en PostgreSQL y el máximo es de 32 KB Esta copia costante a disco genera un intenso trabajo de I/O , al leer la data la pasamos del disco a la RAM y vicevarsa al escribir.

7
Almacenamiento en PostgreSQL

8
Estructura de una página
PostgreSQL: Para las operaciones de L/E primero se consulta al Buffer Manager (memoria RAM) si contiene la página, sino se hace la búsqueda en memoria secundaria. 1.Las páginas contienen “items” los cuales apuntan a tuplas o entradas de índices junto con metadata. 2.Para el caso de PostgreSQL las operaciones de L/E primero se consulta al Buffer Manager (memoria RAM) si contiene la página. 3.En caso contrario se buscaría en el disco duro. Y si no la tiene???
 si contiene la página, sino se hace la búsqueda en memoria secundaria. 1.Las páginas contienen items los cuales apuntan a tuplas o entradas de índices. junto con metadata. 2.Para el caso de PostgreSQL las operaciones de L/E primero se consulta al Buffer. Manager (memoria RAM) si contiene la página. 3.En caso contrario se buscaría en el disco duro. Y si no la tiene")
9
Tipo de organización de archivos en PostgreSQL
Utiliza los índices para reducir los tiempos de ejecución de las consultas que recibe, pero internamente implementa distintos métodos, en caso de que no exista un índice, utilizará una búsqueda secuencial en las tuplas que cumplen con la condición y si existe el sistema lo utiliza. En conclusión se puede decir que el SMBD utiliza ambos tipos de acceso, tanto indexado secuencial como aleatorio.

10
Índices Los índices se utilizan, principalmente, para mejorar el perfomance de una base de datos. Se definen sobre las columnas de la tabla que se utilicen en consultas repetidamente. Su uso inapropiado resultará en un funcionamiento más lento, ya que los tiempos de actualización e inserción incrementaran razonablemente.

11
Índices en PostgreSQL Postgres provee accesos de tipo btree (árbol-b), rtree (árbol- r) y hash para índices secundarios. Btree: el atributo indexado esta vinculado con uno de los siguientes operadores: <, <=, =, >=, >. Rtree :el atributo indexado esta vinculado con uno de los siguientes operadores: <<, &<, &>, ~=, &&. Hash: el atributo indexado esta vinculado con el operador =. Valor absoluto & AND binario | OR binario # XOR binario ~ Negación binaria << Corrimiento binario a la izquierda >> Corrimiento binario a la derecha Operadores geométricos << A la izquierda de? && Se superpone a? '((0,0),(1,1))'::caja && '((0,0),(2,2))'::caja &< Se superpone por la izquierda? '((0,0),(1,1))'::caja &< '((0,0),(2,2))'::caja &> Se superpone por la derecha? '((0,0),(3,3))'::caja &> '((0,0),(2,2))'::caja ~= Parecido a @ Contenido en >> A la derecha de?
,(1,1)) ::caja && ((0,0),(2,2)) ::caja. &< Se superpone por la izquierda ((0,0),(1,1)) ::caja &< ((0,0),(2,2)) ::caja. &> Se superpone por la derecha ((0,0),(3,3)) ::caja &> ((0,0),(2,2)) ::caja. ~= Parecido Contenido en. >> A la derecha de")
12
Índices: B-tree B-tree

13
Índices: Hash

14
Índices: R-tree

15
Índices: Creación En postgres podemos crear manualmente un índice haciendo uso de la sentencia: También se declaran índices automáticamente al crear claves sobre tablas. En el ejemplo: Se declara un índice de nombre name en la tabla de nombre table haciendo uso del método method, sobre las columnas especificadas por medio del nombre del campo, o una expresión entre paréntesis.

16
Manejo de memoria -Sistema de transacciones -Almacenamiento Relacional
Correspondiente con el manejo de memoria se encuentra el Storage Manager (Manejador de almacenamiento) que contiene cinco módulos los cuales proveen la administración de transacciones y el acceso a la BD Los módulos que componen el Storage Manager son: -Sistema de transacciones -Almacenamiento Relacional -Gestión del Tiempo -Control de concurrencia y gestión de fecha y hora -Acceso a registros
 que contiene cinco módulos los cuales proveen la administración de transacciones y el acceso a la BD. Los módulos que componen el Storage Manager son: -Sistema de transacciones. -Almacenamiento Relacional. -Gestión del Tiempo. -Control de concurrencia y gestión de fecha y hora. -Acceso a registros.")
17
Memoria: Operación Vacuum
Necesaria ejecutarla periódicamente El proceso que realiza la limpieza de la base de datos en PostgreSQL se llama vacuum. La necesidad de llevar a cabo procesos de vacuum periódicamente se justifica por los siguientes motivos: • Recuperar el espacio de disco perdido en borrados y actualizaciones de datos. • Actualizar las estadísticas de datos utilizados por el planificador de consultas SQL. • Protegerse ante la pérdida de datos por reutilización de identificadores de transacción. Para llevar a cabo un vacuum, deberemos ejecutar periódicamente las sentencias vacuum y analyze. En caso de que haya algún problema o acción adicional a realizar, el sistema nos lo indicará: demo=# VACUUM; El método del Lazy Vacuum es más usado que el Vacuum Full, esto se debe a que es más rápido y tiene buen efecto.

18
Memoria: Configuración
La configuración PostgreSQL puede ser manipulada fácilmente a través del archivo de configuración postgresql.conf Algunos parámetros de manejo de memoria son: Shared_Buffers: Maintenance_work_mem: Effective_cache_size: Shared_Buffers: Tamaño de la memoria total para postgres. Mainenance_work_mem: Memoria para mantenimiento y análisis. Effective_cache_size: Memoria disponible para la cache del sistema de archivos de postgres. Work_mem: Memoria para operaciones habituales.

19
Concurrencia A diferencia de la mayoría de otros sistemas de bases de datos que usan bloqueos para el control de concurrencia, PostgreSQL mantiene la consistencia de los datos con un modelo multiversión llamado: MVCC (Multi-Version Concurrency Control).
.")
20
Concurrencia: MVCC Que es MVCC? Como funciona? Ejemplos.
Casos Conflictivos.

21
MVCC Es una técnica de concurrencia optimista en donde ninguna tarea o hilo es bloqueado mientras se realiza una operación en la tabla. Las transacciones ven una imagen de la data, correspondiente al ultimo commit recibido, al momento de iniciarla. MVCC nunca modifica ó elimina los datos, en su lugar nuevas filas de información se van añadiendo conforme se crea o actualiza la data y se marcan los datos anteriores como “no visible”. La data nunca es “visible” por otras transacciones hasta que no haya hecho “commit”. Las operaciones de lectura nunca bloquean a las de escritura y viceversa.

22
MVCC: casos conflictivos
En el caso en el que se realicen 2 updates concurrentemente, es posible asignar el nivel de aislamiento (isolation) de las transacciones por medio de la instrucción: READ COMMITTED: lee el registro luego que la primera transacción haya terminado y luego completa su operación. SERIALIZABLE: recomienza la transacción que encuentra un conflicto de este estilo.
 de las transacciones por medio de la instrucción: READ COMMITTED: lee el registro luego que la primera transacción haya terminado y luego completa su operación. SERIALIZABLE: recomienza la transacción que encuentra un conflicto de este estilo.")
23
MVCC: Ejemplo

24
Recuperación Enfoques fundamentales para la copia de seguridad de datos en PostgreSQL: SQL dump Backup completo Backup a nivel de Ficheros

25
Recuperación: Sql Dump
La forma más sencilla de hacer un backup de una base de datos completa es la siguiente: pg_dump basededatos > fichero.sql Y puede ser restaurada usando: psql basededatos < fichero.sql

26
Recuperación: Sql Dump
Otras técnicas para el manejo de bases de datos más grandes: Dumps comprimidos: Backup con: pg_dump nombrebd | gzip > nombreArchComprimido.gz Restauración con: > gunzip -c nombreArchComprimido.gz | psql nombrebd

27
Recuperación: Backup Completo
También existe un comando para guardar todas las bases de datos del sistema y las variables globales también: pg_dumpall > ArchivoSalida Ejemplo: Backup con: pg_dumpall > data.dump Recuperación con: psql -f data.dump template1

28
Recuperación: Backup a Nivel de Ficheros
Este método implica copiar directamente los ficheros de la base de datos Ejemplo: Suponiendo que se encuentra en /var/pgsql/data sería así: tar -czvf backup.tar.gz /var/pgsql/data Restauración: Mover los ficheros a su ruta y levantarlo de nuevo

29
Archivado Continuo y Logfiles
En la documentación de PostgreSQL recomiendan combinar estos sistema con el de copiado a nivel físico para una estrategia compleja de Copias de Seguridad. Los archivos de log o log files de Postgres se almacenan automáticamente y por defecto en la carpeta de postgres Es necesario guardar los logfiles generados en otro lugar además del default Los logfiles al almacenar indefinidamente el estado del servidor llegan a ser muy voluminosos Hace falta una pequeña conclusión o pto que una lo escrito

30
Log files: Rotación Si cambiamos el parámetro Logging_collector a true en el archivo “Postgresql.conf” activamos el rotador de logfiles por defecto de postgres. Si deseamos hacer uso de un programa rotador de log files externo, es necesario redireccionar la salida estándar del servidor al programa deseado. Explicación? En cualquier caso, es conveniente disponer de mecanismos de rotación de los ficheros de registro; es decir, que cada cierto tiempo (12 horas, un día, una semana...), se haga una copia de estos ficheros y se empiecen unos nuevos, lo que nos permitirá mantener un histórico de éstos (tantos como ficheros podamos almacenar según el tamaño que tengan y nuestras limitaciones de espacio en disco).
, se haga una copia de estos ficheros y se empiecen unos nuevos, lo que nos. permitirá mantener un histórico de éstos (tantos como ficheros podamos almacenar. según el tamaño que tengan y nuestras limitaciones de espacio en disco).")
31
Conclusión PostgreSQL cuenta con una serie de características atractivas como: Su portabilidad por estar basado en lenguaje de consultas SQL. Su amplia variedad de índices Soporta base de datos de gran tamaño Integrado totalmente bajo el esquema ACID Alta concurrencia Desventaja Consume muchos recursos, en parte por el intenso trabajo de E/S al buscar y copiar datos en disco.

Presentaciones similares


 Encriptación.>")
















