Descargar la presentación
La descarga está en progreso. Por favor, espere

1
… de la semana pasada

2
El comando ‘histogram’ en STATA

3
Histogram inf_edad, bin(12) kdensity
 kdensity")
4
Box Plot (Gráfico de cajas)
Se muestra gráficamente los datos utilizando 5 números (estadísticas de resumen) X Q Mediana Q X Mínimo 1 3 Máximo 4 6 8 10 12
 X. Q. Mediana. Q. X. Mínimo Máximo")
5
Relación entre el perfil de la distribución y el Box Plot
Sesgada izquierda Simétrica Sesgada derecha Q Mediana Q Q Mediana Q Q Mediana Q 1 3 1 3 1 3

6
El comando ‘Graph’ en STATA

7
graph box inf_edad

8
Box plot

9
Los gráficos ‘box-plot’ permiten realizar comparaciones

10
Gráficos ‘tallo y hoja’ comando ‘stem’ de STATA

12
Scatter-plots y Ejemplos de Relaciones
No-lineales

17
Representación gráfica y problemas éticos
Last year, 25 percent of our sales dollar was profits. Depending on whether we present it to our stockholders or the unions, we don’t want to give it the same emphasis. Ganancias 25% . That’s easy. For our stockholders, we’ll show it in our annual report as a coin in perspective and take the 25 percent profits from the front … Ganancias 25% Ganancias 25% Whereas for the union, we’ll show it from the back where it won’t look anywhere as impressive.

18
Representación gráfica y problemas éticos
Labor Costs Oops, we certainly don’t want to advertise that sharp increase in administrative costs, it may raise questions by our stockholders. Administrative Costs Administrative Costs No sweat. We’ll switch the two components around. This way, by placing the administrative costs at the top, it doesn’t look so damning. As a matter of fact, it looks like it’s going down. Labor Costs

19
Representación gráfica y problemas éticos
100 Now, if you could only show this declining sales picture as going up, all my problems would be solved. 75 50 25 ‘87 ‘88 ‘89 ‘90 ‘91 ‘92 100 Sure thing; no problem. A bit of perspective here, a bit of fore-shortening there, and now the line looks like it’s going up. 75 50 25 ‘87 ‘88 ‘89 ‘90 ‘91 ‘92

20
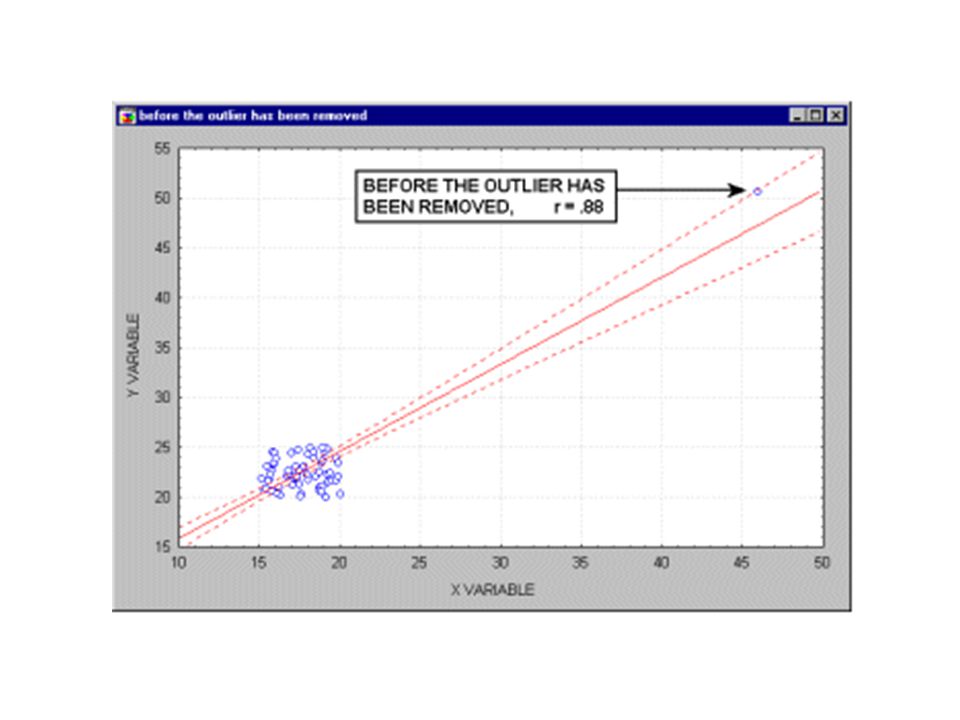
Manejo de datos fuera de rango (outliers)
Los Outliers son valores que se consideran “No Pertenecen” al conjunto de datos. Razones para darse: 1. Errores de medición Resultados atípicos La recomendación es corregir los errores (si es posible) y remover las observaciones atípicas. PERO! Y si así es la ciencia ?! Mejor hacer doble análisis: con y sin ‘outliers’
 y remover las observaciones atípicas. PERO! Y si así es la ciencia ! Mejor hacer doble análisis: con y sin ‘outliers’")
23
Análisis de OUTLIERS: Datos Simétricos
Valores que se exceden en 3 DS de la media outlier region outlier region -3s + 3s

24
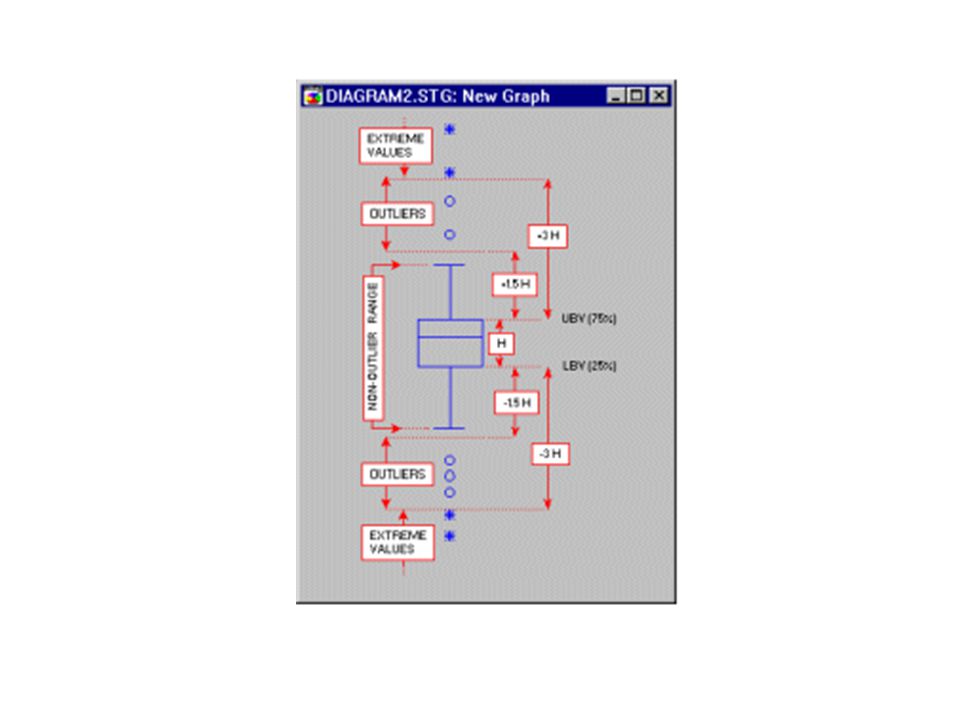
Análisis de OUTLIERS: Datos sesgados:
Valores que se exceden de 3 rangos intercuartiles por debajo del primer cuartil Q1 o por encima del tercer cuartil (Q3) (percentiles 25 y 75 respectivamente) Sesgada izquierda Sesgada Positiva outlier region outlier region Q1 Q3 Q1 Q3 Q1 – 3(Q3 – Q1) Q3 + 3(Q3 – Q1)
 (percentiles 25 y 75 respectivamente) Sesgada izquierda. Sesgada Positiva. outlier region. outlier region. Q1. Q3. Q1. Q3. Q1 – 3(Q3 – Q1) Q3 + 3(Q3 – Q1)")
25
Tratamientos TB MDR

26
Probabilidad de Conversión en Bk y Cultivo durante el tratamiento Estandarizado

27
Proporción acumulada de casos Bk y cultivo negativos a lo largo del tratamiento dentro de los que fueron positivos

28
Semana 4. Estadística descriptiva.
Prevalencia e incidencia. Sensibilidad y especificidad. Manejo de proporciones, razones y tasas provenientes de datos nominales en estudios epidemiológicos. Análisis exploratorio con variables continuas. Exploración gráfica y tabular bivariada. Estimación puntual e intervalos de confianza. Relación entre la sensibilidad, valor predictivo positivo y prevalencia de la enfermedad. Teorema de Bayes.

29
Universo “real”: marco muestral Sujetos bajo estudio: muestra
Proceso: Universo teórico DELIMITACION Universo “real”: marco muestral Cualquier persona con malaria en el norte del Perú Casos de malaria en Sullana Casos enero-marzo 2004 MUESTREO GENERALIZACION Sujetos bajo estudio: muestra

30
Tipos de inferencia estadística:
Estimación: Cálculo numérico de un cierto parámetro en la población En forma puntual y con intervalo de variabilidad Prueba de hipótesis: Respuesta a una hipótesis o pregunta sobre el valor de un parámetro en la población No se logra tener certeza: la respuesta se da como una probabilidad

31
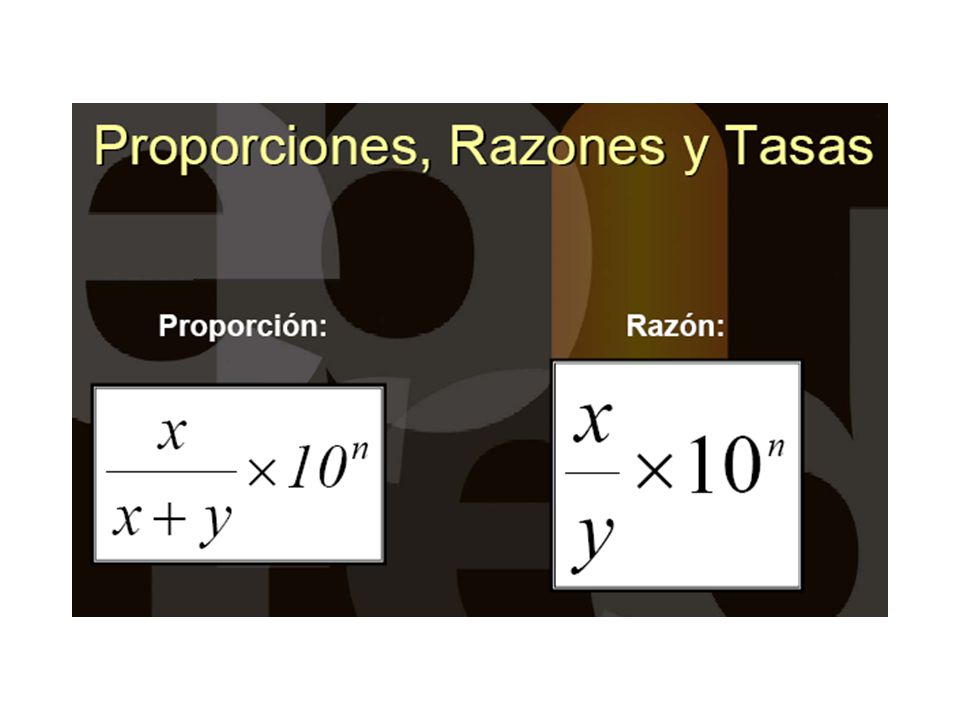
Manejo de proporciones, razones y tasas

34
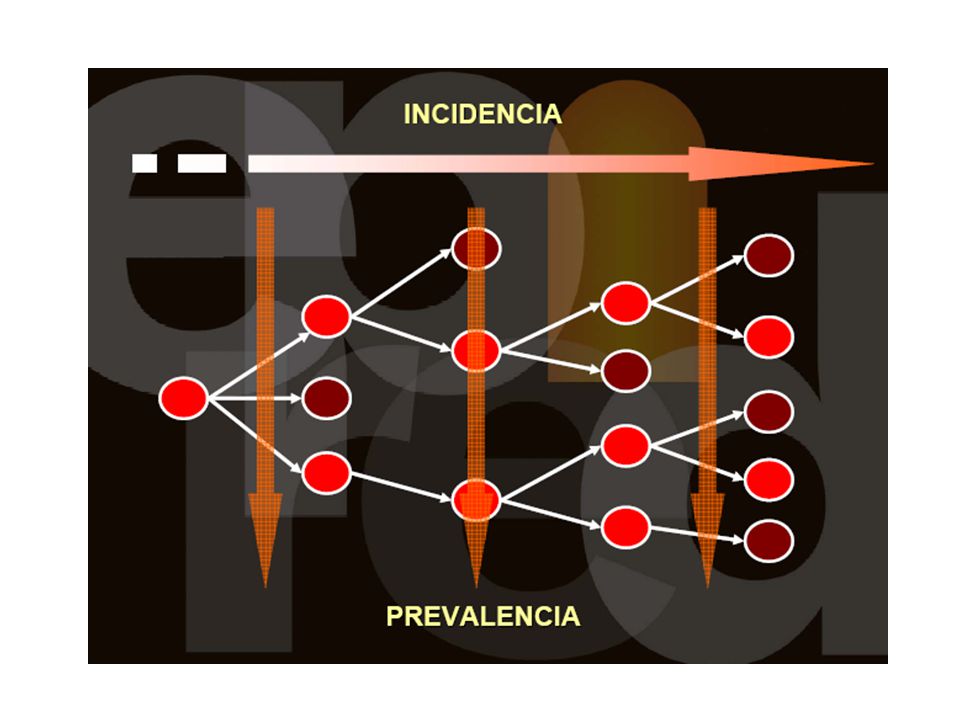
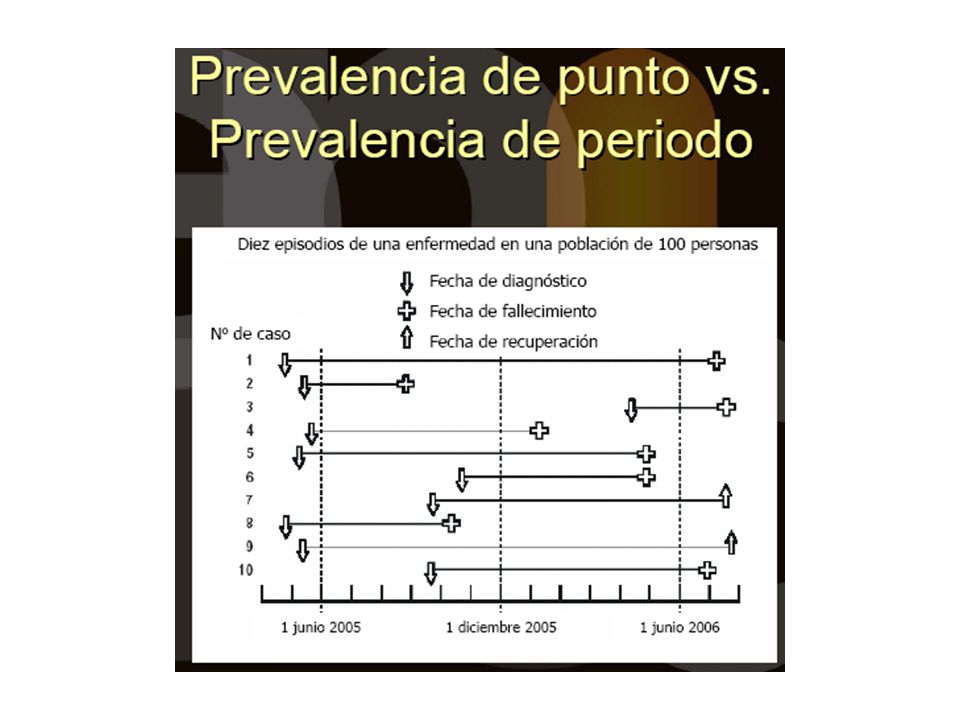
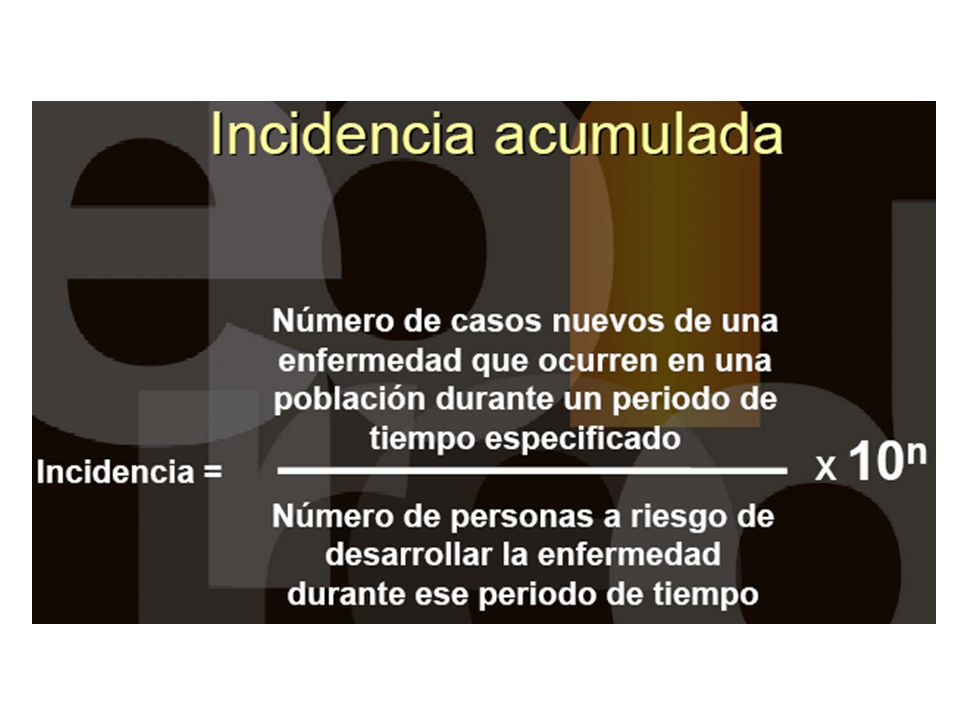
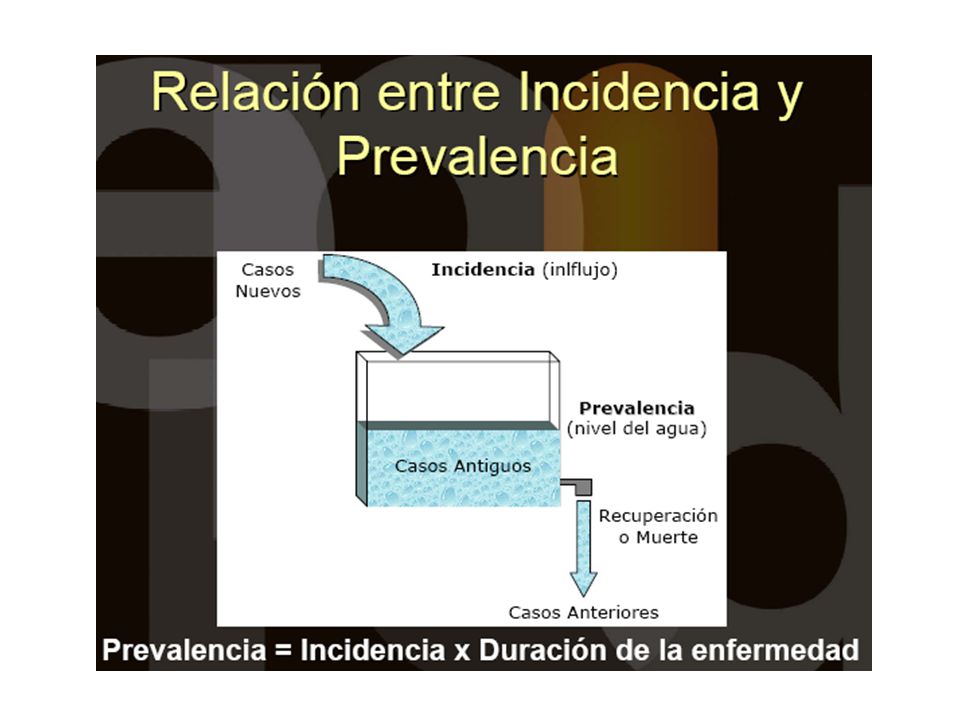
Prevalencia e incidencia

43
Tasa o densidad de incidencia:
Numero de eventos / Tiempo en riesgo, varía de 0 a infinito Expresa “velocidad” de ocurrencia, no la probabilidad de ocurrencia Resume el riesgo en un sólo indicador Unidades de tiempo definidas por el analista Supuestos: - exposición no tiene efecto acumulativo - riesgo es uniforme en el tiempo

45
¿Cuando se cumplen estos supuestos?
Eventos “aleatorios” a través del tiempo, el riesgo no cambia en el tiempo El riesgo no tiene “memoria”, no depende de la última vez que hubo un evento

46
Algunos ejemplos: Picaduras de animales ponzoñosos
Accidentes de tránsito Algunas enfermedades infecciosas en las que el riesgo no se acumula en el tiempo (TB, HIV) No se aplica a la mayoría de enfermedades crónicas o degenerativas
 No se aplica a la mayoría de enfermedades crónicas o degenerativas.")
47
Ejemplo: 15 30+ 15+ 25 20+ 20 20+ 10 15+ 15 Lima Iquitos (1+1+1) / ( ) 3 / 125 = (riesgo anual 2.4%) (1+1) / ( ) 2 / 100 = (riesgo anual 2.0%) Cuando llega a haber un evento, el tiempo en riesgo (denominador) sólo se cuenta hasta que ocurre el evento
 / ( ) 3 / 125 = (riesgo anual 2.4%) (1+1) / ( ) 2 / 100 = (riesgo anual 2.0%) Cuando llega a haber un evento, el tiempo en riesgo (denominador) sólo se cuenta hasta que ocurre el evento.")
49
Describiendo las tasas:
. cii 125 3, poisson -- Poisson Exact -- Variable | Exposure Mean Std. Err [95% Conf. Interval] | . cii 100 2, poisson |

50
Comparando las tasas: . iri 3 2 125 100 | Exposed Unexposed | Total
Cases | | Person-time | | | | Incidence Rate | | | Point estimate | [95% Conf. Interval] | Inc. rate diff. | | Inc. rate ratio | | (exact) Attr. frac. ex. | | (exact) Attr. frac. pop | | (midp) Pr(k>=3) = (exact) (midp) 2*Pr(k>=3) = (exact)
 Attr. frac. ex. | | (exact) Attr. frac. pop | .1 | (midp) Pr(k>=3) = (exact) (midp) 2*Pr(k>=3) = (exact)")
51
Preparando los datos: tiempoevento es una variable que es igual a la edad a la que fumó por primer vez (si fumó) o a la edad actual si es que nunca fumo. Hay que tener cuidado con los valores perdidos generate tiempoevento= p59 if p59!=88 replace tiempoevento= inf_edad if (p58==4) fumo es una variable que toma el valor 0 si la persona nunca fumó en su vida ó 1 si fumó alguna vez generate fumo= (p58!=4) if p58!=.
 o a la edad actual si es que nunca fumo. Hay que tener cuidado con los valores perdidos. generate tiempoevento= p59 if p59!=88. replace tiempoevento= inf_edad if (p58==4) fumo es una variable que toma el valor 0 si la persona nunca fumó en su vida ó 1 si fumó alguna vez. generate fumo= (p58!=4) if p58!=.")
52
Aplicando a nuestro ejemplo:

53
Tasas de incidencia estratificadas:

54
Sensibilidad y especificidad

55
Principios en programas de monitoreo
Validez – la habilidad para predecir quien tiene la no la tiene Sensibilidad – la habilidad de un test para correctamente identificar a los que tienen la enfermedad Una prueba con alta densibilidad tendrá pocos falsos negativos Especificidad – la habilidad de una prueba para correctamente identificar aquellos quienes no tienen la enfermedad Una prueba con alta especificidad tendrá pocos falsos positivos

56
Principios en programas de monitoreo (cont.)
Una prueba ideal de monitoreo deberá tener 100% de sensibilidad y 100% de especificidad -no debería tener falsas negativas ni falsos positivos En la práctica, esos están inversamente relacionados Es posible variar la sensibilidad y la especificidad, variando el nivel en el cual la prueba se considera positiva

57
Calculando mediciones de validez
Diagnóstico verdadero Resultado de la prueba Enfermedad No enfermedad Total Positivo a b a+b Negativo c d c+d Total a+c b+d a+b+c+d Sensibilidad = a/(a+c); la probabilidad de tener una prueba positiva si es realmente positivo Especificidad = d/(b+d); la probabilidad de tener una prueba negativa, si realmente es negativa Valor predictivo positivo = a/(a+b); la probabilida de tener la enfermedad si la prueba es positiva Valor predictivo negativo = d/(c+d); la probabilidad de no tener la enfermedad si la prueba es negativa Prevalencia = (a+c)/(a+b+c+d) Precisión (eficiencia de la prueba) = (a+d)/(a+b+c+d)
; la probabilidad de tener una prueba positiva si es realmente positivo. Especificidad = d/(b+d); la probabilidad de tener una prueba negativa, si realmente es negativa. Valor predictivo positivo = a/(a+b); la probabilida de tener la enfermedad si la prueba es positiva. Valor predictivo negativo = d/(c+d); la probabilidad de no tener la enfermedad si la prueba es negativa. Prevalencia = (a+c)/(a+b+c+d) Precisión (eficiencia de la prueba) = (a+d)/(a+b+c+d)")
58
Note las relaciones en monitoreo
Especificidad + tasa de falsos positivos = 1 d/(b+d) + b/(b+d) = 1 Si la especificidad está incrementada, la tasa de falsos positivos está disminuida Si la especificidad está disminuida, la tasa de falsos positivos está incrementada. Sensibilidad + tasa de falsos negativos = 1 a/(a+c) + c/(a+c) = 1 Si la sensibilidad está incrementada, la tasa de falsos negativos está disminuida Si la sensibilidad está disminuida, la tasa de falsos negativos está incrementada
 + b/(b+d) = 1. Si la especificidad está incrementada, la tasa de falsos positivos está disminuida. Si la especificidad está disminuida, la tasa de falsos positivos está incrementada. Sensibilidad + tasa de falsos negativos = 1. a/(a+c) + c/(a+c) = 1. Si la sensibilidad está incrementada, la tasa de falsos negativos está disminuida. Si la sensibilidad está disminuida, la tasa de falsos negativos está incrementada.")
59
Probabilidad de enfermedad
Probabilidad de enfermedad pre-prueba = prevalencia de la enfermedad Probabilidad de enfermedad post-prueba = Si normal, c/(c+d) Si positiva, a/(a+b)
 Si positiva, a/(a+b)")
60
Relación entre Sensibilidad y Especificidad
Normals= normales Diseased= enfermos

61
Sensibilidad y especificidad del nivel de glucosa en sangre
Sensibilidad y especificidad del nivel de glucosa en sangre de 110 mg/100 ml para determinación del status diabético Nivel sanguíneo de glucosa (mg/100 ml) Diabéticos (%) No diabéticos (%) Aquellos con niveles arriba de 110 mg/100 ml son clasificados como diabéticos 92.9 (verdaderos positivos) 51.6 (Falsos positivos) Aquellos con niveles inferiores a 110 mg/100 ml son clasificados como no diabéticos 7.1 (falsos negativos) 48.4 (verdaderos negativos) 100.0 100.0
 Diabéticos. (%) No diabéticos. (%) Aquellos con niveles arriba de 110 mg/100 ml son clasificados como diabéticos (verdaderos. positivos) (Falsos. positivos) Aquellos con niveles inferiores a 110 mg/100 ml son clasificados como no diabéticos (falsos. negativos) (verdaderos. negativos)")
62
¿Qué debe preferirse: alta sensibilidad o alta especificidad?
Si se tiene una enfermedad fatal sin tratamiento (como casos tempranos de SIDA), prefiera alta especificidad Si está monitoreando para la prevención de la transmisión de una enfermedad transmisible (como el monitoreo de VIH en donadores de sangre), prefiera sensibilidad
, prefiera alta especificidad. Si está monitoreando para la prevención de la transmisión de una enfermedad transmisible (como el monitoreo de VIH en donadores de sangre), prefiera sensibilidad.")
63
Recuerde…. Sensibilidad y especificidad son funciones de la prueba de monitoreo Si usas una prueba de monitoreo en una población de baja prevalencia, tendrás un valor predictivo positivo bajo y potencialmente muchos falsos positivos

64
Trasladado a la vida real…..
Elisa tiene casi 90% de sensibilidad y 99% de especificidad Población Prevalencia de VIH Valor predictivo+ Valor predictivo- 58% NJ (7 million) 1.5% 99.8% Si enfermedad No enfermedad Total Prueba + 94,500 68,950 163,450 Prueba - 10,500 6,826,050 6,836,550 7 millones Total 105,000 6,895,000 Eficiencia de la prueba = (P+ + P-)/Total probados = 98.9% Pero, 10,500 personas que son VIH+ creen que no tienen la enfermedad Otros 68,950 están asustados creyendo que tienen la enfermedad y requieren más pruebas
 1.5% 99.8% Si enfermedad. No enfermedad. Total. Prueba + 94, , ,450. Prueba - 10,500. 6,826,050. 6,836, millones. Total. 105,000. 6,895,000. Eficiencia de la prueba = (P+ + P-)/Total probados = 98.9% Pero, 10,500 personas que son VIH+ creen que no tienen la enfermedad. Otros 68,950 están asustados creyendo que tienen la enfermedad y requieren más pruebas.")
65
Teorema de Bayes

67
La falacia del interrogador
El problema de la confesión Sea A el suceso “el acusado es culpable” Sea C el suceso “el acusado ha confesado” Consideremos P(A) como la probabilidad de culpabilidad del acusado, antes de “las nuevas pruebas” de su autoconfesión P(C / A) : probabilidad de que ha confesado el delito dado que es realmente culpable. P(C / A ): probabilidad de que ha confesado el delito dado que no es culpable c Entonces P(A/C) = P(C / A) P(A) P(C / A) P(A) + P(C/A ) P(A ) c
 como la probabilidad de culpabilidad del acusado, antes de las nuevas pruebas de su autoconfesión. P(C / A) : probabilidad de que ha confesado el delito dado que es realmente culpable. P(C / A ): probabilidad de que ha confesado el delito dado que no es culpable. c. Entonces. P(A/C) = P(C / A) P(A) P(C / A) P(A) + P(C/A ) P(A ) c.")
68
Relación entre la sensibilidad, valor predictivo positivo y prevalencia de la enfermedad

70
Estimación puntual e intervalos de confianza

71
Estimación: Puntual: determina que posible valor del parámetro de la población es mas consistente con los datos observados en la muestra. Ejemplo: ell cálculo de una tasa de incidencia, un RR o un promedio Por intervalo: cuantifica la incertidumbre o variabilidad que tiene una estimación. Ejemplo: el cálculo de un intervalo de confianza

72
Estimación puntual e intervalos de confianza
Los parámetros de una población tienen un valor fijo, (es un número exacto) Usualmente estos parámetros no se conocen, por que es complicado medir a ‘toda la población’ Ante esto, los parámetros se ‘estiman’ a partir de una ‘muestra’ de la población. La estimación puede ser ‘puntual’ o en un ‘intervalo de confianza’
 Usualmente estos parámetros no se conocen, por que es complicado medir a ‘toda la población’ Ante esto, los parámetros se ‘estiman’ a partir de una ‘muestra’ de la población. La estimación puede ser ‘puntual’ o en un ‘intervalo de confianza’")
73
Intervalo de confianza:
Intervalo construido bajo condiciones tales que con una cierta probabilidad (usualmente 95%) contenga al parámetro deseado Intervalo calculado de acuerdo a principios tales que 95 de cada 100 intervalos similarmente construidos contendrán el valor del parámetro Uno puede tener 95% de confianza en afirmar que ese intervalo contiene el valor real del parámetro
 contenga al parámetro deseado. Intervalo calculado de acuerdo a principios tales que 95 de cada 100 intervalos similarmente construidos contendrán el valor del parámetro. Uno puede tener 95% de confianza en afirmar que ese intervalo contiene el valor real del parámetro.")
74
Conceptualmente: Intervalo calculado con LA UNICA muestra obtenida
Intervalos de confianza de varias muestras (solo teórico) Rango de valores valores del parámetro Verdadero valor del parámetro
 Rango de valores valores del parámetro. Verdadero valor del parámetro.")
75
Es mejor estimar el intervalo de confianza de un parámetro antes que su estimación puntual…
El intervalo de confianza es una ‘variable aleatoria’ El 95% Intervalo de Confianza, es un intervalo que tiene un 95% de probabilidad de cubrir el verdadero valor del parámetro estimado

76
El Teorema del Límite Central da validez a los intervalos de confianza
La media de una muestra “grande” de datos de cualquier tipo sigue una distribución normal Esto aún se cumple para datos binomiales (sexo, prevalencia, sensibilidad, etc) Qué es una muestra grande? Eso varía según cada tipo de dato (entre otras cosas) A medida que el tamaño de muestra crece, la distribución de la media muestral se hace más normal
 Qué es una muestra grande Eso varía según cada tipo de dato (entre otras cosas) A medida que el tamaño de muestra crece, la distribución de la media muestral se hace más normal.")
77
n=2 n=5 n=30 n=3 n=15 n=60

78
Efectos del ‘muestreo’ en la estimación de un parámetro

79
En resumen: Un intervalo de confianza tiene una cierta probabilidad (usualmente 95%) de contener al parámetro deseado El TLC da validez a esta afirmación en muestras grandes para todo tipo de datos En datos binomiales, el IC tiene una probabilidad de 95% de incluir a la prevalencia o proporción de interés

80
Comandos en STATA para los Intervalos de Confianza: ci

81
Intervalos de confianza de variables normales
Std.Err. = Std.Dev / sqrt(N)
")
82
Ci varlist, level( )
")
83
Intervalos de confianza de proporciones

84
Usando los menues de STATA 8

Presentaciones similares











 Betty C. Jung RN, MPH, CHES ¿Quién es Betty C. Jung?>")















