Descargar la presentación
La descarga está en progreso. Por favor, espere

1
PARTE I ANDRI GIOVANNI HERNANDEZ CAMPOSECO

2
ANDRI GIOVANNI HERNANDEZ CAMPOSECO Check point video: http://www.youtube.com/watch?v=FFzi4WLYl84 Dead Lock: http://www.youtube.com/watch?v=m28Da9zqrqk Concurrencia : http://www.youtube.com/watch?v=kVTPnMSk_Zc Puntos de Verificación, Tipos de Concurrencia y problemas, Bloqueo mortal.

3
Puntos De Verificacion CheckpointsPuntos De Verificacion Checkpoints: Cuando ocurre una falla en el sistema es necesario consultar la bit á cora para determinar cu á les son las transacciones que necesitan volver a hacerse y cuando no necesitan hacerse. Estos puntos de verificaci ó n nos ayudan para reducir el gasto de tiempo consultando la bit á cora. El punto de verificaci ó n es un registro que se genera en la bit á cora para concluir en todo lo que se encuentra antes de ese punto est á correcto y verificado. Si el sistema se llega a caer, se realiza la bit á cora buscando del final al inicio el primer registro checkpoint, ya encontrado se procesan los registros que se encuentra despu é s del checkpoint. El proceso de recuperaci ó n ya depende del tipo que estemos utilizando.

4
Puntos De Verificacion CheckpointsPuntos De Verificacion Checkpoints: La operación de recuperación requiere recorrer todo el registro de la base de datos. Así, el buscar todas las transacciones a las cuales es necesario aplicarles un UNDO o REDO puede tomar una cantidad de trabajo considerable. Para reducir este trabajo se pueden poner puntos de verificación (checkpoints) en el registro de la base de datos para indicar que en esos puntos la base de datos está actualizada y consistente. En este caso, un REDO tiene que iniciar desde un punto de verificación y un UNDO tiene que regresar al punto de verificación más inmediato anterior. La colocación de puntos de verificación se realiza con las siguientes acciones: Se escribe un “begin_checkpoint” en el registro de la base de datos. Se recolectan todos los datos verificados en la base de datos estable. Se escribe un “fin_de_checkpoint” en el registro de la base de datos.
 en el registro de la base de datos para indicar que en esos puntos la base de datos está actualizada y consistente. En este caso, un REDO tiene que iniciar desde un punto de verificación y un UNDO tiene que regresar al punto de verificación más inmediato anterior. La colocación de puntos de verificación se realiza con las siguientes acciones: Se escribe un begin_checkpoint en el registro de la base de datos. Se recolectan todos los datos verificados en la base de datos estable. Se escribe un fin_de_checkpoint en el registro de la base de datos..")
5
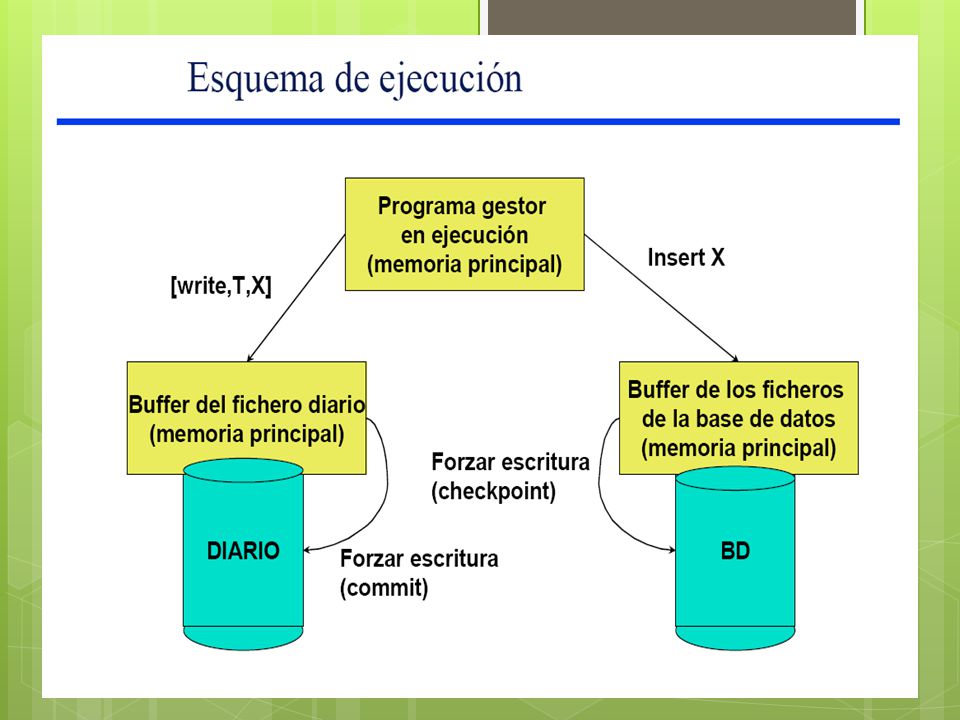
Puntos De Verificacion CheckpointsPuntos De Verificacion Checkpoints: Los puntos de checkpoint en el diario garantizan que la información de las transacciones que han terminado antes de ese punto está en la base de datos. Un checkpoint consistente en: –Suspender la ejecución de las transacciones temporalmente. –Forzar la escritura de todas las actualizaciones de buffer a disco. –Escribir [checkpoint] en el diario – Hacer que las transacciones continúen

7
Concurrencia

8
Cuando se ejecutan concurrentemente varias transacciones en la base de datos, puede dejar de conservase la consistencia de los datos. Es necesario que el sistema controle la interacción entre las transacciones concurrentes, y dicho control se lleva a cabo mediante uno de los muchos mecanismos llamados esquemas de control de concurrencia.

9
Problemas clásicos de Concurrencia: Actualización Perdida Ocurre cuando se pierde la actualización hecha por una transacción T1 por la acción de otra transacción T2 sobre el mismo elemento de datos. Lectura Sucia Ocurre cuando una transacción T2 lee un valor de un elemento de dato dejado por otra transacción T1 que no hizo commit antes de que T2 leyera el dato. Fenómeno Fantasma: Una transacción sumariza los elementos de datos de un conjunto de tuplas, sin embargo otra transacción esta insertando una nueva tupla con datos que deberían ser tomados en cuenta por la primera transacción.

10
Protocolos basados en bloqueo Se pueden usar varios esquemas de control de concurrencia para asegurar la secuencialidad. Todos estos esquemas o bien retrasan una operación o bien abortan la transacción que ha realizado la operación. Los más comunes son los protocolos de bloqueo, los esquemas de ordenación por marcas temporales, las técnicas de validación y los esquemas multiversión. Una forma de asegurar la secuencialidad es exigir que el acceso a los elementos de datos se haga en exclusión mutua; es decir, mientras una transacción accede a un elemento de datos, ninguna otra transacción puede modificar dicho elemento. El método más habitual que se usa para implementar este requisito es permitir que una transacción acceda a un elemento de datos sólo si posee actualmente un bloqueo sobre dicho elemento.

11
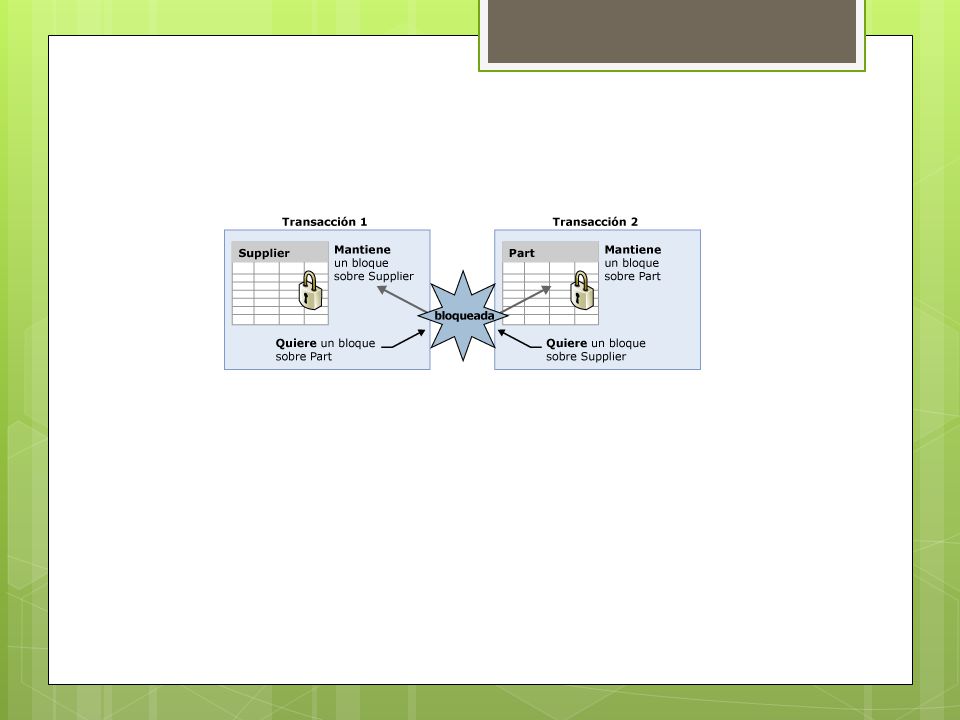
Bloqueo Mortal Interbloqueos Un interbloqueo se produce cuando dos o más tareas se bloquean entre sí permanentemente teniendo cada tarea un bloqueo en un recurso que las otras tareas intentan bloquear. Por ejemplo: La transacción A tiene un bloqueo compartido de la fila 1. La transacción B tiene un bloqueo compartido de la fila 2. La transacción A ahora solicita un bloqueo exclusivo de la fila 2 y se bloquea hasta que la transacción B finalice y libere el bloqueo compartido que tiene de la fila 2. La transacción B ahora solicita un bloqueo exclusivo de la fila 1 y se bloquea hasta que la transacción A finalice y libere el bloqueo compartido que tiene de la fila 1. La transacción A no puede completarse hasta que se complete la transacción B, pero la transacción B está bloqueada por la transacción A. Esta condición también se llama dependencia cíclica: la transacción A tiene una dependencia de la transacción B y la transacción B cierra el círculo teniendo una dependencia de la transacción A. Ambas transacciones con un interbloqueo esperarán para siempre, a no ser que un proceso externo rompa el interbloqueo.La supervisión de interbloqueos del SQL Server Database Engine (Motor de base de datos de SQL Server) de Microsoft comprueba periódicamente si hay tareas con un interbloqueo. Si el monitor detecta una dependencia cíclica, selecciona una de las tareas como el sujeto y finaliza su transacción con un error. Esto permite a la otra tarea completar su transacción. La aplicación con la transacción que terminó con un error puede reintentar la transacción, que suele completarse después de que la otra transacción interbloqueada haya finalizado. A veces, los interbloqueos se denominan "abrazo mortal".
 de Microsoft comprueba periódicamente si hay tareas con un interbloqueo. Si el monitor detecta una dependencia cíclica, selecciona una de las tareas como el sujeto y finaliza su transacción con un error. Esto permite a la otra tarea completar su transacción. La aplicación con la transacción que terminó con un error puede reintentar la transacción, que suele completarse después de que la otra transacción interbloqueada haya finalizado. A veces, los interbloqueos se denominan abrazo mortal ..")
13
GRACIAS POR SU ATENCION

14
PARTE II ANDRI GIOVANNI HERNANDEZ CAMPOSECO

15
Técnicas de recuperación de bases de datos ANDRI GIOVANNI HERNANDEZ CAMPOSECO

16
Conceptos de recuperación. Descripción dela recuperación y clasificación de los algoritmos de recuperación Recuperarse al fallo de una transacción significa que la base de datos se restaura al estado coherente mas reciente, inmediatamente anterior al momento del fallo para esto el sistema guarda las información sobre los cambios de las transacciones esta información se guarda en el registro del sistema. 1. Si hay un fallo como la caída del disco, el sistema restaura una copia se seguridad del registro, hasta el momento del fallo. 2. Cuando el daño se vuelve inconsistente, se pueden rehacer algunas operaciones para restaurar a un estado consistente. En este caso no se necesita una copia archivada. Actualización Diferida Actualización inmediata No se actualiza físicamente la base de datos Hasta que no haya alcanzado su punto de confirmación La base de datos puede ser actualizada por Algunas Operaciones antes de que esta ultima alcance su punto de confirmación.

17
Almacenamiento en cache en cache (búfer) de los bloques de disco. El proceso de recuperación se entrelaza con funciones del sistema operativo en particular con el almacenamiento en cache o en búfer en la memoria principal, Normalmente se reserva una colección de búferes en memoria, denominados cache DBMS. Se utiliza un directorio para rastrear los elementos de la base de datos que se encuentra en los búferes. bit sucio que puede incluirse en la entrada del directorio, para indicar si se ha modificado o no el búfer. Pin-unpin dice que una pagina en cache se esta accediendo actualmente. Actualización en el lugar (in place) escribe en el bufer el mismo ubicación de disco original. Shadowing(en la sombra) escribe un bufer actualizado en una ubicación diferente. BFIM before image imagen antes de la actualización. AFIM after imagen después de la actualización. Registro antes de la escritura, robar/no-robar y forzar no forzar En este caso, el mecanismo de recuperación debe garantizar la grabación de la BFIM de los datos en la entrada apropiada del registro del sistema y que esa entrada se vuelque en el disco antes que la BFIM sea sobrescrita con la AFIM de la base de datos del disco.
 escribe en el bufer el mismo ubicación de disco original. Shadowing(en la sombra) escribe un bufer actualizado en una ubicación diferente. BFIM before image imagen antes de la actualización. AFIM after imagen después de la actualización. Registro antes de la escritura, robar/no-robar y forzar no forzar En este caso, el mecanismo de recuperación debe garantizar la grabación de la BFIM de los datos en la entrada apropiada del registro del sistema y que esa entrada se vuelque en el disco antes que la BFIM sea sobrescrita con la AFIM de la base de datos del disco..")
18
puntos de control en el registro del sistema y puntos de control difusos Otro tipo de entrada en el registro es el denominado punto de control [checkpoint] En este punto el sistema escribe en la base de datos en disco todos los búferes Del DBMS que se han modificado. No tienen que rehacer sus operaciones ESCRIBIR en caso de una caída del sistema. El gestor de recuperaciones de un DBMS debe decidir en que intervalos tomar un punto de control. La toma de un punto de control consiste en las siguiente acciones: 1. Suspender temporalmente la ejecución de las transacciones. 2. Forzar la escritura de disco de todos los búferes de memoria que se hayan modificado. 3. Escribir un registro [checkpoint] en el registro del sistema y forzar la escritura Del registro en el disco 4. Reanudar la ejecución de las transacciones.
![puntos de control en el registro del sistema y puntos de control difusos Otro tipo de entrada en el registro es el denominado punto de control [checkpoint] En este punto el sistema escribe en la base de datos en disco todos los búferes Del DBMS que se han modificado.](http://images.slideplayer.es/12/3393959/slides/slide_18.jpg "No tienen que rehacer sus operaciones ESCRIBIR en caso de una caída del sistema. El gestor de recuperaciones de un DBMS debe decidir en que intervalos tomar un punto de control. La toma de un punto de control consiste en las siguiente acciones: 1. Suspender temporalmente la ejecución de las transacciones. 2. Forzar la escritura de disco de todos los búferes de memoria que se hayan modificado. 3. Escribir un registro [checkpoint] en el registro del sistema y forzar la escritura Del registro en el disco 4. Reanudar la ejecución de las transacciones..")
19
Anulación de transacciones Si una transacción falla por cualquier razón es posible tener que anular la transacción Si una transacción t es anulada,, también debe anularse cualquier transacción S que Lea el valor de algún elemento de datos X escrito por T. Anulación en cascada

20
1 Técnicas de recuperación basadas en la actualización diferida. Deferir o posponer las actualizaciones de la base de datos hasta que la transacción complete su ejecución satisfactoriamente y alcance su punto de confirmación 1.1 recuperación mediante la actualización diferida en un entorno monousuario El algoritmo RDU se utiliza un procedimiento rehacer, Proporcionado con posterioridad, Para rehacer determinadas operaciones escribrir_elemento.

21
1.2 Actualización diferida con ejecución concurrente en un entorno multiusuario Planificación de la ejecución de las transacciones Cuando se tomo el punto de control en el momento t1 la transacción T1 Se habría confirmado.

22
Paginación en la sombra (shadowing). Este esquema no requiere el uso de un registro del sistema en un entorno monousuario. Durante la ejecución de la transacción, el directorio sombra nunca se modifica.

23
Algoritmo de recuperación ARIES. a)El registro del sistema en el momento de la caída b) Las tablas de transacciones y de paginas sucias en el momento de Punto de control c) Las tablas de transacciones y de paginas sucias después de la fase de análisis
El registro del sistema en el momento de la caída b) Las tablas de transacciones y de paginas sucias en el momento de Punto de control c) Las tablas de transacciones y de paginas sucias después de la fase de análisis.")
24
GRACIAS POR SU ATENCION

Presentaciones similares













 Microsoft SQL Server 2008 R2 (2013) Suscribase a http://addkw.com/ o escríbanos.>")





