Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Regresión Linear Correlación de Pearson, r Regresión Múltiple Regresión Logística Regresión de Poisson

2
Propósitos de RL Evaluar si las dos variables están asociadas (r)
Predecir en base a una variable, ¿qué se obtiene de la otra? (ARS) Evaluar grado de concordancia entre los valores de las dos variables (ARS)
 Evaluar grado de concordancia entre los valores de las dos variables (ARS)")
3
Supuestos Existencia (para cualquier valor de la variable X, Y es una variable al azar con una cierta probabilidad de distrib teniendo un promedio y varianza finitos) Independencia (los valores de Y son estadísticamente independientes uno de otro). Linearidad (el promedio de Y es una función linear de X)
 Independencia (los valores de Y son estadísticamente independientes uno de otro). Linearidad (el promedio de Y es una función linear de X)")
4
4. Homocedasticidad (La varianza de Y es la misma para cualquier X)
5. Distribución normal (Para cualquier valor de X, Y tiene distribución normal)
")
5
Variables Dependiente: eje Y Independiente: eje X Intervalares
Distribución normal Gráfico: PLOT DE DISPERSIÓN Pares de observaciones

6
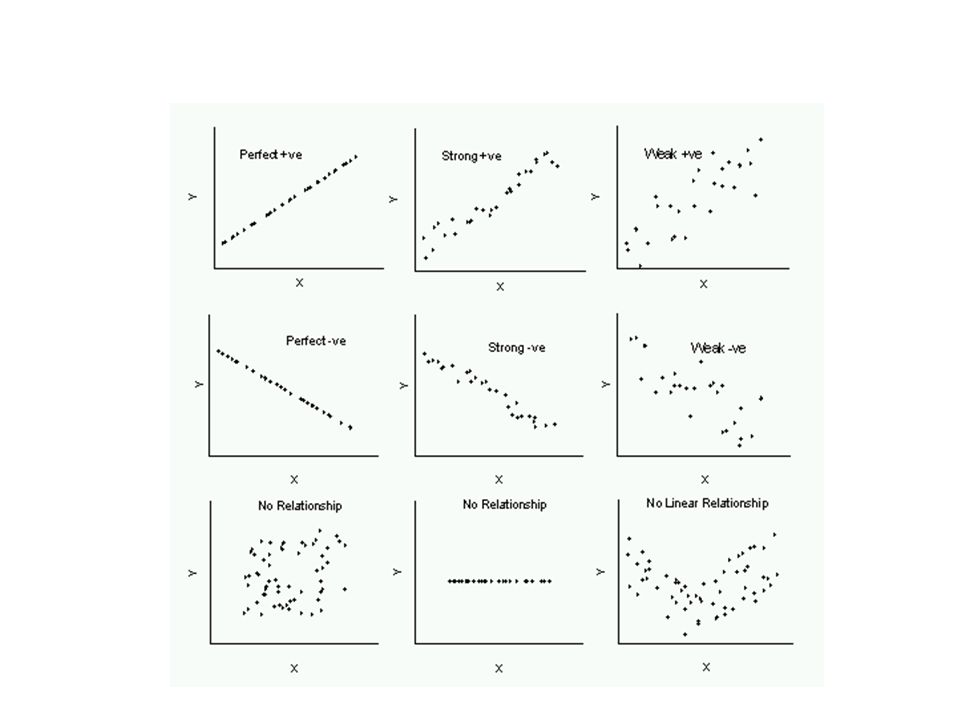
Tipo de relaciones

7
Var dep Pendiente Var indep
Regresión linear La línea recta es descrita por ecuación: Y = 2 + 5X Intercepto FPLOT y = x+2 Var dep Pendiente Var indep

8
Hipótesis nula b=0 pendiente = 0 a=0 intercepto = 0

9
Relación entre presión sistólica mm/Hg vs. Edad (años)
Y a = intercepto b = pendiente X

10
Systat Residual

11
Stata 10

12
Relación fisuras vs. Año (C Holuigue, 2005)
Relación fisuras vs. Año (C Holuigue, 2005). Año 2000: inicio del suplemento de ácido fólico en la harina.
. Año 2000: inicio del suplemento de ácido fólico en la harina.")
13
ES ESTO UNA RELACIÓN LINEAL? NO !!!

14
Evolución de peso vs días en niños con fisuras (con y sin tratamiento ortopédico). (N: control: 40; Fisurados con trat ortop: 32; Fisurados sin trat ortop: 20) Jara y Vergara, 2009, UM.
 Jara y Vergara, 2009, UM..")
15
Evolución de peso vs días en niños con fisuras, (con y sin tratamiento ortopédico). Jara y Vergara, 2009, UM.

16
Evolución de peso vs días en niños con fisuras, (con y sin tratamiento ortopédico). Jara y Vergara, 2009, UM.

17
Evolución de peso vs días en niños con fisuras, (con y sin tratamiento ortopédico). Jara y Vergara, 2009, UM.

18
Requisitos Las dos variables deben ser continuas
Deben ser independientes una de la otra Deben tener distribución normal

19
Calcular Y = a + bX Demostrar Ho: b = 0 IC 95% de a; IC 95% de b
a = intercepto b = pendiente Demostrar Ho: b = 0 IC 95% de a; IC 95% de b Correlación de Pearson (r)
")
20
Edad vs. Presión sistólica en 33 pacientes.
ANALISIS DE REGRESIÓN Edad vs. Presión sistólica en 33 pacientes. Edad PS Edad PS Edad PS Edad PS 81 217 n = 33 åx = åy = åxy = åx2 = åy2 = x = 46,73 y = 138,64

21
= – (1542) 2 / 33 = 7662,6 = – (4575) 2 / 33 = 22219,6 = – (1542)(4575)/33 = 9366,7
(4575)/33 = 9366,7.")
23
Pendiente e intercepto
a: intercepto, en mm de Hg b: pendiente, ps aumenta 1,22 mmHg por cada año de edad.

25
Correlación de Pearson
Karl Pearson, Correlación de Pearson r = 0,71 (Fuerza de la asociación entre las dos variables, puede variar entre -1 y 1, entre más cerca a uno mejor dicha asociación 0,65 a 1 BUENA 0,4 a 0,649 REGULAR < de 0,4 MALA. r2 = 0.51

26
¿Qué tan bueno es el modelo?
r2= Proporción de la variación total en la variable y, dependiente, en este caso de la presión sistólica, que es explicada por la variación en la variable independiente x, o edad en este caso). O sea 51% de la variación en y es explicada por la variable x (edad).
. O sea 51% de la variación en y es explicada por la variable x (edad).")
28
Error estándar de pendiente e intercepto

29
Error estándar de b y a

30
Intervalo de Confianza (95%) de la pendiente
b ± (t31, 0.05) (SEb) = 1,22 ± (1,96) (0,2129) = 1,22 ± 0,417 Test de significancia para Ho b = 0 b ,22 t31 = = = 5,74 p<0,001 SEb ,2129
 (SEb) = 1,22 ± (1,96) (0,2129) = 1,22 ± 0,417. Test de significancia para Ho b = 0. b - 0 1,22. t31 = = = 5,74 p<0,001. SEb 0,2129.")
31
Resultados con systatwg
Dep Var: PRESION N: 33 Multiple R: Squared multiple R: 0.515 Adjusted squared multiple R: Standard error of estimate: Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT EDAD Analysis of Variance Source Sum-of-Squares df Mean-Square F-ratio P Regression Residual SSY - SSE SSY = SSY - SSE: Suma de cuadrados de la reg. Valor de F, en tabla de anova es para determinar si la b (pendiente) es significatvia
 CONSTANT EDAD Analysis of Variance. Source Sum-of-Squares df Mean-Square F-ratio P. Regression Residual SSY - SSE. SSY = SSY - SSE: Suma de cuadrados de la reg. Valor de F, en tabla de anova es para. determinar si la b (pendiente) es significatvia.")
32
Resultados con Systat v. 12
Dependent Variable PS N 33 Multiple R 0.718 Squared Multiple R 0.515 Adjusted Squared Multiple R 0.500 Standard Error of Estimate 18.639 Resultados con Systat v. 12 Regression Coefficients B = (X'X)-1X'Y Effect Coefficient Standard Error Std. Coefficient Tolerance t p-value CONSTANT 81.517 10.465 0.000 . 7.789 EDAD 1.222 0.213 0.718 1.000 5.741 Qué escribir ? Y = 81,52 + 1,22X r = 0,718 r2 = 0,515
-1X Y. Effect. Coefficient. Standard Error. Std. Coefficient. Tolerance. t. p-value. CONSTANT EDAD Qué escribir Y = 81,52 + 1,22X. r = 0,718. r2 = 0,515.")
33
250 200 Residual PRESION 150 100 50 20 30 40 50 60 70 80 90 EDAD

34
Nube ?

35
Valores observados (PS), Estimados y Residuales
Case PS ESTIMATE RESIDUAL 1 22.590 2 18.368 3 5.146 4 -8.522 5 -1.744 6 6.034 7 -1.189 8 1.366 9 99.000 10 -3.301 11 16.587 12 7.365 13 39.365 14 -0.747 15 16 17 -8.415 18 19 40.363 20 21 22 0.141 23 24 25 -4.971 26 27 0.584 28 3.361 29 -3.528 30 12.582 31 3.693 32 2.358 33 36.469

36
Cajas de dispersión de PS, Estimada y residual

37
Estudio de pérdida de PD vs
Estudio de pérdida de PD vs. Ingreso y = # de dtes perdidos x = ingreso (en dólares x 1000) y = 3,5 + 0,043x (número de dtes perdidos con 0 ingreso sería en promedio 3,5). Si tiene ingreso de U$10 000, perdida de dtes sería: 3,5 + 0,43 = 3,93 dtes perdidos U$ ,5 + 0,043 (50) 3,5 + 2,15 = 5,65 dtes perdidos
 y = 3,5 + 0,043x (número de dtes perdidos con 0 ingreso sería en promedio 3,5). Si tiene ingreso de U$10 000, perdida de dtes sería: 3,5 + 0,43 = 3,93 dtes perdidos U$ ,5 + 0,043 (50) 3,5 + 2,15 = 5,65 dtes perdidos")
38
Regresión – Características de una relación (Wilkinson, 1996)
¿Existe? ¿Qué fuerza tiene? ¿Qué tamaño? ¿Qué dirección tiene? ¿Qué patrón tiene?

39
Existencia de la relación.
El valor de p en la tabla de análisis de varianza de la regresión nos indica si el modelo es significativamente diferente del azar. Los test t y valores de p asociados con los coeficientes individuales nos indican si existe una relación entre cada variable independiente y la variable dependiente.

40
Fuerza de la asociación.
Uno no está satisfecho con saber si existe una relación además quiere saber que tan fuerte es. Generalmente la vemos con el valor de R múltiple, el R múltiple al cuadrado, el R cuadrado ajustado, y el error estándar de la media. El mejor de todos es R cuadrado ajustado. R múltiple al cuadrado indica la proporción de varianza en la variable dependiente que puede ser explicada por la(s) variable(s) independiente(s).
 variable(s) independiente(s).")
41
Tamaño de la asociación
A veces uno está interesado en el tamaño de los coeficientes de la regresión más que en demostrar que difieren de 0. Para esto simplemente ver los valores de los coeficientes.

42
Dirección de la asociación.
El signo de los coeficientes nos da esta dirección.

43
Patrón de la asociación.
Los plots y los estadísticos basados en los valores residuales nos dan información acerca del patrón de la relación : Es la relación linear? Presentan los plots algún valor “escapado”, o fuera de lugar (outlier”)? Existe indicación por los valores de Cook, residual estandarizado, o Leverage de algún caso influyente? Están los residuales curvados o por otro lado presentan forma o dirección irregular? En otras palabras deberá agregarse otras variables al modelo? Los residuales están formando una banda horizontal a lo largo de todo el rango de la variable dependiente?, o sea están los residuales homoscedásticos? Tienen los residuales una distribución normal? Homocedasticidad: de -homo (igual) y scedastic: disperso
 Existe indicación por los valores de Cook, residual estandarizado, o Leverage de algún caso influyente Están los residuales curvados o por otro lado presentan forma o dirección irregular En otras palabras deberá agregarse otras variables al modelo Los residuales están formando una banda horizontal a lo largo de todo el rango de la variable dependiente , o sea están los residuales homoscedásticos Tienen los residuales una distribución normal Homocedasticidad: de -homo (igual) y scedastic: disperso.")
44
Análisis de Regresión Linear
MODEL CS = CONSTANT+LSMUFC ESTIMATE Dep Var: CS N: 30 Multiple R: Squared multiple R: 0.392 Adjusted squared multiple R: Standard error of estimate: 6.543 Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT LSMUFC
 CONSTANT LSMUFC")
45
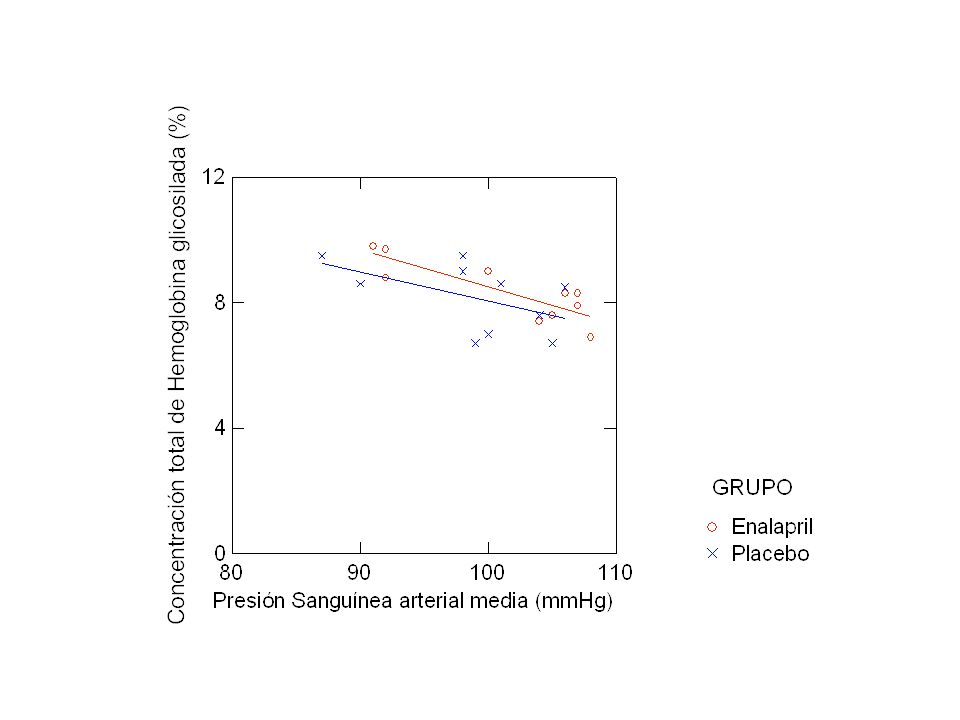
Regresión Linear, comparación entre dos grupos
CASO PA HB_GLI GRUPO$ GRUPO 1 91 9,8 Enalapril 2 104 7,4 3 107 7,9 4 8,3 5 106 6 100 9,0 7 92 9,7 8 8,8 9 105 7,6 10 108 6,9 11 98 9,5 Placebo 12 6,7 13 7,0 14 101 8,6 15 99 8,7 16 87 17 18 19 8,5 20 90 Regresión Linear, comparación entre dos grupos Presión arterial (PA) y Hemoglobina Glicosilada (HB_GLI) en dos Grupos: con Enalapril (1) y Placebo (0)
 y Hemoglobina Glicosilada. (HB_GLI) en dos. Grupos: con Enalapril (1) y Placebo (0)")
47
Donde está la diferencia?

48
Donde está la diferencia?

49
Caso PA HB GRUPO ,8 Enalapril ,4 Enalapril ,9 Enalapril ,3 Enalapril ,3 Enalapril ,0 Enalapril ,7 Enalapril ,8 Enalapril ,6 Enalapril ,9 Enalapril Promedios: , ,37 DS: , ,9615 DS de la línea de regresión (Sres): 0,5485 Caso PA HB GRUPO ,5 Placebo ,7 Placebo ,0 Placebo ,6 Placebo ,7 Placebo ,5 Placebo ,0 Placebo ,6 Placebo ,5 Placebo ,6 Placebo Promedios: 98, ,17 DS: , ,0914 DS de la línea de regresión (Sres): 0,9866
: 0,5485. Caso PA HB GRUPO. 98 9,5 Placebo ,7 Placebo ,0 Placebo ,6 Placebo ,7 Placebo ,5 Placebo ,0 Placebo ,6 Placebo ,5 Placebo ,6 Placebo. Promedios: 98,8 8,17. DS: 6,161 1,0914. DS de la línea de regresión (Sres): 0,9866.")
50
Resultado con Systat v. 11 Análisis de regresión de cada grupo, Enalapril y Placebo
Dep Var: HB_GLIC N: 10 Multiple R: Squared multiple R: 0.711 Adjusted squared multiple R: Standard error of estimate: 0.548 Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT PA PLACEBO Dep Var: HB_GLIC N: 10 Multiple R: Squared multiple R: 0.274 Adjusted squared multiple R: Standard error of estimate: 0.987 Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT PA
 CONSTANT PA PLACEBO. Dep Var: HB_GLIC N: 10 Multiple R: Squared multiple R: Adjusted squared multiple R: Standard error of estimate: Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT PA")
51
Resultado con Systat v. 11 Comparando los dos grupos
Dep Var: HB_GLIC N: 20 Multiple R: Squared multiple R: 0.464 Adjusted squared multiple R: Standard error of estimate: 0.779 Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT PA GRUPO
 CONSTANT PA GRUPO")
52
Hipótesis nula Las pendientes son iguales (bE = bP)
Los interceptos son iguales (aE = aP) Las correlaciones son iguales (rE = rP)
 Las correlaciones son iguales (rE = rP)")
53
Intervalo de confianza para la diferencia de dos pendientes
1. Calcular DS mezclada (pooled) residual según: 2. luego: 3. IC 95% =
 residual según: 2. luego: 3. IC 95% =")
54
Ecuación y correlación para los grupos PLACEBO y ENALAPRIL
Grupo PLACEBO: Y=17,33 – 0,093X r = -0,523 Grupo ENALAPRIL: Y=20,189 – 0,117X r = -0,843 Son las pendientes iguales?

55
Incluye 0 por lo tanto no hay dif significativa entre las pendientes

56
Análisis de Regresión Múltiple (RM)
MODEL CS = CONSTANT+BUFFER+VFS ESTIMATE Dep Var: CS N: 30 Multiple R: Squared multiple R: 0.001 Adjusted squared multiple R: Standard error of estimate: 8.540 Effect Coefficient Std Error Std Coef Tolerance t P(2 Tail) CONSTANT BUFFER VFS Analysis of Variance Source Sum-of-Squares df Mean-Square F-ratio P Regression Residual
 CONSTANT BUFFER VFS Analysis of Variance. Source Sum-of-Squares df Mean-Square F-ratio P. Regression Residual")
57
Estudio de pérdida de PD vs
Estudio de pérdida de PD vs. Ingreso y = # de dtes perdidos x = ingreso (en dólares x 1000) y = 3,5 + 0,043x (número de dtes perdidos con 0 ingreso sería en promedio 3,5). Si tiene ingreso de U$10 000, perdida de dtes sería: 3,5 + 0,43 = 3,93 dtes perdidos U$ ,5 + 0,043 (50) 3,5 + 2,15 = 5,65 dtes perdidos
 y = 3,5 + 0,043x (número de dtes perdidos con 0 ingreso sería en promedio 3,5). Si tiene ingreso de U$10 000, perdida de dtes sería: 3,5 + 0,43 = 3,93 dtes perdidos U$ ,5 + 0,043 (50) 3,5 + 2,15 = 5,65 dtes perdidos")
58
Estudio de pérdida de PD vs
Estudio de pérdida de PD vs. Ingreso y = # de dtes perdidos x1= ingreso (en dólares x 1000) x2 = edad (en años) y = x1 + x2 Variable Modelo 1 Modelo 2 (Intercepto) 3,50 ± 0,89 (<0,001) 1,10 ± 1,10 (0,32) Ingreso 0,043 ± 0,017 (0,01) -0,083 ± 0,041 (0,04) Edad N A 0,158 ± 0,047 (0,001)
 x2 = edad (en años) y = x1 + x2. Variable. Modelo 1. Modelo 2. (Intercepto) 3,50 ± 0,89 (<0,001) 1,10 ± 1,10 (0,32) Ingreso. 0,043 ± 0,017 (0,01) -0,083 ± 0,041 (0,04) Edad. N A. 0,158 ± 0,047 (0,001)")
59
RL simple: personas con menos ingreso parece que tienen menos pérdida de pd. RM: dos individuos de la misma edad, con cada U$1000 adicionales de ingreso, disminuye la pérdida de dtes en 0,083.

60
Coeficiente -0,083 describe asociación entre pérdida de dientes e ingreso, CONTROLANDO EDAD.
EXISTEN CAMBIOS CONSIDERABLES CUANDO UN MODELO ES MODIFICADO, COMO POR EJEMPLO AGREGANDO UNA NUEVA VARIABLE, O TRANSFORMÁNDOLA.

61
Regresión Logística Variable dependiente o de interés en el estudio: binaria (tiene infarto / no tiene inf.) En lugar de utilizar una combinación de variables exploratorias para predecir la variable dependiente como en RM, se predice una transformación de la variable dependiente

62
Variable binaria (0 / 1) 0 = No (No tuvo infarto)
1 7/10=0,7 Variable binaria (0 / 1) 0 = No (No tuvo infarto) 1 = Si (Tuvo infarto) El promedio de estos valores en una muestra en estudio es igual a la proporción de individuos con la característica.
 0 = No (No tuvo infarto) 1 = Si (Tuvo infarto) El promedio de estos valores en una muestra en estudio es igual a la proporción de individuos con la característica.")
63
Modelo de regresión logística:
Predecirá la proporción de sujetos con la característica de interés (o la probabilidad de un individuo de tener la característica) para cualquier combinación de las variables exploratorias en el modelo. Se utiliza una transformación de esta proporción ya que si no es imposible trabajar con valores fuera del rango de 0 a 1
 para cualquier combinación de las variables exploratorias en el modelo. Se utiliza una transformación de esta proporción ya que si no es imposible trabajar con valores fuera del rango de 0 a 1.")
64
Transformación Se llama logit (p) (p: proporción de individuos con la característica) p: proporción con infarto 1-p: proporción sin infarto Relación (odds): p / (1-p)
: p / (1-p)")
65
Hipertensión, tabaco, obesidad, ronquera (Norton y Dunn, 1985)
Fuma Obeso Ronca N Número de hombres con Hipertensión N (%) 60 (18) 1 17 (11) 8 (13) 2 (0) 187 (19) 85 (15) 51 (29) 23 (35) Total 433 (18)
 (18) (11) 8. 1 (13) 2. 0 (0) (19) (15) (29) (35) Total (18)")
66
Análisis de RL de los datos de la tabla anterior
Parameter Estimates Parameter Estimate Standard Error Z p-value 95 % Confidence Interval Lower Upper 1 CONSTANT -2.378 0.380 -6.254 0.000 -3.123 -1.633 2 FUMA -0.068 0.278 -0.244 0.807 -0.613 0.477 3 OBESIDAD 0.695 0.285 2.439 0.015 0.137 1.254 4 RONCA 0.872 0.398 2.193 0.028 0.093 1.651

67
Odds Ratio Estimates Parameter Odds Ratio Standard Error 95 % Confidence Interval Lower Upper 2 FUMA 0.934 0.260 0.542 1.612 3 OBESIDAD 2.004 0.571 1.146 3.505 4 RONCA 2.392 0.951 1.097 5.213

68
Area under ROC Curve : 0.617

69
Análisis de RL de los datos de la tabla anterior SIN FUMAR
Parameter Estimates Parameter Estimate Standard Error Z p-value 95 % Confidence Interval Lower Upper 2 OBESIDAD 0.695 0.285 2.440 0.015 0.137 1.254 3 RONCA 0.865 0.397 2.182 0.029 0.088 1.643 Odds Ratio Estimates Parameter Odds Ratio Standard Error 95 % Confidence Interval Lower Upper 2 OBESIDAD 2.005 0.571 1.146 3.505 3 RONCA 2.376 0.943 1.092 5.170

70
Area under ROC Curve : 0.609

71
ROC: Receiver Operating Curve
Plot de la sensibilidad vs 1-especificidad para cada posible punto de corte, y unión de ellos. Si el “costo” de un resultado falso negativo es el mismo que del resultado de un falso positivo, la mejor zona de corte es aquella que maximiza la suma de la sensibilidad y especificidad, la cual es el punto más cerca al rincón superior izquierdo

72
Guía para análisis de regresión
Método Dependiente Independiente Propósito Linear Continua Describir extensión, dirección y fuerza de la relación entre dos variables. Múltiple Describir extensión, dirección y fuerza de la relación entre varias variables independientes y una variable dependiente. Logística Dicotómica Mezcla Determinar como una o más variables independientes están relacionadas a la probabilidad de ocurrencia de un posible resultado. Poisson Discreta Determinar como una o más variables independientes están relacionadas con el conteo de un posible resultado Varianza Nominales Describir relación entre una variable continua y una o más variables dependientes

73
RESUMEN Regresión lineal: x / y: intervalares, independiente / dependiente. Regresión múltiple: una dependiente, varias dependientes (intervalares). Regresión logística: una dependiente (nominal), varias independientes (puede haber nominales, ordinales, intervalares).
, varias independientes (puede haber nominales, ordinales, intervalares).")
Presentaciones similares
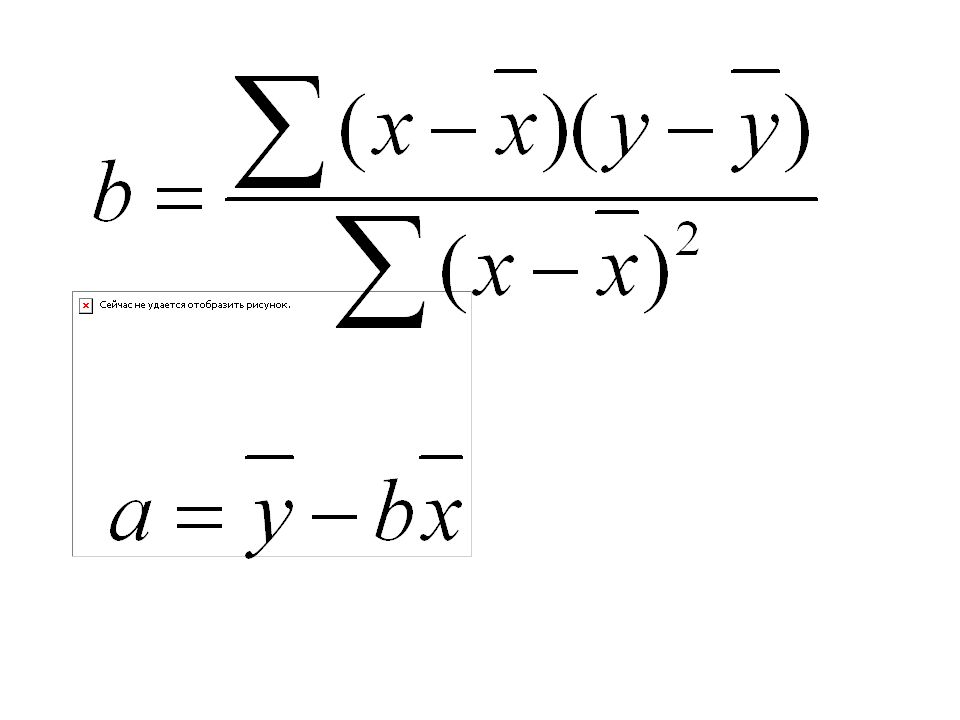










 a partir de los valores de x (variable.>")









