Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Diana M. Kelmansky Instituto de Cálculo FCEN-UBA
Experimentos de Microarreglos: desde la biología molecular a la estadística Diana M. Kelmansky Instituto de Cálculo FCEN-UBA

2
¿Qué son los microarreglos?
Microarreglos: pequeños soportes sólidos sobre los que se inmobilizan ó pegan, miles de secuencias de diferentes genes, en posiciones fijas ordenadas

3
Workshop on Robustness and Statistical Inference
Dos tecnologías Delivery Synthesis arrays chips Workshop on Robustness and Statistical Inference Madrid October

4
spotted: oligonucleotidos (oligos) son “espoteados” –spotted- directamente sobre el arreglo
síntesis directa base por base: los oligonucleótidos se fabrican in situ utilizando métodos tales como fotolitografía (ej. Affymetrix chips) o síntesis química (ej., ink-jet Agilent) ?????????????????????????????????
 o síntesis química (ej., ink-jet Agilent)")
5
Portaobjeto y cabezal de impresión - print head

6
http://www. stat. berkeley
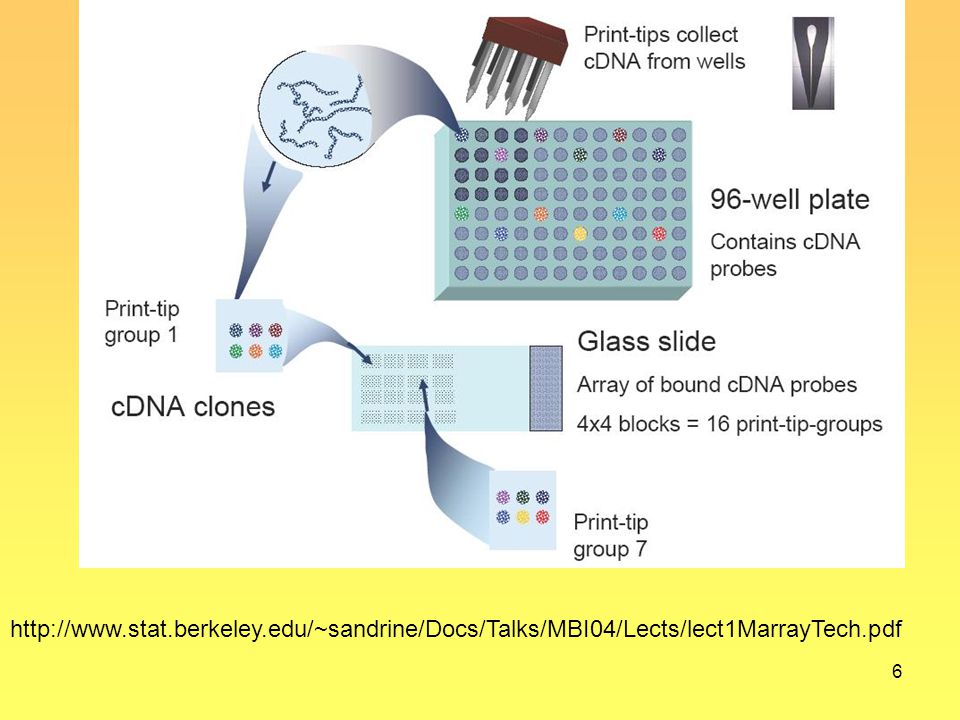
7
Un segmento de un spot de un microarreglo - las hebras son las moléculas de ADN depositadas - figura tomada de (Duggan et al., Nature Genetics 21: 10-14, 1999)
")
8
Objetivo: Identificar genes expresados diferencialmente
Cambios en la abundancia de: genes expresados: mRNA – arreglo de transcriptomas ADN genomico entre condiciones diferentes

9
¡Grandes Esperanzas! Datos obtenidos en PubMed
Schena M,et al. Quantitative monitoring of gene expression patterns with a complementary DNA microarray. Science (1995)
")
10
¡Grandes Esperanzas! Mark Schena Microarray Analysis – Wiley 2003
Al final de la introducción: “Fifty years from now, and long after human disease has been eradicated, we will look back incredulously at the start of this millennium and wonder how we ever endured cancer, heart disease, AIDS and thousands of other illnesses that compromise our well-being”

11
¿De qué se trata todo esto?
¿Cómo está relacionado con estadística? Comencemos

12
Expresión de un gen Casi todas las células de nuestro cuerpo contienen un conjunto completo de cromosomas y genes idénticos. Sólo una fracción de estos genes están “encendidos” . Este subconjunto, que está “expresado”, le confiere propiedades específicas a cada tipo de célula. "Gene expression“ . Términos utilizados para describir la transcripción de la información contenida dentro de los cromosomas en moléculas de ARN mensajero. Luego estas son traducidas a las proteinas que realizan principales funciones de las células

13
Adenina Timina Guanina Citosina

14
ROSALIND FRANKLIN la fotógrafa del ADN
Francis Crick, James Watson y Maurice Wilkins -modelo del ADN 1953- en base al trabajo de Rosalind Franklin como bióloga molecular y cristalógrafa Murió de cáncer en 1958 con 37 años Premio Nobel de Medicina

15
Transcripción

16
Dogma central de la biología molecular
Doble cadena de ADN transcripción o expresión Simple cadena de ARNm traducción Proteína Microarreglo

17
¿Cómo funciona un microarreglo?
Utiliza la capacidad de las moléculas de ARNm de adherirse específicamente, o hibridar a su cadena complementaria de ADN cADN probe ...AAAAAGCTAGTCGATGCTAG... ARN target ...UUUUUCGAUCAGCUACGAUC...

19
Al finalizar el experimento tenemos
two color spotted microarray un microarreglo de dos colores

20
Datos Imagen superpuesta de un sector de un Microarreglo
con colores artificiales ¿Cuáles son los datos en un experimento de microarreglos ? Archivos tiff de las imágenes digitales escaneadas Una para cada color La intensidad de cada pixel representa la abundancia del gen transcripto en el sitio correspondiente del arreglo Procesamiento de la imagen Datos Crudos

21
Imperfecciones de los spots

22
Redondeamos – microarrays de dos canales-
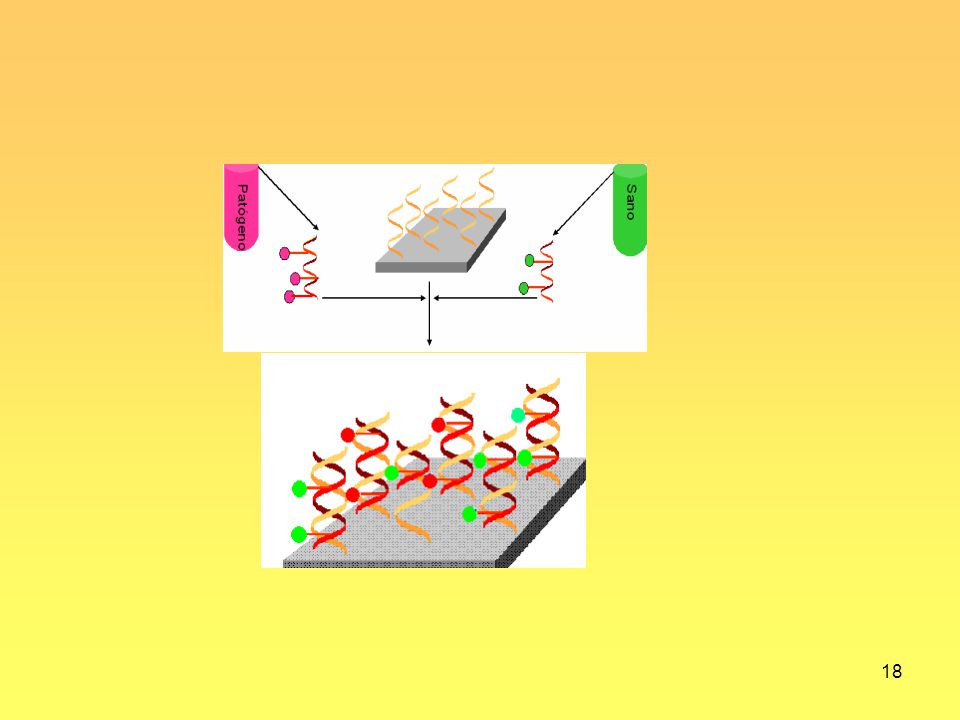
ARNm tejido patógeno de hígado cADN etiqueta fluorescente (label) (Cy5) reverse ARNm tejido sano de hígado cADN etiqueta fluorescente (label) (Cy3) transcription Hibridice igual cantidad de mARN para cada muestra sobre el microarreglo Lave el microarray para eliminar pegado inespecífico - unspecific binding. Escanee el microarray con longitudes de onda diferentes para exitar a cada uno de los tintes 2 imágenes digitales, una para el fluor Cy3 y la otra para el Cy5 representan las intensidades para cada una de las muestras en el estudio datos crudos pixel por pixel Señal de fluorescencia “Promedio” para cada gen = nivel de expresión del gen + otros estadísticos datos iniciales gen por gen Este experimento tiene muchos errores sistemáticos y aleatorios
 (Cy5) reverse. ARNm tejido sano de hígado cADN etiqueta fluorescente (label) (Cy3) transcription. Hibridice igual cantidad de mARN para cada muestra sobre el microarreglo. Lave el microarray para eliminar pegado inespecífico - unspecific binding. Escanee el microarray con longitudes de onda diferentes para exitar a cada uno de los tintes. 2 imágenes digitales, una para el fluor Cy3 y la otra para el Cy5. representan las intensidades para cada una de las muestras en el estudio. datos crudos pixel por pixel. Señal de fluorescencia Promedio para cada gen = nivel de expresión del gen. + otros estadísticos datos iniciales gen por gen. Este experimento tiene muchos errores sistemáticos y aleatorios.")
23
MA-plot Diagrama de dispersión (Scatter plot) de
M = log2 ( Xred / Xgreen ) = log2 ( Xred ) - log2 ( Xgreen ) versus A = (log2 ( Xred ) + log2 ( Xgreen )) / 2 Intensidad
 = log2 ( Xred ) - log2 ( Xgreen ) versus. A = (log2 ( Xred ) + log2 ( Xgreen )) / 2. Intensidad.")
24
Experimento SELF-SELF ideal
MA plot MXY plot

25
Sesgo dependiente de la intensidad
Experimento SELF-SELF real MA plot MXY plot Sesgo dependiente de la intensidad sesgo espacial

26
Objetivo: Identificación de genes expresados diferencialmente
Requiere múltiples tests con un nivel global razonable (false discovery rate)
")
27
Algunos aspectos estadísticos de los experimentos y análisis de datos de microarrays
Diseño. El diseño del experimento afecta la validez y la eficiencia de los resultados. “In other contexts, and possibly in these, the results have been driven by study inadequacies rather than by biology. Beware! (T. Speed 2005)”
")
28
Algunos aspectos estadísticos de los experimentos y análisis de datos de microarrays
Preprocesamiento. análisis de imágen cuantificación de los “spots”: distinguir las intensidades del foreground de las del background y los artifacts. Medidas resumen. normalización - control del sesgo dentro y entre microarreglos, transformaciones de los datos.

29
Algunos aspectos estadísticos de los experimentos y análisis de datos de microarrays
Inferencia. Procedimientos de tests simultáneos Multiple testing procedures. Generalmente respecto a qué genes están expresados diferencialmente.

30
Algunos aspectos estadísticos de los experimentos y análisis de datos de microarrays
Clustering y discriminación (llamados Clasificación por “microarray biologists”). Clases (categorías, etiquetas): pueden ser muestras ( 1 - cientos) o genes . ( )
. Clases (categorías, etiquetas): pueden ser. muestras ( 1 - cientos) o. genes . ( )")
31
Clustering y discriminación - cont
Clases desconocidas – clasificación no supervisada: cluster analysis por los estadísticos, unsupervised learning por los computadores científicos class discovery por biólogos de microarreglos.

32
Clustering y discriminación - cont
Clases definidas de antemano – clasificación supervisada - supervised classification – sobre por lo menos una parte de los datos: Los objetivos incluyen describir diferencias entre clases y/o clasificar observaciones fututas. Llamadas clasificación o discriminación y class prediction por microarray biologists. Los datos para los que las clases son conocidas forman el llamado training o learning set, aquellos datos cuyas clases no son utilizadas pero conocidas forman el test set. También se utiliza Allocation para describir la asignación de clases a los nuevos datos. Estas distinciones no son universales.

33
A) Diseño. Consenso 1: La replicación biologica es indispensable.
Pueden realizarse dos tipos de replicaciones replicación técnica: el ARNm de un único caso biológico es utilizado en múltiples microarreglos replicaciones biológicas: se extrae ARNm de diferentes sujetos

34
A) Diseño. Consenso 2: Es necesario aumentar la potencia mediante el tamaño de la muestra.
Deben realizarse análisis de potencia: Aplicando estimaciones específicas para experimentos de microarrays Más replicaciones proveen mayor potencia. No hay concenso respecto de cuales procedimientos para hallar el tamaño de la muestra son los mejores.

35
A) Diseño. Consenso 3: “Pooling” muestras biologicas puede ser útil.
La variabilidad entre arreglos puede ser reducida “pooling” ARNm de replicaciones biológicas. Por ejemplo: 15 casos divididos en 5 pools de 3, cada pool corrido en un array por separado tendrá: más potencia que 5 casos corridos an arreglos diferentes menos potencia que cuando los 15 casos son corridos en arregos diferentes

36
A) Diseño. Consenso 3: “Pooling” muestras biologicas puede ser útil
A) Diseño. Consenso 3: “Pooling” muestras biologicas puede ser útil. Cont Sin embargo: Pooling ARN de n casos y creando n replicaciones técnicas no es una estrategia mejor que hibridizar n arrays a las n muestras individuales de RNA: Problema potencial: el ‘poisoned pool’, un outlier puede arruinar los resultados.
 Diseño. Consenso 3: Pooling muestras biologicas puede ser útil. Cont. Sin embargo: Pooling ARN de n casos y creando n replicaciones técnicas no es una estrategia mejor que hibridizar n arrays a las n muestras individuales de RNA: Problema potencial: el ‘poisoned pool’, un outlier puede arruinar los resultados.")
37
A) Diseño. Consenso 4: Evite los factores de confusión - confounding
Las mediciones de Microarrays pueden estar muy influenciadas por factores externos. Por ejemplo: Si dos tratamientos son aplicados a dos grupos de pacientes cuando los factores externos no están totalmente balanceados entre los grupos esto puede confundir el estudio y llevar a conclusiones falsas. (Confounding – epidemiología) Los arreglos deberían provenir de un únco lote y procesados en el mismo día por el mismo técnico. Analizar la misma cantidad de muestras de los dos grupos en estudio y aleatorizar los casos a los niveles de estos factores (lotes de arreglos, técnicos, día)
 Los arreglos deberían provenir de un únco lote y procesados en el mismo día por el mismo técnico. Analizar la misma cantidad de muestras de los dos grupos en estudio y aleatorizar los casos a los niveles de estos factores (lotes de arreglos, técnicos, día)")
38
B) Preprocesamiento Análisis de la imagen. Hay diferentes propuestas, fundamentalmente en la distinción entre las intensidades del forward y el backward – segmentation. Normalization. Diversos procedimientos para permitir las comparaciones entre los arreglos.

39
C) Inferencia . Consenso
Solo fold change |M| > k, no es adecuado Mi = log2(Ri/Gi) Utilice un estadístico que incorpore la variabilidad t = Use “variance shrinkage” Use métodos de estimación del FDR en las comparaciones múltiples
 Utilice un estadístico que incorpore la variabilidad. t = Use variance shrinkage Use métodos de estimación del FDR en las comparaciones múltiples.")
40
D) Classificación Consenso 1
La clasificación no supervisada se utiliza en exceso. Es una de las primeras técnicas estadísticas utilizadas en el análisis de microarrays y es una de las preferidas. El investigador tiene garantizada la obtención de un agrupamiento (clustering) de genes, sin importar el tamaño de la muestra, la calidad de los datos, el diseño del experimento o cualquier otra validez biológica que esté asociada con el agrupamiento.
 de genes, sin importar. el tamaño de la muestra, la calidad de los datos, el diseño del experimento o. cualquier otra validez biológica que esté asociada con el agrupamiento.")
41
D) Clasificación Consenso 1. Cont.
Clasificación no supervisada, debería ser validada utilizando procedimientos basados en re-muestreo (resampling-based procedures). Si la clasificación no supervisada es inevitable, debería proveerse algún tipo de medida de reproducibilidad. Aquellos procedimientos que re-muestrean a nivel de caso – más que a nivel de gen- todos tienen una performance razonable y ninguno es considerado el mejor.
. Si la clasificación no supervisada es inevitable, debería proveerse algún tipo de medida de reproducibilidad. Aquellos procedimientos que re-muestrean a nivel de caso – más que a nivel de gen- todos tienen una performance razonable y ninguno es considerado el mejor.")
42
D) Classificación Consenso 2
Los procedimientos de clasificación supervisada requieren cross-validación independiente. Las reglas de predicción están basadas en una cantidad relativamente pequeña de muestras de distintos tejidos de tipos conocidos que contienen los datos de expresión de muchos (posiblemente miles) de genes. Problemas posibles: sobreajuste (overfitting), sesgo de selección (selection bias)
 de genes. Problemas posibles: sobreajuste (overfitting), sesgo de selección (selection bias)")
43
Estudios futuros Microarray data analysis: from disarray to consolidation and consensus Allison D, Cui X, Page G, Sabripour M (2006) Nature Reviews | Genetics Vol 7 Jan Sugieren estudiar If and how the vast number of genes assayed in microarray experiments could be used to partially compensate for small sample sizes when using resampling-based inference. For all statistical procedures, the fact that transcripts are not necessarily independent (co-regulation) should be considered.
 Nature Reviews | Genetics Vol 7 Jan. Sugieren estudiar. If and how the vast number of genes assayed in microarray experiments could be used to partially compensate for small sample sizes when using resampling-based inference. For all statistical procedures, the fact that transcripts are not necessarily independent (co-regulation) should be considered.")
44
MÁS ESTADÍSTICA Semilinear High-Dimensional Model for Normalization of Microarray Data: A Theoretical Analysis and Partial Consistency (2005) Fan J, Peng H, Huang T. JASA, vol. 100, no. 471, pp With discussion. “All of the discussants call for more statistical understanding of various procedures in use. We agree whole heartedly with this and contribute the article under discussion in the hope that it will stimulate more statisticians to work on this area.”
 Fan J, Peng H, Huang T. JASA, vol. 100, no. 471, pp With discussion. All of the discussants call for more statistical understanding of various procedures in use. We agree whole heartedly with this and contribute the article under discussion in the hope that it will stimulate more statisticians to work on this area.")
45
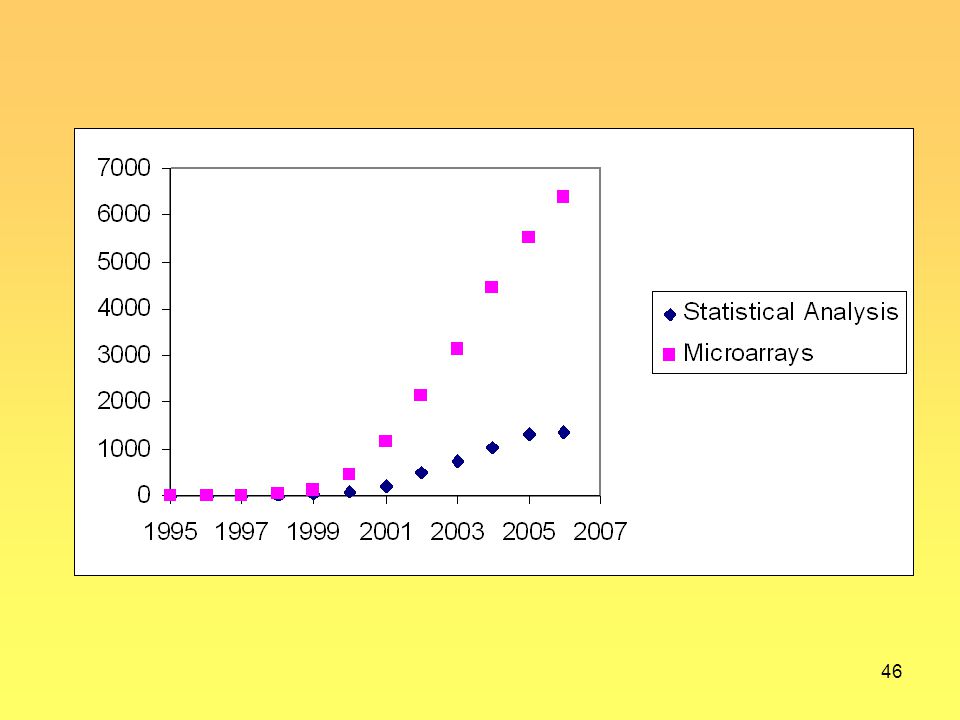
¿Cuántos incluyen análisis estadístico?
¿Recuerdan? ¿Cuántos incluyen análisis estadístico?

47
Algunas referencias A Model Based Background Adjustement for Oligonucleotide Expression Arrays. Wu Z, Irizarry RA, Gentleman R, Martinez Murillo F, Spencer F (2004) JASA, 99, Semilinear High-Dimensional Model for Normalization of Microarray Data: A Theoretical Analysis and Partial Consistency (2005) Fan J, Peng H, Huang T. JASA, vol. 100, no. 471, pp Selection bias in gene extraction on the basis of microarray gene-expression data. Ambroise C, McLachlan G (2002) PNAS Prediction by Supervised Principal Components. Bair E, Hastie T, Paul D, Tibshirani T (2006) JASA, vol. 101, no. 473, pp Microarray data analysis: from disarray to consolidation and consensus Allison D, Cui X, Page G, Sabripour M (2006) Nature Reviews | Genetics Vol 7 Jan
 JASA, 99, Semilinear High-Dimensional Model for Normalization of Microarray Data: A Theoretical Analysis and Partial Consistency (2005) Fan J, Peng H, Huang T. JASA, vol. 100, no. 471, pp Selection bias in gene extraction on the basis of microarray gene-expression data. Ambroise C, McLachlan G (2002) PNAS. Prediction by Supervised Principal Components. Bair E, Hastie T, Paul D, Tibshirani T (2006) JASA, vol. 101, no. 473, pp Microarray data analysis: from disarray to consolidation and consensus. Allison D, Cui X, Page G, Sabripour M (2006) Nature Reviews | Genetics Vol 7 Jan.")
48
¡MUCHAS GRACIAS!

Presentaciones similares








 Noviembre de 2004.>")
 Noviembre de 2004.>")
 29 de julio de 2004.>")








