Descargar la presentación
La descarga está en progreso. Por favor, espere

1
CLADOS Granada 17 Diciembre 2009

2
Evolución del proyecto Resultados Presupuesto

3
Anomalías en marcadores (SNPs) Anomalías estructurales (SNP y CNV) CLADOS. Detección de anomalías estructurales mediante modelos gráficos probabilísticos: factores genéticos de susceptibilidad a enfermedades

4
Objetivos Objetivo: red bayesiana para diagnóstico de susceptibilidad a la EM No es para el diagnóstico de la enfermedad (datos de expresión genética, mRNA)
")
5
Usan genotipos en vez de haplotipos Las variables son los genotipos simples Valores: AA, aa, A/a Los consideran independientes (ausencia de epístasis) Ej. Medidas ponderadas de riesgo (Lancet 2009) Modelan las dependencias: AA-BB, AA-B/b, etc. Ej. Redes bayesianas (Nature Genetics 2005) Factores genéticos de susceptibilidad a enfermedades: algunas soluciones
 Modelan las dependencias: AA-BB, AA-B/b, etc. Ej. Redes bayesianas (Nature Genetics 2005) Factores genéticos de susceptibilidad a enfermedades: algunas soluciones.")
6
Objetivos Objetivo: red bayesiana para diagnóstico de susceptibilidad a la EM Representación de los factores genéticos de riesgo Selección de variables: Selección a gran escala: TDT-2G Selección fina: TDT P, reconstrucción filogenética 3. Agrupación de valores 4. Aprendizaje automático de la estructura de la red bayesiana

7
1. Representación de los factores genéticos de riesgo Representar genes, no nucleótidos: SNPs (A/a, B/b, etc.) -> haplotipos (tag SNPs) (AB, Ab, aB, ab) Problemas Los marcadores no suelen contener al gen Los marcadores cambian entre muestras (Affymetrix, Illumina) No genes, sino haplotipos en desequilibrio de ligamiento: Asociación entre nucleótidos de posiciones cercanas debido a la baja recombinación gengen
 -> haplotipos (tag SNPs) (AB, Ab, aB, ab) Problemas Los marcadores no suelen contener al gen Los marcadores cambian entre muestras (Affymetrix, Illumina) No genes, sino haplotipos en desequilibrio de ligamiento: Asociación entre nucleótidos de posiciones cercanas debido a la baja recombinación gengen.")
8
SNPs asociados y DL 2 pequeños bloques de baja recombinación 2. Selección de variables

9
Selección burda TDT-2G: alta sensibilidad

10
2. Selección de variables Una variable de L SNPs tiene 2 L valores (haplotipos) distintos Los loci asociados pueden ser muy largos (L muy grande) Selección a fina escala TDT P : alta sensibilidad y especificidad Acotar la zona de asociación intentando aumentar la especificidad al locus de susceptibilidad a la enfermedad (reducir efecto de DL)
 distintos Los loci asociados pueden ser muy largos (L muy grande) Selección a fina escala TDT P : alta sensibilidad y especificidad Acotar la zona de asociación intentando aumentar la especificidad al locus de susceptibilidad a la enfermedad (reducir efecto de DL).")
11
Ejemplo TDT P

12
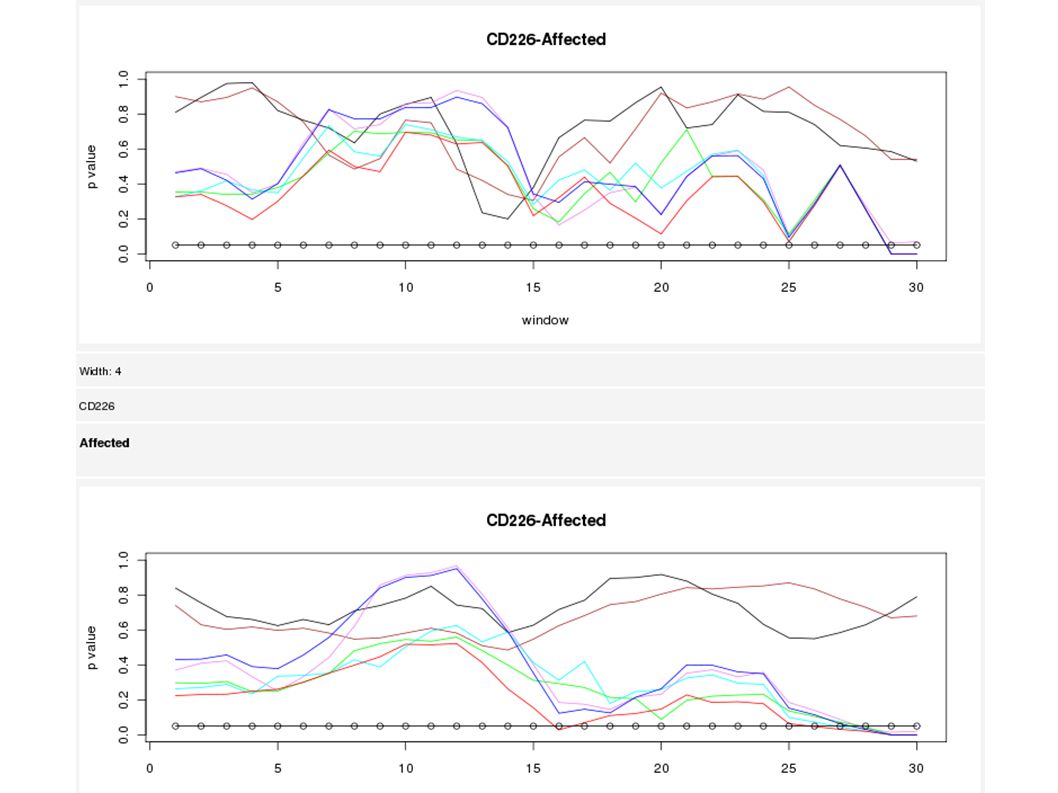
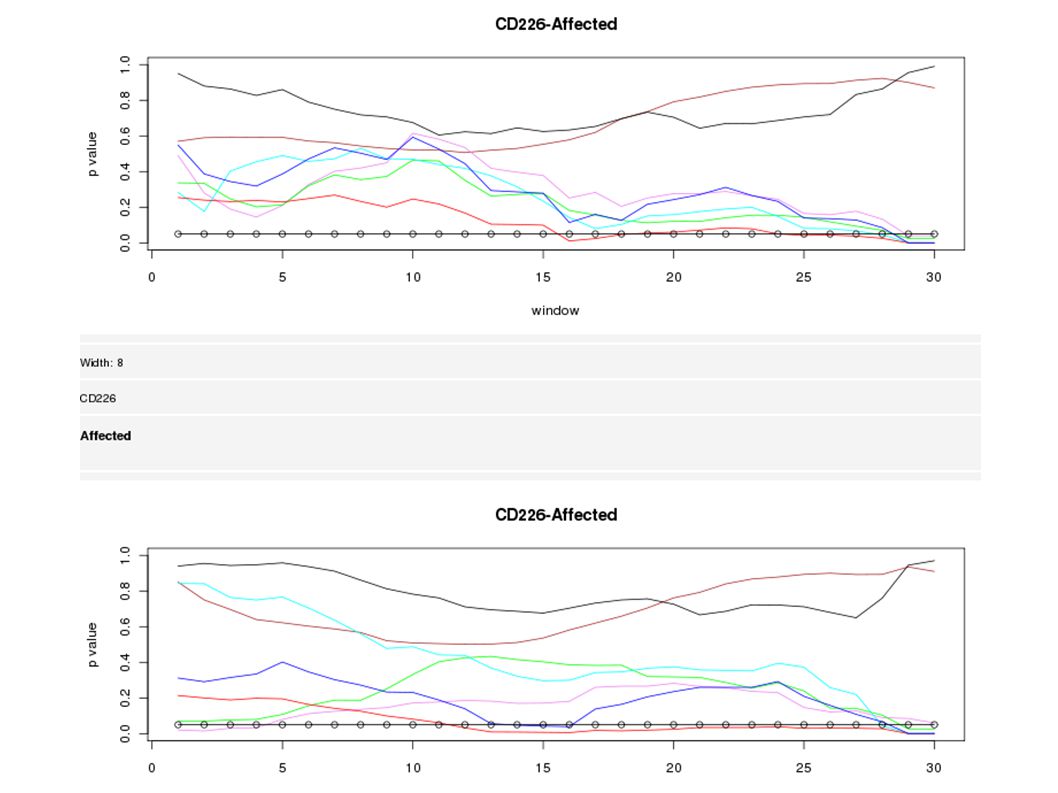
Problemas: muchas discontinuidades, incluso usando ventanas deslizantes El resultado depende del tamaño de la ventana 2. Selección de variables

13
Diferentes anchos de ventanas 124124 68 10

14
2. Selección de variables Mucha incertidumbre Haplotipos largos a veces capturan mejor la asociación El marcador con asociación más fuerte cambia con el ancho del haplotipo (ventana)
.")
17
3. Reducción de los valores Mucha incertidumbre Haplotipos largos a veces capturan mejor la asociación El marcador con asociación más fuerte cambia con el ancho del haplotipo (ventana) El comportamiento depende de la muestra (subpoblación) 2. Selección de variables
 El comportamiento depende de la muestra (subpoblación) 2. Selección de variables.")
18
SNPs asociados Negro: Asociados en IMSGC (tríos) Rojo: Asociados en WTCCC (caso/control) Verde: Asociados en ambos Muy pocos en común Buscar comunes en el mismo bloque de baja recombinación
 Rojo: Asociados en WTCCC (caso/control) Verde: Asociados en ambos Muy pocos en común Buscar comunes en el mismo bloque de baja recombinación")
19
2. Selección de variables Mucha incertidumbre si queremos determinar el locus de susceptibilidad Haplotipos largos a veces capturan mejor la asociación El marcador con asociación más fuerte cambia con el ancho del haplotipo (ventana) El comportamiento depende de la muestra (subpoblación) No es importante para modelar los factores de riesgo
 El comportamiento depende de la muestra (subpoblación) No es importante para modelar los factores de riesgo.")
20
3. Agrupación de valores Simplificación parcial Por la baja frecuencia de las mutaciones y de recombinaciones, sólo una minoría de haplotipos existen en la población Aun así, el número de haplotipos distintos es considerable y pueden aparecer nuevos valores

21
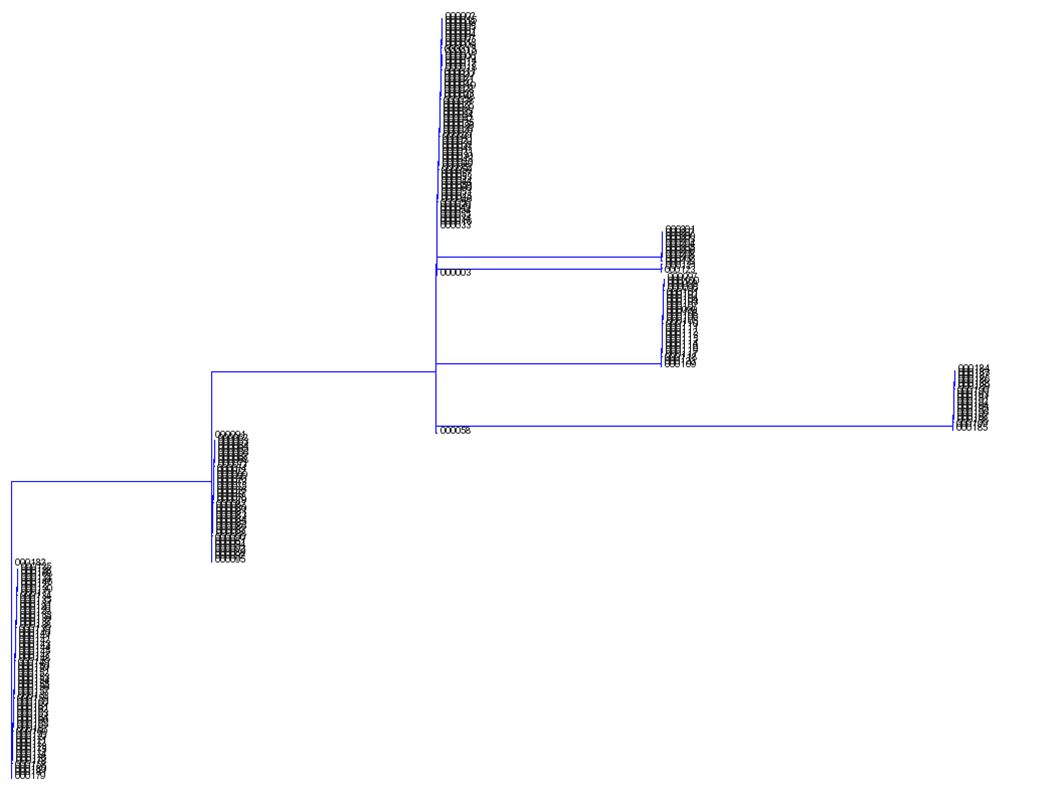
Necesidad de conocer la relación entre los haplotipos para poder agruparlos Árboles filogenéticos TreeDT (Sevon et al., IEEE Trans. Comp Biol. & Bioinformatics 2007) Caso/control Test estadístico basado en árboles (otros: Seltman et al. 2001 AJHG) No modelan la recombinación, sólo mutaciones Grafos ancestrales de recombinación: Modelan la recombinación (Lam et al. 2000 AJHG) 3. Agrupación de valores
 Caso/control Test estadístico basado en árboles (otros: Seltman et al AJHG) No modelan la recombinación, sólo mutaciones Grafos ancestrales de recombinación: Modelan la recombinación (Lam et al AJHG) 3. Agrupación de valores.")
22
Longitud arcos no proporcional θ=0; T

23
Longitud arcos proporcional θ=0; T

24
Longitud arcos no proporcional θ=0; U

26
Longitud arcos no proporcional θ=0,0032; T

27
Longitud arcos proporcional θ=0,0032; T

28
Longitud arcos no proporcional θ=0,0032; U

29
Longitud arcos proporcional θ=0.0032; U

30
θ=0; T θ=0,003; U θ=0; U θ=0,003; T

31
Medidas de distancia intra-árbol Según haplotipo de referencia Distancia al más ancestral (más frecuente) (L) Distancia completa (LxL) Según modelo Mutaciones Recombinaciones Ambas 3. Agrupación de valores

32
Estudios relacionados TreeDT (Sevon et al., IEEE Trans. Comp Biol. & Bioinformatics 2007) Caso/control Test estadístico basado en árboles (otros: Seltman et al. 2001, Lam et al. 2000)
 Caso/control Test estadístico basado en árboles (otros: Seltman et al. 2001, Lam et al. 2000).")
33
Del cladograma a la agrupación Hacerlas binarias (usar valores centrales): De 2 L a 2 (haplotipo riesgo sí/no) Selección de los valores representativos: Usar el haplotipo más frecuente de T/U (más ancestral): hT, hU o sólo hT y umbral Otras posibilidades??? Calcular la distancia filogenética a hT, hU Los marcadores no coinciden Usar muestra caso/control (permitir subpoblaciones) 3. Agrupación de valores
 3. Agrupación de valores.")
34
Muestra de tríos (1000 tríos): usada para obtener los haplotipos de susceptibilidad Muestra caso/control (3000 inds. en total): 1/3 para obtener haplotipo fundador y umbral Resto para aprender/probar el modelo Redes bayesianas Clasificador simple: ausencia de epístasis TAN Redes más genéricas: K2? 4. Aprendizaje automático? de la estructura de la red
: 1/3 para obtener haplotipo fundador y umbral Resto para aprender/probar el modelo Redes bayesianas Clasificador simple: ausencia de epístasis TAN Redes más genéricas: K2. 4. Aprendizaje automático. de la estructura de la red.")
Presentaciones similares



















 dados los dato? Red Bayesiana (RB) ◦ Red de.>")