Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Master en Recursos Humanos Análisis de Conglomerados (Cluster Analysis): prácticas con SPSS Ana María López Área de Metodología de las Ciencias del Comportamiento Departamento de Psicología Experimental
: prácticas con SPSS Ana María López Área de Metodología de las Ciencias del Comportamiento Departamento de Psicología Experimental")
2
El objetivo es agrupar a los sujetos en función de su parecido en las subescalas del WISC-R. dado que todas las variables son cuantitativas utilizaremos como medida de disimilaridad la distancia euclídea y como procedimiento de agregación los métodos de la media, mínimo y máximo. La matriz con la que vamos a trabajar es: datos1. Para ejecutar un análisis de conglomerados con SPSS en primer lugar hay que seleccionar el menú Analizar como muestra el siguiente cuadro:datos1 Conglomerados jerárquicos

3
En segundo lugar seleccionamos Conglomerados jerárquicos y accedemos al siguiente cuadro: Conglomerados jerárquicos El cuadro contiene: 1.la lista de variables del archivo. De esta lista seleccionamos aquellas sobre las que deseemos evaluar el parecido de los sujetos. En nuestro caso son las correspondientes a las subescalas del WISC-R. Una vez seleccionadas las variables las trasladamos al cuadro Variables. 2.Existe la posibilidad de agrupar (Conglomerar) casos, este es el uso más frecuente del análisis de conglomerados, o de agrupar variables y el resultado sería el equivalente a un análisis factorial. 3.Además disponemos de una serie de botones que nos permiten acceder a las diferente opciones implementadas en SPSS. En las transparencias siguientes comentaremos las opciones de los cuadros: Estadísticos, Gráficos, Método y Guardar en este orden.
 casos, este es el uso más frecuente del análisis de conglomerados, o de agrupar variables y el resultado sería el equivalente a un análisis factorial. 3.Además disponemos de una serie de botones que nos permiten acceder a las diferente opciones implementadas en SPSS. En las transparencias siguientes comentaremos las opciones de los cuadros: Estadísticos, Gráficos, Método y Guardar en este orden..")
4
Conglomerados jerárquicos Cuadro Estadísticos: En este cuadro podemos solicitar: 1.además del Historial de conglomeración que lo proporciona por defecto si tenemos seleccionada la opción Estadísticos dell cuadro Análisis de conglomerados jerárquico, la Matriz de distancias. 2.Podemos pedir que nos proporcione una tabla con el conglomerado de pertenencia de cada sujeto si nos decidimos por una solución en un número de conglomerados determinado o en un rango. Estas opciones son muy útiles cuando tenemos claro el número de conglomerados que constituye la solución a nuestro problema de investigación. No obstante lo más importante no es visualizar la tabla crear una variable en el archivo de datos con valores que indican el conglomerado al que pertenece el sujeto esto podemos hacerlo con las opciones del cuadro Guardar variables nuevas.

5
Conglomerados jerárquicos Cuadro Método: En este cuadro podemos 1.seleccionar entre una larga lista de métodos de conglomeración: vinculación inter-grupo (método de la media), vinculación intra- grupos (distancia media entre las distancias de los elementos del grupo unión), vecino más próximo (mínimo), vecino más lejano (máximo), agrupación de centroides (distancia entre centroides), agrupación de medianas (media de centroides) y Método de Ward (minimiza la varianza intragrupo). En principio convendría explorar con distintos métodos hasta encontrar la solucción más satisfactoria. El método de Ward sólo puede aplicarse a variables cuantitativas. 2.Seleccionar la medida de distancia adecuada a la métrica de las variables. 3.Podemos optar por calcular las distancias entre los sujetos a partir de puntuaciones estandarizadas con las opciones del cuadro Transformar valores. Se recomienda estandarizar cuando las variables están medidas en escalas distintas.

6
Conglomerados jerárquicos Cuadro Guardar variables nuevas: Este cuadro nos permite crear nuevas variables en el archivo de datos con el grupo de pertenencia de cada sujeto. Podemos crear una única variable correspondiente a una Solución única en K conglomerados. Esta variable toma valores desde 1 hasta K e indica el grupo al que pertenece el sujeto. Si seleccionamos un Rango de soluciones crea una variable para cada una de las soluciones desde Número mínimo de conglomerados hasta Número máximo de conglomerados. Por ejemplos si en Número mínimo de conglomerados escribimos 2 y en Número máximo 4 creará 3 variables: una para la solución en dos conglomerados, otras para la solución en tres conglomerados y la última para la solución en cuatro conglomerados.

7
Resultados Conglomerados jerárquicos

8
* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * Dendrogram using Average Linkage (Between Groups) Rescaled Distance Cluster Combine
 Rescaled Distance Cluster Combine")
9
Vinculación simple (método del mínimo) Dendrogram using Single Linkage Rescaled Distance Cluster Combine
 Dendrogram using Single Linkage Rescaled Distance Cluster Combine")
10
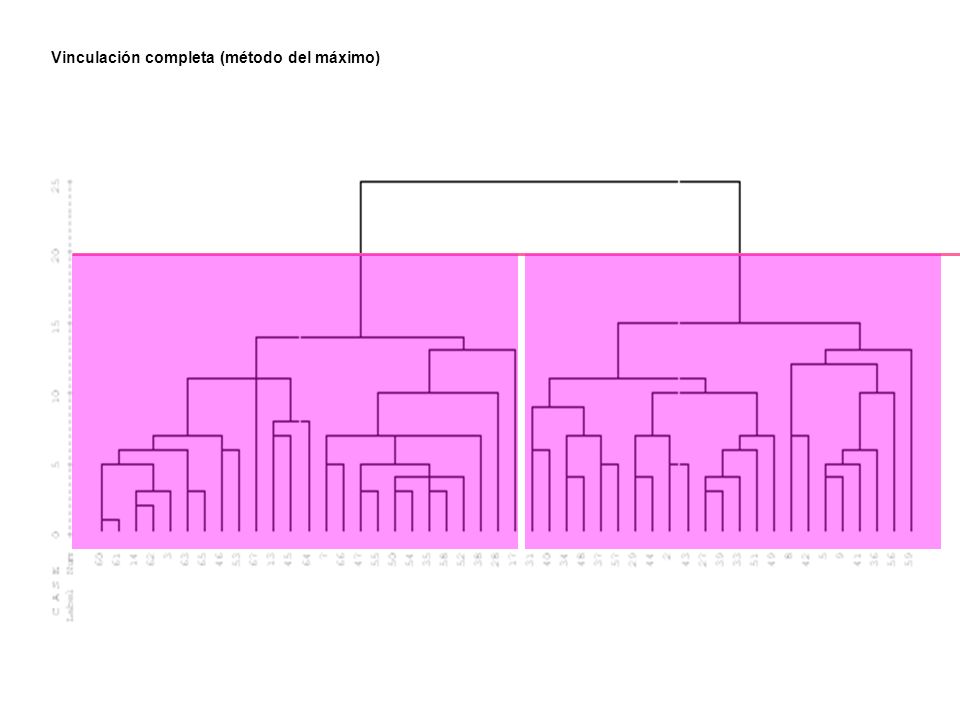
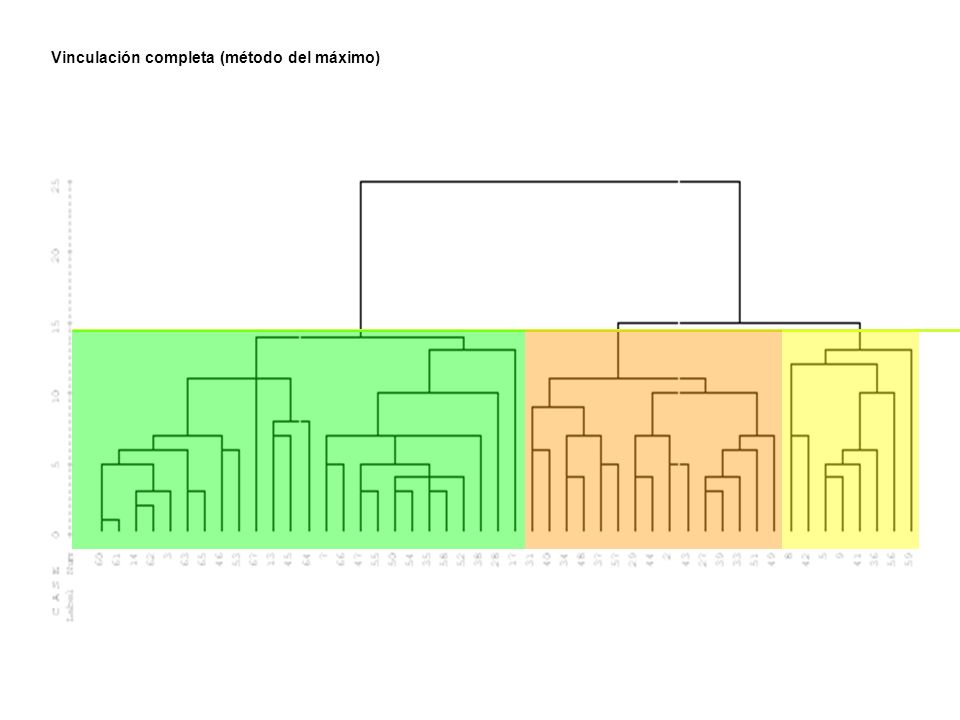
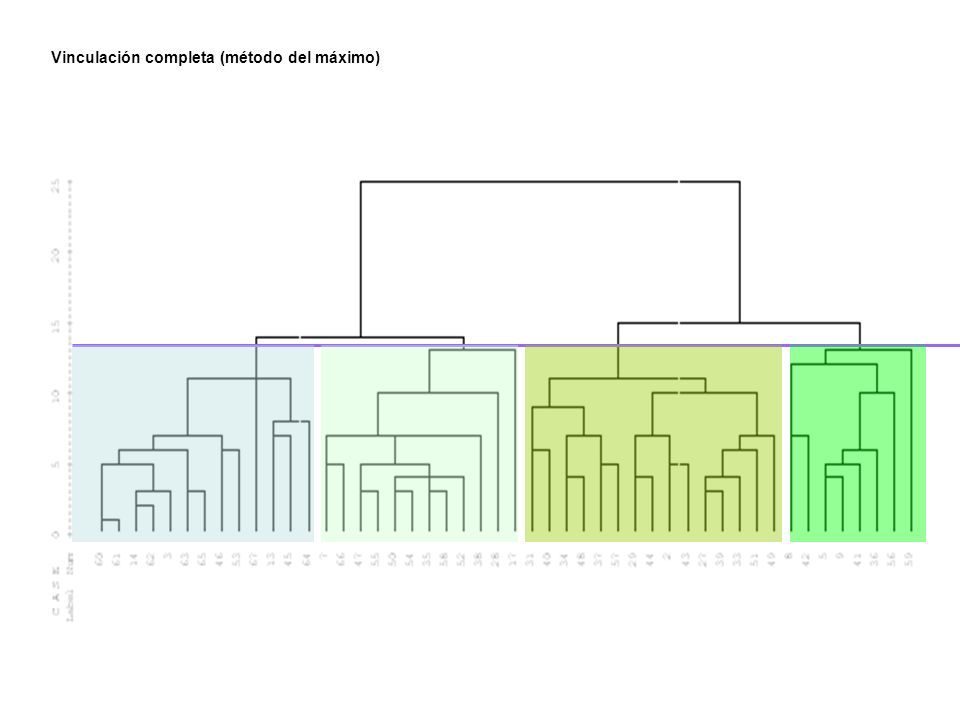
Vinculación completa (método del máximo)
")
14
Resultados: Si a partir del dendograma anterior, en el cuadro Guardar variables nuevas, seleccionamos Rango de soluciones y en Número mínimo de conglomerados escribimos 2 y en Número máximo de conglomerados escribimos 4 se crean tres nuevas variables en el editor de datos que clasifican a los sujetos en función del cluster al que pertenecen para cada una de las soluciones en dos, tres y cuatro conglomerados. Las nuevas variables se denominan: CLU4_1, CLU3_1 y CLU2_1 como podemos observar en la porción del editor de datos siguiente.

15
Resultados: La interpretación de los conglomerados depende del valor medio de las variables en cada uno de ellos. Es decir, para caracterizar a cada clase y diferenciarla de las demás vamos a obtener el centroide de cada una de ellas y vamos a realizar un gráfico de lineas. Vamos también a realizar una análisis de frecuencias para saber el número de sujetos de cada cluster y para cada solución. Tabla de frecuencia

16
Resultados: Perfil de medias de cada solución Tablas personalizadas Los gráficos de perfiles obtenerlos del archivo: perfilesperfiles

17
Resultados: Perfil de medias de cada solución Tablas personalizadas

18
Resultados: Perfil de medias de cada solución Tablas personalizadas

19
Con la misma matriz y variables con las que hemos realizado el análisis de conglomerados jerárquico vamos a realizar un análisis de conglomerados de k-medias. Ahora del menú Clasificar seleccionamos Conglomerado de K medias Conglomerados de k medias

20
El cuadro contiene: 1.la lista de variables del archivo. De esta lista seleccionamos aquellas sobre las que deseemos evaluar el parecido de los sujetos. En nuestro caso son las correspondientes a las subescalas del WISC-R. Una vez seleccionadas las variables las trasladamos al cuadro Variables. 2.Por defecto el Nº de conglomerados en que divide a los sujetos es 2 pero podemos segmentar la muestra en un número mayor de clases. Sólo tenemos que sustituir el 2 por otro número. 3.Sabemos que la primera partición la inducen un número de sujetos igual al número de conglomerados elegidos mediante diferentes procedimientos. Por defecto SPSS elige a los dos sujetos más distantes. Podemos no obstante escribir en un archivo los centros de los conglomerados que dan lugar a la primera partición marcando en Leer iniciales. 4.También podemos escribir en un archivo los centros de los conglomerados finales seleccionando Escribir finales.

21
Conglomerados de k medias Si pulsamos en los botones Guardar del cuadro anterior obtenemos podemos crear una nueva variable en el editor de datos de manera que asigne a cada sujeto un valor que identifica el conglomerado al que pertenece. : Si pulsamos en el botón Opciones podemos seleccionar una Tabla de ANOVA con la única utilidad de identificar a las variables que desde un punto de vista descriptivo discriminan entre los conglomerados. Las inferencias a partir de estos resultados de ANOVA serían incorrectas. :

22
Resultados: Análisis de conglomerados de K medias

23
Resultados: Análisis de conglomerados de K medias

24
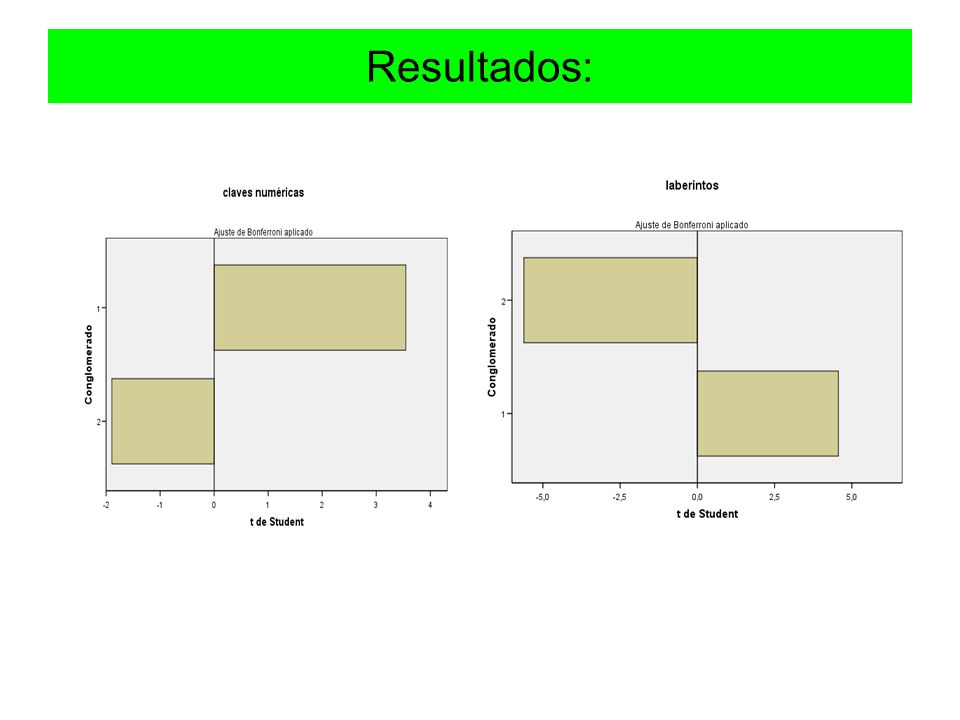
Resultados:

25
Dado que en la matriz además de las variables de la evaluación intelectual disponemos de otras variables de naturaleza cualitativa tales como la presencia de ansiedad, válvulas, retrasos en el desarrollo, etc. Vamos a realizar un análisis de conglomerados en dos fases. Para ello elegimos Conglomerado en dos fases… Conglomerados en dos etapas

26
A diferencia del resto de los procedimientos aquí disponemos de dos cuadros: en uno insertamos las variables cualitativas y en el otro las cuantitativas. Conglomerados en dos etapas

27
Como en el resto de los cuadros de diálogo si pinchamos en el botón Gráficos podemos seleccionar dos tipos de gráficos que nos ayudarán a interpretar el perfil de los conglomerados tanto en las variables cualitativas como cuantitativas. Conglomerados en dos etapas

28
Pulsando en el botón Resultados podemos Estadísticos Descriptivos por conglomerado y Frecuencias de los conglomerados. Conglomerados en dos etapas

29
Resultados: Conglomerados en dos fases Perfiles de los conglomerados

30
Resultados: Frecuencias

31
Resultados: Importancia de los atributos

32
Resultados: Importancia de los atributos

33
Resultados: Variación intra-conglomerado

34
Resultados: Importancia según agrupación

35
Resultados:

Presentaciones similares







.>")


>")









